
DIMENSIONAL DATA MODELS
In Chapter 2, we introduced data warehousing and described, at a high level, how we might approach a design. The approach we adopted follows the style of some of the major luminaries in the development of data warehousing generally. This approach to design can be given the general description of dimensional. Star schemes and snowflake schemes are both examples of a dimensional data model.
The dimensional approach was adopted in our introduction for the following reasons:
Dimensional data models are easy to understand. Therefore, they provide an ideal introduction to the subject.
They are unambiguous.
They reflect the way that business people perceive their businesses.
Most RDBMS products now provide direct support for dimensional models.
Research shows that almost all the literature supports the dimensional approach.
Unfortunately, although the dimensional model is generally acclaimed, there are alternative approaches and this has tended to result in “religious” wars (but no deaths as far as I know).
Even within the dimensional model camp there are differences of opinion. Some people believe that a perfect star should be used in all cases, while others prefer to see the hierarchies in the dimensions and would tend to opt for a snowflake design.
Where deep-rooted preferences exist, it is not the purpose of this book to try to make “road to Damascus” style conversions by making nonbelievers “see the light.” Instead, it is intended to present some ideas and systematic arguments so that readers of this book can make their own architectural decisions based on a sound understanding of the facts of the matter. In any case, I believe there are far more serious design issues that we have to consider once we have overcome these apparent points of principle. Principles aside, we have also to consider any additional demands that customer relationship management might place on the data architecture.
A good objective for this chapter would be to devise a general high-level data architecture for data warehousing. In doing so, we'll discuss the following issues:
Dimensional versus third normal form (3NF) models
Stars versus snowflakes
What works for CRM
Dimensional Versus 3NF
There are two principal arguments in favor of dimensional models:
They are easy for business people to understand and use.
Retrieval performance is generally good.
The ease of understanding and ease of use bit is not in dispute. It is a fact that business people can understand and use dimensional models. Most business people can operate spreadsheets and a dimensional model can be likened to a multidimensional spreadsheet. We'll be exploring this in Chapter 5 when we start to investigate the dot modeling methodology.
The issue surrounding performance is just as clear cut. The main RDBMS vendors have all tweaked their query optimizers to enable them to recognize and execute dimensional queries more efficiently, and so performance is bound to be good in most instances. Even so, where the dimension tables are massively large, as the customer dimension can be, joins between such tables and an even bigger fact table can be problematic. But this is not a problem that is peculiar to dimensional models. 3NF data structures are optimized for very quick insertion, update, and deletion of discrete data items. They are not optimized for massive extractions of data, and it is nonsensical to argue for a 3NF solution on the grounds of retrieval performance.
What Is Data Normalization?
Normalization is a process that aims to eliminate the unnecessary and uncontrolled duplication of data, often referred to as 'data redundancy'. A detailed examination of normalization is not within the scope of this book. However, a brief overview might be helpful (for more detail see Bruce, 1992, or Batini et al., 1992).
Normalization enables data structures to be made to conform to a set of well-defined rules. There are several levels of normalization and these are referred to as first normal form (1NF), second normal form (2NF), third normal form (3NF), and so on. There are exceptions, such as Boyce-Codd normal form (BCNF), but we won't be covering these. Also, we won't explore 4NF and 5NF as, for most purposes, an understanding of the levels up to 3NF is sufficient.
In relational theory there exists a rule called the entity integrity rule. This rule concerns the primary key of any given relation and assigns to the key the following two properties:
Within any relation, there are dependencies between the key attributes and the nonkey attributes. Take the following Order relation as an example:
| Order | ||
|---|---|---|
| Order number | Primary key | |
| Item number | Primary key | |
| Order date | ||
| Customer ID | ||
| Product ID | ||
| Product description | ||
| Quantity | ||
Dependencies can be expressed in the form of “determinant” rules, as follows:
The Order Number determines the Customer ID.
The Order Number and Item Number determine the Product ID.
The Order Number and Item Number determine the Product Description.
The Order Number and Item Number determine the Quantity.
The Order Number determines the Order Date.
Notice that some of the items are functionally dependent on Order Number (part of the key), whereas others are functionally dependent on the combination of both the Order Number and the Order Item (the entire key). Where the dependency exists on the entire key, the dependency is said to be a fully functional dependency.
