
7 Common Setups
When you set up a complex system such as MySQL Cluster, you need to think about a number of architectural concepts, including topics such as load balancing with the MySQL servers themselves, designing for future scalability, and building a highly available setup. Quite commonly, you need to include additional software and integration between the different pieces of your server architecture. This chapter discusses some of the topics that are important regarding MySQL Cluster setups and suggests some commonly used possible solutions for the problems discussed.
A couple of different pieces need to be load balanced and set up for failover in MySQL Cluster:
![]() Automatic failover and load balancing within the data nodes—This failover and load balancing happen automatically, totally transparently to your application. Generally, the application does not need to concern itself with this aspect of failover.
Automatic failover and load balancing within the data nodes—This failover and load balancing happen automatically, totally transparently to your application. Generally, the application does not need to concern itself with this aspect of failover.
![]() Load balancing and failover in front of the MySQL nodes—You have to set up this type of load balancing manually. This is normally a fairly simple task, thanks to the nature of MySQL Cluster, compared to something such as MySQL replication. It is possible to read/write from any MySQL server, so failover is as simple as connecting to another MySQL server and resuming whatever task you were doing. Load balancing is also normally quite simple because the query load is already partially balanced (by the data nodes), so, depending on the types of queries you are doing, the MySQL servers normally have less load already.
Load balancing and failover in front of the MySQL nodes—You have to set up this type of load balancing manually. This is normally a fairly simple task, thanks to the nature of MySQL Cluster, compared to something such as MySQL replication. It is possible to read/write from any MySQL server, so failover is as simple as connecting to another MySQL server and resuming whatever task you were doing. Load balancing is also normally quite simple because the query load is already partially balanced (by the data nodes), so, depending on the types of queries you are doing, the MySQL servers normally have less load already.
There are many possibilities for setting up load balancing and failover for the MySQL servers (“SQL nodes”). The following sections discuss some different commonly used options and their pros and cons.
The official MySQL JDBC, Connector/J, supports automatic failover and basic load balancing capabilities, starting from MySQL Cluster version 3.1. The load balancing algorithm is fairly basic round-robin support that chooses the server to connect to. In the event that it cannot connect or gets disconnected from a server, it automatically chooses another server in the list and uses that to do queries. This failover results in losing only the transaction you are currently running, so you have to retry just that transaction.
To set up the JDBC driver for this type of failover, you need to do two additional things compared to a normal setup. First, in the connection URL, you need to specify a list of all the possible MySQL servers. The list of servers would look like this:
jdbc:mysql://mysqld1,mysqld2,mysqld3,mysqld4/dbname
Second, you need to add some additional parameters to the URL. (It is also possible to set them through the use of the JDBC Properties object instead of through the direct URL.) The minimum required URL parameters that you need to set are autoReconnect=true, roundRobinLoadBalance=true, and failOverReadOnly=false. These settings cause the JDBC driver to connect to a new server in the event that the current one fails, they cause it to choose the servers in a round-robin fashion, and finally, they allow the client to read and write to the failed over server. There is also a special configuration option you can use that sets all three of these settings. You set this bundle by using useConfigs=clusterBase.
You may consider some additional parameters as well, such as queriesBeforeRetryMaster and secondsBeforeRetryMaster. These settings cause the JDBC driver to attempt to reconnect to the original server after a set number of queries or based on time. This can be useful for allowing a server to automatically resume being used after it returns to service.
Your final JDBC URL might look similar to this:
jdbc:mysql://host1,host2/db?useConfigs=clusterBase&secondsBeforeRetryMaster=60
Now when a MySQL server fails, only your current transaction will be aborted. You can then catch the exception and retry the transaction. The parameters you have set cause the JDBC driver to transparently connect to a new server, and when you issue the queries for the transaction, they execute there. The JDBC driver attempts to fail back to the old server every 60 seconds until it succeeds.
The advantage of this setup is that, compared to other solutions, it is relatively easy to do and doesn’t require any additional hardware or software.
The obvious big disadvantage of this setup is that it only works for Java, and not for any other programming languages. Another drawback is that it isn’t the most sophisticated of load balancing systems, and it may not work adequately in some scenarios.
