
Chapter 9. Service API and Contract Design with REST Services and Microservices

Parts of this chapter refer to HTTP syntax and REST-related technologies that are covered in the SOA with REST: Principles, Patterns & Constraints series textbook.
REST service contracts are typically designed around the primary functions of HTTP methods, which make the documentation and expression of REST service contracts distinctly different from operation-based Web service contracts. Regardless of the differences in notation, the same overarching contract-first approach to designing REST service contracts is paramount when building services for a standardized service inventory.
With REST services in particular, the following benefits can be achieved:
• REST service contracts can be designed to logically group capabilities related to the functional contexts established during the service-oriented analysis process.
• Conventions can be applied to formally standardize resource names and input data representation.
• Complex methods can be defined and standardized to encapsulate a set of pre-defined interactions between a service and a service consumer.
• Service consumers are required to conform to the expression of the service contract, not vice versa.
• The design of business-centric resources and complex methods can be assisted by business analysts who may be able to help establish an accurate expression and behavior of business logic.
This chapter provides service contract design guidance for service candidates modeled as a result of the service-oriented analysis stage covered in Chapter 7.
Note that the physical design of REST service contract APIs may reveal functional requirements that are more suitable for alternative implementation mediums. The need to design a richer API or transactional functionality, for example, can warrant consideration of the use of SOAP-based Web services, as explained in Chapter 8.
9.1 Service Model Design Considerations
REST service contracts are based on the functional contexts established during the service-oriented analysis process. Depending on the nature of the functionality within a given context, each service will have already been categorized within a service model. Following are a set of service contract design considerations specific to each service model.
Entity Service Design
Each entity service establishes a functional boundary associated with one or more related business entities (such as invoice, claim, customer, and so on). The types of service capabilities exposed by a typical entity service are focused on functions that process the underlying data associated with the entity (or entities).
REST entity service contracts are typically dominated by service capabilities that include inherently idempotent and reliable GET, PUT, or DELETE methods. Entity services may need to support updating their state consistently with changes to other entity services. Entity services will also often include query capabilities for finding entities or parts of entities that match certain criteria, and therefore return hyperlinks to related and relevant entities.
If complex methods are permitted as part of a service inventory’s design standards, then entity services may benefit from supplementing the standard HTTP method-based capabilities with the pre-defined interactions represented by complex methods.
Figure 9.1 provides an example of an entity service with two standard HTTP methods and two complex methods.
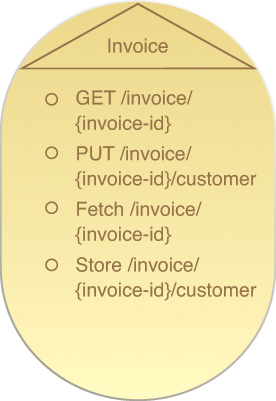
Figure 9.1 An entity service based on the Invoice business entity that defines a functional scope that limits the service capabilities to performing invoice-related processing. This agnostic Invoice service will be reused and composed by other services within the same service inventory in support of different automated business processes that need to process invoice-related data. This particular invoice service contract displays two service capabilities based on primitive methods and two service capabilities based on complex methods.
Complex methods are covered toward the end of this chapter in the Complex Method Design section.
Utility Service Design
Like entity services, utility services are expected to be agnostic and reusable. However, unlike entity services, they do not usually have pre-defined functional scopes. Therefore, we need to confirm, before finalizing the service contract, that the method and resource combinations we’ve chosen during the service-oriented analysis phase are what we want to commit to for a given utility service design.
Whereas individual utility services group related service capabilities, the services’ functional boundaries can vary dramatically. The example illustrated in Figure 9.2 is a utility service acting as a wrapper for a legacy system.
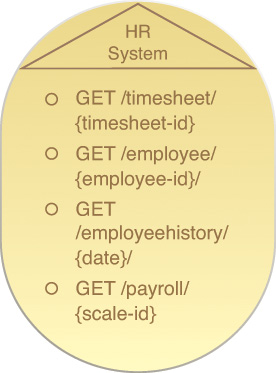
Figure 9.2 This utility service contract encapsulates a legacy HR system (and is accordingly named). The service capabilities it exposes provide generic, read-only data access functions against the data stored in the underlying legacy repository. For example, the Employee entity service (composed by the Verify Timesheet task service) may invoke an employee data-related service capability to retrieve data. This type of utility service may provide access to one of several available sources of employee and HR-related data.
Microservice Design
The predominant design consideration that applies to microservice contracts is the flexibility we have in how we can approach contract design. Due to the fact that microservices are typically based on an intentionally non-agnostic functional context, they will usually have limited service consumers. Sometimes a microservice may only have a single service consumer. Because we assume that the microservice will never need to facilitate any other service consumers in the future (because it is not considered reusable outside of a business process), the application of a number of service-orientation principles becomes optional.
Most notably, this includes the Standardized Service Contract (291) principle. Micro-service APIs can be, to a certain extent, non-standard so that their individual capabilities can be optimized in support of their runtime performance and reliability requirements. This flexibility further carries over to the application of the Service Abstraction (294) and Service Loose Coupling (293) principles.
Exceptions to this design freedom pertain primarily to how the microservice interacts as part of the greater service composition. The cost of achieving the individual performance requirements of a microservice needs to be weighed against the requirements of the overall service-oriented solution it is a part of.
For example, the Standardized Service Contract (291) principle may need to be applied to an extent to ensure that a microservice contract is designed to support a standard schema that represents a common business document. Allowing the microservice to introduce a non-standard schema may benefit the processing efficiency of the microservice, but the resulting data transformation requirements for that data to be transformed into the standard schema used by the remaining service composition members may be unreasonable.
Figure 9.3 shows the service contract for the microservice that was modeled in Chapter 6.
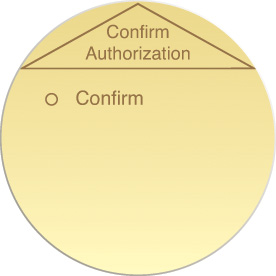
Figure 9.3 A microservice contract with a single-purpose, non-agnostic functional scope. The service provides three capabilities specific to and in support of its parent business process.
Task Service Design
Task services will typically have few service capabilities, sometimes limited to only a single one. This is due to the fact that a task service contract’s primary use is for the execution of automated business process (or task) logic. The service capability can be based on a simple verb, such as Start or Process. That verb, together with the name of the task service (that will indicate the nature of the task) is often all that is required for synchronous tasks. Additional service capabilities can be added to support asynchronous communication, such as accessing state information or canceling an active workflow instance, as shown in Figure 9.4.
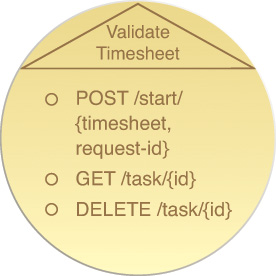
Figure 9.4 A sample task service, recognizable by the verb in its name. The contract only provides a service capability used by the composition initiator to trigger the execution of the Validate Timesheet business process that the task service logic encapsulates. In this case, the service capability receives a timesheet resource identifier that will be used as the basis of the validation logic, plus a unique consumer-generated request identifier that supports reliable triggering of the process. Two additional service capabilities allow consumers to asynchronously check on the progress of the timesheet validation task, and to cancel the task while it is in progress.
REST-based task services will often have service capabilities triggered by a POST request. However, this method is not inherently reliable. A number of techniques exist to achieve a reliable POST, including the inclusion of additional headers and handling of response messages, or the inclusion of a unique consumer-generated request identifier in the resource identifier.
To provide input to a parameterized task service it will make sense for the task service contract to include various identifiers into the capability’s resource identifier template (that might have been parameters in a SOAP message). This frees up the service to expose additional resources rather than defining a custom media type as input to its processing.
If the task service automates a long-running business process it will return an interim response to its consumer while further processing steps may still need to take place. If the task service includes additional capabilities to check on or interact with the state of the business process (or composition instance), it will typically include a hyperlink to one or more resources related to this state in the initial response message.
MUA follows proven REST service contract design techniques together with custom design standards established specifically for the MUA enterprise. Architects use select service candidates modeled in Chapter 7 as the basis for their service contract designs.
Confer Student Award Service Contract (Task)
A student who submits an award conferral application will do so through a Web browser. A separate user interface is therefore designed to allow users to enter the application details. It is the submission of this browser-based form that initiates the task service.
