
The data Warehouse implementation approach presented in this chapter describes the activities related to implementing one rollout of the date warehouse. The activities discussed here build on the results of the data warehouse planning described in the previous chapter.
The data warehouse implementation team builds or extends an existing warehouse schema based on the final logical schema design produced during planning. The team also builds the warehouse subsystems that ensure a steady, regular flow of clean data from the operational systems into the data warehouse. Other team members install and configure the selected front-end tools to provide users with access to warehouse data.
An implementation project should be scoped to last between three to six months. The progress of the team varies, depending (among other things) on the quality of the warehouse design, the quality of the implementation plan, the availability and participation of enterprise resource persons, and the rate at which project issues are resolved.
User training and warehouse testing activities take place toward the end of the implementation project, just prior to the deployment to users. Once the warehouse has been deployed, the day-to-day warehouse management, maintenance, and optimization tasks begin. Some members of the implementation team may be asked to stay on and assist with the maintenance activities to ensure continuity. The other members of the project team may be asked to start planning the next warehouse rollout or may be released to work on other projects.
Acquire and set up the development environment for the data warehouse implementation project. This activity includes the following tasks, among others: install the hardware, the operating system, the relational database engine; install all warehousing tools; create all necessary network connections; and create all required user IDs and user access definitions.
Note that most data warehouses reside on a machine that is physically separate from the operational systems. In addition, the relational database management system used for data warehousing need not be the same database management system used by the operational systems.
At the end of this task, the development environment is set up, the project team members are trained on the (new) development environment, and all technology components have been purchased and installed.
There may be instances where the team has no direct access to the operational source systems from the warehouse development environment. This is especially possible for pilot projects, where the network connection to the warehouse development environment may not yet be available.
Regardless of the reason for the lack of access, the warehousing team must establish and document a consistent, reliable, and easy-to-follow procedure for obtaining copies of the relevant tables from the operational systems. Copies of these tables are made available to the warehousing team on another medium (most likely tape) and are restored on the warehouse server. The creation of copies can also be automated through the use of replication technology.
The warehousing team must have a mechanism for verifying the correctness and completeness of the data that are loaded onto the warehouse server. One of the most effective completeness checks is meaningful business counts (e.g., number of customers, number of accounts, number of transactions) that are computed and compared to ensure data completeness. Data quality utilities can help assess the correctness of the data.
The use of copied tables as described above implies additional space requirements on the warehouse server. This should not be a problem during the pilot project.
Translate the detailed logical and physical warehouse design from the warehouse planning stage into a final physical warehouse design, taking into consideration the specific, selected database management system.
The key considerations are:
Schema design. . Finalize the physical design of the fact and dimension tables and their respective fields. The warehouse database administrator (DBA) may opt to divide one logical dimension (e.g., customer) into two or more separate ones (e.g., a customer dimension and a customer demographic dimension) to save on space and improve query performance.
Indexes. . Identify the appropriate indexing method to use on the warehouse tables and fields, based on the expected data volume and the anticipated nature of warehouse queries. Verify initial assumptions made about the space required by indexes to ensure that sufficient space has been allocated.
Partitioning. . The warehouse DBA may opt to partition fact and dimension tables, depending on their size and on the partitioning features that are supported by the database engine. The warehouse DBA who decides to implement partitioned views must consider the trade-offs between degradation in query performance and improvements in warehouse manageability and space requirements.
Easily 60 percent to 80 percent of a warehouse implementation project is devoted to the back-end of the warehouse. The back-end subsystems must extract, transform, clean, and load the operational data into the data warehouse. Understandably, the back-end subsystems vary significantly from one enterprise to another due to differences in the computing environments, source systems, and business requirements. For this reason, much of the warehousing effort cannot simply be automated away by warehousing tools.
The first among the many subsystems on the back-end of the warehouse is the data extraction subsystem. The term extraction refers to the process of retrieving the required data from the operational system tables, which may be the actual tables or simply copies that have been loaded into the warehouse server.
