
Hour 9. Utilizing the Power of Grouping, Aggregation, and Map Reduce
What You’ll Learn in This Hour:
![]() Grouping documents based on a field value
Grouping documents based on a field value
![]() Creating an aggregation pipeline
Creating an aggregation pipeline
![]() Using aggregation pipelines to manipulate the results
Using aggregation pipelines to manipulate the results
![]() Building map reduce operations with reduce and finalize functions
Building map reduce operations with reduce and finalize functions
![]() Using map reduce to reduce a set of documents into a specific form
Using map reduce to reduce a set of documents into a specific form
A powerful feature of MongoDB is the capability to perform complex operations on the server that manipulate the values in documents to generate a completely new dataset. You can then return a set of data that is based on the documents stored in the database but in a totally different format. The advantage is that the processing can take place on the server without having to send the documents to the client first.
In this hour, you learn how to use the group, aggregation, and map reduce frameworks in MongoDB to manipulate a set of documents into different formats before returning the results to the client.
Grouping Results of Find Operations in the MongoDB Shell
When performing operations on large datasets, it is often useful to group the results based on the distinct values of one or more fields in a document. This can be done in code after retrieving the documents, but it is much more efficient to have the MongoDB server do it for you as part of a single request that is already iterating though the documents.
To group the results of a query, you can use the group() method on the Collection object. The group request first collects all the documents that match a query. Then it adds a group object to an array based on distinct values of a set of keys, performs operations on the group objects, and returns the array of group objects. The syntax for the group() methods appears here:
group({key, reduce, initial, [keyf], [cond], finalize})
The following list describes the parameters of the group() method:
![]() keys: An object that expresses the keys to group by. The properties in the object are the fields to group. For example, to group by the first and last fields in the documents, you would use
keys: An object that expresses the keys to group by. The properties in the object are the fields to group. For example, to group by the first and last fields in the documents, you would use
{key: {first: 1, last: 1}}
![]() cond: Optional. Specifies the
cond: Optional. Specifies the query object that defines which documents to be included in the initial set. For example, to include documents that have a field size greater than 5, you would use
{cond: {size: {$gt: 5}}
![]() initial: Specifies an initial
initial: Specifies an initial group object with initial fields and values to use when aggregating data while grouping. An initial object is created for each distinct set of keys. The most common use is a counter that tracks a count of items that match the keys. For example:
{initial: {"count": 0}}
![]() reduce: A
reduce: A function(obj, prev) with two parameters, obj and prev. This function is executed on each document that matches the query. The obj parameter is the current document, and the prev is the current object that was created by the initial parameter. You can then use the obj object to update the prev object with new values, such as counts or sums. For example, to increment the count value, you would use
{reduce: function(obj, prev) { prev.count++; }}
![]() finalize: A
finalize: A function(obj) that accepts one parameter, obj, which is the final object resulting from the initial parameter and updated as prev in the reduce function. This function is called on the resulting object for each distinct key before returning the array in the response.
![]() keyf: An optional field that is an alternative to the
keyf: An optional field that is an alternative to the key field. Instead of specifying an object in which the properties are the keys to group by, you can specify a function that returns a key object to use for the grouping. This enables you to use a function to dynamically set which keys to group by.
Using Aggregation to Manipulate the Data During Requests from the MongoDB Shell
A great benefit of MongoDB is the capability to aggregate the results of database queries into a completely different structure than the original collections. The MongoDB aggregation framework is a great framework that simplifies the process of piping one operation into another in a series to produce some extraordinary results with the data.
Aggregation is the concept of applying a series of operations to documents on the MongoDB server as they are being compiled into a result set. This is much more efficient than retrieving them and processing them in your application because the MongoDB server can operate on chunks of data locally.
The following sections describe the MongoDB aggregation framework and how to implement it from the MongoDB shell.
Understanding the aggregate() Method
The Collection object provides the aggregate() method to perform aggregation operations on data. The syntax for the aggregate() method follows:
aggregate(operator, [operator], [...])
The operator parameters are a series of aggregation operators, shown in Table 9.1, that enable you to define what aggregation operation to perform on the data during that step in the pipeline. After the first operator has been applied, the resulting data is passed to the next operator, which processes the data and passes the results on to the next operator, and so on through the end of the pipeline.