Upon receiving the submission, a server-side script organizes the form data into an XML document based on the following media type:
application/vnd.edu.mua.student-award-conferral-application+xhtml+xml
Example 9.1 provides a submitted application form completed with sample data collected from the human user. This represents the data set that kickstarts and drives the execution of an entire instance of the Confer Student Award business process.
Example 9.1 Sample application data, as submitted to the Web server. This document structure contains both human-readable and machine-processable information.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" >
<head>
<title>Student Award Conferral Application</title>
</head>
<body>
<p>Student:
<a rel="student"
href="http://student.mua.edu/student/555333">
John Smith (Student Number 555333)
</a>
</p>
<p>Award:
<a rel="award"
href="http://award.mua.edu/award/BS/CompSci">
Bachelor of Science with Computer Science Major
</a>
</p>
<p>Event:
<a rel="event"
href="http://event.mua.edu/achievement">
Outstanding Achievement
</a>
</p>
</body>
</html>
Figure 9.5 displays the Confer Student Award service contract. The preceding media type is deliberately designed to include human-readable and machine-readable data in a form suitable for long-term archival. The document is submitted to a service capability corresponding directly to the Start capability defined in the Confer Student Award service candidate.
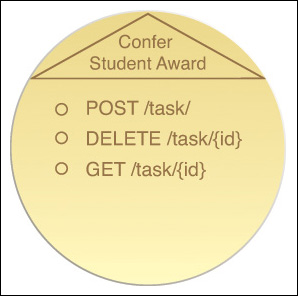
As also shown in Figure 9.5, during the design process for this service contract it was decided to add new service capabilities to provide the following functions:
• DELETE /task/{id} – This capability was added to allow an executing instance of the Confer Student Award business process to be terminated.
• GET /task/{id} – This capability allows the state of an executing instance of the Confer Student Award business process to be queried.
Note that the sensitive nature of this kind of application means that the GET /task/{id} capability can be accessed only by authorized staff and by the student. The DELETE /task/{id} capability is only accessible by the student to cancel the application process.
Event Service Contract (Entity)
The Event entity service is equipped with a GET /event/{id} service capability, which is used to query event information and corresponds to the Get Details capability candidate from the Event service candidate (Figure 9.6).
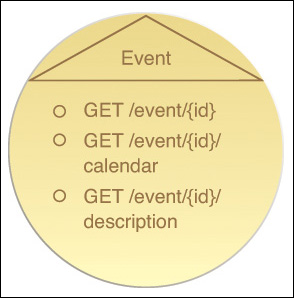
During the service-oriented design process, architects decided to add further GET /event/{id}/calendar and GET /event/{id}/description capabilities that allow for the retrieval of more specific event information. These capabilities were not added specifically in support of the Confer Student Award business process, but more so to provide a broader range of anticipated reusable functionality.
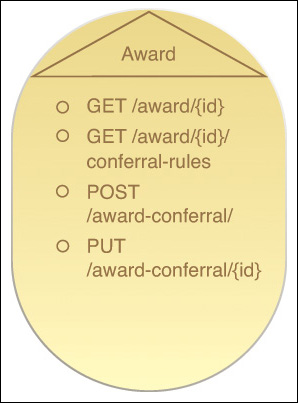
Award Service Contract (Entity)
In addition to implementing the three service capabilities from the original Award service candidate (Figure 9.6), some of MUA’s SOA architects decide to make some further changes.
Back in Chapter 7, MUA analysts determined that the following action was to be encompassed by the Confer Student Award task service logic:
• Verify Student Transcript Qualifies for Award Based on Award Conferral Rules
However, with the rules being specific to each award type they determine that it should be the Award entity service that applies the bulk of these rules. Nevertheless, some generic checks do need to be applied so the logic is divided between the Confer Student Award task service and the Award entity service.
To avoid requiring the task service to pass full transcript details into the Award entity service for verification, it is decided to use a code-on-demand approach. The Award entity service provides the logic, but the logic is executed by the task service. The decision to define the logic centrally within the Award entity service is justified based on the need to produce human-readable output (for students), alongside machine-readable output (for the Confer Student Award service). As a result, the Entity service provides a new GET /award/conferral-rules service capability (Figure 9.7) that supports the output of two formats for the rules logic: the first in human-readable form and the second in a form that can be readily embedded into the task service’s logic.
MUA architects choose JavaScript for this purpose because they find that JavaScript runtimes are readily available for many of the technology platforms that have been used to develop services within the inventory. Choosing JavaScript over other technologies also accounts for its being the language of choice for the user interface tier of the service inventory.
The same service capability is able to return the conferral rules in JavaScript or as human-readable HTML. The decision as to which transformation to carry out depends on which Accept header was provided by the service consumer. For example, the Confer Student Award task service requests the application/javascript media type, while service consumers requiring human-readable output will request the text/html media type.
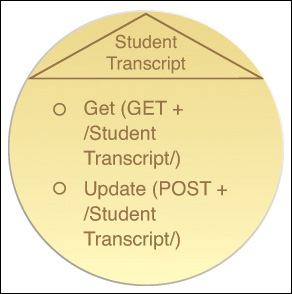
Student Transcript Service Contract (Entity)
The Student service was originally intended as a centralized entity service that would encompass all student-related functionality and data access. However, iterations of the REST service modeling process that occurred subsequent to the examples covered in Chapter 7 resulted in a service inventory blueprint that revealed the Student service candidate as being far more coarsely grained than any other. This was primarily due to the complexity of the Student entity and its relationships to other related entities.
Upon review of the Student service candidate, it was determined to create a set of student-related entity services. One of these more specialized variations became the Student Transcript service candidate (Figure 9.8).
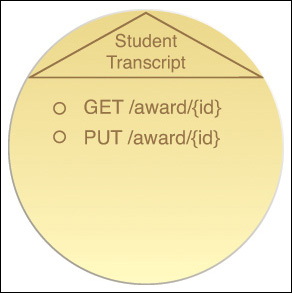
Figure 9.8 The Student Transcript service candidate that was defined subsequent to the Student service candidate. This service effectively replaces the Student service in the Confer Student Award service composition.
Because the Confer Student Award business process only requires access to student transcript information, it only needs to compose the Student Transcript service, not the actual Student service. As shown in Figure 9.9, the Student Transcript service contains service capabilities that correspond to the service capability candidates provided by the Student Transcript service candidate.
Notification and Document Service Contracts (Utility)
The Notification service and Document service process similar human-readable data. Notifications sent via email or hard copy can both be encoded as a human-readable document format, such as HTML or PDF.
The Notification service is retained for email notifications while the Document service has been evolved into a printer-centric and postal delivery–centric utility service. The Confer Student Award task service can send a document to the student in the preferred format by looking up the preferred delivery method in the original application form.
As shown in Figure 9.10, the Notification and Document services can each be invoked with the POST method.
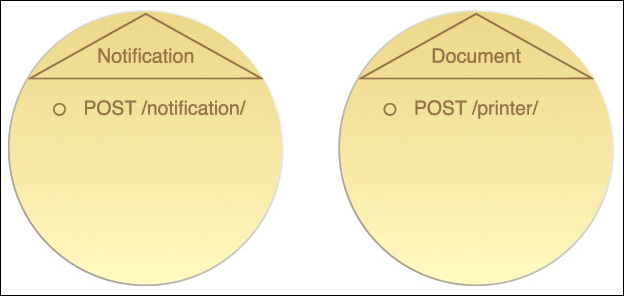
The sample student (John Smith) from the application form used as input for the Confer Student Award task service has nominated his contact preference with a hyperlink to mailto:[email protected]. The service inventory standard for handling such an address is to transform the URL into http://notification.mua.edu/[email protected] and use a POST method for its delivery. John Smith’s notification will be delivered via email to this address.
9.2 REST Service Design Guidelines
The following is a series of common guidelines and considerations for designing REST service contracts.
Uniform Contract Design Considerations
When creating a uniform contract for a service inventory, we have a responsibility to equip and limit its features so that it is streamlined to effectively accommodate requirements and restrictions unique to the service inventory. The default characteristics of Web-centric technology architecture can provide an effective basis for a service inventory’s uniform contract, although additional forms of standardization and customization are likely required for non-trivial service inventory architectures.
The following sections explore how common elements of a uniform contract (methods, media types, and exceptions in particular) can be customized to meet the needs of individual service inventories.
