
Chapter 2. Analytical Foundations of HR Measurement
The preceding chapter noted the importance of analytics within a broader frame work for a decision-based approach to human capital measurement. As you will see in the chapters that follow, each type of HR measurement has its own particular elements of analytics, those features of data analysis and design that ensure that the findings are legitimate and generalizable. However, it’s also true that nearly every element of human resource management (HRM) relies on one or more supporting analytical concepts. These concepts are often the elements that scientists have identified as essential to drawing strong conclusions, or they reflect the tenets of economic analysis that ensure that the inferences that we draw from measures properly account for important economic factors such as inflation and risk.
As you read through the various chapters of this book, each of which focuses on a different aspect of HR measurement, you will repeatedly encounter many of these analytical concepts. In the interests of efficiency, we present some of the most common ones here so that you can refer back to this chapter as often as necessary to find a single location for their description and definition. They have in common general guidelines for interpreting data-based information. We present them in two broad groups: concepts in statistics and research design, and concepts in economics and finance. Within each category, we address issues in rough order from general to specific. Let’s begin by considering why measures expressed in economic terms tend to get the attention of business leaders.
Traditional Versus Contemporary HR Measures
HRM activities—those associated with the attraction, selection, retention, development, and utilization of people in organizations—commonly are evaluated by using measures of individual behaviors, traits, or reactions, or by using statistical summaries of those measures. The former include measures of the reactions of various groups (top management, customers, applicants, or trainees), what individuals have learned, or how their behavior has changed on the job. Statistical summaries of individual measures include various ratios (for example, accident frequency or severity), percentages (for example, labor turnover), measures of central tendency and variability (for example, mean and standard deviation of performance measures, such as bank-teller shortages and surpluses), and measures of correlation (for example, validity coefficients for staffing programs, or measures of association between employee satisfaction and turnover).
Measuring individual behaviors, traits, or reactions and summarizing them statistically is the hallmark of most HR measurements, which are often largely drawn from psychology. More and more, however, the need to evaluate HRM activities in economic terms is becoming apparent. In the current climate of intense competition to attract and retain talent domestically and globally, operating executives justifiably demand estimates of the expected costs and benefits of HR programs, expressed in economic terms. They demand measures that are strategically relevant to their organizations and that rely on a defined logic to enhance decisions that affect important organizational outcomes. Reporting employee turnover levels for every position in an organization may seem to business leaders to be an administrative exercise for the HR department. However, they can often readily see the importance of analyzing and understanding the business and economic consequences of turnover among high performers (“A” players) who are difficult to replace, in a business unit that is pivotal to strategic success (for example, R&D in a pharmaceutical organization). Developing such measures certainly requires attention to calculating turnover appropriately and to the statistical formulas that summarize it. However, it also requires an interdisciplinary approach that includes information from accounting, finance, economics, and behavioral science. Measures developed in this way can help senior executives assess the extent to which HR programs are consistent with and contribute to the strategic direction of an organization.
Four Levels of Sophistication in HR Analytics
HR analytics is fact-based decision making. In the sections that follow, we describe four levels of sophistication used by Google’s People Analytics Group: counting, clever counting, insight, and influence.1 Each higher level requires mastery of the lower levels.
- Counting: All relevant data about the workforce are tracked, organized, and accessible. Getting this basic step right can be difficult. HR technology solutions—both off the shelf and internally built—can be clunky. The challenges of continually updating the database and ensuring that all end users, from line managers to HR generalists, are getting the data they need are unceasing. Google’s current solution is a hybrid external vendor/internal customization model. It allows users to display headcount, attrition, promotion, and other data through customizable dashboards that have the ability to filter the data and display it according to hierarchy, employee location, and cost center, for example.
- Clever counting: Extrapolating from descriptive data yields new insights. For example, consider workforce planning. Using basic data on promotions, attrition, headcount by level, and anticipated organizational growth rate makes it possible to project the “shape” of your organization (the percentage of employees at each level) at the end of a year, at the end of two years, or after three-plus years. With the proper formulas in place, users can input anticipated future attrition/promotion and organizational growth rates to model different scenarios. By assigning salaries to employees at each level, one can see the financial impact of having an organizational shape that looks like a typical pyramid (with fewer employees at each level as one moves up the organization) or a more uniform distribution across levels, which would occur if the organization is not hiring but employees continue to receive promotions.
- Insight: What drivers of the trends do you find through clever counting? The preceding example of modeling organizational shape is most useful if we can understand what’s driving each component of the model. For example, we may find that the organization’s projected shape in five years is top heavy. Why? Close investigation might show that promotion rates are too high, combined with attrition that is higher at lower levels than it is at higher levels. This process of inquiry provides the insight needed to understand the results of more sophisticated analyses.
- Influence: The results of counting, clever counting, and insight can help make a difference. At this level, the relevant question is, how can we shape outcomes rather than just measure them? Insight from the organizational shape models described can lead to change if you partner with the right people in your organization. The overall objective is to ensure that managers have a shared understanding of the goals (for example, sustaining a pyramidal organizational structure) and the levers they can pull to achieve those goals. For example, if analysis shows that the current or projected future shape of the organization is top heavy, the levers include these:
• Decrease yearly promotion rates
• Launch attrition-prevention programs if insight has revealed that highest-performing employees are most likely to terminate
• Backfill vacant positions at lower levels
The four steps to analytical sophistication do not apply only to workforce planning. Instead, they apply to any data collection and analysis activity, such as employee opinion surveys, employee selection research, or employee diversity analyses. Your goal should always be to get to the last step: influence.
Next, we describe some fundamental concepts from statistics and research design that help ensure that the kind of data gathered, and the calculations used to summarize the data, are best suited to the questions the data should answer. They are general interpretive concepts.
Fundamental Analytical Concepts from Statistics and Research Design
We make no attempt here to present basic statistical or research methods. Many excellent textbooks do that much more effectively than we can in the space available. Instead, we assume that the reader is generally familiar with these issues; our purpose here is to offer guidelines for interpretation and to point out some important cautions in those interpretations. In the following sections, we address three key concepts: generalizations from sample data, correlation and causality, and experimental controls for extraneous factors.
Generalizing from Sample Data
As a general rule, organizational research is based on samples rather than on populations of observations. A population consists of all the people (or, more broadly, units) about whom or which a study is meant to generalize, such as employees with fewer than two years of experience, customers who patronize a particular store, or trucks in a company’s fleet. A sample represents a subset of people (or units) who actually participate in a study. In almost all cases, it is not practical or feasible to study an entire population. Instead, researchers draw samples.
