
Chapter 3
INTEGRATING THE DATA RESOURCE
The approach to understanding and integrating disparate data.
Integrating the data resource is the first of two components for fully integrating data resource management. The chapter begins with a summary of the Common Data Architecture concepts, principles, and techniques for preventing data disparity, described in detail in Data Resource Simplexity. Those concepts, principles, and techniques will be used extensively during the data resource transition process.
Next, the chapter provides an overview of the concepts and principles for understanding and integrating disparate data within the context of a common data architecture. The following nine chapters (Chapters 4 through Chapter 12) describe the specific concepts, principles, and techniques for understanding the existing disparate data, designating a preferred data architecture, and performing data transformation to create a comparate data resource.
The second component for fully integrating data resource management is described in detail in Chapter 13 on Integrating the Data Culture.
CONCEPTS
I’ve had many experiences over the years dealing with disparate data in a wide variety of public and private sector organizations. I’ve used many different techniques to understand and resolve disparate data, and have published many of those techniques. All those techniques had good and bad features, and I learned from each experience. The concepts, principles, and techniques described here are the best I’ve found (so far) for understanding and resolving disparate data and creating a comparate data resource.
The most important single thing I’ve learned through all of these experiences, as described in Data Resource Simplexity, is that the creation of disparate data must cease before any attempt is made to understand and resolve those disparate data. Disparate data are created much faster than they can ever be resolved. If the creation of disparate data is not stopped before attempting to resolve those disparate data, the resolution effort will be for naught.
Lest you missed that message—The creation of disparate data must be stopped before any effort is made to understand and resolve those disparate data!
The following concepts are summarized from Data Resource Simplexity to set the stage for integrating the data resource. Data Resource Simplexity described in detail what went wrong that resulted in disparate data and what needs to be done to stop the creation of disparate data. That’s the starting point for effective and efficient data resource integration.
Data Sharing Concept
The data sharing concept states that shared data are transmitted over the data sharing medium as preferred data. Any organization, whether source or target, that does not have or use data in the preferred form is responsible for translating the data.
The Common Data Architecture provides a construct for readily sharing data, whether disparate or comparate, as shown in Figure 3.1. When the source data are in the preferred form, they can be readily shared over the data sharing medium. When the data are not in the preferred form, the source organization must translate those non-preferred data to the preferred form before they are shared over the data sharing medium.

Figure 3.1. Data sharing concept.
Similarly, when the target organization uses the preferred data, those data can be readily received from the data sharing medium. When the target organization does not use preferred data, they must translate the preferred data to their organization’s non-preferred form.
The data sharing concept allows source and target organizations to independently change their data resource from disparate to comparate without impacting other organizations. It avoids the constant changes to data transfer files that is common in many organizations, which eases data sharing and improves productivity.
The data sharing concept has been used with great success in many public sector organizations that readily share data between public agencies, and in some large private sector organizations. Organizations that want to begin a data resource integration initiative can start by establishing a data sharing initiative, where all data are defined within a common context so they can be thoroughly understood and readily shared in the preferred form to meet the current and future business information demand.
Common Data Architecture Concept
The Common Data Architecture is the common context for inventorying and documenting all data, understanding the content and meaning of data, improving data quality, understanding and integrating disparate data, defining new data, managing dynamic data deployment, and managing change, regardless of where the data reside, who uses them, how they are used, or how they are structured.
The Common Data Architecture ensures that data are integrated within the organization, and often across organizations in the public sector. It enables a shift from reactive data resource management to proactive data resource management. It promotes development of a comparate data resource that can be readily shared.
The Common Data Architecture is a principle-based paradigm based on sound theory, concepts, and principles that have been known for a long time. It provides a set of techniques that supports the concepts and principles. It is not hypothetical, esoteric, or academic. It is a simple and elegant, practical, and proven way to develop a comparate data resource.
I began in the 1970s developing the concept, although I didn’t know at the time that it would become the Common Data Architecture concept. At that time, the concept of a single organization-wide data architecture did not exist. In fact, the concept of any type of data architecture seldom existed. Data modeling was becoming prominent, and emphasis on logical data modeling based on the business was just emerging.
Data models were often developed independently, with little coordination between data models. The scope of data models varied with the scope of the development project. Canonical synthesis emerged, but had little effect on developing a single data architecture for the organization. The result was the beginning of a trend of disparate data models and disparate data resources.
The concept evolved through the 1980s, as experience was gained in understanding how to design a data resource that could be readily shared. The evolution was driven by problems found with data management in a wide variety of public and private sector organizations. I defined disparate data in the late 1980s and comparate data in the early 1990s.
The concept of a formal Common Data Architecture emerged in the early 1990s. The concept has been continually refined until today, where it is now the definitive approach for understanding all data in a common context, designating a preferred data architecture, and developing a comparate data resource. Although minor enhancements may be made based on problems encountered, the concept is substantially complete.
Basic Principles
The Common Data Architecture contains four basic principles: subject oriented, integrated, business driven, and supported by a comprehensive Data Resource Guide.
A subject-oriented data resource is a data resource that is built from data subjects that represent business objects and events in the business world that are of interest to the organization. The basic structure of a comparate data resource is based on data subjects and the relations between those data subjects. All characteristics of a data subject are stored with that data subject.
Architected data are any data that are formally understood and managed within a common data architecture, including both disparate and comparate data. Non-architected data are any data that are not formally managed within a common data architecture. Partially architected data is the situation where some data are managed within a common data architecture and some data are not managed within a common data architecture.
A business driven data resource is a data resource where the design, development, and maintenance are driven by business needs, as defined by the business information demand. The data resource is about the business, by the business, and for the business. The Common Data architecture provides the construct for an orientation towards business needs.
The organization perception principle states that the comparate data resource developed to support an organization’s business must be based on the organization’s perception of the business world. If a comparate data resource is to support an organization’s business activities, that comparate data resource must be based primarily on the organization’s perception of the business world and how the organization chooses to operate in that business world.
A Data Resource Guide provides a complete, comprehensive, integrated index to the organization’s data resource. It provides a thorough understanding of the data resource, and is readily available to everyone in the organization so they can use the data resource to support their business needs. It provides one version of truth about the data resource, in the same manner that a comparate data resource provides one version of truth about the business.
Common Data Architecture Scope
The scope of the Common Data Architecture is shown in Figure 3.2. The disparate data, as well as any new data, are integrated into a comparate data resource. The comparate data resource is supported by a comprehensive Data Resource Guide that fully documents the data resource. People can go to that Data Resource Guide, find the data they need to perform their business activities, and extract those data to the appropriate information systems that meet the business information demand. All of those tasks are performed within the context of a Common Data Architecture.

Figure 3.2. Common Data Architecture Scope.
Common Data Architecture Size
The common data architecture continues to increase in size during the data resource integration process. First, the common data architecture grows for each project until all of the disparate data have been inventoried and cross-referenced. It grows very rapidly, particularly during the initial projects, and often looks complex, insurmountable, overwhelming, and discouraging.
Second, a common data architecture grows as derived data are identified and defined. Primitive data generally grow to a plateau and then remain relatively constant or grow slowly. Derived data continue to grow steadily, often at an exponential rate, with development of evaluational data.
Third, a common data architecture grows as the preferred data are defined. As definitions, structure, and integrity rules are defined for the preferred data architecture, the size of the common data architecture continues to grow.
