

All processes have a processing environment (not to be confused with environment variables that are, as we will see, just one part of the processing environment). The processing environment consists of a unique set of information and conditions that is determined by the current state of the system and by the parent of the process. A process can access processing environment information and, in some cases, modify it. This is accomplished either directly or by using the appropriate system calls or library functions.
Associated with each process is a unique positive integer identification number called a process ID (PID). As process IDs are allocated sequentially, when a system is booted, a few system processes, which are initiated only once, will always be assigned the same process ID. For example, on a Linux system process 0 (historically known as swapper) is created from scratch during the startup process. This process initializes kernel data structures and creates another process called init. The init process, PID 1, creates a number of special kernel threads[1] to handle system management. These special threads typically have low PID numbers.
Other processes are assigned free PIDs of increasing value until the maximum system value for a PID is reached. The maximum value for PIDs can be found as the defined constant PID_MAX in the header file <linux/threads.h> (on older systems check <linux/tasks.h>). When the highest PID has been assigned, the system wraps around and begins to reuse lower PID numbers not currently in use.
The system call getpid can be used to obtain the PID (Table 2.1). The getpid system call does not accept an argument. If it is successful, it will return the PID number. If the calling process does not have the proper access permissions, the getpid call will fail, returning a value of – 1 and setting errno to EPERM (1).
Table 2.1. Summary of the getpid System Call.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary |
| |||
Return | Success | Failure | Sets | |
The process ID | –1 | Yes | ||
A process can determine its own PID by use of the getpid system call, as shown in the following code segment:
cout << "My process ID is " << getpid() << endl;
The getpid system call is of limited use. Usually the PID will be different on each invocation of the program. The manual page entry for getpid notes that the most common use for this system call is the generation of unique temporary file names. However, for everyday use, the library function mkstemp is much better suited for the production of unique temporary file names.
Every process has an associated parent process ID (PPID). The parent process is the process that forked (generated) the child process. The ID of the parent process can be obtained by using the system call getppid (Table 2.2).
Table 2.2. Summary of the getppid System Call.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary |
| |||
Return | Success | Failure | Sets | |
The parent process ID | –1 | –Yes | ||
Like the getpid system call, getppid does not require an argument. If it is successful, it will return the PID number of the parent process. The getppid call will fail, returning a value of −1 and setting errno to EPERM (1) if the calling process does not have the proper access permissions.
The following code segment displays the PPID:
cout << "My Parent Process ID is " << getppid( ) << endl;
Unfortunately, there is no system call that allows a parent process to determine the PIDs of all its child processes. If such information is needed, the parent process should save the returned child PID value from the fork system call as each child process is created.
Every process belongs to a process group that is identified by an integer process group ID value. When a process generates child processes, the operating system automatically creates a process group. The initial parent process is known as the process leader. The process leader's PID will be the same as its process group ID.[2] Additional process group members generated by the process group leader inherit the same process group ID. The operating system uses process group relationships to distribute signals to groups of processes. For example, should a process group leader receive a kill or hang-up signal causing it to terminate, then all processes in its group will also be passed the same terminating signal. A process can find its process group ID from the system call getpgid. In some versions of Linux you may find the getpgid system call absent. In these versions the system call getpgrp (which requires no PID argument) provides the same functionality as the getpgid system call. The getpgid system call is defined in Table 2.3.
Table 2.3. Summary of the getpgid System Call.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary |
| |||
Return | Success | Failure | Sets | |
The process group ID | –1 | –Yes | ||
If successful, this call will return the process group ID for the pid that is passed. If the value of pid is 0, the call is for the current process (eliminating the need for a separate call to getpid). If the getpgid system call fails, a – 1 is returned and the value in errno is set to one of the values in Table 2.4 to indicate the source of the error.
Table 2.4. getpgid Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
1 | EPERM | Not owner | Invalid access permissions for the calling process. |
3 | ESRCH | No such process | No such process ID as |
A short program using the getpgid system call is shown in Program 2.1. Before looking over the program, a brief explanation concerning the compilation of the program is in order. As UNIX has evolved, developers have established a number of standards such as ANSI C, POSIX. 1, POSIX. 2, BSD, SVID, X/Open, and others. On occasion, system calls (such as getpgid) and library functions created under one standard (say, BSD) are modified slightly to meet the requirements for another standard (such as POSIX). When using the g++ compiler, defining the constant _GNU_SOURCE instructs the compiler to use the POSIX definition if there is a conflict.
Example 2.1. Displaying process group IDs.
File : p2.1.cxx
| /*
| Displaying process group ID information
| */
| #define _GNU_SOURCE
+ #include <iostream>
| #include <sys/types.h>
| #include <unistd.h>
| using namespace std;
| int
10 main( ){
| cout << "
Initial process PID " << getpid()
| << " PPID "<< getppid()
| << " GID " << getpgid(0)
| << endl << getpgid(pid_t(getppid())) << endl;
+
| for (int i = 0; i < 3; ++i)
| if (fork( ) == 0) // Generate some processes
| cout << "New process PID " << getpid()
| << " PPID "<< getppid()
20 << " GID " << getpgid(0)
| << endl;
| return 0;
| }
Figure 2.1 displays the output of the program.
Example 2.1. Program 2.1 output.
Initial process PID 3350 PPID 3260 GID 3350 New process PID 3351 PPID 3350 GID 3350 New process PID 3352 PPID 3351 GID 3350 New process PID 3353 PPID 3350 GID 3350 New process PID 3356 PPID 3353 GID 3350 New process PID 3355 PPID 3351 GID 3350 New process PID 3354 PPID 3352 GID 3350 New process PID 3357 PPID 3350 GID 3350
Note that the actual ID numbers change each time the program is run. The relationship of the processes within the process group is shown in Figure 2.2.

All of the processes generated by the program indicate that they belong to the same process group: the process group of the initial process 3350. If the parent of a process dies[3] (terminates) before its child process(es), the process init (which is process ID 1) will inherit the child process and become its foster parent. The process group ID for a process does not change if this inheritance occurs.
A process may change its process group by using the system call setpgid, which sets the process group ID (Table 2.5).
The setpgid system call sets the process group pid to that of pgid. If the value for pid is 0, the call refers to the current process. Otherwise, the call refers to the specified PID. The value for pgid represents the group to which the process will belong. If the value for pgid is 0, the pid referenced process will become the process leader. For this call to be successful, the invoking process must have the correct permissions to institute the requested change. The setpgid system call returns 0 if successful, or returns a –1 and sets errno if it fails. The value errno is assigned when setpgid fails is given in Table 2.6.
Table 2.5. Summary of the setpgid System Call.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary |
| |||
Return | Success | Failure | Sets | |
0 | –1 | Yes | ||
Table 2.6. setpgid Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
1 | EPERM | Operation not permitted |
|
3 | ESRCH | No such process | No such process ID as |
22 | EINVAL | Invalid argument | The |
For those of us who talk fast or listen casually, it is easy to confuse the process group ID with the process's group ID. A process's group ID is covered in Section 2.6.
In addition to process groups, UNIX also supports the concept of a session. A session is a collection of related and unrelated processes and process groups. As with process grouping, there are a number of system calls (e.g., setsid, getsid) that can be used to create and manipulate a session. The process calling setsid becomes the session leader as well as the process group leader. In this arrangement, there is no controlling tty (terminal device). Keep in mind a process inherits its controlling terminal from its parent. Certain input sequences, such as a quit (CTRL+) or an interrupt (CTRL+C), received by a controlling terminal are automatically propagated to other processes in the session.
All UNIX files (executable and otherwise) have an associated set of owner permission bits that are used by the operating system to determine access. The permission bits are grouped into three sets of three bits each. Each bit within a set determines if a file can be read, written to, or executed. The three sets correspond to three classes of users: the file owner, those in the file owner's group and all other users. We can think of the nine permission bits as representing a three-digit octal number, as shown in Figure 2.3. This permission set would indicate that the file owner has read, write, and execute permission; group members have read and write permission; and all others have execute-only permission. The permissions for a file are part of the information stored by the operating system in an I-list (with one unique entry per file). When a file is accessed, its attributes are stored in a system inode table.