If we are to draw reliable (that is, stable and consistent) and valid (that is, accurate) conclusions concerning the population, it is imperative that the sample be “like” the population—a representative sample. When the sample is like the population, we can be fairly confident that the results we find based on the sample also hold for the population. In other words, we can generalize from the sample to the population.2
One way to generate a representative sample is to use random sampling. A random sample is achieved when, through random selection, each member of a population is equally likely to be chosen as part of the sample. A table of random numbers, found in many statistics textbooks, can be used to generate a random sample. Here is how to use such a table. Choose any starting place arbitrarily. Look at the number—say, 004. Assuming that you have a list of names, such as applicants, count down the list to the fourth name. Choose it. Then look at the next number in the table, count down through the population, and choose that person, until you have obtained the total number of observations you need.
Sometimes a population is made up of members of different groups or categories, such as males and females, or purchasers of a product and nonpurchasers. Assume that, among 500 new hires in a given year, 60 percent are female. If we want to draw conclusions about the population of all new hires in a given year, based on our sample, the sample itself must be representative of these important subgroups (or strata) within the population. If the population is composed of 60 percent females and 40 percent males, we need to ensure that the sample is similar on this dimension.
One way to obtain such a sample is to use stratified random sampling. Doing so allows us to take into account the different subgroups of people in the population and helps guarantee that the sample represents the population on specific characteristics. Begin by dividing the population into subsamples or strata. In our example, the strata are based on gender. Then randomly select 60 percent of the sample observations from this stratum (for example, using the procedure described earlier) and the remaining 40 percent from the other stratum (males). Doing so ensures that the characteristic of gender in the sample represents the population.3
Many other types of sampling procedures might be used,4 but the important point is that it is not possible to generalize reliably and validly from a sample to a population unless the sample itself is representative. Unfortunately, much research that is done in HR and management is based on case studies, samples of convenience, and even anecdotal evidence. Under those circumstances, it is not possible to generalize to a broader population of interest, and it is important to be skeptical of studies that try to do so.
Drawing Conclusions about Correlation and Causality
Perhaps one of the most pervasive human tendencies is to assume incorrectly that just because two things increase and decrease together, one must cause the other. The degree of relationship between any two variables (in the employment context, predictor and criterion) is simply the extent to which they vary together (covary) in a systematic fashion. The magnitude or degree to which they are related linearly is indicated by some measure of correlation, the most popular of which is the Pearson product-moment correlation coefficient, r. As a measure of relationship, r varies between –1.00 and +1.00. When r is 1.00, the two sets of scores (x and y) are related perfectly and systematically to each other. Knowing a person’s status on variable x allows us to predict without error his or her standing on variable y.
In the case of an r of +1.00, high (low) predictor scores are matched perfectly by high (low) criterion scores. For example, performance review scores may relate perfectly to recommendations for salary increases. When r is –1.00, however, the relationship is inverse, and high (low) predictor scores are accompanied by low (high) criterion scores. For example, consider that as driving speed increases, fuel efficiency decreases. In both cases, positive and negative relationships, r indicates the extent to which the two sets of scores are ordered similarly. Given the complexity of variables operating in business settings, correlations of 1.00 exist only in theory. If no relationship exists between the two variables, r is 0.0, and knowing a person’s standing on x tells us nothing about his or her standing on y. If r is moderate (positive or negative), we can predict y from x with a certain degree of accuracy.
Although correlation is a useful procedure for assessing the degree of relationship between two variables, by itself it does not allow us to predict one set of scores (criterion scores) from another set of scores (predictor scores). The statistical technique by which this is accomplished is known as regression analysis, and correlation is fundamental to its implementation.5
Sometimes people interpret a correlation coefficient as the percentage of variability in y that can be explained by x. This is not correct. Actually, the square of r indicates the percentage of variance in y (the criterion) that can be explained, or accounted for, given knowledge of x (the predictor). Assuming a correlation of r = .40, then r2 = .16. This indicates that 16 percent of the variance in the criterion may be determined (or explained), given knowledge of the predictor. The statistic r2 is known as the coefficient of determination.
A special problem with correlational research is that it is often misinterpreted. People often assume that because two variables are correlated, some sort of causal relationship must exist between the two variables. This is false. Correlation does not imply causation! A correlation simply means that the two variables are related in some way. For example, consider the following scenario. An HR researcher observes a correlation between voluntary employee turnover and the financial performance of a firm (for example, as measured by return on assets) of –.20. Does this mean that high voluntary turnover causes poor financial performance of a firm? Perhaps. However, it is equally likely that the poor financial performance of a firm causes voluntary turnover, as some employees scramble to desert a sinking ship. In fact, such a reciprocal relationship between employee turnover and firm performance has now been demonstrated empirically.6
At a broader level, it is equally plausible that some other variable (for example, low unemployment) is causing employees to quit, or that a combination of variables (low unemployment in country A at the same time as a global economic recession) is causing high voluntary turnover in that country and low overall financial performance in a firm that derives much of its income from other countries. The point is that observing a correlation between two variables just means they are related to each other; it does not mean that one causes the other.
In fact, there are three necessary conditions to support a conclusion that x causes y.7 The first is that y did not occur until after x. The second requirement is that x and y are actually shown to be related. The third (and most difficult) requirement is that other explanations of the relationship between x and y can be eliminated as plausible rival hypotheses.
Statistical methods alone generally cannot establish that one variable caused another. One technique that comes close, however, is structural equation modeling (SEM), sometimes referred to as LISREL (the name of one of the more popular software packages). SEM is a family of statistical models that seeks to explain the relationships among multiple variables. It examines the structure of interrelationships, expressed in a series of equations, similar to a series of multiple regression equations. These equations depict all of the relationships among constructs (the dependent and independent variables) involved in the analysis.
Although different methods can be used to test SEM models, all such models share three characteristics:
- Estimation of multiple and interrelated dependence relationships
- An ability to represent unobserved concepts in these relationships and to correct for measurement error in the estimation process
- Defining a model to explain the entire set of relationships8
SEM alone cannot establish causality. What it does provide are statistical results of the hypothesized relationships in the researcher’s model. The researcher can then infer from the results what alternative models are most consistent with theory. The most convincing claims of causal relationships, however, usually are based on experimental research.
