
Chapter 7. External DSL implementation artifacts
This chapter covers
- The processing pipeline of an external DSL
- Parser classification
- Developing an external DSL using ANTLR
- The Eclipse Modeling Framework and Xtext
External DSLs, like the internal ones, have a layer of abstraction on top of an existing domain model. Where they differ is how they implement the layer. External DSLs build their own language-processing infrastructure: the parsers, the lexers, and the processing logic.
We’re going to start with a discussion of the overall architecture of the processing infrastructure of an external DSL. The internal DSLs get this infrastructure free from the underlying host language, but the external DSLs need to build them from the ground up. First, we’re going to look at hand-written parsers, and then move on to develop your first custom external DSL using the ANTLR parser generator. In the final section of the chapter, we’ll look at a different paradigm of DSL development: the model-driven approach of the Eclipse Modeling Framework (EMF), using Xtext, as a comprehensive environment for external DSL development. Figure 7.1 provides a roadmap of our progress through the chapter.
Figure 7.1. Our roadmap through the chapter

In this chapter, you’ll learn how to develop a language-processing infrastructure using the tools available on the market today. When you’re done, you can use this infrastructure to develop your own DSL processor.
7.1. Anatomy of an external DSL
You’ve already seen in section 1.5 how an external DSL is structured on top of a custom language infrastructure. In this section, we’ll look at the details of how the architecture of the DSL evolves along with the model of the domain that it describes. I’ll also describe some of the implementation options and the trade-offs that you need to make as a DSL designer.
7.1.1. The simplest option first
Let’s start with the simplest of options that you have when designing an external DSL. Your DSL has a custom syntax that you’ve developed a parser for. The parsing engine first lexicalizes the input stream, converting them to recognizable tokens. These tokens are also known as the terminals of the grammar. The tokens are then fed on to the production rules and parsed as valid sentences of the grammar. This process is shown in figure 7.2.
Figure 7.2. The simplest form of an external DSL. The parsing infrastructure does everything necessary to produce the target actions. The phases of processing the DSL script (lexicalization, parsing, generating the AST, and code generation) are all bundled in one monolithic block.

The parsing infrastructure is the only processor that does everything required to process the input DSL script and generate the necessary output.
![]()
The parsing infrastructure doesn’t need to be very sophisticated for every instance of the DSL that you want to process. It’s not uncommon to have simple data structures like string manipulators or regular expression processors as the parsing engine for simple languages of the domain. In most of these cases, you can bundle together the steps of lexicalization, parsing, and code generation into a consolidated set of actions.
The design shown in figure 7.2 doesn’t scale when it becomes more complex. If you have a simple requirement that’s not likely to scale up in complexity, you can choose this implementation of a do-all kind of language processing infrastructure. But not all problems in the world are simple. As you’ll see next, the only way to address complexity is to modularize concerns and introduce a suitable level of abstraction.
7.1.2. Abstracting the domain model
In figure 7.2, the do-all box of the parsing infrastructure handled all the processing that needed to be done to generate the target output. As I mentioned earlier, this approach doesn’t scale with the growing complexity of the language. Even if you consider a moderately complex DSL, the single box needs to perform all the following tasks within one monolithic abstraction:
- Parse the input, based on a set of grammar rules.
- Store the parsed language into a form of AST. For simpler use cases, you can skip the AST generation phase and embed actions to execute directly within the grammar.
- Annotate the AST, enriching it in the form of intermediate representations for generating target actions.
- Process the AST and perform actions like code generation.
That’s a lot of work for one abstraction. Let’s see if we can make this a little simpler.
Modularizing the big box
Let’s try to separate some of these responsibilities to make the design of the big box more modular. Figure 7.3 shows one way to do that.
Figure 7.3. Separation of concerns for the four responsibilities that the single box in figure 7.2 was doing. Each dotted region can now encapsulate the identified functionalities.

In figure 7.3, parsing is one of the core functionalities that you can identify as a separate abstraction. One of the natural side effects of parsing is the generation of an AST. The AST identifies the structural representation of the language in a form that’s independent of the language syntax. Depending on what you want to do from the AST, you have to augment it with additional information like object types, annotations, and other contextual notes that you’ll need in the next phase of processing. Your AST becomes much richer and starts accumulating the semantic information of your language.
The semantic model
When you’re working on a DSL for a specific domain, the enriched AST becomes the semantic model for the domain itself. The reason the top two regions overlap in figure 7.3 is that the core-parsing process needs to generate some sort of data structure.
The next process in the pipeline will enrich this data structure with the domain knowledge. The completion of this process leads to figure 7.4, where we identify the semantic model of the domain as one of the core abstractions of the DSL processing pipeline.
Figure 7.4. We’ve split the parsing infrastructure box of figure 7.2 into two separate abstractions. The parser takes care of the core parsing of the syntax. The semantic model is now a separate abstraction from the parsing engine. It encapsulates all the domain concerns that are ready to be fed into the machinery that generates all the target actions.
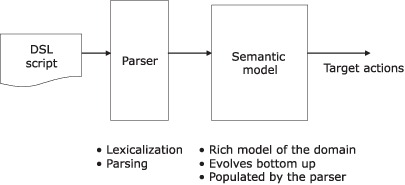
The semantic model is a data structure that’s enhanced with domain semantics after the DSL scripts are processed through the pipeline. Its structure is independent of the DSL syntax and is more aligned to the solution domain model of the system. It’s the perfect abstraction that decouples the input syntax-oriented scripting structure from the target actions.
As part of the target output, the DSL processor can do quite a few things. It can generate code that becomes part of the application. It can generate resources that are consumed and interpreted by the application runtime, like the object-relational mapping files in Hibernate that generate the data model. (Hibernate is an object-relational mapping [ORM] framework. For more information, go to http://www.hibernate.org.) The semantic model keeps you isolated from both sides and serves as the independent repository of all the necessary domain functionalities.
One other major benefit of having a well-designed semantic model is that your application is more testable. The entire domain model of your application can be tested independently of the syntax layer of your DSL. Let’s look at the semantic model in more detail and see how the model evolves during the development cycle of an external DSL.
Populating the semantic model
The semantic model serves as the repository of the domain model. The parser populates the semantic model as it consumes the input stream of the DSL script. The design of the semantic model is completely independent of the DSL syntax and evolves bottom-up from smaller abstractions, as with internal DSLs. Figure 7.5 illustrates how the semantic model evolves bottom-up as the repository of the domain structure, attributes, and behavior.
Figure 7.5. The semantic model evolves bottom-up as a composition of smaller domain abstractions. You develop smaller abstractions for domain entities, as indicated by the dotted rectangles. You then compose them together to form larger entities. In the end, you have the entire domain abstracted in your semantic model.

