
Chapter 7
Refine Message Design for Quality
This chapter covers seven patterns that address issues with API quality. Arguably, it would be hard to find any API designers and product owners who do not value qualities such as intuitive understandability, splendid performance, and seamless evolva-bility. That said, any quality improvement comes at a price—a literal cost such as extra development effort but also negative consequences such as an adverse impact on other qualities. This balancing act is caused by the fact that some of the desired qualities conflict with each other—just think about the almost classic performance versus security trade-offs.
We first establish why these issues are relevant in “Introduction to API Quality.” The next section presents two patterns dealing with “Message Granularity.” Three patterns for “Client-Driven Message Content” follow, and two patterns aim at “Message Exchange Optimization.”
These patterns support the third and the fourth phases of the Align-Define-Design-Refine (ADDR) design process for APIs that we introduced at the start of Part 2.
Introduction to API Quality
Modern software systems are distributed systems: mobile and Web clients communicate with backend API services, often hosted by a single or even multiple cloud providers. Multiple backends also exchange information and trigger activities in each other. Independent of the technologies and protocols used, messages travel through one or several APIs in such systems. This places high demands on quality aspects of the API contract and its implementation: API clients expect any provided API to be reliable, responsive, and scalable.
API providers must balance conflicting concerns to guarantee a high service quality while ensuring cost-effectiveness. Hence, all patterns presented in this chapter help resolve the following overarching design issue:
How to achieve a certain level of quality of a published API while at the same time utilizing the available resources in a cost-effective way?
Performance and scalability concerns might not have a high priority when initially developing a new API, especially in agile development—if they arise at all. Usually, there is not enough information on how clients will use the API to make informed decisions. One could also just guess, but that would not be prudent and would violate principles such as making decisions in the most responsible moment [Wirfs-Brock 2011].
Challenges When Improving API Quality
The usage scenarios of API clients differ from each other. Changes that benefit some clients may negatively impact others. For example, a Web application that runs on a mobile device with an unreliable connection might prefer an API that offers just the data that is required to render the current page as quickly as possible. All data that is transmitted, processed, and then not used is a waste, squandering valuable battery time and other resources. Another client running as a backend service might periodically retrieve large amounts of data to generate elaborate reports. Having to do so in multiple client-server interactions introduces a risk of network failures; the reporting has to resume at some point or start from scratch when such failures occur. If the API has been designed with its request/response messages tailored to either use case, the API very likely is not ideally suited for the other one.
Taking a closer look, the following conflicts and design issues arise:
Message sizes versus number of requests: Is it preferable to exchange several small messages or few larger ones? Is it acceptable that some clients might have to send multiple requests to obtain all the data required so that other clients do not have to receive data they do not use?
Information needs of individual clients: Is it valuable and acceptable to prioritize the interests of some customers over those of others?
Network bandwidth usage versus computation efforts: Should bandwidth be preserved at the expense of higher resource usage in API endpoints and their clients? Such resources include computation nodes and data storage.
Implementation complexity versus performance: Are the gained bandwidth savings worth their negative consequences, for instance, a more complex implementation that is harder and more costly to maintain?
Statelessness versus performance: Does it make sense to sacrifice client/provider statelessness to improve performance? Statelessness improves scalability.
Ease of use versus latency: Is it worth speeding up the message exchanges even if doing so results in a harder-to-use API?
Note that the preceding list is nonexhaustive. The answers to these questions depend on the quality goals of the API stakeholders and additional concerns. The patterns in this chapter provide different options to choose from under a given set of requirements; adequate selections differ from API to API. Part 1 of this book provided a decision-oriented overview of these patterns in the “Deciding for API Quality Improvements” section of Chapter 3, “API Decision Narratives.” In this chapter, we cover them in depth.
Patterns in This Chapter
The section “Message Granularity” contains two patterns: EMBEDDED ENTITY and LINKED INFORMATION HOLDER. DATA ELEMENTS offered by API operations frequently reference other elements, for example, using hyperlinks. A client can follow these links to retrieve the additional data; this can become tedious and lead to a higher implementation effort and latency on the client side. Alternatively, clients can retrieve all data at once when providers directly embed the referenced data instead of just linking to it.
“Client-Driven Message Content” features three patterns. API operations sometimes return large sets of data elements (for example, posts on a social media site or products in an e-commerce shop). API clients may be interested in all of these data elements, but not necessarily all at once and not all the time. PAGINATION divides the data elements into chunks so that only a subset of the sequence is sent and received at once. Clients are no longer overwhelmed with data, and performance and resource usage improve. Providers may offer relatively rich data sets in their response messages. If the problem is that not all clients require all information all the time, then a WISH LIST allows these clients to request only the attributes in a response data set that they are interested in. WISH TEMPLATE addresses the same problem but offers clients even more control over possibly nested response data structures. These patterns address concerns such as accuracy of the information, data parsimony, response times, and processing power required to answer a request.
Finally, the “Message Exchange Optimization” section features two patterns, CONDITIONAL REQUEST and REQUEST BUNDLE. The other patterns in this chapter offer several options to fine-tune message contents to avoid issuing too many requests or transmitting data that is not used; in contrast, CONDITIONAL REQUESTS avoid sending data that a client already has. While the number of messages exchanged stays the same, the API implementation can respond with a dedicated status code to inform the client that more recent data is not available. The number of requests sent and responses received can also impair the quality of an API. If clients have to issue many small requests and wait for individual responses, bundling them into a larger message can improve throughput and reduce the client-side implementation effort. The REQUEST BUNDLE pattern presents this design option.
Figure 7.1 provides an overview of the patterns in this chapter and shows their relations.
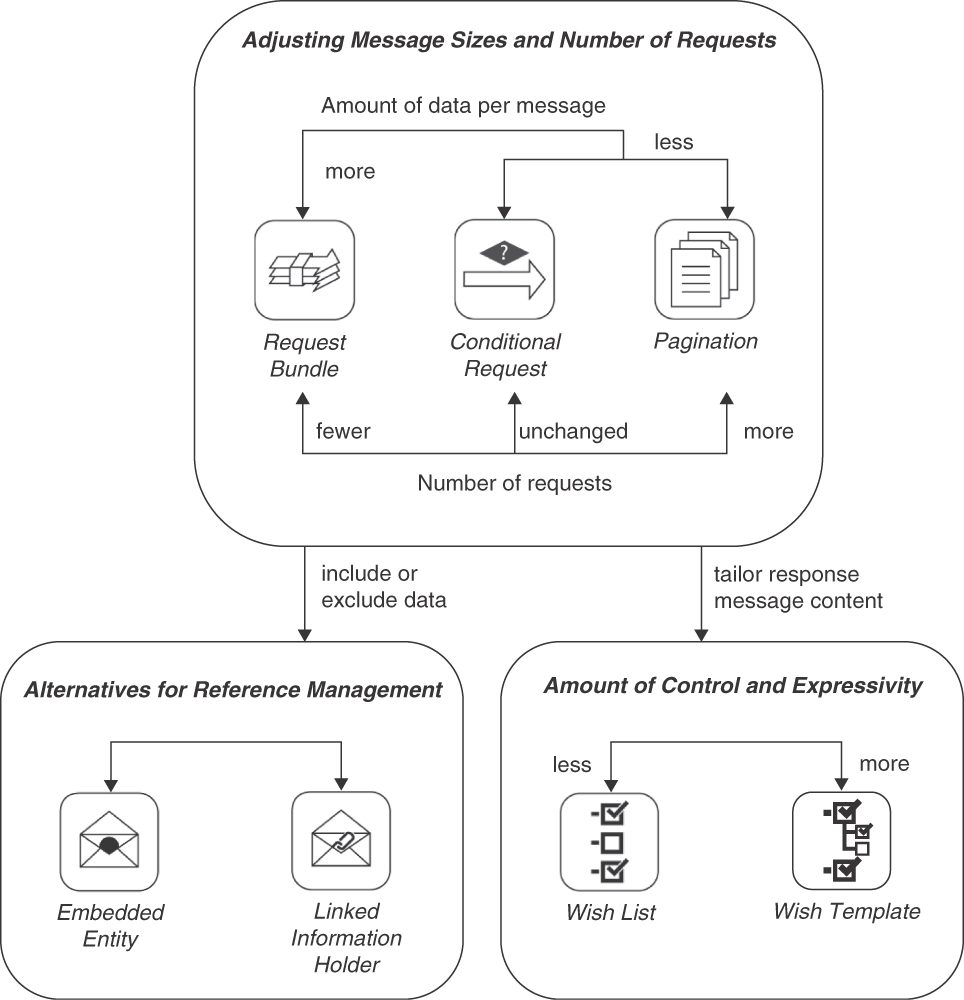
Figure 7.1 Pattern map for this chapter (API quality)
Message Granularity
Information elements in request and response message representations, concepts from our API domain model (see Chapter 1, “Application Programming Interface (API) Fundamentals”), often reference other ones to express containment, aggregation, or other relationships. For instance, operational data such as orders and shipments typically is associated with master data such as product and customer records. To expose such references when defining API endpoints and their operations, the two basic options are as follows:
EMBEDDED ENTITY: Embed the referenced data in a possibly nested DATA ELEMENT (introduced in Chapter 6, “Design Request and Response Message Representations”) in the message representation.
LINKED INFORMATION HOLDER: Place a LINK ELEMENT (also Chapter 6) in the message representation to look up the referenced data via a separate API call to an INFORMATION HOLDER RESOURCE (Chapter 5, “Define Endpoint Types and Operations”).
These message sizing and scoping options have an impact on the API quality:
Performance and scalability: Both message size and number of calls required to cover an entire integration scenario should be kept low. Few messages that transport a lot of data take time to create and process; many small messages are easy to create but cause more work for the communications infrastructure and require receiver-side coordination.
Modifiability and flexibility: Backward compatibility and extensibility are desired in any distributed system whose parts evolve independently of each other. Information elements contained in structured, self-contained representations might be hard to change because any local updates must be coordinated and synchronized with updates to the API operations that work with them and related data structures in the API implementation. Structured representations that contains references to external resources usually is even harder to change than self-contained data because clients have to be aware of such references so that they can follow them correctly.
Data quality: Structured master data such as customer profiles or product details differs from simple unstructured reference data such as country and currency codes (Chapter 5 provides a categorization of domain data by lifetime and mutability). The more data is transported, the more governance is required to make this data useful. For instance, data ownership might differ for products and customers in an online shop, and the respective data owners usually have different requirements, for example, regarding data protection, data validation, and update frequency. Extra metadata and data management procedures might be required.
Data privacy: In terms of data privacy classifications, the source and the target of data relationships might have different protection needs; an example is a customer record with contact address and credit card information. More fine-grained data retrieval facilitates the enforcement of appropriate controls and rules, lowering the risk of embedded restricted data accidentally slipping through.
Data freshness and consistency: If data is retrieved by competing clients at different times, inconsistent snapshots of and views on data in these clients might materialize. Data references (links) may help clients to retrieve the most recent version of the referenced data. However, such references may break, as their targets may change or disappear after the link referring to it has been sent. By embedding all referenced data in the same message, API providers can deliver an internally consistent snapshot of the content, avoiding the risk of link targets becoming unavailable. Software engineering principles such as single responsibility may lead to challenges regarding data consistency and data integrity when taken to the extreme because data may get fragmented and scattered.
The two message granularity patterns, EMBEDDED ENTITY and LINKED INFORMATION HOLDER in this section address these issues in opposite ways. Combining them on a case-by-case basis leads to adequate message sizes, balancing the number of calls and the amount of data exchanged to meet diverse integration requirements.
