
11 Web services
- Representing a client request as a map
- Representing a server response as a map
- Passing data forward
- Combining data from different sources
The architecture of modern information systems is made of software components written in various programming languages like JSON, which communicate over the wire by sending and receiving data represented in a language-independent data exchange format. DOP applies the same principle to the communication between inner parts of a program.
►Note When a web browser sends a request to a web service, it’s quite common that the web service itself sends requests to other web services in order to fulfill the web browser request. One popular data exchange format is JSON.
Inside a program, components communicate by sending and receiving data represented in a component independent format—namely, immutable data collections. In the context of a web service that fulfills a client request by fetching data from a database and other web services, representing data, as with immutable data collections, leads to these benefits:
11.1 Another feature request
After having delivered the database milestone on time, Theo calls Nancy to share the good news. Instead of celebrating Theo’s success, Nancy asks him about the ETA for the next milestone, Book Information Enrichment with the Open Library Books API. Theo tells her that he’ll get back to her with an ETA by the end of the day. When Joe arrives at the office, Theo tells him about the discussion with Nancy.
THEO I just got a phone call from Nancy, and she is stressed about the next milestone.
JOE What’s in the next milestone?
THEO Do you remember the Open Library Books API that I told you about a few weeks ago?
►Note You can find the Open Library Books API at https://openlibrary.org/dev/docs/api/books.
THEO It’s a web service that provides detailed information about books.
THEO Nancy wants to enrich the book search results. Instead of fetching book information from the database, we need to retrieve extended book information from the Open Library Books API.
JOE What kind of book information?
THEO Everything! Number of pages, weight, physical format, topics, etc... .
JOE What about the information from the database?
THEO Besides the information about the availability of the books, we don’t need it anymore.
JOE Have you already looked at the Open Library Books API?
THEO It’s a nightmare! For some books, the information contains dozen of fields, and for other books, it has only two or three fields.
THEO I have no idea how to represent data that is so sparse and unpredictable.
JOE When we represent data as data, that’s not an issue. Let’s have a coffee and I’ll show you.
11.2 Building the insides like the outsides
While Theo drinks his macchiato, Joe draws a diagram on a whiteboard. Figure 11.1 shows Joe’s diagram.

JOE Before we dive into the details of the implementation of the book search result enrichment, let me give you a brief intro.
Joe takes a sip of his espresso. He then points to the diagram (figure 11.1) on the whiteboard.
JOE Does this look familiar to you?
JOE Can you show me, roughly, the steps in the data flow of a web service?
Theo moves closer to the whiteboard. He writes a list of steps (see the sidebar) near the architecture diagram.
JOE Excellent! Now comes an important insight about DOP.
JOE We should build the insides of our systems like we build the outsides.
JOE How do components of a system communicate over the wire?
JOE Does the data format depend on the programming language of the components?
THEO No, quite often it’s JSON, for which we have parsers in all programming languages.
JOE What the idiom says is that, inside our program, the inner components of a program should communicate in a way that doesn’t depend on the components.
JOE Let me explain why traditional OOP breaks this idiom. Perhaps it will be clearer then. When data is represented with classes, the inner components of a program need to know the internals of the class definitions in order to communicate.
JOE In order to be able to access a member in a class, a component needs to import the class definition.
THEO How could it be different?
JOE In DOP, as we have seen so far, the inner components of a program communicate via generic data collections. It’s similar to how components of a system communicate over the wire.
?Tip We should build the insides of our systems like we build the outsides.
THEO Why is that so important?
JOE From a design perspective, it’s important because it means that the inner components of a program are loosely coupled.
THEO What do you mean by loosely coupled?
JOE I mean that components need no knowledge about the internals of other components. The only knowledge required is the names of the fields.
?Tip In DOP, the inner components of a program are loosely coupled.
THEO And from an implementation perspective?
JOE As you’ll see in a moment, implementing the steps of the data flow that you just wrote on the whiteboard is easy. It comes down to expressing the business logic in terms of generic data manipulation functions. Here, let me show you a diagram.
Joe steps up to the whiteboard and sketches the drawing in figure 11.2. As Joe finishes, his cell phone rings. He excuses himself and steps outside to take the call.