The difference with external DSLs lies in the way you populate the semantic model in the course of the parsing process. When you’re using internal DSLs, you populate smaller abstractions in the host language. You use the compositional features of the host language to build the larger whole. With external DSLs, you populate smaller abstractions as you parse the syntax of your language. As your parse tree grows up, the semantic model is fleshed out into a concrete representation of the domain knowledge.
After you’ve populated the semantic model, you can use it to generate code, manipulate databases, or produce models to be used by other components of your application. Now look again at figure 7.4. Are you convinced of the benefits that separating abstractions brings to the architecture of your DSL system?
Architecturally speaking, both internal and external DSLs form a layer on top of the semantic model. With an internal DSL, you use the parser of the host language; the contracts that you publish to the user take the form of a thin veneer on top of the semantic model. With external DSLs, you build your own infrastructure that parses the DSL script and executes actions. These actions lead to the population of the semantic model.
The parser that you implement as part of the infrastructure recognizes the syntax of the DSL script. Some important aspects of implementing external DSLs that you need to master are the techniques you can use to implement the various forms of parsers and lexical analyzers.
In the next section, we’re going to discuss parsing techniques. Rather than provide a detailed treatise on parser implementations, I’ll give a brief overview of the landscape and discuss parsing techniques and the class of grammars that each addresses. When you use the most appropriate set of tools to develop your external DSLs (like parser generators), you might not need a detailed exposition of how parsers are implemented. But, depending on the class of language that you design, a fair knowledge of parsing techniques always comes in handy. The references at the end of the chapter can point you to relevant information about this topic.
7.2. The role of a parser in designing an external DSL
The DSL script that you execute is fed into a lexical analyzer. The analyzer then tokenizes the stream into identifiable units that are recognized by the parser. When the parser has consumed the entire stream of input and has reached a successful terminal stage, we say that it has recognized the language. Figure 7.6 shows a schematic diagram of the process.
Figure 7.6. The process of parsing. The language script is fed into the lexical analyzer that tokenizes and feeds them into the parser.
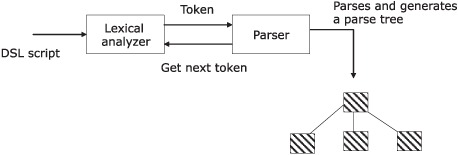
When I talk about lexical analyzers and parsers, I’m not assuming that they’re complex. Their complexity depends on the language that you design. As I mentioned earlier, if your DSL is simple enough, you might not need separate stages for lexicalization and parsing. Your parser might simply consist of a string processor that manipulates input scripts, based on regular expression processing. In such cases, you can get away with a handcrafted parser, as opposed to a more complicated one that you’d need to design when you’re using a more sophisticated infrastructure. Let’s see how you’d build a parser for a nontrivial DSL, using such an infrastructure that generates the parser for you.
7.2.1. Parsers and parser generators
The parser that you design is an abstraction for the grammar of your language. If you choose to implement the entire parser by hand, you’d need to:
- Develop the BNF syntax for the language
- Write the parser that mirrors the syntax
Unfortunately, when you develop a parser manually, the entire grammar gets embedded within the code base. Any change in the grammar means that you’ll have to make a significant change in the code that implements it. This kind of problem is typical when you’re programming at a lower level of abstraction (appendix A provides a more detailed explanation).
A better alternative to writing nontrivial parsers by hand is to use a parser generator. A parser generator lets you program at a higher level of abstraction. You simply have to define two things:
- The grammar rules, in Extended Backus Naur Form (EBNF) syntax
- Custom actions that you want to execute on recognition of grammar rules
With a parser generator, the infrastructure code for implementing the parser for your grammar will be encapsulated within the generator itself. Standard procedures for error handling and parse-tree generation become part of the generator; they work the same way for every parser that you create out of it.
As with any technique that offers a higher level of abstraction, you have to write, manage, and maintain less code. Another big advantage of using parser generators is that many of them are capable of generating the target parser in multiple languages. Table 7.1 contains information about some of the commonly used parser generators.
Table 7.1. Parser generators available today
|
Parser generator |
Associated lexical analyzer |
Details |
|---|---|---|
| YACC | LEX | Part of the UNIX distribution (originally developed in 1975) that generates parsers in C. |
| Bison | Flex | Part of the GNU distribution with almost similar functionality as YACC and LEX, but can generate parsers in C++. |
| ANTLR (go to http://antlr.org) | Packaged with ANTLR | Implemented by Terrance Parr. Capable of generating parsers in a host of target languages like Java, C, C++, Python, and Ruby. |
| Coco/R | Generates a scanner | Coco/R is a compiler generator, which takes an attributed grammar of a source language and generates a scanner and a parser for that language. |
Besides the list in table 7.1, there are a few other parser generators like Java Compiler Compiler (JavaCC), developed by Sun Microsystems (go to https://javacc.dev.java.net/) and IBM Jikes Parser Generator (http://www10.software.ibm.com/developerworks/opensource/jikes/project/). Both Jikes and JavaCC generate Java parsers and offer functionalities similar to YACC and Bison.
Whether you use a hand-written parser or one constructed by a generator, it’s the syntax of your language that directs the parser. When the parser recognizes the language, it generates a parse tree that encapsulates the whole process of recognition into a recursive data structure. If you’ve added custom actions to your grammar rules, the parse tree that’s generated is augmented with that additional information, forming your semantic model. Let’s see how the parser generator does this translation from custom syntax to the semantic model of your domain by looking at an example of a language that’s processed using ANTLR.
7.2.2. Syntax-directed translation
When your external DSL implementation processes a piece of DSL script, it starts with the recognition of its syntax. You parse the syntax and translate it to generate the semantic model. The semantic model acts as the repository for the next action that you execute. But how do you recognize the syntax? Table 7.2 shows the two sets of artifacts that you need for this recognition to be successful.
Table 7.2. Recognizing the DSL syntax
|
Artifact |
What it does |
|---|---|
| A context-free grammar that identifies the set of valid productions | The grammar specifies the syntactic structure of the DSL. DSL scripts that obey the rules defined in the grammar are the only ones that are considered to be valid. Note: I’m going to use the ANTLR parser generator for all examples in this section to specify the grammar. |
| A set of semantic rules that you apply to the attributes of the symbols that your grammar recognizes. These rules are then used to generate the semantic model. | Along with each grammar rule, you can define actions that are executed when the rule is recognized by the parser. The action can be the generation of the parse tree or any other trigger that you want to generate, as long as the action is related to the rule being recognized. Defining an action is easy. Every parser generator allows foreign code to be embedded, along with the DSL-based production definitions of the grammar. For example, ANTLR lets you embed Java code, YACC lets you embed C. |
Figure 7.7 illustrates how the grammar rules that you supply along with the custom actions get processed by the parser generator to generate the semantic model.
Figure 7.7. The parser generator takes the grammar rules and the custom actions as input. It then generates the lexical analyzer and the parser, which accept the DSL script and generate the semantic model. Then you can integrate this model with the core application.