Using Aggregation Framework Operators
The aggregation framework MongoDB provides is extremely powerful, in that it enables you to pipe the results of one aggregation operator into another multiple times. For illustration, look at the following dataset:
{o_id:"A", value:50, type:"X"}
{o_id:"A", value:75, type:"X"}
{o_id:"B", value:80, type:"X"}
{o_id:"C", value:45, type:"Y"}
The following aggregation operator set pipelines the results of the $match into the $group operator and then returns the grouped set in the results parameter of the callback function. Notice that, when referencing the values of fields in documents, the field name is prefixed by a dollar sign—for example, $o_id and $value. This syntax tells the aggregate framework to treat it as a field value instead of a string.
aggregate( { $match:{type:"X"}},
{ $group:{set_id:"$o_id", total: {$sum: "$value"}}},
function(err, results){});
After the $match operator completes, the documents that would be applied to $group would be
{o_id:"A", value:50, type:"X"}
{o_id:"A", value:75, type:"X"}
{o_id:"B", value:80, type:"X"}
Then after the $group operator is applied, a new array of objects is sent to the callback function with set_id and total fields:
{set_id:"A", total:"125"}
{set_id:"B", total:"80"}
Table 9.1 defines the types of aggregation commands you can include in the operators parameter to the aggregate() method.
Implementing Aggregation Expression Operators
When you are implementing the aggregation operators, you are building new documents that will be passed to the next level in the aggregation pipeline. The MongoDB aggregation framework provides a number of expression operators that help when computing values for new fields or comparing existing fields in the documents.
When operating on a $group aggregation pipe, multiple documents will match the defined fields in the new documents created. MongoDB provides a set of operators that you can apply to those documents and use to compute values for a field in the new group document. For example, to set a field named maximum in the new group object that represents the maximum value for value field in the original dataset you would use. Table 9.2 lists the $group expression operators.

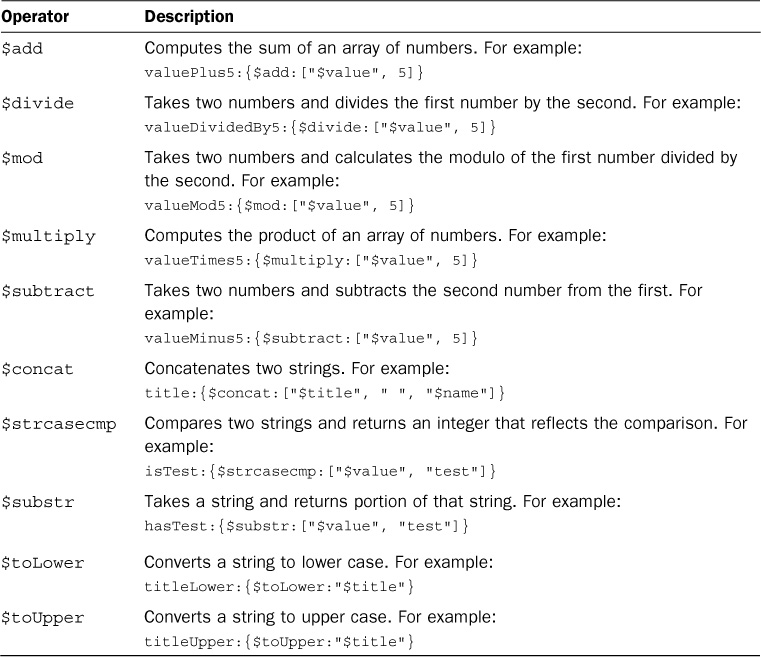
Several string and arithmetic operators also can be applied when computing new field values. Table 9.3 lists some of the more common operators that can be applied when computing new field values in the aggregation operators.
Applying Map Reduce to Generate New Data Results Using the MongoDB Shell
A great benefit of MongoDB is the capability to map reduce the results of database queries into a completely different structure than the original collections. Map reduce is the process of mapping the values on a database lookup and then reducing them into a completely different form to make it more consumable.
Using map reduce, you can manipulate the data on the MongoDB server before it is returned to the client, thus reducing both processing on the client and the amount of data that must be returned. The following sections describe the MongoDB map reduce framework and how to use it.
