
Chapter 2
DATA RESOURCE INTEGRATION CONCEPT
Integration includes both the data resource and data culture.
The Data Resource Management Framework contains two segments for Data Architecture and Data Culture. The Data Architecture segment represents the data resource, and the Data Culture segment represents the business of managing the data resource. Each of these components must be formally integrated to achieve a comparate data resource that supports the current and future business information demand.
Organizations often emphasize integration of the data resource without considering integration of the organizational culture managing that data resource. Chapter 2 provides an overview of the integration process for the data resource and the data culture. The integration concepts and principles are described for overall data resource management integration, data resource integration, and data culture integration. The various states of the data resource and data culture are described.
Integration of the data resource within a Common Data Architecture is described in more detail in Chapters 3 through 12. Integration of the organization’s data culture into a Common Data Culture is described in more detail in Chapter 13.
INTEGRATING DATA RESOURCE MANAGEMENT
Most public and private sector organizations are not formally integrating their disparate data resource or the fragmented management of their data resource. Most integration efforts that are initiated are usually incomplete or inconsistent, and seldom go to any meaningful conclusion. By meaningful conclusion, I mean resolving a substantial portion of their disparate data resource and fragmented data culture, and making that integration persistent over time. By substantial, I mean eighty percent or more of their disparate data resource, and ninety percent or more of their fragmented data culture.
Many public and privates sector organizations have started some type of data resource integration initiative, but have not been as successful as expected. In some situations, the result has been worse than expected, with the data resource becoming more disparate and the data culture becoming more fragmented. The basic reason for the failure is that the organization didn’t have a robust strategy for approaching integration.
Concept
An organization’s data resource management, including the data resource and the data culture, must be substantially integrated within the Data Resource Management Framework. The Data Resource Management Framework provides the overall construct for understanding and resolving a disparate data resource and a fragmented data culture.
How does an organization go about resolving their disparate data resource? How does an organization create a comparate data resource? How does an organization proceed from the current state of low quality data to the ideal state of high quality data? How does an organization go about integrating their data culture? How does an organization go from a state of fragmented data culture to a state of cohesive data culture? These valid questions are answered in the current and subsequent chapters.
The disparate data resource and the fragmented data culture must each be integrated to have formal data resource management. If only the disparate data resource is integrated, the fragmented data culture leads to continued data disparity. If only the fragmented data culture is integrated, the disparate data resource continues to be a problem.
The primary reason for integrating the disparate data resource and the fragmented data culture is to be able to meet the organization’s current and future business information demand. That demand has historically not been met through the disparate data resource, the fragmented data culture, or both. Therefore, both the disparate data resource and the fragmented data culture must be integrated.
The lexical challenge in data resource management is a monumental problem, as described in Data Resource Simplexity and Chapter 1 of the current book. That lexical challenge is pervasive through all aspects of data resource management. To make any real progress toward data resource management integration, the lexical challenge must be resolved right up front.
The following terms apply to data resource management integration and are used consistently throughout the book. Additional, more detailed, terms are presented throughout the book as the integration process is described in more detail. Some of these terms may be mainstream terms to which a specific meaning has been applied, while other terms may be contrary to mainstream terms. In either case, the terms are specifically defined and used consistently throughout the book.
Data Resource Management Integration
Discordant is being at variance; disagreeing; quarrelsome; relating to disagreement or clashing. Discordant data resource management is the situation where the overall management of an organization’s data resource, including the data resource itself and the data culture, has a high variance and disagreement.
Concordant means agreeing; in a state of agreement; a harmonious combination. Concordant data resource management is the situation where the overall management of an organization’s data resource, including the data resource itself and the data culture, is in agreement and harmony.
Integrate means to form or blend into a whole; to unite with something else; to incorporate into a larger unit; to bring into common organization. Integration is the act or process of integrating.
Data resource management integration is the overall integration of the management of an organization’s data resource, including integration of the data resource itself and integration of the data culture. It is the process of moving from discordant data resource management to concordant data resource management. It includes all components of the Data Resource Management Framework. Both the data resource itself and the data culture must be integrated to fully support the current and future business information demand.
Data Resource Management Transition
Transition is the passage from one state, stage, or place to another; a movement, development, or evolution from one form, stage, or style to another. It is moving in a consistent direction toward a desired goal. It implies permanence of the passage or evolution without a return to the former state.
Data resource management transition is the transition from a state of discordant data resource management to a state of concordant data resource management. It includes both data resource transition and data culture transition. The transition has a direction and purpose, and permanence to the extent that a return is not made to discordant data resource management.
Traditionally, organizations have been concentrating on the how of data integration—the physical integration of the data. That’s where the industry emphasis is placed, and most organizations follow that trend. Organizations need to concentrate on the what of data resource management integration with the objective of sharing of comparate data. That’s not where the industry emphasis is being placed.
The what of data resource management integration needs to be the first step, followed by the how of data resource integration and the how of data culture integration. Therefore, organizations need to move systematically from the what of data resource management integration through the how of data resource integration and the how of data culture integration. That’s the only way that the business information demand will be met.
Basic Principles
Several basic principles apply to data resource management integration, including contrarian thinking, integration is not a migration, descriptive and prescriptive aspects, retrospective and prospective aspects, probabilistic and deterministic aspects, the need to be value added, effectiveness and efficiency, integration is a discovery process, the point of diminishing returns, understanding and uncertainty, and the need for prevention before resolution. Each of these principles is described below.
Contrarian Thinking
Data resource management transition follows the principle of contrarian thinking. Contrarian thinking is not following the herd and thinking outside the box. Current wisdom is not simply accepted without question. Current practices are always scrutinized for better ways. The questions Why? or Why not? are frequently asked. Wanting to know what others are doing, and why, is persistent. Multiple voices are encouraged to speak on issues. Risk taking and innovations are valued and leveraged for maximum benefit. Thinking gray is common, without group think or crowd mentality. Synergy and teamwork are encouraged.
Contrarian thinking was used for developing the current concepts, principles, and techniques for data resource management integration. It’s also used for getting people involved to resolve a disparate data resource and a fragmented data culture.
