
5
DI anti-patterns
In this chapter
- Creating tightly coupled code with Control Freak
- Requesting a class’s Dependencies with a Service Locator
- Making a Volatile Dependency globally available with Ambient Context
- Forcing a particular constructor signature with Constrained Construction
Many dishes require food to be cooked in a pan with oil. If you’re not experienced with the recipe at hand, you might start heating the oil, and then turn your back to read the recipe. But once you’re done cutting the vegetables, the oil is smoking. You might think that the smoking oil means the pan is hot and ready for cooking. This is a common misconception with inexperienced cooks. When oils start to smoke, they also start to break down. This is called their smoke point. Not only do most oils taste awful once heated past their smoke point, they form harmful compounds and lose beneficial antioxidants.
In the previous chapter, we briefly compared design patterns to recipes. A pattern provides a common language we can use to succinctly discuss a complex concept. When the concept (or rather, the implementation) becomes warped, we have an anti-pattern on our hands.
Heating oil past its smoke point is a typical example of what can be considered to be a cooking anti-pattern. It’s a commonly occurring mistake. Many inexperienced cooks do this because it seems a reasonable thing to do, but loss of taste and unhealthful foods are negative consequences.
Anti-patterns are, more or less, a formalized way of describing common mistakes that people make again and again. In this chapter, we’ll describe some common anti-patterns related to DI. During our career, we’ve seen all of them in use in one form or other, and we’ve been guilty of applying all of them ourselves.
In many cases, anti-patterns represent sincere attempts at implementing DI in an application. But because of not fully complying with DI fundamentals, the implementations can morph into solutions that do more harm than good. Learning about these anti-patterns can give you an idea about what traps to be aware of as you venture into your first DI projects. But even if you’ve been applying DI for years, it’s still easy to make mistakes.
Anti-patterns can be fixed by refactoring the code toward one of the DI patterns introduced in chapter 4. Exactly how difficult it is to fix each occurrence depends on the details of the implementation. For each anti-pattern, we’ll supply some generalized guidance on how to refactor it toward a better pattern.
Legacy code sometimes requires drastic measures to make your code Testable. This often means taking small steps to prevent accidentally breaking a previously working application. In some cases, an anti-pattern might be the most appropriate temporary solution. Even though the application of an anti-pattern might be an improvement over the original code, it’s important to note that this doesn’t make it any less an anti-pattern; other documented and repeatable solutions exist that are proven to be more effective. The anti-patterns covered in this chapter are listed in table 5.1.
| Anti-pattern | Description |
| Control Freak | As opposed to Inversion of Control, Dependencies are controlled directly. |
| Service Locator | An implicit service can serve Dependencies to consumers, but it isn’t guaranteed to do so. |
| Ambient Context | Makes a single Dependency available through a static accessor. |
| Constrained Construction | Constructors are assumed to have a particular signature. |
The rest of this chapter describes each anti-pattern in greater detail, presenting them in order of importance. You can read from start to finish or only read the ones you’re interested in — each has a self-contained section. If you decide to read only part of this chapter, we recommend that you read Control Freak and Service Locator.
Just as Constructor Injection is the most important DI pattern, Control Freak is the most frequently occurring of the anti-patterns. It effectively prevents you from applying any kind of proper DI, so we’ll need to focus on this anti-pattern before we address the others — and so should you. But because Service Locator looks like it’s solving a problem, it’s the most dangerous. We’ll address that in section 5.2.
5.1 Control Freak
What’s the opposite of Inversion of Control? Originally the term Inversion of Control was coined to identify the opposite of the normal state of affairs, but we can’t talk about the “Business as Usual” anti-pattern. Instead, Control Freak describes a class that won’t relinquish control of its Volatile Dependencies.
As an example, the Control Freak anti-pattern happens when you create a new instance of a Volatile Dependency by using the new keyword. The following listing demonstrates an implementation of the Control Freak anti-pattern.

Listing 5.1 A Control Freak anti-pattern example
public class HomeController : Controller
{
public ViewResult Index()
{
var service = new ProductService(); ①
var products = service.GetFeaturedProducts();
return this.View(products);
}
}
Every time you create a Volatile Dependency, you explicitly state that you’re going to control the lifetime of the instance and that no one else will get a chance to Intercept that particular object. Although the new keyword is a code smell when it comes to Volatile Dependencies, you don’t need to worry about using it for Stable Dependencies.2
The most blatant example of Control Freak is when you make no effort to introduce Abstractions in your code. You saw several examples of that in chapter 2 when Mary implemented her e-commerce application (section 2.1). Such an approach makes no attempt to introduce DI. But even where developers have heard about DI and composability, the Control Freak anti-pattern can often be found in some variation.
In the next sections, we’ll show you some examples that resemble code we’ve seen used in production. In every case, the developers had the best intentions of programming to interfaces, but never understood the underlying forces and motivations.
5.1.1 Example: Control Freak through newing up Dependencies
Many developers have heard about the principle of programming to interfaces but don’t understand the deeper rationale behind it. In an attempt to do the right thing or to follow best practices, they write code that doesn’t make much sense. For example, in listing 3.9, you saw an example of a ProductService that uses an instance of the IProductRepository interface to retrieve a list of featured products. As a reminder, the following repeats the relevant code:
public IEnumerable<DiscountedProduct> GetFeaturedProducts()
{
return
from product in this.repository.GetFeaturedProducts()
select product.ApplyDiscountFor(this.userContext);
}
The salient point is that the repository member variable represents an Abstraction. In chapter 3, you saw how the repository field can be populated via Constructor Injection, but we’ve seen other, more naïve attempts. The following listing shows one such attempt.
Listing 5.2 Newing up a ProductRepository
private readonly IProductRepository repository;
public ProductService()
{
this.repository = new SqlProductRepository(); ①
}
The repository field is declared as the IProductRepository interface, so any member in the ProductService class (such as GetFeaturedProducts) programs to an interface. Although this sounds like the right thing to do, not much is gained from doing so because, at runtime, the type will always be a SqlProductRepository. There’s no way you can Intercept or change the repository variable unless you change the code and recompile. Additionally, you don’t gain much by defining a variable as an Abstraction if you hard-code it to always have a specific concrete type. Directly newing up Dependencies is one example of the Control Freak anti-pattern.
Before we get to the analysis and possible ways to address the resulting issues generated by a Control Freak, let’s look at some more examples to give you a better idea of the context and common failed attempts. In the next example, it’s apparent that the solution isn’t optimal. Most developers will attempt to refine their approach.
5.1.2 Example: Control Freak through factories
The most common and erroneous attempt to fix the evident problems from newing up Dependencies involves a factory of some sort. When it comes to factories, there are several options. We’ll quickly cover each of the following:
- Concrete Factory
- Abstract Factory
- Static Factory
If told that she could only deal with the IProductRepository Abstraction, Mary Rowan (from chapter 2) would introduce a ProductRepositoryFactory that would produce the instances she needs to get. Let’s listen in as she discusses this approach with her colleague Jens. We predict that their discussion will, conveniently, cover the factory options we’ve listed.
