
5
Data
One of the most important tasks associated with analyzing crime and intelligence information is to know your data. Data and information are the currency within the analytical community; however, very little if any of the information that falls under the purview of crime and intelligence analysis is ever collected with that purpose in mind. Unlike the business and academic communities, in which data sets are designed and constructed with thought given to the ultimate analysis at almost every step of the way, some of the data that falls in the analysts’ laptops are so ugly that only a mother could love them. Without data and information, however, we analysts would perish. Data truly are the lifeblood of the analytical community, and some of the most unruly data sets can prove to be the most rewarding once they have been tamed and analyzed.
Where Do Analysts Come From?
“Imagination is more important than knowledge . . .”
Albert Einstein
“A senior intelligence official used to ask his subordinates two questions about new analysts they wished to hire: ‘Do they think interesting thoughts? Do they write well?’ This official believed that, with these two talents in hand, all else would follow with training and experience.”
Lowenthal, p. 791
In my experience, statistical degrees might make a good scientist, but a good analyst needs much more. Over time, I have almost always found it is easier to teach someone with an understanding of crime and criminals and a need to know “why” how to analyze crime than it is to give domain knowledge to a statistician. Until the Vulcan mind meld becomes a reality, it seems that the only way to acquire domain expertise is through experience and a hunger for a deeper understanding of “why.”
As indicated in the above quotes, the ability to “think interesting thoughts,” or think creatively, also seems to be a prerequisite. It often appears that the bad guys are always working on new ways to commit crimes and escape detection. Building a better mousetrap involves going above and beyond, often to the outer limits of our understanding of what can be expected, or even possible, in an effort to stay ahead in the game. Good analysts often have a dark side that they not only are in touch with but also are relatively comfortable tapping. To anticipate the “what if” and “how,” we can find ourselves considering the proverbial “perfect crime,” placing ourselves in a criminal’s mind in an effort to unlock the secrets of the crimes that he has committed and to anticipate what might lie ahead, what it is that he would really like to do if given the chance.
In many ways, statistics and formal analytics are just a mathematical manifestation of how analysts think and function in their native state. As data mining tools become increasingly more accessible and easier to use, the need to teach the statistician will diminish, as those with intuitive analytical savvy and domain expertise will gain a controlling interest in the field. Data mining tools are highly intuitive and very visual. Good analysts, as well as many operational personnel, seem to gravitate toward them naturally, embracing the intuitive processing and actionable output. Data mining tools represent the hammers and chisels that these information artisans can use to reveal the underlying form and structure in the data. It is my expectation that the new data mining tools will change dramatically what analytical positions in the future look like and how they function, as well as the role that operational personnel will play in analysis and how they will work with the analytical staff. As data and information assume the role of a seamless interface between analytical and operational personnel, I anticipate the emergence of an “agent analyst” class of personnel who can function in both worlds, utilizing data and intelligence as integral tools in the operational environment, while guiding the analytical process from collection to output.
Data mining has been referred to as “sense making,” which often is how the request for analysis is phrased. It is not unusual to find some random lists of telephone numbers, a couple of delivery dates, and a bank statement delivered along with a plea for some clue as to the “big picture” or what it all means: “Please help me make some sense of this!” There are a few tips for understanding and managing data and information that will be addressed in this chapter, but it would be impossible to anticipate every data source that is likely to surface. It is better to develop the ability to work with and through data in an effort to reveal possible underlying trends and patterns. This is a craft in some ways. In my experience, there is a degree of creativity in the type of pattern recognition that is associated with a good analyst: the ability to see the meaning hidden among the general disorder in the information. Data mining truly can be described as a discovery process. It is a way to illuminate the order that often is hidden to all but the skilled eye.
5.1 Getting Started
When I worked in the lab as a scientist, one of the most important lessons that I learned was to know your subjects. The same is true for analysts. As it is not advisable to experience crime firsthand, either as a victim or a perpetrator, there are other ways to know and understand the data and information. This is particularly true for information that arrives with some regularity, like offense reports. Subject knowledge has been addressed in greater detail in Chapter 2; in brief, it can be extremely useful for the analyst to develop some familiarity with the operational environment. Whether through routine ride-alongs, attendance at roll call, field training, or observing suspect interviews, the more that the analyst can understand about where the data and information came from, the better the subsequent analysis.
5.2 Types of Data
Several years ago, I responded to a homicide scene during the very early hours of the morning. Everyone was pretty tired, but as I walked into the house to view the scene, a member of the command staff who was taking a graduate course in criminal justice statistics stopped me and asked for a quick tutorial on the difference between continuous and nominal data. I have been asked some really strange questions at crime scenes, but this one was memorable by its sheer absurdity. What did distinctions between different types of data have to do with death investigation? In some ways nothing, but in other ways it has everything to do with how data should be analyzed and used to enhance the investigative process.
Leave it to researchers to figure out a way describe and characterize even data, creating subcategories and types for different kinds of information. There is a reason for this, other than the pain and agony that most students experience when trying to figure out what it all means during a class in statistics and probability (also known as “sadistics and impossibilities”). Data and information are categorized and grouped based on certain mathematical attributes of the information. This can be important, because different types of analytical approaches require certain properties of the data being used. As a result, it is important to have at least a basic understanding of the different types of data and information that might be encountered, and how this might guide selection of a particular analytical approach or tool.
5.3 Data2
Continuous variables can take on an unlimited number of values between the lowest and highest points of measurement. Continuous variables include such things as speed and distance. Continuous data are very desirable in inferential statistics; however, they tend to be less useful in data mining and are frequently recoded into discrete data or sets, which are described next.
