


IBM Platform Symphony
This chapter provides details of the IBM Platform Symphony. The following topics are covered in this chapter:
5.1 Overview
IBM Platform Symphony is the most powerful management software for running low-latency compute-intensive and data-intensive applications on a scalable, multi-tenant, and heterogeneous grid. It accelerates various parallel applications, quickly computing results while it makes optimal use of available infrastructure.
Figure 5-1 represents applications in terms of workload classification, data types, use cases, time span characteristics, and required infrastructure.
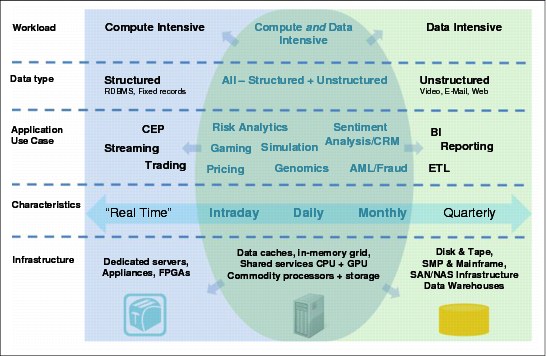
Figure 5-1 Multidimensional application analysis
Figure 5-2 on page 113 provides an overview of the IBM Platform Symphony family of products. Specialized middleware layers provide support for both compute-intensive and data-intensive workloads.
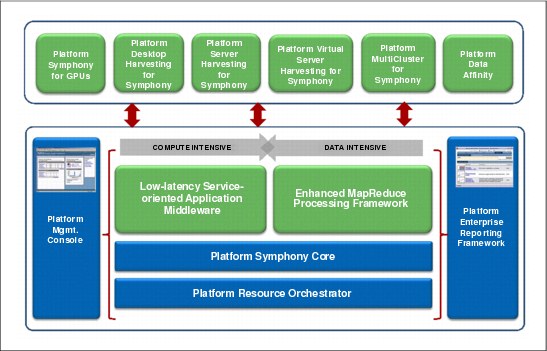
Figure 5-2 IBM Platform Symphony family high-level overview
With Symphony, users can manage diverse sets of applications, allocating resource according to policy to guarantee application service-level agreements (SLAs) while they maximize performance and utilization.
For compute-intensive applications, Symphony offers low latency and high throughput support (Figure 5-3 on page 114). It can address submillisecond task requirements and scheduling 17,000 tasks per second.
For data-intensive workloads, it provides best in class run time for Hadoop MapReduce. The IBM Platform Symphony MapReduce framework implementation supports distributed computing on large data sets with some key advantages:
•Higher performance: 10X for short-run jobs
•Reliability and high availability
•Application lifecycle rolling upgrades
•Dynamic resource management
•Co-existence of up to 300 MapReduce applications (job trackers)
•Advanced scheduling and execution
•Open data architecture: File systems and databases
•Full Hadoop compatibility: Java MR, PIG, HIVE, and so on
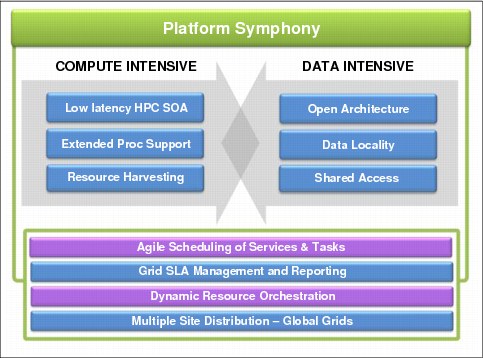
Figure 5-3 Symphony framework for compute-intensive and data-intensive computing
Enterprise-level resource ownership and sharing
IBM Platform Symphony enables strong policy enforcement on resource ownership and sharing. Resources can be shared across multiple line of businesses (LOBs), which are called Consumers in Symphony terminology. All details are transparent between different types of applications (service-oriented architecture (SOA) and Batch), which provides a flexible and robust way of configuring and managing resources for applications.
Performance and scalability
IBM Platform Symphony offers extreme scalability, supporting 10,000 cores per application and 40,000 cores per grid. Symphony supports heterogeneous environments that are based on Linux, AIX, or Microsoft Windows. Symphony has the following characteristics:
•At least 5,000 hosts in a single cluster
•1,000 concurrent clients per application
•5,000 service instances can be used by one application in parallel with ~97% processor efficiency
•Although not officially benchmarked, further tests with up to 20,000 service instances showed high processor efficiency
•Single task latency (round-trip): Under 1 ms
•Session round-trip: 50 ms
•Task throughput: 7,300 messages/sec (1 Kb message)
•Number of tasks per session: 1 M
•Single input message size: 800 Mb (450 on Windows) (32-bit client). Size is limited for a 32-bit client machine but not for a 64-bit client.
•Single output message size: 800 Mb (450 on Windows) (32-bit client). Size is limited for a 32-bit client machine but not for a 64-bit client.
•Single common data size: 800 Mb (450 on Windows) (32-bit client). Size is limited for a 32-bit client machine but not for a 64-bit client.
|
Certified numbers: The preceding numbers are certified. Actual performance and scalability can be higher.
|
Automatic failover capabilities
IBM Platform Symphony has built-in failure resilience with automatic failover for all components and for applications. Even if the IBM Platform Enterprise Grid Orchestrator (EGO) has problems, it does not affect the continual running of SOA middleware and applications. Only new resource allocation and resource ownership and sharing are temporarily unavailable.
IBM Platform Symphony has the following failover characteristics:
•It relies on the shared file system for host failure management.
•A shared file system is required among management hosts for failover if runtime states need to be recovered and if a management component host fails.
•Without a shared file system, the failover can still happen although previous runtime states are not recovered.
•No shared file system is required for compute nodes. All system and application binaries and configurations are deployed to the local disk of each compute node.
Dynamic and flexible structure
IBM Platform Symphony provides a seamless management of global resources on a flexible shared environment. Resource allocation flexibility is based on demand and business policy.
Compute hosts can join and leave a Symphony grid dynamically, which means less administration overhead. There is ongoing communication between the grid members. In this service-oriented model, a host is no longer considered a member of the grid after it leaves for longer than a configurable timeout.
Total application segregation
The following characteristics are provided with the total application segregation:
•No dependency exists among SOA middleware in different consumers.
•All SOA application properties are defined in the application profile of individual applications. No dependency and interference exist among different applications. Changes in one application do not affect the running of other applications.
•Consumer administration is in full control of SOA middleware and applications for the consumer.
•An update to an application affects the running workload only and takes effect on the subsequent workload.
Heterogeneous environment support
Linux, Windows, and Solaris compute nodes can be in the same grid. Linux, Windows, and Solaris application services can co-exist in the same service package and work in the same consumer.
Data collection and reporting
The following characteristics are shown for data collection and reporting:
•Data collection and reporting is built on top of the Platform Enterprise Reporting Framework (PERF).
•Data is collected from the grid and applications, and this data is maintained in a relational database system.
•Predefined, standard reports ship with the software.
•Custom reports can be built by clients in a straightforward manner.
•Further customization is possible with help from Platform Professional Services.
System monitoring events
When a predefined event happens, a Simple Network Management Protocol (SNMP) trap is triggered. The key system events are listed:
•Host down
•Key grid component down
•Grid unlicensed
•Application service failures
•Consumer host under-allocated
The key SOA application events are listed:
•Client lost
•Session aborted, suspended, resumed, and priority changed
•Task became an error
Auditing
Symphony auditing traces all important operations and security-related activities:
•EGO cluster operations: Any Symphony actions:
– Host operations (close or open)
– User logon/logoff and user operations (add, delete, or modify)
– Consumer operations (add or delete)
•EGO service operations (EGO service started or stopped)
•Service packages (added, removed, enabled, or disabled)
•SOA applications:
– Application operations (enabled and disabled)
– Sessions (sessions of an application that is ended, suspended, or resumed)
Command-line interface (CLI) support
The following categories are supported CLI function categories:
•System startup and shutdown:
– Start up, restart, and shut down EGO daemons
– Restart and shut down the SOA middleware (SOAM) daemons and GUI servers on EGO
•Day-to-day administration:
– Create, modify, and delete user accounts
– Assign user accounts to a consumer
•Workload management:
– Enable and disable applications
– Deploy modules
– View and control applications and workload
– View task details
– View details of finished sessions and tasks
•Troubleshooting
Dynamically turn on and off debug level, debug class, and workload trace
Application development
For developers, Platform Symphony presents an open and simple to program application programming interface (API), offering support (client side) for C/C++, C#, Java, Excel, Python, and R.
5.1.1 Architecture
Symphony provides an application framework so that you can run distributed or parallel applications on a scale-out grid environment. It manages the resources and the workload on the cluster. The resources are virtualized so that Symphony can dynamically and flexibly assign resources, provisioning them and making them available for applications to use.
Symphony can assign resources to an application on demand when the work is submitted, or assignment can be predetermined and preconfigured.
Figure 5-4 illustrates the Symphony high-level architecture.
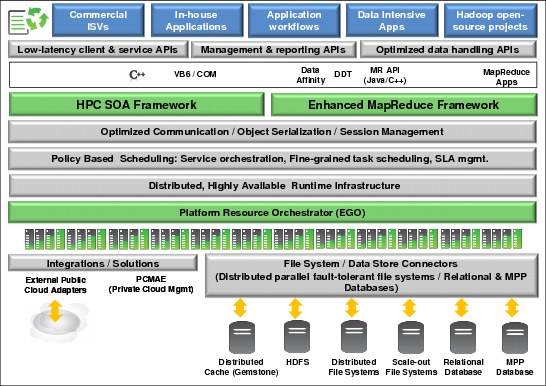
Figure 5-4 IBM Platform Symphony architecture
Symphony maintains historical data, includes a web interface for administration and configuration, and also has a CLI for administration.
A workload manager interfaces directly with the application, receiving work, processing it, and returning the results. A workload manager provides a set of APIs, or it can interface with more runtime components to enable the application components to communicate and perform work. The workload manager is aware of the nature of the applications it supports using terminology and models consistent with a certain class of workload. In an SOA environment, workload is expressed in terms of messages, sessions, and services.
A resource manager provides the underlying system infrastructure to enable multiple applications to operate within a shared resource infrastructure. A resource manager manages the computing resources for all types of workloads.
As shown on Figure 5-4 on page 117, there is one middleware layer for compute-intensive workloads (High Performance Computing (HPC) SOA framework) and another for data-intensive workloads (Enhanced MapReduce Framework). For more details, see 5.2, “Compute-intensive and data-intensive workloads” on page 119 and 5.3, “Data-intensive workloads” on page 126.
5.1.2 Target audience
Figure 5-5 shows the target audience for IBM Platform Symphony.
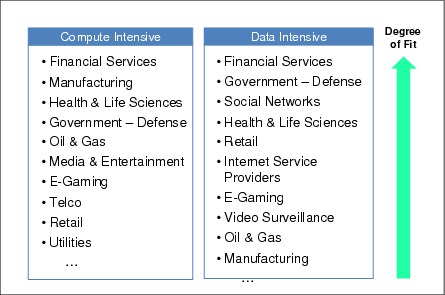
Figure 5-5 Target markets
5.1.3 Product versions
Symphony is available in four editions:
•Developer
•Express
•Standard
•Advanced
Product add-ons are optional and serve to enhance the functionality of the Standard and Advanced editions. Table 5-1 and Table 5-2 summarize the features and add-ons that are associated with each Symphony edition.
Table 5-1 IBM Platform Symphony features
|
Features
|
IBM Platform Symphony Edition
|
|||
|
Developer
|
Express
|
Standard
|
Advanced
|
|
|
Low-latency HPC SOA
|
X
|
X
|
X
|
X
|
|
Agile service and task scheduling
|
X
|
X
|
X
|
X
|
|
Dynamic resource orchestration
|
|
X
|
X
|
X
|
|
Standard and custom reporting
|
|
|
X
|
X
|
|
Desktop, server, and virtual server harvesting capability
|
|
|
X
|
X
|
|
Data affinity
|
|
|
|
X
|
|
MapReduce framework
|
X
|
|
|
X
|
|
Maximum hosts/cores
|
Two hosts
|
240 cores
|
5,000 hosts and 40,000 cores
|
5,000 hosts and 40,000 cores
|
|
Maximum application managers
|
|
5
|
300
|
300
|
Table 5-2 shows the IBM Platform Symphony add-ons.
Table 5-2 IBM Platform Symphony add-ons
|
Add-ons
|
IBM Platform Symphony Edition
|
|||
|
Developer
|
Express
|
Standard
|
Advanced
|
|
|
Desktop harvesting
|
|
|
X
|
X
|
|
Server and virtual server harvesting
|
|
|
X
|
X
|
|
Graphics processing units (GPU)
|
|
|
X
|
X
|
|
IBM General Parallel File System (GPFS)
|
|
|
X
|
X
|
|
GPFS-Shared Nothing Cluster (SNC)
|
|
|
|
X
|
5.2 Compute-intensive and data-intensive workloads
The following section describes compute-intensive applications workloads.
Service-oriented architecture (SOA) applications
An SOA application consists of two logic parts:
SOA = Client (client logic) + Service (business logic)
The Client sends requests to Service and Service responds with results, during the whole computation. Multiple running instances expand and shrink as resources and the processors change.
Process-oriented architecture applications
Process-oriented applications (POA) are also known as Batch. Input is fixed at the beginning, and results are obtained at the end of the computation.
Figure 5-6 shows a comparison between SOA and POA applications.
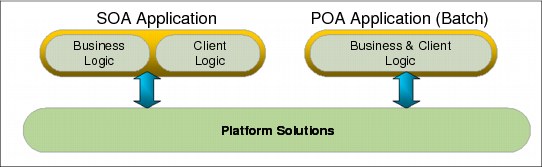
Figure 5-6 SOA versus POA applications
Symphony is targeted toward SOA applications.
5.2.1 Basic concepts
Client applications submit work to the grid and to the relevant service that is deployed in Symphony. Applications are deployed to the workload manager. Each application requests resources from the resource manager when it has an outstanding workload.
The resource manager manages the compute resources. It assesses the demand of the various applications and assigns resources to run the service business logic.
Figure 5-7 represents the relationships among the basic components that are found in a Symphony cluster.
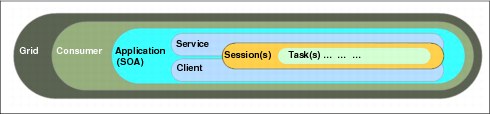
Figure 5-7 Representation of component relationships
Grid
The grid is the owner of all interconnected computing resources, such as nodes, processors, and storage. The grid has users and applications that use the computing resources in a managed way.
Consumer
The use and consumption of resources are organized in a structured way through consumers. A consumer is the unit through which an application can get and consume resources from the grid.
Consumers can be organized hierarchically to model the nature of an organization.
Application
Applications use resources from the grid through consumers. Applications need to be deployed to leaf consumers first. Only one application can run under each leaf consumer.
Applications can be different types: SOA, Batch, and so on. Each application has an application profile, which defines everything about the application.
Client
The client is a component that is built with Symphony Client APIs that is able to interact with the grid through sessions, send requests to services, and receive results from services.
Service
A service is a self-contained business function that accepts requests from the client and returns responses to the client. A service needs to be deployed onto a consumer and can run in multiple concurrent instances. A service uses computing resources.
Session
A client interacts with the grid through sessions. Each session has one session ID that is generated by the system. A session consists of a group of tasks that are submitted to the grid. The tasks of a session can share common data.
Task
A task is the autonomic computation unit (within a session). It is a basic unit of work or parallel computation. A task can have input and output messages. A task is identified by a unique task ID within a session, which is generated by the system.
5.2.2 Core components
Figure 5-8 shows the Symphony core components in a layered architecture.
