CHAPTER 2
PROFILING
Profiling—the tactics used to research and pinpoint how web sites are structured and how their applications work—is a critical, but often overlooked, aspect of web hacking. The most effective attacks are informed by rigorous homework that illuminates as much about the inner workings of the application as possible, including all of the web pages, applications, and input/output command structures on the site.
The diligence and rigor of the profiling process and the amount of time invested in it are often directly related to the quality of the security issues identified across the entire site, and it frequently differentiates “script-kiddie” assessments that find the “low-hanging fruit,” such as simple SQL injection or buffer overflow attacks, from a truly revealing penetration of an application’s core business logic.
Many tools and techniques are used in web profiling, but after reading this chapter, you’ll be well on your way to becoming an expert. Our discussion of profiling is divided into two segments:
• Infrastructure profiling
• Application profiling
We’ve selected this organizational structure because the mindset, approach, and outcome inherent to each type of profiling are somewhat different. Infrastructure profiling focuses on relatively invariant, “off-the-shelf” components of the web application (we use the term “off-the-shelf” loosely here to include all forms of commonly reused software, including freeware, open source, and commercial). Usually, vulnerabilities in these components are easy to identify and subsequently exploit. Application profiling, on the other hand, addresses the unique structure, logic, and features of an individual, highly customized web application. Application vulnerabilities may be subtle and may take substantial research to detect and exploit. Not surprisingly, our discussion of application profiling thus takes up the bulk of this chapter.
We’ll conclude with a brief discussion of general countermeasures against common profiling tactics.
INFRASTRUCTURE PROFILING
Web applications require substantial infrastructure to support—web server hardware/software, DNS entries, networking equipment, load balancers, and so on. Thus, the first step in any good web security assessment methodology is identification and analysis of the low-level infrastructure upon which the application lies.
Footprinting and Scanning: Defining Scope
The original Hacking Exposed introduced the concept of footprinting, or using various Internet-based research methods to determine the scope of the target application or organization. Numerous tools and techniques are traditionally used to perform this task, including:
• Internet registrar research
• DNS interrogation
• General organizational research
The original Hacking Exposed methodology also covered basic infrastructure reconnaissance techniques such as:
• Server discovery (ping sweeps)
• Network service identification (port scanning)
Because most World Wide Web–based applications operate on the canonical ports TCP 80 for HTTP and/or TCP 443 for HTTPS/SSL/TLS, these techniques are usually not called for once the basic target URL has been determined. A more diligent attacker might port scan the target IP ranges using a list of common web server ports to find web apps running on unusual ports.
TIP
See Chapter 8 for a discussion of common attacks and countermeasures against web-based administration ports.
CAUTION
Don’t overlook port scanning—many web applications are compromised via inappropriate services running on web servers or other servers adjacent to web application servers in the DMZ.
Rather than reiterating in detail these methodologies that are only partially relevant to web application assessment, we recommend that readers interested in a more expansive discussion consult the other editions of the Hacking Exposed series (see the “References & Further Reading” section at the end of this chapter for more information), and we’ll move on to aspects of infrastructure profiling that are more directly relevant to web applications.
Basic Banner Grabbing
The next step in low-level infrastructure profiling is generically known as banner grabbing. Banner grabbing is critical to the web hacker, as it typically identifies the make and model (version) of the web server software in play. The HTTP 1.1 specification (RFC 2616) defines the server response header field to communicate information about the server handling a request. Although the RFC encourages implementers to make this field a configurable option for security reasons, almost every current implementation populates this field with real data by default (although we’ll cover several exceptions to this rule momentarily).
TIP
Banner grabbing can be performed in parallel with port scanning if the port scanner of choice supports it.
Here is an example of banner grabbing using the popular netcat utility:
D:>nc -nvv 192.168.234.34 80
(UNKNOWN) [192.168.234.34] 80 (?) open
HEAD / HTTP/1.0
[Two carriage returns]
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Fri, 04 Jan 2002 23:55:58 GMT
[etc.]
Note the use of the HEAD method to retrieve the server banner. This is the most straightforward method for grabbing banners.
There are several easier-to-use tools that we employ more frequently for manipulating HTTP, which we already enumerated in Chapter 1. We used netcat here to illustrate the raw input-output more clearly.
Advanced HTTP Fingerprinting
In the past, knowing the make and model of the web server was usually sufficient to submit to Google or Bugtraq and identify if there were any related exploits (we’ll discuss this process in more depth in Chapter 3). As security awareness has increased, however, new products and techniques have surfaced that now either block the server information from being displayed, or report back false information to throw attackers off.
Alas, information security is a never-ending arms race, and more sophisticated banner grabbing techniques have emerged that can be used to determine what a web server is really running. We like to call the HTTP-specific version of banner grabbing fingerprinting the web server, since it no longer consists of simply looking at header values, but rather observing the overall behavior of each web server within a farm and how individual responses are unique among web servers. For instance, an IIS server will likely respond differently to an invalid HTTP request than an Apache web server. This is an excellent way to determine what web server make and model is actually running and why it’s important to learn the subtle differences among web servers. There are many ways to fingerprint web servers, so many in fact that fingerprinting is an art form in itself. We’ll discuss a few basic fingerprinting techniques next.
Unexpected HTTP Methods
One of the most significant ways web servers differ is in how they respond to different types of HTTP requests. And the more unusual the request, the more likely the web server software differs in how it responds to that request. In the following examples, we send a PUT request instead of the typical GET or HEAD, again using netcat. The PUT request has no data in it. Notice how even though we send the same invalid request, each server reacts differently. This allows us to accurately determine what web server is really being used, even though a system administrator may have changed the banner being returned by the server. The areas that differ are bolded in the examples shown here:

Server Header Anomalies
By looking closely at the HTTP headers within different servers’ responses, you can determine subtle differences. For instance, sometimes the headers will be ordered differently, or there will be additional headers from one server compared to another. These variations can indicate the make and model of the web server.
For example, on Apache 2.x, the Date: header is on top and is right above the Server: header, as shown here in the bolded text:
HTTP/1.1 200 OK
Date: Mon, 22 Aug 2005 20:22:16 GMT
Server: Apache/2.0.54
Last-Modified: Wed, 10 Aug 2005 04:05:47 GMT
ETag: "20095-2de2-3fdf365353cc0"
Accept-Ranges: bytes
Content-Length: 11746
Cache-Control: max-age=86400
Expires: Tue, 23 Aug 2005 20:22:16 GMT
Connection: close
Content-Type: text/html; charset=ISO-8859-1
On IIS 5.1, the Server: header is on top and is right above the Date: header—the opposite of Apache 2.0:
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.1
Date: Mon, 22 Aug 2005 20:24:07 GMT
X-Powered-By: ASP.NET
Connection: Keep-Alive
Content-Length: 6278
Content-Type: text/html
Cache-control: private
On Sun One, the Server: and Date: header ordering matches IIS 5.1, but notice that in the Content-length: header “length” is not capitalized. The same applies to Content-type:, but for IIS 5.1 these headers are capitalized:
HTTP/1.1 200 OK
Server: Sun-ONE-Web-Server/6.1
Date: Mon, 22 Aug 2005 20:23:36 GMT
Content-length: 2628
Content-type: text/html
Last-modified: Tue, 01 Apr 2003 20:47:57 GMT
Accept-ranges: bytes
Connection: close
On IIS 6.0, the Server: and Date: header ordering matches that of Apache 2.0, but a Connection: header appears above them:
HTTP/1.1 200 OK
Connection: close
Date: Mon, 22 Aug 2005 20:39:23 GMT
Server: Microsoft-IIS/6.0
X-Powered-By: ASP.NET
X-AspNet-Version: 1.1.4322
Cache-Control: private
Content-Type: text/html; charset=utf-8
Content-Length: 23756
The httprint Tool
We’ve covered a number of techniques for fingerprinting HTTP servers. Rather than performing these techniques manually, we recommend the httprint tool from Net-Square (see the “References & Further Reading” at the end of this chapter for a link). Httprint performs most of these techniques (such as examining the HTTP header ordering) in order to skirt most obfuscation techniques. It also comes with a customizable database of web server signatures. Httprint is shown fingerprinting some web servers in Figure 2-1.
SHODAN
SHODAN is a computer search engine targeted at computers (routers, servers, etc.) that has interesting repercussions for information security. Available since December 2009, it combines an HTTP port scanner with a search engine index of the HTTP responses, making it trivial to find specific web servers. In this way, SHODAN magnifies the
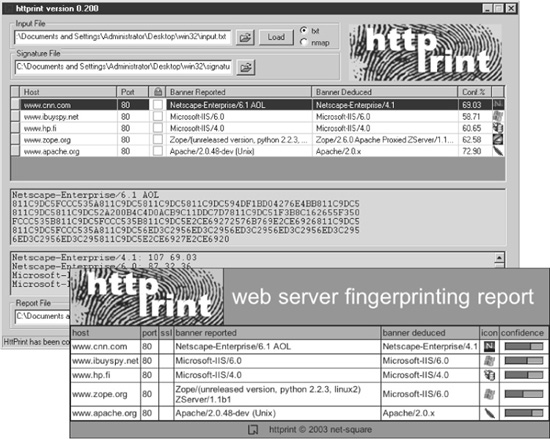
Figure 2-1 Httprint tool and results
usefulness of simple banner grabbing by automating it and making it searchable. Large portions of the Internet have already been indexed by SHODAN, creating some interesting scenarios related to security. For example, you could easily identify:
• All the IIS servers in the .gov domain
• All the Apache servers in Switzerland
• All IP addresses of systems possessing a known vulnerability in a specific web server platform
Figure 2-2 illustrates the potential power of SHODAN. Hopefully, these examples also illustrate the utility of SHODAN and its potential repercussions. If there was ever a reason to avoid displaying banners that disclose sensitive information about web servers, this is it!
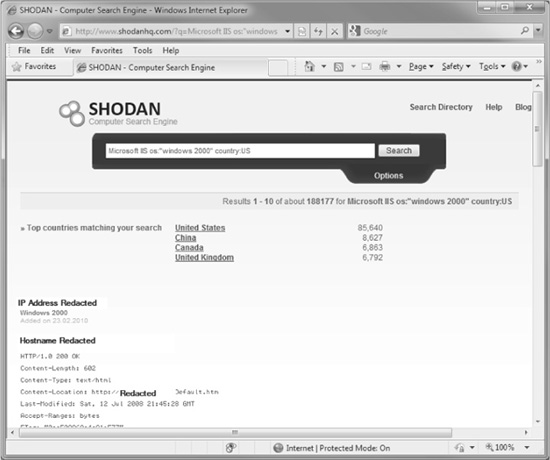
Figure 2-2 SHODAN finds all IIS servers running Windows 2000 in the United States.
Infrastructure Intermediaries
One issue that can skew the outcome of profiling is the placement of intermediate infrastructure in front of the web application. This intermediate infrastructure can include load balancers, virtual server configurations, proxies, and web application firewalls. Next, we’ll discuss how these interlopers can derail the basic fingerprinting techniques we just discussed and how they can be detected.
Virtual Servers
One other thing to consider is virtual servers. Some web hosting companies attempt to spare hardware costs by running different web servers on multiple virtual IP addresses on the same machine. Be aware that port scan results indicating a large population of live servers at different IP addresses may actually be a single machine with multiple virtual IP addresses.
Detecting Load Balancers
Because load balancers are usually “invisible,” many attackers neglect to think about them when doing their assessments. But load balancers have the potential to drastically change the way you do your assessments. Load balancers are deployed to help make sure no single server is ever overloaded with requests. Load balancers do this by dividing web traffic among multiple servers. For instance, when you issue a request to a web site, the load balancer may defer your request to any one out of four servers. What this type of setup means to you is that while one attack may work on one server, it may not work the next time around if it’s sent to a different server, causing you much frustration and confusion. Although in theory all of the target’s servers should be replicated identically and no response from any of the servers should be different than any other, this just simply isn’t the case in the real world. And even though the application may be identical on all servers, its folder structure (this is very common), patch levels, and configurations may be different on each server where it’s deployed. For example, there may be a “test” folder left behind on one of the servers, but not on the others. This is why it’s important not to mess up any of your assessments by neglecting to identify load balancers. Here’s how you try to detect if a load balancer is running at your target’s site.
