
Reengineering the Data Warehouse
Simplicity is prerequisite for reliability.
—Edsger W. Dijkstra
Introduction
In Chapter 6 we discussed the different generations of data warehousing, the challenges of the data warehouse, and some modern thoughts on evolving the data warehouse. Earlier chapters have provided us with an in-depth look at Big Data, and its challenges, problems, and solutions. The big questions that stare at us at this juncture are: What will the data warehouse evolve to in the new architecture landscape? Is there even room for a data warehouse? Is there a future for the current investment? This chapter provides us an introduction to reengineering the data warehouse or modernizing the data warehouse. This is the foundational step in building the new architecture for the next-generation data warehouse.
The data warehouse has been built on technologies that have been around for over 30 years and infrastructure that is at least three generations old, compared to the advancements in the current-state infrastructure and platform options. There are several opportunities that are being missed by organizations, including:
• Gaining competitive advantage
• Reducing operational and financial risks
• Optimizing core business efficiencies
• Analyzing and predicting trends and behaviors
One can argue that an enterprise data warehouse is not responsible for many of these types of insights, true and false. The promise of the data warehouse is an enterprise repository for data and a platform for the single version of truth. The issue, however, is due to complexities of users, processes, and data itself. The data warehouse performance has eroded over time steadily and degraded to the extent that it needs to be modernized by a combination of infrastructure and software upgrades to ensure that its performance can be sustained and maintained.
Enterprise data warehouse platform
In Chapter 6 we saw a few layers under the hood with respect to the limitations of a database, however, that makes only one component of the entire infrastructure platform called the enterprise data warehouse. There are several layers of infrastructure that make the platform for the EDW:
A cross-section examination of this infrastructure platform is shown in Figure 7.1.
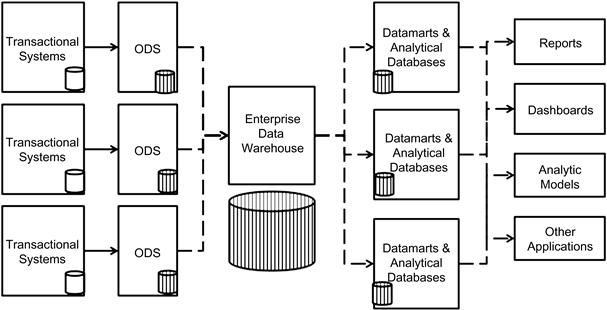
There are several layers of data distributed from transactional systems into the ODS or staging areas and finally into the data warehouse, to be passed downstream to analytical databases. Let us examine Figure 7.1.
Transactional systems
Transactional systems are the source databases from any application—web or client server—and are very small in size and have a lower degree of complexity of data processing. The data life cycle is not more than a day or a week at a maximum. Data is copied from this system to downstream databases including the ODS, staging area, and data warehouse. The databases here have very minimal latencies and are always tuned to perform extremely fast writes.
Operational data store
The ODS is an optional architecture component and is used for operational reporting purposes. The data collected in the ODS varies in weeks to months, sometimes even a year. The ODS is an aggregation of the data from the transactional systems. The data model undergoes minimal changes, but the complexity of the ODS is inherited from the integration of multiple data sources into one database. The ODS serves two operations: loading data from transactional systems, and running report queries from users. The mixture of two different types of operations causes data to be moved from disk to memory and back to disk in a repeated manner. This causes a lot of performance issues on the overall ODS. There are several potential possibilities to reengineer the ODS, which we will discuss later in this chapter. The ODS is one key area for the modernization exercise.