Not a Migration
Data resource management integration is a transition, not a migration. Migration is a movement to change location periodically, especially by moving seasonally from one region or country to another. It’s wandering without a long term purpose, or wandering with only current objectives in mind, like nomadic wandering or bird migration. It’s a lack of a permanent settlement, especially resulting from seasonal or periodic movement.
Data management today places considerable emphasis on data migration, and that’s the problem! Too much short term wandering without any long term purpose has already been done. Too much creating additional disparate data without understanding what already exists has already been done. Too much emphasis on the data resource and not the data culture. Formal data resource management integration must be done to resolve the existing disparate data and fragmented data culture.
The term data migration is a major part of the lexical challenge. Again, people are pumping the words without really understanding what they are saying. Therefore, the term is inappropriate and is not used within the context of data resource management integration.
Descriptive and Prescriptive
Descriptive is to describe; referring to, consulting, or grounded in matters of observation or experience; expressing the quality, kind, or condition of what is denoted by a modified term. It is finding out what currently exists and describing it. Prescriptive is serving to prescribe; acquired by, founded on, or determined by prescription or long-standing custom. It’s describing how to get from an existing situation to a desired situation.
Data resource management integration is both descriptive and prescriptive. The descriptive aspect is determining what currently exists in the data resource and within the data culture, and describing them in enough detail that integration can proceed to a meaningful conclusion. It includes thoroughly understanding the current state of the data resource and the data culture. The data resource is described within the context of a Common Data Architecture and the data culture is described within the context of a Common Data Culture.
The prescriptive aspect is describing how to get from a disparate data resource state to a comparate data resource state, and from a fragmented data culture to a cohesive data culture state. It includes both describing the desired state (to-be) and how to get from the current state (as-is) to the desired state.
Retrospective and Prospective
Retrospective is the act or process of surveying the past; based on memory; affecting things past; looking back, contemplating, or directing to the past. It is looking at what has happened in the past to reach what currently exists. Prospective is likely to come about; likely to be or become; expected to happen; looking to the future. It is looking ahead at what’s needed.
Data resource management integration is both retrospective and prospective. The retrospective aspect is looking at what has happened to the data resource and the data culture in the past and how they arrived at their current state. It’s how the organization arrived at the current disparate data resource state and the fragmented data culture state. The prospective aspect is looking ahead at what is needed for a comparate data resource and a cohesive data culture. It’s what the organization desires for it’s the management of a critical resource.
The retrospective aspect is descriptive in nature—describing what currently exists and how the organization arrived at that current state. The prospective aspect is prescriptive in nature—prescribing what needs to be done and how to achieve that end state.
Deterministic and Probabilistic
Probabilistic is of, referring to, based on, or affected by probability, randomness, or chance. Deterministic is the quality or state of being determined; every event, act, and decision is the consequence of some previous event, act, and decision.
In the past and in the present day, data resource management has been a mixture of probabilistic and deterministic. Many of the problems seen today resulted from a probabilistic approach to data resource management. The data resource and the data culture seem to have just happened. To correct these problems, and ensure that data resource management leads to a comparate data resource and a cohesive data culture, the approach must be deterministic, based on sound concepts, principles, and techniques.
Value Added
The value added concept has been around for many years. Basically, every step in a process must be value added, meaning that the step adds value to any previous step or steps. Every step in a process must add value. Any step in a process that does not add value, must be removed.
The problem with data resource management to date is that many process steps are not value added. Many steps are redundant or virtually useless. A good example of redundant steps is repeatedly modeling the same set of data many times over. A good example of useless steps is esoteric or very abstract modeling that does not add any understanding and often adds confusion. The result is a fragmented data culture and the creation of a disparate data resource. The problems can only be corrected by ensuring that any process in data resource management is a fully value added process.
Effectiveness and Efficiency
In simple terms, effectiveness is doing the right thing. It’s performing the right processes for properly managing data as a critical resource. Any process or process step that is not needed to achieve the end objective are considered to be ineffective.
In simple terms, efficiency is doing the thing right. It’s performing a process as expeditiously as possible. Any process that is not performed in the most expeditious manner is inefficient, wastes resources, and could produce undesirable results. Whether a process is effective or not, it can be performed efficiently or inefficiently.
Both effectiveness and efficiency are closely related to the value added concept. Value added means that the right processes are performed, that they are performed efficiently, and that they add value.
Past data resource management has been both ineffective and inefficient, resulting in a fragmented data culture, a loss of productivity, and creation of a disparate data resource. Data resource management must be both effective and efficient.
A Discovery Process
Data resource management integration is a discovery process that requires thought, analysis, intuition, perception, and a bit of luck. It’s an evolutionary process due to the uncertainty with the disparate data resource. Anyone involved in data resource management transition must be an explorer, detective, investigator, archeologist, and so on, to find and understand the existing data resource and data culture. It’s an evolutionary process due to the uncertainty that is faced with a disparate data resource and a fragmented data culture.
Point of Diminishing Returns
Data resource management integration has a point of diminishing returns. It is not feasible for most organizations to achieve one hundred percent integration of the data resource and the data culture. The cost is too prohibitive to achieve perfect quality in either the data resource or the data culture.
Quality is endless, and perfect quality is seldom necessary to operate the business successfully. Each organization must determine the level of quality they need based on the cost to achieve that quality. Data resource management integration is then performed until that level of quality is achieved. Going beyond that level becomes too costly for the organization.
Data resource management integration must be just good enough for business success. Where is the biggest bang for the buck? What is the return on investment? What is the benefit / cost ratio? What is the benefit to the business? All of these questions must be answered to establish a point of diminishing returns before data resource management integration begins.
The level of quality improvement is what’s good for the organization prospectively. The past quality can be reviewed retrospectively to determine problems that need to be resolved. However, the improvement in quality is from the current situation forward.
Understanding and Uncertainty
Albert Einstein once said if he had only one hour to save the world he would spend fifty-five minutes defining the problem and only five minutes finding the solution. The statement shows that thoroughly understanding the problem is absolutely necessary before that problem can be solved. Thoroughly understanding disparate data is absolutely necessary before those disparate data can be resolved and a comparate data resource built.