Port Scan Surrounding IP Ranges
One simple way to identify individual load-balanced servers is to first determine the IP address of the canonical server and then script requests to a range of IPs around that. We’ve seen this technique turn up several other nearly identical responses, probably all load-balanced, identical web servers. Infrequently, however, we encounter one or more servers in the farm that are different from the others, running an out-of-date software build or perhaps alternate services like SSH or FTP. It’s usually a good bet that these rogues have security misconfigurations of one kind or another, and they can be attacked individually via their IP address.
TimeStamp Analysis
One method of detecting load balancers is analyzing the response timestamps. Because many servers may not have their times synchronized, you can determine if there are multiple servers by issuing multiple requests within one second. By doing this, you can analyze the server date headers. And if your requests are deferred to multiple servers, there will likely be variations in the times reported back to you in the headers. You will need to do this multiple times in order to reduce the chances of false positives and to see a true pattern emerge. If you’re lucky, each of the servers will be off-sync and you’ll be able to then deduct how many servers are actually being balanced.
ETag and Last-Modified Differences
By comparing the ETag and Last-Modified values in the header responses for the same requested resource, you can determine if you’re getting different files from multiple servers. For example, here is the response for index .html multiple times:
ETag: "20095-2de2-3fdf365353cc0"
ETag: "6ac117-2c5e-3eb9ddfaa3a40"
Last-Modified: Sun, 19 Dec 2004 20:30:25 GMT
Last-Modified: Sun, 19 Dec 2004 20:31:12 GMT
The difference in the Last-Modified timestamps between these responses indicates that the servers did not have immediate replication and that the requested resource was replicated to another server about a minute apart.
Load Balancer Cookies
Some proxy servers and load balancers add their own cookie to the HTTP session so they can keep better state. These are fairly easy to find, so if you see an unusual cookie, you’ll want to conduct a Google search on it to determine its origin. For example, while browsing a web site, we noticed this cookie being passed to the server:
AA002=1131030950-536877024/1132240551
Since the cookie does not give any obvious indications as to what application it belongs to, we did a quick Google search for AA002= and turned up multiple results of sites that use this cookie. On further analysis, we found that the cookie was a tracking cookie called “Avenue A.” As a general rule, if you don’t know it, then Google it!
Enumerating SSL Anomalies
This is a last-ditch effort when it comes to identifying proxies and load balancers. If you’re sure that the application is, in fact, being load balanced but none of the methods listed previously work, then you might as well try to see if the site’s SSL certificates contain differences, or whether the SSL certificates each support the same cipher strengths. For example, one of the servers may support only 128-bit encryption, just as it should. But suppose the site administrator forgot to apply that policy to other servers, and they support all ciphers from 96-bit and up. A mistake like this confirms that the web site is being load balanced.
Examining HTML Source Code
Although we’ll talk about this in more depth when we get to the “Application Profiling” section later in this chapter, it’s important to note that HTML source code can also reveal load balancers. For example, multiple requests for the same page might return different comments in HTML source, as shown next (HTML comments are delineated by the <!-- brackets):
<!-- ServerInfo: MPSPPIIS1B093 2001.10.3.13.34.30 Live1 -->
<!-- Version: 2.1 Build 84 -->
<!-- ServerInfo: MPSPPIIS1A096 2001.10.3.13.34.30 Live1 -->
<!-- Version: 2.1 Build 84 -->
One of the pages on the site reveals more cryptic HTML comments. After sampling it five times, the comments were compared, as shown here:
<!-- whfhUAXNByd7ATE56+Fy6BE9I3B0GKXUuZuW -->
<!-- whfh6FHHX2v8MyhPvMcIjUKE69m6OQB2Ftaa -->
<!-- whfhKMcA7HcYHmkmhrUbxWNXLgGblfF3zFnl -->
<!-- whfhuJEVisaFEIHtcMPwEdn4kRiLz6/QHGqz -->
<!-- whfhzsBySWYIwg97KBeJyqEs+K3N8zIM96bE -->
It appears that content of the comments are MD5 hashes with a salt of whfh at the beginning. Though we can’t be sure. We’ll talk more about how to gather and identify HTML comments in the upcoming section on application profiling.
Detecting Proxies
Not so surprisingly, you’ll find that some of your most interesting targets are supposed to be invisible. Devices like proxies are supposed to be transparent to end users, but they’re great attack points if you can find them. Listed next are some methods you can use to determine whether your target site is running your requests through a proxy.
TRACE Request
A TRACE request tells the web server to echo back the contents of the request just as it received it. This command was placed into HTTP 1.1 as a debugging tool. Fortunately for us, however, it also reveals whether our requests are traveling through proxy servers before getting to the web server. By issuing a TRACE request, the proxy server will modify the request and send it to the web server, which will then echo back exactly what request it received. By doing this, we can identify what changes the proxy made to the request.
Proxy servers will usually add certain headers, so look for headers like these:
"Via:","X-Forwarded-For:","Proxy-Connection:"
TRACE / HTTP/1.1
Host: www.site.com
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.1
Date: Tue, 16 Aug 2005 14:27:44 GMT
Content-length: 49
TRACE / HTTP/1.1
Host: www.site.com
Via: 1.1 192.168.1.5
When your requests go through a reverse proxy server, you will get different results. A reverse proxy is a front-end proxy that routes incoming requests from the Internet to the backend servers. Reverse proxies will usually modify the request in two ways. First, they’ll remap the URL to point to the proper URL on the inside server. For example, TRACE /folder1/index.aspx HTTP/1.1 might turn into TRACE /site1/folder1/index.asp HTTP/1.1. Second, reverse proxies will change the Host: header to point to the proper internal server to forward the request to. Looking at the example, you’ll see that the Host: header was changed to server1.site.com.
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.1
Date: Tue, 16 Aug 2005 14:27:44 GMT
Content-length: 49
TRACE / HTTP/1.1
Host: server1.site.com
Standard Connect Test
The CONNECT command is primarily used in proxy servers to proxy SSL connections. With this command, the proxy makes the SSL connection on behalf of the client. For instance, sending a CONNECT https://secure.site.com:443 will instruct the proxy server to make the connection an SSL connection to secure.site.com on port 443. And if the connection is successful, the CONNECT command will tunnel the user’s connection and the secure connection together. However, this command can be abused when it is used to connect servers inside the network.
A simple method to check if a proxy is present is to send a CONNECT to a known site like www.google.com and see if it complies.
NOTE
Many times a firewall may well protect against this technique, so you might want to try to guess some internal IP addresses and use those as your test.
The following example shows how the CONNECT method can be used to connect to a remote web server:
*Request*
CONNECT remote-webserver:80 HTTP/1.0
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 4.0)
Host: remote-webserver
*Successful Response*
HTTP/1.0 200 Connection established
Standard Proxy Request
Another method you might try is to insert the address of a public web site and see if the proxy server returns the response from that web site. If so, this means you can direct the server to any address of your choice, allowing your proxy server to be an open, anonymous proxy to the public or, worse, allowing the attacker to access your internal network. This is demonstrated next. At this point, a good technique to use would be to attempt to identify what the internal IP address range of your target is and then port scan that range.
TIP
This same method can be successfully applied using the CONNECT command as well.
For example, a standard open proxy test using this mechanism would look something like the following:
GET http://www.site.com/ HTTP/1.0
You could also use this technique to scan a network for open web servers:
GET http://192.168.1.1:80/ HTTP/1.0
GET http://192.168.1.2:80/ HTTP/1.0
You can even conduct port scanning in this manner:
GET http://192.168.1.1:80/ HTTP/1.0
GET http://192.168.1.1:25/ HTTP/1.0
GET http://192.168.1.1:443/ HTTP/1.0
Detecting Web App Firewalls
Web application firewalls are protective devices that are placed inline between the user and the web server. The app firewall analyzes HTTP traffic to determine if it’s valid traffic and tries to prevent web attacks. You could think of them as Intrusion Prevention Systems (IPS) for the web application.
Web application firewalls are still relatively rare to see when assessing an application, but being able to detect them is still very important. The examples explained in the following sections are not a comprehensive listing of ways to fingerprint web application firewalls, but they should give you enough information to identify one when you run into this defense.
Detecting whether an application firewall is running in front of an application is actually quite easy. If, throughout your testing, you keep getting kicked out, or the session times out when issuing an attack request, an application firewall is likely between you and the application. Another indication would be when the web server does not respond the way it generally does to unusual requests but instead always returns the same type of error. Listed next are some common web app firewalls and some very simple methods of detecting them.
Teros
The Teros web application firewall technology will respond to a simple TRACE request or any invalid HTTP method such as PUT with the following error:
TRACE / HTTP/1.0
Host: www.site.com
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
HTTP/1.0 500
Content-Type: text/html
<html><head><title>Error</title></head><body>
<h2>ERROR: 500</h2>
Invalid method code<br>
</body></html>
Another easy way to detect a Teros box is by spotting the cookie that it issues, which looks similar to this:
st8id=1e1bcc1010b6de32734c584317443b31.00.d5134d14e9730581664bf5cb1b610784)
The value of the cookie will, of course, change but the cookie name st8id is the giveaway, and in most cases, the value of the cookie will have the similar character set and length.
F5 TrafficShield
When you send abnormal requests to F5’s TrafficShield, you might get responses that contain errors like those listed here. For instance, here we send a PUT method with no data:
PUT / HTTP/1.0
Host: www.site.com
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
HTTP/1.0 400 Bad Request
Content-Type: text/html
<html><head><title>Error</title></head>
<body><h1>HTTP Error 400</h1>
<h2>400 Bad Request</h2>
The server could not understand your request.<br>Your error ID is:
5fa97729</body></html>
TrafficShield also has a standard cookie that is used with its device. The cookie name is ASINFO, and here is an example of what the cookie looks like:
ASINFO=1a92a506189f3c75c3acf0e7face6c6a04458961401c4a9edbf52606a4c47b1c
3253c468fc0dc8501000ttrj40ebDtxt6dEpCBOpiVzrSQ0000
Netcontinuum
Detecting a Netcontinuum application firewall deployment is similar to the others. Just look for its cookie. In the event that its cookie is not present, we’ve noticed that these devices respond to every invalid request with a 404 error—which is quite abnormal for any web server to do. The Netcontinuum cookie is shown here:
NCI__SessionId=009C5f5AQEwIPUC3/TFm5vMcLX5fjVfachUDSNaSFrmDKZ/
LiQEuwC+xLGZ1FAMA+
URLScan
URLScan is a free ISAPI filter that provides great flexibility for controlling HTTP requests, but we don’t consider URLScan a true application firewall. Products like these don’t provide dynamic protection; instead, they rely on a lengthy configuration file of signatures or allowed lengths to stop attacks. Detecting URLScan can be simple, as long as it is implemented with its default rules.
For example, by default, URLScan has a rule that restricts a path to a length of 260 characters, so if you send a request that has a path of more than 260 characters, URLScan will respond with a 404 (http://www.site.com/ (261/’s)). URLScan will also reject the request if you add any of the following headers to the request:
• Translate:
• If:
• Lock-Token:
• Transfer-Encoding:
Using these headers will cause URLScan to return a 404. But, in any other situation, the web server would just ignore the extra headers and respond normally to the request that you sent it.
SecureIIS
SecureIIS is like URLScan on steroids—it is a pumped-up commercial version that adds a nice GUI and some nifty features. Using it is a lot easier than editing a big configuration file like URLScan, but detecting it is pretty similar. Study the default rules that it ships with and break them—this will cause SecureIIS to return a deny response, which, by default, is a 406 error code (note that the commercial version allows this to be changed).
