
Chapter 4. Discovering and Using Keywords to Attract Your Target Audience
As we indicated in Chapter 3, the search-first writing methodology begins with keyword research, after which you write pages to attract your target audience and address their needs with relevant content. The two inputs to your writing plan are a description of the target audience and a set of keywords that the target audience is likely to use. Armed with this information, writing Web content that is optimized for search engines—particularly Google—is a fairly simple matter of making sure Google’s crawler can find the keywords in strategic places on your pages. This chapter covers those three tactics, along with some necessary background information on the linguistics of search engines:
• Defining your target audience
• Linguistic considerations for keywords
• Discovering the keywords related to your topic that the audience most often uses
• Developing Web content with those keywords in strategic places on your pages
Defining the Target Audience
Defining your target audience is another aspect of Web writing that does not resemble many print contexts. In public relations, the writer develops a list of press analysts, editors, and publishers and writes press releases for them. In sales, the writer typically has a lot of information about the client for whom the sales proposal is written. Grant writers have details about the reviewers for their grant proposals before they write.
Those are just a few of the cases in the print medium in which the audience is well known. There are also many more cases in which you really know very little about your audience in print, except perhaps that they are interested in what you write. If they are not interested in what you write, they will stop reading. But this is not very helpful in crafting messages that appeal to their needs. When we form a picture of our audience, we strive to understand things such as their prior knowledge, common experiences, shared beliefs, and shared assumptions, so that we can use these traits to engage the reader, and to narrow our focus to what the reader needs. In short, given what we know about our audience, we want to maximize relevance for them. A corollary of this is that we also want to minimize what is irrelevant to the reader. Irrelevant content acts as friction and distracts readers from getting what they need.
Whether you know a lot or a little about your target audience in print, your audience analysis vastly differs from Web audience analysis. In print, you discover who reads the publication for which you are writing and try to appeal to their common traits. Lacking such knowledge, you engage them with compelling storytelling techniques, compelling them to do things your way. But on the Web, you don’t simply discover traits about your target audience. You define your target audience by some common traits and seek to attract only people who have those traits to your site. Print is passive; the Web is active. When you are confident that you are attracting your target audience to your pages, you are free to address them and use their defined traits as the common ground that you need to achieve mutual understanding.
Web audience analysis is less about discovering common audience traits than about defining them. In passive media such as print, you discover common audience traits (such as subscribing to a vertical journal) and use these traits to help you make assumptions about their common knowledge. These assumptions help you focus on what they need, rather than writing for the least common denominator. But in active media such as the Web, you can’t make these assumptions as readily because of the diversity of the audience. So you are forced to define the audience that you want to attract and write in ways that will tend to attract that audience through search.
When you define audience traits, you simply identify the interests of your target audience. For example, suppose you have a writing and editing service and want to attract clients who are interested in this kind of offering. If you narrow your focus on this simple trait, your audience might be highly diverse, but they have one trait in common—they need writing and editing services. Unlike with print, the more you narrow your definition of your target, the more effective your Web writing will be. If you try to associate the main trait you seek with a set of likely complementary traits, you risk writing irrelevant content for those who do not share those complementary traits.
For the moment, let’s assume that the only thing you know about your audience is that they came to your site from Google using keywords that you coded into your pages. That doesn’t seem like a lot of information to go on. However, as you follow our information path through this book, you will find that it is more than you might think. It is just a simplifying assumption. We will go into depth about what you can know about your audience, and how to gain this knowledge in Chapter 5. But if you only know that your users came to your site from Google using certain keyword phrases, you know that most content topics related to those keywords will likely be relevant. We’ll explore this here by explaining how to design information that will be maximally relevant for users who come to your pages from Google.
Some Linguistic Considerations Related to Keywords
Until now, we have talked about the keywords that your target audience enters into search fields, without talking about what keywords are and how they work so that Google can identify relevant content. Strictly speaking, keywords are strings of characters that people enter into search fields. Actually, it is a bit of a misnomer to call them “keywords,” because many users enter phrases or word combinations into search fields, to try to zero in on the most relevant content. The shorter the string of characters entered, the less likely it is that the search will return relevant results. On the other hand, as we have mentioned before, sophisticated search users enter long-tail keywords because the longer and more complex the search string, the more likely the result will be relevant.
Google indexes Web content by keywords. When a user enters a keyword string into a search field, Google uses its algorithm to determine the most relevant content in its index for the search term. We will delve into further aspects of the Google algorithm later in this chapter, but for now, think of it as a matching algorithm. If a user enters a string that exactly matches the keywords that Google associates with a piece of content in its index, there’s a good chance that piece of content will appear in the first few pages of results. If there are no exact matches, Google tries to match parts and pieces of a keyword string to the content in its index. This means that unless a query is made using the advanced search function, Google’s algorithm will associate any of the words in a keyword string to find the best matches, in any combination.
Users of Google’s advanced search function can use Boolean specifications to designate not only the words in a keyword phrase, but also the logic of their combination (Figure 4.1). For example, Google’s Advanced Search screen has a field with “all these words” as its label. If a user enters ibm developer soa in that field, Google will only find pages that contain all those words. Users can also exclude content by putting words to exclude in the appropriate field. Another trick for queries is to use quotation marks to tell Google to only show content with that exact phrase; Entering "ibm soa" (including the quote marks) will only return phrases that contain that particular phrase.
Figure 4.1. The Google Advanced Search Application.
(Source: /www.google.com/advanced_search?hl=en)
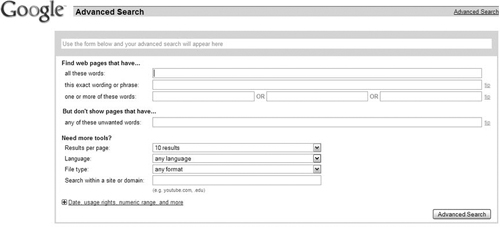
If users don’t get the desired results from a keyword string, they often go back and modify the string. For example, a novice user might enter the word blue in a search field. For such a vague search term, Google might return a staggeringly huge number of results, none of which would be useful. So, the user might go back and enter Big Blue, indicating that she’s not just interested in the color, but in one of its many associations, this time with IBM. And she could further refine her keyword string to narrow her search through trial and error. Users often find content this way: They start with vague, generic terms and gradually narrow their search down by adding modifiers.
