


Deployment
In this chapter, we describe the deployment for your IBM FileNet Content Manager solution. We provide advice about how to automate deployment from organizational and technical points of view. We describe the repository design elements and the repository infrastructure components that are part of a FileNet Content Manager solution.
When you read through this chapter, you will understand the deployment of a FileNet Content Manager system.
The chapter will give you the following insights:
•Summary
9.1 Overview
Why is deployment important to you?
The most important reason is to ensure consistency in two areas:
•Ensure consistency in your deployment.
•Ensure consistency of the metadata model across the environments and in different stages.
Deployment has different technical meanings. For instance, if you talk to your WebSphere Application Server administrator, the administrator will mostly associate deployment with web or enterprise application deployment via IBM WebSphere Network Deployment Manager Console. As another example, in the IBM Case Manager product, deployment refers to the process of migrating and installing an IBM Case Manager solution that was developed in one environment into another environment.
In this chapter, we discuss the following aspects of deployment:
•FileNet Content Manager data model deployment
•FileNet Content Manager repository deployment
•Discuss the technical and organizational dependencies of FileNet Content Manager deployments in general
In the following sections, you will get information that deployment is defined as a collection of related assets used in an application. At the end, the assets will be packaged together and delivered as an application solution. Therefore, we will treat this package as a solution and talk about solution deployment.
Each deployment starts with the following questions and considerations:
•Which objects need to be deployed?
•What is the source and the destination?
This chapter describes deployment methods and approaches. It provides details about the tools and features available in the IBM products that can be used in the deployment process.
The deployment discussed in this chapter does not cover content migration, upgrade scenarios, or switching to a different platform. Chapter 11, “Upgrade and migration” on page 371 covers some topics regarding upgrading to the current release of FileNet Content Manager as of this writing.
|
Note: This chapter assumes that you are performing the deployment.
|
The next section gives us an overview about technical environments and their organizational role in our deployment strategy.
9.2 Deployment environments
With multiple environments, more people can work on different tasks simultaneously without interfering with each other. For example, you can have an environment for developers to create code, an environment for developers to perform functional testing, and another testing environment for system integrators to test everything. Every company needs a production environment in which only tested and deployed software runs. Development and testing must not be done in the production environment.
Synchronizing the various environments becomes a new challenge. You want to make sure that every environment behaves identically after having the same changes applied. This verification ensures that no surprises occur after deploying to the production environment. Of course, because development and even the test environments usually do not have the same hardware as the production environment, performance and load test results typically differ.
9.2.1 Single stage development environment
A single stage development environment is a FileNet Content Manager development system installed manually or by using Composite Platform Installation Tool (CPIT). Refer to 3.1.9, “Setting up a sandbox or demo environment” on page 49 for more information about CPIT.
Typically, this environment is disconnected from the destination environment where you want to deploy your solution. To be able to test deployment to a different environment, you can create additional object stores within the same FileNet Content Manager domain. The main purpose is to perform a regression test of your solution before it is deployed to the disconnected destination environment. These additional object stores will simulate the object stores targeted by the deployment process in the destination environment for the solution. The additional object store is often called the target object store and the destination environment is also called the target environment.
|
Recommendations: Create at least one additional object store in your development environment to simulate the deployment of your solution to another environment.
|
Another reason to have several object stores in each environment is so that your repository design objects are separate from your data object store when the application runs. In your design object store, you have no instantiated application or solution data. This is advantageous in that you have no technical constraints by deleting a property or changing repository design objects. The repository where the design objects are stored is also called a metastore. For more information about designing a metastore, see Chapter 4, “Repository design” on page 81. IBM Case Manager maintains a metastore automatically for you and is part of the solution design process that is seamlessly integrated in the solution deployment model. In IBM Case Manager, the design object store acts as the metastore.
For more information about IBM Case Manager, see this website:
9.2.2 Multi-stage deployment environments
The term environment in this section describes a collection of servers that typically belong to one FileNet Content Manager domain for one particular purpose. The purpose can be development, regression testing, acceptance testing, load testing, performance testing, or production.
Typical projects split their infrastructure into at least three environments:
•Development
•User acceptance, testing, and quality assurance
•Production
|
Recommendations: Development must not be done in the same environment as the production site or test site. Segregating these activities in different environments avoids the introduction of unwanted configuration changes or code changes by developers before those changes are ready to be tested or put into production. Furthermore, we highly advise that you use the same Lightweight Directory Access Protocol (LDAP) foundation across all stages except the development environment. We discuss the security later in “Exporting user and group information” on page 306.
|
While trying to isolate phases of the software development cycle into different environments, the complexity of maintaining different stages becomes challenging.
|
Note: Maintain deployment in an organized manner to ensure consistency in any case.
|
Larger companies tend to add these additional environments to the basic three environments identified earlier:
•Performance testing
•Training
•Staging
You might add more environments for the following reasons:
•A need to mitigate risks associated with multiple projects running at the same time interfering with each other, while retaining the ability to reproduce errors from the production system in a test environment
•A need for multiple training environments so that many people can be educated in a short period of time
The more environments that you have, the more important it is to maintain and synchronize them correctly.
The segregation of environments by the FileNet Content Manager domain is a best practice. The isolation achieved by this approach is optimal to allow people to work simultaneously and independently on the same project but in different phases without adversely affecting each other. In particular, giving each environment its own FileNet Content Manager domain makes it easy to grant domain-wide permissions in each environment to different groups. For example, developers can be given full permission to configuration objects in the development environment but no permission to configuration objects in the production environment.
The next section provides guidance to set up a formal deployment process before you start using the IBM FileNet Deployment Manager utility in later sections.
9.3 Deployment by using a formal methodology
Establish clear guidelines and common processes for the deployment to ensure that you have the ability to consistently deploy an application. The explanations and graphics in this section will help you to achieve this goal.
In this section, we focus on the following areas of common process management to establish a common understanding of deployment in a software development project:
•Release management
•Change management
•Configuration management
Figure 9-1 provides an overview of a standard software development process.

Figure 9-1 Overview of the processes for software development
Figure 9-1 on page 276 shows three phases of a software development lifecycle: development, testing, and production. Each phase can correspond to one or more individual environments. This lifecycle is the groundwork for our deployment strategy.
|
Note: Development or change running directly on production without using the staging-based approach is a bad practice and can cause loss of consistency.
|
In each phase, the regression testing has a different focus. In development, your automated regression test is done on your local resources. You cannot map these results to another environment. You will get a statement about the functional verification test (FVT) in development. In testing, you can perform system verification testing (SVT) with load and performance tests to get the business requirements verified and qualified. In production, a short functional verification test is typically performed by starting the application and creating test data that has no impact on the production environment and must be reversible.
|
Recommendations: In each environment, always create test data in a dedicated storage area that has no special requirements for retention or security and that is separate from the production storage. You must sanitize the production data that is used as test data for FVT/SVT in each environment.
|
The illustration in Figure 9-1 on page 276 also shows that a change management process is indispensable.