Staging area
The staging area is another database that is built and deployed in every data warehouse. The purpose of the staging area is to gather data for data quality and data preparation exercises for loading data into the data warehouse. While the data is scrubbed on a daily or every other day basis, maintaining the volumes at lower levels compared to the ODS or data warehouse, there is a lot of activity on the staging area, which often shares the same disk space on the storage layer with the rest of the data warehouse tables. This activity includes data quality and data preparation for loading to the data warehouse, apart from any specific data integration prior to data warehouse loading. These activities, while not creating any overhead from data volume, cause a lot of overhead from the data complexity perspective. The current dilemma for architects is whether to create a separate storage area for the staging area or to completely remove the staging area from the data warehouse data infrastructure, and relocate the same to the ODS or a separate preprocessing database. The disk activity generated by the staging area activities in terms of overloading the data warehouse, competes with the same memory, processor, disk, and network as the data warehouse. This causes several performance issues that database and system administrators have tuned for years. The platform is irrelevant, as the problem manifests across the board.
Data warehouse
The biggest and most complex data structures that has been built on the RDBMS platform is the data store for all the data deemed as an enterprise asset. The data warehouse contains not only current data, but also past history of several years online and offline. The data warehouse is the source of data for all downstream systems including reporting platforms, analytics, dashboards, and specialty applications like CRM, compliance reporting, and financial reporting.
The data structures within the data warehouse can range from simple tables that are reference data to complex aggregate tables and even multidimensional cubes. The data contained in these data structures is constantly changing either in the loading of new data from sources, or in the refresh of complex aggregate structures, while being simultaneously queried by downstream applications for refresh and other data requirements. This flurry of activity requires constant management of infrastructure to provide performance between the loading and the concurrent querying, generating heavy traffic across the infrastructure, which over a period of time becomes fragile and susceptible to failure, leading to performance issues, breakdown of data processing and query processing, and eventually resulting in the failure of the entire data warehouse.
Datamarts
Datamarts are specialty databases built for solving reporting and analysis needs of departmental users, and provide specific subject area–based views of the data to the users. In some organizations that follow BUS architecture for data warehousing, datamarts represent subject areas for that data warehouse. The activities on the datamart are very similar to the data warehouse with users constantly querying data and executing reports and analytics. There are two architectural impacts due to the datamart that can affect the performance of both the data warehouse and the datamart:
• Data extraction for the datamart—this is a load on the data warehouse, the underlying infrastructure, and the storage. The impact of this process can be minimal when completed during off hours, as opposed to report refresh or interactive analysis.
• Querying and analytics on the datamart—if the data warehouse and the datamart share the physical infrastructure layers, chances of network and storage contention is a very valid situation. These activities can create significant performance and scalability impacts on the data warehouse.
Analytical databases
Analytical databases are specialty databases that are used by analytical applications such as SAS, SPSS, SSAS, and R. These databases are highly complex and large in volume. In most RDBMS systems today, these databases are being natively supported in the same platform that supports the data warehouse. Whether separate or in the same database, the analytical database queries are extremely complex and long running, often creating multiple intermediate temporary data structures on-the-fly. The unpredictable nature of the underlying statistical model creates this complexity. If these databases are built as a separate instance, they still share the same storage and network layer as the data warehouse and the datamarts. When a user executes queries on the analytical database, it increases the contention for shared resources. The direct effect of this contention is the slowdown of the entire infrastructure. (Note: At this point in time we are still discussing a shared-everything architecture and its impacts, which are the foundational platform for traditional database architecture and deployment.)
Issues with the data warehouse
What Figure 7.1 depicts is the domino effect of data bottlenecks on the infrastructure, and the bottom line in this situation is the introduction of latencies across the entire infrastructure. The impact of the latencies transcends across multiple layers within the data warehouse and the dependent applications and cumulatively leads to business decision latencies. These latencies can be summed up as “opportunity costs” that often drive away the premise of competitive advantages, clinically precise insights, and opportunities to innovate new business trends. Quite often this is the core reason for the slow adoption or quick attrition from the data warehouse.
The second threat in these widespread silos of data comes in the form of data security. While the data warehouse is the designated corporate repository, due to the performance and scalability issues that surround the data warehouse from the discussion so far, we know that smaller footprints of the data exist in spreadmarts (Excel spreadsheets driving a pseudo-datamart), and datamarts and other data-consumption formats pose a threat to securing the data at rest, loss of data from the enterprise, and compliance violations in regards to data privacy.
