
Chapter 8. Becoming a Search Result
If it isn’t in Google, it probably doesn’t exist.
That statement may strike you as an exaggeration, but a lot of people act as if it were true. They run a quick Google search, and if they don’t find what they’re after right away, they’re more likely to adjust their query than move on to another search engine. So if your site is listed on AltaVista, Yahoo, and every other search index on the planet, but Google doesn’t know about it, chances are good that millions of people are going to miss it, too.
So if you’ve got a site and you want people to find it, you gotta get in Google; this chapter tells you how to go about it. And if you want to add a Google search to your own site, you can learn how to do that here, too. (This chapter assumes, however, that you already know your way around the back end of your Web site.)
Note
If you need information on building a Web site, running a Web server, or constructing Web pages, consult a book on Webmastering, like Creating Web Sites: The Missing Manual (www.oreilly.com/catalog/creatingwstmm/). For guidance on Web site design, you might take a gander at Learning Web Design (www.oreilly.com/catalog/learnWeb2/).
If you want to try your hand at writing Google-based applications, you also need to learn about the Google API (http://api.google.com/)—which stands for Application Programming Interface, the programmer’s way of talking to Google. For that, pick up a copy of Google Hacks (www.oreilly.com/catalog/googlehks/), the consummate guide to programming for Google.
Here’s what you won’t find in this chapter: tips on gaming the Google engine, interfering with the proper functioning of its index, or otherwise playing the Google ranking game unfairly. While Google tries its darndest to keep up with such attempts—and does a pretty good job of it—people have found some dirty tricks that pay off in the short run. If you came to this chapter looking for that sort of edge, you’re going to be disappointed.
A sense of fairness ought to keep you playing straight. But if it doesn’t, consider this: Google is known for ignoring or even removing from its database sites that try to trick the crawlers or interfere in the proper operation of the Google engine. Don’t become one of those losers.
Getting Your Site Ready for Google
If you want people—and Google—to notice your site, you’ve got to make it presentable. That means paying attention to visual, interactive, and technical details.
While Google doesn’t give a hoot about color scheme or whether your humor site is actually funny, it does care about many of the same things your visitors do. If your site is difficult for Google to roam through and read, the search engine is unlikely to index it properly and show it in search results as you’d like.
Tip
As a Webmaster, it behooves you to keep up with the latest trends in search engines and how best to prepare your site for maximum indexing, impact, and, ultimately, visitors. (Geeks and other techno-wonks call this process search engine optimization, or SEO.)
Two fabulous resources for all things Webmaster-and search-engine-related are Search Engine Watch (www.searchenginewatch.com) and Webmaster World (www.webmasterworld.com).
The Fundamental Steps
Here’s how you can win friends and influence Google.
Don’t hide indoors
Google tracks only what is actually on the Web and readily accessible. Just because your site is on a server (a networked computer that holds the files that make up a Web site) doesn’t mean other people can see it. If you trap your site behind a corporate firewall, at the end of a DSL or cable-modem link that doesn’t allow traffic to your home server, or make it unreachable in any other way to the general public, Google will never find it. It may sound obvious, but many a fledgling Webmaster has missed this point.
If you set up your site at work and you can’t reach it from outside your corporate network, chances are your company doesn’t like its employees running Web sites from its computers and has set up their system to prevent it. Check with your IT department about their policy and where best to put your site on their system.
If you’ve set up your site at home, make sure your Internet service provider lets you run a server over their network. Many don’t, so it’s important to ask. But they may well provide some space for your site on their servers. In fact, many individuals’ sites actually live on their ISP’s servers.
Appear stable
Google—and your visitors—are likely to be put off by complex URLs that are hard to decode and differentiate from one another. For instance, nobody but you and your server knows what to make of http://www.example.com/products.cgi?cat=autoparts&partnum=6502.
Humans like easily readable, memorable addresses. But Google has its own logic for avoiding complicated URLs. The problem, as Google sees it, is that complex addresses often point to dynamic pages—those that your site has created temporarily, in response to a query. And a dynamic page suggests to Google that your site may have a large database underlying it—one for which it would take Google’s spiders eons to discern all the possible ways people could view the data.
For example, say your site sells hosiery, and it’s connected to your huge database containing descriptions and prices for thousands of pairs of socks and leggings. When somebody searches your Web site for blue children’s stockings, your site might generate a page just for that person, showing the eight items that match the query. If Google catches a whiff of this setup, it flees in terror, assuming that to properly track your site, it would need to index thousands or millions of pages, many of which might show the same things in a different order.
The most well-known system for creating dynamic pages is called CGI, which stands for Common Gateway Interface and is the “Look at me, I’m building Web pages on the fly” of file types. CGI scripts are bits of programming code you can set to build Web pages on request out of databases and other bits and bobs. If you’re using CGI scripts, Google may not properly index your site—which is what’s happening if Google seems to know about all of your site except for the parts served up by a CGI script. If the situation is dire enough (that is, Google is ignoring you altogether), you might want to consider reconfiguring your system.
Warning
Other dynamic pages that Google may consider too hot to handle include those built with templating systems like PHP, JSP, and ASP, and those named after programming languages like Perl (.pl), and Python (.py), to name a few.
Because it knows what it’s getting, Google is more comfortable with sites consisting of pages that you always have up (known as static pages). URLs with endings like .html and .htm indicate stability and are thus Google-friendly.
Alternatively, you can try massaging your Web site application or content management system so that it produces clear and simple URLs rather than a litany of session variables strung together like so many Christmas lights. Why use http://www.example.com/products.cgi?cat=autoparts&partnum=6502, for example, when http://www.example.com/autoparts/6502.html will do?
Provide a clear path into your site
Google, like everyone else, hates wasting time on superfluous pages. The most serious offender is the splash page, those annoying intro pages that you sometimes have to view or click through before you get to a site’s real home page. Splash pages typically feature Flash animations that can suck important minutes out of your day, but offer nary a real link to anything. Google—and many visitors—take a dim view of splash pages. Do everyone a favor and skip them. You can show off your graphic sensibility and your Flash skills on real pages in your site.
Identify yourself clearly and concisely
Your friendly, homey design touches and inviting color scheme draw people in by the ton. But they don’t mean a thing to poor color-blind and design-sense-deprived Google. All the Google robots and spiders have to go by are the metadata—the details you embed in your Web pages’ HTML code, like the title (<title> Hosiery R Us</title>, for example).