Designing and Standardizing Methods
When we discuss methods in relation to the uniform contract, it is considered shorthand for a request-response communications mechanism that also includes methods, headers, response codes, and exceptions. Methods are centralized as part of the uniform contract to ensure that there are always a small number of ways of moving information around within a particular service inventory, and that existing service consumers will work correctly with new or modified services as they are added to the inventory. Although it is important to minimize the number of methods in the uniform contract, methods can and should be added when service inventory interaction requirements demand it. This is a natural part of evolving a service inventory in response to business change.
Note
Less well-known HTTP methods have come and gone in the past. For example, at various times the HTTP specification has included a PATCH method consistent with a partial update or partial store communications mechanism. PATCH is currently specified separately from HTTP methods in the IETF’s RFC 5789 document. Other IETF specifications, such as WebDAV’s RFC 4918 and the Session Initiation Protocol’s RFC 3261, introduced new methods as well as new headers and response codes (or special interpretations thereof).
HTTP provides a solid foundation by supplying the basic set of methods (such as GET, PUT, DELETE, POST) proven by use on the Web and widely supported by off-the-shelf software components and hardware devices. But the need to express other types of interactions for a service inventory may arise. For example, you may decide to add a special method that can be used to reliably trigger a resource to execute a task at most once, rather than using the less reliable HTTP POST method.
HTTP is designed to be extended in these ways. The HTTP specification explicitly supports the notion of extension methods, customized headers, and extensibility in other areas. Leveraging this feature of HTTP can be effective, as long as new extensions are added carefully and at a rate appropriate for the number of services that implement HTTP within an inventory. This way, the total number of options for moving data around (that services and consumers are required to understand) remains manageable.
Note
At the end of this chapter we explore a set of sample extended methods (referred to as complex methods). Each utilizes multiple basic HTTP methods or a single basic HTTP method multiple times to perform pre-defined, standardized message interactions.
Common circumstances that can warrant the creation of new methods include:
• Hyperlinks may be used to facilitate a sequence of request-response pairs. When they start to read like verbs instead of nouns and tend to suggest that only a single method will be valid on the target of a hyperlink, we can consider introducing a new method instead. For example, the “customer” hyperlink for an invoice resource suggests that GET and PUT requests might be equally valid for the customer resource. But a “begin transaction” hyperlink or a “subscribe” hyperlink suggests only POST is valid and may indicate the need for a new method instead.
• Data with must-understand semantics may be needed within message headers. In this case, a service that ignores this metadata can cause incorrect runtime behavior. HTTP does not include a facility for identifying individual headers or information within headers as “must-understand.” A new method can be used to enforce this requirement because the custom method will be automatically rejected by a service that doesn’t understand the request (whereas falling back on a default HTTP method will allow the service to ignore the new header information).
It is important to acknowledge that introducing custom methods can have negative impacts when exploring vendor diversity within an implementation environment. It may prevent off-the-shelf components (such as caches, load balancers, firewalls, and various HTTP-based software frameworks) from being fully functional within the service inventory. Stepping away from HTTP and its default methods should only be attempted in mature service inventories when the effects on the underlying technology architecture and infrastructure are fully understood.
Some alternatives to creating new methods can also be explored. For example, service interactions that require a number of steps can use hyperlinks to guide consumers through the requests they need to make. The HTTP Link header (RFC 5988) can be considered to keep these hyperlinks separate from the actual document content.
Designing and Standardizing HTTP Headers
Exchanging messages with metadata is common in service-oriented solution design. Because of the emphasis on composing a set of services together to collectively automate a given task at runtime, there is often a need for a message to provide a range of header information that pertains to how the message should be processed by intermediary service agents and services along its message path.
Built-in HTTP headers can be used in a number of ways:
• To add parameters related to a request method as an alternative to using query strings to represent the parameters within the URL. For example, the Accept header can supplement the GET method by providing content negotiation data.
• To add parameters related to a response code. For example, the Location header can be used with the 201 Created response code to indicate the identifier of a newly created resource.
• To communicate general information about the service or consumer. For example, the Upgrade header can indicate that a service consumer supports and prefers a different protocol, while the Referrer header can indicate which resource the consumer came from while following a series of hyperlinks.
This type of general metadata may be used in conjunction with any HTTP method.
HTTP headers can also be utilized to add rich metadata. For this purpose custom headers are generally required, which reintroduces the need to determine whether or not the message content must be understood by recipients or whether it can optionally be ignored. This association of must-understand semantics with new methods and must-ignore semantics with new message headers is not an inherent feature of REST, but it is a feature of HTTP.
When introducing custom HTTP headers that can be ignored by services, regular HTTP methods can safely be used. This also makes the use of custom headers backwards-compatible when creating new versions of existing message types.
As previously stated in the Designing and Standardizing Methods section, new HTTP methods can be introduced to enforce must-understand content by requiring services to either be designed to support the custom method or to reject the method invocation attempt altogether. In support of this behavior, a new Must-Understand header can be created in the same format as the existing Connection header, which would list all the headers that need to be understood by message recipients.
If this type of modification is made to HTTP, it would be the responsibility of the SOA Governance Program Office responsible for the service inventory to ensure that these semantics are implemented consistently as part of inventory-wide design standards. If custom, must-understand HTTP headers are successfully established within a service inventory, we can explore a range of applications of messaging metadata. For example, we can determine whether it is possible or feasible to emulate messaging metadata such as what is commonly used in SOAP messaging frameworks based on WS-* standards.
While custom headers that enforce reliability or routing content (as per the WS-ReliableMessaging and WS-Addressing standards) can be added to recreate acknowledgement and intelligent load balancing interactions, other forms of WS-* functions are subject to built-in limitations of the HTTP protocol. The most prominent example is the use of WS-Security to enable message-level security features, such as encryption and digital signatures. Message-level security protects messages by actually transforming the content so that intermediaries along a message path are unable to read or alter message content. Only those message recipients with prior authorization are able to access the content.
This type of message transformation is not supported in HTTP/1.1. HTTP does have some basic features for transforming the body of the message alone through its Content-Encoding header, but this is generally limited to compression of the message body and does not include the transformation of headers. If this feature was used for encryption purposes the meaning of the message could still be modified or inspected in transit, even though the body part of the message could be protected. Message signatures are also not possible in HTTP/1.1 as there is no canonical form for an HTTP message to sign, and no industry standard that determines what modifications intermediaries would be allowed to make to such a message.
Designing and Standardizing HTTP Response Codes
HTTP was originally designed as a synchronous, client-server protocol for the exchange of HTML pages over the World Wide Web. These characteristics are compatible with REST constraints and make it also suitable as a protocol used to invoke REST service capabilities.
Developing a service using HTTP is very similar to publishing dynamic content on a Web server. Each HTTP request invokes a REST service capability and that invocation concludes with the sending of a response message back to the service consumer.
A given response message can contain any one of a wide variety of HTTP codes, each of which has a designated number. Certain ranges of code numbers are associated with particular types of conditions, as follows:
• 100-199 are informational codes used as low-level signaling mechanisms, such as a confirmation of a request to change protocols.
• 200-299 are general success codes used to describe various kinds of success conditions.
• 300-399 are redirection codes used to request that the consumer retry a request to a different resource identifier, or via a different intermediary.
• 400-499 represent consumer-side error codes that indicate that the consumer has produced a request that is invalid for some reason.
• 500-599 represent service-side error codes that indicate that the consumer’s request may have been valid but that the service has been unable to process it for internal reasons.
The consumer-side and service-side exception categories are helpful for “assigning blame” but do little to actually enable service consumers to recover from failure. This is because, while the codes and reasons provided by HTTP are standardized, how service consumers are required to behave upon receiving response codes is not. When standardizing service design for a service inventory, it is necessary to establish a set of conventions that assign response codes concrete meaning and treatment.
Table 9.1 provides common descriptions of how service consumers can be designed to respond to common response codes.
