
Chapter 8. Turing and Reverse
8.1. Doggie's Little Get Along
- One weekend I messed with the guts of my jukebox.
- I wanted to zip it up to tweet like a bird
- When the wires got crossed and the records spun backward
- And this is the happy voice that I heard:
- Whoopee Tie Yi Yay,
- The world's getting better and your love's getting strong
- Whoopee Tie Yi Yay,
- Your lame dog will walk by the end of this song.
- The music was eerie, sublime and surreal,
- But there was no walrus or devil.
- The notes rang wonderfully crystalline clear
- Telling us that it was all on the level:
- Whoopee Tie Yi Yay
- This weekend your sixty-foot yacht will be floated.
- Whoopee Tie Yi Yay
- The boss just called to tell you, “You're promoted.”
- So after a moment I began to start thinking
- What if I rewired the touch tone?
- After a second of cutting and splicing, it suddenly rang.
- This was voice that came from the phone:
- Whoopee Tie Yi Yay
- This is the Publisher's Clearing House to Tell You've Won
- Whoopee Ti Yi Yay
- A new car, an acre of dollars and a house in the sun.
- A few minutes later my lost sweetheart called:
- The guy she ran off with wasn't worth Jack.
- He wore a toupee and the truck was his mother's.
- Now she could only beg for me back.
- Whoopee Tie Yi Yay
- Why spend your grief on a future that's wrecked
- Whoopee Tie Yi Yay
- Why look backward when hindsight is always so perfect.
8.2. Running Backward
The song that introduces this chapter is all about what happens to a man when he finds a way to play the country music on his jukebox backward. His dog walks, his girlfriend returns, and the money rolls in. The goal of this chapter is to build a machine that hides data as it runs forward. Running it in reverse allows you to recover it. The main advantage of using such a machine is that some theoretical proofs show that this machine can't be attacked by a computer. These theoretical estimates of the strength of the system are not necessarily reliable for practical purposes, but they illustrate a very interesting potential.
Chapter 7 described how to use grammars to hide data in realistic-sounding text. The system derived its strength from the structure of the grammars and their ability to produce many different sentences from a simple collection of inputs. The weaknesses of the system were also fairly apparent. Grammars that were context-free could not really keep track of scores of ballgames or other more complicated topics. They just produced sentences with no care for the context. A bit of cleverness could go a long way, but anyone who has tried to create complicated grammars begins to understand the limitations of the model.
This chapter will concentrate on a more robust and complete model known as the Turing machine, a concept was named after Alan Turing, who created it in the 1930s as a vehicle for exploring the limits of computation. Although the model doesn't offer a good way to whip up some good mimicry, it does offer a deeper theoretical look at just how hard it may be to break the system.
A good way to understand the limits of context-free grammars is to examine the type of machine that is necessary to recognize them. When testing this, I built a parser for recovering the data from the mimicry using a model of a push-down automata. The automata refers to a mechanism that is a nest of if-then and goto statements. The push-down refers to the type of memory available to it—in this case a push-down stack that can store information by pushing it onto a stack of data and retrieve it by pulling it off. Many people compare this to the dishracks that are found in cafeterias. Dishes are stored in a spring-loaded stack. The major limitation of this type of memory is the order. Bits of information can only be recalled from the stack in the reverse order in which they were put onto the stack. There is no way to dig deeper.
It is possible to offer you solid proof that push-down automata are the ideal computational model for describing the behavior of context-free grammars, but that solution is a bit dry. A better approach is to illustrate it with a grammar:
You can find a good proof in [AHU83].
| start | → | Thelma and Louise what when ‖ Harry and Louise what when |
| what | → | went shooting with where ‖ bought insurance with where |
| with | → | with Bob and Ray ‖ with Laverne and Shirley |
| when | → | on Monday. ‖ on Tuesday. ‖ on Wednesday. ‖ on Thursday. |
| where | → | in Kansas ‖ in Canada |
A typical sentence produced by this grammar might be “Thelma and Louise went shooting with Bob and Ray in Kansas on Monday.” This was produced by making the first choice of production from each variable and thus hiding the six bits 000000. But when the first choice was made and Thelma and Louise became the subjects of the sentence, the question about the date needed to be stored away until it was needed later. You can either think of the sentence as developing the leftmost variable first or you can think of it as choosing the topmost variable from the stack. Here's a table showing how a sentence was produced. It illustrates both ways of thinking about it.
