
Processes can also help us toward more human-readable rules. It is not a substitute to rules as was the case with DSLs and decision tables. It is a way of defining the execution flow between complex rules. The rules are then easier to understand.
With jBPM we can externalize the execution order from the rules. The execution order can then be managed externally. Potentially, you may define more execution orders for one KnowledgeBase object.
jBPM is a process engine, a standalone product that is very closely integrated with Drools. It can execute arbitrary actions or user-defined work items at specific points within the process. It can even be persisted, as we'll see in Chapter 8, Defining Processes with jBPM, which shows a bigger example of using processes.
Before we talk about how to manage rule execution order, we have to understand Drools Agenda. When a object is inserted into the knowledge session, Drools tries to match this object with all the possible rules. If a rule has all its conditions met, its consequence can be executed. We say that a rule is activated. Drools records this event by placing this rule onto its agenda (it is a collection of activated rules). As you may imagine, many rules can be activated and also deactivated depending on what objects are in the rule session. After the fireAllRules method call, Drools picks one rule from the agenda and executes its consequence, which may or may not cause further activations or deactivations. This continues until the Drools agenda is empty.
The purpose of the agenda is to manage the execution order of rules.
The following are the methods for managing the rule execution order (from the user's perspective). They can be viewed as alternatives to processes. All of them are defined as rule attributes:
salience: This is the most basic one. Every rule has asaliencevalue. By default it is set to0. Rules with a higher salience value will fire first. The problem with this approach is that it is hard to maintain. If we want to add a new rule with some priority, we may have to shift the priorities of existing rules. It is often hard to figure out why a rule has a certain salience, so we have to comment every salience value. It creates an invisible dependency on other rules.activation-group: This used to be calledxor-group. When two or more rules with the same activation group are on agenda, Drools will fire just one of them. Be careful when usingactivation-groupif you are processing more sets of facts in one session (for example, more customers), and let's say there are two rules,goldenCustomerandstandardCustomerthat share the sameactivation-groupattribute. If one of these rules fire for any customer, then the other rule won't fire for any customer, which is probably not what we want.agenda-group: Every rule has an agenda group. By default it isMAIN; however, it can be overridden. This allows us to partition Drools agenda into multiple groups that can be executed separately at different times.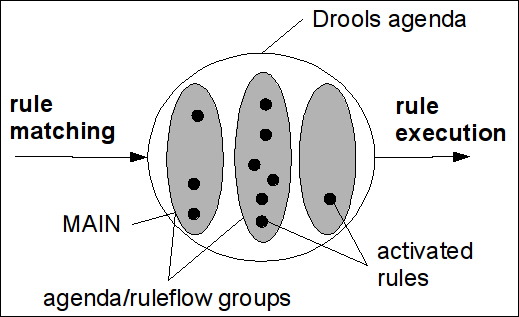
Figure 7: Partitioned Agenda with activated rules
This picture shows matched rules coming from the left-hand side, going into agenda. One rule is chosen from the agenda at a time and then executed/fired.
At runtime we can programmatically set the active agenda group (through the setFocus method of KnowledgeHelper: the drools.setFocus(String agendaGroup) method), or declaratively by setting the rule attribute's autofocus to true. When a rule is activated and has this attribute set to true, the active agenda group is automatically changed to the rule's agenda group. Drools maintains a stack of agenda groups. Whenever the focus is set to a different agenda group, Drools adds this group onto this stack. When there are no rules to fire in the current agenda group, Drools pops from the stack and sets the current agenda group to the next one.
Note that only one instance of each of these attributes is allowed per rule (for example, a rule can be only in one
ruleflow-group; however, it can also define a salience value within that group).