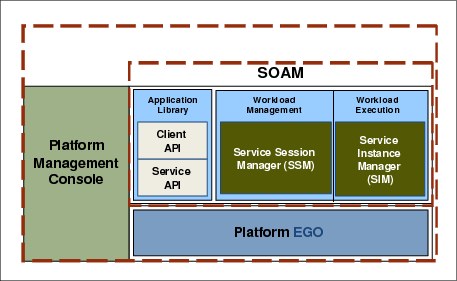
Figure 5-8 Symphony layered architecture
Enterprise Grid Orchestrator
The Enterprise Grid Orchestrator (EGO) is the resource manager that is employed by Symphony to manage the supply and distribution of resources, making them available to applications. EGO provides resource provisioning, remote execution, high availability, and business continuity.
EGO provides cluster management tools and the ability to manage supply versus demand to meet SLAs. The EGO system view defines three different host roles: management, compute, or client.
Management host
Management hosts are hosts that are designated to run the management components of the grid. By default, these hosts do not run the workload of the user.
Master host This host is the first host that is installed. The main scheduler of the grid resides here. The master host controls the rest of the hosts of the grid and is the interface to the clients of the grid. There is only one master host at a time.
Master candidate A candidate host can act as the master if the master fails. There can be more than one master candidate.
Session manager host One or more management hosts run session managers. There is one session manager per available slot on a management host. There is one session manager per application.
Web server host The web server host runs the Platform Management Console. The host is elected as the web server host.
Compute host
Compute hosts are designated to execute work. Compute hosts are those hosts in the cluster that provide computing resources to consumers.
Client host
The client hosts are used for submitting work to the grid. Normally, client hosts are not members of the grid. For more detail about Symphony client installation, see “Installing the IBM Platform Symphony Client (UNIX)” on page 180 for UNIX hosts and “Installing the IBM Platform Symphony Client (Windows)” on page 180 for Microsoft Windows hosts.
EGO system components
EGO uses the following system components:
LIM The LIM is the load information manager process. The master LIM starts VEMKD and PEM on the master host. There is one master LIM per cluster. There is also a LIM process on each management host and compute host. The LIM process monitors the load on the host and passes the information to the master LIM, and starts PEM.
VEMKD The VEM kernel daemon runs on the master host. It starts other daemons and responds to allocation requests.
PEM The process execution manager (PEM) works for the VEMKD by starting, controlling, and monitoring activities, and collecting and sending runtime resource usage.
EGOSC The EGO service controller requests appropriate resources from the VEMKD and controls system service instances.
EGO services
An EGO service is a self-contained, continuously running process that is managed by EGO. EGO ensures the failover of EGO services. Many of the Symphony management components are implemented as EGO services, for example, WebGUI, Session Director (SD), and Repository Service (RS).
For an in-depth look at EGO architecture and internals, see “IBM Platform Symphony Foundations” on page 180.
SOA middleware
SOA middleware (SOAM) is responsible for the role of workload manager and manages service-oriented application workloads within the cluster, creating a demand for cluster resources.
When a client submits an application request, the request is received by SOAM. SOAM manages the scheduling of the workload to its assigned resources, requesting more resources as required to meet SLAs. SOAM transfers input from the client to the service, then returns results to the client. SOAM releases excess resources to the resource manager.
For details about SOAM and its components, see “IBM Platform Symphony Foundations” on page 180.
Figure 5-9 illustrates an example workload manager workflow.
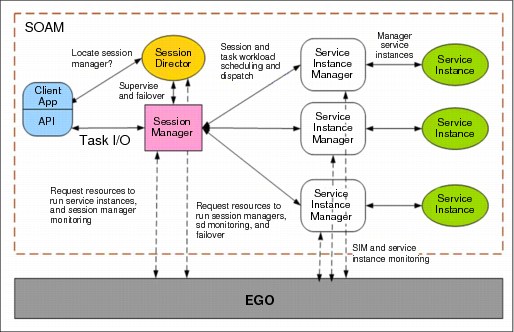
Figure 5-9 SOAM workflow
Platform Management Console
The Platform Management Console (PMC) is your web interface to IBM Platform Symphony. The PMC provides a single point of access to the key system components for cluster and workload monitoring and control, configuration, and troubleshooting.
For more details about the PMC interface, see Chapter 1 in IBM Platform Symphony Foundations, SC22-5363-00.
Platform Enterprise Reporting Framework
Platform Enterprise Reporting Framework (PERF) provides the infrastructure for the reporting feature. The Symphony reporting engine has two functions:
•Data collection
It collects data from the grid and applications and maintains this data in a relational database.
•Reporting:
– It provides standard reports that display the data graphically or in tables.
– It allows users to build custom reports.
|
Editions: Reporting is only available with the Standard and Advanced editions of Symphony.
|
Figure 5-10 shows the PERF architecture and flow.
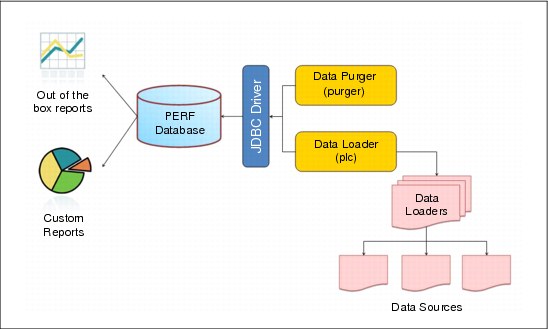
Figure 5-10 PERF architecture diagram
For more details about the PERF components, see “IBM Platform Symphony Foundations” on page 180.
5.2.3 Application implementation
Symphony service-oriented applications consist of a client application and a service. When the application runs, a session is created that contains a group of tasks. The application profile provides information about the application.
Application profile
The application profile defines characteristics of the application and defines the behavior of the middleware and the service. There is one application profile per application. The application profile defines the characteristics of an application and the environment in which the application runs.
The application profile provides the following information:
•The information that is required to run the application
•The scheduling policies that apply to the application
•Configuration information for the session manager and the service instance managers
•Configuration information for sessions and services
The application profile provides the linkage between the application, client, service package, and service.
Here are a few key settings in the application profile:
Application name This name identifies the application. Clients select the correct application by using the application name.
Session type A session type is a way of applying settings at a session level. One application might need several different session types, for example, high priority and low priority sessions of the same application.
Service A service is the link with the service package that instructs Symphony which service package to use and how to launch it.
IBM Platform Symphony Developer Edition
IBM Platform Symphony Developer Edition (DE) provides an environment for application developers to grid-enable, test, and run their service-oriented applications. Symphony DE provides a complete test environment. It simulates the grid environment that is provided by IBM Platform Symphony. Developers can test their client and service in their own cluster of machines before they deploy them to the grid.
To run the Symphony workload on the grid, the application developer creates a service package and adds the service executable into the package: no additional code changes are required.
|
Symphony Developer Edition: Symphony Developer Edition provides extensive documentation about how to develop and integrate applications into Symphony, including tutorials and samples for custom-built applications. The development guide is included in the documentation.
|
5.2.4 Application Deployment
Application deployment has two parts:
Service deployment The first part deploys the service binaries and associated files of an application to the grid or SOAM.
Application registration The second part registers the profile of the application to SOAM or the grid.
|
Important: When you register an application, the services that it uses must be already deployed.
|
An application can be either deployed by using the “Add or Remove Application” GUI wizard or by using the CLI (soamdeploy and soamreg).
|
CLI: If you do not use the wizard, you basically perform the Service Deployment and Application Registration in two separate steps by using the PMC.
|
Service package deployment
Symphony services are deployed to the cluster and made available in either of the following ways:
•By using the Symphony repository service
•By using a third-party deployment tool
Deployment using the repository service
An administrator or developer deploys a service package to the repository service. When a compute host needs the package, it requests the package from the repository service.
How it works
An application is created when its service is deployed and the application profile registered. A service package is first deployed to the central database. Then, the service package is downloaded by compute nodes when needed.
Repository Service (RS) of Symphony, an EGO service, is responsible for application deployment.
5.2.5 Symexec
With Symphony, you can run existing executables as Symphony workload (Symexec) on the grid without code changes. There is no need to use Symphony standard APIs and there is no need to recompile and relink.
Executables are handled in a similar way to the SOA workload, except for the following conditions:
•A specialized service instance runs the executable.
•The specialized service instance starts, runs the executable, and exits when the executable finishes.
Symphony supports all application types, either interactive or Batch. The executables can be compiled or script programs. They are handled similarly to SOA workload except that there is a specialized service instance, Execution Service, that runs all the executables.
For more details, see the Cluster and Application Management Guide, SC22-5368-00.
5.3 Data-intensive workloads
IBM Platform Symphony addresses data-intensive workloads through the data affinity feature and the MapReduce framework.
|
Data affinity feature: The data affinity feature is not the same as data locality in Hadoop MapReduce. Although these features are similar in concept, the former is used at the application and session level of any Symphony workload and the latter relates exclusively to MapReduce.
|
5.3.1 Data affinity
When tasks generate intermediate data that is used by later tasks, the scheduler might dispatch them in a different host than the host where the data is created. This process requires data transfer to the node where the work is taking place, which can lead to inefficient use of the processor and resource under-utilization. To overcome these issues, IBM Platform Symphony offers data-aware scheduling. This scheduling type considers the data location (that is, the physical compute host) of data sets that are created by a task and that are to be used by subsequent tasks, thus preventing data transfers among compute nodes. The diagram in Figure 5-11 illustrates this concept.
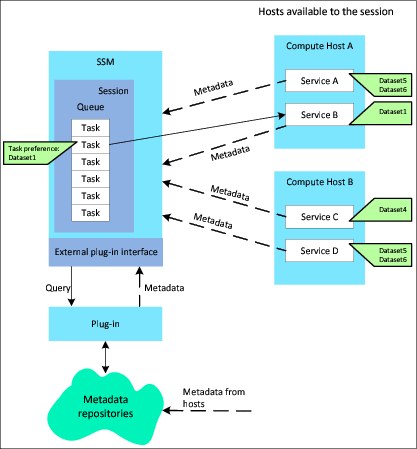
Figure 5-11 Data-aware scheduling at the task level
With the data-aware scheduling feature, you can specify a preference association between a task and a service instance or host that has the data that is required to perform the work. In Figure 5-11, the task prefers to run on the service instance that already has Dataset1. The Symphony Session Manager (SSM) collects metadata from all resources that are available for the session to know where each piece of data resides. In Figure 5-11, Service B with Dataset1 is available so the task is dispatched there.
5.3.2 MapReduce
IBM Platform Symphony MapReduce is based on the Hadoop framework. In this book, we used the Apache Hadoop implementation for testing and demonstration purposes. However, there are multiple implementations of Hadoop, all based on the same framework. IBM also has its own implementation: IBM InfoSphere® BigInsights™.
IBM InfoSphere BigInsights enhances Hadoop technology by delivering best-in-class analytical capabilities with enterprise-grade features for administration, workflow, provisioning, and security. It provides clients with rich analytical tools and simplifies the management of Hadoop clusters either when deployed natively or on Platform Symphony managed grids.
|
IBM InfoSphere BigInsights: To learn more about IBM InfoSphere BigInsights and its benefits, see this website:
|
To understand the architecture and differences from a Hadoop-based deployment, we describe briefly how Hadoop MapReduce and Hadoop Distributed File System (HDFS) work for all open source and commercial implementations.
Hadoop overview
Hadoop is an Apache project that provides the MapReduce framework and a distributed file system called HDFS. Hadoop helps solve data-intensive problems that require distributed and parallel processing on a large data set by using commodity hardware. A Hadoop cluster consists of the following components, which depending on the deployment can run in its own machine or a set of machines, in the case of the DataNode:
•NameNode
NameNode keeps an in-memory image of the HDFS tree and metadata of files and directories. It also has the edit log (modified in every write operation) and the fsimage (the HDFS metadata state). The fsimage is updated by the SecondaryNameNode.
•DataNode
This slave machine responds to requests to store or retrieve data blocks and to execute tasks through the TaskTracker process that runs on each node.
•JobTracker
The JobTracker schedules tasks among the TaskTrackers that run on slave nodes.
•TaskTracker
The TaskTracker spawns one or more tasks to complete a MapReduce operation and retrieves and stores data blocks via the DataNode.
•SecondaryNameNode
The SecondaryNameNode is not a replacement of the NameNode as its name might suggest. It periodically merges the contents of the edit log to the fsimage.
Figure 5-12 on page 129 shows a graphic representation of the Hadoop components and their interaction.
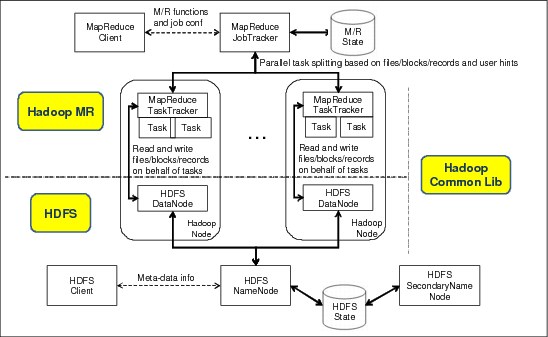
Figure 5-12 Hadoop application framework
With this architecture, you can analyze the big data by distributing the processing to the machines that own the files. This architecture makes up the data locality feature of MapReduce. The “map” part is defined by a a function that the user develops to process key/value pairs to produce a set of intermediate key/value results that a “reduce” function merges for the same key.
A number of open source projects harness the power of the Hadoop application framework. The following Apache projects relate to Hadoop:
•Avro
Avro is a data serialization framework that uses JavaScript Object Notation (JSON).
•Cassandra
Cassandra is a distributed database management system that integrates with Hadoop MapReduce and HDFS.
•HBase
HBase is a non-relational distributed database that runs on top of HDFS.
•Hive
Hive is a data warehouse system for data summarization, analysis, and ad hoc queries to process data sets that are stored in an HDFS file system.
•Mahout
Mahout is an implementation of machine learning algorithms that run on top of Hadoop.
•Pig
Pig is a platform for creating MapReduce programs, but it uses a higher-level language to analyze large data sets.
•ZooKeeper
ZooKeeper allows the coordination of a distributed application through a highly available shared hierarchical namespace.
We describe how pain points that are encountered in Hadoop clusters are addressed by IBM Platform Symphony MapReduce. The following pain points are the most common:
•Limited high availability (HA) features in the workload engine
•Large overhead during job initiation
•Resource silos that are used as single-purpose clusters that lead to under-utilization
•Lack of sophistication in the scheduling engine:
– Large jobs can still overwhelm cluster resources
– Lack of real-time resource monitoring
– Lack of granularity in priority management
•Predictability difficult to manage
•No mechanisms for managing a shared services model with an SLA
•Difficulties for managing and troubleshooting as the cluster scales
•Lack of application lifecycle and rolling upgrades
•Limited access to other data types or resting data
•Lack of enterprise-grade reporting tools
•HDFS NameNode without automatic failover logic
IBM Platform Symphony MapReduce
IBM Platform Symphony MapReduce is an enterprise-class distributed runtime engine that integrates with open source and commercial, for example, IBM InfoSphere BigInsights and Cloudera CDH3, Hadoop-based applications. The IBM Platform Symphony MapReduce Framework addresses several pain points that typical Hadoop clusters experience. With it, you can incorporate robust HA features, enhanced performance during job initiation, sophisticated scheduling, and real-time resource monitoring. Typically, stand-alone Hadoop clusters, which are often deployed as resource silos, cannot function in a shared services model. They cannot host different workload types, users, and applications. See Figure 5-13 on page 131.
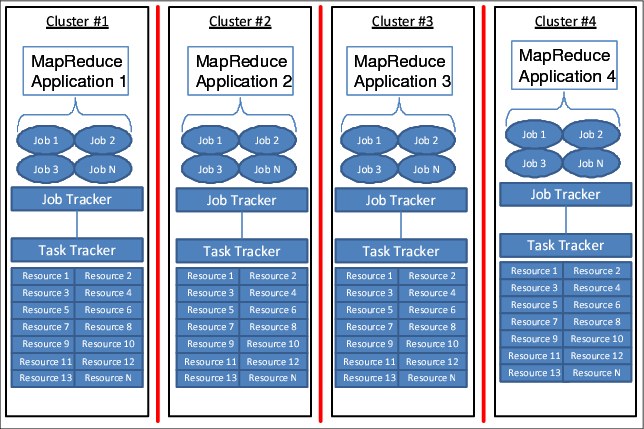
Figure 5-13 Hadoop resource silos
Figure 5-14 on page 132 shows that IBM Platform Symphony offers the co-existence of compute-intensive and data-intensive workloads for higher resource utilization and, at the same time, better manageability.