| Stack | Pending Sentence | Pending with Variables |
|---|---|---|
| start | noun | |
| what when | Thelma and Louise | Thelma and Louise what when |
| with where when | Thelma and Louise went shooting | Thelma and Louise went shooting with where |
| where when | Thelma and Louise went shooting with Bob and Ray | Thelma and Louise went shooting with Bob and Ray where when |
| when | Thelma and Louise went shooting with Bob and Ray in Kansas | Thelma and Louise went shooting with Bob and Ray in Kansas when |
| empty | Thelma and Louise went shooting with Bob and Ray in Kansas on Monday. | Thelma and Louise went shooting with Bob and Ray in Kansas on Monday. |
Both metaphors turn out to be quite close to each other. The context-free grammars and the stack-based machines for interpreting them are equivalent. This also illustrates why it is possible to imitate certain details about a baseball game like the number of outs or the number of strikes, while it is much harder, if not impossible, to give a good imitation of the score. There is no way to rearrange the information on the stack or to recognize it out of turn.
The Turing machine is about as general a model of a computer as can be constructed. Unlike the push-down automata, a Turing machine can access any part of its memory at any time. In most models, this is described as a “tape” that is read by a head that can scan from left to right. You can also think of the “tape” as regular computer memory that has the address 0 for the first byte, the address 1 for the second byte, and so on.
The main advantage of using a Turing machine is that you access any part of the memory at any time. So you might store the score of the baseball game at the bytes of memory with addresses 10140 and 10142. Whenever you needed this, you copy the score to the output. This method does not offer any particularly great programming models that would make it easier for people to construct a working Turing mimicry generator. Alas.
The real reason for exploring Turing machines is that there are a wide variety of theoretical results that suggest the limits on how they can be analyzed. Alan Turing originally developed the models to explore the limits of what computers can and can't do [Tur36a, Tur36b]. His greatest results showed how little computers could do when they were turned against themselves. There is very little that computers and the programs they run can tell us definitively about another computer program.
These results are quite similar to the work of Kurt Gödel, who originally did very similar work on logical systems. His famous theorem showed that all logical systems were either incomplete or inconsistent. The result had little serious effect on mathematics itself because people were quite content to work with incomplete systems of logic— they did the job. But the results eroded the modernist belief that technology could make the world perfect.
Turing found that the same results that applied to Gödel's logical systems could apply to computers and the programs that ran on them. He showed, for instance, that no computer program could definitively answer whether another computer program would ever finish. It might be able to find the correct answer for some subset of computer programs, but it could never get the right answer for all of them. The program was either incomplete or inconsistent.
Others have extended Turing's results to show that it is practically impossible to ask the machines to say anything definitive about computers at all. Rice's theorem showed that computers can only answer trivial questions about other computers [HU79]. Trivial questions were defined as those that were either always true or always false.
Abraham Lincoln was really the first person to discover this fact when he told the world, “You can fool some of the people all of the time and all of the people some of the time. But you can't fool all of the people all of the time.” The same holds true if you substitute “computer program” or “turing machine” for “people.”
To some extent, these results are only interesting on a theoretical level. After all, a Macintosh computer can examine a computer program written for an IBM PC and determine that it can't execute it. Most of the time, a word processor might look at a document and determine that it is in the wrong format. Most of the time, computers on the Internet can try to establish a connection with other computers on the Internet and determine whether the other computer is speaking the right language. For many practical purposes, computers can do most things we tell them to do.
The operative qualifier here is “most of the time.” Everyone knows how imperfect and fragile software can be. The problems caused by the literal machines are legendary. They do what they're told to do, and this is often incomplete or imperfect—just like the theoretical model predicted they would be.
