
Chapter 12
DATA TRANSFORMATION PROCESS
Managing the transformation of data and applications!
The last chapter described the concepts and principles for transforming data during the virtual data resource state and the comparate data resource state based on the preferred physical data architecture, the existing disparate data, and the organization’s operating environment. The concept of a data broker was described for managing data transformation until applications using disparate data could be transformed to using comparate data. The three formal phases and their eleven formal steps for extracting, transforming, and loading data were described.
Chapter 12 describes the techniques for transforming disparate data to comparate data to build a comparate data resource and support applications using comparate data. It also describes the techniques for transforming comparate data to disparate data to support applications using disparate data until they can be transformed. These techniques are based on the concepts and principles described in the last chapter and solve the third basic problem of data redundancy and the fourth basic problem of data variability found in a disparate data resource. The ultimate result of data transformation is a comparate data resource that supports the current and future business information demand of an organization.
DATA TRANSFORMATION PREPARATION
Preparation for data transformation includes the scope of data transformation, the sequence of data transformation, and the involvement in data transformation. These topics are different than described for data inventorying, data cross-referencing, and preferred data designations, because they involve actually changing the data, rather than understanding the data.
Data Transformation Scope
The scope of data transformation can be different from the scope for data inventorying, data cross-referencing, and preferred data designations. However, the data transformation scope must be within the scope of data that have already been inventoried and cross-referenced, and for which preferred data designations have been made, because data transformation is based on the preferred physical data architecture. Data transformation cannot proceed without a preferred physical data architecture.
The scope of data transformation must also include the scope of application transformation. The development of a comparate data resource and the transformation of applications to using comparate data must be carefully integrated. In other words, the scope has expanded from understanding the disparate data and designing a comparate data resource, to building the comparate data resource, transforming the disparate data, and transforming existing applications using those comparate data.
Data Transformation Sequence
The sequence of data transformation depends on the organization’s plans to develop a comparate data resource and transform applications from using disparate data to using comparate data. An organization can perform the data inventory and data cross-reference steps to understand their existing disparate data. An organization can also make the preferred data designations to understand how a comparate data architecture would be developed. Then plans can be made to actually transform the data.
For example, data inventorying, data cross-referencing, and preferred data designations may have been done for all public works data. Those processes provide a complete understanding of the disparate public words data within the context of a common data architecture. However, only public water system data will be transformed, to be followed later by sewer data, power data, street data, and so on. The plans for transforming disparate data must be integrated with the plans for transforming applications to using comparate data. Those tasks cannot be done independently.
Data Transformation Involvement
Involvement in data transformation includes data stewards, database professionals, application analysts and programmers, business professionals, and project managers. Data stewards have knowledge of the data and how those data are used by the business. Database professionals know the existing disparate data resource and develop the comparate data resource. They develop and maintain the data depot for data transformation, and the data brokers. Application analysts and programmers know how the applications can be transformed to use comparate data, and can assist with the development and maintenance of data brokers.
Business professionals provide input about the processes performed in the applications and the data needed by the business. They develop the business cases and reporting requirements to verify the comparate data and applications. Project managers ensure that the entire process is orchestrated so that the business operations are not impacted. The entire data transformation process becomes much more involved than understanding the disparate data.
One caution about transforming data and applications is that the process should not be hampered by extensive application changes. Business professionals and application managers often see an opportunity to make extensive application changes during data transformation. Although those changes seem feasible, extensive application changes during data transformation could be difficult unless very carefully planned. A better approach is to transform the data with only the application transformations necessary to use comparate data, and then make additional application enhancements at a later date.
DATA TRANSFORMATION
Data transformation includes the three formal phases and eleven formal steps described in the previous chapter. It uses the general extract-transform-load approach, but includes specific steps for transforming disparate data based on a physical preferred data architecture and applying data integrity rules to ensure high quality data to support the business.