Let’s do a sample exercise of language interpretation for a small order-processing DSL using the ANTLR parser generator. We’ll define the lexical analyzer and the grammars and embed a few custom actions that’ll populate the semantic model of our language.
Setting up the ANTLR example
The language is similar (albeit simpler) to the order-processing DSL that we developed in chapter 2 using Groovy. This example will teach you the steps you need to perform to use a parser generator to develop an external DSL. You’ll develop the syntax of your DSL and generate the semantic model that produces a custom abstraction of all the orders that are being placed.
Consider the following snippet as the series of orders that a client can place with the trading organization:
buy IBM @ 100 for NOMURA sell GOOGLE @ limitprice = 70 for CHASE
The entire order placement instruction consists of repeating lines of the same format. You’ll design an external DSL using ANTLR that processes these scripts. Then, you’ll generate data structures as the semantic model. To keep things simple, we’ll consider each line as a separate order and the entire collection as a list of orders placed by the client. The first step is to design the lexical analyzer that’ll preprocess the input script into a sequence of symbols that our grammar can recognize.
Designing the lexical analyzer
The lexer reads the input stream and converts the characters into tokens as per the token definitions specified in the lexical analyzer. With ANTLR, you can specify lexer rules either inline with the grammar specification or as a separate file. In our example, we’ll put all the token specifications in a separate file that we’ll call OrderLexer.g; ANTLR specifications live in a file with a .g extension (for grammar). Note that the specification given in the following listing uses a DSL structure that’s readable and expressive as a token language.
Listing 7.1. OrderLexer.g: The lexer for your DSL in ANTLR

The lexer rules are matched in a greedy way. When the lexer tries to match rules with the input stream, it uses the rule that has the maximum match. In case of a tie, it picks up the rule that appears first in the order within the specification file.
The next step is to jump into the syntax of your language. That syntax is identified by grammar rules that you design.
Designing the grammar rules
In this step, you define the grammar rules, which are based on the syntax of your DSL. It’s a pretty simple DSL, and is for illustration purposes only. We’re going to skip over a lot of the error processing functionalities and focus on the architecture of the grammar rules. For a detailed treatment of how ANTLR defines grammar rules and the various options that it offers to the user, refer to [2] of section 7.6.
The grammar rules in listing 7.2 are defined in a separate file, OrderParser.g. That file follows the EBNF notation, which is incredibly expressive to a language designer. Later, when you integrate the lexer and the parser along with the processor code that drives the parser, you’ll see how ANTLR generates the actual parser code from these EBNF specifications. Note that the generator does all the heavy lifting of implementing the actual parser. You, as the developer, get to focus on the task of defining the specific syntax.
Listing 7.2. OrderParser.g: Grammar rules for your DSL in ANTLR

For anyone familiar with the EBNF notation, these grammar rules look expressive. We want to build a collection of orders ![]() . Each order consists of a line that specifies the order placement details
. Each order consists of a line that specifies the order placement details ![]() . We’re keeping a reference to the lexer class at the beginning of the grammar file within the options block
. We’re keeping a reference to the lexer class at the beginning of the grammar file within the options block ![]() .
.
ANTLR comes with a GUI-based interpreter environment (ANTLRWorks; go to http://www.antlr.org/works)) in which you can run sample DSL scripts interactively through the specified grammar. It builds the parse tree for you. You can also debug your rules, in case there are any parsing exceptions.
Now you must be wondering why the grammar that we specified in listing 7.2 doesn’t have any custom action for the necessary syntax-directed translation. The reason is because I want to give you a feel for the lightweight DSL syntax that the grammar specification for ANTLR gives you. The grammar rules themselves are sufficient for the successful recognition of a valid DSL script; you don’t need anything else! In the next section, we’ll discuss how to embed Java code as custom action definitions within each of the grammar rules.
Embedding foreign code as custom actions
As you saw in listing 7.2, the ANTLR grammar lets you build a default parse tree through the parser that it generates. If you want to augment the parse tree with additional information or generate a separate semantic model by parsing the DSL script, you can do it by defining custom actions with embedded foreign code. In this section, we’ll add custom actions to the grammar rules that we defined in listing 7.2 and generate a collection of custom Java objects by parsing the DSL script.
We begin by defining a plain old Java object (POJO) Order. When the script is parsed, it generates a semantic model consisting of List of Order objects. The following listing shows the resulting actions embedded in our grammar rules.
Listing 7.3. OrderParser.g: Action code embedded in the grammar rules