It is possible to set up a very primitive load balancing setup by using round-robin DNS. With this method, you basically set up a DNS name, which can resolve to any of the MySQL servers operating in your cluster. Then you need to set up a very short time-to-live (TTL) for the DNS requests. After that, you tell your application to connect to the hostname, and it then gets a different IP address each time you request to connect. It is possible to remove a node from the DNS setup when it goes down or when you want to remove it from service.
One big drawback of this method is that it doesn’t gracefully handle node failures automatically. In the event of a sudden MySQL server failure, the DNS server continues to give out the IP address for the now-down server. You can handle this in two ways:
![]() Your application can try to connect and, if it fails, request a new DNS entry, and then it can attempt to connect again—repeating as necessary until it can finally connect. The drawback with this method is that it can take a while for the connection attempt to fail, and it can fail quite a few times if you have multiple MySQL servers down.
Your application can try to connect and, if it fails, request a new DNS entry, and then it can attempt to connect again—repeating as necessary until it can finally connect. The drawback with this method is that it can take a while for the connection attempt to fail, and it can fail quite a few times if you have multiple MySQL servers down.
![]() You can have some sort of monitoring system that detects a MySQL server shutdown and removes it from the DNS setup. This requires additional software, and if you are going to go this route, you should look into the software solutions mentioned later in this chapter, in the section “Software Load Balancing Solutions,” because they can do this detection and failure in a more graceful way than round-robin DNS.
You can have some sort of monitoring system that detects a MySQL server shutdown and removes it from the DNS setup. This requires additional software, and if you are going to go this route, you should look into the software solutions mentioned later in this chapter, in the section “Software Load Balancing Solutions,” because they can do this detection and failure in a more graceful way than round-robin DNS.
A second problem with round-robin DNS is that the load balancing is fairly simple, and it is not dynamic. DNS always does a round-robin request serving, which in some cases is less than ideal. Some clients also ignore very small TTLs, so if you have only a small number of client machines, you might find that by chance, they all end up hitting the same SQL node for a period of time.
It is possible to use a hardware load balancer with MySQL Cluster as a front end for the SQL nodes. Cisco products and products such as Big-IP are examples of hardware solutions to this problem. Normally, these hardware solutions are quite customizable and reliable. When using them with MySQL Cluster, you need to make sure they are set up to bind connections at the protocol session level. That means they should balance a single connection to the same server for the duration of the connection. The method for doing this setup depends entirely on the hardware solution in use. You should consult your hardware vendor if you have any problems making this binding.
The advantage of hardware solutions is that, generally, you can customize them to do most of what you want. For example, most hardware solutions can automatically detect whether the MySQL server isn’t responding, and they can then remove it automatically from the possible connections and add it back again when the server comes back up. In addition, they can possibly do more sophisticated load balancing solutions than just round-robin.
Generally, the biggest drawback of a hardware solution is cost. Typically, hardware solutions run in the tens of thousands of dollars, which may be more than the cost of your entire cluster. In addition, technically, a hardware load balancer can become a single point of failure. To minimize this, you need to set up redundant hardware load balancers, which increases the cost and complexity of the solution.
A number of software solutions can be used for load balancing. The most common products that can do this are Linux Virtual Server (LVS), Linux-HA, and products based on these (such as Ultra Monkey). There are many other solutions for other operating systems that should be adequate as well. A brief description of what these particular systems do should help provide insight into any other system that you might want to use:
![]() LVS—LVS (www.linuxvirtualserver.org) allows you to set up multiple Linux servers, all with a single virtual IP address. Behind the scenes, these servers can do load balancing. LVS can use many different algorithms, such as least connections, weighted round-robin, and many others. It allows for connections to be tied to a single real server, to ensure transactional integrity behind the scenes.
LVS—LVS (www.linuxvirtualserver.org) allows you to set up multiple Linux servers, all with a single virtual IP address. Behind the scenes, these servers can do load balancing. LVS can use many different algorithms, such as least connections, weighted round-robin, and many others. It allows for connections to be tied to a single real server, to ensure transactional integrity behind the scenes.