Data transformation is unique to each organization, their disparate data, and their operating environment. Considering all of the different organizations, all of the different forms of disparate data, and all of the different operating environments, literally tens of thousands of unique situations exist. Describing each of these unique situations, or even a few of them, is way beyond the scope of the current book, and could fill many books on specific data transformation.
Therefore, the techniques described below are general techniques that can be applied to specific situations by people knowledgeable about those situations. The specific logic for performing the processes depends on database professionals, application programmers, and the particular operating environment. Many complaints I’ve received about unique situations not being described are valid, but knowledge of specific situations must be combined with general techniques to form specific techniques for each unique situation.
Data Extract Phase
Data extract was defined in the last chapter as the formal process of identifying and extracting the preferred disparate data and loading those data into a data depot for data transformation. Data extract consists of identifying the target data, identifying the source data needed to prepare those target data, and loading the source data into a data depot for data transformation.
Identify Target Data
Identify target data is the formal process of determining the desired target data. The target data are documented as a data set, as shown below. Since data transformation is based on the physical preferred data architecture, the physical data names are used. Note that the preferred physical data names do not show the variation name. The preferred variation is always used during data transformation.
DEPTMT
DEPTMT_NM
DEPTMT_ACRNM
DEPTMT_TYP_CD
EMPLYE
EMPLY_SSN
EMPLY_NM
EMPLY_BRTH_DT
DEPTMT_NM
The logical target data names could also be shown for business professionals accustomed to looking at the preferred logical data architecture. Note that the data characteristic variations are not shown. Since data transformation is based on the preferred data, the preferred data characteristic variation is always used.
Department
Department. Name
Department. Acronym
Department Type. Code
Employee
Employee. Social Security Number
Employee. Name Complete
Employee. Birth Date
Department. Name
Identify Source Data
Identify source data is the formal process of determining the source data that will be needed to prepare the target data. The preferred data source for each target data item is determined based on the data source rules. The process is to take each target data item and determine the preferred source for that data item using the data source rules and the data cross-references. The example below shows the sources for each target data item identified in the target data.
DEPTMT
DEPTMT_NM DEPT:DEPT_NM
DEPTMT_ACRNM DEPT:ACRONYM
DEPTMT_TYP_CD CODES:DTYPE
EMPLYE
EMPLY_SSN EMPL:SSN
EMPLY_NM PYRL:PYRL_NM
EMPLY_BRTH_DT AA:BDATE
DEPTMT_NM EFILE:DNM
Multiple data sources may need to be identified when conditional data source rules exist. For example, an employee’s birth date may be obtained from two sources based on their hire date. The example below shows how the sources would be designated.
EMPLY_BRTH_DT
When EMPLY_HRE_DT <= December 31, 1999 << PYRL:PYRL_BD
When EMPLY_HRE_DT >= January 1, 2000, << TNG:BRDT
Disparate data often contain combined data, which were broken down to data product unit variations during data inventorying. The breakdown of those combined data are used to identify the data item that needs to be sourced from the disparate data.
For example, a disparate data comment field contains the project name and the project start date, which need to be separated in the comparate data resource. The source data is the same for both the project name and project start date, as shown below.
Target Data
PRJCT_NM
PRJCT_STRT_DT
Source Data
PRJCT_NM PRJ:CMT
PRJCT_STRT_DT PRJ:CMT
Contributing data items may need to be obtained to support derived data, even though those contributing data items may not appear in the target data. The situation may apply to operational data or to evaluational data. All of the source data needed to support the derived data are identified as source data.
For example, all of the vehicle trip miles may need to be obtained for deriving the total miles a vehicle was used for business. The example below shows the target data is Vehicle. Business Miles and the source data are the individual Vehicle Trip. Miles, which are obtained from the miles in the vehicle trip disparate data file.
Target Data
VEHCL:BUSNS_MILS
Source Data
VEHCLTRP:MILS VCLTRP:MLS
Non-redundant data records may exist in different disparate data files. All of these data records need to be identified and brought into the data depot for transformation. For example, student records need to be sourced from data files for grade school students, middle school students, and high school students, and combined into one comparate data file for all students. In addition, the data names are different in the disparate data files.