Actual extraction can be achieved through a wide variety of mechanisms, ranging from sophisticated third-party tools to custom-written extraction scripts or programs developed by in-house IT staff. Third-party extraction tools are typically able to connect to mainframe, midrange and UNIX environments; thus freeing their users from the nightmare of handling heterogeneous data sources. These tools also allow users to document the extraction process (i.e., they have provisions for storing metadata about the extraction).
These tools, unfortunately, are quite expensive. For this reason, organizations may also turn to writing their own extraction programs. This is a particularly viable alternative if the source systems are on a uniform or homogenous computing environment (e.g., all data reside on the same RDBMS, and they make use of the same operating system). Custom-written extraction programs, however, may be difficult to maintain, especially if these programs are not well documented. Considering how quickly business requirements will change in the warehousing environment, ease of maintenance is an important factor to consider.
The transformation subsystem literally transforms the data in accordance with the business rules and standards that have been established for the data warehouse.
Several types of transformations are typically implemented in data warehousing.
Format changes. . Each of the data fields in the operational systems may store data in different formats and data types. These individual data items are modified during the transformation process to respect a standard set of formats. For example, all date formats may be changed to respect a standard format, or a standard data type is used for character fields such as names, addresses.
Deduplication. . Records from multiple sources are compared to identify duplicate records based on matching field values. Duplicates are merged to create a single record of a customer, a product, an employee, or a transaction. Potential duplicates are logged as exceptions that are manually resolved. Duplicate records with conflicting data values are also logged for manual correction if there is no system of record to provide the "master" or "correct" value.
Splitting up fields. . A data item in the source system may need to be split up into one or more fields in the warehouse. One of the most commonly encountered problems of this nature deals with customer addresses that have simply been stored as several lines of text. These textual values may be split up into distinct fields: street number, street name, building name, city, mail or zip code, country, etc.
Integrating fields. . The opposite of splitting up fields is integration. Two or more fields in the operational systems may be integrated to populate one warehouse field.
Replacement of values. . Values that are used in operational systems may not be comprehensible to warehouse users. For example, system codes that have specific meanings in operational systems are meaningless to decision-makers. The transformation subsystem replaces the original with new values that have a business meaning to warehouse users.
Derived values. . Balances, ratios, and other derived values can be computed using agreed formulas. By precomputing and loading these values into the warehouse, the possibility of miscomputation by individual users is reduced. A typical example of a precomputed value is the average daily balance of bank accounts. This figure is computed using the base data and is loaded as-is into the warehouse.
Aggregates. . Aggregates can also be precomputed for loading into the warehouse. This is an alternative to loading only atomic (base-level) data in the warehouse and creating in the warehouse the aggregates records based on the atomic warehouse data.
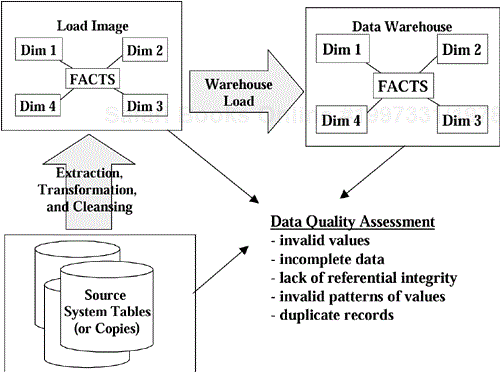
The extraction and transformation subsystems (see Figure 9-1) create load images, i.e., tables and fields populated with the data that are to be loaded into the warehouse. The load images are typically stored in tables that have the same schema as the warehouse itself. By so doing, the extraction and transformation subsystems greatly simplify the load process.

Data quality problems are not always apparent at the start of the implementation project, when the team is concerned more about moving massive amounts of data rather than the actual individual data values that are being moved. However, data quality (or to be more precise, the lack of it) will quickly become a major, show-stopping problem if it is not addressed directly.
One of the quickest ways to inhibit user acceptance is to have poor data quality in the warehouse. Furthermore, the perception of data quality is in some ways just as important as the actual quality of the data warehouse. Data warehouse users will make use of the warehouse only if they believe that the information they will retrieve from it is correct. Without user confidence in the data quality, a warehouse initiative will soon lose support and eventually die off.