The growth of the common data architecture tapers off as the disparate data are transformed to comparate data. Ideally, the preferred data architecture becomes the only component remaining within the common data architecture. However, organizations may want to keep the understanding of those disparate data around for reference, even though the disparate themselves have been transformed and no longer exist.
The size of an organization’s data resource is measured both in the breadth and depth of the data. Data volume breadth is how many data entities and data attributes are in the data resource and data models, and how many data files and data items are in the databases. It depends on the number of business facts and how those business facts are grouped into data entities and stored in data files. Data volume depth is how many data occurrences exist for the data entities and how many data records are stored in the data files.
The common data architecture size is based on the data volume breadth. The data volume depth has relatively little influence on the size of the common data architecture. The more data entities, data attributes, and data occurrences, and the more data files and data records, the larger the common data architecture.
Organizations should plan on the common data architecture growing during data resource integration. They should not plan on any reduction in the size of the common data architecture until disparate data have been removed from the data resource, and little possibility exists for disparate data to be found in applications, reports, documents, and so on.
Simple Approach
The Common Data Architecture ensures that a comparate data resource is an elegant and simple approach to facing the complexity of a disparate data resource and building a comparate data resource. It follows Albert Einstein’s simplicity principle that states everything should be a simple as possible … but not simpler. The Common Data Architecture follows that principle. It’s the simplest approach to both developing a comparate data resource and to integrating a disparate data resource.
The Common Data Architecture also follows Occam’s Razor. As initially translated, it means Entities should not be multiplied more than necessary. That is, the fewer assumptions an explanation of a phenomenon depends on, the better it is. It essentially means keep it simple.
Higher Level of Technology
The Common Data Architecture follows another of Albert Einstein’s principles that a problem cannot be resolved with the same technology that was used to create the problem. The resolution requires a higher level of technology.
Einstein’s principle provides a new direction for creating a higher level of technology to solve the problems of an ever-growing disparate data resource. The Common Data Architecture is that higher level of technology.
Includes Data Integrity
The Common Data Architecture supports both semantic and structural integration, as described in the last chapter. It does not favor one over the other and resolves the ongoing discussion about whether data resource integration should be driven by the semantics of the data or the structure of the data.
The only missing component from formal data resource integration is the data integrity. The Common Data Architecture ensures that data resource integration includes data integrity. Data resource integration is not driven by data integrity, as it is by semantics and structure, but it must include data integrity to understand the quality of existing disparate data and ensure the quality of the comparate data.
Customized Approach
The Common Data Architecture is not a one-size-fits-all approach. It contains the concepts, principles, and techniques for building and maintaining a comparate data resource, and for resolving disparate data. These concepts, principles, and techniques are combined with an organization’s problems, needs, and operating environment to provide a customized approach for understanding disparate data and building a comparate data resource.
Emphasizes Understanding
The common data architecture does not integrate the data—it provides a base for understanding the data so they can be integrated. People need to understand the data with respect to the business before those data can be integrated. Data resource integration is primarily an understanding issue, and secondarily a data issue. A common data architecture provides the context for thoroughly understanding the data with respect to the business.
Aldous Huxley said that facts do not cease to exist because they are ignored. Similarly, the meaning of the data does not change because people don’t thoroughly understand that meaning. Also, the true meaning of the data does not change based on people’s understanding of the meaning. Only the business changes based on the understanding of the data.
Understanding the data includes semantic understanding, structural understanding, and integrity understanding. It includes understanding the data and how those data support the business. When people understand both the data and how the data support the business, the stage is set for data resource integration.
As understanding goes up, uncertainty goes down. When people are uncertain about the data, they are uncertain about the business. When people understand the data, they understand the business, and the business has a better chance of being successful. Therefore, the data must be thoroughly understood to have a successful business.
Understanding data within a common context avoids the elephant syndrome by focusing on the whole picture. The elephant syndrome is the situation where a blindfolded person feels one portion of an elephant, such as trunk, leg, tail, ear, and so on, and tries to describe the object they feel, usually incorrectly. Trying to understand data without a common context is like trying to describe the elephant while blindfolded.
It should become clear why the category of data in context was inserted into the scheme of data, information, and knowledge. Data in context requires a thorough understanding of the data, both for understanding the business and for data resource integration. Without data in context, only raw data exist and there can be no real understanding of the business or successful data resource integration.
Data resource integration is not a precise process because of the uncertainty in disparate data, it’s a cyclic and evolutionary process that discovers meaning and enhances understanding. Sometimes the process deals with vagueness, but it’s vagueness at the business level, not at the data level. Resolving vagueness at the data level helps resolve vagueness at the business level.
Remodeling Analogy
Integrating disparate data is much like remodeling a house. When people start remodeling a house, they have no idea where the plumbing, electrical, phone, and heating ducts are located. They can only observe electrical outlets, phone jacks, light fixtures, heat registers, and so on. However, those terminations don’t identify where things are routed within the walls and floors. People can crawl under the house or in the attic to get a better idea of where things are located. They can pull circuit breakers and turn off water valves, but they still are not sure where everything is located until they tear out the walls, usually with surprises.
The same situation is true for integrating disparate data. People can observe documents, screens, and reports. They can look at the database definitions. They can run automated documentation tools. They still have very little idea about the true content and meaning of the disparate data until they begin to tear those data apart, usually with surprises.
Wouldn’t it be nice to know all of the things about a house, like its structure, plumbing, wiring, heating, lumber quality, roofing, paint, anomalies, and so on? Wouldn’t it be nice to have a comprehensive architecture for a house that contained the description of all components, the structure of those components, and the integrity of those components? Wouldn’t that blueprint make use and maintenance of the house much easier?
The same applies to disparate data. Wouldn’t it be nice to know all of the things about data, their structure, their meaning, and their anomalies? Wouldn’t it be nice to have a comprehensive blueprint so that people do not have to make assumptions about the data? Wouldn’t it be nice to be able to readily identify, locate, and access the data needed to support business activities, and know those data are accurate and current?
A house is remodeled by making an initial model of what exists, based on perceptions, assumptions, and available documentation. As the remodeling process continues, things are discovered, perceptions change, and assumptions are proven or changed. The initial model is enhanced to represent the current state of knowledge. When the remodeling is completed, an accurate model of the house is available.
That’s exactly what data resource integration accomplishes. It starts with an initial common data architecture based on an organization’s perception of the business world. As the process continues, new things are discovered, perceptions change, and assumptions are proven or changed. The initial common data architecture is enhanced to represent the current understanding about the disparate data, and it continues to evolve until all disparate data are integrated. The data resource integration process provides one accurate model of all disparate data.
Building Code Analogy
Every data resource is different, just like every house is different. Data resources, like houses, were built to serve a particular purpose and do not fit a specific, universal, or generic design constraint. However, houses do need to follow a certain set of building codes to ensure the house is structurally sound and safe for the occupants.
The Common Data Architecture contains the concepts, principles, and techniques for building and maintaining a comparate data resource. It’s the building codes for an organization’s data resource. It helps ensure that the data resource is built according to the building codes, while still adequately representing the organization’s perception of the business world where it operates.
In other words, the building codes for a comparate data resource are consistent across all organizations, but the comparate data resource that is actually developed represents the unique needs of the organization.
