
The data warehouse planning approach presented in this chapter describes the activities related to planning one rollout of the data warehouse. The activities discussed below build on the results of the warehouse strategy formulation described in Chapter 6.
Data warehouse planning further details the preliminary scope of one warehouse rollout by obtaining detailed user requirements for queries and reports, creating a preliminary warehouse schema design to meet the user requirements, and mapping source system fields to the warehouse schema fields. By so doing, the team gains a thorough understanding of the effort required to implement that one rollout.
A planning project typically lasts between five to eight weeks, depending on the scope of the rollout. The progress of the team varies, depending (among other things) on the participation of enterprise resource persons, the availability and quality of source system documentation, and the rate at which project issues are resolved.
Upon completion of the planning effort, the team moves into data warehouse implementation for the planned rollout. The activities for data warehouse implementation are discussed in Chapter 9.
Identify all parties who will be involved in the data warehouse implementation and brief them about the project. Distribute copies of the warehouse strategy as background material for the planning activity.
Define the team setup if a formal project team structure is required. Take the time and effort to orient the team members on the rollout scope, and explain the role of each member of the team. This approach allows the project team members to set realistic expectations about skill sets, project workload, and project scope.
Assign project team members to specific roles, taking care to match skill sets to role responsibilities. When all assignments have been completed, check for unavoidable training requirements due to skill-role mismatches (i.e., the team member does not possess the appropriate skill sets to properly fulfill his or her assigned role).
If required, conduct training for the team members to ensure a common understanding of data warehousing concepts. It is easier for everyone to work together if all have a common goal and an agreed approach for attaining it. Describe the schedule of the planning project to the team. Identify milestones or checkpoints along the planning project timeline. Clearly explain dependencies between the various planning tasks.
Considering the short time frame for most planning projects, conduct status meetings at least once a week with the team and with the Project Sponsor. Clearly set objectives for each week. Use the status meeting as the venue for raising and resolving issues.
Decisional Requirements Analysis is one of two activities that can beconducted in parallel during Data Warehouse Planning; the other activity being Decisional Source System Audit (described in the nextsection). The object of Decisional Requirements Analysis is to gain a thorough understanding of the information needs of decision-makers.

Decisional requirements analysis represents the top-down aspect of data warehousing. Use the warehouse strategy results as the starting point of the decisional requirements analysis; a preliminary analysis should have been conducted as part of the warehouse strategy formulation.
Review the intended scope of this warehouse rollout as documented in the warehouse strategy document. Finalize this scope by further detailing the preliminary decisional requirements analysis. It will be necessary to revisit the user representatives. The rollout scope is typically expressed in terms of the queries or reports that are to be supported by the warehouse by the end of this rollout. The Project Sponsor must review and approve the scope to ensure that management expectations are set properly.
Document any known limitations about the source systems (e.g., poor data quality, missing data items). Provide this information to source system auditors for their confirmation. Verified limitations in source system data are used as inputs to finalizing the scope of the rollout—if the data are not available, they cannot be loaded into the warehouse.
Take note that the scope strongly influences the implementation time frame for this rollout. Too large a scope will make the project unmanageable. As a general rule, limit the scope of each project or rollout so that it can be delivered in three to six months by a full-time team of 6 to 12 team members.
It is not unusual for enterprises to go directly into warehouse planning without previously formulating a warehouse strategy. This typically happens when a group of users is clearly driving the warehouse initiative and are more than ready to participate in the initial rollout as user representatives. More often than not, these users have already taken the initiative to list and prioritize their information requirements.
In this type of situation, a number of tasks from the strategy formulation will have to be conducted as part of the planning for the first warehouse rollout. These tasks are as follows:
Determine organizational context. . An understanding of the organization is always helpful in any warehousing project, especially since organizational issues may completely derail the warehouse initiative.
Define data warehouse rollouts. . Although business users may have already predefined the scope of the first rollout, it helps the warehouse architect to know what lies ahead in subsequent rollouts.
Define data warehouse architecture. . Define the data warehouse architecture for the current rollout (and if possible, for subsequent rollouts).
Evaluate development and production environment and tools. . The strategy formulation was expected to produce a short-list of tools and computing environments for the warehouse. This evaluation will be finalized during planning by the actual selection of both environments and tools.