The third threat that arises from the loosely coupled data is the reliability of data. The islands of data with minimal governance will provide multiple versions of truth even with a data warehouse being in the organization. The multiple versions of truth mean loss of confidence in the data and its associated metrics, which ultimately leads to reliability questions on the data.
The fourth threat of loose and multiple distributions of data is additional complexity of processing, which results in limited scalability across the spectrum. This lack of scalability due to processing complexities coupled with inherent data issues and limitations of the underlying hardware, application software, and other infrastructure, creates a multilayered scalability problem (we have discussed the scalability issues in Chapter 6 and will discuss more in Chapter 8). There is no one-size-fits-all solution possibility in this layer to counter the issues effectively.
The fifth threat that arises in this architecture is the portability of data. Due to multiple distributions, the data architecture is not uniform, and the additional lack of governance in many cases and nonmaintenance of governance in other cases creates issues with portability of data. The lack of portability leads to further islands of solutions in many enterprises, and this architecture often resembles the tower of Babel.
The last threat from distributed data silos is more tied to cost and total cost of ownership. Multiple silos of solutions require infrastructure, software, and personnel for maintenance. All of these items add to the cost, and in many organizations the budget for newer programs often gets consumed toward such maintenance efforts.
These threats and issues provide one of the fundamental reasons for reengineering the EDW. The other reasons for reengineering include:
• Lower cost of infrastructure.
• Organic or inorganic growth of business.
• New technology advances and improvements that can be leveraged in combination with some of the reasons mentioned above.
The biggest issue that contributes to the current state of the data warehouse is the usage of technologies built for OLTP to perform data warehouse operations. Take a look at what we do in a transactional world. We run discrete transactions that are related to the purchase of a product or service or interactions of the customer at a ATM, for example, and in each of these situations, we do not have any volume or transformation. A database needs to simply log the information into a repository and we are done with a transaction commit. Extending the same concept to supply chain, sales, CRM, and ERP, we need to store a few more records at any given point in time from any of these transactions, and there is still minimal volume and complexity in this situation. The data from the OLTP with some transformations is what gets loaded into the data warehouse. What changes in the equation is data from all the different systems is loaded into the data warehouse, making it extremely complex to navigate through. It does not matter whether you have a star schema or third normal form (3NF)—the problem transcends all the underlying RDBMS. to make the data warehouse scalable and fit, there are multiple techniques that can be utilized with the options available from the modern architectures.
Choices for reengineering the data warehouse
The most popular and proven options to reengineer or modernize the data warehouse are discussed in the following sections. (Note: We will discuss cloud computing, data virtualization, data warehouse appliance, and in-memory in Chapter 9, after we discuss workload dynamics in Chapter 8.)
Replatforming
A very popular option is to replatform the data warehouse to a new platform including all hardware and infrastructure. There are several new technology options in this realm, and depending on the requirement of the organization, any of these technologies can be deployed. The choices include data warehouse appliances, commodity platforms, tiered storage, private cloud, and in-memory technologies. There are benefits and disadvantages to this exercise.
• Replatforming provides an opportunity to move the data warehouse to a scalable and reliable platform.
• The underlying infrastructure and the associated application software layers can be architected to provide security, lower maintenance, and increase reliability.
• The replatform exercise will provide us an opportunity to optimize the application and database code.
• The replatform exercise will provide some additional opportunities to use new functionality.
• Replatforming also makes it possible to rearchitect things in a different/better way, which is almost impossible to do in an existing setup.
• Replatforming takes a long cycle time to complete, leading to disruption of business activities, especially in large enterprises and enterprises that have traditional business cycles based on waterfall techniques. One can argue that this can be planned and addressed to not cause any interruption to business, but this seldom happens in reality with all the possible planning.