 Pattern: EMBEDDED ENTITY
Pattern: EMBEDDED ENTITY
When and Why to Apply
The information required by a communication participant contains structured data. This data includes multiple elements that relate to each other in certain ways. For instance, master data such as a customer profile may contain other elements providing contact information including addresses and phone numbers, or a periodic business results report may aggregate source information such as monthly sales figures summarizing individual business transactions. API clients work with several of the related information elements when creating request messages or processing response messages.
How can one avoid exchanging multiple messages when their receivers require insights about multiple related information elements?
One could simply define one API endpoint for each basic information element (for instance, an entity defined in an application domain model). This endpoint is accessed whenever API clients require data from that information element, for example, when it is referenced from another one. But if API clients use such data in many situations, this solution causes many subsequent requests when references are followed. This could possibly make it necessary to coordinate request execution and introduce conversation state, which harms scalability and availability; distributed data also is more difficult than local data to keep consistent.
How It Works
For any data relationship that the receiver wants to follow, embed a DATA ELEMENT in the request or response message that contains the data of the target end of the relationship. Place this EMBEDDED ENTITY inside the representation of the source of the relationship.
Analyze the outgoing relationships in the new DATA ELEMENT and consider embedding them in the message as well. Repeat this analysis until transitive closure is reached—that is, until all reachable elements have been either included or excluded (or circles are detected and processing stopped). Review each source-target relationship carefully to assess whether the target data is really needed on the receiver side in enough cases. A yes answer to this question warrants transmitting relationship information as EMBEDDED ENTITIES; otherwise, transmitting references to LINKED INFORMATION HOLDERS might be sufficient. For instance, if a purchase order has a uses relation to product master data and this master data is required to make sense of the purchase order, the purchase order representation in request or response messages should contain a copy of all relevant information stored in the product master data in an EMBEDDED ENTITY.
Figure 7.2 sketches the solution.
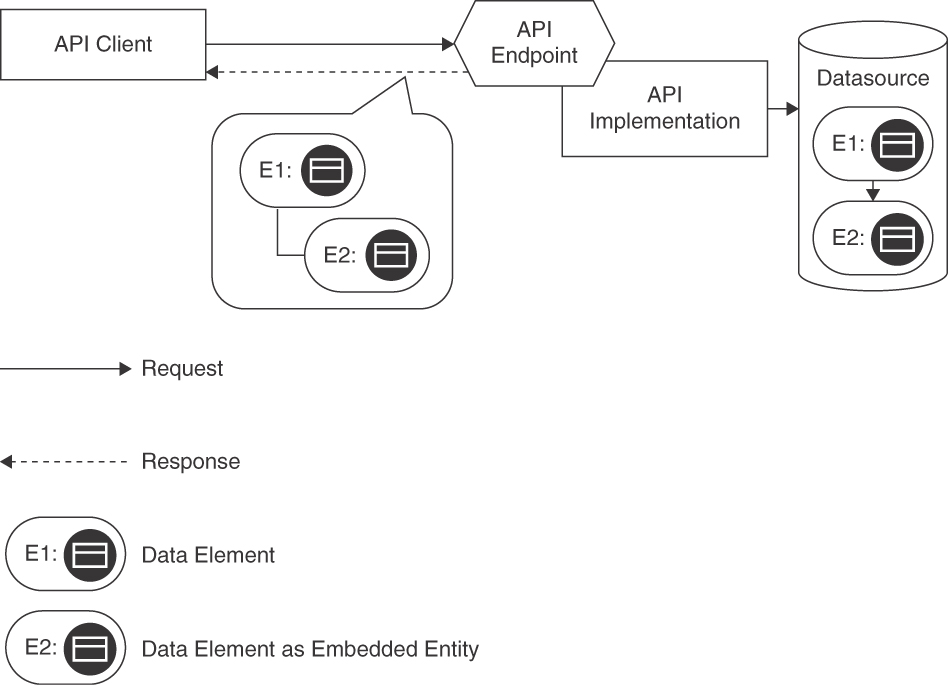
Figure 7.2 EMBEDDED ENTITY: Single API endpoint and operation, returning structured message content that matches the structure of the source data in the API implementation to follow data relations
Including an EMBEDDED ENTITY in a message leads to a PARAMETER TREE structure that contains the DATA ELEMENT representing the related data. Additional METADATA ELEMENTS in this tree may denote the relationship type and other supplemental information. There are several options for structuring the tree, corresponding to the contained DATA ELEMENT. It may be nested, for instance, when representing deep containment relationship hierarchies; it may be flat and simply list one or more ATOMIC PARAMETERS. When working with JSON in HTTP resource APIs, JSON objects (possibly including other JSON objects) realize these options. One-to-many relationships (such as a purchase order referring to its order items) cause the EMBEDDED ENTITY to be set-valued. JSON arrays can represent such sets. The options for representing many-to-many relationships are similar to those in the LINKED INFORMATION HOLDERS pattern; for instance, the PARAMETER TREE might contain dedicated nodes for the relationships. Some redundancy might be desired or tolerable, but it also may confuse consumers who expect normalized data. Bidirectional relationships require special attention. One of the directions can be used to create the EMBEDDED ENTITY hierarchy; if the opposite direction should also be made explicit in the message representation, a second instance of this pattern might be required, causing data duplication. In that case, it might be better to express the second relationship with embedded ID ELEMENTS or LINK ELEMENTS instead.
In any of these cases, the API DESCRIPTION has to explain the existence, structure, and meaning of the EMBEDDED ENTITY instances.
Example
Lakeside Mutual, our microservices sample application introduced in Chapter 2, “Lakeside Mutual Case Study,” contains a service called Customer Core that aggregates several information items (here, entities and value objects from domain-driven design [DDD]) in its operation signatures. API clients such as the Customer Self-Service frontend can access this data via an HTTP resource API. This API contains several instances of the EMBEDDED ENTITY pattern. Applying the pattern, a response message might look as follows:1
curl -X GET http://localhost:8080/customers/gktlipwhjr{"customer": {"id": "gktlipwhjr"},"customerProfile": {"firstname": "Robbie","lastname": "Davenhall","birthday": "1961-08-11T23:00:00.000+0000","currentAddress": {"streetAddress": "1 Dunning Trail","postalCode": "9511","city": "Banga"},"email": "[email protected]","phoneNumber": "491 103 8336","moveHistory": [{"streetAddress": "15 Briar Crest Center","postalCode": "","city": "Aeteke"}]},"customerInteractionLog": {"contactHistory": [],"classification": "??"}}
1. Note that the data shown is fictitious, generated by https://www.mockaroo.com.
The referenced information elements are all fully contained in the response message; examples are customerProfile and customerInteractionLog. No URI links to other resources appear. Note that the customerProfile entity actually embeds nested data in this exemplary data set (for example, currentAddress and moveHistory), while the customerInteractionLog does not (but is still included as an empty EMBEDDED ENTITY).
Discussion
Applying this pattern solves the problem of having to exchange multiple messages when receivers require multiple related information elements. An EMBEDDED ENTITY reduces the number of calls required: if the required information is included, the client does not have to create a follow-on request to obtain it. Embedding entities can lead to a reduction in the number of endpoints, because no dedicated endpoint to retrieve linked information is required. However, embedding entities leads to larger response messages, which usually take longer to transfer and consume more bandwidth. Care must also be taken to ensure that the included information does not have higher protection needs than the source and that no restricted data slips through.
It can be challenging to anticipate what information different message receivers (that is, API clients for response messages) require to perform their tasks. As a result, there is a tendency to include more data than most clients need. Such design can be found in many PUBLIC APIS serving many diverse and possibly unknown clients.
Traversing all relationships between information elements to include all possibly interesting data may require complex message representations and lead to large message sizes. It is unlikely and/or difficult to ensure that all recipients will require the same message content. Once included and exposed in an API DESCRIPTION, it is hard to remove an EMBEDDED ENTITY in a backward-compatible manner (as clients may have begun to rely on it).
If most or all of the data is actually used, sending many small messages might require more bandwidth than sending one large message (for instance, because protocol header metadata is sent with each small message). If the embedded entities change at different speeds, retransmitting them causes unnecessary overhead because messages with partially changed content can only be cached in their entirety. A fast-changing operational entity might refer to immutable master data, for instance.
The decision to use EMBEDDED ENTITY might depend on the number of message consumers and the homogeneity of their use cases. For example, if only one consumer with a specific use case is targeted, it is often good to embed all required data straight away. In contrast, different consumers or use cases might not work with the same data. In order to minimize message sizes, it might be advisable not to transfer all data. Both client and provider might be developed by the same organization—for example, when providing “Backends for Frontends” [Newman 2015]. Embedding entities can be a reasonable strategy to minimize the number of requests in that case. In such a setting, they simplify development by introducing a uniform regular structure.
Combinations of linking and embedding data often make sense, for instance, embedding all data immediately displayed in a user interface and linking the rest for retrieval upon demand. The linked data is then fetched only when the user scrolls or opens the corresponding user interface elements. Atlassian [Atlassian 2022] discusses such a hybrid approach: “Embedded related objects are typically limited in their fields to avoid such object graphs from becoming too deep and noisy. They often exclude their own nested objects in an attempt to strike a balance between performance and utility.”
“API Gateways” [Richardson 2016] and messaging middleware [Hohpe 2003] can also help when dealing with different information needs. Gateways can either provide two alternative APIs that use the same backend interface and/or collect and aggregate information from different endpoints and operations (which makes them stateful). Messaging systems may provide transformation capabilities such as filters and enrichers.
Related Patterns
LINKED INFORMATION HOLDER describes the complementary, opposite solution for the reference management problem. One reason for switching to the LINKED INFORMATION HOLDER might be to mitigate performance problems, for instance, caused by slow or unreliable networks that make it difficult to transfer large messages. LINKED INFORMATION HOLDERS can help to improve the situation, as they allow caching each entity independently.
If reducing message size is the main design goal, a WISH LIST or, even more expressive, a WISH TEMPLATE can also be applied to minimize the data to be transferred by letting consumers dynamically describe which subset of the data they need. WISH LIST or WISH TEMPLATE can help to fine-tune the content in an EMBEDDED ENTITY.
OPERATIONAL DATA HOLDERS reference MASTER DATA HOLDERS by definition (either directly or indirectly); these references often are represented as LINKED INFORMATION HOLDERS. References between data holders of the same type are more likely to be included with the EMBEDDED ENTITY pattern. Both INFORMATION HOLDER RESOURCES and PROCESSING RESOURCES might deal with structured data that needs to be linked or embedded; in particular, RETRIEVAL OPERATIONS either embed or link related information.
More Information
Phil Sturgeon features this pattern as “Embedded Document (Nesting)” in [Sturgeon 2016b]. See Section 7.5 of Build APIs You Won’t Hate for additional advice and examples.
 Pattern: LINKED INFORMATION HOLDER
Pattern: LINKED INFORMATION HOLDER
When and Why to Apply
An API exposes structured data to meet the information needs of its clients. This data contains elements that relate to each other (for example, product master data may contain other information elements providing detailed information, or a performance report for a period of time may aggregate raw data such as individual measurements). API clients work with several of the related information elements when preparing request messages or processing response messages. Not all of this information is always useful for the clients in its entirety.2
How can messages be kept small even when an API deals with multiple information elements that reference each other?
A rule of thumb for distributed system design states that exchanged messages should be small because large messages may overutilize the network and the end-point processing resources. However, not all of what communication participants want to share with each other might fit into such small messages; for instance, they might want to follow many or all of the relationships within information elements. If relationship sources and targets are not combined into a single message, participants have to inform each other how to locate and access the individual pieces. This distributed information set has to be designed, implemented, and evolved; the resulting dependencies between the participants and the information they share have to be managed. For instance, insurance policies typically refer to customer and product master data; each of these related information elements might, in turn, consist of several parts (see Chapter 2 for deeper coverage of the data and domain entities in this example).