Google may interpret your metadata hierarchically when it’s trying to decide how relevant your page is to a particular search. For example, if you have a first-order heading like <h1>Socks</h1> followed by a word set off in italics, like <i>plaid</i>, Google might consider the word in the heading more important than the word in italics. Which is just what you want—if somebody is looking for socks. But if your site is primarily about plaid items, and you want people searching for plaid to find you near the top of their results, you probably ought to make the word “plaid” a heading and not just an italicized comment.
Here are more tricks to help Google read between the lines, and therefore index your site appropriately:
Title your pages properly. Nothing says “half-baked” quite like a site where all the pages have the same title, an utterly meaningless title, or no title at all. Title or subtitle different sections of your site appropriately. Take the 11 seconds to add <title>Al’s Auto Parts: Support</title> to your HTML code.
Tip
Watch out for the dreaded “New Page” title that some Web page software automatically slaps onto any new HTML page. Microsoft FrontPage, for instance, automatically dubs your new pages serially as New Section 3.1, New Section 3.2 , and so on—which is definitely not what you want to see in your Google results.
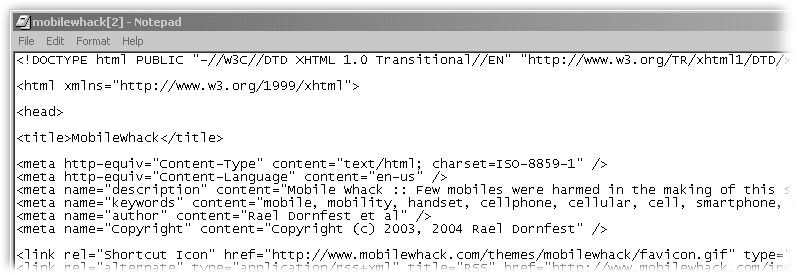
Provide meta tags. meta tags are bits of detail about your site that you can embed in HTML tags. The cool thing is, they’re invisible to your visitors but useful to Web robots. Google doesn’t say how much attention it pays to meta tags, but it can’t hurt to add them, and they might just be useful to another search engine, too. Useful options include a description (as in, <meta name="description” content="A blog about computers, politics, and the punk rock underworld.” />), some keywords (for example, <meta name="keywords” content="fenders, hoses, wiper blades” />), and perhaps even who’s put it together (<meta name="author” content="Jonny Slick” />). Figure 8-1 shows some possible meta tags.
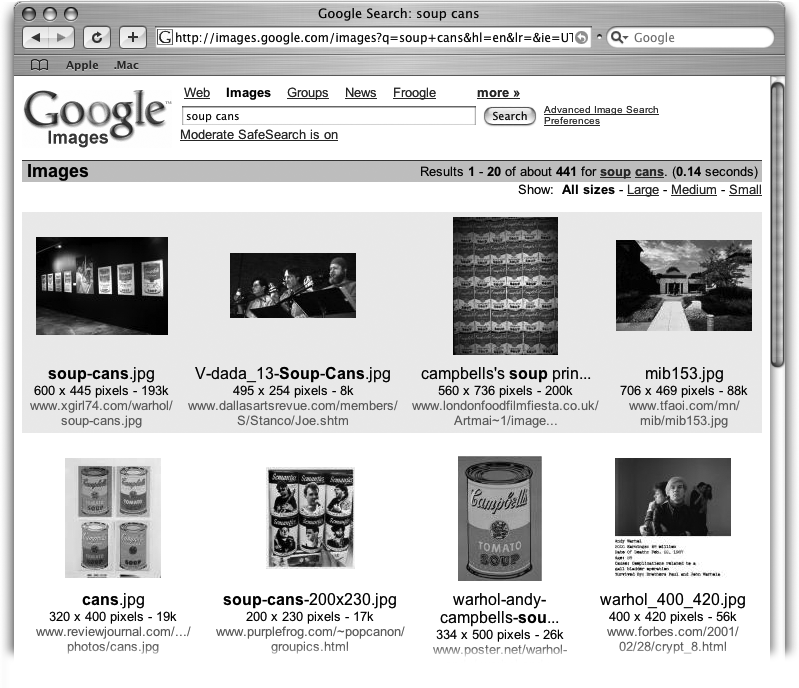
Augment your pictures with alt tags . Ever wonder how Google Images (Section 3.1) knows what’s a photo of your Aunt Sarah on her 101st birthday and what’s a snap of your summer holiday in Spain? Mostly, Google takes hints from nearby text. But what if your nearby text mentions Aunt Sarah and ugly Uncle Phil? You can help ensure that Google understands and properly indexes your pictures by giving them descriptive titles in alt—or “alternative” information— tags.
Tagging pictures is particularly important because most image-editing software automatically names pictures things like camera_1.jpg or set55_02.tif, which never helps anyone—Google or human—figure out that you’re really offering a lovely photo of Monarch butterflies migrating or a diagram of the food chain. And if you’ve renamed those pictures butterfly.jpg and diagram.tif, you haven’t helped much, either. But when you associate an alt tag with a picture, you can give explicit details, like this: <img src="butterfly.jpg” alt="Monarch butterflies migrating over Kansas” />). The alt tag then appears as your picture loads on your Web page—and with your picture in Google Images—helping everyone find your meticulous migration study. Figure 8-2 shows you how the alt tag looks in a Google Images search.
Don’t fence yourself in with an overabundance of frames
Frames—pieces of Web pages you can designate to appear independently, like a scrolling column that moves while the navigation bar stays put—are confusing to robots and people alike. Use them sparingly, if you must use them at all, and label them clearly (for example, <frame src="menu.html” name="menubar"> and <frame src="home.html” name="content">). You should also provide a <noframes> option just in case the spider—or, indeed, your visitor’s browser— doesn’t know what to do with frames.
Tip
Danny Sullivan’s excellent article, “Search Engines and Frames” (www.searchenginewatch.com/Webmasters/article.php/2167901), provides much-needed advice on keeping your frames search-engine friendly.
Find and fix broken links
Google’s spiders, like nearly all Web site visitors, have zero interest in guessing where this or that link should have taken them. In fact, spiders have nothing but links to go on to find the rest of your site; don’t stop them short with a broken link. Before you publish a new article or add any new links within your site, preview the content in your browser and make sure that any links you’ve embedded do in fact point where they’re supposed to.