As we've already said, processes can externalize the execution order from the rule definitions. Rules have to just define a ruleflow-group attribute, which is similar to the agenda-group attribute. It is then used to define the execution order. A simple process is shown in the following screenshot:
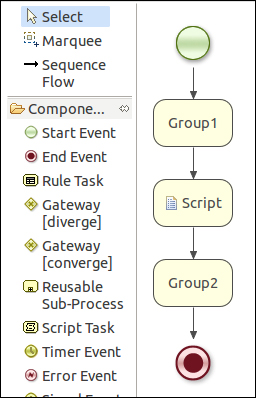
Figure 8: Simple process (in file example.bpmn)
This is a process opened with the Drools Eclipse plugin. On the left-hand side are components that can be used when building a process. On the right-hand side is the process itself. It has a start node, which goes to rule-flow group called Group1. After it finishes execution a script is executed, then the flow continues to another ruleflow group called Group2, and finally it finishes in an end node.
Process definitions are stored in a file with the .bpmn extension. This file has an XML format and defines the structure and layout for presentational purposes.
Note
Another useful rule attribute for managing whose rules can be activated is lock-on-active. It is a special form of the no-loop attribute. It can be used in combination with ruleflow-group or agenda-group. If it is set to true and an agenda-group or ruleflow-group attribute becomes active/focused, it discards any further activations for a rule until a different group becomes active. Please note that activations that are already on the agenda are allowed to fire.
A process consists of various nodes. Each node has a name, type, and other specific attributes. You can see and change these attributes by opening the standard Properties view in Eclipse while editing the process file. Now let's take a look at the basic node types.
This is an initial node. The process begins here. Each process needs one start node. This node has no incoming connection, just one outgoing connection.
It is a terminal node. When an execution reaches this node, the whole process is terminated (all active nodes are canceled). This node has one incoming connection and no outgoing connections.
This is used to execute some arbitrary block of code. It is similar to a rule consequence; it can reference global variables and can specify dialect.
This node will activate a ruleflow-group attribute, as specified by its RuleFlowGroup attribute. It should match the value in ruleflow-group attribute.
This node splits the execution flow into one or many branches. It has two properties: name and type. The name property is just for display purposes. The type property can have three values: AND, OR, and XOR:
AND: With this, the execution continues through all branches.OR: With this, each branch has a condition. The condition is basically the same as a rule condition. If the condition istrue, the flow continues through this branch. There must be at least one condition that istrue; otherwise, an exception will be thrown.XOR: Similar to theORtype, each branch has a condition, but in this case with a priority. The flow continues through just one branch, whose condition istrueand has the lowest value in the priority field. There must be at least one condition that istrue; otherwise, an exception will be thrown. Please note that this concept (lowest value means highest priority) is different from the concept used with thesaliencevalue (lowest value means lowest priority).
The dialog for defining OR and XOR split types looks as follows:
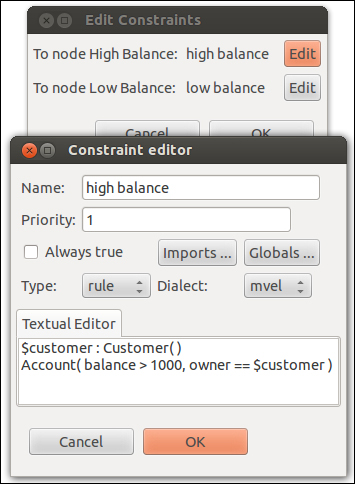
Figure 9: Drools Eclipse plugin ruleflow constraint editor
It is accessible from the standard Eclipse Properties view.
This joins multiple branches into one. It has two properties: name and type. The name property is for display purposes. The type property decides when the execution will continue. It can have the following values:
AND: With this, join waits for all incoming branches; the execution then continuesXOR: With this, the join node waits for one incoming branch
Please consult the Drools manual for additional node types.
If you look at the data transformation rule in Chapter 4, Transforming Data, you'll see that in some rules we've used the salience value to define a rule execution order. For example, all addresses needed to be normalized (that is, converted to enums) before we could report the unknown countries. The unknown country rule used salience value of -10, which meant that it would fire only after all address normalization rules. We'll now extract this execution order logic into a process to demonstrate how it works. The process might look as follows:

Figure 10: Partial process for ETL
When the execution starts, it goes through the start node straight into the diverging gateway. In this case it is an and type gateway. It basically creates two parallel branches that will be executed concurrently (note that this doesn't mean multiple threads). We can see that the flow is explicitly specified. Address normalization happens before the unknown country
reporting. Parallel to this branch is a default rule task. It contains the other rules. Finally, a converging gateway of type and is used to block until all branches complete and then the flow continues to the end node. We had to use the converging gateway (instead of going straight to the end node), because as soon as some branch in a process reaches the end node, it terminates the whole process (that is, our branches may be canceled before competition, which is not what we want).
