


System architecture
IBM FileNet Content Manager is a collection of tightly integrated components that are bundled together as a common platform. The broad functionality provided by these integrated components constitutes an enterprise content and process management platform. Some of the key elements of this platform are a metadata repository, a workflow system, an application that can be used by all clients to access content and participate in processes, and a storage framework that supports a wide range of storage devices and platforms.
In this chapter, we introduce the components of an IBM FileNet Content Manager system, discuss the logical and physical layout options, and discuss how to scale the system to meet both local and global business needs.
We discuss the following topics:
For information about the internal system architecture of IBM FileNet Content Manager and the P8 Platform, see IBM FileNet P8 Platform and Architecture, SG24-7667.
3.1 Basic components
An IBM FileNet Content Manager system typically includes the following components:
•Content Platform Engine
A collection of services and components for managing different types of business-related content and automating business processes.
•FileNet Workplace XT (optional)
A presentation-tier application for working with both content and processes. It also provides administrative tools for designing and managing processes. FileNet Workplace XT is a useful tool for performing a quick validation of an IBM FileNet Content Manager installation, and for reproducing issues seen with custom applications.
•IBM Content Navigator (optional)
An extensible presentation tier for working with both content and processes. Like FileNet Workplace XT, IBM Content Navigator can also be used to validate an IBM FileNet Content Manager installation and to replicate issues seen with custom applications. For more information about IBM Content Navigator, see Customizing and Extending IBM Content Navigator, SG24-8055.
•Directory service
A Lightweight Directory Access Protocol (LDAP) directory server, frequently the corporate LDAP server, used by IBM FileNet Content Manager to authenticate users and to access authorization information for artifacts managed by the Content Platform Engine.
•Database server
Hosts the databases used to store the metadata associated with the business content and processes, and configuration information for an IBM FileNet Content Manager implementation.
•Application server
Hosts the Content Platform Engine and other Java EE applications, including FileNet Workplace XT and IBM Content Navigator, that are used as part of an IBM FileNet Content Manager implementation.
•Storage
Database, file, or fixed storage areas for storing the business content.
Figure 3-1 on page 39 illustrates a basic layout of an IBM FileNet Content Manager environment.
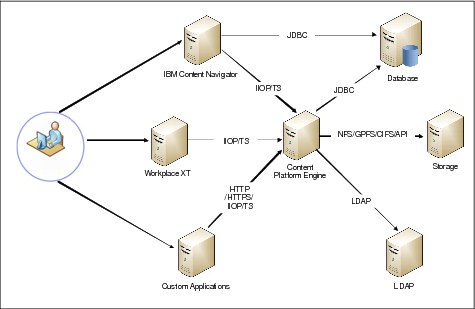
Figure 3-1 Basic components of P8 Content Manager configuration
Although FileNet Workplace XT and Content Navigator are popular application components, they are not absolutely required for a functioning IBM FileNet Content Manager system.
3.1.1 Additional components
In addition to the basic components, an IBM FileNet Content Manager environment can be configured to include the following components:
•Content Search Services (CSS)
Allows you to index and search for text within documents and in the metadata that is used to describe a document
•Rendition Engine
Is used to generate PDF or HTML versions of documents
3.1.2 Data organization
The business content and processes associated with an IBM FileNet Content Manager implementation are organized into a logical grouping called a P8 domain. The definition of the P8 domain is stored in a database known as the global configuration database (GCD).
The GCD stores information about the following items:
•Object stores and any workflow systems that have been defined for the P8 domain
A P8 domain can have one or more content stores, known as object stores, and one or more workflow systems. The role of an object store is to store business-related content. A workflow system is a repository for storing and managing process-related information.
•Configuration information that is common to all object stores and workflow systems, such as the LDAP configuration used with the environment
•Components that are available for reuse within the environment, such as fixed content storage devices and marking sets
Fixed content storage devices are a specific class of storage device, for example, IBM Tivoli® Storage Manager that is defined once within a P8 domain, but that can be used by any or all of the object stores to store content.
A marking set is a special construct used to enhance the security model that can be applied to an object store.
•Logical grouping of components to support distributed configurations
Figure 3-2 illustrates the logical relationship between a P8 domain, and its associated configuration information, object stores, and workflow systems.
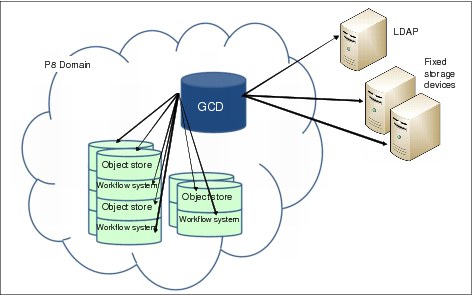
Figure 3-2 P8 domain
Figure 3-3 illustrates the relationship between the components that are used by IBM FileNet Content Manager to instantiate a P8 domain and the software components that comprise the P8 domain.
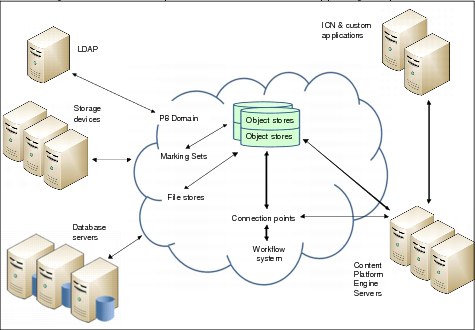
Figure 3-3 Relationship between P8 domain and supporting components
3.1.3 Object stores
An object store manages business content. Each object store manages:
•A database for metadata
The metadata describes the artifacts that are stored in the object store.
•One or many storage areas that represent the physical storage area location of the business content
The storage area can be in a database, a file system, a fixed content device, such as IBM Tivoli Storage Manager, Network Appliance SnapLock, or EMC Centera, or a combination of these options.
A P8 domain can have many object stores. The number of object stores in a domain, and the physical location of the database and storage areas associated with an object store are dependent on your business needs and will be discussed in more detail later in this chapter.
3.1.4 Storage considerations
When creating an object store, you can choose to utilize database storage or storage areas external to the database.
If you choose:
•Database storage, all metadata and document content is stored in the object store database
Use this option when creating object stores that will have little document content. Object stores that fit into this category include ones that are used to store only configuration information, or file plans for IBM Enterprise Records implementations.
