
Chapter 1. Why Use Redux?
State is the heart of all rich applications, and as application developers we spend a lot of time managing state within our applications. Without state a web application is nothing more than a static HTML page. If we want to build feature rich web applications we must become proficient at managing state.
Managing state is problematic
As web technologies have matured, web applications have become more complex and feature rich, pushing the boundaries of what’s possible. These feature-rich web applications come at a cost, and that cost is complexity. A large piece of that complexity is the management of application state.
Managing this complexity and the extra state required to enable these rich features is hard. Traditionally, we have used two-way data binding to manage state, allowing state to be automatically updated by binding it to the view layer. This is the approach a lot of frameworks took in the early days of web applications, and it’s still in use today.
This works out fine for smaller applications, but has proven to be difficult as the complexity of web applications have increased, often resulting in opaque systems where data flow and state changes are non-deterministic and hard to debug. As more features are implemented into these troublesome architectures, the issue is compounded, creating a vicious circle.
Part of this complexity is a result of mixing state mutation and asynchronicity, two concepts that are inherently difficult to understand. In Redux circles this problem is referred to as Mentos and Coke. The point being that these concepts can be unpredictable and messy when mixed.
How Redux helps
Redux aims to decouple state mutation and asynchronicity, separating them so that you can reason about them individually. If you have a problem with state, you can debug the state tree to determine how the state was created without having to worry about asynchronous logic. Likewise, if you have a problem with your asynchronous logic, you can focus on debugging it without having to worry about state.
Not only is this better for your sanity, it opens up a range of additional benefits, ranging from improvements to developer workflows to easier unit testing. All of this due to the separation of asynchronous logic from state mutation.
Redux does more than simply separate these concerns, it also implements restrictions on how state can be mutated, making state mutations predictable, and the state of your application much easier to reason about.
Redux wants to give you control back, it wants you to enjoy programming again, and it’s going to do this by providing you with an architecture that is developer friendly, predictable, and robust.
Redux background
Redux was created by Dan Abramov, who is currently a developer working on React at Facebook. Dan created Redux while working on a talk called “Hot Reloading with Time Travel for React Europe 2015.” In order to demonstrate these two concepts, a predictable architecture that used a single state tree was required. It was this desire that drove the creation of Redux.
The birth of Redux
Dan initially tried to use traditional Flux, but he had many difficulties. For example, in order to hot reload store logic, a store had to be a pure function. This wasn’t the case with traditional Flux stores that have behavior such as subscribe and register built in. As you remove this behavior from traditional Flux stores, you end up with stateless stores, and the first step towards Redux.
Note: In Redux we call these stateless stores reducers, and we’ll refer to them as that from now on.
Once you have stateless stores, which we’re now calling reducers, you can hot reload the state logic. These reducers were still tied to a dispatcher though. So, instead of having multiple stateless reducers, a single reducer was introduced. This single reducer removed the need for a dispatcher because actions then have a single destination.
The obvious problem with having a single reducer is that there is no separation of responsibilities. This is easily overcome by the fact that reducers are just pure functions, and that means they can be composed of other functions. So a single reducer can be composed of many smaller reducer functions, each one with a particular responsibility.
At this point you essentially have Redux. You have a single store and a single root reducer created from a pure function. These are two of the Redux core principles. This early implementation has been improved and polished, becoming the library that we know today.
Redux influences
Let’s examine the major Redux influencers.
Elm
Redux produces an architecture that is very similar to the architecture used in Elm - a functional programming language for HTML apps. It can even be considered an almost direct translation into JavaScript. While this is true, Redux is not simply a direct copy of Elm. Elm is more of an indirect influence, and the fact that they are very similar is proof that great architectures naturally arise from similar design goals.
ES6
ES6 is heavily used in Redux. You will benefit greatly from being comfortable reading and writing ES6 code when learning Redux. Redux doesn’t use ES6 just for the sake of it, the language features most used actually make writing Redux application code much easier.
We’re not saying that you need to stop and learn ES6 inside-out before continuing, rather that you should be comfortable with it, because you’re going to see a lot of it, and you’ll pick things up much quicker if you can focus on learning one thing at a time.
At the very least, you should be comfortable reading arrow syntax functions, and have a good understanding of the const and let keywords, as well as the spread operators for arrays and objects. Object spreads are currently an in-progress proposal for the JavaScript language, and widely available through tools like babel, and useful when writing reducer logic.