We assume that you have some experience using search engines. In particular, you might have had the experience of trying to find content related to a keyword and finding the results completely different than you anticipated. Typically, this happens when Google has a hard time interpreting your search query. Why? Well, natural language is extremely complex—too complex for computers to divine the meaning of a few words taken out of context (see Figure 4.2). In particular, a lot of words have multiple literal meanings, called homonyms. Read the dictionary to see several definitions for the same word, and you can begin to understand the challenge. Another common set of linguistic complexity is called homographs: words that share the same spelling but are pronounced differently. For example, the words lead (as in leadership) and lead (as in pencil lead) look identical to Google unless they are put in the context of their parts of speech, prefixes or suffixes. Many more variations on homographs can be found in the English language. (See the sidebar for a more complete discussion of the variations.) We won’t delve too deeply into the complexity here. Suffice it to say that the most effective keywords have some of this context built in (with prefixes, suffixes, and use of various parts of speech).
Figure 4.2. A graph of linguistic complexities related to keywords.
(Source: http://en.wikipedia.org/wiki/Homonyms)
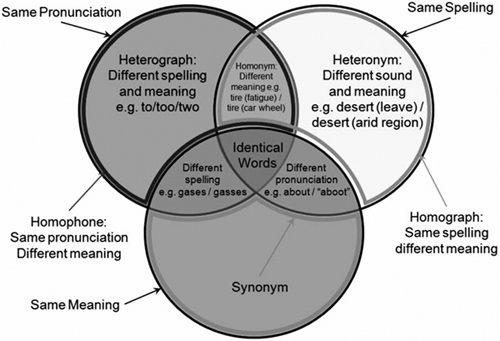
It’s hard to take a few words in a search string and understand what the searcher meant by them. And once the computer makes an educated guess, it is even harder to find the most relevant content for that meaning. The same keyword with the same meaning is typically highly relevant only to a subset of the population, and totally irrelevant to the rest. Google is a marvel of human ingenuity because it does a pretty good job not only of divining the meaning of a search query, but of providing relevant search results. But not all of that is linguistic. About half of Google’s algorithm deals with the popularity or link equity of pages in its index. This helps Google determine the pages most likely to be relevant to the searcher. We will discuss PageRank in Chapter 7. For now, it’s enough to know that Google doesn’t simply rely on the semantics (the linguistics of meaning) of search strings, but also builds a context around the pages in its index by considering such extra-linguistic features as links.
Discovering Keywords Used by Your Target Audience
The central aspect of search-first writing is to connect with your target audience by crafting Web experiences using what you know about Google. The first step in this process is called keyword discovery or keyword research. Many Web publishers assume that they should just write what they want to communicate and let the search engines naturally find their content. This works if the vocabulary you use happens to coincide with the vocabulary your target audience uses to find pages of interest in Google. However, in our experience, creating search-optimized content by accident rarely happens. Especially when writing in marketing settings, writers often fail to realize that their company’s specific vocabulary pervades their writing. This means that the writers are using too much specialized, branded language. This neglects search optimization or leaves it to chance, which produces very poor results. Don’t leave your search optimization to chance this way.
By using keyword research, you can gain some measure of control over search optimization by ensuring that the vocabulary you use on your pages is the same as that of your target audience. Keyword research tells you how many people searched on a particular term in a given month. This is not the only information you need, but it is a starting point. If you don’t do keyword research, you can own the top position in Google for a term that very few people search on but get very little traffic to your pages as a result. If you use a coined or branded term, chances are that people who find your page from Google will find it relevant to them. That might be good enough for certain circumstances, but it is not good enough for most. Keyword research can help you discover the terms that are both relevant to your target audience and get a relatively high volume of traffic. That is the goal of keyword research.
On the other end of the scale, you can rank well for words that lots of users search on and get lots of traffic to your pages as a result. But if most of those users bounce off your pages, indicating that they find the content irrelevant, you will need to find terms that are more relevant to your target audience. It is better to have decent levels of traffic with low bounce rates than high levels of traffic with a lot of bounce. Each time that users bounce off your page, you leave a negative impression in their minds, and you hurt your ranking in Google. On the other hand, each user who comes to your page and is drawn to engage with your content by clicking your links will have a positive experience. Again, the goal is to combine relatively high traffic with relatively low bounce rates, because ultimately, low bounce rates tend to lead to high engagement rates. Engagement is the best way to measure the relevance of your content for your target audience. (We discuss how to measure bounce and engagement in Chapter 9).
You can’t do your keyword research just once, though. If you find high bounce rates, you will need to revisit your content, choose new keywords and republish—and do more keyboard research. Page-level research and keyword research are iterative processes. From your initial keyword research, you can make a good educated guess as to which terms your target audience is most likely to use when searching for content. But this initial guess often misses the mark. Then, you need to do deeper keyword research and craft content that better targets your audience. So, keyword research should be a central part of your everyday Web operations. In particular, it should always precede the writing of each piece of your Web content. It is better to write with the keywords that your target audience uses than to retrofit content with keywords after the fact, keywords which may not perfectly match the content you’ve created. The good news is that if your initial research misses the mark, the power of the Web allows you to make changes and republish relatively easily. Take advantage of that power.
Case Study: IBM Smarter Planet Search Efforts
In 2009 IBM launched an initiative to lead the industry in helping to solve large problems facing the world, such as climate change. IBM branded this effort “Smarter Planet.” It created content to help organizations understand how to use technology to better manage healthcare, traffic, energy, agriculture, infrastructure, and similar large-scale efforts. The content was created to raise awareness of important issues facing the planet, and to encourage a more general audience to try to solve some of these problems with technology.
From a search perspective, this is a challenging content model. In a lot of IBM marketing contexts, content is written to support an established brand, such as DB2. A Web content effort to support IBM’s DB2 information management software might contain separate pages to drive demand for branded product, and to raise the awareness of users who search on targeted keywords when considering this type of software, such as the term database software. Search optimization with branded terms is relatively easy. For example, users who search on DB2 are likely to engage with a page that contains it. But if users search on the generic term database software as a general term, they are less likely to engage with pages that have DB2 content than those who searched on the branded keyword. That’s because they might be more interested in other database software offerings. However, in the time span covered in Figure 4.3, hundreds of thousands of users searched on database software every month, while only about 18,000 searched for “DB2.” But notice the high click rate for DB2. If you have a branded term with the brand equity of DB2, you know you’ll get high demand-generation engagement rates on that term. If you can also manage to build awareness with a certain percentage of users who searched on the generic term database software, you can count your search efforts as successful.
Figure 4.3. IBM’s search performance for four keywords.
(Source: IBM Corp.)