Mary: We need an instance of
IProductRepositoryin thisProductServiceclass. ButIProductRepositoryis an interface, so we can’t just create new instances of it, and our consultant says that we shouldn’t create new instances ofSqlProductRepositoryeither.
Jens: What about some sort of factory?
Mary: Yes, I was thinking the same thing, but I’m not sure how to proceed. I don’t understand how it solves our problem. Look here —
Mary starts to write some code to demonstrate her problem. This is the code that Mary writes:
public class ProductRepositoryFactory
{
public IProductRepository Create()
{
return new SqlProductRepository();
}
}
Concrete Factory
Mary: This
ProductRepositoryFactoryencapsulates knowledge about how to createProductRepositoryinstances, but it doesn’t solve the problem, because we’d have to use it in theProductServicelike this:var factory = new ProductRepositoryFactory(); this.repository = factory.Create();
See? Now we need to create a new instance of the
ProductRepositoryFactoryclass in theProductService, but that still hard-codes the use ofSqlProductRepository. The only thing we’ve achieved is moving the problem into another class.
Jens: Yes, I see — couldn’t we solve the problem with an Abstract Factory instead?
Let’s pause Mary and Jens’ discussion to evaluate what happened. Mary is entirely correct that a Concrete Factory class doesn’t solve the Control Freak issue but only moves it around. It makes the code more complex without adding any value. ProductService now directly controls the lifetime of the factory, and the factory directly controls the lifetime of ProductRepository, so you still can’t Intercept or replace the Repository instance at runtime.
It’s fairly evident that a Concrete Factory won’t solve any DI problems, and we’ve never seen it used successfully in this fashion. Jens’ comment about Abstract Factory sounds more promising.
Abstract Factory
Let’s resume Mary and Jens’ discussion and hear what Jens has to say about Abstract Factory.
Jens: What if we made the factory abstract, like this?
public interface IProductRepositoryFactory { IProductRepository Create(); }
This means we haven’t hard-coded any references to
SqlProductRepository, and we can use the factory in theProductServiceto get instances ofIProductRepository.
Mary: But now that the factory is abstract, how do we get a new instance of it?
Jens: We can create an implementation of it that returns
SqlProductServiceinstances.
Mary: Yes, but how do we create an instance of that?
Jens: We just new it up in the
ProductService... Oh. Wait —
Mary: That would put us back where we started.
Mary and Jens quickly realize that an Abstract Factory doesn’t change their situation. Their original conundrum was that they needed an instance of the abstract IProductRepository, and now they need an instance of the abstract IProductRepositoryFactory instead.
Now that Mary and Jens have rejected the Abstract Factory as a viable option, one damaging option is still open. Mary and Jens are about to reach a conclusion.
Static Factory
Let’s listen as Mary and Jens decide on an approach that they think will work.
Mary: Let’s make a Static Factory. Let me show you:
public static class ProductRepositoryFactory { public static IProductRepository Create() { return new SqlProductRepository(); } }
Now that the class is static, we don’t need to deal with how to create it.
Jens: But we’ve still hard-coded that we return
SqlProductRepositoryinstances, so does it help us in any way?
Mary: We could deal with this via a configuration setting that determines which type of
ProductRepositoryto create. Like this:public static IProductRepository Create() { IConfigurationRoot configuration = new ConfigurationBuilder() .SetBasePath(Directory.GetCurrentDirectory()) .AddJsonFile("appsettings.json") .Build(); string repositoryType = configuration["productRepository"]; switch (repositoryType) { case "sql": return new SqlProductRepository(); case "azure": return AzureProductRepository(); default: throw new InvalidOperationException("..."); } }
See? This way we can determine whether we should use the SQL Server–based implementation or the Microsoft Azure–based implementation, and we don’t even need to recompile the application to change from one to the other.
Jens: Cool! That’s what we’ll do. That consultant must be happy now!
There are several reasons why such a Static Factory doesn’t provide a satisfactory solution to the original goal of programming to interfaces. Take a look at the Dependency graph in figure 5.1.
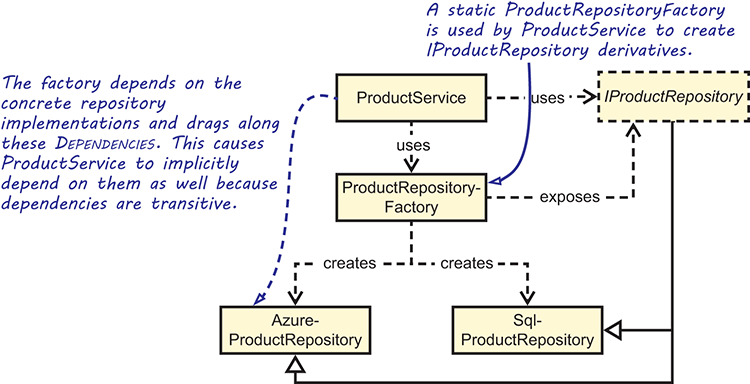
Figure 5.1 Dependency graph for the proposed ProductRepositoryFactory solution
All classes need to reference the abstract IProductRepository as follows:
ProductServicebecause it consumesIProductRepositoryinstancesProductRepositoryFactorybecause it createsIProductRepositoryinstancesAzureProductRepositoryandSqlProductRepositorybecause they implementIProductRepository
ProductRepositoryFactory depends on both the AzureProductRepository and SqlProductRepository classes. Because ProductService directly depends on ProductRepositoryFactory, it also depends on both concrete IProductRepository implementations — recall from section 4.1.4 that dependencies are transitive.
As long as ProductService has a dependency on the static ProductRepositoryFactory, you have unsolvable design issues. If you define the static ProductRepositoryFactory in the domain layer, it means that the domain layer needs to depend on the data access layer, because ProductRepositoryFactory creates a SqlProductRepository that’s located in that layer. The data access layer, however, already depends on the domain layer because SqlProductRepository uses types and Abstractions like Product and IProductRepository from that layer. This causes a circular reference between the two projects. Additionally, if you move ProductRepositoryFactory into the data access layer, you still need a dependency from the domain layer to the data access layer because ProductService depends on ProductRepositoryFactory. This still causes a circular dependency. Figure 5.2 shows this design issue.

Figure 5.2 Cyclic dependency between the domain and the data access layers that’s caused by the static ProductRepositoryFactory
No matter how you move your types around, the only way to prevent these circular dependencies between projects is by creating a single project for all types. This isn’t a viable option, however, because it tightly couples the domain layer to the data access layer and disallows your data access layer from being replaced.
Instead of loosely coupled IProductRepository implementations, Mary and Jens end up with tightly coupled modules. Even worse, the factory always drags along all implementations — even those that aren’t needed! If they host on Azure, they still need to distribute Commerce.SqlDataAccess.dll (for example) with their application.