Eliminating Alternative Explanations Through Experiments and Quasi-Experiments
The experimental method is a research method that allows a researcher to establish a cause-and-effect relationship through manipulation of one or more variables and to control the situation. An experimental design is a plan, an outline for conceptualizing the relations among the variables of a research study. It also implies how to control the research situation and how to analyze the data.9
For example, researchers can collect “before” measures on a job—before employees attend training—and collect “after” measures at the conclusion of training (and when employees are back on the job at some time after training). Researchers use experimental designs so that they can make causal inferences. That is, by ruling out alternative plausible explanations for observed changes in the outcome of interest, we want to be able to say that training caused the changes. Many preconditions must be met for a study to be experimental in nature. Here we merely outline the minimum requirements needed for an experiment.
The basic assumption is that a researcher controls as many factors as possible to establish a cause-and-effect relationship among the variables being studied. Suppose, for example, that a firm wants to know whether online training is superior to classroom training. To conduct an experiment, researchers manipulate one variable (known as the independent variable—in this case, type of training) and observe its effect on an outcome of interest (a dependent variable—for example, test scores at the conclusion of training). One group will receive classroom training, one group online training, and a third group no training. The last group is known as a “control” group because its purpose is to serve as a baseline from which to compare the performance of the other two groups. The groups that receive training are known as “experimental” or “treatment” groups because they each receive some treatment or level of the independent variable. That is, they each receive the same number of hours of training, either online or classroom. At the conclusion of the training, we will give a standardized test to the members of the control and experimental groups and compare the results. Scores on the test are the dependent variable in this study.
Earlier we said that experimentation involves control. This means that we have to control who is in the study. We want to have a sample that is representative of the broader population of actual and potential trainees. We want to control who is in each group (for example, by assigning participants randomly to one of the three conditions: online, classroom, or no training). We also want to have some control over what participants do while in the study (design of the training to ensure that the online and classroom versions cover identical concepts and materials). If we observe changes in post-training test scores across conditions, and all other factors are held constant (to the extent it is possible to do this), we can conclude that the independent variable (type of training) caused changes in the dependent variable (test scores derived after training is concluded). If, after completing this study with the proper controls, we find that those in one group (online, classroom, or no training) clearly outperform the others, we have evidence to support a cause-and-effect relationship among the variables.
Many factors can serve as threats to valid inferences, such as outside events, experience on the job, or social desirability effects in the research situation.10
Is it appropriate to accept wholeheartedly a conclusion from only one study? In most cases, the answer is no. This is because researchers may think they have controlled everything that might affect observed outcomes, but perhaps they missed something that does affect the results. That something else may have been the actual cause of the observed changes! A more basic reason for not trusting completely the results of a single study is that a single study cannot tell us everything about a theory.11 Science is not static, and theories generated through science change. For that reason, there are methods, called meta-analysis, that mathematically combine the findings from many studies to determine whether the patterns across studies support certain conclusions. The power of combining multiple studies provides more reliable conclusions, and this is occurring in many areas of behavioral science.12
Researchers approaching organizational issues often believe that conducting a carefully controlled experiment is the ultimate answer to discovering the important answers in data. In fact, there is an important limitation of experiments and the data they provide. Often they fail to focus on the real goals of an organization. For example, experimental results may indicate that job performance after treatment A is superior to performance after treatments B or C. The really important question, however, may not be whether treatment A is more effective, but rather what levels of performance we can expect from almost all trainees at an acceptable cost, and the extent to which improved performance through training “fits” the broader strategic thrust of an organization.13 Therefore, even well-designed experiments must carefully consider the context and logic of the situation, to ask the right questions in the first place.
Quasi-Experimental Designs
In field settings, major obstacles often interfere with conducting true experiments. True experiments require the manipulation of at least one independent variable, the random assignment of participants to groups, and the random assignment of treatments to groups.14 However, some less complete (that is, quasi-experimental) designs still can provide useful data even though a true experiment is not possible. Shadish, Cook, and Campbell offer a number of quasi-experimental designs with the following rationale:15
The central purpose of an experiment is to eliminate alternative hypotheses that also might explain results. If a quasi-experimental design can help eliminate some of these rival hypotheses, it may be worth the effort.
Because full experimental control is lacking in quasi-experiments, it is important to know which specific variables are uncontrolled in a particular design. Investigators should, of course, design the very best experiment possible, given their circumstances; where “full” control is not possible, however, they should use the most rigorous design that is possible. For example, suppose you were interested in studying the relationship between layoffs and the subsequent financial performance of firms. Pfeffer recently commented on this very issue:
It’s difficult to study the causal effect of layoffs—you can’t do double-blind, placebo-controlled studies as you can for drugs by randomly assigning some companies to shed workers and others not, with people unaware of what “treatment” they are receiving. Companies that downsize are undoubtedly different in many ways (the quality of their management, for one) from those that don’t. But you can attempt to control for differences in industry, size, financial condition, and past performance, and then look at a large number of studies to see if they reach the same conclusion.16
As a detailed example, consider one type of quasi-experimental design.17
This design, which is particularly appropriate for cyclical training programs, is known as the recurrent institutional cycle design. For example, a large sales organization presented a management development program, known as the State Manager Program, every two months to small groups (12–15) of middle managers (state managers). The one-week program focused on all aspects of retail sales (new product development, production, distribution, marketing, merchandising, and so on). The program was scheduled so that all state managers (approximately 110) could be trained over an 18-month period.
This is precisely the type of situation for which the recurrent institutional cycle design is appropriate—a large number of persons will be trained, but not all at the same time. Different cohorts are involved. This design is actually a combination of two (or more) before-and-after studies that occur at different points in time. Group I receives a pretest at Time 1, then training, and then a post-test at Time 2. At the same chronological time (Time 2), Group II receives a pretest, training, and then a post-test at Time 3. At Time 2, therefore, an experimental and a control group have, in effect, been created. One can obtain even more information (and with quasi-experimental designs, it is always wise to collect as much data as possible or to demonstrate the effect of training in several different ways) if it is possible to measure Group I again at Time 3 and to give Group II a pretest at Time 1. This controls the effects of history. Moreover, Time 3 data for Groups I and II and the post-tests for all groups trained subsequently provide information on how the training program is interacting with other organizational events to produce changes in the criterion measure.
Several cross-sectional comparisons are possible with the “cycle” design:
Group I post-test scores at Time 2 can be compared with Group II post-test scores at Time 2.