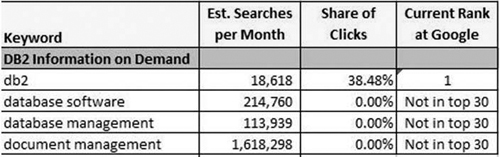
In the case of Smarter Planet, there is no one brand to rely on—all your efforts are to build awareness of terms that have limited brand equity in the marketplace. The challenge with this content from a search perspective is easily understood by looking at the keywords that the team chose. Their first inclination was to use the terms that the writers used to describe the issues. For example, for a page with the heading Smart Utilities, the keyword chosen for the <title> tag was <title> IBM – a smarter planet – utilities</title>. Users who searched on that exact string in Google naturally found the content. The problem was, however, that very few users searched on that exact string.
After performing keyword research, the team determined that the best balance of branding and keyword value was the term Smart Grid. The research indicated that nearly 2,000 users searched on that term in a month. In addition, those who searched on the term were likely to be interested in the Smarter Planet content related to smart utilities. Fortunately, the only things that needed to be changed on the page were the <title> tag and the <H1> tag. The body copy already contained the words smart and grid in it. This is a bit unusual. Typically, if you make a keyword change, you also have to rewrite the copy to incorporate the new keyword into it. That is why it is always better to do your keyword research before you write the copy. You want to make sure your vocabulary is consistent with the vocabulary that your target audience uses to communicate about topics of interest, and to find content with Google.
Fortunately, the team performed keyword research prior to writing subsequent Smarter Planet content. This ensured that as soon as the content was published, it started receiving relatively high volumes of targeted traffic. In other words, the copy was optimally relevant for the audience, according to our search-first definition.
So you need to do your keyword research before writing. How do you do this? Conducting keyword research is a matter of figuring out what terms related to your topic are most often searched on and choosing the words or phrases from that list that you think your audience is most likely to use. As we indicated above, it is an iterative process—you make an educated guess and test your success, prepared to make adjustments to tune the relevance of your pages for your target audience.
Figuring out which terms are most often searched on is a matter of using tools such as Google AdWords to test possible words and phrases. There are dozens of tools (see the sidebar for a more complete list) for finding the most often-searched-on terms, with a variety of cost structures and feature sets, including the Keyword Discovery Tool (www.keyworddiscovery.com/start.html) or Aaron Wall’s Free Keyword List Generator (http://tools.seobook.com/keyword-list/) to discover the demand for a keyword. Demand is a function of the number of users who search on a term in a given time frame, typically a month.
In addition to demand, you also need to measure competition for your keywords. Competition can be measured in several ways. But technically, it’s the search strength of the pages that rank on Google’s top page for your chosen keywords. The best way to learn this is simply by searching on the words and looking into the pages that rank well in Google. How well optimized are these pages? How interwoven are they in the topic or field surrounding them? A keyword that has lots of high-powered competition might not be your best choice. But some words are central to your mission, so you absolutely have to own them. Smarter Planet is such a keyword for IBM. So you do what it takes to rank well for those words.
A quick-and-dirty way to test the words that you think might be popular is simply by typing them into Google. As shown in Figure 4.4, under Google’s default setting of “Provide query suggestions in the search box,” you’ll see various incremental possible matches for your search string, with the total number of “hits,” while you type in your entries. This only gives you a rough estimate of the competition for the keywords. To get the information you need to determine competition, you’ll have to use the tools that measure competition, such as Covario. Because we try to focus on free tools in this book, we will not delve into a description of Covario. Feel free to check it out on your own (www.covario.com/). Wordtracker (www.wordtracker.com/) has a free tool to help you measure keyword competition.
Figure 4.4. A quick-and-dirty keyword discovery tool to get a rough estimate of keyword competition from the Google search page. We recommend using Wordtracker or a similar tool to validate your initial keyword competition data.
(Source: www.google.com)
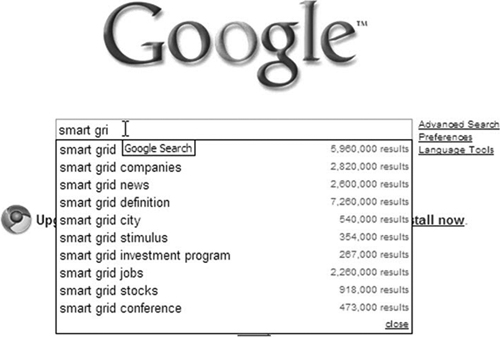
Keyword Discovery Tools
No one can keep track of all the keyword tools on the market today. And no single tool gives you a complete picture of keyword demand and competition. However, we recommend using four main tools to come at the problem from four perspectives: Google AdWords, Google Insights, The Keyword Discovery Tool, and Aaron Wall’s Advanced Keyword Research tool. We also include descriptions of other tools here in case you want to go deeper still into keyword research. These include the Keyword Density and Prominence Analyzer, Wordtracker, and Wikipedia’s article traffic statistics tool. All of these tools are discussed below.
In addition to the tools listed below, consider researching your competitors for the keywords they use. An easy way to obtain a keyword list of competitors is to type keywords into Google to see what sites are ranking high. You can then research and analyze your “seed” words by using various free or paid keyword research tools. Below is a list of various free and paid tools. It is by no means comprehensive, but it could help you get started with your keyword discovery.
These tools are evolving and changing faster than a print book can keep up with them. So please note that the keyword tools landscape will likely have changed between the writing and printing of this book. One common trend is that free tools become paid tools as they gain popularity. So please also be advised that some of the tools we list as free might be paid as you read this.
- Google AdWords Keyword Tool:http://adwords.google.com/select/KeywordToolExternal. This can help you get new keyword ideas. This tool is helpful for Web site content, as well as for Ad campaign keywords. It’s a free tool that shows estimated traffic numbers and works best when used with short keywords, one or two words in length. You can also type in the URL of your competitor and Google AdWords will show the keywords your competitor is using (see Figure 4.5).
Figure 4.5. A Google AdWords Keyword tool output. Though the tool is designed for understanding the impact of a word on a Google ad campaign, it works as an organic keyword research tool as well.
(Source: Google)
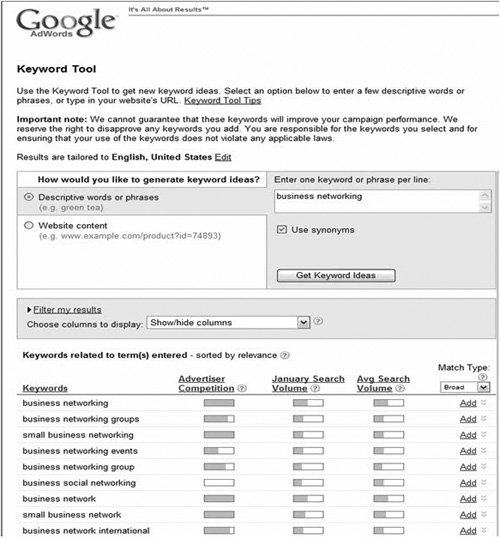
- Google Insights:www.googleinsights.com. This tool lets you find keywords and emerging keywords in top searches and rising searches, but not actual volume (see Figure 4.6). It is scaled and normalized at 100%, so it measures interest level. You can gauge pertinent interest in specific keywords. These insights can help you determine which keywords resonate best, based on searcher interest.