Theo stands alone for a few minutes in front of the whiteboard, meditating about “building the insides of our systems like we build the outsides.” Without really noticing it, he takes a marker and starts drawing a new diagram (see figure 11.3), which summarizes the insights that Joe just shared with him.
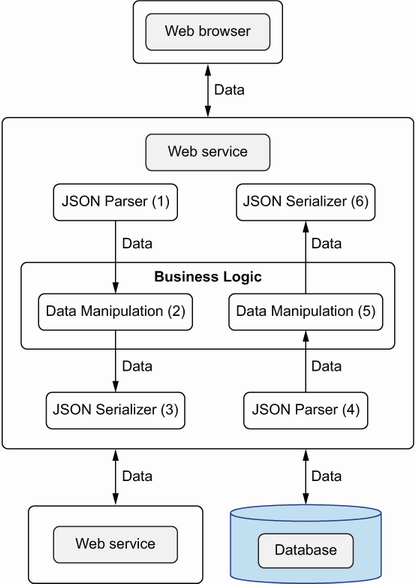
Figure 11.3 Building the insides of our systems like building the outsides. The inner components of a web service communicate with data. As an example, here is a typical flow of a web service handling a client request: (1) Parse the client JSON request into data. (2) Manipulate data according to business logic. (3) Serialize data into a JSON request to a database and another Web service. (4) Parse JSON responses into data. (5) Manipulate data according to business logic. (6) Serialize data into a JSON response to the client.
11.3 Representing a client request as a map
After a few minutes, Joe comes back. When he looks at Theo’s new drawing in figure 11.3, he seems satisfied.
JOE Sorry for the interruption. Let’s start from the beginning—parsing a client request. How do you usually receive the parameters of a client request?
THEO It depends. The parameters could be sent as URL query parameters in a GET request or as a JSON payload in the body of a POST request.
JOE Let’s suppose we receive a JSON payload inside a web request. Can you give me an example of a JSON payload for an advanced search request?
THEO It would contain the text that the book title should match.
JOE And what are the details about the fields to retrieve from the Open Library Books API?
THEO They won’t be passed as part of the JSON payload because they’re the same for all search requests.
JOE I can imagine a scenario where you want the client to decide what fields to retrieve. For instance, a mobile client would prefer to retrieve only the most important fields and save network bandwidth.
THEO Well, in that case, I would have two different search endpoints: one for mobile and one for desktop.
JOE What about situations where the client wants to display different pieces of information, depending on the application screen. For instance, in an extended search result screen, we display all the fields. In a basic search result screen, we display only the most important fields. Now you have four different use cases: desktop extended, desktop basic, mobile extended, and mobile basic. Would you create four different endpoints?
THEO OK, you’ve convinced me. Let’s have a single search endpoint and let the client decide what fields to retrieve.
JOE Can you show me an example of a JSON payload for a search request?
Because there’s not much code, Theo writes the search request on the whiteboard. It takes very little time to show how the clients would decide on what fields to retrieve for each search result.
Listing 11.1 Example of the search request payload
JOE Excellent! Now, the first step is to parse the JSON string into a data structure.
THEO Let me guess, it’s going to be a generic data structure.
JOE Of course! In that case, we’ll have a map. Usually, JSON parsing is handled by the web server framework, but I’m going to show you how to do it manually.
THEO Wait! What do you mean by the web server framework?
JOE Stuff like Express in Node.js, Spring in Java, Django in Python, Ruby on Rails, ASP.net in C#, and so forth.
THEO Oh, I see. So, how do you manually parse a JSON string into a map?
JOE In JavaScript, we use JSON.parse. In Java, we use a third-party library like Gson (https://github.com/google/gson), maintained by Google.
Joe opens his laptop and writes two code fragments, one in JavaScript and the other in Java with Gson. When he’s done, he shows the code to Theo.
Listing 11.2 Parsing a JSON string in JavaScript
var jsonString = '{"title":"habit","fields":["title","weight","number_of_pages"]}'; JSON.parse(jsonString);
Listing 11.3 Parsing a JSON string in Java with Gson
var jsonString = '{"title":"habit","fields":["title","weight","number_of_pages"]}'; gson.fromJson(jsonString, Map.class);
JOE Can you write the JSON schema for the payload of a search request?
