
Chapter 7
DATA CROSS-REFERENCING CONCEPT
Data cross-referencing greatly improves data understanding.
The next step after a data inventory is to cross-reference the inventoried data to a common data architecture. Cross-referencing data to a common data architecture solves the second problem with disparate data. Most organizations do not fully understand the content and meaning of their disparate data. Data cross-referencing builds on the understanding gained in the data inventory and provides organizations with a full understanding of the content, meaning, structure, and integrity of disparate data.
Chapter 7 describes the concepts and principles for cross-referencing the inventoried data to a common data architecture. The next chapter describes the techniques for cross-referencing the inventoried data to a common data architecture. Chapters 9 and 10 describe how to develop a preferred data architecture based on the cross-referenced data.
CONCEPT AND PRINCIPLES
The data cross-reference concept is the inventoried disparate data are cross-referenced to a common data architecture to further increase the understanding of those disparate data within a common context. An initial understanding of disparate data was gained during the data inventory process. That initial understanding is increased through a cross-referencing of the inventoried disparate data to a common data architecture.
Data cross-referencing is where the rubber meets the road. It’s where a thorough understanding of the content, meaning, structure, and integrity of the data come together. Combined data were broken down to their individual components during the data inventory. Those components are put together in a normalized manner within a common data architecture.
Data cross-referencing solves the second problem with disparate data, which is the organization at large does not thoroughly understanding the disparate data. Cross-referencing disparate data to a common data architecture, and documenting that cross-referencing, provides a thorough understanding of the data and makes that understanding available to the organization at large.
The data cross-reference objective is to thoroughly understand the content, meaning, structure, and integrity of all data at the organization’s disposal within the context of a common data architecture so that a comparate data resource can be developed that fully supports the current and future business information demand. The objective is to take the initial understanding of disparate data that was documented at an elemental level during the data inventory and increase that understanding within the context of a common data architecture at the organization level. That thorough understanding sets the stage for designating a preferred data architecture and developing a comparate data resource.
Cross-referencing disparate data to a common data architecture is a critical, non-trivial process. It requires a thorough understanding of both the disparate data and the common data architecture. It also requires tremendous patience and diligence to make sure that appropriate data cross-references are made.
Failure to make appropriate data cross-references affects the preferred data designations, the development of data transformation rules, and development of a comparate data resource. Decisions made during data cross-referencing have ripple effects through the entire data resource integration process.
A data cross-reference is a logical mapping between disparate data names and common data names. It’s a link between components of the inventoried disparate data and components in a common data architecture. The three data cross-references are between data products and data subject variations, between data product units or variations and data characteristic variations, and between data product codes or variations and data reference set variations.
The terms mapping and data mapping are not used because they are often confused with cartographic mapping. The terms cross-walking and data cross-walking are not used because they represent a movement of data between two points that does not include formal data transformation or the application of data integrity rules. Data cross-referencing is a reference only, not a movement of data, and leads to formal data transformation with the application of data integrity rules.
Data resource integration is based on both semantic integration and structural integration, as described in Chapter 2. The data inventory started that integration process by breaking down the existing data products to their basic components based on both meaning and structure. The data cross-reference process continues by putting those components together in a normalized form within the context of a common data architecture.
Principles
Several principles apply to data cross-referencing, including understanding disparate data, the umwelt principle, organization agility, a discovery process, effective data cross-referencing, an interim common data architecture, enhancing the data inventory, enhancing a common data architecture, adjusting a common data architecture, a simple but detailed process, data cross-referencing is deterministic, data normalization, data cross-referencing sequence, and data cross-referencing involvement. Each of these principles is described below.
Data Understanding
The disparate data understanding principle was described in Chapter 4 as all disparate data variability, including data names, definitions, structure, integrity, and existing documentation will be understood and formally documented at a detailed level within the context of a common data architecture. Any attempt to resolve data disparity and integrate a disparate data resource without thoroughly understanding the disparate data will likely end in failure or a result that is less than fully successful. That principle applies to the entire data resource integration process.
Understanding is the key to high quality data resource integration. The question is How to understand the data—really understand the data. Not just an awareness gained during data inventory, but a deep understanding of the content, meaning, structure, and integrity of the data. Traditional data understanding is often done in an atmosphere of confusion, pressure, and conflicting descriptions. It’s often done with limited documentation and limited input from knowledgeable individuals.
Real data understanding in a positive atmosphere begins with the data inventory process. That initial understanding is based on what is already known about the existing data based on primary and supplemental sources of insight. When the data inventory is complete, the extent of that existing data understanding has been reached, and another level of understanding needs to be achieved to further increase the data understanding.