Discrete data are associated with a limited number of possible values. Gender or rank are examples of discrete variables because there are a limited number of mutually exclusive options. Binary data are a type of discrete data that encompass information that is confined to two possible options (e.g., male or female; yes or no). Discrete and binary data also are called sets and flag data, respectively.
Understanding the different types of data and their definitions is important because some types of analyses have been designed for particular types of data and may be inappropriate for another type of information. The good news is that the types of information most prevalent in law enforcement and intelligence, sets and flag data, tend to be the most desirable for data mining. With traditional, inferential statistics methodologies, on the other hand, discrete variables are disadvantageous because statistical power is compromised with this type of categorical data. In other words, a bigger difference between the groups of interest is needed to achieve a statistically significant result.
We also can speak of data in terms of how they are measured. Ratio scales are numeric and are associated with a true zero—meaning that nothing can be measured. For example, weight is a ratio scale. A weight of zero corresponds to the absence of any weight. With an interval scale, measurements between points have meaning, although there is no true zero. For example, although there is no true zero associated with the Fahrenheit temperature scale, the difference between 110 and 120 degrees Fahrenheit is the same as the difference between 180 and 190 degrees: 10 degrees. Ordinal scales imply some ranking in the information. Though the data might not correspond to actual numeric figures, there is some implied ranking. Sergeant, lieutenant, major, and colonel represents an ordinal scale. Lieutenant is ranked higher than sergeant, and major is ranked higher than lieutenant. Although they do not correspond directly to any type of numeric values, it is understood that there is a rank ordering of these categories. Finally, nominal scales really are not true scales because they are not associated with any sort of measurable dimension or ranking; the particular designations, even if numeric, do not correspond to quantifiable features. An example of this type of data is any type of categorical data, such as vehicle make or numeric patrol unit designations.
Finally, unformatted or text data truly are unique. Until recently, it was very difficult to analyze this type of information because the analytical tools necessary were extremely sophisticated and not generally available. Frequently, text data were recoded and categorized into some type of discrete variables. Recent advancements in computational techniques, however, have opened the door to analyzing these data in their native form. By using techniques such as natural language processing, syntax and language can be analyzed intact, a process that extends well beyond crude keyword searches.
5.4 Types of Data Resources
Working with the Operators to Get Good Data
The business community provides some guidance on data collection. In some cases, information gathering is anything but obvious, often hidden behind the guise of some sort of discount or incentive. For example, many supermarkets have adopted discount cards in an effort to provide incentives for gathering information. Rather than using coupons, the customer need only provide the store discount card to obtain reduced prices on various items. It is quick and easy, and the customer saves money. In exchange, the store gains very detailed purchasing information. Moreover, if a registration form is required to obtain the discount card, the store has access to additional shopper information that can be linked to purchasing habits. For example, stores might request specific address information so that they can mail flyers regarding sale items and specials to customers. Additional financial and demographic information might be required for check cashing privileges. This additional information provides significant value when added to the actual shopping information. Direct mailing campaigns can be targeted to select groups of shoppers or geographic areas, while common shopping patterns can be used to strategically stock shelves and encourage additional purchasing.
This same principle can be applied in crime analysis data collection. One frequently voiced frustration from sworn personnel, particularly those working in patrol, is that they do not receive any benefits from all of the paperwork that they complete. Field interview reports can take a considerable amount of time, but they frequently confer benefits only to the investigative personnel. Analysts can greatly improve data quality and volume by engaging in some proactive work to highlight the value of accurate, reliable, and timely data collection to the specific personnel units most likely to be tasked with the majority of this work. Providing maps or other analytical products on a regular basis can strengthen the partnership between these frequently overworked, yet underappreciated, line staff and the analytical personnel. These folks also can be a tremendous source of knowledge and abundant domain expertise, given their direct proximity to the information source.
It is also important, whenever possible, to highlight any quality-of-life increases that might be associated with a particular analytical product or initiative. For example, the New Year’s Eve initiative in the Richmond Police Department was associated with significant reductions in random gunfire and increased weapons seizures,3 which were achieved with fewer personnel resources than originally anticipated. These results in and of themselves were impressive; however, one additional benefit was that approximately fifty members of the department originally expecting to work that evening were able to take the night off. While this might not be the most notable finding from a public safety perspective, it was pretty important to the department members who were able to take the night off and spend it with their families and friends.
Partnering with the operational personnel reaps many benefits. Having a colleague in the field can provide direct feedback regarding the reliability and validity of specific sources of information, as well as guidance regarding the direction and need for future analytical products. Some of the most interesting projects that I have been involved with started out with the following question from someone working in the field: “Hey doc, have you ever thought about this . . .?” Moving closer to an integrated operator-analyst approach benefits all participants. The analyst obtains access to better information and guidance regarding actionable analytical end products, and the operational personnel can not only better understand but even play a role in guiding the analytical process. Once information has been established as a thin, fluid interface between the analytical and operational domains, the process becomes even more dynamic, operators and analysts working handcuff-in-glove to achieve information dominance and operational superiority. Data mining and the associated technologies provide the tools necessary to realize this goal.
Records Management Systems
Most departments maintain large records management systems that contain crime incident data. In most cases, however, these “databases” were not necessarily designed to be analyzed. Rather, these databases were created and are used for case management and general crime counting. As a result, these databases frequently have standard or “canned” queries that facilitate gathering frequently used information or reports; however, these often have limited utility for crime analysis.