THEO Sure. It would look something like this.
Listing 11.4 The JSON schema for a search request
var searchBooksRequestSchema = { "type": "object", "properties": { "title": {"type": "string"}, "fields": { "type": "array", "items": { "enum": [ "title", "full_title", "subtitle", "publisher", "publish_date", "weight", "physical_dimensions", "number_of_pages", "subjects", "publishers", "genre" ] } } }, "required": ["title", "fields"] };
JOE Nice! You marked the elements in the fields array as enums and not as strings. Where did you get the list of allowed values?
THEO Nancy gave me the list of the fields that she wants to expose to the users. Here, let me show you her list.
Listing 11.5 The important fields from the Open Library Books API
- title - full_title - subtitle - publisher - publish_date - weight - physical_dimensions - number_of_pages - subjects - publishers - genre
11.4 Representing a server response as a map
JOE What does the Open Library Books API look like?
THEO It’s quite straightforward. We create a GET request with the book ISBN, and it gives us a JSON string with extended information about the book. Take a look at this.
When Theo executes the code snippet, it displays a JSON string with the extended information about 7 Habits of Highly Effective People.
Listing 11.6 Fetching data from the Open Library Books API
fetchAndLog( "https:/ /openlibrary.org/isbn/978-1982137274.json" ); ❶ //{ // "authors": [ // { // "key": "/authors/OL383159A", // }, // { // "key": "/authors/OL30179A", // }, // { // "key": "/authors/OL1802361A", // }, // ], // "created": { // "type": "/type/datetime", // "value": "2020-08-17T14:26:27.274890", // }, // "full_title": "7 Habits of Highly Effective // People : Revised and Updated Powerful // Lessons in Personal Change", // "isbn_13": [ // "9781982137274", // ], // "key": "/books/OL28896586M", // "languages": [ // { // "key": "/languages/eng", // }, // ], // "last_modified": { // "type": "/type/datetime", // "value": "2021-09-08T19:07:57.049009", // }, // "latest_revision": 3, // "lc_classifications": [ // "", // ], // "number_of_pages": 432, // "publish_date": "2020", // "publishers": [ // "Simon & Schuster, Incorporated", // ], // "revision": 3, // "source_records": [ // "bwb:9781982137274", // ], // "subtitle": "Powerful Lessons in Personal Change", // "title": "7 Habits of Highly Effective // People : Revised and Updated", // "type": { // "key": "/type/edition", // }, // "works": [ // { // "key": "/works/OL2629977W", // }, // ], //}
❶ A utility function that fetches JSON and displays it to the console
JOE Did Nancy ask for any special treatment of the fields returned by the API?
THEO Nothing special besides keeping only the fields I showed you.
THEO Yes. For example, here’s the JSON string returned by the Open Library Books API for 7 Habits of Highly Effective People after having kept only the necessary fields.
Listing 11.7 Open Library response for 7 Habits of Highly Effective People
{ "title":"7 Habits of Highly Effective People : Revised and Updated", "subtitle":"Powerful Lessons in Personal Change", "number_of_pages":432, "full_title":"7 Habits of Highly Effective People : Revised and Updated Powerful Lessons in Personal Change", "publish_date":"2020", "publishers":["Simon & Schuster, Incorporated"] }
THEO Also, Nancy wants us to keep only the fields that appear in the client request.
JOE Do you know how to implement the double field filtering?
THEO Yeah, I’ll parse the JSON string from the API into a hash map, like we parsed a client request, and then I’ll use _.pick twice to keep only the required fields.
JOE It sounds like a great plan to me. Can you code it, including validating the data that is returned by the Open Library API?
THEO Sure! Let me first write the JSON schema for the Open Library API response.
Theo needs to refresh his memory with the materials about schema composition in order to express the fact that either isbn_10 or isbn_13 are mandatory. After a few moments, he shows the JSON schema to Joe.