That next level of understanding is the content, meaning, structure, and integrity of the data with respect to the business world where the organization operates. When people understand the data with respect to the business world as perceived by the organization, those data will support the business information demand. In fact, the use of data that are well understood is limited only by people’s imagination.
The Umwelt Principle
The organization perception principle was stated in Chapter 3 as the comparate data resource developed to support an organization’s business must be based on the organization’s perception of the business world. If a comparate data resource is to support an organization’s business activities, that comparate data resource must be based primarily on the organization’s perception of the business world and how the organization chooses to operate in that business world.
Umwelt is a German word meaning the environment or the world around. It’s the world as perceived by an organism based on its cognitive and sensory powers. It’s the environmental factors collectively that are capable of affecting an organism’s behavior. It’s a self-centered world where organisms can have different umwelten, even though they share the same environment. It’s an organism’s perception of the current surroundings and previous experiences which are unique to that organism. It’s the world as experienced by a particular organism.
Change organism to organization, which is really a collection of organisms, and change environment to business environment and you have an umwelt for an organization. The organization umwelt principle states that each organization has a particular perception of the business world in which they operate based on previous experiences that are unique to that organization. Those experiences affect the organization’s behavior in the business world, and determine how the organization adapts to a changing business world and operates in that business world.
The organization umwelt principle supports the organization perception principle and emphasizes the importance of understanding both the business environment and the data supporting the business in that environment. The umwelt principle drives development of a common data architecture and the cross-referencing of the inventoried disparate data to that common data architecture.
The umwelt principle also emphasizes that each organization has a unique perception of the business world and chooses to operate according to that perception without being judged right or wrong. An organization can change their perception of the business world and how they operate in it based on experiences that are unique to that organization. One perception of the business world that is suitable for all organizations does not exist. Each organization has its own unique perception of the business world.
The umwelt principle explains why universal data models, generic data architectures, purchased applications, and so on, don’t work. Simply, one perception of the business world does not work for all organizations. The common phrases are How dare you force your umwelt on my organization? Who gave you the authority to tell me how to perceive the business world? Who had the authority to give that authority?
The situation is like the difference between building codes and individual buildings. Building codes state the requirements for safe construction of buildings, but do not state the design of buildings. The design is based on the intended use of the building by the occupant. The same is true for bridges, airplanes, ships, cars, and so on. Codes specify requirements for safety, but the design is based on perceived use.
The umwelt principle also explains why Party does not appear in a common data architecture. Other than celebratory events or political parties, Party will not appear in an organization’s perception of the business world where they operate. Party, if it exists at all, is a result of data denormalization, and will not be discussed further in data cross-referencing. All of the examples I’ve seen of Party are simply a data modeler forcing their umwelt on the organization.
Common perceptions of the business environment can be described for use by organizations as they see fit. However, these common perceptions are not standard or official, and cannot be forced upon an organization. Organizations are free to choose their perception of the business world—their own umwelten.
Organization Agility
Agility is the quality or state of being agile; marked by ready ability to move with quick easy grace; mentally quick and resourceful. The organization agility principle states that an organization must be agile to remain successful in their business endeavor. Agility depends on how the organization perceives the business world and how well it adjusts to changes in that business world. It depends on how well the organization understands the business world, how quickly the organization perceives changes in that business world, and how quickly they can respond to those changes.
Responding to changes in the business world depend, to some extent, on how quickly the data resource changes to reflect changes in the business world. The data resource agility principle states that an organization’s data resource must be agile enough to change in a manner that supports the business change needed to remain successful in a dynamic business world. The data resource must change so that it provides one version of truth about the business world where the organization operates. How the data resource can be used to detect changes in the business world and how the data resource can be adjusted to reflect those changes are key issues for an agile organization. Thoroughly understanding the data resource supports real organization agility.
Discovery Process
The data resource discovery principle described in Chapter 2 states that data resource integration is a discovery process where any insights about the data resource are captured, understood, and documented. The process is performed by people, who may be supported by automated tools.
The data inventory process was a discovery process that uncovered the existing content, meaning, structure, and integrity of the disparate data. Data cross-referencing is also a discovery process that discovers and documents additional understanding of the data within the context of a common data architecture.
Effective Data Cross-Referencing
The effective data cross-referencing principle states that thoroughly understanding existing disparate data is only effective when those data are inventoried and documented at a detailed level and are cross-referenced to a common data architecture. Attempting to cross-reference disparate data to other disparate data is both inefficient and ineffective. The result is more confusion and a data resource integration process that either fails or is less than fully successful.