Leaping Broad Chasms
I saw a diagram many years ago where a man on a pogo-stick was bouncing along across a stretch of flat land. However, he was approaching a broad chasm and the length of each pogo-stick bounce was far less than the width of the chasm. He had a very startled look on his face. Many organizations are in the same situation with their disparate data resource.
The near side of the chasm is a disparate data resource and the far side of the chasm is a comparate data resource. Understanding and integrating the disparate data is the chasm. Bridging that chasm seems daunting, if not impossible. The Common Data Architecture provides the bridge necessary to span broad data resource integration chasms incrementally.
Data Architectnology
Data architectnology is the technology for producing comparate data within a common data architecture. It’s the formal technology for building a common data architecture within an organization and managing data within that architecture. It consists of specific concepts, principles, and techniques for developing a comparate data resource. It’s very formal and detailed, yet results are very elegant and simple.
Data architectnology uses the least energy to develop and maintain a comparate data resource. It minimizes the energy to incorporate business and technology change—to keep the data resource current. It minimizes the energy to ensure integrity and accuracy. It minimizes the energy to understand and resolve disparate data.
Data Model Concept
A data model includes formal data names, comprehensive data definitions, proper data structures, and precise data integrity rules. A complete data model must include all four of these components.
The data model concept is the development of a data model, for a specific audience, representing a particular business activity, using appropriate data modeling techniques, based on data contained in the Data Resource Guide. The data model is an expression of knowledge about the data resource that is presented in an appropriate form for a specific audience. It is best to use the appropriate form consistently across the organization.
The data model concept is shown in Figure 3.3. On the left, the business information demand drives an analysis of that demand within the context of a common data architecture, which is documented in the Data Resource Guide. On the right, disparate data go through an understanding process within the context of a common data architecture, which is documented in the Data Resource Guide.
The appropriate data are taken from the Data Resource Guide, for a particular business activity, to produce a data model, using appropriate data modeling techniques, for a specific audience. All data models are developed within the context of a common data architecture. The concept changes the orientation from a model driven data architecture to architecture driven data models.
Five-Tier Five-Schema Concept
The Five-Tier Five-Schema concept represents all of the schemas involved in data resource management within the context of a common data architecture, as shown in Figure 3.4. The five tiers are strategic logical, tactical logical, operational, analytical, and predictive. The five schemas in the operational, analytical, and predictive tiers are business schema, data view schema, logical schema, deployment schema, and physical schema.

Figure 3.3. Data model concept.
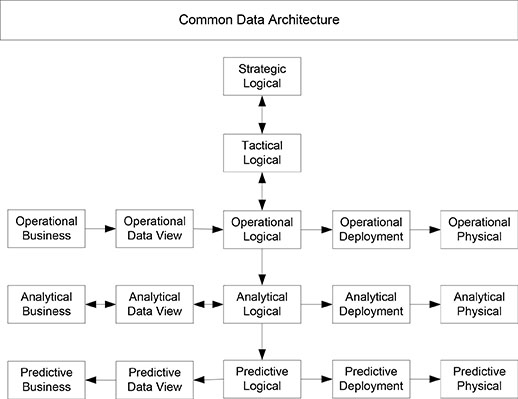
Figure 3.4. Five-Tier Five-Schema Concept.
Data resource integration deals with understanding the existing disparate schemas and developing comparate schemas within the Five-Tier Five-Schema concept. Disparate business schemas, data view schemas, logical schemas, deployment schemas, and physical schemas are all understood and resolved within the context of a common data architecture.
Data Rule Concept
The concept of data rules is briefly summarized below. Data Resource Simplexity provides a more detailed description of the data integrity rules, and Appendix A contains examples of data integrity rules.
A rule is an authoritative, prescribed direction for conduct, or a usual, customary, or generalized course of action or behavior; a statement that describes what is true in most or all cases; a standard method or procedure for solving problems. A data rule is a subset of business rules that deals with the data column of the Zachman Framework. They specify the criteria for maintaining the quality of the data resource.
Data rules are further classified data integrity rules, data source rules, data extraction rules, data translation rules, and data transformation rules. Data integrity rules specify the criteria that need to be met to insure that the data resource contains the highest quality necessary to support the current and future business information demand. The other data rules are described in subsequent chapters.
Data integrity rules are further classified as described below.
A data value rule is a data integrity rule that specifies the unconditional data domain for a data attribute that applies under all conditions. It specifies the rule with respect to the business, not with respect to the database management system. No exceptions are allowed to a data value rule.
A conditional data value rule is a data integrity rule that specifies the domain of allowable values for a data attribute when conditions or exceptions apply. It specifies both the conditions for optionality and the condition for a relationship between data values in other data attributes. It specifies the rule with respect to the business, not with respect to the database management system.
A data structure rule is a data integrity rule that specifies the data cardinality for a data relation between two data entities that applies under all conditions. No exceptions are allowed to a data structure rule.
A conditional data structure rule is a data integrity rule that specifies the data cardinality for a data relation between two data entities where conditions or exceptions apply. It specifies both the conditions and exceptions with respect to the business, not with respect to the database management system.
A data derivation rule is a data integrity rule that specifies the contributors to a derived data value, the algorithm for deriving the data value, and the conditions for deriving a data value. A data rederivation rule is a data integrity rule that specifies when any rederivation is done after the initial derivation. A derived data value may be rederived when the conditions change or the contributors change, which often occurs in a dynamic business environment. The derivation algorithm and the contributors are usually the same, but timing of the rederivation needs to be specified.
A data retention rule is a data integrity rule that specifies how long data values are retained and what is done with those data values when their usefulness is over. It specifies the criteria for preventing the loss of critical data through updates or deletion, such as when the operational usefulness is over, but the evaluational usefulness is not over.
A data selection rule is a data integrity rule that specifies the selection of data occurrences based on selection criteria. The selection notation in the data naming taxonomy is used to document the selected set of data occurrences.
A data translation rule is a data rule that defines the translation of a data value from one unit to another unit. It represents the translation of the values of a single fact to different units, and is not considered to be a data derivation rule.
A data deployment rule specifies how the data are deployed from the primary data site to secondary data sites, and how those deployed data are kept in synch with the primary data site.
A data integrity violation action specifies the action to be taken with the data when the data violate a data integrity rule. That action may be to override the error with meaningful data, to suspend the data pending further correction, to apply a default data value, to accept the data, or to delete the data. Overriding the error could include implementing an algorithm to correct the data, such as reformatting a phone number. The new data are again passed through the data integrity rules to ensure they pass.
A data integrity notification action specifies the action to be taken for notifying someone that data have failed the data integrity rules and a violation action was taken. The action may alert someone who is responsible for taking action, or place an appropriate entry in an error log that will be reviewed by someone at a later date. The notification action includes the implementation of an algorithm to correct the data.
Data integrity rules use When rather than If because it is more meaningful to the business, and it indicates a logical condition rather than a mathematical condition. Also, a When condition does not have a corresponding Else clause like the If condition. An Else clause often leads to poor data integrity because everything else does not always fall into the Else clause. A much better approach is to specify When for every possible condition that could exist.
Data Resource Data Concept
One of the major lexical challenges in data resource management is the term meta-data. It has been used, misused, and abused to the point that the meaning is totally unclear. The traditional definition of data about data is a tautology and provides no denotative meaning. The term needs to be abandoned. The cause is lost!
