
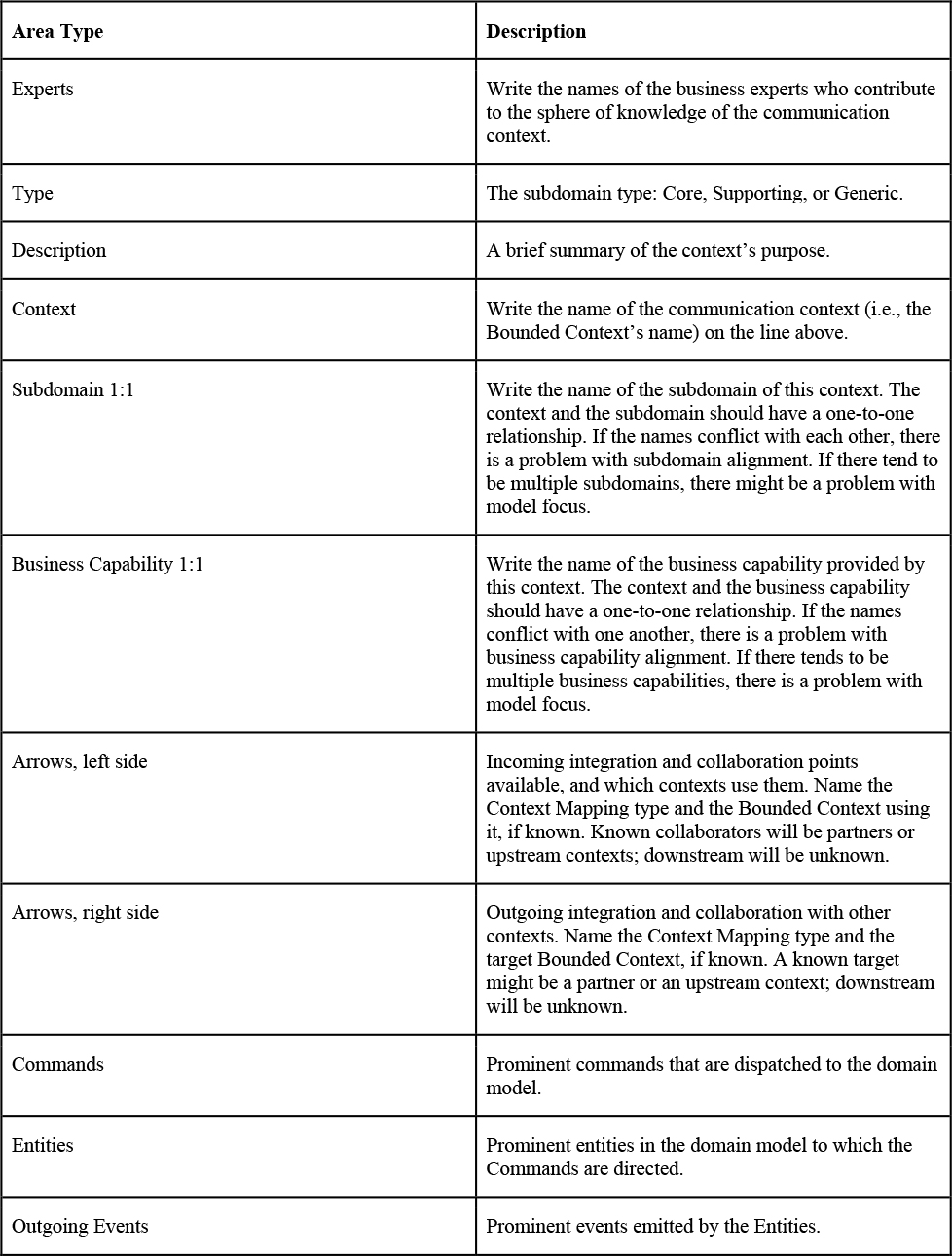
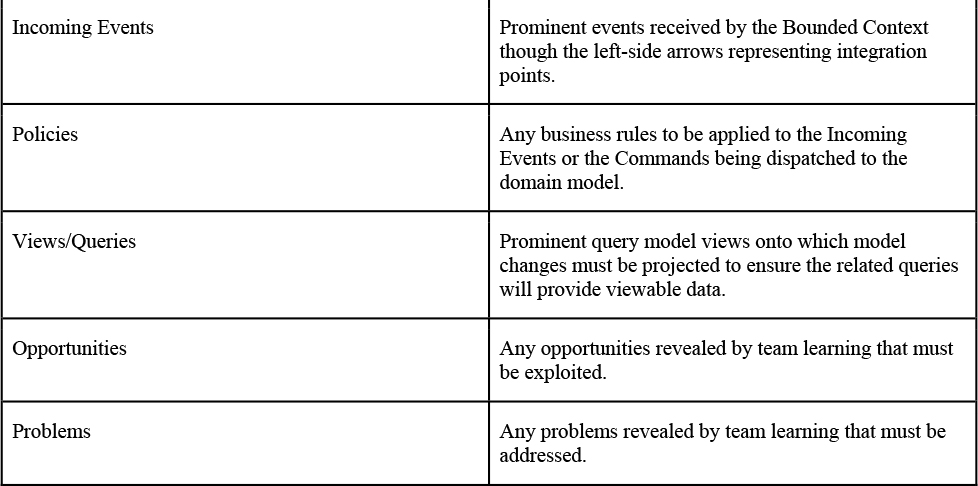
6. Mapping, Failing, and Succeeding—Choose Two
In any project involving a Core Domain, it’s almost inconceivable that this context of innovation would not need to integrate with any other systems or subsystems, including Big Ball of Mud legacy systems. It’s even likely that some other new supporting and generic subdomains will be implemented as Bounded Contexts that a Core Domain must lean on for “remote” functionality. Here, “remote” might refer to contextual modules in the same Monolith that are segregated from the others but without a network between them, or it might actually mean physically remote.
This chapter starts with mapping team relationships and integrations between multiple contexts of expertise. Later, we see a number of warnings about poor modeling practices that cause failures. These are not the quick failures that eventually result in good outcomes, so they must be avoided. Next, we explore practices that tend to lead to success. Finally, we demonstrate how to apply the experimentation and discovery tools within a problem space and its solutions.
Context Mapping
The mappings between any two Bounded Contexts are known as Context Maps. This section provides diagrams and explanations that effectively describe the various kinds of mappings. Diagrams are great, but Context Maps go beyond drawings. They help teams recognize the situations they face and provide tools to spot and address specific modeling situations. The primary roles of Context Maps are as follows:
▪ Cross-team communications
▪ Project thinking, learning, and planning
▪ Integration situation discovery and desired solutions
Context Maps are recognized as real inter-team relationships and implemented as source code integrations patterns. This section discusses how any two Bounded Contexts can integrate with each other using Context Maps.
A Context Mapping between any two Bounded Contexts is represented in a diagram as a line between the two contexts, as illustrated in Figure 6.1. The line can have multiple meanings, including the kind of team communication that exists or that must be established to succeed and the way integration will be achieved.