Interim Common Data Architecture
The interim common data architecture principle states that interim common data architectures may be developed in very large organizations where it is not possible to achieve a final common data architecture in one step because of the size of the task. Data products are cross-referenced to interim common data architectures, and those interim data architectures are cross-referenced to a final common data architecture. Only one level of interim data architectures is allowed.
Enhancing and Adjusting the Data Inventory
The continuous enhancement principle described in Chapter 5 states that documentation of disparate data should be continuously enhanced as additional insight is gained. Documenting and understanding disparate data is not a one-time process—it’s an ongoing process through all phases of data resource integration. Any time additional insight is gained about disparate data, that insight must be documented.
Additional insight into disparate data may be gained during data cross-referencing. The data inventory was done one source of insight at a time, and an overall perspective was usually lacking. The data cross-reference looks at the total data inventory with respect to a common data architecture. That perspective often provides additional insight into the disparate data. That additional insight must be used to enhance the existing documentation.
The additional insight may be an enhancement to definitions or data integrity rules. The additional insight might lead to adjustments of the data inventory, such as a further breakdown of data product sets, data product units, data product codes, or possibly a combination of what was thought to be basic components. These additional insights are immediately documented while they are fresh in mind, rather than leaving the documentation until later or ignoring the insights altogether.
These enhancements and adjustments to the data inventory provide better understanding of the existing disparate data, provide better cross-referencing, and lead to better preferred data designations.
Enhancing the Common Data Architecture
The continuous enhancement principle also applies to a common data architecture. An initial common data architecture is established prior to data cross-referencing, as described later. That initial common data architecture is continually enhanced during the data cross-referencing process. As components from the Data Product Model are cross-referenced, the common data architecture needs to be enhanced. The details of that enhancement are described later in the current chapter and in the next chapter.
Adjusting the Common Data Architecture
A common data architecture needs to be reviewed periodically during data cross-referencing to ensure that it adequately represents the organization’s perception of the business world. As a common data architecture is continually enhanced to cover the data cross-references, the organizations perception of the business world is sometimes forgotten. In addition, the data cross-referencing can result in the organization changing its perception of the business world. Therefore, a common data architecture needs to be reviewed periodically, and adjustments made to ensure that it adequately represents the organization’s perception of the business world.
The common data architecture adjustment principle states that a common data architecture should be periodically reviewed and adjusted during data cross-referencing to ensure that it adequately represents the organization perception of the business world. Even though nothing appears to have changed, a good policy is to routinely review a common data architecture to determine if it needs to be adjusted.
Adjusting Data Cross-References
Adjustments to a common data architecture may lead to existing data cross-references becoming inappropriate. Therefore, whenever a common data architecture is adjusted, the existing data cross-references should be reviewed to ensure they are still correct. If the existing data cross-references are not correct, they need to be changed.
In addition, when additional insight is gained about the disparate data and a common data architecture, even though a common data architecture was not adjusted, a good policy is to review the data cross-references to ensure they are correct. If the existing data cross-references are not correct, they need to be changed.
Simple But Detailed Approach
Data cross-referencing is relatively simple, straight forward, and methodical, but it’s very detailed. Although a simple task, data cross-referencing is time consuming and requires considerable thought and analysis to determine the real meaning and structure of the disparate data with respect to a common data architecture. However, it’s not impossible. When the data cross-references have been made, the other tasks of data resource integration are relatively easy.
Some data cross-references are determined fairly easily, while others require considerable searching and analysis. Generally, about 70% to 80% of the data cross-referencing is relatively easy. About 10% to 15% of the data cross-referencing is more difficult and takes some thought and analysis. About 5% to 10% of data cross-referencing are extremely difficult and take real investigation. A small percentage of data cannot be understood or cross-referenced.
The best approach is to make data cross-references as soon as enough insight has been gained to make the cross-reference with reasonable certainty. The data cross-reference can always be changed when additional insight is gained.
Deterministic – Prospective – Descriptive
Data cross-referencing is deterministic because it formally breaks the disparate data down to their basic components and cross-references those components to a common data architecture. It ensures that data redundancy and variability are understood and resolved. It provides more benefit than probabilistic cross-referencing between data products.
Data cross-referencing is prospective because a common data architecture is established to support the data cross-referencing. That common data architecture will be used to designate a preferred data architecture. Therefore, the orientation is prospective toward a comparate data resource.
