
As already mentioned in Section 8.3, a memory region can be associated with some portion of either a regular file in a disk-based filesystem or a block device file. This means that an access to a byte within a page of the memory region is translated by the kernel into an operation on the corresponding byte of the file. This technique is called memory mapping.
Two kinds of memory mapping exist:
- Shared
Any write operation on the pages of the memory region changes the file on disk; moreover, if a process writes into a page of a shared memory mapping, the changes are visible to all other processes that map the same file.
- Private
Meant to be used when the process creates the mapping just to read the file, not to write it. For this purpose, private mapping is more efficient than shared mapping. But any write operation on a privately mapped page will cause it to stop mapping the page in the file. Thus, a write does not change the file on disk, nor is the change visible to any other processes that access the same file.
A process can create a new memory mapping by issuing an
mmap( ) system call (see Section 15.2.2 later in this chapter).
Programmers must specify either the MAP_SHARED
flag or the MAP_PRIVATE flag as a parameter of the
system call; as you can easily guess, in the former case the mapping
is shared, while in the latter it is private. Once the mapping is
created, the process can read the data stored in the file by simply
reading from the memory locations of the new memory region. If the
memory mapping is shared, the process can also modify the
corresponding file by simply writing into the same memory locations.
To destroy or shrink a memory mapping, the process may use the
munmap( ) system call (see the later section Section 15.2.3).
As a general rule, if a memory mapping is shared, the corresponding
memory region has the VM_SHARED flag set; if it is
private, the VM_SHARED flag is cleared. As
we’ll see later, an exception to this rule exists
for read-only shared memory mappings.
A memory mapping is represented by a combination of the following data structures:
The inode object associated with the mapped file
The
address_spaceobject of the mapped fileA file object for each different mapping performed on the file by different processes
A
vm_area_structdescriptor for each different mapping on the fileA page descriptor for each page frame assigned to a memory region that maps the file
Figure 15-4 illustrates how the data structures are
linked. In the upper-left corner, we show the inode, which identifies
the file. The i_mapping field of each inode object
points to the address_space object of the file. In
turn, the i_mmap or
i_mmap_shared fields of each
address_space object point to the first element of
a doubly linked list that includes all memory regions that currently
map the file; if both fields are NULL, the file is
not mapped by any memory region. The list contains
vm_area_struct descriptors that represent memory
regions, and is implemented by means of the
vm_next_share and
vm_pprev_share fields.
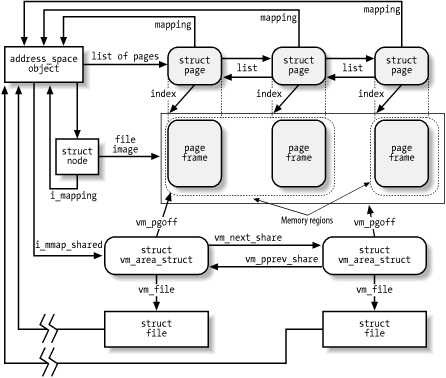
The vm_file field of each memory region descriptor
contains the address of a file object for the mapped file; if that
field is null, the memory region is not used in a memory mapping. The
file object contains fields that allow the kernel to identify both
the process that owns the memory mapping and the file being mapped.
The position of the first mapped location is stored into the
vm_pgoff field of the memory region descriptor; it
represents the file offset as a number of page-size units. The length
of the mapped file portion is simply the length of the memory region,
which can be computed from the vm_start and
vm_end fields.
Pages of shared memory mappings are always included in the page cache; pages of private memory mappings are included in the page cache as long as they are unmodified. When a process tries to modify a page of a private memory mapping, the kernel duplicates the page frame and replaces the original page frame with the duplicate in the process Page Table; this is one of the applications of the Copy On Write mechanism that we discussed in Chapter 8. The original page frame still remains in the page cache, although it no longer belongs to the memory mapping since it is replaced by the duplicate. In turn, the duplicate is not inserted into the page cache since it no longer contains valid data representing the file on disk.
Figure 15-4 also shows a few page descriptors of
pages included in the page cache that refer to the memory-mapped
file. Notice that the first memory region in the figure is three
pages long, but only two page frames are allocated for it;
presumably, the process owning the memory region has never accessed
the third page. Although not shown in the figure, the page
descriptors are inserted into the clean_pages,
dirty_pages, and locked_pages
doubly linked lists described in Section 14.1.2.
The kernel offers several hooks to customize the memory mapping
mechanism for every different filesystem. The core of memory mapping
implementation is delegated to a file object’s
method named mmap. For most disk-based filesystems
and for block device files, this method is implemented by a general
function called generic_file_mmap( ), which is
described in the next section.
