
Chapter 11
DATA TRANSFORMATION CONCEPT
Where the rubber meets the road!
When the preferred physical data architecture has been designated for one segment of the data disparate data resource, or for the entire disparate data resource, the existing disparate data can be transformed to comparate data according to that preferred physical data architecture. The last six chapters described the concepts and processes in the formal state that were used to understand the existing disparate data and designate a preferred data architecture. Now it’s time to transform those disparate data to comparate data, either in the virtual state or comparate state, based on the preferred data architecture designations.
Chapter 11 describes the concepts and principles for transforming disparate data to comparate data based on the preferred data architecture and the current operating environment of an organization. The concepts and principles for transforming comparate data to disparate data to maintain those disparate data until all applications using those disparate data can be transformed are also described. The techniques and processes for transforming disparate data to comparate data, and comparate data to disparate data, are described in the next chapter.
CONCEPTS AND PRINCIPLES
The concept for formal data transformation and the principles supporting the concept are described below.
Data Transformation Concept
The data resource integration concept was defined in Chapter 2 as resolving the disparate data to produce a comparate data resource that meets the current and future business information demand. Data resource integration was defined as the thorough understanding of existing disparate data within a common data architecture, the designation of preferred data, and the development of a comparate data resource based on those preferred data. Data integration was defined as the merging of data from multiple, often disparate, sources, usually based on some record of reference, to provide a single output. It does not resolve any data disparity, and may further increase data disparity.
Data resource transition was defined in Chapter 2 as the transition of an organization’s data resource from a disparate state, through the formal data resource state and virtual data resource state, to a comparate data resource state. It’s the pathway that is followed from a disparate data resource to a comparate data resource that is unique to each organization. Formal data resource integration was defined as any data resource integration done within the context of a common data architecture. Informal data resource integration was defined as any data resource integration done outside the context of a common data architecture.
The only difference between the virtual state and the comparate state is whether the data transformation is done temporarily, on an as-needed basis, or is done permanently. The virtual state is the temporary transformation of data and the comparate state is the permanent transformation of data.
Data resource transformation is the formal process of formally transforming a disparate data resource to a comparate data resource within the context of a common data architecture according to the preferred data architecture designations. It’s a subset of overall data resource transition that is based on the preferred physical data architecture. It’s a metamorphosis of the physical disparate data to form physical comparate data.
Data resource transformation includes transforming disparate data to comparate data to achieve a comparate data resource, and transforming comparate data to disparate data to maintain existing applications until they can be transformed to use comparate data. It’s a very detailed process that requires careful planning, but it’s far from impossible. Data resource transformation is absolutely necessary to achieve a high quality data resource that meets the current and future business information demand, but is often ignored by most traditional data transformation approaches.
The data resource transformation concept states that all data transformation, whether disparate data to comparate data or comparate data to disparate data, will be done within the context of a common data architecture, using the preferred data architecture designations, according to formal data transformation rules. The best existing disparate data are extracted and transformed to comparate data to create a single, high quality version of truth about the business.
The data resource transformation objective is to transform the best of the existing disparate data to a high quality comparate data resource so it can support the current and future business information demand. The objective is more than just connecting a few databases and merging the data, building bridges between databases, or sending electronic messages over a network. It’s a precise, detailed, and very rigorous process that creates a high quality comparate data resource.
Data transformation is the process of transforming disparate data to comparate data, or comparate data to disparate data, within the context of a common data architecture. It’s one step in the overall extract-transform-load process that is done during data resource transformation. Formal data transformation is done within the context of a common data architecture and follows all of the concepts, principles, and techniques for formal data resource integration. Informal data transformation is done outside the context of a common data architecture, seldom follows formal concepts, principles, and techniques, and seldom resolves data disparity. The traditional data transformation done today is informal data transformation.
Forward data transformation is the formal transformation of disparate data to comparate data. Data are extracted from the preferred data source, transformed, and loaded into the data target. Forward data transformation can eventually be eliminated when the disparate data resource has been completely transformed to a comparate data resource. Reverse data transformation is the formal transformation of comparate data to disparate data. It’s necessary to maintain disparate data that supports disparate applications until they can be converted to comparate data. Reverse data transformation can eventually be eliminated when applications are no longer based on disparate data.
The data transformation concept is shown in Figure 11.1. The existing disparate data are shown on the left. The existing disparate operational data are used to create disparate historical data and disparate evaluational data, as shown by the dashed lines. The disparate historical data can also be used to create disparate evaluational data. The initial data disparity is perpetuated throughout the data resource and impacts the business information demand.