The decisional source system audit is a survey of all information systems that are current or potential sources of data for the data warehouse.
A preliminary source system audit during warehouse strategy formulation should provide a complete inventory of data sources. Identify all possible source systems for the warehouse if this information is currently unavailable.

Data sources are primarily internal. The most obvious candidates are the operational systems that automate the day-to-day business transactions of the enterprise. Note that aside from transactional or operational processing systems, one often-used data source is the enterprise general ledger, especially if the reports or queries focus on profitability measurements.
If external data sources are also available, these may be integrated into the warehouse.
The best resource persons for a decisional source system audit of internal systems are the database administrators (DBAs), system administrators (SAs) and other IT staff who support each internal system that is a potential source of data. With their intimate knowledge of the systems, they are in the best position to gauge the suitability of each system as a warehouse data source.
These individuals are also more likely to be familiar with any data quality problems that exist in the source systems. Clearly document any known data quality problems, as these have a bearing on the data extraction and cleansing processes that the warehouse must support. Known data quality problems also provide some indication of the magnitude of the data cleanup task.
In organizations where the production of managerial reports has already been automated (but not through an architected data warehouse), the DBAs and IT support staff can provide very valuable insight about the data that are presently collected. These staff members can also provide the team with a good idea of the business rules that are used to transform the raw data into management reports.
Conduct individual and group interviews with the IT organization to understand the data sources that are currently available. Review all available documentation on the candidate source systems. This is without doubt one of the most time-consuming and detailed tasks in data warehouse planning, especially if up-to-date documentation of the existing systems is not readily available.
As a consequence, the whole-hearted support of the IT organization greatly facilitates this entire activity.
Obtain the following documents and information if these have not yet been collected as part of the data warehouse strategy definition:
Enterprise IT architecture documentation. . This refers to all documentation that provides a bird's-eye view of the IT architecture of the enterprise, including but not limited to:
System architecture diagrams and documentation—A model of all the information systems in the enterprise and their relationships to one another.
Enterprise data model—A model of all data that currently stored or maintained by the enterprise. This may also indicate which systems support which data item.
Network architecture—A diagram showing the layout and bandwidth of the enterprise network, especially for the locations of the project team and the user representatives participating in this rollout.
User and technical manuals of each source system. . This refers to data models and schemas for all existing information systems that are candidate data sources. If extraction programs are used for ad hoc reporting, obtain documentation of these extraction programs as well. Obtain copies of all other available system documentation, whenever possible.
Database sizing. . For each source system, identify the type of database used, the typical backup size, as well as the backup format and medium. It is helpful to also know what data are actually backed up on a regular basis. This is particularly important if historical data are required in the warehouse and such data are available only in backups.
Batch window. . Determine the batch windows for each of the operational systems. Identify all batch jobs that are already performed during the batch window. Any data extraction jobs required to feed the data warehouse must be completed within the batch windows of each source system without affecting any of the existing batch jobs already scheduled. Under no circumstances will the team want to disrupt normal operations on the source systems.
Future enhancements. . What application development projects, enhancements, or acquisition plans have been defined or approved for implementation in the next 6 to 12 months, for each of the source systems? Changes to the data structure will affect the mapping of source system fields to data warehouse fields. Changes to the operational systems may also result in the availability of new data items or the loss of existing ones.
Data scope. . Identify the most important tables of each source system. This information is ideally available in the system documentation. However, if definitions of these tables are not documented, the DBAs are in the best position to provide that information. Also required are business descriptions or definitions of each field in each important table, for all source systems.
System codes and keys. . Each of the source systems no doubt uses a set of codes for the system will be implementing key generation routines as well. If these are not documented, ask the DBAs to provide a list of all valid codes and a textual description for each of the system codes that are used. If the system codes have changed over time, ask the DBAs to provide all system code definitions for the relevant time frame. All key generation routines should likewise be documented. These include rules for assigning customer numbers, product numbers, order numbers, invoice numbers, etc. Check whether the keys are reused (or recycled) for new records over the years. Reused keys may cause errors during deduplication and must therefore be thoroughly understood.