The matter for us is compounded by the fact that this application is not as straightforward as opening up word processing documents. The goal is to hide information so it can't be found. There is no cooperation between the information protector and the attacker trying to puncture the veil of secrecy. A better model is the world of computer viruses. Here, one person is creating a computer program that will make its way through the world and someone else is trying to write an anti-virus program that will stop a virus. The standard virus-scanning programs built today look for tell-tale strings of commands that are part of the virus. If the string is found, then the virus must be there. This type of detection program is easy to write and easy to keep up to date. Every time a new virus is discovered, a new tell-tale string is added to the list.
Can you abort a virus? Can you baptize one? How smart must a virus be to be a virus?
But more adept viruses are afoot. There are many similar strings of commands that will do a virus's job. It could possibly choose any combination of these commands that are structured correctly. What if a virus scrambled itself with each new version? What if a virus carried a context-free grammar of commands that would produce valid viruses? Every time it copied itself into a new computer or program, it would spew out a new version of itself using the grammar as its copy. Detecting viruses like this is a much more difficult proposition.
You couldn't scan for sequences of commands because the sequences are different with each version of the virus. You need to build a more general model of what a virus is and how it accomplishes its job before you can continue. If you get a complete copy of the context-free grammar that is carried along by a virus, you might create a parser that would parse each file and look for something that came from this grammar. If it was found, then a virus would be identified. This might work sometimes, but what if the virus modified the grammar in the same way that the grammars were expanded and contracted on page 119? The possibilities are endless.
The goal for this chapter is to capture the same theoretical impossibility that gives Turing machines their ability to resist attacks by creating a cipher system that isn't just a cipher. It's a computing machine that runs forward and backward. The data is hidden as it runs forward and revealed as it runs backward. If this machine is as powerful as a Turing machine, then there is at least the theoretical possibility that the information will never be revealed. Another computer that could attack all possible machines by reversing them could never work in all cases.
8.2.1. Reversing Gears
Many computer scientists have been studying reversible computers for some time, but not for the purpose of hiding information. Reversible machines have a thermodynamic loophole that implies that they might become quite useful as CPUs become more and more powerful. Ordinary electronic circuits waste some energy every time they make a decision, but reversible computers don't. This wasted energy leaves a normal chip as heat, which is why the newest and fastest CPUs come with their own heat-conducting fins attached to the top. Some of the fastest machines are cooled by liquid coolants that can suck away even more heat. The build up of waste heat is a serious problem—if it isn't removed, the CPU fails.
The original work on reversible computers was very theoretical and hypothetical. Ed Fredkin offered a type of logic gate that would not expend energy. [Fre82] Normal gates that take the AND of two bits are not reversible. For instance, if x AND y is 1, then both x and y can be recovered because both must have been 1. But if x AND y is 0, then nothing concrete is known about either x or y. Either x or y might be a 1. This makes it impossible to run such a normal gate in reverse.
The Fredkin gate, on the other hand, does not discard information so it can be reversed. Figure 8.1 shows such a gate, and the logic table that drives it. There are three lines going in and three lines leaving. One of the incoming lines is a control line. If it is on, then the other two lines are swapped. If it is off, then the other lines are reversed. This gate can be run in reverse because there is only one possible input for each output.
Figure 8.1. An illustration of a Fredkin gate. If the control line is on, then the output lines are switched. Otherwise, they're left alone.

(Drawn from Bennett's figure.[BL85])
The Scientific American article by Charles Bennett and Rolf Landauer makes a good introduction to reversible machines.[BL85]
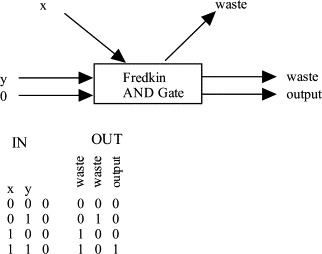
Figure 8.2 shows an AND gate built out of a Fredkin gate. One of the two input lines from a normal AND gate is used as the control line. Only one of the output lines is needed to give us the answer. The other two bits are wasted. Ordinarily, the information here would be thrown away by sending the bits to ground, where they would heat up the chip. A truly reversible machine would store the bits at this location until the computer was run in reverse. Then the gate would have all of the information ready to compute the inverse. An OR gate would be built in the same way, but it would have one input fixed to be a 1.