Too many people charge ahead with resolving disparate data before understanding those disparate data, which is a brute-force-physical approach. The result is often failure or a result that is less than desirable. The result is often the creation of additional disparate data. Therefore, it’s most important to thoroughly understand the disparate data before any attempt is made to resolve those disparate data.
The basic principle is that the quality of any solution to a problem is proportional to the quality of the understanding of that problem. The better the understanding of the problem, the better the solution to that problem will be. In addition, a better understanding of the problem often leads to an easier solution to that problem.
Some people involved in data resource integration concentrate on budgets, organizational structures, project management, commitment, interpersonal communication, and so on. These items are certainly important as support, but are not primary to data resource management integration.
The primary emphasis is on data resource management, not on ancillary items. The primary emphasis is thoroughly understanding the data with respect to the business and the culture to manage those data. Understanding the data resource and the culture, and documenting that understanding is the key. With a thorough understanding, the organization can agree on how to integrate the data resource and the data culture. When an agreement is reached, the actual data resource management integration becomes relatively routine.
Preventing Discordance Before Resolving Discordance
I made the point in Data Resource Simplexity that the creation of disparate data must be stopped before the existing disparate data can be resolved. The creation of disparate data progresses much faster than those disparate data can be resolved. If the creation of disparate data is not stopped before an attempt is made to resolve those disparate data, the disparate data resolution process will never be completed.
The process of stopping the creation of disparate data before resolving existing disparate data may be done for the organization at large or for a major data subject area. That choice is up to the organization. The point to be made is that the continued creation of disparate data in any specific data subject area must be stopped before an attempt is made to resolve the existing disparate data in that data subject area.
A similar situation exists with a fragmented data culture. The proliferation of a fragmented data culture must be stopped before the existing data culture can be resolved. Little good comes from resolving the fragmented data culture in one part of the organization while the fragmented data culture runs rampant in another part of the organization.
Unlike resolving disparate data, which can be done one data subject area at a time, resolving a fragmented data culture must be done on an organization wide basis. The reason is that data and business processes are orthogonal to each other. In other words, many different business processes across the organization use the same set of data. Therefore, the fragmented data culture must be resolved before any attempt to resolve disparate data is made.
Data Resource Simplexity is about stopping the creation of disparate data by developing data within a Common Data Architecture, and about stopping the creation of a fragmented data culture by managing the data resource within a Common Data Culture. It presented the concepts, principles, and techniques for stopping the development of disparate data and a fragmented data culture. The current book is about resolving the existing disparate data resource and fragmented data culture.
The problem faced by most organizations is that they seldom see the benefits of prevention until it’s too late. Prevention is often perceived as not being beneficial and as impacting business operations. However, the future impact of non-prevention can result in a devastating loss to the organization.
The reason that organizations don’t see the benefits of prevention is that the distinction between memory and imagination is often blurred. What an organization believes about the quality of their data resource is often quite different from the actual quality of their data resource. When an organization believes that their data resource quality is high, they fail to see the benefits of preventing further disparity, or even the need to resolve existing disparity.
The often discouraging news is that organizations only see the benefits of prevention after going through data resource management integration. Only after realizing the impacts of non-prevention, after the fact, can an organization begin to see the benefits of prevention. One of my biggest hopes, which I may never see, is for organizations that have seen the benefits of prevention after data resource integration to somehow pass that information on to other organizations. The data resource management profession would be much more respected if they could make organizations aware of the benefits of prevention.
INTEGRATING THE DATA RESOURCE
Data resource integration is one segment of data resource management, as shown in the Data Resource Management Framework and described above. An overview of data resource integration sets the stage for the following chapters that describe the data resource integration process in detail. The overview includes the concepts, the lexical challenge, basic principles, and the data resource states.
Concept
The data resource integration concept is to resolve the disparate data and produce a comparate data resource that meets the current and future business information demand. An awareness of the data resource and a thorough understanding of it lead to the resolution of the disparate data. The result is an integrated data resource that is readily shared across the organization.
Many data integration approaches today concentrate on specific sets of data for a specific purpose. They are often uncoordinated and seldom substantially resolve the disparate data. Data resource integration applies to the entire data resource and emphasizes the substantial resolution of disparate data.
Data resource integration is like archeology. Archeology looks at the bones and skeletons, makes assumptions about climate and geology, and tries to figure out the life cycle of ancient species. Data resource integration looks at the exiting disparate data, makes assumptions about the environment at the time the data were captured and stored, and tries to figure out the intent and meaning of those data.
The data resource integration concept is often ignored in many data integration initiatives. After looking at many different data resource integration initiatives in many different public and private sector organizations, it appears that the only thing standard about data resource integration is a non-standard approach to data integration. That situation needs to be changed to a formal approach to data resource integration.
Common Data Architecture
The formal integration of anything must be done within some common context. Integration cannot be done successfully unless it is done within some overarching construct within which the integration is performed. Many people have tried to integrate data without an overarching construct, but the effort either completely fails or is less than fully successful.
I had a memorable experience with one state that was attempting to understand their data before integration by cross-referencing the data in each database of each agency to databases in every other agency. The project was encountering some difficulty, as can be imagined. After some analysis, we determined that the process would never go to completion, and if it did go to completion, the state didn’t have enough computer capacity to store the results. Further, the results would have little meaning for integrating those data.
The Common Data Architecture is a single, formal, comprehensive, organization-wide, data architecture that provides a common context within which all data are understood, documented, integrated, and managed. It transcends all data at the organization’s disposal, includes primitive and derived data; elemental and combined data; fundamental and specific data, structured and complex structured data; automated and non-automated data; current and historical data; data within and without the organization; high level and low level data; and disparate and comparate data. It includes data in purchased software, custom-built application databases, programs, screens, reports, and documents. It includes all data used by traditional information systems, expert systems, executive information systems, geographic information systems, data warehouses, object oriented systems, and so on. It includes centralized and decentralized data, regardless of where they reside, who uses them, or how they are used.
The Common Data Architecture is a paradigm, an archetype, a construct for an organization to use for developing a comparate data resource that adequately supports the current and future business information demand. It’s an elegant and simple solution that provides a higher level of technology to understand and resolve a disparate data resource and create a comparate data resource.