One of the default rules is to limit the length of any header value to 1024 characters. So just set a header value above that limit and see if the request gets denied. SecureIIS’s Default Deny Page is quite obvious: it states that a security violation has occurred and even gives the SecureIIS logo and banner. Of course, most people using this product in production will have that changed. Observing the HTTP response can be more revealing, as SecureIIS implements an unusual 406 “Not Acceptable” response to requests with over-large headers.
APPLICATION PROFILING
Now that we’ve covered the logistics of infrastructure profiling, we can get to the meat of surveying the application itself. It may be mundane and boring work, but this is where we’ve consistently experienced big breakthroughs during our professional consulting work.
The purpose of surveying the application is to generate a complete picture of the content, components, function, and flow of the web site in order to gather clues about where underlying vulnerabilities might be. Whereas an automated vulnerability checker typically searches for known vulnerable URLs, the goal of an extensive application survey is to see how each of the pieces fit together. A proper inspection can reveal problems with aspects of the application beyond the presence or absence of certain traditional vulnerability signatures.
Cursorily, application profiling is easy. You simply crawl or click through the application and pay attention to the URLs and how the entire web site is structured. Depending on your level of experience, you should be able to recognize quickly what language the site is written in, basic site structure, use of dynamic content, and so on. We can’t stress enough how vital it is to pay close attention to each detail you uncover during this research. Become a keen note-taker and study each fact you unearth, because it just may be an insignificant-looking CSS file that contains an informational gem, such as a comment that directs you to a certain application.
This section will present a basic approach to web application profiling comprised of the following key tasks:
• Manual inspection
• Search tools
• Automated crawling
• Common web application profiles
Manual Inspection
The first thing we usually do to profile an application is a simple click-through. Become familiar with the site, look for all the menus, and watch the directory names in the URL change as you navigate.
Web applications are complex. They may contain a dozen files, or they may contain a dozen well-populated directories. Therefore, documenting the application’s structure in a well-ordered manner helps you track insecure pages and provides a necessary reference for piecing together an effective attack.
Documenting the Application
Opening a text editor is the first step, but a more elegant method is to create a matrix in a program like Microsoft Excel to store information about every page in the application. We suggest documenting things such as:
• Page name Listing files in alphabetical order makes tracking down information about a specific page easier. These matrices can get pretty long!
• Full path to the page This is the directory structure leading up to the page. You can combine this with the page name for efficiency.
• Does the page require authentication? Yes or no.
• Does the page require SSL? The URI for a page may be HTTPS, but that does not necessarily mean the page cannot be accessed over normal HTTP. Put the DELETE key to work and remove the “S”!
• GET/POST arguments Record the arguments that are passed to the page. Many applications are driven by a handful of pages that operate on a multitude of arguments.
• Comments Make personal notes about the page. Was it a search function, an admin function, or a Help page? Does the page “feel” insecure? Does it contain privacy information? This is a catch-all column.
A partially completed matrix may look similar to Table 2-1.
NOTE
We will talk about authentication more in Chapter 4, but for now, it is important to simply identify the method. Also, just because the /main/login.jsp page requires authentication does not mean that all pages require authentication; for instance, the /main/menu.jsp page may not. This step is where misconfigurations will start to become evident.
Another surveying aid is the flowchart. A flowchart helps consolidate information about the site and present it in a clear manner. With an accurate diagram, you can

Table 2-1 A Sample Matrix for Documenting Web Application Structure
visualize the application processes and perhaps discover weak points or inadequacies in the design. The flowchart can be a block diagram on a white board or a three-page diagram with color-coded blocks that identify static pages, dynamic pages, database access routines, and other macro functions. Many web spidering applications such as WebSphinx have graphing capabilities. Figure 2-3 shows an example web application flowchart.
For a serious in-depth review, we recommend mirroring the application on your local hard drive as you document. You can build this mirror automatically with a tool (as we’ll discuss later in the “Automated Web Crawling” section), or you can populate it manually. It is best to keep the same directory structure as the target application. For example:
www.victim.com
/admin/admin.html
/main/index.html
/menu/menu.asp
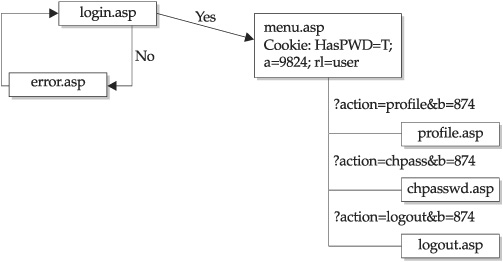
Figure 2-3 A flowchart like this sample can be quite helpful in documenting web application structure.
TIP
Modulate the effort spent mirroring the target site versus how often you expect it to change in the coming months.
Some other information you should consider recording in your matrix/flowchart includes the following:
• Statically and dynamically generated pages
• Directory structure
• Common file extensions
• Common files
• Helper files
• Java classes and applets
• Flash and Silverlight objects
• HTML source code
• Forms
• Query strings and parameters
• Common cookies
• Backend access points
We’ll talk about each of these in more detail in the next few sections.
Statically and Dynamically Generated Pages
Static pages are the generic .html files usually relegated to FAQs and contact information. They may lack functionality to attack with input validation tests, but the HTML source may contain comments or information. At the very least, contact information reveals e-mail addresses and usernames. Dynamically generated pages (.asp, .jsp, .php, etc.) are more interesting. Record a short comment for interesting pages such as “administrator functions,” “user profile information,” or “cart view.”
As we noted earlier, as you manually profile an application, it’s a good idea to mirror the structure and content of the application to local disk. For example, if www.victim.com has an /include/database.inc file, then create a top-level directory called “www.victim.com” and a subdirectory called “include”, and place the database.inc file in the include directory. The text-based browser, lynx, can accelerate this process:
[root@meddle ]# mkdir www.victim.com
[root@meddle ]# cd www.victim.com
[root@meddle www.victim.com]# lynx -dump www.victim.com/index.html >
index.html
Netcat is even better because it will also dump the server headers:
[root@meddle ]# mkdir www.victim.com
[root@meddle ]# cd www.victim.com
[root@meddle www.victim.com]# echo -e "GET /index.html HTTP/1.0
" |
> nc -vv www.victim.com 80 > index.html
www.victim.com [192.168.33.101] 80 (http) open
sent 27, rcvd 2683: NOTSOCK
To automate the process even more (laziness is a mighty virtue!), create a wrapper script for netcat. This script will work on UNIX/Linux systems and Windows systems with the Cygwin utilities installed. Create a file called getit.sh and place it in your execution path. Here’s an example getit.sh script that we use in web security assessments:
#!/bin/sh
# mike's getit.sh script
if [ -z $1 ]; then
echo -e "
Usage: $0 <host> <URL>"
exit
fi
echo -e "GET $2 HTTP/1.0
" |
nc -vv $1 80
Wait a minute! Lynx and Mozilla can handle pages that are only accessible via SSL. Can I use netcat to do the same thing? Short answer: No. You can, however, use the OpenSSL package. Create a second file called sgetit.sh and place it in your execution path:
#!/bin/sh
# mike's sgetit.sh script
if [ -z $1 ]; then
echo -e "
Usage: $0 <SSL host> <URL>"
exit
fi
echo -e "GET $2 HTTP/1.0
" |
openssl s_client -quiet -connect $1:443 2>/dev/null
NOTE
The versatility of the “getit” scripts does not end with two command-line arguments. You can craft them to add cookies, user-agent strings, host strings, or any other HTTP header. All you need to modify is the echo –e line.
Now you’re working on the command line with HTTP and HTTPS. The web applications are going to fall! So, instead of saving every file from your browser or running lynx, use the getit scripts shown previously, as illustrated in this example:
[root@meddle ]# mkdir www.victim.com
[root@meddle ]# cd www.victim.com
[root@meddle www.victim.com]# getit.sh www.victim.com /index.html >
index.html
www.victim.com [192.168.33.101] 80 (http) open
sent 27, rcvd 2683: NOTSOCK
[root@meddle www.victim.com ]# mkdir secure
[root@meddle www.victim.com ]# cd secure
[root@meddle secure]# sgetit.sh www.victim.com /secure/admin.html >
admin.html
The OpenSSL s_client is more verbose than netcat and always seeing its output becomes tiring after a while. As we go through the web application, you will see how important the getit.sh and sgetit.sh scripts become. Keep them handy.
You can download dynamically generated pages with the getit scripts as long as the page does not require a POST request. This is an important feature because the contents of some pages vary greatly depending on the arguments they receive. Here’s another example; this time getit.sh retrieves the output of the same menu.asp page, but for two different users:
[root@meddle main]# getit.sh www.victim.com
> /main/menu.asp?userID=002 > menu.002.asp
www.victim.com [192.168.33.101] 80 (http) open
sent 40, rcvd 3654: NOTSOCK
[root@meddle main]# getit.sh www.victim.com
> /main/menu.asp?userID=007 > menu.007.asp
www.victim.com [192.168.33.101] 80 (http) open
sent 40, rcvd 5487: NOTSOCK
Keep in mind the naming convention that the site uses for its pages. Did the programmers dislike vowels (usrMenu.asp, Upld.asp, hlpText.php)? Were they verbose (AddNewUser.pl)? Were they utilitarian with the scripts (main.asp has more functions than an obese Swiss Army knife)? The naming convention provides an insight into the programmers’ mindset. If you found a page called UserMenu.asp, chances are that a page called AdminMenu.asp also exists. The art of surveying an application is not limited to what you find by induction. It also involves a deerstalker cap and a good amount of deduction.
Directory Structure
The structure of a web application will usually provide a unique signature. Examining things as seemingly trivial as directory structure, file extensions, naming conventions used for parameter names or values, and so on, can reveal clues that will immediately identify what application is running (see the upcoming section “Common Web Application Profiles,” later in this chapter, for some crisp examples of this).
Obtaining the directory structure for the public portion of the site is trivial. After all, the application is designed to be surfed. However, don’t stop at the parts visible through the browser and the site’s menu selections. The web server may have directories for administrators, old versions of the site, backup directories, data directories, or other directories that are not referenced in any HTML code. Try to guess the mindset of the administrators and site developers. For example, if static content is in the /html directory and dynamic content is in the /jsp directory, then any cgi scripts may be in the /cgi directory.
Other common directories to check include these:
• Directories that have supposedly been secured, either through SSL, authentication, or obscurity: /admin/ /secure/ /adm/
• Directories that contain backup files or log files: /.bak/ /backup/ /back/ / log/ /logs/ /archive/ /old/
• Personal Apache directories: /∼root/ /∼bob/ /∼cthulhu/
• Directories for include files: /include/ /inc/ /js/ /global/ /local/
• Directories used for internationalization: /de/ /en/ /1033/ /fr/
This list is incomplete by design. One application’s entire directory structure may be offset by /en/ for its English-language portion. Consequently, checking for /include/ will return a 404 error, but checking for /en/include/ will be spot on. Refer back to your list of known directories and pages documented earlier using manual inspection. In what manner have the programmers or system administrators laid out the site? Did you find the /inc/ directory under /scripts/? If so, try /scripts/js/ or /scripts/inc/js/ next.