If Mary and Jens ever need a third type of IProductRepository, they’ll have to change the factory and recompile their solution. Although their solution may be configurable, it isn’t extensible; if a separate team, or even company, needs to create a new Repository, they’ll have no options without access to the source code. It’s also impossible to replace the concrete IProductRepository implementations with test-specific implementations, because that requires defining the IProductRepository instance at runtime, instead of statically in a configuration file at design time.
In short, a Static Factory may seem to solve the problem but, in reality, only compounds it. Even in the best cases, it forces you to reference Volatile Dependencies. Another variation of this anti-pattern can be seen when overloaded constructors are used in combination with Foreign Defaults, as you’ll see in the next example.
5.1.3 Example: Control Freak through overloaded constructors
Constructor overloads are fairly common in many .NET code bases (including the BCL). Often, the many overloads provide reasonable defaults to one or two full-blown constructors that take all relevant parameters as input. (This practice is called Constructor Chaining.) At times, we see other uses when it comes to DI.
An all-too-common anti-pattern defines a test-specific constructor overload that allows you to explicitly define a Dependency, although the production code uses a parameterless constructor. This can be detrimental when the default implementation of the Dependency represents a Foreign Default rather than a Local Default. As we explained in section 4.4.2, you typically want to supply all Volatile Dependencies using Constructor Injection — even those that could be a Local Default.
The following listing shows the ProductService class with a default and an overloaded constructor. It’s an example of what not to do.
Listing 5.3 ProductService with multiple constructors
private readonly IProductRepository repository;
public ProductService() ①
: this(new SqlProductRepository()) ①
{ ①
} ①
public ProductService(IProductRepository repository) ②
{ ②
if (repository == null) ②
throw new ArgumentNullException("repository"); ②
②
this.repository = repository; ②
} ②
At first sight, this coding style might seem like the best of both worlds. It allows fake Dependencies to be supplied for the sake of unit testing; whereas, the class can still be conveniently created without having to supply its Dependencies. The following example shows this style:
var productService = new ProductService();
By letting ProductService create the SqlProductRepository Volatile Dependency, you again force strong coupling between modules. Although ProductService can be reused with different IProductRepository implementations, by supplying them via the most flexible constructor overload while testing, it disables the ability to Intercept the IProductRepository instance in the application.
Now that you’ve seen a few of examples of Control Freak, we hope you have a better idea what to look for — occurrences of the new keyword next to Volatile Dependencies. This may enable you to avoid the most obvious traps. But if you need to untangle yourself from an existing occurrence of this anti-pattern, the next section will help you deal with such a task.
5.1.4 Analysis of Control Freak
Control Freak is the antithesis of Inversion of Control. When you directly control the creation of Volatile Dependencies, you end up with tightly coupled code, missing many (if not all) of the benefits of loose coupling outlined in chapter 1.
Control Freak is the most common DI anti-pattern. It represents the default way of creating instances in most programming languages, so it can be observed even in applications where developers have never considered DI. It’s such a natural and deeply rooted way to create new objects that many developers find it difficult to discard. Even when they begin to think about DI, they have a hard time shaking the mindset that they must somehow control when and where instances are created. Letting go of that control can be a difficult mental leap to make; but, even if you make it, there are other, although lesser, pitfalls to avoid.
The negative effects of the Control Freak anti-pattern
With the tightly coupled code that’s the result of Control Freak, many benefits of modular design are potentially lost. These were covered in each of the previous sections, but to summarize:
- Although you can configure an application to use one of multiple preconfigured Dependencies, you can’t replace them at will. It isn’t possible to provide an implementation that was created after the application was compiled, and it certainly isn’t possible to provide specific instances as an implementation.
- It becomes harder to reuse the consuming module because it drags with it Dependencies that may be undesirable in the new context. As an example of this, consider a module that, through the use of a Foreign Default, depends on ASP.NET Core libraries. This makes it harder to reuse that module as part of an application that should’t or can’t depend on ASP.NET Core (for example, a Windows Service or mobile phone application).
- It makes parallel development more difficult. This is because the consuming application is tightly coupled to all implementations of its Dependencies.
- Testability suffers. Test Doubles can’t be used as substitutes for the Dependency.
With careful design, you can still implement tightly coupled applications with clearly defined responsibilities so that maintainability doesn’t suffer. But even so, the cost is too high, and you’ll retain many limitations. Given the amount of effort required to accomplish that, there’s no reason to continue investing in Control Freak. You need to move away from Control Freak and toward proper DI.
Refactoring from Control Freak toward DI
To get rid of Control Freak, you need to refactor your code toward one of the proper DI design patterns presented in chapter 4. As an initial step, you should use the guidance given in figure 4.9 to determine which pattern to aim for. In most cases, this will be Constructor Injection. The refactoring steps are as follows:
- Ensure that you’re programming to an Abstraction. In the examples, this was already the case; but in other situations, you may need to first extract an interface and change variable declarations.
- If you create a particular implementation of a Dependency in multiple places, move them all to a single creation method. Make sure this method’s return value is expressed as the Abstraction and not the concrete type.
- Now that you have only a single place where you create the instance, move this creation out of the consuming class by implementing one of the DI patterns, such as Constructor Injection.
In the case of the ProductService examples in the previous sections, Constructor Injection is an excellent solution.

Listing 5.4 Refactoring away from Control Freak using Constructor Injection
public class ProductService : IProductService
{
private readonly IProductRepository repository;
public ProductService(IProductRepository repository)
{
if (repository == null)
throw new ArgumentNullException("repository");
this.repository = repository;
}
}
Control Freak is by far the most damaging anti-pattern, but even when you have it under control, more subtle issues can arise. The next sections look at more anti-patterns. Although they’re less problematic than Control Freak, they also tend to be easier to resolve, so be on the lookout, and fix them as they’re discovered.
5.2 Service Locator
It can be difficult to give up on the idea of directly controlling Dependencies, so many developers take Static Factories (such as the one described in section 5.1.2) to new levels. This leads to the Service Locator anti-pattern.
As it’s most commonly implemented, the Service Locator is a Static Factory that can be configured with concrete services before the first consumer begins to use it. (But you’ll equally also find abstract Service Locators.) This could conceivably happen in the Composition Root. Depending on the particular implementation, the Service Locator can be configured with code by reading a configuration file or by using a combination thereof. The following listing shows the Service Locator anti-pattern in action.
Listing 5.5 Using the Service Locator anti-pattern
public class HomeController : Controller
{
public HomeController() { } ①
public ViewResult Index()
{
IProductService service =
Locator.GetService<IProductService>(); ②
var products = service.GetFeaturedProducts(); ③
return this.View(products);
}
}
Instead of statically defining the list of required Dependencies, HomeController has a parameterless constructor, requesting its Dependencies later. This hides these Dependencies from HomeController’s consumers and makes HomeController harder to use and test. Figure 5.3 shows the interaction in listing 5.5, where you can see the relationship between the Service Locator and the ProductService implementation.

Figure 5.3 Interaction between HomeController and Service Locator
Years ago, it was quite controversial to call Service Locator an anti-pattern. The controversy is over: Service Locator is an anti-pattern. But don’t be surprised to find code bases that have this anti-pattern sprinkled all over the place.