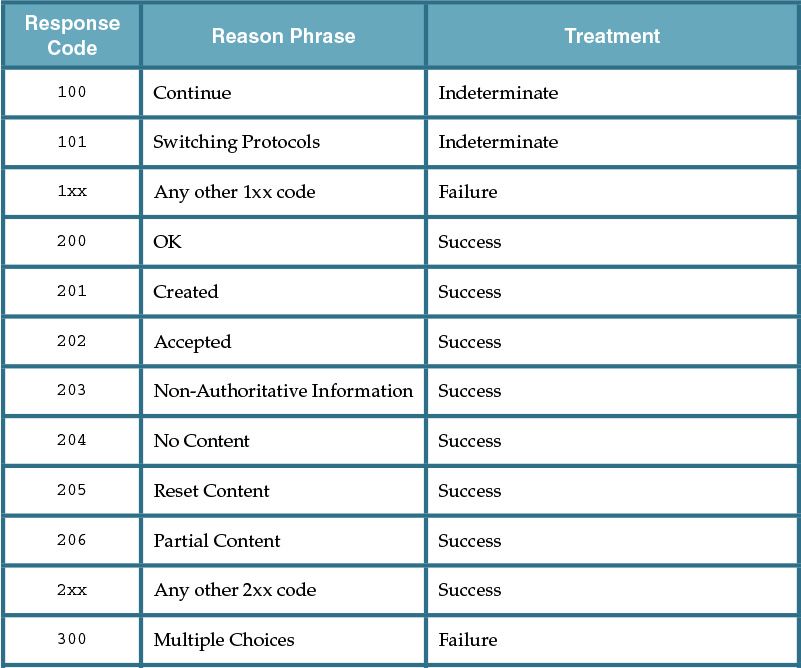
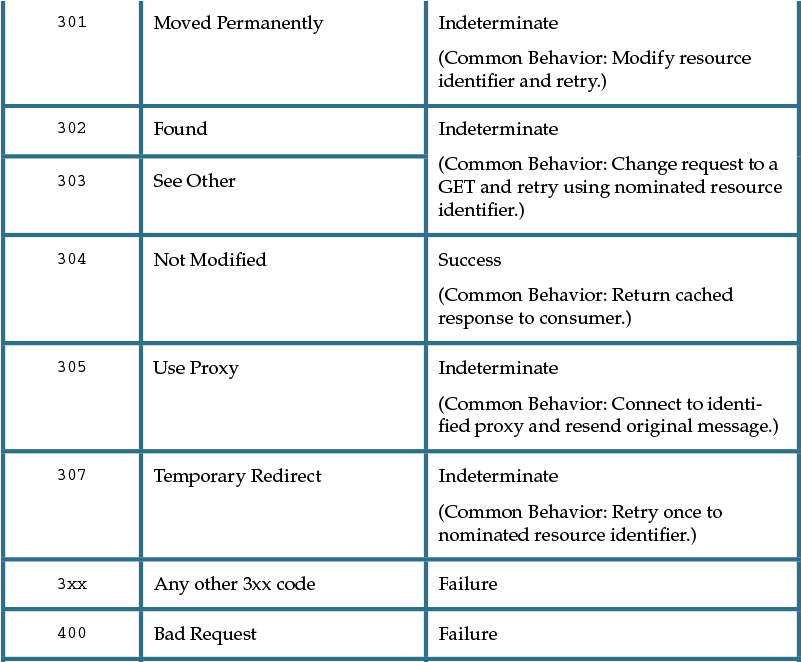
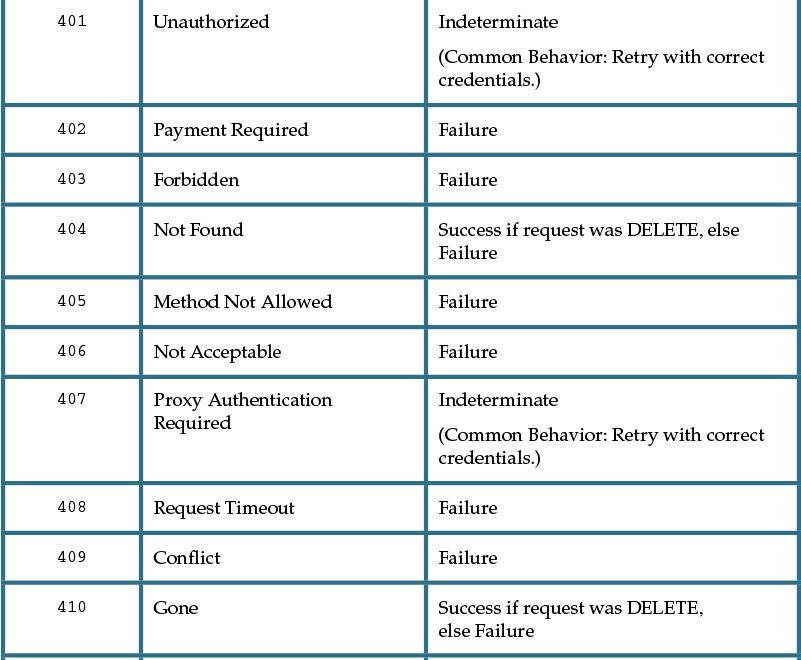
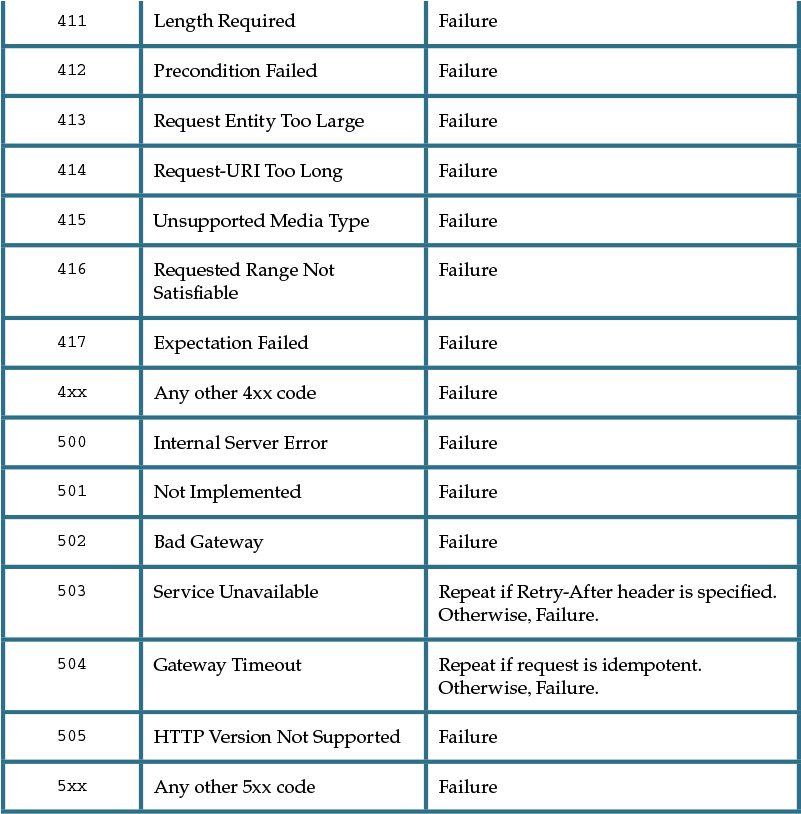
As is evident when reviewing Table 9.1, HTTP response codes go well beyond the simple distinction between success and failure. They provide an indication of how consumers can respond to and recover from exceptions.
Let’s take a closer look at some of the values from the Treatment column in Table 9.1:
• Repeat means that the consumer is encouraged to repeat the request, taking into account any delay specified in responses such as 503 Service Unavailable. This may mean sleeping before trying again. If the consumer chooses not to repeat the request, it must treat the method as failed.
• Success means the consumer should treat the message transmission as a successful action and must therefore not repeat it. (Note that specific success codes may require more subtle interpretation.)
• Failed means that the consumer must not repeat the request unchanged, although it may issue a new request that takes the response into account. The consumer should treat this as a failed method if a new request cannot be generated. (Note that specific failure codes may require more subtle interpretation.)
• Indeterminate means that the consumer needs to modify its request in the manner indicated. The request must not be repeated unchanged and a new request that takes the response into account should be generated. The final outcome of the interaction will depend on the new request. If the consumer is unable to generate a new request then this code must be treated as failed.
Because HTTP is a protocol and not a set of message processing logic, it is up to the service to decide what status code (success, failure, or otherwise) to return. As previously mentioned, because consumer behavior is not always sufficiently standardized by REST for machine-to-machine interactions, it needs to be explicitly and meaningfully standardized as part of an SOA project.
For example, indeterminate codes tend to indicate that service consumers must handle a situation using their own custom logic. We can standardize these types of codes in two ways:
• Design standards can determine which indeterminate codes can and cannot be issued by service logic.
• Design standards can determine how service consumer logic must interpret those indeterminate codes that are allowed.
Customizing Response Codes
The HTTP specification allows for extensions to response codes. This extension feature is primarily there to allow future versions of HTTP to introduce new codes. It is also used by some other specifications (such as WebDAV) to define custom codes. This is typically done with numbers that are not likely to collide with new HTTP codes, which can be achieved by putting them near the end of the particular range (for example, 299 is unlikely to ever be used by the main HTTP standard).