Figure 6.1 A Context Mapping of two Bounded Contexts is represented by the line between the contexts.
In mapping the reality of which conditions currently exist, an effort is made to assess the actual relationships and communications between teams as the result of the organizational structure and politics. This realistic view makes it clear that it might not be possible to change most of the dynamics, but highlights where concerted efforts to improve could pay off.
Before venturing into the individual Context Mapping types, consider a few salient points about the various patterns. First, Context Maps are initially useful for mapping what exists. There will almost always be some preexisting systems, which will comprise subsystems with which the new context must integrate. Show what those existing subsystems are, and indicate the current relationship that the new context’s team has with each of the teams in the external subsystems and their integration offerings. The Context Mapping patterns are not mutually exclusive—they will tend to overlap. For example, a Partnership could include the use of a Shared Kernel and/or a Published Language. A team might seek some goals to improve its mapping of situations from what exists to what would be most useful. Sometimes that works.
Now consider an overview of the different Context Mapping types:
▪ Partnership. Two teams work together as an interdependent unit to achieve closely aligned goals, which generally must be delivered in unison.
▪ Shared Kernel. Two or more teams share a small model of domain concepts that the teams agree upon. The agreement includes sharing the language of the small model. Each of the individual teams is free to design additional model elements that are specific to its language.
▪ Customer–Supplier Development. A team is in a customer position as an integrator with a supplier team. The customer is said to be downstream from the supplier because the supplier holds sway over what the customer’s integration mechanisms will have.
▪ Conformist. A downstream team must integrate with an upstream model, such as with Customer–Supplier Development. For any number of reasons, the downstream cannot translate the upstream model into its downstream language, but instead must conform to the upstream’s model and language.
▪ Anticorruption Layer. A downstream team must integrate with an upstream model, such as with Customer–Supplier Development. The downstream team translates the upstream model so that it fits into its own model and language.
▪ Open-Host Service. An open API is offered by a context’s team that provides a flexible means to exchange information between its context and others.
▪ Published Language. A standardized format with language-based type names and attributes is developed for exchanging information between two or more contexts. This language is published, meaning that it offers well-defined schemas including documents for query results, commands for operations, and events of outcomes.
▪ Separate Ways. A downstream team could integrate with an upstream model, such as with Customer–Supplier Development; however, to avoid that in exchange for limited benefits, it chooses to create its own one-off solution.
Now let’s consider the details of each Context Mapping pattern.
Partnership
As is common with partnerships, there are two parties involved in this one. Some partnerships involve more individuals or organizations, but generally we think of a partnership as being only two sided. In the discussion of this Context Mapping type, let’s limit a Partnership mapping to being one that occurs between two teams.
Each team owns its own Bounded Context, but of course these must work together in some constructive and mutually beneficial way. In Figure 6.2, the tight inter-team dependencies are depicted by the thick line between the two Bounded Contexts. Thus, the point of the Partnership is largely centered on the relationship between the teams, but there is also the possibility that they understand each other’s languages more than would normally be the case.

Figure 6.2 Two teams responsible for different Bounded Contexts may require a Partnership.
It’s often true that two teams have aligned goals and neither one can succeed without the other. They must align their efforts and communication closely with those shared goals, which means they must coordinate a lot in terms of supporting features, integrations, testing, and timelines. For instance, if the teams depend on each other, then they likely share some sort of model and the two ultimate deployments cannot go live separately. At least one must be deployed shortly before the other, or both together.
Now, in terms of autonomy, this isn’t the best idea; actually, it’s not a good idea at all. But sometimes it’s necessary. For the sake of building team autonomy into the organizational culture and structure, a Partnership might be only a short-term measure to accomplish a strategic initiative. Indeed, maintaining this relationship over the long term might be stressful for the operations of both teams and autonomy won’t be possible. In some of the upcoming concrete examples we present in this chapter, it’s clear that maintaining a high-contact Partnership over the long haul is unnecessary.
It’s less of a burden when the two teams are actually just subteams creating subdomains within the same single team’s responsibilities. In other words, a team of seven might have all seven team members working on a Core Domain, but then split off two or three members to create a Supporting Subdomain because it seems best to cleanly separate a model that isn’t really a core part of the strategy. Or perhaps it is core, but the experts involved and the pace of change between the two efforts are far different because they are driven by different strategic priorities.
As an example, consider the Risk subdomain team. The Risk team is to become more focused on actuarial tasks through machine learning. This team gradually realizes that they have also, by default, inherited the job of calculating policy premium rates. After all, the rates are very closely tied to the outcomes of the risk determinations. The team understands that although this is a necessary part of the business, and possibly even core in its own right, the actuarial risk-based algorithms are driven by different business experts and change at a different pace than the rate calculations do.
Undoubtedly, the actuarial outcomes will produce disparate data types over time, but the Risk team doesn’t want to take on the added burden of designing a standard information exchange specification for the rate calculations to consume. The Risk team would prefer that this standard be developed by a team that is focusing more intently on the premium rate needs. It might be that a separated Rate team would even implement the standard.
Creating a separation between the two contexts (Risk and Rate) means that there must be two teams. Even so, the two teams must work closely together for two reasons:
▪ The information exchange standard must be specified by the Rate team but approved by the Risk team, so it requires ongoing coordination.
▪ Both the Risk and Rate products must be ready for release at the same time.
It won’t be a good idea to maintain this Partnership over the long haul, so the two teams will address breaking their close ties in the future when less coordination is necessary. They’ll rely on other Context Mapping patterns for that.
Shared Kernel
A Shared Kernel is a mapping in which it is possible to share a small model among two or more Bounded Contexts—a sharing that is actually embraced as part of each consuming context’s Ubiquitous Language. A Shared Kernel is both an inter-team relationship and a technical, code-centric relationship.
Inter-team communication is key here; otherwise, it’s less likely that any teams involved would know one team already possesses a model that could be shared, or even be aware of the need and potential to share. Alternatively, two or more teams might need to recognize that there will be shared concepts between contexts in a large system, and understand that they should form a bit of a standard around it. The complexity and precision of the model in this scenario is high enough that not sharing it would be worse for all potential beneficiaries.
As an example, perhaps a given system or even several subsystems within an entire organization require a standard money type. Programmers who do not understand how monetary calculations and exchanges between currencies should be handled can cause some really big problems with money—even legal problems. Because most monetary schemes employ a decimal point to indicate a fraction of the whole denomination, it’s common for programmers to think that floating-point numbers are the best type to use. Actually doing so would cause monetary losses and/or gains that would eventually cause large financial discrepancies. Floating-point values are the worst way to model money within a given business. First, the practice of rounding is fraught with peril for both single- and double-precision floating-point numbers. If decimal precision is needed for financial calculations, then using a “big decimal” type offers precision to a few billion decimal places. Second, a monetary value is often best treated as a whole integer without a decimal point, scaling, or rounding. In this case, there is an implied and visual formatting decimal point placed so many digits from the right in the whole string of digits. Currency conversions and support for multiple currencies also come into play here.