The benefit of these databases is that they have a known, stable structure. Queries can be developed and reused repeatedly because the structure associated with this type of database generally does not change frequently. The disadvantages associated with using a records management system, however, can include the reliability and validity of the data, as well as the detail, type, and nature of information, and even access. Common limitations associated with generic records management systems include incomplete or inaccurate data. Unfortunately, reliability, validity, and completeness seem to be most compromised in the information required for crime analysis, particularly information relating to MO. MO characteristics generally are not included in routine crime reports or canned queries, so it is not until the analyst attempts to use it that the holes in the data are revealed. Moreover, MO information can be compromised if the particular categories of information are not anticipated and collected. For example, information relating to the type of weapon, nature of the offense, and time of day frequently are collected, but specific details regarding the behavioral nature of the crime, including the type of approach (e.g., con/ruse, blitz, etc.), verbal themes, and other behavioral characteristics used to analyze and link crimes frequently are incomplete or absent. Much of this information can be found in the narrative portion of the report. However, in most agencies, the narrative section has limited availability and utility, given the degree of complexity associated with the analysis of this type of information. Recent advantages in natural language processing and text mining offer great promise for the retrieval of this information.
Another limitation associated with large records management systems can be timely data entry. Ideally, the data and information would be entered into the database during the collection process, or immediately thereafter. Unfortunately, reports frequently are completed and then wait for review before the information is transcribed and entered. This can be particularly time-consuming if the information is collected in a location that is geographically distinct from the data entry and analysis location, or if field reports must be collected and shipped to another location for entry and subsequent analysis in another part of the world. Even processing records in another part of town can introduce a level of delay that is undesirable.
On the other hand, initial data entry can be almost simultaneous in departments with mobile data computers, which facilitate direct data entry in the field. Although data review and validation might be delayed somewhat, the basic crime incident information generally is entered in a timely fashion. In agencies where reports are completed with paper and pencil and then forwarded for data entry, significant delays can occur. While this might not be a problem with historical reviews or long-term trend analysis and modeling, for certain types of analysis, including the behavioral analysis of violent crime and/or analysis of a rapidly escalating series, any delay is unacceptable because it can cost lives. Often in these cases, the analyst is required to create specialized databases for certain types of crime or series under active investigation.
Technology has improved to the point where direct data entry in the field can be associated with a concomitant rapid analytical response, even in the absence of a live analyst. Crime frequently occurs at inconvenient times, particularly during the evenings and weekends when most civilian analysts are off duty. The ability to rapidly integrate crime incident information into the context of historical data as well as rapidly emerging trends and patterns can provide the investigator valuable analytical support at the very beginning of an investigation when it is needed the most, rather than later when the analytical staff return. While still at the scene, an investigator can enter the relevant information and receive a rapid analytical response, which can provide timely access to associated cases, existing leads, and investigative guidance. By adding an analytical overlay or inserting an analytical filter into remote data entry, an organization can add value to the mobile data and analytical capacity while at the same time increasing investigative efficacy.
Ad Hoc or Self-Generated Databases
In some situations, the department’s records management system does not meet the needs of timely, complete crime analysis. Specialized databases can be created to address this need. These may be ongoing or case-specific. For example, in a department without direct field entry of data or limited availability of MO characteristics in existing data resources, the analytical team might construct databases specifically designed for crime or intelligence analysis. These databases might either be offense-specific, such as a homicide database or a robbery database, or associated with a unique series or pattern of crimes, such as a serial rapist or an unusual series of burglaries. These databases will include standard information likely to be found in the department’s records management system (e.g., case number and date, time, and location of offense), as well as information related to specific or unique MO characteristics or behavioral themes.
It is not unusual for a task force or department to establish a specialized database for a particular series of crimes or a high-profile crime. For example, child abduction cases frequently receive large amounts of data and information that need to be entered, managed, and analyzed very rapidly in support of these often fast-breaking investigations. Tip databases are created in an effort to manage the rapid accumulation of data and information in response to a high-profile incident. For example, in the first few weeks of the Laci Peterson investigation, more than 2600 tips were received by law enforcement authorities.4 Similarly, at the height of the Washington D.C. sniper investigation, authorities received as many as 1000 tips an hour.5 The sheer volume of information associated with these cases requires some sort of automated system of information management.
Limitations to this approach include the initial time commitment necessary to create the database, an ongoing commitment to data entry, and the possibility of errors associated with data entry. While creation and maintenance of specific analytical databases requires a commitment from the analyst or analytical team, it can reap huge benefits in terms of detail, additional information, analytically relevant information, and timely data entry.
What do you include in a self-generated database? As much as you think that you will need, and then some. When it is time to conduct the analysis, it always seems that no matter how many variables and how much detail was included in the original data set, it would have been better to have included just a little more. Behavioral characteristics and themes and MO features are always a good starting point. Some variables will become standard (e.g., approach, demeanor), while others might be unique to a specific pattern of offending or crime series. It generally is a good idea to include the information in as close to its original form as possible. Automated recoding later can be more efficient and accurate than trying to recode during the data entry process. In addition, early exploration of the data might indicate a need for one form of recoding over another. For example, during an analysis of police pursuits, preliminary analysis of the data revealed potential differences among high-speed pursuits as compared to those at lower speeds. This was not readily apparent, however, until the data had been entered in their original form and then explored.
One challenge associated with tip databases is the fact that the analyst and investigative team typically have very little information early in the investigation, while the database is being created. With such limited information, it might be unclear which variables should be included because the overall direction of the investigation might not have emerged or been developed. Moreover, although the team always tries to be objective, a favored outcome, suspect, or interpretation can dramatically impact the structure of the database as well as the interpretation of individual data elements or reports.
The analyst is challenged further by an overwhelming amount of information with an associated need for rapid analysis. During the D.C. sniper investigation, the investigative process was complicated by the involvement of multiple localities, jurisdictions, states, and task forces. The net result of this type of situation is a data repository that is beyond the analytical capacity of a single analyst or even an analytical team or task force. There is just too much information to absorb, categorize, remember and draw meaning from, and this significantly compromises the overall investigation. In these cases, the best solution is to employ automated search strategies and analysis. Software does not favor any suspects or outcomes and does not become overwhelmed by the amount of information or the nature of the case.
