
When a User Mode process invokes a
system call, the CPU switches to Kernel Mode and starts the execution
of a kernel function. In Linux a system call must be invoked by
executing the int $0x80 assembly language
instruction, which raises the programmed exception that has vector
128 (see Section 4.4.1
and Section 4.2.4, both in Chapter 4).
Since the kernel implements many different system calls, the process
must pass a parameter called the system call number
to identify the required system call;
the eax register is used for this purpose. As we
shall see in Section 9.2.3 later in this chapter,
additional parameters are usually passed when invoking a system call.
All system calls return an integer value. The conventions for these
return values are different from those for wrapper routines. In the
kernel, positive or 0 values denote a successful termination of the
system call, while negative values denote an error condition. In the
latter case, the value is the negation of the error code that must be
returned to the application program in the errno
variable. The errno variable is not set or used by
the kernel. Instead, the wrapper routines handles the task of setting
this variable after a return from a system call.
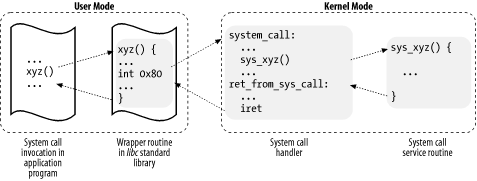
The system call handler, which has a structure similar to that of the other exception handlers, performs the following operations:
Saves the contents of most registers in the Kernel Mode stack (this operation is common to all system calls and is coded in assembly language).
Handles the system call by invoking a corresponding C function called the system call service routine .
Exits from the handler by means of the
ret_from_sys_call( )function (which is coded in assembly language).
The name of the service routine associated with the
xyz
( ) system call is
usually
sys_
xyz
( ); there are, however, a few exceptions to this rule.
Figure 9-1 illustrates the relationships between the application program that invokes a system call, the corresponding wrapper routine, the system call handler, and the system call service routine. The arrows denote the execution flow between the functions.
To associate each system call number with its corresponding service
routine, the kernel uses a system call dispatch table
, which is stored in the
sys_call_table array and has
NR_syscalls entries (usually 256). The
n
th entry contains the service routine address
of the system call having number n.
The NR_syscalls macro is just a static limit on
the maximum number of implementable system calls; it does not
indicate the number of system calls actually implemented. Indeed, any
entry of the dispatch table may contain the address of the
sys_ni_syscall( ) function, which is the service
routine of the “nonimplemented”
system calls; it just returns the error code
-
ENOSYS.
The
trap_init( ) function, invoked during kernel
initialization, sets up the Interrupt Descriptor Table (IDT) entry
corresponding to vector 128 (i.e., 0x80) as
follows:
set_system_gate(0x80, &system_call);
The call loads the following values into the gate descriptor fields (see Section 4.4.1):
- Segment Selector
The
_ _KERNEL_CSSegment Selector of the kernel code segment.- Offset
The pointer to the
system_call( )exception handler.- Type
Set to 15. Indicates that the exception is a Trap and that the corresponding handler does not disable maskable interrupts.
- DPL (Descriptor Privilege Level)
Set to 3. This allows processes in User Mode to invoke the exception handler (see Section 4.2.4).
The system_call( )
function implements the system call handler. It starts by saving the
system call number and all the CPU registers that may be used by the
exception handler on the stack — except for
eflags, cs,
eip, ss, and
esp, which have already been saved automatically
by the control unit (see Section 4.2.4).
The SAVE_ALL macro, which was already discussed in
Section 4.6.1.4, also loads the Segment
Selector of the kernel data segment in ds and
es:
system_call: pushl %eax SAVE_ALL movl %esp, %ebx andl $0xffffe000, %ebx
The function also stores the address of the process descriptor in
ebx. This is done by taking the value of the
kernel stack pointer and rounding it up to a multiple of 8 KB (see
Section 3.2.2).
Next, the system_call( ) function checks whether
the PT_TRACESYS flag included in the
ptrace field of current is set
— that is, whether the system call invocations of the executed
program are being traced by a debugger. If this is the case,
system_call( ) invokes the syscall_trace( ) function twice: once right before and once right after
the execution of the system call service routine. This function stops
current and thus allows the debugging process to
collect information about it.
A validity check is then performed on the system call number passed
by the User Mode process. If it is greater than or equal to
NR_syscalls, the system call handler terminates:
cmpl $(NR_syscalls), %eax jb nobadsys movl $(-ENOSYS), 24(%esp) jmp ret_from_sys_call nobadsys:
If the system call number is not valid, the function stores the
-ENOSYS value in the stack location where the
eax register has been saved (at offset 24 from the
current stack top). It then jumps to ret_from_sys_call( ). In this way, when the process resumes its execution in
User Mode, it will find a negative return code in
eax.
