
BIG DATA AND DATA ANALYTICS
Data and data exchange are key factors of success for traditional supply chains. The more hierarchical structure of these traditional supply chains influences the way data is generated, exchanged, and analyzed, as well as the potential value-add of data for all stakeholders. In contrast, for digital supply networks (DSNs), stakeholders are working together at a more agile and collaborative level. This creates tremendous opportunities when it comes to capitalizing on the true value of data at the network level for all areas of business. However, the dynamics and complexity of such DSNs pose some distinct challenges when it comes to data, data exchange, and being able to derive insights from large amounts of shared data within the network.
In this chapter we discuss the importance of data as the lifeblood of digital transformation and DSNs. We highlight the impact of the increasing availability of large amounts of data (big data) on operations and business models, and we discuss the changing perception of the value of data in itself. We introduce the “five Vs” of big data and data management, highlighting specifically the impact of data quality and the data lifecycle. The increasing amount and associated value of data makes the topic of data security and authority important, especially in a DSN environment. We illustrate the key aspects of data security and authority before we touch upon selected technical developments, legislation, and infrastructure that enable this data revolution and provide us with unpreceded access to large quantities of data in a timely or even real-time manner. Interoperability, interfaces, and standards, as well as cloud platforms are some of the aspects we discuss in the last two sections of this chapter. These last sections serve as a transition to the next chapter, which will focus on machine learning, artificial intelligence (AI), and robotics applications that are the key to unlocking valuable insights for the organization or digital supply network.
IMPACT AND VALUE OF DATA
Data is currently at the peak of expectations in all areas of business. Today, we live in a time when data is available at unpreceded levels. At the same time, our ability to analyze these large amounts of data to derive insights is continuously maturing. However, data by itself is useless unless it can add value and make an impact for an organization or system. Table 3.1 illustrates selected DSN areas and tasks that directly or indirectly profit from the increasing amount of and access to data and the insights within it that can be unlocked through data analytics. While the table highlights key points, this is by no means comprehensive as new, innovative, and value-adding data-driven applications are emerging daily. Furthermore, these areas and tasks are collaborative efforts within DSN. Therefore, the impact of data increases significantly compared to using data only from individual organizations. Actually, in DSN many tasks cannot be successfully completed without access to and the ability to analyze relevant data.
TABLE 3.1 DSN areas and tasks with the highest impact and value of data (not comprehensive and in no specific order)

Next, we explore how data is developing into a valuable resource in its own right and discuss the impact of data on an organization’s or network’s operations as well as the overall business model.
Data Accessibility and Acquisition
Digital supply networks are defined by their digital nature, connectivity, and the ability to electronically exchange and analyze data in real time. A key enabling factor of DSN is the ability to collect, process, communicate, and store data from a diverse set of sources. These data sources include but are not limited to information technology (IT) systems (e.g., ERP, CRM), sensors (e.g., temperature, GPS), operational technology (OT) systems (e.g., machine tools), publicly available data (e.g., social media, reviews), as well as financial (e.g., transaction data, stock market). These data sources can be located anywhere—within the organization, within the DSN, or externally, adding an extra layer of complexity to the system.
The type of data source is one key factor when it comes to accessibility. On the technical side, DSNs can be considered cyber-physical systems (CPS) or cyber-physical production systems (CPPS). In CPS, the physical world (machines, trucks, workers) and the virtual world (sensors, software, algorithms) are merging, creating a joint system. Sensors connect physical assets to the network, and through the Internet of Things (IoT) or the Industrial Internet of Things (IIoT), collect data and share that data via the Internet or cloud.
Another key factor is acquisition, and this involves a different layer of complexity. DSNs are collaborative networks, comprising various organizations and actors within the DSN that interact with various organizations and actors outside of the immediate DSN. While a DSN has an overall joint objective, the different actors within may have slightly different individual objectives that influence their ability and/or willingness to share data. Actors outside of the DSN are even more likely to have their own agendas and be rather restrictive in the sharing of data, especially as data is increasingly seen as a competitive asset. This can influence data accessibility as much as the technical infrastructure. In the following sections we dive deeper into the notion of the skyrocketing value of data, touch upon the nature of (big) data within DSN, and provide an overview of key policies and technical infrastructure components.