A common data architecture (not capitalized) represents the actual common data architecture built by an organization for their data resource, based on concepts, principles, and techniques of the Common Data Architecture. The common data architecture contains all of the data used by the organization, as defined by the Common Data Architecture.
A common data architecture provides the overarching construct for providing a common view of all data. All variations in data names, meanings, formats, structures, integrity, and so on, are understood within the context of a common data architecture. All preferred data for developing the comparate data resource are designated within the context of a common data architecture. All data transformation rules are developed within the context of a common data architecture.
Formal Data Resource Integration
Formal data resource integration is any data resource integration done within the context of a common data architecture. It’s more than a simple extract – transform – load. It’s more than minor data cleansing. It’s more than physically merging databases. Data resource integration is moving steadily through a series of very formal, but relatively simple, steps that go from a disparate data resource to a comparate data resource.
Informal data resource integration is any data resource integration done outside the context of a common data architecture. It usually does not result in a comparate data resource or any substantial resolution to the disparate data. It may result in increased data disparity. The term data resource de-integration is sometimes used to describe the results of informal data resource integration.
The Lexical Challenge
A formal approach to data resource integration requires that the lexical challenge be resolved. The definitions below set the stage for formal data resource integration.
The term integration is used often in many different contexts, but is largely undefined. It could mean integration of disparate data, integration of current and historical data, integration across platforms, integration for analysis to support business intelligence, and so on. I’ve seldom seen the term used properly for the integration of disparate data and never seen it used for the integration of a disparate data culture.
Many people use the term information integration, data integration, and data resource integration interchangeably. Yet again, interchanging these terms is most inappropriate and contributes to the lexical challenge in data resource management. All three terms have valid meanings, and the terms should be formally defined and used appropriately.
I’ve seen a variety of other terms, such as data purification, data cleansing, data scrubbing, data reconciliation, data conditioning, data filtering, data washing, data rinsing, data hygiene, data health, data decontamination, and so on. All of these terms are slang terms that are used without any formal definition and contribute to the lexical challenge. People are again pumping the words without any denotative meaning about what those words represent.
The terms below are formally defined to provide a denotative meaning and are used consistently throughout the book to resolve the lexical challenge.
Data Resource Integration and Transition
Data resource integration is the thorough understanding of existing disparate data within a common data architecture, the designation of preferred data, and the development of a comparate data resource based on those preferred data. It is the act or process to form, coordinate, or blend disparate data into a comparate data resource. It resolves the existing data disparity.
Data resource integration is not a simple union of data records from multiple databases or a simple join of existing databases. Nor is it a combination of existing databases. The process is much more detailed and requires thoroughly understanding the disparate data within a common context, then making informed decisions about how to create a comparate data resource.
An integrated data resource is a data resource where all data are integrated within a common context and are appropriately deployed for maximum use supporting the current and future business information demand. Data awareness and data understanding are increased. Data variability is at a minimum and data redundancy is reduced to a known and manageable level. Data integrity is known and at the desired level. The data are as current as the organization needs to conduct its business.
Data resource transition is the transition of an organization’s data resource from a disparate data resource state, through an interim data resource state and a virtual data resource state, to a comparate data resource state. It’s the pathway that is followed from a disparate data resource to a comparate data resource. It’s unique to each organization depending on their current situation and future needs.
Data resource transition is a consistent movement toward the long term objective of a comparate data resource that provides one version of truth about the business. Ultimately, the comparate data resource contains only one source for each business fact. The comparate data resource may be replicated for operational efficiency, but the replications must be kept in synch with the primary source on a regular basis.
Data Integration
Merge means to blend or combine together, to become combined or united. Data integration is the merging of data from multiple, often disparate, sources, usually based on some record of reference, to provide a single output, such as an interim database or report. It does not resolve any existing data disparity, and may further increase data disparity. It is seldom done within the context of a common data architecture.
Data integration usually means combining two or more sets of data, often from different databases or operating environments, together in the same physical location for operational processing, which is not the concept of data resource integration. The initial databases remain unchanged and the disparity still exists. Simply merging disparate data into a single location will not resolve data disparity.
Data Migration and Consolidation
Data migration is the movement of data to change location periodically from one database or platform to another depending on the physical environment and the needs of the organization. The migration seldom includes a thorough understanding of the data and is usually done outside of any context. The term migration is acceptable because periodic movements can be made depending on the conditions.
Data consolidation is the process of merging existing data from different sources into one location. The data may be restructured slightly, but nothing is done to thoroughly understand the data or to resolve data disparity.
Database merge is the process of merging separate compatible databases together into one single database. The data are not altered in any way. Data records are simply merged into one database. For example, middle school and high school student databases are merged together into one combined database for middle school and high school students.
Data conversion is the process of changing the same physical data schema from one database management system to another database management system. The data values are not altered in any way. They are simply moved from one database management system to another.
Database conversion is the process of changing a database management system from one operating environment to another operating environment. The data are not altered in any way. The database management system is simply moved from one operating platform to another.
Information Integration
Information integration is the integration of information, using the formal definition of information, from multiple sources into an understandable set of information for a specific use. It’s the process of taking disparate information and developing comparate information for some business activity.
For example, a person may be doing a web search for the medical treatment of some illness. The information that person gains from each web site is relevant and timely, according to the formal definition of information. However, the different sets of information gained from all of the web sites is disparate in the sense that the information is not in the same format, the same construct, the same sequence, and so on. The disparate information is difficult for a person to assimilate.
The person needs to integrate that information in some meaningful and cohesive manner that makes the information interpretable and comprehensible to the individual for treatment of the illness. How that disparate information is integrated is beyond the scope of the current book, and depends on the individual and the subject matter. The point to be made is that the integration of information is different from the integration of a disparate data resource.
Data Transformation
Data transformation deals with actually changing the structure, meaning, integrity, and sometimes the values, of the data. It will not be defined or described here. It will be defined and described in great detail in Chapter 11 on Data Transformation Concept, and in Chapter 12 on Data Transformation Process.
Basic Principles
Several basic principles support data resource integration, including integrating at the data level, semantic and structural integration, a detailed process, not reengineering, no single record of reference, no physical approaches, not scrap and rework, no lack of technical talent, and supporting tools. Each of these principles is described below.