The designation of target data and source data are shown below. If conditional data sourcing were needed for data from multiple disparate data files, the conditions would be designated as described above.
Target Data
STDNT_NM_CMPLT
STDNT_BRTH_DT
STDNT_HGHT
And so on.
Source Data – Elementary School
STDNT_NM_CMPLT ESTD:NM
STDNT_BRTH_DT ESTD:BD
STDNT_HGHT ESTD:HT
And so on.
Source Data – Middle School
STDNT_NM_CMPLT MDL:NAME
STDNT_BRTH_DT MDL:BIRTH
STDNT_HGHT MDL:H
And so on.
Source Data – High School
STDNT_NM_CMPLT STD:NME
STDNT_BRTH_DT STD:BDT
STDNT_HGHT STD:TALL
And so on.
Note that the data integration key could be used to identify possible redundant data occurrences between the disparate data files. For example, a particular student may appear in both the middle school and the high school disparate data files. Since the primary keys are different in those disparate data files, the data integration key would be used to identify those redundant data occurrences. Data would then be sourced from those redundant data occurrences based on the conditional data source rules.
The examples above are simple examples. However, the disparate data situation in most organizations is often quite confusing. A combination of unconditional data sourcing, conditional data sourcing, combined facts in disparate data, derived data contributors, and non-redundant and redundant data occurrences is usually the norm for most data transformation processes. The above notations are combined to form a complete statement of the data that need to be sourced.
Extract Source Data
Extract source data is the formal process of extracting the source data from the preferred data source based on the specifications, performing any database conversions necessary between the data source and the data depot, and placing the source data into a data depot for data transformation. The data extract is based on the source data specified in the Identify Source Data step described above.
Data are extracted from the source by some type of routine, either within a database management system or from an application outside a database management system. Individual routines for extracting source data from a specific data source or database are shown in Figure 12.1. Each routine extracts data from one database and places those data in the data depot.
One routine for extracting data from multiple data sources or databases is shown in Figure 12.2. One routine extracts data from multiple data sources and places those data in the data depot. Both approaches are valid, and a combination of approaches can be used, depending on the specific operating environment.
The data extract routine uses a primary key matrix and existing physical primary keys to extract the appropriate data occurrences or data instances. It can use the data integration key to identify possible redundant data occurrences and either use the appropriate data occurrence, or flag the redundant data occurrences for evaluation and decision. It can extract current data instances and corresponding historical data instances.
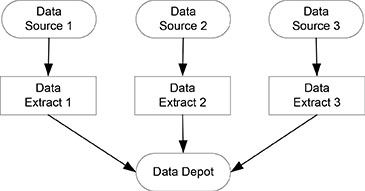
Figure 12.1. Individual data extract routines.

Figure 12.2. A single data extract routine.
The data extract routine can break down combined disparate data and place the specified source data in the data depot. The breakdown is based on the specifications placed in the data product unit variation during the data inventory process.
A data converter is an application that changes the data between heterogeneous databases. It does not transform the data in any way. It only changes the physical format of the data from one database environment to another database environment. The data extract routine uses a data converter, when necessary, to change the physical format of the data from the disparate database to the data depot database.
Specific data extract routines need to be written based on the disparate data and the operating environment. Database technicians and application programmers are usually very skilled at developing data extract routines, once they know the exact specifications. The key is to develop the exact specifications before building the data extract routines. Proceeding with any data extract without complete specifications often leads to low quality data and creates more disparate data.
After the source data have been extracted and processed according to the specifications, the data are placed in the data depot for data transformation, using their disparate data names so the connection can be made to any documentation done during data inventorying. Combined disparate data that are broken down during data inventorying use the data product unit variation name.
Historical data instances are extracted similar to current data instances. The only difference is that the primary key contains some type of time or date indication. Otherwise, the same specifications for data sourcing, breaking down combined disparate data, contributors to derived data, and redundant data instances apply.