While you’re at it, do your pals downstream a favor and make sure your outbound links (your links to other Web sites) are still valid. Remember: The next downstream site the Google spider doesn’t find could be your own.
Let Google in
Make sure you aren’t fencing Google out with robots.txt files (notes telling robots that they can’t look at all or part of your site) or meta rules (notes telling robots that they can’t perform certain behaviors on a particular page, like indexing it, caching it, or following links to other pages). For an introduction to the art of letting robots in and keeping them out, read the box in Section 8.3 and “Hiding from Google” in Section 8.5.2.
Tip
For even more loving detail on making your Web site inviting to Google, be sure to take a stroll through Brett Tabke’s Search Engine Optimization Template (www.clickmojo.com/more/122_0_1_0_M/). Brett is the proprietor of WebmasterWorld.com and knows an awful lot about search engine optimization.
That should do it. With your virtual tie tied and shoes shined, it’s high time you introduced yourself to Google and the Web.
Getting Google’s Attention
You can get into Google’s index two ways, and both are worth pursuing. First, you can simply wave your arms and tell Google you want to be part of its index. Second, you can link to other sites—and have them link to yours—so that when Google crawls the Web and follows links from one site to another, it automatically discovers yours.
Tip
For a refresher on the difference between being crawled and getting indexed, take a gander at the discussion at the beginning of the chapter.
Introduce Yourself to Google
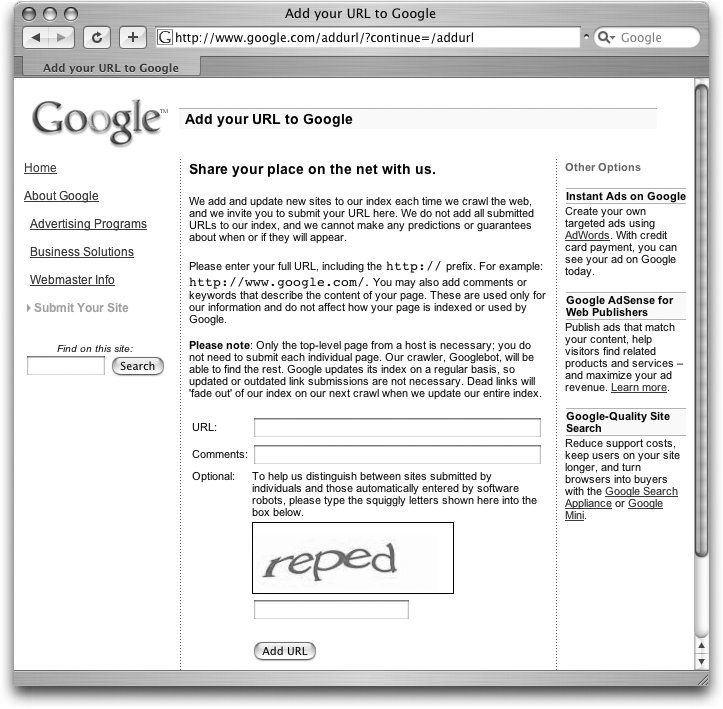
Virtually speaking, you can just walk over to Google and say, “Hello.” Simply visit the “Add your URL to Google” page at www.google.com/addurl.html, type your site’s Web address into the URL field, and click Add URL (see Figure 8-3). You only need introduce Google to your home page; it’ll use your links to find the rest of the site you’ve linked to and made available for public consumption. Once Google knows about your site, it sends out the Googlebot for a look—anywhere from one day to a couple of weeks after you sign up.
Google doesn’t make any promises about when your site is likely to appear in search results, though it usually takes between 24 hours and a week. Google also doesn’t give any guarantee that they’ll actually add your site to their index. And, unfortunately, you have no way to tell whether Google has indexed your site or whether it’s rejected you without actually performing the crawl. If you submitted a URL a couple of weeks ago and Google doesn’t seem to know anything about you, check out the guidelines and rules for Webmasters at www.google.com/webmasters/guidelines.html, and then resubmit your site.
Tip
Google suggests listing your site with Yahoo (http://docs.yahoo.com/info/suggest/) and the Open Directory Project (http://www.dmoz.org, Section 8.5). Once you’re in either Yahoo or the Open Directory, Google should find and index your site in six to eight weeks. It’s a belt-and-suspenders step worth taking.
Link Up I
The other route into Google is via links. When Google’s spiders crawl the Web, they check old pages for new text, pictures, and links—and then they follow the new links, looking for new pages to add to Google’s index. So a great way to get into Google is to have other sites already in the index link to yours.
If you’ve got a friend, business associate, neighbor, or peer with a Web site or Weblog (Section 6.1.4.16) already known to Google, see if he’s up for linking to yours. If he goes for it, he’s essentially introducing your site to Google by association. (You can return the favor by linking back to his site, thereby increasing his PageRank rating.)
Link Up II
Sites on just about every subject are itching for news and events of interest to their readers. And if you have something whiz-bang interesting or Earth-shatteringly important on your site, you can try to catch the eye of a site you think should know you—who might then link to your site.
On sites that you’d like to link to you, look for “Suggest a Link” or “Submit a Story” features. Write up a meaty-though-modest description, fill in the form as directed, and suggest they take a gander at something in particular on your site. If they go for it, you’re that much closer to being in the Google database.
Does Google Know You’re There?
You’ve done everything in your power to get Google’s attention. Now, how do you know when the Googlebot (www.google.com/bot.html), Google’s Web-crawling robot, has come calling? Of course, if your site starts appearing in Google results, you can rest easy knowing Google is hip to you.
Otherwise, it’s not particularly obvious when the Googlebot arrives, investigates, and leaves your site. With a little simple research, however, you can figure out what parts of your site Google is and isn’t finding.
The place to look is your Web site’s logs, which keep a record of comings and goings from your site—requests and responses in Webmaster vernacular. They make for an entertaining read, in a geeky way, and are worth getting familiar with.
Web server logs are simple text files, as shown in Figure 8-4, and you can read them by using a simple text editor or Unix command-line tools. You can also peruse them through a log-analysis tool, a desktop application, an administrative tool, or a Web-based service.
If you know where your logs are kept and you have access to them (some Web site administrators keep them off-limits), go ahead and take a look. If not, contact your local server administrator or Internet Service Provider and ask them where you can find the logs.