Data cross-referencing is descriptive because it continues describing the existing disparate data within the context of a common data architecture. Even though a common data architecture is prospective, understanding existing disparate data within a common data architecture is a descriptive process.
Data Normalization
Disparate data are often quite un-normalized at the data file level, the data item level, the data code level, and for time. Even some logical data models are un-normalized at the data entity level, the data attribute level, the data reference item level, and for time. These un-normalized data are normalized within the context of a common data architecture during data cross-referencing.
Data cross-referencing is based on both the data meaning and the data structure, which are based on the organization’s perception of the business world according to the organization perception principle and the organization umwelt principle. The organization’s perception of the business world is primary, and data normalization according to that perception is secondary.
Data cross-referencing normalizes data characteristics within data subjects, business facts within data characteristics, data properties within data reference items, and time into current and historical instances. The normalization is done as the basic components identified during data inventory are cross-referenced to a common data architecture. The result is a fully normalized data structure that can be used to designate a preferred data architecture.
Data Cross-Reference Sequence
The last chapter described the sequence of data inventorying and data cross-referencing. The entire scope of data could be inventoried and documented, and then the data cross-referencing could be done. Alternatively, the data cross-referencing could be done as soon as small sets of data are inventoried. When the techniques are understood, either approach is appropriate.
Several sequences could be followed by an individual within data cross-referencing. The first is to start at the beginning of the data inventory and cross-reference each data product unit or data reference set to a common data architecture. The second is to skip around and cross-reference the easiest components first, which builds success motivation for tackling more difficult components. The third is to tackle the most difficult components first and crack the code, then move on to the easier components.
Another approach is to use a group of knowledgeable people, where each contributes their understanding to the cross-reference. The group could meet and offer their knowledge in a group setting. The knowledge is shared, but the time commitment is higher. Alternatively, the data cross-referencing could cycle among individuals in the group and each would add the cross-references they understood. The knowledge is not readily shared, but the time commitment is lower.
All approaches work well, and are largely a personal preference. Rather than force a particular sequence, I let each group decide how they would prefer to sequence the data cross-referencing.
Data Cross-Referencing Involvement
Anyone knowledgeable about the disparate data should be involved in data cross-referencing. However, the more people that get involved in data cross-referencing, the greater the cost of data resource integration. More understanding requires more involvement, which increases the cost.
Some organizations tend to limit involvement in data cross-referencing to get the process completed quicker at a lower cost. However, acceptance of the data cross-referencing and enhancement of a common data architecture is lower. Less acceptance of a common data architecture usually means less acceptance of the preferred data architecture, and less acceptance of data resource integration.
Therefore, the best approach is to have a core team of knowledgeable people do the data cross-referencing, but make the results readily available to anyone in the organization interested in data resource integration. In addition, comments should be readily accepted from those interested people, because their insight may be quite valuable. The result is also more readily accepted.
Data Cross-Reference Approaches
Data cross-referencing can be done in three different ways: product-to-product, product-to-common, and common-to-common. The first is not a valid approach for several reasons, but the other two are valid approaches. Each approach is described below.
Product-To-Product
A typical approach to data integration is cross-referencing data products to other data products. A product-to-product cross-reference is a data cross-reference between data products without the benefit of a common data architecture. Product-to-product cross-references are between sets of disparate data, usually databases, bridges, or feeds between information systems. The result is layer upon layer of cross-referenced disparate data that provide little understanding of those disparate data.
Many of the product-to-product cross-references connect data items with different content, different format, different meaning, or different sets of coded data values. These cross-references result in comments like nearly the same as, very close to, most of the codes used in, and so on, that only add to the disparate data problem. The results are difficult to interpret and provide no base for real data transformation or integration.
Product-to-product cross-references will likely never be completed because of the number of databases, bridges, feeds, and ongoing changes in the data. The masses of data stored become unmanageable. I worked with one state attempting to conduct product to product cross-references with their databases. A quick calculation showed that storage was not available to handle the result, and ongoing changes would soon make the cross-references out of date.
Even if product-to-product cross-references were completed between databases, bridges, and feeds, the data on screens, reports, and forms, and all the derived, summary, and aggregated data are seldom included. Changes over time are seldom considered. Suggestions have been made that databases be considered primary sources and that screens, reports, and forms be considered secondary sources. The secondary sources are then cross-referenced to the primary sources. However, the derived, summary, and aggregated data, and changes over time, often can’t be cross-referenced. These secondary-to-primary cross-references provide little understanding of disparate data and often lead to more confusion.