One option is to always (transitively) include all the related information elements of each transmitted element in request and response messages throughout the API, as described in the EMBEDDED ENTITY pattern. However, this approach can lead to large messages containing data not required by some clients and harm the performance of individual API calls. It couples the stakeholders of this data.
2. This pattern context is similar to that of EMBEDDED ENTITY but emphasizes the diversity of client wants and needs.
How It Works
Add a LINK ELEMENT to messages that pertain to multiple related information elements. Let the resulting LINKED INFORMATION HOLDER reference another API endpoint that exposes the linked element.
The referenced API endpoint often is an INFORMATION HOLDER RESOURCE representing the linked information element. This element might be an entity from the domain model that is exposed by the API (possibly wrapped and mapped); it can also be the result of a computation in the API implementation.
LINKED INFORMATION HOLDERS might appear in request and response messages; the latter case is more common. Typically, a PARAMETER TREE is used in the representation structure, combining collections of LINK ELEMENTS and, optionally, METADATA ELEMENTS explaining the link semantics; in simple cases, a set of ATOMIC PARAMETERS or a single ATOMIC PARAMETER might suffice as link carriers.
Figure 7.3 illustrates the two-step conversation realizing the pattern.
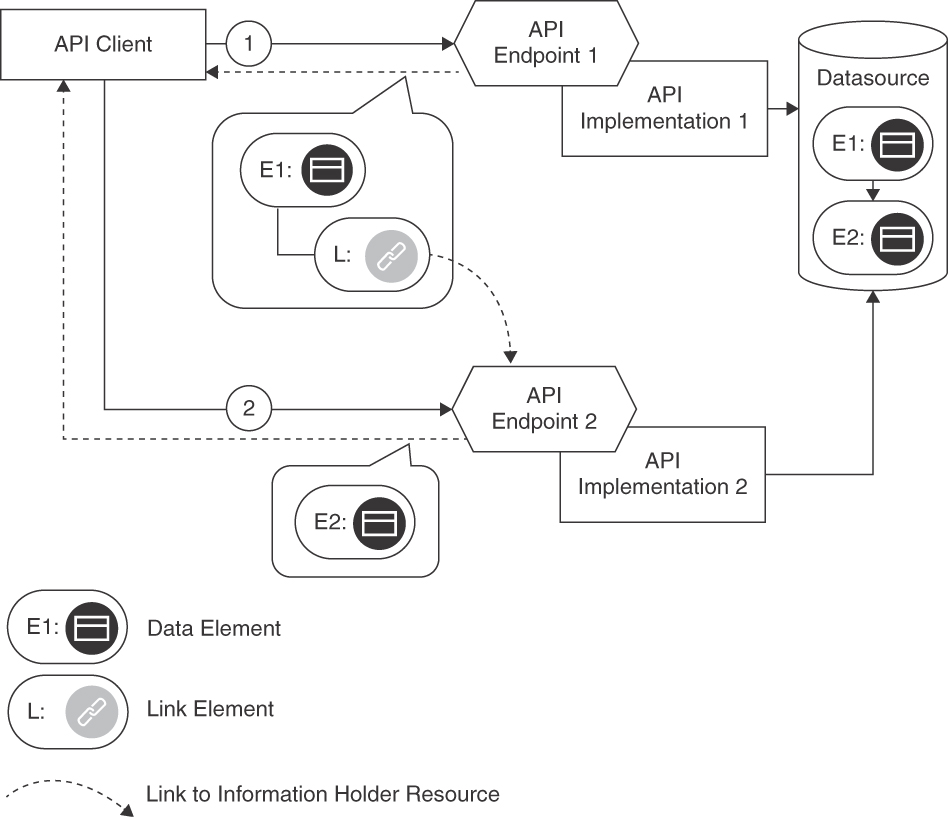
Figure 7.3 LINKED INFORMATION HOLDER: Two API endpoints are involved. The first response contains a link rather than data from the data source; the data is retrieved from it in a follow-on request to the second endpoint
The LINK ELEMENT that constitutes the LINKED INFORMATION HOLDER provides location information, for instance, a URL (with domain/hostname and port number when using HTTP over TCP/IP). The LINK ELEMENT also has a local name to be able to identify it within the message representation (such as a JSON object). If more information about the relation should be sent to clients, this LINK ELEMENT can be annotated with details about the corresponding relationship, for instance, a METADATA ELEMENT specifying its type and semantics. In any case, API clients and providers must agree on the meaning of the link relationships and be aware of coupling and side effects introduced. The existence and the meaning of the LINKED INFORMATION HOLDER, including cardinalities on both ends of the relation, has to be documented in the API DESCRIPTION.
One-to-many relationships can be modeled as collections, for instance, by transmitting multiple LINK ELEMENTS as ATOMIC PARAMETER LISTS. Many-to-many relationships (such as that between books and their readers in a library management system) can be modeled as two one-to-many relationships, with one collection linking the source data to the targets and a second one linking the target data to the sources (assuming that the message recipient wants to follow the relation in both directions). Such design may require the introduction of an additional API endpoint, a relationship holder resource, representing the relation rather than its source or target. This endpoint then exposes operations to retrieve all relationships with their sources and targets; it may also allow clients to find the other end of a relationship they already know about. Different types of LINK ELEMENTS identify these ends in messages sent to and from the relationship holder resource. Unlike in the EMBEDDED ENTITY pattern, circular dependencies in the data are less of an issue when working with LINKED INFORMATION HOLDERS (but still should be handled); the responsibility to avoid endless loops in the data processing shifts from the message sender to the recipient.
Example
Our Lakeside Mutual sample application for Customer Management utilizes a Customer Core service API that aggregates several information elements from the domain model of the application, in the form of entities and value objects from DDD. API clients can access this data through a Customer Information Holder, implemented as a REST controller in Spring Boot.
The Customer Information Holder, called customers, realizes the INFORMATION HOLDER RESOURCE pattern. When applying LINKED INFORMATION HOLDER for its customerProfile and its moveHistory a response message may look as follows:
curl -X GET http://localhost:8080/customers/gktlipwhjr{"customer": {"id": "gktlipwhjr"},"links": [{"rel": "customerProfile","href": "/customers/gktlipwhjr/profile"}, {"rel": "moveHistory","href": "/customers/gktlipwhjr/moveHistory"}],"email": "[email protected]","phoneNumber": "491 103 8336","customerInteractionLog": {"contactHistory": [],"classification": "??"}}
Both profile and moveHistory are implemented as sub-resources of the Customer Information Holder. The customerProfile can be retrieved by a subsequent GET request to the URI /customers/gktlipwhjr/profile. How does the client know that a GET request must be used? This information could have been included in a METADATA ELEMENT. In this example, the designers of the API decided not to include it. Instead, their API DESCRIPTION specifies that GET requests are used by default to retrieve information.
Discussion
Linking instead of embedding related data results in smaller messages and uses fewer resources in the communications infrastructure when exchanging individual messages. However, this has to be contrasted with the possibly higher resource use caused by the extra messages required to follow the links: Additional requests are required to dereference the linked information. Linking instead of embedding might demand more resources in the communications infrastructure. Additional INFORMATION HOLDER RESOURCE endpoints have to be provided for the linked data, causing development and operations effort and cost, but allowing to enforce additional access restrictions.
When introducing LINKED INFORMATION HOLDERS into message representations, an implicit promise is made to the recipient that these links can be followed successfully. The provider might not be willing to keep such a promise infinitely. Even if a long lifetime of the linked endpoint is guaranteed, links still may break, for instance, when the data organization or deployment location changes. Clients should expect this and be able to follow redirects or referrals to the updated links. To minimize breaking links, the API provider should invest in maintaining link consistency; a LINK LOOKUP RESOURCE can be used to do so.
Sometimes the data distribution reduces the number of messages exchanged. Different LINKED INFORMATION HOLDERS may be defined for data that changes at a different velocity. Clients then can request frequently changing data whenever they require the latest snapshot of it; they do not have to re-request slower changing data that is embedded with it (and therefore tightly coupled).
The pattern leads to modular API designs but also adds a dependency that must be managed. It potentially has performance, workload, and maintenance costs attached. The EMBEDDED ENTITY pattern can be used instead if justified from a performance point of view. This makes sense if a few large calls turn out to perform better than many small ones due to network and endpoint processing capabilities or constraints (this should be measured and not guessed). It might be required to switch back and forth between EMBEDDED ENTITY and LINKED INFORMATION HOLDER during API evolution; with TWO IN PRODUCTION, both designs can be offered at the same time, for instance, for experimentation with a potential change. The API refactor-ings “Inline Information Holder” and “Extract Information Holder” of the Interface Refactoring Catalog [Stocker 2021b] provide further guidance and step-by-step instructions.
LINKED INFORMATION HOLDER is well suited when referencing rich information holders serving multiple usage scenarios: usually, not all message recipients require the full set of referenced data, for instance, when MASTER DATA HOLDERS such as customer profiles or product records are referenced from OPERATIONAL DATA HOLDERS such as customer inquiries or orders. Following links to LINKED INFORMATION HOLDERS, message recipients can obtain the required subsets on demand.
The decision to use LINKED INFORMATION HOLDER and/or to include an EMBEDDED ENTITY might depend on the number of API clients and the level of similarity of their use cases. Another decision driver is the complexity of the domain model and the application scenarios it represents. For example, if one client with a specific use case is targeted, it usually makes sense to embed all data. However, if there are several clients, not all of them might appreciate the same comprehensive data. In such situations, LINKED INFORMATION HOLDERS pointing at the data used only by a fraction of the clients reduces the message sizes.
Related Patterns
LINKED INFORMATION HOLDERS typically reference INFORMATION HOLDER RESOURCES. The referenced INFORMATION HOLDER RESOURCES can be combined with LINK LOOKUP RESOURCE to cope with potentially broken links. By definition, OPERATIONAL DATA HOLDERS reference MASTER DATA HOLDERS; these references can either be included and flattened as EMBEDDED ENTITIES or structured and then progressively followed using LINKED INFORMATION HOLDERS.
Other patterns that help reduce the amount of data exchanged can be used alternatively. For instance, CONDITIONAL REQUEST, WISH LIST, and WISH TEMPLATE are eligible; PAGINATION is an option too.
More Information
“Linked Service” [Daigneau 2011] is a similar pattern but is less focused on data. “Web Service Patterns” [Monday 2003] has a “Partial DTO Population” pattern that solves a similar problem; DTO stands for Data Transfer Object.
See Build APIs You Won’t Hate, Section 7.4 [Sturgeon 2016b], for additional advice and examples, to be found under “Compound Document (Sideloading).”
The backup, availability, consistency (BAC) theorem investigates data management issues further [Pardon 2018].
Client-Driven Message Content (aka Response Shaping)
In the previous section, we presented two patterns to handle references between data elements in messages. An API provider can choose between embedding or linking related data elements, and also combine these two options to achieve suitable message sizes. Depending on the clients and their API usage, their best usage may be clear. But usage scenarios of clients might be so different that an even better solution would be to let clients themselves decide at runtime which data they are interested in.
The patterns in this section offer two different approaches to optimize this facet of API quality further, response slicing and response shaping. They address the following challenges:
Performance, scalability, and resource use: Providing all clients with all data every time, even to those that only have a limited or minimal information need, comes at a price. From a performance and workload point of view, it therefore makes sense to transmit only the relevant parts of a data set. However, the pre- and postprocessing required to rightsize the message exchanges also require resources and might harm performance. These costs have to be balanced against the expected reduction of the response message size and the capabilities of the underlying transport network.