![]() Linux-HA—The Linux-HA project (www.linux-ha.com) is designed to provide a flexible high-availability framework for Linux (and other UNIX systems as well). The main piece of Linux-HA is called Heartbeat, which is a server that monitors the MySQL servers and removes them from possible connections if they suffer critical failures.
Linux-HA—The Linux-HA project (www.linux-ha.com) is designed to provide a flexible high-availability framework for Linux (and other UNIX systems as well). The main piece of Linux-HA is called Heartbeat, which is a server that monitors the MySQL servers and removes them from possible connections if they suffer critical failures.
![]() Ultra Monkey—Ultra Monkey (www.ultramonkey.org) is a software solution that is designed to integrate Linux-HA and LVS into a single standalone solution, which allows for easier integration and building of fully load balanced and highly available solutions. The advantage of using software such as Ultra Monkey instead of the separate pieces is that it is easier to install, maintain, and configure a single-package solution.
Ultra Monkey—Ultra Monkey (www.ultramonkey.org) is a software solution that is designed to integrate Linux-HA and LVS into a single standalone solution, which allows for easier integration and building of fully load balanced and highly available solutions. The advantage of using software such as Ultra Monkey instead of the separate pieces is that it is easier to install, maintain, and configure a single-package solution.
There are a few big advantages to using a software solution such as these. First, all the software mentioned here is completely open source and freely available. Obviously, if you are designing a low-cost cluster, this is very attractive. Second, the software is very flexible. You can configure many different options, depending on the needs of your MySQL Cluster setup. This includes options such as load balancing algorithms, failover algorithms, rejoining algorithms, and so on.
The drawback of these software solutions is that they can be difficult to set up. While packages such as Ultra Monkey make setup easier, it is still generally more work to set up and maintain a system such as this than to use a hardware solution. Another possible drawback is that it can be more difficult to get support contracts to support these technologies. Many Linux distributions provide some support, and some commercial companies also provide support, but there is not a single source of support, as is possible with hardware solutions.
There are many different ways to lay out cluster nodes across the physical systems. You need to consider many factors in your decision as to what is the best physical layout for your application. The following sections explain some of the benefits and drawbacks of running nodes in different places.
The simplest setup that is possible for a highly available system is two main machines and a third system to hold the management server. On the two main systems, you run your application, a MySQL server, and a data node. These machines handle all the actual processing and execution of the queries. Figure 7.1 illustrates what this basic setup would look like.
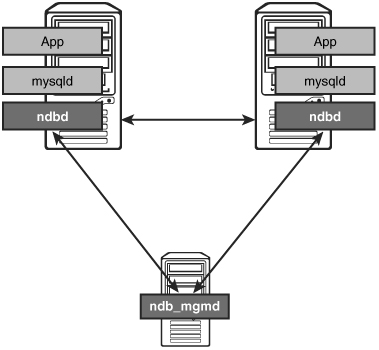
The third machine can be relatively low performance due to the fact that it is running only the management server and does not take part in any of the query process. The only reason you need a third machine is due to network partitioning problems mentioned in previous chapters.
Note
Tim Pearson has ported the management daemon onto the OpenWRT operating system, which runs on some switches. If you have such a switch, you can use this daemon as the management daemon. See http://pcos.dyndns.org for more details.
There are a few main advantages to this setup. The most important aspect is that it doesn’t require a lot of hardware, but it still maintains high availability. You can lose any one of the three machines without affecting the availability of the database. Also, the performance is relatively good because most communication can happen locally. Of course, there is network traffic between the servers, but it will be minimal compared to what it would be with more hardware.
The drawback is that this isn’t a very scalable solution. It is difficult to add more machines to the environment without having to re-architect the cluster setup.
In many applications, scalability isn’t as important as high availability, and this scenario is perfect for those applications. An example would be for a company intranet server for a small or medium-size business. The overall traffic in that scenario is quite small, averaging a few requests per second, but you want to maintain high availability to ensure smooth operations of the company’s processes.
One thing to note is that it is possible to start with a setup such as this and then migrate to one of the larger setups mentioned later in this chapter. It might even be possible to do this migration without having to lose availability for the application. As long as you aren’t growing beyond the two data nodes, it should be possible to add/move the applications and MySQL servers to different physical locations without shutting down the server.