Extraction mechanisms. . Check if data can be extracted or read directly from the production databases. Relational databases such as Oracle or Sybase are open and should be readily accessible. Application packages with proprietary database management software, however, may present problems, especially if the data structures are not documented. Determine how changes made to the database are tracked, perhaps through an audit log. Determine also if there is a way to identify data that have been changed or updated. These are important inputs to the data extraction process.
Design the data warehouse schema that can best meet the information requirements of this rollout. Two main schema design techniques are available:
Normalization. . The database schema is designed using the normalization techniques traditionally used for OLTP applications;
Dimensional modeling. . This technique produces denormalized, star schema designs consisting of fact and dimension tables. A variation of the dimensional star schema also exists (i.e., snowflake schema).
There are ongoing debates regarding the applicability or suitability of both these modeling techniques for data warehouse projects, although dimensional modeling has certainly been gaining popularity in recent years. Dimensional modeling has been used successfully in large data warehousing implementations across multiple industries. The popularity of this modeling technique is also evident from the number of databases and front-end tools that now support optimized performance with star schema designs (e.g., Oracle RDBMS 8, R/olap XL).
A discussion of dimensional modeling techniques is provided in Chapter 12.
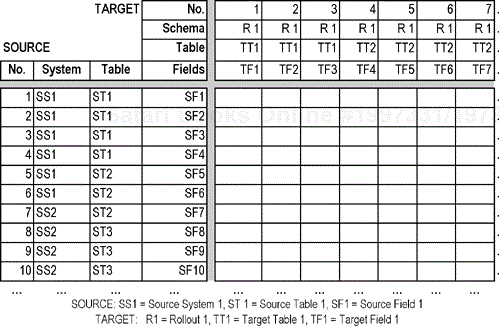
The Source-To-Target Field Mapping documents how fields in the operational (source) systems are transformed into data warehouse fields. Under no circumstances should this mapping be left vague or open to misinterpretation, especially for financial data. The mapping allows non-team members to audit the data transformations implemented by the warehouse.

A single field in the data warehouse may be populated by data from more than one source system. This is a natural consequence of the data warehouse's role of integrating data from multiple sources.
The classic examples are Customer Name and Product Name. Each operational system will typically have its own customer and product records. A data warehouse field called Customer Name or Product Name will therefore be populated by data from more than one system.
Conversely, a single field in the operational systems may need to be split into several fields in the warehouse. There are operational systems that still record addresses as lines of text, with field names like Address Line 1, Address Line 2, etc. These can be split into multiple address fields such as Street Name, City, Country, and Mail/Zip Code. Other examples are numeric figures or balances that have to be allocated correctly to two or more different fields.
To eliminate any confusion as to how data are transformed as the data items are moved from the source systems to the warehouse database, create a source-to-target field mapping that maps each source field in each source system to the appropriate target field in the data warehouse schema. Also, clearly document all business rules that govern how data values are integrated or split up. This is required for each field in the source-to-target field mapping.
The source-to-target field mapping is critical to the successful development and maintenance of the data warehouse. This mapping serves as the basis for the data extraction and transformation subsystems. Figure 8-1 shows an example of this mapping.
Revise the data warehouse schema on an as-needed basis if the field-to-field mapping yields missing data items in the source systems. These missing data items may prevent the warehouse from producing one or more of the requested queries or reports. Raise these types of scope issues as quickly as possible to the Project Sponsor.
If users require the loading of historical data into the data warehouse, two things must be determined quickly:
Changes in schema. . Determine if the schemas of all source systems have changed over the relevant time period. For example, if the retention period of the data warehouse is two years and data from the past two years have to be loaded into the warehouse, the team must check for possible changes in source system schemas over the past two years. If the schemas have changed over time, the task of extracting the data immediately becomes more complicated. Each different schema may require a different source-to-target field mapping.
Availability of historical data. . Determine also if historical data are available for loading into the warehouse. Backups during the relevant time period may not contain the required data items. Verify assumptions about the availability and suitability of backups for historical data loads.
These two tedious tasks will be more difficult to complete if documentation is out of date or insufficient and if none of the IT professionals in the enterprise today are familiar with the old schemas.
Finalize the computing environment and tool set for this rollout based on the results of the development and production environment and tools study during the data warehouse strategy definition. If an exhaustive study and selection had been performed during the strategy definition stage, this activity becomes optional.