How do you document deployment requirements in a change request as the deployer? As a best practice in typical client situations, you include at least one spreadsheet with multiple worksheets inside that are added to your change management system. This deployment sheet allows you to track the changes that you made across the stages. It also provides detailed history about the implementation schedules and results. We agree that it is absolutely crucial to have a good change management process in place be able to track the same level of detail also for the non-production environments.
In the next sections, we present more details about release, change, and configuration management, as well as testing, before we dive into a discussion of moving the applications from development to production. To understand how deployment works, it is important that you understand how a software development process works.
9.3.1 Release management
Today, it is popular to run component-based architectures (Java EE and .NET applications) and service-oriented architectures (SOA). These approaches transform the enterprise into a highly interoperable and reusable collection of services that are positioned to better adapt to ever-changing business needs.
For example, typically, you can implement a web service that is reused and called by different components of our applications. This can be also a workflow that was exposed by using a WebSphere Service Registry and Repository.
As architectural approaches lead to more reuse and separation, the development of enterprise applications continues to require well-defined processes and more tiers of technology. As a result, certain areas of enterprise application development increase in complexity. In enterprise development (for example, Java EE and .NET), software vendors have made many efforts to reduce this complexity. They provide advanced code generation and process automated tooling and simplify complex aspects of enterprise development through the use of proven design patterns and best practices.
|
Note: It is important to understand the business and technical requirements and to implement them in a systematic and formal way. In a deployer role, you often only get to work with the technical requirements.
|
One way to meet this challenge is by introducing the role of a release manager. In most large companies, this role becomes crucial for large-scale deployments. A release manager is not always one person and can be implemented as a team with diverse technical skills. Additionally, some tasks are distributed to different teams within the company or to external partners as a result of the release management process.
A software release manager is responsible for handling the following tasks and requests:
•Risk assessment
•Deployment and packaging
•Patch management (commercial or customized bug fixes)
For example: operating systems, application servers, and FileNet Content Manager fixes
•From the software development area:
– Software change requests (modifications)
– New function requests (additional features and functions)
•From the quality assurance (quality of code) area:
– Software defects of custom code/commercial code
– Testing (code testing)
•Software configuration management (the rollout of new custom application releases, hardware, and supplier software upgrades)
Select one or more of these roles and match them to job functions in your company to manage deployment.
Later sections of this chapter describe the use of IBM FileNet Deployment Manager. It is important to understand and create a sequence of activities first as a part of the deployment planning.
In general, release management relates to the features and functions of the software; how the software is designed, developed, packaged, documented, tested, and deployed.
A solid release management process can produce the following documentation:
•Project plan
•Release notes
•Test matrix, test plan, and test results
•Installation scripts and documentation
•Support documentation
•User documentation
•Training material
•Operations documentation
The following documentation and information can help the release manager for a FileNet Content Manager solution perform release management tasks:
•Hardware and software compatibility matrices from all involved vendors of your solution.
•Release notes, technotes, and the latest fix packs with their descriptions.
•Available export and import options to deploy the solution between development and production environments.
•Search and replace scripts used to prepare exported assets for use in the target environment where object stores, users, or groups differ from the source environment. Tools required for needed data transformations.
•Deployment guidelines in the IBM FileNet P8 Information Center
•Online help
In addition, the IBM Rational® product line from IBM can be helpful in supporting release management, change management, and testing:
Release management delegates several of the underlying support processes to the change and configuration management that is discussed in 9.3.2, “Change management” on page 281 and 9.3.3, “Configuration management” on page 286.
A release can consist of multiple components in specific configurations of the involved components. Release management handles the validation of combinations of application releases, commercial components, customized components, and others. While a specific component is developed on the basis of a concrete version of its underlying commercial application programming interface (API), at the moment of deployment to production, this combination might have changed in the bigger context of our solution. The management of combinations of versions of involved components is a time-consuming activity and needs to be scheduled and planned carefully and early.
Another aspect of release management deals with objects that have been created in production that affect the configuration of the solution and might affect deployment. In FileNet Content Manager solutions, these types of objects include folder structures, entry templates, search templates, and others. Release management must have a strategy in place to handle or restrict bidirectional deployment between multiple environments.
|
Recommendations: Have a strategy in place to handle or restrict changes to the production environment that might affect the overall solution configuration and future deployment. Have a policy that all application changes must be made first in development and test environments, then deployed to production.
Typically, a bidirectional deployment is only defined between a development environment and a testing environment.
|
We talked about the role of release manager and their organizational tasks in a FileNet Content Manager deployment process. The release manager works with the change coordinator that we describe in the next section of this chapter.
9.3.2 Change management
In most organizations, change management is the process of overseeing, coordinating, and managing all changes to the following areas:
•Hardware
•System software
•All documentation and procedures associated with running, supporting, and maintaining production systems
In the previous section, we discussed the role of the release manager. In this section, we describe the change coordinator role.
With FileNet Content Manager solutions, there are two important points associated with change management:
•The number and details of configuration items needed for a proper deployment
•The creation of an impact analysis to evaluate the effect of the deployment on the satellite systems (Table 9-1)
Table 9-1 Shows a sample impact analysis worksheet
|
Type
|
Component
|
Name
|
Task description
|
Tool
|
Package
|
Notes
|
|
A
|
Property
template
|
MyProperty1
|
Remove
default
value
|
FDM
|
004_SRC_TGT_A_
Properties_
YYYY_MM_DD
|
FDM import
option
always
update
|
|
B
|
Stored
procedure
|
MyProcedureAB
|
Replace
|
DB2-CLI
|
004_SRC_TGT_B_
MyProcedureAB_ YYYY_MM_DD
|
Delete all
previous
versions
|
|
C
|
Web
service
|
MyWebService3
|
Deploy
|
WAS console
|
004_SRC_TGT_C_
MyWebService3_
YYYY_MM_DD
|
Uninstall old web service first
|
Table 9-1 shows an example communication between the change coordinator role and a FileNet Content Manager solution development team. It shows information that is needed to create change requests that relate to different deployment types. In this sample sheet, the change coordinator first identifies the type of deployment used. This worksheet indicates that three IT departments (A,B, and C) of the company will potentially be affected by the entire master change.
The package column shows an example of a naming convention:
DEPLOYNO_SRCSYSTEM_TARGETSYSTEM_TYPE_NAME_TIMESTAMP
With this naming convention, the change requester, if a complaint is made, can determine the package that caused the query. The owner of the deployer role can find the associated log files and change comments. For more information about naming conventions, see 4.3, “Repository naming standards” on page 87.
You create one master change request with three different tasks assigned to your three different departments with their responsibilities and schedules. The order of execution was previously identified by the development team.
|
Tip: Ensure that the dependencies of the deployment types are mapped to your change management system.
|
What are the advantages of separating deployment into different types?