Figure 8.2. An AND gate built out of a Fredkin gate. The extra waste bits must be stored at the gate so that computation can be reversed later. [BL85]
There are a number of other mechanical approaches to building a reversible computer. Ed Fredkin and Tommaso Toffoli developed a billiard ball computer that could be made to run in reverse if a suitable table could be found [FT82]. It would need to be perfectly smooth so the balls would move in synchrony. The table itself must be frictionless and the bumpers would need to return all of the energy to the balls so that nothing would be lost and there would be just as much kinetic energy at the beginning of the computation as at the end.
Figure 8.3 shows how two billiard balls can build an AND gate. The presence of a ball is considered to be the on state, so if both balls are there, they will bounce off each other and only one ball will continue on its way. If the balls reach the end of the computation, then they can bounce off a final wall and make their way back. It should be easy to see that this gate will work both forward and backward. OR gates are more complicated and include extra walls to steer the balls.
Figure 8.3. The three possible outcomes of a billiard ball AND gate. The presence of a ball indicates an on signal. If only one ball is present, then no bounce occurs and it continues on its way. If both are present, then they bounce off each other. If none are present, then nothing happens.

(Adapted from Bennett)
This is an interesting concept, but it is hardly useful. No one can build such a frictionless material. If they could, it might be years before we got to actually trying to use it to compute. There would be too many other interesting things to do, like watching people play hockey on it. More practical implementations, however, use cellular automata that come before and after it. Toffoli described reversible cellular automata in his Ph.D. thesis [Tof77a] and in other subsequent articles [Tof77b, TM87]. N. Margolus offers one solution that implements the billiard ball models. [Mar84]
David Hillman has written about reversible one-dimensional cellular automata [Hil91b, Hil91a].
The key result about reversible computers comes from Charles Bennett who showed that any computation can be done with a reversible Turing machines. He created a few basic examples of reversible Turing machines with well defined commands for moving the read/write head of the tape and changing the state of the machine.
The transition rules for these machines often look quite similar to the Fredkin gate. There is just as much information coming out of each step as going into it. This is balanced correctly so the position that leads to another position can always be inferred and the machine can be reversed.
This result shows that anything that can be done with a computer can be done with a reversible computer. All that is necessary is finding a way to save the information from each step so it can be effectively run in reverse. But what does this mean if you want to hide information? It means that any computation can be used to hide information in the final outcome. How much can be stored? It all depends on the calculation. Ordinarily, any random number generator that is used to add realism or to scramble the outcome of a game can be replaced by a collection of data to be hidden. This data can be recovered as the machine runs in reverse.
Reversible computation is also great for debugging programs.
How would such a system work? One obvious solution is to create a universal, reversible Turing machine format. A standard program running on everyone's computer would be able to read in a Turing machine and run it forward or backward. If you wanted to send a message, you would pack in the data and run the machine until it stopped. The result would be the output, perhaps some computer-generated poetry, and a pile of waste data that must be kept around in order to run the machine in reverse.
At the other end, the recipient would load this information into the same universal, reversible Turing machine and run it backward to recover the data. The one problem with this scenario is that any attacker could also have the same universal, reversible Turing machine. They could intercept the message and reverse it. For the technique to be successful, some data must be kept secret from the attacker. This could travel separately. In the grammar machine from Chapter 7, the grammar acts as the key. It must be distributed separately.
One solution is to keep the structure of the Turing machine secret and let it act as a key. Only the output and the extra, “waste” bits of information must be transmitted to the recipient. Anyone can intercept the message, but they cannot read it without a copy of the program that created it.
How difficult can this be? Obviously, there will be some programs that are pretty easy to crack. For instance, a program that merely copies the data to be hidden and spits it out would be easy to deduce. The output would maintain all of the structure of the original document. More and more complicated programs would get more and more complicated to deduce. Eventually, something must be too hard to crack. The tough question is whether there is some threshold that can be established where it is positively known that programs that are beyond it are completely safe.
Such a threshold can never be well-defined. That is, there can be no neat machine that will examine any program and say, “This can't be broken.” There might be machines that could point out flaws in programs and show how they could be broken, but they would not be guaranteed to find all flaws.