A data quality subsystem on the back-end of the warehouse therefore is a critical component of the overall warehouse architecture.
An understanding of the causes of data errors makes these errors easier to find. Since most data errors originate from the source systems, source system database administrators and system administrators, with their day-to-day experiences working with the source systems, are very critical to the data quality effort.
Data errors typically result from one or more of the following causes.
Missing values. . Values are missing in the source systems due either to incomplete records or optional data fields.
Lack of referential integrity. . Referential integrity in source systems may not be enforced because of inconsistent system codes or codes whose meanings have changed over time.
Errors in precomputed data. . Some of the data in the warehouse can be precomputed prior to warehouse loading as part of the transformation process. If the computations or formulas are wrong, then erroneous data will be loaded into the warehouse.
Different units of measure. . The use of different currencies and units of measure in different source systems may lead to data errors in the warehouse if figures or amounts are not first converted to a uniform currency or unit of measure prior to further computations or data transformation.
Duplicates. . Deduplication is performed on source system data prior to the warehouse load. However, the deduplication process depends on comparisons of data values to find matches. If the data were not available to start with, the quality of the deduplication may be compromised. Duplicate records may therefore be loaded into the warehouse.
Fields to be split up. . As mentioned earlier, there are times when a single field in the source system has to be split up to populate multiple warehouse fields. Unfortunately, it is not possible to manually split up the fields one at a time because of the volume of the data. The team often resorts to some automated form of field-splitting, which may not be 100 percent correct.
Multiple hierarchies. . Many warehouse dimensions will have multiple hierarchies for analysis purposes. For example, the time dimension typically has a day-month-quarter-year hierarchy. This same time dimension may also have a day-week hierarchy and a day-fiscal month-fiscal quarter-fiscal year hierarchy. Lack of understanding of these multiple hierarchies in the different dimensions may result in erroneous warehouse loads.
Conflicting or inconsistent terms and rules. . The conflicting or inconsistent use of business terms and business rules may mislead warehouse planners into loading two distinctly different data items into the same warehouse field, or vice versa. Inconsistent business rules may also cause the misuse of formulas during data transformation.
Below is an approach for improving the overall data quality of the enterprise.
Assess current level of data quality. . Determine the current data quality level of each of the warehouse source systems. While the enterprise may have a data quality initiative that is independent of the warehousing project, it is best to focus the data quality efforts on warehouse source systems—these systems obviously contain data that are of interest to enterprise decision-makers.
Identify key data items. . Set the priorities of the data quality team by identifying the key data items in each of the warehouse source systems. Key data items, by definition, are the data items that must achieve and maintain a high level of data quality. By prioritizing data items in this manner, the team can target its efforts on the more critical data areas and therefore provides greater value to the enterprise.
Define cleansing tactics for key data items. . For each key data item with poor data quality, define an approach or tactic for cleaning or raising the quality of that data item. Whenever possible, the cleansing approach should target the source systems first, so that errors are corrected at the source and not propagated to other systems.
Define error-prevention tactics for key data items. . The enterprise should not stop at error-correction activities. The best way to eliminate data errors is to prevent them from happening in the first place. If error-producing operational processes are not corrected, they will continue to populate enterprise databases with erroneous data. Operational and data-entry staff must be made aware of the cost of poor data quality. Reward mechanisms within the organization may have to be modified to create a working environment that focuses on preventing data errors at the source.
Implement quality improvement and error-prevention processes. . Obtain the resources and tools to execute the quality improvement and error-prevention processes. After some time, another assessment may be conducted, and a new set of key data items may be targeted for quality improvement.
Data quality assessments can be conducted at any time at different points along the warehouse back-end. As shown in Figure 9-2, assessments can be conducted on the data while it is in the source systems, in warehouse load images or in the data warehouse itself.
Note that while data quality products assist in the assessment and improvement of data quality, it is unrealistic to expect any single program or data quality product to find and correct all data quality errors in the operational systems or in the data warehouse. Nor is it realistic to expect data quality improvements to be completed in a matter of months. It is unlikely that an enterprise will ever bring its databases to a state that is 100 percent error free.