Listing 11.8 The JSON schema for the Open Library Books API response
var basicBookInfoSchema = { "type": "object", "required": ["title"], "properties": { "title": {"type": "string"}, "publishers": { "type": "array", "items": {"type": "string"} }, "number_of_pages": {"type": "integer"}, "weight": {"type": "string"}, "physical_format": {"type": "string"}, "subjects": { "type": "array", "items": {"type": "string"} }, "isbn_13": { "type": "array", "items": {"type": "string"} }, "isbn_10": { "type": "array", "items": {"type": "string"} }, "publish_date": {"type": "string"}, "physical_dimensions": {"type": "string"} } }; var mandatoryIsbn13 = { "type": "object", "required": ["isbn_13"] }; var mandatoryIsbn10 = { "type": "object", "required": ["isbn_10"] }; var bookInfoSchema = { "allOf": [ basicBookInfoSchema, { "anyOf": [mandatoryIsbn13, mandatoryIsbn10] } ] };
THEO Now, assuming that I have a fetchResponseBody function that sends a request and retrieves the body of the response as a string, let me code up the how to do the retrieval. Give me a sec.
Theo types away in his IDE for several minutes. He shows the result to Joe.
Listing 11.9 Retrieving book information from the Open Library Books API
var ajv = new Ajv({allErrors: true}); class OpenLibraryDataSource { static rawBookInfo(isbn) { var url = `https:/ /openlibrary.org/isbn/${isbn}.json`; var jsonString = fetchResponseBody(url); ❶ return JSON.parse(jsonString); } static bookInfo(isbn, requestedFields) { var relevantFields = ["title", "full_title", "subtitle", "publisher", "publish_date", "weight", "physical_dimensions", "genre", "subjects", "number_of_pages"]; var rawInfo = rawBookInfo(isbn); if(!ajv.validate(bookInfoSchema, rawInfo)) { var errors = ajv.errorsText(ajv.errors); throw "Internal error: Unexpected result from Open Books API: " + errors; } var relevantInfo = _.pick(_.pick(rawInfo, relevantFields), requestedFields); return _.set(relevantInfo, "isbn", isbn); } }
❶ Fetches JSON in the body of a response
►Note The JavaScript snippets of this chapter are written as if JavaScript were dealing with I/O in a synchronous way. In real life, we need to use async and await around I/O calls.
JOE Looks good! But why did you add the isbn field to the map returned by bookInfo?
THEO It will allow me to combine information from two sources about the same book.
11.5 Passing information forward
JOE If I understand it correctly, the program needs to combine two kinds of data: basic book information from the database and extended book information from the Open Library API. How are you going to combine them into a single piece of data in the response to the client?
THEO In traditional OOP, I would create a specific class for each type of book information.
THEO You know, I’d have classes like DBBook, OpenLibraryBook, and CombinedBook.
THEO But that won’t work because we decided to go with a dynamic approach, where the client decides what fields should appear in the response.
JOE True, and classes don’t bring any added value because we need to pass data forward. Do you know the story of the guy who asked his friend to bring flowers to his fiancée?
Joe takes a solemn position as if to speak before a gathering of peers. With a deep breath, he tells Theo the following story. Entranced, Theo listens carefully.
THEO That doesn’t make any sense! Why would Willy have to read the letter in order to fulfill his duty?
JOE That’s exactly the point of the story! In a sense, traditional OOP is like Hugo’s friend, Willy. In order to pass information forward, OOP developers think they need to “open the letter” and represent information with specific classes.
THEO Oh, I see. And DOP developers emulate the spirit of what Hugo expected from a delivery person; they just pass information forward as generic data structures.
THEO That’s a subtle but funny analogy.
JOE Let’s get back to the question of combining data from the database with data from the Books API. There are two ways to do this—nesting and merging.
Joe goes to the whiteboard. He finds an area to draw table 11.1 for Theo.
Table 11.1 Two ways to combine hash maps
JOE In nesting, we add a field named extendedInfo to the information fetched from the Open Library API.
THEO I see. And what about merging?
JOE In merging, we combine the fields of both maps into a single map.
THEO If there are fields with the same name in both maps, what then?
JOE Then you have a merge conflict, and you need to decide how to handle the conflict. That’s the drawback of merging.
►Note When merging maps, we need to think about the occurrences of conflicting fields.
THEO Hopefully, in the context of extended search results, the maps don’t have any fields in common.
THEO Would I need to write custom code for merging two maps?