Note that these basic principles for data resource integration are in addition to the basic principles described above for data resource management integration.
Integration at the Data Level
Data resource integration must be done at the data level. It cannot be done at the information level, the knowledge level, or the intelligence level. In fact, as will be described in detail through the following chapters, the integration must be done at the data variation level. The disparate data must be thoroughly done at the data variation level so those data can be successfully integrated.
Thoroughly understanding data at the variation level requires mentally separating the data from the product or database where those data are used or stored. Mentally separating the data from the product or database allows the data to be understood within the context of a common data architecture. Therefore, all data must be logically separated from the product or database to be thoroughly understood within a common data architecture and properly integrated.
Semantic and Structural Integration
The typical approaches to data resource integration have been either semantic or structural. Considerable discussion and conflict surround whether the semantics or the structure should drive data resource integration.
Formal data resource integration includes both semantic data integration and structural data integration. A choice between semantics or structure does not need to be made. Within the concept of a common data architecture, both semantics and structure are treated equally. In other words, a true understanding of the data is based on both semantics and structure.
Semantics is the meaning of the data with respect to the business, based on how they perceive the business world and operate in that business world. Structure is the arrangement of the data with respect to the business, based on formal data normalization and denormalization techniques. The structure is determined somewhat by the semantics, but largely by normalization and denormalization techniques.
Therefore, both the semantics and the structure must be thoroughly understood with respect to the business to resolve disparate data and develop a comparate data resource. Both are driven by the organization’s perception of the business world. Neither is more important than the other.
A Detailed Process
Data resource integration is a very detailed process: however, it is not impossible if a few simple concepts, principles, and techniques are followed. Many people believe that data resource integration is a very difficult process, meaning complex or complicated, which is why many people look for quicker physical options and software tools. However, the process is not complex or complicated, it’s just very detailed.
Data resource integration is not a major, one-time, one-pass, total resolution of the organization’s disparate data. The resources required, the time involved, and the impacts on the business prevent tackling the entire disparate data resource in one pass. A more reasonable approach is a slow, steady, very detailed, evolutionary transition from a disparate data resource to a comparate data resource one major data subject at a time. The most successful approach is a slow change of disparate data to comparate data that produces benefits along the way. A known, planned, well-managed transition with short term benefits that promote success motivation is the only reasonable approach.
Not Reengineering
I initially referred to data reengineering, but abandoned that term because for something to be reengineered it must have been engineered in the first place. The disparate data resource in most organizations was obviously not engineered—it was just created. Hence, there can be no reengineering.
I then introduced data refining and defined it as refining disparate data within a common context to increase the awareness and understanding of data, remove data variability and redundancy, and develop an integrated data resource. The analogy was similar to oil refining that takes crude oil, refines it into useful products, stores those products for future use, and discards waster products.
However, oil refining only separates the products that already exist in crude oil. It cannot create products that don’t already exist in the crude oil and has very little waste that is discarded. Resolving disparate data may well create new products and has considerable waste that is ultimately discarded.
Similarly, re-architecting the data does not apply. Most data were never really architected in the first place, hence re-architecting those data cannot occur. Architecting the data could be used, since the disparate data are being brought together within a common data architecture. However, data resource integration is more than just bringing the data together within a common data architecture. Therefore, the term data resource integration will be used throughout the book.
No Single System of Reference
I frequently run across the terms system of reference, record of reference, or system of record. These terms mean that, out of all the disparate data, a single system of reference should be found and that system of reference should become the comparate data resource. All other systems are then discarded. Miraculously, data resource integration is complete.
However, I’ve never seen any public or private sector organization where the system of reference approach worked. An organization’s disparate data resource is usually so entangled with databases, applications, bridges, feeds, and so on, that it’s nearly impossible to find a single system of reference. Further, if a single system of reference were designated, it’s nearly impossible to simply abandon all other data and use the single system of reference. The applications tied to the other data would not be able to operate.
I’ve heard a variation of the same theme, which I refer to as the big behemoth. The largest database in the organization that connects to the most applications is designated as the system of reference. It becomes, almost automatically, the comparate data resource. All other applications either convert to that database or are abandoned. I like to use the term the law of gross tonnage when referring to the big behemoth.
The problem with the big behemoth approach is that it may be the biggest, but not necessarily the best. It likely contains redundant and variable data and still exhibits all of the features of disparate data. As such, it cannot ever be considered as the comparate data resource.
The best approach is to put all data through the data resource integration process and, at the very least, thoroughly understand those data and determine their disparity. Then an informed decision can be made about developing a comparate data resource. In nearly every situation where I’ve been involved, no single system of reference exists and some degree of data resource integration always occurs.
No Physical Approaches
I’ve described two physical approaches above and in Data Resource Simplexity that are essentially forbidden in data resource integration. The first is the brute-force-physical approach where people jump right into the physical changes to the databases. Adjustments are made to the databases and to the applications in an attempt to resolve data disparity. However, little progress is made toward data resource integration, and the result is often worse than the initial situation.
The second is the suck-and-squirt approach where data, usually from a system of reference, are sucked out of one database, pushed through some superficial data cleansing tool, and squirted into another database under the assumption that the result is comparate data. Again, little progress is made toward data resource integration, and the result is often worse than the initial situation.
The problem with these physical approaches is that people presume to thoroughly understand the data, and forge ahead to physically change those data. These people avoid the formal process to thoroughly understand the disparate data and formally plan the transformation to comparate data. By avoiding the formal process, the result is usually a more disparate data resource and wasted productivity. Therefore, it’s best to go through the formal process, thoroughly understand the disparate data, plan the comparate data resource, and then transform the data according to that plan.
Not Scrap and Rework
I’ve heard scrap and rework used many times in reference to data resource integration. The term might be good for manufacturing, but it does not apply to data resource integration. No organization can afford to scrap their existing data resource and then build a comparate data resource from scratch. It just won’t happen.
The data resource is the raw material for developing information to meet the business information demand and that raw material has tremendous intrinsic value. Scrapping that raw material leaves nothing for developing information, and without information, the organization virtually ceases to operate. Scrap and rework may apply where the product is scrapped and raw material is used to build a new product. It may even apply to scrapping the raw material when that raw material has no intrinsic value and can be easily replaced. However, no organization can afford to scrap their valuable data resource and then rebuild it again.