Data as a Valuable Resource in Its Own Right
Everybody agrees that (high-quality) data is a valuable resource for businesses, be it on the analyst, organization, or complex supply network level. However, today data is still predominantly connected to a certain business case, and its real or perceived value is tied to a distinct analytics goal, product, product family, or capital equipment, just to name a few. In the age of DSNs, we start to see the emergence of data being considered a valuable resource within its own right. While the value of data remains in the insights that can be derived from it, the direct relation to a certain clearly defined use case is not as obvious any longer.
Data itself, together with the ability to tap into the hidden truth within it (see Chapter 4, “Machine Learning, AI, and Robotics”) enables disruptive innovation, including new business models or even entirely new industries. Data emerges as the lifeblood of industry disruption and provides organizations with the right strategy and abilities to develop a sustained competitive advantage.
Impact on Operations
Operations have always been driven by data. Logistics and supply chain management have been a fertile area for simulation, mathematical modeling, and operations research. It is broadly accepted that the better and more comprehensive the available data, the greater the potential for optimization. The technological advancements over the past decade provide unpreceded growth in the sheer amount, granularity, and timeliness of data relevant for operational efficiency optimization. Deeper integration of IT/OT systems, data exchange and flow, and data analytics allow DSN to be proactive instead of reactive, thus avoiding issues such as bullwhip effects or other coordination issues that are common problems within traditional supply chains. Overall, the impact of data on the operations of DSN cannot be overstated and is rather a necessity to manage the complexity and dynamics embodied within.
Impact on Business Models
In contrast to operations, which were always to some extent data-driven, data-driven business models are a newer development. One might argue that to successfully position an organization in the competitive marketplace requires an understanding of the market, and thus, the interpretation of some form of (market) data. This may be true. However, in this case when we talk about data-driven business models in a DSN context, our understanding of data-driven goes well beyond that traditional notion. In a DSN setting, the business model of each individual member organization as well as the DSN as a whole depends on data to begin with. Data sharing agreements are now commonplace within DSN, and data increasingly determines the share of revenue and risk for the different stakeholders. DSNs most likely have partners within the collaborative enterprise that focus on data analytics, and the results influence the activities and strategy of the DSN.
Generally, we see the emergence of new and innovative business models that are solely build on data. Nonownership business models such as pay-per-use or pay-per-outcome require a sophisticated technical infrastructure on one hand, but also an organizational setup with diverse stakeholders with different capabilities including designer, manufacturer, service providers, and operators to be successful. DSNs provide a possible vehicle to manage this complex collaborative setup. The benefits that emerge from such a data-driven business model are manifold, including lower overhead and operational cost, increasing customer loyalty and lock-in, improved product quality, continuous revenue, and detailed insights into real customer interaction with the product(s). Overall, the impact of data on future business models is tremendous and offers great rewards for DSNs that successfully innovate.
BIG DATA
In the previous section, we talked about data, its impact and value within DSNs. In this section, we examine what data looks like today and will look like in the future within emerging DSNs.
Five “Vs” of Big Data
Today, almost every organization is referring to its data management and analytics as “big data.” However, the “big” in big data not only refers to “lots of data” but is defined by a number of dimensions that each present a distinct challenge for data management, infrastructure, and analytical tools and systems. The definition of big data has several variations. The most common and accepted one defines big data through the “five Vs” of volume, velocity, variety, veracity, and value (see Figure 3.1). Common variations of this popular definition include the three Vs, focusing on the three core dimensions (volume, velocity, and variety), and seven Vs, adding two additional dimensions (variability and visualization) (see Table 3.2).
