
2. Essential Strategic Learning Tools
A strategy is the what aspect of business creation, leading to new initiatives that are intentionally unique and produce a combination of profit sources. It asks, what must our business do to differentiate, or extend and increase its uniqueness, from other businesses? This makes strategic planning a means to attain innovation, but there must actually be innovation in recognizing a valuable, differentiated strategy.
So you can’t go out and ask people, you know, what the next big thing is. There’s a great quote by Henry Ford, right? He said, “If I’d have asked my customers what they wanted, they would have told me ‘A faster horse.’”
—Steve Jobs
This doesn’t mean that it would be fruitless to ask a customer what they think is the next big thing. Actually “a faster horse” can be a great hint that “faster travel” is the critical takeaway. It is important to talk with customers and the public in general. Still, the business should have the talent to gain a keen understanding of the what part of business. It’s a requisite for success. It must be sought after, and the dig-and-find happens through learning. Note the earlier part of the quote from Jobs, speaking of Apple’s own internal talent with regard to the iPod.
We did iTunes because we all love music. We made what we thought was the best jukebox in iTunes. Then we all wanted to carry our whole music libraries around with us. The team worked really hard. And the reason that they worked so hard is because we all wanted one. You know? I mean, the first few hundred customers were us.
It’s not about pop culture, and it’s not about fooling people, and it’s not about convincing people that they want something they don’t. We figure out what we want. And I think we’re pretty good at having the right discipline to think through whether a lot of other people are going to want it, too. That’s what we get paid to do.
—Steve Jobs
To learn well, it sure helps to have good tools for digging to unearth knowledge from people and facts. This chapter provides strategic discovery tools and demonstrates how they can be used. Some of the best tools are more inside than outside.
Making Decisions Early and Late, Right and Wrong
Decisions can be paralyzing if you don’t learn how to thrive on making timely, as well as right and wrong, decisions. Both can work to our advantage. Don’t fear decision making. Understand when decisions should be made. Some decisions are best made as early as possible; others are best made as late as possible. Some decisions will be right; some will be wrong. Gain the fortitude and acquire the techniques required to celebrate hard decisions, right and wrong.
A common principle of #agile is that all decisions should be made at the last responsible moment [Cohn]. How do we know when we have reached this “last responsible moment” decision point at any given time? Advice is provided by Mary and Tom Poppendieck:
Concurrent software development means starting development when only partial requirements are known and developing in short iterations that provide the feedback that causes the system to emerge. Concurrent development makes it possible to delay commitment until the last responsible moment, that is, the moment at which failing to make a decision eliminates an important alternative. If commitments are delayed beyond the last responsible moment, then decisions are made by default, which is generally not a good approach to making decisions. [Poppendieck]
More concisely, it can be said that decisions should not be made irresponsibly, whether they are made early or late [LeanArch]. Irresponsible decision making occurs when there is not enough insight to support any given decision, which is likely an occasion of making decisions too early. Yet, gaining necessary insight is possible if there is currently enough information to support a decision. If information is available but unvetted, the next steps should be obvious.
As time advances, avoiding necessary decisions is even worse than making the wrong decisions. Self-motivated workers don’t sit around waiting for things to happen. Early on, writing some initial code or defining general-purpose modeling abstractions is common behavior, and usually involves at least a few opinionated developers going in different directions. These arbitrary actions lead to commitments but exclude the team from the decision-making process. That pattern sets a definite structure for the application or the underlying architecture that can last for the entire software life cycle.
Ask yourself, is it really desirable to commit to uncontrolled structure, form, and abstraction based on unconfirmed assumptions? Obviously, it is best to consciously decide on the direction that application architecture should take. Even so, it’s possible for a team to drag its collective feet for fear of creating the wrong architecture.
Decisions can be made if the team has enough information to get started. This might involve several practitioners providing different viewpoints, but kicking the can down the road can’t go on indefinitely. Moreover, if we make some poor decisions, they are not necessarily written in stone. Assuming a team can be honest about the negative impacts of accepting poor decisions and not allowing them to go unaddressed, they will take corrective action as quickly as possible. Refactoring an architectural structure early on is not a large time sink. Later on, that cost increases. Making course corrections is all part of learning, and learning should lead to changes.
Yet, if we waited a long time to start structuring the application before we made the wrong decision, what would be gained? Would delaying have brought about the same decision that was made when corrective action was taken? Or was experiencing the ill effects of a wrong decision what led to the better decision? Experience has shown that the latter tends to prevail. This is why we record debt and pay it as soon as possible. That is actually mature decision making at the last responsible moment.
This points back to attitude: Don’t be paralyzed by decision making or by making a decision that proves to be wrong. As a computer scientist—a purposeful juxtaposition to a software developer—almost everything done can be treated as an experiment. We are confident that some experiments are only confirmations that our assumptions were correct. Other experiments are undertaken to determine if anything we thought stands up to the test.
In the end, making some decisions early on is irresponsible. For example, settling upfront on architecture, such as using Microservices, or trying to create generalized solutions and modeling abstractions, is wrong. These decisions should be postponed until we prove that those choices are justified and necessary.
The difference between experts and amateurs has much to do with timing.
In his essay “Delaying Commitment” (IEEE Software, May/June 1988), leading British computer scientist and professor Harold Thimbleby observes that the difference between amateurs and experts is that experts know how to delay commitments and conceal their errors for as long as possible, repairing flaws before they cause problems. Amateurs try to get everything right the first time, so overloading their problem-solving capacity that they end up committing early to wrong decisions [DrDobbs].
What Thimbleby didn’t say is that the expert continuously records debt and pays it, even if it is done informally in their isolated thoughts.
The outcome of making decisions is the learning process it triggers. Decision leads to actions, which cause new requirements and knowledge to emerge. At the same time, progress is made in solving core application challenges. Don’t neglect this aspect of decision making, because in the end it comes down to learning and knowledge acquisition. As described in Chapter 1, “Business Goals and Digital Transformation,” knowledge is the most important asset in any business. Knowledge changes everything.
There is still the risk that our uncertainties will influence us in other ways. Cognitive biases regularly lead people to make irresponsible decisions. We may also fall for fallacies such as the Fear of Missing Out, among others [LogFal]. Consider some influences in the context of irresponsibly choosing Microservices:
▪ Appeal to authority. An appeal to authority is an argument stemming from a person judged to be an authority and affirming a proposition to the claim that the proposition is true. For example, if someone recognized as an expert claims that Microservices are good and Monoliths are bad, the listener can make decisions that are harmful and inappropriate for their own context.
▪ Appeal to novelty. Appeals to novelty assume that the newness of an idea is evidence of its truth. If Microservices are the newest fad, adoption is a must.
▪ Bandwagon fallacy. Similar to Fear of Missing Out. The bandwagon fallacy occurs when arguments appeal to the growing popularity of an idea as a reason for accepting it as true. People take the mere fact that an idea suddenly attracts adherents as a reason to join in with the trend and become adherents of the idea themselves. Microservices are growing in popularity so we have to adopt them very quickly as well.
Tools are available that can help fight all kinds of fallacies and confirmation biases. One of them is to use critical thinking.
Critical thinking is a type of thinking pattern that requires people to be reflective, and pay attention to decision-making which guides their beliefs and actions. Critical thinking allows people to deduct with more logic, to process sophisticated information and to look at various sides of issues, so that they can produce more solid conclusions. [CT]
Software development involves a considerable amount of decision making, whether or not a specific decision has a large impact. It’s rarely straightforward to trace the roads taken, and the roads not taken, through the software life cycle. This is especially the case for the project newcomer. Yet, it’s even difficult for long-time team members to recall every past decision. Perhaps a given team member wasn’t directly involved in a specific decision. More often, the sheer number of decisions made by a team, combined with the fact that the memories of those decisions aren’t strengthened by frequent travel through the hippocampus, impedes instant recall. Under these conditions, a team is often left with only the result of a decision, without a way of tracing why it was made.