If you’re not familiar with the EBNF style of writing grammar rules and how to embed action code within them, you can look
at [2] in section 7.6. Note that the rules you define can have return values ![]() that get propagated upward as the parsing continues. Computations bubble up and you end up forming the collection of Order objects
that get propagated upward as the parsing continues. Computations bubble up and you end up forming the collection of Order objects ![]() .
.
The next listing is the abstraction for the Order class. I’ve made this pretty simple for illustration purposes.
Listing 7.4. Order.java: The Order abstraction
public class Order {
private String buySell;
private String security;
private int price;
private String account;
public Order(String bs, String sec, int p, String acc) {
buySell = bs;
security = sec;
price = p;
account = acc;
}
public String toString() {
return new StringBuilder()
.append("Order is ")
.append(buySell)
.append("/")
.append(security)
.append("/")
.append(price)
.append("/")
.append(account)
.toString();
}
}
In the next section, we’ll write the main processor module that integrates the ANTLR generated lexer, the parser, and any other custom Java code. Let’s see how you can parse your DSL script and generate necessary output.
Building the parser module
Now you can use ANTLR to build the parser and integrate it with the driver code. Before we do that, we need to write the driver that takes character streams from input, feeds them to our lexer to generate tokens and to the parser to recognize our DSL script. The following listing shows the driver code, the Processor class.
Listing 7.5. Processor.java: The driver code for our parser module