Figure 4.6. A typical Google Insights output. Note that Google Insights publishes the following proviso with this tool: “The numbers on the graph reflect how many searches have been done for a particular term, relative to the total number of searches done on Google over time. They don’t represent absolute search volume numbers, because the data is normalized and presented on a scale from 0-100; each point on the graph is divided by the highest point, or 100. The numbers next to the search terms above the graph are summaries, or totals.”
(Source: Google)
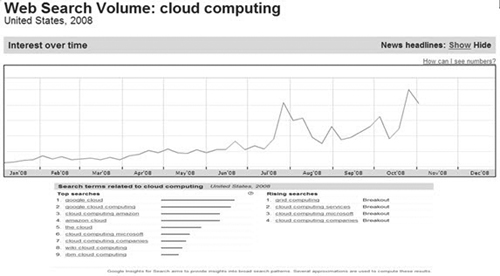
- Keyword Discovery:www.keyworddiscovery.com/login.html. This has free and paid versions, such as a Search Term Suggestion Tool that provides a good breadth and depth of terms (see Figure 4.7). It is a Web-based system that compiles search statistics from 180 search engines worldwide. Currently, the free version only allows you to import keyword results one word at a time, rather than from multiple keywords. Bulk import ability is also limited. For these reasons, we recommend paying for the better performance of the paid tool. The paid version also includes competitive analysis and competitive intelligence.
Figure 4.7. A typical output of the Trellian Keyword Discovery tool.
(Source: www.trellian.com)
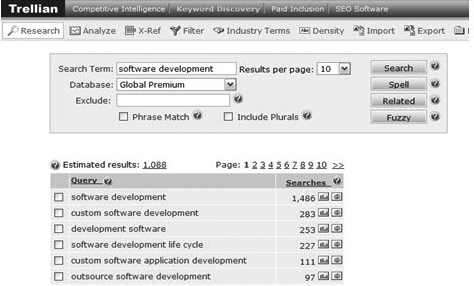
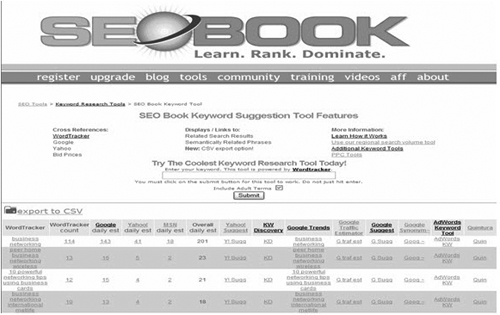
- Aaron Wall’s Advanced Keyword Research Tool:http://tools.seobook.com/keyword-tools/seobook/. This tool cross references Wordtracker, Google, Yahoo, and Bid Prices (see Figure 4.8). It shows estimated volumes in search engines by displaying and linking to related search results, semantically related phrases, and Quintura (described in Chapter 5).
Figure 4.8. A typical output of Aaron Wall’s Advanced Keyword Research tool.
(Source: tools.seebook.com)
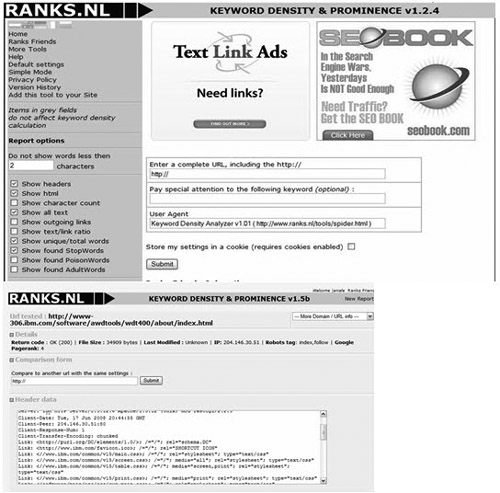
- Keyword Density and Prominence Analyzer, also known as Ranks.nl. Use this to do a competitive analysis and determine what keyword phrases your competitors are best optimized for (see Figure 4.9). You can just enter the URL and not use the actual keyword. Look for a Keyword Text Density of 2 through 10 and for Keyword Prominence of 80% or greater to help determine the topic of your page.
Figure 4.9. The Keyword Density and Prominence Analyzer input and output.
(Source: ranks.nl)
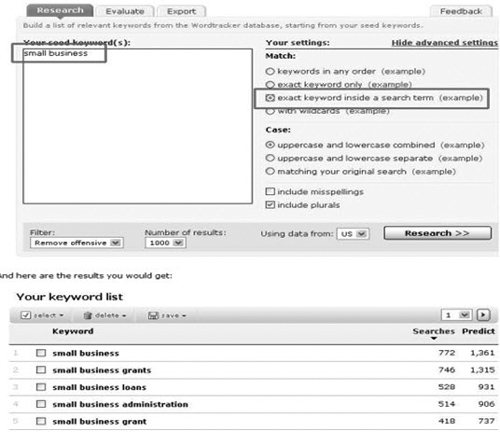
- Wordtracker:http://freekeywords.wordtracker.com/. This tool helps you find the top keywords that you can use, based on Dogpile and Metacrawler. It eliminates bots as it looks at meta search engines, which is to say that it eliminates searches from individuals who are not really part of your audience. It also can give you a sense of keyword competition, as well as demand (see Figure 4.10).
Figure 4.10. A Wordtracker output.
(Source: http://freekeywords.wordtracker.com/)
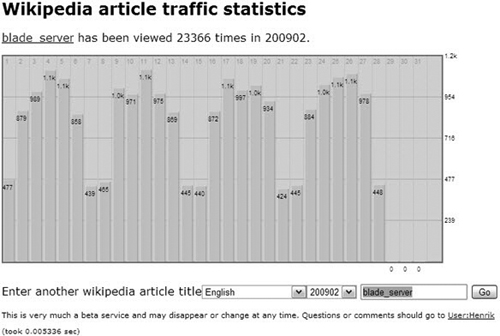
- Wikipedia article traffic statistics:http://stats.grok.se/. This tool can help you determine interest in a topic in Wikipedia in terms of the number of visits to that page (Figure 4.11 and 4.12). Because Wikipedia currently ranks in the top three for thousands of keywords, this can be an easy way to validate traffic volume, as compared to volumes to other traffic research tools. If an article related to a topic has very high traffic in Wikipedia, chances are there is high demand for its related keywords in Google and other search engines.