Functional programming
Redux embraces functional programming and incorporates many functional programming concepts into its methodology. Although functional programming is not a prerequisite to learning Redux, knowing about the core concepts of functional programming will certainly help reduce the initial learning curve.
Immutability
Immutability is a related concept to functional programming. Immutable data is simply data that cannot be changed after it has been created. Redux embraces immutability, since it’s at the core of at least one of the three principles of redux: state must be read only.
Redux doesn’t enforce this, and you’re free to use mutable or immutable objects to model your state, but you should follow the rules of immutability and ensure that you don’t mutate state to benefit from the predicability that it provides. This also ensures that scenarios like time travel debugging will work correctly, and that UI components will update properly.
Flux
Redux is inspired by Flux - an application architecture for building user interfaces that uses a unidirectional data flow. If you compare the two you will notice similarities - both help to manage application state, and both implement mechanisms for managing how changes are made to the state.
Although similar, there are some key differences between the two. One key difference is that in Flux there is the concept of a dispatcher. A dispatcher is responsible for relaying actions to listening stores. Redux, however, eliminates the need for a dispatcher through the use of a single reducer, pure functions, and function composition.
Another key difference is that Flux has many stores with each store managing a separate piece of state for a particular area of the application. In Redux there is only one store and one single source of state - referred to as the single source of truth. You can still manage state for different areas of the application, but in Redux you use reducers, and function composition, to achieve this.
Both approaches solve the same problem, they just do so it in slightly different ways.
Unidirectional data flow
With roots in functional reactive programming, unidirectional data flow has gained popularity in recent years. The main principle is that data flows through your application in a single direction, making the flow of data through your application much easier to reason about.
With unidirectional data flow architectures like Flux and Redux, your state is contained in stores (a single store, in Redux) and updates to the state are managed through actions that describe how the state should be transformed. The view layer can then subscribe to the store(s) to receive new state whenever it’s changed.
The following diagram illustrates the typical data flow in a Redux application. Here you can see that an action is dispatched to the store, so the store then passes the existing state and the action to the reducer, which transforms the state. The new state then flows through to any listeners, such as views. A view can dispatch further actions, starting the process again.
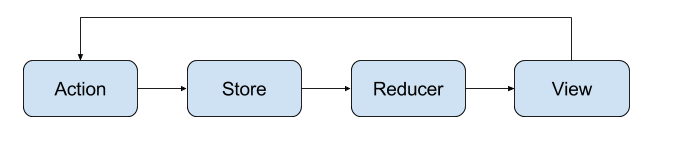
With data flowing in one direction to your views, they become functions of your application state, making them much more predictable. You can give the views the same data and you will get the same result, which is similar to a pure function.
Two way data binding
Another approach to managing data flow is two way data binding or bidirectional data flow. This has been a common approach for many years, and while it can work well for some applications, it does have known problems, such as cascading updates. A cascading update is where a change to state in one model can result in unpredictable changes to state throughout the application.
Two way data binding works by syncing the data between a model and a view. This is where the name two way data binding comes from, since the data is bound to both the model and the view, and can flow in either direction.
Changes to the model are propagated to the view and vice versa. For example, entering text into an input box in the view can result in a direct modification of data on the model. This is discouraged in a unidirectional architecture, and changes are never directly made to state.
Another major problem with two way data binding is that it results in complicated and unpredictable data flow. When state can be mutated by multiple sources, it’s difficult to reproduce and debug issues involving changes to that state.
The following diagram illustrates the problem with two way data binding.
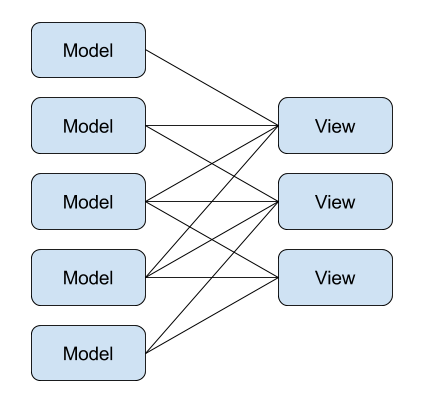
In the above diagram you can see that the dependencies between models and views have become incomprehensible. For the majority of models, it is no longer clear which views are mutating its state, so debugging issues relating to state becomes difficult. This is just a simple contrived example. The problem is usually much worse in large applications where the number of models and views are usually in double digits.
The three principles
The whole concept of Redux revolves around three core principles.