No Lack of Technical Talent
Once we figure out what needs to be done, there is no want for technical talent about how to get it done. How will we ever accomplish all this? Who will do the work? How will it get done? All are monumental questions I’ve heard many times. I’ve found that once the existing disparate data situation has been described, the preferred data architecture has been prescribed, and the data transformation rules have been defined, technical talent is readily available, generally enthusiastic, and very willing to tackle the task of creating a comparate data resource.
Supporting Tools
Generally, software tools cannot be purchased that can perform the entire data integration process for an organization. Software tools are available for scanning, inventorying, data quality improvement (such as addresses), data documentation, and so on. However, software tools are not available to understand the disparate data and transform those data to a comparate data resource. Improved software tools to support various aspects of data resource integration may come in the future, once the data resource integration process is formally defined. However, the difficulty of understanding disparate data and the uniqueness of each organization makes a complete data integration tool virtually impossible.
Beware of software tools that will completely resolve disparate data. Look carefully at the product to determine what it can do for the organization’s disparate data resource and how it can support a data resource integration initiative. Usually, those software tools will perform far less than is claimed by the vendor.
Another reason that software tools for data resource integration don’t exist is that those tools will work themselves out of existence. Once the disparate data are gone, the tools have no further use, hence vendors hesitate to invest in those tools. To some extent, vendors may have a vested interest in keeping disparate data around, because they can continue to sell software, books, consulting, and so on.
Organizations have two basic scenarios they can follow. First, they can look for software tools that perform the data resource integration process with minimum human intervention. Second, they can establish a formal approach for understanding and resolving disparate data, and look for software tools to support various aspects of that approach. The first approach has a high probability of failure and likely creates more disparate data. The second has a high probability of success and likely results in creation of a comparate data resource.
One organization that engaged me had purchased all of the books and software tools, and took many classes about integrating data. However, they could not get started, even with understanding the data. The basic problem is that tools can’t understand the data or decide how to integrate those data. Only people can understand data and determine how to resolve those data—tools only support and document that understanding. One phrase I frequently use is Tools won’t solve the sins of disparate data. Only people working within the context of a common data architecture can resolve the sins of disparate data.
A better approach for an organization is to develop their own custom data resource integration tools to match their unique environment. As mentioned above, I’ve found no lack of technical talent in an organization once the disparate data have been described and the comparate data resource has been prescribed. Most technical people are more than willing to resolve the disparate data mess.
Data Resource States
Data resource transition consists of four states, progressing from a low quality disparate data resource, through a formal data resource and a virtual data resource, to a high quality comparate data resource, as shown in Figure 2.1. All four states are part of the organization’s data resource. The disparate data resource state is outside the common data architecture. The formal data resource state, virtual data resource state, and comparate data resource state are managed within a common data architecture.
An organization’s data resource matures as it moves through the transition states. The existing disparate data resource is immature. The maturity improves as the data are understood, and the variability and redundancy are reduced. The comparate data resource is the mature state. Each of these states is described below.
Disparate Data Resource State
The disparate data resource state is the current state of a disparate data resource in an organization and is outside the context of a common data architecture. The data exhibit the four characteristics of disparate data: unknown existence, unknown meaning, high redundancy, and high variability. The disparate data cycle is in full swing and the natural drift of the data resource is toward disparity. It’s the least desirable state of the data resource and is the initial state for the data resource transition process.
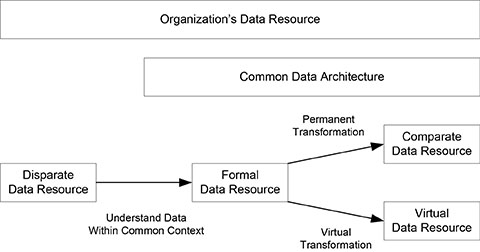
Figure 2.1. Data resource transition states.
Formal Data Resource State
The formal data resource state is a necessary state where the disparate data are readily understood within the context of a common data architecture. It’s the first step in the data resource transition process where disparate data are put in context using a common data architecture. It’s not a separate data resource since the data are only understood within a formal context.
The disparate data are inventoried and cross-referenced to the common data architecture. The data awareness problem and the understanding problem common with disparate data are resolved. Preferred data are designated and data translation rules are developed between the non-preferred and preferred data variations. These processes set the stage for reducing or resolving data redundancy and data variability. The integrity is known but has not been adjusted to the desired level.
The formal data resource state is an interim, non-destructive state where the existing data are not altered in any manner or moved from their present location. One of the problems with many techniques today is their destructive approach, which mandates the alteration or movement of existing data to improve understanding, often outside any formal construct. Such an approach is enough to turn most people against any effort to develop a comparate data resource.
Virtual Data Resource State
The virtual data resource state is an interim state between the formal data resource and a comparate data resource where real-time data transformation is performed to produce interim comparate data. The data are transformed in real time, according to formal data transformation rules, in either direction between disparate data and comparate data. Disparate data may be transformed to comparate data to support new applications or databases. Comparate data may be transformed to disparate data to support disparate applications or databases.
The data transformation is usually transparent to the recipient and is usually done through a formal data broker. The data transformation is non-persistent because the disparate data have not been resolved. Virtual data transformation is sometimes referred to as just in time data transformation, or just in time comparate data.
The virtual data resource state helps support the business operations while the comparate data resource is being developed and applications are being adjusted to access comparate data. It changes the natural drift of the data resource from disparate toward comparate data. Data bridges are resolved and applications are changed from using disparate data to using comparate data. It’s the interim state of virtual data sharing as organizations strive to achieve the ideal state of a comparate data resource.
Comparate Data Resource State
The comparate data resource state is the desired state where disparate data have been substantially and permanently transformed to comparate data and the disparate data are substantially gone from the organization’s data resource. It’s a persistent data transformation where the data are subject oriented according to the organization’s perception of the business world and are integrated within the common data architecture. The disparate data cycle is broken and the natural drift of the data resource is toward comparate data.