Information needs of individual clients: An API provider might have to serve multiple clients with different information needs. Usually, providers do not want to implement custom APIs or client-specific operations but let the clients share a set of common operations. However, certain clients might be interested in just a subset of the data made available via an API. The common operations might be too limited or too powerful in such cases. Other clients might be overwhelmed if a large set if data arrives at once. Delivering too little or too much data to a client is also known as underfetching and overfetching.
Loose coupling and interoperability: The message structures are important elements of the API contract between API provider and API client; they contribute to the shared knowledge of the communication participants, which impacts the format autonomy aspect of loose coupling. Metadata to control data set sizing and sequencing becomes part of this shared knowledge and has to be evolved along with the payload.
Developer convenience and experience: The developer experience, including learning effort and programming convenience, is closely related to understandabil-ity and complexity considerations. For instance, a compact format optimized for transfer might be difficult to document and understand, and to prepare and digest. Elaborate structures enhanced with metadata that simplify and optimize processing cause extra effort during construction (both at design time and at runtime).
Security and data privacy: Security requirements (data integrity and confidentiality in particular) and data privacy concerns are relevant in any message design; security measures might require additional message payloads such as API KEYS or security tokens. An important consideration is which payload can and should actually be sent; data that is not sent cannot be tampered with (at least not on the wire). The need for certain, data-specific security measures might actually lead to different message designs (for instance, credit card information might be factored out into a dedicated API endpoint with specifically secured operations). In the context of slicing and sequencing large data sets, all parts can be treated equally unless they have different protection needs. The heavy load caused by assembling and transmitting large data sets can expose the provider to denial-of-service attacks.
Test and maintenance effort: Enabling clients to select which data to receive (and when) creates options and flexibility with regards to what the provider has to expect (and accept) in incoming requests. Therefore, the testing and maintenance effort increases.
The patterns in this section, PAGINATION, WISH LIST, and WISH TEMPLATE, address these challenges in different ways.
 Pattern: PAGINATION
Pattern: PAGINATION
When and Why to Apply
Clients query an API, fetching collections of data items to be displayed to the user or processed in other applications. In at least one of these queries, the API provider responds by sending a large number of items. The size of this response may be larger than what the client needs or is ready to consume at once.
The data set may consist of identically structured elements (for example, rows fetched from a relational database or line items in a batch job executed by an enterprise information system in the backend) or of heterogeneous data items not adhering to a common schema (for example, parts of a document from a document-oriented NoSQL database such as MongoDB).
How can an API provider deliver large sequences of structured data without overwhelming clients?
In addition to the forces already presented in the introduction to this section, PAGINATION balances the following ones:
Session awareness and isolation: Slicing read-only data is relatively simple. But what if the underlying data set changes while being retrieved? Does the API guarantee that once a client retrieves the first page, the subsequent pages (which may or may not be retrieved later) will contain a data set that is consistent with the subset initially retrieved? How about multiple concurrent requests for partial data?
Data set size and data access profile: Some data sets are large and repetitive, and not all transmitted data is accessed all the time. This offers optimization potential, especially for sequential access over data items ordered from the most recent to the oldest, which may no longer be relevant for the client. Moreover, clients may not be ready to digest data sets of arbitrary sizes.
One could think of sending the entire large response data set in a single response message, but such a simple approach might waste endpoint and network capacity; it also does not scale well. The size of the response to a query may be unknown in advance, or the result set may be too large to be processed at once on the client side (or on the provider side). Without mechanisms to limit such queries, processing errors such as out-of-memory exceptions may occur, and the client or the endpoint implementation may crash. Developers and API designers often underestimate the memory requirements imposed by unlimited query contracts. These problems usually go unnoticed until concurrent workload is placed on the system or the data set size increases. In shared environments, it is possible that unlimited queries cannot be processed efficiently in parallel, which leads to similar performance, scalability, and consistency issues—only combined with concurrent requests, which are hard to debug and analyze anyway.
How It Works
Divide large response data sets into manageable and easy-to-transmit chunks (also known as pages). Send one chunk of partial results per response message and inform the client about the total and/or remaining number of chunks. Provide optional filtering capabilities to allow clients to request a particular selection of results. For extra convenience, include a reference to the next chunk/page from the current one.
The number of data elements in a chunk can be fixed (its size then is part of the API contract) or can be specified by the client dynamically as a request parameter. METADATA ELEMENTS and LINK ELEMENTS inform the API client how to retrieve additional chunks subsequently.
API clients then process some or all partial responses iteratively as needed; they request the result data page by page. Hence, subsequent requests for additional chunks might have to be correlated. It might make sense to define a policy that governs how clients can terminate the processing of the result set and the preparation of partial responses (possibly requiring session state management).
Figure 7.4 visualizes a sequence of requests that use PAGINATION to retrieve three pages of data.
Variants The pattern comes in four variants that navigate the data set in different ways: page based, offset based, cursor or token based, and time based.
Page-Based Pagination (a somewhat tautological name) and Offset-Based Pagination refer to the elements of the data set differently. The page-based variant divides the data set into same-sized pages; the client or the provider specify the page size. Clients then request pages by their index (like page numbers in a book). With Offset-Based Pagination, a client selects an offset into the whole data set (that is, how many single elements to skip) and the number of elements to return in the next chunk (often referred to as limit). Both approaches may be used interchangeably (the offset can be calculated by multiplying the page size with the page number); they address the problem and resolve the forces in similar ways. Page-Based Pagination and Offset-Based Pagination do not differ much with respect to developer experience and other qualities. Whether entries are requested with an offset and limit or all entries are divided into pages of a particular size and then requested by an index is a minor difference. Either case requires two integer parameters.
These variants are not well suited for data that changes in between requests and therefore invalidates the index or offset calculations. For example, given a data set ordered by creation time from most recent to oldest, let us assume that a client has retrieved the first page and now requests the second one. In between these requests, the element at the front of the data set is removed, causing an element to move from the second to the first page without the client ever seeing it.
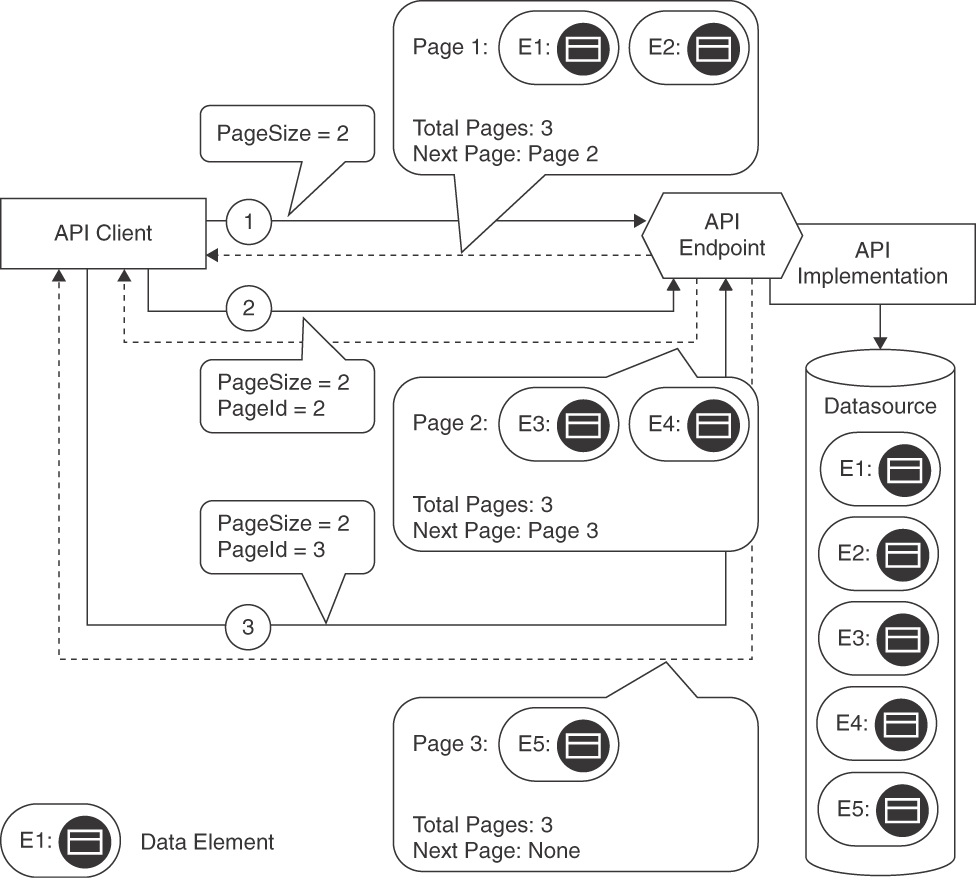
Figure 7.4 PAGINATION: Query and follow-on requests for pages, response messages with partial results
The Cursor-Based Pagination variant solves this problem: it does not rely on the absolute position of an element in the data set. Instead, clients send an identifier that the provider can use to locate a specific item in the data set, along with the number of elements to retrieve. The resulting chunk does not change even if new elements have been added since the last request.
The remaining fourth variant, Time-Based Pagination, is similar to Cursor-Based Pagination but uses timestamps instead of element IDs. It is used in practice less frequently but could be applied to scroll through a time plot by gradually requesting older or newer data points.
Example
The Lakeside Mutual Customer Core backend API illustrates Offset-Based Pagination in its customer endpoint:
curl -X GET http://localhost:8080/customers?limit=2&offset=0This call returns the first chunk of two entities and several control METADATA ELEMENTS. Besides the link relation [Allamaraju 2010] that points at the next chunk, the response also contains the corresponding offset, limit, and total size values. Note that size is not required to implement PAGINATION on the provider side but allows API clients to show end users or other consumers how many more data elements (or pages) may be requested subsequently.
{"offset": 0,"limit": 2,"size": 50,"customers": [...,...],"_links": {"next": {"href": "/customers?limit=2&offset=2"}}}
The preceding example can easily be mapped to the corresponding SQL query LIMIT 2 OFFSET 0. Instead of talking about offsets and limits, the API could also use the page metaphor in its message vocabulary, as shown here:
curl -X GET http://localhost:8080/customers?page-size=2&page=0{"page": 0,"pageSize": 2,"totalPages": 25,"customers": [...,...],"_links": {"next": {"href": "/customers?page-size=2&page=1"}}}
Using Cursor-Based Pagination, the client first requests an initial page of the desired size 2:
curl -X GET http://localhost:8080/customers?page-size=2{"pageSize": 2,"customers": [...,...],"_links": {"next": {"href": "/customers?page-size=2&cursor=mfn834fj"}}}
The response contains a link to the next chunk of data, represented by the cursor value mfn834fj. The cursor could be as simple as the primary key of the database or contain more information, such as a query filter.
Discussion
PAGINATION aims to substantially improve resource consumption and performance by sending only the data presently required and doing so just in time.
A single large response message might be inefficient to exchange and process. In this context, data set size and data access profile (that is, the user needs), especially the number of data records required to be available to an API client (immediately and over time), require particular attention. Especially when returning data for human consumption, not all data may be needed immediately; then PAGINATION has the potential to improve the response times for data access significantly.
From a security standpoint, retrieving and encoding large data sets may incur high effort and cost on the provider side and therefore lead to a denial-of-service attack. Moreover, transferring large data sets across a network can lead to interruptions, as most networks are not guaranteed to be reliable, especially cellular networks. This aspect is improved with PAGINATION because attackers can only request pages with small portions of data instead of an entire data set (assuming that the maximum value for the page size is limited). Note that in a rather subtle attack, it could still be enough to request the first page; if a poorly designed API implementation loads a vast data set as a whole, expecting to feed the data to the client page by page, an attacker still is able to fill up the server memory.