Gains made in training for Group I (Time 2 post-test scores) can be compared with gains in training for Group II (Time 3 post-test scores).
Group II post-test scores at Time 3 can be compared with Group I post-test scores at Time 3 (that is, gains in training versus gains [or no gains] during the no-training period).
To interpret this pattern of outcomes, all three contrasts should have adequate statistical power (that is, at least an 80 percent chance of finding an effect significant, if, in fact, the effect exists).18 A chance elevation of Group II, for example, might lead to gross misinterpretations. Hence, use the design only with reliable measures and large samples.19
This design controls history and test-retest effects, but not differences in selection. One way to control for possible differences in selection, however, is to split one of the groups (assuming it is large enough) into two equivalent samples, one measured both before and after training and the other measured only after training, as shown in Table 2-1.
Table 2-1. Example of an Institutional Cycle Design

Comparison of post-test scores in two carefully equated groups (Groups IIa and IIb) is more precise than a similar comparison of post-test scores from two unequated groups (Groups I and II).
A final deficiency in the “cycle” design is the lack of adequate control for the effects of maturation. This is not a serious limitation if the training program is teaching specialized skills or competencies, but it is a plausible rival hypothesis when the objective of the training program is to change attitudes. Changes in attitudes conceivably could be the result of maturational processes such as changes in job and life experiences or growing older. To control for this effect, give a comparable group of managers (whose age and job experience coincide with those of one of the trained groups at the time of testing) a “post-test-only” measure. To infer that training had a positive effect, post-test scores of the trained groups should be significantly greater than those of the untrained group receiving the “post-test-only” measure.
Campbell and Stanley aptly expressed the logic of all this patching and adding:20
One starts out with an inadequate design and then adds specific features to control for one or another of the recurrent sources of invalidity. The result is often an inelegant accumulation of precautionary checks, which lacks the intrinsic symmetry of the “true” experimental designs, but nonetheless approaches experimentation.
Remember, a causal inference from any quasi-experiment must meet the basic requirements for all causal relationships: that cause must precede effect, that cause must covary with effect, and that alternative explanations for the causal relationship are implausible.21 Patching and adding may help satisfy these requirements.
Fundamental Analytical Concepts from Economics and Finance
The analytical concepts previously discussed come largely from psychology and related individual-focused social sciences. However, the fields of economics and finance also provide useful general analytical concepts for measuring HRM programs and consequences. Here, the focus is often on properly acknowledging the implicit sacrifices implied in choices, the behavior of markets, and the nature of risk.
We consider concepts in the following seven areas:
• Fixed, variable, and opportunity costs/savings
• The time value of money
• The estimated value of employee time using total pay
• Cost-benefit and cost-effectiveness analyses
• Utility as a weighted sum of utility attributes
• Conjoint analysis
• Sensitivity and break-even analysis
Fixed, Variable, and Opportunity Costs/Savings
We can distinguish fixed, variable, and opportunity costs, as well as reductions in those costs, which we call “savings.” Fixed costs or savings refer to those that remain constant, whose total does not change in proportion to the activity of interest. For example, if an organization is paying rent or mortgage interest on a training facility, the cost does not change with the volume of training activity. If all training is moved to online delivery and the training center is sold, the fixed savings equal the rent or interest that is now avoided.
Variable costs or savings are those that change in direct proportion to changes in some particular activity level.22 The food and beverage cost of a training program is variable with regard to the number of training participants. If a less expensive food vendor replaces a more expensive one, the variable savings represent the difference between the costs of the more expensive and the less expensive vendors.
Finally, opportunity costs reflect the “opportunities foregone” that might have been realized had the resources allocated to the program been directed toward other organizational ends.23 This is often conceived of as the sacrifice of the value of the next-best alternative use of the resources. For example, if we choose to have employees travel to a training program, the opportunity cost might be the value they would produce if they were back at their regular locations working on their regular jobs. Opportunity savings are the next-best uses of resources that we obtain if we alter the opportunity relationships. For example, if we provide employees with laptop computers or handheld devices that allow them to use e-mail to resolve issues at work while they are attending the offsite training program, the opportunity savings represent the difference between the value that would have been sacrificed without the devices and the reduced sacrifice with the devices.
The Time Value of Money: Compounding, Discounting, and Present Value24
In general, the time value of money refers to the fact that a dollar in hand today is worth more than a dollar promised sometime in the future. That is because a dollar in hand today can be invested to earn interest. If you were to invest that dollar today at a given interest rate, it would grow over time from its present value (PV) to some future value (FV). The amount you would have depends, therefore, on how long you hold your investment and on the interest rate you earn. Let us consider a simple example.
If you invest $100 and earn 10 percent on your money per year, you will have $110 at the end of the first year. It is composed of your original principal, $100, plus $10 in interest that you earn. Hence, $110 is the FV of $100 invested for one year at 10 percent. In general, if you invest for one period at an interest rate of r, your investment will grow to (1 + r) per dollar invested.
Suppose you decide to leave your $100 investment alone for another year after the first? Assuming that the interest rate (10 percent) does not change, you will earn $110 × .10 = $11 in interest during the second year, so you will have a total of $110 + $11 = $121. This $121 has four parts. The first is the $100 original principal. The second is the $10 in interest you earned after the first year, and the third is another $10 you earn in the second year, for a total of $120. The last dollar you earn (the fourth part) is interest you earn in the second year on the interest paid in the first year ($10 × .10 = $1).
This process of leaving your money and any accumulated interest in an investment for more than one period, thereby reinvesting the interest, is called compounding, or earning interest on interest. We call the result compound interest. At a general level, the FV of $1 invested for t periods at a rate of r per period is as follows:
![]()
FVs depend critically on the assumed interest rate, especially for long-lived investments. Equation 2-1 is actually quite general and allows us to answer some other questions related to growth. For example, suppose your company currently has 10,000 employees. Senior management estimates that the number of employees will grow by 3 percent per year. How many employees will work for your company in five years? In this example, we begin with 10,000 people rather than dollars, and we don’t think of the growth rate as an interest rate, but the calculation is exactly the same:
10,000 × (1.03)5 = 10,000 × 1.1593 = 11,593 employees
There will be about 1,593 net new hires over the coming five years.