We use the tokenization support that ANTLR provides and its built-in classes for reading from the input stream. In the listing,
after we construct the parser ![]() , we invoke the method from the start symbol of the grammar, orders(), which is generated by ANTLR. All the classes that are referred to in the listing (like OrderLexer, Common-TokenStream, and OrderParser) are either generated by ANTLR from our grammar rules or are part of the ANTLR runtime. We’re assuming that the DSL is in
a file whose path is specified as the first argument of the command-line invocation.
, we invoke the method from the start symbol of the grammar, orders(), which is generated by ANTLR. All the classes that are referred to in the listing (like OrderLexer, Common-TokenStream, and OrderParser) are either generated by ANTLR from our grammar rules or are part of the ANTLR runtime. We’re assuming that the DSL is in
a file whose path is specified as the first argument of the command-line invocation.
As a sample action of what you can do with the semantic model, the program in listing 7.5 prints the list of Order objects that’s generated by the parsing process. If this were a real program, you could feed these objects directly into other modules of your system to integrate the DSL with your core application stack.
We’ve done a lot of work in this section. Let’s look back at all we’ve been through.
How far we’ve come
ANTLR has classes like org.antlr.Tool that work on your grammar files to generate the Java code. Then your build process can compile all Java classes, including the ones that form parts of your custom codebase. Table 7.3 contains a summary of what we’ve done so far to build the entire infrastructure for processing our external DSL.
Table 7.3. Building an external DSL with the ANTLR parser generator
|
Step |
Description |
|---|---|
|
In listing 7.1, we built the lexer OrderLexer.g. We used the token definitions for our order-processing DSL. Note: Your lexer definition file should always be separate from the parser. Keeping it separate makes your lexer reusable across parsers. |
|
In listing 7.2, we defined the syntax of our DSL in OrderParser.g, based on ANTLR syntax. The grammar recognizes valid syntax for the DSL and flags an exception for any invalid syntax. |
|
In listing 7.3, we enriched the grammar definition with custom Java code that injects semantic actions into the parsing process. We’re building our semantic model using these code snippets. |
|
In listing 7.5, we have custom Java code that models an Order abstraction and a driver process that uses ANTLR infrastructure to invoke our DSL script into the parsing pipeline. |
Now you have a basic idea of the entire development lifecycle for building and processing an external DSL using a parser generator. This approach is pretty common. When you want to design an external DSL by building a language that’s based on a custom infrastructure, this is the process that you’ll follow.
ANTLR is a great parser generator. It’s used extensively to build custom parsers and DSLs. But there’s still more that ANTLR can do. So far, we haven’t talked about the class of grammars that ANTLR can handle. Theoretically, you can parse any language if you don’t have any constraints on the efficiency of the parser that’s generated. But in real life, we need to make compromises. When you’re developing a DSL, you want to have the most efficient parser that can parse your language. You don’t want a generic parser that can parse many other languages but has a low efficiency coefficient for your language. ANTLR is just one tool that can generate a parser capable of recognizing a specific class of languages.
As a DSL designer, you need to be aware of the general classification of parsers, their implementation complexities, and the class of languages that each of them is capable of handling. The next section provides an overview of parser taxonomies and their complexities.
7.3. Classifying parsers
When a parser recognizes the input stream that you give to it, it generates the complete parse tree for the language script. Parsers are classified based on the order in which the nodes of the parse tree are constructed. The parser might start constructing the parse tree from the root; these parsers are called top-down parsers. Conversely, the parse tree might be constructed starting from the leaves and moving up towards the root. We call these bottom-up parsers. Top-down and bottom-up parsers vary in the complexity of their implementations and the class of grammars that they recognize. As a DSL designer, it’s worthwhile to make yourself familiar with the general concepts associated with both of them. Look at figure 7.8, which illustrates how parse trees are constructed by each type of parser.
Figure 7.8. How top-down and bottom-up parsers construct their parse trees.
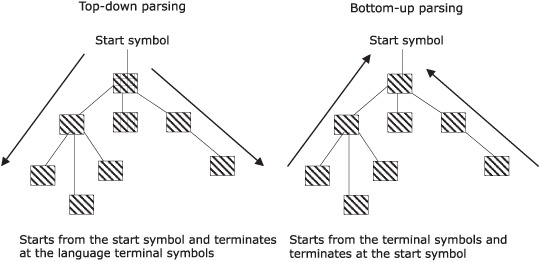
In this section, we’ll discuss how you can classify parsers based on the way they construct the parse tree and derive the language out of the production rules. Within the two classes of parsers (top-down and bottom-up), there are quite a few variations that add to the class of languages that they recognize at the expense of a little complexity in implementation. I assume a basic familiarity with parsing techniques, look-ahead processing, parse trees, and other fundamental language-processing concepts. If you need background on these topics, see [3] in section 7.6.
Let’s start with top-down parsers and look at some of the implementation variations within them.
7.3.1. Simple top-down parsers
As I mentioned earlier, a top-down parser constructs the parse tree starting from the root and proceeds with a leftmost derivation of the input stream. This means it starts processing the input from the left symbol and moves toward the right symbol.
The most general form of top-down parser is the recursive descent (RD) parser. You might be asking yourself, what does recursive descent mean? Recursive means that these parsers are implemented in terms of recursive function calls (see [1] in section 7.6). The descent part refers to the fact that the parse tree construction starts at the top (which also explains the top-down category).
We’re going to start with the simplest RD parser and gradually work our way through the complex variants that are powerful enough to recognize a broader class of languages as long as you use an efficient implementation. First, we’re going to discuss LL(1) and LL(k) RD parsers. These two classes of top-down parsers are the basic implementations that cover most of what you’ll need to design external DSLs.
LL(1) recursive descent parser
An LL(1) RD parser is a top-down parser that can parse the syntactic structures of a language based on a single look-ahead token. What does LL(1) mean? The first L denotes that the parser processes the input string from left-to-right. The second L denotes that when the parser constructs the parse tree from the root down to the leaves, it descends into the children from left to right. As you might’ve guessed from the definition, the 1 indicates the number of look-ahead tokens. Because there’s only one look-ahead token, the parser selects the next production rule to apply based on the match of this single token.
What if the parser can’t find an exact matching rule based on the single lookahead token? This might happen because your grammar can have multiple production rules that start with the same symbol. Remember the LL(1) parser can look-ahead only one token. In order to resolve this ambiguity of multiple rules matching the same look-ahead token, you can either use an LL(k) parser where k > 1, or you can use left-factoring to change your grammar definition to make it acceptable to an LL(1) RD parser (see [1] in section 7.6 for details).
Sometimes you might want a top-down parser to handle left recursion. If your language has a grammar rule of the form A : A a | b, then your top-down parser goes into an infinite loop. Remember that I mentioned earlier that RD parsers are implemented using recursive calls. A left recursion in the production rule makes it recurse forever. There are rule-rewriting techniques you can use to convert left-recursive rules. See [3] in section 7.6 for details.
LL(k) recursive descent parser
The LL(k) is a more powerful variant of LL(1) in the sense that it has a larger lookahead set. It uses this set to determine which production rule to apply on the input token. Yes, a larger look-ahead set means that this parser is more complex than the LL(1). But it’s worth investing in that complexity, considering the benefits of generating more powerful parsers.
How much more powerful is this parser than the LL(1)? Because LL(k) parsers have such an enhanced look-ahead set, they can parse many computer languages. It’s still limited in the sense that the parser can disambiguate grammar rules that are disjoint in only the first k tokens. But you can augment an LL(k) parser with more sophisticated features. One feature is backtracking, which makes the parser recognize languages that have arbitrary look-ahead sets. We’ll discuss backtracking parsers in section 7.3.2.
ANTLR generates LL(k) parsers with an arbitrary look-ahead set and is the most suitable for implementing DSLs in real-life applications. Many large software applications like Google App Engine, Yahoo Query Language (YQL) and IntelliJ IDEA use ANTLR for parsing and interpreting custom languages.
You know the basics, so we can jump right into a discussion of some of the advanced top-down parsers. You might not use them very often, but it’s always useful to know about them and appreciate the techniques that they employ to make efficient implementations. In fact, we’ll be using one of these techniques in chapter 8 when we discuss how to design external DSLs using Scala parser combinators.
7.3.2. Advanced top-down parsers
The advanced parsing techniques give more power to your parsers, but at the expense of added complexity to the implementation. Keep in mind that you’ll usually use parser generators or parser combinators that abstract the implementation complexities within them. As a developer, you’ll use the published interfaces of those abstractions.
Recursive descent backtracking parser