Figure 4.11. The Wikipedia article traffic statistics tool interface.
(Source: http://stats.grok.se/)

Figure 4.12. The Wikipedia article interest tool output for the term blade server.
(Source: http://stats.grok.se/)
When we consult with content teams about SEO with regard to keyword research, our clients sometimes think that keyword research tools are 100% accurate. This is a misconception, because we generally see varying results when using different tools for the same keyword. The results for each tool are based on a different sample searches and different sources. Some tools, like Wordtracker, use specific search engines. No tool can capture 100% of all Internet searches for a given keyword.
For example, the popular free Google AdWords Keyword Research tool (Figure 4.13) is really a pay-per-click (PPC) tool that also counts any clicks on an impression as an actual search. When Google provides approximate numbers, it draws from a variety of sources, not just the number of searches on a term in a given month. It also includes clicks on impressions, parked domain advertisements (domains registered for possible future use or to prevent competitive purchase) and searches from partner engines as well. All of these, along with the addition of robot searches, can inflate the numbers.
Figure 4.13. A Google AdWords interface.
(Source: Google)
![]()
So with these Google results, if you divide the approximate average search volume of 14,800 per month by 30 (the number of days in month) you get around 493 searches per day. The conundrum is that you still cannot determine how many searches came from particular actions, such as clicks on impressions. What Google is measuring is more about users’ interest in the keyword (in this case, server virtualization) than about actual searches. The search volume numbers should be used to compare various keywords.
In general, keyword research tools provide value by showing searcher interest, competition for keywords, semantically related alternatives, keyword comparisons, and seed words to use in social media for further long-tail research. We advise that you use them in conjunction with each other, because no one tool provides a complete picture of the demand, competition, and relevance for your content of a particular keyword.
Getting Started with Keyword Research
No matter what tools you use, you need to have an idea about the keywords to test out in the first place. This is a complex process involving several steps. The first step for keyword discovery is to obtain a list of so-called seed words. These are the usual descriptive words, also known as themes, topics, core terms, or keyword clouds. This process involves brainstorming about the main words that your target audience associates with a topic. The cloud should contain all the grammatical variations of the words, as well as all synonyms. Seed words are typically root words, from which it is relatively easy to add prefixes, suffixes, and contextual combinations of the words.
It’s important to start this process with the most generic words you can think of and gradually narrow the list down until you have a manageable list to test in your tool. For example, when an IBM content team needed a list of keywords for a set of Web pages promoting environmentally friendly technologies, the team joked that it needed to start the process with the terms earth, air, fire and water—the most elementary terms in Aristotle’s lexicon. Though it was a joke, it demonstrated just how broad the initial pass of possible terms and their relations needed to be. Starting with a small, broad list ensures that you won’t miss any terms that might particularly connect with your target audience. You can always go back and narrow your keyword list down, but it is really hard to go back and include a whole cloud of related terms after the fact.
If it seems daunting to sit down with a content team in front of a white board and write down the most elementary words, with all their linguistic variations, the keyword tools can help. Many of them can generate all possible grammatical variations of terms, and their synonyms, from a small list. Of course, they ultimately help you determine how many users search on the keywords. They also provide insights on which terms are more competitive and which terms drive more qualified visitors. See the sidebar for a description of the four to seven tools we recommend, in order. Suffice it to say that the goal is to have a list of related keywords that will attract your targeted audience through Google. When you have your list of keywords, you then try to write one page of content for each keyword in your Web architecture. We discuss these architectural considerations in Chapter 6.
As we said, the ideal state is to have all your keywords before you write, but that is not always possible. Many search optimization efforts happen after the fact. In a sense, it is easier to do keyword research after the fact, though it might not be as effective. The reason is that there are all kinds of tools that enable you to scan your existing content for keyword frequency and develop a list of seed words from that list. Tools such as the Word Frequency Calculator (www.darylkinsman.ca/tools/wordfreq.shtml) enable you to cut and paste your existing copy into a box and generate a report on the words that appear most often. You can also exclude stop words (articles and logical connectors) or focus just on elements such as nouns or verbs. If a word appears often in an existing piece of content, it’s a candidate to add to your keyword cloud.
Of course, word frequency is not the only consideration. For example, you might have a legal disclaimer on the bottom of every page that contains words completely irrelevant to the content on a page, yet a frequency counter might list them as the most frequently used words on it. Tools can help, but it typically takes human intelligence, especially from the writers and editors of the content, to develop a list of seed words from a set of existing content.
Once you have the cloud of words you want to test, you can run it through the keyword tools. Typically, you’ll discover that the keywords you chose when you first published your content are not often searched on (as was the case in the case study in the sidebar). The keyword tools will generate reports that show which related words or phrases were most often searched on. Then again, you will need human intelligence to determine which words best target the desired audience while generating more traffic from search than the original words. Often, several very similar words will have similar search numbers. In that case, you make your best guess and test after the fact. It is often more important to get the content up and connect with your target audience right away than to deliberate to perfectly target your audience, and thus delay your publishing efforts. As we say at IBM, search optimization is like washing your hair: Lather, rinse, repeat.
Step-by-Step Keyword Research
This three-part graphic developed by Elliance.com shows the keyword discovery and research process in a nutshell. (Source: Elliance.com)
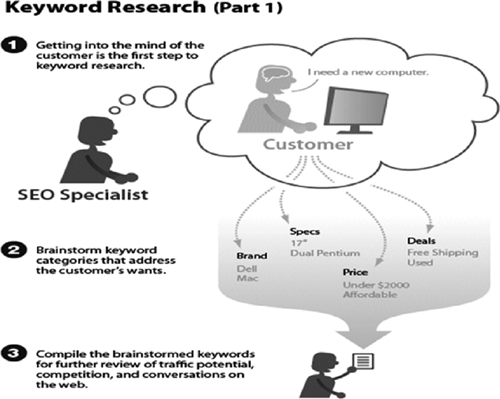
© 2007 Elliance, Inc. | elliance.com
The process of identifying the optimal keyword for a Web page can follow these simple steps:
- Review content on the page for main or repeating themes and generate a seed list.
a. Break down the text to surface ongoing topics and themes within your content.
b. Review words, phrases, text structure, and patterns to help you locate semantic relationships that can lead you to finding related keywords.