The desired comparate data are shown on the right. Comparate operational data are used to create comparate historical data and comparate evaluational data, as shown by the solid lines. Comparate historical data can also be used to create comparate evaluational data. Comparate data are perpetuated throughout the data resource to support the business information demand.
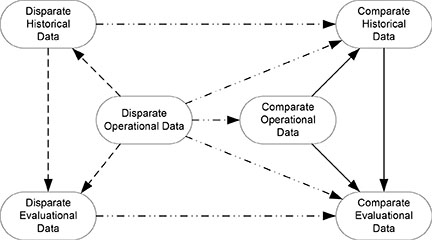
Figure 11.1 Data transformation concept.
Data transformation is shown in the center with dashed-dotted lines. Disparate historical data are transformed to comparate historical data. Disparate evaluational data are transformed to comparate evaluational data. Disparate operational data are transformed to comparate operational data, and may be transformed to comparate historical and comparate evaluational data. Each of these data transformations follows the same principles and techniques.
Data transformation is not the same as deploying data or replicating data. Deploying and replicating data simply moves or copies the existing data to another location. Data transformation is not the same as merging or combining existing data. Data transformation actually changes the data structure and data values from a disparate state to a comparate state.
Data Transformation Principles
Data transformation principles include a formal process, a destructive process, a technical process, application data transformation, data transformation rules, data bridges, data broker, data depot, and data integration key. Each of these principles is described below.
Formal Process
The formal data transformation principle states that formal data transformation will be used to create a comparate data resource. Informal data transformation will not be considered or used. The emphasis will be on forward data transformation, with reverse data transformation only to the extent needed to maintain disparate data until applications can be transformed to use comparate data. Formal data transformation is deterministic, prospective, and prescriptive.
Formal data transformation is performed between the existing physical disparate data and the desired physical comparate databases that were developed according to the preferred physical data architecture. The data inventory, cross-referencing, and preferred logical data architecture provide the link between the existing physical disparate data and the desired physical comparate data. Accordingly, the physical data names are used for data transformation.
Both data integration and data resource integration can use the same data transformation techniques. The difference is that data integration is generally less formal and has not gone through the formal processes of data inventory, cross-referencing, and preferred data architecture designations, and does not result in a permanent comparate data resource. Data resource integration has gone through the formal processes and results in a permanent comparate data resource.
Formal data resource integration relies on insights gained through the formal processes to make informed decisions about selecting the best disparate data and transforming those data to build a comparate data resource. It’s not perfect, but it’s the best that can be done based on the existing disparate data.
Destructive Process
Data transformation is a destructive process because it actually changes the data structure and data values from their disparate state to a comparate state. All of the previous processes for data inventorying, data cross-referencing, and preferred data designations were non-destructive because they did not alter the data in any way. They only provided an understanding and made preferred data designations within the context of a common data architecture. Data transformation takes the disparate data apart and builds a comparate data resource.
Detailed Process
Many people believe that data transformation is a difficult, or impossible, process and resort to a traditional Extract-Transform-Load process that seldom transforms the data. The traditional Extract-Transform-Load process may provide some superficial cleansing of the data, but seldom provides any robust transformation of the data structure or data values. It seldom produces a comparate data resource.
Formal data transformation is a very detailed process, but is far from impossible. It’s based on very sound concepts and principles that produce a comparate data resource. It takes thought, effort, and time, but the result is a comparate data resource that meets the business information demand.
When the data transformation process is understood, each organization develops their own techniques for performing the data transformation based on their particular operating environment. My experience has been that when the formal data transformation rules have been developed, the database technical staff and application programmers are infinitely clever at performing the data transformation. When they see the specifications of what needs to be done, they know how to implement those specifications in their operating environment.
Application Data Transformation
A disparate data application is any application that reads and stores disparate data. A comparate data application is any application that reads and stores comparate data. Application data transformation is the process of transforming disparate data applications from reading and storing disparate data to reading and storing comparate data. The entire application may not be changed, but the data read and data store routines of the application can be changed from disparate data to comparate data.
Weak application data transformation is the use of routines to read and store comparate data while the application still operates with the disparate data. Strong application data transformation is the complete transformation of an application to read and store comparate data as well as operate with comparate data. Typically, weak application data transformation is done during data resource transformation.
Data Transformation Rules
A data transformation rule is a data rule that specifies how the data will be transformed within the context of a common data architecture based on the existing disparate data and the preferred physical data architecture. Data transformation rules can be specified both ways between disparate data and comparate data.