This uncertainty is a pain, but it affects the enemy in the same way. The enemy can not come up with an arbitrary machine that will be able to examine every message you send and discover the program that was used to hide the data. It may be able to find some solutions, but there will be no brute-force attack that will work in all cases.
This is a nice beginning for security, but it is not absolute. The one-time pad offers a similar security blanket. No brute-force attack that will break the system, as long as the key bits are completely random. What is completely random? In practice, it means that the attacker can't build a machine that will predict the pattern of the bits. This is substantially easier to achieve for one-time pads than it is for reversible Turing machines. There are numerous sources of completely random information and noise that can be used as the basis for a one-time pad. The random snow from a noisy section of the radio spectrum can make the good beginning for such a pad.
See Section 2.2 on page 22 for details.
The rest of this chapter will concentrate on actually constructing a reversible Turing machine that could be used to create hidden messages in text. It will be based, in part, on the grammar approach from Chapter 7 because text is a good end product for the process. There is no reason why the work couldn't be adapted to produce other mimicry.
8.3. Building a Reversible Machine
If every Turing machine can be reconstructed in a reversible manner, then every possible machine is a candidate for being turned into a vehicle for hidden information. Obviously, though, some machines are more interesting than others. For instance, loan companies use computer programs to evaluate the credit of applicants and these programs respond with either “qualified” or “unqualified”. That's just one bit of information and it seems unlikely that anyone will be able to hide much of anything in that bit. On the other hand, programs that produce complex worlds for games like Doom spit out billions of bits. There is ample room in the noise. Imagine if some secret information was encoded in the dance of an attacking droid. You might get your signal by joining an internet group game of Doom. The information would come across the wire disguised as instructions for where to draw the attacker on the screen. Your version of Doom could extract this.
Some reversible machines are inherently error limiting and self-resynchronizing in both directions, as shown by Peter Neumann[Neu64] for David Huffman's information-lossless sequential machines. [Huf59]
This chapter will show how to build two different reversible machines. The first, a simple reversible Turing machine, is provided as a warm-up. It is based on the work of Charles Bennett and it shows how to take the standard features of a Turing machine and tweak them so that there is only one possible state that could lead to another. This makes it possible to rewind the behavior.
The second machine is an extension of the grammar-based mimicry from Chapter 7. That system used only context-free grammars. This one lets you simulate any arbitrary computation to add realism to the text that it produces. The data hidden by the system won't be recovered by parsing. It will come by running the machine in reverse. This means that a practical way needs to be constructed to ship the extra variables and “waste” bits along.
8.3.1. Reversible Turing Machines
An ordinary Turing machine consists of a set of states, S, a set of symbols that can appear on the tape, ∑, and a set of transition rules, δ, that tell the machine what happens when. For instance, δ might specify that if the machine is in state s2, and the symbol σ4 is on the tape underneath the read/write head, then the read/write head should write the symbol σ5 on the tape, move the head to the right one notch and change to state s42. This is how you program a Turing machine. The abstraction is fairly crude, but it makes it simpler to keep track of all the possibilities.
If a certain puritanical tradition, for instance, is profoundly suspicious of the novel, this is because the novel is felt to celebrate and encourage misconduct, rather than censure and repress it. —D.A. Miller in The Novel and The Police
Converting such a machine to run backward is pretty straightforward. The main problem is looking for combinations of states and tape symbols that lead to the same states. That is when it is impossible to put the machine in reverse because there are two different preceding situations that could have led to the present one. The easiest solution is to keep splitting up the states until there is no confusion.
For each state, si ε S, construct a list of triples of states, tape symbols, and direction (sj, σk, L) that could lead to the state si. That is, if the machine is in state sj with the read/write head over the symbol σl, then it will write σk and move to the left one step. In other words, if the machine is running backward and it finds itself in state, si, with symbol σk to the right of it, then it can move to the right, change to state sj, and overwrite σk with σl and not violate the program. That is, this is a correct move.
There will be a conflict if there are triples of the form (s*, σ*, L) and (s*, σ*, R) in the same set. (Let s* stand for any element si from S.) This is because it is possible that the machine will end up someplace with one of the symbols to the left and one to the right. You might be able to make meta-arguments that such a combination could never exist because of the structure of the program, but these are often hard to prove.