Although commonly neglected or completely unconsidered, decision tracking should be one of the most important activities in software development. Tools such as Architecture Decision Record (ADR) help teams maintain a decision log, which is very helpful in tracking the team’s decision journey, including what happened and why. ADR helps connect the initial subject of the decision to the expected and ultimate outcome of that decision. The section “Strategic Architecture,” later in this chapter, describes ADR and other techniques in more detail.
A wealth of software development techniques exist that can help teams in deferring binding long-term decisions and tracing the decisions being made in the life cycle of a software development project. These are described later in this book. One such tool is the Ports and Adapters Architecture, which is discussed in Chapter 8, “Foundation Architecture.” In addition, cognitive frameworks such as Cynefin, which is described later in this chapter, may be used to aid in decision making.
Culture and Teams
Creating an #agile culture that uses experimentation and learning requires that people be rewarded for being wrong as long as that process eventually leads to being right, whatever “right” ends up being. Businesses that want to succeed at digital transformation must change their culture from a perspective of software as support to the view of software as product. Culture is a big deal, and so is how teams are formed and supported.
The culture of a business encompasses values and behaviors that contribute to its unique physical, social, and psychological environment. Culture influences the way teams interact, the context within which knowledge is created, the acceptance or resistance they will have toward certain changes, and ultimately the way they share knowledge or withhold it. Culture represents the collective values, beliefs, and principles of organizational members [Org-Culture].
Organizations should strive for what is considered a healthy culture. The aim is to derive cultural benefits, such as a better alignment with achieving the organization’s vision, mission, and goals. Other benefits include increased team cohesiveness among the company’s various departments and divisions, higher employee motivation, and greater efficiency.
Culture is not set in stone. It can be improved or damaged depending on the actions of leadership and employees. If the culture is currently unhealthy, it needs to be altered to yield sound, healthy benefits.
Building of a healthy organizational culture should be set in motion before attempts are made to build anything else. Businesses that don’t take healthy cultural aspects far enough risk losing their workforce, and consequently a part of their knowledge base. This failure also undermines productivity and innovation in the long term, which leads to the business becoming less successful.
A culture that focuses on facilitating innovation is valued by leaders and employees alike. Although leaders claim to understand what building a culture for innovation entails, creating and sustaining it is hard. An impediment to building cultures that are innovative is, obviously, not understanding what such a culture is and how to cultivate it.
Failure Is Not Fatal
An organization’s viewpoint on failure is one of the most important cultural factors, for good or for ill. Why are so many teams afraid to fail? The fear of failure determines the way that the team members make decisions, or completely avoid making them. More accurately, the fear of making the wrong decision, which then leads to failure, is often the reason that decisions are perpetually deferred or never made.
Recall from earlier in this chapter that the engineering model trumps the contractor model by allowing for failure so that the organization can learn. Failure is not the objective. Instead, the point is to challenge assumptions enough that some failure is inevitable. All experimentational failure is a means to an end, to learn what works. It’s said that if a team doesn’t fail at all, they are not exploring. Instead, the team is resting their decisions on what they already know as best, and that’s very likely ordinary.
Is the fear of failure worse than failure itself? Which is worse, failing or never trying? The Wright brothers began aeronautical research and experimentation in 1899, with many failures following their initial efforts. It is said that they owed much of their success to the many failures of others before them. Most people remember only their first successful powered airplane flight of 1903. That is, in fact, the way it should be—celebrate the arrival and the route taken.
Building an #agile, failure-tolerant culture that fosters willingness to experiment and provides people with psychological safety can only increase business success and competitive advantage. However, it has to be counterbalanced by some exacting behaviors. While an organization’s culture should be tolerant to failures, it should be intolerant toward incompetence and complacency [Pisano]. This attitude is especially very important in software development, as it is fraught with uncertainty. The large number of Big Ball of Mud (see Chapter 1, “Business Goals and Digital Transformation”) systems, and the fact that these are the norm throughout the world, proves that failure in the midst of some success is quite common. This problem ends up being recursive, however, which leads to strategic demise.
1. Creating a Big Ball of Mud from the outset is a failure in terms of software development principles (this doesn’t imply that it was intentional).
2. The fact that the Big Ball of Mud system actually functions to the extent that it is useful is an initial success for the business.
3. Given no effort to change the long-term impacts of 1, the Big Ball of Mud system codebase will only become worse, which will have a greater effect later.
4. The Big Ball of Mud system’s ability to respond to change decreases to the point of inertia, which ultimately produces failure in terms of providing for the business’s long-term needs.
Failures can lead to interesting learning opportunities. Important lessons learned can also be a result of poor model designs, brittle code, deficient architectures, flawed analysis, and general incompetence. Recognizing these situations before point 3, and certainly before point 4 is critical.
Therefore, the distinction has to be made between positive and negative failures. Positive failure yields information and knowledge, while negative failure can be expensive and harmful to businesses. The rewards of failure should only be realized in the face of tangible learning outcomes and knowledge that ultimately result in success. The Wright brothers failed many times, but they also eventually succeeded in flight.
Failure Culture Is Not Blame Culture
The relationship between failure and blame culture is often not well understood. Blame culture is negative, as it is based on punishment of failures, whether those failures eventually lead to positive or negative results. In a blame culture, learning outcomes are not celebrated, and often not taken into account as truly critical to ultimate success. Instead, they are discarded.
Blame culture also hinders any initiatives in experimentation. The result is that things continue to be done in the same, pedestrian, ordinary way. Everybody is afraid to try something new, because if they fail, they will be blamed. In organizations with a blame culture, successes are at best passed over, as if there was no possibility of a failure, and failures are punishable. No one wants to take risks. This smells like the contractor model.
As a result, instead of innovating, businesses attempt to increase profit through operational efficiencies. A few of the most popular approaches are the use of mergers and acquisitions. These account for numerous personnel consolidations, which do lead to greater profits. This route does not often attempt business innovation as a profitable pursuit. Instead, operational efficiencies are seen as the easiest way to continue producing favorable annual reports to shareholders. Although this strategy can work for a time, it can’t produce endless gains. In fact, it’s just a different path to diminishing returns. Without another merger or acquisition, profits edge toward zero.
To say the least, a business focused on operational efficiencies is a breeding ground for blame culture. This flawed culture uses (passive-)aggressive management, micromanagement inside of teams, invasive time tracking of a team’s work, and pushing team members to work late hours as a way to meet deadlines. Blame plays a major role when performance is so critically scrutinized that the only way to avoid looking bad is to make others look bad.
Experimentation need not be more expensive than the lack of it. The same goes for communication that leads to effective learning through knowledge sharing. Consider both in the face of Conway’s Law.
Getting Conway’s Law Right
As stated in Chapter 1, “Business Goals and Digital Transformation,” we cannot “get better” at Conway’s Law, just as we cannot “get better” at the law of gravity. Laws are unavoidable. With gravity on the earth scale, there is no alternation in a normal setting. If you stand somewhere in France or in the United States, the force of gravity is the same. However, at the universe scale, gravity is not the same. Depending on whether a person is on the earth or the moon, they will not experience gravity in the same way. This holds as well for Conway’s Law.1
1 Until we experience software development on the moon, we’ll state only that different conditions can change the influence of Conway’s Law for teams on earth.
Each organization experiences Conway’s Law differently because each one is structured and organized differently. Making organizational changes will either reduce or intensify the influence of Conway’s Law. As highlighted in Team Topologies [TT], if the desired theoretical system architecture doesn’t fit the organizational model, then one of the two will need to change.
Yet, it is a mistake to think that any reorganization should be undertaken only for technical architecture purposes. Technical architecture is a supporting requirement for business strategic architecture. The individual team organization must facilitate the necessary contextual conversations between the business experts and the software development experts. “Domain expert engagement is to architecture as end user engagement is to feature development. You should find that end users and domain experts are your most treasured contacts in Lean and Agile projects” [LA].
There is the organizational pattern “Inverse Conway Maneuver” coined in 2015 by people from ThoughtWorks. It was codified when Microservices became very popular. The pattern advises to organize teams according to the desired architecture structure, rather than expecting existing teams to match up to the architectural goals. By reconfiguring teams for the optimal inter-team communication, the desired architecture is more likely due to the optimized communications structure. [TW-ICM]
Mel Conway’s original paper addresses this very “maneuver” in the conclusion. Pertinent quotes from that paper are listed here for context:
“We have found a criterion for the structuring of design organizations: a design effort should be organized according to the need for communication.”