Attempting to enumerate the directory structure can be an arduous process, but the getit scripts can help whittle any directory tree. Web servers return a non-404 error code when a GET request is made to a directory that exists on the server. The code might be 200, 302, or 401, but as long as it isn’t a 404 you’ve discovered a directory. The technique is simple:
[root@meddle]# getit.sh www.victim.com /isapi
www.victim.com [192.168.230.219] 80 (http) open
HTTP/1.1 302 Object Moved
Location: http://tk421/isapi/
Server: Microsoft-IIS/5.0
Content-Type: text/html
Content-Length: 148
<head><title>Document Moved</title></head>
<body><h1>Object Moved</h1>This document may be found <a HREF=”http://
tk-421/isapi/”>
here</a></body>sent 22, rcvd 287: NOTSOCK
Using our trusty getit.sh script, we made a request for the /isapi/ directory; however, we omitted an important piece. The trailing slash was left off the directory name, causing an IIS server to produce a redirect to the actual directory. As a by-product, it also reveals the internal hostname or IP address of the server—even when it’s behind a firewall or load balancer. Apache is just as susceptible. It doesn’t reveal the internal hostname or IP address of the server, but it will reveal virtual servers:
[root@meddle]# getit.sh www.victim.com /mail
www.victim.com [192.168.133.20] 80 (http) open
HTTP/1.1 301 Moved Permanently
Date: Wed, 30 Jan 2002 06:44:08 GMT
Server: Apache/2.0.28 (Unix)
Location: http://dev.victim.com/mail/
Content-Length: 308
Connection: close
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>301 Moved Permanently</title>
</head><body>
<h1>Moved Permanently</h1>
<p>The document has moved <a href="http://dev.victim.com/mail/">here</a>.</p>
<hr />
<address>Apache/2.0.28 Server at dev.victim.com Port 80</address>
</body></html>
sent 21, rcvd 533: NOTSOCK
That’s it! If the directory does not exist, then you will receive a 404 error. Otherwise, keep chipping away at that directory tree.
Another tool that can reduce time and effort when traversing a web application for hidden folders is OWASP DirBuster. DirBuster is a multithreaded Java application that is designed to brute-force directories and files on a web server. Based on a user-supplied dictionary file, DirBuster will attempt to crawl the application and guess at non-linked directories and files with a specific extension. For example, if the application uses PHP, the user would specify “php” as a file extension and DirBuster would guess for a file named [dictionary word].php in every directory the crawler encounters (see Figure 2-4). DirBuster can recursively scan new directories that it finds and performance is adjustable. It should be noted that recursive scanning with DirBuster generates a lot of traffic, and the thread count should be reduced in an environment where an excessive number of requests is undesirable.
Common File Extensions
File extensions are a great indicator of the nature of an application. File extensions are used to determine the type of file, either by language or its application association. File extensions also tell web servers how to handle the file. While certain extensions are executable, others are merely template files. The list shown next contains common extensions found in web applications and what their associations are. If you don’t know
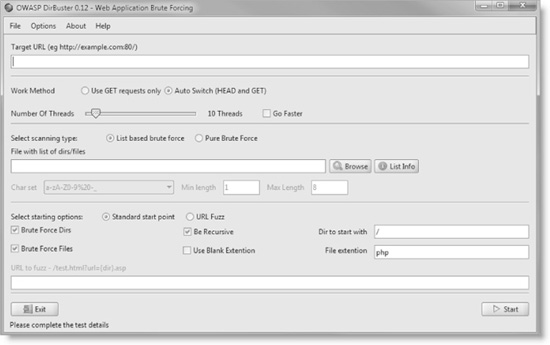
Figure 2-4 OWASP DirBuster tool is used to brute-force hidden directories and files.
what application an extension is associated with, just try searching the extension using an Internet search engine like Google (for example, using the syntax “allinurl:.cfm”). This will allow you to identify other sites that may use that extension, which can help you narrow down what applications the extension is associated with.
TIP
Another handy resource for researching file extensions is http://filext.com/, which allows you to find out what application an extension is associated with.
Table 2-2 lists some common file extensions and the application or technology that typically uses them.
Keep Up-to-Date on Common Web Application Software
Because assessing web applications is our job, we usually want to familiarize ourselves with popular web application software as much as possible. We’re always playing around with the latest off-the-shelf/open-source web applications. Go to www.sourceforge.net or www.freshmeat.net and look at the 50 most popular freeware web applications. These are used in many applications. Just by knowing how they work and how they feel will help you to recognize their presence quickly when assessing a site.
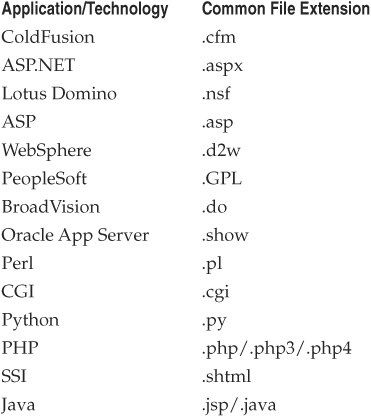
Table 2-2 Common File Extensions and the Application or Technology That Typically Uses Them
Common Files
Most software installations will come with a number of well-known files, for instance:
• Readme
• ToDo
• Changes
• Install.txt
• EULA.txt
By searching every folder and subfolder in a site, you might just hit on plenty of useful information that will tell you what applications and versions are running and a nice URL that will lead you to a download page for software and updates. If you don’t have either the time or the ability to check every folder, you should always be sure to at least hit the site’s root directory where these file types are often held (for example, http://www.site.com/Readme.txt). Most administrators or developers will follow a default install, or they will unzip the entire contents of the archive right into the web root. These guys are very helpful!
Helper Files
Helper file is a catch-all appellation for any file that supports the application but usually does not appear in the URL. Common “helpers” are JavaScript files. They are often used to format HTML to fit the quirks of popular browsers or perform client-side input validation.
• Cascading Style Sheets CSS files (.css) instruct the browser on how to format text. They rarely contain sensitive information, but enumerate them anyway.
• XML Style Sheets Applications are turning to XML for data presentation. Style sheets (.xsl) define the document structure for XML requests and formatting. They tend to have a wealth of information, often listing database fields or referring to other helper files.
• JavaScript Files Nearly every web application uses JavaScript (.js). Much of it is embedded in the actual HTML file, but individual files also exist. Applications use JavaScript files for everything from browser customization to session handling. In addition to enumerating these files, it is important to note what types of functions the file contains.
• Include Files On IIS systems, include files (.inc) often control database access or contain variables used internally by the application. Programmers love to place database connection strings in this file—password and all!
• The “Others” References to ASP, PHP, Perl, text, and other files might be in the HTML source.
URLs rarely refer to these files directly, so you must turn to the HTML source in order to find them. Look for these files in Server Side Include directives and script tags. You can inspect the page manually or turn to your handy command-line tools. Download the file and start the search. Try common file suffixes and directives:

[root@meddle tb]# getit.sh www.victim.com /tb/tool.php > tool.php
[root@meddle tb]# grep js tool.php
www.victim.com [192.168.189.113] 80 (http) open
var ss_path = "aw/pics/js/"; // and path to the files
document.write("<SCRIPT SRC="" + ss_machine + ss_path +
"stats/ss_main_v-" + v +".js"></SCRIPT>");
Output like this tells us two things. One, there are aw/pics/js/ and stats/ directories that we hadn’t found earlier. Two, there are several JavaScript files that follow a naming convention of ss_main_v-*.js, where the asterisk represents some value. A little more source-sifting would tell us this value.
You can also guess common filenames. Try a few of these in the directories you enumerated in the previous step:
![]()
Again, all of this searching does not have to be done by hand. We’ll talk about tools to automate the search in the sections entitled “Search Tools for Profiling” and “Automated Web Crawling” later in this chapter.
Java Classes and Applets
Java-based applications pose a special case for source-sifting and surveying the site’s functionality. If you can download the Java classes or compiled servlets, then you can actually pick apart an application from the inside. Imagine if an application used a custom encryption scheme written in a Java servlet. Now, imagine you can download that servlet and peek inside the code.
Finding applets in web applications is fairly simple: just look for the applet tag code that looks like this:
<applet code = "MainMenu.class"
codebase="http://www.site.com/common/console" id = "scroller">
<param name = "feeder" value
="http://www.site.com/common/console/CWTR1.txt">
<param name = "font" value = "name=Dialog, style=Plain, size=13">
<param name = "direction" value = "0">
<param name = "stopAt" value = "0">
</applet>
Java is designed to be a write-once, run-anywhere language. A significant byproduct of this is that you can actually decompile a Java class back into the original source code. The best tool for doing this is the Java Disassembler, or jad. Decompiling a Java class with jad is simple:
[root@meddle]# jad SnoopServlet.class
Parsing SnoopServlet.class... Generating SnoopServlet.jad
[root@meddle]# cat SnoopServlet.jad
// Decompiled by Jad v1.5.7f. Copyright 2000 Pavel Kouznetsov.
// Jad home page:
// http://www.geocities.com/SiliconValley/Bridge/8617/jad.html
// Decompiler options: packimports(3)
// Source File Name: SnoopServlet.java
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Enumeration;
import javax.servlet.*;
import javax.servlet.http.*;
public class SnoopServlet extends HttpServlet
{
...remainder of decompiled Java code...
You don’t have to be a full-fledged Java coder in order for this tool to be useful. Having access to the internal functions of the site enables you to inspect database calls, file formats, input validation (or lack thereof), and other server capabilities.
You may find it difficult to obtain the actual Java class, but try a few tricks such as these:
• Append .java or .class to a servlet name. For example, if the site uses a servlet called “/servlet/LogIn”, then look for “/servlet/LogIn.class”.
• Search for servlets in backup directories. If a servlet is in a directory that the servlet engine does not recognize as executable, then you can retrieve the actual file instead of receiving its output.
• Search for common test servlets. Some of these are SessionServlet, AdminServlet, SnoopServlet, and Test. Note that many servlet engines are case-sensitive, so you will have to type the name exactly.
Applets seem to be some of the most insecure pieces of software. Most developers take no consideration of the fact that these can easily be decompiled and give up huge amounts of information. Applets are essentially thick clients that contain all the code needed to communicate with the server. Multiple times we have seen an applet send straight SQL queries directly to the application or the applet use a special guest account to do certain functions and the username and password will be embedded in the code. Always rejoice if you see an applet that is used for sensitive types of actions, as nine times out of ten you will find some really good security issues once it is decompiled. If the applet cannot be decompiled due to the use of some good obfuscation techniques, then reverse engineer the applet by studying the communication stream to the web server. Most applets will follow the proxy settings in your browser, so by setting them to point to your handy proxy tool, most of the applet’s communication will be visible. In some cases, the applet will not follow the browser proxy settings. In this scenario, falling back to old-school methods will work, so pull out the trusty sniffer program.
Flash and Silverlight Objects
Interactive web site components are becoming more prevalent. As developers embrace new technologies such as Flash and Silverlight, more application logic is being pushed to the client. In parallel with this trend, client-side logic has become the target of choice for modern attackers. Just as it is possible to disassemble Java applets, it is possible to peek inside the functionality of client-side code like Flash SWF files and the .NET modules that power Silverlight components. We’ll cover attacks against Flash and Silverlight, as well as defensive countermeasures, in Chapter 9.
HTML Source Code
HTML source code can contain numerous juicy tidbits of information.
HTML Comments
The most obvious place attackers look is in HTML comments, special sections of source code where the authors often place informal remarks that can be quite revealing. The <-- characters mark all basic HTML comments.
HTML comments are a hit-or-miss prospect. They may be pervasive and uninformative, or they may be rare and contain descriptions of a database table for a subsequent SQL query, or worse yet, user passwords.
The next example shows how our getit.sh script can obtain the index.html file for a site, and then pipe it through the UNIX/Linux grep command to find HTML comments (you can use the Windows findstr command similarly to the grep command).
NOTE
The ! character has special meaning on the Unix/Linux command line and will need to be escaped using "in grep searches.
[root@meddle ]# getit.sh www.victim.com /index.html | grep "<!--"
www.victim.com [192.168.189.113] 80 (http) open
<!-- $Id: index.shtml,v 1.155 2002/01/25 04:06:15 hpa Exp $ -->
sent 17, rcvd 16417: NOTSOCK
At the very least, this example shows us that the index.html file is actually a link to index.shtml. The .shtml extension implies that parts of the page were created with Server Side Includes. Induction plays an important role when profiling the application, which is why it’s important to familiarize yourself with several types of web technologies.
Pop quiz: What type of program could be responsible for the information in the $Id shown in the previous example?
You can use this method (using our getit script or the automated web crawling tool of your choice) to dump the comments from the entire site into one file and then review that file for any interesting items. If you find something that looks promising, you can search the site for that comment to find the page it’s from and then carefully study that page to understand the context of the comment. This process can reveal even more interesting information, including:
• Filename-like comments You will typically see plenty of comments with template filenames tucked in them. Download them and review the template code. You never know what you might find.