Therefore, directly cross-referencing disparate data to disparate data won’t work, and often makes the situation worse. It does not lead to increased understanding and provides very little support for data transformation or data resource integration.
Product-To-Common
A far better approach is to make cross-references between data products and a common data architecture. A product-to-common cross-reference is a data cross-reference between data products and a common data architecture. The effective data cross-referencing principle emphasizes that disparate data must be inventoried at a detailed level and cross-referenced to a common data architecture for those data to be thoroughly understood and properly integrated. The product-to-common cross-references lead to increased understanding and directly support data resource integration.
When product-to-product references are needed, they are developed through the common data architecture. These indirect product-to-product cross-references are developed only when necessary and are easier to manage than direct product-to-product cross-references. They can be used as necessary to support data transformation.
The product-to-common cross-references are the cross-references described in the current chapter and the next chapter. Data product components are cross-referenced to corresponding components in the common data architecture to provide a complete understanding of the meaning, structure, and integrity of disparate data. That complete understanding fully supports data resource integration.
Common-To-Common
Normally, data products are cross-referenced to a final common data architecture through product-to-common cross-references. However, in very large organizations, such as governmental agencies or multi-national organizations, it’s not always possible to achieve a final common data architecture in one step because of the size of the task. The interim common data architecture principle allows the development of one level of interim common data architectures, which are then cross-referenced to a final common data architecture.
Successive levels of interim common data architectures are not acceptable because they inevitably lead to additional effort with no corresponding increase in understanding. They unnecessarily delay achievement of a common view of disparate data.
An interim common data architecture is a common data architecture that is developed for cross-referencing one major segment of the data resource for a very large organization. When the interim common data architectures are completed, they are treated as data products and are cross-referenced to a final common data architecture. Interim common data architectures are usually coordinated by tactical data stewards.
A common-to-common cross-reference is a data cross-reference between an interim common data architecture that is treated as a data product, and the final common data architecture. A final common data architecture is a common data architecture that includes all data in the organization’s data resource and is used to designate a preferred data architecture. It can be developed from product-to-common cross-references or common-to-common cross-references.
Developing interim common data architectures does not mean that those interim common data architectures are developed in isolation. Tactical data stewards should seek commonality as soon as possible between the interim common data architectures by discussing and exchanging thoughts on commonality during development of the interim common data architectures. That exchange makes the common-to-common cross-referencing easier and faster.
When all of the interim common data architectures are cross-referenced to a final common data architecture, the common-to-common cross-references are collapsed so that the data products are directly cross-referenced to the final common data architecture. The interim common data architectures may be maintained for reference, but data resource integration proceeds based on the final common data architecture. Performing data resource integration through a final common data architecture and interim common data architectures is extremely difficult.
The interim common data architectures must be cross-referenced to a final common data architecture before designating the preferred data architecture. Designating the preferred data architecture before all interim data architectures are cross-referenced to a final common data architecture could to be a wasted effort. Additional insight is often gained through cross-referencing additional interim data architectures to a final common data architecture.
COMMON DATA ARCHITECTURE COMPONENTS
The components of a common data architecture used for data cross-referencing are shown in Figure 7.1. The diagram is not intended to be a complete data model. It only shows the components of a common data architecture that are used for data cross-referencing and the data relations between those components. Each of the components is described below.

Figure 7.1. Common data architecture components.
Data Subject
A data subject was defined in Chapter 3 as a person, place, thing, concept, or event that is of interest to the organization and about which data are captured and maintained in the organization’s data resource. Data subjects are defined from business objects and business events, making the data resource subject oriented based on the business. Data subject names are unique within a common data architecture. The definition describes the data subject.
Data Subject Variation
A data subject is recursive to provide data subject variations. A data subject variation is a variation of a data subject to support data selections, subsets of data, and data roles, and to support evaluational data subjects. Only one level of recursion is allowed, because the intent is to document variations of a data subject, not a hierarchy of data subjects.
A data subject variation can represent manifestations of a data focus in an aggregated data structure. For example, the Student Analytics Focus is the parent data subject. Student Analytics 1, Student Analytics 2, and so on, are the data subject variations. The data subject variation name is formed by an extension to the data subject name.
A data subject variation can also represent data selections, subsets of data, and data roles. The data occurrence group and data occurrence role notations of the Data Naming Taxonomy are used to name the data subject variation. For example, a subset of middle school students might be named [Middle School] Student. Plumbers that are a subset of Contractors might be named “Plumbing” Contractor. The subset of data aggregated for student analytics might be named [Selection 1] Student Analytics 4.