If the structure of the desired responses is not set oriented, so that a collection of data items can be partitioned into chunks, PAGINATION cannot be applied. Compared to response messages using the PARAMETER TREE pattern without PAGINATION, the pattern is substantially more complex to understand and thus might be less convenient to use, as it turns a single call into a longer conversation. PAGINATION requires more programming effort than does exchanging all data with one message.
PAGINATION leads to tighter coupling between API client and provider than single message transfers because additional representation elements are required to manage the slicing of the result sets into chunks. This can be mitigated by standardizing the required METADATA ELEMENTS. For example, with hypermedia, one just follows a Web link to fetch the next page. A remaining coupling issue is the session that may have to be established with each client while the pages are being scanned.
If API clients want to go beyond sequential access, complex parameter representations may be required to perform random access by seeking specific pages (or to allow clients to compute the page index themselves). The Cursor-Based Pagination variant with its—from a client perspective, opaque—cursor or token usually does not allow random access.
Delivering one page at a time allows the API client to process a digestible amount of data; a specification of which page to return facilitates remote navigation directly within the data set. Less endpoint memory and network capacity are required to handle individual pages, although some overhead is introduced because PAGINATION management is required (discussed shortly).
The application of PAGINATION leads to additional design concerns:
Where, when, and how to define the page size (the number of data elements per page). This influences the chattiness of the API (retrieving the data in many small pages requires a large number of messages).
How to order results—that is, how to assign them to pages and how to arrange the partial results on these pages. This order typically cannot change after the paginated retrieval begins. Changing the order as an API evolves over its life cycle might make a new API version incompatible with previous ones, which might go unnoticed if not communicated properly and tested thoroughly.
Where and how to store intermediate results, and for how long (deletion policy, timeouts).
How to deal with request repetition. For instance, do the initial and the subsequent requests have to be idempotent to prevent errors and inconsistencies?
How to correlate pages/chunks (with the original, the previous, and the next requests).
Further design issues for the API implementation include the caching policy (if any), the liveness (currentness) of results, filtering, as well as query pre- and postprocessing (for example, aggregations, counts, sums). Typical data access layer concerns (for instance, isolation level and locking in relational databases) come into play here as well [Fowler 2002]. Consistency requirements differ by client type and use case: Is the client developer aware of the PAGINATION? The resolution of these concerns is context-specific; for instance, frontend representations of search results in Web applications differ from batch master data replication in BACKEND INTEGRATIONS of enterprise information systems.
With respect to behind-the-scenes changes to mutable collections, two cases have to be distinguished. One issue that has to be dealt with is that new items might be added while the client walks through the pages. The second issue concerns updates to (or removal of) items on a page that has already been seen by the client. PAGINATION can deal with new items but will usually miss changes to already downloaded items that happened while a PAGINATION “session” was ongoing.
If the page size was set too small, sometimes the result of PAGINATION can be annoying for users (especially developers using the API), as they have to click through and wait to retrieve the next page even if there are only a few results. Also, human users may expect client-side searches to filter an entire data set; introducing PAGINATION may incorrectly result in empty search results because the matching data items are found in pages that have not yet been retrieved.
Not all functions requiring an entire record set, such as searching, work (well) with PAGINATION, or they require extra effort (such as intermediate data structures on the API client side). Paginating after searching/filtering (and not vice versa) reduces workload.
This pattern covers the download of large data sets, but what about upload? Such Request Pagination can be seen as a complementary pattern. It would gradually upload the data and fire off a processing job only once all data is there. Incremental State Build-up, one of the Conversation Patterns [Hohpe 2017], has this inverse nature. It describes a solution similar to PAGINATION to deliver the data from the client to the provider in multiple steps.
Related Patterns
PAGINATION can be seen as the opposite of REQUEST BUNDLE: whereas PAGINATION is concerned with reducing the individual message size by splitting one large message into many smaller pages, REQUEST BUNDLE combines several messages into a single large one.
A paginated query typically defines an ATOMIC PARAMETER LIST for its input parameters containing the query parameters and a PARAMETER TREE for its output parameters (that is, the pages).
A request-response correlation scheme might be required so that the client can distinguish the partial results of multiple queries in arriving response messages; the pattern “Correlation Identifier” [Hohpe 2003] might be eligible in such cases.
A “Message Sequence” [Hohpe 2003] also can be used when a single large data element has to be split up.
More Information
Chapter 10 of Build APIs You Won’t Hate covers PAGINATION types, discusses implementation approaches, and presents examples in PHP [Sturgeon 2016b]. Chapter 8 in the RESTful Web Services Cookbook deals with queries in a RESTful HTTP context [Allamaraju 2010]. Web API Design: The Missing Link covers PAGINATION under “More on Representation Design” [Apigee 2018].
In a broader context, the user interface (UI) and Web design communities have captured PAGINATION patterns in different contexts (not API design and management, but interaction design and information visualization). See coverage of the topic at the Interaction Design Foundation Web site [Foundation 2021] and the UI Patterns Web site [UI Patterns 2021].
Chapter 8 of Implementing Domain-Driven Design features stepwise retrieval of a notification log/archive, which can be seen as Offset-Based Pagination [Vernon 2013]. RFC 5005 covers feed paging and archiving for Atom [Nottingham 2007].
 Pattern: WISH LIST
Pattern: WISH LIST
When and Why to Apply
API providers serve multiple different clients that invoke the same operations. Not all clients have the same information needs: some might use just a subset of the data offered by an endpoint and its operations; other clients might need rich data sets.
How can an API client inform the API provider at runtime about the data it is interested in?
When addressing this problem, API designers balance performance aspects such as response time and throughput with factors influencing the developer experience such as learning effort and evolvability. They strive for data parsimony (or Datensparsamkeit).
These forces could be resolved by introducing infrastructure components such as network- and application-level gateways and caches to reduce the load on the server, but such components add to the complexity of the deployment model and network topology of the API ecosystem and increase related infrastructure testing, operations management, and maintenance efforts.
How It Works
As an API client, provide a WISH LIST in the request that enumerates all desired data elements of the requested resource. As an API provider, deliver only those data elements in the response message that are enumerated in the WISH LIST (“response shaping”).
Specify the WISH LIST as an ATOMIC PARAMETER LIST or flat PARAMETER TREE. As a special case, a simple ATOMIC PARAMETER may be included that indicates a verbosity level (or level of detail) such as minimal, medium, or full.
Figure 7.5 sketches the request and response messages used when introducing a WISH LIST:
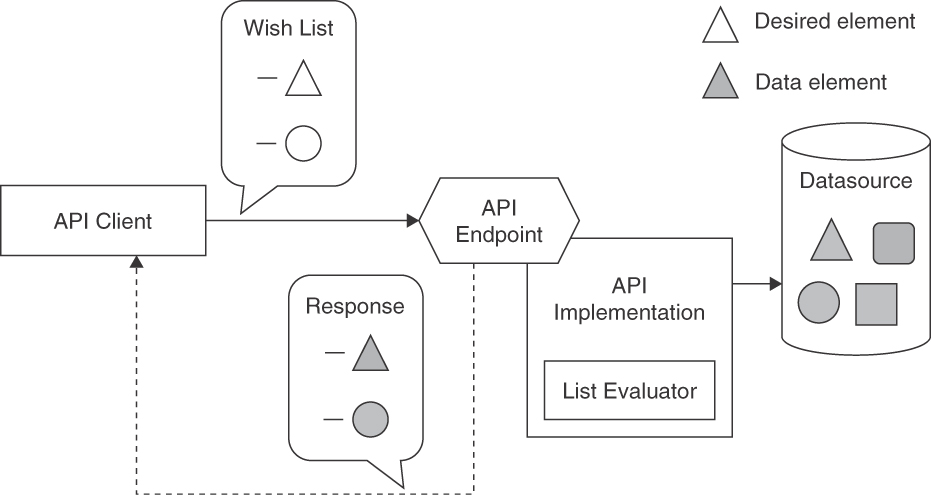
Figure 7.5 WISH LIST: A client enumerates the desired data elements of the resource
The List Evaluator in the figure has two implementation options. It often is translated to a filter for the data source so that only relevant data is loaded. Alternatively, the API implementation can fetch a full result set from the data source and select the entities that appear in the client wish when assembling the response data. Note that the data source can be any kind of backend system, possibly remote, or database. For instance, the wish translates into a WHERE clause of a SQL query when the data source is a relational database. If a remote system is accessed via an API, the WISH LIST might simply be passed on after having been validated (assuming that the downstream API also supports the pattern).
Variants A common variant is to provide options for expansion in responses. The response to the first request provides only a terse result with a list of parameters that can be expanded in subsequent requests. To expand the request results, the client can select one or more of these parameters in the WISH LIST of a follow-on request.
Another variant is to define and support a wildcard mechanism, as known from SQL and other query languages. For instance, a star * might request all data elements of a particular resource (which could then be the default if no wishes are specified). Even more complex schemes are possible, such as cascaded specifications (for example, customer.* fetching all data about the customer).
Example
In the Lakeside Mutual Customer Core application, a request for a customer returns all of its available attributes.
curl -X GET http://localhost:8080/customers/gktlipwhjrFor customer ID gktlipwhjr, this would return the following:
{"customerId": "gktlipwhjr","firstname": "Max","lastname": "Mustermann","birthday": "1989-12-31T23:00:00.000+0000","streetAddress": "Oberseestrasse 10","postalCode": "8640","city": "Rapperswil","email": "[email protected]","phoneNumber": "055 222 4111","moveHistory": [ ],"customerInteractionLog": {"contactHistory": [ ],"classification": {"priority": "gold"}}}
To improve this design, a WISH LIST in the query string can restrict the result to the fields included in the wish. In the example, an API client might be interested in only the customerId, birthday, and postalCode:
curl -X GET http://localhost:8080/customers/gktlipwhjr?fields=customerId,birthday,postalCode
The returned response now contains only the requested fields:
{"customerId": "gktlipwhjr","birthday": "1989-12-31T23:00:00.000+0000","postalCode": "8640"}
This response is much smaller; only the information required by the client is transmitted.
Discussion
WISH LIST helps manage the different information needs of API clients. It is well suited if the network has limited capacity and there is a certain amount of confidence that clients usually require only a subset of the available data. The potential negative consequences include additional security threats, additional complexity, as well as test and maintenance efforts. Before introducing a WISH LIST mechanism, these negative consequences must be considered carefully. Often, they are treated as an afterthought, and mitigating them can lead to maintenance and evolution problems once the API is in production.
By adding or not adding attribute values in the WISH LIST instance, the API client expresses its wishes to the provider; hence, the desire for data parsimony (or Datensparsamkeit) is met. The provider does not have to supply specialized and optimized versions of operations for certain clients or to guess data required for client use cases. Clients can specify the data they require, thereby enhancing performance by creating less database and network load.
Providers have to implement more logic in their service layers, possibly affecting other layers down to data access as well. Providers risk exposing their data model to clients, increasing coupling. Clients have to create the WISH LIST, the network has to transport this metadata, and the provider has to process it.
A comma-separated list of attribute names can lead to problems when mapped to programming language elements. For instance, misspelling an attribute name might lead to an error (if the API client is lucky), or the expressed wish might be ignored (which might lead the API client to the impression that the attribute does not exist). Furthermore, API changes might have unexpected consequences; for instance, a renamed attribute might no longer be found if clients do not modify their wishes accordingly.
Solutions using the more complex variants introduced earlier (such as cascaded specifications, wildcards, or expansion) might be harder to understand and build than simpler alternatives. Sometimes existing provider-internal search-and-filter capabilities such as wildcards or regular expressions can be reused.
This pattern (or, more generally speaking, all patterns and practices sharing this common goal and theme of client-driven message content) is also known as response shaping.