Despite the long-term nature of the effort, however, the absolute worst thing that any warehouse Project Manager can do is to ignore the data quality problem in the vain hope that it will disappear. The enterprise must be willing and prepared to devote time and effort to the tedious task of cleaning up data errors rather than sweeping the problem under the rug.
All data errors found are, under ideal circumstances, corrected at the source, i.e., the operational system database is updated with the correct values. This practice ensures that subsequent data users at both the operational and decisional levels will benefit from clean data.
Experience has shown, however, that correcting data at the source may prove difficult to implement for the following reasons:
Operational responsibility. . The responsibility for updating the source system data will naturally fall into the hands of operational staff, who may not be so inclined to accept the additional responsibility of tracking down and correcting past data-entry errors.
Correct data are unknown. . Even if the people in operations know that the data in a given record are wrong, there may be no easy way to determine the correct data. This is particularly true of customer data (e.g., a customer's social security number). The people in operations have no other recourse but to approach the customers one at a time to obtain the correct data. This is tedious, time-consuming, and potentially irritating to customers.
Many of the available warehousing tools have features that automate different areas of the warehouse extraction, transformation, and data quality subsystems.
The more data sources there are, the higher the likelihood of data quality problems. Likewise, the larger the data volume, the higher the number of data errors to correct.
The inclusion of historical data in the warehouse will also present problems due to changes (over time) in system codes, data structures, and business rules.
The warehouse load subsystem takes the load images created by the extraction and transformation subsystems and loads these images directly into the data warehouse. As mentioned earlier, the data to be loaded are stored in tables that have the same schema design as the warehouse itself. The load process is therefore fairly straightforward from a data standpoint.
The load subsystem should be able to perform the following:
Drop indexes on the warehouse. . When new records are inserted into an indexed table, the relational database management system immediately updates the index of the table in response. In the context of a data warehouse load, where up to hundreds of thousands of records are inserted in rapid succession into one single table, the immediate re-indexing of the table after each insert results in a significant processing overhead. As a consequence, the load process slows down dramatically. To avoid this problem, drop the indexes on the relevant warehouse tables prior to each load.
Load dimension records. . In the source systems, each record of a customer, product, or transaction is uniquely identified through a key. Likewise, the customers, products, and transactions in the warehouse must be identifiable through a key value. Source system keys are often inappropriate as warehouse keys, and a key generation approach is therefore used during the load process. Insert new dimension records, or update existing records based on the load images.
Load fact records. . The primary key of a Fact table is the concatenation of the keys of its related dimension records. Each fact record therefore makes use of the generated keys of the dimension records. Dimension records are loaded prior to the fact records to allow the enforcement of referential integrity checks. The load subsystem therefore inserts new fact records or updates old records based on the load images. Since the data warehouse is essentially a time series, most of the records in the Fact table will be new records.
Compute aggregate records, using base fact and dimension records. . After the successful load of atomic or base-level data into the warehouse, the load subsystem may now compute aggregate records by using the base-level fact and dimension records. This step is performed only if the aggregates are not precomputed for direct loading into the warehouse.
Rebuild or regenerate indexes. . Once all loads have been completed, the indexes on the relevant tables are rebuilt or regenerated to improve query performance.
Log load perceptions. . Log all referential integrity violations during the load process as load exceptions. There are two types of referential integrity violations: (a) missing key values—one of the key fields of the fact record does not have a value; and (b) wrong key values—the key fields have values, but one or more of them do not have a corresponding dimension record. In both cases, the warehousing team has the option of (a) not loading the record until the correct key values are found or (b) loading the record, but replacing the missing or wrong key values with hard-coded values that users can recognize as a load exception.
The load subsystem, as described above, assumes that the load images do not yet make use of warehouse keys; i.e., the load images contain only source system keys. The warehouse keys are therefore generated as part of the load process.
Warehousing teams may opt to separate the key generation routines from the load process. In this scenario, the key generation routine is applied on the initial load images (i.e., the load images created by the extraction and transformation subsystems). The final load images (with warehouse keys) are then loaded into the warehouse.