If a system doesn’t provide a shared money type with the versatility and correctness required to meet financial standards, as seen in the Monetary Shared Kernel in Figure 6.3, everyone involved should go home and rethink their life.

Figure 6.3 A Shared Kernel named Monetary includes Money and other monetary types.
Note that Figure 6.3 does not indicate that Monetary is a separate Bounded Context. It is not—but it is also not just a library. Monetary is a portion of a model that at least two teams agree to share. To make this point clearer, a Money object or record is not persisted by the Monetary model. Rather, the Bounded Contexts that share and consume the Monetary model are responsible for persisting Money values in their own separate storages. That is, Underwriting persists any Money values in its owned data storage, and Risk persists any Money instances in its separately owned data storage.
Such shared models are important in other domains as well. For example, consider equities trading that supports fixed bid prices for buy trades by collecting share prices across several sell orders, which together average out to the fixed price of the buy. This model concept is sometimes referred to as a “quote bar.” It could be part of a Shared Kernel that provides common trading components in a model that is consumed by various specialty trading subdomains.
Another potential problem arises with the use of national or international coding standards. For instance, the medical and healthcare domains use ICD-10 codes, which are recognized in nearly 30 nations for billing and reimbursement collection purposes. More than 100 nations use ICD-10 codes for reporting statistics on causes of death. These kinds of standards form natural Shared Kernel models.
One common mistake is to consider some kinds of information (such as events) exchanged between Bounded Contexts to be a Shared Kernel. This is not typically the case because often an event, when received by a consuming Bounded Context, is translated into a command or a query at the outer boundary. When this kind of translation occurs, the specific external event type is never known at the heart of the consuming Bounded Context—that is, in its domain model. Performing a translation from an external language to the local language means that the external language is not consumed as an acceptable language for the local context. Because it is not part of the local context’s Ubiquitous Language, it is not shared between two contexts.
The local domain model treats a truly shared type, such as money, as if it were part of its Ubiquitous Language. If an external event were permitted to have meaning in the local domain model, then it might be considered part of a Shared Kernel. That’s actually not a good practice because it creates a strong coupling between the producer and the consumer of such events. Translating from the external event to an internal command is a better choice.
Customer–Supplier Development
Consider the dynamics involved when there is a high degree of autonomy between teams:
▪ There are two teams.
▪ One team is considered upstream.
▪ The other team is considered downstream.
▪ The downstream team needs integration support from the upstream.
▪ The upstream team holds sway over what the downstream team gets.
This relationship provides autonomy for the upstream team. The downstream team can also achieve a high degree of autonomy, but they still have a dependency on the upstream. The downstream remains in a favorable situation only as long as the upstream provides the necessary integration features for this team. The downstream might need only what the upstream already provides, which would leave each team in a good position to remain on their own pace. Yet, the opposite could be true if the upstream doesn’t have and can’t/won’t provide what the downstream needs. It might also be that the downstream team’s voice is big enough and their demands sufficiently impactful on the upstream that it sets the upstream team back on their heels with respect to their own planned feature releases. The relationship might even have negative enough consequences that the downstream pressure causes the upstream team to cut corners, which results in making their own model brittle. Given a significant measure of these consequences applied to both sides, the efforts of the two teams could be derailed unless care is taken to help them work together. In fact, this kind of political clout could actually serve to flip the upstream and downstream relationships altogether.
For example, suppose that in an effort to remain autonomous, the upstream team intends to make rapid progress on their own model. However, these achievements might come at the expense of the downstream. That would happen if the upstream changed in a way that no longer supported the downstream, such as breaking previously established information exchange protocols and schemas. A typical case is when other pressures on the upstream force incompatible changes for one or more previously dependent downstream contexts. The regression first hurts the downstream team, but without a doubt the upstream team will soon suffer as they must fix their broken exchange contracts.
Creating a formal Customer–Supplier Development relationship puts both the upstream and downstream teams on more solid footing. The following is necessary:
Establish a formal relationship between the two teams that keeps each side honest in their communication and commitment toward support, and in being a customer that understands they are not the solitary pressure that their supplier, and possibly a former partner, faces.
Although it is possible for the upstream to succeed independently of the downstream, establishing a formal, named relationship tends to reinforce an understanding that there must be agreement between the two teams, but not to the extent of Partnership. Agreement is essential for overall success.
This pattern might be more difficult to effect outside the same organization. Yet even if the upstream team is entirely external as a separate organization, they must still embrace the understanding that their customers count and have a say. Although customers are not really always right, it helps to acknowledge that they do pay the supplier real money, and that’s what makes them “right.” Otherwise, customer retention will be impossible—and so will job retention. The larger, more powerful, and more influential the supplier, the less likely it is to exercise altruistic behavior—that is, unless the customer is similarly larger, more powerful, more influential, and paying a lot for the service.
Having the upstream team establish API and information schema standards for their offerings will help. Even so, the upstream supplier must be willing to accept some responsibility to deliver on the requests of the downstream customers, which further necessitates some negotiations on what is to be delivered and when. Once these parameters are in place, measures must be taken to ensure that the downstream customers will receive some reliable stream of necessary support.
The previous discussion of the Partnership relationship between Risk and Rate determined that maintaining this interdependency over the long haul would be stressful on the operations of both teams and autonomy would not be possible. In time, as their synchronized releases lead to reliable stability, it will be possible to transition out of the Partnership. It’s likely that the teams can then establish a Customer–Supplier Development relationship moving forward. Figure 6.4 depicts the Context Map for this relationship.

Figure 6.4 A Customer–Supplier Development relationship between two teams.
It might at first seem that the Rate Context would be upstream, because under the Partnership it is responsible for specifying the information exchange protocol and schema. Yet, even in that relationship Risk has the power to accept or reject the specification. In actuality, there is already a bit of Customer–Supplier Development relationship built into the Partnership, albeit a small one because coordinating release priorities tends to overrule taking a hard line on schema quality. The teams would like to establish a more versatile specification that might better support future risk determinations. At the same time, they know that attempting to achieve this outcome will be less than fruitful, especially very early on. Thus, they decide to push this effort off to the last responsible moment. The teams agree that a second or third version of the contract will need to be developed later, at which point they will have learned enough to better determine how a more flexible schema might be established.
Conformist
A Conformist relationship is in force when at least two of a few conditions exist. An upstream model is large and complex, and . . .
▪ A downstream team cannot afford to translate an upstream model, generally related to time, ability, and/or team bandwidth. Thus, they conform out of necessity.
▪ The downstream team will not realize any strategic advantage from translating the upstream model. This might be a matter of determining that the downstream model can be sufficiently close to the upstream model; or the downstream solution might be temporary, so it would be wasteful to make the solution more elaborate.
▪ The downstream team can’t come up with a better model for their context.
▪ The design of the upstream integration information exchange schema is a one-to-one mapping of the upstream internal model structure, and changes to the internal model are reflected directly into the exchange schema (this is a poor upstream design).
In such cases, the downstream team decides to (or is forced to) conform entirely to the upstream model. In other words, the downstream uses the Ubiquitous Language of the upstream, and the structure or shape will be one-to-one.