Finally, the specific service routine associated with the system call
number contained in eax is invoked:
call *sys_call_table(0, %eax, 4)
Since each entry in the dispatch table is 4 bytes long, the kernel
finds the address of the service routine to be invoked by multiplying
the system call number by 4, adding the initial address of the
sys_call_table dispatch table and extracting a
pointer to the service routine from that slot in the table.
When the service routine terminates, system_call( ) gets its return code from eax and
stores it in the stack location where the User Mode value of the
eax register is saved. It then jumps to
ret_from_sys_call( ), which terminates the
execution of the system call handler (see Section 4.8.3):
movl %eax, 24(%esp) jmp ret_from_sys_call
When the process resumes its execution in User Mode, it finds the
return code of the system call in eax.
Like ordinary functions, system calls often require some input/output parameters, which may consist of actual values (i.e., numbers), addresses of variables in the address space of the User Mode process, or even addresses of data structures including pointers to User Mode functions (see Section 10.4).
Since the system_call( ) function is the common
entry point for all system calls in Linux, each of them has at least
one parameter: the system call number passed in the
eax register. For instance, if an application
program invokes the fork( ) wrapper routine, the
eax register is set to 2 (i.e., _ _NR_fork) before executing the int $0x80
assembly language instruction. Because the register is set by the
wrapper routines included in the libc library,
programmers do not usually care about the system call number.
The fork( ) system call does not require other
parameters. However, many system calls do require additional
parameters, which must be explicitly passed by the application
program. For instance, the mmap( ) system call may
require up to six additional parameters (besides the system call
number).
The parameters of ordinary C functions are passed by writing their
values in the active program stack (either the User Mode stack or the
Kernel Mode stack). Since system calls are a special kind of function
that cross over from user to kernel land, neither the User Mode or
the Kernel Mode stacks can be used. Rather, system call parameters
are written in the CPU registers before invoking the int 0x80 assembly language instruction. The kernel then copies
the parameters stored in the CPU registers onto the Kernel Mode stack
before invoking the system call service routine because the latter is
an ordinary C function.
Why doesn’t the kernel copy parameters directly from the User Mode stack to the Kernel Mode stack? First of all, working with two stacks at the same time is complex; second, the use of registers makes the structure of the system call handler similar to that of other exception handlers.
However, to pass parameters in registers, two conditions must be satisfied:
The length of each parameter cannot exceed the length of a register (32 bits).[66]
The number of parameters must not exceed six (including the system call number passed in
eax), since the Intel Pentium has a very limited number of registers.
The first condition is always true since, according to the POSIX
standard, large parameters that cannot be stored in a 32-bit register
must be passed by reference. A typical example is the
settimeofday( ) system call, which must read a
64-bit structure.
However, system calls that have more than six parameters exist. In such cases, a single register is used to point to a memory area in the process address space that contains the parameter values. Of course, programmers do not have to care about this workaround. As with any C function call, parameters are automatically saved on the stack when the wrapper routine is invoked. This routine will find the appropriate way to pass the parameters to the kernel.
The six registers used to store system call parameters are, in
increasing order, eax (for the system call
number), ebx, ecx,
edx, esi, and
edi. As seen before, system_call( ) saves the values of these registers on the Kernel Mode
stack by using the SAVE_ALL macro. Therefore, when
the system call service routine goes to the stack, it finds the
return address to system_call( ), followed by the
parameter stored in ebx (the first parameter of
the system call), the parameter stored in ecx, and
so on (see Section 4.6.1.4). This stack
configuration is exactly the same as in an ordinary function call,
and therefore the service routine can easily refer to its parameters
by using the usual C-language constructs.
Let’s look at an example. The sys_write( ) service routine, which handles the write( ) system call, is declared as:
int sys_write (unsigned int fd, const char * buf, unsigned int count)
The C compiler produces an assembly language function that expects to
find the fd, buf, and
count parameters on top of the stack, right below
the return address, in the locations used to save the contents of the
ebx, ecx, and
edx registers, respectively.
In a few cases, even if the system call doesn’t use
any parameters, the corresponding service routine needs to know the
contents of the CPU registers right before the system call was
issued. For example, the do_fork( ) function that
implements fork( ) needs to know the value of the
registers in order to duplicate them in the child process
thread field (see Section 3.3.2.1). In these cases, a single parameter of type
pt_regs allows the service routine to access the
values saved in the Kernel Mode stack by the
SAVE_ALL macro (see Section 4.6.1.5):
int sys_fork (struct pt_regs regs)
The return value of a service routine must be written into the
eax register. This is automatically done by the C
compiler when a return
n
;
instruction is executed.