FIGURE 3.1 Five Vs of Big Data: Volume, Velocity, Value, Veracity, and Variety

TABLE 3.2 Three Vs, five Vs, and seven Vs of big data

VOLUME. The dimension volume describes the sheer amount of data that is required to justify the term “big data.” The volume that is associated with big data varies from industry to industry and use case to use case. Social media is often used as an extreme example of the large volume of data that is available for analytics. Hundreds of millions of messages, pictures, and videos are uploaded to social media sites daily and make up a massive amount of data that clearly meets the requirement of big data. In an industrial setting such as DSN, while the overall amount might be smaller, we experience an extreme growth rate when it comes to the amount of data with millions of connected devices within the IIoT continuously collecting data. Some processes create massive amounts of data within a single application. An example is laser welding, where the weld pool is controlled and optimized using high-resolution images, creating gigabytes of data for each part being manufactured.
VELOCITY. This dimension, on the other hand, refers to the speed at which new data is generated. Social media generates data at unbelievable speeds due to the large user base. Similarly, technological progress allows us to sample sensor data at much higher frequencies, and thus we are faced with new data coming in at extremely high rates. New communication protocols such as 5G and sensors reduce the latency further. Therefore both the growing number of data-producing sources and the speed at which each node is capable of producing new data contribute to the velocity of new data being generated.
VARIETY. The third core dimension of big data, variety, covers the diversity of kinds of data that make up big data. Image data, audio and video files, sensor data, standardized order data, location data, encrypted files, tweets, text files, and several more variations, including all thinkable combinations of these, pose a distinct challenge for data analytics and the processing of big data.
VERACITY. With the ever-increasing speed and volume of data being generated and the growing number of data-producing sources, the big data dimension veracity is emerging as a necessity. Veracity focuses on the quality of data and also the trustworthiness of the data source. In a big data environment, we cannot manually control all sources and certify the credibility of each node and data point. Increasingly, algorithms are tasked with plausibility checks and other advanced methods to ensure that the quality of the data fed into the analytical systems allows us to trust the insights derived from it. The old adage “garbage in, garbage out” stands true for big data analytics as well; however, managing the influx of data is presenting new challenges.
VALUE. This is a key dimension when it comes to big data and data analytics. Without providing value through decision support or otherwise useful and actionable insights from the data, the analytical effort and resources invested are hard to justify. In essence, “value” in this case refers to the ability to translate the wealth of big data into business. Value has to be understood broadly, as we only learn what constitutes good, data-driven business decisions within a DSN. New value propositions are emerging, and thus the value perspective of big DSN data is under constant development—and organizations and networks that are innovative and creative to turn big data insights into value will gain an edge in the competitive landscape.
Volume, velocity, variety, veracity, and value make up the five Vs of big data. Next we briefly introduce two additional Vs—which with the first five are sometimes referred to as the seven Vs—that are used in the big data context. In a DSN context, the two additional Vs, variability and visualization, are important aspects to consider when it comes to the data and data analytics strategy.
VARIABILITY. The dimension variability highlights a difficult problem for big data applications: the changing meaning and/or context of data over time. Variability is different from variety in that it does not refer to different variations of data, but rather data that changes in meaning over time. To make matters worse, this change of meaning and/or context is often not easy (or very hard) to predict. Variability presents a critical issue for data homogenization as well as for data analytics. Awareness about variability of data is crucial to manage the risk and trust put into the insights derived from big data analytics.
VISUALIZATION. This is the last key dimension of big data that we are going to discuss. It is grounded in the cognitive ability and individual preference of human stakeholders. Big data, as we learned, refers to large amounts of complex data that is, generally speaking, impossible for human minds to grasp without the assistance of advanced algorithms. However, to truly unlock value, the insights derived from the big data sets need to be communicated to human decision makers in a way that corresponds with their abilities, roles, and ideally preferences. For example, the machine operator will, in most cases, prefer a more detailed graphical representation of the results compared to the CEO’s higher-level dashboard.
Structured and Unstructured Data
DSNs are natively located within a big data setting. Expanding on the core dimension of variety, it is important to better understand the differences of—and challenges presented by—structured, semi-structured, and unstructured data. Figure 3.2 provides a simplified visualization of the differences between structured, semi-structured, and unstructured data. The different shapes represent varying types of data (e.g., audio, picture, sensor readings). Table 3.3 (see next page) provides an overview of typical examples where the different types of data emerge within DSN operations.