Another challenge associated with tip databases is that the information frequently arrives in narrative format. Tipsters rarely call the hotline with detailed, well-categorized information that has been recoded to match the existing database structure. Rather, they tend to provide information that is in a narrative format, frequently is incomplete, and sometimes even is inaccurate. Armed with natural language processing and text mining tools, an analyst can explore and analyze large amounts of narrative information extremely efficiently.
Consistency, consistency, consistency! This can be an issue when multiple analysts are entering the same data. Even subtle differences in data entry can greatly increase the variability, with concomitant reductions in the reliability and analytical value of a data set. The decision to develop and maintain a database is huge; do not sabotage your efforts with inconsistency or variability in the data entry process. There is enough variability in crime and intelligence data; the analyst does not need to introduce more in the data categorization and entry process.
The analyst frequently is called to analyze data or information that is collected specifically for a particular case. These data often embody the most difficult yet interesting work that an analyst can become involved in. The opportunity to pull meaning and investigative value from a seemingly unintelligible mass of information can be one of the most exciting challenges that an analyst encounters. While it is impossible to anticipate the exact nature of these data sources, learning some basic data management techniques can help to not only evaluate the reliability and validity but also do any data cleaning or recoding that might be required. Some common data resources are addressed later in this chapter and throughout the text.
Additional Data Resources
The analyst is likely to encounter two types of data that have their own sets of issues and challenges: relational data, like those associated with incident-based reporting and police calls for service, and dispatch data. These data are used frequently in public safety analysis; therefore, their unique features and challenges are worth addressing.
Relational Data
Relational databases are comprised of a series of associated or linked tables.6 This facilitates the inclusion of a greatly expanded amount of information; however, it can create some challenges in analysis and interpretation of data, as outlined below. An example of a relational database that is frequently encountered in law enforcement and public safety is the National Incident-Based Reporting System, or NIBRS.’7 In marked contrast to Uniform Crime Reports (UCR), with NIBRS data a single incident can be associated with multiple offenses, victims, and suspects. For example, if two suspects broke into a home, vandalized the kitchen, stole a television set, and assaulted the homeowner when he came home early, it would be a single incident associated with as many as four separate offenses, two suspects, and one victim under NIBRS rules. With UCR, only the most serious offense would be reported. The other, “lesser included” crimes would not be reported. While NIBRS results in more complete reporting of crime statistics, there are challenges associated with databases of this nature.
First, it is possible to greatly magnify the prevalence of crime if crimes are counted by offense rather than incident. In the example above, simply adding up the offenses would greatly exaggerate total crime statistics. As many as four “crimes” could be reported for what really is one single crime incident that was associated with multiple offenses. Similarly, it is possible to underreport crime when there are multiple victims. For example, using an incident-based reporting method, a double homicide counts as one homicidal incident with two victims. This can be confusing for those accustomed to reporting homicide totals in terms of a body count.
In terms of crime analysis, however, one particular challenge associated with relational data as opposed to a simple “flat file” is that it can be difficult to maintain relationships between variables and to ensure that certain variables are not overemphasized during an analysis, particularly using standard methods. For example, gang-related crime frequently involves multiple suspects associated with a single incident. As illustrated in Figure 5-1, a gang robbery was perpetrated by three suspects, while another robbery was associated with a single suspect. When this information is entered into a spreadsheet, there are three records associated with gang-related robbery suspects as compared to a single suspect record associated with the other robbery. At a minimum, the gang-related information will be overrepresented in an analysis of robbery-related suspect characteristics unless some precautions are taken to ensure that each incident is counted only once.
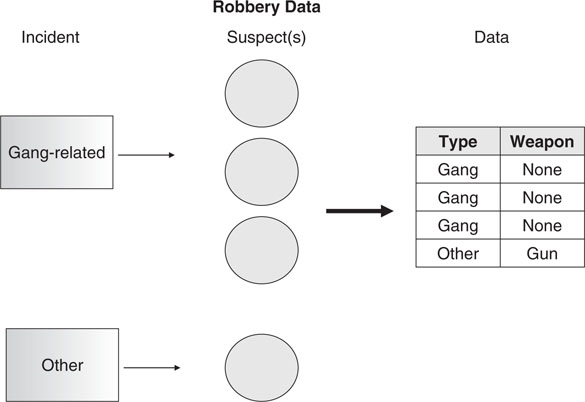
Figure 5-1 Relational data are associated with some unique challenges. In this example, a gang-related robbery was perpetrated by three suspects while another robbery was associated with only one suspect. In a relational database, there could be as many as three suspect records associated the gang-related robbery, compared to a single suspect record associated with the other robbery. The gang-related information will be overrepresented in the analysis unless some precautions are taken to ensure that each incident is counted only once.
For example, if the gang members used intimidation while the suspect in the other robbery used a gun, a simple suspect-based count of weapon involvement would indicate that weapons were used in only 25% of the robberies, when in fact a gun was used in one of the two, or 50%, of the incidents. On the other hand, the prevalence of gang-related crime might be skewed if suspect-based statistics are used to generate that information. It is always important to think logically about what the question really is and what is the best way to count it. Some crimes, including those involving juveniles and gangs, frequently involve multiple suspects. Obviously, this is not much of an issue with only two incidents; however, when faced with hundreds of incidents, it is important to ensure that these issues are considered and that crime is counted accurately.