A much better term is data resource data. Data resource data are any data necessary for thoroughly understanding, formally managing, and fully utilizing the data resource to support the business information demand. Similarly, data resource information is any set of data resource data in context, with relevance to one or more people at a point in time or for a period of time. The data resource information demand is the organization’s continuously increasing, constantly changing, need for current, accurate, integrated information about the data resource that is necessary for formally managing the data resource.
The data resource data are stored and maintained in the Data Resource Guide. Data resource data are retrieved from the Data Resource Guide to support formal data resource management, including understanding existing disparate data and developing a comparate data resource.
Good data resource data are necessary to understand the data resource. Understanding the data resource is necessary to understand the business. Understanding the business is necessary to have good business intelligence and meet business goals. Therefore, the term data resource data will be used throughout the book.
Terminology
The lexical challenge in data resource management is only resolved with specific terms that have a denotative meaning. The matrix in Figure 3.5 shows the specific terms used for managing data, including the business, the Common Data Architecture, mathematics, logical data models, and physical databases, and the relationship between the terms. The matrix has been enhanced since Data Resource Simplexity, based on comments received. A column was added for the terms as used in mathematics so they could be compared to the terms used in data modeling. A row was added for the grouping of data from the business to the physical database. The result is a complete set of terms that have denotative meaning and can be used by anyone from business professional to database technician.
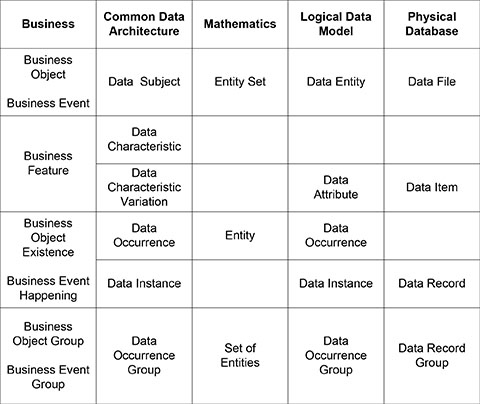
Figure 3.5. Matrix of terms and relationships.
Business Terms
A business object is a person, place, thing, or concept in the real world, such as a customer, river, city, account, and so on. A business event is any happening in the real world, such as a sale, purchase, fire, flood, accident, and so on. A business feature is a trait or characteristic of a business object or event, such as a customer’s name, a city’s population, a fire date, and so on. A business object existence is the actual existence of a business object, such as a specific person, river, vehicle, account, and so on.
A business event happening is the actual happening of a business event, such as a specific sale, purchase, a fire, a flood, an accident, and so on. A business object group is a subset of business objects based on specific selection criteria. A business event group is a subset of business events based on specific selection criteria.
Common Data Architecture Terms
A data subject is a person, place, thing, concept, or event that is of interest to the organization and about which data are captured and maintained in the organization’s data resource. Data subjects are defined from business objects and business events, making the data resource subject oriented based on the business.
A data characteristic is an individual fact that describes or characterizes a data subject. It represents a business feature and contains a single fact, or closely related facts, about a data subject, such as the make of a vehicle, or a person’s height. Each data subject is described by a set of data characteristics.
A data characteristic variation is a variation in the content or format of a data characteristic. It represents a variant of a data characteristic, such as different units of measurement, different monetary units, different sequences in a person’s name, and so on. Each data characteristic usually has multiple variations, particularly in a disparate data resource.
A data occurrence is a logical record that represents the existence of a business object or the happening of a business event in the business world, such as an employee, a vehicle, and so on. It represents a business object existence or a business event happening.
A data instance is a specific set of data values for the characteristics in a data occurrence that are valid at a point in time or for a period of time. Many data instances can exist for each data occurrence, particularly when historical data are maintained. One data instance is the current data instance and the others are historical data instances.
A data occurrence group is a subset of data occurrences within a specific data subject based on specific criteria, such as all the employees that have pilot licenses form a pilot certified employee data occurrence group. A data occurrence group represents a business object group or a business event group.
Mathematic Terms
An entity in mathematics is a single existent, such as an employee John. J Smith. It’s equivalent to a data subject. An entity set in mathematics is a group of like entities, such as Employees. It’s equivalent to a data occurrence. A set of entities in mathematics is a subgroup of an entity set, such as Retirement Eligible Employees. It’s equivalent to a data occurrence group.
Logical Data Model Terms
An entity is a being, existence; independent, separate, or self-informed existence, the existence of a thing compared to its attributes; something that has separate and distinct existence and object or conceptual reality. A data entity is a person, place, thing, event, or concept about which an organization collects and manages data. The name is singular since it represents single data occurrences. It represents a data subject in a logical data model.
An attribute is an inherent characteristic, an accidental quality, an object closely associated with or belonging to a specific person, place, or office; a word describing a quality. A data attribute is the variation of an individual fact that describes or characterizes a data entity. It represents a data characteristic variation in a logical data model. Even in a logical data model, a data attribute usually has specific content or format, such as measurement units, or a normal or abbreviated name sequence. Therefore, it is equivalent to a data characteristic variation, not a data characteristic.
Database Terms
A data file is a physical file of data that exists in a database management system, such as a computer file, or outside a database management system, such as a manual file. It is referred to as a table in a relational database. A data file generally represents a data entity, subject to adjustments made during formal data denormalization. A data item is an individual field in a data record and is referred to as a column in a relational database. A data item represents a data attribute, subject to adjustments made during formal data denormalization. A data record is a physical grouping of data items that are stored in or retrieved from a data file. It is referred to as a row or tuple in a relational database. A data record represents a data instance in a data file. A data record group is a subset of data records based on specific selection criteria. A data record group represents a data occurrence group in a data file.
Rationale
I’ve been asked many times why I created new terms for use within the Common Data Architecture. After all, the terms data entity and data attribute are quite acceptable. What benefit do the new terms provide, other than creating more terms to remember?
The reason is that data entity and data attribute are used within logical data models. Those logical data models are often quite disparate with the development of your model – my model, your technique – my technique, and so on. Therefore, the data entities and data attributes in those data models are disparate. Something that is disparate itself cannot be used as an overarching construct to understand and resolve disparity.
In addition, the data attributes typically used in logical data models are already some variation of the business feature, such as a date format or sequence of a person’s name. Therefore, the term data attribute cannot be used to represent a variation in the format or content of itself. Another term is needed, which is the data characteristic variation.
People have suggested I just use the terms common data entity, common data attribute, and common data attribute variation. The suggestion has merit, and has been tried. The problem is in the meaning when those terms are used to understand and resolve disparate data. For example, the phrase a data attribute is cross-referenced to a common data attribute variation could be quite confusing, even with denotative definitions of the terms. Therefore, a totally new set of terms were created to form the overarching construct for understanding and resolving disparate data.
The reader should begin to see the relationship between the terms and the reason for specifying different terms. The reason will become even clearer as the process of data resource integration is described.
Additional Terms
Several additional terms apply to understanding and resolving a disparate data resource.
Primitive data are data that are obtained by measurement or observation of an object or event in the business world. Derived data are data that are obtained from other data, not by the measurement or observation of an object or event.