Once you’ve opened the logs, you can find traces of the Googlebot. A typical visit follows these steps:
First, the Googlebot knocks and sees if it’s welcome. When it hits your site, the first thing the Googlebot does is request your site’s robots.txt file to see if it even has permission to come in and take a look around. (Read more about robots.txt in the box “Robot Rules of the Road” in Section 8.5.3.) The request looks something like this:
208.201.239.21 - - [19/Feb/2004:19:16:05 -0800] "
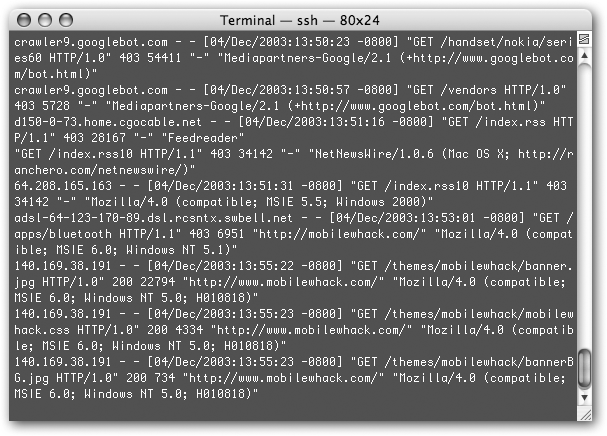
GET /robots.txtHTTP/1.1" 200 199 "-" "Googlebot/2.1 (+http://www.googlebot.com/bot.html)"Figure 8-4. Here’s a piece of a raw server log from Mobilewhack.com. The first two requests are from the Googlebot, which is looking for access to the site’s sections on Nokia’s series 60 phones and vendors. The rest of the requests are from other entities on the Web (things like browsers and other search engines’ bots).Here’s what you’re looking at: The first set of numbers is your site’s IP address. The stuff in the brackets is the date and time of the Googlebot’s request. The actual request is the /robots.txt part. HTTP/1.1 is the version of HTTP in use (HTTP is the language Web browsers and servers speak); 200 is the status code for that request (200 says the request was successful; 404 means it failed); and 199 is the number of bytes transferred. The dash in quotes tells you there’s no login necessary for people (or bots) to access the site. And everything else is the user-agent identification (that is, the Googlebot’s cyber-credentials).
If the Googlebot finds a robots.txt file, it reads it and follows any rules that tell it where not to go. If it can’t find robots.txt, the Googlebot assumes it has permission to index your site in its entirety.
Next, the Googlebot requests the index pages for your site’s directories. As you know, you build Web sites out of pages that you store in folders, called directories. And you nest directories within each other, much the way you store files on your hard drive. Usually, you put an index page (index.html or index.htm, for example) into each directory, which acts as the home page for that directory.
For example, your site may contain the directory www.yoursite.com/products. When a robot asks your server for a directory (/products) rather than a specific Web page (/products/cheddar.html), your server shows it the directory’s index. In Web server parlance, this request for the index is /, (say “slash”), and it’s simply the Web way of asking for a list of the contents of the directory following the slash. Put another way, the slash is like asking, “What’s in this room?” In the server log, the request looks like this:
208.201.239.21 - - [19/Feb/2004:18:46:46 -0800] "
GET /productsHTTP/1.1" 200 5719 "-" "Googlebot/2.1 (+http://www.googlebot.com/bot.html)"and the / after the word GET tells your server to “offer up the index page for this directory.” In this case, the Googlebot is asking for the index page for the products directory. If the request specified no directory and looked like this— “GET /HTTP/1.1”—that would mean the Googlebot was knocking at your site’s front door, asking to see the contents of the main directory for the whole place. (By extension, the request GET /products is like asking to look in, say, the cupboard.)
Next, the Googlebot follows all the links and image tags on the index pages. When you hit a Web page, your browser follows HTML image tags to find, download, and display any pictures on that page. The Googlebot does the same thing. Similarly, just as you follow hyperlinks to move between pages on a site or between sites, so does the Googlebot. As it goes, the Googlebot gleans text and underlying HTML from your pages and reports the info back to the Google indexer, which adds it to the master list.
Note
In your server logs, you should see a lot of requests from the Googlebot, one after another, as it asks to crawl each page. The requests should all look a lot like the one above for the /products directory. For example, when the Googlebot requests the contents of a page called tshirts, it’ll look something like this:
208.201.239.21 - - [19/Feb/2004:18:58:15 -0800] "GET /tshirts/ HTTP/1.1" 200 6358 "-" "Googlebot/2.1 (+http://www.googlebot.com/bot.html)".
The Googlebot conducts this process throughout your site. It follows working links until it hits something it’s seen before or something with no link, like an image. When the bot’s done with your site, it heads off to other sites you’ve linked to.
Don’t be too concerned if the Googlebot has come and gone, but your site isn’t yet showing up in Google results. It takes some time for Google to index, store, and make available to the search engine everything it’s found.
Even so, some material may not make it into the index at all, particularly if the Googlebot found duplicate text or encountered a glitch. For example, a stray robots.txt file in the wrong place could have sent the Googlebot packing. Or some part of your site might not be linked to anything else within your site, rendering it invisible to the Googlebot.
If your logs reveal that the Googlebot has come calling, but after a week or two your site still isn’t coming up in search results, recheck your logs, robots.txt files, and your site itself for anything that might have thrown Google off.
Note
The only way to tell Google that your site is not in its index is to submit or resubmit your URL.
Don’t you just hate it when you’re using a search box on a Web site devoted to all things reptilian, and a search for “snake” brings up sites devoted to plumbers’ tools and drain-cleaning services? To help Webmasters get listed in search results that actually pertain to their topic, Google has come up with a little recipe it calls "Site-Flavored Search.”
To give your Web site a taste of Site-Flavored Google search, head to labs.google.com/personalized/siteflavored. On this page, you can type in your site’s URL and have Google analyze its content and create a profile. This may make it sound like your Web site is looking to date other Web sites—and in a way, it kind of is, because you want to have it find other sites with similar interests.
After you click the Get Profile button on the page, Google scans your site and tries to categorize it under a number of general labels—www.nasa.gov is profiled as a “Technology” site, for example—based on the kind of information Google finds. If you think Google is off the mark and has misunderstood your site, you can adjust, tinker, and fine-tune the profile. If you have a Web site about music, you can label it as Music and even add on some deeper descriptions under the Music tag, like R&B or Hip Hop.