At a system level, the permissions of a file are modified using the chmod command. The permissions of a file can be listed with the ls command using the -l (long format) flag. For example, in the ls command output shown in Figure 2.4, the file owner (root) of the file (vi) has permission to read (r), write (w), and execute (x) the file. Members of the file owner's group can read and execute the file, as can users classified as other. In Linux, the group name for a file is shown by default when issuing the ls -l command. In some forms of UNIX (such as true-blue BSD), the -g flag must be added to the command (i.e., ls -lg) to obtain the group name.
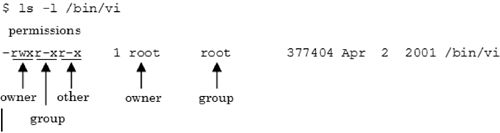
The interpretation of the permission bits for directories is slightly different than for files. When the file is a directory, setting the read bit indicates the directory can be read or displayed. Setting the write bit indicates files or links can be added or removed from the directory, and setting execute permission indicates traversal permission is granted. If traversal permission is not set, the directory name can only be used as part of a path name but cannot be examined directly.
When generating files in UNIX, such as by I/O redirection or compiling a source program into an executable, the operating system will assign permissions to the file. The default permissions assigned to the file are determined by a bitwise operation on two three-digit octal mask values. These mask values are the creation mask and the umask. Unless otherwise specified (such as when creating or opening a file within a program), the creation mask used by the system is 777 for executable and directory files and 666 for text files. The default umask value is set by the system administrator and is most commonly 022. If you want to change the value of umask and would like the value available to all your processes, insert the command umask nnn (where nnn is the new value for umask) in your startup .login (or .profile) file.
At a system level the current umask value may be displayed/modified by using the umask command. An example using the umask command is shown in Figure 2.5 (notice that leading 0s are displayed on some systems).
When a new file is created, the system will exclusive OR (XOR) the creation mask for the file with the current umask value. The exclusive OR operation acts the same as a subtract (without any borrow) of the umask value from the creation mask. The net result determines the permissions for the new file. For example, generating a text file called foo using command-line I/O redirection, as shown in Figure 2.6.
This will set the permissions for the text file foo to 644 (666 minus 022). This is verified by the output of the ls command using the –l option, as shown in Figure 2.7.
Example 2.7. The default permissions of a plain text file.
linux$ ls -l foo -rw-r--r-- 1 gray faculty 10 Jan 1 14:58 foo
If we generate a directory (or executable file such as a.out using the C/C++ compiler), the default permissions, using the 022 umask, will be 755 (777 minus 022). See Figure 2.8.
Example 2.8. The default permission of a directory entry.
linux$ mkdir bar linux$ ls -ld bar drwxr-xr-x 2 gray faculty 4096 Jan 1 15:00 bar
The use of system calls chmod, stat (file status information), and umask that allow a process access to this information is presented in Section 2.7.
In UNIX, with the exception of a few special system processes, processes are generated by users (root and otherwise) who have logged on to the system. During the login process the system queries the password file[4] to obtain two identification (ID) numbers. The numbers the system obtains are in the third and fourth fields of the password entry for the user. These are, respectively, the real user ID (UID) and real group ID (GID) for the user. For example, in the sample password file entry
ggluck:x:1025:1001:Garrett Gluck:/home/student/ggluck:/bin/tcsh
the user login ggluck has a real user ID of 1025 and a group ID of 1001. The real user ID should be (if the system administrator is on the ball) a unique integer value, while the real group ID (also an integer value) may be common to several logins. Group ID numbers should map to the group names stored in the file /etc/group.[5] In general, IDs of less than 500 usually (but not always) indicate user logins with special status.
For every process the system also keeps a second set of IDs called effective IDs, the effective user ID (EUID) and effective group ID (EGID). The operating system uses the real IDs to identify the real user for things such as process accounting or sending mail, and the effective IDs to determine what additional permissions should be granted to the process. Most of the time the real and effective IDs for a process are identical. However, there are occasions when nonprivileged users on a system must be allowed to access/modify privileged files (such as the password file). To allow controlled access to key files, Linux has an additional set of file permissions, known as set-user-ID (SUID) and set-group-ID (SGID), that can be specified by the file's owner. When indicated, these permissions tell the operating system that when the program is run, the resulting process should have the privileges of the owner/group of the program (versus the real user/group privileges associated with the process). In these instances, the effective IDs for the process become those indicated for the file's owner. A listing for an suid program follows.
-r-s--x--x 1 root root 13536 Jul 12 2000 /usr/bin/passwd
As shown, this passwd program (the executable for the system-level command passwd) has its owner permissions set to r-s. The letter s in the owner's category, found in place of the letter x, indicates that when this program is run, the process should have the privileges of the file owner (which is root). The set-user information is stored by the system in a tenth permission bit and can be modified using the system level command, chmod. The SUID setting for the passwd program allows the non-privileged user running it to temporarily have root (superuser) privileges. In this case, the user running the program will be able to modify the system password files, as the permissions on the password files indicate that they are owned and can only be modified by root. Needless to say, programs that have their SUID or SGID bit set should be carefully thought out, especially if the programs are owned by the superuser (root).
At a system level, the command id (as shown in Figure 2.9) displays the current user, group ID, and group affiliation information. Note that while a file can belong to only one group, a user can belong to many groups.
In a programming environment, the system calls that return the user/group real and effective IDs for a process are given in Table 2.7.
Table 2.7. Summary of User/Group Real and Effective ID Calls System.
Include File(s) |
<sys/types.h> <unistd.h> | Manual Section | 2 | |
Summary |
uid_t getuid( void ); uid_t geteuid( void ); gid_t getgid( void ); gid_t getegid( void ); | |||
Return | Success | Failure | Sets | |
The requested ID | ||||
There are corresponding system calls that can be passed ID values to set (change) the user/group real and effective IDs. Additionally, Linux implements a file system user ID used by the kernel to limit a user's access to a given file system. The file system ID is set with the setfsuid system call. The use of setfsuid and the calls to set user/group real and effective IDs are beyond the scope of this text.
In addition to process ID information, the process environment contains file system information. Associated with each open file is an integer file descriptor value that the operating system uses as an index to a 1,024-entry file descriptor table located in the u (user) area for the process. The per-process file descriptor table references a system file table, which is located in kernel space. In turn, the system file table maps to a system inode table that contains a reference to a more complete internal description of the file.
When a child process is generated, it receives a copy of its parent's file descriptor table (this includes the three descriptors—stdin, stdout, and stderr) with the file pointer offset associated with each open file. If a file is marked as shareable, the operating system will need to save each file pointer offset separately. The relationship of process and system tables are shown in Figure 2.10.
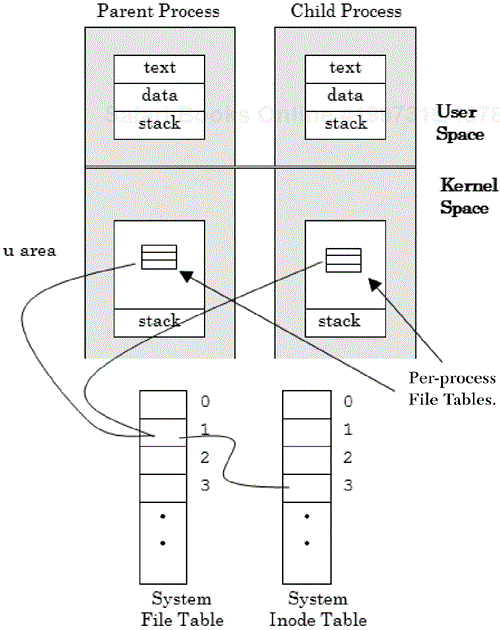
There are a number of system calls that a process can use to obtain file information. Of these, the stat system calls (shown in Table 2.8) provide the process with a comprehensive set of file-related information somewhat analogous to the information that can be obtained by using the system-level stat command found in Linux. For example, the command
linux$ stat a.out File: "a.out" Size: 14932 Blocks: 32 Regular File Access: (0755/-rwxr-xr-x) Uid: ( 500/ gray) Gid: (1000/ faculty) Device: 815 Inode: 97541 Links: 1 Access: Tue Jan 1 16:05:58 2002 Modify: Tue Jan 1 16:05:57 2002 Change: Tue Jan 1 16:05:57 2002
displays information about the file a.out found in the current directory.