Where all the attributes have at least a functional dependency on the primary key, the relation is said to be in 1NF. This is the case in our example. Where all the attributes are engaged in a fully functional relationship with the primary key, the relation is said to be in 2NF. In order to change our relation to 2NF, we have to split some of the attributes into a separate relation as follows:
| Order | ||
|---|---|---|
| Order number | Primary key | |
| Order date | ||
| Customer ID | ||
| Order Item | ||
| Order number | Primary key | |
| Item number | Primary key | |
| Product ID | ||
| Product description | ||
| Quantity | ||
These relations are now in 2NF, since all the nonkey attributes are fully functionally dependent on their primary key.
There is one relationship that we have not picked up so far: The Product ID determines the Product Description. This is known as a transitive dependency because the Product ID itself can be determined by the combination of Order Number and Order Item (see dependency 2 above). In order for a relation to be classified as a 3NF relation, all transitive dependencies must be removed. So now we have three relations, all of which are in 3NF:
| Order | |
|---|---|
| Order number | Primary key |
| Order date | |
| Customer ID | |
| Order Item | |
| Order number | Primary key |
| Item number | Primary key |
| Product ID | |
| Quantity | |
| Product | |
| Product ID | Primary key |
| Product description | |
There is one major advantage in a 3NF solution and that is flexibility. Most operational systems are implemented somewhere between 2NF and 3NF, in that some tables will be in 2NF, whereas most will be in 3NF. This adherence to normalization tends to result in quite flexible data structures. We use the term flexible to describe a data structure that is quite easy to change should the need arise. The changing nature of the business requirements has already been described and, therefore, it must be advantageous to implement a data model that is adaptive in the sense that it can change as the business requirements evolve over time.
But what is the difference between dimensional and normalized?
Let's have another look at the simple star schema for the Wine Club, from Figure 2.3, which we first produced in our introduction in Chapter 2 (see Figure 3.1).
Figure 3.1. Star schema for the Wine Club.

Some of the attributes of the customer dimension are:
| Customer Dimension | |
|---|---|
| Customer ID (Primary key) | |
| Customer name | |
| Street address | |
| Town | |
| County | |
| Zip Code | |
| Account manager ID | |
| Account manager name | |
This dimension is currently in 2NF because, although all the nonprimary key columns are fully functionally dependent on the primary key, there is a transitive dependency in that the account manager name can also be determined from the account manager ID. So the 3NF version of the customer dimension above would look like this:
| Customer Dimension | |
|---|---|
| Customer ID (Primary key) | |
| Customer name | |
| Street address | |
| Town | |
| County | |
| Zip Code | |
| Account manager ID | |
| Account Manager Dimension | |
| Account Manager ID | |
| Account Manager Name | |
The diagram is shown in Figure 3.2.
Figure 3.2. Third normal form version of the Wine Club dimensional model.
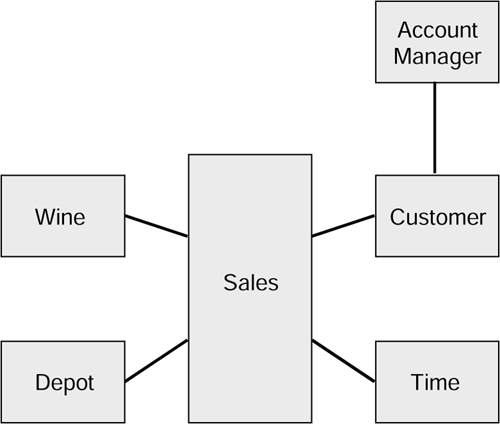
So what we have done is convert a star into the beginnings of a snowflake and, in doing so, have started putting the model into 3NF. If this process is carried out thoroughly with all the dimensions, then we should have a complete dimensional model in 3NF.
Well, not quite. We need also to look at the fact table. But first, let's go back to the original source of the Sales fact table, the Order, and Order Item table.
They have the following attributes:
| Order | ||
|---|---|---|
| Order number | (Primary key) | |
| Customer ID | ||
| Time | ||
| Order Items | ||
| Order number | (Primary key) | |
| Order Items | (Primary key) | |
| Wine ID | ||
| Depot ID | ||
| Quantity | ||
| Value | ||
Both these tables are in 3NF. If we were to collapse them into one table, called Sales, by joining them on the Order Number, then the resulting table would look like this
| Sales | ||
|---|---|---|
| Order number | (Primary key part 1) | |
| Order item | (Primary key part 2) | |
| Customer ID | ||
| Wine ID | ||
| Time | ||
| Depot ID | ||
| Quantity | ||
| Value | ||
This table is now in 1NF because the Customer ID and Time, while being functionally dependent on the primary key, do not display the property of “full” functional dependency (i.e., they are not dependent on the Order Item).