FIGURE 3.2 Schematic of Differences Between Structured, Semi-Structured, and Unstructured Data Sets

TABLE 3.3 Examples of structured, semi-structured, and unstructured data

While both structured and unstructured data can be generated by humans and automated systems alike, they present distinct differences with regard to searchability, required storage infrastructure, and ease of using data analytics and machine learning algorithms. Today, there are sophisticated and mature analytical tools available to discover insights from structured data, while the algorithms aimed at unstructured data are not as mature but rapidly developing. The latter present a huge opportunity as the value hidden in and expected from mining big data lakes made up of mostly unstructured data is tremendous. In a complex and dynamic system such as DSN, there is a large and growing portion of generated data that falls in the unstructured category. It is essential for all stakeholders to understand the implications of this in order to manage expectations and also develop innovative strategies to access the hidden insights within this often-untapped resource.
STRUCTURED DATA is typically stored in a relational database management system (RDBMS) that enables search queries using Structured Query Language (SQL). Structured data follows a predefined, often standardized data model that enables efficient search operations for both human operators and automated algorithms. In a DSN environment, several core data streams are considered structured data, such as demand forecasts, ERP transactions, and EDI invoices. Nevertheless, we increasingly have to deal with a more diverse set of data, and this change is expected to accelerate and continue.
SEMI-STRUCTURED DATA is a combination of structured data that does not follow standard data models associated with RDBMS or other standard schemas. However, it provides additional metadata in the form of semantic descriptors, tags, or keywords that enable search functionalities and other analytics.
UNSTRUCTURED DATA is essentially everything that does not fall under the umbrella of structured data described above. Unstructured data can typically not be stored in a classic RDBMS, but uses nonrelational databases such as “non SQL”, sometimes called “not only SQL”, (NoSQL). Unstructured data is not unstructured in the true meaning of the word as the data items do indeed have a certain (internal) structure. However, there is no common structure present that follows predefined and/or standardized data models or schemas.
Whether a data set is considered structured, semi-structured, or unstructured has an impact on the perceived data quality; however, it does not necessarily impact the technical data quality. In the next section, we will explore what technical data quality means in a DSN context.
Data Quality
Data quality is a multidimensional concept that is defined relative to the stakeholder’s analytical objectives. This goes hand in hand with technical requirements toward data quality put forth by data processing and analytics tools, applications, and services. Low data quality can result in major issues for organizations, ranging from operational to strategic errors. Once problems occur and can be traced back to data quality issues, it is often too late to address them effectively and efficiently. In order to avoid problems, data quality should be a continuous effort that starts as early as the design of the collection or acquisition, communication and storage, and data management processes, system, and infrastructure, as well as the data analytics tools and objectives.
As mentioned, data quality is a multidimensional concept that comprises technical as well as organization or contextual issues. Technical data quality issues include errors, missing values, corrupted files, completeness, and timeliness just to name a few. Conversely, organizational data quality issues include interpretability, representation, annotation, and relevance among several others.
Data Lifecycle
When it comes to data, the conversation is almost always driven by the question of how to access and collect more data to sharpen the analytics and derive more accurate predictions. The associated cost of this data is often neglected. This cost needs to be justified by the value the data actually provides. Today, many organizations and DSNs struggle with the question of when data can be deleted. With storage costs dropping in price, the solution many refer to is “don’t delete any, we might need it in the future.” This provides a short-term release from the pressure to find a better answer to this difficult question, but it is not a solution for the problem. Storing data that exceeds its useful life is expensive not only in the form of storage cost but also in potentially preventing efficient and effective data analytics. While the former is of course a nuisance and should be prevented, the latter is the truly costly issue that stems from avoiding addressing the question.