Data Transform Phase
Data transform was defined in the last chapter as the formal process of transforming disparate data into comparate data, in the data depot, using formal data transformation rules. It consists of data reconstruction, data translation, data recasting, data restructuring, and data derivation.
Reconstruct Data
Reconstruct data is the formal process of rebuilding complete historical data that are not stored as full data records. It is typically used for developing comparate evaluational data, and is seldom used for developing comparate operational data.
When operational data values change, the former data value may be saved as history. Either the changed data values, and the appropriate key, or all data values may be saved as history. When all data values have been saved, data reconstruction does not need to be done.
A data reconstruction rule is a data rule that specifies the reconstruction of historical data into full historical data instances in preparation for data transformation. The data reconstruction rule shows the conditions for data reconstruction and the data reconstruction that is performed.
For example, student data need to be reconstructed from the present back through 1984. The reconstruct rule is shown below, showing the dates for data reconstruction and the data that need to be reconstructed. Note that the preferred physical data names are used in the data reconstruct rule, since the data reconstruction can involve many different physical data names across multiple current and historical data files.
Student
Reconstruct! Current back through January 1984
STDNT_NME
STDNT_BRTH_DT
STDNT_WGHT
STDNT_CHNG_DT
And so on.
The reconstructed data may be all of the extracted source data or only a subset of the extracted source data. The data reconstruct rule shows only the data that are to be reconstructed.
The typical approach is to start with the current historical data instance and work backward in time through the historical data to create the historical data instances. Whenever a data value changes for any of the data shown in the data reconstruct rule, an historical data instance is created for each of the data attributes shown in the data reconstruct rule. The appropriate primary key is formed and the historical data instance is saved. The process continues until the limit of historical data is reached, or until the time limit stated in the data reconstruct rule is reached.
Multiple non-redundant data files may each have their own history. The data reconstruct rule needs to be applied to each of these data files. The resulting historical data occurrences represent the changes from all of the non-redundant data files.
For example, the student data from an elementary school data file, middle school data file, and high school data file each have their own history data files. Historical data instances are created from each of those data files and merged as one set of historical data instances that apply to the current data instances.
Multiple redundant data files that have their own history need to be treated differently. Only the data sourced from each data file are involved in the creation of historical data instances. Data that are not sourced from a data file are not used to create historical data instances.
For example, several data files contain redundant student data occurrences. The data source rules show which data are extracted from those data files. The data reconstruct rule shows which of those extracted data are used to create historical data instances. Data that are not extracted are not used to create historical data instances.
Translate Data
Translate data is the formal process of translating the extracted data values to the preferred data values, if they are not already in the preferred format or content, using appropriate data translation rules. Data translation rules were defined earlier as specifying the algorithm for translating data values between preferred and non-preferred data designations.
For example, a student’s birth date could be translated from the MDY format to the CYMD format, as shown below.
STDT
BRTH_DT Translation! MDY >> CYMD
Similarly, a student’s name could be translated from the inverted sequence to the normal sequence, as shown below.
STDT
NM Translation! Name Inverted >> Name Normal
A student’s height could be converted from inches to millimeters, as shown below.
STDT
HT Translation! Inches >> Millimeters, 1 Digit
The data names are the physical disparate data names that were loaded from the data source. The data translation rules are shown in their formal notation. Fundamental data translation rules can be used where appropriate. When the format is variable, algorithms could be used to identify the format so the appropriate data translation rules could be used.
Data reference items are translated to the preferred data reference set variation using a matrix. For example, a student’s disability data reference item coded data values and names would be translated to the preferred data reference set variation as shown below.
Disability. Translation!
School; Employment; Health; New; *
10 Sight A Seeing V Vision S Sight
20 Hearing H Hear S Sound H Hearing
30 Physical P Physical A Accidental P Physical
40 Develop D Developed G Genetic D Developmental
The translated data values can be placed back into the existing data item, or a new data item can be created. In the examples above, the student’s birth date, name, height, and disability would be translated back into the same data item that was extracted from the data source.