“Flexibility of organization is important to effective design.”
“Reward design managers for keeping their organizations lean and flexible.”
Conway deserves credit for having the insight to codify the solution to the law that he observed so long ago in 1967 (and published in 1968).
The question remains, how can teams be organized effectively to improve the communication between teams? We list some opportunities here:
▪ Keep the team together. According to Bruce Tuckman [Tuckman], the team must undergo the steps of forming and norming, before it reaches the performing stage. It takes time for team members to find ways of effectively working with each other. Many exchanges are informal and a matter of habit. Teams build a tacit knowledge that enables them to perform2–but that takes time.
2 When a team is working in project mode and the project is considered complete, the team is often disbanded and the software is handed over to the maintenance team. The tacit knowledge of the former team doesn’t survive the transition.
▪ Limit the team size. You should build the smallest possible team, but no smaller, to work on a given software domain solution. Coordination and communication costs inside big teams become worse asymptotically as the team grows. Moreover, the team size factor is dictated not only by the first Conway’s Law (“Communication dictates design”); that is, communication paths can also be estimated by applying Fred Brooks’s intercommunication formula: n(n − 1) / 2 [Brooks]. The more people who compose a team, the worse communication will be. There will be too many communication paths. For example, with 10 people there will be 45 communication paths,3 and with 50 people there will be 1,225 paths. Teams of 5 to 10 people are considered optimal.
3 10 * (10 – 1) / 2 = 45.
▪ Make independent teams. Effective coordination between teams that are dependent on each other requires much time and effort. Minimizing code dependencies, coordination of releases, and deployments can have positive impacts on delivery times and the quality.
▪ Organize teams around business capabilities. Software development is a very complex process requiring a wide variety of skills. Therefore, encourage diversity of skills inside the team. If the team is composed of people having different skills, such as business expert, software architect, developer, tester, DevOps, and even an end user, they can be equal to the task. Such a range of skills not only affords autonomy for decision making and accountability, but also, according to Conway’s Law, enables building of a healthier structure (not focused on siloed skills). With this approach, it won’t be necessary to have a lot of communication outside of the team to carry out daily responsibilities.
▪ Define communication gateways for teams. A team with a broad skill set and vital autonomy can optimize in-team communication, but must still shape inter-team communication through gateways. The result might be a similar shape as the communication between architecture components. Consider inter-team discussions to require protocols, along with mapping and translation between teams. The protocols should establish boundaries to protect against interfering with team goals, distractions, and possibly even unauthorized exchanges. These should reflect a one-to-one relationship with the integrating software architectures. The topic of context mapping is discussed in Chapter 6, “Mapping, Failing, and Succeeding—Choose Two.”
▪ Assign a single responsibility to the team. Requiring a single team to manage too many tasks and contexts in the same architecture, or worse, assigning multiple projects in parallel, will not end well. Unless these mistakes are avoided, communication complexity will increase and overlap, with the risk of mixing together and confusing contextual concepts. Yet, single responsibility doesn’t necessarily mean a single context, because the team may decide that solving a single problem space may require multiple contexts.
▪ Eliminate multitasking from the team. Although not directly related to Conway’s Law, human brains don’t multitask very effectively, and especially not in complex problem-solving situations. Multitasking requires context switching. Humans are bad at this because we require context-dependent memory. Each context switch can require several or even dozens of minutes to complete. Multitasking is not just a productivity killer—it also breaks down effective communication channels. The misperception that multitasking works for humans is remedied by observing the large number of errors produced by a person who tries it, such as completely overlooking steps that are basic to anyone giving due focus. It’s amazing how below average very intelligent people become under such circumstances.
Figure 2.1 depicts different team organizations yielding different architecture structures that match the respective team organizations. On the left, teams are silos of skills. Often, the team at the communication cross-roads—the backed team in Figure 2.1—has all the burden of communication and coordination between the others—DBA teams and UI teams. What makes the teams even less efficient is that they work in multiple business contexts—here, it’s Claims, Underwriting, and Insurance Products—which is an additional source of complexity to take into account. The interdependencies and highly coordinated communications complicate value delivery to the business.

Figure 2.1 Conway’s Law. Left: Skill silos. Right: Cross-functional skills, business capabilities.
On the right side of Figure 2.1, teams are cross-functional and aligned with business capabilities. Note that these teams are autonomous and responsible for the whole life cycle of the subsystem architecture that they own. Their day-to-day responsibility is not just the software development; the team also has insight into how software they developed behaves in production. This leads to better contact with end users, as the team members have to assist them as part of their support work. It is a kind of virtuous circle, because the new insights from customers and users help teams to enhance the business capability for which they are responsible.
A point not to be overlooked is the criticality of creating teams primarily for the sake of in-team contextual communication between business experts and software development experts. If a given team can talk across to other teams with great ease but can’t have deep communication with business experts in support of building their own strategic deliverables, the fundamental communication problem has not been solved, and is possibly even worse than before the reorganization.
Enabling Safe Experimentations
Acknowledging the difference between blame and failure culture is the first step toward building a better and healthy culture. The next step is to enable safe experimentation for businesses—which doesn’t mean an organization simply allows its teams to throw in random architectural choices or technologies.
Safe experimentation means discipline, and discipline means carefully selecting ideas that will potentially yield great learning results and knowledge. There are different interpretations of “safety,” but as Erik Hollnagel states, “Safety is a freedom from unacceptable risk” [Hollnagel]. In other words, this process must allow for prevention of unwanted events and protection against unwanted outcomes.
While the safe experimentation is ongoing, the learning process is evaluated, and the information gathered is inspected, which enables the organization to decide whether the experimentation should be moved forward or cancelled. What counts is increasing safety by reducing failures and, therefore, the risk for the business. Killing a safe experimentation is less risky than trying out new things blindly and calling it experimentation; otherwise, everything can be called experimentation.
Modules First
So, we’re going from “essential strategic learning tools,” including a discussion of a culture of failure as necessary to succeed, directly into some techie topic of “modules”? First of all, this topic is really not very technical. Everyone understands that containers of various kinds are made to hold items inside (e.g., kitchen drawers and drawers for storing food in a refrigerator). How the containers are labeled and what is put inside of each should be logical. Otherwise, when it comes time to retrieve the desired items from a container, they will be hard to find. For software development, teams must get this right before trying to do much else. Wasn’t the same assertion made in Chapter 1 regarding Conway’s Law? Yes, exactly.
Conway’s Law continues [Conway]:
Why do large systems disintegrate? The process seems to occur in three steps, the first two of which are controllable and the third of which is a direct result of our homomorphism.
First, the realization by the initial designers that the system will be large, together with certain pressures in their organization, make irresistible the temptation to assign too many people to a design effort.
Second, application of the conventional wisdom of management to a large design organization causes its communication structure to disintegrate.
Third, the homomorphism insures that the structure of the system will reflect the disintegration which has occurred in the design organization.
Considering modules only a “techie topic” is to sell short one of the most valuable tools that supports strategic learning.
Modularity is also the solution to how humans deal with very complex problems that must be solved. No one person is able to keep in mind the whole business problem space and deal efficiently with it. Before solving a big problem, humans tend to decompose what they know into smaller sets of problems. The smaller problems are easier to reason about. Of course, solutions to smaller problems are then combined to address the big problem; otherwise, modularity would be useless.
This way of solving problems has deep roots in psychology and reflects the limitations of the human mind. The human brain can keep a very limited set of concepts in focus at one time. This is described in George A. Miller’s paper from 1956, “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information” [Miller]. Miller’s Law says that humans can keep 7 ± 2 “chunks” or pieces of information in short-term memory. The exact number can vary from person to person, but what is sure is that this capacity is very limited. Due to this limitation, humans work out a hierarchical decomposition of information into smaller chunks, until they are about the right size to feed our mental model without causing stress on cognitive load, which would prevent processing of the information.