One way to think about this pattern is by recognizing that the API of the upstream is used to exchange information and perform operations, with no attempt to more optimally adapt it to the local downstream model. If data from the upstream must be manipulated in any way, or even persisted, and later sent back to the upstream, it exists in the downstream much as it would be in the upstream.
As shown in Figure 6.5, the downstream Rate Context is a Conformist to the upstream Risk Context’s Assessment Results model. This is because premium rate calculations are based on risk assessments, and there is no need to change that for rate calculations. The Rate Context team has the major influence on the upstream Assessment Results model specification, which makes consuming the exchange schema and conforming to the model language and structure more than palatable.

Figure 6.5 A downstream Conformist consumes an upstream model as is.
There is no reason to translate the upstream, as doing so would be unnecessary, time-consuming, and pretentious work that would also increase risk. If translation was chosen as the preferred approach, every time that the upstream Assessment Results model changed, the downstream model’s translation layer would have to change as well. Of course, the Rate team will have to react to the upstream changes to the Assessment Results model, but because they have a strong influence on the specification, they can actually plan ahead for the necessary consumer code modification(s).
Ideally, each team’s context will be as cohesive as possible and as decoupled as possible from the other contexts. Coupling and cohesion are defined in terms of the amount of work it takes to change something [StrucDesign]. If either of the two contexts don’t change that often, the coupling is not really an issue. It is a good rule of thumb to consider the frequency of changes and to prevent coupling if it will impact teams in a negative way.
It really makes no sense to translate in this particular case, but it is not possible to make a blanket rule. Instead, those decisions should be made on a case-by-case basis. Due consideration should be given to the compatibility of the upstream Ubiquitous Language to the downstream consumer’s Ubiquitous Language, but the other factors listed previously must also be weighed. In addition, the following Context Mappings identify other consequences of adopting a translation approach.
Anticorruption Layer
An Anticorruption Layer is the exact opposite of a Conformist. This pattern takes a defensive integration perspective by making every effort to prevent the upstream model from corrupting the downstream model. The downstream is the implementer of the Anticorruption Layer because this team must take responsibility for translating whatever is available in the upstream into the language and structure of their consuming model. It is also possible that the downstream will have to send data changes back upstream. When that takes place, the downstream model must be translated back to what the upstream understands.
In many cases, the upstream system is a legacy Big Ball of Mud. If that’s true, don’t expect the upstream to have a rich client-facing API and well-defined information exchange schema. Integration with the upstream might require being granted a user account for the upstream database and performing ad hoc queries. Although this book is not meant to make technology recommendations, it does seem appropriate to acknowledge that the introduction of GraphQL represents a game-changer for such jobs. Yet, we shouldn’t consider the existence of GraphQL an excuse to design integrations in a substandard way that requires its use.
Even if the upstream model does have a rich client-facing API and a well-defined information exchange schema, the downstream team might still decide to translate the upstream model to its own Ubiquitous Language. Imposing one or many loanwords1 from the upstream context might not fit well with the downstream Ubiquitous Language. The team might decide that forming a calque2 is natural for some local terms, and/or that defining an entirely different term might be even better. All of these options could be mixed together as deemed appropriate. The translation decisions belong to the downstream team.
2 A calque is composed of one or more words from one language that are transliterated into a target language. For example, the English “beer garden” calques the German “biergarten.”
1 A loanword is one or more words taken into a target language exactly as is from another language. For example, all languages other than French that use “déjà vu” are using a loanword.
The point is not necessarily that the upstream model is a mess, which is difficult to readily exchange information with, and that heroic feats must be performed to translate it for downstream consumption. Rather, the salient point is that if the downstream does not think and speak in terms of the upstream, then a translation would be helpful and could even be appropriate from the standpoint of downstream team time and abilities.
Figure 6.6 depicts an Anticorruption Layer accessing a Big Ball of Mud legacy system that has the current NuCoverage premium calculation rules. This is done as a Risk Context team interim step, which will suffice until an improved model can be fully implemented locally.
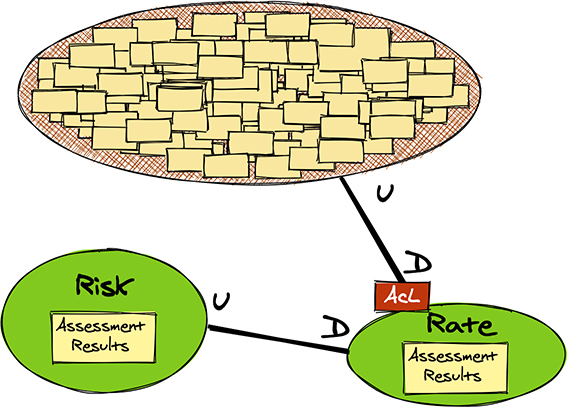
Figure 6.6 The Rate Context queries a legacy system for premium calculation rules.
The model shown in Figure 6.6 will be more versatile in terms of adding, editing, removing, enabling, and disabling rules. These rules can, in turn, be used for experimental A/B testing in production. Until that time, the Rate Context team has put in place what they consider to be a fairly good representation of their fully designed future model. Thus, they will translate the upstream rules into their local model as a means of testing their assumptions regarding the new local model. At the present time it is less important to have a versatile model when a working model is a necessity.
Open-Host Service
Sometimes teams have foreknowledge of the needs of current and future integration clients and enough time to plan for them. At other times a team might not know of any integration needs and then later get caught trying to play catch-up. Creating an Open-Host Service can be the answer to both of these situations.
Think of an Open-Host Service as an API for exchanging information, where some exchanges might require the API provider to support data mutations from downstream onto their upstream model.
Now, consider the following potential integration situations in which the upstream team may find themselves. Let’s look at the Rate team as an example.
Team Knows Early
During a lunch conversation, the team implementing a Rate Context learns that at least one other downstream team will require access to their model. The downstream team is interested in analytics around the calculated premium rates. During the same lunch, the newly downstream analytics team declaring their dependency suggests that another team, and possibly more, will also be in need of the same kinds of integrations. The now (suddenly) upstream team hasn’t interviewed the other teams, and is only aware of the one. Should they go to the effort of providing an API for the single dependent downstream team of which they currently are aware? Or should they just provide a database user account for this team?
The upstream Rate team could design an API that takes care of the single downstream client, but without many bells and whistles. This might require the downstream analytics team to take on a bit of overhead to translate the consumed model on their own from less than optimal exchanges with the upstream API. At least for now it seems to be a read-only API, meaning it’s simply query-based.
If the upstream Rate team were to interview the other potential downstream clients, they could make a better determination of the broader needs. If they get an affirmative answer from one or more clients, it could be worth putting more effort into development of the API, especially if the other teams need to exchange information beyond queries. The Rate team conducts some interviews and learns that now at least three teams, including analytics, will need API access, and the other two teams will need to push new and changed information back to the Rate Context.