In our dimensional model, we have decided not to include the Order Number and Order Item details. If we remove them, is there another candidate key for the resulting table? The answer is, it depends! Look at this version of the Sales table:
| Sales | ||
|---|---|---|
| Customer ID | (Primary key part 2) | |
| Wine ID | (Primary key part 1) | |
| Time | (Primary key part 3) | |
| Depot ID | ||
| Quantity | ||
| Value | ||
The combination of Customer ID, Wine ID, and Time have emerged as a composite candidate key. Is this realistic? The answer is yes, it is. But, it all depends on the Time. The granularity of time has to be sufficiently fine as to ensure that the primary key has the property of uniqueness. Notice that we did not include the Depot ID as part of the primary key. The reason is that it does not add any further to the uniqueness of the key and, therefore, its inclusion would violate the other property of primary keys, that of minimality.
The purpose of this treatise is not to try to convince you that all dimensional models are automatically 3NF models; rather, my intention is to show that it is erroneous to say that the choice is between dimensional models and 3NF models. The following sums up the discussion:
Star schemes are not usually in 3NF.
Snowflake schemes can be in 3NF.
Stars and Snowflakes
The second religious war is being fought inside the dimensional model camp. This is the argument about star schema versus snowflake schema.
Kimball (1996) proscribes the use of snowflake schemas for two reasons. The first is the effect on performance that has already been described. The second reason is that users might be intimidated by complex hierarchies.
My experience has shown his assertion, that users and business people are uncomfortable with hierarchies, to be quite untrue. My experience is, in fact, the opposite. Most business people are very aware of hierarchies and are confused when you leave them out or try to flatten them into a single level.
Kimball (1996) uses the hierarchy in Figure 3.3 as his example.
Figure 3.3. Confusing and intimidating hierarchy.

It is possible that it is this six-layer example in Figure 3.3 that is confusing and intimidating, rather than the principle. In practice, hierarchies involving so many layers are almost unheard of. Far more common are hierarchies like the one reproduced from the Wine Club case study, shown in Figure 3.4.
Figure 3.4. Common organizational hierarchy.

These hierarchies are very natural to managers because, in real-life scenarios, customers are organized into geographic areas or market segments and the managers' desire is to be able to ask questions about the business performance of this type of segmentation. Similarly, managers are quite used to comparing the performance of one department against other departments, or one product range against other product ranges.
The whole of the business world is organized in a hierarchical fashion. We live in a structured world. It is when we try to remove it, or flatten it, that business people become perplexed. In any case, if we present the users of our data warehouse with a star schema, all we have done, in most instances, is precisely that: We have flattened the hierarchy in a kind of “denormalization” process.
So I would offer a counter principle with respect to snowflake schemas:
There is no such thing as a true star schema in the eyes of business people. They expect to see the hierarchies.
Where does this get us? Well, in the dimensional versus 3NF debate, I suspect a certain amount of reading-between-the-lines interpretation is necessary and that what the 3NF camp is really shooting for is the retention of the online transaction processing (OLTP) schema in preference to a dimensional schema. The reason for this is that the OLTP model will more accurately reflect the underlying business processes and is, in theory at least, more flexible and adaptable to change. While this sounds like a great idea, the introduction of history usually makes this impossible to do. This is part of a major subject that we'll be covering in detail in Chapter 4.
It is worth noting that all online analytical processing (OLAP) products also implement a dimensional data model. Therefore, the terms OLAP and dimensional are synonymous.
This brings us neatly onto the subject of data marts. The question “When is it a data warehouse and when is it a data mart”? has also been the subject of much controversy. Often, it is the commercial interests of the software vendors that carry the greatest influence. The view is held, by some, that the data warehouse is the big, perhaps enterprise-wide, repository and that data marts are much smaller, maybe departmental, extractions from the warehouse that the users get to analyze.
By the way, this is very closely associated with the previous discussion on 3NF versus dimensional models. Even the most enthusiastic supporter of the 3NF/OLTP approach is prepared to recognize the value that dimensional models bring to the party when it comes to OLAP. In a data warehouse that has an OLAP component, it is that OLAP component that the users actually get to use. Sometimes it is the only part of the warehouse that they have direct access to. This means that the bit of the warehouse that the users actually use is dimensional, irrespective of the underlying data model. In a data warehouse that implements a dimensional model, the bit that the users actually use is, obviously, also dimensional. Therefore, everyone appears to agree that the part that the users have access to should be dimensional. So it appears that the only thing that separates the two camps is some part of the data warehouse that the users do not have access to.
Returning to the issue about data marts, we decline to offer a definition on the basis that a subset of a data warehouse is still a data warehouse. There is a discussion on OLAP products generally in Chapter 10.