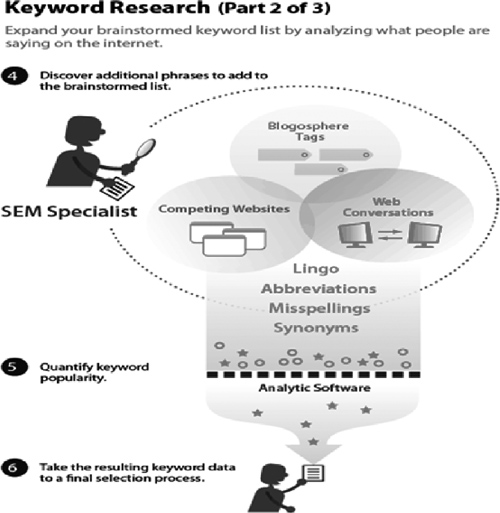
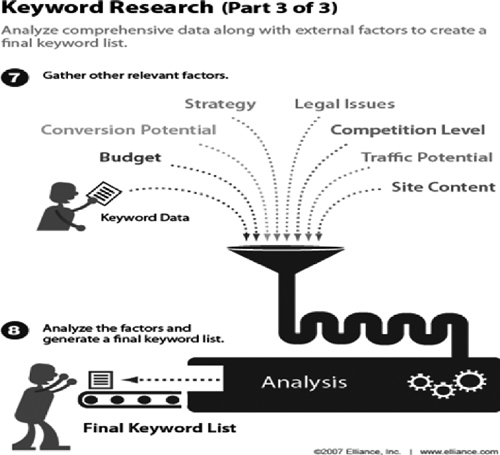
- Use keyword research tools to help you generate more fully defined keyword candidates from your seed list. These steps will help you further understand what words people really use and what words are actually driving people to the site.
a. Find related terms. Stemming those words and associated text can help vary and balance your content to help avoid overuse or misuse of keywords.
b. Use a variety of tools to allow for a more comprehensive set of keyword recommendations. We will go over some available tools below.
- Review competition for keywords (in search engines).
a. Determine the search volume and competition for the keywords through tools such as Google AdWords, the Keyword Discovery Tool, or other available tools.
b. Research each keyword candidate to discover keyword variations, number of searches, and competition for the keyword.
You can never research your competition enough. Actually, it’s an opportunity to learn from other approaches, with the caveat that competitive pages may not necessarily be well optimized. This part of the exercise allows you to review what is being done elsewhere to get additional ideas for your site.
- You are now at the point where you can productively brainstorm with your client by sharing analysis, research, and keyword recommendations. Prioritize your keyword candidate list in order:
a. High: The keyword is a close match to your site’s content and is very popular or moderately popular or has a high conversion rate.
b. Medium: The keyword is a close match to your site and is somewhat popular, with acceptable conversion rates.
c. Low: The keyword is a close match to your site and has enough searches to be worth a paid placement bid—buying keywords to appear at the top or right column in Google results is called paid placement—but is not worthy of organic search optimization. It may have too much competition for organic optimization.
- Select keywords after you have done all competitive research and keyword discovery with available free and/or paid tools.
Optimizing Web Pages with Your Keywords
Google sends crawlers or spiders through the Web to find content that might be relevant to its users. These are simply programs that scan pages and return information about pages back to Google. Based on this information, Google then places the pages into its index. The index listing for a piece of content contains the information about the page that the crawler gathered, which helps the algorithm rank the page against others on the Web for the same keywords.
Optimizing pages for a given keyword is about providing the information the Google crawler is looking for in an efficient way. If the crawler has to work hard to find the information it’s seeking, it might not capture the information you want it to, and the content that ends up in Google will have an incomplete index entry. For example, if a page includes a Flash experience or a lot of JavaScript, the crawler might not capture all its content, and the page will not rank well. (For this reason, we recommend HTML or XML pages, with limited JavaScript, and Flash modules that sit like graphics files in the HTML or XML.) Without a complete index entry, the algorithm will not rank the page as highly as it would with a complete one. Optimizing a page is about making sure that the content on the page is structured for easy crawling and accurate indexing.
One of the reasons Google does a better job than any other search engine is the tuning of its crawler. Crawlers scan certain elements on a page to determine relevance. They look for parts of the code, in addition to the body copy. They especially look for the <title> tag, which is the text that appears at the top bar of a browser window on the left (number 1 in Figure 4.14). They also look for the <h1> tag or heading for a page (number 2 in Figure 4.14). Then they scan the body copy on a page (number 3 in Figure 4.14). And they look for links. This is very similar to the way users scan a page before determining whether or not to engage with its content. So tuning your pages for Google’s crawler will also help you tune your pages for your users.
Figure 4.14. The ibm.com Product Lifecycle Management page. Item number 1 is how the browser displays the <title> tag. Item number 2 is how the browser displays the <H1> tag or heading. Item number 3 is how the browser displays the body copy. The crawler scans these three elements, first looking for keywords and their derivatives. Note that this page was later optimized. It is used here as an example of how to improve your pages.
(Source: IBM Corp.)
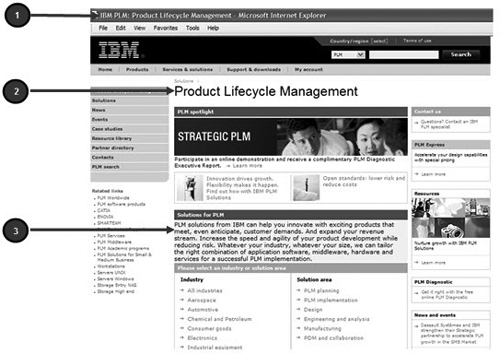
The Google crawler scans the text in the source code for a page. At IBM, when we audit pages, we select View > Source from the browser menu and try to emulate the crawler by searching for the <title> tag, <h1> tag, and placement of the body copy and the links. Then we try to ensure that the chosen keyword appears in those places. That’s easy enough for the <title> tag and <h1> tag. But ensuring this for body copy can get a little tricky. Because we are mostly concerned about how to write for the Web, as opposed to how to code pages for the Web, we will focus on the body copy.
The most important aspect of writing body copy is ensuring that it contains the keywords that appear in the <title> tag. The next most important is the <h1> tag. In the example in Figure 4.14, the keyword is Product Lifecycle Management (PLM). Beyond that simple requirement, there are a variety of techniques you can use to optimize your body copy.