The process is to work through each data item extracted from the data source to determine if the data value is in the preferred format or content. When the data value is not in the preferred format or content, a data translation rule is specified. When all of the data translation rules have been specified, the process of data translation can begin.
Recast Data
Recast data is the formal process of adjusting data values for historical continuity. It aligns data values for a common historical perspective using data recast rules. A data recasting rule is a data rule that specifies the adjustment of data values to a specific time period, such as adjusting financial data values to a specific time period for a comparison of trends independent of monetary inflation.
For example, 30 years of budget data could be recast to the beginning of the 30 year period for an analysis of trends independent of inflation, as shown below. The 30 year period is from 1970 through 1999, the values are recast to 1970, using Recast Algorithm 6. Recast Algorithm 6 specifies the adjustments applied to each year during the 30 year period
Recast! 1970 through 1999 to 1970 using Recast Algorithm 6
BDG:OBJ
BDG:SOB
BDG:PRG
BDG:SPRG
And so on.
The data names are the physical disparate data names that were loaded from the data source. The recast data values can be placed back into the existing data item, or new data items can be created for the recast data values.
The process is to identify any data that needs to be recast, determine the time period for recasting, determine the point for recasting, and specify the algorithm for recasting the data values during the time period. When the data recasting rules have been specified, the process of recasting can begin.
Restructure Data
Restructure data is the formal process of changing the structure of the disparate source data to the structure of the comparate target data. It takes physical disparate data structures that have existed in the past and changes those structures to the preferred physical data structure. Data restructuring may involve combining data into fewer data entities, or splitting data into more data entities.
The data restructuring is shown as a list with the physical source data names on the left and the preferred physical data names on the right. The physical source data names may be either the names of the data extracted from the source, or the names of the data resulting from data translation or data recasting.
The example below shows a data restructure list. The employee’s name obtained from the payroll data file becomes the employee’s name in the new employee data file. The birthdate from the affirmative action data file becomes the employee’s birth date. The ethnicity code obtained from the training file becomes the employee’s ethnicity code.
EMPLYE
PYRL: NAM NM
AA:BIRTH_DATE BRTH_DT
TNG:ETHNICITY ETHNTY_CD
And so on.
The process is to go through all of the extracted, translated, and recast data and place those data according to the preferred physical data architecture. The data restructure list may be more detailed than the example above, but the process is the same. When the data restructure list has been completed, the data can be moved according to that list.
Derive Data
Derive data is the formal process of deriving target data from source data according to formal data derivation rules. It applies to deriving individual data values, to summarizing operational data, and to aggregating evaluational data to the lowest level of detail desired. A data derivation rule was defined in Chapter 3 as a data integrity rule that specifies the contributors to a derived data value, the algorithm for deriving the data value, and the conditions for deriving the data value.
For example, an employee’s years of service is calculated annually on the employee’s increment date, based on their yearly increment date and their hire data, as shown below. The data in the data depot have their preferred physical data name, but the derivation algorithm uses the logical data names according to a common data architecture.
EMPLYE
SVC_YRS
Derivation! Annually on Employee. Yearly Increment Date
Employee. Yearly Increment Date – Employee. Hire Date
Similarly, the Vehicle. Business Miles are derived from all of the Vehicle Trip. Miles that were extracted as described above.
VEHCL
BUSNS_MLS
Derivation! January 1{Sum VEHCLTRP:MLS}December 3
Many different types of data derivation rules can be prepared, as described in Chapter 3 and shown in Appendix A. Data derivations rules are described in more detail in Data Resource Simplexity.
The process is to specify all of the data derivation rules that apply to the restructured data in the data depot. When those rules have been specified, they can be applied to the data.
Data Load
Data load was defined in the last chapter as the formal process of loading the target database after the data transformation has been completed. The transformed data are edited according to the preferred data integrity rules, loaded into the target database, and reviewed to ensure the load was successful before the data are released for use.