Understanding the mapReduce() Method
The Collection object provides the mapReduce() method to perform map reduce operations on data before returning the results to the client. The syntax for the mapReduce() method follows:
mapReduce(map, reduce, arguments)
The map parameter is a function that is applied on each object in the dataset and emits a key and value. The value is added to an array based on the key name to be used during the reduce phase. The following shows the format of the map function:
function(){
<do stuff to calculate key and value>
emit(key, value);
}
The reduce parameter is a function that is applied after the map function is run on all objects with the reduce function. The reduce function must accept a key as the first parameter and the array of values that match the key as the second. The reduce function must then use the array of values to calculate a single value for the key and return that result. The following shows the format for the reduce function:
function(key, values){
<do stuff to on values to calculate a single result>
return result;
}
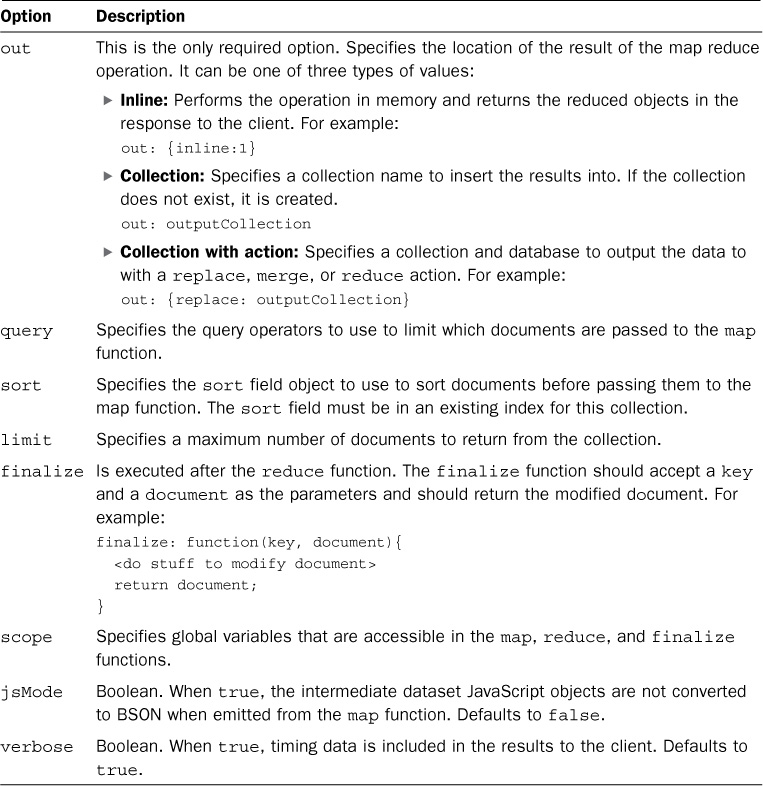
The arguments parameter of the mapReduce() method is an object that defines the options to use when retrieving documents to be applied to the map function. Table 9.4 shows the options that can be specified in the arguments parameter.
The following code shows an example of using map reduce and specifying the out and query and sort options:
results = myCollection.mapReduce(
function() { emit(this.key, this.value); },
function(key, values){ return Array.sum(values); },
{
out: {inline: 1},
query: {value: {$gt: 6}
}
);
Summary
In this hour, you learned how to use the group, aggregation, and map reduce frameworks in MongoDB to manipulate a set of documents into different formats before returning the results to the client. The group framework enables you to group objects by field values and then return a dataset based on the grouping.
The aggregation framework enables you to apply different aggregation operators in a series to manipulate the return dataset in steps to achieve easily consumable results. The map reduce framework applies map, reduce, and finalize functions that first reduce the object dataset based on a key and then reduce the dataset to a more easily consumable form.
Q&A
Q. How many aggregation operators can be used in a single aggregate() method call?
A. There really isn’t a limit. However, at a certain point, you achieve diminishing returns.
Q. Can I use the group() method on a sharded cluster?
A. No. However, you can use the aggregation framework with the $group operator in a sharded environment.
Workshop
The workshop consists of a set of questions and answers designed to solidify your understanding of the material covered in this hour. Try answering the questions before looking at the answers.
Quiz
1. What does the map function emit to the aggregation framework?
2. How do you return the map-reduced objects as part of the response to the client?
3. Which aggregation operator do you use to group documents?
4. True or false: You can specify only one key in the group() method.
Quiz Answers
1. map should emit a key and value: emit(key, value).
2. Add the out:{inline: 1} option to the mapReduce() call.
3. $group
4. False.
Exercises
1. Implement a script that applies a group() method that groups words in the example dataset by size and returns the count.
2. Implement a script that applies an aggregate() pipeline that finds words that end in t, and then uses a reduce method that either increments a new field named rCount if the letters field contains an r or increments a new field named sCount if the letters field contains an s.