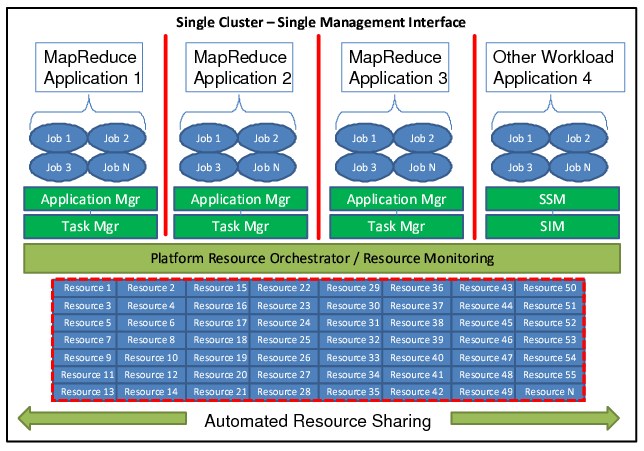
Figure 5-14 Single cluster for multiple types of workloads
Figure 5-15 on page 133 depicts the architecture of the framework to integrate with Hadoop applications. The MapReduce applications, for example, Pig, Hive, and Jaql, run without recompilation on the IBM Platform Symphony Framework. The slave nodes in Hadoop are part of the same compute resource pools of the Symphony cluster so that other technical computing application workloads can use them.
The sophisticated workload scheduling capabilities of Symphony and the resource orchestrator ensure a high utilization of the cluster nodes. The management console GUI is consistent for any Symphony application and allows application configuration and real-time job monitoring.
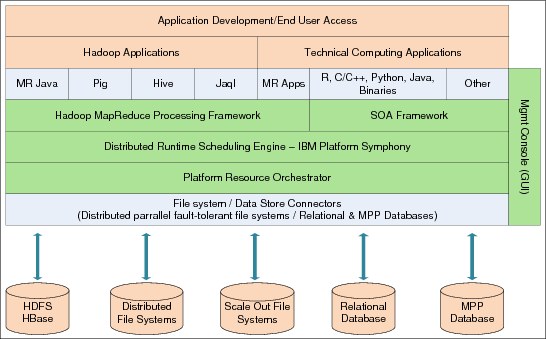
Figure 5-15 IBM Platform Symphony MapReduce Framework architecture
When you integrate MapReduce applications into Symphony, the JobTracker and TaskTracker are bypassed and replaced by the SSM and the Service Instance Manager (SIM) to take over in a job execution scenario. In this scheme, Symphony scheduling and resource management capabilities handle the job lifecycle, which results in faster execution and manageability (see Figure 5-16).
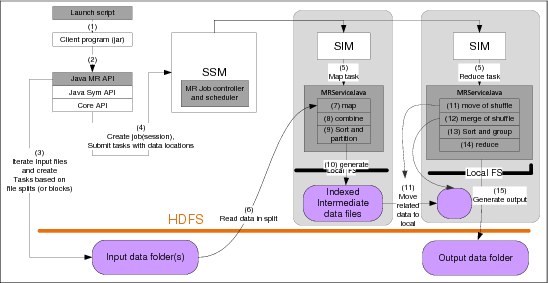
Figure 5-16 Job execution and monitoring
High availability for MapReduce
Hadoop has built-in features for handling failures at the TaskTracker level. The TaskTrackers send heartbeats to the JobTracker. If they stop or become too infrequent, the failed TaskTrackers are removed from the pool. If a task fails, it can be scheduled on another TaskTracker from the pool. However, the JobTracker is a single point of failure (SPOF) so the NameNode and Hadoop have no automated way to handle a SPOF.
When you use the IBM Platform Symphony MapReduce framework, the JobTracker and TaskTracker are not used. Instead, Symphony uses the SSM and the SIM. The high availability of those components is already embedded in Symphony design through EGO.
For NameNode, high availability is achieved through EGO, which runs HDFS daemons as services in the MapReduce framework. In a failure, EGO restarts them on the same or other host. DataNodes knows which host to contact because NameNode uses a naming service. The naming service is a Domain Name System (DNS) that uses the Linux named daemon that is built into Symphony. The naming service has a well-known hostname that the DNS maps to the active NameNode IP address. The illustration in Figure 5-17 shows this scheme. In this example, the NameNode writes its metadata to a shared disk location (for example, Network File System (NFS) or General Parallel File System (GPFS)), which is a requirement for a failover scenario.
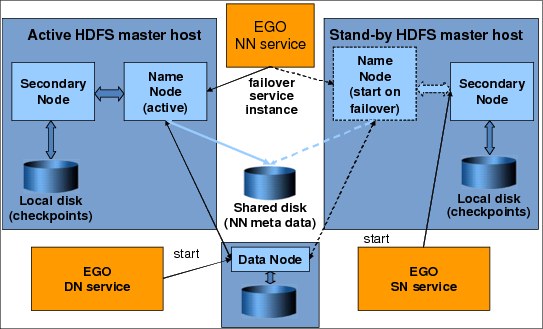
Figure 5-17 NameNode high availability in IBM Platform Symphony MapReduce
5.4 Reporting
There are nine built-in standard reports that are available. Users can also define their own reports as custom reports.
Standard report characteristics
The standard reports have these characteristics:
•Adjustable time span
•Chart or table view
•Comma-separated value (CSV) export functionality
To generate a standard report, click Reports → Standard Reports → Reports (List) → Host Resource Usage, and select the Metric and Produce Report.
Data schema tables
All Symphony standard reports are based the following data tables:
•EGO-level data tables:
– CONSUMER_RESOURCE_ALLOCATION
– CONSUMER_RESOURCELIST
– CONSUMER_DEMAND
– EGO_ALLOCATION_EVENTS
– RESOURCE_ATTRIBUTES
– RESOURCE_METRICS
•SOAM-level data tables:
– SESSION_ATTRIBUTES
– TASK_ATTRIBUTES
– SESSION_PROPERTY
– SESSION _HISTORY
Figure 5-18 shows the reporting infrastructure.
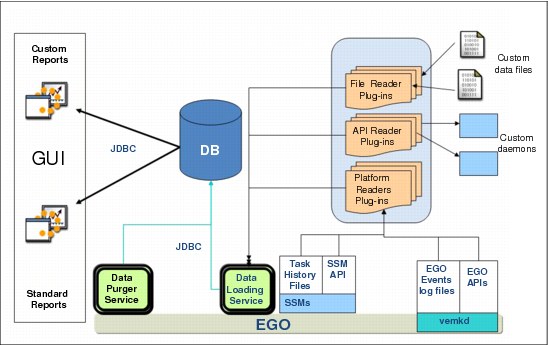
Figure 5-18 Reporting infrastructure
For details about data and data tables, see the Symphony Knowledge Center, topic Data Schema Tables for IBM Platform Symphony on the Manage section.
5.5 Getting started
This section provides details about how to deploy Symphony.
5.5.1 Planning for Symphony
This section describes the necessary planning steps for Symphony.
|
Important: When you plan for a new Symphony cluster, read IBM Platform Symphony Foundations, SC22-5363-00. Follow the installation diagrams that are presented in the Symphony cluster installation guide section.
|
Pre-installation checklist
Take notes of the pre-installation decisions that are based on the requirements that are explained in the cluster installation guide. For this book, we decided to configure a small but complete cluster, which is suitable for production use or small-scale application testing.
Installer OS account
We chose the root operating system account for installation. This choice provided the flexibility to use different execution accounts for different grid applications.
Cluster administrator OS account
We set the grid administrator OS account to egoadmin. We created this account in Lightweight Directory Access Protocol (LDAP) before we started the installation process.
Installation directory
The management node installation directory is on the following GPFS shared directory:
/gpfs/fs1/symmaster
The compute node installation directory is on the following GPFS shared directory:
/gpfs/fs1/symcompute
Shared directory and failover
We configured a management node shared file system so that management node failover can be configured. The management node shared file system is on the following GPFS shared directory:
/gpfs/fs1/symshare
|
Temporary NFS mount: The command that is used to configure the management node shared file system expects the location to be configured as an NFS mount. After configuration, this requirement no longer exists. To use the GPFS file system as the management node shared file system location, we temporarily mounted it as an NFS share and then unmounted it. GPFS is the preferred solution option for high-performance grids.
|
Hosts
We configured two managements hosts: i05n45 and i05n46. We decided to configure the first host as the master host and the second host as the master candidate for failover.
The following servers are available for task execution purposes: i05n47, i05n48, i05n49, i05n50, i05n51, i05n52, i05n53, i05n54, and i05n55. These servers are to be configured as compute hosts.
Each compute host has 12 cores that are installed. Therefore, a total of 132 cores exist in the grid and a maximum of 108 cores are available for workload processing.
Database
For large production clusters, we suggest that you use a commercial database to store reporting data. If you choose to enable the non-production database, you must choose the master host or any management host as the database host.
|
Requirement: The Advanced edition on 64-bit Linux hosts requires a database to support the Platform Management Console. If you do not set up a database (either a non-production database or an external database), you cannot perform these tasks:
•Generate reports (both Symphony and MapReduce)
•View performance charts for MapReduce jobs
•Configure rack and chassis by using rackconfig.sh and display rack view
|
Ports
The default base port that is used by Symphony is 7869. We suggest that you use the default value unless you have systems that run other services in that port. Remember that Symphony requires seven consecutive ports that start from the base port, for example, 7869 - 7875. Ensure that all ports in that range are available prior to installation.
|
Important: On all hosts in the cluster, you must have the same set of ports available.
|
If you need to set a different base port, use the BASEPORT environment variable when you define the cluster properties for installation. For example, to use 17869 as the base port, define BASEPORT=17869 in the install.config file.
Symphony also requires more ports for services and daemons. Table 5-3 describes the required ports for each service.
Table 5-3 Additional port requirements
|
Service
|
Required ports
|
|
Web server
|
8080, 8005, and 8009
|
|
Service director
|
53
|
|
Web service
|
9090
|
|
Loader controller
|
4046
|
|
Derby database
|
1527
|
Workload execution mode
At installation, it is necessary to decide whether a single user (non-root) is the primary user of the grid. If so, use the Simplified workload execution mode (WEM) approach where the Symphony applications run under one user account.
Otherwise, to provide better flexibility to allow different applications and users to run applications from the grid, use the Advanced WEM approach. Symphony applications run under the workload execution account of the consumer, which is a configurable account. Different consumers can have different workload execution accounts.
Do not let the Advanced name discourage this installation because the default values from Platform can run most workloads.
Cluster name
The default cluster name is cluster1. You must customize the installation if you want to specify your own unique cluster name. Do not use a valid host name as the cluster name.
|
Important: The cluster name is permanent; you cannot change it after you install.
|
To specify the cluster name and not use cluster1, set the environment variable CLUSTERNAME=<Name>.
Multi-head installations
Symphony requires a configuration parameter named OVERWRITE_EGO_CONFIGURATION. If this parameter is set to Yes, which is (default = No), the Symphony default configuration overwrites the EGO configuration. For example, it overwrites EGO ConsumerTrees.xml, adds sd.xml in the EGO service conf directory, and overwrites the EGO Derby DB data files.
If you plan a multi-head cluster (a cluster that runs both Symphony and IBM Platform Load Sharing Facility (LSF)), it is acceptable for IBM Platform LSF and Symphony workloads to share EGO resources in the cluster. In that case, we need to avoid overwriting the EGO configuration. For more details about multi-head installations, see 5.7, “Symphony and IBM Platform LSF multihead environment” on page 164.
The environment that is planned in this section is single-headed, so we ensure that the variable OVERWRITE_EGO_CONFIGURATION is set to Yes. Table 5-4 shows the pre-installation checklist summary.
Table 5-4 Example of pre-installation checklist for Symphony cluster planning
|
Requirement
|
Value
|
Comments
|
|
Installer OS account
|
root
|
|
|
Cluster administrator OS account
|
egoadmin
|
|
|
Installation directory for management hosts
|
/gpfs/fs1/symmaster/ego
|
|
|
Installation directory for compute hosts
|
/gpfs/fs1/symcompute/ego
|
|
|
Share directory for failover
|
/gpfs/fs1/symshare
|
Fully controlled by the cluster administrator and accessible from all management hosts.
|
|
Database
|
Derby
|
Non-production.
|
|
Base port
|
7869
|
Default value.
|
|
All required ports are available?
|
Yes
|
|
|
Cluster name
|
symcluster
|
|
|
Is this environment a multihead environment?
|
No
|
OVERWRITE_EGO_CONFIGURATION=Yes.
|
|
Workload execution mode
|
Advanced
|
|
|
Java home directory
|
/usr/java/latest
|
|
|
Master host
|
i05n45
|
|
|
Additional management hosts
|
i05n46
|
Configured for failover.
|
|
File server hosts
|
i05n[67-68]
|
GPFS file system that is mounted on /gpfs/fs1 on all servers.
|
|
Database host
|
i05n45
|
Using Derby non-production database.
|
|
Compute hosts
|
i05n[47-55]
|
Each compute host has 12 cores installed.
|
Software packages
Ensure that you have all the required software packages and entitlement files available. The list that we used is shown in Table 5-5.
Table 5-5 Software packages and entitlement file list
|
Type
|
File name
|
|
EGO package
|
ego-lnx26-lib23-x64-1.2.6.rpm
|
|
SOAM package
|
soam-lnx26-lib23-x64-5.2.0.rpm
|
|
EGO compute host package
|
egocomp-lnx26-lib23-x64-1.2.6.rpm
|
|
Entitlement file
|
platform_sym_adv_entitlement.dat
|
5.5.2 Installation preferred practices
This section provides some installation preferred practices for a Symphony environment.
Shared installation directory for master and management hosts
It is possible to share a common installation between hosts and avoid installing binaries on all hosts in the cluster, if you have a shared parallel file system environment, such as GPFS. This shared parallel file system environment is useful and time-saving, especially on large clusters. Next, we describe the steps to install the necessary packages for the master and management node on /gpfs/fs1/symmaster/ego.
|
Reference diagrams: If you are not using a shared file system, see the diagrams “Install on the Master Host” and “Add a Management Host” in the document Overview: Installing Your IBM Platform Symphony Cluster, GC22-5367-00. You need to install the EGO and SOAM packages locally on each additional management host that you want to add to the cluster.
|
Properties file
To define cluster properties in a file, we created a simple text file install.config and entered each variable on a new line. Example 5-1 shows the variables, which are used for the installation in our master host, that are based on the pre-installation decisions that are summarized on Table 5-4 on page 138.
Example 5-1 Contents of our install.config file for Symphony master host installation
DERBY_DB_HOST=i05n45
CLUSTERNAME=symcluster
OVERWRITE_EGO_CONFIGURATION=yes
JAVA_HOME=/gpfs/fs1/java/latest
CLUSTERADMIN=egoadmin
SIMPLIFIEDWEM=N
RPM Package Manager database on shared directories
On Linux, the IBM Platform Symphony installation is done through RPM Package Manager (RPM):
The EGO package is required to be installed before the SOAM package. It is important to keep a consistent rpm database to avoid dependency problems during installation.
When you install Symphony on a shared file system, manually initialize an rpm database to be used by the rpm installation. We suggest that you create the rpm database on the same directory structure that is dedicated for the installation binaries.