Present Value and Discounting
We just saw that the FV of $1 invested for one year at 10 percent is $1.10. Suppose we ask a slightly different question: How much do we have to invest today at 10 percent to get $1 in one year? We know the FV is $1, but what is its PV? Whatever we invest today will be 1.1 times bigger at the end of the year. Because we need $1 at the end of the year:
PV × 1.1 = $1
Solving for the PV yields $1/1.1 = $0.909. This PV is the answer to the question, “What amount invested today will grow to $1 in one year if the interest rate is 10 percent?” PV is therefore just the reverse of FV. Instead of compounding the money forward into the future, we discount it back to the present.
Now suppose that you set a goal to have $1,000 in two years. If you can earn 7 percent each year, how much do you have to invest to have $1,000 in two years? In other words, what is the PV of $1,000 in two years if the relevant rate is 7 percent? To answer this question, let us express the problem as this:
$1,000 = PV × 1.07 × 1.07
$1,000 = PV × (1.07)2
Solving for PV:
PV = $1,000/1.1449 = $873.44
At a more general level, the PV of $1 to be received t periods into the future at a discount rate of r is as follows:
![]()
The quantity in brackets, 1/(1+ r)t, is used to discount a future cash flow. Hence, it is often called a discount factor. Likewise, the rate used in the calculation is often called the discount rate. Finally, calculating the PV of a future cash flow to determine its worth today is commonly called discounted cash flow (DCF) valuation. If we apply the DCF valuation to estimate the PV of future cash flows from an investment, it is possible to estimate the net present value (NPV) of that investment as the difference between the PV of the future cash flows and the cost of the investment. Indeed, the capital-budgeting process can be viewed as a search for investments with NPVs that are positive.25
When calculating the NPV of an investment project, we tend to assume not only that a company’s cost of capital is known, but also that it remains constant over the life of a project. In practice, a company’s cost of capital may be difficult to estimate, and the selection of an appropriate discount rate for use in investment appraisal is also far from straightforward. The cost of capital is also likely to change over the life of a project because it is influenced by the dynamic economic environment within which all business is conducted. If these changes can be forecast, however, the NPV method can accommodate them without difficulty.26
Now back to PV calculations. PVs decline as the length of time until payment grows. Look out far enough, and PVs will be close to zero. Also, for a given length of time, the higher the discount rate is, the lower the PV. In other words, PVs and discount rates are inversely related. Increasing the discount rate decreases the PV, and vice versa.
If we let FVt stand for the FV after t periods, the relationship between FV and PV can be written simply as one of the following:
![]()
The last result is called the basic PV equation. There are a number of variations of it, but this simple equation underlies many of the most important ideas in corporate finance.27
Sometimes one needs to determine what discount rate is implicit in an investment. We can do this by looking at the basic PV equation:
PV = FVt / (1 + r)t
There are only four parts to this equation: the present value (PV), the future value (FVt), the discount rate (r), and the life of the investment (t). Given any three of these, we can always find the fourth. Now let’s shift gears and consider the value of employees’ time.
Estimating the Value of Employee Time Using Total Pay
Many calculations in HR measurement involve an assessment of the value of employees’ time (for example, those involving exit interviews, attendance at training classes, managing problems caused by absenteeism, or the time taken to screen job applications). One way to account for that time, in financial terms, is in terms of total pay to the employee. The idea is to use the value of what employees earn as a proxy for the value of their time. This is very common, so we provide some guidelines here. However, at the end, we also caution that the assumption that total pay equals the value of employee time is not generally valid.
Should “total pay” include only the average annual salary of employees in a job class? In other words, what should be the valuation base? If it includes only salary, the resulting cost estimates will underestimate the full cost of employees’ time, because it fails to include the cost of employee benefits and overhead. Overhead costs include such items as rent, energy costs, and equipment. More generally, overhead costs are those general expenses incurred during the normal course of operating a business. At times, these costs may be called general and administrative or payroll burden. They may be calculated as a percentage of actual payroll costs (salaries plus benefits).28
To provide a more realistic estimate of the cost of employee time, therefore, many recommend calculating it as the mean salary of the employees in question (for example, technical, sales, managerial) times a full labor-cost multiplier.29 The full labor-cost multiplier incorporates benefits and overhead costs.
To illustrate, suppose that in estimating the costs of staff time to conduct exit interviews, we assume that an HR specialist is paid $27 per hour, and that it takes 15 minutes to prepare and 45 minutes to conduct each interview, for a total of 1 hour of his or her time. If the HR specialist conducts 100 exit interviews in a year, the total cost of his or time is, therefore, $2,700. However, after checking with the accounting and payroll departments, suppose we learn that the firm pays an additional 40 percent of salary in the form of employee benefits and that overhead costs add an additional 35 percent. The full labor-cost multiplier is, therefore, 1.75, and the cost per exit interview is $27 × 1.75 = $47.25. Over a 1-year period and 100 exit interviews, the total cost of the HR specialist’s time is, therefore, $4,725—a difference of $2,025 from the $2,700 that included only salary costs.
Note that total pay, using whatever calculation, is generally not synonymous with the fixed, variable, or opportunity costs of employee time. It is a convenient proxy but must be used with great caution. In most situations, the costs of employee time (wages, benefits, overhead costs to maintain the employees’ employment or productivity) simply don’t change as a result of their allocation of time. They are paid no matter what they do, as long as it is a legitimate part of their jobs. If we require employees to spend an hour interviewing candidates, their total pay for the hour is no different than if we had not required that time. Moreover, they would still be paid even if they weren’t conducting interviews. The more correct concept is the opportunity cost of the lost value that employees would have been creating if they had not been using their time for interviewing. That is obviously not necessarily equal to the cost of their wages, benefits, and overhead. That said, it is so difficult to estimate the opportunity cost of employees’ time that it is very common for accounting processes just to recommend multiplying the time by the value of total pay. The important thing to realize is the limits of such calculations, even if they provide a useful proxy.
Cost-Benefit and Cost-Effectiveness Analyses
Cost-benefit analysis expresses both the benefits and the costs of a decision in monetary terms. One of the most popular forms of cost-benefit analysis is return on investment (ROI) analysis.