Unfortunately, there is no easy guideline on how to answer such a problem. Each case, organization, and DSN is different and so is the lifecycle of data. There is no one-size-fits-all solution to when data can be deleted (e.g., after two years, four months, seven days, and three hours). In the worst case, each data item has an individual expiration date that needs to be determined. Many companies move toward not deleting data completely but rather reducing the granularity of the data stored. As an example, after an individually determined time frame t1, an organization transforms data with a hypothetical resolution of 50 data points per millisecond in an aggregated data set with a resolution of 6 data points per second. At a later point t2, they aggregate further to one data point per hour, and so forth. This compromise enables the company to still retain and document its data picture, while reducing its hosting costs and processing efforts. Despite these intermediate solutions, the overall problem of when to safely delete data in a DSN is yet to be solved.
CYBERSECURITY, DATA GOVERNANCE, AND DATA AUTHORITY
Cybersecurity is crucial for every connected enterprise within DSN. In a nutshell, it encompasses all processes and practices that aim at preventing malicious attacks on computers, databases, servers, networks, and any other connected system or data source. With the rapid rise of IIoT and the associated growth of network-connected devices and systems, cybersecurity has risen to one of the top concerns of decision makers in DSN.
From a business perspective, aside from intentionally malicious attacks, questions regarding data ownership, governance, and authority need to be addressed within a DSN to function. Adding complexity, DSNs are often multinational constructs and therefore have to adhere to varying laws, policies, practices, and mindsets when it comes to data privacy and cybersecurity.
Ownership
In a DSN, each node of the network generates data—whether related to manufacturing, logistics, or accounting processes—and also consumes data for analysis, planning, or coordination. As we established previously, data is considered a competitive advantage, and the question of data ownership is not trivial in a DSN. Individual member organizations are often hesitant to share detailed data with others, at times for a good reason. Therefore, it is crucial for the success of the DSN as a whole to address this issue from the start and develop a transparent data ownership and sharing agreement among the members. New, innovative approaches associate a value (in dollars or a virtual data currency) to data that is shared to ensure accountability and reward for organizations willing to share data within the DSN.
One of these new initiatives addressing the ownership, data sovereignty, and data sharing across organizations is the International Data Spaces Association.*
Cybersecurity and Data Security
Cybersecurity is a broad, multidisciplinary field. It has a technical dimension (not within the scope of this book) as well as an organizational/business dimension. On the organizational/business side, cybersecurity can be further clustered in several subdimensions, of which we will briefly introduce two variants relevant for DSN. First, there are one-directional cybersecurity or data security threats, meaning that an attacker gains access to data and information (aka a data leak). We can differentiate further between access to individual documents and other information items, or the more severe direct access to databases, CAD files, and/or machine tools with real-time process data. Second, two-directional cybersecurity threats describe attacks where the intruder not only gains access to data and information but also is able to delete or manipulate data. Again, there are different levels, one where historical data is deleted, altered, or manipulated with malicious intentions, and a second level where the attacker can manipulate process parameters, CAD files of future products, and so on that can result not only in economic but also safety issues for operators and users.
Laws, Policies, and Regional Differences
We briefly covered the ownership as well as cybersecurity related issues when it comes to big data and data analytics in DSN. In this section, we touch upon a developing subject that every DSN needs to pay close attention to, especially when operating internationally: laws and policies, as well as differences in mindsets.
Virtually every country, sometimes even state and region, has different laws and policies in place. In lieu of a detailed discussion that would go beyond the scope of this book, we highlight selected examples of three major markets for DSN—the United States, European Union, and China, in Table 3.4. The concept of data sovereignty tries to bridge the differences and establish that data is subject to the laws and policies of the country or region where it was collected.
TABLE 3.4 Selected examples of data-related policies and laws in the United States, European Union, and China

Besides the policies and laws of different regions, we recommend to also take into account the different mindsets that exist when it comes to data and data sharing. There are distinct differences between regions and countries. For example, the Scandinavian countries are very open and transparent, whereas Germany is very strict when it comes to data privacy. Awareness and transparency is crucial to avoid costly misunderstandings within the DSN that will affect its operations and collaboration.
INTEROPERABILITY
In digital supply networks, diverse stakeholders collaborate and exchange goods, data, and information. At the same time, the different organizations within a DSN use a variety of different software and hardware systems, tools, and services. It is neither practical nor economical to streamline the legacy systems in use by the different stakeholders. Therefore, interoperability plays an essential role in enabling effective and efficient data exchange within a DSN.