You can see that type A is the job of the IBM FileNet Content Manager administration department. Type B is the responsibility of the database administration department. And, type C is the department that works with application server infrastructure. The dependencies between them might be that a type A deployment can only happen if a type C deployment occurred first.
With this layer-based approach, you can delegate responsibilities to those departments with the appropriate skills. These entities usually have their own process model to implement such changes. At the end, you receive a well-documented and detailed change. This approach improves quality and accuracy due to the involvement of many people, the “many eyes” principle.
Let us look at the change management process in relation to the different software development phases. When the development system is not part of your change management process, the following situations can occur when changes are applied to the development environment without being documented or in an uncontrolled manner.
|
Recommendations: Every change applied to the production system must be carefully tracked, documented, and, where possible, automated. Automation of changes reduces the risks of error-prone manual deployment processes. Every bidirectional change from test to development must also be strictly documented because in a typical three-stage environment, the test environment becomes the master system for production from the deployment point of view.
|
If you inspect the data in Table 9-1 on page 281, you see that some areas outside of FileNet Content Manager are affected but still belong to our FileNet Content Manager solution.
Consider the following areas related to FileNet Content Manager when managing the change process:
•Commercial code and assets (versions of FileNet Content Manager, as well as individual patches and levels of its add-ons, such as IBM Case Manager)
•Custom code and assets (for example, the versions of the application leveraging a commercial API, such as the FileNet Content Manager API, or versioned assets, such as FileNet Content Manager code modules)
|
Recommendations: Deployment starts in the development phase. Incorporate a defined build process that acknowledges changes to commercial components and custom components in a controlled manner. A build process can be established with commercial products, such as Rational, or a manually defined set of process steps and shell scripts that build the custom application. As the deployer, work together with your development team to implement a common build process.
|
In software development companies, there is often a department called the build team. Investigate whether you have a department that can assist you in creating a build process.
At the beginning of the deployment of every custom application or FileNet Content Manager deployment by using IBM FileNet Deployment Manager, we advise you to handle commercial code and custom code separately. For the targeted solution release, everything must be assembled via an automated process if possible in observance of the dependencies.
|
Note: Always keep an integral point of view on the deployment process. If you follow these guidelines, you will treat deployment as a solution.
|
Figure 9-2 on page 284 shows the areas for which you distinguish between custom code (red area) and commercial code (green area):
•IBM Content Navigator
•FileNet Content Manager
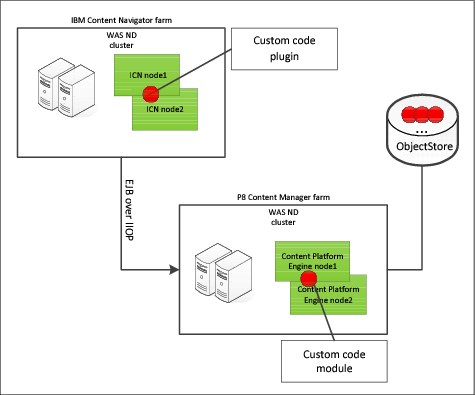
Figure 9-2 Custom code at the level of object store and IBM Content Navigator
Figure 9-2 shows you that a custom application is dependent on the commercial code but treated separately. Part of code works inside the application but has dependencies to parts of the commercial code to make a functional verification successful. Therefore, it makes sense to declare deployment into at least two or three layers with different technical and organizational responsibilities. To determine whether the custom code plug-in inside of IBM Content Navigator has been deployed correctly, conduct a regression test by calling the plug-in inside IBM Content Navigator. The functional verification is done by the business department that belongs to the application layer, not by the owner of the implementer or deployer role.
A regression test of a custom code module in FileNet Content Manager determines whether a new version in FileNet Content Manager has been generated for the code module after running the related IBM FileNet Deployment Manager import package.
Figure 9-3 on page 285 shows the layer-based deployment approach.

Figure 9-3 Layer-based deployment approach
|
Note: From an architectural point of view, this diagram might differ from your environment in distinguishing between the back end and the front end.
|
This three-layer approach shows the differences of deployment types and also the different departments with their responsibilities for the solution. The solution contains the presentation layer (the application tier as shown in Figure 9-2 on page 284) where IBM Content Navigator is running. The IBM Content Navigator depends on a service layer where the underlying configuration database is deployed. The service layer also provides the support for the FileNet Content Manager base layer where your FileNet Content Manager is running. In our example, it is IBM WebSphere Application Server Network Deployment. Each layer has its own deployment type and process.
For more information about the separation of custom code and commercial code and the build process for IBM Content Navigator, see 9.7.5, “Exporting and importing other components” on page 311 and Customizing and Extending IBM Content Navigator, SG24-8055. For more information about the separation of custom and commercial assets during repository design, see Chapter 4, “Repository design” on page 81.
In summary, a layer-based approach is necessary to split responsibilities, reduce risk, and improve the quality of the IBM FileNet Content Manager solution. These layers represent different change requests based on deployment types that are determined by the development team and documented in a common worksheet. A layer-based approach also shows the complexity of deployments.
To speed up the change requests and reduce their complexity, it is essential to automate. The next section describes tooling that can be used to achieve useful configuration management.
9.3.3 Configuration management
Typical FileNet Content Manager projects use three environments, but many projects use five or more environments to satisfy the diverse needs of development, training, testing, staging, performance measuring, and production. Every environment has its own set of configuration items, such as server names, IP addresses, and versions of the various components (commercial and customized).
While an enterprise configuration management database might not be suitable to track all parameters needed for the deployment process, it is the responsibility of configuration management to track applied changes.
From our experience, when performing automated deployments for FileNet Content Manager-based applications, it is generally a good practice to employ a centralized datastore. The centralized datastore tracks the specific values of parameters:
•Object store name
•Object store Globally Unique Identifier (GUID)
•Directory objects’ prefix per environment
•Virtual server name of Content Platform Engine farms
•Virtual server names of Application Engine farms
•Database names
•Database server names
•Ports
These parameter values can be used by the build process for specific environments. It makes sense to keep track also of the access control entries (ACE) from an access control list (ACL) of a FileNet Content Manager repository design object.
Retain a zip/tar file of all release-specific data, including code, exported assets, and documentation, in a central datastore. Typically, you maintain release-specific data by using a code version control system. IBM clients can use IBM Rational ClearCase®, for example.
|
Recommendations: Implement a central datastore that tracks the parameters, such as GUIDs, object store names, and project names, that you need for the deployment. The datastore needs to be implemented for all target environments in one location that is accessible to every environment. The best way is to use this datastore via FileNet Content Manager API to automatically track changes and specifications vigilantly.
|
9.3.4 Testing
There are multiple ways to address environments associated with testing. One way is to split testing into two major phases that typically happen in different environments:
•Development environment
In this environment, the following tests are commonly conducted:
– Unit testing verifies that the detailed design for a unit (component or module) has been correctly implemented.
– Integration testing verifies that the interfaces and interaction between the integrated components (modules) work correctly and as expected.
– System testing verifies that an integrated system meets all requirements.