Table 2.8. Summary of the stat System Calls.
Include File(s) |
<sys/types.h> <sys/stat.h> <unistd.h> | Manual Section | 2 | ||
Summary |
int stat(const char *file_name, struct stat *buf); int lstat(const char *file_name, struct stat *buf); int fstat(int filedes, struct stat *buf); | ||||
Return | Success | Failure | Sets | ||
0 | –1 | Yes | |||
As its first argument, the stat system call takes a character pointer to a string containing the path for a file. The lstat system call is similar to stat except when the file referenced is a symbolic link. In the case of a symbolic link, lstat returns information about the link entry, while stat returns information about the actual file. The fstat system call takes an integer file descriptor value of an open file as its first argument.
All three stat system calls return, via their second argument, a pointer to a stat structure. The stat structure is defined in its entirety in the header file <sys/stat.h> and the <bits/stat.h>. The <bits/stat.h> file is automatically included by <sys/stat.h> and should not be directly included by the programmer. The stat structure normally contains members for
dev_t st_dev; /* device file resides on */ ino_t st_ino; /* this file's number */ u_short st_mode; /* protection */ short st_nlink; /* number of hard links to the file */ short st_uid; /* user ID of owner */ short st_gid; /* group ID of owner */ dev_t st_rdev; /* the device identifier(special files only)*/ off_t st_size; /* total size of file, in bytes */ time_t st_atime; /* file data last access time */ time_t st_mtime; /* file data last modify time */ time_t st_ctime; /* file data last status change time */ long st_blksize; /* preferred blocksize for file system I/O*/ long st_blocks; /* actual number of blocks allocated */
The special data types (e.g., dev_t, ino_t) of individual structure members are mapped to standard data types in the header file <sys/types.h>. If the stat system calls are successful, they return a value of 0. Otherwise, they return a value of −1 and set errno. As these system calls reference file information, there are numerous error situations that may be encountered. The value that errno may be assigned and an explanation of the associated perror message are shown in Table 2.9.
Table 2.9. stat Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
2 | ENOENT | No such file or directory | File does not exist (or is NULL). |
4 | EINTR | Interrupted system call | Signal was caught during the system call. |
9 | EBADF | Bad file number | The value in |
12 | ENOMEM | Cannot allocate memory | Out of memory (i.e., kernel memory). |
13 | EACCES | Permission denied | Search permission denied on part of file path. |
14 | EFAULT | Bad address | Path references an illegal address. |
20 | ENOTDIR | Not a directory | Part of the specified path is not a directory. |
36 | ENAMETOOLONG | File name too long | The path value exceeds system path/file name length. |
40 | ELOOP | Too many levels of symbolic links | The |
67 | ENOLINK | The link has been severed | The path value references a remote system that is no longer active. |
72 | EMULTIHOP | Multihop attempted | The path value requires multiple hops to remote systems, but file system does not allow it. |
75 | EOVERFLOW | Value too large for defined data type | A value for a member of the structure referenced by |
A program showing the use of the stat system call is shown in Program 2.2.
Example 2.2. Using the stat system call.
| /*
| Using the stat system call
| */
| #include <iostream>
+ #include <cstdio>
| #include <sys/types.h>
| #include <sys/stat.h>
| #include <unistd.h>
| using namespace std;
10 const int N_BITS = 3;
| int
| main(int argc, char *argv[ ]){
| unsigned int mask = 0700;
| struct stat buff;
+ static char *perm[] = {"---", "--x", "-w-", "-wx",
| "r--", "r-x", "rw-", "rwx"};
| if (argc > 1) {
| if ((stat(argv[1], &buff) != -1)) {
| cout << "Permissions for " << argv[1] << " ";
20 for (int i=3; i;-i) {
| cout << perm[(buff.st_mode & mask) >> (i-1)*N_BITS];
| mask >>= N_BITS;
| }
| cout << endl;
+ } else {
| perror(argv[1]);
| return 1;
| }
| } else {
30 cerr << "Usage: " << argv[0] << "file_name
";
| return 2;
| }
| return 0;
| }
When this program is run and passed its own name on the command line, the output is as shown in Figure 2.11.
The system command sequence ls -l for the same file produces the same set of permissions as shown in Figure 2.12.
Example 2.12. Verifying Program 2.2 output with the ls command.
linux$ ls -l a.out -rwxr-xr-x 1 gray faculty 15290 Jan 2 07:26 a.out
In a programming environment, the access permissions of a file can be modified with the chmod/fchmod system calls (Table 2.10).
Table 2.10. Summary of the chmod/fchmod System Calls.
Include File(s) |
<sys/types.h> <sys/stat.h> | Manual Section | 2 | |
Summary |
int chmod( const char *path, mode_t mode ); int fchmod( int fildes, mode_t mode ); | |||
Return | Success | Failure | Sets | |
0 | –1 | Yes | ||
Both system calls accomplish the same action and differ only in the format of their first argument. The chmod system call takes a character pointer reference to a file path as its first argument, while fchmod takes an integer file descriptor value of an open file. The second argument for both system calls is the mode. The mode can be specified literally as an octal number (e.g., 0755) or by bitwise ORing together combinations of defined permission constants found in the header file <sys/stat.h>. Unless the effective user ID of the process is that of the superuser, the effective user ID and the owner of the file whose permissions are to be changed must be the same. If either system call is successful, it returns a 0. Otherwise, the call returns a −1 and sets the value in errno. As with the stat system calls, the number of error conditions is quite extensive (see Table 2.11).
Table 2.11. chmod/fchmod Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
1 | EPERM | Operation not permitted | Not owner or file or superuser. |
2 | ENOENT | No such file or directory | File does not exist (or is NULL). |
4 | EINTR | Interrupted system call | Signal was caught during the system call. |
5 | EIO | I/O error | I/O error while attempting read or write to file system. |
9 | EBADF | Bad file number | The value in |
12 | ENOMEM | Cannot allocate memory | Out of memory (i.e., kernel memory). |
13 | EACCES | Permission denied | Search permission denied on part of file path. |
14 | EFAULT | Bad address |
|
20 | ENOTDIR | Not a directory | Part of the specified |
30 | EROFS | Read-only file system | File referenced by |
36 | ENAMETOOLONG | File name too long | The |
40 | ELOOP | Too many levels of symbolic links | The |
67 | ENOLINK | The link has been severed | The |
72 | EMULTIHOP | Multihop attempted | The |
The umask value, which is inherited from the parent process, may be modified by a process with the umask system call (Table 2.12).
Table 2.12. Summary of the umask System Call.
Include File(s) |
<sys/types.h> <sys/stat.h> | Manual Section | 2 | |
Summary |
| |||
Return | Success | Failure | Sets | |
The previous | ||||
When invoked, umask both changes the umask value to the octal integer value passed and returns the old (previous) umask value.[6] If you use the umask system call to determine the current umask setting, you should call umask a second time, passing it the value returned from the first call, to restore the settings to their initial state. For example,
mode_t cur_mask;
cur_mask = umask(0);
cout << "Current mask: " << setfill('0') << setw(4) << oct
<< cur_mask << endl;
umask(cur_mask);
The library function getcwd is used to copy the absolute path of the current working directory of a process to an allocated location. The function is defined as shown in Table 2.13. It returns a pointer to the directory pathname. The function expects two arguments. The first is a pointer to the location where the pathname should be stored. If this argument is set to NULL, getcwd uses malloc to automatically allocate storage space. The second argument is the length of the pathname to be returned (plus 1 for the � to terminate the string). The include file <sys/param.h> contains the defined constant MAXPATHLEN that can be used to assure a buffer of sufficient size (i.e., MAXPATHLEN+1). In the following code snippet the space allocated to hold the path information will be just what is needed to store the absolute path (most likely less than MAXPATHLEN+1).