If, on the other hand, the warehouse strategy was not formulated, the enterprise must now evaluate and select the computing environment and tools that will be purchased for the warehousing initiative. This activity may take some time, especially if the evaluation process requires extensive vendor presentations and demonstrations, as well as site visits. This activity is therefore best performed early on to allow for sufficient time to study and select the tools. Sufficient lead times are also required for the delivery (especially if importation is required) of the selected equipment and tools.
Using the short-listed or final tools and production environment, create a prototype of the data warehouse.

A prototype is typically created and presented for one or more of the following reasons:
To assist in the selection of front-end tools. . It is sometimes possible to ask warehousing vendors to present a prototype to the evaluators as part of the selection process. However, such prototypes will naturally not be very specific to the actual data and reporting requirements of the rollout.
To verify the correctness of the schema design. . The team is better served by creating a prototype using the logical and physical warehouse schema for this rollout. If possible, use actual data from the operational systems for the prototype queries and reports. If the user requirements (in terms of queries and reports) can be created using the schema, then the team has concretely verified the correctness of the schema design.
To verify the usability of the selected front-end tools. . The warehousing team can invite representatives from the user community to actually use the prototype to verify the usability of the selected front-end tools.
To obtain feedback from user representatives. . The prototype is often the first concrete output of the planning effort. It provides users with something tangible that they can see and touch. It allows users to experience for the first time the kind of computing environment they will have when the warehouse is up. Such an experience typically triggers a lot of feedback (both positive and negative) from users. It may even cause users to articulate previously unstated requirements. Regardless of the type of feedback, however, it is always good to hear what the users have to say as early as possible. This provides the team more time to adjust the approach or the design accordingly.
During the prototype presentation meeting, the following should be made clear to the business users who will be viewing or using the prototype:
Objective of the prototype meeting. . State the objectives of the meeting clearly to properly orient all participants. If the objective is to select a tool set, then the attention and focus of users should be directed accordingly.
Nature of data used. . If actual data from the operational systems are used with the prototype, make it clear to all business users that the data have not yet been integrated or cleansed or transformed. Users should understand that the data have not yet been quality assured. If dummy or test data are used, then this should be clearly communicated as well. Users who are concerned with the correctness of the prototype data have unfortunately sidetracked many prototype presentations.
Prototype scope. . If the prototype does not yet mimic all the requirements identified for this rollout, then say so. Don't wait for the users to explicitly ask whether the team has considered (or forgotten!) the requirements they had specified in earlier meetings or interviews.
With the scope now fully defined and the source-to-target field mapping fully specified, it is now possible to draft an implementation plan for this rollout. Consider the following factors when creating the implementation plan:
Number of source systems, and their related extraction mechanisms and logistics. . The more source systems there are, the more complex the extraction and integration processes will be. Also, source systems with open computing environments present fewer complications with the extraction process than do proprietary systems.
Number of decisional business processes supported. . The larger the number of decisional business processes supported by this rollout, the more users there are who will want to have a say about the data warehouse contents, the definition of terms, and the business rules that must be respected.
Number of subject areas involved. . This is a strong indicator of the rollout size. The more subject areas there are, the more fact tables will be required. This implies more warehouse fields to map to source systems and, of course, a larger rollout scope.
Estimated database size. . The estimated warehouse size provides an early indication of the loading, indexing, and capacity challenges of the warehousing effort. The database size allows the team to estimate the length of time it takes to load the warehouse regularly (given the number of records and the average length of time it takes to load and index each record).
Availability and quality of source system documentation. . A lot of the team's time will be wasted on searching for or misunderstanding the data that are available in the source systems. The availability of good-quality documentation will significantly improve the productivity of source system auditors and technical analysts.
Data quality issues and their impact on the schedule. . Unfortunately, there is no direct way to estimate the impact of data quality problems on the project schedule. Any attempts to estimate the delays often produce unrealistically low figures, much to the consternation of warehouse project managers. Early knowledge and documentation of data quality issues will help the team anticipate problems. Also, data quality is very much a user responsibility that cannot be left to IT to solve. Without sufficient user support, data quality problems will continually be a thorn in the side of the warehouse team.
Required warehouse load rate. . A number of factors external to the warehousing team (particularly batch windows of the operational systems and the average size of each warehouse load) will affect the design and approach used by the warehouse implementation team.