Edit Data
Edit data is the formal process of applying the preferred data edits to the transformed data to ensure the quality of the data before they are loaded into the target database. The process is to apply the preferred data integrity rules as defined in a common data architecture to the transformed data in the data depot. Any data that fail the data integrity rules trigger a violation action and a notification action.
Data that fail the data edits remain in the data depot until the failure can be resolved. Algorithms could be implemented to resolve the failure so that the data pass the data integrity rules, or the data could be held in suspense for a person to review and resolve. Data that fail the data edits should never be loaded into the target database.
Some people allow data that fail the data edits to enter the comparate database with a flag showing that the data failed the edit. Those flags are later reviewed and corrections are made to the data. However, in the vast majority of situations, those flags are seldom reviewed and the failed data are seldom corrected. The result is a lower quality comparate data resource. Therefore, only data that successfully pass the data edits should be placed in the comparate data resource.
Load Data
Load data is the formal process of loading the data from the data depot into the target database. Any database conversion that is necessary is done during the data load process. Only data that pass the preferred data edits are loaded into the target database. Data that fail the preferred data edits remain in the data depot until the problem is resolved.
Review Data
Review data is the formal process of reviewing the data that have been transformed and loaded into the target database to ensure they are appropriate for production use. The review makes the final determination of whether the transformed and loaded data are appropriate for use. If all of the data transformation processes were successful, the data passed the data integrity rules, and the load was successful, the data can be released for use.
The failure is identified and the data are re-transformed or re-edited before another data load is attempted. The worst scenario is that the data need to be removed from the data depot, the source data need to be re-extracted, and the data transformation process needs to be performed on the new set of data.
DATA TRANSFORMATION SUPPORT
Support for data transformation includes reverse data transformation, data brokering, managing evaluational data, managing missing data and default data, and maintaining data transformation documentation. Each of these topics is described below.
Reverse Data Transformation
Forward data transformation is the formal transformation of disparate data to comparate data. Data are extracted from the preferred data source, transformed, and loaded into the data target. The processes described above are forward data transformation. Reverse data transformation is the formal transformation of comparate data to disparate data. It’s necessary to maintain disparate data that supports disparate applications until they can be converted to comparate data.
Reverse data transformation follows the same phases and steps described above. The only difference is that the source data are extracted from the comparate data resource and the target data are loaded into the existing disparate data resource. The process is performed only for new data that are initially entered into the new comparate data resource and need to be placed into the existing data resource to support disparate data applications.
The data extract phase identifies new data that have been added into the comparate data resource, identifies where those new data will be placed in the existing disparate data resource, and extracts the new data to the data depot for transformation. Data converters are used as necessary to change the data from one database management system to another. The physical data names are used during the load data phase.
The data transform phase follows the same general sequence described above, although the processes may be different. Historical data may need to be reconstructed when the disparate data contain full historical data instances and the comparate data contain partial historical data records. Historical data may need to be de-constructed when the disparate data contain partial historical data instances and the comparate data contain complete historical data instances.
The data values may need to be translated from the preferred variation in the comparate data resource to a non-preferred variation in the disparate data resource. Data translation rules are prepared using the same notation described above.
Data seldom need to be recast during reverse data transformation, and also seldom need to be un-recast during reverse data transformation. If those situations do occur, the same process described above is used.
The comparate data are restructured to the disparate data as described above for restructuring the disparate data to the comparate data. The same process described above is used for the data restructuring.
Data derivation may need to be done, but is usually minimal. The same process described above is used for data derivation.
The data load phase usually does not perform any data edits. The comparate data generally have much higher integrity than the disparate data, eliminating the need for applying any data edits. The data are loaded into the disparate data resource from the data depot using a data converter when necessary. A review of the loaded data is made prior to releasing the data for use.
Some reverse data transformations cannot be performed, such as splitting coded data values. Data transformation that goes from specific to general is easy to perform, but data transformation that goes from general to specific is difficult to perform without additional insight.
Reverse data transformation may need to break down or combine data values in the disparate data resource. The original data inventory documentation can be consulted to determine how data values need to be combined or broken down. Those specifications are added to the processes described above for reverse data transformation.