• Replatforming often means reverse engineering complex business processes and rules that may be undocumented or custom developed in the current platform. These risks are often not considered during the decision-making phase to replatform.
• Replatforming may not be feasible for certain aspects of data processing or there may be complex calculations that need to be rewritten if they cannot be directly supported by the functionality of the new platform. This is especially true in cross-platform situations.
• Replatforming is not economical in environments that have large legacy platforms, as it consumes too many business process cycles to reverse engineer logic and documenting the same.
• Replatforming is not economical when you cannot convert from daily batch processing to microbatch cycles of processing.
Platform engineering
With advances in technology, there are several choices to enable platform engineering. This is fundamentally different from replatforming, where you can move the entire data warehouse. With a platform engineering approach, you can modify pieces and parts of the infrastructure and get great gains in scalability and performance.
The concept of platform engineering was prominent in the automotive industry where the focus was on improving quality, reducing costs, and delivering services and products to end users in a highly cost-efficient manner. By following these principles, the Japanese and Korean automakers have crafted a strategy to offer products at very competitive prices while managing the overall user experience and adhering to quality that meets performance expectations. Borrowing on the same principles, the underlying goal of platform engineering applied to the data warehouse can translate to:
• Reduce the cost of the data warehouse.
• Increase efficiencies of processing.
• Simplify the complexities in the acquisition, processing, and delivery of data.
There are several approaches to platform engineering based on the performance and scalability needs of the data warehouse; the typical layers of a platform include those shown in Figure 7.2.
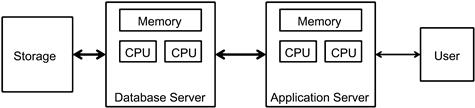
Platform reengineering can be done at multiple layers:
• Storage level. In this approach the storage layer of the data is engineered to process data at very high speeds for high or low volumes. This is not an isolation exercise. When storage is customized, often the network and the operating system are also modified to process data at twice the speed of the storage to manage multiple cycles of data transfer between the storage and the database servers. This is not a very popular option, as it needs large-scale efforts, the ROI question cannot be answered in simple math, and the total operating costs often surpass the baseline expectations.
• Server reengineering. In this approach the hardware and its components can be replaced with more modern components that can be supported in the configuration. For example, replacing processors, memory upgrades, and network card upgrades are all common examples of server platform reengineering. The issue with server reengineering is the scalability is limited by the processer design and flexibility and by the underlying operating system design that can leverage the processor capabilities. Due to the dual impact, the scalability from server upgrades is very limited. Though commoditization of hardware components has brought down the cost of the upgrades, the benefits do not outweigh the costs at any point in time, if the server alone is reengineered as a component.
• Network reengineering. In this approach the network layout and the infrastructure are reengineered. In the last five years (2008 to present) we have seen a huge evolution in the network technologies from gigabit Ethernet to fiber-optic networks. Transporting data across the network and the associated firewalls has always been a challenge. With the availability of both higher-bandwidth cards and underlying network infrastructure, we can leverage the network upgrade or reengineering to circumvent long waits for data at application, database, and storage tiers in the architecture. This is a significant change that will provide a boost for performance whether implemented as a stand-alone or as a part of major reengineering.
• Data warehouse appliances. In this approach the entire data warehouse or datamart can be ported to the data warehouse appliance (the scope of this migration option does not include Big Data). The data warehouse appliance is an integrated stack of hardware, software, and network components designed and engineered to handle data warehouse rigors. There are several benefits to this approach:
• Integrated stack, purpose built for the data warehouse.
• Lower overhead costs in maintenance.
• One-time migration cost depending on platform.
• Better performance and scalability.
• Incremental application migration based on phased deployment.
• Application server. In this approach the application server is customized to process reports and analytic layers across a clustered architecture. By creating a scalable architecture for the front end, the complexity of managing user loads is resolved, but this leads to an inverse problem with managing the data workloads—there are additional servers spawned. Once again we need to ensure that the back-end systems can scale along with front-end applications to handle the concurrency and the performance service levels.