It’s important to note that if you look at only the static structure of classes, a DI Container looks like a Service Locator. The difference is subtle and lies not in the mechanics of implementation, but in how you use it. In essence, asking a container or locator to resolve a complete object graph from the Composition Root is proper usage. Asking it for granular services from anywhere else but the Composition Root implies the Service Locator anti-pattern. Let’s review an example that shows Service Locator in action.
5.2.1 Example: ProductService using a Service Locator
Let’s return to our tried-and-tested ProductService, which requires an instance of the IProductRepository interface. Assuming we were to apply the Service Locator anti-pattern, ProductService would use the static GetService method, as shown in the following listing.
Listing 5.6 Using a Service Locator inside a constructor
public class ProductService : IProductService
{
private readonly IProductRepository repository;
public ProductService()
{
this.repository = Locator.GetService<IProductRepository>();
}
public IEnumerable<DiscountedProduct> GetFeaturedProducts() { ... }
}
In this example, we implement the GetService method using generic type parameters to indicate the type of service being requested. You could also use a Type argument to indicate the type, if that’s more to your liking.
As the following listing shows, this implementation of the Locator class is as short as possible. We could have added Guard Clauses and error handling, but we wanted to highlight the core behavior. The code could also include a feature that enables it to load its configuration from a file, but we’ll leave that as an exercise for you.
Listing 5.7 A simple Service Locator implementation
public static class Locator
{
private static Dictionary<Type, object> services = ①
new Dictionary<Type, object>();
public static void Register<T>(T service)
{
services[typeof(T)] = service;
}
public static T GetService<T>() ②
{ ②
return (T)services[typeof(T)]; ②
}
public static void Reset()
{
services.Clear();
}
}
Clients such as ProductService can use the GetService method to request an instance of the abstract type T. Because this example code contains no Guard Clauses or error handling, the method throws a rather cryptic KeyNotFoundException if the requested type has no entry in the dictionary. You can imagine how to add code to throw a more descriptive exception.
The GetService method can only return an instance of the requested type if it has previously been inserted in the internal dictionary. This can be done with the Register method. Again, this example code contains no Guard Clause, so it would be possible to Register a null value, but a more robust implementation shouldn’t allow that. This implementation also caches registered instances forever, but it isn’t that hard to come up with an implementation that allows creating new instances on every call to GetService. In certain cases, particularly when unit testing, it’s important to be able to reset the Service Locator. That functionality is provided by the Reset method, which clears the internal dictionary.
Classes like ProductService rely on the service to be available in the Service Locator, so it’s important that it’s previously configured. In a unit test, this could be done with a Test Double implemented by a Stub, as can be seen in the following listing.7
Listing 5.8 A unit test depending on a Service Locator
[Fact]
public void GetFeaturedProductsWillReturnInstance()
{
// Arrange
var stub = ProductRepositoryStub(); ①
Locator.Reset(); ②
Locator.Register<IProductRepository>(stub); ③
var sut = new ProductService();
// Act
var result = sut.GetFeaturedProducts(); ④
// Assert
Assert.NotNull(result);
}
The example shows how the static Register method is used to configure the Service Locator with the Stub instance. If this is done before ProductService is constructed, as shown in the example, ProductService uses the configured Stub to work against ProductRepository. In the full production application, the Service Locator will be configured with the correct ProductRepository implementation in the Composition Root.
This way of locating Dependencies from the ProductService class definitely works if our only success criterion is that the Dependency can be used and replaced at will. But it has some serious shortcomings.
5.2.2 Analysis of Service Locator
Service Locator is a dangerous pattern because it almost works. You can locate Dependencies from consuming classes, and you can replace those Dependencies with different implementations — even with Test Doubles from unit tests. When you apply the analysis model outlined in chapter 1 to evaluate whether Service Locator can match the benefits of modular application design, you’ll find that it fits in most regards:
- You can support late binding by changing the registration.
- You can develop code in parallel, because you’re programming against interfaces, replacing modules at will.
- You can achieve good separation of concerns, so nothing stops you from writing maintainable code, but doing so becomes more difficult.
- You can replace Dependencies with Test Doubles, so Testability is ensured.
There’s only one area where Service Locator falls short, and that shouldn’t be taken lightly.
Negative effects of the Service Locator anti-pattern
The main problem with Service Locator is that it impacts the reusability of the classes consuming it. This manifests itself in two ways:
- The class drags along the Service Locator as a redundant Dependency.
- The class makes it non-obvious what its Dependencies are.
Let’s first look at the Dependency graph for the ProductService from the example in section 5.2.1, shown in figure 5.4.

Figure 5.4 Dependency graph for a ProductService
In addition to the expected reference to IProductRepository, ProductService also depends on the Locator class. This means that to reuse the ProductService class, you must redistribute not only it and its relevant Dependency IProductRepository, but also the Locator Dependency, which only exists for mechanical reasons. If the Locator class is defined in a different module than ProductService and IProductRepository, new applications wanting to reuse ProductService must accept that module too.

Figure 5.5 The only thing Visual Studio’s IntelliSense can tell us about the ProductService class is that it has a parameterless constructor. Its Dependencies are invisible.
Perhaps we could even tolerate that extra Dependency on Locator if it was truly necessary for DI to work. We’d accept it as a tax to be paid to gain other benefits. But there are better options (such as Constructor Injection) available, so this Dependency is redundant. Moreover, neither this redundant Dependency nor IProductRepository, its relevant counterpart, is explicitly visible to developers wanting to consume the ProductService class. Figure 5.5 shows that Visual Studio offers no guidance on the use of this class.
If you want to create a new instance of the ProductService class, Visual Studio can only tell you that the class has a parameterless constructor. But if you subsequently attempt to run the code, you get a runtime error if you forgot to register an IProductRepository instance with the Locator class. This is likely to happen if you don’t intimately know the ProductService class.
The ProductService class is far from self documenting: you can’t tell which Dependencies must be present before it’ll work. In fact, the developers of ProductService may even decide to add more Dependencies in future versions. That would mean that code that works for the current version can fail in a future version, and you aren’t going to get a compiler error that warns you. Service Locator makes it easy to inadvertently introduce breaking changes.
The use of generics may trick you into thinking that a Service Locator is strongly typed. But even an API like the one shown in listing 5.7 is weakly typed, because you can request any type. Being able to compile code invoking the GetService<T> method gives you no guarantee that it won’t throw exceptions left and right at runtime.
When unit testing, you have the additional problem that a Test Double registered in one test case will lead to the Interdependent Tests code smell, because it remains in memory when the next test case is executed. It’s therefore necessary to perform Fixture Teardown after every test by invoking Locator.Reset().8 This is something that you must manually remember to do, and it’s easy to forget.
A Service Locator may seem innocuous, but it can lead to all sorts of nasty runtime errors. How do you avoid those problems? When you decide to get rid of a Service Locator, you need to find a way to do it. As always, the default approach should be Constructor Injection, unless one of the other DI patterns from chapter 4 provides a better fit.