Required warehouse availability. . The warehouse itself will also have batch windows. The maximum allowed down time for the warehouse also influences the design and approach of the warehousing team. A fully available warehouse (24 hours × 7 days) requires an architecture that is completely different from that required by a warehouse that is available only 12 hours a day, 5 days a week. These different architectural requirements naturally result in differences in cost and implementation time frame.
Lead time for delivery and setup of selected tools, development, and production environment. . Project schedules sometimes fail to consider the length of time required to setup the development and production environments of the warehousing project. While some warehouse implementation tasks can proceed while the computing environments and tools are on their way, significant progress cannot be made until the correct environment and tool sets are available.
Time frame required for IT infrastructure upgrades. . Some IT infrastructure upgrades (e.g., network upgrade or extension) may be required or assumed by the warehousing project. These dependencies should be clearly marked on the project schedule. The warehouse Project Manager must coordinate with the infrastructure Project Manager to ensure that sufficient communication exists between all concerned teams.
Business sponsor support and user participation. . There is no way to overemphasize the importance of Project Sponsor support and end user participation. No amount of planning by the warehouse Project Manager (and no amount of effort by the warehouse project team) can make up for the lack of participation by these two parties.
IT support and participation. . Similarly, the support and participation of the database administrators and system administrators will make a tremendous difference to the overall productivity of the warehousing team.
Required vs. existing skill sets. . The match (or mismatch) of personnel skill sets and role assignments will likewise affect the productivity of the team. If this is an early or pilot project, then training on various aspects of warehousing will most likely be required. These training sessions should be factored into the implementation schedule as well and, ideally, should take place before the actual skills are required.
The actual data warehouse planning activity will rarely be a straightforward exercise. Before conducting your planning activity, read through this section for planning tips and caveats.
In the absence of true decision support systems, enterprises have, over the years, been forced to find stopgap or interim solutions for producing the managerial or decisional reports that decision-makers require. Some of these solutions require only simple extraction programs that are regularly run to produce the required reports. Other solutions require a complex series of steps that combine manual data manipulation, extraction programs, conversion formulas, and spreadsheet macros.
In the absence of a data warehouse, many of the managerial reporting requirements are classified as ad hoc reports. As a result, most of these report generation programs and processes are largely undocumented and are known only by the people who actually produce the reports. This naturally leads to a lack of standards (i.e., different people may apply different formulas and rules to the same data item), and possible inconsistencies each time the process is executed. Fortunately, the warehouse project team will be in a position to introduce standards and consistent ways of manipulating data.
Following the data trail (see Figure 8-2) from the current management reports, back to their respective data sources can prove to be a very enlightening exercise for Data Warehouse Planners.
Through this exercise, the data warehouse planner will find:
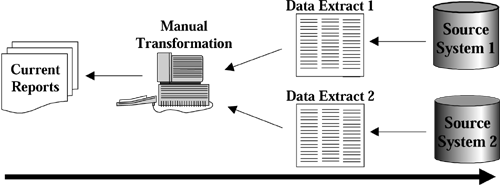
All data sources currently used for decisional reporting. . At the very least, these data sources should also be included in the decisional source system audit. The team has the added benefit of knowing beforehand which fields in these systems are considered important.
All current extraction programs. . The current extraction programs are a rich input for the source-to-target field mapping. Also, if these programs manipulate or transform or convert the data in any way, the transformation rules and formulas may also prove helpful to the warehousing effort.
All undocumented manual steps to transform the data. . After the raw data have been extracted from the operational systems, a number of manual steps may be performed to further transform the data into the reports that enterprise managers currently use. Interviews with the appropriate persons should provide the team with an understanding of these manual conversion and transformation steps (if any).
Aside from the above items, it is also likely that the data warehouse planner will find subtle flaws in the way reports are produced today. It is not unusual to find inconsistent use of business terms, formulas, and business rules, depending on the person who creates and reads the reports. This lack of standard terms and rules contributes directly to the existence of conflicting reports from different groups in the same enterprise, i.e., the existence of "different versions of the truth."
Each data item that is required to produce the reports required by decision-makers comes from one or more of the source systems available to the enterprise. Understandably, there will be data items that are not readily supported by the source systems.
Data limitations generally fall into one of the following types.