Now, back to the point of modules. Applying these components to complex problem solving helps manage chunks of information that have undergone the process of decomposition. This makes complex problem solving possible because humans can use stepwise processing to create successful outcomes.
Modularity is an indispensable foundation for Conway’s Law as well. That’s because modules are where we should capture critical communication and what is learned from it. At the same time, modules can save teams from smearing mud all over their solution space. Modules are used both as conceptual boundaries and as physical compartments.
Don’t worry. It will all make sense in a moment. Consider how modules support learning through communication.
Figure 2.2 shows three modules: Insurance Products, Underwriting, and Claims. Each of the three is the home of a separate business capability.

Figure 2.2 A module is both a conceptual boundary and a physical compartment.
A team consists of both business and software development stakeholders. For the sake of this example, one team is assumed to work on only one of the three business capabilities. The team that will be discussed here is responsible for delivering a solution for Underwriting.
For this team, Underwriting is considered the primary context for their conversations. To provide an Underwriting solution, however, the team will also likely need to discuss Insurance Products and Claims, and even other capabilities of the business. Yet, they have no responsibility or authority in those other conversational contexts.
Because their conversations will take various paths through the entire business domain, team members must recognize when their discussions “exit” their own context, “enter” another context, and possibly still others, and then “return” to their own context. When in conversation, if the team learns something relative to their own context, they should record some words or expressions in their contextual module that they consider to be keepers—that is, ones that will definitely help drive their further discussions and the ultimate solution.
A conceptual module doesn’t have a location, so where are the conversations literally recorded? For now this could be on a whiteboard, in a wiki, or in another kind of document. Certainly, the issue of not losing this information from an erased whiteboard should influence how it’s captured more permanently.
If it helps for the sake of their communication, the team can also record any part of their conversation that applies to another module, but the team doesn’t have authority to make firm, lasting decisions about those other contexts. In fact, if the team requires any official details about the other contexts, they will have to communicate with the respective teams. So, any terms or expressions they come up with for foreign contexts are only proxies for the real things for which the other teams are responsible. Also, whether proxy or official, the terms and expressions recorded for other contexts are placed in the respective contextual module, not in the team’s module.
As the team’s conversations progress, they lead to more learning, and the team continues to identify additional business concepts. Figure 2.3 reflects the progress, including the notion that creating additional modules inside the main Underwriting module helps to further organize their conversations as they become more specific.
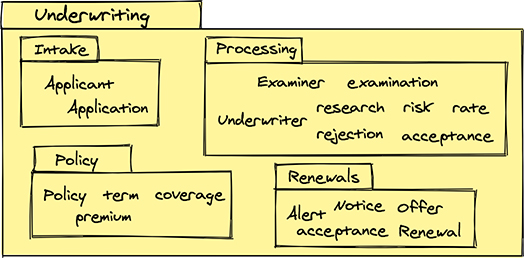
Figure 2.3 A module compartment of other module compartments used to organize source code.
A fair question is, would it make sense to promote the internal modules—Intake, Processing, Policy, and Renewals—to top-level modules of their own? That’s a possibility to consider in time, and there are advantages to doing so. But where exactly? At this time, the team should fall back on the earlier advice that in essence asserts, “the team doesn’t yet have enough information to accept that decision.” It would be irresponsible to go there now. Future conversations might lead in that direction, but jumping to that conclusion now doesn’t make sense. At this time, calling this a (non-)decision based on the currently identified concepts, and the team’s understanding of the cohesiveness of each concept relative to the others, makes them less likely to be separated.
This is pretty cool. It’s like the team is trying to keep everything all tidy inside their own conceptual boundary. But they’re not just trying—they’re succeeding. This is a major step in the right direction for avoiding the Big Ball of Mud. Considering that good communication and making decisions are the primary strengths behind software development, the team is definitely on the right track.
It’s essential to also reflect these measures in the software implementation. The team must prevent the reflection of order in their conversational design into a software model from being undermined over time. This leads to the second use of modules: A module is also a physical compartment. The team should create a physical module in which to place their source code. Using what’s exemplified in Figure 2.3, Table 2.1 lists examples of corresponding software modules.
Table 2.1 Modules of Underwriting Provide Explicit Compartments for the Implementation
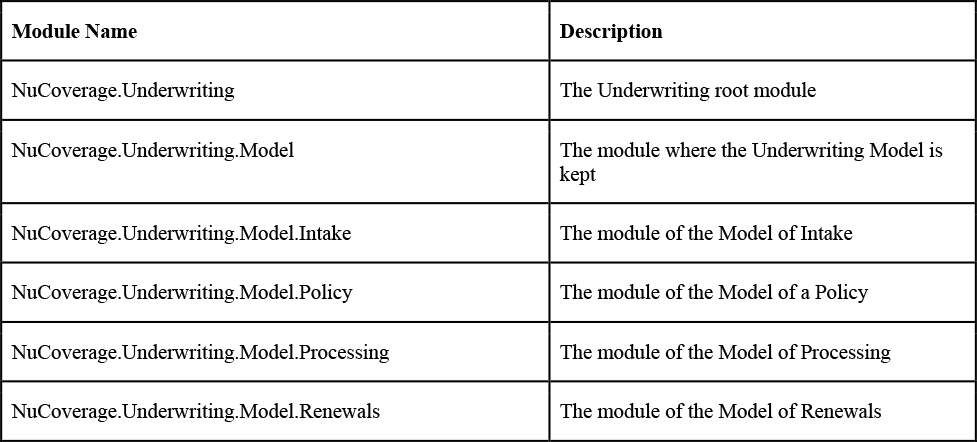
Depending on the actual programming language in use, these modules can be declared a bit differently, but that’s not important now. What is important is that the team can create compartments with very explicit names that clearly identify where things belong. Given their basic sensibility, there’s no way for confusion or disorderliness to exist at this point in time.
Another advantage of this approach is that if at any future time the team does decide to promote any of the models to become a top-level module on its own, the refactoring of what exists is quite straightforward. Considering this point, it’s clear that modularity trumps knee-jerk deployment decisions every single time.
Deployment Last
Choosing Microservices first is dangerous. Choosing Monoliths for the long term is also dangerous. As with any decision making in #agile, these decisions should be made at the last responsible moment. The following are two principles from the Agile Manifesto:
▪ Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
▪ Deliver working software frequently, at intervals ranging from a couple of weeks to a couple of months, with a preference to the shorter timescale.
Today, “a preference to the shorter timescale” can mean days, hours, or even minutes. In summary, this translates to deliver early and deliver often.
Under such conditions, how can deployment decisions be delayed for as long as possible? Think type rather than inception and frequency. Deployment type is a choice, and there are multiple deployment options from which to choose. Choices can change. Delivery inception and ongoing frequency are mandatory, regardless of the deployment choices.4
4 Chapter 9, “Message- and Event-Driven Architectures,” covers how this may be different for the serverless architecture, which may include function as a service (FaaS).
Early on, it is best to choose a deployment option that supports fast experimentation, implementation, and delivery. This specifically points to using a Monolithic architecture in the early stages, because trying to solve distributed computing problems before the business problems are understood is an act of futility.
To get this right out in the open, many software developers love the ideas behind distributed computing. It’s cool, thrilling even, to consider the prospects. For those who have never attempted this at all, or have little experience, it’s exciting to think in terms of getting elbow deep into distributed computing as soon as possible.
It’s a bit like anything new, such as driving. When you’re young, the opportunity to drive is generally a highly anticipated adventure. After the challenge of driving is no longer new, driving fast might be a new thrill to seek. After a high-cost speeding citation or a bad accident (plus a high-cost citation!) curtails the allure of high-speed driving on public roads, the realization sets in that driving is for the most part a means to an end. Still, the idea of getting an incredible sports car and having access to a racetrack elicits new thrilling thoughts. Even so, in time the appeal of traveling safely from one point to another is hard to deny. Especially when you have a family, it’s top priority.
Those who have done distributed computing find it challenging, and there is undeniable pleasure in getting it to work well. At the same time, distributed computing is not a thrill sport. And it’s hard. Any experienced software developer who is capable of being both realistic and responsible will admit that distributed computing is a means to an end. It should be the business drivers that lead to considering any computing infrastructure that will produce good customer outcomes.