Refactoring from Service Locator toward DI
Because Constructor Injection statically declares a class’s Dependencies, it enables the code to fail at compile time, assuming you practice Pure DI. When you use a DI Container, on the other hand, you lose the ability to verify correctness at compile time. Statically declaring a class’s Dependencies, however, still ensures that you can verify the correctness of your application’s object graphs by asking the container to create all object graphs for you. You can do this at application startup or as part of a unit/integration test.
Some DI Containers even take this a step further and allow doing more-complex analysis on the DI configuration. This allows detecting all kinds of common pitfalls. A Service Locator, on the other hand, will be completely invisible to a DI Container, making it impossible for it to do these kinds of verification on your behalf.
In many cases, a class that consumes a Service Locator may have calls to it spread throughout its code base. In such cases, it acts as a replacement for the new statement. When this is so, the first refactoring step is to consolidate the creation of each Dependency in a single method.
If you don’t have a member field to hold an instance of the Dependency, you can introduce such a field and make sure the rest of the code uses this field when it consumes the Dependency. Mark the field readonly to ensure that it can’t be modified outside the constructor. Doing so forces you to assign the field from the constructor using the Service Locator. You can now introduce a constructor parameter that assigns the field instead of the Service Locator, which can then be removed.
Refactoring a class that uses Service Locator is similar to refactoring a class that uses Control Freak. Section 5.1.4 contains further notes on refactoring Control Freak implementations to use DI.
At first glance, Service Locator may look like a proper DI pattern, but don’t be fooled: it may explicitly address loose coupling, but it sacrifices other concerns along the way. The DI patterns presented in chapter 4 offer better alternatives with fewer drawbacks. This is true for the Service Locator anti-pattern, as well as the other anti-patterns presented in this chapter. Even though they’re different, they all share the common trait that they can be resolved by one of the DI patterns from chapter 4.
5.3 Ambient Context
Related to Service Locator is the Ambient Context anti-pattern. Where a Service Locator allows global access to an unrestricted set of Dependencies, an Ambient Context makes a single strongly typed Dependency available through a static accessor.
The following listing shows the Ambient Context anti-pattern in action.
Listing 5.9 Using the Ambient Context anti-pattern
public string GetWelcomeMessage()
{
ITimeProvider provider = TimeProvider.Current; ①
DateTime now = provider.Now;
string partOfDay = now.Hour < 6 ? "night" : "day";
return string.Format("Good {0}.", partOfDay);
}
In this example, ITimeProvider presents an Abstraction that allows retrieving the system’s current time. Because you might want to influence how time is perceived by the application (for instance, for testing), you don’t want to call DateTime.Now directly. Instead of letting consumers call DateTime.Now directly, a good solution is to hide access to DateTime.Now behind an Abstraction. It’s all too tempting, however, to allow consumers to access the default implementation through a static property or method. In listing 5.9, the Current property allows access to the default ITimeProvider implementation.
Ambient Context is similar in structure to the Singleton pattern.9 Both allow access to a Dependency by the use of static class members. The difference is that Ambient Context allows its Dependency to be changed, whereas the Singleton pattern ensures that its singular instance never changes.
The access to the system’s current time is a common need. Let’s dive a little bit deeper into the ITimeProvider example.
5.3.1 Example: Accessing time through Ambient Context
There are many reasons one would need to exercise some control over time. Many applications have business logic that depends on time or the progression of it. In the previous example, you saw a simple case where we displayed a welcome message based on the current time. Two other examples include these:
- Cost calculations based on day of the week. In some businesses, it’s normal for customers to pay more for services during the weekend.
- Sending notifications to users using different communication channels based on the time of day. For instance, the business might want email notifications to be sent during working hours, and by text message or pager, otherwise.
Because the need to work with time is such a widespread requirement, developers often feel the urge to simplify access to such a Volatile Dependency by using an Ambient Context. The following listing shows an example ITimeProvider Abstraction.
Listing 5.10 An ITimeProviderAbstraction
public interface ITimeProvider
{
DateTime Now { get; } ①
}
The following listing shows a simplistic implementation of the TimeProvider class for this ITimeProvider Abstraction.
Listing 5.11 A TimeProviderAmbient Context implementation
public static class TimeProvider ①
{
private static ITimeProvider current =
new DefaultTimeProvider(); ②
public static ITimeProvider Current ③
{
get { return current; }
set { current = value; }
}
private class DefaultTimeProvider : ITimeProvider ④
{
public DateTime Now { get { return DateTime.Now; } }
}
}
Using the TimeProvider implementation, you can unit test the previously defined GetWelcomeMessage method. The following listing shows such test.
Listing 5.12 A unit test depending on an Ambient Context
[Fact]
public void SaysGoodDayDuringDayTime()
{
// Arrange
DateTime dayTime = DateTime.Parse("2019-01-01 6:00");
var stub = new TimeProviderStub { Now = dayTime };
TimeProvider.Current = stub; ①
var sut = new WelcomeMessageGenerator(); ②
// Act
string actualMessage = sut.GetWelcomeMessage(); ③
// Assert
Assert.Equal(expected: "Good day.", actual: actualMessage);
}
This is one variation of the Ambient Context anti-pattern. Other common variations you might encounter are these:
- An Ambient Context that allows consumers to make use of the behavior of a globally configured Dependency. With the previous example in mind, the
TimeProvidercould supply consumers with a staticGetCurrentTimemethod that hides the used Dependency by calling it internally. - An Ambient Context that merges the static accessor with the interface into a single Abstraction. In respect to the previous example, that would mean that you have a single
TimeProviderbase class that contains both theNowinstance property and the staticCurrentproperty. - An Ambient Context where delegates are used instead of a custom-defined Abstraction. Instead of having a fairly descriptive
ITimeProviderinterface, you could achieve the same using aFunc<DateTime>delegate.
Ambient Context can come in many shapes and implementations. Again, the caution regarding Ambient Context is that it provides either direct or indirect access to a Volatile Dependency by means of some static class member. Before doing the analysis and evaluating possible ways to fix the problems caused by Ambient Context, let’s look at another common example of Ambient Context.
5.3.2 Example: Logging through Ambient Context
Another common case where developers tend to take a shortcut and step into the Ambient Context trap is when it comes to applying logging to their applications. Any real application requires the ability to write information about errors and other uncommon conditions to a file or other source for later analysis. Many developers feel that logging is such a special activity that it deserves “bending the rules.” You might find code similar to that shown in the next listing even in the code bases of developers who are quite familiar with DI.
Listing 5.13 Ambient Context when logging
public class MessageGenerator
{
private static readonly ILog Logger =
LogManager.GetLogger(typeof(MessageGenerator)); ①
public string GetWelcomeMessage()
{
Logger.Info("GetWelcomeMessage called."); ②
return string.Format(
"Hello. Current time is: {0}.", DateTime.Now);
}
}
There are several reasons why Ambient Context is so ubiquitous in many applications when it comes to logging. First, code like listing 5.13 is typically the first example that logging libraries show in their documentation. Developers copy those examples out of ignorance. We can’t blame them; developers typically assume that the library designers know and communicate best practices. Unfortunately, this isn’t always the case. Documentation examples are typically written for simplicity, not best practice, even if their designers understand those best practices.