Elemental data are individual facts that cannot be subdivided and retain any meaning. Combined data are a concatenation of individual facts.
Fundamental data are data that are not stored in databases and are not used in applications, but support the definition of specific data. Specific data are data that are stored in databases and are used in applications. Data inheritance is the process of using fundamental data to support consistent definitions of specific data.
DATA ARCHITECTURE COMPONENTS
The problems and principles for the five components of the Data Architecture Segment of the Data Resource Management Framework are summarized below. Data Resource Simplexity should be consulted for a more detailed description.
Data Names
Data names is the first component of the Data Architecture Segment. A data name is a label for a fact or a set of related facts contained in the data resource, appearing on a data model, or displayed on screens, reports, or documents. Informal means casual, not in accord with prescribed forms, unofficial, or inappropriate for the intended use. An informal data name is any data name that is casual and inappropriate for the intended purpose of readily and uniquely identifying each fact, or set of related facts, in an organization’s data resource. It has no formality, structure, nomenclature, or taxonomy.
J.C. Fabricius, a student of Carl Linneaus, stated in Philosophia Entomologica that if the names are lost, the knowledge also disappears. That statement is of profound importance to data resource management, including data resource integration. Formal data names are mandatory for understanding and resolving disparate data, and building a comparate data resource.
Informal Data Names
The problems with informal data names are summarized below.
A meaningless data name is any data name that has no formal meaning with respect to the business.
A non-unique data name is any data name, whether abbreviated or unabbreviated, that is not unique across the organization or across multiple organizations engaged in the same business activity.
A data name synonym is the same business fact with different data names. A data name homonym is different business facts with the same data name.
A structureless data name is any data name that has no formal structure to the words composing the data name.
An incorrect data name is any data name that does not correctly represent the contents of the data component. Incorrect data names are just flat wrong.
A multiple fact data field is any data field that contains multiple unrelated business facts. Multiple unrelated facts lead to incorrect data names.
An informal data name abbreviation is any abbreviated data name that has no formality to the abbreviation.
Disparate data names usually contain many data name synonyms and homonyms.
Data names may be physically or process oriented, indicating how the data are captured, how they are stored, or how they are used.
Many components of the data resource, such as data sites, data versions, data reference sets, coded data values, data occurrence groups, and so on, are seldom formally named.
Formal Data Names
Formal means having an outward form or structure, being in accord with accepted conventions, consistent and methodical, or being done in a regular form. A formal data name readily and uniquely identifies a fact or group of related facts in the data resource, based on the business, and using formal data naming criteria.
The formal data naming criteria are summarized below.
Every component of the data resource must have one and only one primary data name
The primary data name must be based on the data naming taxonomy.
The primary data name must be the real-world, fully spelled out data name that is not codified or abbreviated in any way, and is not subject to any length restrictions.
The primary data name must be unique across the organization’s data resource.
The primary data name must provide consistency across the organization’s data resource.
The primary data name must be fully qualified, meaningful, understandable, and unambiguous to everyone in the organization.
The primary data name must indicate the content and meaning of the data with respect to the business, not how the data are collected, stored, or used. It might not provide the complete business meaning, but it must indicate the business meaning.
The primary data name must identify variations in the format and content.
The primary data name must indicate the logical structure of the data. It might not provide the complete structure, but it must indicate the structure.
The primary data name words must progress from general to specific.
All other data names are alias data names and are cross-referenced to the primary data name.
The formal data name principles are summarized below.
Taxonomy is the science of classification, a system for arranging things into natural, related groups based on common features. The data naming taxonomy provides a primary name for all existing and new data, and all components of the data resource. It provides a way to uniquely identify all components of the data resource as well as all of the disparate data. It meets all of the data naming criteria and complies with the three components of semiotic theory.
The data naming taxonomy is a structural taxonomy that is based on data structure not on data use. Any data naming taxonomy based on data use is unstable and eventually leads to data synonyms and homonyms. The structural approach is stable over time because the structure of the data is relatively stable over time.
A common word is a word that has consistent meaning whenever it is used in a data name. A data name vocabulary is the collection of all twelve sets of common words representing the twelve components of the data naming taxonomy.
The primary data name principle states that each business fact, or set of closely related business facts, in the data resource must have one and only one primary data name. All other data names are aliases of the primary data name.
A primary data name is the formal data name that is the fully spelled out, real world, unabbreviated, un-truncated, business name of the data that has no special characters or length limitations. An alias data name is any data name, other than the formal data name, for a fact or group of related facts in the data resource.
The primary data name abbreviation principle states that data name word abbreviations, data name abbreviation algorithms, and data name abbreviation schemes be developed to consistently provide formal data name abbreviations. A data name abbreviation is the shortening of a primary data name to meet some length restriction. A formal data name abbreviation is the formal shortening of a primary data name to meet a length restriction according to formal data name word abbreviations and a formal data name abbreviation algorithm.
A data name abbreviation algorithm is a formal procedure for abbreviating the primary data name using an established set of data name word abbreviations. A data name abbreviation scheme is a combination of a set of data name word abbreviations and a data name abbreviation algorithm.
Data Definitions
Data definitions are the second component of the Data Architecture Segment. A definition is a statement conveying a fundamental character or the meaning of a word, phrase, or term. It is a clear, distinct, detailed statement of the precise meaning or significance of something.
Vague Data Definitions
Vague means not clearly expressed; stated in indefinite terms; not having a precise meaning; not clearly grasped, defined or understood. A vague data definition is any data definition that does not thoroughly explain in simple, understandable terms, the real content and meaning of the data with respect to the business.
The problems with vague data definitions are summarized below.
Non-existent data definitions have never been developed, or were developed at one time and have since been misplaced or lost. Whatever the reason, there exists considerable data in the data resource that have no data definition.
Unavailable data definitions are data definitions that are not readily available. The best data definitions may have been written, but if they are not readily available, it’s the same as being non-existent.
Short data definitions are data definitions that are short, truncated phrases, or incomplete sentences that provide little meaning.
Meaningless data definitions are data definitions that are meaningless to the business. The English and grammar may be acceptable, but the explanation of the content and meaning of the data with respect to the business is useless.
Outdated data definitions are data definitions that are not current with the business. The business of most organizations constantly changes over time, and the data values representing the business also change to reflect the business change. However, the data definitions are not kept current with the changes in the business or the data.
Incorrect data definitions are data definitions that are incorrect or inaccurate with respect to the business. The definitions are not in synch with the data name, the data structure, the data integrity rules, or the business.
Unrelated data definitions are data definitions that are unrelated to the content and meaning of the data with respect to the business. The data definition may be useful in another context, but it is not useful for understanding the data with respect to the business.
Comprehensive Data Definitions
Comprehensive means covering completely or broadly. A comprehensive data definition is a data definition that provides a complete, meaningful, easily read, readily understood definition that thoroughly explains the content and meaning of the data with respect to the business. It helps people thoroughly understand the data and use the data resource efficiently and effectively to meet the current and future business information demand.
I’ve received a few comments that comprehensive is not the opposite of vague, because a definition could be comprehensive yet still vague. Specific is the opposite of vague, while partial, fragmentary, incomplete, and limited are the opposite of comprehensive. The comments are valid, but not substantial enough to change the existing terms.