All
system call parameters must be carefully checked before the kernel
attempts to satisfy a user request. The type of check depends both on
the system call and on the specific parameter. Let’s
go back to the write( ) system call introduced
before: the fd parameter should be a file
descriptor that describes a specific file, so sys_write( ) must check whether fd really is a file
descriptor of a file previously opened and whether the process is
allowed to write into it (see Section 1.5.6). If any of these conditions are not true, the
handler must return a negative value — in this case, the error
code -EBADF.
One type of checking, however, is common to all system calls. Whenever a parameter specifies an address, the kernel must check whether it is inside the process address space. There are two possible ways to perform this check:
Verify that the linear address belongs to the process address space and, if so, that the memory region including it has the proper access rights.
Verify just that the linear address is lower than
PAGE_OFFSET(i.e., that it doesn’t fall within the range of interval addresses reserved to the kernel).
Early Linux kernels performed the first type of checking. But it is quite time consuming since it must be executed for each address parameter included in a system call; furthermore, it is usually pointless because faulty programs are not very common.
Therefore, starting with Version 2.2, Linux employs the second type
of checking. This is much more efficient because it does not require
any scan of the process memory region descriptors. Obviously, this is
a very coarse check: verifying that the linear address is smaller
than PAGE_OFFSET is a necessary but not sufficient
condition for its validity. But there’s no risk in
confining the kernel to this limited kind of check because other
errors will be caught later.
The approach followed is thus to defer the real checking until the last possible moment — that is, until the Paging Unit translates the linear address into a physical one. We shall discuss in Section 9.2.6, later in this chapter, how the Page Fault exception handler succeeds in detecting those bad addresses issued in Kernel Mode that were passed as parameters by User Mode processes.
One might wonder at this point why the coarse check is performed at
all. This type of checking is actually crucial to preserve both
process address spaces and the kernel address space from illegal
accesses. We saw in Chapter 2 that the RAM is
mapped starting from PAGE_OFFSET. This means that
kernel routines are able to address all pages present in memory.
Thus, if the coarse check were not performed, a User Mode process
might pass an address belonging to the kernel address space as a
parameter and then be able to read or write any page present in
memory without causing a Page Fault exception.
The check on addresses passed to system calls is performed by the
verify_area( ) function, which acts on two
parameters: addr and
size.[67]
The function checks the address interval
delimited by addr and addr + size - 1, and is essentially equivalent to the following C
function:
int verify_area(const void * addr, unsigned long size)
{
unsigned long a = (unsigned long) addr;
if (a + size < a || a + size > current->addr_limit.seg)
return -EFAULT;
return 0;
}The function first verifies whether addr
+
size, the highest address to
be checked, is larger than 232 -1; since
unsigned long integers and pointers are represented by the GNU C
compiler (gcc) as 32-bit numbers, this is
equivalent to checking for an overflow condition. The function also
checks whether addr + size exceeds the value
stored in the addr_limit.seg field of
current. This field usually has the value
PAGE_OFFSET for normal processes and the value
0xffffffff for kernel threads. The value of the
addr_limit.seg field can be dynamically changed by
the get_fs and set_fs macros;
this allows the kernel to invoke system call service routines
directly and to pass addresses in the kernel data segment to them.
The access_ok macro performs the same check as
verify_area( ). The only difference is its return
value: it yields 1 if the specified address interval is valid and 0
otherwise. The _ _addr_ok macro also returns 1 if
the specified linear address is valid and 0 otherwise.
System call service routines
often need to read or write data contained in the
process’s address space. Linux includes a set of
macros that make this access easier. We’ll describe
two of them, called get_user( ) and
put_user( ). The first can be used to read 1, 2,
or 4 consecutive bytes from an address, while the second can be used
to write data of those sizes into an address.
Each function accepts two arguments, a value x to
transfer and a variable ptr. The second variable
also determines how many bytes to transfer. Thus, in
get_user(x,ptr), the size of the variable pointed
to by ptr causes the function to expand into a
_ _get_user_1( ), _ _get_user_2( ), or _ _get_user_4( ) assembly language
function. Let’s consider one of them, _ _get_user_2( ):
_ _ get_user_2:
addl $1, %eax
jc bad_get_user
movl %esp, %edx
andl $0xffffe000, %edx
cmpl 12(%edx), %eax
jae bad_get_user
2: movzwl -1(%eax), %edx
xorl %eax, %eax
ret
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
retThe eax register contains the address
ptr of the first byte to be read. The first six
instructions essentially perform the same checks as the
verify_area( ) functions: they ensure that the 2
bytes to be read have addresses less than 4 GB as well as less than
the addr_limit.seg field of the
current process. (This field is stored at offset
12 in the process descriptor, which appears in the first operand of
the cmpl instruction.)
