
Chapter 3. DSL-driven application development
This chapter covers
- Integrating internal and external DSLs in a core application
- Managing errors and exceptions
- Optimizing performance
In the two previous chapters, we’ve looked at many of the user- and implementation-level perspectives of DSLs. You’ve seen how expressive abstractions lead to an easier understanding of the code base and reduce the feedback cycle from the domain experts. But at the end of the day, however expressive the DSL is that you design, you need to integrate it with the model of your core Java application. (Your application might not be in Java; I’m using that as an example.) You’re also going to need to take care of certain aspects related to the integration upfront. In this chapter, we’ll talk about those issues, as well as others that you need to address when you consider developing a whole application that uses DSLs.
You develop your main application using a primary language of the platform, like Java. For some of the business rules or configuration specifications, you might decide to use DSLs written in languages that can be more expressive than Java. How can you integrate them seamlessly within your core application? Because DSLs tend to evolve independently of the main application, your architecture needs to be flexible enough to compose the changing DSLs with minimal impact on the running application. Figure 3.1 shows how I’m going to address these issues as you progress through the chapter.
Figure 3.1. How you’ll progress through the chapter and learn the issues related to DSL-driven application development

We’re going to consider three main aspects of DSL-driven application development:
- Integration issues
- Handling exceptions and errors
- Managing performance
DSLs don’t work in isolation. When you’re integrating them with your application, you need to consider numerous issues, including the fact that both the DSLs and your core application can raise exceptions that manifest as errors to the DSL users. How do you handle them? (We’ll discuss this in section 3.4.) The chapter concludes with an overview of performance concerns that might arise when you use a DSL.
By the end of the chapter, you’ll understand how you should architect your application so that it integrates seamlessly with DSLs written in a different language.
3.1. Exploring DSL integration
Like all beautiful abstractions, a DSL needs to integrate with the other components of your application architecture. In most common use cases, a DSL models the changing artifacts of your applications, like business rules and configuration parameters. It’s important that you design your DSL and the application such that they can evolve independently of each other and yet be able to integrate seamlessly with the workflow.
In this section, we’ll explore various ways to make DSL integration seamless. Remember, a DSL might address the concerns of one, specific domain, but it can be used across multiple, larger domains. Whether the DSL is used in this way depends on how generic the domain that it addresses is. A DSL that manipulates date and time can be used across all applications that need to handle date calculations, but a DSL that deals with corporate tax regulations might be useful within a more limited context. The date-manipulation DSL must be more malleable so that it can integrate with multiple application contexts.
Before we go into the details of integrating DSLs into your application, look at figure 3.2, which shows how your DSL-driven application architecture looks.
Figure 3.2. A macroscopic view of DSL-based application architecture. Note the decoupling of the DSLs from the core application. They have different evolution timelines.

In a typical layered architecture, a DSL can be used at any level so long as it publishes the right context for integration with that layer of the application. Integrating internal DSLs is easier because they’re designed primarily as libraries in the same language as your application. External DSL integration is trickier and needs to plug in through published, specific end points that your application can subscribe to. Before we delve any deeper into the integration aspects of internal and external DSLs with specific use cases for your application architecture, here are some reasons why you should care about DSL integration.
3.1.1. Why you should care about DSL integration
Just as you need to care about wiring the components of your core application, you need to think about integrating the whole application with externally pluggable DSL scripts. A DSL can evolve independently of your application, so you need to have the right amount of coupling between them.
![]()
When you use an expressive language like Groovy, Ruby, or Scala as the main language of your core application, you might not have any integration issues; you’ll never feel the need to plug in DSL scripts written in any other language. The issues that I describe in the following sections mostly relate to integrating DSL scripts with a Java application.
Developers tend to be aggressive using DSLs of multiple languages within the same application without thinking beforehand about how to integrate them. If you choose the wrong language for DSL implementation, the perfectly healthy looking architecture in figure 3.2 could very well turn out to be a nightmare for the application developer. No one wants to be in the position of our friend in figure 3.3.
Figure 3.3. Our application architect is having a nightmarish time thinking about how to integrate DSLs written in various languages with the core application. It’s a time bomb that’s waiting to explode. Can you help him out?
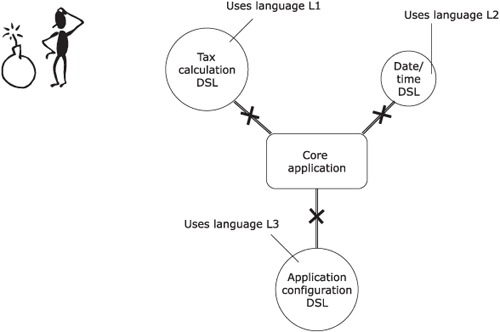
Table 3.1 describes which aspects you need to consider to ensure that the DSL you develop integrates seamlessly with your application and to avoid being in the situation of the poor guy in figure 3.3.
Table 3.1. Integrating DSLs into your core application
|
Issue to address |
As an architect you should . . . |
|---|---|
| Separation of concerns | |
| How do you ensure that the DSL has clearly defined boundaries between the core problem that it addresses and the application context that it interacts with? | Define the bounded context of the DSL correctly and think about how it might be used in situations different from the current application. Look at the principle of distillation of abstraction design that I discuss as one of the core qualities in appendix A. |
| Evolution of the DSL API | |
| The DSL API needs to evolve independently of the application context | Make sure the evolution of the API maintains backward compatibility. If the DSL is a third-party one, raise a red alert the moment you notice incompatible changes being made in the DSL APIs. If you don’t, these changes will come back to bite you later. |
| Avoid language cacophony | |
| Using too many languages in DSLs leads to chaos in the development and maintenance of the whole architecture. This isn’t only a technology issue, but a personnel issue as well. People might not be cooperative if they have to maintain code that uses too many languages. | Ensure that the language you choose for implementing DSLs has seamless interoperability with the host language of your application. Compromise on the flexibility of your DSL’s syntax, rather than use a language that doesn’t offer the best integration abilities with the core application ecosystem. Just because languages are running on the same virtual machine (VM) doesn’t imply seamless interoperability. Consider this a warning. If the language that you’re using to implement a DSL offers multiple ways to interoperate with the host language of the application, choose the one that offers the most natural form of integration rather than using generic sandbox-based scripting environments. We’ll discuss such options in section 3.2 in the context of Groovy and Java interoperability. |
Now that you have an understanding of why you need a definite strategy for integrating DSLs into core applications, let’s look at some of their use patterns. We’ll start with internal DSLs, where integration is done mostly in the form of APIs that are available in the DSL library.