I’ve also received comments that a comprehensive data definition should include the purpose of the data. Those comments depend on the meaning of purpose. If purpose means the use of the data, then the purpose should not be included in the definition because it will never be complete, and may inhibit people from seeing other purposes for the data. If purpose means meaning with respect to the business, then the purpose must be included in the definition because it increases understanding of the data from a business perspective.
The comprehensive data definition criteria are summarized below.
The data definition must be meaningful with respect to the business.
The data definition must not include data entry instructions, source of the data, or use of the data.
The data definition must be understandable by anyone using the data resource to support their business needs.
The data definition must be denotative and not lead to any connotative meaning.
The data definition must provide a complete definition without any length limitation.
The data definition must accurately represent the business.
The data definition must be kept current with the business.
The data definition must be in synch with the formal data name.
The comprehensive data definition principles are summarized below.
The denotative meaning principle states that a comprehensive data definition must have a strong denotative meaning that limits any individual connotative meanings. The denotative meaning principle supports semiotic theory and the development of comprehensive data definitions.
A denotative meaning is the direct, explicit meaning provided by a data definition. A connotative meaning is the idea or notion suggested by the data definition, that a person interprets in addition to what is explicitly stated.
The meaningful data definition principle states that a comprehensive data definition must define the real content and meaning of the data with respect to the business. It is not based on the use of the data, how or where the data are used, how they were captured or processed, the privacy or security issues, or where they were stored.
The thorough data definition principle states that a comprehensive data definition must be thorough to be fully meaningful to the business. To be thorough, a data definition must not have any length limitation. The data definition must be long enough to fully explain the data in business terms.
The accurate data definition principle states that a comprehensive data definition must accurately represent the business. The data definition could be meaningful, and it could be thorough, but it may not be accurate.
The current data definition principle states that a comprehensive data definition must be kept current with the business.
The data name - definition synchronization principle states that a comprehensive data definition and a formal data name must be kept in synch. Formal data names help guide development of comprehensive data definitions, and comprehensive data definitions help verify formal data names. Synchronization is a two-way, value-added approach ensuring that formal data names match comprehensive data definitions.
Fundamental data definitions are the comprehensive data definitions for fundamental data. Specific data definitions are the comprehensive data definitions for specific data.
The data definition inheritance principle states that specific data definitions can inherit fundamental data definitions or other specific data definitions to minimize the size and increase the consistency of specific data definitions. The define once and inherit many times approach results in maximum meaning and consistency with minimum wording.
Fundamental data definition inheritance is the process of comprehensively defining fundamental data and allowing specific data definitions to inherit those fundamental data definitions. Specific data definition inheritance is the process of specific data definitions inheriting other specific data definitions.
Data Structure
Data structure is the third component of the Data Architecture Segment. A data structure is a representation of the arrangement, relationships, and contents of data subjects, data entities, and data files in the organization’s data resource. The term is often used in a physical sense, meaning the physical structure of the data for implementation. Although physical structure is one aspect of a data structure, it is not the only aspect. A data structure must also represent the logical structure of the data, independent of the physical operating environment.
Improper means not suited to the circumstances or needs. An improper data structure is a data structure that does not provide an adequate representation of the data supporting the business for the intended audience.
The problems with improper data structures are summarized below.
A detail overload with semantic statements, data cardinality, data attributes, and primary and foreign keys.
The wrong audience focus with the wrong detail, poor presentation format, and audiences not covered.
Inadequate business representation with incomplete business detail, incomplete business coverage, and redundant business coverage.
Poor structuring techniques for data normalization and denormalization, primary key designations, data definition inclusion, and incorrect data structure.
Proper Data Structure
Proper means marked by suitability, rightness, or appropriateness; very good, excellent; strictly accurate, correct; complete. A proper data structure is a data structure that provides a suitable representation of the business, and the data supporting the business, that is relevant to the intended audience.
The proper data structure criteria are summarized below.
Proper data structures must represent the structure of the data with respect to the business.
Proper data structures must contain a diagram of the data entities and the relations between data entities.
Proper data structures must contain the structure and roles of the data attributes.
Proper data structures must contain formal data names.
Proper data structures must not contain data definitions.
Proper data structures must cover the entire data resource for an organization.
Proper data structures must be developed by appropriate data structuring techniques.
The presentation of proper data structures must be oriented toward the intended audiences.
The presentation of proper data structures must include only relevant materials that are presented in an understandable manner.
Proper data structures must be developed for all appropriate audiences.
The proper data structure principles are summarized below.
Follow established theories, concepts, and principles from outside data resource management and within data resource management.
Follow formal data normalization and data denormalization techniques.
The data structure components principle states that a proper data structure must integrate data entity-relation diagrams, data relations, semantic statements, data cardinalities, and data attribute structures. All of these components must be developed to have a complete proper data structure.
The technically correct – culturally acceptable principle states that a proper data structure must be both technically correct in representing the data and culturally acceptable for the intended audience. A proper data structure must integrate all of the technical detail about the data resource and present it in a manner that is acceptable to the recipients.
The data structure uniformity principle states that all proper data structures in an organization must have a uniform format.
The structurally stable – business flexible principle states that a proper data structure must remain structurally stable across changing technology and changing business needs, yet adequately represent the current and future business as it changes. Being structurally stable and business flexible encourages business process improvement, which is extremely difficult, if not impossible, without a stable, comparate data resource.
The appropriate detail principle states that a proper data structure must contain all the detail needed for all audiences, but only provide the detail desired by a specific audience. The principle allows a wide variety of audiences to become involved in developing and maintaining a comparate data resource.
The data structure integration principle states that each component of proper data structures must be stored once and only once within the organization’s data resource, and then integrated as necessary when data structures are presented to specific audiences.
Proper sequence principle states that proper design proceeds from development of logical data structures that represent the business and how the data support the business, to the development of physical data structures for implementing databases.
The proper data structure can be easily read to any audience.
The application alignment principle states that purchased applications must be selected that align with the business and prevent or minimize warping the business into the application.
The generic data structure principle states that universal data models and generic data architectures can be used to guide an understanding of the organization’s data, but should not be used in lieu of thoroughly understanding the organization’s business.
Data Integrity Rules
Data integrity rules is the fourth component of the Data Architecture Segment. Integrity is the state of being unimpaired, the condition of being whole or complete, or the steadfast adherence to strict rules. Data integrity is a measure of how well the data are maintained in the data resource after they are captured or created. It indicates the degree to which the data are unimpaired and complete according to a precise set of rules.
Data integrity rules specify the criteria that need to be met to ensure the data resource contains the highest quality necessary to support the current and future business information demand. Examples of data integrity rules are shown in Appendix A.
Imprecise Data Integrity Rules
Imprecise means not precise, not clearly expressed, indefinite, inaccurate, incorrect, or not conforming to a proper form. Imprecise data integrity rules are data integrity rules that do not provide adequate criteria to ensure high quality data. Low data integrity results from the poor specification of data integrity rules, poor enforcement of data integrity rules, or both.
The problems with imprecise data integrity rules are summarized below.
Ignoring a high data frequency of data errors.
Incomplete data integrity rules.
Delayed data error identification.
Default data values.
Non-specific data domains.
Non-specific data optionality.
Undefined data derivation and data rederivation.
Uncontrolled data deletion.