Traditionally associated with hard assets, ROI relates program profits to invested capital. It does so in terms of a ratio in which the numerator expresses some measure of profit related to a project, and the denominator represents the initial investment in a program. More specifically, ROI includes the following:30
- The inflow of returns produced by an investment
- The offsetting outflows of resources required to make the investment
- How the inflows and outflows occur in each future time period
- How much what occurs in future time periods should be “discounted” to reflect greater risk and price inflation
ROI has both advantages and disadvantages. Its major advantage is that it is simple and widely accepted. It blends in one number all the major ingredients of profitability, and it can be compared with other investment opportunities. On the other hand, it suffers from two major disadvantages. First, although the logic of ROI analysis appears straightforward, there is much subjectivity in the previous items 1, 3, and 4. Second, typical ROI calculations focus on one HR investment at a time and fail to consider how those investments work together as a portfolio. Training may produce value beyond its cost, but would that value be even higher if it were combined with proper investments in individual incentives related to the training outcomes?31
Consider a simple example of the ROI calculation over a single time period. Suppose your company develops a battery of pre-employment assessments for customer service representatives that includes measures of aptitude, relevant personality characteristics, and emotional intelligence. Payments to outside consultants total $100,000 during the first year of operation. The measured savings, relative to baseline measures in prior years, total $30,000 in reduced absenteeism, $55,000 in reduced payments for stress-related medical conditions, and $70,000 in reduced turnover among customer service representatives. The total expected benefits are, therefore, $155,000.
ROI = Total expected benefit/program investment
ROI = $155,000 / $100,000 = 55 percent
Cost-effectiveness analysis is similar to cost-benefit analysis, but whereas the costs are still measured in monetary terms, outcomes are measured in “natural” units other than money. Cost-effectiveness analysis identifies the cost of producing a unit of effect (for example, in a corporate-safety program, the cost per accident avoided). As an example, consider the results of a three-year study of the cost-effectiveness of three types of worksite health-promotion programs for reducing risk factors associated with cardiovascular disease (hypertension, obesity, cigarette smoking, and lack of regular physical exercise) at three manufacturing plants, compared to a fourth site that provided health-education classes only.32
The plants were similar in size and in the demographic characteristics of their employees. Plants were allocated randomly to one of four worksite health-promotion models. Site A provided health education only. Site B provided a fitness facility; site C provided health education plus follow-up that included a menu of different intervention strategies; and site D provided health education, follow-up, and social organization of health promotion within the plant.
Over the three-year period of the study, the annual, direct cost per employee was $17.68 for site A, $39.28 for site B, $30.96 for site C, and $38.57 for site D (in 1992 dollars). The reduction in risks ranged from 32% at site B to 45% at site D for high-level reduction or relapse prevention, and from 36% (site B) to 51% (site D) for moderate reduction. These differences were statistically significant.
At site B, the greater amount of money spent on the fitness facility produced less risk reduction (–3%) than the comparison program (site A). The additional cost per employee per year (beyond those incurred at site A) for each percent of risks reduced or relapses prevented was –$7.20 at site B (fitness facility), $1.48 for site C (health education plus follow-up), and $2.09 at site D (health education, follow-up, and social organization of health promotion at the plant). At sites C and D, the percent of effectiveness at reducing risks/preventing relapse was about 1.3% to 1.5% per dollar spent per employee per year, and the total cost for each percent of risk reduced or relapse prevented was less than $1 per employee per year (66¢ and 76¢ at sites C and D, respectively).
In summary, both cost-benefit and cost-effectiveness analyses can be useful tools for evaluating benefits, relative to the costs of programs or investments. Whereas cost-benefit analysis expresses benefits in monetary terms and can accommodate multiple time periods and discount rates, cost-effectiveness analysis expresses benefits in terms of the cost incurred to produce a given level of an effect. Cost-benefit analysis enables us to compare the absolute value of the returns from very different programs or decisions, because they are all calculated in the same units of money. Cost-effectiveness, on the other hand, makes such comparisons somewhat more difficult because the outcomes of the different decisions may be calculated in very different units. How do you decide between a program that promises a cost of $1,000 per avoided accident versus a program that promises $300 per unit increase of employee satisfaction? Cost-effectiveness can prove quite useful for comparing programs or decisions that all have the same outcome (for example, which accident-reduction program to choose).
It’s a dilemma when one must decide among programs that produce very different outcomes (such as accident reduction versus employee satisfaction) and when all outcomes of programs cannot necessarily be expressed in monetary terms. However, many decisions require such comparisons. One answer is to calculate “utilities” (from the word use) that attempt to capture systematically the subjective value that decision makers place on different outcomes, when the outcomes are compared directly to each other.
Utility as a Weighted Sum of Utility Attributes
Utility analysis is a tool for making decisions. It is the determination of institutional gain or loss anticipated from various courses of action, after taking into account both costs and benefits. For example, in the context of HRM, the decision might be which type of training to offer or which selection procedure to implement. When faced with a choice among alternative options, management should choose the option that maximizes the expected utility for the organization across all possible outcomes.33
In general, there are two types of decisions: those for which the outcomes of available options are known for sure (decisions under certainty), and those for which the outcomes are uncertain and occur with known or uncertain probabilities (decisions under uncertainty). Most theories about judgment and decision-making processes have focused on decisions under uncertainty, because they are more common.34
One such theory is subjective expected utility theory, and it holds that choices are derived from only two parameters:
• The subjective value, or utility, of an option’s outcomes
• The estimated probability of the outcomes
By multiplying the utilities with the associated probabilities and summing over all consequences, it is possible to calculate an expected utility. The option with the highest expected utility is then chosen.
A rational model of decision making that has been used as a guide to study actual decision behavior and as a prescription to help individuals make better decisions is known as multi-attribute utility theory (MAUT). MAUT is a type of subjective expected utility theory that has been particularly influential in attempts to improve individual and organizational decision making. Here is a brief conceptual overview of how it works.
Using MAUT, decision makers carefully analyze each decision option (alternative program or course of action under consideration) for its important attributes (things that matter to decision makers). For example, one might characterize a job in terms of attributes such as salary, chances for promotion, and location. Decision weights are assigned to attributes according to their importance to decision makers. Each available option is then assessed according to a utility scale for its expected value on all attributes. After multiplying the utility-scale values by the decision weights and summing the products, the option with the highest value is selected.35 Total utility values for each option are therefore computed by means of a payoff function, which specifies how the attribute levels are to be combined into an overall utility value.
To illustrate, suppose that a new MBA receives two job offers. She decides that the three most important characteristics of these jobs that will influence her decision are salary, chances for promotion, and location. She assigns the following weights to each: salary (.35), chances for promotion (.40), and location (.25). Using a 1–5 utility scale of the expected value of each job offer on each attribute, where 1 = low expected value and 5 = high expected value, suppose she assigns ratings to the two job offers as shown in Table 2-2.