Table 2.13. Summary of the getcwd Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
| |||
Return | Success | Failure | Sets | |
A pointer to the current directory name | NULL | Yes | ||
char *path; path = getcwd(NULL, MAXPATHLEN+1); cout << path << endl; cout << "Path length: " << strlen(path) << endl; // sufficient to hold path
If getcwd fails, it returns a NULL and sets errno (Table 2.14). If malloc is used to dynamically allocate storage, the space should be returned with free when it is no longer needed.
Table 2.14. getcwd Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
13 | EACCES | Permission denied | Search permission denied on part of file path. |
22 | EINVAL | Invalid argument | The value for |
34 | ERANGE | Numerical resultout of range | The value for |
The system call chdir is used to change the current working directory (as is the cd[7] command at system level). See Table 2.15.
The chdir system call takes a character pointer reference to a valid pathname (the process must have search permission for all directories referenced) as its argument. The fchdir system call takes an open file descriptor of a directory as its argument. If successful, the system call returns a 0, and the new working directory for the process will be the one specified. If the call fails, a −1 is returned and errno is set (Table 2.16).
Table 2.15. Summary of the chdir/fchdir System Calls.
Include File(s) |
| Manual Section | 2 | |
Summary |
int chdir( const char *path ); int fchdir( int fildes ); | |||
Return | Success | Failure | Sets | |
0 | –1 | Yes | ||
Table 2.16. chdir/fchdir Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
2 | ENOENT | No such file or directory | File does not exist (or is NULL). |
4 | EINTR | Interrupted system call | Signal was caught during the system call. |
5 | EIO | I/O error | I/O error while attempting read or write to file system. |
9 | EBADF | Bad file number | The value in |
12 | ENOMEM | Cannot allocate memory | Out of memory (i.e., kernel memory). |
13 | EACCES | Permission denied | Search permission denied on part of file path. |
14 | EFAULT | Bad address |
|
20 | ENOTDIR | Not a directory | Part of the specified |
36 | ENAMETOOLONG | File name too long | The |
40 | ELOOP | Too many levels of symbolic links | The |
67 | ENOLINK | The link has been severed | The |
72 | EMULTIHOP | Multihop attempted | The |
As system resources are finite, every process is restrained by certain operating system-imposed limits. At the command line, the ulimit command (which is actually a built-in command found in the Bourne shell [/bin/sh]) provides the user with a means to display and modify current system limits available to the shell and the processes that are started by it.[8]
The command ulimit -Ha displays the hard limits for the system. The hard limits can be increased only by the superuser. An example showing the hard limits of a system is shown in Figure 2.13.
Example 2.13. Typical hard limits on a Linux system.
linux$ ulimit -Ha core file size (blocks, -c) unlimited data seg size (kbytes, -d) unlimited file size (blocks, -f) unlimited max locked memory (kbytes, -l) unlimited max memory size (kbytes, -m) unlimited open files (-n) 1024 pipe size (512 bytes, -p) 8 stack size (kbytes, -s) unlimited cpu time (seconds, -t) unlimited max user processes (-u) 4095 virtual memory (kbytes, -v) unlimited
A soft limit, displayed when ulimit is passed the -Sa (Soft, all) command-line option, is a limit that can be set by the user. A soft limit is typically lower than the established hard limit. Note that the limits for the current process on this system are slightly less for stack size, as shown in Figure 2.14.
Example 2.14. Individual process resource limits.
linux$ ulimit -Sa
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) unlimited
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4095
virtual memory (kbytes, -v) unlimited
Resource limit information for a process can be obtained in a programming environment as well. Historically, the ulimit system call was used to obtain part of this information. In more recent versions of the operating system the ulimit system call has been superseded by the getrlimit/setrlimit calls described below. However, ulimit still bears a cursory investigation, as it is sometimes found in legacy code (Table 2.17).
Table 2.17. Summary of the ulimit System Call.
Include File(s) |
| Manual Section | 3 | |
Summary |
long ulimit(int cmd /* , long newlimit */ ); | |||
Return | Success | Failure | Sets | |
Nonnegative long integer | –1 | Yes | ||
The argument cmd can take one of four different values:
Obtain file size limit for this process. The value returned is in units of 512-byte blocks.
Set the file size limit to the value indicated by
newlimit. Non-superusers only can decrease the file size limit. This is the only command in which the argumentnewlimitis used.Obtain the maximum break value. This option is not supported by Linux.
Return the maximum number of files that the calling process can open.
If ulimit is successful, it returns a positive integer value; otherwise, it returns a −1 and sets the value in errno (Table 2.18).
Table 2.18. ulimit Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
13 | EPERM | Permission denied | Calling process is not superuser. |
22 | EINVAL | Invalid argument | The value for |
The newer getrlimit/setrlimit system calls provide the process more complete access to system resource limits (Table 2.19).
Table 2.19. Summary of the getrlimit/setrlimit System Calls.
Include File(s) |
<sys/time.h> <sys/resource.h> <unistd.h> | Manual Section | 2 | |
Summary |
int getrlimit(int resource, struct rlimit
*rlim);
int setrlimit(int resource, const struct
rlimit *rlim);
| |||
Return | Success | Failure | Sets | |
0 | −1 | Yes | ||
The rlimit structure:
struct rlimit {
rlimit_t rlim_cur; /* current (soft) limit */
rlimit_t rlim_max; /* hard limit */
};
along with a number of defined constants used by the two functions:
RLIMIT_CPU /* CPU time in seconds */ RLIMIT_FSIZE /* Maximum filesize */ RLIMIT_DATA /* max data size */ RLIMIT_STACK /* max stack size */ RLIMIT_CORE /* max core file size */ RLIMIT_RSS /* max resident set size */ RLIMIT_NPROC /* max number of processes */ RLIMIT_NOFILE /* max number of open files */ RLIMIT_MEMLOCK /* max locked-in-memory address space*/ RLIMIT_AS /* address space (virtual memory) limit */ RLIMIT_INFINITY /* actual value for 'unlimited' */
are found in the header file <sys/resource.h> and its associated include files. A program using the getrlimit system call is shown in Program 2.3.
Example 2.3. Displaying resource limit information.
| /*
| Using getrlimt to display system resource limits
| */
| #include <iostream>
+ #include <iomanip>
| #include <sys/time.h>
| #include <sys/resource.h>
| using namespace std;
| int
10 main( ){
| struct rlimit plimit;
| char *label[ ]={"CPU time", "File size",
| "Data segment", "Stack segment",
| "Core size","Resident set size",
+ "Number of processes", "Open files",
| "Locked-in-memory", "Virtual memory",
| 0};
| int constant[]= { RLIMIT_CPU , RLIMIT_FSIZE,
| RLIMIT_DATA , RLIMIT_STACK,
20 RLIMIT_CORE , RLIMIT_RSS,
| RLIMIT_NPROC , RLIMIT_NOFILE,
| RLIMIT_MEMLOCK, RLIMIT_AS };
|
| for (int i = 0; label[i]; ++i) {
+ getrlimit(constant[i], &plimit);
| cout << setw(20) << label[i] << " Current: "
| << setw(10) << plimit.rlim_cur << " Max: "
| << setw(10) << plimit.rlim_max << endl;
| }
30 return 0;
| }
The output sequence from this program (Figure 2.15) is comparable to the output of the system-level ulimit command shown earlier.
Example 2.15. Program 2.3 output.
linux$ p2.3
CPU time Current: 4294967295 Max: 4294967295
File size Current: 4294967295 Max: 4294967295
Data segment Current: 4294967295 Max: 4294967295
Stack segment Current: 8388608 Max: 4294967295
Core size Current: 4294967295 Max: 4294967295
Resident set size Current: 4294967295 Max: 4294967295
Number of processes Current: 16383 Max: 16383
Open files Current: 1024 Max: 1024
Locked-in-memory Current: 4294967295 Max: 4294967295
Virtual memory Current: 4294967295 Max: 4294967295
The setrlimit system call, like the ulimit call, can be used only by the non-superuser to decrease resource limits. If these system calls are successful, they return a 0; otherwise, they return a −1 and set the value in errno (Table 2.20).