•External storage, metadata is stored in the object store database, but the document content is stored externally to the database in a shared file system or on a fixed content device, such as IBM Tivoli Storage Manager
For a full list of supported storage types, see the IBM FileNet P8 Hardware and Software Requirements guide:
Although the type of storage you use is likely to depend on corporate standards, various storage features also drive your decision-making process.
Where and how content is stored are defined using storage policies. Storage policies can be set up at the object store level, the document class level, and on individual documents. For information about defining storage policies, see the following link in the P8 Information Center:
Minimizing storage requirements
IBM FileNet Content Manager provides the following features to help reduce storage requirements:
•Retention management
•Deduplication
•Compression
Retention management
Retention management defines how long content must be kept before it can be deleted. With retention management, a date is set that defines the earliest that content can be deleted. Retention management differs from records management in that it is usually driven by corporate rather than legal requirements.
In IBM FileNet Content Manager v5.1 and earlier releases, support was provided for static retention periods. That is, when a document was added to an object store, you were able to define the minimum period that the document must be kept. Now, IBM FileNet Content Manager also supports dynamic retention.
With dynamic retention, the length of time a document must be kept can be updated at any time by users with the appropriate level of permissions.
Defining retention periods helps with storage management only if you also regularly delete content that has passed its retention requirement. Set up regular jobs to delete content that is no longer needed as described in 4.11.2, “Automatic disposition” on page 139.
Deduplication
Preventing duplicate copies of the same content from being stored in an object store can save a significant amount of space.
A common scenario where this feature is beneficial is when email is archived into an object store via IBM Content Collector. Often, several clients will receive the same email with the same attachments. If the content is stored in a storage area, enabling deduplication will ensure that only one copy of the content is stored. The IBM FileNet Content Manager software tracks the documents associated with the content, and will not delete the content until all the associated documents have been deleted.
Deduplication occurs at the content rather than block level. So, additional space savings can be achieved by also using compression.
Compression
Two types of compression are available:
•If you are using IBM DB2®, consider enabling row compression on large object store database tables to improve application response times.
•You can also choose to compress storage areas. The compression is block-based and, depending on the type of files being stored, might not provide a significant savings. The overhead introduced with this capability can affect both upload and download performance, so test this feature in your environment to ensure that any performance impact is offset by the space savings.
Reducing storage costs
You can reduce storage costs by moving less frequently accessed content to less expensive forms of media. You need to define what is “less expensive” for your organization. For example, some organizations have different tiers of storage so that content that is accessed frequently is stored on “tier 1” storage, while less frequently accessed content is stored on “tier 2” storage. The requirement for a document to be on “tier 1” versus “tier 2” content can change over the life of the document.
IBM FileNet Content Manager provides APIs for moving content from one form of storage to another. To take advantage of this capability, make sure the object store design enables you to identify easily the types of documents that can be moved and when they need to be moved.
Securing content
When content is stored, you can encrypt the data prior to it being stored on the underlying storage (file store, fixed content device, or database).
The requirement for data encryption is set at the storage container level and can be enabled or disabled at any time. When the encryption is enabled, any data added to the storage device will be encrypted, but existing content is not affected by enabling or disabling the encryption capability.
The overhead introduced with this capability can affect both upload and download performance.
Data encryption can be used with the other storage features, including data compression and deduplication.
3.1.5 Workflow systems
A workflow system manages the process-related data. Like object stores, there can be multiple workflow systems in a single P8 domain, but the database tables used to instantiate a workflow system must be collocated with a specific object store database.
Within the workflow system, the processes run inside of an isolated region that acts as an individual processing space. Workflow systems can contain multiple isolated regions, and each isolated region can contain multiple workflow definitions and related data. And although workflows can use content from any object store in the P8 domain, the workflow processing cannot span multiple isolated regions.
For ease of maintenance, a best practice is to segregate isolated regions into separate workflow systems and to associate each workflow system with a separate object store.
Applications connect to an isolated region using a connection point. Connection points are defined at the P8 domain level using the IBM Administration Console for Content Platform Engine (ACCE).
|
Notes:
•The concept of a workflow system is no different than the workflow database of earlier IBM FileNet Content Manager releases.
•Prior to IBM FileNet Content Manager v5.2, the process-related data can be collocated with an object store, or it can be stored in a separate database.
•Clients upgrading from IBM FileNet Content Manager v5.1 and earlier releases are not required to merge process databases with object store databases.
|
For more information about using business processes with IBM FileNet Content Manager, see Introducing IBM FileNet Business Process Manager, SG24-7509.
3.1.6 Management tools
Various tools are needed to build and manage an IBM FileNet Content Manager environment. Some of the tools are supplied as part of the IBM FileNet Content Manager software, and other tools are provided by the vendors of the infrastructure components (database, application server, and LDAP) that are used with IBM FileNet Content Manager.
For example, prior to configuring the Content Platform Engine, use the tools supplied by the database vendor to create the databases and tables required for the GCD, at least one object store, and at least one workflow system. IBM Content Navigator also requires a database in which to store configuration information.
|
Recommendations: Although creating a workflow system is not required when setting up an IBM FileNet Content Manager environment, consider creating an initial workflow system and validating basic workflow functionality when configuring the Combined Platform Engine.
|
After the basic IBM FileNet Content Manager installation and configuration are complete, the database tools will also be needed for tasks, such as backing up the environment, and creating complex indexes to improve performance.
See the FileNet P8 Information Center for a full list of the tasks that need to be completed before starting an IBM FileNet Content Manager installation:
The following administrative tools are supplied with IBM FileNet Content Manager:
•Configuration Manager
Running the Content Platform Engine installation program lays down the software but does not perform any configuration tasks. So, after you run the installation program, use the Configuration Manager to identify the following information:
– The application server to host the Content Platform Engine application and services.
– The LDAP server that will provide the authentication and authorization services required by IBM FileNet Content Manager.
Authentication defines who can access the system. Authorization identifies what clients are allowed to do after they have been authenticated.
– Data sources that identify the databases to be used for the GCD, object stores, and workflow systems.
The Configuration Manager is also used to deploy the Content Platform Engine application ear or war file.
•ACCE
A web-based tool for defining P8 domain and object store configuration data.
ACCE replaces the FileNet Enterprise Manager tool that was provided with previous IBM FileNet Content Manager releases.
•Deployment Manager
A thick client tool used to move object store configuration data and content between object stores in the same or different P8 domains. This tool is also used to reassign object stores to different P8 domains.
Chapter 9, “Deployment” on page 271 in this Redbooks publication provides detailed information about using the Deployment Manager.