3.2. Internal DSL integration patterns
You design an internal DSL as a library either in the same language that your application is implemented in or in one that offers a seamless interoperability with it. In both cases, the integration doesn’t need any external infrastructure; it’s like yet another API call between the boundaries of the DSL and the core application. I call this homogeneous integration because the languages involved interoperate well enough within the constraints of the underlying VM. Look at figure 3.4, which illustrates how DSLs developed using Java, Groovy, and Spring configuration integrate homogeneously on the JVM. You could deploy each of the DSLs as a jar file that the main application can refer to.
Figure 3.4. All three DSLs integrate homogeneously with the core application. Each DSL can be deployed as jar files that interoperate seamlessly in the JVM.

Suppose you’re developing an application using Java as the primary programming language. But because you’re a polyglot, you choose to use the power of Groovy to implement your XML Builder functionality. (Builders offer a great way to process XML in Groovy. Go to http://www.ibm.com/developerworks/java/library/j-pg04125/.) Then you discover a third-party JRuby-based DSL that you can use to load all your Spring beans to manage application configurations. How should you integrate your DSLs with your core application? The integration has to be such that it shouldn’t incur too much complexity for the user, but at the same time you need to keep the DSL sufficiently decoupled from the core application so that it can manage its own evolution and lifecycle over time. You can integrate your DSL written in these JVM languages with the Java application in a number of ways.
When you consider the collection of languages on the JVM, most offer a number of ways to integrate with Java. Table 3.2 lists the ways you can use each of them. But you need to be aware of the pros and cons of each and use the option that best suits your problem.
Table 3.2. Integration points published by internal DSLs
|
Internal DSL pattern |
Published integration point |
|---|---|
| Java 6 Scripting Engine (discussed in section 3.2.1) | Use the corresponding scripting engine that comes with Java 6 to integrate DSLs written in scripting languages like Groovy. |
| DSL wrapper (discussed in section 3.2.2) | Wrap Java objects with smarter APIs written in languages like JRuby, Scala, or Groovy and use the Java integration capabilities of these languages. |
| Language-specific integration features (discussed in section 3.2.3) | Directly integrate with Java through abstractions that can load and parse scripts directly. Groovy offers such direct integration. |
| Spring-based integration (discussed in section 3.2.4) | Use Spring to load beans written in dynamic languages directly into your application through declarative configuration. |
![]()
When we talk about integration in the following sections, we’re assuming that the core application is developed using Java. This use case is the one that’s used most frequently today. Another point to note is that even though all these languages offer varying degrees of integration capabilities with Java, integration among them is at an immature stage. You won’t find a Groovy application using Ruby for a DSL.
Let’s look at the patterns listed in table 3.2 and see how some of the JVM languages use them to integrate with a Java-based application.
3.2.1. Using the Java 6 scripting engine
Java as a platform has become ubiquitous. For some time, programmers have been talking about a unification layer that allows interoperability across all the languages that the platform embraces. Using Java 6 scripting, you can embed scripting languages within Java applications by using the appropriate engines. Now you can even integrate DSLs that were implemented using languages like Groovy or JRuby through the Java APIs defined in the javax.script package. Let’s look at an example of this kind of integration, using our order-processing DSL from chapter 2 as a case study.
Preparing the Groovy DSL
In section 2.2.2, we implemented a Groovy script that executed the DSL for order creation. In this section, we’ll look at the same DSL, integrated and invoked from within a Java application. This example will give you an idea of the power of Java scripting as an enabler of DSL integration.
Let’s assume that we have the Groovy DSL implementation for processing client orders (ClientOrder.groovy) shown in the following listing (the content of this listing is repeated from section 2.2.2).
Listing 3.1. ClientOrder.groovy: order-processing DSL in Groovy
ExpandoMetaClass.enableGlobally()
class Order {
def security
def quantity
def limitPrice
def allOrNone
def value
def bs
def buy(su, closure) {
bs = 'Bought'
buy_sell(su, closure)
}
def sell(su, closure) {
bs = 'Sold'
buy_sell(su, closure)
}
def getTo() {
this
}
private buy_sell(su, closure) {
security = su[0]
quantity = su[1]
closure()
}
}
def methodMissing(String name, args) {
order.metaClass.getMetaProperty(name).setProperty(order, args)
}
def getNewOrder() {
order = new Order()
}
def valueAs(closure) {
order.value = closure(order.quantity, order.limitPrice[0])
order
}
Integer.metaClass.getShares = { -> delegate }
Integer.metaClass.of = { instrument -> [instrument, delegate] }
The Order abstraction in this code that we developed on the Groovy side captures the order details that the user enters. In another script file, order.dsl in listing 3.2, the DSL user does the scripting (also in Groovy) that uses the implementation in listing 3.1 to place orders for the client. Note that this script is based purely on the DSL that we designed in listing 3.1 and assumes minimal understanding of the workings of the programming language. In addition to creating the orders, the script accumulates them into a collection that’s returned to the caller. But who’s the caller? Don’t worry, you’ll find out soon.
Listing 3.2. order.dsl: Groovy script for placing orders

In listing 3.2, the user uses newOrder to create a new Order abstraction that gets filled up with attributes like buy or sell, the share to transact, limit price, valuation strategy,
and so on. Every order that gets created is appended to a collection ![]() . The collection is returned at
. The collection is returned at ![]() .
.
Now we come to the interesting part of the story: you are going to integrate the DSL implementation and the script with the main Java application.
Integrating the DSL implementation and the script
The code fragment in listing 3.3 shows a snippet of code from the main application. This snippet expects the collection of orders to be returned from the DSL execution so that it can further process the orders. The Java code in the snippet uses the scripting engine for Groovy. Similarly, implementations of scripting engines are available for other JVM languages like JRuby, Clojure, Rhino, and Jython that can be integrated into your Java application as seamlessly as this Groovy one (go to https://scripting.dev.java.net/ for more information).
Listing 3.3. Java application code that invokes the Groovy DSL

Let’s look at the steps that led to the integration. Figure 3.5 shows a sequence diagram, annotated with the actions that listing 3.3 performs on the DSL script and implementation.
Figure 3.5. Integrating the Groovy DSL through the Java 6 scripting engine. The interaction diagram shows all the steps involved in evaluating the Groovy DSL script within the sandbox of the ScriptEngine.

As you can see, Java 6 scripting APIs provide a viable option for integrating your DSL into your Java application using almost any JVM language. javax.script also offers APIs that let you set up bindings of variables at various scopes to exchange information between your DSL and the Java components.