•Testing environment
In this environment, the following tests are commonly conducted:
– System integration testing verifies that a system is integrated into the external or third-party systems as defined in the system requirements.
– User acceptance testing is conducted by the users, customer, or client to validate whether they accept the system. This is typically a manual testing process with documented expected behavior and the tested behavior.
– Load and performance testing.
|
Recommendations: Whenever a software system undergoes changes, verify that the system functions as desired in a test environment, before deploying to production. Include time and resources to test and make corrections based on testing whenever planning and scheduling a software release. Applying this best practice without fail helps avoid costly and time-consuming problems in production.
|
Regression tests
For all environments, automated regression testing must be implemented to be able to verify earlier test cases. In production, you mostly perform a smoke test, which means testing only the most critical functions of a system. The automated regression testing suite might include from each relevant aspect one test object, such as a test document class, a test search template, a test folder, and a test workflow. In the deployment of repository design objects, it is best practice to deploy repository design objects on the same environment in another object store by using IBM FileNet Deployment Manager utility.
The regression test must be used after having modified software (either commercial or custom code) for any change in functionality or any fix for defects. A regression test reruns previously passed tests on the modified software to ensure that the modifications do not unintentionally cause a regression of previous functionality. Regression testing can be performed at any or all of the previously mentioned test levels. The regression tests are often automated. Automating the regression test can be an extremely powerful and efficient way to ensure basic readiness. The implementation of automated regression tests is time-consuming and the test cases must be adjusted every time a change occurs in the business functionality.
|
Recommendations: Establish a small suite of automated regression tests in each environment. The best synergies are achieved by having the deployment of the test assets and the test script as automated as possible. One side effect is that this automation of regression tests affects the repository design and you must be able to revert changes.
|
Test automation
Two areas of consideration for automating tests are available:
•Load and performance test
•Regression test
While the load and performance test might be executed only on major version changes (commercial or custom releases), the effort to maintain the code for the automation might be substantial.
|
Hint: It is essential that you test with production data. Have a process in place to make production data anonymous before you start testing.
|
If you use the datastore to track all repository design objects, you can revert those changes that were made by your regression suite.
|
Recommendations: Ensure that your testing environment or performance load environment is preloaded with test data. The data inserted by your regression suite must simulate the amount of data generated by average concurrent users to get a baseline performance matrix.
|
The regression test must be generic enough so that the scripts are written once, and maybe updated if there are minor changes, but typically stay pretty stable over time. This approach can be reached by developing a regression test framework. We advise that you store the scripts together with the supporting version of the test application in one location. Typically, this location is your source code version control system.
Test automation tools are available from IBM and other vendors. For example, see the IBM Rational products website:
|
Recommendations: Distinguish load and performance tests from regression tests. Each area has its own characteristics.
You can typically use the existing testing infrastructure for load and performance tests. For regression testing, it makes no sense to use a centralized large and complex infrastructure. It is more important that the tests can be executed and quickly show simple results.
|
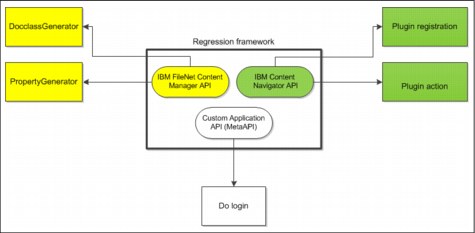
Figure 9-4 Generic framework of reusable regression tests
Figure 9-4 shows an example of a regression framework that can be used to perform basic regression testing of a FileNet Content Manager solution. A framework approach enables more flexibility and reusability during iterative development phases. The framework can be automated by using a script interface and the configuration information is provided by the central datastore.
Your regression suite can contain smoke test procedures.
Test documentation
Before we move to a discussion of the actual deployment, we must discuss the testing documentation and its importance.
In a FileNet Content Manager project, multiple departments with different skill sets are involved. It is difficult to perform user acceptance testing or integration testing without a clear concept of what needs to be tested, how it must be tested, what the expected behavior is, and how the tests must be conducted. This documentation is derived by the requirements analysis of the business needs.
Documenting the test cases with descriptions of the inputs and expected behavior is useful. Test descriptions must have enough information to achieve repeatability, which means that multiple testers can perform the same test (in an identical environment) while working from the test documentation and get the same results. After the execution of the tests, collect and document all of the observed system behaviors. Using this information, the release manager can decide to proceed with the new release or to delay the release if there are more bugs to fix.
Several of the tests might fail. It is crucial to document the behavior but also the resolution. The knowledge base must be part of problem management. Combining test documentation with a searchable interface to find known problems is advantageous.
In FileNet Content Manager and authorization, the detailed, different levels of security must be tested by using an intersection of security principals. More information about security is in Chapter 5, “Security” on page 151.
|
Recommendations: Carefully document your tests with sufficient detail before the tests are executed. Make the test documentation database searchable to search for problems previously seen by users. Create a knowledge database and publish it on a social media platform, for example, in an internal wiki.
|
The social media platform is available from IBM and other vendors. For example, try out IBM Connections. For IBM Connections information, see this website:
9.4 Deployment approaches
The term deployment is typically used in two contexts when mentioned in combination with FileNet Content Manager solutions:
•In a broad sense, the term includes all of the activities that are needed to move from one entire environment to another environment.
•In a stricter sense, the term describes the actual execution. Less frequently, this type of deployment is called migration or transport. It describes the typical automated process of export, convert, and reimport of application-related items, such as application code, configuration settings, and repository assets.
Most of the implementation preparation work occurs in the development environment. In the development environment, the IBM FileNet components, the Java EE and .NET applications, and configurations provide an exportable blueprint for the same configuration that is used for testing and the quality assurance environment. The security configuration can be different and needs to be mapped separately.
There are at least three preferred practices to deploy (transport) changes from one environment to another:
•Cloning (AIX logical partition (LPAR)-based cloning or VMware based cloning)
•Exporting, converting, and importing using the IBM FileNet Deployment Manager utility
•Using scripted generation of all the necessary documents and structures
9.4.1 Cloning
You can deploy changes from one environment to another by cloning the source environment and bringing it up as a new but identical instance of the source environment.
Cloning is practical when you temporarily need a dedicated environment. It must be an exact copy of what you have already in place, for example:
•In a training class, you need to be able to quickly revert or go forward to a well-known working environment (by a teacher over lunchtime) for the next class or for the next part of the lectures. (A few students might not be able to follow the exercises and then are unable to continue with the rest of the class because their environment has not been set up correctly.)
•Many parallel identical training environments are needed to educate more people in a short period of time.
•Development environments are needed to work in parallel.
•Test environments are needed for specific tests.