Even if you choose to install by using the .bin file that is provided by the platform, it also extracts rpm files and requires that you have an rpm database. Here is a sample command to initialize an rpm database on /gpfs/fs1/symmaster/rpmdb:
/bin/rpm --initdb --dbpath /gpfs/fs1/symmaster/rpmdb
RPM installation
First, we copy our install.config file to /tmp and initialize the rpm database on /gpfs/fs1/symmaster. Then, we run the rpm install command, overriding the default rpmdb path using --dbpath and passing the ego installation path on the shared directory by using --prefix. We first install the EGO package and then the SOAM package.
Example 5-2 shows the output from the Symphony Master host installation on our cluster. It also describes the rpmdb preparation step that we described earlier.
Example 5-2 Master host installation
[root@i05n45 /]# rpm --initdb --dbpath /gpfs/fs1/symmaster/rpmdb
[root@i05n45 /]# rpm --dbpath /gpfs/fs1/symmaster/rpmdb -ivh --prefix /gpfs/fs1/symmaster/ego ego-lnx26-lib23-x64-1.2.6.rpm
Preparing... ########################################### [100%]
A cluster properties configuration file is present: /tmp/install.config. Parameter settings from this file may be applied during installation.
The installation will be processed using the following settings:
Workload Execution Mode (WEM): Advanced
Cluster Administrator: egoadmin
Cluster Name: symcluster
Installation Directory: /gpfs/fs1/symmaster/ego
Connection Base Port: 7869
1:ego-lnx26-lib23-x64 ########################################### [100%]
Platform EGO 1.2.6 is installed successfully.
Install the SOAM package to complete the installation process. Source the environment and run the <egoconfig> command to complete the setup after installing the SOAM package.
[root@i05n45 /]# rpm --dbpath /gpfs/fs1/symmaster/rpmdb -ivh --prefix /gpfs/fs1/symmaster/ego soam-lnx26-lib23-x64-5.2.0.rpm
Preparing... ########################################### [100%]
1:soam-lnx26-lib23-x64 ########################################### [100%]
IBM Platform Symphony 5.2.0 is installed at /gpfs/fs1/symmaster/ego.
Symphony cannot work properly if the cluster configuration is not correct.
After you install Symphony on all hosts, log on to the Platform Management
Console as cluster administrator and run the cluster configuration wizard
to complete the installation process.
Configuring the master host
The cluster administrator user on our configuration is egoadmin. To run egoconfig and complete the cluster configuration, it is necessary to log in as egoadmin. The configuration procedure is shown on Example 5-3.
Example 5-3 Running egoconfig to complete the cluster configuration
[egoadmin@i05n45 ~]$ . /gpfs/fs1/symmaster/ego/profile.platform
[egoadmin@i05n45 ~]$ egoconfig join i05n45
You are about to create a new cluster with this host as the master host. Do you want to continue? [y/n]y
A new cluster <symcluster> has been created. The host <i05n45> is the master host.
Run <egoconfig setentitlement "entitlementfile"> before using the cluster.
[egoadmin@i05n45 ~]$ egoconfig setentitlement /gpfs/fs1/install/Symphony/platform_sym_adv_entitlement.dat
Successfully set entitlement.
Configuring the shared management directory for failover
When you configure the shared management directory for failover, the cluster uses configuration files under the shared directory EGO_CONFDIR=share_dir/kernel/conf. Use the command egoconfig mghost to set up the correct value of share_dir.
|
EGO_CONFDIR: The value of the environment variable EGO_CONFDIR changes if the cluster keeps configuration files on a shared file system. When user documentation refers to this environment variable, substitute the correct directory.
|
Example 5-4 shows an example of how egoconfig expects the location of the shared directory to be configured as an NFS mount. We tried to run the command by passing the GPFS mounted location and it fails.
Example 5-4 Output error from egoconfig
[egoadmin@i05n45 ~]$ egoconfig mghost /gpfs/fs1/symshare
This host will use configuration files on a shared directory. Do you want to continue? [y/n]y
Warning: stop all cluster services managed by EGO before you run egoconfig. Do you want to continue? [y/n]y
mkdir: cannot create directory `/gpfs/fs1/symshare/kernel': Permission denied
mkdir: cannot create directory `/gpfs/fs1/symshare/kernel': Permission denied
Error when disposing the config files
Command failed.
On Example 5-5, we run the same command after we mount the same location also as an NFS mount. The configuration is now successful. After configuration, the NFS mount is not a requirement and we can unmount the NFS share.
Example 5-5 Configuring the shared configuration directory on GPFS by using an NFS mount
[egoadmin@i05n45 ~]$ egoconfig mghost /gpfs/fs1/symshare
This host will use configuration files on a shared directory. Do you want to continue? [y/n]y
Warning: stop all cluster services managed by EGO before you run egoconfig. Do you want to continue? [y/n]y
The shared configuration directory is /gpfs/fs1/symshare/kernel/conf. You must reset your environment before you can run any more EGO commands. Source the environment /gpfs/fs1/symmaster/ego/cshrc.platform or /gpfs/fs1/symmaster/ego/profile.platform again.
Enabling secure shell
It is possible to configure EGO to allow the egosh command to use Secure Shell (SSH) to start the cluster instead of Remote Shell (RSH). Grant root privileges to a cluster administrator. Enable SSH on the host from which you want to run egosh commands.
To enable SSH, perform the following configuration.
Define or edit the EGO_RSH parameter in $EGO_CONFDIR/ego.conf on the host from which you want to run the egosh command, for example:
EGO_RSH="ssh -o ’PasswordAuthentication no’ -o ’StrictHostKeyChecking no’"
If you want to revert to RSH usage, remove the new line in ego.conf or update it:
EGO_RSH=rsh
|
Important: The user account of the user who starts the cluster must be able to run the ssh commands across all hosts.
|
Example 5-6 shows the content of the ego.conf that is at the shared configuration directory /gpfs/fs1/symshare/kernel/conf/. We introduced a new variable EGO_RSH=ssh to configure EGO to use ssh start processes on other hosts in the cluster.
Example 5-6 Modified ego.conf
# $Id: TMPL.ego.conf,v 1.7.56.1.86.3.2.2.18.1 2012/03/20 07:59:18 qzhong Exp $
# EGO kernel parameters configuration file
#
# EGO master candidate host
EGO_MASTER_LIST="i05n45"
# EGO daemon port number
EGO_LIM_PORT=7869
EGO_KD_PORT=7870
EGO_PEM_PORT=7871
# EGO working and logging directory
EGO_WORKDIR=/gpfs/fs1/symshare/kernel/work
EGO_LOGDIR=/gpfs/fs1/symmaster/ego/kernel/log
# EGO log mask
EGO_LOG_MASK=LOG_NOTICE
# EGO service directory
EGO_ESRVDIR=/gpfs/fs1/symshare/eservice
# EGO security configuration
EGO_SEC_PLUGIN=sec_ego_default
EGO_SEC_CONF=/gpfs/fs1/symshare/kernel/conf
# EGO event configuration
#EGO_EVENT_MASK=LOG_INFO
#EGO_EVENT_PLUGIN=eventplugin_snmp[SINK=host,MIBDIRS=/gpfs/fs1/symmaster/ego/kernel/conf/mibs]
# EGO audit log configuration
EGO_AUDIT_LOG=N
EGO_AUDIT_LOGDIR=/gpfs/fs1/symmaster/ego/audits
# Parameters related to dynamic adding/removing host
EGO_DYNAMIC_HOST_WAIT_TIME=60
EGO_ENTITLEMENT_FILE=/gpfs/fs1/symshare/kernel/conf/sym.entitlement
# EGO resource allocation policy configuration
EGO_ADJUST_SHARE_TO_WORKLOAD=Y
EGO_RECLAIM_FROM_SIBLINGS=Y
EGO_VERSION=1.2.6
EGO_RSH=ssh
|
Configure SSH correctly: SSH must be configured correctly on all hosts. If the egosh command fails due to improper SSH configuration, the command is automatically retried by using RSH.
|
Starting services
Symphony provides a script to configure the automatic startup of EGO-related services during system initialization. First, set up your environment variables, then run egosetrc.sh (as root user) to enable automatic start-up.
There is also a pre-built script to grant root privileges to the cluster administrator user that is defined during installation. Run egosetsudoers.sh (as root user) to generate or update the /etc/ego.sudoers file.
The procedure to display the complete cluster is shown in Example 5-7, including simple test commands that can be used to check whether the services are up and running. For the full list of ego commands, see IBM Platform Symphony Reference, SC22-5371-00.
Example 5-7 Cluster start procedure
[egoadmin@i05n45 ~]$ . /gpfs/fs1/symmaster/ego/profile.platform
[egoadmin@i05n45 ~]$ egosh ego start
Start up LIM on <i05n45.pbm.ihost.com> ...... done
[egoadmin@i05n45 ~]$ egosh ego info
Cluster name : symcluster
EGO master host name : i05n45.pbm.ihost.com
EGO master version : 1.2.6
[egoadmin@i05n45 ~]$ egosh resource list
NAME status mem swp tmp ut it pg r1m r15s r15m ls
i05n45.* ok 46G 4095M 3690M 0% 6 0.0 0.2 0.3 0.1 1
[egoadmin@i05n45 ~]$ egosh service list
SERVICE STATE ALLOC CONSUMER RGROUP RESOURCE SLOTS SEQ_NO INST_STATE ACTI
WEBGUI STARTED 1 /Manage* Manag* i05n45.* 1 1 RUN 1
plc STARTED 2 /Manage* Manag* i05n45.* 1 1 RUN 2
derbydb STARTED 3 /Manage* Manag* i05n45.* 1 1 RUN 3
purger STARTED 4 /Manage* Manag* i05n45.* 1 1 RUN 4
NameNode DEFINED /HDFS/N*
DataNode DEFINED /HDFS/D*
MRSS ALLOCAT* 5 /Comput* MapRe*
Seconda* DEFINED /HDFS/S*
WebServ* STARTED 8 /Manage* Manag* i05n45.* 1 1 RUN 7
RS STARTED 6 /Manage* Manag* i05n45.* 1 1 RUN 5
Service* STARTED 7 /Manage* Manag* i05n45.* 1 1 RUN 6
Adding a management host
The procedure to add more management hosts is quick and straightforward with a shared installation directory, on a shared file system environment, such as GPFS. Next, we describe the steps to set up a management host as the master candidate in our cluster.
First, log in as the cluster administrator user on the host that you want to add as a management host. Ensure that all port requirements that are listed in “Pre-installation checklist” on page 136 are satisfied before you proceed. Example 5-8 shows the procedure that we followed to add i05n46 as a management host in our cluster and to configure it as a master host candidate for failover.
|
Remember: As explained in “Configuring the shared management directory for failover” on page 141, the shared directory location for failover must be mounted as an NFS share before you run the egoconfig mghost command.
|
Example 5-8 Add i05n46 as master host candidate
[egoadmin@i05n46 ~]$ . /gpfs/fs1/symmaster/ego/profile.platform
[egoadmin@i05n46 ~]$ egoconfig mghost /gpfs/fs1/symshare
This host will use configuration files on a shared directory. Do you want to continue? [y/n]y
Warning: stop all cluster services managed by EGO before you run egoconfig. Do you want to continue? [y/n]y
The shared configuration directory is /gpfs/fs1/symshare/kernel/conf. You must reset your environment before you can run any more EGO commands. Source the environment /gpfs/fs1/symmaster/ego/cshrc.platform or /gpfs/fs1/symmaster/ego/profile.platform again.
[egoadmin@i05n46 ~]$ . /gpfs/fs1/symmaster/ego/profile.platform
[egoadmin@i05n46 ~]$ egosh ego start
Start up LIM on <i05n46.pbm.ihost.com> ...... done
[egoadmin@i05n46 ~]$ egosh ego info
Cluster name : symcluster
EGO master host name : i05n45.pbm.ihost.com
EGO master version : 1.2.6
[egoadmin@i05n46 ~]$ egoconfig masterlist i05n45,i05n46
The master host failover order is i05n45,i05n46. To make changes take effect, restart EGO on the master host with the command egosh ego restart.
After we restart EGO on the master host (i05n45) and the changes take effect, the new management host appears on the resource list as shown on Example 5-9.
Example 5-9 Master and master candidate are shown on the cluster resource list
[egoadmin@i05n45 ~]$ egosh resource list
NAME status mem swp tmp ut it pg r1m r15s r15m ls
i05n45.* ok 46G 4095M 3690M 0% 6 0.0 0.2 0.3 0.1 1
i05n46.* ok 43G 4094M 3690M 0% 214 0.0 0.0 0.0 0.0 0
Shared installation directory for compute hosts
We also suggest that you use a shared common installation directory for compute hosts to avoid installing binaries on all compute hosts in the cluster. Next, we describe the steps to install the necessary packages for compute hosts on /gpfs/fs1/symcompute/ego.
|
Resource for using a non-shared file system: If you are not using a shared file system, see the diagram “Add a Compute Host and Test” in Overview: Installing Your IBM Platform Symphony Cluster, GC22-5367-00.
|
Properties file
Example 5-10 shows the contents of our install.config file.
Example 5-10 Contents of our install.config file for Symphony compute host installation
CLUSTERNAME=symcluster
OVERWRITE_EGO_CONFIGURATION=yes
JAVA_HOME=/gpfs/fs1/java/latest
CLUSTERADMIN=egoadmin
SIMPLIFIEDWEM=N
RPM installation
First, we copy our install.config file to /tmp and initialize the rpm database on /gpfs/fs1/symcompute. Then, we run the rpm install command, overriding the default rpmdb path by using --dbpath and passing the EGO installation path on the shared directory by using --prefix. We first install the EGO compute host package and then the SOAM package.
Example 5-11 shows the output from the Symphony compute host package installation on our cluster.
Example 5-11 Compute host installation
[root@i05n52 /]# rpm --initdb --dbpath /gpfs/fs1/symcompute/rpmdb
[root@i05n52 /]# rpm --dbpath /gpfs/fs1/symcompute/rpmdb -ivh --prefix /gpfs/fs1/symcompute/ego egocomp-lnx26-lib23-x64-1.2.6.rpm
Preparing... ########################################### [100%]
A cluster properties configuration file is present: /tmp/install.config. Parameter settings from this file may be applied during installation.
The installation will be processed using the following settings:
Workload Execution Mode (WEM): Advanced
Cluster Administrator: egoadmin
Cluster Name: symcluster
Installation Directory: /gpfs/fs1/symcompute/ego
Connection Base Port: 7869
1:egocomp-lnx26-lib23-x64 ########################################### [100%]
Platform EGO 1.2.6 (compute host package) is installed at /gpfs/fs1/symcompute/ego.
Remember to use the egoconfig command to complete the setup process.
[root@i05n45 /]# rpm --dbpath /gpfs/fs1/symcompute/rpmdb -ivh --prefix /gpfs/fs1/symcompute/ego soam-lnx26-lib23-x64-5.2.0.rpm
Preparing... ########################################### [100%]
1:soam-lnx26-lib23-x64 ########################################### [100%]
IBM Platform Symphony 5.2.0 is installed at /gpfs/fs1/symcompute/ego.
Symphony cannot work properly if the cluster configuration is not correct.
After you install Symphony on all hosts, log on to the Platform Management
Console as cluster administrator and run the cluster configuration wizard
to complete the installation process.
Add compute hosts
We show on Example 5-12 the process to add i05n52 as a compute host to our cluster.
Example 5-12 Adding i05n52 as a compute host to the cluster
[egoadmin@i05n52 ~]$ egoconfig join i05n45
You are about to join this host to a cluster with master host i05n45. Do you want to continue? [y/n]y
The host i05n52 has joined the cluster symcluster.
[egoadmin@i05n52 ~]$ egosh ego start
Start up LIM on <i05n52.pbm.ihost.com> ...... done
[egoadmin@i05n52 ~]$ egosh ego info
Cluster name : symcluster
EGO master host name : i05n45.pbm.ihost.com
EGO master version : 1.2.6
[egoadmin@i05n52 ~]$ egosh resource list
NAME status mem swp tmp ut it pg r1m r15s r15m ls
i05n45.* ok 45G 4096M 3691M 1% 0 0.0 0.7 0.3 0.2 3
i05n46.* ok 43G 4094M 3690M 0% 214 0.0 0.0 0.0 0.0 0
i05n52.* ok 46G 4094M 3690M 4% 1 0.0 0.8 0.3 0.2 1
We can optimize the process of adding new compute nodes to the cluster by using Parallel Distribute Shell (pdsh) to start LIM on several compute nodes. Pdsh is a remote shell client that executes commands on multiple remote hosts in parallel:
On Example 5-13, we source the Symphony environment variables and start LIM on the rest of the compute hosts on our cluster by using a single pdsh command.