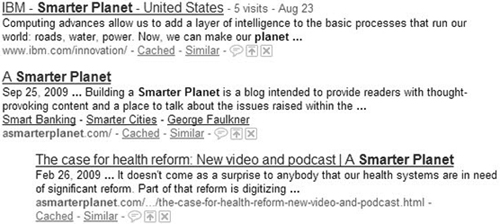
Ensure that Google pulls the text you want it to display in its SERP (the search engine results page, which it shows when it completes a search). This is the 150 characters of text that Google publishes to users between the title and the URL on the SERP (see Figure 4.15). There are two ways to do this. You can type exactly what you want into the <meta content="description"> tag, or you can focus on the first 150 words of the body copy. The easier of the two is to put it into the <meta content="description"> tag, because this gives you some freedom to write a first sentence that is more compelling for humans in your body copy. But, generally speaking, if your first sentence is identical to the 150-character snippet on the SERP, it’s good enough. If it’s compelling enough to get a user to click through from the SERP, it’s compelling enough to put in the first sentence of your body copy.
Figure 4.15. Three listings on Google’s SERP for the keyword Smarter Planet. In the first two cases, the <meta content="description"> tag specifies the copy we want to portray to the target audience to get them to click through. In the third case, Google pulls the first 150 characters of the body copy.
(Source: www.google.com)
Beyond what you want to display on the SERP, you can do a lot of things with the body copy to enhance its position in search engines for your keywords. We will focus on the most important tactics in this section: spelling out acronyms, pumping up keyword density, ensuring keyword proximity, stemming verbs, using synonyms and other related words, using descriptive link text, and bolding for emphasis.
• Spelling out acronyms: In the example in Figure 4.14. the term Product Lifecycle Management is abbreviated PLM. In print, the common style for acronyms and other abbreviations is to spell them out on first reference and never spell them out again. This is not a good tactic for the Web. The crawler needs to see the full unabbreviated form of the keyword in all three primary locations. So, for example, the body copy in Figure 4.14 starts with the abbreviated form. That’s a no-no. It should start by spelling out Product Lifecycle Management (PLM). It can use the abbreviated form in the body copy afterwards. But unlike in print, the abbreviated form should be used only when readability is not affected. Use the spelled-out form as often as possible. That’s what the crawler is looking for. That’s one action item we took when we later optimized that page.
• Pumping up keyword density: After the first sentence, ideally, between 2 and 4 percent of your body copy should contain the keyword in your <title> and <H1> tags. This might seem absurd to writers accustomed to using the entire lexicon available to them to engage the reader. But it is a goal to strive for in Web copy writing. There are ways of pumping up keyword density without overwhelming the reader with repetitive language. The strict rule in the print world that dictates that you should find alternative words if you see the same word twice in a short span of text does not apply on the Web, especially when it comes to keywords. That said, you don’t want to go over the 4 percent rule, lest you invoke the dreaded spam algorithm that Google uses to weed out blatant attempts to trick it into driving traffic to irrelevant content for the sake of ad dollars.
• Ensuring keyword proximity: All things considered, if your keyword contains multiple words, the closer the words are in proximity, the easier it is for the crawler to associate them. For example, if the above body copy contained the phrase managing your product lifecycles, the crawler would have an easier time making the association with the keyword than if it contained the phrase it is important to manage the lifecycle of the products in your portfolio. The words need not be in the same order, or even adjacent to each other, for the crawler to associate them with the keywords in the <title> and <h1> tags. But the closer the better.
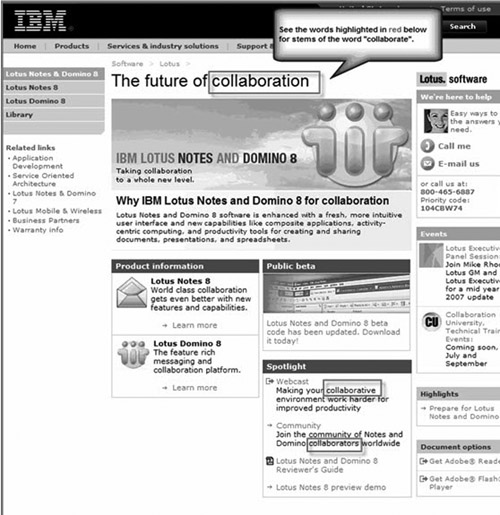
• Stemming: This is the use of alternative grammatical forms of words. For example, from stem you could have stem, stemmed, stemming, stems, etc. Because users will enter keywords in many different forms, you have a better chance of getting search results if you make it a point to stem your verbs in your body copy. Of course, you don’t want to mix tenses. But you can use the gerund (stemming) and the present perfect (stems) form in the same paragraph, for example. Another reason to stem is that it enables you to gain more keyword density without replicating the same words over and over again. And it is relatively easy to mix the different forms of nouns, as in Figure 4.16, to use adjectives in adverbial phrases, and to apply other similar strategies.
Figure 4.16. This example from the IBM site shows stemming with the use of collaboration, collaborative, and collaborators on the page.
(Source: IBM Corp.)
• Using synonyms and other related words: When you do your initial keyword research, you will develop your seed words, then from that you will develop a keyword cloud of related words from your set of seed words. Don’t discard the keyword cloud after you choose your keywords. This is a handy tool to use as you write. For every sentence in the English language, there are something like thirty alternative ways of expressing the same thing with different related words. Chances are, your audience will use the entire range of these expressions, especially considering audience diversity. The more of these you can capture by using the entire keyword cloud, the better your search results will be.
• Using descriptive link text: Because the crawler doesn’t just look at the body copy, but especially focuses on links, it is important that your links be as descriptive as your body text. Don’t just replicate the heading of the site to which you’re linking: Describe the site, preferably with the keywords in your <title> and <h1> tags. And don’t just use generic links like Learn more or Download the PDF. Use the keywords of the page or media piece to which you are linking.
• Bolding for emphasis: Web users’ eyes tend to cue into bullet points, bolding, and other ways of emphasizing text. If you have the opportunity to do this with your keywords, it’s a good practice. It’s good for the crawler and for the user who comes to your site from Google using those keywords. You are less likely to get bounce and more likely to get engagement if it is easy for the user to understand the relevance of your page in a few seconds of scanning.
Many site owners mistakenly believe that ranking high for any term closely related to the content of their page will produce an influx of targeted visitors. Although this may get you more traffic, these high rankings will not always drive qualified visitors to your site or page. Your goal is to find keywords that are relevant to your audience. That means using the words and phrases common to your target audience in your body copy. The above techniques can help you hedge your bets that your diverse audience will use one form or another of the keywords in your cloud, which you developed from your seed words.
In Chapter 5, we will explain how to discover and use not only the keyword phrases that your target audience uses, but their exact language. This involves sophisticated long-tail research and social media mining tactics. Wherever feasible, it’s important to learn as much as possible about your target audience, especially the words and phrases that they use in search and social media contexts. Because Web content is never finished and testing is an integral part of the publishing process, your efforts can start with search and mature into social media as time and resources permit.