Apart from that, developers tend to apply Ambient Context for loggers because they need logging in almost every class in their application. Injecting it in the constructor could easily lead to constructors with too many Dependencies. This is indeed a code smell called Constructor Over-injection, and we’ll discuss it in chapter 6.
Jeff Atwood wrote a great blog post back in 2008 about the danger of logging.10 A few of his arguments follow:
- Logging means more code, which obscures your application code.
- Logging isn’t free, and logging a lot means constantly writing to disk.
- The more you log, the less you can find.
- If it’s worth saving to a log file, it’s worth showing in the user interface.
When working on Stack Overflow, Jeff removed most of the logging, relying exclusively on logging of unhandled exceptions. If it’s an error, an exception should be thrown.
We wholeheartedly agree with Jeff’s analysis, but would also like to approach this from a design perspective. We’ve found that with good application design, you’ll be able to apply logging across common components, without having it pollute your entire code base. Chapter 10 describes in detail how to design such an application.
There are many other examples of Ambient Context, but these two examples are so common and widespread that we’ve seen them countless times in companies we’ve consulted with. (We’ve even been guilty of introducing Ambient Context implementations ourselves in the past.) Now that you’ve seen the two most common examples of Ambient Context, the next section discusses why it’s a problem and how to deal with it.
5.3.3 Analysis of Ambient Context
Ambient Context is usually encountered when developers have a Cross-Cutting Concern as a Volatile Dependency, which is used ubiquitously. This ubiquitous nature makes developers think it justifies moving away from Constructor Injection. It allows them to hide Dependencies and avoids the necessity of adding the Dependency to many constructors in their application.
Negative effects of the Ambient Context anti-pattern
The problems with Ambient Context are related to the problems with Service Locator. Here are the main issues:
- The Dependency is hidden.
- Testing becomes more difficult.
- It becomes hard to change the Dependency based on its context.
- There’s Temporal Coupling between the initialization of the Dependency and its usage.
When you hide a Dependency by allowing global access to it through Ambient Context, it becomes easier to hide the fact that a class has too many Dependencies. This is related to the Constructor Over-injection code smell and is typically an indication that you’re violating the Single Responsibility Principle.
When a class has many Dependencies, it’s an indication that it’s doing more than it should. It’s theoretically possible to have a class with many Dependencies, while still having just “one reason to change.”11 The larger the class, however, the less likely it is to abide by this guidance. The use of Ambient Context hides the fact that classes might have become too complex, and need to be refactored.
Ambient Context also makes testing more difficult because it presents a global state. When a test changes the global state, as you saw in listing 5.12, it might influence other tests. This is the case when tests run in parallel, but even sequentially executed tests can be affected when a test forgets to revert its changes as part of its teardown. Although these test-related issues can be mitigated, it means building a specially crafted Ambient Context and either global or test-specific teardown logic. This adds complexity, whereas the alternative doesn’t.
The use of an Ambient Context makes it hard to provide different consumers with different implementations of the Dependency. For instance, say you need part of your system to work with a moment in time that’s fixed at the start of the current request, whereas other, possibly long-running operations, should get a Dependency that’s live-updated.12 Providing consumers with different implementations of the Dependency is exactly what happened in listing 5.13, as repeated here:
private static readonly ILog Logger =
LogManager.GetLogger(typeof(MessageGenerator));
To be able to provide consumers with different implementations, the GetLogger API requires the consumer to pass along its appropriate type information. This needlessly complicates the consumer.
The use of an Ambient Context causes the usage of its Dependency coupled on a temporal level. Unless you initialize the Ambient Context in the Composition Root, the application fails when the class starts using the Dependency for the first time. We rather want our applications to fail fast instead.
Although Ambient Context isn’t as destructive as Service Locator, because it only hides a single Volatile Dependency opposed to an arbitrary number of Dependencies, it has no place in a well-designed code base. There are always better alternatives, which is what we describe in the next section.
Refactoring from Ambient Context toward DI
Don’t be surprised to see Ambient Context even in code bases where the developers have a fairly good understanding of DI and the harm that Service Locator brings. It can be hard to convince developers to move away from Ambient Context, because they’re so accustomed to using it. On top of that, although refactoring a single class toward DI isn’t hard, the underlying problems like ineffective and harmful logging strategies are harder to change. Typically, there’s lots of code that logs for reasons that aren’t always clear. Finding out whether these logging statements could be removed or should be turned into exceptions instead can often be a slow process when the original developers are long gone. Still, assuming a code base already applies DI, refactoring away from Ambient Context toward DI is straightforward.
A class that consumes an Ambient Context typically contains one or a few calls to it, possibly spread over multiple methods. Because the first refactoring step is to centralize the call to the Ambient Context, the constructor is a good place to do this.
Create a private readonly field that can hold a reference to the Dependency and assign it with the Ambient Context’s Dependency. The rest of the class’s code can now use this new private field. The call to the Ambient Context can now be replaced with a constructor parameter that assigns the field and a Guard Clause that ensures the constructor parameter isn’t null. This new constructor parameter will likely cause consumers to break. But if DI was applied already, this should only cause changes to the Composition Root and the class’s tests. The following listing shows the (unsurprising) result of the refactoring, when applied to the WelcomeMessageGenerator.
Listing 5.14 Refactoring away from Ambient Context to Constructor Injection
public class WelcomeMessageGenerator
{
private readonly ITimeProvider timeProvider;
public WelcomeMessageGenerator(ITimeProvider timeProvider)
{
if (timeProvider == null)
throw new ArgumentNullException("timeProvider");
this.timeProvider = timeProvider;
}
public string GetWelcomeMessage()
{
DateTime now = this.timeProvider.Now;
...
}
}
Refactoring Ambient Context is relatively simple because, for the most part, you’ll be doing it in an application that has already applied DI. For applications that don’t, it’s better to fix Control Freak and Service Locator problems first before tackling Ambient Context refactorings.
Ambient Context sounds like a great way to access commonly used Cross-Cutting Concerns, but looks are deceiving. Although less problematic than Control Freak and Service Locator, Ambient Context is typically a cover-up for larger design problems in the application. The patterns described in chapter 4 provide a better solution, and in chapter 10, we’ll show how to design your applications in such way that logging and other Cross-Cutting Concerns can be applied more easily and transparently across the application.
The last anti-pattern considered in this chapter is Constrained Construction. This often originates from the desire to attain late binding.
5.4 Constrained Construction
The biggest challenge of properly implementing DI is getting all classes with Dependencies moved to a Composition Root. When you accomplish this, you’ve already come a long way. Even so, there are still some traps to look out for.
A common mistake is to require Dependencies to have a constructor with a particular signature. This normally originates from the desire to attain late binding so that Dependencies can be defined in an external configuration file and thereby changed without recompiling the application.