Solution vendors want to provide the entire stack from the data acquisition layer to the business intelligence and analytics layer, and they all favor the platform engineering approach. This provides a lot of opportunity for the vendors to experiment and create a strong proprietary architecture. While this is innovative, it creates a lot of scalability problems, and if those problems need to be addressed, you need to remove the cost factor out of the equation.
While platform engineering is not a simple exercise, I do recommend separating the multiple layers in the architecture to create a robust application layer that can scale up and out independent of the underlying data. As a separate step, we can then reengineer or modernize the infrastructure for the data layers. To create this layer of abstraction and flexibility between the layers, we need to understand how each layer works on a workload architecture with the rest of the layers (see Chapter 8 for more on this).
Data engineering
Data engineering is a relatively new concept where the data structures are reengineered to create better performance. In this exercise, the data model developed as a part of the initial data warehouse is often scrubbed and new additions are made to the data model. Typical changes include:
• Partitioning—a table can be vertically partitioned depending on the usage of columns, thus reducing the span of I/O operations. This is a significant step that can be performed with minimal effect on the existing data, and needs a significant effort in ETL and reporting layers to refresh the changes. Another partition technique already used is horizontal partitioning where the table is partitioned by date or numeric ranges into smaller slices.
• Colocation—a table and all its associated tables can be colocated in the same storage region. This is a simple exercise but provides powerful performance benefits.
• Distribution—a large table can be broken into a distributed set of smaller tables and used. The downside is when a user asks for all the data from the table, we have to join all the underlying tables.
• New data types—several new data types like geospatial and temporal data can be used in the data architecture and current workarounds for such data can be retired. This will provide a significant performance boost.
• New database functions—several new databases provid native functions like scalar tables and indexed views, and can be utilized to create performance boosts.
Though there are several possibilities, data engineering can be done only if all other possibilities have been exhausted. The reason for this is there is significant work that needs to be done in the ETL and reporting layers if the data layer has changes. This requires more time and increases risk and cost. Therefore, data engineering is not often a preferred technique when considering reengineering or modernizing the data warehouse.
Modernizing the data warehouse
When you consider modernizing the data warehouse, there are several questions that need to be addressed.
• Migration options—a key question that needs to be answered for deciding the modernization strategy and approach is the selection of one of these choices:
• Do we rip/replace the existing architecture? Depending on the choice of whether you are moving to a self-contained platform, such as the data warehouse appliance, or migrating the entire platform, this choice and its associated impact needs to be answered.
• Do we augment the existing architecture? If you choose platform reengineering as the approach, this is a preferred approach to complete the migration process.
• Migration strategy—the following questions need to be articulated to formulate the strategy to build the roadmap for the reengineering or modernizing process:
• What is the biggest problem that you are facing? A clear articulation on the nature of the problem and the symptoms of where the problem manifests needs to be documented. The documentation needs to include examples of the problem, including the SQL, formulas, and metrics.
• How mature is your data warehouse? A documentation of the data warehouse processes and the associated business transformation rules needs to be analyzed for determining the maturity of the data warehouse. This will help in planning the migration process.
• How complex is your ETL process? A documented analysis of the ETL process is needed to complete the ETL migration and determine the associated complexity. If the ETL process is the major reason for the reengineering, you need to determine if just changing the ETL process and its infrastructure will provide the performance and scalability.
• How complex is your BI and analytics? A documented analysis of the BI and analytics process and infrastructure is needed to complete the BI migration and determine the associated complexity. If the BI or analytics process is the major reason for the reengineering, you need to determine if just changing the BI and/or analytics process and its infrastructure will provide the performance and scalability.
• How complex is your security configuration? A critical component of the ETL and BI infrastructure is the associated security configuration. Depending on the migration option, the impact on the security infrastructure can be significant or minimal. If the impact of the security changes is significant, it will impact the overall performance in the new architecture and require extensive testing for the migration.