Dispatch Data
One set of data maintained by most law enforcement agencies is police dispatch, or calls for service (CFS) data. This information can have tremendous value when examining how police resources are deployed. These data also provide some insight into general crime trends and patterns in the community in that they reflect complaint data, or citizen-initiated police work.
Like most public safety data, however, CFS data have significant limitations that are not distributed uniformly in many cases. For example, a complaint of “man down” can mean almost anything from a sleeping vagrant to a murder. It is not unusual for the nature of the complaint to have very little in common with what actually happened.
Figure 5-2 depicts a vehicle driving through a neighborhood, engaging in random gunfire—something not unusual in many high-risk communities, particularly those with active gang rivalries. In this situation, the vehicle enters the neighborhood in the 600 block of Elm Street and one of the occupants starts firing a weapon in the vicinity of 545 Elm Street. The vehicle travels north on Elm, east on Fourth, and north again on Maple Avenue, with five associated bursts of gunfire.

Figure 5-2 This street map illustrates a vehicle driving through a neighborhood engaging in random gunfire.
As can been seen on the spreadsheet in Table 5-1, the calls start coming into the dispatch center almost immediately. Three separate calls come in within minutes of the first burst of gunfire at 545 Elm Street. These are immediately recognized as being the same incident and are all assigned the same call number. A fourth call comes in from someone at the corner of Sixth and Elm, who reports having heard random gunfire in the neighborhood. Without a specific address, the caller’s location is entered and the report is given a new call number, reflecting the new address. A few minutes later, three additional calls come in from Fourth Street. These calls are seen as related to each other but not to the earlier incident, so a new call number is assigned to these three complaints. As the car turns north on Maple Avenue, three additional calls come in to the dispatch center. Again, these calls are not identified as being part of the same incident and are given unique call numbers. Finally, the first caller at 545 Elm Street, frustrated at not seeing a patrol car in the neighborhood yet, calls again to report random gunfire in the neighborhood. Because this call came in later than the first call from that address, it is not linked to the earlier calls and is given another unique call number. By the time this incident ends, the dispatch center has received a total of eleven calls from citizens reporting random gunfire (Table 5-2), which are aggregated into seven distinct calls, yet all are associated with a single series of random gunfire spanning both geography and time.
Table 5-1 This table was created from the citizen complaints associated with the random gunfire illustrated in Figure 5-2.

Table 5-2 In this table, the eleven citizen complaints from a single series of random gunfire have been aggregated into seven distinct calls, highlighting some of the challenges associated with using citizen complaint data as well as other public safety–related information.

Which is the more accurate measure: complaints, CFS, or unique incidents? Further comparison of the map and the call sheet highlights some of the challenges associated with analyzing CFS. For example, should the total number of complaints (11) or unique calls (7) be used for analysis? Depending on the nature of the analysis, either option might be correct. For an analysis of workload and deployment, it might be necessary only to know how many citizen-initiated complaints resulted in the dispatch of police personnel. In this case, the number of unique calls generally would suffice. But, what if the question related to community violence and how many incidents of random gunfire occurred in a community? Clearly, neither the number of complaints nor the number of calls would address that question directly. Further examination of the data would be required, perhaps with the use of maps and a timeline. What happens when gunfire erupts and nobody calls? In some locations it is not unusual to receive a call of a man down, only to find a dead body surrounded by evidence of gunfire and to have received no citizen complaints of gunfire, whether due to fear or a lack of social efficacy.8
This issue of incident counting becomes further complicated if multiple units are dispatched to the same incident and are recorded as unique records in the database, or if a unit needs to disengage from a specific call to answer another call with greater urgency and then returns to the initial call. Depending on how the data are recorded and maintained, the latter situation might be recorded as a single unit responding twice to the same call, two unique dispatch records for a single call, or two unique calls for service. Which measure is correct really depends on the nature of the question. The most important point, though, is that the analyst clearly understands the limitations of the measure selected and is able to convey those limitations to the command staff or other end users of the analysis so that they can be taken into account when any decisions are made based on those data.
Other Considerations
Another important feature in this discussion is that not all crime is distributed evenly. In fact, it is rare to find evenly distributed crime. For example, criminals, at least successful criminals, will tend to select affluent areas to look for expensive jewelry and electronics, while most open-air drug markets are more likely to be located in higher-risk areas. Even something as simple as traffic stops can be skewed by police patrol deployment, since areas associated with high crime also tend to be associated with increased police deployment. Logic follows that the greater the police presence, the more likely someone is to get caught with that expired city decal or burned-out headlight. Drugs, guns, and violence typically go together, and certain types of vehicles tend to be stolen more than others. Whether this is due to a preference for certain vehicles or the fact that some vehicles might just be easier to steal than others is important for prevention efforts.
5.5 Data Challenges
Reliability and Validity
Regardless of how perfect a data set might seem to be, it almost always has some shortcomings. In law enforcement and intelligence analysis, the data and information generally are anything but perfect. In fact, I often experience “data envy” when reading scientific or business-related papers on data mining because of the tremendous amount of quality control the authors often have over their data. In contrast, it is not unusual for an analyst to receive some data or information in a format completely unsuitable for analysis. For example, a billing invoice, complete with headers and other meaningless formatting, might contain information critical to the development of a timeline or identification of routine expenditures. Not only do these data come in a less than desirable format, there frequently is the expectation that they will be turned around very quickly. Any delay in the investigative process can make the difference between a case that is cleared and one that languishes with no proper closure for a long time, if ever. The last thing that anyone wants is a delay in the investigative process because the analyst can neither tolerate nor accommodate less than perfect data.