If such a conflict occurs, then create a new state and split apart the actions. All of the triples that moved left into the old state, si, can stay pointing to state, si. The triples that moved right, however, will be moved to point to the new state sj. The transition rules out of sj will be a duplicate of si.
To a large extent, splitting these states is the same as finding a place to keep a “waste” bit around. The Fredkin AND gate generates some waste bits that must be stored. Splitting the state creates a waste bit.
The same splitting process must be done if there are two triples of the form: (sa, σk, L) and (sb, σk, L). Both of these states, sa and sb, lead to the same symbol existing to the right of the current position of the read/write head. Choosing is impossible. Again, a new state must be added and the transition rules duplicated and split.
It should be obvious that a Turing machine will grow substantially as it is made reversible. This growth can even be exponential in many cases. There is no reason why anyone would want to program this way. The complications are just too great. But this example is a good beginning.
8.3.2. Reversible Grammar Generators
The goal of this book is to produce something that seems innocuous but hides a great deal of information from plain sight. Chapter 7 did a good job of this with a context-free grammar, but there are numerous limitations to that approach. This part of the book will build a reversible, Turing-equivalent machine that will be able to do all basic computations, but still be reversible. It will get much of its performance by imitating the Fredkin gate, which merely swaps information instead of destroying it.
Numerous problems that need to be confronted in the design of this machine. Here are some of them:
- Extra State At the end of the computation, there will be plenty of extra “waste” bits hanging around. These need to be conveyed to the recipients so they can run their machines in reverse. There are two possible solutions. The first is to send the extra state through a different channel. It might be hidden in the least significant bits of a photo or sent through some other covert channel. The second is to use a crippled version of the machine to encode the bit as text without modifying any of the state. That is, reduce the capability of the machine until it acts like the context-free grammar machine from Chapter 7.
- Ease of Programmability Anyone using the machine will need to come up with a collection of grammars to simulate some form of text. Constructing these can be complicated, and it would be ideal if the language could be nimble enough to handle many constructions. The solution is to imitate the grammar structure from Chapter 7. There will be variables and productions, but you can change the productions en route using reversible code.
- Minimizing Extra State Any extra bits must be transported through a separate channel at the end and so they should be kept to a minimum. For that reason, all strings should be predefined as constants. They can't be changed. If they could be changed, then the final state of all strings would need to be shipped to the recipient. This would be too much baggage.
- Arithmetic Arithmetic is generally not reversible. 3 + 2 is not reversible, but it can be reversed if one half of the equation is kept around. So adding the contents of register A1 and register A2 and placing the result in register A1is reversible. The contents of A2 can be subtracted from A1 to recover the original value of A1. For the most part, addition, subtraction, multiplication, and division are reversible if they're expressed in this format. The only problem is multiplication by zero. This must be forbidden.
- Structure of Memory What form will the memory take? Ordinary computers allow programmers to grab and shift blocks of memory at a time. This is not feasible because it would require too many extra waste bits would need to be stored. Block moves of data are not reversible. Swaps of information are. For that reason, there is an array of registers. Each one holds one number that can be rounded off in some cases. The final state of the registers will be shipped as extra state to the recipient so any programmer should aim to use them sparingly. Unfortunately, the rules of reversibility can make this difficult.
- Conditional Statements Most conditional statements that choose between branches of a program can be reversed, but sometimes they can't be. Consider
the case that says, “If x is less than 100, then add 1 to x. Otherwise, add 1 to p.” Which path do you take if you're running in reverse and x is 100? Do you subtract 1 from p or not? Either case is valid.
One solution is to execute each branch storing results in temporary variables. When the conditional statement is encountered,
the proper choices are swapped into place.
Another solution is to forbid the program to change the contents of the variables that were used to choose a branch. This
rules out many standard programming idioms. Here's one way to work around the problem:

- Loops Loops may be very handy devices for a programmer, but they can often be an ambiguous obstacle when a program must run in
reverse. One easy example is the while loop often written to find the last element in a string in C. That is, a counter moves
down the string until the termination character, a zero, is found. It may be easy to move backward up the string, but it is
impossible to know where to stop.