The comparate data resource is the ideal, mature situation for an organization’s data resource. The disparate data are formally transformed one final time to a comparate data resource, usually through a data broker. The majority of data bridges are gone and the majority of applications have been transformed to directly use and maintain comparate data.
Some disparate data may still exist, but they are beyond the point of diminishing returns where it is not feasible to transform the data. A few applications may still use or maintain disparate data, but they are usually minor applications and it’s not feasible to transform them.
The comparate data resource resolves most of the problems that perpetuate the disparate data cycle. The formal data resource state started breaking the disparate data cycle by raising the awareness and increasing the understanding of disparate data. The virtual data resource state further breaks the disparate data cycle by allowing access to those disparate data and real-time transformation to and from comparate data. The comparate data resource state has completely broken the disparate data cycle and the predominant drift of the data resource is toward comparity.
The comparate data resource state may not be achieved for ten years or more in most public and private sector organizations. However, progress toward a comparate data resource can be made within six months of beginning data resource integration, and substantial progress can be made in the first few years of a data resource integration initiative.
INTEGRATING THE DATA CULTURE
Data culture integration is one segment of data resource management, as shown in the Data Resource Management Framework. An overview of data culture integration sets the stage for Chapter 13, which describes data culture integration in detail. The overview includes the concept, the basic principles, and the data culture states.
Concept
The data culture integration concept is to resolve the fragmented data culture and create a cohesive data culture for the management of a critical data resource. A thorough understanding of the current fragmented data culture leads to its resolution and the creation of a cohesive data culture. That cohesive data culture, along with a comparate data resource, supports formal data resource management.
Fragmented is broken apart, detached, or incomplete; consisting of separate pieces. A fragmented data culture is a data culture that is broken apart into separate pieces that are unrelated, incomplete, and inconsistent. It is similar to a disparate data resource, and leads to the creation of a disparate data resource. A fragmented data culture cannot effectively or efficiently manage an organization’s data resource.
Cohesive is sticking together tightly, a union between similar parts. A cohesive data culture is a data culture composed of business processes that are integrated to effectively and efficiently manage an organization’s data resource. The business processes are seamless, consistent, and work together in a coordinated manner to develop and maintain a comparate data resource.
Common Data Culture
The Common Data Culture is a single, formal, comprehensive, organization-wide data culture that provides a common context within which the organization’s data culture is understood, documented, and integrated. It includes all components in the Data Culture Segment of the Data Resource Management Framework for a reasonable data orientation, acceptable data availability, adequate data responsibility, expanded data vision, and appropriate data recognition.
The Common Data Culture is a paradigm, an archetype, a construct for an organization to use for understanding their fragmented data culture and developing a cohesive data culture. It transcends all data resource management functions, the fragmented and cohesive data culture, and all data in the organization’s data resource as defined for the Common Data Architecture.
It’s an elegant and simple approach that pulls all of the fragmented data resource management functions and processes together to provide consistent management of the organization’s data resource, in an efficient and effective manner, so the data resource fully supports the current and future business information demand. It is based on formal concepts, principles, and techniques, similar to the Common Data Architecture, for coordinating data resource management.
A common data culture (lower case) is the actual data culture built by an organization for the proper management of their data resource. It’s based on the concepts, principles, and techniques of the Common Data Culture. It provides the overarching construct for a common view of the organization’s data culture. All variations in the data culture are understood within the context of a common data culture. The preferred data culture is defined within the context of a common data culture. Data culture integration is done within the context of a common data culture.
Formal Data Culture Integration
Data culture integration is the thorough understanding of the existing fragmented data culture within a common data culture, the designation of a preferred data culture, and the transition toward that preferred data culture. It’s the act or process of integrating and coordinating the organization’s data management function and processes into a cohesive data culture. It resolves a fragmented data culture by getting people to work together to build and maintain a comparate data resource.
Data culture integration is not a simple union of existing data management processes. It’s not simply understanding and documenting the existing data culture. It’s more detailed and requires thoroughly understanding the fragmented data culture within a common context, determining the preferred data culture, and transitioning to that preferred data culture.
Formal data culture integration is any data culture integration done within the context of a common data culture. Informal data culture integration is any data culture integration done outside the context of a common data culture. It usually does not resolve variability in the data culture and seldom leads to development and maintenance of a comparate data resource.
An integrated data culture is a data culture where all of the data management functions and processes in an organization are integrated within a common context, and are oriented toward developing and maintaining a comparate data resource. Data culture variability has been resolved and data resource management is performed consistently across the organization.
Data culture transition is the transition of an organization’s data culture from a fragmented data culture state, through a formal data culture state, to a cohesive data culture state. It’s a pathway that is followed from a fragmented data culture to a cohesive data culture. It’s unique to each organization depending on their existing data culture and desired data culture.
Data culture transition is separate from data resource transition. However, it must be done in parallel with data resource integration and with equal emphasis as data resource integration so that the data resource is managed consistently across the organization. Data resource integration without data culture integration will not resolve the disparate data situation.
Data culture transformation is actually changing the data culture in an organization and will not be described here. It will be described in detail in Chapter 13 on Data Culture Integration.
Basic Principles
Several basic principles support data culture integration, including being done in concert with data resource integration, integrating the complete data culture, integrating the data culture organization-wide, being simple yet difficult, must be persistent, not data governance, and must be both internal and external. Each of these principles is described below.
Note that these basic principles for data culture integration are in addition to the basic principles described for data resource management integration.
In Concert with Data Resource Integration
Data culture integration must be done in concert with data resource integration. Ideally, data culture integration should be done before data resource integration. However, that approach is seldom feasible because it’s difficult to implement a new data culture, then wait before applying that new data culture to management of the data resource. Therefore, it’s best to implement both data resource integration and data culture integration together.
Integrate the Complete Data Culture
All components of the cohesive data culture, including data orientation, data availability, data responsibility, data vision, and data recognition, must be implemented at the same time. Implementing only a subset of those components does not fully resolve the fragmented data culture. If the fragmented data culture is not fully resolved, disparate data could still be produced.
Organization-Wide
Data culture integration must be performed organization-wide. Little good comes from implementing the cohesive data culture to only part of the organization. Other parts of the organization simply continue creating disparate data. Since the data are usually orthogonal to the organization structure, the disparate data cannot be resolved as long as some of the business units have not been included in data culture integration. Therefore, data culture integration must be organization-wide.