Table 2-2. Multi-Attribute Utility Table Showing Job Attributes and Their Weights, the Values Assigned to Each Attribute, and the Payoff Associated with Each Alternative Decision
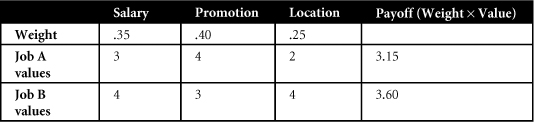
Based on this calculation of multi-attribute utility, the new MBA should accept job B because it maximizes her expected utility across all possible outcomes. MAUT models can encompass a variety of decision options, numerous and diverse sets of attributes reflecting many different constituents, and very complex payoff functions, but they generally share the characteristics shown in the simple example in the preceding table.36
Conjoint Analysis
Conjoint analysis (CA) is another technique that researchers in a variety of fields use to study judgment and decision making.37 Its purpose is to identify the hidden rules that people use to make tradeoffs between different products or services, and the values they place on different features. Consider choices among employee benefits, for example. If a company understands precisely how employees make decisions and what they value in the various benefits offered, then it becomes possible to identify the optimum level of benefits that balance value to employees against cost to the company.
CA researchers generally present decision tasks to respondents, who provide their preferences for products or concepts with different attributes (for example, expected product reliability or color) and different levels of those attributes (for example, high/medium/low or red/blue/green, respectively). Ratings or rankings then serve as the dependent variable and attribute levels serve as independent variables in the general equation:
![]()
Here, β represents the relative importance of an attribute and n equals the number of attributes. Note how Equation 2-4 resembles an analysis of variance or standard regression equation. Indeed, in its simplest form, CA is similar to an ANOVA, where attribute levels are dummy or contrast coded.38 Like other multivariate methods used to investigate dependence relationships, CA derives a linear function of attribute levels that minimizes error between actual and estimated values. Researchers can use several software packages (such as SAS or Sawtooth) to estimate this function.
Whereas many multivariate methods require all independent variables to have the same (for example, linear) relationship with the dependent variable, CA allows each one to have a different relationship (for example, linear, quadratic, or stepwise), thereby making it extremely flexible when investigating complex decision-making issues.39
We noted earlier that CA researchers specify levels for each attribute (that is, independent variable) and then present respondents with scenarios having attributes with different combinations of these levels. Because levels are known, researchers need only to collect respondent ratings to use as the dependent variable. In so doing, they can estimate or “decompose” the importance that respondents assign to each attribute. Hence, researchers can learn how important different attributes are to respondents by forcing them to make tradeoffs in real time.40
Sensitivity and Break-Even Analysis
Both of these techniques are attempts to deal with the fact that utility values are estimates made under uncertainty. Hence, actual utility values may vary from estimated values, and it is helpful to decision makers to be able to estimate the effects of such variability. One way to do that is through sensitivity analysis.
In sensitivity analysis, each of the utility parameters is varied from its low value to its high value while holding other parameter values constant. One then examines the utility estimates that result from each combination of parameter values to determine which parameter’s variability has the greatest effect on the estimate of overall utility.
In the context of evaluating HR programs, sensitivity analyses almost always indicate that utility parameters that reflect changes in the quality of employees caused by improved selection, as well as increases in the number (quantity) of employees affected, have substantial effects on resulting utility values.41 Utility parameters that reflect changes in the quality of employees include improvements in the validity of the selection procedure, the average score on the predictor, and dollar-based increases in the variability of performance.
Although sensitivity analyses are valuable in assessing the effects of changes in individual parameters, they provide no information about the effects of simultaneous changes in more than one utility parameter. Break-even analysis overcomes that difficulty.
Instead of estimating the level of expected utility, suppose that decision makers focus instead on the break-even value that is critical to making a decision. In other words, what is the smallest value of any given parameter that will generate a positive utility (payoff)? For example, suppose we know that a training program conducted for 500 participants raises technical knowledge by 10 percent or more for 90 percent of the participants. Everyone agrees that the value of the 10 percent increase is greater than $1,000 per trainee. The total gain is, therefore, at least (500 × .90 = 450 × $1,000) $450,000. Assuming that the cost of the training program is $600 per trainee, the total cost is therefore $300,000 (500 × $600). Researchers and managers could spend lots of time debating the actual economic value of the increase in knowledge, but, in fact, it does not matter because even the minimum agreed-upon value ($1,000) is enough to recoup the costs of the program. More precisely, when the costs of a program are matched exactly by equivalent benefits—no more, no less—the program “breaks even.” This is the origin of the term break-even analysis.42
The major advantages of break-even analysis suggest a mechanism for concisely summarizing the potential impact of uncertainty in one or more utility parameters.43 It shifts emphasis away from estimating a utility value toward making a decision using imperfect information. It pinpoints areas where controversy is important to decision making (that is, where there is doubt about whether the break-even value is exceeded), versus where controversy has little impact (because there is little risk of observing utility values below break-even). In summary, break-even analysis provides a simple expedient that allows utility models to assist in decision making even when some utility parameters are unknown or are uncertain.
Conclusion
As noted at the outset, the purpose of this chapter is to present some general analytical concepts that we will revisit throughout this book. The issues that we discussed comprised two broad areas:
• Some fundamental analytical concepts from statistics and research design
• Some fundamental analytical concepts from economics and finance
In the first category, we considered the following concepts: cautions in generalizing from sample data, correlation and causality, and experiments and quasi-experiments. In the second category, we considered some economic and financial concepts in seven broad areas: fixed, variable, and opportunity costs/savings; the time value of money; estimates of the value of employee time using total pay; cost-benefit and cost-effectiveness analyses; utility as a weighted sum of utility attributes; conjoint analysis; and sensitivity and break-even analysis. All of these concepts are important to HR measurement, and understanding them will help you to develop reliable, valid metrics. It will be up to you, of course, to determine whether those metrics fit the strategic direction of your organization.
References
1. Cascio, Wayne, and Brian Welle, “Using HR Data to Make Smarter Organizational Decisions,” pre-conference workshop presented at the annual conference of the Society for Industrial and Organizational Psychology, Atlanta, Ga., April 2010.
2. Jackson, S. L., Research Methods and Statistics: A Critical Thinking Approach (Belmont, Calif.: Wadsworth/Thomson Learning, 2003).