Related Patterns
WISH TEMPLATE addresses the same problem as WISH LIST but uses a possibly nested structure to express the wishes rather than a flat list of element names. Both WISH LIST and WISH TEMPLATE usually deal with PARAMETER TREES in response messages because patterns to reduce message sizes are particularly useful when dealing with complex response data structures.
Using a WISH LIST has a positive influence on sticking to a RATE LIMIT, as less data is transferred when the pattern is used. To reduce the transferred data further, it can be combined with CONDITIONAL REQUEST.
The PAGINATION pattern also reduces response message sizes by splitting large repetitive responses into parts. The two patterns can be combined.
More Information
Regular expression syntax or query languages such as XPath (for XML payloads) can be seen as an advanced variant of this pattern. GraphQL [GraphQL 2021] offers a declarative query language to describe the representation to be retrieved against an agreed-upon schema found in the API documentation. We cover GraphQL in more detail in the WISH TEMPLATE pattern.
Web API Design: The Missing Link [Apigee 2018] recommends comma-separated WISH LISTS in its chapter “More on Representation Design.” James Higginbotham features this pattern as “Zoom-Embed” [Higginbotham 2018].
“Practical API Design at Netflix, Part 1: Using Protobuf FieldMask” in the Net-flix Technology Blog [Borysov 2021] mentions GraphQL field selectors and sparse fieldsets in JSON:API [JSON API 2022]. It then features Protocol Buffer FieldMask as a solution for gRPC APIs within the Netflix Studio Engineering. The authors suggest that API providers may ship client libraries with prebuilt FieldMask for the most frequently used combinations of fields. This makes sense if multiple consumers are interested in the same subset of fields.
 Pattern: WISH TEMPLATE
Pattern: WISH TEMPLATE
When and Why to Apply
An API provider has to serve multiple different clients that invoke the same operations. Not all clients have the same information needs: some might need just a subset of the data offered by the endpoint; other clients might need rich, deeply structured data sets.
How can an API client inform the API provider about nested data that it is interested in? How can such preferences be expressed flexibly and dynamically?3
3. Note that this problem is very similar to the problem of the pattern Wish List but adds the theme of response data nesting.
An API provider that has multiple clients with different information might simply expose a complex data structure that represents the superset (or union) of what the client community wants (for example, all attributes of master data such as product or customer information or collections of operational data entities such as purchase order items). Very likely, this structure becomes increasingly complex as the API evolves. Such a one-size-fits-all approach also costs performance (response time, throughput) and introduces security threats.
Alternatively, one could use a flat WISH LIST that simply enumerates desired attributes, but such a simple approach has limited expressiveness when dealing with nested data structures.
Network-level and application-level gateways and proxies can be introduced to improve performance, for instance, by caching. Such responses to performance issues add to the complexity of the deployment model and network topology and come with design and configuration effort.
How It Works
Add one or more additional parameters to the request message that mirror the hierarchical structure of the parameters in the corresponding response message. Make these parameters optional or use Boolean as their types so that their values indicate whether or not a parameter should be included.
The structure of the wish that mirrors the response message often is a PARAMETER TREE. API clients can populate instances of this WISH TEMPLATE parameter with empty, sample, or dummy values when sending a request message or set its Boolean value to true to indicate their interest in it. The API provider then uses the mirrored structure of the wish as a template for the response and substitutes the requested values with actual response data. Figure 7.6 illustrates this design.
The Template Processor in the figure has two implementation options, depending on the chosen template format. If a mirror object is already received from the wire and structured as a PARAMETER TREE, this data structure can be traversed to prepare the data source retrieval (or to extract relevant parts from the result set). Alternatively, the templates may come in the form of a declarative query, which must be evaluated first and then translated to a database query or a filter to be applied to the fetched data (these two options are similar to those in the List Evaluator component of a WISH LIST processor shown in Figure 7.5). The evaluation of the template instance can be straightforward and supported by libraries or language concepts in the API implementation (for instance, navigating through nested JSON objects with JSONPath, XML documents with XPath, or matching a regular expression).
For complex template syntaxes constituting a domain-specific language, the introduction of compiler concepts such as scanning and parsing might be necessary.
Figure 7.7 shows the matching input and output parameter structure for two top-level fields, aValue and aString, and a nested child object that also has two fields, aFlag and aSecondString. The output parameters (or response message elements) have integer and string types, and the mirror in the request message specifies matching Boolean values. Setting the Boolean to true indicates interest in the data.
Example
The following MDSL service contract sketch introduces a <<Wish_Template>> highlighted with a stereotype:
data type PersonalData P // unspecified, placeholderdata type Address P // unspecified, placeholderdata type CustomerEntity <<Entity>> {PersonalData?, Address?}endpoint type CustomerInformationHolderServiceexposesoperation getCustomerAttributesexpecting payload {"customerId":ID, // the customer ID<<Wish_Template>>"mockObject":CustomerEntity// has same structure as desired result set}delivering payload CustomerEntity
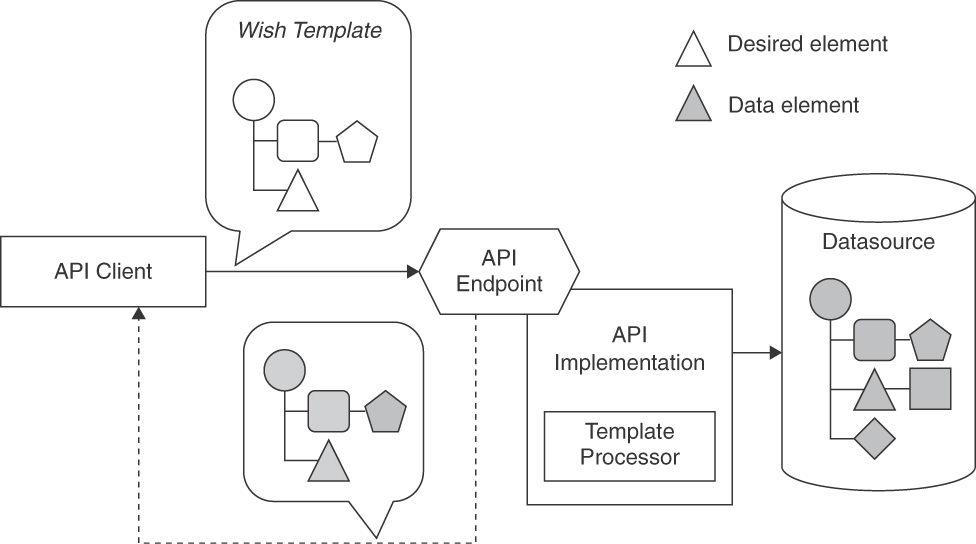
Figure 7.6 WISH TEMPLATE components and processing steps
In this example of an API, the client can send a CustomerEntity mirror (or mock) object that may include PersonalData and/or Address attributes (this is defined in the data type definition CustomerEntity). The provider can then check which attributes were sent (ignoring the dummy values in the wish) and respond with a filled-out CustomerEntity instance containing PersonalData and/or Address.
Discussion
Data parsimony (or Datensparsamkeit) is an important general design principle in distributed systems that are performance- and security-critical. However, this principle is not always applied when iteratively and incrementally defining an API end-point: it is typically easier to add things (here, information items or attributes) than to remove them. That is, once something is added to an API, it is often hard to determine whether it can be safely removed in a backward-compatible way (without breaking changes, that is) as many (maybe even unknown) clients might depend on it. By specifying selected attribute values in the WISH TEMPLATE instance and filling it with marker values or Boolean flags, the consumer expresses its wishes to the provider; thus, the desire for data parsimony and flexibility is met.
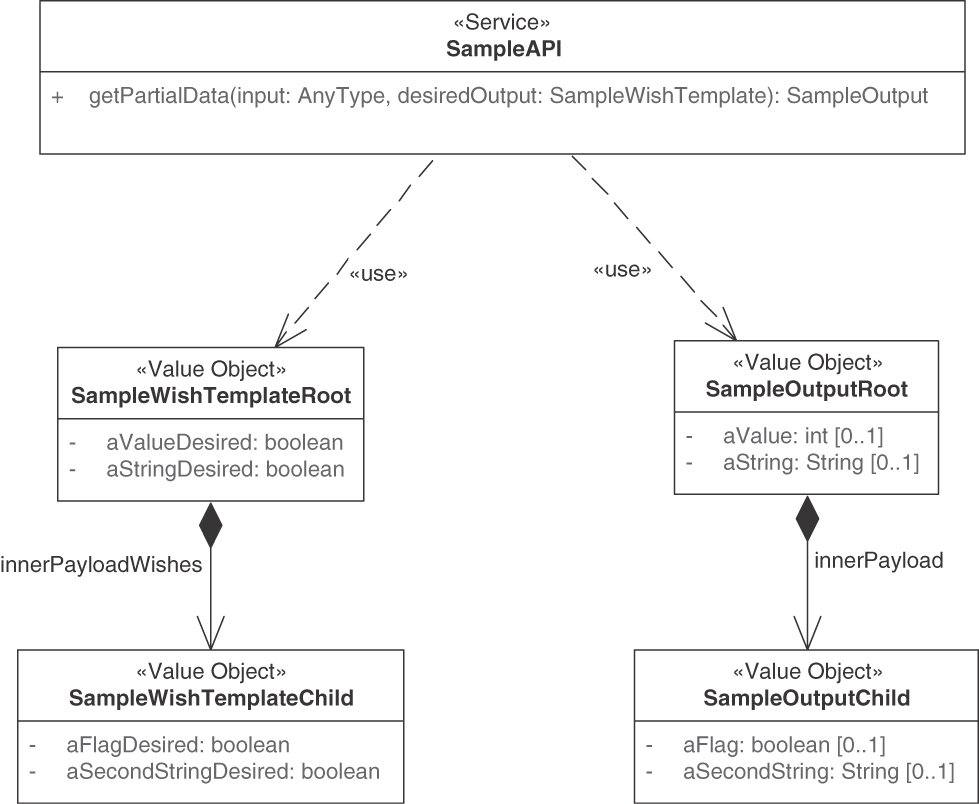
Figure 7.7 Possible structure of mock/mirror object (WISH TEMPLATE)
When implementing this pattern, several decisions have to be made, including how to represent and populate the template. The sibling pattern WISH LIST mentions a comma-separated list of wishes as one approach, but the PARAMETER TREES forming the WISH TEMPLATE are more elaborate and therefore require encoding and syntactic analysis. While highly sophisticated template notations might improve the developer experience on the client side and performance significantly, they also run the risk of turning into a larger, rather complex piece of middleware embedded into the API implementation (which comes with development, test, and maintenance effort as well as technical risk).
Another issue is how to handle errors for wishes that cannot be fulfilled, for example, because the client specified an invalid parameter. One approach could be to ignore the parameter silently, but this might hide real problems, for instance, if there was a typo or the name of a parameter changed.
The pattern is applicable not only when designing APIs around business capabilities but also when working with more IT-infrastructure-related domains such as software-defined networks, virtualization containers, or big data analysis. Such domains and software solutions for them typically have rich domain models and many configuration options. Dealing with the resulting variability justifies a flexible approach to API design and information retrieval.
GraphQL, with its type system, introspection, and validation capabilities, as well as its resolver concept can be seen as an advanced realization of this pattern [GraphQL 2021]. The WISH TEMPLATES of GraphQL are the query and mutation schemas providing declarative descriptions of the client wants and needs. Note that the adoption of GraphQL requires the implementation of a GraphQL server (effectively realizing the Template Processor in Figure 7.6). This server is a particular type of API endpoint located on top of the actual API endpoints (which become resolvers in GraphQL terms). This server has to parse the declarative description of queries and mutations and then call one or more resolvers, which in turn may call additional ones when following the data structure hierarchy.