• Old code Look for links that might be commented out. They could point to an old portion of the web site that could contain security holes. Or maybe the link points to a file that once worked, but now, when you attempt to access it, a very revealing error message is displayed.
• Auto-generated comments A lot of comments that you might see are automatically generated by web content software. Take the comment to a search engine and see what other sites turn up those same comments. Hopefully, you’ll discover what software generated the comments and learn useful information.
• The obvious We’ve seen things like entire SQL statements, database passwords, and actual notes left for other developers in files such as IRC chat logs within comments.
Other HTML Source Nuggets
Don’t stop at comment separators. HTML source has all kinds of hidden treasures. Try searching for a few of these strings:
![]()
If you find SQL strings, thank the web hacking gods—the application may soon fall (although you still have to wait for Chapter 8 to find out why). The search for specific strings is always fruitful, but in the end, you will have to just open the file in Notepad or vi to get the whole picture.
NOTE
When using the grep command, play around with the –i flag (ignore case), –AN flag (show N lines after the matching line), and –BN flag (show N lines before the matching line).
Once in a while, syntax errors creep into dynamic pages. Incorrect syntax may cause a file to execute partially, which could leave raw code snippets in the HTML source. Here is a snippet of code (from a web site) that suffered from a misplaced PHP tag:
Go to forum!
"; $file = "http://www.victim.com/$subdir/list2.php?
f=$num"; if (readfile($file) == 0) { echo "(0 messages so far)"; } ?>
Another interesting thing to search for in HTML are tags that denote server-side execution, such as <? and ?> for PHP, and <% and %> and <runat=server> for ASP pages. These can reveal interesting tidbits that the site developer never intended the public to see.
HTML source information can also provide useful information when combined with the power of Internet search engines like Google. For example, you might find developer names and e-mail addresses in comments. This bit of information by itself may not be that interesting, but what if you search on Google and identify that the developer posted multiple questions related to the development of his or her application? Now you suddenly have nice insight into how the application was developed. You could also assume that same information could be a username for one of the authenticated portions of the site and try brute-forcing passwords against that username.
In one instance, a Google search on a username that turned up in HTML comments identified several other applications that the developer had written that were downloadable from his web site. Looking through the code, we learned that his application uses configuration data on the developer’s own web site! With a bit more effort, we found a DES administer password file within this configuration data. We downloaded this file and ran a password-cracking tool against it. Within an hour, we got the password and logged in as the administrator. All of this success thanks to a single comment and a very helpful developer’s homepage.
Some final thoughts on HTML source-sifting: the rule of thumb is to look for anything that might contain information that you don’t yet know. When you see some weird-looking string of random numbers within comments on every page of the file, look into it. Those random numbers could belong to a media management application that might have a web-accessible interface. The tiniest amount of information in web assessments can bring the biggest breakthroughs. So don’t let anything slide by you, no matter how insignificant it may seem at first.
Forms
Forms are the backbone of any web application. How many times have you unchecked the box that says, “Do not uncheck this box to not receive SPAM!” every time you create an account on a web site? Even English majors’ in-boxes become filled with unsolicited e-mail due to confusing opt-out (or is it opt-in?) verification. Of course, there are more important, security-related parts of the form. You need to have this information, though, because the majority of input validation attacks are executed against form information.
When manually inspecting an application, note every page with an input field. You can find most of the forms by a click-through of the site. However, visual confirmation is not enough. Once again, you need to go to the source. For our command-line friends who like to mirror the entire site and use grep, start by looking for the simplest indicator of a form, its tag. Remember to escape the < character since it has special meaning on the command line:
[root@meddle]# getit.sh www.victim.com /index.html |
grep -i <form www.victim.com [192.168.33.101] 80 (http) open sent 27,
rcvd 2683: NOTSOCK
<form name=gs method=GET action=/search>
Now you have the name of the form, gs; you know that it uses GET instead of POST; and it calls a script called “search” in the web root directory. Going back to the search for helper files, the next few files we might look for are search.inc, search.js, gs.inc, and gs.js. A lucky guess never hurts. Remember to download the HTML source of the /search file, if possible.
Next, find out what fields the form contains. Source-sifting is required at this stage, but we’ll compromise with grep to make things easy:
[root@meddle]# getit.sh www.victim.com /index.html |
grep -i "input type" www.victim.com [192.168.238.26] 80 (http) open
<input type="text" name="name" size="10" maxlength="15">
<input type="password" name="passwd" size="10" maxlength="15">
<input type=hidden name=vote value="websites">
<input type="submit" name="Submit" value="Login">
This form shows three items: a login field, a password field, and the submit button with the text, “Login.” Both the username and password must be 15 characters or less (or so the application would like to believe). The HTML source reveals a fourth field called “name.” An application may use hidden fields for several purposes, most of which seriously inhibit the site’s security. Session handling, user identification, passwords, item costs, and other sensitive information tend to be put in hidden fields. We know you’re chomping at the bit to actually try some input validation, but be patient. We have to finish gathering all we can about the site.
If you’re trying to create a brute-force script to perform FORM logins, you’ll want to enumerate all of the password fields (you might have to omit the " characters):
[root@meddle]# getit.sh www.victim.com /index.html |
> grep -i "type="password""
www.victim.com [192.168.238.26] 80 (http) open <input type="password"
name="passwd" size="10" maxlength="15">
Tricky programmers might not use the password input type or have the words “password” or “passwd” or “pwd” in the form. You can search for a different string, although its hit rate might be lower. Newer web browsers support an autocomplete function that saves users from entering the same information every time they visit a web site. For example, the browser might save the user’s address. Then, every time the browser detects an address field (i.e., it searches for “address” in the form), it will supply the user’s information automatically. However, the autocomplete function is usually set to “off” for password fields:
[root@meddle]# getit.sh www.victim.com /login.html |
> grep -i autocomplete
www.victim.com [192.168.106.34] 80 (http) open
<input type=text name="val2"
size="12" autocomplete=off>
This might indicate that "val2" is a password field. At the very least, it appears to contain sensitive information that the programmers explicitly did not want the browser to store. In this instance, the fact that type="password" is not being used is a security issue, as the password will not be masked when a user enters her data into the field. So when inspecting a page’s form, make notes about all of its aspects:
• Method Does it use GET or POST to submit data? GET requests are easier to manipulate on the URL.
• Action What script does the form call? What scripting language was used (.pl, .sh, .asp)? If you ever see a form call a script with a .sh extension (shell script), mark it. Shell scripts are notoriously insecure on web servers.
• Maxlength Are input restrictions applied to the input field? Length restrictions are trivial to bypass.
• Hidden Was the field supposed to be hidden from the user? What is the value of the hidden field? These fields are trivial to modify.
• Autocomplete Is the autocomplete tag applied? Why? Does the input field ask for sensitive information?
• Password Is it a password field? What is the corresponding login field?
Query Strings and Parameters
Perhaps the most important part of a given URL is the query string, the part following the question mark (in most cases) that indicates some sort of arguments or parameters being fed to a dynamic executable or library within the application. An example is shown here:
http://www.site.com/search.cgi?searchTerm=test
This shows the parameter searchTerm with the value test being fed to the search.cgi executable on this site.
Query strings and their parameters are perhaps the most important piece of information to collect because they represent the core functionality of a dynamic web application, usually the part that is the least secure because it has the most moving parts. You can manipulate parameter values to attempt to impersonate other users, obtain restricted data, run arbitrary system commands, or execute other actions not intended by the application developers. Parameter names may also provide information about the internal workings of the application. They may represent database column names, be obvious session IDs, or contain the username. The application manages these strings, although it may not validate them properly.
Fingerprinting Query Strings
Depending on the application or how the application is tailored, parameters have a recognizable look and implementation that you should be watching for. As we noted earlier, usually anything following the ? in the query string includes parameters. In complex and customized applications, however, this rule does not always apply. So one of the first things that you need to do is to identify the paths, filenames, and parameters. For example, in the list of URLs shown in Table 2-3, spotting the parameters starts out easy and gets more difficult.
The method that we use to determine how to separate these parameters is to start deleting items from the URL. An application server will usually generate a standard error message for each part. For example, we may delete everything up to the slash from the URL, and an error message may be generated that says something like “Error Unknown Procedure.” We then continue deleting segments of the URL until we receive a different error. Once we reach the point of a 404 error, we can assume that the removed section was the file. And you can always copy the text from the error message and see if you can find any application documentation using Google.
In the upcoming section entitled “Common Web Application Profiles,” we’ll provide plenty of examples of query string structure fingerprints. We’ve shown a couple here to whet your appetite:
file.xxx?OpenDocument or even !OpenDatabase (Lotus Domino)
file.xxx?BV_SESSIONID=(junk)&BV_ENGINEID=(junk) (BroadVision)

Table 2-3 Common Query String Structure
Analyzing Query Strings and Parameters
Collecting query strings and parameters is a complicated task that is rarely the same between two applications. As you collect the variable names and values, watch for certain trends. We’ll use the following example (again) to illustrate some of these important trends:
http://www.site.com/search.cgi?searchTerm=testing&resultPage=testing
&db=/templates/db/archive.db
There are three interesting things about these parameters:
• The resultPage value is equal to the search term—anything that takes user input and does something other than what it was intended for is a good prospect for security issues.
• The name resultPage brings some questions to mind. If the value of this parameter does not look like a URL, perhaps it is being used to create a file or to tell the application to load a file named with this value.
• The thing that really grabs our attention, however, is db=/templates/db/archive.db, which we’ll discuss next.
Table 2-4 shows a list of things we would try within the first five minutes of seeing the db=/[path] syntax in the query string. Any application logic that uses the file system path as input is likely to have issues. These common attack techniques against web application file-path vulnerabilities will illustrate the nature of many of these issues.
We would also try all of these tactics on the resultPage parameter. If you want to really dig deeper, then do a search for search.cgi archive.db, or learn more about how the search engine works, or assume that “db” is the database that is being searched.

Table 2-4 Attack Attempts and Implications
Be creative—perhaps you could guess at other hidden database names that might contain not-for-public consumption information; for instance:
db=/templates/db/current.db
db=/templates/db/intranet.db
db=/templates/db/system.db
db=/templates/db/default.db
Here are some other common query string/parameter “themes” that might indicate potentially vulnerable application logic:
• User identification Look for values that represent the user. This could be a username, a number, the user’s social security number, or another value that appears to be tied to the user. This information is used for impersonation attacks. Relevant strings are userid, username, user, usr, name, id, uid. For example:
/login?userid=24601.
Don’t be intimidated by hashed values to these user parameters. For instance, you may end up with a parameter that looks like this:
/login?userid= 7ece221bf3f5dbddbe3c2770ac19b419
In reality, this is nothing more than the same userid value just shown but hashed with MD5. To exploit this issue, just increment the value to 24602 and MD5 that value and place it as the parameter value. A great tactic to use to identify these munged parameter values is to keep a database of hashes of commonly used values such as numbers, common usernames, common roles, and so on. Then, taking any MD5 that is found in the application and doing a simple comparison will catch simple hashing techniques like the one just mentioned.
• Session identification Look for values that remain constant for an entire session. Cookies also perform session handling. Some applications may pass session information on the URL. Relevant strings are sessionid, session, sid, and s. For example:
/menu.asp?sid=89CD9A9347
• Database queries Inspect the URL for any values that appear to be passed into a database. Common values are name, address information, preferences, or other user input. These are perfect candidates for input validation and SQL injection attacks. There are no simple indicators of a database value other than matching a URL’s action with the data it handles. For example:
/dbsubmit.php?sTitle=Ms&iPhone=8675309
• Look for encoded/encrypted values Don’t be intimidated by a complex-looking value string in a parameter. For instance, you might see ASP.NET’s viewstate parameter:
"__VIEWSTATE=dDwtNTI0ODU5MDE1Ozs+ZBCF2ryjMpeVgUrY2eTj79HNl4Q="
This looks complex, but it’s nothing more than a Base64-encoded value. You can usually determine this by just seeing that the string consists of what appears to be random upper- and lowercase A–Z and 0–9 with perhaps a scattered few +’s and /’s. The big giveaway is the = sign (or two) at the end of the string. It’s easy to pass this string through a base64 decoder tool and see what the site’s developers are keeping in there. Some other common encoding/encryption algorithms used in web applications include MD5, SHA-1, and the venerable XOR. Length is usually the key to detecting these. Be careful though; many web applications will combine multiple hashes and other types of data. Identifying things like the separators is key to making it easier to determine what is being used.