If delivering software to the cloud is a means to the end of producing business-driven customer satisfaction, it’s likely that at least some distributed computing will be required. All the same, finding ways to reduce the total distribution of computing resources or reducing the complexities as much as possible should be the top priority. If still in doubt about this, please return to Chapter 1 and reread the section, “Digital Transformation: What Is the Goal?”
We’re not advocating for Monoliths over Microservices. We’re advocating for the best possible decision for the business circumstances. Avoiding the problems inherent to distributed computing—inter-subsystem software communication that involves a network connection—best supports early delivery and sustained delivery. Early on, there is no need to face the scale and performance challenges because they simply don’t exist.
When the business decides at the last responsible moment that opening up greater access to the system is in sight, the team must be prepared to measure how the system handles the increasing load. When performance and scale indicators are trending toward the need to address these issues, extracting one or more modules from a Monolith into Microservices is likely a reasonable way forward. Admittedly, this requires a style of development using architecture and design techniques that reflect the loose coupling of Microservices but work seamlessly inside a Monolith, and without the failure conditions common to distributed computing.
When the team has decided on modules first, and when deployment options start out as simple as possible, that approach puts them on solid ground to make decisions based on empirical information at the most responsible time.
Everything in Between
After modules, but before advanced deployment decisions, there is considerable work to be done. The work involves the following tasks:
▪ Identifying which business capabilities will be hosted in a given part of the system
▪ Pinpointing impactful strategic functionality
▪ Understanding software development complexity and risk
▪ Collaborating to understand the overall business process
▪ Reasoning out the assertions employed to prove all this works correctly.
The sections that follow cover the first three of these tasks. Chapter 3, “Events-First Experimentation and Discovery,” covers collaborative learning around business processes, and reasoning on software correctness assertions.
Business Capabilities, Business Processes, and Strategic Goals
A business capability is a function of the business that exists to generate revenues. Some functions are core business capabilities, while others are not. A core business capability is one at which the business must excel and differentiate within. The business must innovate in its core capabilities. A supporting business capability is one that is needed to make one or more of the core capabilities work, but not one in which the business should attempt to innovate. Yet, a supporting capability might not be available for off-the-shelf purchase, in which case it must likely be built. There are also generic business capabilities, such as those that keep the business functioning but don’t directly support the business core capabilities. These generic business capabilities should be purchased (licensed, subscription, etc.) wherever possible.
Note that a business capability is a what of the business, not the how. Consider that Underwriting is an NuCoverage business capability. How the company performs this capability could be by humans using snail mail and telephones, or it could be with fully automated digital workflow processing. The what and the how are two different things. How being an implementation detail is important, but one that could change over time. Even so, the what—Underwriting—will likely exist into the foreseeable future.
NuCoverage must innovate to offer insurance products at competitive discounts and still drive gains that are at least as good as those realized by the competition. Additionally, NuCoverage will now innovate by offering its insurance products with white labels. These are clearly direct revenue generators. Yet, which are the core business capabilities and which are supporting business capabilities? Consider the reasoning illustrated in Figure 2.4 and described in the list that follows.

Figure 2.4 Some NuCoverage business capabilities. Solid boxes are present business capabilities; dashed boxes are future business capabilities.
▪ Underwriting is the capability that produces a decision on whether a given insurable risk is worth issuing a policy or whether a policy must be denied. The business capability is implemented with digital workflow processing, but how the workflow processing is accomplished is not a business capability.
▪ Because Underwriting doesn’t occur in a vacuum, assume that some form of risk management is necessary to distinguish what’s a good business investment from what’s bad for the business. In insurance, this risk management centers on actuarial concerns, and is complex enough to hold the status of being a science. The current Actuarial business capability is based on industry data and experience, but will be enhanced with larger datasets and fast machine learning (ML) algorithms in the future that can determine good risks versus bad risks. The future algorithms will be the implementation, but are not the business capability.
▪ Every insurance company must handle claims filed against policies, and NuCoverage is no exception. Fair loss recovery is the deal that insurance companies make with insureds. For a digital-first insurance company, deeply understanding a policyholder loss and the applicable coverage is a core business capability. It’s a matter of not overpaying on the replacement value, but also not taking a reputation hit due to unfair settlements. How would Claims work? That’s a necessary question to answer, but the how is different from the what that is the business capability.
▪ NuCoverage grew to the point where using an enterprise resource planning (ERP) system helps the operational side of the business be efficient, and this is not by any means unimportant. Operational efficiencies should benefit NuCoverage as much as possible. Yet, as previously noted, thriving on operational efficiencies alone is not a sustainable business model. Because the ERP is not core to revenue generation, it is generic with respect to the core capabilities of the business. Not to oversimplify matters, but to highlight the distinction between core and other capabilities, selecting an ERP was in essence a matter of choosing between multiple products that checked all the same boxes on the features and benefits list.
▪ NuCoverage is now on the cusp of entering the white-label insurance platform market. Although it might be considered only a change to a different technology set, it’s even more of a mindset adjustment. NuCoverage must shift into a software-as-a-product mode rather than viewing software as support. Just getting this up and running is core. It will move away from being core in time, after it’s a well-oiled machine, but presently it’s critically important to make the WellBank deal successful.
The preceding points prompts the need to answer a few questions. Is Underwriting a core business capability? Is Actuarial a supporting business capability? Are there details under Claims that might reveal more business capabilities? How will NuCoverage succeed in taking such a big leap to incorporate a completely new business model without harming its current one? These questions are answered later when we examine them more closely against strategic design.
For now, let’s focus on the business processes—the hows of a business and their relationship to the what, a Business capability. Business processes are a succession of activities that define and support business capabilities and, therefore, the strategic business goals. Most processes involve multiple business capabilities that work together, as represented in Figure 2.5.

Figure 2.5 Business processes involve multiple business capabilities to support a strategic goal.
For example, the Claims business capability involves many business processes, such as Check Claim Request and Settle Claim, that support the capability. The Check Claim Request business process existed before NuCoverage defined a new strategic goal—namely, supporting white-label insurance—but it must certainly be adapted to the new goal as seen in Figure 2.5. Consider how the Check Claim Request business process currently works:
1. It kicks in when a new claim against a policy is recorded. Checking a claim request might require coordination of multiple business capabilities aside from Claims. For instance, the Policy business capability would needed to check whether the policy is still active. It might happen that a claim is recorded toward an inactive or just expired policy. Obviously, the request could be dropped most of the time, but not necessarily always. There are always corner cases in any business that have to be addressed.
2. Once the check is done, the Policy business capability provides the coverage information, which determines how the claim should be handled.
3. Next, the Policy Holder Management business capability provides the current and historical views of the policy holder information. It might be useful to check any information related to the driver involved in a claim if there are any issues recorded against the driver’s driving license, such as suspension or a cancellation. or to check the current policyholder’s postal address for the claim follow-up process.
4. A check with the Actuarial business capability is done to discard any fraudulent claim request.
To support the white-label business strategic goal, NuCoverage might decide to implement a parallel Check Claim Request for mobile devices. This could become an enabler for making more deals with agent customers, such as WellBank. It is important to note that more business capabilities would be involved in this process, all operating at the same time. The Claims business capability might also be part of wider business processes at the organization level.
An important question remains unanswered. How can teams discuss and discover business capabilities and business processes without conflating or confusing the two, leading the session astray? Here are some rules of thumb:
▪ The best way to differentiate a business capability from a business process is with a naming style. Generally, business capabilities should be named with a noun–verb combination, such as Subscription Billing5 or Claim Processing.6 In contrast, business processes should be named with a verb–noun combination, such as Check Claim Request.
6 Elsewhere in the book, Claims might be used for brevity instead of the full name Claims Processing.
5 The name Billing was chosen for this business capability because it is a verb, and it demonstrates how it could be mistaken for a business process. Note that the whole name is Subscription Billing, which adheres to the rules of business capability naming. Elsewhere in the book, Billing might be used for brevity.
▪ A business process demonstrates that a company is interested in how to get things done, and the corresponding process models are an excellent depiction of how the business flows. Thus, the business capabilities capture the structure, whereas the business processes capture the flow.