Specific service inventories can follow this approach by introducing custom response codes as part of the service inventory design standards. In support of the Uniform Contract {311} constraint, custom response codes should only be defined at the uniform contract level, not at the REST service contract level.
When creating custom response codes, it is important that they be numbered based on the range they fall in. For example, 2xx codes should be communicating success, while 4xx codes should only represent failure conditions.
Additionally, it is good practice to standardize the insertion of human-readable content into the HTTP response message via the Reason Phrase. For example, the code 400 has a default reason phrase of “Bad Request.” This is enough for a service consumer to handle the response as a general failure, but it doesn’t tell a human anything useful about the actual problem. Setting the reason phrase to “The service consumer request is missing the Customer address field” or perhaps even “Request body failed validation against schema http://example.com/customer” is more helpful, especially when reviewing logs of exception conditions that may not have the full document attached.
Consumers can associate generic logic to handle response codes in each of these ranges, but may also need to associate specific logic to specific codes. Some codes can be limited so that they are only generated if the consumer requests a special feature of HTTP, which means that some codes can be left unimplemented by consumers that do not request these features.
Uniform contract exceptions are generally standardized within the context of a particular new type of interaction that is required between services and consumers. They will typically be introduced along with one or more new methods and/or headers. This context will guide the kind of exceptions that are created. For example, it may be necessary to introduce a new response code to indicate that a request cannot be fulfilled due to a lock on a resource. (WebDAV provides the 423 Locked code for this purpose.)
When introducing and standardizing custom response codes for a service inventory uniform contract, we need to ensure that:
• Each custom code is appropriate and absolutely necessary
• The custom code is generic and highly reusable by services
• The extent to which service consumer behavior is regulated and is not too restrictive so that the code can apply to a large range of potential situations
• Code values are set to avoid potential collision with response codes from relevant external protocol specifications
• Code values are set to avoid collision with custom codes from other service inventories (in support of potential cross-service inventory message exchanges that may be required)
Response code numeric ranges can be considered a form of exception inheritance. Any code within a particular range is expected to be handled by a default set of logic, just as if the range were the parent type for each exception within that range.
In this section we have briefly explored response codes within the context of HTTP. However, it is worth noting that REST can be applied with other protocols (and other response codes). It is ultimately the base protocol of a service inventory architecture that will determine how normal and exceptional conditions are reported.
For example, you could consider having a REST-based service inventory standardized on the use of SOAP messages that result in SOAP-based exceptions instead of HTTP exception codes. This allows the response code ranges to be substituted for inheritance of exceptions.
Designing Media Types
During the lifetime of a service inventory architecture we can expect more changes will be required to the set of a uniform contract’s media types than to its methods. For example, a new media type will be required whenever a service or consumer needs to communicate machine-readable information that does not match the format or schema requirements of any existing media type.
Some common media types from the Web to consider for service inventories and service contracts include:
• text/plain; charset=utf-8 for simple representations, such as integer and string data. Primitive data can be encoded as strings, as per built-in XML Schema data types
• application/xhtml+xml for more complex lists, tables, human-readable text, hypermedia links with explicit relationship types, and additional data based on microformats.org and other specifications
• application/json for a lightweight alternative to XML that has broad support by programming languages
• text/uri-list for plain lists of URIs
• application/atom+xml for feeds of human-readable event information or other data collections that are time-related (or time ordered)
Before inventing new media types for use within a service inventory, it is advisable to first carry out a search of established industry media types that may be suitable.
Whether choosing existing media types or creating custom ones, it is helpful to consider the following best practices:
• Each specific media type should ideally be specific to a schema. For example, application/xml or application/json are not schema-specific, while application/atom+xml used as a syndication format is specific enough to be useful for content negotiation and to identify how to process documents.
• Media types should be abstract in that they specify only as much information as their recipients need to extract via their schemas. Keeping media types abstract allows them to be reused within more service contracts.
• New media types should reuse mature vocabularies and concepts from industry specifications whenever appropriate. This reduces the risk that key concepts have been missed or poorly constructed, and further improves compatibility with other applications of the same vocabularies.
• A media type should include a hyperlink whenever it needs to refer to a related resource whose representation is located outside the immediate document. Link relation types may be defined by the media type’s schema or, in some cases, separately, as part of a link relation profile.
• Custom media types should be defined with must-ignore semantics or other extension points that allow new data to be added to future versions of the media type without old services and consumers rejecting the new version.
• Media types should be defined with standard processing instructions that describe how a new processor should handle old documents that may be missing some information. Usually these processing instructions ensure that earlier versions of a document have compatible semantics. This way, new services and consumers do not have to reject the old versions.
All media types that are either invented for a particular service inventory or reused from another source should be documented in the uniform contract profile, alongside the definition of uniform methods.
HTTP uses Internet media type identifiers that conform to a specific syntax. Custom media types are usually identified with the notation:
application/vnd.organization.type+supertype
where application is a common prefix that indicates that the type is used for machine consumption and standards. The organization field identifies the vendor namespace, which can optionally be registered with IANA.
The type part is a unique name for the media type within the organization, while the supertype indicates that this type is a refinement of another media type. For example, application/vnd.com.examplebooks.purchase-order+xml may indicate that:
• The type is meant for machine consumption.
• The type is vendor-specific, and the organization that has defined the type is “examplebooks.com.”
• The type is for purchase orders (and may be associated with a canonical Purchase Order XML schema).
• The type is derived from XML, meaning that recipients can unambiguously handle the content with XML parsers.
Types meant for more general interorganizational use can be defined with the media type namespace of the organization ultimately responsible for defining the type. Alternatively, they can be defined without the vendor identification information in place by registering each type directly, following the process defined in the RFC 4288 specification.
Designing Schemas for Media Types
Within a service inventory, most custom media types created to represent business data and documents will be defined using XML Schema or JSON Schema. This can essentially establish a set of standardized data models that are reused by REST services within the inventory to whatever extent feasible.
For this to be successful, especially with larger collections of services, schemas need to be designed to be flexible. This means that it is generally preferable for schemas to enforce a coarse level of validation constraint granularity that allows each schema to be applicable for use with a broader range of data interaction requirements.
REST requires that media types and their schemas be defined only at the uniform contract level. If a service capability requires a unique data structure for a response message, it must still use one of the canonical media types provided by the uniform contract. Designing schemas to be flexible and weakly typed can accommodate a variety of service-specific message exchange requirements, but perhaps not for all cases.
Example 9.2 provides an example of a flexible schema design.
Example 9.2 One of the most straightforward ways of making a media type more reusable is to design the schema to support a list of zero or more items. This enables the media type to permit one instance of the underlying type, but also allows queries that return zero or more instances. Making individual elements within the document optional can also increase reuse potential.
Media type = application/vnd.com.actioncon.po+xml
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://example.org/schema/po"
xmlns="http://example.org/schema/po">
<xsd:element name="LineItemList" type="LineItemListType"/>
<xsd:complexType name="LineItemListType">
<xsd:element name="LineItem" type="LineItemType"
minOccurs="0"/>
</xsd:complexType>
<xsd:complexType name="LineItemType">
<xsd:sequence>
<xsd:element name="productID" type="xsd:anyURI"/>
<xsd:element name="productName" type="xsd:string"/>
<xsd:element name="available" type="xsd:boolean"
minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>
</xsd:schema>
Complex Method Design
The uniform contract establishes a set of base methods used to perform basic data communication functions. As we’ve explained, this high-level of functional abstraction is what makes the uniform contract reusable to the extent that we can position it as the sole, overarching data exchange mechanism for an entire inventory of services. Besides its inherent simplicity, this part of a service inventory architecture automatically results in the baseline standardization of service contract elements and message exchange.
The standardization of HTTP on the World Wide Web results in a protocol specification that describes the things that services and consumers “may,” “should,” or “must” do to be compliant with the protocol. The resulting level of standardization is intentionally only as high as it needs to be to ensure the basic functioning of the Web. It leaves a number of decisions as to how to respond to different conditions up to the logic within individual services and consumers. This “primitive” level of standardization is important to the Web, where we can have numerous foreign service consumers interacting with third-party services at any given time.
A service inventory, however, often represents an environment that is private and controlled within an IT enterprise. This gives us the opportunity to customize this standardization beyond the use of common and primitive methods. This form of customization can be justified when we have requirements for increasing the levels of predictability and quality-of-service beyond what the World Wide Web can provide.