•Consistency Checker
Used to validate that pointers in the object store database that reference content in a storage area are correct.
•FileNet Enterprise Manager
A thick client tool used to administer P8 domains and object stores. This tool is being replaced by ACCE.
•Process Configuration Console, Process Administrator, Process Designer, and Tracker
These are Java applets that are started from FileNet Workplace XT and that are used to instantiate a process region, and to design and manage business processes.
3.1.7 Bulk Import Tool
The Bulk Import Tool is installed by the Content Platform Engine installer and is used to add large volumes of documents to an object store. This tool is used only if you have purchased the IBM Production Imaging Edition license.
For more information about using the Bulk Import Tool, see the P8 Information Center:
3.1.8 Hardware layout
IBM FileNet Content Manager can be configured for use with both small and large deployments. Each component can be installed on a single or on multiple servers; you can also collocate all the components on a single server. This flexibility allows the environment to be scaled for both performance needs and to support security requirements.
For example, the application tier, provided by products such as IBM Content Navigator, can be installed within a DMZ. However, the Content Platform Engine is located behind firewalls inside the corporate network. Figure 3-4 illustrates separating elements of the system in different infrastructure security layers.
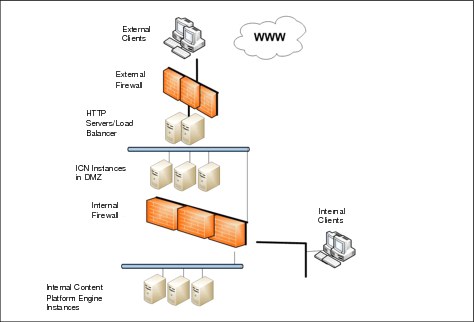
Figure 3-4 IBM FileNet Content Manager configuration based on security requirements
For more details about configuring the hardware layout based on security requirements, see IBM FileNet P8 Platform and Architecture, SG24-7667.
3.1.9 Setting up a sandbox or demo environment
Setting up enterprise applications and associated hardware can be both costly and time-consuming. For a quick start and to gain familiarity with a specific release, consider setting up a single-server configuration of IBM FileNet Content Manager. Use the Composite Platform Installation Tool (CPIT) supplied with IBM FileNet Content Manager to install and configure this environment. CPIT completes the following tasks:
•Installs and configures:
– Tivoli Directory Server as the LDAP
– DB2 as the database server
– IBM WebSphere® Application Server as the application server
– Content Platform Engine
– FileNet Workplace XT
– IBM Content Navigator
•Creates:
– The databases required for the GCD, one content store, one workflow system, and the IBM Content Navigator configuration information
– Administrative user accounts and groups in the LDAP
– The GCD
– One content store
– One workflow system
After the CPIT installation completes, use the single-server installation to perform these tasks:
•Gain familiarity with IBM FileNet Content Manager in general, or the latest new features.
•Define requirements and specifications for new applications or updates to existing applications.
•Start building a new solution or refining an existing solution.
3.1.10 Using Information Center and other product documentation
IBM FileNet Content Manager ships with documentation that can be deployed on a Java EE server, but to ensure you are using the latest documentation, use the information center published on the IBM website:
The Information Center has a number of useful features:
•Setting the search scope to match the components used in your environment
•The ability to print selected topics
For example, use these two features together to generate a custom installation or upgrade guide.
One of the most important guides for anyone setting up or maintaining an IBM FileNet Content Manager environment is the IBM FileNet P8 Hardware and Software Requirements guide. This guide documents the supported types and levels of the infrastructure that can be used with IBM FileNet Content Manager. See the following link to download the guide:
Figure 3-5 illustrates the Home page of the IBM FileNet P8 Information Center. The information center contains information about the IBM FileNet Content Manager and other components in the P8 Product Family that integrate with IBM FileNet Content Manager.

Figure 3-5 IBM FileNet P8 Information Center
3.2 Scalability
When planning for an enterprise-wide system, there are a number of environments to configure, and the workload and scaling requirements for each are likely to be different. Consider configuring the following IBM FileNet Content Manager environments:
•Sandbox
Typically, a single-server installation that can be used by system architects and project leads to learn about new software releases and for demonstration purposes.
•Development
The environment used by the development team to build custom applications for an IBM FileNet Content Manager deployment. The size and configuration of this environment is typically driven by the number of developers on the project.
•System test
The environment used by the test organization and representatives of the client teams to verify that the application being built meets their needs in terms of functionality, usability, and response times.
This environment is also used for integration testing to ensure that elements of a single solution or that multiple enterprise-wide solutions complement each other, can coexist, and interact as expected.
The size and configuration of this environment is usually a scaled-down version of the expected production configuration.
•Load and performance test
The environment used to ensure that the production system can cope with the expected load and provide clients with response times that enable them to complete their work. The system needs to be configured similarly to the production system in terms of hardware and data (both the type of data and the volume need to emulate what is available in the production environment).
•Production fix
When introducing new functionality into a production environment, a best practice is to introduce the changes into development, then promote the changes first to system test, then to load and performance test, and ultimately to the production environment. This path is recommended to help ensure that the new functionality meets both the functional and performance needs of a production application.
However, when following this methodology, occasionally an issue occurs in production that cannot be replicated in the lower environments because they are not running the same software as the production environment.
A production fix environment is a scaled-down version of the production environment that is always running the same level of software as that in production. When a production issue occurs, the fix is first introduced into the production fix environment to ensure that the fix resolves the reported issue and does not introduce any new issues. (If appropriate, the fix, although it might be in a slightly different form, needs to also be introduced to the lower environments.)
•Production
The environment hosting IBM FileNet Content Manager and other applications that provide the required business functionality.
This environment must be built to meet current business needs and be easy to both expand and contract as capacity needs and response time requirements change.
When designing the layout of each environment, consider many elements:
•Expected volume of activity from both automated applications and clients
•Types of activities that will be performed
•Volume of content that will be stored
•Required response times
•Geographic locations that must be supported
When planning for a geographically dispersed environment, the amount of hardware needed at each site can be different.
The IBM Capacity Planner is a tool that provides guidelines on “how much” is needed given your business requirements. For more information about this tool and capacity planning in general, refer to Chapter 8, “Capacity planning with IBM Content Capacity Planner” on page 253.
When scaling an IBM FileNet Content Manager environment, you can choose to scale:
•Hardware using both horizontal and vertical techniques.