Data Brokering
A data broker is an application that acts as an intermediary between disparate data and comparate data in databases or applications. It performs formal data transformations in both directions between disparate data and comparate data. Data brokering is the process of using data brokers to perform formal data transformation.
The data brokering process is shown in Figure 12.3. The forward and reverse data transformations described above are shown vertically in the center of the diagram. Forward data transformation is down from disparate data to comparate data, and reverse data transformation is up from comparate data to disparate data.
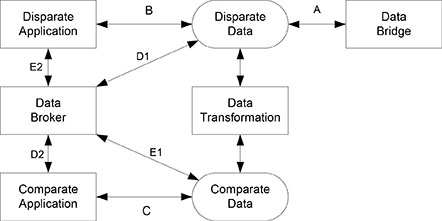
Figure 12.3. Data brokering process.
A data bridge is an application that moves data from one disparate data file to another disparate data file to keep the two data files in synch. The primary purpose is to maintain redundant data in a disparate data resource. Route A shows the data bridges, which will likely be replaced by more formal data bridges.
The data brokering process is shown on the left side of the diagram. Route B represents a disparate data application using disparate data, and requires no data brokering. Route C represents a comparate data application using comparate data, and requires no data brokering.
Routes D1 and D2 are the transformation of data from a disparate data resource, through a data broker, to a comparate data application, and the transformation of data from a comparate data application, through a data broker, to a disparate data resource. Routes E1 and E2 are the transformation of data from a comparate data resource, through a data broker, to a disparate data application, and the transformation of data from a disparate data application, through a data broker, to a comparate data resource. Route D1 replaces the data bridges.
The data broker uses the same transform data processes described above for forward and reverse data transformation. The basic difference is that the data transformation in the center of the diagram maintains the disparate and comparate databases independent of any applications, while the data broker transforms data between applications and databases.
Databases and applications are often tightly coupled, which could be difficult to manage. The tight coupling is one source of disparate data and low quality data. The data broker concept can break that tight coupling to maintain the application-specific databases until the applications can be transformed to use comparate data.
The terms wrapping, encapsulation, and middleware have been used for data transformation. These processes, when done with formal data transformation as described above, are essentially the same as a data broker. However, doing these processes outside of formal data transformation and a common data architecture leads to a perpetuation of disparate data, or an increase in disparate data. Therefore, the best approach is to use formal data transformation within a common data architecture as described above.
Evaluational Data
The question about evaluational data always comes up during data transformation. The basic question is whether disparate evaluational data should be transformed to comparate evaluational data, or whether the disparate operational data should be transformed to comparate operational data and then renormalized to comparate evaluational data. The typical approach is to transform the evaluational data, or to simply ignore any transformation of evaluational data.
However, the primary problem with most existing disparate operational and evaluational data is the quality of those data. The data seldom went through any formal data integrity rules or data edits. The low quality of the disparate operational data was perpetuated into the evaluational data obtained from those operational data.
In addition, the disparate evaluational data have been sliced, diced, and stored, which has perpetuated the low quality into the analysis of evaluational data. The resulting analytical data is seldom documented as to the source data, the selection criteria, and the analysis performed. The result is questionable analytical data, making the transformation of those analytical data questionable.
Attempting to transform the existing disparate operational data and the existing disparate evaluational data inevitably leads to a mismatch between the resulting comparate operational data and comparate evaluational data. Data integrity can be applied to the disparate operational data during data transformation, but it’s extremely difficult to apply data integrity to the disparate evaluational data during data transformation.
The best approach, for those organizations interested in high quality operational and evaluational data, is to formally transform the disparate operational data as described above. Then, those high quality comparate operational data are formally renormalized to comparate evaluational data, which retain the high quality. Finally, the analysis of the evaluational data is performed with formal documentation of the source data, the selection criteria, and the analysis performed. The result is high quality analytical data.