For example, let’s say that we would like to introduce a design standard whereby all accounting-related documents (invoices, purchase orders, credit notes, etc.) must be retrieved with logic that, upon encountering a retrieval failure, automatically retries the retrieval a number of times. The logic would further require that subsequent retrieval attempts do not alter the state of the resource representing the business documents (regardless of whether a given attempt is successful).
With this type of design standard, we are essentially introducing a set of rules and requirements as to how the retrieval of a specific type of document needs to be carried out. These are rules and requirements that cannot be expressed or enforced via the base, primitive methods provided by HTTP. Instead, we can apply them in addition to the level of standardization enforced by HTTP by assembling them (together with other possible types of runtime functions) into aggregate interactions. This is the basis of the complex method.
A complex method encapsulates a pre-defined set of interactions between a service and a service consumer. These interactions can include the invocation of standard HTTP methods. To better distinguish these base methods from the complex methods that encapsulate them, we’ll refer to base HTTP methods as primitive methods (a term only used when discussing complex method design).
Complex methods are qualified as “complex” because they:
• Can involve the composition of multiple primitive methods
• Can involve the composition of a primitive method multiple times
• Can introduce additional functionality beyond method invocation
• Can require optional headers or properties to be supported by or included in messages
As previously stated, complex methods are generally customized for and standardized within a given service inventory. For a complex method to be standardized, it needs to be documented as part of the service inventory architecture specification. We can define a number of common complex methods as part of a uniform contract that then become available for implementation by all services within the service inventory.
Complex methods have distinct names. The complex method examples that we’re covering are called:
• Fetch – A series of GET requests that can recover from various exceptions
• Store – A series of PUT or DELETE requests that can recover from various exceptions
• Delta – A series of GET requests that keep a consumer in sync with changing resource state
• Async – An initial modified request and subsequent interactions that support asynchronous request message processing
Services that support a complex method communicate this by showing the method name as part of a separate service capability (Figure 9.11), alongside the primitive methods that the complex method is built upon. When project teams create consumer programs for certain services, they can determine the required consumer-side logic for a complex method by identifying what complex methods the service supports, as indicated by its published service contract.
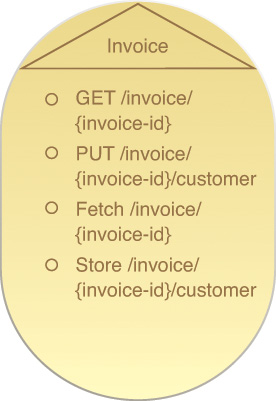
Figure 9.11 An Invoice service contract displaying two service capabilities based on primitive methods and two service capabilities based on complex methods. We can initially assume that the two complex methods incorporate the use of the two primitive methods, and proceed to confirm this by studying the design specification that documents the complex methods.
Note
When applying the Service Abstraction (294) principle to REST service composition design, we may exclude entirely describing some of the primitive methods from the service contract. This can be the result of design standards that only allow the use of a complex method in certain situations. Going back to the previous example about the use of a complex method for retrieving accounting-related documents, we may have a design standard that prohibits these documents from being retrieved via the regular GET method (because the GET method does not enforce the additional reliability requirements).
It is important to note that the use of complex methods is by no means required. Outside of controlled environments in which complex methods can be safely defined, standardized, and applied in support of the Increased Intrinsic Interoperability goal, their use is uncommon and generally not recommended. When building a service inventory architecture, we can opt to standardize on certain interactions through the use of complex methods or we can choose to limit REST service interaction to the use of primitive methods only. This decision will be based heavily on the distinct nature of the business requirements addressed and automated by the services in the service inventory.
Despite their name, complex methods are intended to add simplicity to service inventory architecture. For example, let’s imagine we decide not to use pre-defined complex methods and then realize that there are common rules or policies that we applied to numerous services and their consumers. In this case, we will have built the common interaction logic redundantly across each individual consumer-service pair. Because the logic was not standardized, its redundant implementations will likely exist differently. When we need to change the common rules or policies, we will need to revisit each redundant implementation accordingly. This maintenance burden and the fact that the implementations will continue to remain out of sync make this a convoluted architecture that is unnecessarily complex. This is exactly the problem that the use of complex methods is intended to avoid.
The upcoming sections introduce a set of sample complex methods organized into two sections:
• Stateless Complex Methods
• Stateful Complex Methods
Note that these methods are by no means industry standard. Their names and the type of message interactions and primitive method invocations they encompass have been customized to address common types of functionality.
Note
The Case Study Example at the end of this chapter further explores this subject matter. In this example, in response to specific business requirements, two new complex methods (one stateless, the other stateful) are defined.
Stateless Complex Methods
This first collection of complex methods encapsulates message interactions that are compliant with the Stateless {308} constraint.
Fetch Method
Instead of relying only on a single invocation of the HTTP GET method (and its associated headers and behavior) to retrieve content, we can build a more sophisticated data retrieval method with features such as
• Automatic retry on timeout or connection failure
• Required support for runtime content negotiation to ensure the service consumer receives data in a form it understands
• Required redirection support to ensure that changes to the service contract can be gracefully accommodated by service consumers
• Required cache control directive support by services to ensure minimum latency, minimum bandwidth usage, and minimum processing for redundant requests
We’ll refer to this type of enhanced read-only complex method as a Fetch. Figure 9.12 shows an example of a pre-defined message interaction of a Fetch method designed to perform content negotiation and automatic retries.

Store Method
When using the standard PUT or DELETE methods to add new resources, set the state of existing resources, or remove old resources, service consumers can suffer request timeouts or exception responses. Although the HTTP specification explains what each exception means, it does not impose restrictions as to how they should be handled. For this purpose, we can create a custom Store method to standardize necessary behavior.
The Store method can have a number of the same features as a Fetch, such as requiring automatic retry of requests, content negotiation support, and support for redirection exceptions. Using PUT and DELETE, it can also defeat low bandwidth connections by always sending the most recent state requested by the consumer, rather than needing to complete earlier requests first.
The same way that individual primitive HTTP methods can be idempotent, the Store method can be designed to behave idempotently. By building upon primitive idempotent methods, any repeated, successful request messages will have no further effect after the first request message is successfully executed.
For example, when setting an invoice state from “Unpaid” to “Paid”:
• A “toggle” request would not be idempotent because repeating the request toggles the state back to “Unpaid.”
• The “PUT” request is idempotent when setting the invoice to “Paid” because it has the same effect, no matter how many times the request is repeated.
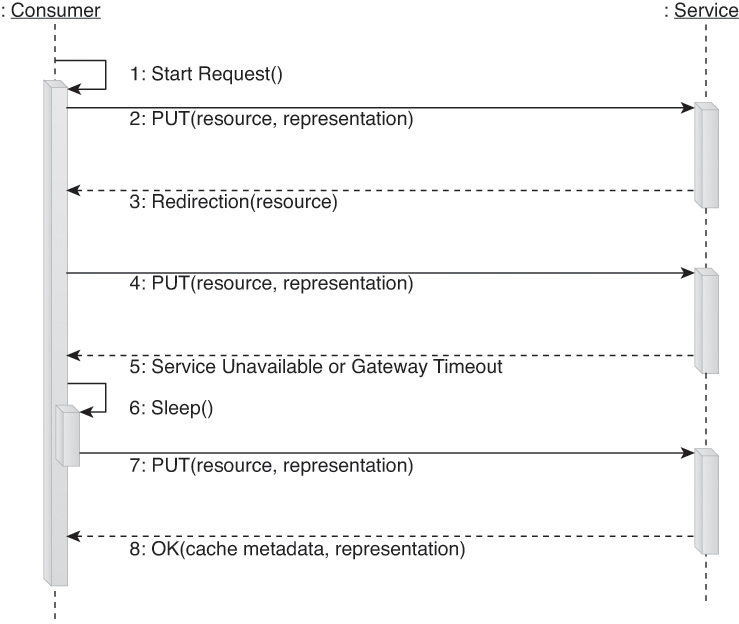
It is important to understand that the Store and its underlying PUT and DELETE requests are requests to service logic, not an action carried out on the service’s underlying database. As shown in Figure 9.13, these types of requests are stated in an idempotent manner in order to efficiently allow for the retrying of requests without the need for sequence numbers to add reliable messaging support.
Service capabilities that incorporate this type of method are an example of the application of the Idempotent Capability [345] pattern.
Delta Method
It is often necessary for a service consumer to remain synchronized with the state of a changing resource. The Delta method is a synchronization mechanism that facilitates stateless synchronization of the state of a changing resource between the service that owns this state and consumers that need to stay in alignment with the state.