4. See, for example, Cochran, W. G., Sampling Techniques, 3rd ed. (New York: Wiley, 1997); and Kerlinger, F. N., and H. B. Lee, Foundations of Behavioral Research, 4th ed. (Stamford, Conn.: Thomson Learning, 2000).
5. For more on this, see Cohen, J., and P. Cohen, Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences, 3rd ed. (Hillsdale, N.J.: Lawrence Erlbaum, 2002); and Dancey, C. P., and J. Reidy, Statistics Without Maths for Psychology: Using SPSS for Windows, 3rd ed. (Harlow, England: Prentice Hall, 2004). Draper, N. R., and H. Smith, Applied Regression Analysis, 3rd ed. (New York: Wiley, 1998).
6. Guilford, J. P., and B. Fruchter, Fundamental Statistics in Psychology and Education, 6th ed. (New York: McGraw-Hill, 1978).
7. Kelly, K., S. Ang, G. H. H. Yeo, and W. F. Cascio, “Employee Turnover and Firm Performance: Modeling Reciprocal Effects,” paper presented at the annual conference of the Academy of Management, Philadelphia, Penn., August 2007.
8. Rosnow, R. L., and R. Rosenthal, Understanding Behavioral Science: Research Methods for Consumers (New York: McGraw-Hill, 1984).
9. Hair, J. F., Jr., W. C. Black, B. J. Babin, R. E. Anderson, and R. L. Tatham, Multivariate Data Analysis, 6th ed. (Upper Saddle River, N.J.: Prentice Hall, 2006).
11. For more on this, see Shadish, W. R., T. D. Cook, and D. Campbell, Experimental and Quasi-Experimental Designs for Generalized Causal Inference (Boston: Houghton Mifflin, 2002).
13. Schmidt, F. L., and J. Hunter, “History, Development, Evolution, and Impact of Validity Generalization and Meta-Analysis Methods, 1975–2001,” in Validity Generalization: A Critical Review, ed. K. R. Murphy (Mahwah, N.J.: Lawrence Erlbaum (2003a). Schmidt, F. L., and J. E. Hunter, “Meta-Analysis,” in Handbook of Psychology: Research Methods in Psychology 2, ed. J. A. Schinka and W. F. Velicer (New York: John Wiley & Sons, 2003b).
14. Cascio, W. F., and H. Aguinis, Applied Psychology in Human Resource Management, 7th ed. (Upper Saddle River, N.J.: Prentice-Hall, 2011).
17. Pfeffer, J., “Lay Off the Layoffs,” Newsweek Vol. 155(7) (February 15, 2010), downloaded from www.newsweek.com on February 15, 2010.
18. As presented by Cascio and Aguinis, 2011.
19. Cohen, J., Statistical Power Analysis for the Behavioral Sciences, 2nd ed. (Hillsdale, N.J.: Lawrence Erlbaum, 1988).
21. Campbell, D. T., and J. C. Stanley, Experimental and Quasi-Experimental Designs for Research (Chicago: Rand McNally, 1963).
23. Swain, M. R., W. S. Albrecht, J. D. Stice, and E. K. Stice, Management Accounting, 3rd ed. (Mason, Ohio: Thomson/South-Western, 2005).
24. Ibid.; and Rothenberg, J., “Cost-Benefit Analysis: A Methodological Exposition,” in Handbook of Evaluation Research 2, ed. M. Guttentag and E. Struening (Beverly Hills, Calif.: Sage, 1975).
25. Material in this section is drawn largely from Brealey, R. A., S. C. Myers, and F. Allen, Principles of Corporate Finance, 9th ed. (New York: McGraw-Hill/Irwin, 2007); Ross, S. A., R. W. Westerfield, and B. D. Jordan, Fundamentals of Corporate Finance, 9th ed. (Burr Ridge, Ill.: McGraw-Hill/Irwin, 2010); and Watson, D., and A. Head, Corporate Finance: Principles and Practice, 5th ed. (London: Pearson Education, 2009). This is just a brief introduction to these concepts at a conceptual level and includes only rudimentary calculations.
29. Audit guide for consultants (August 1999). Downloaded from www.wsdot.wa.gov/NR/rdonlyres/53951C28-068F-4505-835B-58B2C9C05C7C/0/Chapter6.pdf on May 17, 2010. Also www.wsdot.wa.gov/publications/manuals/fulltext/m0000/AuditGuide/C6.pdf. on May 17, 2010. Overhead and indirect costs. Downloaded from www.ucalgary.ca/evds/files/evds/overhead_indcosts.pdf on May 17, 2010.
30. Raju, N. S., M. J. Burke, J. Normand, and D. V. Lezotte, “What Would Be If What Is Wasn’t? Rejoinder to Judiesch, Schmidt, and Hunter,” Journal of Applied Psychology 78 (1993): 912–916.
31. Boudreau, J. W., and P. M. Ramstad, “Talentship and HR Measurement and Analysis: From ROI to Strategic Organizational Change,” Human Resource Planning 29, no. 1 (2006): 25–33.
32. Boudreau, J. W., and P. M. Ramstad, Beyond HR: The New Science of Human Capital (Boston, Mass.: Harvard Business School Publishing, 2007).
33. Erfurt, J. C., A. Foote, and M. A. Heirich, “The Cost-Effectiveness of Worksite Wellness Programs for Hypertension Control, Weight Loss, Smoking Cessation, and Exercise,” Personnel Psychology 45 (1992): 5–27.
34. Cascio, W. F., “Utility Analysis,” in Encyclopedia of Industrial and Organizational Psychology 2, ed. S. Rogelberg (Thousand Oaks, Calif.: Sage, 2007).
35. Slaughter, J. E., and J. Reb, “Judgment and Decision-Making Process,” in Encyclopedia of Industrial and Organizational Psychology 1, ed. S. Rogelberg (Thousand Oaks, Calif.: Sage, 2007).
37. Boudreau, J. W., “Utility Analysis for Decisions in Human Resource Management,” in Handbook of Industrial and Organizational Psychology 2, ed. M. D. Dunnette and L. M. Hough (Palo Alto, Calif.: Consulting Psychologists Press, 1991).
38. For more on conjoint analysis, see Hair et al. (2006). See also Lohrke, F., B. B. Holloway, and T. W. Woolley, “Conjoint Analysis in Entrepreneurship Research: A Review and Research Agenda,” Organizational Research Methods 13, no. 1 (2010): 16–30.