Once you complete the site profiling, click the button at the top of the page to generate a chunk of HTML that you can paste into your own Web page’s code. This Google-generated code creates a special Site-Flavored Search box on your site, complete with a Custom Search button. Now, when people use this special search box on your site, they’ll get results similar in flavor to your own site, meaning people searching for Prince should have a better chance of getting results about the prolific pop star rather than a member of the royal family.
Google Site-Flavored Search is still in the beta stage, and to use it, you need to have at least Netscape 5, Internet Explorer 5, or Mozilla 1.4, and have JavaScript enabled. And although Google eventually gets around to adding tons of languages, for now, all your flavored searches need to be in English.

Rising in Google Results
The Googlebot has found your site, you and Google are becoming fast friends, and your site has just entered the PageRank popularity contest. How do you become a rising search engine star, reaching one of the coveted top spots on the first page of search results?
The secret to pleasing Google turns out to be rather straightforward: please your visitors. Happy visitors lead to inbound links, because when people like a site, they link to it from their own sites. And when there are links, Google rankings follow. That’s it.
Here are some suggestions for pleasing your visitors:
Keep things fresh, focused, and fascinating. Outdated material can be a real turn-off, while nothing keeps visitors coming back like fresh, hot-off-the-keyboard prose and links.
Note
Some search engine experts believe that Google indexes rapidly changing sites more often than those updated only every now and then.
So take the time to update your site when appropriate. And when you’ve got fresh reading material available, make it immediately obvious by maintaining a What’s New page, adding new items to the top of the home page, or listing the latest additions in a sidebar. You can’t expect your visitors to remember what they read last time and hunt around for the new stuff.
Also, provide new links whenever you can. While some Web sites believe that every link provided to other Web sites offers another reason for visitors to leave, in practice the opposite is true. If your site is a rich resource for what’s happening on the Web, your readers will come to see you as a trusted friend, putting you on their virtual speed-dial and visiting more frequently.
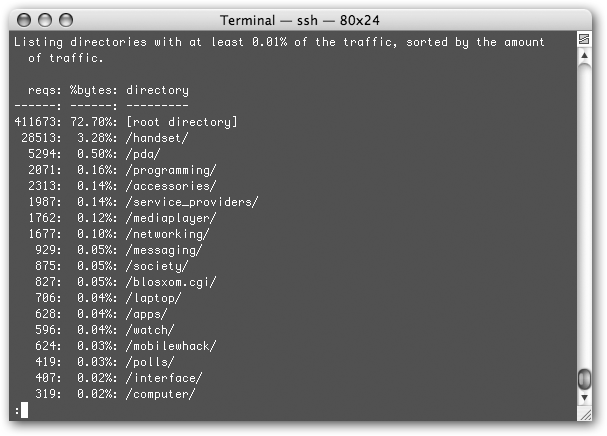
Be responsive. Keep a watchful eye on your server logs to learn what’s popular. If you discover certain sections of your site or particular articles draw the most visitors, consider filling out those parts of your site with more stories. If you find that a lot of people are coming to you through certain search engine queries, you have some great hints about what they’re looking for and whether they’re finding it on your site. And if you know they’re searching on your site itself and not finding what they want, respond to their wishes by providing just what they were looking for. Figure 8-5 shows you a typical log file.
Figure 8-5. Server logs can look like anything from a text-only listing to a fancy report provided by your ISP or by Google (Section 8.3). In this plain-Jane log, the column on the left shows the number of visits over time, and the column on the right shows the section of the Web site people visited. (The middle column, percentage of bytes transferred, is mostly useless because the volume depends on what’s on that page. A page with lots of pictures is going to transfer a higher percentage than a text-only page.) This log tells you that the home page (“root”) of this site gets the most traffic, followed by the “handset” section.Tip
Visitors who find your site through a search engine usually carry a record of their query with them to your site. Most log-analysis tools make note of these search terms, including them in any generated reports. Thus, if you know the right place to look, you can usually figure out what people were searching for when they came to your site. Chapter 10 is all about Google Analytics, a free tool for analyzing your Web site traffic.
Give each page, article, or product its own permanent URL. When people want to send their best friend the URL for your page about family eggplant recipes, they really hate adding: “Click on the third link down in the What’s New section, below the picture of Barney.” They may hate it so much that they stop bothering with your site at all.
There are two ways you can make your site harder for people to use. First, if you put a lot of articles on one page, you force people to say, “It’s the fifth story on the page.” It also forces you to keep the article in that slot if you want people to find it. Second, using frames for whole pages causes your visitors to see the same URL in their address bar no matter what page of your site they’re on—which means they can’t send friends a link without also providing a roadmap to find the page in question. (That’s yet another excellent reason to eschew frames.)
So make things simple for your visitors and Google: Every time you create a page on your site, link to it from at least one other page—and, if possible, don’t change the page’s name.
Let them share. Go a step better and let visitors hang a hat on your site through forums, feedback forms, and customization. Read the feedback channels on a regular basis and become an active participant in discussions of your site.
Plain and simple wins the race. Keep your Web pages as lightweight as possible. Just because you’re at the end of a high-speed broadband connection doesn’t mean your visitors are. In fact, many Web surfers still poke along at 56 K, not to mention those visiting from their cellphones and PDAs—who often have very slow connections.