You can use local VMware based images to clone a system. For a large system, however, this might not be a workable solution. Large systems are often not as flexible as small systems, or there is a lack of powerful machines that can be made available in a timely manner for cloning. Sometimes, the security and networking policies do not allow these virtual environments to connect to back-end machines.
|
Note: IBM AIX LPAR-based cloning and IBM AIX workload partition (WPAR)-based cloning are alternatives to VMware based cloning. The cloning methods that you use depend on your infrastructure. For more information, see IBM FileNet P8 Platform and Architecture, SG24-7667.
|
The next logical step is to use virtual farms that host applications at larger client sites. This approach might not be practical for the following reasons:
•From the corporate network, they cannot be accessed unless using remote desktop applications. A direct interaction is not possible due to using the same host names and IP addresses multiple times in the same network.
•Single virtual images are typically not powerful enough for the full stack of components that are needed for a solution (the stack includes the directory server, database, application server, and other FileNet Content Manager components).
A good way to still rely on virtualization techniques is described in 3.3.1, “A virtualized IBM FileNet Content Manager system” on page 60. The solution is built on individual images hosting the various IBM FileNet P8 components, including the database and directory server. The images are accessed by a gateway, which shields the network topology of the FileNet Content Manager solution from the corporate network by using network address translation (NAT) and virtual private network (VPN) access.
You clone an environment by copying all files representing the storage of virtual images. With this approach, you can clone an environment within hours with little knowledge. Use this approach predominantly for development and training.
For cloning, consider the following topics:
•Action plan (execution order, manual tasks, and script environment)
•Virtualization technology (native virtualization and para-virtualization)
•Storage technology (logical volume mirroring)
•Post-cloning activities (host name and network preparation)
9.4.2 Custom-scripted export, transform, and import
A common way of deploying an environment is the process of exporting, transforming, optionally installing, and importing. A key advantage of this approach is that it allows you to carry forward incremental changes from the source to the target environment without requiring the recreation of the entire target environment. The major difficulty with this approach lies in the number of dependencies between different components and the number of manual steps that are needed to achieve a target configuration that matches the source configuration.
In the past, we have seen projects struggle for months when using a manual process to move Java EE applications that include FileNet Content Manager components. Today, we can deploy similar projects in 1 - 2 days. The following factors contribute to the improvements:
•Introduction of a solid release management process
•Separation of commercial code from custom code and automation of the build process mainly for Java EE based or .NET based applications
•Adherence to the proposed guideline of stable GUIDs to reduce dependencies
•Implementation of a central datastore (database-based or file-based) in which environment-specific information is stored and serves as the datastore for scripting
•Automation wherever possible
Deployments typically apply assets from the development environment to the testing environment. The production environment typically receives deployments from the testing and acceptance test environment.
There are cases for which you might consider the reverse:
•Documents with configuration characters, such as search templates, add entry templates, custom objects, and folders, that have been created in a production environment. (This raises the question of what a release needs to contain and restrict.)
•Hot-fixing a serious production problem in the staging area.
•Refreshing and populating a training environment or acceptance test system with anonymized or obscured production data.
For example, you can use IBM InfoSphere® Optim™ Data Lifecycle Management Solutions to anonymize or obscure production data:
•The activity for transformation can take place as described in Deploying IBM FileNet P8 applications in the IBM FileNet P8 Information Center, before or just after import. Custom scripts can be called to make the necessary transformation. The transformation can also be conducted on the exported files before importing. The IBM FileNet Deployment Manager utility has a script interface. This script interface allows you to run a code fragment on each object before or after import. Furthermore, it allows you to run a script once before or after import. You can combine all four of them. For more information about the IBM FileNet Deployment Manager utility, see the IBM FileNet P8 Information Center where you can find an example of creating marking sets during import.
9.4.3 Scripted generation
This approach assumes that after a basic object store has been generated, every property template, document class, folder, and other structural asset is generated by a script.
This approach has been proven to work, but the effort to maintain this type of script is huge and every change must be put into the script code. All of the benefits of using a tool, such as the IBM Administration Console for Content Platform Engine (ACCE) (or IBM FileNet Enterprise Manager, are lost with this approach. There is little benefit in using this approach unless it is to overcome limitations where there is no alternative.
Nevertheless, this approach can be used to create basic structures, such as a P8 domain, create generic object stores with their add-ons, marking sets, folder structures, or maintain application roles.
For object stores and their add-ons, you can customize the schema script that is used to generate the object store tables over Java Database Connectivity (JDBC). The advantage of customizing the script is to create custom indexes. With a customized object store add-on, you can create specific metadata for your custom FileNet application.
The script-based approach has a problem because every change within the FileNet Content Manager master system needs to be synchronized with the script source. You can develop a wrapper to perform this work but developing a wrapper can be time-consuming. In the next sections, we describe other FileNet Content Manager population techniques.
9.5 Deployment based on cloning
One of the biggest challenges to making an environment clonable is the system dependencies that cannot be easily removed, such as the dependencies related to a Microsoft Active Directory. Changes might take time to implement and can impede the cloning process.
Figure 9-5 on page 296 illustrates that each source LDAP can be replicated to its own instance and serve as the dedicated LDAP for your FileNet Content Manager environment.

Figure 9-5 Example of LDAP replicas
Figure 9-5 shows using IBM Tivoli Directory Integrator or the Active Directory Lightweight Directory Service replicating from a Microsoft Active Directory. Additionally, you can enable referrals in each naming context to have a distinguished name (DN) available that does not exist in the current naming context. Referrals are not problematic if you have UserPrincipalNames (UPN) enabled in FileNet Content Manager across the naming contexts due to the unique short name requirement.
|
Recommendations: When introducing FileNet Content Manager to your company, use a dedicated LDAP provider for FileNet Content Manager. This can be achieved by using IBM Tivoli Directory Server or Active Directory Lightweight Directory Service (AD LDS) with unidirectional synchronization, if necessary, and illustrated in Figure 9-5 on page 296. This gives you the ability to maintain the security principals by yourself and reduces organizational dependencies to other departments significantly.
|
9.5.1 Cloning an object store
Follow this manual procedure to clone an IBM FileNet Content Manager object store where the IBM FileNet Deployment Manager reassign object store functionality is not available.
To clone an object store, follow these steps:
1. Create an empty object store database with minimum requirements.
2. Create a data source on your application server pointing to the empty object store database.
3. Create in the target P8 domain an object store that has the same name as the object store from the source P8 domain. (Now, we have created a container in the global configuration database (GCD) for our object store from the source P8 domain that will later be “partially” incorporated.)
4. Shut down IBM FileNet Content Manager.
5. Bring the source object store database online.
6. Change the data source defined in step 2 to match the database defined in step 5.
7. Start IBM FileNet Content Manager.
This procedure does not preserve the GUID of the source object store and can be used to incorporate an object store from a different IBM FileNet Content Manager P8 domain. If the source P8 domain uses a different naming context, the security objects might not match with your target P8 domain.
When this procedure is completed, you can delete the object store database that you created in step 1.
9.5.2 Topology
Figure 9-6 illustrates a clonable topology with three identical environments that use VMware images. Every domain is formed by a collection of servers that are part of multiple VMware images. All images of one domain are connected over a private network to a special image that is called the router. The router implements network address translation (NAT) and virtual private network (VPN) gateway functionality by using tunneling over Secure Shell (SSH) or other products. The other network link of the router is mapped to a network card that has access outside, which can be to the corporate network.