The Delta method follows processing logic based on the following three basic functions:
1. The service keeps a history of changes to a resource.
2. The consumer gets a URL referring to the location in the history that represents the last time the consumer queried the state of the resource.
3. The next time the consumer queries the resource state, the service (using the URL provided by the consumer) returns a list of changes that have occurred since the last time the consumer queried the resource state.
Figure 9.14 illustrates this using a series of GET invocations.

The service provides a “main” resource that responds to GET requests by returning the current state of the resource. Next to the main resource it provides a collection of “delta” resources that each return the list of changes from a nominated point in the history buffer.
The consumer of the Delta method activates periodically or when requested by the core consumer logic. If it has a delta resource identifier it sends its request to that location. If it does not have a delta resource identifier, it retrieves the main resource to become synchronized. In the corresponding response the consumer receives a link to the delta for the current point in the history buffer. This link will be found in the Link header (RFC 5988) with relation type Delta.
The requested delta resource can be in any one of the following states:
1. It can represent a set of one or more changes that have occurred to the main resource since the point in history that the delta resource identifier refers to. In this case, all changes in the history from the nominated point are returned along with a link to the new delta for the current point in the history buffer. This link will be found in the Link header with relation type Next.
2. It may not have a set of changes because no changes have occurred since its nominated point in the history buffer, in which case it can return the 204 No Content response code to indicate that the service consumer is already up-to-date and can continue using the delta resource for its next retrieval.
3. Changes may have occurred, but the delta has already expired because the nominated point in history is now so old that the service has elected not to preserve the changes. In this situation, the resource can return a 410 Gone code to indicate that the consumer has lost synchronization and should re-retrieve the main resource.
Delta resources use the same caching strategy as the main resource.
The service controls how many historical deltas it is prepared to accumulate, based on how much time it expects consumers will take (on average) to get up-to-date. In certain cases where a full audit trail is maintained for other purposes, the number of deltas can be indefinite. The amount of space required to keep this record is constant and predictable regardless of the number of consumers, leaving each individual service consumer to keep track of where it is in the history buffer.
Async Method
This complex method provides pre-defined interactions for the successful and canceled exchange of asynchronous messages. It is useful for when a given request requires more time to execute than what the standard HTTP request timeouts allow.
Normally if a request takes too long, the consumer message processing logic will time out or an intermediary will return a 504 Gateway Timeout response code to the service consumer. The Async method provides a fallback mechanism for handling requests and returning responses that does not require the service consumer to maintain its HTTP connection open for the total duration of the request interaction.
As shown in Figure 9.15, the service consumer issues a request, but does so specifying a call-back resource identifier. If the service chooses to use this identifier, it responds with the 202 Accepted response code, and may optionally return a resource identifier in the Location header to help it track the place of the asynchronous request in its processing queue.

When the request has been fully processed, its result is delivered by the service, which then issues a request to the callback address of the service consumer. If the service consumer issues a DELETE request (as shown in Figure 9.16) while the Async request is still in the processing queue (and before a response is returned), a separate pre-defined interaction is carried out to cancel the asynchronous request. In this case, no response is returned and the service cancels the processing of the request.
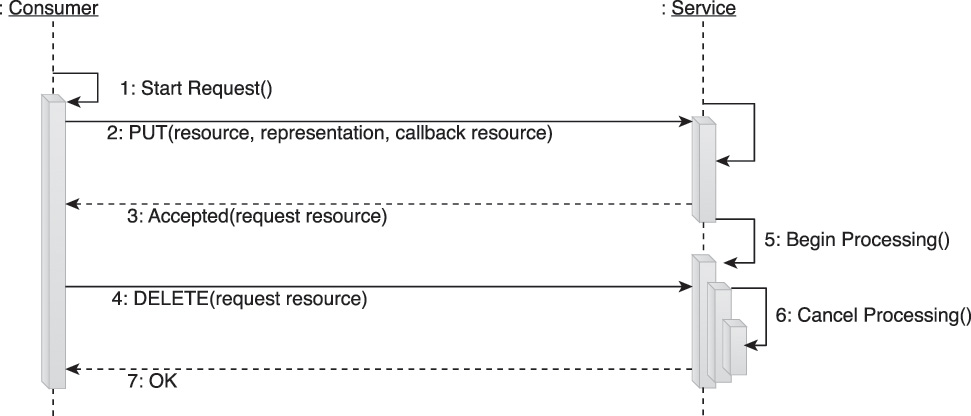
If the consumer cannot listen for callback requests, it can use the asynchronous request identifier to periodically poll the service. After the request has been successfully handled, it is possible to retrieve its result using the previously described Fetch method before deleting the asynchronous request state. Services that execute either interaction encompassed by this method must have a means of purging old asynchronous requests if service consumers are unavailable to pick up responses or otherwise “forget” to delete request resources.
Stateful Complex Methods
The following two complex methods use REST as the basis of service design but incorporate interactions that intentionally breach the Stateless {308} constraint. Although the scenarios represented by these methods are relatively common in traditional enterprise application designs, this kind of communication is not considered native to the World Wide Web. The use of stateful complex methods can be warranted when we accept the reduction in scalability that comes with this design decision.
Trans Method
The Trans method essentially provides the interactions necessary to carry out a two-phase commit between one service consumer and one or more services. Changes made within the transaction are guaranteed to either successfully propagate across all participating services, or all services are rolled back to their original states.
This type of complex method requires a “prepare” function for each participant before a final commit or rollback is carried out. Functionality of this sort is not natively supported by HTTP. Therefore, we need to introduce a custom PREP-PUT method (a variant of the PUT method), as shown in Figure 9.17.
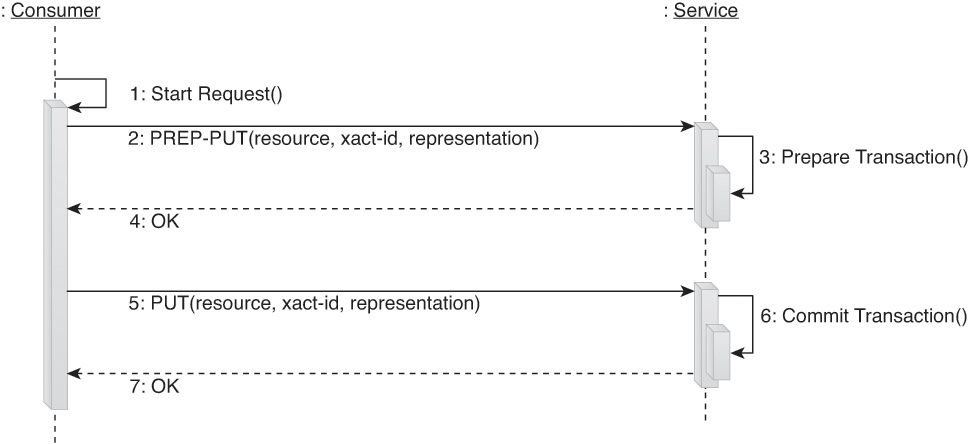
In this example the PREP-PUT method is the equivalent of PUT, but it does not commit the PUT action. A different method name is used to ensure that if the service does not understand how to participate in the Trans complex method, it then rejects the PREP-PUT method and allows the consumer to abort the transaction.
Carrying out the logic behind a typical Trans complex method will usually require the involvement of a transaction controller to ensure that the commit and rollback functions are truly and reliably carried out with atomicity.
PubSub Method
A variety of publish-subscribe options are available after it is decided to intentionally breach the Stateless {308} constraint. These types of mechanisms are designed to support real-time interactions in which a service consumer must act immediately when some pre-determined event at a given resource occurs.
There are various ways that this complex method can be designed. Figure 9.18 illustrates an approach that treats publish-subscribe messaging as a “cache-invalidation” mechanism.