Summary
The search-first Web writing methodology is a radical departure from print writing, where you passively attract readers interested in your books and articles. In Web writing, you actively attract an audience that is more likely to find your content relevant if it is written for them with the building blocks of Web content—keywords. This chapter describes the tactics at the core of the search-first writing methodology. The following insights are important to understanding how to put the search-first methodology into practice.
• Define your target audience according to the words and phrases they are likely to enter into Google.
• Research the keywords most often used in Google search queries to maximize the volume of traffic to your pages, while minimizing bounce rates.
• Write your content only after you have done a thorough analysis of how to target your audience with the keywords that your research suggests.
• Implement your keyword research into your writing by ensuring keyword density, proximity, word stemming, and using related words, synonyms, and descriptive link text.
• Measure the effectiveness of your first efforts with an eye toward republishing your content, to reduce bounce rates and improve engagement.
• Continually refine your language to better engage your target audience with relevant content.
International Keyword Research
International keyword research, also referred to as multilingual keyword research, can be a complex task. Here’s why. You have to define whether the language usage is for international (universal), local (specific targeted country) or regional (geographic areas such as Latin America) areas. You must also carefully consider idioms and cultural distinctions, along with “sociological, contextual and intrinsic aspects of the language,” as mentioned at the Spanish speaking SEO report (http://www.spanishseo.org/tips-for-multilingual-keyword-research/).
Although keyword research tools can help you, it is important to engage native speakers early within your process of compiling a seed list. It is difficult to conduct sufficiently thorough keyword research in a second language unless one understands and speaks that language. That person should also be familiar with your products and/or niche.
Very few of the available keyword research tools conduct multiple language searches. If you search for terms in Simplified Chinese with a tool that doesn’t support the required encoding (the most popular variety of which is UTF-8, a representation of the Unicode character set), all you would see is indecipherable characters. For example, the Japanese text ![]() would render as
would render as ![]() rather than as the proper UTF-8 characters.
rather than as the proper UTF-8 characters.
For more information about Unicode, see the Unicode Consortium page: http://unicode.org/standard/WhatIsUnicode.html.
One seemingly useful tool might be automatic translation, also known as machine translation. However, it falls short of providing adequate translation interpretation. Automatic translation tools all do more or less literal translations, but they don’t understand the meaning of the text within its context. Therefore, the resulting terms will rarely be appropriate and can be highly misleading. A simple example of this is the UK word flat, which as a noun typically means an apartment or living space, whereas in the U.S., it typically means a deflated tire or level field. Another example is when some languages combine multiple terms into one word. In German, computer mouse becomes Computermaus, but most German speakers refer to this computer device as a Maus.
There are also difficulties in the translations of English words. There are many linguistic issues owing to the various meanings of words and to cultural differences. Because of these, many keyword research tools do not provide meaningful, inflected permutations. Getting good translations of English terms is not as easy as it would seem.
As noted by Marios Alexandrou,1 some automated translation tools, such as Alta Vista’s Babel Fish, “are prone to do literal translations rather than ones that match how people actually speak.” Even numbers can be a problem. Some languages only have different words for one, two, three and many. And for singulars and plurals, there are stemming differences and problems in translation throughout all countries and languages.
1 See www.allthingssem.com/international-seo-keyword-research/.
There are also gender differences. As you’ve probably experienced before, words in many Romance languages have gender, and this affects the articles used with them. In Spanish, for example, gender articles are sometimes included in search keywords, and sometimes not, depending on the context. When searching for the word servidores (servers), a Spanish speaker might type either servidores or los servidores when searching for a phrase such as los servidores de los años 1990 (the servers that existed in the 1990s).
To make things even more interesting, gender articles can differ between language, such as el sol (the sun in Spanish, masculine) versus Die Sonne (the sun in German, feminine). This would just be a case of ensuring accurate translation from English.
You also need to consider, what do you translate, and what do you not translate? What should be translated depends on the country, language, and audience. You need to ask yourself what people look for in translations, both in English and in other languages. The key in terms of search may be to find what users are primarily looking for. This can be a problem because translators are often faced with two options:
- Using the term from the original language, and possibly needing to explain it (but also increasing the reader’s knowledge). For example, the term data warehouse sometimes is used in Spanish technical texts, but it may need explanation the first time it appears.
- Simply translating or explaining the term, making it easier for the reader but not increasing his or her knowledge. If a consistent translation is used (such as the Spanish infraestructura for infrastructure), this can work well. But if a word has more than one acceptable translation, or can only be explained, this makes keyword optimization harder.
The key in terms of search may be to find for sure what users are primarily looking for.
Another problem involves the way that words “migrate” from one language to another. Would Chinese words find their way into Japanese, or the other way around? Some languages will have some words in common. Japanese and Chinese for example, would produce similar results for many one-word or two-word search items. But in Japanese, once grammar, punctuation, or foreign words are introduced, it will be completely distinct from Chinese.
Fortunately, with the majority of languages, it is quite possible that any internationally accepted words would be searched for in English, surrounded by the grammar of the original language. In our experience, the Web has increased even further the amount of borrowed English words in other languages. For example, words like login, Facebook, server, and database, which come from English, have reached wide usage in other languages. So, some well-known product or brand names such as Windows or Facebook shouldn’t be translated, since most people will still refer to their original names in English.
Some languages have more synonyms than others, which can cause problems. Local knowledge of search and industry terms would be key in selecting which of several synonyms to allocate with higher priority. For example, for the term drink, we may have more than one term in some languages, but one single term in others:
English: Drink, beverage
Spanish: Bebida, algo de tomar, trago, gaseosa, copa
German: Getränk
Japanese: ![]()
Selecting someone in-country who is aware of the most commonly used terms in daily conversation might be a good way to tackle which keywords are best to include where.
So when you begin your international keyword research, think about the following.
• Define your language objectives.
• Involve a native speaker experienced with your company’s product or niche market.
• Have an awareness/understanding that not all keyword tools are equal and some may not properly provide useful multilingual keyword research. Consider having your terms professionally translated where possible.
• Conduct market research where possible to determine who your local competitors are and what terms they are using.
• Get the keywords before you create the content. A more successful approach would be to come up with keywords from scratch—think of what the right keywords would be for someone who speaks another language, rather than just taking the English and forcing a translation. What term should be used, versus what would a translation say? You need to discern if the terms are reflective of the searcher’s queries and local marketplace.
• Engage your customers to find out how they came to your site, and what terms and search engines they used. Information from native speakers in your foreign markets can be the most insightful.
Below are some tools that work well for international keyword research.
• Google AdWords tool: http://adwords.google.com/select/KeywordToolExternal
• Google Traffic Estimator: http://adwords.google.com/select/TrafficEstimatorSandbox