Problems with Java 6 scripting
Java 6 scripting is one of the most generic ways to get JVM languages to interoperate. And like any generic strategy, there’s always a better option for the specific language that you’re working with. Because the DSL script gets loaded in a separate ClassLoader and executes in its own sandbox, you face problems of interoperability between the Groovy and Java abstractions. Note how we get a list of Objects from the Groovy DSL script within Java in listing 3.3, as opposed to a list of Order abstractions. The only way you can invoke Order methods on it is by using reflection. Also, because the script executes in the sandbox of the ScriptEngine, when there’s an exception, the line numbers mentioned in the stack trace don’t match the line numbers in the source file. This situation can make it difficult to debug exceptions thrown from the DSL script. Let’s explore some better options for integrating an internal DSL.
![]()
Scripting engines were introduced in Java 6 as a generic way to handle script execution from within Java programs. The design principles of the Java 6 ScriptEngine-based APIs cater to all JVM languages that implement an infrastructure that’s compliant with Java Specification Request (JSR) 233. If the language that you plan to use for DSL implementation offers its own specific ways of integrating with Java, review it carefully before deciding in favor of implementations that are JSR 233 compliant. Using the language-specific solution is probably best practice because it’s likely to be simpler and more idiomatic.
You just saw how the scripting APIs of Java 6 work to enable polyglotism on the JVM. I picked up the example in Groovy because we implemented a Groovy DSL in chapter 2 that could be seamlessly plugged into the Java application without much of a fuss. You can use similar techniques to plug DSLs written in other JVM languages like JRuby, Clo-jure, or Rhino into your Java applications.
![]()
Polyglotism encourages use of multiple languages even within a single solution domain. The languages need to have good interoperability and well-published integration points. Usually such a family of languages operates on a common runtime like the JVM that hosts languages like Java, Scala, Ruby, Groovy, and so on. One of the main ideas behind DSLs is to use the most suitable language to design your domain API and integrate it with the core application through the common runtime.
You can integrate your DSL at various levels. The Java scripting option we discussed in section 3.2.1 lets you embed your DSL within the execution framework of the ScriptEngine and invoke the DSL scripts. It has the advantage that your DSL is totally decoupled from the application and executes within the sandbox of the ScriptEngine context. The disadvantage of this approach is that it’s not intuitive to have the DSL components interact easily with the environment of the main application.
Let’s look at another approach to DSL integration that operates at a different level than script engines and integrates more closely with the host language of your application.
3.2.2. Using a DSL wrapper
In this integration approach, you build the DSL as a wrapper layer on top of the main application components using the rich features that the DSL host language offers. You can adopt this approach to make your legacy applications publish smarter APIs. Using the rich language features of yet another JVM language, you can make more expressive domain components based on the legacy abstractions. Not only will your domain experts love them, but your fellow API users will also enjoy using them.
Setting up the example
In this example, we’ll use Scala, the statically typed language for the JVM that also has nice interoperability features with Java. Suppose your main application is written in Java and all your domain objects are implemented as part of the application. Your client is aware of the hype and fun of DSL-based development and asks you to implement some smart DSL features on top of their existing legacy Java trading application. This scenario is perfect for you to integrate by wrapping.
To help explain the concept of integrating by wrapping, I’m going to use another example from the world of securities trading. Figure 3.6 shows an overview of the trade process. Don’t forget to read the sidebar; it provides enough background information for you to follow along.
Figure 3.6. Role of trading and settlement accounts in the trade process

![]()
In order to trade, a client needs to open an account (called the trading account) with the Stock Trading Organization (STO). All trades for the client are booked in that account and recorded by the STO. When the trade is done, the settlement process has to be initiated. That process does the final balancing of the securities and currencies that were exchanged between the two parties.
For example: client XXX buys 100 shares of SONY @50 USD per share through STO Nomura Securities. The STO gets those securities from the stock exchange where a broker does the sell. After the trade is made, there’s a settlement process during which 100 shares of SONY and approximately 5000 USD are exchanged between the two counterparties. This settlement is done through an account (the settlement account), which can be same as the trading account of the client or it can be a different account.
To review, the trading account is used for doing the trade, and the settlement account is used for settling the trade. They can be the same account or different ones. Figure 3.6 shows an overview of the process.
Consider the Account domain model, an entity from our friendly domain of securities trading operations. An account is an entity through which the firm, its clients, and the brokers manage trading and settlement activities. The sidebar in this section gives a brief explanation of the role of accounts and their types in trading and settlement operations.
![]()
If you’ve forgotten what trading and settlement mean in the context of our domain, review the callouts in chapters 1 and 2.
Listing 3.4 contains a simplified view of the domain model for the Account entity that we’ll use to discuss the wrapper approach to DSL integration. Account is a Java class on which we’ll implement Scala wrappers. Ultimately, you’re going to find out how the usage patterns in client APIs become more succinct and expressive when you use a wrapper.
Listing 3.4. Account domain object in Java
public class Account {
public enum STATUS { OPEN, CLOSED }
public enum TYPE { TRADING, SETTLEMENT, BOTH }
private String number;
private String firstName;
private List<String> names = new ArrayList<String>();
private STATUS status = STATUS.OPEN;
private TYPE accountType = TYPE.TRADING;
private double interestAccrued = 0.0;
public Account(String number, String firstName) {
this.number = number;
this.firstName = firstName;
}
public Account(String number, String firstName, TYPE accountType) {
this(number, firstName);
this.accountType = accountType;
}
//.. getters ommitted
public double calculate(final Calculator c) {
interestAccrued = c.calculate(this);
return interestAccrued;
}
public boolean isOpen() {
return status.equals(STATUS.OPEN);
}
public Account addName(String name) {
names.add(name);
return this;
}
}
If you’ve been programming in Java, I’m sure you’re neither amused nor surprised by the verbosity and boilerplate stuff that the model in listing 3.4 uses. Let’s try to figure out how you can make the abstraction smart enough so your client can get some APIs that let him express his intents in a more domain-rich vocabulary. At the end of this exercise, you’ll have a DSL that’ll integrate nicely into the guts of your Java application.
Building the DSL
Let’s start with the abstraction AccountDSL in Scala that acts as an adapter to the Account Java class, and implement something called smart domain APIs. Remember, your ultimate goal is to make the Account class so smart that the client can apply the language on existing instances of the Account class, no matter what DSL you design. In the following code snippets, I’ll show you how to enrich the AccountDSL abstraction incrementally. I’ll also discuss potential uses of the DSL so that you get a feel for the enrichment as it occurs in the domain abstraction.
The following listing shows the DSL layer in Scala that we’ll use seamlessly with the Java Account class.