• Boolean arguments These are easy to tamper with since the universe of possible values is typically quite small. For example, with Boolean arguments such as “debug,” attackers might try setting their values to TRUE, T, or 1. Other Boolean parameters include dbg, admin, source, and show.
Common Cookies
The URL is not the only place to go to recognize what type of application is running. Application and web servers commonly carry their own specific cookie, as the examples in Table 2-5 illustrate.
Backend Access Points
The final set of information to collect is evidence of backend connectivity. Note that information is read from or written to the database when the application does things like updating address information or changing passwords. Highlight pages or comments within pages that directly relate to a database or other systems.
Certain WebDAV options enable remote administration of a web server. A misconfigured server could allow anyone to upload, delete, modify, or browse the web document root. Check to see if these options are enabled (we’ll talk more about how to identify and assess WebDAV in Chapter 3).
Search Tools for Profiling
Search engines have always been a hacker’s best friend. It’s a good bet that at least one of the major Internet search engines has indexed your target web application at least once in the past. The most popular and effective search engines at the time of this writing include Google, Bing, Yahoo!, Ask, AOL, and many others (you can find links in the “References & Further Reading” section at the end of this chapter).
Our personal favorite is Google. Here are some of the basic techniques we employ when taking a search engine–based approach to web application profiling (the following examples are based on Google’s syntax):
• Search for a specific web site using “site:www.victim.com” (with the quotation marks) to look for URLs that contain www.victim.com.
• Search for pages related to a specific web site using related:www.victim.com to return more focused results related to www.victim.com.
• Examine the “cached” results that pull the web page’s contents out of Google’s archive. Thus, you can view a particular page on a site without leaving the comfort of www.google.com. It’s like a superproxy!

Table 2-5 Common Cookies Used by Off-the-Shelf Web Software
• Investigate search results links called similar pages. These work like the “related” keyword noted earlier.
• Examine search results containing newsgroup postings to see if any relevant information has been posted about the site. This might include users complaining about login difficulties or administrators asking for help about software components.
• Make sure to search using just the domain name such as site:victim.com. This can return search results such as “mail.victim.com” or “beta.victim.com”.
• To locate specific file types use the filetype operator, such as “filetype:swf”, which will filter the results to only include Flash SWF files that contain the corresponding keywords of your search.
Another really effective way to leverage search to profile a site is to pay close attention to how the application interacts with its URLs while inspecting a site. Attempt to pick out what is unique about the URL. For instance, it could be a filename or an extension or even the way the parameters work. You want to try to identify something fixed, and then perform a Google search on that and see if you can find any documentation or other sites that might be running it. For example, during a recent assessment of an application, we were clicking through and studying how the URLs were set up. The homepage URL looked something like the following:
http://site/wconnect/ace/home.htm
A link on the homepage to “online courses” appeared as follows:
https://site/wconnect/wc.dll?acecode%7ESubGroup%7EONL%7EOnline%2BCourses
Following this link, we navigated our way further into the site, noting the following URLs:
https://site/wconnect/ wc.dll?acecode∼GroupCatalog∼GROUP∼ONLFIN∼Financial+ Planning+Online∼ONL
https://site/wconnect/ wc.dll?acecode∼GroupCatalog∼GROUP∼ONLFIN∼Financial+ Planning+Online∼ON L∼&ORDER=LOCATION
Notice that everywhere we turned, parameters were being passed to wc.dll. So we needed to find out just a little bit more about this file. To do so, we took /wconnect/wc.dll to Google and ran a search. The results gave us a list of other sites also running this file. After some quick research, we identified the file as belonging to an application called “Web Connection” developed by West-Wind. Digging even further, we went to the support section on West-Wind’s site and found the administration guide. And while reading the documentation, we noticed a web-based administration page available at http://site/wconnect/admin.asp. So we returned to the web site and attempted to access this page. But our request for the administration page was welcomed with an “IP address rejected” error because we were attempting to access a restricted area from an unauthorized IP address. This appears to be good use of access control lists (ACLs) by the administrator. We figured this could really be a dead end because we wouldn’t be able to figure out a way to spoof our IP address. Because we live for challenges, however, we returned to the documentation once again. It was then that we noticed there was a URL that allowed us to access a status page of the application just by inputting http://site.com/wconnect/wc.dll?_maintain_ShowStatus. This page is shown in Figure 2-5.
Through this request, we managed to access the application’s status page successfully. When we looked closely at the status page, we noticed something interesting: a link that read “Back to Admin Page.” This was noteworthy, as we hadn’t come to this page from the admin page! When clicking the link, it sent us back to the admin.asp page, which was denied (as expected). But we knew we were onto something worth investigating. We felt we were on the brink of a penetration as we had just accessed an administrative function without accessing the administrative page. After returning once again to the documentation, we learned that the administration page is simply a jump-off page from the function calls implemented by wc.dll. Thus, if we knew the administrative function calls, we could just call them directly through the wc.dll file without having to access the admin.asp page. This is just the kind of breakthrough that makes all of the work and the research of profiling worthwhile!
We returned to the documentation to identify all of the function calls that may provide deeper access into the system and find anything interesting that could prove helpful in our task. Within the manual, we found a description of the parameters of the wconnect.ini file from which the application reads its settings. The documentation mentioned a parameter that can be defined that runs an .exe file. This is what the documentation stated:
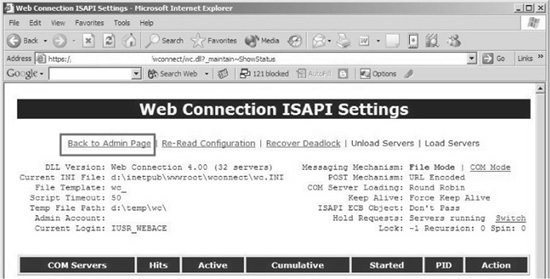
Figure 2-5 The _maintain∼ShowStatus parameter output from the wc.dll dynamic page generation component
“StartEXE: Starts an EXE specified in ExeFile in the DLL ini file for file based messaging. The EXE is started in the System context so it will run invisibly when started from a service.”
This was exactly what we were looking for. Now we needed a way to modify the value of this parameter so it would launch the .exe file that we would define. Luckily, we found an API in the documentation called “wwMain∼EditConfig.” The documentation noted that this API call permitted editing of the Web Connection Configuration files remotely. The documentation helpfully described a link that displays a page with the server’s config files for remote editing:
http://site.com/wconnect/wc.dll?wwMain∼EditConfig
Bingo, just what we needed! We inserted this URL into our browser and up popped the page we needed to edit and update the .ini files. We then found the ExeFile parameter and changed the value to c:winntsystem32cmd.exe /c "dir /S c: > d:inetpub wwwrootdir.txt”. This is shown in Figure 2-6.
That gave us the full directory listing of all of the files on the system and dumped them into a text file located in the web root. We updated the .ini file. Now, the only thing left to do was to figure out a way for the appserver to reread the configuration file so that our command would be executed.
Looking back in the documentation, we found exactly what we needed: http://site.com/wc.dll?_maintain∼StartExe. This would cause the application to restart and run our command. When it was finished, we had access to our newly created file by accessing http://site.com/dir.txt.
All this started from a simple Google query! Remember this as you consider the structure and logic of your web site. We’ll talk about possible countermeasures to this approach in the “General Countermeasures” section later in this chapter.
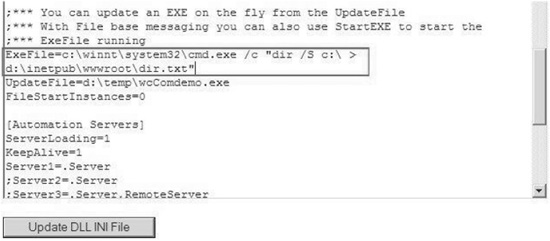
Figure 2-6 Manipulating the ExeFile parameter to execute arbitrary commands on a victim system. My, what you can find with Google!
Open Source Intelligence
Beyond Google there are other search engines with a specific focus that can be invaluable in finding specific information. Whether you want to find information on a person or inquire about public records, chances are a specialized search engine has been made to find what you desire. Services such as Melissa Data can help you freely gather information on people associated with a target web application. Even an e-mail address or a phone number for human resources affiliated with a target may be as valuable as—or more valuable than—information on technical resources when profiling a target application. A tool that automates much of the effort in gathering such information is Maltego. Defined as an open source intelligence-gathering tool, Maltego helps visualize the relationships among people, organizations, web sites, Internet infrastructure, and many other links. Figure 2-7 shows Maltego profiling a web site.
Maltego can aid in information gathering, and it can find affiliations between components within an organization. Even with information as simple as a domain name or an IP address, it can query publicly available records to discover connections. A complete list of the queries the tool can perform can be found at http://ctas.paterva.com/view/Category:Transforms.
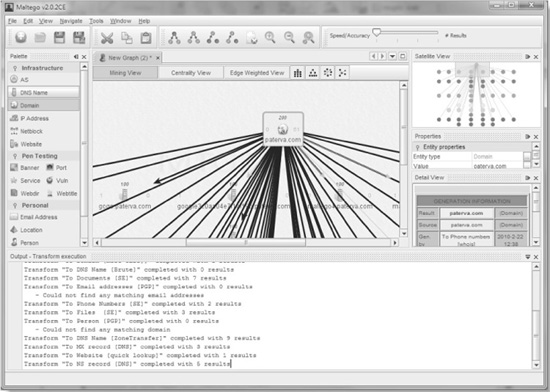
Figure 2-7 The open-source intelligence tool Maltego profiles a web site.
Social networks are another growing source of intelligence. A hypothetical attack might involve a malicious user joining LinkedIn (www.linkedin.com) and posing as an employee of a particular company. He could connect to other employees and gain information on them that could then be leveraged for further attacks. To deflect such attacks, users of social networks need to beware of where they share sensitive information and with whom they share it. Businesses have begun to raise awareness of such risks through internal education campaigns and, in some instances, have even begun to monitor employee Twitter feeds and Facebook profiles for sensitive information related to work projects. In March 2010, Israeli military officials cancelled a planned attack after a combat soldier leaked details on his Facebook page. Fearing the enemy had read the information pertaining to the specific time and location of the strike, the officials deemed it too risky to continue with the planned operation. Without proper education and a policy for employees to follow, this type of information leak could happen at any organization.
Robots.txt
Before we depart our tour of the many uses of Internet search engines, we want to make note of one additional search-related issue that can greatly enhance the efficiency of profiling. The robots.txt file contains a list of directories that search engines such as Google are supposed to index or ignore. The file might even be on Google, or you can retrieve it from the site itself:
[root@meddle]# getit.sh www.victim.com /robots.txt
User-agent: *
Disallow: /Admin/
Disallow: /admin/
Disallow: /common/
Disallow: /cgi-bin/
Disallow: /scripts/
Disallow: /Scripts/
Disallow: /i/
Disallow: /images/
Disallow: /Search
Disallow: /search
Disallow: /links
Disallow: /perl
Disallow: /ipchome
Disallow: /newshome
Disallow: /privacyhome
Disallow: /legalhome
Disallow: /accounthome
Disallow: /productshome
Disallow: /solutionshome
Disallow: /tmpgeos/
A file like this is a gold mine! The Disallow tags instruct a cooperative spidering tool to ignore the directory. Tools and search engines rarely do. The point is that a robots.txt file provides an excellent snapshot of the directory structure—and maybe even some clear pointers toward misconfigurations that can be exploited later.