•Java virtual machines (JVMs) using application cluster technology, such as WebSphere Network Deployment, or by adding independent JVMs and load balancers.
3.2.1 Horizontal scalability
Horizontal scaling, also known as scale-out, means to add additional computer systems to the existing environment. This approach is common in Microsoft Windows environments. Clients who prefer horizontal scaling distribute applications through a large number of inexpensive machines. Blade servers generally group multiple compact servers in a rack and allow a large number of servers in a small physical space.
3.2.2 Vertical scalability
Vertical scaling, also known as scale-up, means to use more powerful servers or extend the existing ones to be more powerful. This approach is frequently used in the mainframe world and is also available in UNIX and Windows environments. An example is adding more CPUs and RAM to the existing system. Vertical scalability is often used with virtualization (see 3.3, “Virtualization” on page 57). Servers are consolidated and multiple previously stand-alone servers are merged and run virtualized on a large machine.
The core IBM FileNet P8 components can be scaled vertically and horizontally. As an extension to vertical scalability, clients can scale up a server that is running an application server instance with multiple deployed applications. The benefit is better application segregation and more effective use of memory resources.
Instead of just scaling up the server with additional hardware, you can use multiple Java EE instances on a single physical server, with each application running independently in its own Java EE instance. By separating the applications, you achieve more efficient use of system resources.
3.2.3 Clustering
Since Content Platform Engine is a Java EE application deployed on an application server, the system can be scaled out further using the clustering technology provided by the application server. For example, using WebSphere Network Deployment, additional application servers can be configured. The Content Platform Engine, FileNet Workplace XT, IBM Content Navigator, and custom applications can be automatically deployed from the WebSphere Network Deployment management node to these additional servers. The advantage of this type of configuration is easier maintenance because software is updated manually in only one location and the deployment to the managed nodes is automatic.
Figure 3-6 on page 55 illustrates this type of clustering.
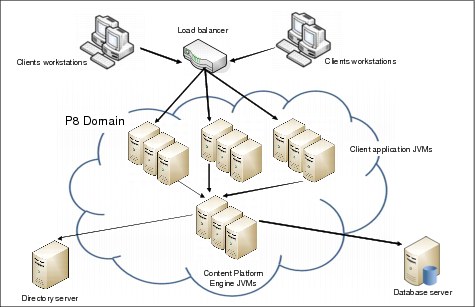
Figure 3-6 Scaling using application server clustering technology
Alternatively, the applications can be deployed independently and load balancers can be used to spread the load between the servers. When using this model, a best practice is to collocate each Content Platform Engine instance with the appropriate client application instance as shown in Figure 3-7 on page 56 to minimize the loss of sessions and resources when a server becomes unavailable. The disadvantage of scaling using this approach is that if either a client application or a Content Platform Engine instance goes down, the client’s session is lost and work might need to be resubmitted. However, the stand-alone application server software used in this configuration is usually less expensive than cluster-aware versions of the application server software.
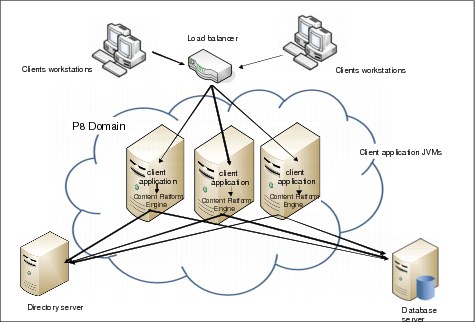
Figure 3-7 Scaling application servers using a stack approach
To distribute the load to the client applications, use an external HTTP server with a load balancer, even when the client applications are installed using an application server clustering technology.
3.2.4 P8 domain and object store scaling
Each P8 domain can contain many object stores, but a practical limit needs to be set based on considerations, such as how long it takes to upgrade to a new IBM FileNet Content Manager release or apply software updates, and the need to roll out applications in different time frames.
There are no specific limits on the number of artifacts in an object store, but from a practical perspective, a limit needs to be identified for each object store. The limit needs to be based on these factors:
•The time required to perform backups and restores.
•The efficiency with which indexes can be created and maintained.
•The performance as perceived by your clients; for example, the larger the data set, the longer it might take to run searches and to add documents.
Other reasons for segregating object stores:
•In global deployments, legal requirements regarding the physical location of any content and the location of the clients accessing the data
•Security requirements
In addition, requirements for workflow processing can influence the need for multiple isolated regions, workflow systems, and object stores.
The IBM FileNet Content Manager makes it easy to add new object stores to an existing P8 domain, and the FileNet Deployment Manager tool also makes it simple to move object stores to new P8 domains. However, to take advantage of these capabilities, custom applications must be designed to accommodate these features:
•When ingesting content, the destination object store must be configurable.
•When searching for content, the search needs to be capable of looking in multiple object stores.
3.2.5 Scaling Content Search Services
When scaling Content Search Services (CSS), you must address both the required indexing throughput and the client search requirements. Like the other components of IBM FileNet Content Manager, the CSS scaling is achieved using both horizontal and vertical scaling of the CSS servers.
Indexing is a CPU-intensive and memory-intensive process, so configurations that allow these items to be scaled are important. In addition, since the text extraction process for the indexing process occurs on the Content Platform Engine, using CSS places an increased load on the Content Platform Engine and therefore requires additional scaling of the Content Platform Engine.
For optimal performance, use separate, dedicated index and search servers.
3.3 Virtualization
Virtualization has become a major trend in the IT industry. The drivers for virtualization are cost reduction and providing better management of hardware resources. Virtualization can be applied over servers, storage, and applications. In this section, we focus on server virtualization.
In general, multiple servers are consolidated into fewer servers and operate inside of their own environment. An abstraction layer between the physical resources and the running application is created. Physical resources are encapsulated as logical resources, and the environment for the application is moved into a virtual machine (VM). The shared resources usually are CPUs, memory, network bandwidth, and hard disk storage.
The benefit of virtualization is better use of the current hardware, because the number of physical boxes decreases, and a physical box becomes a virtual machine. Instead of managing multiple systems, the resource optimization can be concentrated at one point. It also opens new pathways for high availability and disaster recovery, because you can copy entire systems to another location.
Depending on the virtualization technology that you use, the system administrator can assign each virtual machine an individual amount of resources, such as memory or a fraction of CPU resources at run time. This increases system agility and ensures scaling on demand. An administrator can react dynamically to changes in system utilization.