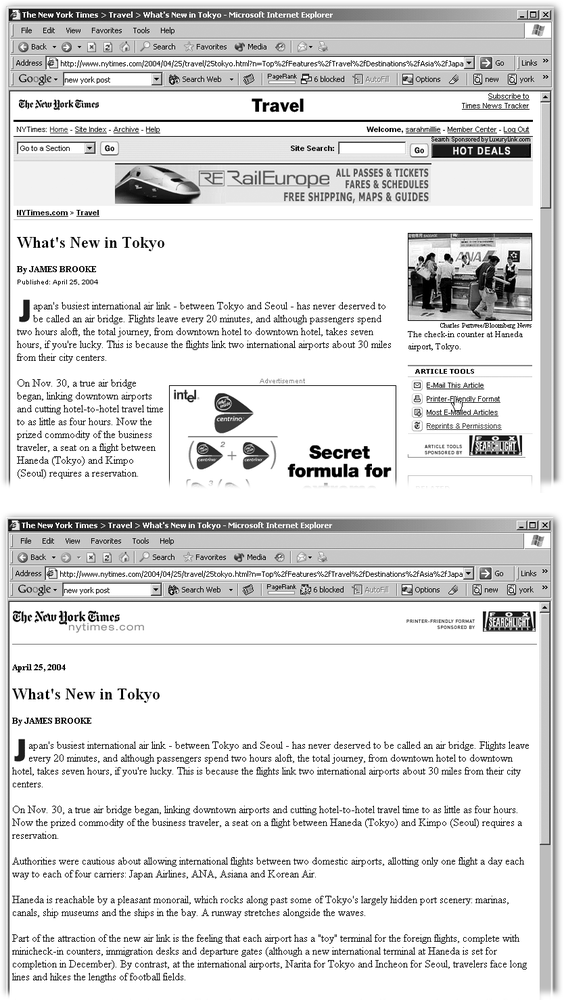
Don’t annoy your visitors. Nothing screams “Go Away” like in-your-face Flash animations, ads strewn all over the place, pages that link to nothing, and dopey gimmicks. It’s all right to have a long article span multiple linked pages, but be fair about how much content is on each page, and avoid click-through pages set up solely for advertising impressions. While you’re at it, provide a Print view for those who want a story all on one page for a manageable print job, as shown in Figure 8-6.
Keep busy trying to please your visitors, and don’t spend time trying to fool Google. The Google folks are smart, and they have set up all manner of checks and balances to make sure the sites they index are on the up-and-up. Indeed, Google considers the following practices unfair—so much so that if they discover you engaging in them, the Googlebot may stop visiting and including you in the index. (Google doesn’t say how long it’ll keep you out in the cold, but anecdotal evidence suggests the icy treatment may be permanent.)
Don’t misrepresent your site to Google by feeding different content to the Googlebot than you do your regular human visitors. This trick is known among Webmasters as cloaking. It entails manipulating your site in response to User-Agent identifiers, which are signatures associated with every request from a Web browser or robot to view a site. Some sites use this identifier to show different content to a bot (User-Agent: Googlebot) than to your garden-variety Web browser (User-Agent: Internet Explorer). It’s a nasty business, and a good way to draw Google’s ire.
Figure 8-6. Top: The Web-friendly version of a story may span several Web pages. Bottom: A printer-friendly view, by contrast, keeps the entire article on one page and is all but bereft of advertising. The printer-friendly version is also a good format for emailing a story to a friend or transferring to a PDA.Stay away from HTML shenanigans intended to confuse the Googlebot. These tricks include giving your page multiple titles, embedding inaccurate keywords, stuffing your page with repetitive keywords, and so forth.
Steer well clear of so-called link farms and link-exchanges that exist solely to boost your Google ranking. They’re an investment in trouble.
Getting Rid of Google
Some Webmasters, for whatever reasons, prefer their sites remain word-of-mouth affairs and shy away from the Google limelight. The most effective way to keep some or all of your content out of Google is making sure it never gets in the Google index in the first place. This is quite a trick. A stray link from a nosy-parker to otherwise undiscovered material can leave you exposed in no time flat—the moment the Googlebot finds it, that is.
Hiding from the Whole World
If you don’t want anyone finding all or a portion of your site, simply failing to mention it or hiding some of it behind obscure URLs won’t do the trick. Assume that if it’s publicly accessible, someone, sometime will stumble across it. To keep your site from falling into the hands of strollers-by:
Don’t put it online in the first place. If your site is meant for coworkers’ or household-members’ eyes only, place it behind a firewall configured to disallow incoming requests to your Web server.
Lock it up tight. Protect your site from prying eyes by limiting access to visitors coming from particular IP addresses or to those supplying the correct user name and password.
Hiding from Google
If, on the other hand, you just don’t want Google to find, crawl, and index your site or portions thereof, no problem. You can set up specific rules, which are instructions that the Googlebot follows:
Invoke the Robot Exclusion rule. The Googlebot, like any well-behaved robot, obeys any explicit request placed in your robots.txt file not to roam your site, keep out of some particular corners, or keep its mitts off files of particular types. Learn more about robots in the box in Section 8.5.3.
Add a robots meta tag. You can tag individual pages as “hands-off” to robots by adding a meta tag (Section 8.1.1.3) to the pages themselves.
Tip
If you want to block the Googlebot from a whole directory, use a robots.txt file (Section 8.5.3).
—To keep Google from indexing a page, add the following to the <head> section of your Web page: <meta name="googlebot" content="noindex">
Tip
Many robots ignore the robots meta tag, but the Googlebot actually does pay attention. You can, nevertheless, try to warn off other robots by replacing googlebot in the meta tag with robots. The Googlebot respects either.
—You may want to keep part of your site out of the Google index. For example, you’d probably rather people visit your product database directly than have them view outdated information on Google. To have the Googlebot index your home page but not follow any of its links to the rest of your site, therefore, use: <meta name="googlebot" content="nofollow">
Tip
If you want to block the Googlebot from a single page or a couple of pages only, add the noindex meta tag to those particular pages, like this: <meta name="googlebot” content="noindex”>. Be sure to put the meta tag between the opening <head> and closing </head> tags.
—You can also control whether or not Google search results display snippets of text from your pages along with their titles. This option is handy if, say, you’ve built up a nice community of visitors who participate regularly in ongoing discussions on your site. To prevent their wisdom from being taken out of context, use: <meta name="googlebot" content="nosnippet">—When it indexes your site, Google caches (Section 1.4.1.4) full copies of your pages on its servers. When your site appears in a list of Google search results, the searcher can look up pages in Google’s cache, rather than on your actual site. The cache may be outdated, as it’s simply a snapshot of a page at the time Google indexed it. If you’d prefer people visit your site directly, use: <meta name="googlebot" content="nocache">
You can combine any number of these properties in your robots meta tags by listing them, one after the other, separated by commas. For example, to prevent both caching and snippet gathering, add the following to your Web page:
<meta name="googlebot" content="nocache, nosnippet">
Tip
For more of the nitty-gritty details on the robots meta tag, visit the official “HTML Author’s Guide to the Robots meta tag” at www.robotstxt.org/wc/meta-user.html.