• How mature is your documentation? Often an ignored aspect in the data warehouse or BI, if your current state documentation is not updated and is legacy or dated, do not even step into the migration or modernization of your data warehouse.
• Cost-benefit analysis—consider the multiple perspectives discussed in this chapter and perform a detailed cost-benefit analysis. The cost should include all the following details by line item:
• Acquisition costs of new infrastructure
• Acquisition costs of new data
• Maintenance costs of current state infrastructure
• Retirement costs of current state infrastructure
• Identification of pitfalls—conduct a detailed proof of concept (POC), which will provide the opportunity to identify the pitfalls and the areas of concern that need further validation in terms of reengineering or modernization. The pitfalls to verify include:
• Scalability of the overall infrastructure
• Develop a robust roadmap for the program that will include:
• IT and business teams’ skills and people requirements
• Migration execution by subject area or application
• Rollback plan in case of issues
Once you have identified the approach, costs, pitfalls, and options for modernizing the data warehouse, you can implement a program. A critical question that we need to still discuss before the modernization aspect is complete is; Do you know the workload that is being addressed in the modernization, and does the modernization address scalability and can this architecture handle Big Data integration? Let us discuss this in a case study.
Case study of data warehouse modernization
A large retail/e-retail organization has been experiencing a slowdown in sales and the responses to their campaigns has been less than expected. The business teams, after a lot of analysis and introspection, have determined that many of their strategies were based on information retrieved from the enterprise data warehouse but significantly transformed to meet their specific requirements. Further analysis revealed that the EDW was not being used as the source for all the data required for decision support, the fundamental reason being the performance and availability of the EDW and its limitations to transform the data as required by a business team.
The Corporate Executives (CxO) team asked for an evaluation and recommendation on modernizing the EDW infrastructure. To enable this process to be completed in a timely manner, a special team of business stakeholders, IT stakeholders, and executives was formed, and an advisory external team was added to this group. The goals of the team were:
• Evaluate the current state of the infrastructure, processes, and usage of the data warehouse.
• Recommend a set of options for a new platform for the data warehouse.
• Recommend a set of optimizations that can be executed for the processes associated with managing the data in the data warehouse.
• Recommend a strategy to modernize the data warehouse to include current and future requirements from a data perspective.
The team executed a four-week exercise and presented the following findings on the performance and health of the EDW.
Current-state analysis
• The infrastructure for the EDW is over a decade old and has been severely underperforming.
• There are several years of data that need to be evaluated and archived from the production systems, as this is slowing down daily processing.
• The software versions for the database platform need upgrades and some of the upgrades cannot work on the current hardware.
• There are tables and aggregates that have not been used for a few years but keep getting processed on a daily basis. We need to have the business users validate if they do not require this data.
• The storage architecture is legacy and upgrading this will provide a lot of benefits.
• The data architecture needs a thorough evaluation, as there are computations from the semantic layers that create a lot of stress on the database from a performance perspective.
• There are several multidimensional storage structures that can be rearchitected with modern design approaches. This would need some additional skills in the team.
Recommendations
There are several options that can be explored to modernize the EDW and the two options that will meet the current needs are:
• Option 1: The traditional route of upgrading the infrastructure platform starting with the servers, operating system, database software, application software, network, and storage systems is one technique.
– No new technologies to evaluate.
– Longer migration due to infrastructure layers that need upgrades.
– Costs can be prohibitive based on the requirements.
– Performance benefits cannot be predictable due to heterogeneous layers of infrastructure.
• Option 2: Evaluate the data warehouse appliance solution from two to four leading vendors, conduct a POC to check for compatibility, and select that as a platform for the EDW.
– Integrated platform of infrastructure and storage.
– Configured and designed to meet the demands of the EDW users.
– Requires minimal maintenance.
– High availability by architecture design.
– New technology configuration, requires some learning.