As your application grows, or if you are architecting a large-scale application to begin with, you should consider some alternate architectures for your application. The following sections describe two possible setups for a more complex web application.
In a one-to-one relationship setup, as shown in Figure 7.2, there is a direct mapping between the MySQL server and your application server. Each instance of your application server has a single running instance of MySQL that it connects to. Normally, this is on the same physical server, using local connections between the two servers. Under this level, you can have any number of data nodes. For example, if you have four Apache servers, you would have four MySQL servers, with each of them running on the same physical server as the Apache server does, and then two data nodes running on different hardware below them. This allows for automatic load balancing because you only have to load balance in front of the application server, which is normally a relatively easy task. Also, this handles hardware failures properly because when the hardware fails, you lose both the application server and the MySQL server, which prevents any waste of resources.
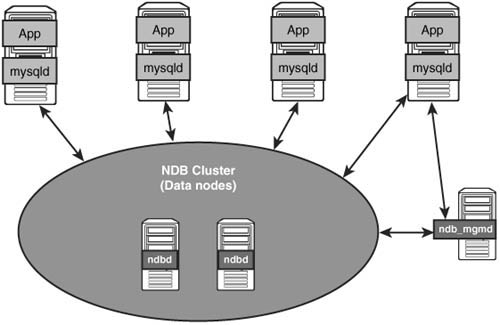
The problem with using this method is that it doesn’t work for all types of applications. It only works where you have a limited number of programs that will connect to MySQL. This works well in situations such as web applications, but it doesn’t work for client/server model types of applications. In addition, it prevents you from scaling different portions of your architecture at different paces because you need to maintain the one-to-one relationship.
In the separate farm setup, you keep the application servers separate from the entire cluster setup. This allows you to scale the different pieces of your application/database setup as needed. If you run into a bottleneck in the application, you can scale by adding more application servers, and the same could apply for MySQL servers or data nodes. As shown in Figure 7.3, these three levels of scaling can allow you to scale to even the largest workloads that applications can see.
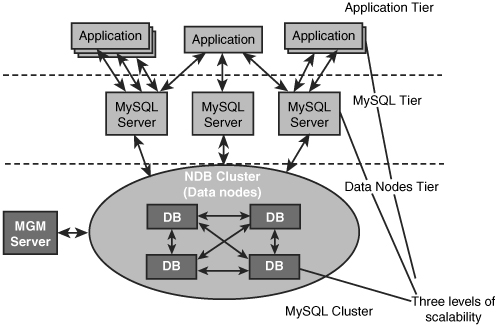
The client/server setup is very similar to the Web farm/MySQL farm discussed in the preceding section. The only difference is that this setup has many clients instead of a small set of application servers as the few connecting clients. An example of this would be an application that runs on a desktop client and logs directly in to MySQL across the network for reporting purposes. In this case, you will need to generally scale the MySQL servers in a much faster way, based on the number of client applications.
The last topic we need to discuss in order to create a highly available, scalable cluster is network redundancy. Although you can just use a normal network setup, doing so results in a single point of failure. If all your network traffic in the cluster is going across either a single router or two, and one shuts down, all the nodes disconnect and shut down your cluster. Again, there are a few different solutions for this.
The first option is to get dual-port network cards that support automatic network failover. These cards should provide automatic failover totally transparent to the cluster nodes. When purchasing these cards, you should talk to the manufacturer to ensure that you have good driver support on the operating system on which you intend to use them. With this setup, you essentially have two networks, with one network acting as the backup in case the primary fails for some reason.
A second option is to have some redundancy in the network itself. It is possible to set up a network with redundancy such that if one network component fails, others can take over the load of the failed one. In a typical setup like this, you should never have all of one node group plugged in to the same physical network device. That way, if the network device fails, you lose at most one machine from the cluster, which does not result in an entire cluster shutdown.
If you decide to go with the redundant network setup, you need to be very careful to ensure that having a larger network setup doesn’t affect performance. As mentioned in Chapter 5, “ Performance,” network latency is extremely important, and as you add more layers of networking, it can result in an overall slowdown in cluster processing.