Listing 3.5. AccountDSL in Scala

The code in the listing uses some of the typical Scala idioms that I describe briefly in the sidebar “Scala 101”. For more Scala details, see [1] in section 3.7.
In listing 3.5, AccountDSL is an adapter to the Java Account class and wraps it as an underlying implementation. At ![]() we convert the Java collection to a Scala one, which we’ll use subsequently with higher-order functions. (Scala collections
are always semantically richer than Java collections in the sense that you can apply higher-order functions to make operations
on them more expressive.) This code uses Scala 2.8 implicit conversions between Java and Scala collections. If you’re still working on a Scala version that’s earlier than 2.8, you can
use the jcl conversion APIs like this:
we convert the Java collection to a Scala one, which we’ll use subsequently with higher-order functions. (Scala collections
are always semantically richer than Java collections in the sense that you can apply higher-order functions to make operations
on them more expressive.) This code uses Scala 2.8 implicit conversions between Java and Scala collections. If you’re still working on a Scala version that’s earlier than 2.8, you can
use the jcl conversion APIs like this:
def names =
(new BufferWrapper[String] {
def underlying = value.getNames
}).toList ::: List(value.getFirstName)
In the method belongsTo, we use a predicate as:
>> (names exists(_ == name))
This predicate is a succinct way to express the following in Scala:
>> (names.exists(n => n == name))
- In Scala, the dot (.) is optional when you invoke methods on a receiver.
- The underscore (_) that we use is shorthand for anything substitutable in Scala. In listing 3.5, _ is the placeholder for supplying the parameter to the higher-order function that exists accepts.
- The Scala type inferencer does an inferencing of the parameter type of the function that exists takes.
- In Scala, operators are methods. We can define << as the method that adds the name to the order object. Using symbolic operators like << might be visually appealing to some, but as a cautionary note, this is a matter of personal choice and can lead to unreadable code if you use it too much.
In listing 3.5, we define a domain API belongsTo ![]() using our new Scala collection and higher-order functions. Note the succinctness of implementation that Scala offers. Finally,
we define an operator-like syntax using << to make our DSL more expressive and concise at
using our new Scala collection and higher-order functions. Note the succinctness of implementation that Scala offers. Finally,
we define an operator-like syntax using << to make our DSL more expressive and concise at ![]() .
.
With the new Scala APIs wrapping our original Java implementation, the client can express his domain intents more succinctly, as we’ll see shortly. Being expressive and concise is one of the major benefits of DSL-driven development. This example clearly demonstrates this power of DSL.
Using Scala Implicits
Before we talk more about the client, we need to take care of one other thing that I promised earlier. You need to make Account interoperable with AccountDSL, so that all the smartness you implement on top of AccountDSL can be applied to Account instances as well. Scala offers implicits that you can use to make any feature that’s already available on AccountDSL work on instances of the Account class too. All you have to do is ensure that an implicit definition of the conversion is available in the lexical scope of execution:
implicit def enrichAccount(acc: Account): AccountDSL = new AccountDSL(acc)
Now that you have transparent conversion from Account to AccountDSL, you can use the new DSL APIs on Account instances too. Let’s create some instances of our Java class Account:
val acc1 = new Account("acc-1", "David P.")
val acc2 = new Account("acc-2", "John S.")
val acc3 = new Account("acc-3", "Fried T.")
In our definition of the enrichAccount method, there’s an implicit modifier in front of the method definition enrichAccount. In Scala, the implicit modifier for a method is used to define an automatic conversion from one type to another. In this case, the method enrichAccount converts an Account to an instance of AccountDSL. Instead of using
scala> enrichAccount(acc1) belongsTo("David P."),
you can directly use an instance of Account to invoke methods of AccountDSL:
scala> acc1 belongsTo("David P.")
It’s like all methods of AccountDSL have been injected into the class Account. Sound familiar? It’s similar to what we do with Ruby monkey patching that lets you split open any class and extend it with additional methods.
But there’s a difference. In Scala, implicits are lexically scoped. The automatic conversion between Account and AccountDSL is available only in the lexical scope of the method enrichAccount. Ruby open classes that allow modifications of existing classes on a global scope are significantly different. For some more insights on the virtues of Scala implicits, see [3] in section 3.7.
Now add a few more account holder names to acc1 using the new operator <<:
acc1 << "Mary R." << "Shawn P." << "John S."
Note how concise yet expressive the previous snippet looks as compared to what we would have done with our original Java APIs:
acc1.addName("Mary R.").addName("Shawn P.").addName("John S.");
Let’s form a collection of accounts and print the first names (firstName) of those accounts that include John S. as one of the owners:
val accounts = List(acc1, acc2, acc3) accounts filter(_ belongsTo "John S.") map(_ getFirstName) foreach(println)
Expressive indeed! In fact, the code is much more expressive than what you would get with the original Java APIs. The reason for the difference is that the richness of Scala as a language helps you craft rich semantics in a reduced surface area of the API. In the previous snippet, we use combinators like filter, map, and foreach that operate on higher-order functions. These combinators make the code much more concise than what you would get with an imperative Java syntax. Are you having fun? Let’s party on!
Get the list of accounts belonging to John S. and compute the sum of accrued-Interest for all accounts for which the accumulated interest is greater than a predefined threshold:
accounts.filter(_ belongsTo "John S.") .map(_.calculate(new CalculatorImpl)) .filter(_ > threshold) .foldLeft(0.0)(_ + _)
This snippet contains applications of the Scala idiom that I explained in an earlier sidebar. The _ is a placeholder for the type-inferenced argument that the predicate in filter takes as input. This snippet expresses the domain problem with more clarity than what you would get out of a language that has more verbose syntax like Java. As I discussed in chapter 1, it’s all thanks to the richness in abstraction design that a more powerful language like Scala offers, by reducing the accidental complexity of your code.
Note the CalculatorImpl object that calculate() takes as input. We defined Calculator as an interface in Java with CalculatorImpl as its implementation:
public interface Calculator {
double calculate(Account account);
}
public class CalculatorImpl implements Calculator {
@Override
public double calculate(Account account) {
//.. implementation
}
}
Most of the time, you’ll have the same implementation of the Calculator interface being passed into the Account#calculate() method. One way to avoid this repetition is to use DI to inject the implementation dynamically during runtime. Scala offers a better alternative: you can make this parameter implicit in all calls of calculate.