This parser adds backtracking infrastructure to an LL(k) RD parser, which gives it the power to process arbitrary-sized look-ahead sets. With backtracking infrastructure in place, the parser can parse ahead as far as it needs to. If it fails to find a match, it can rewind its input and try alternate rules. This capability makes it quite a bit more powerful than the LL(k).
OK, so it can backtrack and choose alternate rules, but is there any order to this process? You can specify hints for ordering in the form of syntactic predicates, as in ANTLR (see [2] in section 7.6). You can declaratively specify the ordering so that the parser can select the most appropriate rule to apply on the input stream.
With this kind of parser, you get much more expressive grammars, called parsing expression grammars (PEGs). PEG is a more expressive form of grammar that extends ANTLR’s backtracking and syntactic predicates (see [4] in section 7.6). PEG adds operators like & and ! that you specify within the grammar rules to implement finer controls over backtracking and parser behaviors. They also make the grammar itself way more expressive. You can develop parsers for PEGs in linear time using techniques like memorizing.
Memoizing parsers
With a backtracking RD parser, partial parsing results can be evaluated repeatedly when the parser backtracks and tries alternative rules. A memoizing parser makes parsing efficient by caching partial results of parsing.
That sounds great, but because the memoizing process means that previously computed results need to be stored, you’re going to need additional memory. But the efficiency you gain over conventional backtracking parser implementations will more than outweigh the pain of needing additional infrastructure. You’ll also be pleased to know that our old friend ANTLR supports memoization.
You can avoid this need for more memory by implementing a packrat parser, which, in addition to having a catchy name, also happens to be a functional pearl (see [6] in section 7.6). You implement this parser by using the natural laziness that functional languages like Haskell have. We’re going to discuss packrat parsers more when we talk about Scala parsers in section 8.2.3.
Predicated parsers
In some cases, an RD parser can’t determine the alternative rule to apply based on syntax alone. To help it make decisions, you can annotate the parser using Boolean expressions. A particular alternative matches only if the Boolean expression evaluates to true.
Typically, you would use a predicated parser when you want a single parser that can parse multiple versions of a language. The core language can be recognized by the base parser, and additional semantic predicates are used to handle extensions and other versions. For more information about predicated parsers, see [1] in section 7.6.
Top-down parsers can be extremely simple, like the LL(1) that we discussed in section 7.3.1. But for complex language parsing, you need sophisticated ones, like the backtracking parsers, memoizing parsers, and predictive parsers that we talked about. Each of these advanced variants makes the parsers recognize a wider class of languages, along with reducing the time and space complexity of implementation. In the next section, we’re going to see another class of parsers that are possibly more versatile than top-down parsers in the sense that they can recognize any deterministic context-free language.
7.3.3. Bottom-up parsers
A bottom-up parser constructs the parse tree starting from the leaves and moving toward the root. It reads the input stream from left to right and constructs a rightmost derivation through successive reduction of grammar rules, proceeding toward the start symbol of the grammar. It’s the opposite direction of what a top-down parser follows.
The most common technique in bottom-up parsers uses what is known as shift-reduce parsing. When the parser scans the input and meets a symbol, it has two alternatives:
- Shift the current token aside (usually to an implementation stack) for subsequent reduction.
- Match the current handle (the substring of the input string that matches the right-hand side of a production rule), and replace it with the nonterminal on the left-hand side of the production. This step is commonly known as the reduction step.
We’re going to talk about two of the most commonly used shift-reduce bottom-up parsers: operator precedence parsers and LR parsers. Operator precedence parsers have limited capability, but are extremely simple to implement by hand. On the other hand, LR parsers are used extensively by most of the parser generators.
Operator precedence parser
This bottom-up parser can recognize only a limited set of languages. It’s based on a static set of precedence rules that are assigned to the terminal symbols.
An operator precedence parser is simple to implement by hand, but it’s of limited use because it can’t handle multiple precedence of the same symbol and it can’t recognize a grammar that has two nonterminals side by side. For example, the following snippet doesn’t use operator precedence grammar because expr operator expr is a rule with more than one adjacent non-terminal:
expr : expr operator expr operator : + | - | * | /
Let’s now look at the most widely used class of bottom up parsers that can implement a large class of languages and are used by popular parser generators like YACC and Bison.
LR(k) parser
An LR(k) parser is the most efficient bottom-up parser. It can recognize a large class of context-free grammars. The L denotes that the parser processes the input string from left-to-right. The R denotes that it constructs the rightmost derivation in reverse during parsing. And as you might have guessed from the definition, the k indicates the number of look-ahead tokens. The parser uses this number to determine which production rule to apply.
An LR parser is table driven. The parser generator constructs a parse table that contains the action that the parser needs to take on recognition of an input symbol. As you saw earlier, the action can be a shift or a reduce. When the whole string is recognized, the parser is said to be reduced to the start symbol of the grammar.
This kind of parser is difficult to implement by hand, but it’s strongly supported by parser generators like YACC and bison.
Variations of the LR parser
The LR parser has three variations: the simple LR (SLR), the look-ahead LR (LALR), and the canonical LR. SLR parsers use a simple logic to determine the look-ahead sets. The parsing process results in lots of conflict states. LALR parsers are more sophisticated than SLR ones and have better look-ahead processing and fewer conflicts. Canonical LR parsers can recognize more language classes than LALR.
What you’ll really be using
Parsers form the core foundation of external DSLs. You need to have a basic idea of how parsers are related to the class of languages that they recognize. I’ve given you a lot of nifty information in this section that’ll help you choose the right kind of parser for your DSL. But when you’re out there developing in the real world, except for when you’re dealing with trivial language implementations, you’ll never be implementing parsers by hand. You’ll choose parser generators.
When you use a parser generator, you can think at a higher level of abstraction. You can specify grammar rules (or the language syntax), and the generator will construct the actual parser implementation for you. But remember, that implementation consists only of the language recognizer and a simple form of the AST. You still have to transform this AST into the semantic model that suits your processing requirement. For this, you need to write action code, embedded within the grammar rules.
In the next section, you’ll learn how to take this approach up another level of abstraction by adding support for rich tooling to the process of DSL development.
7.4. Tool-based DSL development with Xtext
Parser generators like ANTLR are a big step forward toward developing external DSLs at a higher level of abstraction. But you still need to embed your target actions directly within the grammar rules. The EBNF rules and the logic for generating your semantic model are still not sufficiently decoupled. If you need to implement multiple semantic models for a single set of grammar rules, you might even end up duplicating the code for the parser itself; either that, or you’ll have to derive your semantic models from a common base abstraction that the grammar rules offer.
Xtext is a framework for developing external DSLs that leverages the Eclipse platform. With Xtext, you get a complete toolset for managing the entire lifecycle of your DSL. It’s integrated with the Eclipse Modeling Framework (EMF) and it maintains all the artifacts of your DSL development process in the form of managed components. (For more information about EMF, go to http://www.eclipse.org/emf.)
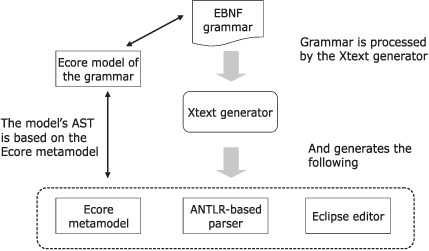
To use Xtext, you’ll have to write an EBNF grammar for your language. The EMF uses this grammar to generate all the following goodies:
- An ANTLR-based parser
- A metamodel for your language, which is based on the Ecore metamodeling language of EMF
- An Eclipse editor that offers syntax highlighting, code assist, code completion, and a customizable outline view of your model
Figure 7.9 shows a snapshot of the postprocessing that Xtext does with the EBNF grammar rules that you define.
Figure 7.9. Xtext processes the textual grammar rules and generates lots of stuff. Chief among the important stuff is the Ecore metamodel that abstracts the syntax that the model of the grammar uses.
Xtext also has composable code generators that generate semantic models that you set requirements for. In this section, we’ll implement the same order-processing DSL that we implemented with ANTLR in section 7.2.2. You’ll see how the comprehensive tooling support and model-based development of Xtext makes it easier to manage the evolution of your DSL. Let’s start with the definition of your language: the EBNF-based Xtext grammar rules.
7.4.1. Grammar rules and the outline view
The grammar that you specify for your DSL uses the EBNF form with some of the additional adornments that Xtext supports. I’m not going to go into the details of the grammar-rule specifications that Xtext supports. The Xtext User Guide has all the juicy details (see [5] in section 7.6). For now, look at the Xtext grammar rules for the order-processing DSL from section 7.2.2 in the following listing.
Listing 7.6. Xtext grammar rules