File memory mapping depends on the demand paging mechanism described
in Section 8.4.3. In fact, a newly
established memory mapping is a memory region that
doesn’t include any page; as the process references
an address inside the region, a Page Fault occurs and the Page Fault
handler checks whether the nopage method of the
memory region is defined. If nopage is not
defined, the memory region doesn’t map a file on
disk; otherwise, it does, and the method takes care of reading the
page by accessing the block device. Almost all disk-based filesystems
and block device files implement the nopage method
by means of the filemap_nopage( )
function.
To create
a new memory mapping, a process issues an mmap( )
system call, passing the following parameters to it:
A file descriptor identifying the file to be mapped.
An offset inside the file specifying the first character of the file portion to be mapped.
The length of the file portion to be mapped.
A set of flags. The process must explicitly set either the
MAP_SHAREDflag or theMAP_PRIVATEflag to specify the kind of memory mapping requested.[106]A set of permissions specifying one or more types of access to the memory region: read access (
PROT_READ), write access (PROT_WRITE), or execution access (PROT_EXEC).An optional linear address, which is taken by the kernel as a hint of where the new memory region should start. If the
MAP_FIXEDflag is specified and the kernel cannot allocate the new memory region starting from the specified linear address, the system call fails.
The mmap( ) system call returns the linear address
of the first location in the new memory region. For compatibility
reasons, in the 80 × 86 architecture, the kernel reserves
two entries in the system call table for mmap( ):
one at index 90 and the other at index 192. The former entry
corresponds to the old_mmap( ) service routine
(used by older C libraries), while the latter one corresponds to the
sys_mmap2( ) service routine (used by recent C
libraries). The two service routines differ only in how the six
parameters of the system call are passed. Both of them end up
invoking the do_mmap_pgoff( ) function described
in Section 8.3.4. We now complete that
description by detailing the steps performed only when creating a
memory region that maps a file.
Checks whether the
mmapfile operation for the file to be mapped is defined; if not, it returns an error code. ANULLvalue formmapin the file operation table indicates that the corresponding file cannot be mapped (for instance, because it is a directory).Checks whether the
get_unmapped_areamethod of the file object is defined. If so, invokes it; otherwise, invokes thearch_get_unmapped_area( )function already described in Chapter 8. On the 80 × 86 architecture, a custom method is used only by the frame buffer layer, so we don’t discuss the case further. Remember that thearch_get_unmapped_area( )allocates an interval of linear addresses for the new memory region.In addition to the usual consistency checks, compares the kind of memory mapping requested and the flags specified when the file was opened. The flags passed as a parameter of the system call specify the kind of mapping required, while the value of the
f_modefield of the file object specifies how the file was opened. Depending on these two sources of information, it performs the following checks:If a shared writable memory mapping is required, checks that the file was opened for writing and that it was not opened in append mode (
O_APPENDflag of theopen( )system call)If a shared memory mapping is required, checks that there is no mandatory lock on the file (see Section 12.7)
For any kind of memory mapping, checks that the file was opened for reading
If any of these conditions is not fulfilled, an error code is returned.
When initializing the value of the
vm_flagsfield of the new memory region descriptor, sets theVM_READ,VM_WRITE,VM_EXEC,VM_SHARED,VM_MAYREAD,VM_MAYWRITE,VM_MAYEXEC, andVM_MAYSHAREflags according to the access rights of the file and the kind of requested memory mapping (see Section 8.3.2). As an optimization, theVM_SHAREDflag is cleared for nonwritable shared memory mapping. This can be done because the process is not allowed to write into the pages of the memory region, so the mapping is treated the same as a private mapping; however, the kernel actually allows other processes that share the file to access the pages in this memory region.Initializes the
vm_filefield of the memory region descriptor with the address of the file object and increments the file’s usage counter.Invokes the
mmapmethod for the file being mapped, passing as parameters the address of the file object and the address of the memory region descriptor. For most filesystems, this method is implemented by thegeneric_file_mmap( )function, which performs the following operations:If a shared writable memory mapping is required, checks that the
writepagemethod of theaddress_spaceobject of the file is defined; if not, it returns the error code-EINVAL.Checks that the
readpagemethod of theaddress_spaceobject of the file is defined; if not, it returns the error code-ENOEXEC.Stores the current time in the
i_atimefield of the file’s inode and marks the inode as dirty.Initializes the
vm_opsfield of the memory region descriptor with the address of thegeneric_file_vm_opstable. All methods in this table are null, except thenopagemethod, which is implemented by thefilemap_nopage( )function.
Recall from Section 8.3.4 that
do_mmap( )invokesvma_link( ). This function inserts the memory region descriptor into either thei_mmaplist or thei_mmap_sharedlist of theaddress_spaceobject, according to whether the requested memory mapping is private or shared, respectively.
When a
process is ready to destroy a memory mapping, it invokes the
munmap( ) system call, passing the following
parameters to it:
The address of the first location in the linear address interval to be removed
The length of the linear address interval to be removed
Notice that the munmap( ) system call can be used
to either remove or reduce the size of each kind of memory region.