The Team Is Surprised
One of the worst situations faced by teams expected to provide open integrations occurs when they are surprised by requirements that show up late. This problem might be caused by the organization’s poor communication structure. Recall Conway’s Law: The systems produced by an organization will reflect its communication structures. Now think of what happens when communication happens latently and the teams that declare their dependencies need the support in short order. The reality is exactly the sad scene anyone would expect. The outcome of the API will reflect the condensed timeline available to implement it. If properly handled, the debt will be recorded and paid. More realistically, if additional teams pile on with similar “oh, BTW” requests for support, the situation will only get worse before it gets better.
Although visible efforts are sometimes made to improve the organizational communication channels, some organizations are too large and complicated to entirely prevent this unhappy situation, at least in the short run. No organization should accept this status quo, because there are ways to break through the silence and walls between teams. Address these barriers early for the good of the teams, projects, and company. Consider implementing weekly lightning (10- to 15-minute) talks across teams working on the same system. Between four and six teams can present their progress in one hour. These meetings must be attended by all parties involved, and the presentations must not consist of fluff or focus on bragging rights. Instead, the teams must share what they have of value, where they are struggling, and what they need.
Another approach is to incorporate an engineering discipline into the system by identifying responsible engineers on each team who must collaborate with a chief engineer to ensure integrations are planned and correctly synchronized. The chief engineer will employ what are known as integrating events or sync and stabilize events—the result of forming purposeful organizational communication structures. These events are planned at intervals and tracked to confirm that all integrating teams deliver subsets of new functionality with working integrations across subsystems. Good integrating events will bring out hidden problems and interactions, as well as places where suboptimization is killing the organization’s overall ability to succeed with this new product. If there are problems in meeting team schedules, the responsible engineer must communicate with the chief engineer as early as these issues become known, but at the latest they should surface at integrating events. This kind of engineering-focused approach is not project management, but rather a matter of engineers working together to meet technical milestones that align with and deliver on business goals.
Suppose the surprise happened to the Rate team because the lunch date got cancelled due to a production problem—this situation, even in a relatively small organization, could easily occur. In the previous scenario, it was only serendipity that allowed the Rate team to learn about the Analytics team requiring information exchange. Likewise, it was only by happenstance that the Rate team got a hint that other teams would eventually require dependencies. If the lunch is rescheduled for the following week, the work topic could be preempted by the goings on at the French Open, the Champions League, the WNBA, or that awesome Oceansize album. And then, surprise!
The major problem in not making time to handle these unplanned bad situations is that the other teams might be forced to go their separate ways, or even integrate with a legacy Big Ball of Mud that might be falling behind the curve as it is replaced, for example, by the new Rate Context. It will also take a lot of effort to integrate with the legacy system and maintain the wishful thinking that what is exchanged will still be relevant after weeks and months, and possibly even years. There’s no way that the Rate team can force integration by delaying the schedule of the other team, even if communication was foiled.
The best that the Rate team can do in the short term is offer to provide some not-so-good access to the downstream. Perhaps opening a set of REpresentational State Transfer (REST) resources would make this solution more acceptable to both teams and enable the time crunch to be met. It might be possible to enlist the help of the downstream team, and that team might indeed have to incur some pain for their latent communication. In fact, probably even a limited API on the modernized Rate Context will be much better to work with than the crufty legacy system.
Still, all of these troublesome situations can be largely avoided by introducing an engineering discipline such as the ones noted here.
Service API
In both of the preceding scenarios, the Rate team and their dependents end up in the same place—all parties face pressure from the outside. With more time to think, plan, and implement, the Rate team would stand on more solid ground. Even so, delivery is the only practical choice, so the team plows forward.
After discovering that three teams will depend on Rate, the challenges seem to lie less with the complexity of the API itself than with the information exchange schemas involved. Because the premium rate rules and calculations will ultimately be altered, perhaps even multiple times per day, and the constant flux in the number of new rules might be substantial, the information exchange schemas will be a moving target. The next section, “Published Language,” describes dealing with this challenge in more detail.
One consideration is that some information might best be made available as a stream of events that have occurred in the upstream Rate Context. Because all three dependents are interested in some subset of the changes that occur in the upstream, the Rate team can make part of the query API a way for the downstream to “subscribe” to the total number of happenings in the Rate Context that they are willing to share. This query API would likely be offered as REST resources. The Risk team might instead place the events on a pub-sub topic.
There are advantages to both strategies. As outlined in Chapter 2, “Essential Strategic Learning Tools,” the organization can use Architecture Decision Records (ADRs) to outline the possible decisions; in this case, there are two. Integration tests can be used to demonstrate the options. The familiarity of downstream teams with either approach might be the deciding factor, but not necessarily. When the decision is made, include it in the ADR.
The Rate team must keep in mind that their event stream might not carry the full payloads that consumers need. If so, the API must support queries that provide deeper information views than the events carry, or perhaps the events themselves should carry richer payloads. One problem with query-backs is the challenges associated with making available the data versions that the events reference. The data now considered current in the upstream could have transitioned one or more times since the event that causes the eventual query-back could be processed by the downstream. Mitigating this scenario might require the upstream to maintain snapshot versions of the potentially queried data. Alternatively, as previously indicated, the events could be designed to carry a large enough payload about the state at the time of the event to negate the query-back. As another possibility, the downstream might have to understand how to deal with query-back results that no longer contain what happened before the current state. The Rate Context provides the Rate Calculated event to consuming downstream contexts, as Figure 6.7 illustrates.
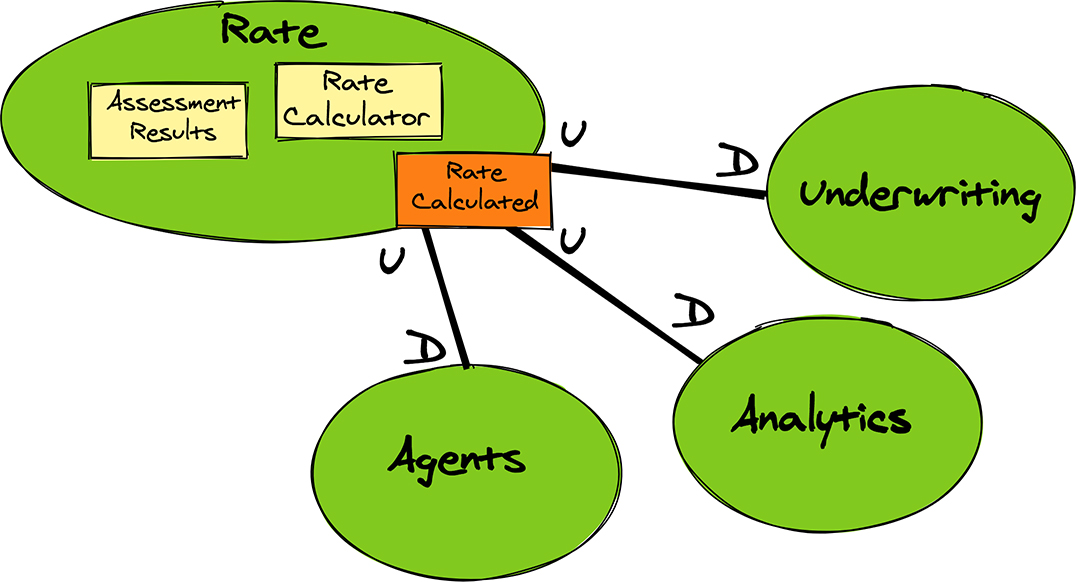
Figure 6.7 An Open-Host Service with multiple downstream consumers.