Interoperability describes exactly that—the ability of digital systems to interact, to exchange, process, and analyze data and information across platforms. Key aspects of interoperability include interfaces and standards. Interfaces enable two applications, systems, or networks to communicate. Standards define data models, schemas, and message formats, as well as other parameters that enable a system to interpret and process the data and information received from other systems. There are plenty of standards available, ranging from open standards, to industry-specific standards, to proprietary standards for specific purposes. Well-known examples of standards relevant to DSN include, but are not limited to, the following:
• ISO 10303. With the official title “Automation systems and integration—Product data representation and exchange,” or STEP, ISO 10303 enables the exchange of CAD models across platforms.
• MTCONNECT is a relatively new standard that enables manufacturers to retrieve process data directly form the machine tool on the shop floor.
• OPEN APPLICATIONS GROUP INTEGRATION SPECIFICATION (OAGIS) provides a canonical business language for information integration by defining common content models and messages for effective communication between applications (A2A) and businesses (B2B).
• ELECTRONIC PRODUCT CODE INFORMATION SERVICES (EPCIS) is a global GS1 standard focused on creating and sharing events often connected to RFID technology (not a requirement).
• ELECTRONIC DATA INTERCHANGE (EDI) is probably the most frequented DSN data exchange technology today that enables the direct exchange of (business) data such as purchase orders or invoices between organizations.
BIG DATA AND DATA ANALYTICS INFRASTRUCTURE
Big data and data analytics within a DSN put forth challenging requirements in terms of enabling infrastructure. Add cybersecurity concerns, proprietary platforms, and interoperability to the equation, and we see why many organizations struggle with setting up the appropriate enabling technologies and infrastructure. The purpose of this section is to provide a basic overview of some key elements of a big data infrastructure from a hosting and business perspective. It is beyond the scope of this book to dig deep into the technical requirements, such as specific types of NoSQL databases and protocols.
The question of where the data should be stored or hosted, processed, and analyzed depends on many factors, including the business case, the location, the industry, and many more. From a DSN controls perspective the questions to be asked include whether we want to centrally control the system, enable decentralized control, or whether some form of hybrid control model suits the purpose best. In the following section, four key elements of a big data infrastructure in terms of data hosting and processing are briefly elaborated on: fog and edge, local, cloud, and hybrid (see Figure 3.3).
FIGURE 3.3 Key Elements of Big Data Infrastructure
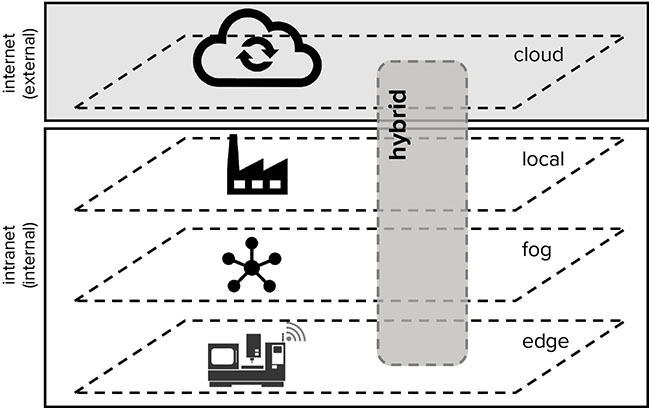
Fog and Edge
Fog and edge computing enable data processing and to some extent analytics closer to the original data source—for example, an IoT sensor system or connected machine tool. The terms “fog” and “edge” are often used interchangeably and the overall objective is similar, yet, they are sometimes differentiated. In fog computing, the intelligence and information processing is located at the local network architecture, while in edge computing the intelligence sits directly at or very close to the sensor, machine tool, or service generating the data. Historically, the cost, speed, and availability of data communication were the main reasons to opt for an edge architecture. In essence, “Fog computing bridges the gap between the cloud and end devices (e.g., IoT nodes) by enabling computing, storage, networking, and data management on network nodes within the close vicinity of IoT devices. Consequentially, computation, storage, networking, decision making, and data management not only occur in the cloud, but also occur along the IoT-to-Cloud path as data traverses to the cloud (preferably close to the IoT devices).”1 On the other hand, “the edge is [technically] the immediate first hop from the IoT devices (not the IoT nodes themselves), such as the Wi-Fi access points or gateways.”2
Today, there are a variety of reasons for enabling edge and/or fog computing capabilities within the big data infrastructure in a DSN. These include but are not limited to latency requirements, encryption, limited connectivity, speed, or reliability of data communication services. Furthermore, the progress in miniaturization, energy efficiency, and computing power further drives the fog/edge capabilities—for example, augmented reality systems with built-in real-time processing.