Data transformation rules can be explicit or implicit. Explicit data transformation rules are stated as a formal data rule using specific notations. Implicit data transformation rules are stated in the form of a table or matrix for data value translations.
Data transformation rules can be specified as data reconstruction rules, data translation rules, data recast rules, and data derivation rules. Each of these data transformation rules will be described below with their respective data transformation process.
Data Bridges
A data cross-walk is the physical movement of data from one data file to another data file without any formal data transformation or the application of data integrity rules. The analogy is like using a cross-walk at an intersection where people cross, but are not altered in the process. The term is not used with data resource transformation because it implies an easy task of moving the disparate data to a comparate data resource without any transformation.
A data bridge is an application that moves data from one disparate data file to another disparate data file to keep the two data files in synch. The primary purpose is to maintain redundant data in a disparate data resource. When one data file is updated, those data are moved across the data bridge to update other data files. Data bridges are basically a data cross-walk between two data files to keep those data files in synch.
Data bridges can work in only one direction, from a primary data file to a secondary data file to keep the secondary data file in synch with the primary data file. Data bridges can also work in both directions when both data files receive updates, to keep those data files in synch with each other.
Many data bridges exist in a disparate data resource and considerable effort is spent building and maintaining data bridges. Most of these data bridges can be replaced with data brokers during data resource transformation, or can be eliminated when the disparate data resource has been transformed to a comparate data resource, often resulting in significant savings.
Data Broker
A broker is one who acts as an intermediary; an agent who makes arrangements. A data broker is an application that acts as an intermediary between disparate data and comparate data in databases or applications. It performs formal data transformations in both directions between disparate data and comparate data. Data brokering is the process of using data brokers to perform formal data transformation.
A data broker can operate between disparate databases to replace existing data bridges. It can manage multiple data bridges more efficiently, and can handle formal data transformation rules, when necessary.
A data broker can operate between disparate data applications and comparate databases by formally transforming the data. A data broker can also operate between comparate data applications and disparate databases by formally transforming the data.
A data broker can operate between disparate data applications and comparate data applications by formally transforming the data in messages between those applications.
Data brokers operate until all disparate data have been transformed to comparate data, and all disparate data applications have been transformed to comparate data applications. Data brokers are slowly eliminated as databases and applications are transformed to comparate data. They are eventually gone when all databases have comparate data and all applications use comparate data.
Data Depot
A depot is a place for storing goods; a store or cache; a place for storing and forwarding supplies; a building for railroad or bus passengers or freight. A data depot is a place for storing data for formal data transformation. It’s a staging area or work area for transforming data independent of the data source or data target. It’s not intended to store data or to be a working database for production operation.
A data depot can be used for either forward data transformation to build comparate databases, or for reverse data transformation to maintain disparate databases until applications can be transformed to use comparate data.
A data depot is a staging area for the formal transformation of data between disparate and comparate databases. Application code is developed to perform the data transformation within a data depot according to formal data transformation rules. A data broker differs from a data depot because it’s an application that performs formal data transformation on small sets of data moving between applications and databases. It does not perform formal data transformation between comparate and disparate databases.
A data converter is an application that changes the data between heterogeneous databases. It does not transform the data in any way. It only changes the physical form of the data from one database environment to another database environment. A data converter may need to be used when extracting disparate data to a data depot, or when loading transformed data into a comparate data resource.
Data Integration Key
A data integration key was defined in the last chapter as a set of data characteristics that could identify possible redundant physical data occurrences in a disparate data resource. It’s not a primary key because it does not uniquely identify a specific data occurrence. It’s not a foreign key because no corresponding primary key exists. It’s only used to identify possible redundant physical data occurrences in a disparate data resource.
A data integration key supports various algorithms and techniques for identifying redundant data in disparate databases. The data integration key, and the algorithms and techniques used for identifying possible redundant data occurrences, must be documented during the data transformation process.
DATA TRANSFORMATION PHASES
Many organizations are not formally transforming their data resource. What transformation they may do is usually incomplete or inconsistent transformation to meet current needs. Most follow a traditional Extract-Transform-Load approach, a suck-and-squirt approach, or a brute-force-physical approach. Some believe that a simple extract, superficial cleansing, and loading will solve all the disparate data problems. These approaches make a very big problem look very easy to resolve, but usually result in more disparate data.