To clone the environment, only the router image needs to be modified and the public interface needs to be set up correctly. An IBM Content Navigator instance resolves the Domain Name System (DNS) of the router image.
|
Note: This approach is useful for development environments only.
|

Figure 9-6 Three identical environments using VMware images
Figure 9-6 shows how an access to a FileNet Content Manager domain can be established by using a separate gateway for each environment.
Cloning offers these advantages:
•Automatic provisioning of environments by using a master clone
•Less effort to create a FileNet Content Manager environment
Cloning has this disadvantage:
•The clone system is static with a fixed version and patch level since it is based on a master clone that was created at one point in time.
9.5.3 Access to the environment
There are two clients:
•The user’s workstation
•A development system hosted on VMware running on the user’s workstation
Even though a large group of developers might have all of the tools necessary to perform their tasks, developers might prefer a pre-configured image to run on their individual workstations. If Microsoft Active Directory is used, use a VMware image that was initially part of the same Active Directory.
9.5.4 Post-cloning activities
After cloning this environment, consider resetting passwords and generating new users and groups for the project. These tasks need to be automated as much as possible.
9.5.5 Backup changes
There is no real benefit in backing up a cloned environment because it can be created again easily with less effort.
9.6 Deployment by export, transform, and import
In this section, we discuss deployment by export, transform, and import either for a full or incremental deployment.
9.6.1 Incremental deployment compared to full deployment
The two major types of deployments are a full deployment and an incremental deployment. A full deployment for a FileNet Content Manager solution means that both the structure information and the content are deployed in one iteration. The target environment gets everything with the assumption that the target object store is empty.
An incremental deployment for a FileNet Content Manager solution means deploying only the changes that have been made since the last deployment. Documents, custom objects, and other objects might have already been instantiated. New changes to the structure must respect the associated constraints.
Before you run the import, you must choose one of the following options:
•Update If Newer
•Always Update
•Never Update
The system property DateLastModified is used by the IBM FileNet Deployment Manager utility to determine whether if an object has changed. This information is required if using the “Update If Newer” option.
Full deployment is a powerful vehicle to move a project the first time through the various stages of deployment. A project includes creating test deployment systems, and, possibly, multiple production systems. So, you can perform multiple full deployments for the project. For test systems, you might clear them out and fully deploy them again. For the production environment, you only perform a full deployment one time for your project.
After populating a production object store with documents, it is impractical to perform a full deployment to the production object store for the following reasons:
•The number of documents that you need to move from production into development and then propagate back is typically too high.
•Security restrictions often prevent us from moving production data to other environments.
•The production system cannot be stopped during the time that it takes to create the next release.
•The duration for moving documents is much longer than just applying structural changes.
•There are documents created in production that have configuration characteristics, such as search templates and entry templates. If you perform a full deployment, you must also move them back to the development environment and propagate them back.
An incremental deployment means the propagation of changes that will transition an environment from a certain status (existing release) to a new status (new release).
There are multiple ways to figure out the differences between the two releases:
•Manually
•By strictly rolling forward changes from the source environment to the target environment and preventing any changes to the target environment between releases
•Automated discovery of the differences
Manually detecting the differences between the source environment and the target environment is time-consuming and error-prone. This option is only valid for small deployments or if the difference is related to only one asset type, such as an instance of the custom object class.
Clients typically choose the second option with the consideration that someone has manually verified both environments. In a multi-stage environment, there is a good chance that mistakes in this approach will be detected in the first deployment step from the development environment to the test environment. When errors are detected at this point, there is an opportunity to fix the underlying problems and retry the same procedure. As soon as the deployment to the test environment passes testing (and is documented), the future deployment to production most likely works smoothly.
The third option is extremely difficult to achieve and potentially too expensive. There are many exceptions when just comparing date times between the various environments. A development or source environment might include more objects than will be used for the target deployment. So, a selective tagging of objects, which are part of a release, seems to be mandatory.
9.6.2 Reducing the complexity of inter-object relationships
GUIDs reduce the complexity of inter-object relationships. A Globally Unique Identifier (GUID) is a 128-bit data identifier, which is used to distinguish objects from each other. If there is a need to merge objects from multiple object stores into a common object store, GUIDs ensure that the objects maintain their uniqueness and that they do not collide with each other in the common object store.
When moving objects between multiple environments, you must consider dependencies. Objects are often dependent on other objects in the object store or on external resources, for example:
•An entry template references a folder and vice versa. In FileNet Workplace XT, you can associate entry templates to a folder. This type of dependency is automatically considered by IBM FileNet Deployment Manager.
•An application’s stored search definition is an XML document in an object store. The XML content references multiple object stores by name and ID. This type of dependency is automatically considered by IBM FileNet Deployment Manager.
•A document references an external website that contains its content. This type of dependency has to be maintained manually.
FileNet Deployment Manager can convert some external dependencies, such as URLs that are referenced by form templates.
For inter-object store dependencies, you can keep the identification of these objects (GUIDs) consistent across various environments. This is not in contradiction to the previously mentioned uniqueness of GUIDs, but it is a consequence for two reasons:
•The objects, which are considered to be kept consistent with the same GUIDs across object stores, have configuration characteristics, such as document classes, folders, property templates, entry templates, search templates, and others.
•The predefined population of an object store after you run the object store creation wizard follows the same pattern.
In Figure 9-7 on page 303, we show two options to deploy a search template that has a dependency on a folder structure. Although you might argue that there are better ways to reference folders by referring to a full path, you might discover similar situations where there are good reasons to depend on a GUID. In the first option, we followed the practice of using stable GUIDs, which we did not follow in the second option:
•Deploying the folder with the same GUID leads to no additional corrections deploying the search template above.
•Deploying the folder and letting the system generate a new GUID leads to a situation where the search template must be changed to refer to the deployed folder.
You can avoid the extra effort of maintaining the dependencies in the target environment by following the pattern of having stable GUIDs.
Figure 9-7 on page 303 illustrates the deployment from development with stable GUIDs in the top box on the right. Not following the stable GUID pattern might require maintaining the dependencies with additional deployment logic.

Figure 9-7 Example of using stable GUIDs
If you use IBM Forms, you must use stable GUIDs across all stages, especially for the version series IDs of workflow definitions.
9.6.3 Deployment automation
The more environments that you need to maintain, the more important it is to automate the deployment to achieve the following goals:
•Save time.
•Reduce errors.
•Reduce risks.
•Ensure similarity among environments.
•Reproduce problems.
The IBM FileNet Deployment Manager utility contains a command-line interface to perform this automation. Examples are in “Automate FileNet Deployment Manager operations from the command-line interface” in the IBM FileNet P8 Information Center.