It might not have been expected that Underwriting is downstream, because it is upstream from Risk, and Rate calculates the premium based on the Risk’s Assessment Results. Yet, it’s understandable that Underwriting must consume the calculated premium somehow. If Underwriting doesn’t subscribe from a downstream position, it would have to perform some pretty strange gyrations to obtain the premium. Importantly, the Rate Calculated event must carry an identity that correlates to the original Underwriting Application or some other type of entity that caused the risk to be assessed and the rate to be calculated. Expectedly, the Analytics Context also consumes the event. Likewise, the Agents Context consumes the event, giving WellBank and other agents the opportunity to see the processing activity shortly after each step happens.
The remainder of the API should be designed with a minimalist mindset, providing only what is absolutely necessary. This API can be offered as REST resources or via asynchronous messaging. It seems almost silly to consider Simple Object Access Protocol (SOAP)–based remote procedure calls (RPC) in contemporary system design, but they are still available for use, and will likely exist in some legacy systems. If RPCs are desired today, normally gRPC would be used rather than SOAP. More to the point, the API should be built up over time as downstream clients drive the functionality and information exchange schemas. This can be achieved by means of Consumer-Driven Contracts [Consumer-Driven-Contracts], which are drawn up as consumers express their needs. When this approach is used, the contracts can be tailored for each consumer. It’s also possible that all consumers might be given the superset of all information determined by the merger of all consumer needs.
The chapters in Part III cover the styles of API designs in more detail. Next, we discuss the other half of the API—that is, how will the information be exchanged?
Published Language
A Bounded Context is often the source of information needed by one or more other collaborating Bounded Contexts in a common system solution, and even by outside systems. If the format of the information is difficult to understand, then its consumption will be tricky and error prone. To avoid this predicament and enhance the exchangeability of pertinent information, organizations can employ a standardized strong schema. In domain-driven terms, this is known as a Published Language. A Published Language can take a few forms, as outlined in Table 6.1.
Table 6.1 Published Language Schemas from International to Single Enterprise Services


The international schema standards listed in Table 6.1 are only a small representation of those available throughout various industries. There are obvious trade-offs when using such standards, but one important thing to note is that using the beefy canonical models has a definite disadvantage for internal enterprise use. These models are not only more difficult to adhere to, but also carry a lot higher transport overhead. If the enterprise is on the cloud, this will have an impact on cost.
Figure 6.8 shows three Published Language examples within NuCoverage. The Risk Context has its own Published Language, with one element being the event named Risk Assessed. The Rate Context has a different Published Language, with one element being Rate Calculated. The Risk Assessed event has an impact on Rate, and the Rate Calculated event is consumed by the Underwriting Context. In turn, the Underwriting Context builds a Quote from one or more Rate Calculated events and emits a Quote Generated event for each completed Quote.

Figure 6.8 The Risk, Rate, and Underwriting provide their own Published Languages.
One way to maintain an international, national, and organization-defined Published Language and make it available to consumers is by means of a schema registry. A worthy schema registry supports business contextual schemas of any number, each with multiple versions, and provides for appropriate compatibility checks between versions. One such schema registry is available as part of the open source, reactive VLINGO XOOM in its Schemata tool [VLINGO-XOOM].
Separate Ways
When a team might integrate with another Bounded Context but the cost is likely to be higher than the potential benefits gained, that team might decide to go their Separate Ways. Teams that go their Separate Ways create their own one-off solutions, or make simpler modeling decisions that help them make short work of the problem they face.
It’s possible that a given Bounded Context might have no integrations at all with other contexts. However, this pattern can be applied on a case-by-case basis. In other words, the team under discussion might integrate with one or more Bounded Contexts, but not with others.
The downside to taking this route appears when the solution chosen creates significant silos of data and/or domain expertise expressed in software that are roughly duplicates of other areas of a system. Some amount of duplication is not always bad, but too much is too much. Don’t Repeat Yourself (DRY) is an adage that applies to knowledge, not code. Creating large silos of duplicate data and repeating knowledge by way of expertise codified in multiple contexts is not the desired effect of the Separate Ways pattern.
Topography Modeling
While participating in an EventStorming session, it might seem difficult to find boundaries. As previously advised, participants should think in terms of business capabilities and recognize communication drivers among experts. These are the best ways to organize boundaries and the best places to start. More refinement will happen as the business grows and changes, and new business capabilities become essential.
Another tool that can help define boundaries and clarify how the boundaries will work together is the topographic approach. Topography can mean a few things. According to the Merriam-Webster dictionary, its definitions include these:
1. a: The art or practice of graphic delineation in detail usually on maps or charts of natural and man-made features of a place or region especially in a way to show their relative positions and elevations.
b: Topographical surveying.
2. a: The configuration of a surface including its relief and the position of its natural and man-made features.
b: The physical or natural features of an object or entity and their structural relationships.
All of these definitions are applicable using this approach.
Yes, the communication within a Bounded Context helps teams understand what belongs inside, but the communication and mapping between Bounded Contexts further inform the contexts themselves. These elements include Context Maps, but grasping the actual flow of detailed information exchange schemas by means of enhanced visual mapping models helps even more. Modeling with topography is a way to better understand the shape and character of your system. Figure 6.9 provides a template for Topography Modeling.

Figure 6.9 Topography Modeling template diagram.
Several areas of the template in Figure 6.9 can be filled in with information (see Table 6.2). The resulting models can be placed on a table top or on a wall in the order of processing flow, similar to an EventStorming timeline. The template provides teams with a number of placeholders that can be used to show more context than is given at a single point in an EventStorming timeline. Additional placeholder areas can be added to any part of the modeling map as needed. This template purposely omits architectural details that, although necessary for runtime operations, serve only to obfuscate the more important parts of the model.
Table 6.2 Topography Modeling Template Areas and Descriptions
Using paper and pen to simulate the processing flow of the system being designed promotes continued additional conversation drivers that can lead to deep insights into the software’s inner workings. Are there missing business capabilities that are needed for complete functionality through collaboration and integration? Do there seem to be areas warranting refinement or areas needing further clarification? Making changes with pen and paper is a lot faster and cheaper means to fail fast, learn, and reboot.
Every team involved in the integrations can carry away copies of their context(s) and the surrounding contextual topographies that collaborate. Each opportunity to discover and learn leads to confidence and a chance to innovate.
Ways to Fail and Succeed
Failure can lead to good because of the learning opportunities it produces. That kind of controlled failure is based on a scientific approach using experimentation and ultimately leads to success. Although learning can come from the failures discussed in this section, these are not the kind of failures that can help the organization in the short term. Instead, these kinds of failures can and should be avoided. They relate to misusing the domain-driven tools, and often lead to overall failure to meet the business goals.