The problems with a loop can be eliminated if the structure is better defined. It is not enough to give a test condition for
the end of the loop. You must specify the dependent variable of the loop, its initial setting, and the test condition. When
the loop is reversed, the machine will run through the statements in the loop until the dependent variable reaches its initial
setting.
This structure is often not strong enough. Consider this loop:
The floor (x) function finds the largest integer less than or equal to x. This function will execute 100 times before it stops. If it is executed in reverse, then it will only go through the loop twice before i is set to its initial value, one. It is clear that i is the defining variable for the loop, but it is also clear that j plays a big part. There are two ways to resolve this problem. The first is to warn programmers and hope that they will notice the mistake before they use the code to send an important message. This leaves some flexibility in their hands. Another solution is to further constrain the nature of loops some more. There is no reason why they can't be restricted to for loops that specify a counter that is incremented at each iteration and to map functions that apply a particular function to every element in a list. Both are quite useful and easy to reverse without conflicts.
- Recursion Recursion is a problem here. If procedures call themselves, then they are building a de facto loop and it may be difficult
to identify a loop's starting position. For instance, here is an example of a loop with an open beginning:
This is just a while loop and it is impossible to back into it and know the initial value of x when it began. One solution is to ban recursion altogether. The standard loop constructs will serve most purposes. This is, alas, theoretically problematic. Much of the theoretical intractability of programs comes from their ability to start recursing. While this might make implementing reversible programs easier, it could severely curtail their theoretical security. Another solution is to save copies of all affected variables before they enter procedures. So, before the procedure Bob begins, the reversible machine will save a copy of x. This version won't be destroyed, but it will become part of the waste bits that must be conveyed along with the output.
Ralph Merkle also notes that most assembly code is reversible and predicts that in the future smart compilers will rearrange instructions to ensure reversibility. This will allow the chips to run cooler once they're designed to save the energy from reversible computations [Mer93].
In the end, the code for this system is quite close to the assembly code used for regular machines. The only difference is that there is no complete overwriting of information. That would make the system irreversible. Perhaps future machines will actually change the programming systems to enhance reversibility. That may come if reversible computers prove to be the best way to reduce power consumption to an acceptable level.
8.3.3. The Reversible Grammar Machine
Although the structure will be very similar to machine code, I've chosen to create this implementation of the Reversible Grammar Machine (RGM) in LISP, one of the best experimental tools for creating new languages and playing around with their limits. It includes many of the basic features for creating and modifying lists plus there are many built-in pattern-matching functions. All of this makes it relatively easy to create a reversible machine, albeit one that doesn't come with many of the features of modern compilers.
Here are the major parts of the system:
- Constant List The major phrases that will be issued by the program as part of its grammar will be stored in this list, constant-list. It is officially a list of pairs. The first element of each pair is a tag-like salutation that is used as a shorthand for the phrase. The second is a string containing the constant data. This constant list is part of the initial program that must be distributed to both sides of the conversation. The constants do not change; so there is no need to transmit them along with the waste state produced by running a program forward. This saves transmission costs. The main purpose of the constant list is to keep all of the phrases that will be output along the way. These are often long, and there is little reason for them to change substantially. Defining them as constants saves space. The constant list can also include any data like the variable list. The data just won't change.
- Variables The data is stored in variables that must be predefined to hold initial values. These initial values are the only way that information can actually be assigned to a variable. The rest of the code must change values through the swap command. The variables are stored in the list var-list, which is as usual a list of pairs. The first element is the variable tag name. The second is the data stored in the variable. There are five types of data available here: lists, strings, integers, floating-point numbers, and tags. Lists are made up of any of the five elements. There is no strict type checking, but some commands may fail if the wrong data is fed to them. Adding two strings, for instance, is undefined. Some care should be taken with the choice of variables. Their contents will need to be sent along with the output so the recipient can reverse the code. The more variables there are, the larger this section of “waste” code may be.