Data layout and design often can be addressed. Beyond format, however, are far more sinister issues that need to be addressed: reliability and validity. Reliability implies a degree of stability in the measure. In other words, reliability means that if you conduct repeated measurements of the same thing over and over again, the measurements will not change significantly. For example, a witness statement is reliable, in statistical terms, if the witness says approximately the same thing at each interview. This same statement has absolutely no value, however, if the witness is not telling the truth. Therefore, the second measure of interest is validity. Validity simply means that the measure, in this case the witness statement, is an accurate measure of truth, or what actually happened. Another term for validity is accuracy.
These definitions differ somewhat from the traditional law enforcement or intelligence definitions of reliability. For example, a reliable informant is one that is both dependable and accurate. In many ways, this working definition of reliability represents a composite of statistical reliability and validity, which only serves to highlight the importance of each measure. A dependable witness with poor information would be of little value, just as one who has good information but cannot be counted on also would have limited utility.
Inaccurate or unreliable data can arise from a variety of sources, including everything from keystroke errors to intentional corruption of data and information. Because these issues are important to accurate analysis and the development of meaningful and reliable models, some of the more common challenges will be addressed in detail.
Data Entry Errors
What happens when you run across a “juvenile offender” with a listed age of 99 or a male with a previous pregnancy in his medical data? Several years ago, when analyzing juvenile offender data, I was assured that the medical section was both accurate and reliable. It turns out that the data were neither.
To convince myself of this, I ran a quick frequency distribution that listed the number of occurrences for each possible value associated with a particular measure. What I found was that a significant number of male offenders were listed as having experienced pelvic inflammatory disease, something uniquely female. It was unlikely that the physician performing the intake medical examination made the error. Rather, it appeared to be an error that occurred later during the data compilation or entry phase. Either way, it significantly compromised the value of the information.
Data entry errors happen. It is a monotonous process, and people get fatigued. There might be incentives for speedy data entry without the necessary quality control, although this seems to be changing, with some automated reliability and validity checks now being included in some records management systems. Sometimes people just do not care. It is not the most glamorous job in law enforcement, and generally is not well compensated. Even under the most stringent conditions, however, data entry and keystroke errors happen. The solution, then, is identifying and correcting them.
Frequently, running a quick frequency distribution can highlight information that appears to be grossly out of range. For example, running a frequency distribution on age will tell us how many 25-year-olds there are, how many 26-year-olds there are, and so on. This method will highlight any data points that are well beyond what one would normally expect and that should be investigated further. As in the earlier example, a 99-year-old juvenile offender clearly is incorrect. In many cases, however, the value “99” is used for missing data or when the information is not known. Therefore, an entry of “99” might mean that the information was unavailable or unknown. This can be clarified and addressed.
It is important to note that there are cases where the information is unknown. Developing ways to indicate this within a data set can be extremely important. If those methods were incorporated, the ages listed as “99” would be excluded automatically, rather than contaminating subsequent analysis. Using indicator variables for missing data also is important because blank fields in a data set can indicate many things. For example, if work history or current employment is left blank in a file or data set, does it mean that the subject in question has never worked, or that this information has not been collected? Similarly, does it mean anything that this information could not be found? For example, it can be significant to know that a listed address does not exist. Understanding the importance and implications of missing, inaccurate, or unreliable data can greatly enhance the value and understanding of the information collected, as well as the subsequent analyses.
Returning to the juvenile offender data, there also were greatly differing reports of prior drug history in the section on substance use history. Further examination revealed that the nurses were streetwise and savvy. Few inmates lied to them about their drug use, and those who did were challenged by these health care providers. As a result, the medical history information collected by the nurses was determined to be relatively accurate. The physicians, on the other hand, frequently came from different environments and tended to have less experience with juvenile offenders. As a consequence, they tended to believe what they were told. One physician in particular was extremely nice and soft-spoken. Interestingly enough, her physical examinations revealed very little substance use and even less sexual activity among the juvenile offenders who she interviewed, which stood in stark contrast to information collected in other environments by other personnel. Unfortunately, this finding cast a shadow of doubt over all of the other information that she collected during the intake process. This situation highlights how easy it is to encounter unreliable information. One detective might be particularly adept in an interview situation, while others might have less skill in eliciting information. All of these factors can significantly affect the reliability of the information.
This highlights another important concept: the reliability check. Whenever possible, it is extremely valuable to cross-check information for consistency and accuracy. In the example with the physician, we were able to check her information with that of other interviewers and found hers to be different. Further examination of the data that she collected proved it to be inaccurate, which cast doubt over almost everything else that she had collected. Similarly, if we can compare some data against known information, it gives a greater degree of comfort with information that cannot be validated or checked. This is not an uncommon practice in law enforcement or intelligence information collection, and represents a form of best practice in the assurance of information integrity.
It also is possible to gain some information from response rates alone. For example, an unmanageable crowd at a crime scene can be unnerving, but the spookiest scenes for me were the ones where nobody was out. The total absence of spectators said something. Similarly, increases in citizen complaints can be a troubling issue to address in an evaluation of a crime reduction initiative. In some communities truly ravaged by crime, the citizens can become so discouraged that they give up: “What is the point in calling if nothing ever changes?” Crime becomes so expected and normal that the outrage is gone. In these situations, one of the first indicators of improvement can be a spike in complaints, as members of the community begin to reengage and participate in community public safety. As in music, sometimes the spaces between the notes can be important to identifying the tune.
Intentional Misrepresentation (aka Criminals Often Lie)
Criminals often misrepresent the facts, both when it matters and when it does not. For that matter, so do witnesses, informants, and many other folks that we use on a regular basis to help us to gather information and data. This is not unique to law enforcement or intelligence data. Responders to marketing surveys lie as well. Consider the last time that you were completely honest and completed every question on a survey, if you even responded to it in the first place. Think again about the last survey that you may or may not have completed. Were you honest? How do you think your less-than-honest responses might have affected the results? Similarly, other people withhold information because they have something to hide, are concerned that they might implicate themselves or someone else, or just because. All of this affects the reliability and particularly the validity of the data that we encounter.