Failure when applying a domain-driven approach is generally related to several different mistakes, all of which might be at play, or possibly just a few of the most insidious ones. Consider the following common pitfalls:
1. No strategic focus. Disregarding the strategic discovery and learning opportunities is missing the point of the domain-driven approach. It will also lead to software development as usual, with all the problems already discussed, because business experts will not be involved and developers will create a divide of tangled components as before. The developers imagine that following some technical ideas from the domain-driven approach is all that is needed, but not applying strategic learning is a big mistake.
2. Doing too much too soon. Using strategic discovery, but only at a cursory level as an excuse to start coding, is fraught with problems. It’s roughly the same as not using strategic design at all, although some boundaries might be discovered that are appropriate in the short term. Even so, problems will occur when trying to apply Bounded Contexts with distributed computing before the teams have a good reason to, or when trying to understand the strategic goals and solve business problems using single-process modularity first. Such a bias will likely lead to over-engineered technical approaches, putting too much emphasis on the solution rather than on the strategy. A domain-driven approach is about discovery, learning, and innovation.
3. Tight coupling and temporal dependencies everywhere. Especially when things move too quickly, too little attention is given to upstream and downstream dependencies between Bounded Contexts. Often this is also due to the style of integration used. For example, REST and RPCs can lead to very tight coupling, both in API dependencies and temporally.3 Making an effort to disentangle data type dependencies is rarely even considered. Frequently, this neglect leads to nearly every integration becoming a Conformist to upstream contexts. Generally, when using REST and RPCs, there is a sense that the network doesn’t exist between two services, even though it does. When the network is unstable, even for a short period of time, that can wreak havoc on integrations, causing cascading failures across a whole system. Even when using messaging and events, the coupling can still be a liability rather than an asset when there is no effort to decouple the data types between contexts.
3 Temporal coupling is harmful because one distributed service will fail when another completes more slowly than expected or tolerable.
4. Replicating data broadly. Every single piece of data has a system of record—that is, an original source and an authority over the data. When any single piece of data is replicated and stored in another location other than its source, there is a risk of losing the source and authority over it. Over time, those employees who understand that the data copy should not be used for conclusive decision making might leave the project, or new employees working on their own might make a wrong assumption about ownership, use the data inappropriately, and possibly even provide a copy of it to others. This can lead to serious problems.
5. Technical failures. There are a few different varieties of these failures:
a. Producing quick fixes to bugs or model disparity can lead to progressive distortion of the Ubiquitous Language.
b. Developers may pursue highly abstract type hierarchies upfront in an effort to open the door to unknown future needs, which rarely prove correct in the long run. In general, abstractions adopted in the name of code reuse or even emphasis on concrete reused goals will lead to unwanted baggage at best, and potentially extensive rework.
c. Assigning insufficiently skilled developers to the project will lead to near certain failure.
d. Not recognizing or recording debt due to business modeling knowledge gaps, or lack of follow-through to pay the recognized and recorded debt, is another technical failure.
Most of these major project failures—from which it might be impossible to recover—have already been addressed in one way or another in this book. The saddest part is that they are all avoidable. With the assistance of one or two domain-driven experts to get a project or program effort under way, and with some guidance over each month of the projects, teams can be both brought up to speed and helped to grow and mature. The following are ways to succeed:
1. Understand the business goals. All stakeholders must keep clearly in mind the business goals to be achieved through a domain-driven effort. Understand that current knowledge is all that is available, and new knowledge can change the project direction.
2. Use strategic learning tools. Once business goals are firmly established in everyone’s mind, dig into the problem space domain by building teams with good organizational communication structures that stand up to Conway’s Law, by using Impact Mapping, EventStorming, Context Mapping, and Topography Modeling. Everything is an experiment until it isn’t. Don’t be discouraged if that time never arrives. Failing in small ways, and doing so rapidly and inexpensively, is discovering and learning at its best.
3. Take time to digest learnings. Don’t be in too big a hurry to start developing concrete solutions. Code should be written very early, but with the intent to experiment, leading to discovery and learning. Sometimes it can take a few days for the context boundaries to settle, and even when these seem correct, at least minor adjustments will likely be necessary. Sometimes the boundaries are correct but some concepts and data are misappropriated. Be willing to move some concepts around to different Bounded Contexts, and recognize when concepts have become more clearly identified with their rightful ownership. This can happen even a few days or more into the project. These kinds of concept and data migrations seem to require more time to settle on when working on legacy modernization and large enterprise digital transformations.
4. Adopt loose coupling and temporal decoupling techniques. The less one Bounded Context knows about another Bounded Context, the better. The less one Bounded Context accepts another Bounded Context’s API, information, and internal structure into its own, the better. The less one Bounded Context depends on another Bounded Context’s ability to complete a task within a given time frame, the better. The less one Bounded Context depends on another Bounded Context to provide information in any order relative to any others, the better. Loose coupling and temporal decoupling are our friends.
5. Respect data origins and authorities. Stakeholders must learn to avoid replicating data outside its authority and access it for single-use operations. Chapter 5, “Contextual Expertise,” provides ways to access data from disparate services while respecting the original sources.
6. Use appropriate tactical tools. This book is light on detailed implementation techniques, but the authors provide a follow-on technical book, Implementing Strategic Monoliths and Microservices (Vernon & Jaskuła, Addison-Wesley, forthcoming). on deep implementation patterns and practices. In brief, avoid technical tools that are unnecessary for the context and that tend to lead to more expensive designs without justification for them.
Champion simplicity in the strategic and tactical tools and approaches used to wrangle with the already complex business domain at hand. Winning strategies guide teams toward delivering on business goals that lead to the ultimate business aspiration: richly rewarding innovations.
Applying the Tools
The section “Applying the Tools” in Chapter 3, “Events-First Experimentation and Discovery,” depicts a recording of an EventStorming session in which NuCoverage discovers a problematic issue: Applicants are dropping out of the application process before it is completed. One opportunity that the team has identified to address this problem is to use machine learning algorithms to assess the risk and calculate the rate; however, it was not clear to the NuCoverage team how machine learning would fit into the overall application processing. They decided to hold another EventStorming session closer to the design level to help them with this specific challenge. After some intensive discussions between team members and business experts, the design of the new application process started to take form.
Recall from Chapter 3 that the current application process is constantly exchanging messages between the Risk Context’s assessment and the Rate Context’s premium calculations so that it can obtain the most accurate projected premium quote to present to the applicant in real time as they progress through the application form. This feeds into the ongoing application information gathering effort by evaluating whether the applicant must answer additional questions. All this dynamicity is used in an effort to simultaneously keep the current projected premium quote before the applicant and allow NuCoverage to assess risk more precisely and (re)calculate an up-to-date premium. Unfortunately, it has produced a long and cumbersome application process that the team will attempt to simplify by introducing machine learning algorithms.