NOTE
Skeptical that sites no longer use the robots.txt file? Try this search on Google (“parent directory” should be in double quotes as shown): “parent directory” robots.txt.
Automated Web Crawling
We’ve spent a great deal of time enumerating manual techniques for profiling web applications and the infrastructure that supports them. We hope that it’s been an informational tour of the “under-the-hood” techniques of web application profiling.
As interesting as these techniques are, we’re the first to admit that they are numbingly repetitive to perform, especially against large applications. As we’ve alluded to several times throughout this discussion, numerous tools are available to automate this process and make it much easier.
We’ve noted that one of the most fundamental and powerful techniques used in profiling is the mirroring of the entire application to a local copy that can be scrutinized slowly and carefully. We call this process web crawling, and web crawling tools are an absolute necessity when it comes to large-scale web security assessments. Your web crawling results will create your knowledge-baseline for your attacks, and this baseline is the most important aspect of any web application assessment. The information you glean will help you to identify the overall architecture of your target, including all of the important details of how the web application is structured, input points, directory structures, and so on. Some other key positives of web crawling include the following:
• Spares tons of manual labor!
• Provides an easily browseable, locally cached copy of all web application components, including static pages, executables, forms, and so on.
• Enables easy global keyword searches on the mirrored content (think “password” and other tantalizing search terms).
• Provides a high-level snapshot that can easily reveal things such as naming conventions used for directories, files, and parameters.
As powerful as web crawling is, it is not without its drawbacks. Here are some things that it doesn’t do very well:
• Forms Crawlers, being automated things, often don’t deal well with filling in web forms designed for human interaction. For example, a web site may have a multistep account registration process that requires form fill-in. If the crawler fails to complete the first form correctly, it may not be able to reach the subsequent steps of the registration process and will thus miss the privileged pages that the application brings you to once you successfully complete registration.
• Complex flows Usually, crawling illustrates logical relationships among directories, files, and so on. But some sites with unorthodox layouts may defy simple interpretation by a crawler and require that a human manually clicks through the site.
• Client-side code Many web crawlers have difficulty dealing with client-side code. If your target web site has a lot of JavaScript, there’s a good chance you’ll have to work through the code manually to get a proper baseline of how the application works. This problem with client-side code is usually found in free and cheap web crawlers. You’ll find that many of the advanced commercial crawlers have overcome this problem. Some examples of client-side code include JavaScript, Flash, ActiveX, Java Applets, and AJAX (Asynchronous Java and XML).
• State problems Attempting to crawl an area within a web site that requires web-based authentication is problematic. Most crawlers run into big trouble when they’re asked to maintain logged-in status during the crawl. And this can cause your baseline to be cut short. The number of techniques that applications use to maintain state is amazingly vast. So we suggest that you profile the authenticated portions of the web site manually or look to a web security assessment product when your target site requires that you maintain state. No freeware crawler will do an adequate job for you.
• Broken HTML/HTTP A lot of crawlers attempt to follow HTTP and HTML specifications when reviewing an application, but a major issue is that no web application follows an HTML specification. In fact, a broken link from a web site could work in one browser but not another. This is a consistent problem when it comes to an automated product’s ability to identify that a piece of code is actually broken and to automatically remedy the problem so the code works the way Internet Explorer intends.
• Web services As more applications are designed as loosely coupled series of services, it will become more difficult for traditional web crawlers to determine relationships and trust boundaries among domains. Many modern web applications rely on a web-based API to provide data to their clients. Traditional crawlers will not be able to execute and map an API properly without explicit instructions on how execution should be performed.
Despite these drawbacks, we wholeheartedly recommend web crawling as an essential part of the profiling process. Next, we’ll discuss some of our favorite web crawling tools.
Web Crawling Tools
Here are our favorite tools to help automate the grunt work of the application survey. They are basically spiders that, once you point to an URL, you can sit back and watch them create a mirror of the site on your system. Remember, this will not be a functional replica of the target site with ASP source code and database calls; it is simply a complete collection of every available link within the application. These tools perform most of the grunt work of collecting files.
NOTE
We’ll discuss holistic web application assessment tools, which include crawling functionality, in Chapter 10.
Lynx
Lynx is a text-based web browser found on many UNIX systems. It provides a quick way to navigate a site, although extensive JavaScript will inhibit it. We find that one of its best uses is for downloading specific pages.
The –dump option is useful for its “References” section. Basically, this option instructs lynx to simply dump the web page’s output to the screen and exit. You can redirect the output to a file. This might not seem useful at first, but lynx includes a list of all links embedded in the page’s HTML source. This is helpful for enumerating links and finding URLs with long argument strings.
[root@meddle]# lynx -dump https://www.victim.com > homepage
[root@meddle]# cat homepage
...text removed for brevity...
References
1. http://www.victim.com/signup?lang=en
2. http://www.victim.com/help?lang=en
3. http://www.victim.com/faq?lang=en
4. http://www.victim.com/menu/
5. http://www.victim.com/preferences?anon
6. http://www.victim.com/languages
7. http://www.victim.com/images/
If you want to see the HTML source instead of the formatted page, then use the –source option. Two other options, –crawl and –traversal, will gather the formatted HTML and save it to files. However, this is not a good method for creating a mirror of the site because the saved files do not contain the HTML source code.
Lynx is still an excellent tool for capturing single URLs. Its major advantage over the getit scripts is the ability to perform HTTP basic authentication using the –auth option:
[root@meddle]# lynx -source https://www.victim.com/private/index.html
Looking up www.victim.com
Making HTTPS connection to 192.168.201.2
Secure 168-bit TLSv1/SSLv3 (EDH-RSA-DES-CBC3-SHA) HTTP connection
Sending HTTP request.
HTTP request sent; waiting for response.
Alert!: Can't retry with authorization! Contact the server's WebMaster.
Can't Access `https://192.168.201.2/private/index.html'
Alert!: Unable to access document.
lynx: Can't access startfile
[root@meddle]# lynx -source -auth=user:pass
> https://63.142.201.2/private/index.html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 FINAL//EN">
<HTML>
<HEAD>
<TITLE>Private Intranet</TITLE>
<FRAMESET BORDER=0 FRAMESPACING=0 FRAMEBORDER=0 ROWS="129,*">
<FRAME NAME="header" SRC="./header_home.html" SCROLLING=NO
MARGINWIDTH="2" MARGINHEIGHT="1" FRAMEBORDER=NO BORDER="0" NORESIZE>
<FRAME NAME="body" SRC="./body_home.html" SCROLLING=AUTO
MARGINWIDTH=2 MARGINHEIGHT=2>
</FRAMESET>
</HEAD>
</HTML>
Wget
Wget (www.gnu.org/software/wget/wget.html) is a command-line tool for Windows and UNIX that will download the contents of a web site. Its usage is simple:
[root@meddle]# wget -r www.victim.com
--18:17:30-- http://www.victim.com/
=> `www.victim.com/index.html'
Connecting to www.victim.com:80... connected!
HTTP request sent, awaiting response... 200 OK
Length: 21,924 [text/html]
0K .......... .......... . 100% @ 88.84 KB/s
18:17:31 (79.00 KB/s) - `www.victim.com/index.html' saved [21924/21924]
Loading robots.txt; please ignore errors.
--18:17:31-- http://www.victim.com/robots.txt
=> `www.victim.com/robots.txt'
Connecting to www.victim.com:80... connected!
HTTP request sent, awaiting response... 200 OK
Length: 458 [text/html]
0K 100% @ 22.36 KB/s
...(continues for entire site)...
The -r or --recursive option instructs wget to follow every link on the home page. This will create a www.victim.com directory and populate that directory with every HTML file and directory wget finds for the site. A major advantage of wget is that it follows every link possible. Thus, it will download the output for every argument that the application passes to a page. For example, the viewer.asp file for a site might be downloaded four times:
• viewer.asp@ID=555
• viewer.asp@ID=7
• viewer.asp@ID=42
• viewer.asp@ID=23
The @ symbol represents the ? delimiter in the original URL. The ID is the first argument (parameter) passed to the viewer.asp file. Some sites may require more advanced options such as support for proxies and HTTP basic authentication. Sites protected by basic authentication can be spidered by:
[root@meddle]# wget -r --http-user:dwayne --http-pass:woodelf >
https://www.victim.com/secure/
--20:19:11-- https://www.victim.com/secure/
=> `www.victim.com/secure/index.html'
Connecting to www.victim.com:443... connected!
HTTP request sent, awaiting response... 200 OK
Length: 251 [text/html]
0K 100% @ 21.19 KB/s
...continues for entire site...
Wget has a single purpose: to retrieve files from a web site. Sifting through the results requires some other simple command-line tools available on any Unix system or Windows Cygwin.
Burp Suite Spider
Burp Suite is a set of attack tools that includes a utility for mapping applications. Rather than having to follow links manually, submitting forms, and parsing the responses, the Burp Spider will automatically gather this information to help identify potentially vulnerable functionality in the web application. Add the site to be crawled to the current target scope and then simply browse the application using the Burp proxy after enabling the Spider feature. Further options can be configured via the Options tab.
Teleport Pro
Of course, for Windows users there is always something GUI. Teleport Pro (www.tenmax.com/teleport/pro/home.htm) brings a graphical interface to the function of wget and adds sifting tools for gathering information.
With Teleport Pro, you can specify any part of a URL to start spidering, control the depth and types of files it indexes, and save copies locally. The major drawback of this tool is that it saves the mirrored site in a Teleport Pro Project file. This TPP file cannot be searched with tools such as grep. Teleport Pro is shown in Figure 2-8.
Black Widow
Black Widow extends the capability of Teleport Pro by providing an interface for searching and collecting specific information. The other benefit of Black Widow is that you can download the files to a directory on your hard drive. This directory is more user-friendly to tools like grep and findstr. Black Widow is shown in Figure 2-9.
Offline Explorer Pro
Offline Explorer Pro is a commercial Win32 application that allows an attacker to download an unlimited number of her favorite web and FTP sites for later

Figure 2-8 Teleport Pro’s many options
offline viewing, editing, and browsing. It also supports HTTPS and multiple authentication protocols, including NTLM (simply use the domainusername syntax in the authentication configuration page under File | Properties | Advanced | Passwords for a given Project). We discuss Offline Explorer Pro throughout this book, since it’s one of our favorite automated crawling tools.
Common Web Application Profiles
We’ve covered a number of web application profiling techniques, from manual inspection and using Internet search engines like Google, to automated crawling approaches. Let’s apply these techniques to a few common off-the-shelf enterprise applications to illustrate how you can recognize them using these simple methods.
Oracle Application Server
Most Oracle applications contain a main subfolder called /pls/. This is where everything in the application is appended. This /pls/ folder is actually Oracle’s PL/SQL module,
Figure 2-9 Black Widow mirrors site contents to the local drive.
and everything that follows it are call parameters. To help you understand, take a look at this Oracle Application URL:
http://site.com/pls/Index/CATALOG.PROGRAM_TEXT_RPT?
p_arg_names=prog_nbr&p_arg_values=39.001
In this example, /pls/ is the PL/SQL gateway; /Index/ is the Database Access Descriptor; and CATALOG. is a PL/SQL package that has the PROGRAM_TEXT_RPT procedure, which accepts the parameters on the rest of the URL.
Detecting an Oracle server is typically very easy because the www.site.com/pls/directory is a dead giveaway. Also, Oracle’s convention of naming its scripts and PL/SQL package with full words such as somename.someothername is another telltale sign. It is also common to see Oracle names in all capital letters, such as NAME.SOMENAME. And many Oracle names will also end with a procedure such as .show or a URL that looks like this:
http://www.site.com/cs/Lookup/Main.show?id=4592
When you see this type of structure, you are most likely looking at an Oracle application.