JOE No! As you might remember from one of our previous sessions, Lodash provides a handy _.merge function.
►Note _.merge was introduced in chapter 5.
THEO Could you refresh my memory?
JOE Sure. Show me an example of maps with data from the database and data from the Open Library Books API, and I’ll show you how to merge them.
THEO From the database, we get only two fields: isbn and available. From the Open Library API, we get six fields. Here’s what they look like.
Listing 11.10 A map with book information from the database
Listing 11.11 A map with book information from the Open Library Books API
var dataFromOpenLib = { "title":"7 Habits of Highly Effective People : Revised and Updated", "subtitle":"Powerful Lessons in Personal Change", "number_of_pages":432, "full_title":"7 Habits of Highly Effective People : Revised and Updated Powerful Lessons in Personal Change", "publish_date":"2020", "publishers":["Simon & Schuster, Incorporated"] };
JOE After calling _.merge, the result is a map with fields from both maps.
Listing 11.12 Merging two maps
_.merge(dataFromDb, dataFromOpenLib); //{ // "available": true, // "full_title": "7 Habits of Highly Effective People : // Revised and Updated Powerful Lessons in Personal Change", // "isbn": "978-1982137274", // "number_of_pages": 432, // "publish_date": "2020", // "publishers": [ "Simon & Schuster, Incorporated"], // "subtitle": "Powerful Lessons in Personal Change", // "title": "7 Habits of Highly Effective People : Revised and Updated" //}
THEO Let me code the JSON schema for the search books response. Here’s how that would look.
Listing 11.13 JSON schema for search books response
var searchBooksResponseSchema = { "type": "object", "required": ["title", "isbn", "available"], "properties": { "title": {"type": "string"}, "available": {"type": "boolean"}, "publishers": { "type": "array", "items": {"type": "string"} }, "number_of_pages": {"type": "integer"}, "weight": {"type": "string"}, "physical_format": {"type": "string"}, "subjects": { "type": "array", "items": {"type": "string"} }, "isbn": {"type": "string"}, "publish_date": {"type": "string"}, "physical_dimensions": {"type": "string"} } };
THEO Yes! I think we now have all the pieces to enrich our search results.
11.6 Search result enrichment in action
JOE Can you write the steps of the enrichment data flow?
Theo goes to the whiteboard. He takes a moment to gather his thoughts, and then erases enough space so there’s room to list the steps.
JOE Perfect! Would you like to try to implement it?
THEO I think I’ll start with the implementation of the book retrieval from the database. It’s quite similar to what we did last month.
►Note See chapter 10 for last month’s lesson.
JOE Actually, it’s even simpler because you don’t need to join tables.
THEO That’s right, I need values only for the isbn and available columns.
Theo works for a bit in his IDE. He begins with the book retrieval from the database.
Listing 11.14 Retrieving books whose title matches a query
var dbSearchResultSchema = { "type": "array", "items": { "type": "object", "required": ["isbn", "available"], "properties": { "isbn": {"type": "string"}, "available": {"type": "boolean"} } } }; class CatalogDB { static matchingBooks(title) { var matchingBooksQuery = ` SELECT isbn, available FROM books WHERE title = like '%$1%'; `; var books = dbClient.query(catalogDB, matchingBooksQuery, [title]); if(!ajv.validate(dbSearchResultSchema, books)) { var errors = ajv.errorsText(ajv.errors); throw "Internal error: Unexpected result from the database: " + errors; } return books; } }
THEO Next, I’ll go with the implementation of the retrieval of book information from Open Library for several books. Unfortunately, the Open Library Books API doesn’t support querying several books at once. I’ll need to send one request per book.
JOE That’s a bit annoying. Let’s make our life easier and pretend that _.map works with asynchronous functions. In real life, you’d need something like Promise .all in order to send the requests in parallel and combine the responses.
THEO OK, then it’s quite straightforward. I’ll take the book retrieval code and add a multipleBookInfo function that maps over bookInfo.
Theo looks over the book retrieval code in listing 11.9 and then concentrates as he types into his IDE. When he’s done, he shows the result in listing 11.15 to Joe.