In addition, victims can be emotional or confused, and often make poor historians. Filling out an accurate and reliable offense report generally is not what is going through their mind as they are getting robbed at gunpoint. It is not unusual to receive a very detailed, if not somewhat exaggerated, description of the weapon and little to no good information regarding the suspect. This is not surprising and reflects victims’ focus during the incident. In addition, the incident might be very brief and occur under less than optimal lighting. While convenience stores generally have done a good job of providing good illumination and height markers by the door, the average victim of a street robbery is at somewhat of a disadvantage regarding all of the information that we might like to include in the analysis.
Unsuccessful Criminals
It bears repeating that almost everything that we know about crime and criminals is based on those who have been caught, unsuccessful criminals. We all laugh when we hear about the bank robber who used his own deposit slip to write the note or the burglar who dropped his wallet on his way out of the house, but the sad fact is that many criminals are caught because they make mistakes. Research on nonadjudicated samples is extremely difficult. For example, asking individuals about involvement in nonadjudicated criminal activity, particularly felonies, is challenging both legally and ethically, due to mandated reporting requirements for some crimes. As a result, studies that involve gathering information on nonadjudicated crimes frequently are difficult to get approved by human subject review committees. There also are challenges in even identifying these populations, particularly those with limited or no contact with the criminal justice system. Certain types of ethnographic research, which frequently involve going out into the communities and locations where criminals operate, can be extremely risky. They also are prone to artifact in that they often rely on subject referrals from other criminals. Since criminals tend to be less than honest and frequently are unreliable, depending on them to help establish a solid research sample can be tenuous at best. Therefore, because most criminal justice research is conducted on identified offender populations, such as those already in prison, there are some significant gaps in our knowledge regarding crime and criminals. Knowing what is normal and what is not is absolutely essential to developing the domain expertise necessary to evaluate the results. This is covered in greater detail in Chapter 10.
Outliers with Value
All outliers are not created equal. Should outliers universally be removed from the analysis or otherwise discounted? Or is an outlier or some other anomaly in the data worth considering? While most outliers represent some sort of error or other clutter in the data, some are extremely important. In my experience, deviation from normal when considering criminal justice or intelligence data often indicates something bad or a situation or person with significant potential for escalation.
5.6 How Do We Overcome These Potential Barriers?
Establishing as many converging lines of evidence as possible for validity checks can be helpful. This can include verification with known, reliable sources of information like arrest records.
We also might look for similarities in false stories. For example, “the bullet came out of nowhere” explanation is likely to arouse suspicion among investigators. An analyst can benefit from the development of similar internal norms, or domain expertise regarding normal trends and patterns, as well as common themes of deception. People just are not that creative when it comes to prevarication, and sometimes information about inaccurate or false statements can be as valuable as credible information. For example, in some types of statement analysis, the linguistic structure of a statement can be as important as the actual content in evaluating the validity of the statement. Most valid statements have a beginning, middle, and an end. False allegations frequently deviate from valid statements in the emphasis of certain portions of the story. Once this type of deviation has been identified, it is possible to begin to evaluate content in a different light and look for potential secondary gain related to a possible false allegation. Data mining can be extremely valuable, particularly regarding commonly occurring patterns associated with false allegations.
But knowing certain data is false does not mean it can be ignored. Just the opposite: It is extremely important to know as many details as possible about any limitations in the data so that they can be dealt with during the analytical process and interpretation of the results. It is like side effects. Generally those that you are not aware of create the most trouble in the end.
5.7 Duplication
What happens when duplicate records are encountered in a data set? This is not at all uncommon, as multiple citizens can call about the same fight or shooting, multiple officers might respond to the same complaint, and so on. In the random gunfire example outlined previously, some complaints were obviously duplicative. As such, they received identical call numbers. In Table 5-2, this same data set is depicted without the duplicates. Obviously, there was duplication beyond what could be culled through simple identification of duplicate call numbers, but this would represent a good start.
When does duplication have value? Perhaps one of the more common areas is in workload studies and deployment. Knowing when multiple units are dispatched to a single incident is important in determining how personnel resources are being used. For example, knowing that multiple officers are dispatched to domestic complaints, while only one officer generally responds to an alarm call, is essential to a complete understanding of police personnel workload. It would be difficult to anticipate every possible situation when duplication occurs and when it is necessary to answer a particular question.
A somewhat more complex example of both necessary and unnecessary duplication in a data set occurred in the following example. Briefly, an organization of interest was linked to a billing invoice that included hundreds of individual telephone conference calls comprised of thousands of individual telephone call records. Further examination of the invoice revealed that some individuals regularly participated in calls with a similar group and that certain individuals appeared to have been involved in multiple conference calls. This was important information, in that identifying the key players and linked individuals helped begin to reveal an organizational structure and associated relationships. Review of the records also revealed that some individuals might have dialed into a particular conference call multiple times. This could have been related to bad or unreliable connections or a variety of other reasons. At this point, though, the underlying cause for the duplication in calls is not nearly as important as the fact that it exists. Calculating frequencies for individual callers had to be delayed until this unnecessary duplication was addressed. Unfortunately, culling the unnecessary duplication within calls while maintaining the necessary duplication between calls can be a very complex task, particularly with a large data set. Automated methods for accurately culling these data were available and saved time while maintaining valuable relationships and features of the data set. In this example, the data set was reduced by almost one-half by removing the unnecessary duplication in the data.