You define an implicit argument to the method calculateInterest and have the implicit default set up in the scope of execution of the DSL ![]() . Now you have an implicit default value for the implementation of Calculator; you don’t need to pass Calculator repeatedly to invocations of calculateInterest. Look at the final version of the calculation of accrued interest for all accounts that belong to John S:
. Now you have an implicit default value for the implementation of Calculator; you don’t need to pass Calculator repeatedly to invocations of calculateInterest. Look at the final version of the calculation of accrued interest for all accounts that belong to John S:
implicit val calc = new CalculatorImpl accounts.filter(_ belongsTo "John S.") .map(_.calculateInterest) .filter(_> threshold) .foldLeft(0.0)(_ + _)
With support for features like closures and higher-order functions, Scala offers you the power to define control abstractions that look like syntax that’s built into the language. Using Java objects as underlying implementations, you can design powerful control constructs that make your DSL succinct and expressive.
Benefits to users
As we discussed in chapter 1, the point is not that a nonprogramming domain expert will be able to program in any DSL that you design. It’s the explicit communicability of the API that matters for a well-designed DSL. In the previous snippet, you’ll notice functional combinators like map, filter, and foldLeft that don’t qualify as very meaningful to the domain person. But the domain person will be able to figure out the following hotspots easily from that snippet:
- Filter the account belonging to John S
- calculateInterest on it
- Filter only those that are > the threshold value
- Add up the interest values
When you offer all these hotspots in a localized surface area of the code base, it becomes easier for the domain expert to comprehend and verify the business logic. With an imperative approach, the same logic would have been spread across a larger code segment, making it much more difficult for someone who doesn’t know programming.
Let’s define a control abstraction using our Account Java object and the Account-DSL that we implemented in listing 3.5:
object AccountDSL {
def withAccount(trade: Trade)(operation: Account => Unit) = {
val account = trade.account
//.. initialization
try {
operation(account)
} finally {
//.. clean up
}
}
}
The underlying abstractions used in this snippet, Account and Trade, are Java classes that might have been enriched using Scala wrappers. Now it’s the turn of your DSL users to use such abstractions to perform useful domain operations. The following DSL code fragment is possible using the control abstraction withAccount and a wrapper to integrate Scala and Java. It’s so much more expressive and closer to the domain syntax than what would have been possible with an only-Java paradigm.
withAccount(trade) {
account => {
settle(
trade using
account.getClient
.getStandingRules
.filter(_.account == account)
.first)
andThen journalize
}
}
This sequence of API invocation does exactly what you see in figure 3.7.
Figure 3.7. The flow as depicted in the preceding code snippet takes an account and describes the sequence until the end of the transaction.
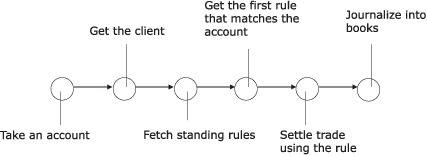
withAccount does all this in only a few lines of clear domain-specific code. Show this snippet to your domain expert. I’m sure he’ll be able to explain to you what it does. I did the same thing with one of the Bob’s on our project team. (Remember Bob? He’s our friendly domain expert from Trampoline Securities who joined us in section 1.4.) Can you imagine what happened? Bob looked over the code and here’s the conversation that followed:
- Bob: You’re picking up the first of the selected standing rules after filtering, right?
- Me: Yeah!
- Bob: But sometimes there’s going to be more than one match for the same account.
- Me: Then how do you decide which rule to pick up?
- Bob: When that happens, every rule has a priority tagged onto it. You need to pick up the one with the highest priority.
- Me: Great!
The next time your manager talks about a big up-front investment for DSL implementation, tell him about what you’ve learned. It’s a myth that every integration effort using a DSL requires a huge outlay of money. The wrapper technique we discussed in this section is a real-life testimony to this. In fact, this technique builds on your current investment in the Java domain model, and you get the added benefit of code that’s smarter and more useful to the domain experts.
You can use the DSL wrapper technique whenever you use Scala as the DSL implementation language on top of Java. You probably noticed you can make your Java objects smarter using the power of Scala type system. The implicits feature is the secret sauce that lets you do it. In the next section, we’ll look at how to use some language-specific integration features to implement DSLs on top of Java. We’ll again take Groovy as an example and revisit the DSL that we discussed in section 3.2.1.
3.2.3. Language-specific integration features
Let’s revisit the original order-processing DSL that you integrated with your core Java application in section 3.2.1. Moving away from the ScriptEngine approach, we’ll use a technique that loads Groovy classes dynamically in your Java application. Loading the classes dynamically ensures better manageability of your Groovy objects, even within the core Java application.
![]()
To get more Groovy information about metaprogramming, closures, and delegates, check out [2] in section 3.7.
Communicating between Java code and Groovy DSL
Suppose that in your trading application you’ve used Java 6 ScriptEngine to integrate your order-processing DSL with the Java application. Things were running fine until one day the client came back with a new requirement: additional processing needs to be done on the collection of orders that the script returns to your Java application. Specifically, he needs to compute the total valuation of all orders that have been placed so far, and he needs custom displays of order attributes for the customer.
Up to this point, you’ve been loading the DSL implementation (ClientOrder.groovy) and the user-defined script (order.dsl) as a single Groovy script that’s executed in the sandbox of the ScriptEngine. The Groovy DSL is completely opaque to the Java code; the script is loaded using a different classloader than your Java classes, which makes them invisible in your main application. You need to buy some time from your client to try to implement alternate ways to integrate the DSL that make Groovy classes more visible to your Java application.
Better integration with Groovy ClassLoader
In this section, we’re going to treat Groovy classes as reusable abstractions in the Java application and use GroovyClassLoader to load only the order-processing script that your user writes. The following listing shows the changes you need to make to your DSL to make things more Groovy.
Listing 3.6. RunScript.java: DSL integration using GroovyClassLoader

Let’s recap how this listing makes DSL integration more meaningful in Groovy. We’ve separated the abstraction ClientOrder.groovy and precompiled it to make the Order class available to the Java application. In the Java class, we execute an instance of ClientOrder to set up the metaclass ![]() . The DSL script order.dsl returns a Closure that contains the DSL code
. The DSL script order.dsl returns a Closure that contains the DSL code ![]() . Next, we set up ClientOrder as the delegate of the Closure to resolve the symbols that the script uses
. Next, we set up ClientOrder as the delegate of the Closure to resolve the symbols that the script uses ![]() . Then, we call the DSL script to return a list of Order objects
. Then, we call the DSL script to return a list of Order objects ![]() . Finally, we can find out the total order valuation by iterating over individual orders
. Finally, we can find out the total order valuation by iterating over individual orders ![]() .
.