Listing 11.15 Retrieving book information from Open Library for several books
class OpenLibraryDataSource { static rawBookInfo(isbn) { var url = `https:/ /openlibrary.org/isbn/${isbn}.json`; var jsonString = fetchResponseBody(url); return JSON.parse(jsonString); } static bookInfo(isbn, requestedFields) { var relevantFields = ["title", "full_title", "subtitle", "publisher", "publish_date", "weight", "physical_dimensions", "genre", "subjects", "number_of_pages"]; var rawInfo = rawBookInfo(isbn); if(!ajv.validate(dbSearchResultSchema, bookInfoSchema)) { var errors = ajv.errorsText(ajv.errors); throw "Internal error: Unexpected result from Open Books API: " + errors; } var relevantInfo = _.pick(_.pick(rawInfo, relevantFields), requestedFields); return _.set(relevantInfo, "isbn", isbn); } static multipleBookInfo(isbns, fields) { return _.map(function(isbn) { return bookInfo(isbn, fields); }, isbns); } }
JOE Nice! Now comes the fun part: combining information from several data sources.
THEO Yeah. I have two arrays in my hands: one with book information from the database and one with book information from Open Library. I somehow need to join the arrays, but I’m not sure I can assume that the positions of the book information are the same in both arrays.
JOE What would you like to have in your hands?
THEO I wish I had two hash maps.
JOE And what would the keys in the hash maps be?
JOE Well, I have good news for you: your wish is granted!
JOE Lodash provides a function named _.keyBy that transforms an array into a map.
THEO I can’t believe it. Can you show me an example?
JOE Sure. Let’s call _.keyBy on an array with two books.
Listing 11.16 Transforming an array into a map with _.keyBy
var books = [ { "title": "7 Habits of Highly Effective People", "isbn": "978-1982137274", "available": true }, { "title": "The Power of Habit", "isbn": "978-0812981605", "available": false } ]; _.keyBy(books, "isbn");
Listing 11.17 The result of keyBy
{ "978-0812981605": { "available": false, "isbn": "978-0812981605", "title": "The Power of Habit" }, "978-1982137274": { "available": true, "isbn": "978-1982137274", "title": "7 Habits of Highly Effective People" } }
JOE Don’t exaggerate, my friend; _.keyBy is quite similar to _.groupBy. The only difference is that _.keyBy assumes that there’s only one element in each group.
THEO I think that, with _.keyBy, I’ll be able to write a generic joinArrays function.
JOE I’m glad to see you thinking in terms of implementing business logic through generic data manipulation functions.
?Tip Many parts of the business logic can be implemented through generic data manipulation functions.
THEO The joinArrays function needs to receive the arrays and the field name for which we decide the two elements that need to be combined, for instance, isbn.
JOE Remember, in general, it’s not necessarily the same field name for both arrays.
THEO Right, so joinArrays needs to receive four arguments: two arrays and two field names.
JOE Go for it! And, please, write a unit test for joinArrays.
Theo works for a while and produces the code in listing 11.18. He then types the unit test in listing 11.19.
Listing 11.18 A generic function for joining arrays
function joinArrays(a, b, keyA, keyB) { var mapA = _.keyBy(a, keyA); var mapB = _.keyBy(b, keyB); var mapsMerged = _.merge(mapA, mapB); return _.values(mapsMerged); }
Listing 11.19 A unit test for joinArrays
var dbBookInfos = [ { "isbn": "978-1982137274", "title": "7 Habits of Highly Effective People", "available": true }, { "isbn": "978-0812981605", "title": "The Power of Habit", "available": false } ]; var openLibBookInfos = [ { "isbn": "978-0812981605", "title": "7 Habits of Highly Effective People", "subtitle": "Powerful Lessons in Personal Change", "number_of_pages": 432, }, { "isbn": "978-1982137274", "title": "The Power of Habit", "subtitle": "Why We Do What We Do in Life and Business", "subjects": [ "Social aspects", "Habit", "Change (Psychology)" ], } ]; var joinedArrays = [ { "available": true, "isbn": "978-1982137274", "subjects": [ "Social aspects", "Habit", "Change (Psychology)", ], "subtitle": "Why We Do What We Do in Life and Business", "title": "The Power of Habit", }, { "available": false, "isbn": "978-0812981605", "number_of_pages": 432, "subtitle": "Powerful Lessons in Personal Change", "title": "7 Habits of Highly Effective People", }, ] _.isEqual(joinedArrays, joinArrays(dbBookInfos, openLibBookInfos, "isbn", "isbn"));
JOE Excellent! Now, you are ready to adjust the last piece of the extended search result endpoint.