If the addresses are valid, the function executes the
movzwl instruction to store the data to be read in
the two least significant bytes of edx register
while setting the high-order bytes of edx to 0;
then it sets a 0 return code in eax and
terminates. If the addresses are not valid, the function clears
edx, sets the -EFAULT value
into eax, and terminates.
The put_user(x,ptr) macro is similar to the one
discussed before, except it writes the value x
into the process address space starting from address
ptr. Depending on the size of
x, it invokes either the _ _put_user_asm( ) macro (size of 1, 2, or 4 bytes) or the _ _put_user_u64( ) macro (size of 8 bytes). Both macros
return the value 0 in the eax register if they
succeed in writing the value, and -EFAULT
otherwise.
Several other functions and macros are available to access the
process address space in Kernel Mode; they are listed in Table 9-1. Notice that many of them also have a variant
prefixed by two underscores (_ _ ). The ones
without initial underscores take extra time to check the validity of
the linear address interval requested, while the ones with the
underscores bypass that check. Whenever the kernel must repeatedly
access the same memory area in the process address space, it is more
efficient to check the address once at the start and then access the
process area without making any further checks.
Table 9-1. Functions and macros that access the process address space
As seen previously,
verify_area( ), access_ok, and
_ _addr_ok make only a coarse check on the
validity of linear addresses passed as parameters of a system call.
Since they do not ensure that these addresses are included in the
process address space, a process could cause a Page Fault exception
by passing a wrong address.
Before describing how the kernel detects this type of error, let’s specify the three cases in which Page Fault exceptions may occur in Kernel Mode. These cases must be distinguished by the Page Fault handler, since the actions to be taken are quite different.
The kernel attempts to address a page belonging to the process address space, but either the corresponding page frame does not exist or the kernel tries to write a read-only page. In these cases, the handler must allocate and initialize a new page frame (see the sections Section 8.4.3 and Section 8.4.4).
The kernel addresses a page belonging to its address space, but the corresponding Page Table entry has not yet been initialized (see Section 8.4.5). In this case, the kernel must properly set up some entries in the Page Tables of the current process.
Some kernel function includes a programming bug that causes the exception to be raised when that program is executed; alternatively, the exception might be caused by a transient hardware error. When this occurs, the handler must perform a kernel oops (see Section 8.4.1).
The case introduced in this chapter: a system call service routine attempts to read or write into a memory area whose address has been passed as a system call parameter, but that address does not belong to the process address space.
The Page Fault handler can easily recognize the first case by determining whether the faulty linear address is included in one of the memory regions owned by the process. It is also able to detect the second case by checking whether the Page Tables of the process include a proper non-null entry that maps the address. Let’s now explain how the handler distinguishes the remaining two cases.
The key to determining the source of a Page Fault lies in the narrow range of calls that the kernel uses to access the process address space. Only the small group of functions and macros described in the previous section are used to access this address space; thus, if the exception is caused by an invalid parameter, the instruction that caused it must be included in one of the functions, or else be generated by expanding one of the macros. The number of the instructions that address user space is fairly small.
Therefore, it does not take much effort to put the address of each
kernel instruction that accesses the process address space into a
structure called the exception table. If we
succeed in doing this, the rest is easy. When a Page Fault exception
occurs in Kernel Mode, the do_page_fault( )
handler examines the exception table: if it includes the address of
the instruction that triggered the exception, the error is caused by
a bad system call parameter; otherwise, it is caused by a more
serious bug.
Linux defines several exception tables. The main exception table is
automatically generated by the C compiler when building the kernel
program image. It is stored in the _ _ex_table
section of the kernel code segment, and its starting and ending
addresses are identified by two symbols produced by the C compiler:
_ _start_ _ _ex_table and _ _stop_ _ _ex_table.
Moreover, each dynamically loaded module of the kernel (see Appendix B) includes its own local exception table. This table is automatically generated by the C compiler when building the module image, and it is loaded into memory when the module is inserted in the running kernel.