As soon as we come out of the execution of the DSL script, we get back a list of Order objects that we can use for other business processing. We couldn’t have done this with the code in listing 3.3, where we used a Java 6 scripting API to integrate our DSL with the Java application. Now your client is happy, and you’ve learned a new way to integrate your Groovy DSL into your Java application.
The final result
Here’s the DSL script order.dsl, changed to return a Closure to the Java application.
Listing 3.7. order.dsl: the DSL script now returns a Closure
{->
orders = []
ord1 =
newOrder.to.buy(100.shares.of('IBM')) {
limitPrice 300
allOrNone true
valueAs {qty, unitPrice -> qty * unitPrice - 500}
}
orders << ord1
ord2 =
newOrder.to.buy(150.shares.of('GOOG')) {
limitPrice 300
allOrNone true
valueAs {qty, unitPrice -> qty * unitPrice - 500}
}
orders << ord2
ord3 =
newOrder.to.buy(200.shares.of('MSOFT')) {
limitPrice 300
allOrNone true
valueAs {qty, unitPrice -> qty * unitPrice - 500}
}
orders << ord3
println "Orders ..."
orders.each { println it }
}
This Groovy DSL is better than the earlier version of the order-processing DSL that you saw in chapter 2. It also offers better Java integration than what you saw with the ScriptEngine-based approach in section 3.2.1.
From a language-specific integration feature, let’s move on to a framework-based integration approach that you can use to integrate internal DSLs with a Java application. Spring offers a suitable platform; the next section shows how to use it.
3.2.4. Spring-based integration
We’ve come to the final integration technique that I summarized in table 3.2. It’s one level up in terms of abstraction because it offers integration through a framework, as opposed to through a language, as discussed earlier. How often have you fantasized about how helpful it would be if some of the business rules that you’ve implemented in Java could have been changed dynamically without having to restart your application?
Spring’s dynamic language support
Since version 2.0, Spring has supported bean implementation using expressive, dynamic languages like Ruby and Groovy. (For more information about Spring, go to http://www.springframework.org.) These beans are also refreshable. A refreshable bean is one that allows itself to reload dynamically when its underlying implementation changes. Let’s consider an example from our financial brokerage domain where an implementation of a TradingService needs to look up rules for computing the accrued interest on coupon bonds.

In this snippet, the business rules for accrued interest calculation are injected at runtime through DI using Spring ![]() . Using the dynamic language support that Spring offers, you can implement these rules using expressive languages like JRuby
or Groovy or Jython. This is an area where a small, rich DSL is a great fit. The benefits are twofold:
. Using the dynamic language support that Spring offers, you can implement these rules using expressive languages like JRuby
or Groovy or Jython. This is an area where a small, rich DSL is a great fit. The benefits are twofold:
- The code is more expressive because the languages themselves are more rich.
- You can auto-reload the runtime instance of the bean when the underlying implementation changes.
In the current example, we can use a Java interface for the rule contract:
public interface AccruedInterestCalculationRule {
BigDecimal calculate(Trade trade);
}
And the backing implementation of the rule can be done using a DSL written in Ruby:
require 'java'
class RubyAccruedInterestCalculationRule {
def calculate(trade)
//.. implementation
end
end
RubyAccruedInterestCalculationRule.new
Now there’s just one thing left to do.
Wiring up the implementation
You can then wire up the whole implementation using the following XML configuration snippet in Spring. Now, when you ask for an instance of AccruedInterestCalculationRule from within your Java program, you get an instance that is implemented using the Ruby DSL.
<lang:jruby
id="accIntCalcRule"
refresh-check-delay="5000"
script-interfaces=
"org.springframework.scripting.AccruedInterestCalculationRule "
script-source="classpath:RubyAccruedInterestCalculationRule.rb">
</lang:jruby>
Congratulations! Using Spring, you’ve successfully integrated a Ruby DSL into your Java application. This model of DSL integration is nonintrusive and keeps the DSL component decoupled from the context where it is used. If you are using Spring as the DI framework in your application, consider this integration pattern as an option for dynamically reloading business-rule DSLs.
Now that you’ve seen the homogeneous integration patterns related to internal DSLs, let’s look at patterns for integrating external DSLs. External DSLs can be any form. You can implement them using a custom language infrastructure. In the next section, we’ll revisit all the external DSL implementation patterns we discussed in section 2.3.2 and see how each publishes explicit integration points for your core application. Note that external DSLs are custom-made for specific applications only; our discussion on integration patterns for external DSLs will be limited to a few common techniques that are currently being used.
3.3. External DSL integration patterns
How do you integrate XML with your application? Did you just scream “Using the XML parser!” If you did, you are correct! Because XML isn’t part of the host language you’re using to implement the application, you need separate machinery to parse and process XML. XML is so commonly used that you get a slew of tools like XPath, XQuery, and a huge number of XML parsers bundled with almost every enterprise solution. Integrating XML with your application is a no-brainer. Unfortunately, the external DSLs that you’ll design for your applications aren’t lucky enough to inherit such a repertoire of tools. Integrating your external DSL with your application is likely to rely on specific techniques that can’t be generalized as a pattern.
Judging from what I said in the last paragraph, you must be thinking that integrating external DSLs is a nightmare in the application development lifecycle. It all depends on how complex the DSL is and the technique that you’re using to develop it. If you use standard tools like ANTLR or YACC to develop parsers for your external DSL, integration is pretty straightforward; read section 2.3.2 again. For every external DSL pattern that we discussed in that section, you can see that the integration points are quite obvious after you’ve designed the DSL.
Let’s look at the patterns of external DSL that we discussed in section 2.3.2 again and try to figure out the integration points that each of them publish. Table 3.3 lists a summary of thoughts for how you can integrate external DSLs with your core application.
Table 3.3. Integration points published by external DSLs
|
External DSL pattern |
Published integration point |
|---|---|
| Context-driven string manipulation | The string is converted to the host language through a tokenization process, using techniques like regular expression matching and dynamic code evaluation. The resultant code snippet is the integration point with the application. |
| Transforming XML to a consumable resource | XML parsers are the most natural form of integration point. After parsing, XML is converted to data structures of the host language that can be directly used by the application. |
| Nontextual representation | The nontextual representation is converted to an AST. You can use the AST as the basis for generating multiple forms of concrete syntax trees. You can target one of the concrete syntax trees to generate the host language of the application, which then becomes the integration point. |
| Mixing DSL with embedded foreign code | The DSL processing engine transforms the DSL into appropriate data structures in the language of the embedded code and plugs in the embedded code snippets as callbacks. The result is a set of data structures in the embedded code that can be directly used in the core application, using the same language. |
| DSL design-based on parser combinators | Parser combinators are implemented as a library in languages like Scala. The rules that you write to parse the external DSL are combinators in the host language. Using embedded snippets of the host language, you build up data structures that get populated by the rules. When the rules reduce to the topmost node of the tree, you have the complete semantic model of the DSL. |
Why didn’t I go into the details of integration patterns for external DSLs like I did for internal DSLs? Internal DSL integration takes place through a host language, but external DSLs often require a more elaborate stack that depends on the specific application domain. Designing a language-processing infrastructure is a more open-ended problem than designing APIs in a host language. It’s difficult to have a generic discussion of external DSL integration patterns without delving into the specific details of what it needs to achieve and the infrastructure involved. We’ll take up these techniques in detail with examples in chapters 7 and 8.