This code is similar to what we used with ANTLR. Some of the newer stuff asks Xtext to generate the metamodel for the language
![]() . If you have an existing Ecore meta-model, you can also ask Xtext to import it to your workspace and synchronize with the
textual representation of the grammar rules that you write. You’ll see more of the internals of the metamodel in section 7.4.2. Another interesting thing is that you can reuse an existing grammar by mixing it in with your rules
. If you have an existing Ecore meta-model, you can also ask Xtext to import it to your workspace and synchronize with the
textual representation of the grammar rules that you write. You’ll see more of the internals of the metamodel in section 7.4.2. Another interesting thing is that you can reuse an existing grammar by mixing it in with your rules ![]() .
.
Xtext generates the default parse tree (AST) from your grammar rules. You can make inline assignments within the grammar to
connect the various elements of the AST that the parser generates ![]() ,
, ![]() .
.
Along with the textual version of the grammar rules, Xtext also displays an outline view that shows the structure of your model as a tree. You can use the outline view to navigate to the various model elements. Figure 7.10 shows the outline view for the grammar we defined in listing 7.6.
Figure 7.10. Hierarchical, or outline view of the model. The outline view shows the structure associated with each rule. You can sort the elements alphabetically and select an element to navigate to the corresponding one in the text editor.

What you see in the figure is the default view of the model. What’s uber-cool is that Xtext allows you to customize almost every aspect of this view. You can customize the outline structure, let users selectively filter contents, and register custom context menus, as well as other things. You only have to override the default implementations. The outline view is part of the toolset for visualizing the model of your language. It works in collaboration with the textual representation of your grammar and gives the process of DSL development a richer feeling.
7.4.2. The metamodel for your grammar
After you define the grammar rules in the text editor and ask Xtext to generate the language artifacts, it generates the complete Ecore metamodel from the grammar. (Ecore contains the core definition of abstractions in EMF.) The metamodel is an abstraction that represents the textual form of your grammar in a model that Xtext can manage easily. The metamodel uses the Ecore metatypes to describe the components of your grammar rules. Figure 7.11 shows the metamodel of our grammar in Xtext.
Figure 7.11. The metamodel of the order-processing DSL. Every production rule from our grammar returns an Ecore model element like EString and EInt.

In this metamodel, notice that the AST of the grammar is being represented by metatypes like EString and EInt, which are some of the abstractions provided by Ecore.
Along with the metamodel, the generator also generates the ANTLR parser, which instantiates the metamodel. It’s the metamodel that controls the entire tooling support offered by Xtext. For more details about the internals of the metamodel, refer to the Xtext User Guide (see [5] of section 7.6).
After the generator has generated the required artifacts, all the wonderful plug-ins are installed. You use the plug-ins to write your DSL scripts in an editor that offers the smartness of syntax highlighting, code assist, and constraint checks. Xtext has the entire language of the DSL in its repository as a model based on EMF; it can add smartness to the way the script is rendered for you. Figure 7.12 shows an editing session for our DSL.
Figure 7.12. The Xtext metamodel provides you with an excellent editor for writing DSLs. See how the code completion suggests alternatives for you? You can also see the syntax highlighting feature, which is quite handy.

Now we’ve embedded our language within Xtext’s repository. Xtext gives us a tooling interface for manipulating the syntax of our DSL and automatically updates its own Ecore model. It also gives us a default AST in a representation as per the parser that it generates. But when you use a DSL, you need to generate a more refined abstraction—the semantic model. As a DSL designer, you want to generate your semantic model through custom code development and you’d like it to be decoupled from the core model of your language. Xtext can do this through code-generating templates that you can use to integrate the grammar rules with the generation of your model. Let’s explore more of Xtext’s capabilities and see what facilities the generator uses to generate code that will construct your semantic model.
7.4.3. Generating code for the semantic model
After you have the grammar rules and the metamodel defined as I’ve described, it’s time to write a code generator that’ll process the models that you created and generate a semantic model for you. You might want to generate multiple semantic models from one grammar. For example, for our order-processing DSL, we might want to generate a Java class that creates a collection of all orders that the user has entered. We could also generate a set of JSON (JavaScript Serialized Object Notation) objects with those orders for transporting them to a data store. Ideally, both these models should be decoupled from the core grammar rules. Figure 7.13 shows how the overall architecture should look.
Figure 7.13. The semantic models need to be decoupled from the grammar rules. For one set of grammar rules, you can have multiple semantic models.