Example 5-13 Starting the compute hosts
[root@i05n52 .ssh]# pdsh -w i05n[47-51,53] ". /gpfs/fs1/symcompute/ego/profile.platform; egosh ego start"
i05n53: Start up LIM on <i05n53.pbm.ihost.com> ...... done
i05n51: Start up LIM on <i05n51.pbm.ihost.com> ...... done
i05n47: Start up LIM on <i05n47.pbm.ihost.com> ...... done
i05n50: Start up LIM on <i05n50.pbm.ihost.com> ...... done
i05n48: Start up LIM on <i05n48.pbm.ihost.com> ...... done
i05n49: Start up LIM on <i05n49.pbm.ihost.com> ...... done
|
Important: It is not necessary to run egoconfig join on all hosts when you use a shared installation directory because they share a common EGO configuration.
|
Hadoop preparation
In our environment, we use the open source Apache Hadoop distribution for testing and demonstration. However, IBM Platform Symphony MapReduce integrates also with IBM InfoSphere BigInsights and other commercial Hadoop implementations. In this section, we describe the preparation for Apache Hadoop version 1.0.1.
The installation and configuration of the MapReduce Framework of Symphony requires a functioning Hadoop cluster setup. Verify the following preparation.
For the Hadoop version, IBM Platform Symphony v5.2 MapReduce Framework supports the following Hadoop versions:
•1.0.1
•1.0.0
•0.21.0
•0.20.2
•0.20.203
•0.20.204
For the Hadoop node layout, in our testing environment, we selected the following nodes:
•i05n45: NameNode and JobTracker
•i05n46: SecondaryNameNode
•i05n47, i05n48, and i05n49: DataNodes
The NameNode and SecondaryNameNode run on the management nodes of the Symphony cluster. This selection is intentional because it is a requirement to later enable HA for those services.
For the installation paths, to take advantage of the GPFS that is installed in our cluster setup, the Hadoop installation has the following layout:
•Installation binaries and shared directory for NameNode HA: /gpfs/fs1/hadoop (see Example 5-14 on page 148)
Example 5-14 Shared Hadoop directories
# ls -ld /gpfs/fs1/hadoop/
drwxr-xr-x 5 hadoop itso 8192 Jul 26 09:52 /gpfs/fs1/hadoop/
# ls -ld /gpfs/fs1/hadoop/shared
drwxr-xr-x 3 lsfadmin itso 8192 Jul 25 12:03 /gpfs/fs1/hadoop/shared
•Local configuration (see Example 5-15), Hadoop and Symphony MapReduce logs, and data directory for all Hadoop nodes: /var/hadoop/
Example 5-15 Local directory for Hadoop nodes
# pdsh -w i05n[45-49] ls -ld /var/hadoop/
i05n48: drwxr-xr-x 6 lsfadmin root 4096 Aug 2 09:59 /var/hadoop/
i05n46: drwxr-xr-x 6 lsfadmin root 4096 Aug 2 09:59 /var/hadoop/
i05n45: drwxr-xr-x 6 lsfadmin root 4096 Aug 2 10:06 /var/hadoop/
i05n49: drwxr-xr-x 6 lsfadmin root 4096 Aug 2 09:59 /var/hadoop/
i05n47: drwxr-xr-x 6 lsfadmin root 4096 Aug 2 09:59 /var/hadoop/
We installed Java Development Kit (JDK) 1.6.0_25 because 1.6.0_21 or higher is required.
Example 5-16 JDK installation
$ ls -l /gpfs/fs1/java/
total 56
rwxr-xr-x 9 root root 8192 Feb 4 23:19 jdk1.6.0_25
lrwxrwxrwx 1 root root 12 Jul 23 16:51 latest -> jdk1.6.0_25/
For the installation owner, it is possible to have a dedicated user for the Hadoop installation (for example, hadoop). However, to implement the HA features that IBM Platform Symphony MapReduce Framework provides, it is necessary that the owner of the Hadoop is the same as the administrator user in Symphony, in this case, lsfadmin.
After all of the preparation is verified, we proceed with the installation and configuration of Hadoop. Follow these steps:
1. Unpack the downloaded package as shown in Example 5-17.
Example 5-17 Unpacking Hadoop
# tar zxf /gpfs/fs1/install/Hadoop/hadoop-1.0.1.tar.gz
# ln -s hadoop-1.0.1/ current/
Because we are using a shared Hadoop installation, we prepare the basic configuration for all nodes. Then, we have to customize some configuration files for specifics of the NameNode.
2. To use the local file system for temporary data and to define the NameNode host, we edit core-site.xml (contents are shown in Example 5-18).
Example 5-18 Contents of core-site.xml
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><
configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/data/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<!-- NameNode host -->
<value>hdfs://i05n45.pbm.ihost.com:9000/</value>
</property>
</configuration>
3. The NameNode directory is stored in the shared file system because of the requirements to make the service highly available by Symphony EGO (this configuration is explained later in this chapter). The data store for each DataNode is under a local file system and the replication level is two for our test environment. In production environments, the replication level is normally three. Example 5-19 show the contents of hdfs-site.xml.
Example 5-19 Contents of hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/gpfs/fs1/hadoop/shared/data/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/var/hadoop/data/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
4. To define the JobTracker node and map and to reduce the tasks per node, we edit mapred-site.xml. The mapred-site.xml content is shown in Example 5-20.
Example 5-20 Contents of mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>i05n45:9001</value>
</property>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>7</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>3</value>
</property>
</configuration>
5. We copy the configuration that we created to the local directories of all nodes, rename the original configuration directory, and then symlink it to the local configuration directory. We use the commands that are shown in Example 5-21.
Example 5-21 Configuration directories setup
# pdsh -i i05n[45-49] cp -r /gpfs/fs1/hadoop/current/conf /var/hadoop/
# mv /gpfs/fs1/hadoop/current/conf /gpfs/fs1/hadoop/current/conf.orig
# ln -s /var/hadoop/conf /gpfs/fs1/hadoop/current/
6. Only for NameNode i05n45, we modify the slaves and masters files to specify DataNodes and SecondaryNameNode as shown in Example 5-22.
Example 5-22 Slaves and masters files
# hostname
i05n45
# cat /var/hadoop/conf/masters
i05n46
# cat /var/hadoop/conf/slaves
i05n47
i05n48
i05n49
7. To start using Hadoop, we log in as the same administrative user for the Symphony cluster lsfadmin. Before we attempt any Hadoop command or job, we ensure that the following environment variables are set in the profile of the user. We either log out and log in or source the file (see Example 5-23).
Example 5-23 Profile environment variables for Hadoop
[lsfadmin@i05n45 ~]$ pwd
/home/lsfadmin
[lsfadmin@i05n45 ~]$ cat .bashrc
# .bashrc
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User-specific aliases and functions
export JAVA_HOME=/gpfs/fs1/java/latest
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH:/gpfs/fs1/hadoop/current/bin
export HADOOP_VERSION=1_0_0
On previous Hadoop versions, you need to define the variable HADOOP_HOME but it is not needed for version 1.0.1. Otherwise, you see a warning message as shown in Example 5-24 on page 151, which can be ignored.
Example 5-24 HADOOP_HOME warning message
[lsfadmin@i05n45 ~]$ hadoop
Warning: $HADOOP_HOME is deprecated.
...
8. We then format the HDFS. The output of that command is displayed in Example 5-25.
Example 5-25 HDFS format output
[lsfadmin@i05n45 ~]$ hadoop namenode -format
12/08/03 16:37:06 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = i05n45/129.40.126.45
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 1.0.1
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1243785; compiled by 'hortonfo' on Tue Feb 14 08:15:38 UTC 2012
************************************************************/
12/08/03 16:37:06 INFO util.GSet: VM type = 64-bit
12/08/03 16:37:06 INFO util.GSet: 2% max memory = 17.77875 MB
12/08/03 16:37:06 INFO util.GSet: capacity = 2^21 = 2097152 entries
12/08/03 16:37:06 INFO util.GSet: recommended=2097152, actual=2097152
12/08/03 16:37:06 INFO namenode.FSNamesystem: fsOwner=lsfadmin
12/08/03 16:37:06 INFO namenode.FSNamesystem: supergroup=supergroup
12/08/03 16:37:06 INFO namenode.FSNamesystem: isPermissionEnabled=true
12/08/03 16:37:06 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
12/08/03 16:37:06 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
12/08/03 16:37:06 INFO namenode.NameNode: Caching file names occurring more than 10 times
12/08/03 16:37:07 INFO common.Storage: Image file of size 114 saved in 0 seconds.
12/08/03 16:37:07 INFO common.Storage: Storage directory /gpfs/fs1/hadoop/shared/data/dfs/name has been successfully formatted.
12/08/03 16:37:07 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at i05n45/129.40.126.45
************************************************************/
Now, everything is ready so we proceed to the start-up of the Hadoop cluster and perform a test. The output is shown in Example 5-26.
Example 5-26 Hadoop start-up and test
[lsfadmin@i05n45 ~]$ start-all.sh
starting namenode, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-namenode-i05n45.out
i05n48: starting datanode, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-datanode-i05n48.out
i05n49: starting datanode, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-datanode-i05n49.out
i05n47: starting datanode, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-datanode-i05n47.out
i05n46: starting secondarynamenode, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-secondarynamenode-i05n46.out
starting jobtracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-jobtracker-i05n45.out
i05n49: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n49.out
i05n48: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n48.out
i05n47: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n47.out
i05n49: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n49.out
i05n48: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n48.out
i05n47: starting tasktracker, logging to /gpfs/fs1/hadoop/hadoop-1.0.1/libexec/../logs/hadoop-lsfadmin-tasktracker-i05n47.out
[lsfadmin@i05n45 ~]$ mkdir tmp
[lsfadmin@i05n45 ~]$ for i in `seq 1 50`; do cat /etc/services >> tmp/infile ;done
[lsfadmin@i05n45 ~]$ for i in `seq 1 50`; do hadoop fs -put tmp/infile input/infile$i; done
[lsfadmin@i05n45 ~]$ hadoop jar /gpfs/fs1/hadoop/current/hadoop-examples-1.0.1.jar wordcount /user/lsfadmin/input /user/lsfadmin/output
****hdfs://i05n45.pbm.ihost.com:9000/user/lsfadmin/input
12/08/03 16:45:10 INFO input.FileInputFormat: Total input paths to process : 50
12/08/03 16:45:11 INFO mapred.JobClient: Running job: job_201208031639_0001
12/08/03 16:45:12 INFO mapred.JobClient: map 0% reduce 0%
12/08/03 16:45:29 INFO mapred.JobClient: map 28% reduce 0%
12/08/03 16:45:32 INFO mapred.JobClient: map 41% reduce 0%
12/08/03 16:45:35 INFO mapred.JobClient: map 42% reduce 0%
...
12/08/03 16:46:04 INFO mapred.JobClient: Reduce output records=21847
12/08/03 16:46:04 INFO mapred.JobClient: Virtual memory (bytes) snapshot=145148067840
12/08/03 16:46:04 INFO mapred.JobClient: Map output records=145260000
Symphony MapReduce configuration
We now have a regular Hadoop cluster and no integration has occurred with the MapReduce Framework of Symphony. If during the installation, you did not define the Hadoop-related environment variables HADOOP_HOME and HADOOP_VERSION (which is the case in our test environment), you have to add the Hadoop settings to Symphony. Ensure that the contents of the $PMR_HOME/conf/pmr-env.sh in the job submission node (in our case, the master Symphony node i05n45) are as shown in Example 5-27 on page 153.
Example 5-27 Contents for $PMR_HOME/conf/pmr-env.sh
export HADOOP_HOME=/gpfs/fs1/hadoop/current
export JAVA_HOME=/gpfs/fs1/java/latest
export HADOOP_VERSION=1_0_0
export PMR_EXTERNAL_CONFIG_PATH=${HADOOP_HOME}/conf
export JVM_OPTIONS=-Xmx512m
export PMR_SERVICE_DEBUG_PORT=
export PMR_MRSS_SHUFFLE_CLIENT_PORT=17879
export PMR_MRSS_SHUFFLE_DATA_WRITE_PORT=17881
export PYTHON_PATH=/bin:/usr/bin:/usr/local/bin
export PATH=${PATH}:${JAVA_HOME}/bin:${PYTHON_PATH}
export USER_CLASSPATH=
export JAVA_LIBRARY_PATH=${HADOOP_HOME}/lib/native/Linux-amd64-64/:${HADOOP_HOME}/lib/native/Linux-i386-32/
In Example 5-27, notice the lines in bold, which are the lines that change. Ensure that you correctly substitute references of @HADOOP_HOME@ with ${HADOOP_HOME}. The HADOOP_VERSION is set to 1_0_0, but we use version 1.0.1. To inform Symphony that the version is either 1.0.0 or 1.0.1, we set this value to 1_0_0.
We use a shared installation of the Symphony binaries, and we have to configure the work directory to be local to each compute node. To do so, in the management console, click MapReduce workload (in the Quick Links section). Then, go to MapReduce Applications → MapReduce5.2 → Modify → Operating System Definition and set the field Work Directory to /var/hadoop/pmr/work/${SUB_WORK_DIR}. Ensure that the directory exists on each node of the cluster and is writable by lsfadmin. See Example 5-28.
Example 5-28 Local work directory for Symphony MapReduce tasks
# pdsh -w i05n[45-49] mkdir -p /var/hadoop/pmr/work/
# pdsh -w i05n[45-49] chown -R lsfadmin /var/hadoop/pmr/work
Restart the MapReduce application so that the new configuration takes effect with the commands soamcontrol app disable MapReduce5.2 and then soamcontrol app enable MapReduce5.2.
With this configuration now, Hadoop is under control of the Symphony MapReduce service and all Symphony scheduling capabilities apply. We can now run jobs via the Symphony MapReduce submission command mrsh or the job submission GUI in the management console (5.6, “Sample workload scenarios” on page 156).
HA configuration for HDFS NameNode
Symphony has the ability to provide HA for the NameNode of a Hadoop cluster through the EGO system services facility, which run HDFS daemons as services. To configure the services, follow these steps:
1. Correctly configure NameNode and SecondaryNameNode in HDFS.
We addressed this step in “Hadoop preparation” on page 147, so there are no additional steps to perform.
2. Configure NameNode and SecondaryNameNode as management hosts in the Symphony cluster.
When we planned the Hadoop installation, we intentionally selected the Symphony master and master candidate hosts as NameNode and SecondaryNameNode, so there are no further actions to comply with this requirement.
3. Set the variable PMR_HDFS_PORT within pmr-env.sh and restart the MapReduce application.
We selected port 9000 for the NameNode so the pmr-env.sh file under $PMR_HOME/conf looks like Example 5-29.
Example 5-29 Contents for $PMR_HOME/conf/pmr-env.sh
export HADOOP_HOME=/gpfs/fs1/hadoop/current
export JAVA_HOME=/gpfs/fs1/java/latest
export HADOOP_VERSION=1_0_0
export PMR_EXTERNAL_CONFIG_PATH=${HADOOP_HOME}/conf
export JVM_OPTIONS=-Xmx512m
export PMR_SERVICE_DEBUG_PORT=
export PMR_MRSS_SHUFFLE_CLIENT_PORT=17879
export PMR_MRSS_SHUFFLE_DATA_WRITE_PORT=17881
export PYTHON_PATH=/bin:/usr/bin:/usr/local/bin
export PATH=${PATH}:${JAVA_HOME}/bin:${PYTHON_PATH}
export USER_CLASSPATH=
export JAVA_LIBRARY_PATH=${HADOOP_HOME}/lib/native/Linux-amd64-64/:${HADOOP_HOME}/lib/native/Linux-i386-32/
export PMR_HDFS_PORT=9000
To restart the MapReduce application, we execute the commands soamcontrol app disable MapReduce5.2 and then soamcontrol app enable MapReduce5.2.