Table 2.20. getrlimit/setrlimit Error Messages.
# | Constant |
| Explanation |
|---|---|---|---|
13 | EPERM | Permission denied | Calling process is not superuser. |
22 | EINVAL | Invalid argument | The value for |
Additional process limit information can be obtained from the sysconf library function (Table 2.21).
Table 2.21. Summary of the sysconf Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
| |||
Return | Success | Failure | Sets | |
Nonnegative long integer | −1 | No (?) | ||
The sysconf function is passed an integer name value (usually in the form of a defined constant) that indicates the limit requested. If successful, the function returns the long integer value associated with the limit or a value of 0 or 1 if the limit is available or not. If the sysconf function fails, it returns a −1 and does not set the value in errno. The limits that sysconf knows about are defined as constants in the header file <unistd.h>.[9] In past versions of the operating system, some of these limit values were found in the header file <sys/param.h>. The constants for some of the more commonly queried limits are listed below:
_SC_ARG_MAX /* space for argv & envp */ _SC_CHILD_MAX /* max children per process */ _SC_CLK_TCK /* clock ticks / sec */ _SC_STREAM_MAX /* max # of data streams per process */ _SC_TZNAME_MAX /* max # of bytes in timezone name spec. */ _SC_OPEN_MAX /* max open files per process */ _SC_JOB_CONTROL /* do we have job control? */ _SC_SAVED_IDS /* do we have saved uid/gids? */ _SC_VERSION /* POSIX version supported YYYYMML format*/
Program 2.4, which displays the values associated with the limits for a system, is shown below.
Example 2.4. Displaying system limits.
File : p2.4.cxx
| /*
| Using sysconf to display system limits
| */
| #include <iostream>
+ #include <iomanip>
| #include <cstdio>
| #include <unistd.h>
| using namespace std;
| int
10 main( ){
| char *limits[ ]={"Max size of argv + envp",
| "Max # of child processes",
| "Ticks / second",
| "Max # of streams",
+ "Max # of bytes in a TZ name",
| "Max # of open files",
| "Job control supported?",
| "Saved IDs supported?",
| "Version of POSIX supported",
20 0};
| int constant[ ]={ _SC_ARG_MAX, _SC_CHILD_MAX,
| _SC_CLK_TCK, _SC_STREAM_MAX,
| _SC_TZNAME_MAX, _SC_OPEN_MAX,
| _SC_JOB_CONTROL,_SC_SAVED_IDS,
+ _SC_VERSION };
| for (int i=0; limits[i]; ++i) {
| cout << setw(30) << limits[i] << " "
| << sysconf(constant[i]) << endl;
| }
30 return 0;
| }
When run on a local system, Program 2.4 produced the output shown in Figure 2.16.
Example 2.16. Output of Program 2.4.
linux$ p2.4
Max size of argv + envp 131072
Max # of child processes 999
Ticks / second 100
Max # of streams 16
Max # of bytes in a TZ name 3
Max # of open files 1024
Job control supported? 1
Saved IDs supported? 1
Version of POSIX supported 199506
If the sysconf function fails due to an invalid name value, a −1 is returned. The manual page indicates errno will not be set; however, some versions of Linux set errno to ENIVAL, indicating an invalid argument.
When events out of the ordinary occur, a process may receive a signal. Signals are asynchronous and are generated when an event occurs that requires attention. They can be thought of as a software version of a hardware interrupt and may be generated by various sources:
Hardware—. Such as when a process attempts to access addresses outside its own address space or divides by zero.
Kernel—. Notifying the process that an I/O device for which it has been waiting (say, input from the terminal) is available.
Other processes—. A child process notifying its parent process that it has terminated.
User—. Pressing keyboard sequences that generate a quit, interrupt, or stop signal.
Signals are numbered and historically were defined in the header file <signal.h>. In Linux signal definitions reside in <bits/signum.h>. This file is included automatically when you include <signal.h>. The <bits/signum.h> should not be directly included in your program. The process that receives a signal can take one of three courses of action:
Perform the system-specified default for the signal. For most signals the default action (what will be done by the process if nothing else has been specified) is to (a) notify the parent process that it is terminating, (b) generate a core file (a file containing the current memory image of the process), and (c) terminate.
Ignore the signal. A process can do this with all but two special signals: SIGSTOP (signal 23), a stop-processing signal that was not generated from the terminal, and SIGKILL (signal 9), which indicates the process is to be killed (terminated). The inability of a process to ignore these special signals ensures the operating system the ability to remove errant processes.
Catch the signal. As with ignoring signals, this can be done for all signals except the SIGSTOP and SIGKILL signals. When a process catches a signal, it invokes a special signal handling routine. After executing the code in the signal handling routine, the process, if appropriate, resumes where it was interrupted.
A child process inherits the actions associated with specific signals from its parent. However, should the child process overlay its process space with another executable image, such as with an exec system call (see Chapter 3, “Using Processes”), all signals that were associated with signal catching routines at specific addresses in the process are reset to their default action in the new process. This resetting to the default action is done by the system, as the address associated with the signal catching routine is no longer valid in the new process image. In most cases (except for I/O on slow devices such as the terminal) when a process is executing a system call and a signal is received, the interrupted system call generates an error (usually returning −1) and sets the global errno variable to the value EINTR. The process issuing the system call is responsible for re-executing the interrupted system call. As the responsibility for checking each system call for signal interrupts carries such a large overhead, it is rare that once a signal is caught the process resumes normal execution. More often than not, the process uses the signal catching routine to perform housekeeping duties (such as closing files, etc.) before exiting on its own. Signals sent to a process/session group leader are also passed to the members of the group. Signals and signal catching routines are covered in considerable detail in Chapter 4, “Primitive Communications.”
Part of the processing environment of every process are the values passed to the process in the function main. These values can be from the command line or may be passed to a child process from the parent via an exec system call. These values are stored in a ragged character array referenced by a character pointer array that, by tradition, is called argv. The number of elements in the argv array is stored as an integer value, which (again by tradition) is referenced by the identifier argc. Program 2.5, which displays command line values, takes advantage of the fact that in newer ANSI standard versions of Linux, the last element of the argv array (i.e., argv[argc]) is guaranteed to be a NULL pointer. However, in most programming situations, especially when backward compatibility is a concern, it is best to use the value in argc as a limit when stepping through argv. If we run the program as p2.5 and place some arbitrary values on the command line, we obtain the output shown in Figure 2.17.
Example 2.5. Displaying command line arguments.
File : p2.5.cxx
| /*
| Displaying the contents of argv[ ] (the command line)
| */
| #include <iostream>
+ using namespace std;
| int
| main(int argc, char *argv[ ]){
| for ( ; *argv; ++argv )
| cout << *argv << endl;
10 return 0;
| }
We can envision the system as storing these command-line values in argc and argv as shown in Figure 2.18.

In this situation (where the system fills the argv array), argc will always be greater than 0, and the first value referenced by argv will be the name of the program that is executing. The system automatically terminates each string with a null character and places a 0 as the last address in the argv array.
In programs, it is a common practice to scan the command line to ascertain its contents (such as when looking for command-line options). At one time programmers wishing to check the contents of the command line for options had to write their own command-line parsing code. However, there is a general-purpose library function called getopt that will do this.[10] The getopt library function is somewhat analogous to the Swiss army knife—it can do many things, but to the uninitiated, upon first exposure, it appears unduly complex (Table 2.22).
Table 2.22. Summary of the getopt Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
int getopt( int argc, char * const argv[],
char *optstring );
extern char *optarg;
extern int optind, opterr, optopt;
| |||
Return | Success | Failure | Sets | |
Next option letter | −1 or ? | |||
The getopt function requires three arguments. The first is an integer value argc (the number of elements in the second argument). The second argument is a pointer to a pointer to an array of characters strings. Usually this is the array of character strings referenced by argv. The third argument is a pointer to a string of valid option letters (characters) that getopt should recognize. As noted, in most settings the values for argc and argv are the same as those for main's first and second arguments. However, nothing prevents users from generating these two arguments to getopt on their own.