▪ Business processes can change frequently due to technology advances, regulation, internal policies, channel preferences, and other factors, so they are considered volatile. Business capabilities capture the essence of what a business does and focus on the outcomes; thus, they change far less often.
A business capability facilitates strategic-level communication. The benefits of using business capabilities for strategic discussions include their higher-level, conceptual, and more abstract notions and intentions. Yet, attempting to identify business capabilities in discussions with business stakeholders can become sidetracked by process. Many business people are process-driven and results-focused, so they naturally prefer to talk about business processes rather than business capabilities.
For all these reasons, it is important to understand and to recognize the difference between a business capability and a business process. This is a subtle but very important distinction. The process creates coupling between business capabilities. Wrongly designed model boundaries mistakenly based on processes instead of business capabilities, and vice versa, could cripple business activities and operations, and they work against natural communication channels in the organization. Chapter 5, “Contextual Expertise,” explores how business capabilities are realized as software models.
The important takeaways are simply stated: Business processes underpin business capabilities, and business capabilities underpin business strategy.
Strategic Delivery on Purpose
One of the biggest problems in software development is developing functionality and features within software that have little to no value to the business. Yes, this is the classic reason for asserting You Aren’t Gonna Need It (YAGNI)—but even so calling YAGNI in such cases mostly fails to happen or fails to be heard.
Oftentimes, this waste happens because software developers don’t have well-established communication channels and collaboration with business stakeholders. This naturally leads to creating software that never should have existed. It’s not so much that some team thought a feature was a good idea in their own opinion and delivered it on the fly. Instead, it’s more often the case that the developers don’t understand the requirements as expressed by business stakeholders. If they don’t know that their implementation is wrong and won’t be used until some future time, it will remain unused and lurking as a distant problem in waiting.
Just as common is the problem in which business stakeholders and influential customers/users demand some functionality, or sales and marketing perceive a need due to becoming aware of the potential for closing a big deal, and that demand drives the addition. Then, after the imagined value is delivered, the demand may evaporate for any number of reasons: The customer/user finds a workaround, or loses zeal, and the sales team closes the deal on a promise, or even loses the deal altogether. At some point, the imagined value is forgotten after the hard and risky work of bringing it to fruition is complete.
Another reason for implementing unnecessary features is even more basic—plain old bad decisions. Of course, this problem can be chalked up to failing to learn, but going so far as to fully implement such features can be too high a price to pay if that cost could be avoided by undertaking less expensive experimentation.
All of these situations are a major source of frustration for both the business stakeholders and the software development team. To add to this morass, when decision logs are not kept, there is little to no traceability other than a reliance on tacit knowledge. At the same time, although decision logs tell a team why something happened, they are of little help in the case of backing out wrong features. Some will argue that source code versioning can point to the means to remove the unused code—and that’s true if the versioning decisions were made with the assumption that the feature could be wrong. Frankly, using source code versioning for backing out features that were not suspected as being wrong, that have lurked for a long time, and on which other features are now dependent, is an iffy proposition at best.
In all of the aforementioned cases, the problem isn’t the weakness of source code versioning. It’s generally one of two problems:
▪ It’s a matter of failed communications, a warning that has already been sounded with a consistent drumbeat in this book.
▪ An opinion and obsession forced a decision, rather than clearly identified goal-based business drivers.
In the first case, please return to the drums section. In the second case, there’s a clear need to surface actual business goals.
A decision-making tool named Impact Mapping [Impact] was built for facilitating such decisions, and could help distinguish strategic functionality investments from mere imaginary value. To pinpoint the impacts that must be made to achieve strategic goals, consider the following questions:
1. Why? List a number of business goals. A complete list of goals is not necessary because goals can be named one at a time. Yet, listing a few or several might help pinpoint the more strategic ones, and indicate how they differ from the lesser important ones. “Make Mary Happy” is not a business goal, and neither is “Make WellBank Happy.” “Bundle Home and Auto Insurance” is a business goal, as are “Quote Home and Auto Bundle Rate by Home Address” and “White-Label Auto Insurance.”
2. Who? For a given goal, identify one or more actors that must be influenced to change their behaviors to make the business goals successful. For the purpose of this tool, an “actor” is a person, a group, an organization, a system, or something similar that must be influenced to achieve the stated goal. Any actor identified can be positive, neutral, or negative. In other words, the influence made must change the behavior of an actor that is already positive with respect to the business. Alternatively, the actor might currently be indifferent or even negative to the business. This could be a user of another solution or the business offering that solution, and in both cases our business must influence a change in behavior.
3. How? Define the impacts that must be made on each actor to achieve the goal. This is not a grab bag of every possible feature that an actor might need, but rather a select set of business activities focused on achieving the strategic goal by changing a very specific behavior, or lack thereof, to an improved one. It’s important to include impacts that address not just positive actors, but also neutral and negative ones. For negative actors, state impacts that could impede this business’s positive impacts, and how the impedances can be combated and removed.
4. What? Name the deliverables necessary to realize each impact. In the context of strategic software, deliverables are generally the software features that implement the means to cause a specific impact. Note, however, that in identifying deliverables, it is possible that software is not the best answer. Or it could be that an interim measure should be taken until the software can be implemented. For example, until NuCoverage can implement a highly automated Actuarial system that is based on fast data analyzed using machine learning algorithms, the company might choose to bootstrap its Underwriting business capability using highly skilled human underwriters. The underwriters can also help, along with actuaries as business experts, in specifying the Actuarial system. In time, the human underwriters can transition to work full-time as experts in a software innovation capacity.
Most software initiatives will start with step 4 and probably never identify steps 3, 2, or 1. In terms of strategic business, steps 1–4 are not only the correct order, but also offer a clear way forward. These steps are used to find even nontechnical or other means of gap filling to achieve a business goal. In doing so, they can also point out ways to decrease financial expenditures because the best deliverables may be more obvious when all answers are not required to look like software.
As pointed out in Impact Mapping [Impact], a mind map is a good way to put this technique to work. Figure 2.6 provides a template and example.

Figure 2.6 Impact map for White-Label Auto Insurance.
Of the impacts shown in Figure 2.6, some are necessary supporting ones, and others are strategic. For example, a supporting impact is that a new Agent, such as WellBank, must be able to register.7 Once registered, supplying the Agent with a means to quickly submit a new, valid application is accomplished by means of a strategic impact: One-Click Application Submission.
7 This is not open to anyone. Becoming an insurance agent has a qualifying process. NuCoverage helps with onboarding new agents through a franchise arrangement, but leaves registration details to the new agent.
Connected with the One-Click Application Submission impact are three deliverables: Import Agent Customer Account, Risk Gatekeeper, and Rate Calculator. The first one, Import Agent Customer Account, does not currently exist in any form. The other two exist to some degree, because they are already being used in support of the current core business. Undoubtedly, a new deliverable will be needed that ties these together. This means that the mappers should identify some controlling component, such as an Underwriting Processor, to manage the background workflow. This discovery is seen in Figure 2.7. Chapter 3 covers these components in more detail.

Figure 2.7 Further discovery within One-Click Application Submission reveals a controlling component named Underwriting Processor.
Using Cynefin to Make Decisions
Software development activities would be far easier if every requirement of the system was known upfront and in precise detail. But, no: Requirements are envisioned and then changed, and changed again, and changed again. Experimentation outcomes, new knowledge acquisition, production usage feedback, external factors such as competitor activity, and market disruptions cannot be factored into the development plan months or even weeks in advance.
Many businesses are convinced that making a few tweaks to the original plan will be enough. NuCoverage will pursue a new market opportunity by means of white-label products. Naturally, this will ripple through its business strategy, through the organization, and all the way to software development. How can the business inform itself to a fuller degree of the effort needed to effect this change?
The Cynefin framework is a tool that can be used for this purpose. It was created by Dave Snowden in 1999 and has been applied with success to many fields, including industry, research, politics, and software development. It helps decision makers identify how they perceive situations and how they make sense of their own behaviors and those of others.