BroadVision
Here’s an example of a BroadVision URL. We’ve placed numbers in bold within this example to highlight some key features.
http://www.site.com/bvsn/bvcom/ep/
programView.(2)do?(3)pageTypeId=8155&programPage=/jsp/www/content/
generalContentBody.jsp&programId=8287&channelId=-8246&(1)BV_
SessionID=NNNN1053790113.1124917482NNNN&BV_
EngineID=cccdaddehfhhlejcefecefedghhdfjl.0
1. The killer signature here is the parameter names: BV_SessionID and BV_EngineID. If you see these anywhere in a URL, you have nailed a BroadVision application. How much more simple can it get?
2. BroadVision applications also usually have .do script extensions.
3. Most BroadVision applications also have parameter names that tend to end in xxxxId=nnnn. By looking at the URL, you’ll notice three parameters that are named this way (pageTypeId=8155, programId=8287, channelId=-8246). This naming scheme is unique in that ID is spelled with a capital I and lowercase d, and usually the value contains a number that is four or more digits. This is a nice way of detecting BroadVision without obvious clues.
Here’s another example BroadVision URL:
http://www.site.com/store/stores/
Main.jsp?pagetype=careers&template=Careers.
jsp&categoryOId=-8247&catId=-8247&subCatOId=-8320&subtemplate=Content.jsp
At first glance, we would suspect BroadVision is present because of the lowercase ds in the IDs and the familiar four or more numeric digits in the values. Another clue that raises our confidence level is the fact that they’re negative numbers—something you see a lot of in BroadVision applications.
PeopleSoft
Here’s an example of a PeopleSoft URL. We’ve again placed numbers in bold within this example to highlight some key features.
http://www.site.com/psp/hrprd/(3)EMPLOYEE/HRMS/c/
ROLE_APPLICANT.ER_APPLICANT_HOME(1).GBL?(2)NAVSTACK=Clear
1. The file extension is a clear giveaway here: .GBL exists in most URLs of sites that run PeopleSoft.
2. NAVSTACK= is also a fairly common thing to see in most PeopleSoft installations. But be careful! There are a lot of PeopleSoft installations without this parameter.
3. Folders and filenames in PeopleSoft tend to be all capitalized.
Another item that gives away PeopleSoft is cookies. PeopleSoft usually sets the following cookies:
PORTAL-PSJSESSIONID=DMsdZJqswzuIRu4n;
PS_
TOKEN=AAAAqwECAwQAAQAAAAACvAAAAAAAAAAsAARTaGRyAgBOdwgAOAAuADEAMBR
dSiXq1mqzlHTJ9ua5ijzbhrj7eQAAAGsABVNkYXRhX3icHYlbCkBQFEWXRz4MwRzo
dvMaAPElmYDkS0k+FIMzONs9q7PatYDb84MQD53//
k5oebiYWTjFzsaqfXBFSgNdTM/EqG9yLEYUpHItW3K3KzLXfheycZSqJR97+g5L;
PS_TOKENEXPIRE=24_Aug_2005_17:25:08_GMT;
PS_LOGINLIST=http://www.site.com/hrprd;
You will usually see the PORTAL-PSJSESSIONID cookie in most PeopleSoft applications. The other three cookies that you see are far less common. In most cases, you’ll find detecting PeopleSoft installations easy because PeopleSoft is clearly identified in the URL. But you can’t just rely on URLs to spot PeopleSoft; many times developers so heavily customize their applications that detecting what application is actually running becomes difficult. So we’ll spend some time discussing how PeopleSoft applications behave and look. Trying to recognize an application through its behavior and “feel” will become easier as you gain experience dealing with web applications. Let’s walk through an example of how to fingerprint an application based on feel and look.
Like many applications, PeopleSoft acts in a unique way. Most PeopleSoft applications will have a menu on the left and a large frame on the right. When clicking the menu items on the left—they are typically direct URLs; you will see the URLs change as you click—the page will load on the right. The content of the page on the right will usually be heavily written with JavaScript. And each link and button typically launches some type of JavaScript action. That’s why, as you hover over these links, you’ll often see plenty of “javascript:” links that will either perform a submit command or open a new window. That’s one of the reasons you can spot a PeopleSoft application right away.
Because most web application servers are highly customizable, telling one web server from another is difficult without studying the URL or the technical specifications. But there are subtle things that you can look for that will help to indicate what application is running. For example, a PeopleSoft application is highly customizable, so it might be difficult to tell a PeopleSoft application by the standard profiling methods via URL or query recognition. Yet most PeopleSoft applications are easily distinguishable by the interface components that are used. For example, in the following two screenshots, you can see both the menu and standard login screen of a known PeopleSoft application:

The following shows a screenshot of an application that is suspected to be a PeopleSoft application, but the URL gives no indication of the usual PeopleSoft parameter structure (https://www.site.com/n/signon.html):
Compare the look and feel of this screenshot with the known PeopleSoft menu shown above. Look at the menus. PeopleSoft’s menus always tend to be very square and almost Xwindows-like. And they will usually have a – in front of all items. Notice how the menu font, size, and color are the same. Also notice the color and shape of the Continue button.
Do you see how the button color and look are the same? We have detected that this application is running PeopleSoft just by looking at it. Another example of this might be Lotus Domino; Lotus makes heavy use of collapsible trees that usually have a certain feel to them. For instance, they may have arrows that point to the side for closed trees or point down for open trees. If we see that behavior on a tree on a web site, it may be a clue that Domino is being used.
Lotus Domino
By now you should have a good understanding of how to quickly start picking areas to look for in a URL to identify what applications are running. Let’s take a look at how we determine whether Lotus Domino is being used.
Here’s an example of a Lotus Domino URL. We’ve again placed numbers in bold within this example to highlight some key features:
http://www.site.com/realtor(1).nsf/pages/
MeetingsSpeakers(2)?OpenDocument
http://www.site.com/DLE/rap.nsf/files/InstructionsforRequestForm/$file/
InstructionsforRequestForm.doc
http://www.site.com/global/anyzh/dand.nsf!OpenDatabase&db=/global/gad/
gad02173.nsf&v=10E6&e=us&m=100A&c=7A98EB444439E608C1256D630055064E
1. The common extension is .nsf. Notice that the extension is .nsf but what looks like folders after this file are actually parameters. realtor.nsf is the only file and following it are parameters to that file.
2. OpenDocument is a Lotus Action; there are many others.
WebSphere
Here’s an example of a WebSphere URL. We’ve again set numbers in bold within this example to highlight some key features:
http://www.site.com/webapp/commerce/command/(1)ExecMacro/site/macros/
proddisp.(2)d2w/(3)report?prrfnbr=3928&prmenbr=991&CATE=&grupo=
1. Look for these keywords in the path: /ExecMacro/, /ncommerce3/, and /Macro/.
2. Look for the extension .d2w.
3. WebSphere tends to always have /report? parameters.
WebSphere usually has a session cookie like the following:
SESSION_ID=28068215,VzdMyHgX2ZC7VyJcXvpfcLmELUhRHYdM91
+BbJJYZbAt K7RxtllNpyowkUAtcTOm;
GENERAL COUNTERMEASURES
As we have seen, much of the process of profiling a web application exploits functionality that is intended by application designers—after all, they do want you to browse the site quickly and easily. However, we have also seen that many aspects of site content and functionality are inappropriately revealed to anonymous browsers due to some common site-design practices and misconfigurations. This section will recount steps that application designers can take to prevent leaks great and small.
A Cautionary Note
After seeing what information is commonly leaked by web applications, you may be tempted to excise a great deal of content and functionality from your site. We recommend restraint, or, to put it another way, “Careful with that axe, Eugene.” The web administrator’s goal is to secure the web server as much as possible. Most information leakage can be stopped at the server level through strong configurations and least-privilege access policies. Other methods require actions on the part of the programmer. Keep in mind that web applications are designed to provide information to users. Just because a user can download the application’s local.js file doesn’t mean the application has a poor design; however, if the local.js file contains the username and password to the application’s database, then the system is going to be broken.
Protecting Directories
As we saw many times throughout this chapter, directories are the first line of defense against prying profilers. Here are some tips for keeping them sealed.
Location Headers
You can limit the contents of the Location header in the redirect so it doesn’t display the web server IP address, which can point attackers toward discrete servers with misconfigurations or vulnerabilities.
By default, IIS returns its IP address. To return its fully qualified domain name instead, you need to modify the IIS metabase. The adsutil.vbs script is installed by default in the Inetpubadminscripts directory on Windows systems:
D:Inetpubadminscriptsadsutil.vbs set w3svc/UseHostName True
D:Inetpubadminscripts
et start w3svc
Apache can stop directory enumeration. Remove the mod_dir module during compilation. The change is simple:
[root@meddle apache_1.3.23]# ./configure --disable-module
=dirConfiguring for Apache, Version 1.3.23
Directory Structure and Placement
Here are some further tips on securing web directories:
• Different user/administrator roots Use separate web document roots for user and administrator interfaces, as shown on the next page. This can mitigate the impact of source-disclosure attacks and directory traversal attacks against application functionality:
/main/ maps to D:IPubpubroot
/admin/ maps to E:IPubadmroot
• IIS Place the InetPub directory on a volume different from the system root, e.g., D:InetPub on a system with C:WINNT. This prevents directory traversal attacks from reaching sensitive files like WINNT epairsam and WINNT System32cmd.exe.
• UNIX web servers Place directories in a chroot environment. This can mitigate the impact of directory traversal attacks.
Protecting include Files
The best protection for all types of include files is to ensure that they do not contain passwords. This might sound trivial, but anytime a password is placed in a file in clear text, expect that password to be compromised. On IIS, you can change the file extension commonly used for include files (.inc) to .asp, or remap the .inc extension to the ASP engine. This change will cause them to be processed server-side and prevent source code from being displayed in client browsers. By default, .inc files are rendered as text in browsers. Remember to change any references within other scripts or content to the renamed include files.
Miscellaneous Tips
The following tips will help your web application resist the surveying techniques we’ve described in this chapter:
• Consolidate all JavaScript files to a single directory. Ensure the directory and any files within it do not have “execute” permissions (i.e., they can only be read by the web server, not executed as scripts).
• For IIS, place .inc, .js, .xsl, and other include files outside of the web root by wrapping them in a COM object.
• Strip developer comments. A test environment should exist that is not Internet-facing where developer comments can remain in the code for debugging purposes.
• If a file must call any other file on the web server, then use path names relative to the web root or the current directory. Do not use full path names that include drive letters or directories outside of the web document root. Additionally, the script itself should strip directory traversal characters (../../).
• If the site requires authentication, ensure authentication is applied to the entire directory and its subdirectories. If anonymous users are not supposed to access ASP files, then they should not be able to access XSL files either.
SUMMARY
The first step in any methodology is often one of the most critical, and profiling is no exception. This chapter illustrated the process of profiling a web application and its associated infrastructure from the perspective of a malicious attacker.
First, we discussed identification of all application-related infrastructure, the services the applications are running, and associated service banners. These are the initial strokes on the large canvas that we will begin to paint as the rest of this book unfolds.
Next, we covered the process of cataloging site structure, content, and functionality, laying the groundwork for all of the subsequent steps in the web application security assessment methodology described in this book. It is thus critical that the techniques discussed here are carried out consistently and comprehensively in order to ensure that no aspect of the target application is left unidentified. Many of the techniques we described require subtle alteration depending on the uniqueness of the target application, and as always, clever inductions on the part of the surveyor will lead to more complete results. Although much of the process of surveying an application involves making valid requests for exported resources, we did note several common practices and misconfigurations that can permit anonymous clients to gain more information than they should.
Finally, we discussed countermeasures to some of these practices and misconfigurations that can help prevent attackers from gaining their first valuable foothold in their climb toward complete compromise.
At this point, with knowledge of the make and model of web server software in play, the first thing a savvy intruder will seek to do is exploit an obvious vulnerability, often discovered during the process of profiling. We will cover tools and techniques for web platform compromise in Chapter 3. Alternatively, with detailed web application profile information now in hand, the attacker may seek to begin attacking the application itself, using techniques we discuss in Chapters 4 through 9.
REFERENCES & FURTHER READING