Missing Data Items. . A data item is considered missing, if no provisions were made to collect or store this data item any of the source systems. This omission particularly occurs with data items that may have no bearing on the day-to day operations of the enterprise but will have tactical or managerial implications.
For example, not all loan systems record the industry to which each loan customer belongs; from an operational level, such information may not necessarily be considered critical. Unfortunately, a bank that wishes to track its risk exposure for any given industry will not be able to produce an industry exposure report if customer industry data are not available at the source systems.
Incomplete (Optional) Data Items. . A data item may be classified as "nice to have" in the operational systems, and so provisions are made to store the data, but no rules are put in place to enforce the collection of such data. These optional data items are available for some customers products, accounts, or orders but may be unavailable for others.
Returning to the above example, a loan system may have a field called Customer Industry, but the application developers may have made the field optional, in recognition of the fact that data about a customer's industry are not readily available. In cases such as this, only a partial industry exposure report can be produced, i.e., only customers with actual data can be classified meaningfully in the report.
Wrong Data. . Errors occur when data are stored in one or more source systems but are not accurate. There are many potential reasons or causes for this, including the following ones:
Data entry error. . A genuine error is made during data entry. The wrong data are stored in the database.
Data item is mandatory but unavailable. . A data item may be defined as mandatory but it may not be readily available, and the random substitution of other information has no direct impact on the day-to-day operations of the enterprise. This implies that any data can be entered without adversely affecting the operational processes.
Returning to the above example, if Customer Industry was a mandatory customer data item and the person creating the customer record does not know the industry to which the customer belongs, he is likely to select, at random, any of the industry codes that are recognized by the system. Only by so doing will he or she be able to create the customer record.
Another data item that can be randomly substituted is the social security number, especially if these numbers are stored for reference purposes only, and not for actual processing. Data entry personnel remain focused on the immediate task of creating the customer record—which the system refuses to do without all the mandatory data items. Data entry personnel are rarely in a position to see the consequences of recording the wrong data.
From the above examples, it is easy to see how the scope of a data warehousing initiative can be severely compromised by data limitations in the source systems. Most pilot data warehouse projects are thus limited only to the data that are available. However, improvements can be made to the source systems in parallel with the warehousing projects. The team should therefore properly document any source system limitations that are encountered. These documents can be used as inputs to upcoming maintenance projects on the operational systems.
A decisional source system audit report may have a source system review section that covers the following topics:
Overview of operational systems. . This section lists all operational systems covered by the audit. A general description of the functionality and data of each operational system is provided. A list of major tables and fields may be included as an appendix. Current users of each of the operational systems are optionally documented.
Missing data items. . List all the data items that are required by the data warehouse but are currently not available in the source systems. Explain why each item is important (e.g., cite reports or queries where these data items are required). For each data item, identify the source system where the data item is best stored.
Data quality improvement areas. . For each operational system, list all areas where the data quality can be improved. Suggestions as to how the data quality improvement can be achieved can also be provided.
Resource and effort estimate. . For each operational system, it might be possible to provide an estimate or the cost and length of time required to either add the data item or improve the data quality for that data item.
Data warehouse planning is conducted to clearly define the scope of one data warehouse rollout. The combination of the top-down and bottom-up tracks gives the planning process the best of both worlds—a requirements-driven approach that is grounded on available data.
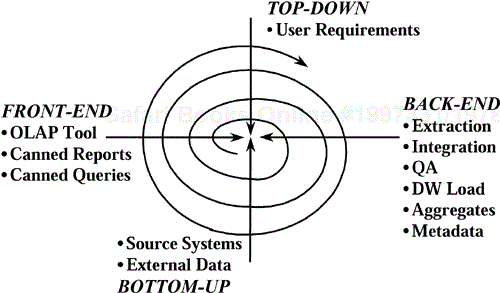
The clear separation of the front-end and back-end tracks encourages the development of warehouse subsystems for extracting, transporting, cleaning, and loading warehouse data independently of the front-end tools that will be used to access the warehouse.
The four tracks converge when a prototype of the warehouse is created and when actual warehouse implementation takes place.
Each rollout repeatedly executes the four tracks (top-down, bottom-up, back-end and front-end), and the scope of the data warehouse is iteratively extended as a result. Figure 8-3 illustrates the concept.