For example, if at the end of the month, usage of a certain virtualized application increases sharply, it can be scaled on demand and assigned more system resources. In that way, the system hardware is used more efficiently.
Another example is systems that are usually idle and have predictable peak times. Given the fact that the peak times occur at different points in time, you can benefit by moving applications from these systems onto one virtualized server.
A third example is systems that are used for training and support. Because virtualization technology provides the option to clone an existing system, you can clone a training system with preloaded data from another system. In the area of client support environments with different operating systems, application version and patch levels can be stored and started on demand. That increases flexibility and speeds up problem deduction, because no time-consuming installation tasks are necessary.
Virtualization approaches differ in the degree of abstraction. In this book, we only provide an overview. For more information about virtualization, see the information provided by the virtualization solution providers.
Virtual machines using virtual machine monitors
Virtual machines (VMs) run on top of a guest operating system. The virtual machine is not aware that it is not running on real hardware. Physical resources, such as a network card, are emulated.
When the VM wants to access resources that are managed in a system context, the access is performed by a virtual machine monitor (VMM). The VMM analyzes the code and provides a replacement function that safely accesses the resources. Figure 3-8 illustrates virtual machines using VMM.

Figure 3-8 Virtual machines using VMM
In certain implementations, the host operating system and VMM are combined into a single layer. Examples of this approach are VMware products or Microsoft Virtual Server.
Virtualization on the operating system level
In this architecture, virtualization is done on the host operating system level. The solution uses a single kernel. Figure 3-9 on page 60 shows the architecture.

Figure 3-9 Virtualization on operating system level
In this scenario, the coupling between the host operating system and the VM is much tighter. Because only one kernel is used, the overhead incurred with this approach is small. However, the disadvantage of virtualization at the operating system level is that it does not allow you to run different operating systems.
The isolation of the single partition is key, because the system operates in one kernel. This is done in the partition management part of the operating system. The resource management, which is where the physical resources such as CPUs and memory are assigned, is also done in the partition management part of the operating system.
This level of virtualization is popular for service providers who offer Internet services or host special services. For this scenario, the low overhead and the automation for replicating and horizontal scaling of virtual servers are key.
3.3.1 A virtualized IBM FileNet Content Manager system
IBM FileNet Content Manager installations can be implemented using a variety of virtual technologies, including IBM logical partitions (LPARs), IBM workload partitions (WPARs), and VMware ESX. For more information about the supported virtual technologies, see the IBM FileNet P8 Hardware and Software Requirements guide.
|
Tip: When performing capacity planning, it is important to identify whether you will be using virtual technologies as this affects the required system resources.
|
Figure 3-10 provides one possibility for deploying an IBM FileNet Content Manager system in a virtualized environment. Multiple virtual machines are involved. Each component is deployed in its own virtual machine, in a separate partition. The figure includes the database server and the directory server, although typically these components are virtualized only in demo or sandbox environments.

Figure 3-10 Deploying each engine in its own virtual machine
This architecture offers the highest flexibility and scalability because of the number of virtual machines that you can have in the configuration.
Collocating engines in a single virtual machine
The opposite approach to multiple single virtual machines is to collocate everything in one virtual machine. See Figure 3-11.
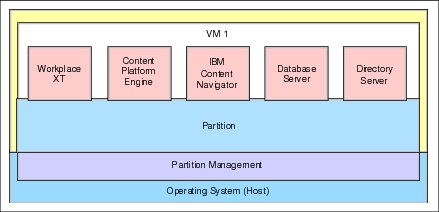
Figure 3-11 Collocating engines in one virtual machine
This approach reduces the complexity; however, scalability is limited. Collocating multiple components in a single virtual machine is suitable for sandbox environments, demo systems, and small development systems.
System duplication
Using virtual technologies can make it easier to duplicate systems, but consider uniqueness requirements when reusing images:
•Host names must be unique and some applications, including WebSphere, are sensitive to host name changes.
•If using a multitiered application solution in a WebSphere Application Server Network Deployment environment, ensure that the cell names are unique at each layer in the tier. See the following article for more details on this issue:
•When using static IP addresses, ensure that duplicate images are updated with new values and that any load balancers are updated to include the new addresses.
3.4 Shared infrastructure
At times, you might want to set up a shared infrastructure. For example, clients roll out IBM FileNet Content Manager as an enterprise-wide solution and want to manage multiple projects on the same system by sharing the resources and infrastructure of the IBM FileNet Content Manager system among the projects.
Another use case is an internal or external application service provider. The application service providers can share the infrastructure with several independent customers or tenants.
In this section, we discuss options for clients using a shared infrastructure model and provide best practices with regard to the requirements.
3.4.1 Communication between the engines
To simplify the description, we use IBM Content Navigator, an out-of-the-box application that comes with IBM FileNet Content Manager, to explain how an application interacts with the Content Platform Engine, object stores, and isolated regions.
How IBM Content Navigator locates an object store
IBM Content Navigator is deployed to an application server. Connections to repositories are defined using the IBM Content Navigator user interface. In addition to being used with IBM FileNet Content Manager, IBM Content Navigator can access Content Manager OnDemand and Content Manager repositories. IBM Content Navigator can also be extended to access other types of repositories if they have a Content Management Interoperability Service (CMIS) interface.
Figure 3-12 on page 64 illustrates configuring IBM Content Navigator access to a specific object store using a specific Content Platform Engine server. In this instance, the supplied URL uses the Internet Inter-ORB Protocol (IIOP) port on a stand-alone WebSphere server. To use a Content Platform Engine deployed on a WebSphere Application Server Network Deployment cluster, the URL has the following form:
corbaloc::node1_hostname:BOOTSTRAP_ADDRESS,:node2_hostname:BOOTSTRAP_ADDRESS/cell/clusters/your_websphere_cluster_name/FileNet/Engine
|
Note: Content Platform Engine can also be accessed via the Web Services transport or Content Engine Web Services (CEWS). Load balancing in this type of configuration is provided by a load balancer and the URL is in the following form:
http://virtual server name:virtual port number/wsi/FNCEWS40MTOM/
Currently, IBM Content Navigator does not support accessing Content Platform Engine using the CEWS transport.
|
After you provide the server URL, and the object store symbolic and display names, click Connect to establish a connection to the Content Platform Engine server. After a connection is established, the other tabs (Configuration Parameters, System Properties, and Browse) are enabled.