There are ongoing debates about loading dirty data (i.e., data that fail referential integrity checks) into the warehouse. Some teams prefer to load only clean data into the warehouse, arguing that dirty data can mislead and misinform. Others prefer to load all data, both clean and dirty, provided that the dirty data are clearly marked as dirty.
Depending on the extent of data errors, the use of only clean data in the warehouse can be equally or more dangerous than relying on a mix of clean and dirty data. If more than 20 percent of data are dirty and only 80 percent are loaded into the warehouse, the warehouse users will be making decisions based on an incomplete picture.
The use of hard-coded values to identify warehouse data with referential integrity violations on one dimension allows warehouse users to still make use of the warehouse data on clean dimensions.
Consider the example in Figure 9-3. If a Sales Fact record is dependent on Customer, Date (Time dimension) and Product and if the Customer key is missing, then a "Sales per Product" report from the warehouse will still produce the correct information.

When a "Sales per Customer" report is produced (as shown in Figure 9-4), the hard-coded value that signifies a referential integrity violation will be listed as a Customer ID, and the user is aware that the corresponding sales amount cannot be attributed to a valid customer.
By handling referential integrity violations during warehouse loads in the manner described above, the users get a full picture of the facts on clean dimensions and are clearly aware when dirty dimensions are used.

The time required for a regular warehouse load is often of great concern to warehouse designers and project managers. Unless the warehouse was designed and architected to be fully available 24 hours a day, the warehouse will be offline and unavailable to its users during the load period.
Much of the challenge in building the load subsystem therefore lies in optimizing the load process to reduce the total time required. For this reason, parallel load features in later releases of relational database management systems and parallel processing capabilities in SMP and MPP machines are especially welcome in data warehousing implementations.
The team may want to test the accuracy and performance of the warehouse load subsystem on dummy data before attempting a real load with actual load images. The team should know as early as possible how much load optimization work is still required.
Also, by using dummy data, the warehousing team does not have to wait for the completion of the extraction and transformation subsystems to start testing the warehouse load subsystem.
Warehouse load subsystem testing, of course, is possible only if the data warehouse schema is already up and available.
Create the data warehouse schema in the development environment while the team is constructing or configuring the warehouse back-end subsystems (i.e., the data extraction and transformation subsystems, the data quality subsystem, and the warehouse load subsystem).
As part of the schema setup, the warehouse DBA must do the following:
Create warehouse tables. . Implement the physical warehouse database design by creating all base-level fact and dimension tables, core and custom tables, and aggregate tables.
Build Indexes. . Build the required indexes on the tables according to the physical warehouse database design.
Populate special referential tables and records. . The data warehouse may require special referential tables or records that are not created through regular warehouse loads. For example, if the warehouse team will use hard-coded values to handle loads with referential integrity violations, the warehouse dimension tables must have records that use the appropriate hard-coded value to identify fact records that have referential integrity violations.
It is usually helpful to populate the data warehouse with test data as soon as possible. This provides the front-end team with the opportunity to test the data access and retrieval tools, even while actual warehouse data are not yet available.
Figure 9-5 presents a typical data warehouse schema.
Metadata have traditionally been defined as "data about data." While such a statement does not seem very helpful, it is actually quite appropriate as a definition—metadata describe the contents of the data warehouse, indicate where the warehouse data originally came from, and document the business rules that govern the transformation of the data.
Warehousing tools also use metadata as the basis for automating certain aspects of the warehousing project.
Chapter 13 in the Technology section of this book discusses metadata in depth.

The data access and retrieval tools are equivalent to the tip of the warehousing iceberg. While they may represent as little as 10 percent of the entire warehousing effort, they are all that users see of the warehouse. As a result, these tools are critical to the acceptance and usability of the warehouse.
Acquire and install the selected data access tools in the appropriate environments and machines. The front-end team will find it prudent to first install the selected data access tools on a test machine that has access to the warehouse. The test machine should be loaded with the software typically used by the enterprise. Through this activity, the front-end team may identify unforeseen conflicts between the various software programs without inconveniencing anyone.
Verify that the data access and retrieval tools can establish and hold connections to the data warehouse over the corporate network.