- Procedure List At each step, some code must be executed. These are procedures. For the sake of simplicity, they are just lists of commands that are identified by tags and stored in the list proc-list. This is a list of pairs. The first element is the tag identifying the procedure, and the second is the list of commands. There are no parameters in the current implementation, but they can be added.
- Commands These are the basic elements for manipulating the data. They must be individually reversible. The set of commands includes the basic arithmetic, the swap command, the if statement and the for loop tool. These commands take the form of classic LISP function calls. The prefix notation that places the command at the front is not as annoying in this case because arithmetic is reversible, so addition looks like this: (add first second). That command adds first and second and places the result in first. There are three other arithmetic commands: sub, mul and div, which stand for subtraction, multiplication and division, respectively. The only restriction is that you can't multiply a number by zero because it is not reversible. This is reported by an error message.
- Output Commands There is one special command, chz, that uses the bits that are being hidden to pick an output from a list. When this command is run in reverse by the recipient, the hidden bits are recovered from the choice. The format is simple: (chz (tag tag…tag)). The function builds up a Huffman tree like the algorithm in Chapter 7 and uses the bits to make a choice. The current version does not include the capability to add weights to the choices, but this feature can be added in the future. The tags can point to either a variable or a constant. In most cases, they'll point to strings that are stored as constants. That's the most efficient case. In some cases, the tags will contain other tags. In this case, the choose function evaluates that tag and continues down the chain until it finds a string to output. For practical reasons, a programmer should be aware of the problems of reversibility. If two different tags point to the same string, then there is no way for the hidden bits to be recovered correctly. This is something that can't be checked in advance. The program can check this on the fly, but the current implementation doesn't do it.
- Code Branches There is an if statement that can be used to send the evaluation down different branches. The format is (if (test if-branch else-branch). The program evaluates the test and if it is true, then it follows the if-branch otherwise it follows the else-branch. The format of the test is quite similar to general LISP. For instance, the test (gt a b) returns true if a is greater than b. The other decision functions are lt, le, ge and eq, which stand for less than, less than or equal to, greater than or equal to, and equal to. The current implementation watches for errors that might be introduced if the two variables used to make a decision were changed along one of the branches. It does this by pushing the names onto the Forbidden-List and then checking to see the list before the evaluation of each operation.
- Program Counter and Code This machine is like most other software programs. There will be one major procedure with the tag main. This is the first procedure executed, and the RGM ends when finished. Other procedures are executed as they're encountered and a stack is used to keep track of the position in partially finished procedures.
The source code is available from the author.
8.4. Summary
Letting a machine run backward is just one way to create the most complicated computer-generated mimicry. You could also create double-level grammars or some other modified grammar-based system.
- The Disguise The text produced by these reversible machines is as good as a computer could do. But that may not be so great. Computers have a long way to go before they can really fool a human. Still, static text can be quite realistic.
- How Secure Is It? Assessing the security of this system is even more complicated than understanding the context-free grammars used in Chapter 7. Theoretically, there is no Turing machine that can make nontrivial statements about the reversible Turing machine. In practice, there may be fairly usable algorithms that can assemble information about the patterns in use. The question of how to create very secure programs for this reversible machine is just as open as the question of how to break certain subclasses.
- How to Use It The LISP software is available from the author. It runs on the XLISP software available for free at many locations throughout the Internet.
- Further Work The LISP code is very rudimentary. It's easy to use if you have access to a LISP interpreter. A better version would offer a wider variety of coding options that would make it easier to produce complicated text. A more interesting question is how to guarantee security. Is it possible to produce a mechanism for measuring the strength of a reversible grammar? Can such a measuring mechanism be guaranteed? An ultimate mechanism probably doesn't exist, but it may be possible to produce several models for attack. Each type of attack would have a corresponding metric for evaluating a grammar's ability to resist is. Any collection of models and metrics would be quite interesting.
Further Reading
The field of reversible computing continues to draw some attention from people trying to build quantum computers. Some recent papers include a survey by Michael Frank and the papers from the tracks at the conference devoted to the topic. [Fra05] In particular, see the work of Daniel B. Miller, Ed Fredkin, Alexis De Vos and Yvan Van Rentergem. [VR05, MF05, TL05, BVR05, Fra05]