Formal data transformation consists of three formal phases with formal steps in each phase. The phases are based on the traditional Extract-Transform-Load approach, but have been substantially enhanced to support formal data transformation. The enhancements avoid traditional approaches mentioned above that lead to additional disparate data.
The diagram in Figure 11.2 shows the three formal data transformation phases and the eleven formal data transformation steps. At a high level, data are extracted from the data source according to data source rules and are placed in a data depot for transformation. The data source and data target remain unaltered during the data transformation process, because all data transformation is done within a data depot.
The data are transformed within the data depot according to a formal set of data transformation rules. If any problem occurs during data transformation, the data depot is emptied, the problem is corrected, the source data are re-extracted, and the data transformation continues. When the data transformation is successful, the transformed data are loaded into the data target.
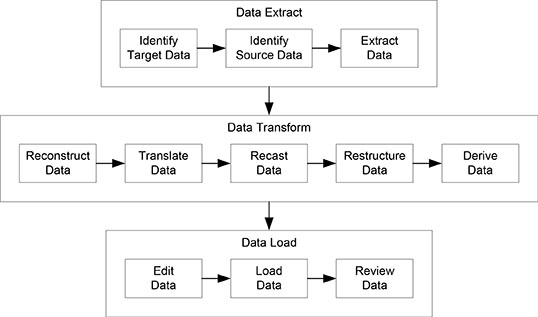
Figure 11.2. Data Transformation Phases.
Data Extract Phase
Data extract is the formal process of identifying and extracting the preferred disparate data and loading those data into a data depot for data transformation. It consists of target data identification, source data identification for those target data, and source data extraction to a data depot. Any data needed from the data target to support the data transformation are also extracted and placed in the data depot.
Data extract can be used for current operational data to build comparate operational databases. It can also be used for current and historical data instances to develop comparate evaluational databases for analytical processing. When data extract is used to develop comparate evaluational databases, the lowest level of source data detail must be extracted to provide for summarizing data to the lowest level evaluational data desired.
Data extract consists of specifications for developing the code to extract the source data. It is not the actual coding that performs the data extract. When the specifications have been developed, the technical staff can develop the specific coding based on the particular operating environment.
Identify Target Data
Identify target data is the formal process of determining the desired target data. The desired target data are specified as the preferred physical data structure and will be used throughout the data transformation process. The preferred logical data structure can be included in the specification if it is useful. The process sets the scope of data transformation.
Identify Source Data
Identify source data is the formal process of determining the source data that will be needed to prepare the target data. The source data are specified as a physical data structure of the disparate data as documented during data inventorying. The logical data structure, based on the data cross-references, can be included in the specification if it is useful. The preferred data source rules are used to identify the source data.
One of the most frequently ignored steps in traditional data transformation is formal data source rules, including conditional data sourcing. Emphasis is often placed on a system of reference or system of record to avoid the details of conditional data sourcing. However, that approach seldom results in the most current or most accurate data, and can impact the target data quality.
Extract Source Data
Extract source data is the formal process of extracting the source data from the preferred data source based on the specifications, performing any database conversions necessary between the data source and the data depot, and placing the source data into a data depot for data transformation.
Data Transform Phase
Data transform is the formal process of transforming disparate data into comparate data, in the data depot, using formal data transformation rules. It consists of data reconstruction, data translation, data recasting, data restructuring, and data derivation. Data transform is where the disparate data are actually transformed to comparate data.
Data transform can be used for both operational data and for evaluational data transformation. Some of the steps within data transform apply to both operational and evaluational data, and some of the steps apply only to evaluational data.
Transforming data is the really difficult part of data resource transformation, because of the detail involved in both the specifications and the coding. Data transform consists of specifications for developing the code to transform the data. It is not the actual coding that performs the data transformation. When the specifications have been developed, the technical staff can develop the specific coding based on the particular operating environment.
Reconstruct Data
Reconstruct data is the formal process of rebuilding complete historical data that are not stored as full data records. It is typically used for developing comparate evaluational data, and is seldom used for developing comparate operational data. It is an optional step for creating comparate evaluational data.
When operational data change, the old data value may be saved as a historical data instance, containing either the changed data values or a full data instance. Historical data instances that are full data instances do not need to be reconstructed. However, historical data instances containing only the changed values do need to be reconstructed to full historical data instances.
A data reconstruction rule is a data rule that specifies the reconstruction of historical data into full historical data instances in preparation for data transformation. The data reconstruction rule shows the conditions for data reconstruction and the data reconstruction that is performed. The data reconstruction rules are designated with the keyword Reconstruction!.