Related Patterns
WISH LIST addresses the same problem but uses a flat enumeration rather than a mock/template object; both these patterns deal with instances of PARAMETER TREE in response messages. The WISH TEMPLATE becomes part of a PARAMETER TREE that appears in the request message.
WISH TEMPLATE shares many characteristics with its sibling pattern WISH LIST. For instance, without client- and provider-side data contract validation against a schema (XSD, JSON Schema), WISH TEMPLATE has the same drawbacks as the simple enumeration approach described in the WISH LIST pattern. WISH TEMPLATES can become more complex to specify and understand than simple lists of wishes; schemas and validators are usually not required for simple lists of wishes. Provider developers must be aware that complex wishes with deep nesting can strain and stress the communication infrastructure.4 Processing can then also get more complex. Accepting the additional effort, as well as the complexity added to the parameter data definitions and their processing, only makes sense if simpler structures like WISH LISTS cannot express the wish adequately.
Using a WISH TEMPLATE has a positive influence on a RATE LIMIT, as less data is transferred when the pattern is used and fewer requests are required.
More Information
In “You Might Not Need GraphQL,” Phil Sturgeon shows several APIs that implement response shaping and how they correspond to related GraphQL concepts [Sturgeon 2017].
Message Exchange Optimization (aka Conversation Efficiency)
The previous section offered patterns that allow clients to specify the partition of large data sets and which individual data points they are interested in. This lets API providers and clients avoid unnecessary data transfers and requests. But maybe the client already has a copy of the data and does not want to receive the same data again. Or they might have to send many individual requests that cause transmission and processing overhead. The patterns described here provide solutions to these two issues and try to balance the following common forces:
Complexity of endpoint, client, and message payload design and programming: The additional effort needed to implement and operate a more complex API endpoint that takes data update frequency characteristics into account needs to be balanced against the expected reduction in endpoint processing and bandwidth usage. Reducing the number of requests does not imply that less information is exchanged. Hence, the remaining messages have to carry more complex payloads.
Accuracy of reporting and billing: Reporting and billing of API usage must be accurate and should be perceived as being fair. A solution that burdens the client with additional work (for instance, keeping track of which version of data it has) to reduce the provider’s workload might require some incentive from the provider. This additional complexity in the client-provider conversation might also have an impact on the accounting of API calls.
4. Olaf Hartig and Jorge Pérez analyzed the performance of the GitHub GraphQL API and found an “exponential increase in result sizes” as they increased the query level depth. The API timed out on queries with nesting levels higher than 5 [Hartig 2018].
The two patterns responding to these forces are CONDITIONAL REQUEST and REQUEST BUNDLE.
 Pattern: CONDITIONAL REQUEST
Pattern: CONDITIONAL REQUEST
When and Why to Apply
Some clients keep on requesting the same server-side data repeatedly. This data does not change between requests.
How can unnecessary server-side processing and bandwidth usage be avoided when invoking API operations that return rarely changing data?
In addition to the challenges introduced at the beginning of this section, the following forces apply:
Size of messages: If network bandwidth or endpoint processing power is limited, retransmitting large responses that the client already has received is wasteful.
Client workload: Clients may want to learn whether the result of an operation has changed since their last invocation in order to avoid reprocessing the same results. This reduces their workload.
Provider workload: Some requests are rather inexpensive to answer, such as those not involving complex processing, external database queries, or other backend calls. Any additional runtime complexity of the API endpoint, for instance, any decision logic introduced to avoid unnecessary calls, might negate the possible savings in such cases.
Data currentness versus correctness: API clients might want to cache a local copy of the data to reduce the number of API calls. As copy holders, they must decide when to refresh their caches to avoid stale data. The same considerations apply to metadata. On the one hand, when data changes, chances are that metadata about it has to change too. On the other hand, the data could remain the same, and only the metadata might change. Attempts to make conversations more efficient must take these considerations into account.
One might consider scaling up or scaling out on the physical deployment level to achieve the desired performance, but such an approach has its limits and is costly. The API provider or an intermediary API gateway might cache previously requested data to serve them quickly without having to recreate or fetch them from the database or a backend service. Such dedicated caches have to be kept current and invalidated at times, which leads to a complex set of design problems.5
In an alternative design, the client could send a “preflight” or “look before you leap” request asking the provider if anything has changed before sending the actual request. But this design doubles the number of requests, makes the client implementation more complex, and might reduce client performance when the network has a high latency.
How It Works
If the condition is not met, the provider does not reply with a full response but returns a special status code instead. Clients can then use the previously cached value. In the simplest case, the conditions represented by METADATA ELEMENTS could be transferred in an ATOMIC PARAMETER. Application-specific data version numbers or timestamps can be used if already present in the request.
5. As Phil Karlton (quoted by Martin Fowler) notes, “There are only two hard things in Computer Science: cache invalidation and naming things” [Fowler 2009]. Fowler provides tongue-in-cheek evidence for this claim.
Make requests conditional by adding METADATA ELEMENTS to their message representations (or protocol headers) and processing these requests only if the condition specified by the metadata is met.
Figure 7.8 illustrates the solution elements.
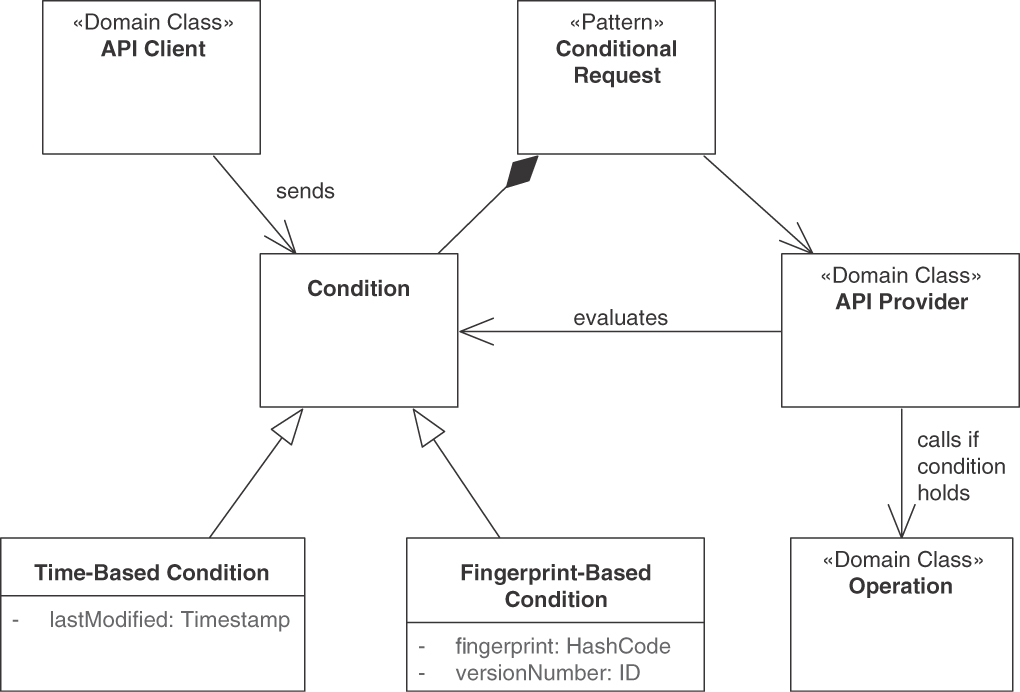
Figure 7.8 CONDITIONAL REQUEST
It is also possible to implement the CONDITIONAL REQUEST pattern within the communication infrastructure, orthogonal and complementary to the application-specific content. To do so, the provider may include a hash of the data served. The client can then include this hash in subsequent requests to indicate which version of the data it already has and for which data it wishes to receive only newer versions. A special condition violated response is returned instead of the complete response if the condition is not met. This approach implements a “virtual caching” strategy, allowing clients to recycle previously retrieved responses (assuming they have kept a copy).
Variants Request conditions can take different forms, leading to different variants of this pattern:
Time-Based Conditional Request: Resources are timestamped with a
last-modifieddate. A client can use this timestamp in the subsequent requests so that the server will reply with a resource representation only if it is newer than the copy the client already has. Note that this approach requires some clock synchronization between clients and servers if it is supposed to work accurately (which might not always be required). In HTTP, theIf-Modified-Sincerequest header carries such a timestamp, and the304 Not Modifiedstatus code is used to indicate that a newer version is not available.Fingerprint-Based Conditional Request: Resources are tagged, that is, fingerprinted, by the provider, using, for example, a hash function applied to the response body or some version number. Clients can then include the fingerprint to indicate the version of the data they already have. In HTTP, the entity tag (
ETag), as described in RFC 7232 [Fielding 2014a], serves that purpose together with theIf-None-Matchrequest header and the previously mentioned304 Not Modifiedstatus code.
Example
Many Web application frameworks, such as Spring, support CONDITIONAL REQUESTS natively. The Spring-based Customer Core backend application in the Lakeside Mutual scenario includes ETags—implementing the fingerprint-based CONDITIONAL REQUEST variant—in all responses. For example, consider retrieving a customer:
curl -X GET --includehttp:://localhost:8080/customers/gktlipwhjr
A response containing an ETag header could start with:
HTTP/1.1 200ETag: "0c2c09ecd1ed498aa7d07a516a0e56ebc"Content-Type: application/hal+json;charset=UTF-8Content-Length: 801Date: Wed, 20 Jun 2018 05:36:39 GMT{"customerId": "gktlipwhjr",...
Subsequent requests can then include the ETag received from the provider previously to make the request conditional:
curl -X GET --include –-header'If-None-Match: "0c2c09ecd1ed498aa7d07a516a0e56ebc"'http://localhost:8080/customers/gktlipwhjr
If the entity has not changed, that is, If-None-Match occurs, the provider answers with a 304 Not Modified response including the same ETag:
HTTP/1.1 304ETag: "0c2c09ecd1ed498aa7d07a516a0e56ebc"Date: Wed, 20 Jun 2018 05:47:11 GMT
If the customer has changed, the client will get the full response, including a new ETag, as shown in Figure 7.9.
Note that the Customer Core microservice implements CONDITIONAL REQUEST as a filter applied to the response. Using a filter means that the response is still computed but then is discarded by the filter and replaced with the 304 Not Modified status code. This approach has the benefit of being transparent to the endpoint implementation; however, it only saves bandwidth and not computation time. A server-side cache could be used to minimize the computational time as well.
Discussion
CONDITIONAL REQUESTS allow both clients and API providers to save bandwidth without assuming that providers remember whether a given client has already seen the latest version of the requested data. It is up to the clients to remind the server about their latest known version of the data. They cache previous responses and are responsible for keeping track of their timestamp or fingerprint and resending this information along with their next requests. This simplifies the configuration of the data currentness interval. Timestamps, as one way to specify the data currentness interval, are simple to implement even in distributed systems as long as only one system writes the data. The time of this system is the master time in that case.