Figure 3-12 Configuring access to an object store using IBM Content Navigator
How IBM Content Navigator locates an isolated region
Each workflow system contains one or more isolated regions. An isolated region is a logical subdivision of the workflow system’s database that contains queue, process, and status information. A connection point is used to identify a specific isolated region in a workflow system. Connection points are defined using the Content Platform Engine administration tools.
To identify the isolated region to be used with a particular repository, click the Configuration Parameters tab in the Repository configuration UI as shown in Figure 3-13 on page 65. Then, select a connection point from the Workflow connection point drop-down list box.

Figure 3-13 Defining the connection point in IBM Content Navigator
3.4.2 Data segregation
In the following section, we discuss the options for data segregation.
|
Note: There are multiple approaches to setting up a system, and you must select the methodology that best fits your business requirements.
|
The level of data segregation does not affect the ability to scale the system; instead, choose the level of segregation based on these factors:
•Application needs
– Who needs access to the application and the associated content?
– How often do application updates need to be rolled out?
– Are there conflicting performance requirements? For example, indexes needed to make one application perform well might have a negative impact on a different application.
•Client locations
You can improve performance by locating the databases used by specific object stores and workflow systems local to the clients.
•Legal requirements
When servicing the needs of global customers, be aware of legal requirements for business content to be kept in the country of origin.
•Volume of content
Even when building a single application, there might still be a need to plan for multiple object stores because of the volume of content being generated. Although there are no specific limits on the number of objects that can be kept in an object store, practical limits are driven by these issues:
– Time required to back up and restore the object store database
– Indexes required to optimize search performance
– Required response times for ingestion and by clients performing day-to-day tasks
•Security requirements
The IBM FileNet Content Manager security model is flexible, but if, for example, there is a need for different administrators based on the content or application requirements, these needs might be best addressed by using separate object stores, workflow systems, and isolated regions.
For more information about the IBM FileNet Content Manager security model, refer to Chapter 5, “Security” on page 151.
3.4.3 Levels of data segregation
Data can be segregated in multiple levels.
Shared object store and isolated region
The form of data segregation with the least physical segregation is for all applications to use the same object store and isolated region. In this type of configuration, the way in which security is applied to the object store and isolated region maintains the required segregation between users and projects.
Separate object stores but shared workflow system
In this configuration, the business content is separated into different object stores, but all business processes are managed in the same workflow system.
This configuration is useful in the following situations:
•The workflow load is comparatively light compared to the volume of content being used.
•There is a need to physically locate content in different geographic regions for legal reasons or for better performance.
For example, if you are building solutions for departments that are located in different geographies, storing the content so that it is local to the departments can improve response times.
In this configuration, the workflow system is collocated with the object store that has the content that is used most frequently with a business process.
Separate object stores each with a workflow system
In this configuration, business processes are tightly integrated with the business content. Each object store is secured in a way that ensures that only the project users are allowed to access it.
Each project looks only at its own content and project data, but since the same hardware is used for all projects, the number of maintenance updates that need to be made to the infrastructure is still limited.
Separate P8 domains
To maintain complete independence between applications, use separate P8 domains. Each P8 domain has its own set of hardware (that can be virtualized), object stores, and workflow systems.
In deployments with a large amount of content, it is often necessary to “roll” to new object stores regularly, and eventually, it might also be necessary to “roll” to a new P8 domain. For instance, after 50 object stores have been created in a P8 domain, a new P8 domain can be created to house the next set of 50 object stores. When the new P8 domain is configured, consider moving the most “current” of the old object stores to the new P8 domain using the FileNet Deployment Manager. If the object stores are connected with active workflows, the associated workflow systems must also be moved.
A separate P8 domain can also be used to give a global view of corporate data for reporting purposes. In this type of scenario, Content Federation Services for IBM Content Integrator is used to federate content from various source P8 domains to a parent P8 domain.
LDAP servers, database servers, and storage devices
The use of common or disparate LDAP servers, database servers, and storage devices is also driven by environmental requirements. Typically, the corporate LDAP server is used for all applications. The number and location of database servers and storage devices are driven by capacity, performance, legal, and maintenance requirements.
3.4.4 Degree of sharing
When deciding on a suitable architecture, review the detailed requirements. A good starting point is to examine the security requirements. Does the system need to manage multiple projects using a common security base? If so, we suggest one domain. If the requirements mandate completely separated security, we suggest multiple domains.
Can the different projects share content with each other? If so, we suggest one domain. If not, consider using multiple domains.
If two projects that use different security structures must share data, use federation to make content visible to both projects. Alternatively, use one of these approaches:
•Put all users in a common directory service and secure the content via an access control list (ACL).
•Use federated repositories to create a single realm. For more information about using federated repositories in WebSphere, see the following link:
Another factor that can affect the degree of sharing is maximizing system availability. This aspect of the data sharing design is influenced by the following factors:
•Location of application users
•Maintenance windows for applying infrastructure and custom application updates
•Service-level agreements (SLAs)
We advise that you use the Data Source sharing feature. For more information, see the “Sharing Data Sources” and “Creating a Database Connection” topics in Administering Content Platform Engine:
3.4.5 Cloud deployments
IBM FileNet Content Manager can be deployed into a cloud environment as long as the cloud can meet your requirements for data segregation, location, and security.
The obvious advantage of a cloud deployment is the ability to access data without the cost of maintaining the servers or software. IBM provides a hosted archive cloud in Italy that uses IBM FileNet Content Manager. The Information Archive enables clients to archive content in a private cloud hosted in an IBM data center.
3.5 Geographically distributed systems
In previous sections, we discussed scalability, virtualization, and data segregation. IBM FileNet Content Manager contains a number of capabilities to extend the system geographically and use it as a distributed system with different locations.
Although centralized data centers can be simpler to administer and maintain, they do not necessarily perform these functions:
•Provide the responsiveness needed by the application users
•Meet the legal requirements for locating data in the country of origin
So, it is important to take these considerations, along with the required level of data segregation, into account when designing an IBM FileNet Content Manager system.
|
Tip: Geographically distributed environments are also built to support business continuity requirements for high availability and disaster recovery. Configuring IBM FileNet Content Manager to meet these types of requirements is covered in Chapter 7, “Business continuity” on page 217.
|
3.5.1 Site, virtual server, and server configuration
To address the needs for a distributed system, each P8 domain can be structured to have the hardware hosting the domain in multiple physical locations and configure the logical components to use hardware in specific locations.
A P8 domain is the environment in which all Content Platform Engine servers operate. Domain information is stored in the global configuration database (GCD). The GCD holds all topological information of the domain, such as servers and assigned resources. It contains the descriptive and location information of the subcomponents.