– There will be some legacy functionality that may not be supported in the appliance.
– Custom or user-defined functions may not be supported in the appliance platform, if the technology is different from the incumbent platform.
– Longer testing cycles to migrate applications to the new platform.
The overall recommendation of the team is that option 2 be selected, and the modernization of the EDW will be developed and deployed on an appliance platform.
Business benefits of modernization
• Enterprise version of data is restored.
• Measure effectiveness of new products on the consumer experience.
• Increase employee productivity and collaboration with customer-facing processes.
• Measure and track business performance goals Key Performance Indicators (KPIs).
• Measure and track improvements in business processes.
• Drive innovation and top-line revenue growth.
• Increase operational efficiencies.
The appliance selection process
The data warehouse appliance selection process was a 12-week exercise that included the following activities.
Request For Information/Request For Proposal (RFI/RFP)
The first step executed was an RFI/RFP that contained sections with the following information.
Vendor information
This section provides the information about the vendor organization and should contain the following:
Product information
This section is regarding the product and its details and should contain the following:
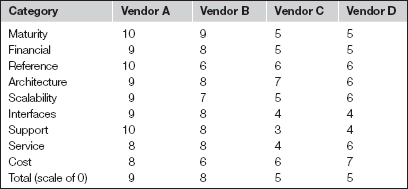
Scorecard
Based on the response from the prior sections, a vendor scorecard was developed and evaluated by the teams. The scorecard looks like the following:
Proof of concept process
The proof of concept process was conducted as an onsite exercise with three vendors, and this included the transportation and setup of the actual appliance in the data center. The entire process of the infrastructure setup was also scored and recorded for a production execution. The remaining steps of the POC included the execution of a set of use cases on the appliance, which was loaded with all the current production data.
• Configuration and setup—the appliance vendors brought their infrastructure and set up the same in the data center. The key pieces of information that were used for creating a scorecard included:
• Data architect/Database administrator tools
• Data loading and setup—the appliance vendors were provided with the current data model and the complete backup of the current data in the EDW. The vendors were asked to load the data into the appliance and the process was timed and scored. The data loading and setup process included:
• Data types and compatibility issues
• Database functions supported and not supported
• Special tools used for loading the data
• POC execution—the proof of concept execution included a set of reports (or report SQL), analytical queries, and queries that do not currently execute due to various reasons.
• The use cases were scored based on response time, accuracy, number of concurrent users, data usage statistics, ease of execution, and number of queries executed concurrently.
• Additional tests were executed by connecting the current ETL and BI applications.
• There were multiple cycles of the use cases execution conducted on the appliance platform with the following constraints:
– Appliance initial setup with no tuning—in this cycle the queries were executed on the appliance based on the initial setup.
– Minimal tuning—in this cycle the appliance was tuned for minimal improvements.
– Complete performance tuning—in this cycle the appliance was tuned to perform at its optimal best.
• Selection phase—the execution of the POC was completed and a final scorecard was created, which included scoring by the business users, scoring by data center teams, and scoring by the POC team. The final recommendation of the vendor was made based on the consensus among all stakeholders and the move to go ahead was taken.
Program roadmap
The next step of the modernization was to plan the migration program from the EDW to the appliance platform. This program roadmap included:
• Architecture analysis—based on the appliance architecture, there are changes that need to be made to the data model, the data architecture itself, the ETL process, and the aggregate tables management process. This analysis provided the gaps that needed to be managed in the migration process and the level of complexity along with the associated risks to be mitigated in the design process of the migration program.
• Skills—the architecture analysis provided a skills gap that needed to be managed with both skills training and additional staffing for the migration.
• Data architecture—the appliance architecture required the data model to be changed from its current state to a simpler 3NF of hybrid architecture. There were not too many changes that needed to be made, and the changes that were made were more aligned to the requirements from the BI layers.