Be aware that this section applies only to scenarios where late binding is desired. In scenarios where you directly reference all Dependencies from the application’s root, you won’t have this problem. But then again, you won’t have the ability to replace Dependencies without recompiling the startup project, either. The following listing shows the Constrained Construction anti-pattern in action.
Listing 5.15 Constrained Construction anti-pattern example
public class SqlProductRepository : IProductRepository
{
public SqlProductRepository(string connectionStr) ①
{
}
}
public class AzureProductRepository : IProductRepository
{
public AzureProductRepository(string connectionStr) ①
{
}
}
All implementations of the IProductRepository Abstraction are forced to have a constructor with the same signature. In this example, the constructor should have exactly one argument of type string. Although it’s perfectly fine for a class to have a Dependency of type string, it’s a problem for those implementations to be forced to have an identical constructor signature. In section 1.2.2, we briefly touched on this issue. This section examines it more carefully.
5.4.1 Example: Late binding a ProductRepository
In the sample e-commerce application, some classes depend on the IProductRepository interface. This means that to create those classes, you first need to create an IProductRepository implementation. At this point, you’ve learned that a Composition Root is the correct place to do this. In an ASP.NET Core application, this typically means Startup. The following listing shows the relevant part that creates an instance of an IProductRepository.
Listing 5.16 Implicitly constraining the ProductRepository constructor
string connectionString = this.Configuration ①
.GetConnectionString("CommerceConnectionString"); ①
var settings = ②
this.Configuration.GetSection("AppSettings"); ②
②
string productRepositoryTypeName = ②
settings.GetValue<string>("ProductRepositoryType"); ②
var productRepositoryType = ③
Type.GetType( ③
typeName: productRepositoryTypeName, ③
throwOnError: true); ③
var constructorArguments =
new object[] { connectionString };
IProductRepository repository = ④
(IProductRepository)Activator.CreateInstance( ④
productRepositoryType, constructorArguments); ④
The following code shows the corresponding configuration file:
{
"ConnectionStrings": {
"CommerceConnectionString":
"Server=.;Database=MaryCommerce;Trusted_Connection=True;"
},
"AppSettings": {
"ProductRepositoryType": "SqlProductRepository, Commerce.SqlDataAccess"
},
}
The first thing that should trigger suspicion is that a connection string is read from the configuration file. Why do you need a connection string if you plan to treat a ProductRepository as an Abstraction?
Although it’s perhaps a bit unlikely, you could choose to implement a ProductRepository with an in-memory database or an XML file. A REST-based storage service, such as the Windows Azure Table Storage Service, offers a more realistic alternative, although, once again this year, the most popular choice seems to be a relational database. The ubiquity of databases makes it all too easy to forget that a connection string implicitly represents an implementation choice.
To late bind an IProductRepository, you also need to determine which type has been chosen as the implementation. This can be done by reading an assembly-qualified type name from the configuration and creating a Type instance from that name. This in itself isn’t problematic. The difficulty arises when you need to create an instance of that type. Given a Type, you can create an instance using the Activator class. The CreateInstance method invokes the type’s constructor, so you must supply the correct constructor parameters to prevent an exception from being thrown. In this case, you supply a connection string.
If you didn’t know anything else about the application other than the code in listing 5.16, you should by now be wondering why a connection string is passed as a constructor argument to an unknown type. It wouldn’t make sense if the implementation was based on a REST-based web service or an XML file.
Indeed, it doesn’t make sense because this represents an accidental constraint on the Dependency’s constructor. In this case, you have an implicit requirement that any implementation of IProductRepository should have a constructor that takes a single string as input. This is in addition to the explicit constraint that the class must derive from IProductRepository.
You could argue that an IProductRepository based on an XML file would also require a string as constructor parameter, although that string would be a filename and not a connection string. But, conceptually, it’d still be weird because you’d have to define that filename in the connectionStrings element of the configuration. (In any case, we think such a hypothetical XmlProductRepository should take an XmlReader as a constructor argument instead of a filename.)
5.4.2 Analysis of Constrained Construction
In the previous example, the implicit constraint required implementers to have a constructor with a single string parameter. A more common constraint is that all implementations should have a parameterless constructor, so that the simplest form of Activator.CreateInstance will work:
IProductRepository repository =
(IProductRepository)Activator.CreateInstance(productRepositoryType);
Although this can be said to be the lowest common denominator, the cost in flexibility is significant. No matter how you constrain object construction, you lose flexibility.
Negative effects of the Constrained Construction anti-pattern

Figure 5.6 You want to create a single instance of the CommerceContext class and inject that instance into both Repositories.
It might be tempting to declare that all Dependency implementations should have a parameterless constructor. After all, they could perform their initialization internally; for example, reading configuration data like connection strings directly from the configuration file. But this would limit you in other ways because you might want to compose an application as layers of instances that encapsulate other instances. In some cases, for example, you might want to share an instance between different consumers, as illustrated in figure 5.6.
When you have more than one class requiring the same Dependency, you may want to share a single instance among all those classes. This is possible only when you can inject that instance from the outside. Although you could write code inside each of those classes to read type information from a configuration file and use Activator.CreateInstance to create the correct type of instance, it’d be really involved to share a single instance this way. Instead, you’d have multiple instances of the same class taking up more memory.
Instead of imposing implicit constraints on how objects should be constructed, you should implement your Composition Root so that it can deal with any kind of constructor or factory method you may throw at it. Now let’s take a look at how you can refactor toward DI.
Refactoring from Constrained Construction toward DI
How can you deal with having no constraints on components’ constructors when you need late binding? It may be tempting to introduce an Abstract Factory that can create instances of the required Abstraction and then require the implementations of those Abstract Factories to have a particular constructor signature. But doing so, however, is likely to cause complications of its own. Let’s examine such an approach.
Imagine using an Abstract Factory for the IProductRepository Abstraction. The Abstract Factory scheme dictates that you also need an IProductRepositoryFactory interface. Figure 5.7 illustrates this structure.

Figure 5.7 An attempt to use the Abstract Factory structure to solve the late-binding challenge
In this figure, IProductRepository represents the real Dependency. But to keep its implementers free of implicit constraints, you attempt to solve the late-binding challenge by introducing an IProductRepositoryFactory. This will be used to create instances of IProductRepository. A further requirement is that any factories have a particular constructor signature.
Now let’s assume that you want to use an implementation of IProductRepository that requires an instance of IUserContext to work, as shown in the next listing.
Listing 5.17 SqlProductRepository that requires an IUserContext
public class SqlProductRepository : IProductRepository
{
private readonly IUserContext userContext;
private readonly CommerceContext dbContext;
public SqlProductRepository(
IUserContext userContext, CommerceContext dbContext)
{
if (userContext == null)
throw new ArgumentNullException("userContext");
if (dbContext == null)
throw new ArgumentNullException("dbContext");
this.userContext = userContext;
this.dbContext = dbContext;
}
}
The SqlProductRepository class implements the IProductRepository interface, but requires an instance of IUserContext. Because the only constructor isn’t a parameterless constructor, IProductRepositoryFactory will come in handy.