9.7 FileNet Content Manager deployment
The process of deployment by using the IBM FileNet Deployment Manager utility is described in “Deploying IBM FileNet P8 applications” in the IBM FileNet P8 Information Center on the IBM FileNet support site.
|
Important: The use of IBM FileNet Enterprise Manager for performing FileNet Content Manager deployments is deprecated. Use the IBM FileNet Deployment Manager utility instead.
|
|
Tip: The IBM FileNet Deployment Manager utility has no customizable query interface so you need to use FileNet Enterprise Manager to perform a custom query and put the results into an export manifest. This export manifest, which is generated by FileNet Enterprise Manager, can be used in IBM FileNet Deployment Manager to perform the remaining export and import steps, including conversion.
|
The IBM FileNet Deployment Manager utility offers a consistent way of performing deployments across different stages and environments. It can be used to deploy data between disconnected FileNet Content Manager systems even if these systems use different LDAP providers and different security principals.
It offers a powerful mapping interface with automatic mapping if the symbolic name of the object store or the short name of a security principal is the same.
We need to know which data can be used for export.
There are three major types of objects to be exported:
•Structure (such as document classes and folders)
•Configuration documents (such as templates, subscriptions, events, custom code modules, and workflow definitions)
•Business documents (images)
Configuration documents do not contain business content but contain configuration information that is used by an application. Configuration documents might need a transformation step before being deployed to the target environment, because they might hold information about dependencies. The majority of configuration documents are automatically converted to match the target environment by the IBM FileNet Deployment Manager utility.
|
Note: Workflow definitions will be treated as content elements but not automatically transferred to the workflow system. You can use the post-save script interface of IBM FileNet Deployment Manager to transfer them to the workflow system by using a Java script.
|
Business documents contain business information and are viewed by users. Business documents typically do not need transformation when they are deployed, because they have no internal or external dependencies.
9.7.1 FileNet Content Manager export
When preparing an export, you need to consider the granularity of the export. It is usually a bad approach to include everything in one export run. If you need to fix a problem, addressing smaller chunks of data rather than one huge XML file makes troubleshooting easier.
Known successful deployments use the following practices:
•Break the deployment apart into a hierarchy of exports.
Example: Document class definition with or without its property definitions
•Strictly separate configuration documents from business documents.
|
Recommendations: Reduce the complexity of exporting by splitting a large export into smaller logical chunks. Separate structure and configuration documents from business documents.
|
Hierarchy of exports
Build a logical hierarchy of exports, which can help you to test the imports sequentially.
Configuration documents, such as entry templates, are documents that include content elements and they are stored as an XML file in the repository. Document class definition is a database object with no content elements. Exporting a document class definition with its property definitions is a simple transaction, whereas exporting a configuration document involves exporting the content elements.
Certain objects, which include all FileNet Content Manager domain-level objects, cannot be exported.
There are Application Engine-related objects that cannot be exported as well. See 9.7.5, “Exporting and importing other components” on page 311.
There is a general export and import sequence:
1. Marking sets
2. Choice lists
3. Property templates
4. Security templates
5. Class definitions (including document, custom object, folder, and so on)
6. Entry templates
7. Stored searches
8. Class subscriptions
9. Event actions
10. Code modules
11. Documents (configuration documents and real documents)
This list is incomplete. We outline the sequence in order to explain the dependencies. There are other workflow system-related assets, such as workflow event actions, workflow subscriptions, and workflow definitions, that are not mentioned here. For more detail, see “Deploying P8 applications” in the IBM FileNet P8 Information Center.
|
Recommendations: Consider the hierarchy of objects and their dependencies by importing them in an order that dependencies can be resolved manually. Inspect the “import options” for each asset in IBM FileNet Deployment Manager utility to find out which dependencies are automatically resolved. If you repeat an export/import, sometimes it does not make sense to include the dependencies in the export package again.
|
Exporting content
Usually, content is versioned. For configuration documents, it does not make sense to export “all versions”. The most recent version is the best choice, so as a rule, discard earlier versions. If you import them to the target system, keep only one version.
Exporting user and group information
When deploying between environments that use different directory servers or different contexts of one directory server, user and group information must be mapped to the target environment. User and group information is contained in the access control lists that are present and that control the access to almost every exported object. User and group information might also be contained in object-specific fields of certain types of objects (for example, entry templates and workplace user preferences). The user and group information must be set correctly before the actual deployment occurs.
|
Recommendations: If you deploy across different environments, do so in the same LDAP context. However, for large environments, the testing and load-performance environments typically do not use the same LDAP as the production environment for security purposes. In this situation, use separate replicated LDAP servers for testing.
|
It is time-consuming to map changes in users and groups manually, because the exported assets have different security in the source and in the target. To overcome this issue, the IBM FileNet Deployment Manager utility offers the use of a “label file” where short names of the security principals from source and target are mapped in advance. In most cases, the initial security on configuration objects does not change often and you are using LDAP groups to maintain security. Another method is to retrieve principals from the target LDAP by using the half map file of the source system. In this case, you need to have identical short names for automatic mapping.
The label file approach has two advantages:
1. Mapping security principals from a disconnected development environment to a testing environment is possible. You have to know which target LDAP principal is matching each source LDAP principal. With this method, you can reassign group A to group B even in the same LDAP.
2. No full LDAP query is performed.
If you deploy data within the same LDAP context, you will choose to retrieve from the half map file to obtain the security principals from the target system. This procedure also does not need to retrieve the entire LDAP.
Automating the export
The IBM FileNet Deployment Manager utility has a command-line interface to generate deployment packages for the three types of deployment data.
Automating the export is not limited to exporting FileNet Content Manager objects. There are other tools available for exporting workflow system-related data. For a list of export and import utilities, see 9.7.4, “IBM FileNet Deployment Manager” on page 309.
9.7.2 CE-objects transformation
Various exported assets need a different treatment for a successful import into the target object store. Table 9-2 shows a partial list to give you an idea of how to distinguish the options.
Table 9-2 FileNet Content Manager assets and transformation
|
Type of asset
|
Transformation required
|
Remarks
|
|
Property Templates
|
Not required
|
Import with the same GUID.
|
|
Choice Lists
|
Not required
|
Import with the same GUID.
|
|
Document Classes
|
Not required
|
Import with the same GUID.
|
|
Workflow Definitions
|
Required
|
Import with the same GUID. Contains references to environment-specific constants, such as Object Store Name and external references for web services.
|
|
Folders
|
Not required
|
Import with the same GUID.
|
|
Search Templates
|
required
|
Import with the same GUID. Contains reference for searching symbolic name of object store within the search XML.
|
|
Entry Templates
|
required
|
Import with the same GUID. Contains reference to the display name of the object store in a document property. Within the XML, there is only the symbolic name of the object store stored.
|
|
Events
|
Not required
|
Dependencies to subscriptions.
|
|
Code Modules
|
Not required
|
Dependencies to subscriptions.
|
|
Subscriptions
|
Not required
|
Can have dependencies, for instance, to Workflow Definition or for Class Definition.
|
|
Business documents
|
Not required
|
Import with the same GUID.
|
The transformation handles the following issues:
•Map security principals
•Map object store references
•Map service references, such as URLs
The transformation does not handle the following example:
•Custom URLs, for instance, using the FileNet Workplace XT base URL is not covered by transformation.
|
Note: IBM is not responsible for testing and supporting your exported files and objects. Always test them in a non-production environment before you deploy them to a production environment.
|
9.7.3 Content Platform Engine import best practice
Importing the exported and transformed objects using the IBM FileNet Deployment Manager utility is straightforward by using the order that is presented in “Hierarchy of exports” on page 305.