If you’ve invoked the Robot Exclusion rule or added a robots meta tag after Google has already found pieces of your site, it may take days or weeks before Google incorporates the changes into its behavior. If time is of the essence and you’d like Google to pay attention to your changes as soon as possible, you can remove your entire site or parts of it from Google and request a reindexing. Read on.
Removing Yourself from Google
What do you do when you’ve made it into Google, only to discover that your site includes a few things you’d hoped the search engine wouldn’t find—like pictures you uploaded during the height of your bachelorette party?
You can, of course, take the drastic step of shutting down your site entirely. This prevents anyone from actually getting to your site. Yet the results themselves— and, more likely than not, cached copies of your pages—already exist in Google’s index. So you’ve ineffectually closed the proverbial barn door after the horse has already left hoofprints in the neighbor’s vegetable garden.
For better and for worse, the Web has an incredible memory: that which is spoken online can never really be unspoken. You can, however, use the same methods described in the previous section to actually remove ill-indexed booty from Google.
Once you’ve invoked the Robot Exclusion rule, peppered appropriate pages with robots meta tags, and taken offline the content you didn’t want online in the first place, you’re ready to request that Google immediately remove the material from its index.
Warning
Requesting your content be removed from the Google index does not put a stop to the Googlebot’s visits; the next time it stumbles across your site, it dutifully roams and re-indexes. Thus, it is vital that you take the steps mentioned in “Hiding from Google” in Section 8.5.2 to stop the Googlebot from indexing your site before you bother to request that Google remove material from its current index. Going about all this in the wrong order is simply a waste of time.
Here’s how to get Google to clean your site out of its index:
Visit Google’s URL Removal page.
Point your Web browser to http://services.google.com/urlconsole/controller.
Establish a Google account.
In the form provided, type your email address and a password (make one up), and click Create Account.
If you already have a Google account, type your email address and password into the “Already have an account?” form and click Login. Skip to step 4.
Check your email.
In just a few minutes, you should receive email from Google containing a link to follow. Click the link or paste the URL into your Web browser. You arrive back at Google’s URL Removal Options page, logged in and ready to remove your content.
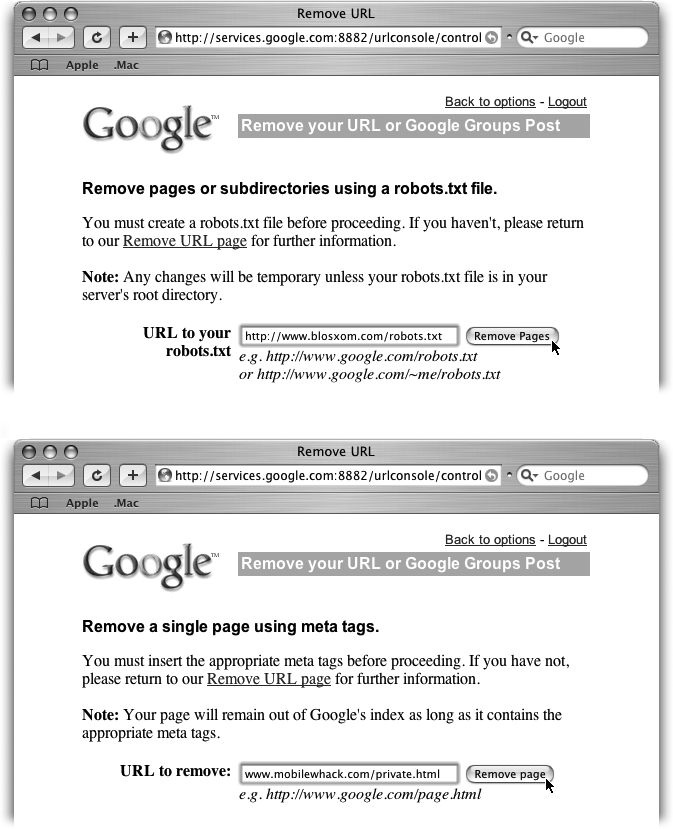
Tell Google whether you want to remove a whole site, a section of a site, or just a page (Figure 8-7).
Google has no way of verifying that you are indeed the owner of the pages you say you want removed. After all, if your site is www.roadrunner.com, Google can’t tell whether the request for removal is coming from a legitimate Webmaster or from Wile E. Coyote. Google thus lets you simply request that it nix pages. Meantime, the Googlebot checks the site in question for a robots.txt file (which would tell Google that it isn’t welcome on that site), or for embedded robots meta tags (which would tell it to ignore specific pages). This system prevents people from shutting each other’s sites out of Google, because Google rejects the request if it finds no robots rules or tags. Again, this process means you must implement those robot rules before you send Google on a mission to your site.
You can also remove an outdated link, although Google will most likely do so automatically the next time it tries to follow that link and can’t.
Indicate the URL for the offending content.
Type in the URL for your robots.txt file, or for the URL of the page you wish removed (Figure 8-8).
Wait.
Your request should take 24 hours or less. Revisit the URL removal page (http://services.google.com/urlconsole/controller) every so often to take a gander at your queued requests; when your request vanishes from the Status list on that page, run a Google search to make sure that it’s removed what you wanted.
Tip
For more detail on removing your site from Google, visit the “Remove Content from Google’s Index” page at www.google.com/remove.html.
Adding Google Searches to Your Site
No doubt you’ve noticed Google search boxes on sites ranging from Uncle Ralph’s Fishing Cornucopia to mega-destinations like Amazon.com. You, too, can add a so-called Google box to your site, providing visitors with a handy shortcut for searching the whole Web. But even better, you can add a Google box that also lets people search your site—saving you the considerable trouble of implementing a local site search yourself and instead tapping the power of Google for your own pages. Figure 8-9 shows you an example.