The process ID is set to dataTransformation. It can be done by clicking on the canvas in the process editor and then in Properties view setting the ID to this value.
Next, we create a copy of the dataTransformation.drl file from Chapter 4, Transforming Data, and we'll name it dataTransformation-ruleflow.drl. We'll make the following changes:
- Each rule gets a new attribute:
ruleflow-group "default". - Except the address normalization rules. For example:
rule addressNormalizationUSA ruleflow-group "address normalization"
Code listing 41: Top part of the USA address normalization rule
- Except unknown country rule that gets the
unknown countryruleflow-group.
We can now create a knowledge base out of the .bpmn and the .drl files:
static KnowledgeBase createKnowledgeBaseFromRuleFlow()
throws Exception {
KnowledgeBuilder builder = KnowledgeBuilderFactory
.newKnowledgeBuilder();
builder.add(ResourceFactory.newClassPathResource(
"dataTransformation-ruleflow.drl"), ResourceType.DRL);
builder.add(ResourceFactory.newClassPathResource(
"dataTransformation.bpmn"), ResourceType.BPMN2);
if (builder.hasErrors()) {
throw new RuntimeException(builder.getErrors()
.toString());
}
KnowledgeBase knowledgeBase = KnowledgeBaseFactory
.newKnowledgeBase();
knowledgeBase.addKnowledgePackages(builder
.getKnowledgePackages());
return knowledgeBase;
}Code listing 42: Method that creates a KnoweldgeBase object with a ruleflow-group
The test setup needs to be changed as well. Processes are fully supported only for stateful sessions. Stateful sessions can't be shared across tests because they maintain state. We need to create a new stateful session for each test. We'll move the session initialization logic from the setupClass method that is called once per test class into the initialize method that will be called once per test method:
static KnowledgeBase knowledgeBase;
StatefulKnowledgeSession session;
@BeforeClass
public static void setUpClass() throws Exception {
knowledgeBase = createKnowledgeBaseFromRuleFlow();
}
@Before
public void initialize() throws Exception {
session = knowledgeBase.newStatefulKnowledgeSession();Code listing 43: Excerpt from the unit test initialization
Once the stateful session is initialized, we can use it.
We'll write a test that will create a new address map with an unknown country. This address map will be inserted into the session; we'll start the process and execute all rules. The test will verify that the unknownCountry rule has been fired:
@Test
public void unknownCountryUnknown() throws Exception {
Map addressMap = new HashMap();
addressMap.put("_type_", "Address");
addressMap.put("country", "no country");
session.insert(addressMap);
session.startProcess("dataTransformation");
session.fireAllRules();
assertTrue(validationReport.contains("unknownCountry"));
}Code listing 44: Test for the unknown country rule with an unknown country
Note that the order of the session methods is important. All facts need to be in the session before the process can be started and rules can be executed.
Please note that in order to test this scenario, we didn't use any agenda filter. This test is more like an integration test where we need to test more rules cooperating together.
Another test that exercises case, where the country is known, is shown here. It proves that the process works:
@Test
public void unknownCountryKnown() throws Exception {
Map addressMap = new HashMap();
addressMap.put("_type_", "Address");
addressMap.put("country", "Ireland");
session.startProcess("dataTransformation");
session.insert(addressMap);
session.fireAllRules();
assertFalse(validationReport.contains("unknownCountry"));
}Code listing 45: Test for the unknown country rule with a known country
Since a stateful session is being used, every test should call the dispose method on the session after it finishes. It can be done like this:
@After
public void terminate() {
session.dispose();
}Code listing 46: Calling the session dispose method after every test