Indeed, the sys_munmap( ) service routine of the
system call essentially invokes the do_munmap( )
function already described in Section 8.3.5. However, if the memory region maps a file,
the following additional steps are performed for each memory region
included in the range of linear addresses to be released:
Invokes
remove_shared_vm_struct( )to remove the memory region descriptor from theaddress_spaceobject list (eitheri_mmapori_mmap_shared).When executing the
unmap_fixup( )function, decrements the file usage counter if an entire memory region is destroyed, and increments the file usage counter if a new memory region is created — that is, if the unmapping created a hole inside a region. If the region has just been shrunken, it leaves the file usage counter unchanged.
Notice that there is no need to flush to disk the contents of the pages included in a writable shared memory mapping to be destroyed. In fact, these pages continue to act as a disk cache because they are still included in the page cache (see the next section).
For reasons of efficiency, page frames are not assigned to a memory mapping right after it has been created at the last possible moment—that is, when the process attempts to address one of its pages, thus causing a Page Fault exception.
We saw in Section 8.4 how the kernel
verifies whether the faulty address is included in some memory region
of the process; if so, the kernel checks the Page Table entry
corresponding to the faulty address and invokes the
do_no_page( ) function if the entry is null (see
Section 8.4.3).
The do_no_page( ) function performs all the
operations that are common to all types of demand paging, such as
allocating a page frame and updating the Page Tables. It also checks
whether the nopage method of the memory region
involved is defined. In Section 8.4.3, we
described the case in which the method is undefined (anonymous memory
region); now we complete the description by discussing the actions
performed by the function when the method is defined:
Invokes the
nopagemethod, which returns the address of a page frame that contains the requested page.If the process is trying to write into the page and the memory mapping is private, avoids a future Copy On Write fault by making a copy of the page just read and inserting it into the inactive list of pages (see Chapter 16). In the following steps, the function uses the new page instead of the page returned by the
nopagemethod so that the latter is not modified by the User Mode process.Increments the
rssfield of the process memory descriptor to indicate that a new page frame has been assigned to the process.Sets up the Page Table entry corresponding to the faulty address with the address of the page frame and the page access rights included in the memory region
vm_page_protfield.If the process is trying to write into the page, forces the
Read/WriteandDirtybits of the Page Table entry to 1. In this case, either the page frame is exclusively assigned to the process, or the page is shared; in both cases, writing to it should be allowed.
The core of the demand paging algorithm consists of the memory
region’s nopage method. Generally
speaking, it must return the address of a page frame that contains
the page accessed by the process. Its implementation depends on the
kind of memory region in which the page is included.
When handling memory regions that map files on disk, the
nopage method must first search for the requested
page in the page cache. If the page is not found, the method must
read it from disk. Most filesystems implement the
nopage method by means of the
filemap_nopage( ) function, which receives three
parameters:
-
area Descriptor address of the memory region, including the required page.
-
address Linear address of the required page.
-
unused Parameter of the
nopagemethod that is not used byfilemap_nopage( ).
The filemap_nopage( ) function executes the
following steps:
Gets the file object address
filefromarea->vm_filefield. Derives theaddress_spaceobject address fromfile->f_dentry->d_inode->i_mapping. Derives the inode object address from thehostfield of theaddress_spaceobject.Uses the
vm_startandvm_pgofffields ofareato determine the offset within the file of the data corresponding to the page starting fromaddress.Checks whether the file offset exceeds the file size. When this happens, returns
NULL, which means failure in allocating the new page, unless the Page Fault was caused by a debugger tracing another process through theptrace( )system call. We are not going to discuss this special case.Invokes
find_get_page( )to look in the page cache for the page identified by theaddress_spaceobject and the file offset.If the page is not in the page cache, checks the value of the
VM_RAND_READflag of the memory region. The value of this flag can be changed by means of themadvise( )system call; when the flag is set, it indicates that the user application is not going to read more pages of the file than those just accessed.If the
VM_RAND_READflag is set, invokespage_cache_read( )to read just the requested page from disk (see the earlier section Section 15.1.1).If the
VM_RAND_READflag is cleared, invokespage_cache_read( )several times to read a cluster of adjacent pages inside the memory region, including the requested page. The length of the cluster is stored in thepage_requestvariable; its default value is three pages, but the system administrator may tune its value by writing into the/proc/sys/vm/page-clusterspecial file.
Then the function jumps back to Step 4 and repeats the page cache lookup operation (the process might have been blocked while executing the
page_cache_read( )function).The page is inside the page cache. Checks its
PG_uptodateflag. If the flag is not set (page not up to date), the function performs the following substeps:Locks up the page by setting the
PG_lockedflag, sleeping if necessary.Invokes the
readpagemethod of theaddress_spaceobject to trigger the I/O data transfer.Invokes
wait_on_page( )to sleep until the I/O transfer completes.