THEO That’s quite easy. We fetch data from the database and from Open Library and join them.
Theo works quite rapidly. He then shows Joe the code.
Listing 11.20 Search books and enriched book information
class Catalog { static enrichedSearchBooksByTitle(searchPayload) { if(!ajv.validate(searchBooksRequestSchema, searchPayload)) { var errors = ajv.errorsText(ajv.errors); throw "Invalid request:" + errors; } var title = _.get(searchPayload, "title"); var fields = _.get(searchPayload, "fields"); var dbBookInfos = CatalogDataSource.matchingBooks(title); var isbns = _.map(dbBookInfos, "isbn"); var openLibBookInfos = OpenLibraryDataSource.multipleBookInfo(isbns, fields); var res = joinArrays(dbBookInfos, openLibBookInfos); if(!ajv.validate(searchBooksResponseSchema, request)) { var errors = ajv.errorsText(ajv.errors); throw "Invalid response:" + errors; } return res; } }
Now comes the tricky part. Theo takes a few moments to meditate about the simplicity of the code that implements the extended search endpoint. He thinks about how classes are much less complex when we use them only to aggregate stateless functions that operate on similar domain entities and then goes to work plotting the code.
Listing 11.21 Schema for the extended search endpoint (Open Books API part)
var basicBookInfoSchema = { "type": "object", "required": ["title"], "properties": { "title": {"type": "string"}, "publishers": { "type": "array", "items": {"type": "string"} }, "number_of_pages": {"type": "integer"}, "weight": {"type": "string"}, "physical_format": {"type": "string"}, "subjects": { "type": "array", "items": {"type": "string"} }, "isbn_13": { "type": "array", "items": {"type": "string"} }, "isbn_10": { "type": "array", "items": {"type": "string"} }, "publish_date": {"type": "string"}, "physical_dimensions": {"type": "string"} } }; var mandatoryIsbn13 = { "type": "object", "required": ["isbn_13"] }; var mandatoryIsbn10 = { "type": "object", "required": ["isbn_10"] }; var bookInfoSchema = { "allOf": [ basicBookInfoSchema, { "anyOf": [mandatoryIsbn13, mandatoryIsbn10] } ] };
Listing 11.22 Extended search endpoint (Open Books API part)
var ajv = new Ajv({allErrors: true}); class OpenLibraryDataSource { static rawBookInfo(isbn) { var url = `https:/ /openlibrary.org/isbn/${isbn}.json`; var jsonString = fetchResponseBody(url); return JSON.parse(jsonString); } static bookInfo(isbn, requestedFields) { var relevantFields = ["title", "full_title", "subtitle", "publisher", "publish_date", "weight", "physical_dimensions", "genre", "subjects", "number_of_pages"]; var rawInfo = rawBookInfo(isbn); if(!ajv.validate(bookInfoSchema, rawInfo)) { var errors = ajv.errorsText(ajv.errors); throw "Internal error: Unexpected result from Open Books API: " + errors; } var relevantInfo = _.pick( _.pick(rawInfo, relevantFields), requestedFields); return _.set(relevantInfo, "isbn", isbn); } static multipleBookInfo(isbns, fields) { return _.map(function(isbn) { return bookInfo(isbn, fields); }, isbns); } }
Listing 11.23 Extended search endpoint (database part)
var dbClient; var dbSearchResultSchema = { "type": "array", "items": { "type": "object", "required": ["isbn", "available"], "properties": { "isbn": {"type": "string"}, "available": {"type": "boolean"} } } }; class CatalogDB { static matchingBooks(title) { var matchingBooksQuery = ` SELECT isbn, available FROM books WHERE title = like '%$1%'; `; var books = dbClient.query(catalogDB, matchingBooksQuery, [title]); if(!ajv.validate(dbSearchResultSchema, books)) { var errors = ajv.errorsText(ajv.errors); throw "Internal error: Unexpected result from the database: " + errors; } return books; } }
Listing 11.24 Schema for the implementation of the extended search endpoint