Precise Data Integrity Rules
Precise means clearly expressed, definite, accurate, correct, and conforming to proper form. Data integrity was defined above. A precise data integrity rule is a data integrity rule that precisely specifies the criteria for high quality data values and reduces or eliminates data errors.
A data definition is not a data rule. Data definitions comprehensively define the meaning of the data. Data rules specify the criteria for maintaining data integrity.
Accuracy is freedom from mistakes or error, conformity to truth or to a standard, exactness, the degree of conformity of a measure to a standard or true value. Data accuracy is a measure of how well the data values represent the business world at a point in time or for a period of time. Data accuracy includes the method used to identify objects in the business world and the method of collecting data about those objects. It describes how an object was identified and the means by which the data were collected.
Data completeness is a measure of how well the scope of the data resource meets the scope of the business information demand. It ensures that all the data necessary to meet the current and future business information demand are available in the organization’s data resource.
Data currentness is a measure of how well the data values remain current with the business. The term data currentness is used rather than currency to prevent any confusion with the management of money (another lexical challenge). Data currentness ensures that data volatility and the collection frequency are appropriate to support the business information demand.
The precise data integrity rule criteria are summarized below.
Data integrity rules must be formally named according to the data naming taxonomy and vocabulary.
Data integrity rules must be normalized to match the normalized data.
Data integrity rules must be comprehensively defined.
Data integrity rules must have a formal notation that is easy to understand and use.
Specific data integrity rules must be defined for each type of situation encountered in the data resource.
Data integrity rules may inherit other data integrity rules, the same as data definitions are inherited.
Data integrity rule lockout must be identified and prevented.
Data integrity rule versions must be properly documented.
Data integrity rules must be stated explicitly.
Data integrity rules may be adjusted by combining and splitting rules.
Data integrity rules must be properly documented and be readily available to all audiences.
Data integrity rules must be denormalized and implemented as data edits as close to the data source as possible.
Data integrity rules must be uniformly enforced across all data.
Actions must be specified when data fail a data integrity rule.
Appropriate people must be notified of data integrity rule violations.
Default actions must be specified and documented.
Data quality improvement must be proactive to prevent data errors before they happen.
The precise data integrity rule principles are summarized below.
The data integrity rule name principle states that every data integrity rule must be formally and uniquely named according to the data naming taxonomy and supporting vocabulary.
The data integrity rule normalization principle states that data integrity rules are normalized to the data resource component which they represent or on which they take action.
The data integrity rule definition principle states that each data integrity rule must be comprehensively defined, just like data entities and data attributes are comprehensively defined. The definition must explain the purpose of the data integrity rule and the action that is taken.
The data integrity rule notation principle states that each data integrity rule must be specified in a notation that is acceptable and understandable to business and data management professionals, must be based on mathematical and logic notation where practical, and must use symbols readily available on a standard keyboard.
The data integrity rule type principle states that nine different types of data integrity rules must be identified and defined. The nine types are data value rules, conditional data value rules, data structure rules, conditional data structure rules, data derivation rules, data rederivation rules, data retention rules, data selection rules, and data translation rules.
Data integrity rules can be developed and inherited in the same way as fundamental data definitions. A fundamental data integrity rule is a data integrity rule that can be developed for and used by many specific data attributes. The data integrity rule is defined once and is applied to many different situations. A specific data integrity rule is a data integrity rule that is developed and applied to the data.
The data rule version principle states that data rule versions are designated by the version notation in the data naming taxonomy. The business constantly changes and the understanding of the business by data management and business professionals increases. Both of these situations lead to a modification of data integrity rules to ensure the data adequately support the business.
An implicit data integrity rule is a data integrity rule that is implied in a proper data structure. The explicit data integrity rule principle states that any implicit data integrity rule shown on a proper data structure must be shown explicitly in a precise data integrity rule. All data integrity rules must be stated explicitly so they can be enforced.
The data integrity rule lockout principle states that the precise data integrity rules must be reviewed to ensure that the rules do not result in a lockout, where data are prevented from entering the data resource.
The data integrity rule edit principle states that precise data integrity rules must be denormalized as the proper data structure is denormalized, and be implemented as physical data edits. Data integrity rules are the logical specification and must match the logical data structure, while data edits are the physical specification and must match the physical data structure.
The data integrity failure principle states that a violation action and a notification action must be taken on any data that fail precise data integrity rules. The violation and notification actions to be taken must be specified and followed.
The data integrity rule management principle states that the management of data integrity rules must be proactive to make optimum use of resources and minimize impacts to the business.
Data Documentation
Data documentation is the fifth component of the Data Architecture Segment. Data documentation applies to all components of the Data Architecture Segment, including data names, data definitions, data structure, and data integrity rules.
Limited Data Documentation
Limited data documentation is any documentation about the data resource that is sparse, incomplete, out of date, incorrect, inaccessible, unknown, poorly presented, poorly understood, and so on.
The problems with limited data documentation are summarized below.
Documentation not complete.
Documentation not current.
Documentation not understandable.
Documentation is redundant.
Documentation not readily available.
Documentation existence unknown.
Robust Data Documentation
Robust means having or exhibiting strength or vigorous health; firm in purpose or outlook; strongly formed or constructed; sturdy. Robust data documentation is documentation about the data resource that is complete, current, understandable, non-redundant, readily available, and known to exist.
The criteria for robust data documentation are summarized below.
The data documentation must be complete for the entire scope of the data resource and for all aspects of the data resource.
The data documentation must be formally designed, the same as business data.
Historical data documentation must be saved to adequately understand the historical data.
The data documentation must be formally documented to prevent a loss of institutional memory.
The data documentation must be current with the business so that it adequately represents the business.
The data documentation must be meaningful and understandable to all audiences.
The data documentation must not be redundant. It must represent one version of the truth about the organization’s data resource.
The data documentation must be readily available to all audiences.
The data documentation must be known to exist.
The data documentation must promote development of a comparate data resource that is readily shared.
The principles for robust data documentation are summarized below.
The data resource data aspect principle states that data documentation must include both the technical aspect and the semantic aspect of the data resource. Both are needed for all audiences to fully understand, manage, and utilize the organization’s data resource.
The complete data documentation principle states that data documentation must cover the entire scope of the data resource, and must include both the technical and the semantic aspects of the data resource.
The data documentation design principle states that all data resource data must be formally designed the same as business data. Data resource data are part of the data resource, the same as business data, and need to be designed the same as business data.
The current data documentation principle states that the data resource data must be kept current with the business. They must represent the current state of the data resource for both business and data management professionals.
The understandable data documentation principle states that the data resource data must be understandable to all audiences. The appropriate data resource data must be selected and presented to the intended audience in a manner appropriate for that audience.
The non-redundant data documentation principle states that the data resource data must represent a single version of truth about the data resource. The data resource data needs to include documentation about the existing disparate data as well as the new comparate data, and the transformation of disparate data to comparate data.
The readily available data documentation principle states that all data resource data must be readily available to all audiences. Both technical and semantic data must be available.
The documentation known to exist principle states that the data resource data must be known to exist so data management and business professionals can take advantage of those data.
The Data Resource Guide principle states that the data resource data must be placed in a comprehensive Data Resource Guide which serves as the primary repository for all data resource data. It contains data resource data about disparate data, comparate data, and the transformation of disparate data to comparate data. The Data Resource Guide contains the single version of truth about the data resource.