As illustrated in Figure 2.8, the Cynefin framework includes four domains: Clear, Complicated, Complex, and Chaotic. A fifth domain, Disorder, is in the center.
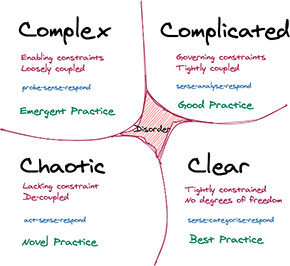
Figure 2.8 Cynefin framework with its five domains.
In the list that follows, business drivers are used as examples. However, the Cynefin domains could also be explained using technical drivers.
▪ Clear. Also known as Obvious or Simple, Clear means that the relationship between cause and effect is known to all, is predictable in advance, and is self-evident for any reasonable person. Common practices are applied and the approach is to sense—see what’s coming in; categorize—make it fit to predefined categories; and respond—decide what to do. Everyone already knows the right answer. NuCoverage’s software development team already knows how to process electronic documents, and it’s obvious to them how it is done.
▪ Complicated. The relationship between cause and effect needs further analysis. In this kind of scenario, a business expert’s knowledge is used to ensure previously successful practices are applied. While there might be multiple solutions to the problem, an expert’s knowledge is used to determine what should be done. The approach is to sense—see what’s coming in; analyze—investigate or analyze using expert knowledge; and respond—decide what to do. Although underwriting is a common process in the insurance industry, software developers would be unable to correctly implement an underwriting solution without relying on expert knowledge to guide them.
▪ Complex. The relationship between cause and effect is clear only in hindsight. Complex problems have more unpredictable results. Although there may be expectations regarding how to reach a correct solution, attempting to implement those solutions may not bring good or even acceptable results. The organization is more likely to reach a good solution only after making mistakes or through observations that lead to hindsight realizations. This is the place where safe experimentations have to take place. Knowledge must be acquired from failures, and the new understanding must be used to drive change in practices, environments, and digital assets. In this domain, the outcome keeps changing such that expert knowledge and common practices cannot be applied with ensured success. Rather, it’s through the result of innovation and emergent practices. The approach is to probe—gather experimental input; sense—observe failure or success; and then respond—decide what to do. Fully automated digital actuarial analysis in multiple lines of insurance is a complex domain.
▪ Chaotic. There is no relationship between cause and effect at the system level. This kind of scenario requires a solution right away. When a crisis is experienced, there is a need to address it before it causes further harm. First, a state of order must be restored. Chaos is caused by an accident that leads to uncontrolled outcomes, and that requires emergency measures to bring the situation under control. The approach is to act—attempt to stabilize; sense—observe failure or success; and respond—decide what to do next. This is the situation where a system failure in one area cascades into other areas and leads to major service disruptions. The system must be first stabilized before any corrective action can be made.
▪ Disorder. This is the domain when you are uncertain of what stage you are in and whether any plans are working. Disorder is the most dangerous situation, one that must be exited as soon as possible. To do so, the situation must be quickly decomposed; the components must be analyzed; the organization must determine to which of the other four domains a given component belongs; and it must choose the proper approach to solve each component of the problem. Planned progress can be made only after order is restored. It’s clear now that Disorder is centralized because the components of the situation are pushed out into one of the other four domains.
With both the Chaotic and Disorder domains, after stabilizing the situation, attention must be given to producing a thorough retrospective and to a prevention plan to avoid the exact or similar future disruptions. Naturally, the prevention plan, including well-informed changes to flawed digital assets, must be carried out very soon, and requires improved monitoring and observation of the affected areas and the overall system.
A key component of the Cynefin framework is knowledge. Understanding each situation helps make both the problem and the solution more obvious. Using the recommended approach of each domain (sense–categorize–respond, etc.) helps to better understand the problem and to transition each to the lower level of complexity. The transitions between domains are made clockwise. It’s important to note that the Clear domain solutions can cause complacency and move to Chaos very quickly. That can happen when tacit knowledge is lost (a key person leaves the company without knowledge transfer), when such knowledge is applied incorrectly, or if a common successful practice becomes obsolete but its use continues.
According to Snowden, using agile project management is a way to transition from the Complex domain into the Complicated domain. Breaking down a large and complex domain into many smaller problems decreases the complexity of the problems that must be solved.
The takeaway is that new software development is at least in the Complicated domain, often in the Complex one, and sometimes in the Chaos domain. Many customers and developers see software development as a Complicated undertaking, but rarely view it as Complex. In general, everyone involved in software development is very good at underestimating complexity, but is surprised when it becomes obvious, and often this ends up in producing solutions that can even lead to chaos, or at least deep debt and entropy.
When a Complex domain is recognized—or worse, when it is not—if the team is neither naive nor intellectually dishonest, they will admit that there is no obvious way to get from problem to solution. Once Complex is understood to be the case, an interactive approach using safe experimentation is a must.
Further, in a Complex domain, the best source of information for decision makers is not prediction, but rather observing what has already happened. Observation provides an empirical model on which iterative experimentation is based. Adapting to frequently changing states helps the team achieve a better understanding of the problem, which makes possible informed decisions in support of correct solutions. The section “Applying the Tools,” later in this chapter, demonstrates how NuCoverage uses the Cynefin framework to determine whether it should use Microservices.
Where Is Your Spaghetti and How Fast Does It Cook?
So far, this book has invested two chapters in ways to strategically innovate with software development so as to seek unique business value through differentiation. The next two chapters take this exploration further, with deep dives into collaborative communication, learning, and improved software organization. The reason? Innovating toward strategic, competitive advantage is hard.
Whatever an individual’s food preferences, pasta and other noodle dishes are generally among the favorites of most. If that’s not the case for a few, it certainly is true for the majority. Just imagining a pile of spaghetti or Asian noodles with a delicious sauce sends people in pursuit of an appetite fix.
With that in mind, it’s hard to imagine the sight of pasta sending our appetites off a cliff. And yet, the term “spaghetti code” was introduced decades ago to describe the sickening source code of a really poor-tasting software system. It makes people want to pursue an altogether different kind of fix. The saddest thing about badly written software is that business complexity is challenging enough without adding implementation complexity.
Spaghetti business always exists before software, and spaghetti code is the bane of a system’s existence. Ad hoc architecture, progressive distortion of the software model, wrongly chosen abstractions, seeking opportunities for code reuse before use is even achieved, and unskilled developers are some of the reasons that software complexity prevents business from tackling business complexity to an innovative degree. Fight software complexity. Achieve by cooking business complexity.
Is taking a small step of cooking spaghetti a giant leap to rocket science? It’s said that “choose-some-noun isn’t rocket science.” In this case, replace “choose-some-noun” with software development: “software development isn’t rocket science.” Yet, business innovation with software continues to solve increasingly difficult problems with regularity.
The tools provided in Chapters 1 and 2, and in the next few chapters, are meant to help cook business spaghetti in 10–12 minutes—that is, more rapidly than this feat would be achieved without the tools. Sometimes it’s not the tools themselves that make for faster cooking. The key is often unlocking human thinking to reach a higher efficiency than is possible without the tools.
Strategic Architecture
Software architecture is commonly seen as a set of decisions to be made by technology-minded professionals. The architecture of a software component, subsystem, and whole-system solution generally belongs to those professionals known as software architects. The term architect has a number of different meanings and implications, and that meaning is generally tied to a business culture. The authors know architects with deep technical qualifications who still work on programming tasks on a regular basis; at the opposite extreme, some architects have only briefly or never implemented software in their careers. In truth, neither end of this spectrum qualifies or disqualifies those serving in the capacity of architect from filling an important role. Qualifications are always based on aptitude, attitude, adaptability, and agility.
Software architects must possess the ability to create a flexible architecture that can readily adapt to strategic changes in support of just-in-time decision making. The worst failings in software architecture are found where architects make architectural decisions that fall outside common practices with proven success, and those lacking real-world constraints—sometimes referred to as ivory tower architects and architectures—and those that are ad hoc with no attempt at manifesting communication-based structures. These failures can be classified into two categories: bad architecture and no architecture. (The first chapter used the term unarchitecture.)