Data subjects contain all of the identifying data characteristics and their data characteristic variations. The data subject variation only inherits the identifying data characteristics as necessary. Attempting to document all of the data characteristics and data characteristic variations for each data subject variation would be a monumental task, and would provide little benefit for understanding the data. Therefore, data characteristics are documented only for data subjects.
Data subject variation names must be unique within the data subject, and are usually formed by a prefix to the parent data subject name, or by an extension to the parent data subject name, as shown above. The definition describes the data subject variation.
Data Characteristic
A data characteristic was defined in Chapter 3 as an individual fact that describes or characterizes a data subject. It represents a business feature and contains a single fact, or closely related facts, about a data subject, such as the make of a vehicle, or a person’s height. Each data subject is described by a set of data characteristics.
Data characteristic names must be unique within a data subject. The same fact may have the same name across different data subjects, but the addition of the data subject name makes the data characteristic name unique. For example, data subjects for Student and Driver may each have a business fact for birth date. The addition of the data subject name makes those business facts unique, such as Student. Birth Date and Driver. Birth Date.
Data Characteristic Variation
A data characteristic variation was defined in Chapter 3 as a variation in the content or format of a data characteristic. It represents a variant of a data characteristic, such as different units of measurement, different monetary units, different lengths, different sequences in a person’s name, and so on. Each data characteristic has at least one data characteristic variation, and may have many data characteristic variations.
Data characteristic names must be unique within a data characteristic. Data characteristic variation names show the variation in content or format as an extension to the data characteristic name. For example, variations in a student’s birth date might be Student. Birth Date, CYMD or Student. Birth Date, M/D/Y.
Data characteristic variation names must be fully qualified to prevent any confusion about the exact format or content. For example, the data characteristic variation name for a student’s name might be Student. Name Complete, Normal 56 Right All Caps, meaning the student’s name is in the normal sequence, 56 characters long, right justified, in all capital letters. Even though the level of detail seems unnecessary and no closely related data characteristic variation is apparent, the opt for detail principle prevails. Additional data characteristic variation names may come along later and the detail avoids the need to go back and adjust previous data characteristic variation names.
A common mistake is to consider a difference in the business fact as a data characteristic variation. For example, a person’s complete name is not a data characteristic variation. It’s a data characteristic containing the person’s first name, middle name, and family name. It’s not the same as data characteristics for the individual components of a person’s name. Similarly, the total depth of a well and the usable depth of a well are two different data characteristics, not variations of the same data characteristic. Therefore, a difference in a business fact is a different data characteristic, not a variation of a data characteristic.
Data Reference Set Variation
A data reference set is a specific set of data codes for a general topic, such as a set of management level codes in an organization. A data reference set is documented as a data subject containing data characteristics for at least the name, coded data value, definition, begin date, and end date. The data subject name for the data reference set is unique within a common data architecture and indicates the contents of the data reference set, such as Management Level or Vehicle Type.
A data reference set variation is a variation of a data reference set that has a difference in the domain of data reference items, their coded data values, their names, or substantial difference in the data definitions. Any difference, however slight, constitutes a different data reference set variation.
Data reference set variation names are unique within the parent data subject, and are usually formed by an extension to the data reference set name using the data naming taxonomy notation. For example, variations for a vehicle data reference set might be Vehicle Type. 1;, Vehicle Type. 2;, and so on.
Data Reference Item
A data property was defined in Chapter 4 as a single feature, trait, or quality within a grouping or classification of features, traits, or qualities belonging to a data characteristic. For example, gender has data properties for male, female, and unknown. Management level has data properties for executive, manager, supervisor, and lead worker.
A data reference item is single set of coded data values, data names, and data definitions representing a single data property in a data reference set variation. Each data reference set variation has many data reference items. Each data reference item represents a single data property. Each data property is characterized by a name, a definition, and possibly a coded data value.
Data Subject Thesaurus
A data subject thesaurus is a list of synonyms and related business terms that help people find data subjects that support their business information needs. It’s a list of business terms and alias data entity names that point to the formal data subject name. For example, the following terms might appear in a data subject thesaurus.
Alias Data Subject
Woodlot Timber Stand
Forest Timber Stand
Trees Timber Stand
Timber Timber Stand
Vegetation Timber Stand
Pupil Student
Attendee Student
Personnel Employee
Worker Employee
Staff Employee
A data subject thesaurus needs to be established before data cross-referencing begins, and needs to be continually enhanced through the data cross-referencing process. A good data subject thesaurus supports data cross-referencing, and supports full use of the data resource after data resource integration has been completed.