Translate Data
Translate data is the formal process of translating the extracted data values to the preferred data values, if they are not already in the preferred format or content, using appropriate data translation rules. It’s an important step to put all data in the preferred form to reduce the variability inherent in disparate data and ensure consistency in the comparate data resource. It needs to be done after data reconstruction and before recasting, restructuring, or deriving data.
Translating data is done for both operational data and evaluational data, including current and historical data instances. All data must be translated into the proper format or content in a comparate data resource.
Data translation rules were defined in Chapter 9 as specifying the algorithm for translating data values between preferred and non-preferred data designations. They only specify translations in format or content between data variations. Their development was described in Chapter 10. Those data translation rules are used in the translate data process.
Recast Data
Recast data is the formal process of adjusting data values for historical continuity. It aligns data values for a common historical perspective using data recast rules. Data recasting follows data translation so that the proper data values are recast. Data recasting is not a translation of data values. It’s an adjustment of the data values, after they have been translated, to provide historical continuity.
Recasting data only applies to certain data, such as financial data to analyze trends independent of monetary inflation. Recasting data is typically done only for evaluational data. Recasting current operational data could destroy their integrity for operational decision making. Recasting data can be done to any current or past time period, and could be done for multiple time periods. Each organization must determine the appropriate time period for recasting data depending on their specific needs.
A data recasting rule is a data rule that specifies the adjustment of data values to a specific time period, such as adjusting financial data values to a specific time period for a comparison of trends independent of monetary inflation. The recasting time period may be in the present or the past. The rule is designated with the keyword Recast!. It contains the time period for the recasting, the point for recasting, and the algorithm used for recasting.
Restructure Data
Restructure data is the formal process of changing the structure of the disparate source data to the structure of the comparate target data. It takes physical disparate data structures that have existed in the past and changes them to a preferred physical data structure. Data restructuring can be performed any time during data transformation, but is best performed after data recasting and before data derivation.
Many structural problems need to be overcome during data restructuring. The physical data structure may be different, primary keys often change over time, the meaning of data often change over time, data may be missing for certain time periods, and so on. These problems result from different perceptions of the business world, changes in perceptions of the business world, lack of formal logical and physical data modeling, different product implementations, and so on, and need to be resolved during data restructuring.
Data restructuring applies primarily to current data instances in operational data, but can be used for current and historical data instances in evaluational data if the restructuring is not too difficult. When restructuring disparate operational data to preferred evaluational data becomes too difficult, the best approach is to restructure only the operational data first. In a subsequent process, preferred physical operational data are renormalized to preferred physical evaluational data.
When evaluational data originate from multiple disparate data sources that are restructured in separate data restructuring processes, the best approach is to perform the operational data restructuring first, followed by renormalizing the preferred physical data to the preferred evaluational data. Trying to perform data restructuring from disparate operational data directly to comparate evaluational data in multiple data restructuring processes often leads to different results. Therefore, the best approach is to restructure all of the operational data first, followed by a renormalization to preferred physical data.
Derive Data
Derive data is the formal process of deriving target data from source data according to formal data derivation rules. It applies to deriving individual data values, to summarizing operational data, and to aggregating evaluational data to the lowest level of detail desired. Data derivation is the last step in the data transformation phase, because all of the data need to be available for derivation.
Data derivation is not the same as data translation. Data derivation creates data values from existing data values. Data translation changes existing data values.
A data derivation rule was defined in Chapter 3 as a data integrity rule that specifies the contributors to a derived data value, the algorithm for deriving the data value, and the conditions for deriving the data value. Data derivation can be a generation data derivation, where the data derivation algorithm generates the derived data values without the input of any other data values. It can be a single contributor data derivation when one data value is the contributor to an algorithm that generates the derived data. It can be a multiple contributor data derivation where many data attributes from the same data entity or different data entities contribute to the derived data. It can be an aggregation data derivation where two or more values of the same data attribute in different data occurrences contribute to the derived data.
Data Load Phase
Data load is the formal process of loading the target database after the data transformation has been completed. The transformed data are edited according to the preferred data integrity rules, loaded into the target database, and reviewed to ensure the load was successful before the data are released for use.
When the data load is successful, the data depot can be cleared for additional data transformation. Alternatively, the contents of the data depot could be archived as a record of the data transformations that were made. That record may be important for data provenance in large organizations or between organizations. However, it cannot be used for operational processing.