DATA RESOURCE INTEGRATION OVERVIEW
Data resource integration is a very detailed, but relatively straight forward, process. It’s based on all of the theory, concepts, and principles described in the last chapter and the current chapter. An overview of the data resource integration process is presented below. The details of the process are presented in the following chapters.
John Zachman often makes the statement It makes one wonder if there actually is a technical solution to the problem. My answer is Yes, there is, and it has been around for many years. The technical solution is in all of the theory, concepts, and principles for managing a data resource described in Data Resource Simplexity. If they had been followed, the data resource would not have become disparate.
The technical solution to integrating a disparate data resource has also been around for a number of years, and is described in the current book. The technical solution exists in the form of concepts, principles, and techniques for understanding and resolving disparate data.
All that data resource managers need to do is understand and apply the theory, concepts, principles, and techniques for preventing disparate data and resolving disparate data. They already exist and just need to be followed.
Discovery Principle
Disparate data integration is a discovery process that requires knowledge, analysis, evaluation, thought, interpretation, reasoning, intuition, vision, an open mind, and some luck. It’s a people oriented process that takes the knowledge and synergy of people to find the true content and meaning of the disparate data. It’s the people who understand the data and the business, and make the discovery.
The real knowledge about disparate data is in people, not in documents, programs, or dictionaries. The discovery process captures that knowledge and documents it as data resource data. The process cannot be performed by tools or automated applications. Tools can only support the discovery process. Knowledgeable people must be involved.
The data resource discovery principle states that data resource integration is a discovery process where any insights about the data resource are captured, understood, and documented. The process is performed by people, who may be supported by automated tools.
Building a comparate data resource is not a precise process because of the uncertainty involved with disparate data. It’s an evolutionary process based on discovery and enhancement that can only be done by people. The process cannot be automated because automated techniques cannot understand the true content and meaning of data. It’s just not possible to run a program that scans data files or applications and dumps a thorough understanding into a data dictionary. The result will be meaningless, and may be worse in some situations. However, tools can support the people who perform data resource integration.
Critical Mass Principle
People analyze disparate data piece by piece to determine the true content and meaning of those disparate data. The analysis requires a real understanding and awareness of the common data architecture, the business activities of the organization, and the data that support those business activities. Just when it appears that the entire process is getting out of hand, the true content and meaning of disparate data will never be determined, and cross-references will never be made, everything collapses into a meaningful understanding. Just when it appears that the task is insurmountable, the critical mass of insight is achieved and disparate data fall into place within the common data architecture.
The critical mass principle states that when the understanding of disparate data appears insurmountable, a critical mass of information is reached and collapses into a meaningful understanding of the disparate data.
My first integration project, many years ago in a county EAM shop, introduced me to both the data resource discovery principle and the critical mass principle. The task was to take a large storage room with rows of filing cabinets containing punched cards and convert them to magnetic tape. The task sounded easy at first. Just take the cards and load them onto magnetic tape. What could be easier?
However, the punched cards had an implied meaning in the rows of cabinets, the cabinets themselves, and the drawers in a cabinet, and the color of the cards. The cards were in a specific sequence and contained considerable redundant data. My task was to understand the punched cards and get them loaded onto magnetic tape in a meaningful and useful manner. The task was not trivial, but I succeeded in getting the magnetic tapes built into what today would be called an integrated data resource.
Incidentally, database disasters are not unique to the electronic age. In the days of punched cards, which often did not have a sequence number of any kind, a real database disaster was to spill a tray of cards. Many hours have been spent rebuilding the database by looking through the punches in the cards and determining how they should be sequenced when put back into the tray.
Approach Overview
An overview of the approach to data resource integration is shown in Figure 3.6. The top row represents the organization’s entire data resource. That data resource may be either the existing disparate data resource or the desired comparate, as shown in the second row. The data resource is understood within a common data architecture, as shown in the third row.
Figure 3.6. Data resource integration overview.
The disparate state is the current state of the data resource that is not well understood. The formal state is a necessary state where the disparate data are understood within a common context. The virtual state is the desired state where data are transformed temporarily to meet operational needs. The comparate state is the ideal state where the data have been permanently transformed.
The data resource is not well understood in the disparate state. It is understood within the context of a common data architecture in the formal state. It is transformed within a common data architecture in the virtual state and comparate state.
The disparate data were likely developed probabilistically, but the comparate data resource is developed deterministically. The change from probabilistic to deterministic is made in the formal state. The understanding of the disparate data is done retrospectively in the formal state. The comparate data are determined prospectively in the formal state, which is carried through the virtual and comparate states. The understanding of the disparate data is documented descriptively in the formal state. The comparate data are determined prescriptively in the formal state, which is carried through the virtual and comparate states.
Process Flow Overview
The general flow of the data resource integration process is shown in Figure 3.7. The disparate data are in the upper left and the comparate data are in the lower right. First, the existing disparate data are inventoried and documented as data resource data. Second, the inventoried data are cross-referenced to a common data architecture so they can be thoroughly understood in a common context. The cross-referencing is documented as data resource data. Third, the preferred data designations are made based on understanding the data in a common context, and are documented as data resource data.
Figure 3.7. Data resource integration process flow.
Fourth, the comparate databases are developed based on the documented preferred data designations. Fifth, the appropriate disparate data are extracted to a data depot in preparation for data transformation based on the preferred data designations. Sixth, the disparate data are transformed to comparate data within the data depot based on the data transformation rules. Seventh, the comparate data are loaded from the data depot into the comparate database based on the data resource data.
Integrating disparate data within a common data architecture is a real change for most people, and it causes them to procrastinate. However, the problem is not whether to integrate the disparate data, but how to start integrating disparate data. The problem is understanding how to build a common data architecture and integrate disparate data within that common data architecture.
SUMMARY
Integrating the data resource is the first of two components for the total integration of data resource management. The second is integrating the data culture. The current chapter described integrating the data resource by presenting concepts, principles, and analogies for understanding and resolving a disparate data resource, and terms related to integrating the data resource.
The five components of the Data Architecture segment of the Data Resource Management Framework were summarized from Data Resource Simplexity. These problems and principles of these components are used to both stop any further data disparity, and to understand and resolve existing data disparity. The point was strongly emphasized that the creation of data disparity must be stopped before the existing data disparity can be resolved.
Two overviews were provided for integrating the data resource. The first was an approach overview that described the relationships between the data resource states, the common data architecture, and the approaches to understanding disparate data and creating comparate data. The second was a flow overview that showed the seven basic steps for understanding and resolving disparate data.
The data resource integration process is not easy, but it’s far from impossible. It’s very detailed and often seems overwhelming, but if one persists, the process will lead to an understanding of the disparate data and the creation of comparate data that meet the current and future business information demand.
QUESTIONS
The following questions are provided as a review of data resource integration, and to stimulate thought about the integration of a data resource.
- What is the data sharing concept?
- How does data resource integration support the data sharing concept?
- How does the Common Data Architecture concept support data resource integration?
- Why is the Common Data Architecture a higher level of technology?
- Why are both semantics and structure important in data resource integration?
- How does the data model concept support data resource integration?
- What does the data rule concept emphasize?
- Why is the data resource data concept important?
- Why are new terms needed for the Common Data Architecture?
- What is the overall process for data resource integration?