In the absence of actual warehouse data, the team may opt to use test data in the data warehouse schema to test the installation of front-end tools.
The prototype initially developed during warehouse planning is refined by incorporating user feedback and by building all predefined reports and queries that have been agreed on with the end-users.
Different front-end tools have different requirements for the efficient distribution of predefined reports and queries to all users. The front-end team should therefore perform the appropriate administration tasks as required by the selected front-end tools.
By building these predefined reports and queries, the data warehouse implementation team is assured that the warehouse schema meets the decisional information requirements of the users.
Support staff who will eventually man the warehouse Help Desk should participate in this activity, since this participation provides excellent learning opportunities.
Define role or group profiles on the database management system. The major database management systems provide the use of a role or a group to define the access rights of multiple users through one role definition.
The warehousing team must determine the appropriate role definitions for the warehouse. The following roles are recommended as a minimum:
Warehouse user. . The typical warehouse user is granted Select rights on the production warehouse tables. Updates are not allowed.
Warehouse administrator. . This role is assigned to users strictly for the direct update of data warehouse dimension records. Select and Update rights are granted on the warehouse dimension records.
Warehouse developer. . This role applies to any warehouse implementation team member who works on the back-end of the warehouse. Users with this role can create development warehouse objects but cannot modify or update the structure and content of production warehouse tables.
Define user profiles for each warehouse user and assign one or more roles to each user profile to grant the user access to the warehouse. While it is possible for multiple users to use the same user profile, this practice is greatly discouraged for the following reasons:
Collection of warehouse statistics. . Warehouse statistics are collected as part of the warehouse maintenance activities. The team will benefit from knowing (a) how many users have access to the warehouse, (b) which users are actually making use of the warehouse, and (c) how often a particular user makes use of the warehouse.
Warehouse security. . The warehousing team must be able to track the use of the warehouse to a specific individual, not just to a group of individuals. Users may also be less careful with IDs and passwords if they know these are shared. Unique user IDs are also required should the warehouse start restricting or granting access based on record values in warehouse tables (e.g., a branch manager can see only the records related to his or her branch).
Audit trail. . If one or more users have Update access to the warehouse, distinct user IDs will allow the warehouse team to track down the warehouse user responsible for each update.
Query performance complaints. . In cases where a query on the warehouse server is slow or has stalled, the warehouse administrator will be better able to identify the slow or stalled query when each user has a distinct user ID.
The production data warehouse load can be performed only when the load images are ready and both the warehouse schema and metadata are set up.
Prior to the actual production warehouse load, it is good practice to conduct partial loads to get some indication of the total load time. Also, since the data warehouse schema design may require refinement, particularly when the front-end tools are first set up, it will be easier and quicker to make changes to the data warehouse schema when very little data have been loaded. Only when the end users have had a chance to provide positive feedback should large volumes of data be loaded into the warehouse.
Data warehouses are not refreshed more than once every 24 hours. If the user requirements call for up-to-the-minute information for operational monitoring purposes, then a data warehouse is not the solution; these requirements should be addressed through an Operational Data Store.
The warehouse is typically available to end users during the working day. For this reason, warehouse loads typically take place at night or over a weekend.
If the retention period of the warehouse is several years, the warehouse team should first load the data for the current time period and verify the correctness of the load. Only when the load is successful should the team start loading historical data into the warehouse. Due to potential changes to the schemas of the source systems over the past few years, it is natural for the warehouse team to start from the most current period and work in reverse chronological order when loading historical data.
The IT organization is encouraged to fully take over the responsibility of conducting user training, contrary to the popular practice of having product vendors or warehouse consultants handle this activity. Instead, the IT organization should ask product vendors or consultants to assist in the preparation of the first warehousing classes. Doing so will enable the warehousing team to conduct future training courses independently.
Conduct training for all intended users of this rollout of the data warehouse. Prepare training materials if required. The training should cover the following topics:
What is a warehouse? . Different people have different expectations of what a data warehouse is. Start the training with a warehouse definition.
Warehouse scope. . All users must know the contents of the warehouse. The training should therefore clearly state what is not supported by the current warehouse rollout. Trainers might need to know what functionality has been deferred to later phases, and why.