Each entry of an exception table is an
exception_table_entry structure that has two
fields:
-
insn The linear address of an instruction that accesses the process address space
-
fixup The address of the assembly language code to be invoked when a Page Fault exception triggered by the instruction located at
insnoccurs
The fixup code consists of a few assembly language instructions that
solve the problem triggered by the exception. As we shall see later
in this section, the fix usually consists of inserting a sequence of
instructions that forces the service routine to return an error code
to the User Mode process. Such instructions are usually defined in
the same macro or function that accesses the process address space;
sometimes they are placed by the C compiler into a separate section
of the kernel code segment called .fixup.
The search_exception_table( ) function is used to
search for a specified address in all exception tables: if the
address is included in a table, the function returns the
corresponding fixup address; otherwise, it returns
0. Thus the Page Fault handler do_page_fault( )
executes the following statements:
if ((fixup = search_exception_table(regs->eip)) != 0) {
regs->eip = fixup;
return;
}The regs->eip field contains the value of the
eip register saved on the Kernel Mode stack when
the exception occurred. If the value in the register (the instruction
pointer) is in an exception table, do_page_fault( ) replaces the saved value with the address returned by
search_exception_table( ). Then the Page Fault
handler terminates and the interrupted program resumes with execution
of the fixup code.
The GNU
Assembler .section directive allows programmers to
specify which section of the executable file contains the code that
follows. As we shall see in Chapter 20, an
executable file includes a code segment, which in turn may be
subdivided into sections. Thus, the following assembly language
instructions add an entry into an exception table; the
"a" attribute specifies that the section must be
loaded into memory together with the rest of the kernel image:
.section _ _ex_table, "a"
.long faulty_instruction_address, fixup_code_address
.previousThe .previous directive forces the assembler to
insert the code that follows into the section that was active when
the last .section directive was encountered.
Let’s consider again the _ _get_user_1( ), _ _get_user_2( ), and _ _get_user_4( ) functions mentioned before. The instructions
that access the process address space are those labeled as
1, 2, and 3:
_ _get_user_1:
[...]
1: movzbl (%eax), %edx
[...]
_ _get_user_2:
[...]
2: movzwl -1(%eax), %edx
[...]
_ _get_user_4:
[...]
3: movl -3(%eax), %edx
[...]
bad_get_user:
xorl %edx, %edx
movl $-EFAULT, %eax
ret
.section _ _ex_table,"a"
.long 1b, bad_get_user
.long 2b, bad_get_user
.long 3b, bad_get_user
.previousEach exception table entry consists of two labels. The first one is a
numeric label with a b suffix to indicate that the
label is “backward”; in other
words, it appears in a previous line of the program. The fixup code
is common to the three functions and is labeled as
bad_get_user. If a Page Fault exception is
generated by the instructions at label 1,
2, or 3, the fixup code is
executed. It simply returns an -EFAULT error code
to the process that issued the system call.
Other kernel functions that act in the User Mode address space use
the fixup code technique. Consider, for instance, the
strlen_user(string) macro. This macro returns
either the length of a null-terminated string passed as a parameter
in a system call or the value 0 on error. The macro essentially
yields the following assembly language instructions:
movl $0, %eax
movl $0x7fffffff, %ecx
movl %ecx, %ebp
movl string, %edi
0: repne; scasb
subl %ecx, %ebp
movl %ebp, %eax
1:
.section .fixup,"ax"
2: movl $0, %eax
jmp 1b
.previous
.section _ _ex_table,"a"
.long 0b, 2b
.previousThe ecx and ebp registers are
initialized with the 0x7fffffff value, which
represents the maximum allowed length for the string in the User Mode
address space. The repne;scasb assembly language
instructions iteratively scan the string pointed to by the
edi register, looking for the value 0 (the end of
string � character) in eax.
Since scasb decrements the ecx
register at each iteration, the eax register
ultimately stores the total number of bytes scanned in the string
(that is, the length of the string).
The fixup code of the macro is inserted into the
.fixup section. The "ax"
attributes specify that the section must be loaded into memory and
that it contains executable code. If a Page Fault exception is
generated by the instructions at label 0, the
fixup code is executed; it simply loads the value 0 in
eax — thus forcing the macro to return a 0
error code instead of the string length — and then jumps to the
1 label, which corresponds to the instruction
following the macro.
[66] We refer, as usual, to the 32-bit architecture of the 80 × 86 processors. The discussion in this section does not apply to 64-bit architectures.
[67] A third parameter named
type specifies whether the system call should read
or write the referred memory locations. It is used only in systems
that have buggy versions of the Intel 80486 microprocessor, in which
writing in Kernel Mode to a write-protected page does not generate a
Page Fault. We don’t discuss this case
further.