When a Content Platform Engine server is brought online, its first task is to interrogate the GCD to get information about the P8 domain and to store a copy of the GCD information in the working directory of the application server.
If the GCD cannot be contacted, the Content Platform Engine server retrieves the domain information from the cached version of the GCD.
When the GCD cannot be contacted, IBM FileNet Content Manager applications still function. Clients can view, update, and add content to object stores, as well as participate in workflows, but tasks that cause an update to the GCD, such as creating new object stores or marking sets, fail.
|
Historical note: In earlier IBM FileNet Content Manager releases, the Content Engine servers cached a local copy of the GCD in memory so that issues with GCD connectivity did not cause the system to fail. However, if the GCD was offline, the Content Engine servers were unable to start.
|
Figure 3-14 on page 71 shows an IBM FileNet Content Manager system distributed over two locations at a domain level. The system is distributed over two locations: the main location and a satellite location.
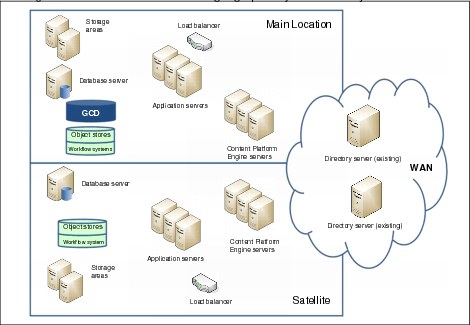
Figure 3-14 Domain level view of a geographically distributed system
A site represents a geographical location. All site resources are well-connected via fast, reliable LAN. There is no functional limit to the number of sites that a single IBM FileNet P8 domain can contain.
A virtual server is the logical service point with which Content Platform Engine clients interact. A virtual server can map to a single independent server instance or to a set of server instances. When a virtual server contains multiple server instances, client requests are load-balanced across the set of server instances through the Java EE application server’s clustering capabilities or through the use of a load balancer that provides scalability and high availability. In either case, applications accessing the virtual server are unaware of the number or type of server instances that reside behind it. There is no functional limit to the number of virtual servers that a single P8 domain can contain. A virtual server can also be configured as an active/passive cluster, although we do not recommend this approach.
A server instance is an individual Java EE application server instance. Multiple server instances (each running in their own JVM) can be hosted on a single physical server. Content Platform Engine clients do not interact directly with a server instance. Logically, clients always go through a virtual server. There is no functional limit to the number of server instances that a single P8 domain can contain.
Figure 3-15 illustrates a hierarchical view of the domain, sites, virtual server, and servers as displayed in ACCE.
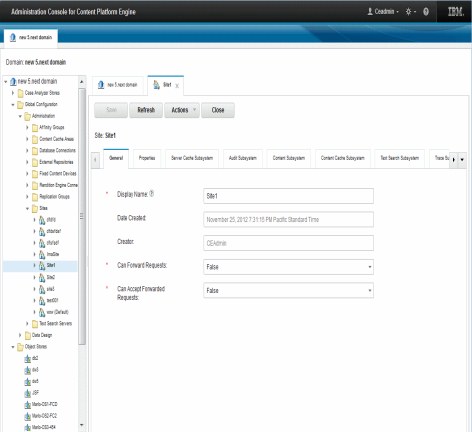
Figure 3-15 Hierarchical view of domain, sites, virtual servers, and servers
This hierarchy simplifies administration, because attributes are inherited from a parent component to its children. It minimizes duplicate configuration. One example is trace logging. If you want to analyze the entire system, you can activate trace logging at the domain level. If you want to activate trace logging only at a special site, virtual server, or server, you can configure it at the appropriate level.
To summarize, dividing a system into hierarchical components is useful for creating a distributed system and simplifies the administration due to the inheritance feature. For more information about domain, sites, virtual server, and server instances, refer to 4.5, “Repository organizational objects” on page 95.
3.5.2 Distributed content caching model
In this section, we discuss the caching mechanism and show the architecture of a geographically distributed system.
Caching is a building block for distributed systems. IBM FileNet Content Manager includes caching at the Content Platform Engine level. It is deeply integrated into the system. The benefits of caching are that it speeds up retrieval and it can be used by any client regardless of who authored the software. Caching addresses content objects and can be used for all types of storage. A document can reside in multiple caches. You can place each cache on the Content Platform Engine server or a network share. Cache servers can be installed at sites where you do not need to perform a full Content Platform Engine installation.
The Content Cache configuration can be customized in the following ways:
•Threshold size
Defines how much space the cache can use before content is removed from the cache.
•Threshold elements
Defines the number of elements that can be added to the cache before content is removed from the cache.
•Amount to prune
Defines the percentage of content that needs to be removed when a threshold is reached.
•Preload content when created
Loads content into the local cache as the content is added to an object store. This feature is especially useful when content is typically used at the same site that the ingestion occurs but the database associated with the object store is at a different location.
If the content is going to be frequently accessed from a site that is different than the one at which the content was ingested, consider developing a custom application to access the content during off-peak hours to load the content into the cache at the remote site.
•Content lifespan
Identifies how long content stays in the cache without being accessed.
When configuring the content cache, you need to be aware of the following information:
•The document content access patterns at each site. For example, will documents need to be viewed within 24 hours of being ingested? Or, are the documents being ingested primarily for archive purposes and are only accessed by clients sporadically?
•Who will be downloading or viewing the document content and where are they located?
If the content is being accessed by clients who are geographically close to the database and storage areas used to store the document information, configuring a specific content cache for those users might not be necessary.
•Any legal requirements regarding the location of content
For more information about using content cache areas, see the following topic in the P8 Information Center:
3.5.3 Request forwarding
When talking about distributed systems, the efficient use of the network bandwidth between the locations is essential.
Request forwarding is used to send requests from a “remote” Content Platform Engine server to a “local” server. In this case, “remote” implies a server that is not local to the object store database that must be accessed to complete the request.
A content cache improves the speed at which clients can view and download documents. However, the request forwarding improves the speed at which processing, for example, a search or an event action, executes because the processing is “pushed” to the Content Platform Engine server that is local to the needed resources. In addition, request forwarding reduces WAN traffic, which also helps overall system performance.
See the P8 Information Center for additional information about request forwarding:
Figure 3-16 on page 75 shows a system distributed over two locations, a main location and a satellite location. Request forwarding is disabled, which is the default setting.