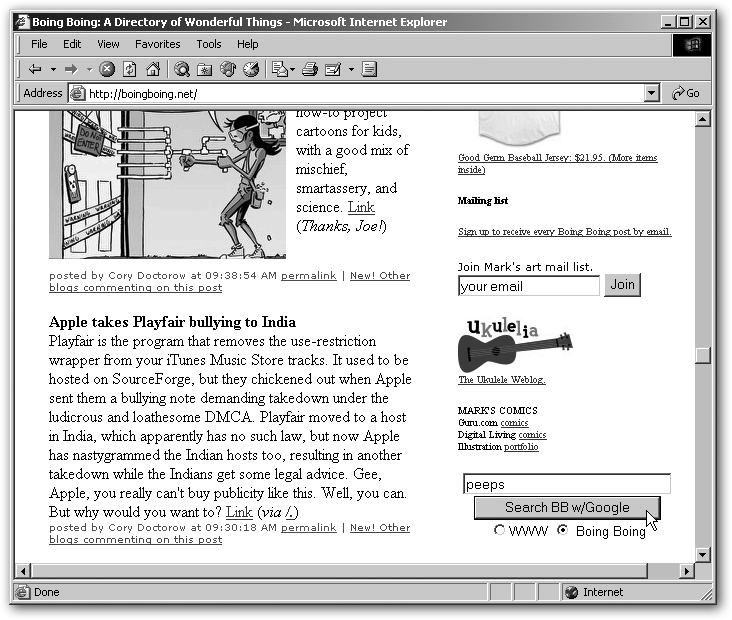
Adding a Box for Searching the Web
You can add Google’s free WebSearch box to your site by simply pasting some HTML into your Web pages. Here’s how: Point your Web browser to www.google.com/searchcode.html. Decide whether you want to add a full-fledged Google WebSearch box to your site or whether you’d prefer to keep things a little tamer with their SafeSearch box (Section 2.8.3)—worth considering if you run a religious site, a children’s site, or a religious children’s site. Highlight the HTML code in either the Web search or SafeSearch box, copy it, and paste it into the HTML code for your Web page. Save your page as you usually do and take a look at it in your Web browser. You should now have your very own Google search box right on your site.
Adding a Box for Searching Your Site
You can turn the Google spotlight on your own site. SiteSearch (www.google.com/searchcode.html#both) is Google’s free search feature for your Web site. It’s as simple to deploy as the copy-and-paste Google box described above. Figure 8-10 shows you how.
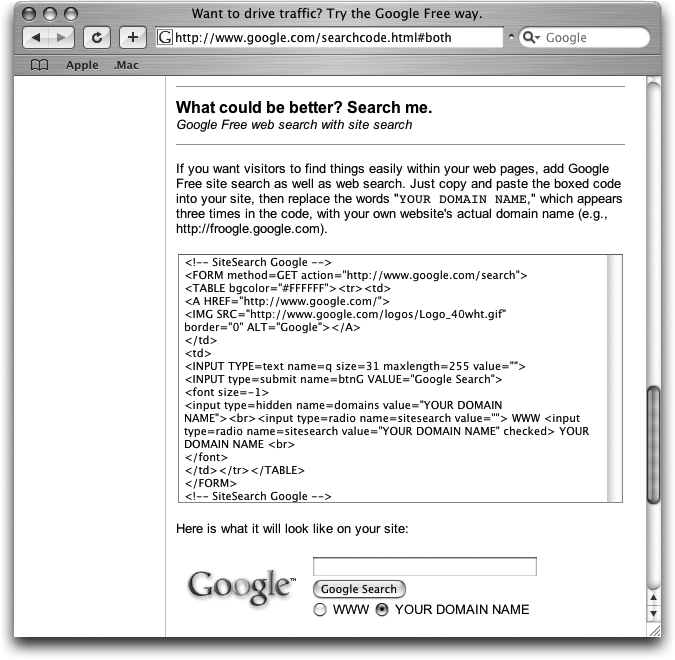
Customizing the SiteSearch box
There’s nothing wrong with the classic look and feel of a Google results page. But with just a dollop of work, you can make Google’s SiteSearch look as if it were built into your site rather than bolted on.
Point your browser to www.google.com/services/free.html, sign up for an account, and follow the simple wizard-like directions to customize the background, text, and link colors on your Google results page. While you don’t end up with anything that looks enormously different from the standard Google results page, you can differentiate yourself a tad, as shown in Figure 8-11.
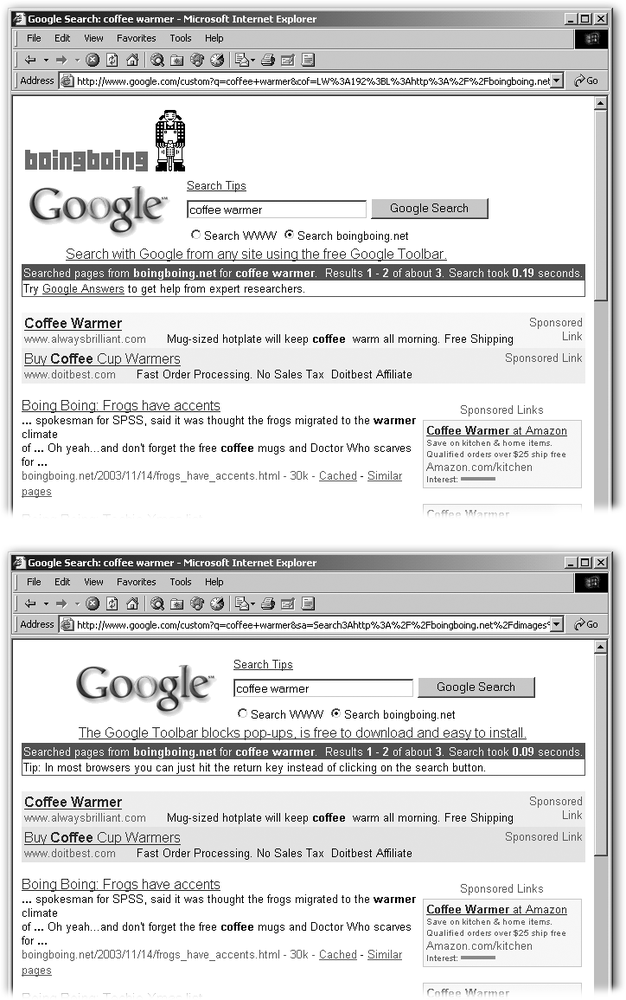
Note
Google offers more search options for your site, at a price. For instance, their Silver/Gold Search (www.google.com/services/silver_gold.html) provides top-notch features like the ability to further customize results pages and run your own ads. It costs a minimum monthly fee of U.S. $599, plus additional click-through fees. Their Custom WebSearch (www.google.com/services/custom.html) is for portal sites issuing four million or more queries per year—with commensurate fees. Learn all about Google Business Solutions at www.google.com/services/.