The format of optstring's content bears further explanation. If an option letter expects a following argument, the option letter in optstring is followed by a colon. For example, if the option letter s (which, say, stands for size) is to be followed by an integer size value, the corresponding optstring entry would be s:. On the command line, the user would enter -s 200 to indicate a size of 200. For a command-line option to be processed properly by getopt, it must be preceded with a hyphen(-), while the argument(s) to the option should have no leading hyphen and may or may not be separated by whitespace from the option.
The getopt function returns, as an integer, one of three values:
−1 indicating all options have been processed.
? indicating an option letter has been processed that was not in the
optstringor an option argument was specified (with the : notation in theoptstring) but none was found when processing the command line. When a?is returned,getoptalso displays an error message on standard error. The automatic display of the error message can be disabled by changing the value stored in the external identifieropterrto 0 (it is set to 1 by default). The offending character (stored as an integer) is referenced by theoptoptvariable.The next option letter in
argvthat matches a letter inoptstring. If the letter matched inoptstringis followed by a colon, then the external character pointeroptargreferences the argument value. Remember that if the argument value is to be treated as a numeric value (versus a string), it must be converted.
The external integer optind is initialized by the system to 1 before the first call to getopt. It will contain the index of the next argument in argv that is not an option. By default getopt processes the argument array in a manner that all non-options are placed at the end of the list. A comparison of the value in optind to the value in argc can be used to determine if all items on the command line have been processed. The getopt function has a relative called getopt_long, which is similar in function to getopt but will process long (those with two leading dashes) command-line arguments. Check the manual page on this function for details. A program demonstrating the use of getopt is shown in Program 2.6.
Example 2.6. Using the library function getopt.
File : p2.6.cxx
| /*
| Command line using getopt
| */
| #define _GNU_SOURCE
+ #include <iostream>
| #include <cstdlib>
| #include <unistd.h>
| using namespace std;
| extern char *optarg;
10 extern int optind, opterr, optopt;
| int
| main(int argc, char *argv[ ]){
| int c;
| char optstring[] = "abs:";
+ opterr = 0; // turn off auto err mesg
| while ((c = getopt(argc, argv, optstring)) != -1)
| switch (c) {
| case 'a':
| cout << "Found option a
";
20 break;
| case 'b':
| cout << "Found option b
";
| break;
| case 's':
+ cout << "Found option s with an argument of: ";
| cout << atoi(optarg) << endl; // convert to integer
| break;
| case '?':
| cout << "Found an option that was not in optstring.
";
30 cout << "The offending character was " << char(optopt) << endl;
| }
| if (optind < argc){
| cout << (argc—optind) << " arguments not processed.
";
| cout << "Left off at: " << argv[optind] << endl;
+ }
| return 0;
| }
A run of the program with some sample command-line options is shown in Figure 2.19.
Example 2.19. Output of Program 2.6.
linux$ p2.6 -abc -s 34 -b joe -a student Found option a Found option b Found an option that was not in optstring. The offending character was c Found option s with an argument of: 34 Found option b Found option a 2 arguments not processed. Left off at: joe
As the output shows, getopt can process options in groups (e.g., -abc) or as singletons (e.g., -b), and is not concerned with the alphabetic order of options. When processing stops, optind can be checked to determine if any command-line options were not part of the specified options.
Each process also has access to a list of environment variables. The environment variables, like the command-line values, are stored as a ragged array of characters. Environment variables, which are most commonly set at the shell level,[11] are passed to a process by its parent when the process begins execution. Environment variables can be accessed in a program by using an external pointer called environ, which is defined as
extern char **environ;
In most older (and in some current) versions of Linux, the environment variables could also be accessed by using a third argument in the function main called envp. When used, the envp argument to main is defined as
main(int argc,char *argv[],char **envp /* OR as *envp[]*/)
As environ and envp can both be used to accomplish the same thing, and current standards discourage the use of envp, only the use of the external pointer environ will be discussed in detail.
The contents of the environment variables can be obtained in a manner similar to the command-line arguments (Program 2.7).
A partial listing of the output of this program run on a local system is show in Figure 2.20.
Example 2.7. Displaying environment variables.
File : p2.7.cxx
| /*
| Using the environ pointer to display the command line
| */
| #include <iostream>
+ using namespace std;
| extern char **environ;
| int
| main( ){
| for ( ; *environ ; )
10 cout << *environ++ << endl;
| return 0;
| }
Example 2.20. Output of Program 2.7.
linux$ p2.7 PWD=/home/faculty/gray/revision/02 VENDOR=intel REMOTEHOST=zeus.cs.hartford.edu HOSTNAME=kahuna LOGNAME=gray SHLVL=2 GROUP=faculty USER=gray PATH=/usr/kerberos/bin:/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:. . . .
The output shows that all environment variables are stored as strings in the format name=value. Many of the environment variables shown here are common to all Linux systems (e.g., USER, PATH, etc.), while others are system-dependent (e.g., VENDOR). Note that by convention environment variables are normally spelled in uppercase. For the more curious, the manual page on environ ($ man 5 environ) furnishes a detailed description of the commonly found environment variables and their uses.
The two library calls shown in Tables 2.23 and 2.24 can be used to manipulate environment variables.
The first library call, getenv, searches the environment list for the first occurrence of a specified variable. The character string argument passed to getenv should be of the format name, where name is the name of the environment variable to find without an appended =. Note that name is case-sensitive (environment variables are often in uppercase). If getenv is successful, it returns a pointer to the string assigned to the environment variable specified; otherwise, it returns a NULL pointer. If getenv fails, it returns a −1 and sets errno to ENOMEM (12—”Cannot allocate memory”). In Program 2.8 the output (shown in Figure 2.21) indicates that in this case the environment variable TERM has been found and that its current value is vt220. Notice that only the string to the right of the equals was returned by getenv.
Table 2.23. Summary of the getenv Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
| |||
Return | Success | Failure | Sets | |
Pointer to the value in the environment | NULL | |||
Table 2.24. Summary of the putenv Library Function.
Include File(s) |
| Manual Section | 3 | |
Summary |
| |||
Return | Success | Failure | Sets | |
0 | −1 | Yes | ||
Example 2.8. Using getenv.
File : p2.8.cxx
| /*
| Displaying the contents of the TERM variable
| */
| #include <iostream>
+ #include <cstdlib>
| using namespace std;
| int
| main( ){
| char *c_ptr;
10 c_ptr = getenv("TERM");
| cout << "The variable TERM is "
| << (c_ptr==NULL ? "NOT found" : c_ptr)
| << endl;
| return 0;
+ }
Example 2.21. Checking the output of Program 2.8.
linux$ echo $TERM vt220 linux$ p2.8 The variable TERM is vt220
Modifying or adding environment variable information, which is usually accomplished with the library function putenv, is a little trickier. The environment variables, along with the command-line values, are stored by the system in the area just beyond the stack segment for the process (see Chapter 1, Section 1.8). This area is accessible by the process and can be modified by the process, but it cannot be expanded. When environment variables are added or an existing environment variable is modified so it is larger (storage-wise) than its initial setting, the system will move the environment variable information from its stack location to the text segment of the process (the putenv function uses malloc to allocate additional space). To further complicate the issue in this situation, envp (if supported) will still point to the table on the stack when referencing the original environment variables, but will point to the text segment for the new environment variable. This is yet another reason to stay clear of envp!
One last caveat appears in the putenv manual page. The argument for putenv should not be an automatic variable (such as a variable local to a function), as these variables become undefined once the function in question is exited.
Program 2.9 demonstrates the putenv function.
Example 2.9. Using putenv.