![]()
In chapter 7, we’ll discuss external DSL design using ANTLR, a commonly used parser generator. We’ll also look at tools that help you generate an external DSL through a workbench. For both ANTLR and the DSL Workbench, we’ll also discuss how to integrate the external DSL with your core application.
Chapter 8 has a detailed discussion about external DSL design using Scala parser combinators.
We’ve just covered all the integration patterns for internal and external DSLs. Now you can handle most of the problems you’ll encounter when you’re integrating your DSL with your core application. Throughout this discussion, I’ve assumed that your core application is developed in Java and that you’re trying to integrate DSLs that were designed in more expressive languages with that application. This use case is the most common one that you’ll encounter in real-world programming, so it is imperative that you have a solid understanding of the integration issues related to the problem.
Figure 3.1 illustrates the most important issue related to DSL-driven application development: integrating the DSL with the core application. This issue is sometimes considered late in the development cycle, as an afterthought, rather than being addressed up front. Now we’ll look at yet another concern that’s often ignored by programmers at the beginning of the DSL development lifecycle. Deciding on a strategy for handling errors and exceptions is something that needs to be high on your priority list, particularly if your DSL has a fairly large user base.
3.4. Handling errors and exceptions
It’s superimportant to be as friendly to your user with error reporting as you are with the expressiveness of your syntax. Because a DSL is a language of limited applicability, your error messages should also speak the language of the domain. Error and exception reporting in a DSL-based environment needs to be disciplined so you never mislead the user, leaving them in a state of confusion. You need to clearly articulate the exact condition that the system is in. This concept is called domain-driven exception reporting, which we’ll discuss in section 3.4.1. We’ll also talk about the two main types of error states that your DSL user will have to face. Together, these comprise the three-pronged view of error and exception handling strategies that you, as a DSL designer, need to consider. This view is shown in figure 3.8.
Figure 3.8. The three-pronged strategy for dealing with errors and exceptional states in a DSL
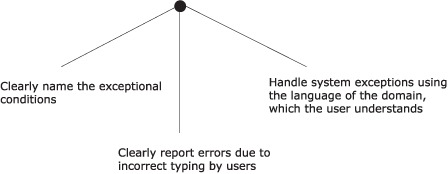
Depending on the type of DSL (internal or external) you have and the implementation language you’re using, the ways in which the error conditions manifest themselves will vary. Table 3.4 contains an overview of the error and exception issues and your responsibilities as a DSL designer.
Table 3.4. What you need to know about errors and exceptions in DSLs
|
Issue |
How to handle as a DSL designer |
|---|---|
| You need to clearly state the exceptional conditions within a DSL. | An exceptional state is also a domain abstraction. Always use the domain language to express any exception that might occur during processing. See section 3.4.1. |
| You need to handle errors that might result when the user types method names, object names, and other things incorrectly. | The exact strategy depends on the implementation language you’re using. See section 3.4.2. |
| You need to handle exceptions that might arise when the system enters an invalid business state. What will happen, for example, when someone tries to transfer funds between accounts and the communication line to the bank is down? | When you report such an exception, be sure to supply all relevant details to the user in the language they understand. See section 3.4.3. |
Let’s look at each of these issues in detail.
3.4.1. Naming an exception
When you name an exceptional condition in the DSL, use the language that the domain uses to describe the situation. The exception might not be an infrastructure fault—it can also be an alternate path of a business use case. The idea is to present such situations in the language of the domain. Here’s an example from a system that settles trades between counterparty accounts:
val fromBalance = fromAccount.getSecurityBalance
if (fromBalance <= tradeQuantity)
throw new SettlementFailedException(
" Insufficient security balance in " +
"account " + counterpartyAccount.getName +
" for settlement completion")
settle(..)
The system has reached an exceptional state; the settlement will fail when the seller doesn’t have a sufficient security balance in his account. This state of affairs is expressed by the exception name SettlementFailedException, the common verbiage that describes the situation in a real-world settlement system. When the user gets this exception, he’s going to know exactly what has happened. He is also going to see the accompanying message, which you’ve written, that clearly states the details of why it failed.
3.4.2. Handling incorrect typing errors
No matter how expressive your DSL, your user is going to make mistakes. It’s human nature. When you’re programming in a statically typed language like Java or Scala, the compiler promptly notifies you of such mistakes as soon as you make them. Anytime you go against the rules of the type system of the language you’re using, the compiler acts as the policeman for you, as in figure 3.9.
Figure 3.9. The compiler is the policeman!

If the user is sufficiently knowledgeable in the host language that implements the DSL, error messages reported by the compiler can be helpful. Modern IDEs that provide code assist and autocompletion facilities can also be helpful with such typing errors. But what can you do when that help is not available?
When the type system can’t help you
A dynamically typed language like Ruby or Groovy doesn’t come with compiler help for type errors. In these languages, most such mistakes are manifested as runtime errors after they’re processed through the usual method dispatch pipeline that the language implements. Without compile-time error checking, well-designed DSLs in dynamic languages take advantage of features like methodMissing to install user-friendly error handlers. A DSL user can get information from these handlers that help them rectify the error.
methodMissing is a useful technique when you’re designing DSLs in a dynamic language. In the following example in Ruby I’ve added just enough context information to make the runtime exception more meaningful to the user:
class Trade
//..
def method_missing(method, *args, &block)
raise NoMethodError, <<ERRORINFO
method: #{method}
args: #{args.inspect}
on: #{self.to_yaml}
ERRORINFO
end
//..
end
If the user supplies a method name that’s not implemented on a trade object, Ruby raises a NoMethodError by default. The snippet contains an implementation of method_missing that provides a custom error handler, adding more context information for the user. (For an example of how to use methodMissing to synthesize new methods in Groovy, see section 2.2.2.)