Let’s generate the Java code using the Xpand templates that Xtext offers.
Code generation using the Xpand template
The Xpand template walks through the AST of your grammar rules and generates the code for you. The first input that it needs is the metamodel, which we’ll specify as <<IMPORT orders>>. Here’s the main template that serves as the entry point and dispatches to all other templates:
≪IMPORT orders≫ ≪DEFINE main FOR Model≫ ≪EXPAND Orders::orders FOR this≫ ≪ENDDEFINE≫
In this snippet, orders is the name of the metamodel we need to import. Every template consists of a name and a metatype on which the template is invoked. In this example, the template is named main and the metatype is specified as Model (Model was an element in our grammar rule that’s represented by Xtext as a metatype in the Ecore metamodel). Our main template is simple. All it does is dispatch to the Orders::orders subtemplate on recognition of the symbol Model. The following listing shows our template definition for Orders::orders.
Listing 7.7. Template for generating the semantic model for orders

When the grammar has recognized the language and has reduced to the start symbol (Model), this template will generate the code as it’s specified in the listing. Table 7.4 shows in detail some of the features of the code generation template.
Table 7.4. Xtext code generation template
|
Feature |
Explanation |
|---|---|
| Can generate any code. In our example, we’re generating a Java class. | The class exposes one method that returns a collection of all orders parsed from the DSL script. The collection that’s returned contains a POJO (ClientOrder) that we defined separately from the grammar. |
| Inline expansion of the order template within orders. | We access the elements from within the production rules and use templates for textual substitution of inline elements. Look at how ≪this.line.price.value≫ serves as the placeholder for the price value when it’s parsed within the DSL script. |
When the templates are ready, you can run the generator once again from the context menu of the project.
Processing the DSL script
Let’s say that this is the DSL script that we need to process:
buy ibm @ 100 for nomura sell google @ limitprice = 200 for chase
For that script, the class shown in the following listing will be generated by Xtext in the file OrderProcessor.java.
Listing 7.8. Class generated by the template in listing 7.7
import java.util.*;
import org.xtext.example.ClientOrder;
public class OrderProcessor {
private List<ClientOrder> cos = new ArrayList<ClientOrder>();
public List<ClientOrder> getOrders() {
cos.add(new ClientOrder("buy", "ibm", 100, "nomura"))
cos.add(new ClientOrder("sell", "google", 200, "chase"))
return Collections.unmodifiableList(cos);
}
}
With Xtext, defining the grammar rules and building the semantic model are sufficiently decoupled. The grammar rule definitions are managed by the smart textual editor that is complemented with the customizable outline view. The semantic model implementation is controlled through the code generators linked with the parsers through the metamodel.
Let’s take a final look at the pros and cons of a hybrid textual and visual environment like Xtext when you’re developing external DSLs.
The good and the bad (but it’s mostly good)
Xtext offers a novel approach to external DSL development. It augments the traditional textual representation of your DSL with a rich toolset. You still have to write your grammar rules in EBNF notation. But behind the scenes, Xtext not only generates the ANTLR parser for you, but also abstracts your grammar rules within a meta-model. The architecture, which is based on the metamodel, manages the entire toolset. You get some powerful editing capabilities for your DSL. Using Xtext-based development, you can also decouple your semantic model from the grammar rules and use Xpand template facilities to generate custom code.
Overall, Xtext gives you a powerful experience when you develop external DSLs because you have the EMF available to you. The only thing you need to keep in mind is that you’re basically dependent on the Eclipse platform. Even so, only the IDE integration in Xtext is Eclipse-dependent. You can use the runtime components like the parsers, the metamodel, the serializers, and the linkers, as well as the Xpand templating in any arbitrary Java process. All this makes Xtext the framework to use when you’re developing an external DSL.
7.5. Summary
In this chapter, you learned some of the design principles of external DSLs. An external DSL needs to have its own language-processing infrastructure. If your DSL is low enough in complexity, you can use a hand-written parser to process the syntax of the language. If your DSL is more complex, you need to use a full-stack parser generator like YACC, Bison, or ANTLR. We discussed ANTLR-based language construction in detail and you developed your own custom, order-processing DSL using it. You saw how the various components of the implementation engine like the lexical analyzer, the parser, and the semantic model coordinate to generate the final DSL processor.
- When you’re designing a DSL, you need to have a clean separation of the syntax and the underlying semantic model.
- In an external DSL, the semantic model can be implemented by host language structures. For syntax parsing, you need to have a parser generator that integrates with the host language. ANTLR is a typical parser generator that integrates well with Java.
- Choose the appropriate parser class for what you need before you design external DSLs that need moderate language-processing capabilities. Making the correct choice will help you moderate the complexity of your implementation.
- Choose the right level of complexity that does the job. For an external DSL, you might not need the full complexity of a general language design.
When you design a nontrivial external DSL with a fairly rich syntax, it’s the parser that forms the core of it. Parsers are classified based on the way they process the input stream and construct the parse tree. There are two main types of parsers: top-down and bottom-up. As a language designer, you need to be aware of the class of languages that each of these implementations can handle. You also need to know the implementation complexity and trade-offs that a specific type of parser implies. We discussed all of these in this chapter when we talked about parser classification.
Judging from the DSL that you designed, you know how to select the right kind of parser for your language. In the final section of this chapter, we moved on to a different paradigm of DSL development that mixed in a rich toolset along with the standard textual model that you’re already familiar with. Using the model-driven approach of the EMF, Eclipse offers Xtext as a comprehensive environment for external DSL development. We developed the same order-processing DSL using Xtext. The process demonstrated how the richness of a model-driven approach complemented with a full toolset can lead to a richer experience of language development.
In the next chapter we’ll look at an entirely different paradigm for developing external DSLs using Scala. Scala offers functional combinators that you can use as building blocks to develop parsing techniques. They’re called parser combinators, and we’ll use them to develop sample external DSLs from our domain of securities trading.
7.6. References
- Parr, Terence. 2009. Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages. The Pragmatic Bookshelf.
- Parr, Terence. 2007. The Definitive ANTLR reference: Building Domain-Specific Languages. The Pragmatic Bookshelf.
- Aho, Alfred V., Monica S. Lam, Ravi Sethi and Jeffrey D. Ullman. 2006. Compilers: Principles, Techniques, and Tools, Second Edition. Addison Wesley.
- Ford, Bryan. 2004. Parsing Expression Grammars: A Recognition Based Syntactic Foundation. Proceedings of the 31st ACM SIGPLAN-SIGACT symposium on principles of programming languages, pp 111-122.
- Xtext User Guide. http://www.eclipse.org/Xtext/documentation/latest/xtext.html.
- Ford, Bryan. 2002. Packrat parsing: simple, powerful, lazy, linear time, functional pearl. Proceedings of the seventh ACM SIGPLAN International Conference on Functional Programming, pp 36-47.