Local (Intranet)
Local storage and processing of data encompasses a broad field. It ranges from physical data storage on individual computer systems, DVDs/CDs, or hard drives, to local networks. For DSNs and big data purposes, the former is not applicable. Therefore, when referring to local computing, we focus on local networks, or an intranet infrastructure. Hosting, processing, and analyzing data locally was broadly used before the cloud infrastructure matured in recent years. It has the advantage of tighter control of the data and knowledge hidden within; however, many downsides exist compared to modern cloud-based infrastructures. In order to achieve similar scalability to a cloud platform, the costs of operating and maintaining the physical servers and software necessary on premises are hard to justify. Furthermore, in a DSN environment, the local setup does not enable the necessary data exchange enabling many of the services and operations in such a collaborative network. In some cases, where cybersecurity or other requirements dictate local hosting with the associated tight control, we see a move to hybrid systems combining the advantages of both local hosts and cloud-based scalability and access.
Cloud (Industrial Internet Platforms)
Cloud computing is broadly defined as services and applications remotely accessed and delivered via a network. Cloud services and applications include but are not limited to hosting services, data processing, and Software as a Service (SaaS). The network that enables access to and delivery of the cloud services and applications is the Internet. Cloud computing essentially decomposed the physical and virtual aspects of big data and data analytics and revolutionized how we interact with, scale, and perceive data in the twenty-first century. In a cloud-based environment, all data and services (e.g., software, analytics) can theoretically be accessed at all times via a web-based service. Cloud computing is often referred to as cloud or Industrial Internet (II)/IIoT platforms, offering a variety of built-in capabilities, standards/protocols, and interfaces. This reduces the initial investment and enables collaboration through joint access to data, services, and analytical insights, a crucial requirement for competitive, data-driven DSNs. Therefore, the cloud is a key component for most DSN big data analytics infrastructures.
Cloud computing and its enabling technological infrastructure have developed significantly, and thus, many initial critiques and issues are solved today. These include latency that prevented cloud services for certain shop floor applications and cybersecurity concerns. With the rapid growth of cloud-based services, other issues arise such as the significant associated energy consumption.
Hybrid Cloud
A hybrid architecture combines all or selected elements to address some specific requirements that cannot be tackled by an individual one alone. That can be challenging latency issues for real-time shop floor control that requires local processing, communication issues that require edge processing to reduce the amount of data transferred, or cybersecurity concerns that require selected data to be hosted on premises. Generally setting up a hybrid system is more complex than a purely cloud or local infrastructure. However, more and more of the leading service providers offer hybrid solutions with seamless integration out-of-box today.
![]()
SUMMARY
![]()
In summary, data is the lifeblood of modern DSNs. While the amount and availability of data is exponentially increasing, new challenges regarding data quality, authority, and also security emerge as differentiators of digital transformation success. It is crucial for companies to understand that high-quality data is the foundation for all other digital transformation initiatives that use AI and machine learning to develop insights.
* www.internationaldataspaces.org. Their technology allows members to add a software readable contract to the data describing the terms and conditions of how the data can be used. The creator of the data keeps full ownership and can share the data for a defined purpose and/or at a defined price. Several major companies are supporting this including SAP, Siemens, Deloitte, Deutsche Telekom, thyssenkrupp, Audi, IBM, Volkswagon, and Google.