5.8 Merging Data Resources
The emergence of regional fusion centers throughout the country represents an analytical windfall for crime analysts. Patterns that transcend jurisdictional boundaries can be identified and analyzed by merging data from neighboring or otherwise related communities. This approach can increase the number of observations, which can be particularly important with rare events. It also can identify other patterns of offending and criminal groups that exploit jurisdictional boundaries. Examples of this may include traveling scam artists, large criminal gangs, and even serial killers like Ted Bundy with his expansive geographic range. By spreading their crimes across a large geographic region that transcends local jurisdictional boundaries, these criminals can elude detection and capture. Groups like the Mid-Atlantic Regional Gang Investigators Network (MARGIN) and the FBI’s VIolent Crime Apprehension Program (VICAP) have been developed in an effort to identify patterns that cross jurisdictions and address this issue.
Data also can be aggregated across collection modalities, reflecting the fact that crime frequently does not exist in one domain. For example, through the analysis of telephone records one might be able to characterize the calling patterns of a drug dealer as he sets up buys and deliveries, while an analysis of banking records and deposits might be necessary to extrapolate cash flow and economic value of the products that he is moving. Being able to analyze all of this information in the same analytical environment starts to develop the big picture, which represents a powerful tool available to the analyst. The following sections provide a few examples that highlight the value of this approach.
5.9 Public Health Data
Be creative. One thing that I realized several years ago through the Cops & Docs program9 was that when new drugs enter a market, people generally get into trouble medically before they get into trouble legally. Analyzing health care and law enforcement-related drug overdose data in the same environment provides a more comprehensive view of a pattern of behavior that transcends the health care and legal systems. Clearly, there are both legal and ethical issues associated with this type of analytical endeavor, but they are not insurmountable. Public health and public safety can be complementary functions, particularly if data and information are shared in a meaningful fashion.
One particular example where this worked extremely well was with trauma patients admitted after being involved in car wrecks. During informal conversation, the health care providers noted that several of the recent admissions for car wrecks were noteworthy in that the patients tested positive for illegal narcotics. A quick tutorial on the finding that many heroin addicts use their drugs almost immediately after purchasing them enlightened the health care providers regarding substance use patterns and their direct link to trauma. This resulted in a comprehensive analysis of health care and law enforcement-related narcotics data in the same analytical environment. Although the health care information was zip code–based and relatively nonspecific due to medical confidentiality requirements and investigative sensitivity, the resulting value-added analysis of the multidisciplinary narcotics data highlighted a population that had been underrepresented in other analyses. Ultimately, both the health care and law enforcement professionals involved benefited from this information exchange, as did the communities experiencing these increases in illegal drug use.
5.10 Weather and Crime Data
Normal seasonal weather trends, as well as dramatic changes, can have an impact on crime trends and patterns. For example, during the colder months, many individuals preheat their vehicles. Since it is easier to steal a vehicle when the ignition key is available, these cold temperatures can be associated with an increased number of vehicle thefts during weekday mornings when people are preparing to leave for work. Similarly, people are frequently tempted to leave their vehicles running during the summer months in an effort to keep their vehicles cool when they run into the convenience store to make a quick purchase. Analyzing crime and weather data in the same analytical environment can add significant value to police operational planning and crime prevention. Data mining and predictive analytics tools are perfectly designed to fully exploit the possibilities associated with this type of novel analysis.
Less frequent but significant weather events also can have an effect on criminal behavior. For example, looting after a devastating weather disaster is not uncommon. Several years ago, we noticed that violent crime, particularly street violence, decreased to almost nothing during a major snow event and that subsequent clearing of the weather and roads was associated with a concomitant spike in crime. While largely anecdotal, this highlights the value that nontraditional crime measures can have with regard to forecasting and strategic crime analysis. Historical weather data are relatively easy to get. For example, local television stations often maintain archival information, which is available over the Internet in some locations.
Again, be creative. Crime patterns frequently are as unique as the individuals involved and can be affected by a variety of obvious, as well as not so obvious, factors in the community. By transcending the analytical boundaries associated with a single type of data or information, the analyst can begin to identify and analyze a larger array of factors and potential consequences associated with the original information of interest.
5.11 Bibliography
1. Lowenthal, M.M. (2000). Intelligence: From secrets to policy. CQ Press, Washington, D.C.
2. Howell, D. (1992). Statistical methods for psychology, 3rd ed. Duxbury Press, Belmont, CA. Those without recent, or even any, statistical training might benefit from acquiring a basic introductory statistics text that can be used as a reference. This is a very good introductory text that would serve well in this capacity.
3. McCue, C., Parker, A., McNulty, P.J., and McCoy, D. Doing more with less: Data mining in police deployment decisions. Violent Crime Newsletter, U.S. Department of Justice, Spring 2004, 1, 4-5.
4. www.KXTV10.com. (2003). Despite avalanche of tips, police stymied in Laci Peterson case, January 9.
5. Eastham, T. (2002). Washington sniper kills 8, truck sketch released. October 12. www.sunherald.com
6. Agosta, L. (2000). The essential guide to data warehousing. Prentice Hall, Upper Saddle River, NJ.
7. The IBR Resource Center can be found at www.jrsa.org. This is an excellent resource that includes many references, as well as analytical syntax specific to IBR data and contact information for others working with this type of information.
8. Sampson, R.J., Raudenbush, S.W., and Earls, F. (1997). Neighborhoods and violent crime: A multi-level study of collective efficacy. Science, 277, 918–924.
9. McCue, C. (2001). Cops and Docs program brings police and ED staff together to address the cycle of violence. Journal of Emergency Nursing, 27, 578–580.