• Infrastructure architecture—the appliance is a self-managing and highly available architecture based on its design principles. The infrastructure architecture that is the biggest change is the storage of the data changed from the traditional SAN to a distributed architecture, which is a one-time change and provides a significant performance boost.
• ETL migration—the appliance platform supported the ETL applications natively, minimizing the configuration and set up of the software on the new platform. There were changes in the ETL process due to changes in the data architecture that needed to be developed and tested. The additional changes that were made to the ETL layer included new modules that were designed and developed to accommodate the migration of custom functions that were not supported in the appliance platform.
• BI migration—the appliance platform supports the BI software and did not require additional setup or configuration process. The changes that were made to this application were in the semantic layers to reflect the changes in the data architecture, hierarchies, lookup and reference tables, additional functions, and data structures to accommodate any custom functions that were in the legacy platform.
• Analytics migration—the appliance platform supported all the analytical functions that were available in the legacy platform and there were no specific migration requirements in this process.
• Migration process—the overall migration process was done after data migration, in four parallel phases:
1. Data migration—this was completed as a one-time migration exercise. New data model deployment and additional data structures were created as a part of the migration. This includes the additional transformations needed by each line of business for their requirements.
2. ETL migration—this was initiated as a process that was implemented in parallel with the BI and analytics migration. There were no dependencies on the user layers to implement the ETL migration.
3. Business intelligence migration—this was implemented in multiple phases within one large phase, in parallel with the ETL and analytics migration.
4. Analytics migration—this was implemented in parallel with BI and ETL migration. The dependency for this phase to complete was the availability of data, which depended on the ETL migration completion, especially for the new data structures.
• Production rollout—the production rollout and operationalization of the appliance platform is a phased operation. This was implemented based on three critical factors:
1. Business continuity—the most critical business applications were the first to be rolled out on this platform based on the priority provided by the governance team.
2. Adoption readiness—the business units that were ready to move to the appliance platform became the second factor for the migration. For example, the financial line of business users were ready to use the new platform first though they had higher risks compared to other users.
3. Completion of migration—the migration of data, ETL, and BI processes had to be complete and signed off by the respective stakeholders.
• Support—the support for the new platform for infrastructure requirements was provided by the vendor teams for the first quarter and subsequently the internal teams:
• Stabilization—the appliance rollout process included a stabilization phase of three months after the production kickoff. This phase provided the time required to mature the initial rollout.
• Sunset legacy systems—the last phase of the migration process was to sunset the legacy hardware. This was done six months after the production rollout.
Modernization ROI
The corporation was able to demonstrate the benefits of the modernization in the first three months of the process, including:
• One version of truth—all the reports and analytics were driven from the central platform, with a certified data stamp of approval, which was provided the data governance organization.
• Auditable and traceable data—all the data in the organization was auditable and any associated traceability for lineage was easily available in a self-service portal of reports.
• Decision support accuracy—after migration to the appliance platform, the sales and marketing organizations were able to make informed decisions with improved accuracy, which was measured in the lift in the campaign response and increased volume of sales as indicated by improved margins for same-store sales.
• Process simplification—a large benefit that is not traditionally measured is the improvement of process times. This impact was very significant for the executives as the teams were able to conduct analysis of different outcomes and provide causal inputs with data and statistics, which was never possible in the legacy environment.
Additional benefits
The appliance platform has also enabled the organization to leapfrog and be ready to integrate data from new sources, including unstructured, semi-structured, and nontraditional sources.
Summary
As seen from this chapter and case study, the modernization of the data warehouse is an exercise that many organizations are currently engaged in executing. There are several steps that need to be executed to complete a modernization program, and if these steps are executed with the appropriate amount of due diligence and the outcomes measured appropriately, there are large measurable benefits.
The next chapter will discuss in depth the workloads of data warehousing. What constitutes a workload? How much workload is the right size to consider for the data warehouse and Big Data? Is the workload architecture dependent on the data or the converse? The next-generation architecture will require these clarifications and forms the focus of the next chapter.