Common Data Name Words
A common word was defined earlier as a word that has consistent meaning whenever it is used in a data name. A data name vocabulary was defined earlier as the collection of all twelve sets of common words representing the twelve components of the data naming taxonomy. Each common word has a definition stating the meaning of that common word, which is very useful for understanding disparate data within a common context.
A data name vocabulary needs to be maintained while developing a common data architecture and cross-referencing inventoried data to that common data architecture. The common words used for data subjects, data characteristics, data characteristic variations, data reference set variations, and data reference items need to be defined, maintained, and consulted whenever a new data name is created in a common data architecture. The use of common words ensures consistency in data names within a common data architecture.
For example, a common word Variable is defined as meaning the format or content of the data value is variable. A data characteristic variation name for the names of streams might be Stream Segment. Name, Variable, and might contain S Nooksack River, Nooksack River South, South Fork Nooksack River, and so on.
PRODUCT-TO-COMMON CROSS-REFERENCE
The cross-references between data products and the common data architecture are shown in Figure 7.2. The three cross-references are between data product sets or variations and data subject variations, between data product units or variations and data characteristic variations, and between data product codes or variations and data reference set variations.
Data Product Cross-Reference
No cross-reference is made between the data products and a common data architecture. A data product represents a high level of data products and has no equivalent in a common data architecture.
Data Product Set Cross-Reference
A data cross-reference is not normally made between a data product set or variation and a data subject. The data product set or variation represents a data file, a data record type, a screen, report, or form, and so on. They are not equivalent to a data subject. Such a cross-reference would mean an exact match between the data product set or variation and a data subject, including all of the data characteristics in that data subject.
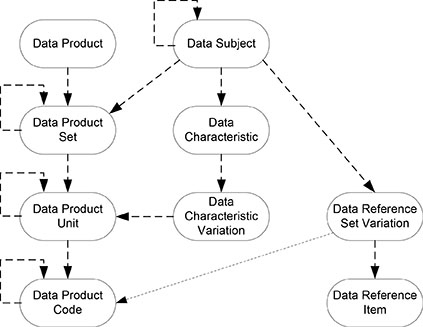
Figure 7.2. Product to common cross-references.
However, a data cross-reference can be made between a data product set or variation and a data subject for designating selections, subsets of data, and data roles. A data product set cross-reference is a cross-reference between a data product set or variation and a data subject variation solely for the purpose of designating data selections, subsets of data, and data roles, or for designating the manifestations of a data focus. Since data subject variations do not have any data characteristics, the cross-reference does not indicate an exact match between data product units and data characteristics.
Data Product Unit Cross-Reference
A data product unit cross-reference is a cross-reference between a data product unit or variation and a corresponding data characteristic variation. Each data product unit or variation is cross-referenced to a data characteristic variation. These are the primary cross-references between data products and a common data architecture.
If the data product unit variation is cross-referenced to a data characteristic variation, then the data product unit is not cross-referenced. If no data product unit variations exist, then the data product unit is cross-referenced to a data characteristic variation. In other words, only the lowest level of detail is cross-referenced. Cross-referencing combined data usually serves no purpose and may confuse the understanding, while delaying the breakdown of combined data. The best approach is to break down combined data during data inventorying and cross-reference only the detail data to a common data architecture.
The cross-reference is always made to a data characteristic variation, not to a data characteristic. Each data characteristic must have at least one variation, and may have many variations, depending on the variability of the disparate data. Therefore, the cross-references must be to a data characteristic variation.
Data Product Code Cross-Reference
A data product code cross-reference is a cross-reference between a data product code or variation and a data reference set variation. Each data product code or variation is cross-referenced to a data reference set variation to which it belongs. The data reference set variation must contain a set of data reference items that exactly matches the set of data product codes containing the data product code or variation being cross-referenced.
Only the lowest level of detail is cross-referenced to a data reference set variation. If data product code variations are cross-referenced to a data reference set variation, then the data product code is not cross-referenced. If no data product code variations exist, then the data product code is cross-referenced to a data reference set variation.
Data Keys and Data Relations
Primary keys and foreign keys are not cross-referenced to a common data architecture. Each primary key and foreign key found in the disparate data will have an equivalent primary key or foreign key in the common data architecture. The only cross-reference is with the data product units or variations forming the primary key or foreign key.
Data relations are implied through the primary keys and foreign keys and are not directly cross-referenced to a common data architecture.