Use of front-end tools. . The users should learn how to use the front-end tools. Highly usable front-ends should require fairly little training. Distribute all relevant user documentation to training participants.
Load timing and publication. . Users should be informed of the schedule for warehouse loads (e.g., "the warehouse is loaded with sales data on a weekly basis, and a special month-end load is performed for the GL expense data"). Users should also know how the warehouse team intends to publish the results of each warehouse load.
Warehouse support structure. . Users should know how to get additional help from the warehousing team. Distribute Help Desk phone numbers, etc.
Training should be conducted for all intended end users of the data warehouse. Some senior managers, particularly those who do not use computers every day, may ask their assistants or secretaries to attend the training in their place. In this scenario, the senior manager should be requested to attend at least the portion of the training that deals with the warehouse scope.
An understanding of the users' computing literacy provides insight to the type and pace of training required. If the user base is large enough, it may be helpful to divide the trainees into two groups—a basic class and an advanced class. Power users will otherwise quickly become bored in a basic class, and beginners will feel overwhelmed if they are in an advanced class. Attempting to meet the training needs of both types of users in one class may prove to be difficult and frustrating.
At the end of the training, it is good practice to identify training participants who will most likely require post-training followup and support from the warehouse implementation team. Also ask participants to evaluate the warehouse training; constructive criticism will allow the trainers to deliver better training in the future.
A subset of the users will be requested to test the warehouse. This user subset may have to undergo user training earlier than others, since user training is a prerequisite to user testing. Users cannot adequately test the warehouse if they do not know what is in it or how to use it.
The data warehouse, like any system, must undergo user testing and acceptance. Some considerations are discussed below.
Representatives of the end-user community are requested to test this warehouse rollout. In general, the following aspects should be tested:
Support of specified queries and reports. . Users test the correctness of the queries and reports of this warehouse rollout. In many cases, this is achieved by preparing the same report manually (or through existing mechanisms) and comparing this report to the one produced by the warehouse. All discrepancies are accounted for, and the appropriate corrections are made. The team should not discount the possibility that the errors are in the manually prepared report.
Performance/response time. . Under the most ideal circumstances, each warehouse query will be executed in less than one or two seconds. However, this may not be realistically achievable, depending on the warehouse size (number of rows and dimensions) and the selected tools. Warehouse optimization at the hardware and database levels can be used to improve response times. The use of stored aggregates will likewise improve warehouse performance.
Usability of client front-end. . Training on the front-end tools is required, but the tools must be usable for the majority of the users.
Ability to meet report frequency requirements. . The warehouse must be able to provide the specified queries and reports at the frequency (i.e., daily, weekly, monthly, quarterly, or yearly) required by the users.
The rollout is considered accepted when the testing for this rollout is completed to the satisfaction of the user community. A concrete set of acceptance criteria can be developed at the start of the warehouse rollout for use later as the basis for acceptance. The acceptance criteria are helpful to users because they know exactly what to test. It is likewise helpful to the warehousing team because they know what must be delivered.
Data warehouse implementation is without question the most challenging part of data warehousing. Not only will the team have to resolve the technical difficulties of moving, integrating, and cleaning data, they will also face the more difficult task of addressing policy issues, resolving organizational conflicts, and untangling logistical delays.
In general, the following areas present the most problems during warehouse implementation and bear the most watching:
Dirty data. . The identification and cleanup of dirty data can easily consume more resources than the project can afford.
Underestimated logistics. . The logistics involved in warehousing typically require more time than originally expected. Tasks such as installing the development environment, collecting source data, transporting data, and loading data are generally beleaguered by logistical problems. The time required to learn and configure warehousing tools likewise contributes to delays.
Policies and political issues. . The progress of the team can slow to a crawl if a key project issue remains unresolved too long.
Wrong warehouse design. . The wrong warehouse design results in unmet user requirements or inflexible implementations. It also creates rework for the schema as well as all the back-end subsystems: extraction and transformation, quality assurance, and loading.
At the end of the project, however, a successful team has the satisfaction of meeting the information needs of key decision-makers in a manner that is unprecedented in the enterprise.