Simple But Difficult
Data culture integration is simpler than data resource integration in many respects, yet it is more difficult to implement. It is simpler in the sense that it is not as detailed as data resource integration, fewer steps are involved, the steps are relatively straight forward, the variability is lower than the data resource, the understanding process is easier, and the documentation is easier. The variability in the data culture is relatively easy to identify, whether or not the data culture is formally documented.
Data culture integration is more difficult than data resource integration in the sense that changing the culture is more difficult than changing the architecture. Having the culture change the architecture is difficult enough, but having the culture change the culture can be quite difficult. People may show some resistance to change when integrating the data resource, but usually see the need. However, people often show great resistance to change when changing the way they manage the data resource. It’s often very difficult to convince people that changing the data culture is mandatory for creating and maintaining a comparate data resource.
Must Be Persistent
Implementing a cohesive data culture must be persistent. If the data culture transition is not persistent, people will drift back to their old ways of managing data and data disparity will increase. Therefore, a considerable effort must be made to understand the resistance to change that people have, and address that resistance. A considerable effort must be made to show people how a cohesive data culture develops a comparate data resource and how reversion to the fragmented data culture creates disparate data, and convince them that data culture integration is important.
Not Data Governance
I’ve talked with many people about data culture integration. Most of those people make some comment like Oh, that’s data governance. They proceed to tell me how they perceive that data governance addresses the data culture issue. However, I haven’t seen anything in data governance that specifically addresses the data culture to the level addressed with a Common Data Culture. I haven’t seen any formal set of concepts, principles, and techniques related to transitioning from a fragmented data culture to a cohesive data culture. Therefore, I don’t believe that data governance adequately addresses the data culture issue. The Common Data Culture approach is much more robust.
Both Internal and External
Data culture integration must be done both within and without the organization. The internal aspect is with the employees in the organization. The employees must buy into data culture integration and commit to making data resource management work if a comparate data resource is to be developed and maintained.
The external aspect includes the consultants, vendors, trainers, and so on, that the organization utilizes to support their data resource management effort. These external people often have their own thoughts, ideas, and agendas, which are frequently not in synch with the organization. Allowing these thoughts, ideas, and agendas to alter the data culture integration or the cohesive data culture is only to the detriment of the organization.
An organization should accept thoughts and ideas, where appropriate, to support their data culture integration effort. But, they should also reject any thoughts and ideas that are contrary to their data culture integration effort. The best approach is to select consultants, vendors, trainers, and so on, that agree with and support the organization’s cohesive data culture, and put appropriate statements in formal agreements.
Data Culture States
Data culture transition consists of three states, progressing from the fragmented data culture state, through a formal data culture state, to a cohesive data culture state, as shown in Figure 2.2. All three states are part of the organization’s data culture. The fragmented data culture state is outside the common data culture. The formal data culture state and cohesive data culture state are within the common data culture.

Figure 2.2. Data culture transition states.
An organization’s data culture matures as it moves through the data culture transition states. The existing fragmented data culture is immature. The maturity improves as the existing data culture is understood, the data culture variability is identified, and the preferred data culture is defined. A cohesive data culture is the mature state. Each of these data culture states is described below.
Fragmented Data Culture
The fragmented data culture state is the situation where every organizational unit, and possibly every person, is managing data in their own way, with their own orientation, vision, processes, and software tools. The data culture is highly variable and exhibits all of the characteristics of a fragmented data culture. The management is informal and seldom documented, and the fragmentation is not known. It is the least desirable state and is the initial state for data culture integration.
Formal Data Culture
The formal data culture state is a necessary state where the data culture is readily understood within the context of a common data culture. The variability of the fragmented data culture is understood and documented, the preferred data culture is designated, and the data culture integration is prescribed. No changes to the data culture have yet been made, pending review and approval by the organization.
Cohesive Data Culture
The cohesive data culture state is the desired state where the fragmented data culture has been substantially and permanently transformed to a cohesive data culture. It’s a persistent integration according to the preferred data culture prescription. A single set of processes has been established across the organization. It’s the ideal, mature state for management of the organization’s data resource.
SUMMARY
The following outline is provided as a summary of the data resource integration concept. Organizations can choose whether they want to develop a comparate data resource and a cohesive data culture. If they choose to develop them, then the following topics are of paramount importance and set the stage for understanding all of the detailed concepts, principles, and techniques related to developing a comparate data resource and a cohesive data culture.
Data Resource Management Integration
Concept is to create concordant data resource management
Basic Principles
Contrarian Thinking
Not a Migration
Descriptive and Prescriptive
Retrospective and Prospective
Deterministic and Probabilistic
Value Added
Effectiveness and Efficiency
A Discovery Process
Point of Diminishing Returns
Prevent Discordance before Resolving Discordance
Data Resource Integration
Concept is to create a comparate data resource
Basic Principles
Integration at the Data Level
Semantic and Structural Integration
A Detailed Process
Not Reengineering
No Single System of Reference
No Physical Approaches
Not Scrap and Rework
No Lack of Technical Talent
Supporting Tools
Data Resource States
Disparate Data Resource State
Formal Data Resource State
Virtual Data Resource State
Comparate Data Resource State
Data Culture Integration
Concept is to create a cohesive data culture
Basic Principles
In Concert with Data Resource Integration
Integrate the Complete Data Culture
Organization-Wide
Simple but Difficult
Must Be Persistent
Not Data Governance
Both Internal and External
Data Culture States
Fragmented Data Culture
Formal Data Culture
Cohesive Data Culture
QUESTIONS
The following questions are provided as a review of the data resource integration concept, and to stimulate thought about data resource integration.
- What is the difference between integration and transition?
- Why is transition not a migration?
- What is a Common Data Architecture?
- What is the difference between semantic integration and structural integration?
- Why does a system of reference seldom exist?
- What is the purpose of each of the data resource states.
- What is a Common Data Culture?
- Why does data culture integration and data resource integration need to be in concert?
- What is the purpose of each of the data culture states?
- Why does an organization need to consider data resource integration and data culture integration?