File : p2.9.cxx
| /*
| Using putenv to modify the environment as seen by parent — child
| */
| #define _GNU_SOURCE
+ #include <iostream>
| #include <cstdlib>
| #include <sys/types.h>
| #include <unistd.h>
| using namespace std;
10 extern char **environ;
| int show_env( char ** );
| int
| main( ){
| int numb;
+ cout << "Parent before any additions **********" << endl;
| show_env( environ );
| putenv("PARENT_ED=parent");
| cout << "Parent after one addition **********" << endl;
| show_env( environ );
20 if ( fork( ) == 0 ){ // In the CHILD now
| cout << "Child before any additions *********" << endl;
| show_env( environ );
| putenv("CHILD_ED=child");
| cout << "Child after one addition *********" << endl;
+ show_env( environ );
| return 0;
| } // In the PARENT now
| sleep( 10 ); // Make sure child is done
| cout << "Parent after child is done **********" << endl;
30 numb = show_env( environ );
| cout << "... and at address [" << hex << environ+numb
| << "] is ... "
| << (*(environ+numb) == NULL ? "Nothing!" : *(environ+numb))
| << endl;
+ return 0;
| }
| /*
| Display the contents of the passed list ... return number found
| */
40 int show_env( char **cp ){
| int i;
| for (i=0; *cp; ++cp, ++i)
| cout << "[" << hex << cp << "] " << *cp << endl;
| return i;
+ }
The abridged output (some of the intervening lines of output were removed for clarity) of this program, when run on a local system, is explained in Figure 2.22.
Example 2.22. Output of Program 2.9.
linux$ p2.9 Parent before any additions ********** [0xbffffc9c] TERM=vt220 <-- 1 . . . [0xbffffd08] CA_DB= Parent after one addition ********** [0x8049ec8] TERM=vt220 . . . [0x8049f34] CA_DB= [0x8049f38] PARENT_ED=parent <-- 2 Child before any additions ********** [0x8049ec8] TERM=vt220 <-- 3 . . . | [0x8049f34] CA_DB= | [0x8049f38] PARENT_ED=parent <-- 3 Child after one addition ********** [0x8049ec8] TERM=vt220 . . . [0x8049f34] CA_DB= [0x8049f38] PARENT_ED=parent [0x8049f3c] CHILD_ED=child <-- 4 Parent after child is done ********** [0x8049ec8] TERM=vt220 . . . [0x8049f34] CA_DB= [0x8049f38] PARENT_ED=parent <-- 5 ... and at address [0x8049f3c] is ... Nothing!
(1)The environment variables start their life in storage just beyond the stack segment (notice the addresses).
(2)This environment variable is added by the parent process. All variables have been moved to the text segment.
(3)Notice the addresses in the child are the same.
(4)This environment variable is added by the child process.
(5)When the child process is gone, so is the environment variable it added.
There are several important concepts that can be gained by examining this program and its output. First, it is clear that the addresses associated with the environment variables are changed (from the stack segment to the text segment) when a new environment variable is added. Second, the child process inherits a copy of the environment variables from its parent. Third, as each process has its own address space, it is not possible to pass information back to a parent process from a child process.[12] Fourth, when adding an environment variable, the name=value format should be adhered to. While it is not checked in the example program, putenv will return a 0 if it is successful and a −1 if it fails to accomplish its mission.
2-12 EXERCISE
Sam figures he has a way for a child process to communicate with its parent via the environment. His solution is to have the child process modify (without changing the storage size and without using putenv) an environment variable that was initially found in the parent. He wrote the following program to test his idea. Will his program work as he thought—why, or why not?
File : sam.cxx
| /*
| Sam's environment program
| */
| #define _GNU_SOURCE
+ #include <iostream>
| #include <cstdlib>
| #include <sys/types.h>
| #include <unistd.h>
| using namespace std;
10 int
| main( ){
| int numb;
| char *p;
| putenv("DEMO=abcdefghijklmnop");
+ p = getenv("DEMO");
| cout << "1. Parent environment has " << p << endl;
|
| if ( fork( ) == 0 ){ // In the CHILD now
| *(p + 9) = 'X'; // Change ref location
20 p = getenv("DEMO");
| cout << "2. Child environment has " << p << endl;
| cout << "3. Exiting child." << endl;
| return 0;
| } // In the PARENT now
+ sleep( 10 ); // Make sure child
 is done
| cout << "4. Back in parent." << endl;
| p = getenv("DEMO");
| cout << "5. Parent environment has " << p << endl;
| return 0;
30 }
is done
| cout << "4. Back in parent." << endl;
| p = getenv("DEMO");
| cout << "5. Parent environment has " << p << endl;
| return 0;
30 }
Linux implements a special virtual filesystem called /proc that stores information about the kernel, kernel data structures, and the state of each process and associated threads. Remember that in Linux a thread is implemented as a special type of process. The /proc filesystem is stored in memory, not on disk. The majority of the information provided is read-only and can vary greatly from one version of Linux to another. Standard system calls (such as open, read, etc.) can be used by programs to access /proc files.
Linux provides a procinfo command that generates a formatted display of /proc information. Figure 2.23 shows the default output of this command. As would be expected, there is a variety of command-line options for procinfo (check the manual page $ man 8 procinfo for specifics). Additionally, while most of the files in /proc are in a special format, many can be displayed by using the command-line cat utility.[13]
Example 2.23. Typical procinfo output.
linux$ procinfo Linux 2.4.3-12enterprise (root@porky) (gcc 2.96 20000731 ) #1 2CPU [linux] Memory: Total Used Free Shared Buffers Cached Mem: 512928 510436 2492 84 65996 265208 Swap: 1068284 544 1067740 Bootup: Thu Dec 27 12:31:23 2001 Load average: 0.00 0.00 0.00 <fr>>1/85 10791 user : 0:12:34.61 0.0% page in : 7194848 nice : 0:00:15.34 0.0% page out: 1714280 system: 0:16:18.81 0.0% swap in : 1 idle : 21d 20:49:43.68 99.9% swap out: 0 uptime: 10d 22:39:26.21 context : 31669318 irq 0: 94556622 timer irq 8: 2 rtc irq 1: 2523 keyboard irq 12: 15009 PS/2 Mouse irq 2: 0 cascade [4] irq 26: 17046596 e100 irq 3: 4 irq 28: 30 aic7xxx irq 4: 6223833 serial irq 29: 30 aic7xxx irq 6: 3 irq 30: 155995 aic7xxx irq 7: 3 irq 31: 918432 aic7xxx
In the /proc file system are a variety of data files and subdirectories. A typical /proc file system is shown in Figure 2.24.
Example 2.24. Directory listing of a /proc file system.
linux$ ls /proc 1 1083 20706 4 684 9228 dma loadavg stat 1025 1084 20719 494 7 9229 driver locks swaps 1030 1085 20796 499 704 9230 execdomains mdstat sys 10457 1086 20797 5 718 9231 fb meminfo sysvipc 10458 19947 20809 511 752 9232 filesystems misc tty 10459 2 3 526 758 9233 fs modules uptime 1057 20268 32463 6 759 9234 ide mounts version 10717 20547 32464 641 765 9235 interrupts mtrr 10720 20638 32466 653 778 9236 iomem net 10721 20652 32468 655 780 997 ioports partitions 10725 20680 32469 656 795 bus irq pci 10726 20695 32471 657 807 cmdline kcore scsi 10731 20696 32473 658 907 cpuinfo kmsg self 10736 20704 32474 669 9227 devices ksyms slabinfo
Numeric entries, such as 1 or 1025, are process subdirectories for existing processes and contain information specific to the process. Nonnumeric entries, excluding the self entry, have kernel-related information. At this point, a full presentation of the kernel-related entries in /proc would be a bit premature, as many of them reflect constructs (such as shared memory) that are covered in detail in later chapters of the text. The remaining discussion focuses on the process-related entries in /proc.
The /proc/self file is a pointer (symbolic link) to the ID of the current process. Program 2.10 uses the system call readlink (see Table 2.25) to obtain the current process ID from /proc/self.
Example 2.10. Reading the /proc/self file.
File : p2.10.cxx
| /*
| Determining Process ID by reading the contents of
| the symbolic link /proc/self
| */
+ #define _GNU_SOURCE
| #include <iostream>
| #include <cstdlib>
| #include <sys/types.h>
| #include <unistd.h>
10 using namespace std;
| const int size = 20;
| int
| main( ){
| pid_t proc_PID, get_PID;
+ char buffer[size];
| get_PID = getpid( );
| readlink("/proc/self", buffer, size);
| proc_PID = atoi(buffer);
| cout << "getpid : " << get_PID << endl;
20 cout << "/proc/self : " << proc_PID << endl;
| return 0;
| }
Table 2.25. Summary of the readlinkSystem Call.