The following common errors might occur at this stage:
•User and group information has not been updated to match the target environment, so users cannot access the objects as expected. The conversion process fails.
•Objects on which other objects depend do not yet exist in the target environment. Create the objects in the correct sequence.
•You have an object store metadata refreshing problem. Ensure that you refresh the IBM FileNet Deployment Manager after the import. Sometimes, the best practice is to close the IBM FileNet Deployment Manager utility and open it again.
•You have circular dependencies. For more information, see “Deploying P8 applications” in the IBM FileNet P8 Information Center.
•The import options have not been set correctly.
•An import process was interrupted by a transaction failure. Check the “Always update” option.
|
Tip: Remember that the IBM FileNet Deployment Manager utility uses multiple transactions during the import process and performs prefetching. So, if the import process fails for a particular package, some transactions are complete and others are not.
|
•The reuse of GUID has not been checked.
|
Recommendations: Do not use a generic administrative account for importing objects. Do not set the special security that is needed by IBM FileNet Deployment Manager for the entire object store administrators group. Always use a dedicated administrative user who has special security enabled for the object store.
|
9.7.4 IBM FileNet Deployment Manager
This section provides general information regarding IBM FileNet Deployment Manager.
There are existing documents that you can reference when you use FileNet Deployment Manager:
•Proven Practice: IBM FileNet Deployment Manager 5.1 Data Migrations
•Migrating IBM Case Manager solutions using FileNet Deployment Manager and Case Manager Administration Client. (This document is valid also for FileNet Content Manager only.)
•Impact of a FileNet Deployment Manager import using the “Update If Newer” option without the “Use Original Create/Update Timestamps” option
•FileNet Deployment Manager fails to import the documents of a certain version series if one of those documents references an object that appears after the document in the deploy data set (explanation of object hierarchy)
•MustGather: FileNet Deployment Manager (FDM)
Hints
When using the FileNet Deployment Manager, remember this list:
•IBM FileNet Deployment Manager is able to transfer objects between different FileNet Content Manager domains within a single compressed file containing all the exported content.
•Object store transplantation between different FileNet Content Manager domains can occur by using the object store reassign function.
•Change the total transaction time to be longer for your connection pool to keep long running import processes active.
•Always inspect the FileNet Content Manager log and IBM FileNet Deployment Manager log after you import. Create pattern matching search strings to extract the data that you need.
Default export and import utilities
There are several default export and import utilities that you can use:
•IBM FileNet Deployment Manager utility and command-line interface
•IBM FileNet Enterprise Manager export/import manifest GUI and ImpExpCmdTool.exe
•WFDeploymentTool.exe
•WFAttachmentFinder.exe
•Process Configuration Console and peObject_export.bat and peObject_import.bat
9.7.5 Exporting and importing other components
In this section, we address exporting and importing the database, full text index, Directory Service Provider, Workflow System, and FileNet Workplace XT.
Database
All changes to rows in the object store database are covered by exporting and importing objects as previously explained.
In addition, you can consider propagating changes that have been applied at the database level, such as adding additional indexes, changing server options, and others. You can typically accomplish this function by extracting the index-related information from the SQL-based scripts that were written to configure the database in the source environment. Check whether the scripts depend on infrastructural information, such as user ID, password, server name, IP addresses, and database name.
Full-text index
Content-based retrieval (CBR) is covered in 4.12.2, “Content-based search” on page 141 and Chapter 11, “Upgrade and migration” on page 371.
Directory Service Provider
You can move parts of a directory either by exporting, transforming, and reimporting the parts by using tools, such as ldiff, or by writing scripts that create users and groups and add the users as members of the groups. The other method is to use IBM Tivoli Directory Integrator.
In any case, you must map the users, groups, and memberships to the target environment, which depends on the security settings in your company. If possible, use the same scripts and transform them based on a naming convention. This step needs to happen prior to the Content Platform Engine import.
Workflow System
Workflow System export and import are straightforward by using the Process Configuration Console or the command-line interface, which supports both full and incremental deployments.
The underlying workflow system APIs contain all the required methods to move Queues, Rosters, and EventLogs, and to validate Workflow Definitions.
You can export the Workflow System configuration by a call to the Workflow System Java API. The import into the Content Platform Engine works in a similar way.
If you currently use other Workflow System features or services, see “Deploying P8 applications” in the IBM FileNet P8 Information Center.
FileNet Workplace XT
Whenever FileNet Workplace XT applications have to be moved between environments, there are business assets and application configuration assets to be deployed.
FileNet Workplace XT stores various objects in an object store:
•Site Preferences
•User Preferences
•Entry Templates
•Stored Searches
•Search Templates
•Application Roles
We have already discussed the business assets under the export, transform, and import process. We do not need to provide further explanations from a methodology point of view.
Table 9-3 provides a short summary about these assets.
Table 9-3 Summary
|
Asset type
|
Automatic transformation?
|
Remarks
|
|
Site Preference
|
No
|
Can be put in place by checking out the Site Preferences manually and checking in the new transformed version.
|
|
User Preferences
|
No
|
Try to avoid deployment and instead customize the general MyWorkplace style for all users; this will save you significant effort.
|
|
Entry Templates
|
Yes
|
Deal with security settings, folders, document classes, and default values.
|
|
Search Templates
|
Yes
|
Dependent on object name and GUID. Remember there are two content elements per object.
|
|
Application Roles
|
No export/import possible
|
Circular references cannot be maintained.
|
FileNet Workplace XT is a web application that spans one war file, which contains the relevant Java APIs to connect to FileNet Content Manager.
9.8 Conclusion
We learned that deployment is divided into two major parts. The first one is the organizational part where you ensure that deployment is comprehensive by using a compliant process that is derived from the software development process. You as owner of the deployer role will be involved in each phase of development but the majority of work is performing the change and configuration management. Deployment without having a strategy in place causes inconsistency sooner or later. The second part of deployment is the procedural part of deployment.
This chapter also contained information about useful techniques and tools for deployment. We included samples of different ways of deploying based on the different kinds of data migrated between the environments. The first tool of choice for FileNet Content Manager data is the IBM FileNet Deployment Manager utility. This tool requires process-oriented procedures to ensure a quality-driven deployment in your company.
Chapter 10, “System administration and maintenance” on page 315, provides information about how to ensure the availability of your FileNet Content Manager solution from an administrative point of view.
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.