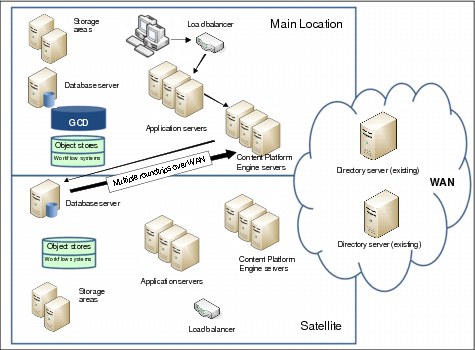
Figure 3-16 Retrieval without request forwarding
If a client on the main location (main) initiates a search request on content residing at the satellite location (sat), the communication goes from IBM Content Navigator (main) to Content Platform Engine (main). Content Platform Engine (main) then contacts the database (sat), and the database data is transferred over the network. Finally, Content Platform Engine (main) communicates the result list back to IBM Content Navigator (main) that presents it to the client.
When Content Platform Engine (main) talks to the database (sat) and searches for metadata, this can require a number of queries, and therefore network round-trips occur to complete the request. If the WAN link between the sites has high latency, delayed response times are the consequence.
Figure 3-17 on page 76 shows the mechanism for IBM FileNet Content Manager with request forwarding enabled.
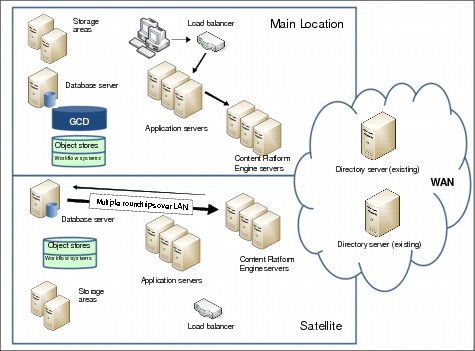
Figure 3-17 Retrieval with request forwarding
When enabling request forwarding, you declare that each defined object store has affinity with a specific site. There are two settings associated with request forwarding: the ability to forward requests and the ability to receive forwarded requests.
Again, the client (main) addresses IBM Content Navigator (main), which contacts Content Platform Engine (main). Instead of directly contacting the database (sat), Content Platform Engine (main) forwards the request to Content Platform Engine (sat), which contacts the database (sat). Content Platform Engine (sat) gathers all data and returns it to Content Platform Engine (main). Again, Content Platform Engine (main) passes the result back to IBM Content Navigator (main) where it is presented to the client.
In general, when request forwarding is configured, client requests to other sites are forwarded to one or more virtual servers at the site associated with the object store. This has the advantage of minimizing the impact of high network latency because the cost-intensive database access is performed locally via the LAN instead of through the WAN.
At the time that a Content Platform Engine server receives a request, it evaluates the request to decide whether to forward it or not. For metadata requests, if all actions in the client request are based on an object store at a different site, Content Platform Engine will attempt to forward it. At the destination site, the administrator enables one or more virtual servers to be able to receive the incoming requests.
Request forwarding is across the Enterprise JavaBeans (EJB) transport layer only and is only supported across homogeneous application servers.
3.5.4 Distributed workflow systems
In IBM FileNet Content Manager 5.1 and earlier releases, workflow processing was handled by a separate engine called the Process Engine and the best practice was to use a centrally located Process Engine. Now that workflow systems are collocated with an object store, as you design your environment, consider the following questions when deciding how to pair up workflow systems with object stores:
•Who will be participating in workflow processing and where are they located?
•Is there document activity as a result of the workflow process and are the documents primarily in a single object store?
Document activity includes using documents as attachments to the workflow or utilizing capabilities, such as the Content Extended operations, as part of the workflow.
3.5.5 Use cases for distributed systems
Let us discuss several use cases and the corresponding architecture. Assume that we have two locations: main location and satellite location.
The main location contains a full IBM FileNet Content Manager system (FileNet Workplace XT, IBM Content Navigator, Content Platform Engine, an object store with a workflow system, file store, database, and Directory Service). You can set up the following options at the satellite location:
•No IBM FileNet Content Manager components are deployed at the satellite location. Only third-party solutions are deployed.
The easiest way to enable the users at the satellite location to use the system is to provide them with the URL of the IBM Content Navigator application (or a custom application) at the main location. You can choose this approach if the satellite location has a similar infrastructure as the main location with high bandwidth and low latency.
An alternate approach is the use of third-party software, such as Microsoft Terminal Server or Citrix, in which the application runs at the main location and only the content displayed in the window is transferred to the remote location. This is a solution for clients who have already deployed this type of technology or for clients who have legal requirements regarding the location of the document content.
•Install IBM Content Navigator only.
Establishing an additional IBM Content Navigator installation at the satellite is a solution for WAN networks, where it is better to have the WAN cloud between IBM Content Navigator and the Content Platform Engine instead of between IBM Content Navigator and the clients. Although the footprint of this solution is small in relation to performance, much better results can be achieved when using caching.
•Install IBM Content Navigator and Content Platform Engine (not recommended).
We do not recommend this setup, because the Content Platform Engine needs to be local to the database for optimal performance.
•Install IBM Content Navigator and Content Platform Engine with a content cache area.
This is the classical scenario for a centralized system, where the satellite users are primarily downloading and viewing content, but they do not perform other types of work on the system. Preloading of content completes the solution, if appropriate.
•Install IBM Content Navigator and Content Platform Engine with a content cache area and request forwarding enabled.
This is the classical scenario for a centralized system, where the satellite uses caching for content retrieval and additional work needs to be done at the satellite in addition to downloading and viewing content.
•Install IBM Content Navigator, Content Platform Engine, and file store (not recommended).
We do not recommend this scenario, because the file store and object store databases need to both be local to the Content Platform Engine for optimal performance.
•Install IBM Content Navigator, Content Platform Engine, the object store database, and the file store.
In this scenario, the P8 domain has more than one object store. Each satellite location has a local object store but can still access data stored in other object stores.
This architecture is useful:
– If users at the satellite location primarily access content only in the local object store.
– An independent satellite must store its own data.
If retrieval from the satellite location to the main location is required, add a content cache area to the main location.
In all the listed configurations, since FileNet Workplace XT is being used primarily as an administrative tool, deploy it at one site only.
3.6 Conclusion
In this chapter, we described IBM FileNet P8 Content Manager architecture. In the next chapter, we provide best practices and recommendations when designing object stores.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.