Include File(s) |
| Manual Section | 2 | |
Summary |
int readlink(const char *path,
char *buf, size_t bufsiz);
| |||
Return | Success | Failure | Sets | |
Number of characters read | −1 | Yes | ||
The readlink system call reads the symbolic link referenced by path and stores this data in the location referenced by buf. The bufsiz argument specifies the number of characters to be processed and is most often set to be the size of the location referenced by the buf argument. The readlink system call does not append a null character to its input. If this system call fails, it returns a –1 and sets errno; otherwise, it returns the number of characters read. In the case of error the values that errno can take on are listed in Table 2.26.
A wide array of data on each process is kept by the operating system. This data is found in the /proc directory in a decimal number subdirectory named for the process's ID. Each process subdirectory includes
cmdline—. A file that contains the command-line argument list that started the process. Each field is separated by a null character.cpu—. When present, this file contains CPU utilization information.cwd—. A pointer (symbolic link) to the current working directory for the process.exe—. A pointer (symbolic link) to the binary file that was the source of the process.Table 2.26.
readlinkError Messages.#
Constant
perrorMessageExplanation
2
ENOENT
No such file or directory
File does not exist.
5
EIO
I/O error
I/O error while attempting read or write to file system.
12
ENOMEM
Cannot allocate memory
Out of memory (i.e., kernel memory).
13
EACCES
Permission denied
Search permission denied on part of file path.
14
EFAULT
Bad address
Path references an illegal address.
20
ENOTDIR
Not a directory
Part of the specified path is not a directory.
22
EINVAL
Invalid argument
Invalid
bufsizvalue.File is not a symbolic link.
36
ENAMETOOLONG
File name too long
The path value exceeds system path/ file name length.
40
ELOOP
Too many levels of symbolic links
The
perrormessage says it all.environ—. A file that contains the environment variable for the process. Like thecmdlinefile, each entry is separated by a null character.fd—. A subdirectory that contains one decimal number entry for each file the process has open. Each number is a symbolic link to the device associated with the file.maps—. A file that contains the virtual address maps for the process as well as the access permissions to the mapped regions. The maps are for various executables and library files associated with the process.root—. A pointer (symbolic link) to the root filesystem for the process. Most often this is/but can (via thechrootsystem call) be set to another directory.stat—. A file that contains process status information (such as used by thepscommand).statm—. A file with status of the process's memory usage.status—. A file that contains much of the same information found instatandstatmwith additional process (current thread) status information. This file is stored in a plain text format and is somewhat easier to decipher.
As noted, the cmdline file has the argument list for the process. This same data is passed to the function main as argv. The data is stored as a single character string with a null character � separating each entry. On the command line, the tr utility can be used to translate the null characters into newlines to make the contents of the file easier to read. For example, the command-line sequence
linux$ cat /proc/cmdline | tr "�" " "
would display the contents of the cmdline file with each argument placed on a separate line. Program 2.11 performs a somewhat similar function. It displays the contents of the command line by accessing the data in the cmdline file of the executing process.
Example 2.11. Reading the cmdline file.
File : p2.11.cxx
| #include <iostream>
| #include <fstream>
| #include <sstream>
| #include <sys/types.h>
+ #include <unistd.h>
| using namespace std;
| const int size = 512;
| int
| main( ){
10
| ostringstream oss (ostringstream::out);
| oss << "/proc/" << getpid( ) << "/cmdline";
| cout << "Reading from file: " << oss.str() << endl;
|
+ static char buffer[size];
| ifstream i_file;
| i_file.open(oss.str().c_str()); // open to read
| i_file.getline(buffer, size, '
'),
|
20 char *p = &buffer[0]; // ref 1st char of seq
| do {
| cout << "[" << p << "]" << endl;
| p += strlen(p)+1; // move to next location
| } while ( *p ); // still ref a valid char
+ return 0;
| }
In line 11 of the program, a new output stream descriptor for a string (oss) is declared. In line 12 the name of the file (using a call to getpid to obtain the process ID) is constructed and written to the string. The specified file is opened and read into buffer. The contents of buffer is parsed and displayed. The processing loop uses the fact that the command-line arguments are separated by a null character to divide the data into its separate arguments. Figure 2.25 shows the output of the program when several arguments are passed on the command line.
Example 2.25. Program 2.11 output.
linux$ p2.11 this is 1 test Reading from file: /proc/12123/cmdline [p2.11] [this] [is] [1] [test]
The framework in which a process carries on its activities is its processing environment. The processing environment consists of a number of components. A series of identification numbers—process ID, parent process ID, and process group ID—are used to reference the individual process, its parent, and the group with which the process is affiliated. In its environment a process has access to resources (i.e., files and devices). Access to these resources is determined by permissions that are initially set when the resource is generated. When accessing files, a process can obtain additional system information about the resource. All processes are constrained by system-imposed resource limits. A process can obtain limit information using the appropriate system call or library function. Processes may receive signals that in turn may require a specific action. The values passed via the command line to the process can be obtained. In addition, the process has access to, and may modify (in some settings), environment variables. Linux also supports a /proc directory that contains special files with information about the kernel, its data structures, and all active processes.
/proc filesystem
argc
argv
chdir system call
chmod system call
cmdline file
command-line values
cpu file
creation mask
cwd pointer
effective group ID (EGID)
effective user ID (EUID)
environ
environ command
environ file
environment variable
fchdir system call
fchmod system call
fd subdirectory
file descriptor table
file permissions
getcwd library function
getenv library function
getgrgid system call
getopt library function
getpgid system call
getpid system call
getppid system call
getpwuid system call
getrlimit system call
init process
inode
lstat system call
maps file
process group
process group ID (GID)
process ID (PID)
process leader
procinfo command
putenv library function
readlink system call
real group ID (GID)
real user ID (UID)
root pointer
session
set-group-ID (SGID)
setpgid system call
setrlimit system call
set-user-ID (SUID)
signal
stat file
stat system call
statm file
status file
sysconf library function
system file table
system inode table
ulimit command
ulimit system call
umask command
umask system call
[1] Threads are covered in detail in Chapter 11. Simplistically, a thread is the flow of control through a process. Operating systems vary on how they actually implement a thread. In Linux a thread is a special type of process that shares address space and resources with its parent process. A kernel thread, which runs only in kernel mode, is responsible for a single kernel function, such as flushing buffers to disk or reclaiming returned memory.
[2] Ah-ha—other than generating temporary file names, another use for the getpid system call!
[3] There seems to be no end to the anthropomorphic references for parent/child processes, even when they border on the macabre!
[4] In older versions of Linux the complete password file (passwd) was found in the /etc directory. In newer versions, for security reasons, the password file, while still present, may have some of its pertinent information stored elsewhere (such as in the file /etc/shadow). While the /etc/passwd file is readable by the ordinary user, supplemental password files usually are not.
[5] If, for some reason, there is no group name for the assigned group number, the system displays the group number when you issue the ls-l command.
[6] This system call appears to have been written before such techniques were frowned upon (i.e., both changing the state of the umask and returning its current value).
[7] The cd command, unlike many other system-level commands, is not run as a child process, so its change will take effect for the current process.
[8] The C shell (/bin/csh) provides a somewhat similar built-in command called limit.
[9] Actually, this is a bit of a fudge. The include file <unistd.h> often includes yet another file that has the constant definitions. There is logic in the <unistd.h> file to include the proper file based on the standard being met (POSIX.1, etc.). At present the actual definitions are found in <bits/confname.h>—which is never to be included directly by the programmer.
[10] If you do shell programming, you should find that your system supports a shell version of this library function called getopt. The shell version uses the library function version to do its parsing.
[11] If at the command-line level you enter the shell command env (or printenv), the system should display a list of environment variables and their contents.
[12] I am sure that many human children would say this is also true for their parent/child relationship—everything (especially tasks) seems to flow one way.
[13] Do not be put off by the fact that the majority of the files in /proc show 0 bytes when a long listing is done—keep in mind this is a not a true filesystem.