var searchBooksRequestSchema = { "type": "object", "properties": { "title": {"type": "string"}, "fields": { "type": "array", "items": { "type": [ "title", "full_title", "subtitle", "publisher", "publish_date", "weight", "physical_dimensions", "number_of_pages", "subjects", "publishers", "genre" ] } } }, "required": ["title", "fields"] }; var searchBooksResponseSchema = { "type": "object", "required": ["title", "isbn", "available"], "properties": { "title": {"type": "string"}, "available": {"type": "boolean"}, "publishers": { "type": "array", "items": {"type": "string"} }, "number_of_pages": {"type": "integer"}, "weight": {"type": "string"}, "physical_format": {"type": "string"}, "subjects": { "type": "array", "items": {"type": "string"} }, "isbn": {"type": "string"}, "publish_date": {"type": "string"}, "physical_dimensions": {"type": "string"} } };
Listing 11.25 Schema for the extended search endpoint (combines the pieces)
class Catalog { static enrichedSearchBooksByTitle(request) { if(!ajv.validate(searchBooksRequestSchema, request)) { var errors = ajv.errorsText(ajv.errors); throw "Invalid request:" + errors; } var title = _.get(request, "title"); var fields = _.get(request, "fields"); var dbBookInfos = CatalogDataSource.matchingBooks(title); var isbns = _.map(dbBookInfos, "isbn"); var openLibBookInfos = OpenLibraryDataSource.multipleBookInfo(isbns, fields); var response = joinArrays(dbBookInfos, openLibBookInfos); if(!ajv.validate(searchBooksResponseSchema, request)) { var errors = ajv.errorsText(ajv.errors); throw "Invalid response:" + errors; } return response; } } class Library { static searchBooksByTitle(payloadBody) { var payloadData = JSON.parse(payloadBody); var results = Catalog.searchBooksByTitle(payloadData); return JSON.stringify(results); } }
?Tip Classes are much less complex when we use them as a means to aggregate stateless functions that operate on similar domain entities.
Joe interrupts Theo’s meditation moment. After looking over the code in the previous listings, he congratulates Theo.
JOE Excellent job, my friend! By the way, after reading The Power of Habit, I quit chewing my nails.
THEO Wow! That’s terrific! Maybe I should read that book to overcome my habit of drinking too much coffee.
JOE Thanks, and good luck with the coffee habit.
THEO I was supposed to call Nancy later today with an ETA for the Open Library Book milestone. I wonder what her reaction will be when I tell her the feature is ready.
JOE Maybe you should tell her it’ll be ready in a week, which would give you time to begin work on the next milestone.
Delivering on time
Joe was right! Theo recalls Joe’s story about the young woodcutter and the old man. Theo was able to learn DOP and deliver the project on time! He’s pleased that he took the time “to sharpen his saw and commit to a deeper level of practice.”
►Note If you are unable to recall the story or if you missed it, check out the opener to part 2.
The Klafim project is a success. Nancy is pleased. Theo’s boss is satisfied. Theo got promoted. What more can a person ask for?
Theo remembers his deal with Joe. As he strolls through the stores of the Westfield San Francisco Center to look for a gift for each of Joe’s children, Neriah and Aurelia, he is filled with a sense of purpose and great pleasure. He buys a DJI Mavic Air 2 drone for Neriah, and the latest Apple Airpod Pros for Aurelia. He also takes this opportunity to buy a necklace and a pair of earrings for his wife, Jane. It’s a way for him to thank her for having endured his long days at work since the beginning of the Klafim project.
►Note The story continues in the opener of part 3.
Summary
-
We build the insides of our systems like we build the outsides.
-
Components inside a program communicate via data that is represented as immutable data collections in the same way as components communicate via data over the wire.
-
In DOP, the inner components of a program are loosely coupled.
-
Many parts of business logic can be implemented through generic data manipulation functions. We use generic functions to
-
Classes are much less complex when we use them as a means to aggregate together stateless functions that operate on similar domain entities.
Lodash functions introduced in this chapter
|
Creates a map composed of keys generated from the results of running each element of |