The new application process requires a bare minimum of data from the application form, with nearly zero complexity demanded of the applicant. The complexity will instead be encapsulated in the machine learning risk assessment and premium price calculation models. What stands out as a result of this discovery and learning iteration is that to achieve the team’s goal, a specific business process is needed to handle interactions between the application forms, risk assessment, and premium rate calculation. The team decided to name it the Application Premium Process. In Figure 6.10, this process is shown on a purple (or lilac or mulberry) sticky note. Once the application form is complete, the Application Submitted event occurs. It is handled by the Application Premium Process, which guides the subsequent next steps. The team continues iterating on the EventStorming session in an effort to discover what the individual processing steps will be.

Figure 6.10 The team identified the Application Premium Process.
The risk assessment based on machine learning algorithms is quite complex. This process will need to access several external data sources and handle complex algorithm calibration steps. As illustrated in Figure 6.11, the NuCoverage team thought it would be the best to model the assessment as a Risk Assessor stateless domain service, as described in Chapter 7, “Modeling Domain Concepts.” It starts the risk assessment step upon receiving the Assess Risk command from Application Premium Process. The outcome of the risk assessment is captured in an Assessment Result aggregate, and the Risk Assessed event is emitted. This event is handled by the Application Premium Process, which will cause the next processing step.

Figure 6.11 Design of the risk assessment step with machine learning.
The next step started by the Application Premium Process triggers the premium rate calculations by issuing Calculate Rate command. The rate calculation processing is likewise a complex step because any number of different calculation rules could apply based on the assessment results, risk weights, and other criteria defined by the specific agent’s business experts. Yet, the calculation step itself is stateless. When these considerations were taken into account, designing the Rate Calculator as a domain service seemed the best option (Figure 6.12). It can change in the future, but given the current knowledge, a domain service is the right choice. After the rate has been calculated, a Rate Calculated event is emitted that contains the calculated Premium as its payload. This event is handled by the Application Premium Process, which will again cause the next step.

Figure 6.12 Design of the premium rate calculation step.
Following the previous steps, a quote can be provided to the applicant. The Application Premium Process further drives the application process by issuing the Record Premium command. This command results in a Policy Quote being generated for the applicant, and presented in the UI. Figure 6.13 illustrates this process.

Figure 6.13 Final step of storing a premium for and issuing a policy quote.
The team decided to review the entire process design once again, with the intention of identifying the different contexts in play for the application-to-quote processing. As indicated by Figure 6.14, the team employed pink stickies placed over the various steps to identify the contexts involved across the timeline. This timeline is the entire result of the EventStorming session. Currently, everybody is happy with the outcome, but they all realize that there is even more to learn.

Figure 6.14 The new application process as a result of the EventStorming session.
The identified Bounded Contexts playing a role in the application process are Underwriting, Risk, and Rate. The Underwriting Context is responsible for gathering application form data at the beginning of the process and issuing a policy quote at the end. It makes sense that the Application Premium Process driving all the steps of the application lives in the Underwriting Context. The Risk Context assesses risks with the help of its associated machine learning algorithms. The Rate Context calculates the premium rates using the appropriate standard rules and those applicable to the specific agent.
As the final step of the design session, the team decided to use Context Mapping to indicate relationships between the different contexts and how integrations will work, making these explicit. Figure 6.15 shows this mapping.

Figure 6.15 Context Mappings between Underwriting, Risk, and Rate.
In the “Partnership” section earlier in this chapter, we noted that when the Risk team realized they had by default inherited rate calculations, that assignment seemed problematic to them given their already intense tasks ahead. This realization influenced the decision to split the original Risk team into two teams to manage the separate contexts, Risk and Rate. Thus, a total of three NuCoverage teams will work on the end-to-end application-to-quote processing. Each of the three teams will work on the Underwriting, Risk, and Rate contexts, respectively. Initially, a pragmatic decision determined that Risk and Rate should work within a Partnership relationship. These two teams’ goals are interdependent, at least in the early stages of implementation, and the overall quoting cannot be accomplished without the success of both. In fact, significant calibration is required between the assessed risk and rate calculation models. It would be unnecessarily difficult to synchronize their designs if the two teams were not committed to a Partnership relationship. As previously explained, a Partnership need not be maintained over the long term. At some point, the Partnership is likely to become a bottleneck, blocking one or both teams from making progress independent of each other as the business moves forward with unrelated priorities.
The teams considered designing a Published Language that would be shared between the Underwriting, Risk, and Rate contexts. This proposed language would include the commands and events necessary to drive the processing. Ultimately, though, it was determined that a single Published Language would be unnecessary because the Application Premium Process will manage cross-context dependencies, whether upstream–downstream, peer-to-peer, or whatever else might be necessary. A Schema Registry will be used to maintain loose coupling even within the Application Premium Process that is implemented inside the Underwriting Context.
The Underwriting Context is downstream to Risk and Rate because they depend on the assessed risk and calculated premium rate. These are decidedly Customer–Supplier relationships. The Underwriting team must synchronize with the Risk and Rate team to implement the application-to-quote process as a whole. Both the Risk and Rate contexts will define their own limited, but independent Published Languages, which the Application Premium Process will use. The Underwriting Context must communicate the application data to Risk Context, but the application data must be formatted according to the Risk Published Language. In contrast, the Rate Context communicates its Rate Calculated and Premium model elements to the Underwriting as its own Published Language. These considerations help normalize those exchanges and provide for the highly desired loose coupling between the contexts.
Summary
This chapter promoted the use of Context Maps to identify relationships between any two teams and their respective Bounded Contexts. Context Mapping helps teams recognize the situations they face and provides tools to recognize and address specific modeling challenges that result in whole-system solutions. Using a topographic approach to Context Mapping assists in defining boundaries and specifying how various Bounded Contexts work together. Warnings were offered about the common pitfalls of misusing the domain-driven tools, which can lead to costly, overall failure. These warnings transitioned to useful guidance for succeeding with proper use of the same tools.
Follow these guiding principles:
▪ Discover the actual existing inter-team relationships by applying Context Maps to each integration point, and (possibly) attempt to work out better circumstances by improving a given relationship and means of integration.
▪ Correctly apply the appropriate Context Mapping options, such as Partnership, Customer–Supplier Development, Conformist, Anticorruption Layer, Open-Host Service, and Published Language, to current and future modeling situations.
▪ Topography modeling is a means of understanding the shape and character of your system and grasping the flow of detailed information exchange between Bounded Contexts.
▪ Carefully avoid misusing the domain-driven tools. Doing so can lead to failure of entire projects and, in turn, to failure to meet business goals.
▪ Most domain-driven pitfalls can be avoided. Engage and retain a domain-driven expert to help launch and keep the system architecture and development on track.
Chapter 7, “Modeling Domain Concepts,” introduces the tactical domain-driven modeling tools, which are used to express a sphere of knowledge in source code free of confusion that results from ambiguity.
References
[Consumer-Driven-Contracts] https://martinfowler.com/articles/consumerDrivenContracts.html
[StrucDesign] W. P. Stevens, G. J. Myers, and L. L. Constantine. “Structured Design.” IBM Systems Journal 13, no. 2 (1974): 115–139.
[VLINGO-XOOM] https://github.com/vlingo and https://vlingo.io