Clearly, software architects should not be the only professionals responsible for architecture. The architecture supports the value chain delivery that is being developed by several different stakeholders. Because architecture is a place that supports communication among the people who have specified a solution, as well as contains a flexible structure to support the current and future decisions around the solution, it really belongs to every stakeholder, including business experts and developers. This leads to a critical point: A software architect must possess the skills to openly facilitate the collaboration that leads to a sound architecture.
Plain and simple, this book promotes a very simple and versatile architecture style. It is known by a few different names. Two of the most common names for this style are Ports and Adapters and Hexagonal. It is also known as Clean Architecture, and a less common name is Onion Architecture. These are all different monikers for the same thing. By any name, this architecture style supports flexibility and adaptability at every point of implementation and change, as you will learn in more detail in Chapter 8, “Foundation Architecture.”
A key perspective on strategic software architecture is how it evolved through time, and for what reasons. It can be difficult to track the motivation behind certain decisions through the life cycle of an application, subsystem, and whole system. Decisions must be explained to those new to a team. It’s also important for long-standing team members to be able to refresh their own memories about, and explain to business stakeholders, why things are the way they are.
Thankfully, there is a simple, agile tool, known as the Architectural Decision Record (ADR), that can assist in this process. ADRs help teams track software decisions made over the long haul. An ADR provides a document template that is used to capture each important architectural decision made, along with its context and consequences.
Each ADR should be stored along with the source code to which it applies, so they are easily accessible for any team member. You might protest that #agile doesn’t require any documentation, and that the current code should be self-explanatory. That viewpoint is not entirely accurate. The #agile approach avoids useless documentation, but allows for any documentation that helps technical and business stakeholders understand the current context. More to the point, ADRs are very lightweight.
A number of ADR templates are available, but Michael Nygard proposed a particularly simple, yet powerful, one [Nygard-ADR]. His point of view is that an ADR should be a collection of records for “architecturally significant” decisions—those that affect the structure, nonfunctional characteristics, dependencies, interfaces, or construction techniques. Let’s examine the structure of this template:
▪ Title: The self-explanatory title of the decision.
▪ Status: The status of the decision, such as proposed, accepted, rejected, deprecated, superseded, etc.
▪ Context: Describe the observed issue that has motivated this decision or change.
▪ Decision: Describe the solution that was chosen and why.
▪ Consequences: Describe what is easier or more difficult due to this change.
The next section provides an example of the ADR of a team within NuCoverage.
Applying the Tools
NuCoverage must determine whether it should continue to run its business with the existing Monolithic application, or to use a different architecture to support their new white-label strategy. Its senior architects recommend using a Microservices architecture. It’s unwise to make such a decision hastily. The business and technical stakeholders decided to use the Cynefin framework to gain a better understanding of the situation by means of a decision-making tool that fosters thorough analysis. Table 2.2 summarizes what they came up with.
Table 2.2 Cynefin at Work to Determine the Risks and Complexities of Migrating from a Monolithic Architecture to a Microservices Architecture.

After significant analysis, all stakeholders involved agree that NuCoverage is in the Complex domain, because no one is confident that the current Monolithic application can be easily transformed to a Microservices-based distributed architecture. There appears to be no broad agreement on the common practices either in the community or among known Microservices experts.
One implication of using a Microservices architecture is that messages must be exchanged between each of the services. To make an architectural decision around this requirement, discussions around various mechanisms are held, which lead to the decision to initially use REST-based messaging. This decision is captured in the ADR shown in Listing 2.1.
Listing 2.1 ADR That Captures the REST Message Exchange Decision
Title: ADR 001: REST Message Exchange Status: Experimental; Accepted Context: Feed event messages to collaborating subsystems Decision: Remain technology agnostic by using Web standards Consequences: Advantages: HTTP; Scale; Inexpensive for experiments Disadvantages: Performance (but unlikely)
The current thought for the best way forward is found in the following points:
▪ Ensure an environment of experimentation with the option to fail, free from reprisals.
▪ Limit the experimentation scope to the current Monolithic application.
▪ Engage two experts from whom the team can learn, and to help avoid the likelihood of failure.
There is a sense of urgency in regard to establishing software architecture and design patterns that can be used by NuCoverage for the safe transformation of its Monolith to a Microservices architecture style, all in support of the new white-label insurance strategic initiative. Even so, the teams are making good progress and look forward to the journey ahead.
Summary
This chapter presented multiple strategic learning tools, including culture as a success enabler. Consider these essential for any business to achieve its strategic goal through differentiation and innovation. Making informed decisions is vital because the outcomes of ad hoc decisions are completely unreliable. Applying context to and forming insights into decisions is essential. To reinforce this, culturally safe experimentation and controlled failure are critical to better decision making, because Conway’s Law is unforgiving of the inferior. As such, partitioning a problem space into smaller chunks feeds understanding, and using well-formed modules is essential to that effort. The recognition of business capabilities as modular divisions within and across which operations occur is core to every business that is expected to lead in revenue generation. Goal-based decisions are better than feature-based decisions, and Impact Mapping helps teams make strategic decisions on purpose. Some tools, such as the Cynefin framework, help with decision making. Others, such as ADRs, enable decisions along with long-term tracing.
The most salient points of this chapter are as follows:
▪ Understanding when decisions are most appropriate is essential to responsible decision making.
▪ The results of experimentation are an important source of knowledge for informed decision making.
▪ Beware of organizational culture and how it affects the safe use of experimentation and controlled failure as a decision-making tool.
▪ Recognizing business capabilities leads to applying modularity for better understanding and problem solving.
▪ Tools such as Cynefin and ADRs can help with decision making and long-term traceability.
The next chapter peers into events-first experimentation and discovery tools, which enables rapid learning and exploration that leads to innovations.
References
[Brooks] Frederick P. Brooks, Jr. The Mythical Man-Month. Reading, MA: Addison-Wesley, 1975.
[Cohn] Mike Cohn. User Stories Applied: For Agile Software Development. Boston: Addison-Wesley, 2004.
[Conway] http://melconway.com/Home/Committees_Paper.html
[CT] “Book Reviews and Notes: Teaching Thinking Skills: Theory and Practice. Joan Baron and Robert Sternberg. 1987. W. H. Freeman, & Co., New York. 275 pages. Index. ISBN 0-7167-1791-3. Paperback.” Bulletin of Science, Technology & Society 8, no. 1 (1988): 101. doi:10.1177/0270467688008001113. ISSN 0270-4676.
[DrDobbs] Mary Poppendieck. “Morphing the Mold.” August 1, 2003. https://www.drdobbs.com/morphing-the-mold/184415014.
[Hollnagel] Erik Hollnagel. “The ETTO Principle: Efficiency–Thoroughness Trade-Off or Why Things That Go Right Sometimes Go Wrong.” https://skybrary.aero/bookshelf/books/4836.pdf.
[Impact] Gojko Adzic. Impact Mapping: Making a Big Impact with Software Products and Projects. https://www.impactmapping.org/.
[LA] James O. Coplien and Gertrud Bjornvig. Lean Architecture: for Agile Software Development. Hoboken, NJ: Wiley, 2010.
[LogFal] https://www.logicalfallacies.info
[Miller] “The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information.” https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two.
[Nygard-ADR] https://github.com/joelparkerhenderson/architecture_decision_record/blob/master/adr_template_by_michael_nygard.md
[Org-Culture] “Organizational Culture.” https://en.wikipedia.org/wiki/Organizational_culture.
[Pisano] Gary P. Pisano. “The Hard Truth about Innovative Cultures.” https://hbr.org/2019/01/the-hard-truth-about-innovative-cultures.
[Poppendieck] Mary Poppendieck and Tom Poppendieck. Lean Software Development: An Agile Toolkit. Boston, MA: Addison-Wesley, 2003.
[TT] Matthew Skelton and Manuel Pais. Team Topologies. Portland, OR: IT Revolution, 2019.
[Tuckman] Bruce W. Tuckman. “Developmental Sequence in Small Groups.” Psychological Bulletin 63 (1965): 384–399.
[TW-ICM] https://www.thoughtworks.com/radar/techniques/inverse-conway-maneuver