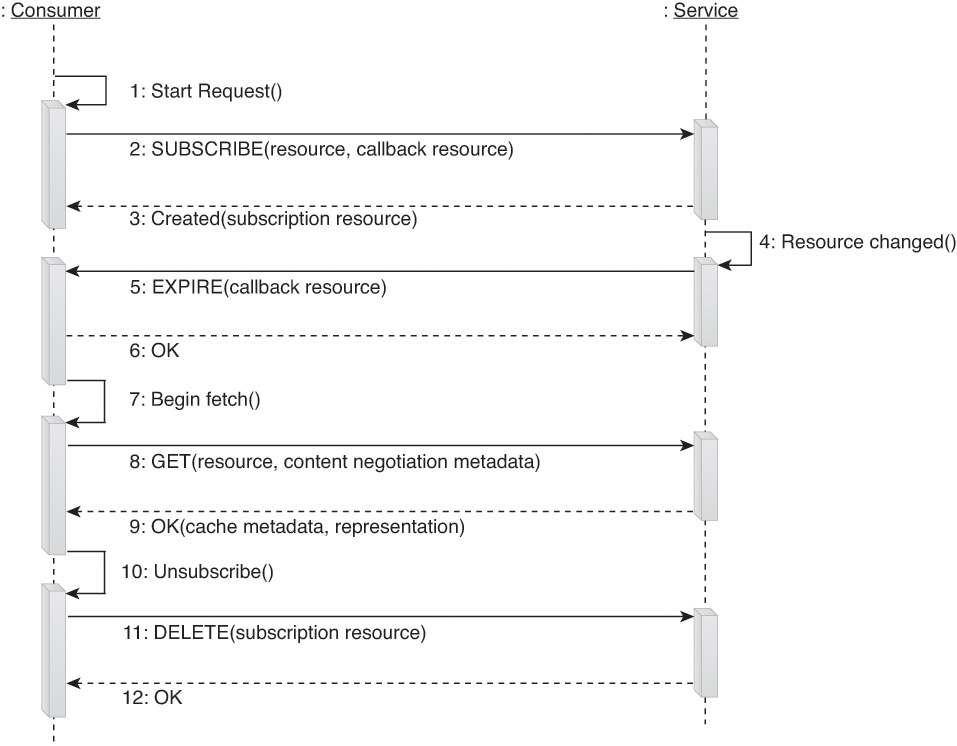
Figure 9.18 An example of a PubSub complex method based on cache invalidation. When the service determines that something has changed on one or more resources, it issues cache expiry notifications to its subscribers. Each subscriber can then use a Fetch complex method (or something equivalent) to bring the subscriber up-to-date with respect to the changes.
This form of publish-subscribe interaction is considered “lightweight” because it does not require services to send out the actual changes to the subscribers. Instead, it informs them that a resource has changed by pushing out the resource identifier, and then reuses an existing, cacheable Fetch method as the service consumers pull the new representations of the changed resource.
The amount of state required to manage these subscriptions is bound to one fixed-sized record for each service consumer. If multiple invalidations queue up for a particular subscribed event, they can be folded together into a single notification. Regardless of whether the consumer receives one or multiple invalidation messages, it will still only need to invoke one Fetch method to bring itself up-to-date with the state of its resources each time it sees one or more new invalidation messages.
The PubSub method can be further adjusted to distribute subscription load and session state storage to different places around the network. This technique can be particularly effective within cloud-based environments that naturally provide multiple, distributed storage resources.
The MUA team responsible for service design encounters a number of requirements for accessing and updating resource state. For example:
• One service consumer needs to atomically read the state of the resource, perform processing, and store the updated state back to the resource.
• Another service consumer needs to support concurrent user actions that modify the same resource. These actions update certain resource properties while others need to remain the same.
Allowing individual services consumers to contain different custom logic that performs these types of functions will inadvertently lead to problems and runtime exceptions when any two service consumers attempt updates to the same resource at the same time.
MUA architects conclude that the simplest way to avoid this is to introduce a new complex method that ensures that a resource is locked while being updated by a given consumer. Using the rules of optimistic locking, an approach commonly used with database updates, they are able to create a complex method that is stateless and takes advantage of existing standard features of the HTTP protocol. They name the method “OptLock” and write up an official description that is made part of the uniform contract profile.
OptLock Complex Method
If two separate service consumers attempt to update the state of a resource at the same time, their actions will clearly conflict with each other as the outcome depends on the order in which their requests reach the service. The OptLock method (Figure 9.19) addresses this problem by providing a means by which a service consumer can determine whether the state of a resource has changed since it was last read by the consumer before attempting an update.
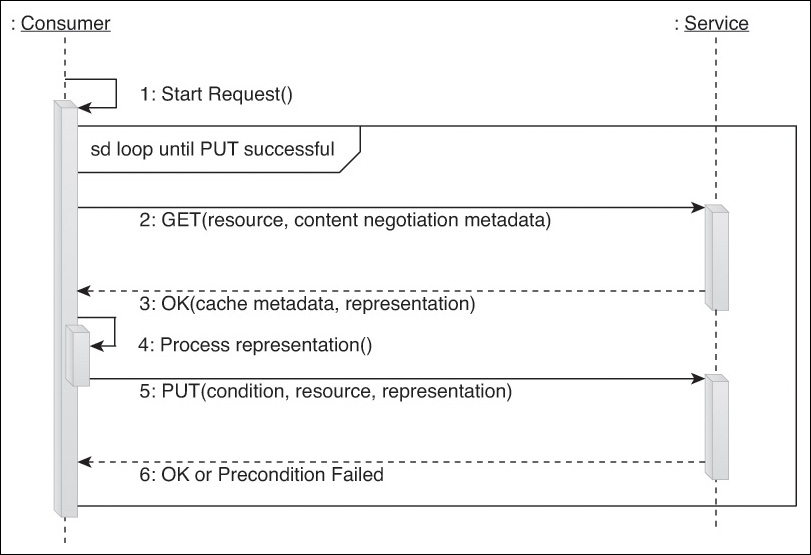
Specifically, a consumer will first retrieve the current state associated with a resource identifier using the Fetch method. Along with the data, the consumer also receives an “ETag.” ETag is a concept from HTTP that uniquely identifies the version of a resource in an opaque fashion. Whenever the resource changes state, its ETag is guaranteed to be different. When the service consumer initiates a Store, it does so conditionally by requesting the service to only honor the Store interaction if the resource’s ETag still matches the one that it had when fetched. This is done with the If-Match header. The service can use the ETag value in the condition to detect whether the resource state has been changed in the meantime.
The OptLock complex method does not introduce any new features to HTTP, but instead introduces new requirements for the handling of GET and PUT requests. Specifically, the GET request must return an ETag value and the PUT request must process the If-Match header. Additionally, if the resource has changed, the service must further guarantee not to carry out the PUT request.
There are several techniques for computing ETags. Some compute a hash value out of the state information associated with the resource, some simply keep a “last modified” timestamp for each resource, and others track the version of the resource state explicitly.
The OptLock method may not scale effectively for high concurrent access to a particular resource. If consumer update requests are denied with an HTTP 409 Conflict response code, the OptLock method prescribes how the consumer can recover by fetching a newer version of the resource over which they have to recompute the change and retry the Store method. However, this may fail again due to a conflicting update request. Service consumers that interact with a resource in this way rely on that particular resource having relatively low rates of write access.
The OptLock complex method becomes available as part of the uniform contract and is implemented by several services. However, scenarios emerge where multiple consumers attempt to modify the resource at the same time, causing regular exceptions and failed updates. These situations occur during peak usage times, and because concurrent usage volume is expected to increase further, it is determined that a more efficient means of serializing updates to the resource needs to be established.
It is proposed that the OptLock complex method be changed to perform pessimistic locking instead, as per the following PesLock complex method description.
PesLock Complex Method
Pessimistic locking provides greater flexibility and certainty than optimistic locking. From a REST perspective, this comes at the cost of introducing stateful interactions and limiting concurrent access while the pessimistic lock is held.
As shown in Figure 9.20, the WebDAV extensions to HTTP provide locking primitives that can be used within a composition architecture that intentionally breaches the Stateless {308} constraint. One consumer may lock out others from accessing a resource, so care must be taken that appropriate access control policies are in place. Consumers can also fail while the lock is held, which means that locks must be able to time out independently of the consumers that register them.

This way, the service consumer would be able to lock the resource for as long as it takes to read the state, modify it, and write it back again. Although other service consumers would still encounter exceptions while attempting to update the resource at the same time as the consumer that has locked it, it is deemed preferable to the unpredictability of managing the resource as part of an optimistic locking model.
This solution is not embraced by all of the MUA architects because retaining the lock on the resource requires that the Stateless {308} constraint be breached. It could further lead to the danger of stale locks starting, impacting performance and scalability. In particular, unless proper measures are taken to ensure that only authorized consumers may lock a resource, this exposes the resources to denial of service attacks by malicious consumers that could lock out all other consumers.
After further discussion, a compromise is reached. The OptLock method will be attempted first. As a fallback, if the consumer tries three times and fails, it will attempt the stateful PesLock method to ensure it is able to complete the action.