4. Store the metadata for the NameNode in a shared file system.
In the Hadoop preparation, we configured the dfs.name.dir in $HADOOP_HOME/conf/hdfs-site.xml to be in our GPFS file system, so there are no additional steps to perform.
5. Set the HDFS host name.
The EGO ServiceDirector maintains a DNS service to map service names to the IP address of the machine that runs the service. For example, the active node for the NameNode service is referred to as NameNode.ego in the ServiceDirector DNS. In our environment, it maps to either the IP address i05n45 or i05n46. In a normal Hadoop installation, the configuration file that holds this URL is core-site.xml. But, now that we are in an HA configuration in Symphony, the file to be maintained for any configuration change is core-site.xml.store. So, we create the file and change the fs.default.name URL to use the ServiceDirector service name for the NameNode. See Example 5-30.
Example 5-30 Contents of $HADOOP_HOME/conf/core-site.xml.store
<?xml version="1.0" ?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/data/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<!-- NameNode host -->
<value>hdfs://NameNode.ego:9000/</value>
</property>
</configuration>
Ensure that you copy this file to all nodes.
6. Verify that the HDFS port is adequate in the files namenode.xml, secondarynode.xml, and datanode.xml.
These configuration files are in the directory $EGO_ESRVDIR/esc/conf/services. In Example 5-31, we show extracts of each file to verify the values.
Example 5-31 File verification
# cat $EGO_ESRVDIR/esc/conf/services/namenode.xml
...
<ego:Command>${EGO_TOP}/soam/mapreduce/5.2/${EGO_MACHINE_TYPE}/etc/NameNodeService.sh</ego:Command>
<ego:EnvironmentVariable name="HADOOP_HOME">@HADOOP_HOME@</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="PMR_HDFS_PORT">9000</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="APP_NAME">MapReduce5.2</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="NAMENODE_SERVICE">NameNode</ego:EnvironmentVariable>
...
# cat $EGO_ESRVDIR/esc/conf/services/secondarynode.xml
...
<ego:ActivitySpecification>
<ego:Command>${EGO_TOP}/soam/mapreduce/5.2/${EGO_MACHINE_TYPE}/etc/SecondaryNodeService.sh</ego:Command>
<ego:EnvironmentVariable name="HADOOP_HOME">@HADOOP_HOME@</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="PMR_HDFS_PORT">9000</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="NAMENODE_SERVICE">NameNode</ego:EnvironmentVariable>
...
# cat $EGO_ESRVDIR/esc/conf/services/datanode.xml
...
<ego:Command>${EGO_TOP}/soam/mapreduce/5.2/${EGO_MACHINE_TYPE}/etc/DataNodeService.sh</ego:Command>
<ego:EnvironmentVariable name="HADOOP_HOME">@HADOOP_HOME@</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="PMR_HDFS_PORT">9000</ego:EnvironmentVariable>
<ego:EnvironmentVariable name="NAMENODE_SERVICE">NameNode</ego:EnvironmentVariable>
...
7. Start the HDFS EGO services.
When the NameNode is started, the DataNode and SecondaryNode services are started automatically (see Example 5-32 on page 156).
Example 5-32 Starting the NameNode service
$ egosh service list
SERVICE STATE ALLOC CONSUMER RGROUP RESOURCE SLOTS SEQ_NO INST_STATE ACTI
WEBGUI STARTED 70 /Manage* Manag* i05n45.* 1 1 RUN 6559
plc STARTED 71 /Manage* Manag* i05n45.* 1 1 RUN 6560
derbydb STARTED 72 /Manage* Manag* i05n45.* 1 1 RUN 6561
purger STARTED 73 /Manage* Manag* i05n45.* 1 1 RUN 6562
SD STARTED 74 /Manage* Manag* i05n45.* 1 1 RUN 6558
NameNode DEFINED /HDFS/N*
DataNode DEFINED /HDFS/D*
MRSS STARTED 100 /Comput* MapRe* i05n47.* 1 3 RUN 7252
i05n48.* 1 6 RUN 7255
i05n49.* 1 2 RUN 7251
Seconda* DEFINED /HDFS/S*
WebServ* STARTED 78 /Manage* Manag* i05n45.* 1 1 RUN 6565
RS STARTED 76 /Manage* Manag* i05n45.* 1 1 RUN 6563
Service* STARTED 77 /Manage* Manag* i05n45.* 1 1 RUN 6564
$ egosh service start NameNode
$ egosh service list
SERVICE STATE ALLOC CONSUMER RGROUP RESOURCE SLOTS SEQ_NO INST_STATE ACTI
WEBGUI STARTED 70 /Manage* Manag* i05n45.* 1 1 RUN 6559
plc STARTED 71 /Manage* Manag* i05n45.* 1 1 RUN 6560
derbydb STARTED 72 /Manage* Manag* i05n45.* 1 1 RUN 6561
purger STARTED 73 /Manage* Manag* i05n45.* 1 1 RUN 6562
SD STARTED 74 /Manage* Manag* i05n45.* 1 1 RUN 6558
NameNode STARTED 162 /HDFS/N* i05n45.* 1 1 RUN 12006
DataNode STARTED 163 /HDFS/D* i05n47.* 1 2 RUN 12008
i05n48.* 1 1 RUN 12007
i05n49.* 1 3 RUN 12009
MRSS STARTED 100 /Comput* MapRe* i05n47.* 1 3 RUN 7252
i05n48.* 1 6 RUN 7255
i05n49.* 1 2 RUN 7251
Seconda* STARTED 164 /HDFS/S* i05n46.* 1 2 RUN 12011
i05n45.* 1 1 RUN 12010
WebServ* STARTED 78 /Manage* Manag* i05n45.* 1 1 RUN 6565
RS STARTED 76 /Manage* Manag* i05n45.* 1 1 RUN 6563
Service* STARTED 77 /Manage* Manag* i05n45.* 1 1 RUN 6564
5.6 Sample workload scenarios
This section provides sample workload scenarios.
5.6.1 Hadoop
In this section, you see the facilities of IBM Platform Symphony MapReduce Framework for job submission and monitoring. Figure 5-19 on page 157 shows the main page of the dashboard.
Figure 5-19 Main page of the IBM Platform Symphony dashboard
Click the MapReduce Workload Quick Link on the left to display MapReduce job monitoring and application configuration options as shown in Figure 5-20 on page 158.
Figure 5-20 MapReduce dashboard
There, you can submit a new MapReduce job by clicking New at the upper-left corner of the page. This selection displays the job submission window pop-up to specify priority, JAR file, class, and additional input parameters for the job as shown in Figure 5-21 on page 159.
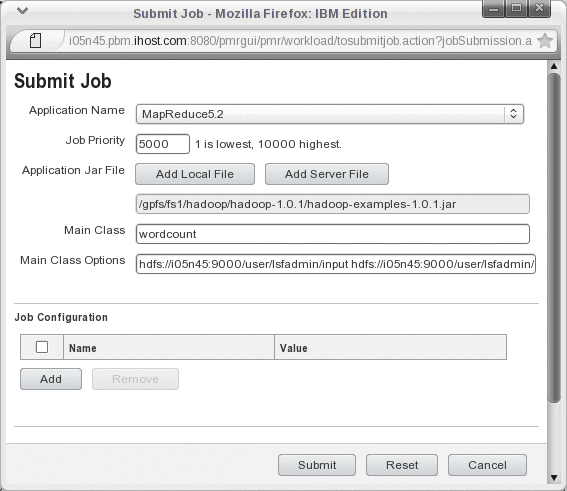
Figure 5-21 MapReduce job submission JAR file selection
After the job is submitted, you see the output of the command as it completes map and reduce tasks (see Figure 5-22 on page 160). The output is the same as the output when you run the command on the command line.
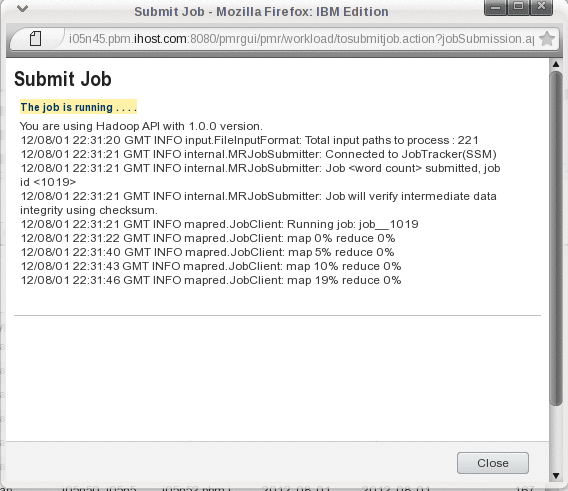
Figure 5-22 MapReduce job submission output
During the execution of the MapReduce job, you can monitor in real time the overall job execution and each task and see whether they are done, pending, or failed. Samples of the monitoring windows that show job and task monitoring appear in Figure 5-23 on page 161 and Figure 5-24 on page 162.
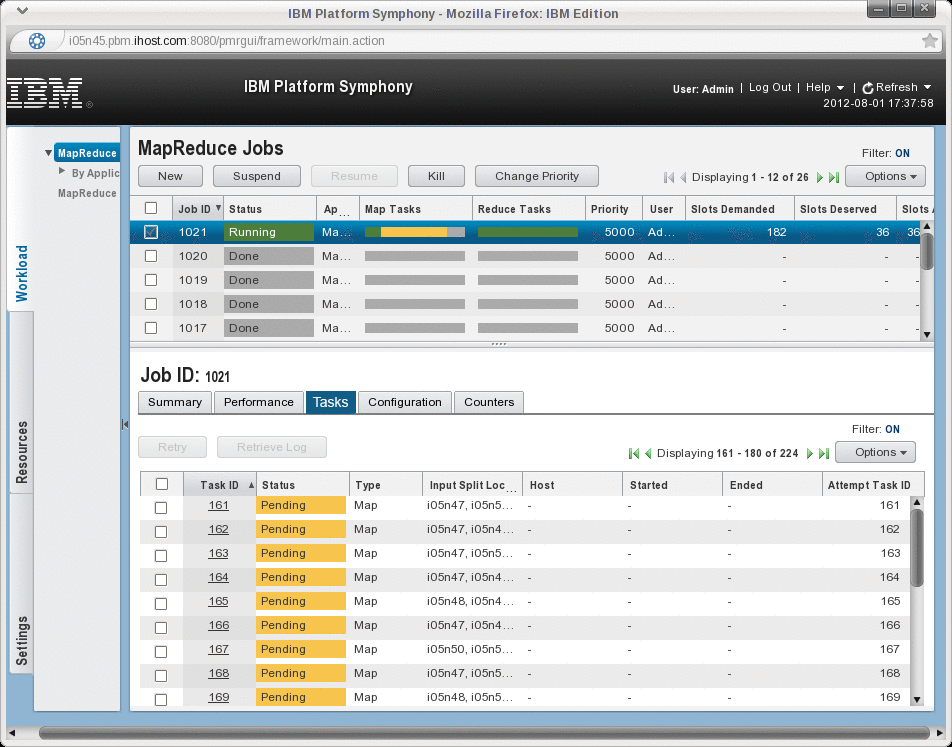
Figure 5-23 MapReduce job monitoring
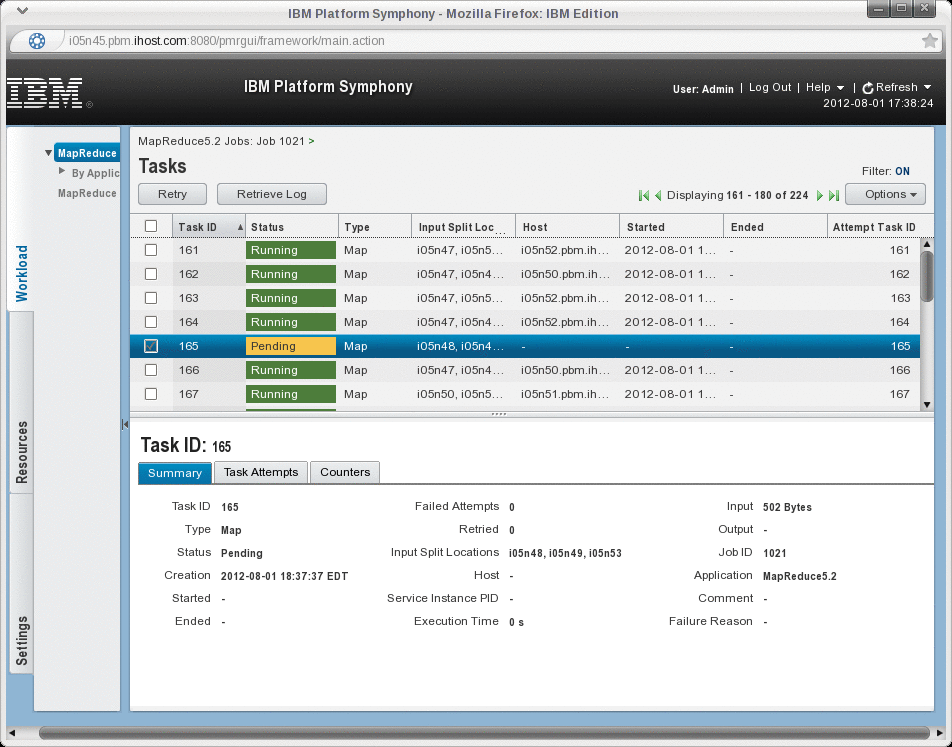
Figure 5-24 MapReduce job task progress
When the job is finished, if you did not close the submission window, you see the summary of the job execution and information about counters of the overall job execution as shown in Figure 5-25 on page 163.
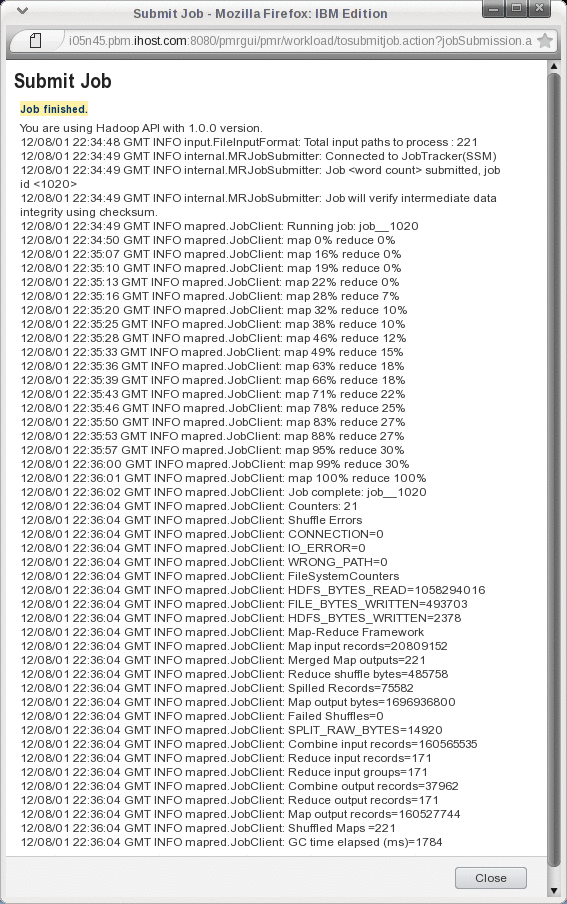
Figure 5-25 MapReduce finished job output
MapReduce job submission can also be accomplished via the command line. The syntax for the job submission is similar as though you are submitting a job through the hadoop command. There are minor differences as illustrated in Figure 5-26 on page 164.