The page is up to date. The function checks the
VM_SEQ_READflag of the memory region. The value of this flag can be changed by means of themadvise( )system call; when the flag is set, it indicates that the user application is going to reference the pages of the mapped file sequentially, thus the pages should be aggressively read in advance and freed after they are accessed. If the flag is set, it invokesnopage_sequential_readahead( ). This function uses a large, fixed-size read-ahead window, whose length is approximately the maximum read-ahead window size of the underlying block device (see the earlier section Section 15.1.2). Thevm_raendfield of the memory region descriptor stores the ending position of the current read-ahead window. The function shifts the read-ahead windows forward (by reading in advance the corresponding pages) whenever the requested page falls exactly in the middle point of the current read-ahead window. Moreover, the function should release the pages in the memory region that are far behind the requested page; if the function reads the n th read-ahead window of the memory region, it flushes to disk the pages belonging to the (n-3)th window (however, the kernel Version 2.4.18 doesn’t release them; see the next section).Invokes
mark_page_accessed( )to mark the requested page as accessed (see Chapter 16).
The msync( )
system call can be used by a process to flush to disk dirty pages
belonging to a shared memory mapping. It receives as parameters the
starting address of an interval of linear addresses, the length of
the interval, and a set of flags that have the following meanings:
-
MS_SYNC Asks the system call to suspend the process until the I/O operation completes. In this way, the calling process can assume that when the system call terminates, all pages of its memory mapping have been flushed to disk.
-
MS_ASYNC Asks the system call to return immediately without suspending the calling process.
-
MS_INVALIDATE Asks the system call to remove all pages included in the memory mapping from the process address space (not really implemented).
The sys_msync( ) service routine invokes
msync_interval( ) on each memory region included
in the interval of linear addresses. In turn, the latter function
performs the following operations:
If the
vm_filefield of the memory region descriptor isNULL, or if theVM_SHAREDflag is clear, returns 0 (the memory region is not a writable shared memory mapping of a file).Invokes the
filemap_sync( )function, which scans the Page Table entries corresponding to the linear address intervals included in the memory region. For each page found, it invokesflush_tlb_page( )to flush the corresponding translation lookaside buffers, and marks the page as dirty.If the
MS_SYNCflag is not set, returns. Otherwise, continues with the following steps to flush the pages in the memory region to disk, sleeping until all I/O data transfers terminate. Notice that, at least in the last stable version of the kernel at the time of this writing, the function does not take theMS_INVALIDATEflag into consideration.Acquires the
i_semsemaphore of the file’s inode.Invokes the
filemap_fdatasync( )function, which receives the address of the file’saddress_spaceobject. For every page belonging to the dirty pages list of theaddress_spaceobject, the function performs the following substeps:Moves the page from the dirty pages list to the locked pages list.
If the
PG_Dirtyflag is not set, continues with the next page in the list (the page is already being flushed by another process).Increments the usage counter of the page and locks it, sleeping if necessary.
Clears the
PG_dirtyflag of the page.Invokes the
writepagemethod of theaddress_spaceobject on the page (described following this list).Releases the usage counter of the page
The
writepagemethod for block device files and almost all disk-based filesystems is just a wrapper for theblock_write_full_page( )function; it is used to pass toblock_write_full_page( )the address of a filesystem-dependent function that translates the block numbers relative to the beginning of the file into logical block numbers relative to positions of the block in the disk partition. (This is the same mechanism that is already described in the earlier section Section 15.1.1 and that is used for thereadpagemethod). In turn,block_write_full_page( )is very similar toblock_read_full_page( )described earlier: it allocates asynchronous buffer heads for the page, and invokes thesubmit_bh( )function on each of them specifying theWRITEoperation.Checks whether the
fsyncmethod of the file object is defined; if so, executes it. For regular files, this method usually limits itself to flushing the inode object of the file to disk. For block device files, however, the method invokessync_buffers( ), which activates the I/O data transfer of all dirty buffers of the device.Executes the
filemap_fdatawait( )function. For each page in the locked pages list of theaddress_spaceobject, the function waits until the page becomes unlocked — when the ongoing I/O data transfer on the page terminates.
[106] The process could also set the
MAP_ANONYMOUS flag to specify that the new memory
region is anonymous — that is, not associated with any
disk-based file (see Section 8.4.3). This
flag is supported by some Unix operating systems, including Linux,
but it is not defined by the POSIX standard. In Linux 2.4, a process
can also create a memory region that is both
MAP_SHARED and MAP_ANONYMOUS.
In this case, the region maps a special file in the
shm filesystem (see Section 19.3.5), which can be accessed by all the
process’s descendants.