Missing and Default Data Values
Missing data values are a frequent problem during data transformation, because disparate data often have missing data values. The data integrity rules need to include the possibility of missing data values. Where appropriate, algorithms can be implemented to replace missing data values. When missing data values are determined by an algorithm, a companion data characteristic needs to be created showing how the missing data value was created. When missing data values cannot be replaced with any degree of certainty, then the missing data values need to be accepted.
Default data values are another problem encountered during data transformation. Some default data values, such as {‘Y’ | ‘N’} Default ‘N’ are appropriate in many situations. However, default data values such as when no ethnicity code, enter C for Caucasian, or when no birth date, enter January 1, 1900 are not acceptable. When possible, unacceptable default data values should be eliminated during data transformation.
Retiring Disparate Data
Disparate data can be retired when those data are no longer needed. When all disparate data applications have been transformed to comparate data applications, and all disparate databases have been transformed to comparate databases, the disparate data can be retired. In most situations, the disparate data are retired one database or one subject area at a time as applications and databases are converted.
When disparate data are retired, the associated data bridges and data brokers can be retired. Forward and reverse data transformation routines can also be retired. However, the specification for forward and reverse data transformation may be retained as a historical record of the data transformations that were made. If questions arise about the data transformations, the specifications can be reviewed to determine how the data were transformed.
When disparate data are retired, the documentation of those disparate data made during data inventorying, data cross-referencing, and preferred data designation should be retained as a historical record. Questions always arise about disparate data in databases, on screens, reports, and forms, in applications, and so on. These questions can usually be answered by referring to the documentation of those disparate data. Eventually, that documentation may be retired, but organizations should not be too hasty in retiring the documentation of their disparate data.
SUMMARY
The scope of data transformation can be different from the scope of data inventorying, data cross-referencing, and preferred data designations, but the data transformation process must follow those other processes and must include application transformation. The sequence of data transformation depends on the organization’s plans to transform both the disparate data and the applications using those disparate data. Involvement in data transformation includes data management professionals, application professionals, and business professionals.
The data extract phase identifies target data, identifies the source data to prepare those target data, and extracts those source data to a data depot for transformation. The data transform phase reconstructs historical data, translates data values to the preferred variation, recasts data for historical continuity, restructures the data into the comparate data structure, and derives data. The processes are based on precise specifications, including data transformation rules. The data load phase edits the transformed data based on the preferred data edits, loads data that pass the data edits into the comparate data resource, and reviews the loaded data to ensure they are appropriate for operational use.
Reverse data transformation transforms comparate data to disparate data to support disparate data applications, following the same general sequence as forward data transformation. Data brokers support the forward and reverse data transformation of data between applications and databases, and replace many of the existing data bridges. Comparate evaluational data are usually developed from comparate operational data, rather than from transformed disparate operational data to ensure high quality data for analysis.
Disparate data can be retired when all applications using those disparate data have been transformed to using comparate data and all disparate databases have been transformed to comparate databases. Data brokers and data bridges can also be retired when they are no longer needed. Data transformation specifications are retained as a historical record of how the data were transformed. Disparate data documentation is retained as a historical record of the understanding of disparate data.
Data transformation ends the process of identifying, understanding, and resolving disparate data. The two major benefits of resolving disparate data are providing a high quality comparate data resource that meets the business information demand, and showing that disparate data are a waste of resources and can severely impact the business. Hopefully, an organization that goes through the process of understanding and resolving disparate data will never again allow the creation of disparate data.
QUESTIONS
The following questions are provided as a review of data transformation, and to stimulate thought about how to implement data transformation.
- How does the sequence of data transformation compare to the sequence of data inventorying, data cross-referencing, and preferred data designations?
- Who is involved in data transformation?
- What processes are performed in the data extract phase?
- Why are data extracted to a data depot?
- What data transformations could be performed in the data depot?
- What processes are performed in the data load phase?
- Why should data that fail the data edits never be placed in the comparate data resource?
- What processes are done differently in reverse data transformation.
- What benefits does data brokering provide?
- When can disparate data be retired?