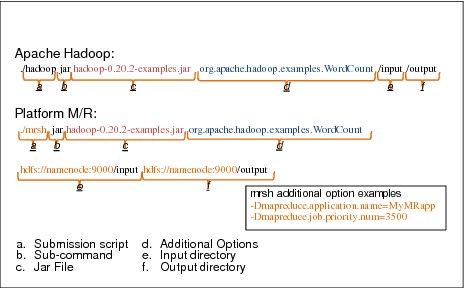
Figure 5-26 Job submission command-line compatibility with Hadoop
The execution of a MapReduce job by using the command line for our setup is shown in Example 5-33. The input and output URLs have NameNode.ego instead of a host name because, in our environment, HA is enabled for the MapReduce processes. This notation does not work if you use Hadoop without Symphony MapReduce Framework and submit a job with the usual hadoop command.
Example 5-33 Command-line MapReduce job submission
$ mrsh jar /gpfs/fs1/hadoop/current/hadoop-examples-1.0.1.jar wordcount -Dmapreduce.job.priority.num=3000 hdfs://NameNode.ego:9000/user/lsfadmin/input hdfs://NameNode.ego:9000/user/lsfadmin/output
You are using Hadoop API with 1.0.0 version.
12/07/31 18:32:05 GMT INFO input.FileInputFormat: Total input paths to process : 221
12/07/31 18:32:06 GMT INFO internal.MRJobSubmitter: Connected to JobTracker(SSM)
12/07/31 18:32:07 GMT INFO internal.MRJobSubmitter: Job <word count> submitted, job id <1005>
12/07/31 18:32:07 GMT INFO internal.MRJobSubmitter: Job will verify intermediate data integrity using checksum.
12/07/31 18:32:07 GMT INFO mapred.JobClient: Running job: job__1005
12/07/31 18:32:08 GMT INFO mapred.JobClient: map 0% reduce 0%
12/07/31 18:32:53 GMT INFO mapred.JobClient: map 1% reduce 0%
12/07/31 18:32:57 GMT INFO mapred.JobClient: map 2% reduce 0%
5.7 Symphony and IBM Platform LSF multihead environment
Multihead stands for multiple workload managers, such as IBM Platform LSF and IBM Platform Symphony, in one cluster. We need to configure IBM Platform LSF to use an EGO consumer for resource allocation to implement a multihead cluster environment. In this setup, the IBM Platform LSF and Symphony workload can share EGO resources in the cluster (Figure 5-27 on page 165).
The Symphony web GUI (PMC) provides an interface to monitor IBM Platform LSF jobs in addition to the jobs for Symphony and Platform MapReduce workloads. However for IBM Platform LSF administration and configuration, you still mostly edit files and use the command-line interface.
This type of environment appeals to clients who need the near-real-time scheduling capabilities of Symphony and also need to run Batch jobs that benefit from a robust batch scheduler, such as IBM Platform LSF.
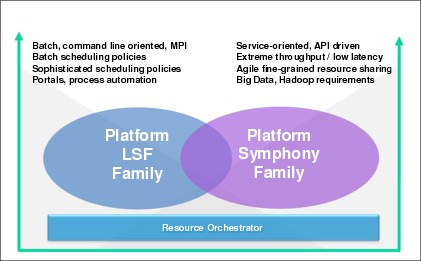
Figure 5-27 IBM Platform LSF and Symphony positioning
In Figure 5-27, we show key workload characteristics that are covered by the IBM Platform LSF and IBM Platform Symphony families. Although these families differ (Figure 5-28 on page 166), they coexist in an increasing number of clients that use complex environments and application pipelines that require a mix of Batch jobs (controlled by IBM Platform LSF) and SOA and MapReduce jobs (controlled by Symphony) to coexist seamlessly.
There is also an infrastructure utilization value in IBM Platform LSF and Symphony coexisting on the same environment to drive resource sharing (cores, RAM, and high-speed connectivity) between multiple projects and departments.
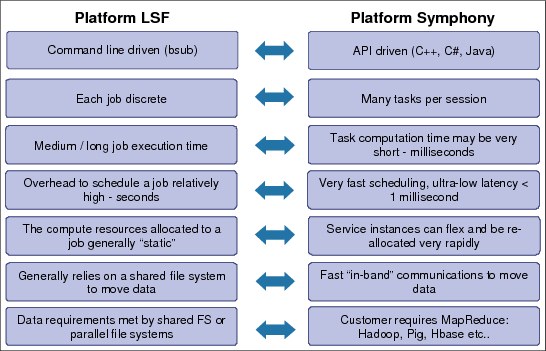
Figure 5-28 Key differences between IBM Platform LSF and Symphony workloads
To support IBM Platform LSF and Symphony resource sharing on top of EGO, it is necessary to use the product package lsf8.3_multihead.zip under IBM Platform LSF distribution, which has been certified to work with Symphony 5.2, including MapReduce.
Features
The following features are supported in a multihead Symphony/IBM Platform LSF cluster. These features are common use cases that we see in Financial Services and Life Sciences:
•Job arrays
•Job dependency
•Resource requirement at EGO-enabled SLA level
•User-based fairshare
•Parallel jobs
•Slot reservation for a parallel job
•Job resource preemption by EGO reclaim between consumers according to the resource plans
Current limitations
Most limitations of the IBM Platform LSF on EGO relate to hosts or host lists. For some features, IBM Platform LSF needs full control of the hosts that are specified statically in configuration files or the command-line interfaces (CLIs). The reason they are not supported is because hosts and slots in IBM Platform LSF on EGO are all dynamically allocated on demand.
The following features are not supported in a multihead configuration:
•Resource limits on hosts or host groups
•Advance reservation on hosts or host groups
•Guaranteed resource pool
•Compute unit
•Host partition
•Guaranteed SLA
•IBM Platform LSF multicluster
•Any places in which a list of hosts or host groups can be specified, for example, 'bsub -m', queues, or host groups
Preferred practices
Lending and borrowing between IBM Platform LSF and Symphony must not occur when you have parallel workloads, or when you are using batch constructs, such as bsub -m <host_group> or bsub -R 'cu[blah]', or even complex resource requirements.
On the parallel workloads, resource reclaim does not work because we cannot reclaim based on a batch reservation. So, we get slots back, but they might not be in the right enclosure or compute unit, or from the correct host group.
For resource reclaim on parallel jobs, the fundamental problem is not in IBM Platform LSF. It relates to the Message Passing Interface (MPI) application that cannot survive if you take away one of its running processes. So our preferred practice suggestion is to configure the IBM Platform LSF parallel job consumer in the EGO resource plan so that it can own slots and lend slots to other consumers (Symphony), but never borrow slots from others, to avoid resource reclaim on parallel jobs. Whenever IBM Platform LSF needs some of these hosts, it can reclaim them back if they are currently borrowed by Symphony.
5.7.1 Planning a multihead installation
We set aside a group of four hosts from the previous Symphony cluster installation that we described in 5.5.2, “Installation preferred practices” on page 139 to create a new multihead cluster. These planning details apply to our multihead installation:
•Multihead master host: i05n50
•Failover: none
•Compute hosts: i05n51, i05n52, and i05n53
•Cluster administrator user: egoadmin (created in LDAP)
•Installation directory (master): /gpfs/fs1/egomaster
•Installation directory (compute): /gpfs/fs1/egocompute
•Workload execution mode: advanced
5.7.2 Installation
We followed the steps that are described in Installing and Upgrading Your IBM Platform Symphony/LSF Cluster, SC27-4761-00, for the Linux master host scenario. This document describes the installation of a new cluster with mixed IBM Platform products (Symphony 5.2 Standard or Advanced Edition and IBM Platform LSF 8.3 Standard Edition, EGO-enabled).
This document also describes how to configure IBM Platform LSF to use an EGO consumer for resource allocation. In this way, the IBM Platform LSF and Symphony workload can share EGO resources in the cluster.
|
Important: It is a requirement to follow the installation steps to ensure that the configuration of the multihead cluster is correct.
|
Symphony master host
Use the 5.5.2, “Installation preferred practices” on page 139 as a reference to install Symphony on the master host. We chose to install again in a shared directory on GPFS. But, this time we did not configure an additional management host for failover.
Example 5-34 has the contents of the install.config that we used. We copied that to /tmp before starting the installation.
Example 5-34 Contents of our install.config file for Symphony master host installation
DERBY_DB_HOST=i05n50
CLUSTERNAME=symcluster
OVERWRITE_EGO_CONFIGURATION=yes
JAVA_HOME=/gpfs/fs1/java/latest
CLUSTERADMIN=egoadmin
SIMPLIFIEDWEM=N
Example 5-35 shows the commands and output from the Symphony master host RPM installation.
Example 5-35 Installing EGO and SOAM on the master host
[root@i05n50 Symphony]# rpm -ivh --prefix /gpfs/fs1/egomaster --dbpath /gpfs/fs1/egomaster/rpmdb/ ego-lnx26-lib23-x64-1.2.6.rpm
Preparing... ########################################### [100%]
A cluster properties configuration file is present: /tmp/install.config. Parameter settings from this file may be applied during installation.
Warning
=======
The /etc/services file contains one or more services which are using
the same ports as 7869. The entry is:
mobileanalyzer 7869/tcp # MobileAnalyzer& MobileMonitor
Continuing with installation. After installation, you can run egoconfig
setbaseport on every host in the cluster to change the ports used by the cluster.
Warning
=======
The /etc/services file contains one or more services which are using
the same ports as 7870. The entry is:
rbt-smc 7870/tcp # Riverbed Steelhead Mobile Service
Continuing with installation. After installation, you can run egoconfig
setbaseport on every host in the cluster to change the ports used by the cluster.
The installation will be processed using the following settings:
Workload Execution Mode (WEM): Advanced
Cluster Administrator: egoadmin
Cluster Name: symcluster
Installation Directory: /gpfs/fs1/egomaster
Connection Base Port: 7869
1:ego-lnx26-lib23-x64 ########################################### [100%]
Platform EGO 1.2.6 is installed successfully.
Install the SOAM package to complete the installation process. Source the environment and run the <egoconfig> command to complete the setup after installing the SOAM package.
[root@i05n50 Symphony]# rpm -ivh --prefix /gpfs/fs1/egomaster --dbpath /gpfs/fs1/egomaster/rpmdb/ soam-lnx26-lib23-x64-5.2.0.rpm
Preparing... ########################################### [100%]
1:soam-lnx26-lib23-x64 ########################################### [100%]
IBM Platform Symphony 5.2.0 is installed at /gpfs/fs1/egomaster.
Symphony cannot work properly if the cluster configuration is not correct.
After you install Symphony on all hosts, log on to the Platform Management
Console as cluster administrator and run the cluster configuration wizard
to complete the installation process.
[egoadmin@i05n50 ~]$ egoconfig join i05n50
You are about to create a new cluster with this host as the master host. Do you want to continue? [y/n]y
A new cluster <symcluster> has been created. The host <i05n50> is the master host.
Run <egoconfig setentitlement "entitlementfile"> before using the cluster.
Symphony compute hosts
Example 5-36 shows the commands and output from the Symphony compute host RPM installation.
Example 5-36 Commands and output from the Symphony compute host RPM installation
[root@i05n51 Symphony]# rpm -ivh --prefix /gpfs/fs1/egocompute --dbpath /gpfs/fs1/egocompute/rpmdb/ egocomp-lnx26-lib23-x64-1.2.6.rpm
Preparing... ########################################### [100%]
A cluster properties configuration file is present: /tmp/install.config. Parameter settings from this file may be applied during installation.
Warning
=======
The /etc/services file contains one or more services which are using
the same ports as 7869. The entry is:
mobileanalyzer 7869/tcp # MobileAnalyzer& MobileMonitor
Continuing with installation. After installation, you can run egoconfig
setbaseport on every host in the cluster to change the ports used by the cluster.
Warning
=======
The /etc/services file contains one or more services which are using
the same ports as 7870. The entry is:
rbt-smc 7870/tcp # Riverbed Steelhead Mobile Service
Continuing with installation. After installation, you can run egoconfig
setbaseport on every host in the cluster to change the ports used by the cluster.
The installation will be processed using the following settings:
Workload Execution Mode (WEM): Advanced
Cluster Administrator: egoadmin
Cluster Name: symcluster
Installation Directory: /gpfs/fs1/egocompute
Connection Base Port: 7869
1:egocomp-lnx26-lib23-x64########################################### [100%]
Platform EGO 1.2.6 (compute host package) is installed at /gpfs/fs1/egocompute.
Remember to use the egoconfig command to complete the setup process.
[root@i05n51 Symphony]# rpm -ivh --prefix /gpfs/fs1/egocompute --dbpath /gpfs/fs1/egocompute/rpmdb/ soam-lnx26-lib23-x64-5.2.0.rpm
Preparing... ########################################### [100%]
1:soam-lnx26-lib23-x64 ########################################### [100%]
IBM Platform Symphony 5.2.0 is installed at /gpfs/fs1/egocompute.
Symphony cannot work properly if the cluster configuration is not correct.
After you install Symphony on all hosts, log on to the Platform Management
Console as cluster administrator and run the cluster configuration wizard
to complete the installation process.
IBM Platform LSF install
Obtain the RPM file that matches your host type from the IBM Platform LSF multihead product package lsf8.3_multihead.zip that is shipped with IBM Platform LSF 8.3. For the details about the package contents, see 3.2, “Software packages” on page 23.
|
Important: The normal IBM Platform LSF package does not work on multihead configurations. The IBM Platform LSF RPM in the lsf8.3_multihead.zip product package is specifically built to support resource sharing on top of EGO and is certified to work with Symphony 5.2, including MapReduce.
|
Example 5-37 shows the IBM Platform LSF installation commands and output.
Example 5-37 IBM Platform LSF installation on the master host
[root@i05n50 multihead]# rpm -ivh --prefix /gpfs/fs1/egomaster --dbpath /gpfs/fs1/egomaster/rpmdb/ lsf-linux2.6-glibc2.3-x86_64-8.3-199206.rpm
Preparing... ########################################### [100%]
1:lsf-linux2.6-glibc2.3-x########################################### [100%]
IBM Platform LSF 8.3 is installed at /gpfs/fs1/egomaster.
To make LSF take effect, you must set your environment on this host:
source /gpfs/fs1/egomaster/cshrc.platform
or
. /gpfs/fs1/egomaster/profile.platform
LSF cannot work properly if the cluster configuration is not correct.
Log on to the IBM Platform Management Console as cluster administrator to run
the cluster configuration wizard and complete the installation process.
You must set LSF entitlement manually on the cluster master host before using LSF.
[root@i05n50 multihead]# cp /gpfs/fs1/install/LSF/platform_lsf_std_entitlement.dat /gpfs/fs1/egomaster/lsf/conf/lsf.entitlement
[egoadmin@i05n50 conf]$ egosh ego shutdown
Shut down LIM on <i05n50.pbm.ihost.com> ? [y/n] y
Shut down LIM on <i05n50.pbm.ihost.com> ...... done
[egoadmin@i05n50 conf]$ egosh ego start
Multihead patch process
There is a patch that is available to resolve some GUI issues after multihead is installed. The lsf8.3_multihead.zip includes a patch directory. The patch details and installation instructions are described in the file readme_for_patch_Symphony_5.2.htm.
Navigate to the $EGO_TOP directory and decompress the lsf-linux2.6-glibc2.3-x86_64-8.3-198556.tar.gz package that can be found under the patch directory. The procedure is shown in Example 5-38.
Example 5-38 Executing the multihead patch process
[root@i05n50 patch]# cp lsf-linux2.6-glibc2.3-x86_64-8.3-198556.tar.gz /gpfs/fs1/egomaster/
[root@i05n50 egomaster]# tar xvzf lsf-linux2.6-glibc2.3-x86_64-8.3-198556.tar.gz
gui/
gui/1.2.6/
gui/1.2.6/lib/
gui/1.2.6/lib/commons-ego.jar
gui/perf/
gui/perf/1.2.6/
gui/perf/1.2.6/perfgui/
gui/perf/1.2.6/perfgui/WEB-INF/
gui/perf/1.2.6/perfgui/WEB-INF/classes/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/csv/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/csv/GenerateCSV$RollupMethod.class
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/csv/GenerateCSV.class
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/batch/
gui/perf/1.2.6/perfgui/WEB-INF/classes/com/platform/perf/report/batch/ReportBuilder.class
gui/perf/1.2.6/perfgui/js/
gui/perf/1.2.6/perfgui/js/reports.js
5.7.3 Configuration
This section walks you through the cluster configuration wizard.