The role of parsers
For an external DSL, when you use parsers to parse the input script, ensure that you report the exact line number and the position in the input string where the error occurred. Such user-friendly error reporting depends a lot on what you’re using to generate the parser of your DSL syntax. Top-down parsers generated by ANTLR offer better support for error reporting than the bottom-up ones generated by YACC. We’ll discuss more of these in chapter 7 when we talk about designing external DSLs using parser generators.
OK. Now you know how to deal with the inevitable typos or erroneous input that a user is bound to try to sneak in. What can you do about business conditions that make some actions impossible?
3.4.3. Handling exceptional business conditions
Your DSL should be able to report the precise exceptional state, using domain-driven exception reporting, which we discussed earlier in section 3.4.1. More importantly, the DSL should have handlers in place that take care of all domain exceptions raised while the DSL is running. This includes all clean-up actions, resource releases, and transaction rollbacks.
Proper exception handling and reporting is also related to the strategy you choose for integrating your DSL script with the core application. Integration strategies that rely on the ScriptEngine-based approach like the one we saw in section 3.2.1 are usually poor at exception reporting. Consider the following example from the section where we discussed embedding Groovy scripts within a Java application:

In this example, we didn’t handle the exception explicitly within the Groovy method. We assumed that it would be handled by
the caller function ![]() . The class javax. script.ScriptException has methods like getFileName() and getLineNumber() that’ll help you locate exactly where the exception occurred. The important point here is to be careful about handling exceptions
that originate from inside your DSL and provide enough context information to the user. For code running in the sandbox of
the ScriptEngine, the right context for handling the exception is not always intuitive. This is yet another reason why you should opt for
better language-specific ways to integrate your DSL, and fall back on the scripting option only if necessary
. The class javax. script.ScriptException has methods like getFileName() and getLineNumber() that’ll help you locate exactly where the exception occurred. The important point here is to be careful about handling exceptions
that originate from inside your DSL and provide enough context information to the user. For code running in the sandbox of
the ScriptEngine, the right context for handling the exception is not always intuitive. This is yet another reason why you should opt for
better language-specific ways to integrate your DSL, and fall back on the scripting option only if necessary
DSLs are designed for readability and expressiveness in the domain. Always try to keep the user in mind when designing DSLs. At the same time, be aware of the performance considerations that a DSL can impose on your design. What’s the trade-off?
3.5. Managing performance
Performance is an important criterion, but, believe it or not, I don’t think it’s the most important one. You can improve the performance of an underperforming application by scaling up or scaling out resources. But when you’ve implemented a spaghetti system without any concern for expressivity or maintainability, you’re going to be stuck with it for the rest of its life.
Even so, you need to consider performance factors when you design an application. Let’s face it—a properly designed DSL usually isn’t a hindrance to the optimal performance of your application. Some of the dynamic languages like Groovy or Ruby are slower compared to Java. But as an application developer or architect, you need to make a trade-off between the raw speed that the application offers and the aspects of making your code base maintainable, expressive, and adaptive to future changes.
Not all parts of your application need to be blazing fast. Portions of it require more ease of maintenance than speed. Consider the configuration parameters of your application. They need to be processed once, possibly when the application starts up. It’s more important for some of the configuration parameters to be externalized and presented to the user in a form that’s more readable than pure code, than for your application to start super quickly. The advantages of added expressiveness far outweigh the problems that might result from an increase in the startup time of the application.
Lots of initiatives are underway to make dynamic languages perform better on the JVM. It makes more sense to invest in using these languages to design expressive DSLs.
If you have an expressive code base today, tomorrow you’ll automatically get the benefits of improved performance when Groovy and Ruby language runtimes become more performant on the JVM.
Why do you think people use languages like Groovy and Ruby for designing a DSL, knowing full well that their code base will be less performant than equivalent Java code? It’s because these languages are maintainable, readable, and adaptive to changes. It’s much easier to grow your DSL when you have an inherently expressive host language underneath. With respect to performance, these factors are equally as important as the raw speed of execution. All of these together determine the evolution path and lifeline of the language that you design for the domain.
Statically typed languages like Scala are almost as performant as native Java. The wrapper model of DSL integration that you saw in section 3.2.2 is unlikely to cause any difference in performance compared to your native Java application.
Script engines that operate in a sandbox environment are somewhat slower, but then again, you don’t use scripts for performance-intensive tasks anyway. Scripting DSLs are mostly used for processing lightweight domain logic that’s usually exposed to end users and domain experts. Embedded DSLs or internal DSLs are mainly implemented as libraries in the host language and don’t incur any performance penalty whatsoever. External DSLs are free standing and implement their own language machinery. In most pragmatic applications, you don’t need to design external DSLs that have the complexity of a full-blown high-level language. In the real world, tools like parser generators (YACC, ANTLR) and parser combinators (as in Scala and Haskell) can be used effectively to easily build the necessary language infrastructure.
Finally, remember the golden rule for performance tuning: benchmark extensively before going for optimization.
3.6. Summary
In this chapter, we discussed all aspects of DSL-driven application development. You learned how to select the right strategy for integrating your DSL with the core application. The patterns of integration we discussed have given you a good idea about when to use the wrapper-based integration approach over the one based on ScriptEngine. The exact strategy depends a lot on the implementation language that you’re using. We also talked about how to handle errors and exceptions and how to report them to users in a language that’s natural to the domain you’re modeling. Finally, we concluded the chapter with a discussion about the trade-offs you might have to make between the performance and manageability of your DSL code.
- DSLs never stand alone. They have to be integrated with your core application. Let this be your golden rule when you’re planning a DSL design, beginning at day one.
- When you design an internal DSL, choose the language that has the best integration capabilities with the core language of your application.
- External DSLs often need additional infrastructure, like parser generators. Keep this in mind when you’re planning the implementation phase so that you have appropriate development resources on your team.
- Follow established best practices while you integrate your DSL with your core application.
With this chapter, we come to the end of the Getting Started section of the book. In the following chapters, we’ll dive deep into all the implementation aspects of DSLs. We’ll cover many of the JVM languages, design and implement DSL snippets using each of them, and then discuss the virtues and gotchas of every approach that they offer. It’s going to be a fascinating ride. Be prepared, stay calm, and buckle up for the trip ahead.
3.7. References
- Odersky, Martin, Lex Spoon, and Bill Venners. 2008. Programming in Scala. Artima.
- König, Dierk, Paul King, Guillaume Laforge, and Jon Skeet, 2009. Groovy in Action, Second Edition. Manning Early Access Program Edition. Manning Publications.
- Ghosh, Debasish. Why I like Scala’s Lexically Scoped Open Classes. Ruminations of a Programmer. http://debasishg.blogspot.com/2008/02/why-i-like-scalas-lexically-scoped-open.html.