- Single source of truth
- State is read only
- Changes are made with pure functions
Let’s look at each one in isolation to understand their value.
Single source of truth
The first principle of Redux is that there is a single source of truth for all state within your application. This single source of truth is a state tree, which is simply a container for the state, which is usually a plain old JavaScript object.
conststate={todos:[]};
This state tree is managed by another component called a store, which we’ll look at later. In Redux there is a single store, and therefore a single location for all of our state.
This is opposite to the approach that most traditional web applications take, where state is scattered throughout the application. For example, in a typical MVC application, state is stored in models, collections, and views.
There are some nice advantages to a single source of truth. For one, it’s much easier to reason about state that is stored in a single location. It’s better for your sanity, but there are other, not-so-obvious, benefits too.
One not-so-obvious benefit is that a single state tree offers us the ability to create universal applications much easier than with other architectures. This is due to the state being in a single location, making it easy to serialize and share between the client and server.
Another not-so-obvious benefit is an improved development experience. Similar to enabling easier universal applications, a single state tree also enables you to easily persist the whole of your application state. It is simply a case of saving the state (e.g. to local storage) and loading it again on page load.
State is read only
The second principle of Redux is that state is read only. This doesn’t mean that you can’t change the state of the application, it means that you should never modify the state tree directly outside of the store.
Instead, modifications to the state tree should be made by dispatching actions. An action is simply an object that describes the change you want to make to the state. They are dispatched with a simple method call, similar to dispatching an event with an event emitter.
Following this principle provides an architecture where changes to state are centralized and applied, one at a time, in a strict order. Like state being read only, this also provides some not-so-obvious benefits.
One such benefit is the ability to rollback, commit, and replay actions to reproduce state, a concept called time travel debugging. It also helps to remove hard-to-debug race conditions where state has been changed in multiple locations in a non-deterministic way, which is a common problem in MVC architectures.
Centralizing changes to state is a different approach to your typical MVC architecture, where state changes can come from multiple places. For example, model state can be changed by the model itself, the model’s collection, or a view that presents the model.
Changes are made with pure functions
The last Redux principle states that changes are made with pure functions. What this means is that the state tree, the single source of truth, can only be changed by passing it to a pure function that then applies the change and returns the new state.
A pure function is simply a function that provides the same output given the same input and has no side effects. In other words, a pure function does not change any external state or interact with the outside world in any way.
In Redux, these pure functions are called reducers. They are called reducers because they follow the same pattern as reducers from functional programming. This means they accept an accumulator and a value and return a new single value, for example the Array.reduce() method. The following is an example of a Redux reducer that exhibits these behaviors.
functionreducer(state=0,action){switch(action.type){case'multiply':returnstate*state;default:returnstate;}}
The main advantages of using pure functions to manage changes to state are predictability and testability. They are predictable because you always get the same output when called with the same input. This also makes them easy to test, as does the fact they don’t interact with the outside world, which results in less mocking and stubbing of external dependencies.
With these benefits in mind, and the fact that there is only a single source of truth, you can see how Redux encourages an application architecture where the core of your state management is predictable and easy to test. Compare this to other approaches, even unidirectional approaches such as Flux. In a Flux architecture state does not possess the qualities of predictability and testability, instead the the opposite is usually true.
And because managing state is such a large part of what you do when developing rich web applications, you benefit greatly from a data flow architecture that provides predictable state that is easy to test. This predictability gives you confidence and control, and the ability to easily test how state changes allows you to verify that your predictions about state transformations are correct.
Looking ahead
We’ve discussed what Redux is, what problems it solves, and what inspired its methodology. In the next chapter we’re going to look at the core concepts that define Redux. As we progress through the book we’re going to build on these core concepts, developing our own Redux application using React for the view layer.
While Redux can be used with other frameworks, it has close ties to React, which has a big community, a lot of support, and many tools available for this particular stack. Support for using Redux with other frameworks is improving, but due to how closely tied Redux and React are, it’s unlikely that you’ll find the same level of support elsewhere.
However, with that said, we will be showing you how to integrate Redux with two of the biggest technologies in use today: React and Angular 2. We’ll look at these integration paths before we start on our sample application.
Conclusion
In this chapter we looked at where Redux came from, its inspirations and the reason for its creation. We also looked at some of the issues Redux attempts to address, learning about both uni directional architectures and two way data binding. Finally, we took a look at the three Redux core principles, which we need to keep in mind as we continue on our path to gain a Redux edge.