Cluster configuration wizard
The cluster configuration wizard automatically determines exactly what configuration needs to be in your cluster.
Follow these steps:
1. Log on to the Platform Management Console as cluster administrator (Admin) and the wizard starts automatically (you must enable pop-up windows in your browser).
2. Read the instructions on the pop-up window that is shown in Figure 5-29 and choose to start the wizard configuration process.
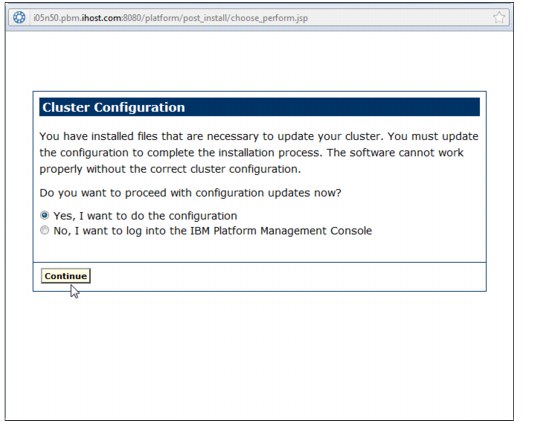
Figure 5-29 Platform Management Console wizard configuration
3. Click Create on the next window to add the necessary consumer to support the IBM Platform LSF/Symphony multihead installation. This window is shown on Figure 5-30 on page 173.
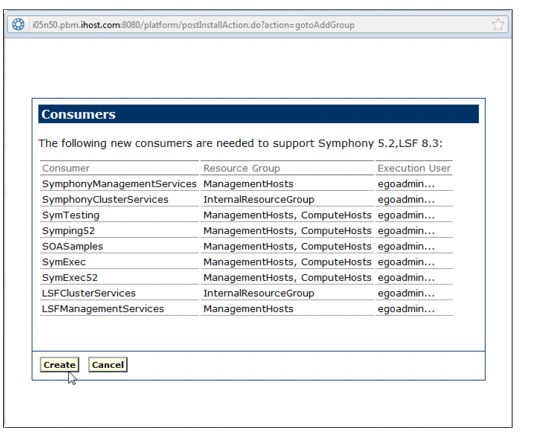
Figure 5-30 Create new consumers
4. Figure 5-31 on page 174 shows the next window, where we select Create to add the necessary services.
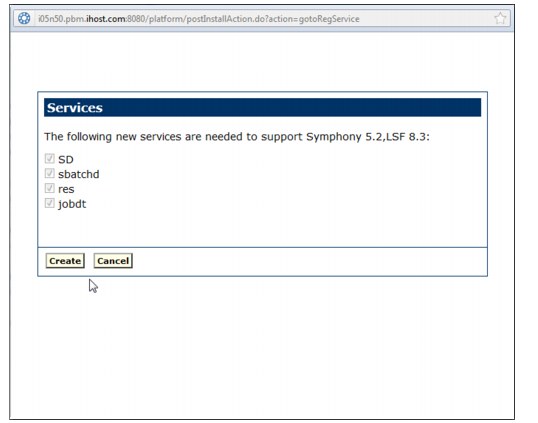
Figure 5-31 Add new services
5. Figure 5-32 shows where you choose to create the new necessary database tables that are required by Symphony and IBM Platform LSF.
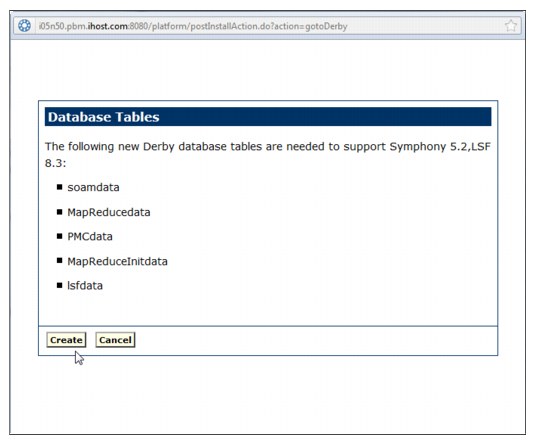
Figure 5-32 Creation of the necessary tables for Symphony and IBM Platform LSF
After the wizard restarts all the services, you can log on to the PMC to check the status of the host in your cluster.
|
Host types: Now, the IBM Platform LSF services are configured to run correctly on hosts of the same type as the master host. If you have a cluster with Microsoft Windows host types, you must manually configure IBM Platform LSF services to run on all additional host types. For details, see “Configure LSF” in chapter 2 of Installing and Upgrading Your IBM Platform Symphony/LSF Cluster, SC27-4761-00.
|
Configuring IBM Platform LSF SLA
We suggest that you enable IBM Platform LSF data collection now so that, in the future, you can produce IBM Platform LSF reports that show IBM Platform LSF SLA workload data.
Locate the loader controller file in the EGO cluster directory:
$EGO_CONFDIR/../../perf/conf/plc/plc_lsf.xml
Find the IBM Platform LSF SLA data loader and change the Enable value to true, as highlighted in the controller file that is shown in Example 5-39 on page 176.
Example 5-39 /gpfs/fs1/egomaster/perf/conf/plc/plc_lsf.xml
<?xml version="1.0" encoding="UTF-8"?>
<PLC xmlns="http://www.platform.com/perf/2006/01/loader"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.platform.com/perf/2006/01/loader plc_dataloader.xsd">
<DataLoaders>
<!--
The data loader implementation:
Name The name of data loader plug-in.
Enable Whether this data loader plug-in is enabled.
Interval The repeat interval of this dataloader instance, in seconds.
LoadXML The configuration file that the data loader uses. This file includes the Reader and Writer elements.
-->
<DataLoader Name="lsfbhostsloader" Interval="300" Enable="true" LoadXML="dataloader/bhosts.xml" />
<DataLoader Name="lsfeventsloader" Interval="10" Enable="true" LoadXML="dataloader/lsbevents.xml" />
<DataLoader Name="sharedresusageloader" Interval="300" Enable="false" LoadXML="dataloader/sharedresourceusage.xml" />
<DataLoader Name="lsfresproploader" Interval="3600" Enable="true" LoadXML="dataloader/lsfresourceproperty.xml" />
<DataLoader Name="lsfslaloader" Interval="300" Enable="true" LoadXML="dataloader/lsfsla.xml" />
<DataLoader Name="bldloader" Interval="300" Enable="false" LoadXML="dataloader/bld.xml" />
</DataLoaders>
</PLC>
Follow these steps to make the changes take effect:
1. Stop the services plc and purger:
egosh service stop plc
egosh service stop purger
2. Start the services plc and purger:
egosh service start plc
egosh service start purger
Creating a new IBM Platform LSF consumer in EGO
Follow these steps:
1. Log on to the Platform Management Console and set up your IBM Platform LSF workload consumer. Create a top-level consumer. For example, create a consumer named LSFTesting.
2. From the PMC Quick Links tab, click Consumers.
3. On the secondary window, select Create a Consumer from the Global Actions drop-down menu, then associate LSFTesting with the resource group ComputeHosts. Use the DOMAINegoadmin as the suggested execution user account.
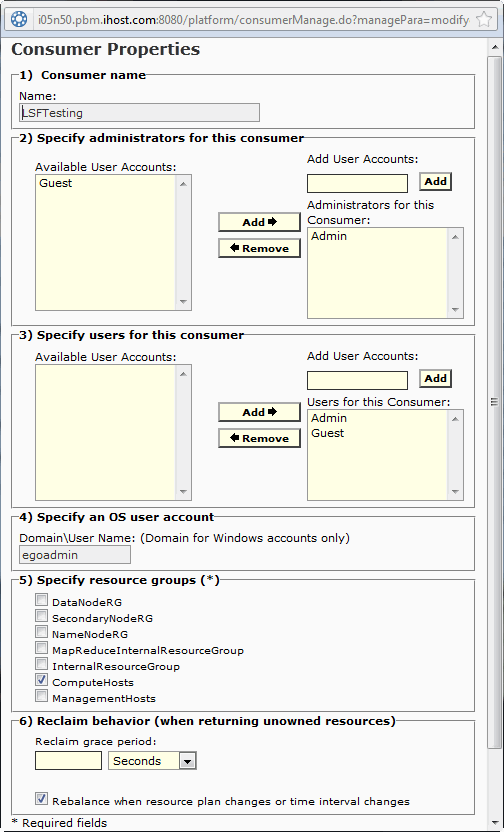
Figure 5-33 LSFTesting consumer properties
5. Next, configure your resource plan and provide the new LSFTesting consumer with sufficient resources for testing purposes. Figure 5-34 on page 178 shows an example resource plan where LSFTesting owns all available slots but can lend them if other consumers need resources. We configured other consumers, such as Symping5.2 and MapReduce5.2, to borrow slots from LFSTesting.
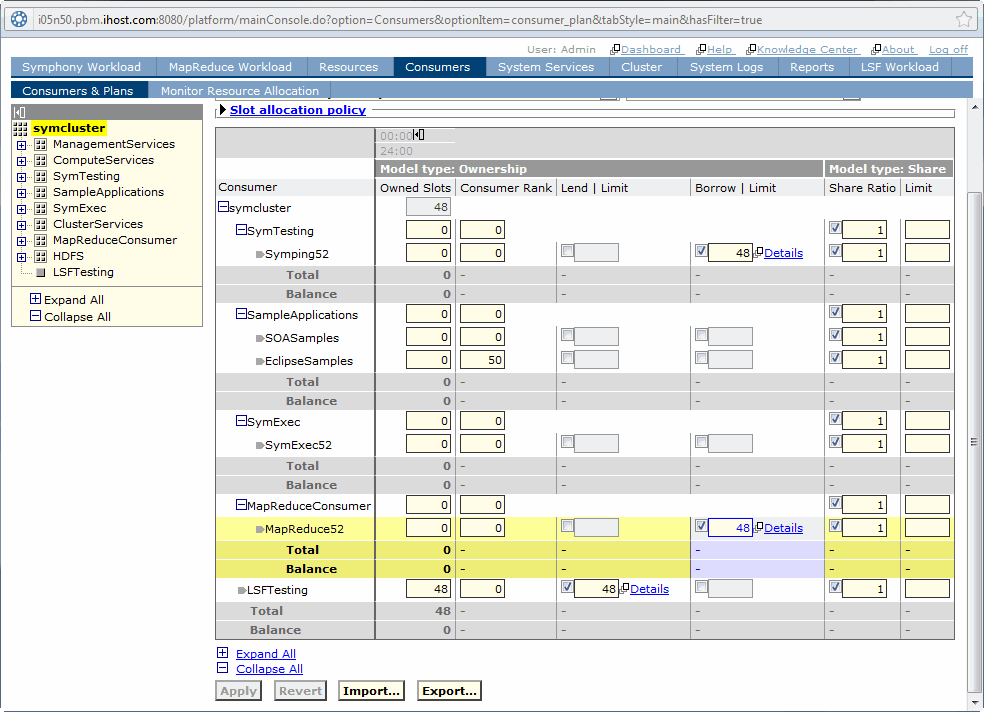
Figure 5-34 Resource plan example
Creating a new EGO-enabled SLA in IBM Platform LSF
Follow these steps to manually update configurations to enable SLA:
1. Navigate to the IBM Platform LSF configuration directory:
$LSF_ENVDIR/lsbatch/cluster_name/configdir/
Example 5-40 /gpfs/fs1/egomaster/lsf/conf/lsbatch/symcluster/configdir/lsb.params
# $Revision: 1.1.2.2 $Date: 2012/04/16 09:04:00 $
# Misc batch parameters/switches of the LSF system
# LSF administrator will receive all the error mails produced by LSF
# and have the permission to reconfigure the system (Use an ordinary user
# name, or create a special account such as lsf. Don't define as root)
# The parameter values given below are for the purpose of testing a new
# installation. Jobs submitted to the LSF system will be started on
# batch server hosts quickly. However, this configuration may not be
# suitable for a production use. You may need some control on job scheduling,
# such as jobs should not be started when host load is high, a host should not
# accept more than one job within a short period time, and job scheduling
# interval should be longer to give hosts some time adjusting load indices
# after accepting jobs.
#
# Therefore, it is suggested, in production use, to define DEFAULT_QUEUE
# to normal queue, MBD_SLEEP_TIME to 60, SBD_SLEEP_TIME to 30
Begin Parameters
DEFAULT_QUEUE = normal interactive #default job queue names
MBD_SLEEP_TIME = 10 #Time used for calculating parameter values (60 secs is default)
SBD_SLEEP_TIME = 7 #sbatchd scheduling interval (30 secs is default)
JOB_SCHEDULING_INTERVAL=1 #interval between job scheduling sessions
JOB_ACCEPT_INTERVAL = 0 #interval for any host to accept a job
ENABLE_EVENT_STREAM = n #disable streaming of lsbatch system events
ABS_RUNLIMIT=Y #absolute run time is used instead of normalized one
JOB_DEP_LAST_SUB=1 #LSF evaluates only the most recently submitted job name for dependency conditions
MAX_CONCURRENT_JOB_QUERY=100 #concurrent job queries mbatchd can handle
MAX_JOB_NUM=10000 #the maximum number of finished jobs whose events are to be stored in the lsb.events log file
ENABLE_DEFAULT_EGO_SLA = LSFTesting
MBD_USE_EGO_MXJ = Y
End Parameters
3. Modify lsb.serviceclasses as shown in Example 5-41. Create the LSFTesting SLA and associate it with LSFTesting consumer.
Example 5-41 lsb.serviceclasses
...
Begin ServiceClass
NAME = LSFTesting
CONSUMER = LSFTesting
DESCRIPTION = Test LSF and Symphony workload sharing resources
GOALS = [VELOCITY 1 timeWindow ()]
PRIORITY = 10
End ServiceClass
...
4. Make the new settings take effect. Log on to the master host as the cluster administrator and run badmin reconfig.
Testing resource sharing between Symphony and IBM Platform LSF workloads
Submit the IBM Platform LSF and Symphony workloads to demonstrate sharing between IBM Platform LSF and Symphony. Use the PMC or command line to monitor the workload and resource allocation.
5.8 References
Table 5-6 on page 180 lists the publication titles and publication numbers of the documents that are referenced in this chapter. They are available at the IBM publications site:
Table 5-6 Publications that are referenced in this chapter
|
Publication title
|
Publication number
|
|
Overview: Installing Your IBM Platform Symphony Cluster
|
GC22-5367-00
|
|
User Guide for the MapReduce Framework in IBM Platform Symphony - Advanced
|
GC22-5370-00
|
|
Release Notes for IBM Platform Symphony 5.2
|
GI13-3101-00
|
|
IBM Platform Symphony Foundations
|
SC22-5363-00
|
|
Installing the IBM Platform Symphony Client (UNIX)
|
SC22-5365-00
|
|
Installing the IBM Platform Symphony Client (Windows)
|
SC22-5366-00
|
|
Integration Guide for MapReduce Applications in IBM Platform Symphony - Adv
|
SC22-5369-00
|
|
IBM Platform Symphony Reference
|
SC22-5371-00
|
|
Upgrading Your IBM Platform Symphony 5.0 or 5.1 Cluster
|
SC22-5373-00
|
|
Upgrading Your IBM Platform Symphony 3.x/4.x Cluster
|
SC22-5374-00
|
|
Installing and Using the IBM Platform Symphony Solaris SDK
|
SC22-5377-00
|
|
Installing Symphony Developer Edition
|
SC22-5378-00
|
|
Installing and Upgrading Your IBM Platform Symphony/LSF Cluster
|
SC27-4761-00
|
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.