Data Cross-Reference Comments
Each data product unit or variation cross-reference and each data product code or variation cross-reference may have an associated cross-reference comment that is separate from the data definition. The comment contains any insights about the cross-reference, problems or uncertainties with the cross-reference, insights needed to finalize the cross-reference, and so on. The cross-reference comment is useful for finalizing the data cross-references before the preferred data architecture is designated.
INITIAL COMMON DATA ARCHITECTURE
A common data architecture provides the common context for data cross-referencing. All disparate data that have been inventoried and documented are cross-referenced to a common data architecture. However, an initial common data architecture needs to be established before cross-referencing can begin.
The best way to establish an initial common data architecture is to look at the business world as perceived by the organization. The organization perception principle and the umwelt principle emphasize that the organization’s perception of the business world is the initial starting point for establishing an initial common data architecture.
Business objects and business events that are critical to the business or support core business functions become data subjects in the initial common data architecture. Business features and traits of those business objects and business events become data characteristics in the initial common data architecture. Formal data names are used for the data subjects and data characteristics. Initial data definitions are entered for the data subjects and data characteristics.
Overgeneralizing an initial common data architecture should be avoided. The initial common data architecture is based on the business objects and events as perceived by the organization. Generalized concepts, like Party, and so on, are not business objects or events and are not part of an initial common data architecture. Any generalizations are done during formal denormalization of a preferred data architecture. Using generic data architectures or universal data models for creating an initial common data architecture should also be avoided. They seldom represent the way an organization perceives the business world.
Data characteristic variations, data reference sets, primary keys and foreign keys, and data integrity rules are not added to an initial common data architecture. These will be added during cross-referencing or during the preferred data architecture designation. Do not attempt to create a complete data model or a desired data model for the initial data architecture—it will be a waste of time and a detriment to cross-referencing. Just get the data subjects and data characteristics in place to get started.
An initial common data architecture will be enhanced as data cross-referencing continues. As the product data are cross-referenced, the initial common data architecture is enhanced to support those cross-references. Additional data subjects, data subject variations, data characteristics, data characteristic variations, data reference set variations, and data reference items are added as needed.
The best approach is to establish an initial common data architecture with major business objects and business events as data subjects, and major features and traits as data characteristics. Then move ahead with data cross-referencing to enhance the initial common data architecture and gain additional understanding about the disparate data.
SUMMARY
Data cross-referencing continues the data understanding process by connecting the inventory of disparate data to a common data architecture. The data inventory provided an initial understanding of the disparate data. Cross-referencing the data inventory to a common data architecture increases that understanding within a common context.
The base for increasing the data understanding is first to understand the disparate data with respect to the organization’s perception of the business world, and second to normalize the data according to the organization’s perception of the business world. The normalization is done at four levels: data characteristics within data subjects, business facts within data characteristics, data properties within data reference items, and time.
Data cross-referencing is a discovery process that is very detailed and requires considerable thought. The process itself is relatively simple. The difficulty is with really understanding the existing disparate data.
An initial common data architecture is developed based on the major business objects and events that the organization perceives in the business world. That initial common data architecture is enhanced during the data cross-referencing process. Trying to develop a complete common data architecture before cross-referencing is usually a wasted effort.
The data inventory may need to be adjusted during data cross-referencing based on increased data understanding. The common data architecture may also need to be adjusted based on increased data understanding. An adjustment of the data inventory or common data architecture may require an adjustment of the data cross-references.
The primary approach to data cross-referencing is to cross-reference data products to the common data architecture. Cross-referencing data products to other data products is a complete waste of time and resources. Cross-referencing interim common data architectures to a final common data architecture is useful in very large organizations.
Cross-references between data products and a common data architecture include data product units or variations to data characteristic variations and data product codes or variations to data reference items. No other cross-references are made between data products and a common data architecture.
Data cross-referencing provides the base for designating a preferred data architecture and developing data transformation rules. The preferred data architecture and data transformation rules will be used to develop a comparate data resource that fully supports the current and future business information demand.
QUESTIONS
The following questions are provided as a review of the process to thoroughly understand disparate data, and to stimulate thought about how to understand disparate data.
- What is the objective of data cross-referencing?
- How are the organization perception principle and the umwelt principle related?
- Why is data cross-referencing done to a common data architecture?
- Why might it be necessary to enhance the data inventory?
- Why might the common data architecture need to be adjusted?
- What are the four levels of data normalization achieved during data cross-referencing?
- What are the three basic approaches to data cross-referencing?
- What are the three cross-references between data products and the common data architecture?
- How is a data subject thesaurus helpful for data cross-referencing?
- How is an initial common data architecture developed?