Edit Data
Edit data is the formal process of applying the preferred data edits to the transformed data to ensure the quality of the data before they are loaded into the target database. The process applies to both operational and evaluational data. The data edits are applied within the data depot so that any data that fail the preferred data integrity rules remain in the data depot and do not enter the target database. The target database may be accessed for data that are involved in the data editing, but the data edit process remains in the data depot.
The preferred data edits should specify the violation action and the notification action to be taken when data fail the edit. The preferred data integrity rules may specify the violation and notification actions for normal processing, but may not apply to data transformation. If these actions have not been specified for data transformation, they need to be specified before data editing begins.
Data quality improvement applications, such as address cleansing applications, may be run while data are in the data depot. These applications must be run before the preferred data edits are performed so that the results of the improvement pass through the data edits. The data quality improvement applications generally improve the chances that data pass the preferred data edits, but may result in the data not passing the preferred data edits. Therefore, they must be run before the preferred data edits are applied.
Applying the preferred data edits only verifies the data integrity. It does not verify the data accuracy—how well the data represent the business world. No data integrity rules or data edits can be specified to evaluate the accuracy of the data.
Load Data
Load data is the formal process of loading the data from the data depot into the target database. Any database conversion that is necessary is done during the data load process. Only data records that pass the preferred data edits are loaded into the target database. The violation action may be to hold the record that contains a violation in the data depot until the violation is corrected, or it may be to hold the entire set of data within the data depot until all violations are corrected. The choice is up to the organization and their particular operating environment.
Review Data
Review data is the formal process of reviewing the data that have been transformed and loaded into the target database to ensure they are appropriate for production use. The review is generally focused on whether or not the load was successful. However, it can focus on other aspects of data transformation and integrity to ensure that the data are appropriate for use. In some situations, the preferred data edits are applied after the data have been loaded as a final verification that the data are appropriate for production use.
When the data fail the review process, the load is reversed and the transformed data are removed from the target database. Adjustments are made to the data transformation, data edits, and data load processes to correct the failure. The data are then reloaded and reviewed to ensure they are appropriate for production use.
Reverse Data Transformation
The above discussion applied largely to forward data transformation. However, reverse data transformation can be used during the virtual data resource state to maintain disparate databases until the applications can be transformed to use comparate data. The process is essentially the same, except that the comparate-to-disparate data transformation rules are reversed to become disparate-to-comparate data transformation rules.
The process may seem like excessive documentation, but it eases the process of transforming data in the virtual state. Eventually, all of the disparate data will be converted to comparate data and all of the disparate data applications will be converted to comparate data applications. Then the reverse data transformation rules need only be retained for historical purposes.
In some situations, the reverse data transformation rules may be needed for the transformation of comparate data to meet disparate external reporting requirements. Creating a comparate data resource for an organization does not eliminate the need to provide data to external organizations as disparate data. The reverse data transformation rules need to be retained to meet these external requirements.
SUMMARY
Formal data transformation begins the process of changing the structure and values of disparate data to comparate data based on the preferred physical data architecture. Data transformation can be done formally within the context a common data architecture or informally, outside of the context of a common data architecture. It can be forward from disparate data to comparate data, or reverse from comparate data to disparate data.
Formal data transformation is a destructive process because it actually changes the data. It’s a detailed process that takes thought, effort, and time, but is achievable. It’s based on formal data transformation rules that are implemented through a data broker between databases and applications until the applications can be transformed to operate on comparate data. Data transformation between databases is done in a data depot that is independent of the source data and target data.
Formal data transformation consists of three formal phases containing eleven formal data steps, shown in the outline below.
Data Extract Phase
Identify Target Data
Identify Source Data
Extract Source Data
Data Transform Phase
Reconstruct Data
Translate Data
Recast Data
Restructure Data
Derive Data
Data Load Phase
Edit Data
Load Data
Review Data
Formal data transformation is the only way for an organization to move from a disparate data environment to a comparate data environment in an effective and efficient manner. Traditional approaches seldom provide any real benefit and often result in an increase in disparate data. The best approach is formal data transformation within the context of a common data architecture.
QUESTIONS
The following questions are provided as a review of transforming disparate data, and to stimulate thought about the process of transforming disparate data.
- What is the data transformation concept?
- Why is data transformation considered a destructive process?
- What’s the difference between data bridges, data converters, and data brokers?
- What is the purpose of a data depot?
- What is the purpose of the three formal phases of data transformation?
- What are the five formal steps of the data transformation phase?
- When are data integrity rules applied to the transformed data?
- What are the different types of data transformation rules?
- What is the purpose of reverse data transformation?
- What does formal data transformation accomplish?