Currently, you want to use an implementation of IUserContext that’s based on ASP.NET Core. You call this implementation AspNetUserContextAdapter (as we discussed in listing 3.12). Because the implementation depends on ASP.NET Core, it isn’t defined in the same assembly as SqlProductRepository. And, because you don’t want to drag a reference to the library that contains AspNetUserContextAdapter along with SqlProductRepository, the only solution is to implement SqlProductRepositoryFactory in a different assembly than SqlProductRepository, as shown in figure 5.8.

Figure 5.8 Dependency graph with SqlProductRepositoryFactory implemented in a separate assembly
The following listing shows a possible implementation for the SqlProductRepository-Factory.
Listing 5.18 Factory that creates SqlProductRepository instances
public class SqlProductRepositoryFactory
: IProductRepositoryFactory
{
private readonly string connectionString;
public SqlProductRepositoryFactory(
IConfigurationRoot configuration) ①
{
this.connectionString =
configuration.GetConnectionString( ②
"CommerceConnectionString");
}
public IProductRepository Create()
{
return new SqlProductRepository( ③
new AspNetUserContextAdapter(),
new CommerceContext(this.connectionString));
}
}
Even though IProductRepository and IProductRepositoryFactory look like a cohesive pair, it’s important to implement them in two different assemblies. This is because the factory must have references to all Dependencies to be able to wire them together correctly. By convention, the IProductRepositoryFactory implementation must again use Constrained Construction so that you can write the assembly-qualified type name in a configuration file and use Activator.CreateInstance to create an instance.
Every time you need to wire together a new combination of Dependencies, you must implement a new factory that wires up exactly that combination, and then configure the application to use that factory instead of the previous one. This means you can’t define arbitrary combinations of Dependencies without writing and compiling code, but you can do it without recompiling the application itself. Such an Abstract Factory becomes an Abstract Composition Root that’s defined in an assembly separate from the core application. Although this is possible, when you try to apply it, you’ll notice the inflexibility that it causes.
Flexibility suffers because the Abstract Composition Root takes direct dependencies on concrete types in other libraries to fulfill the needs of the object graphs it builds. In the SqlProductRepositoryFactory example, the factory needs to create an instance of AspNetUserContextAdapter to pass to SqlProductRepository. But what if the core application wants to replace or Intercept the IUserContext implementation? This forces changes to both the core application and the SqlProductRepositoryFactory project. Another problem is that it becomes quite hard for these Abstract Factories to manage Object Lifetime. This is the same problem as illustrated in figure 5.5.
To combat this inflexibility, the only feasible solution is to use a general-purpose DI Container. Because DI Containers analyze constructor signatures using reflection, the Abstract Composition Root doesn’t need to know the Dependencies used to construct its components. The only thing the Abstract Composition Root needs to do is specify the mapping between the Abstraction and the implementation. In other words, the SQL data access Composition Root needs to specify that in case the application requires an IProductRepository, an instance of SqlProductRepository should be created.
Abstract Composition Roots are only required when you truly need to be able to plug in a new assembly without having to recompile any part of the existing application. Most applications don’t need this amount of flexibility. Although you might want to be able to replace the SQL data access layer with an Azure data access layer without having to recompile the domain layer, it’s typically OK if this means you still have to make changes to the startup project.
Because DI is a set of patterns and techniques, no single tool can mechanically verify whether you’ve applied it correctly. In chapter 4, we looked at patterns that describe how DI can be used properly, but that’s only one side of the coin. It’s also important to study how it’s possible to fail, even with the best of intentions. You can learn important lessons from failure, but you don’t have to always learn from your own mistakes — sometimes you can learn from other people’s mistakes.
In this chapter, we’ve described the most common DI mistakes in the form of anti-patterns. We’ve seen all these mistakes in real life on more than one occasion, and we confess to being guilty of all of them. By now, you should know what to avoid and what you should ideally be doing instead. There can still be issues that look as though they’re hard to solve, however. The next chapter discusses such challenges and how to resolve them.
Summary
- An anti-pattern is a description of a commonly occurring solution to a problem that generates decidedly negative consequences.
- Control Freak is the most dominating of the anti-patterns presented in this chapter. It effectively prevents you from applying any kind of proper DI. It occurs every time you depend on a Volatile Dependency in any place other than a Composition Root.
- Although the
newkeyword is a code smell when it comes to Volatile Dependencies, you don’t need to worry about using it for Stable Dependencies. In general, thenewkeyword isn’t suddenly illegal, but you should refrain from using it to get instances of Volatile Dependencies. - Control Freak is a violation of the Dependency Inversion Principle.
- Control Freak represents the default way of creating instances in most programming languages, so it can be observed even in applications where developers have never considered DI. It’s such a natural and deeply rooted way to create new objects that many developers find it difficult to discard.
- A Foreign Default is the opposite of a Local Default. It’s an implementation of a Dependency that’s used as a default even though it’s defined in a different module than its consumer. Dragging along unwanted modules robs you of many of the benefits of loose coupling.
- Service Locator is the most dangerous anti-pattern presented in this chapter because it looks like it’s solving a problem. It supplies application components outside the Composition Root with access to an unbounded set of Volatile Dependencies.
- Service Locator impacts the reusability of the components consuming it. It makes it non-obvious to a component’s consumers what its Dependencies are, makes such a component dishonest about its level of complexity, and causes its consuming components to drag along the Service Locator as a redundant Dependency.
- Service Locator prevents verification of the configuration of relationships between classes. Constructor Injection in combination with Pure DI allows verification at compile time; Constructor Injection in combination with a DI Container allows verification at application startup or as part of a simple automated test.
- A static Service Locator causes Interdependent Tests, because it remains in memory when the next test case is executed.
- It’s not the mechanical structure of an API that determines it as a Service Locator, but rather the role the API plays in the application. Therefore, a DI Container encapsulated in a Composition Root isn’t a Service Locator — it’s an infrastructure component.
- Ambient Context supplies application code outside the Composition Root with global access to a Volatile Dependency or its behavior by using static class members.
- Ambient Context is similar in structure to the Singleton pattern with the exception that Ambient Context allows its Dependency to be changed. The Singleton pattern ensures that the single created instance will never change.
- Ambient Context is usually encountered when developers have a Cross-Cutting Concern as a Dependency that’s used ubiquitously, making them think it justifies moving away from Constructor Injection.
- Ambient Context causes the Volatile Dependency to become hidden, complicates testing, and makes it difficult to change the Dependency based on its context.
- Constrained Construction forces all implementations of a certain Abstraction to have a particular constructor signature with the goal of enabling late binding. It limits flexibility and might force implementations to do their initialization internally.
- Constrained Construction can be prevented by utilizing a general-purpose DI Container because DI Containers analyze constructor signatures using reflection.
- If you can get away with recompiling the startup project, you should keep your Composition Root centralized in the startup project and refrain from using late binding. Late binding introduces extra complexity, and complexity increases maintenance costs.