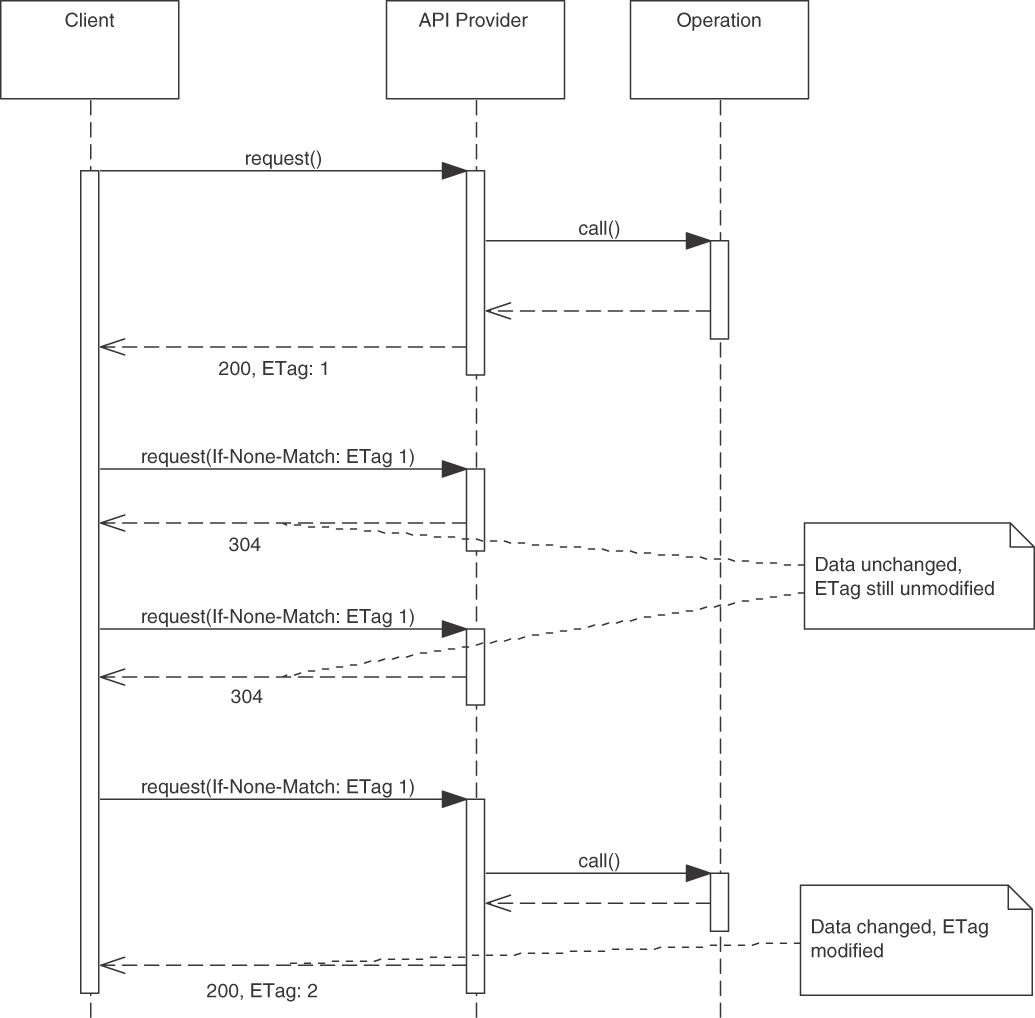
Figure 7.9 CONDITIONAL REQUEST example
The complexity of the provider-side API endpoint does not increase if the pattern is implemented with a filter, as shown in the preceding example. Further improvements, such as additional caching of responses, can be realized for specific endpoints to reduce provider workload. This increases the complexity of the endpoint, as they have to evaluate the conditions, filters, and exceptions, including errors that might occur because of the condition handling or filtering.
Providers also have to decide how CONDITIONAL REQUESTS affect other quality measures such as a RATE LIMIT and whether such requests require special treatment in a PRICING PLAN.
Clients can choose whether or not to make use of CONDITIONAL REQUESTS, depending on their performance requirements. Another selection criterion is whether clients can afford to rely on the server to detect whether the state of the API resources has changed. The number of messages transmitted does not change with CONDITIONAL REQUESTS, but the payload size can be reduced significantly. Rereading an old response from the client cache is usually much faster than reloading it from the API provider.
Related Patterns
Using a CONDITIONAL REQUEST may have a positive influence on a RATE LIMIT that includes response data volumes in the definition of the limit, as less data is transferred when this pattern is used.
The pattern can be carefully combined with either WISH LIST or WISH TEMPLATE. This combination can be rather useful to indicate the subset of data that is to be returned if the condition evaluates to true and the data needs to be sent (again).
A combination of CONDITIONAL REQUESTS with PAGINATION is possible, but there are edge cases to be considered. For example, the data of a particular page might not have changed, but more data was added, and the total number of pages has increased. Such a change in metadata should also be included when evaluating the condition.
More Information
Chapter 10 in the RESTful Web Services Cookbook [Allamaraju 2010] is dedicated to conditional requests. Some of the nine recipes in this chapter even deal with requests that modify data.
 Pattern: REQUEST BUNDLE
Pattern: REQUEST BUNDLE
When and Why to Apply
An API endpoint that exposes one or more operations has been specified. The API provider observes that clients make many small, independent requests; individual responses are returned for these requests. These chatty interaction sequences harm scalability and throughput.
How can the number of requests and responses be reduced to increase communication efficiency?
In addition to the general desire for efficient messaging and data parsimony (as discussed in the introduction to this chapter), the goal of this pattern is to improve performance:
Latency: Reducing the number of API calls may improve client and provider performance, for instance, when the network has high latency or overhead is incurred by sending multiple requests and responses.
Throughput: Exchanging the same information through fewer messages may lead to a higher throughput. However, the client has to wait longer until it can start working with the data.
One might consider using more or better hardware to meet the performance demands of the API clients, but such an approach has its physical limits and is costly.
How It Works
Define a REQUEST BUNDLE as a data container that assembles multiple independent requests in a single request message. Add metadata such as identifiers of individual requests (bundle elements) and a bundle element counter.
There are two options to design the response messages:
One request with one response: REQUEST BUNDLE with a single bundled response.
One request with multiple responses: REQUEST BUNDLE with multiple responses.
The REQUEST BUNDLE container message can, for instance, be structured as a PARAMETER TREE or a PARAMETER FOREST. In the first option, a message structure for the response container that mirrors the request assembly and corresponds to the bundled requests has to be defined. The second option can be implemented with support from the underlying network protocols to support suitable message exchange and conversation patterns. For example, with HTTP, the provider can delay the response until a bundle item has been processed. RFC 6202 [Saint-Andre 2011] presents details on this technique, which is called long polling.
Errors have to be handled both individually and on the container level. Different options exist; for instance, an ERROR REPORT for the entire batch can be combined with an associative array of individual ERROR REPORTS for bundle elements accessible via ID ELEMENTS.
Figure 7.10 shows a REQUEST BUNDLE of three individual requests, A, B, and C, assembled into a single remote API call. Here, a single bundled response is used (Option 1).
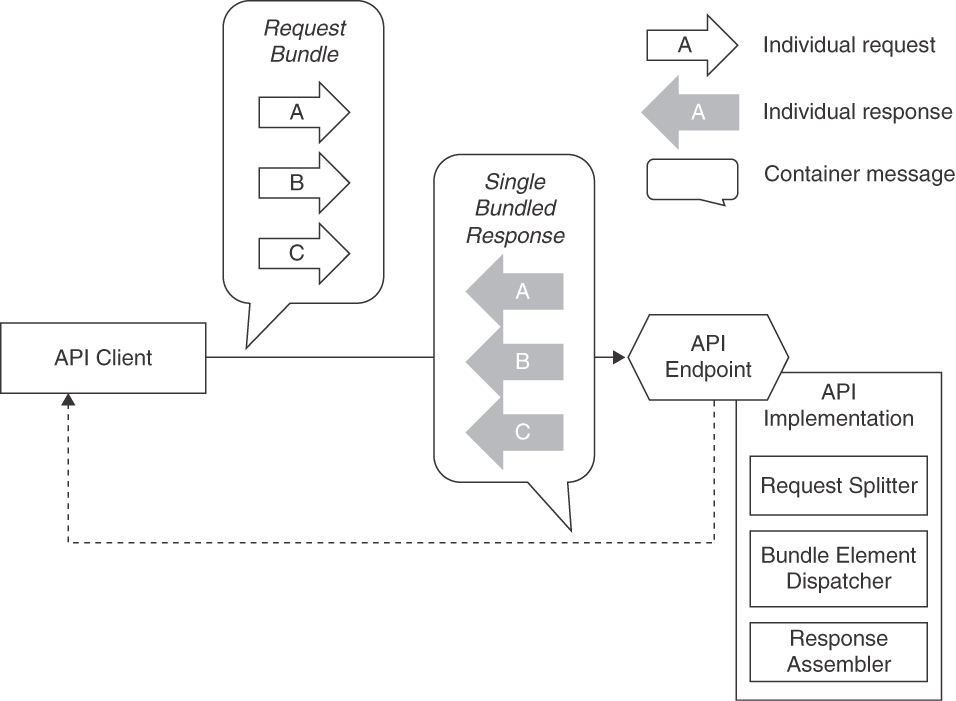
Figure 7.10 REQUEST BUNDLE: Three independent requests, A, B, and C, are assembled in a container message. The provider processes the requests and replies with a Single Bundled Response
The API implementation has to split the request bundle and assemble the response bundle. This can be as straightforward as iterating through an array that the provider-side endpoint hands over, but it also may require some additional decision and dispatch logic, for instance, using a control METADATA ELEMENT in the request to decide where in the API implementation to route the bundle elements to. The API client has to split a bundled response in a similar way if the provider returns a single bundled response.
Example
In the Lakeside Mutual Customer Core service, clients can request multiple customers from the customer’s INFORMATION HOLDER RESOURCE by specifying an ATOMIC PARAMETER LIST of customer ID ELEMENTS. A path parameter serves as a bundle container. A comma (,) separates the bundle elements:
curl -X GET http://localhost:8080/customers/ce4btlyluu,rgpp0wkpecThis will return the two requested customers as DATA ELEMENTS, represented as JSON objects in a bundle-level array (using the single bundled response option):
{"customers": [{"customerId": "ce4btlyluu","firstname": "Robbie","lastname": "Davenhall","birthday": "1961-08-11T23:00:00.000+0000",..."_links": { ... }},{"customerId": "rgpp0wkpec","firstname": "Max","lastname": "Mustermann","birthday": "1989-12-31T23:00:00.000+0000",..."_links": { ... }}],"_links": { ... }}
This example implements the pattern option REQUEST BUNDLE with single bundled response, introduced earlier.
Discussion
By transmitting a bundle of requests at once, the number of messages can be reduced significantly if the client-side usage scenarios include batch or bulk processing (for instance, periodic updates to customer master data). As a consequence, the communication is sped up because less network communication is required. Depending on the actual use case, client implementation effort might also decrease because the client does not have to keep track of multiple ongoing requests. It can process all logically independent bundle elements found in a single response one by one.
The pattern adds to endpoint processing effort and complexity. Providers have to split the request messages and, when realizing REQUEST BUNDLE with multiple responses, coordinate multiple individual responses. Client processing effort and complexity can increase as well because clients must deal with the REQUEST BUNDLE and its independent elements, again requiring a splitting strategy. Finally, the message payload design and processing get more complex, as data from multiple sources has to be merged into one message.
Being independent of each other, individual requests in the REQUEST BUNDLE might be executed concurrently by the endpoint. Hence, the client should not make any assumptions about the order of evaluation of the requests. API providers should document this container property in the API DESCRIPTION. Guaranteeing a particular order of bundle elements causes extra work, for instance ordering a single bundled response in the same way as the incoming REQUEST BUNDLE.
The pattern is eligible if the underlying communication protocol cannot handle multiple requests at once. It assumes that data access controls are sufficiently defined and presented so that all bundle elements are allowed to be processed. If not, the provider must compose partial responses indicating to the client which commands/requests in the bundle failed and how to correct the corresponding input so that invocation can be retried. Such element-level access control can be challenging to handle on the client side.
Clients must wait until all messages in the bundle have been processed, increasing the overall latency until a first response is received; however, compared to many consecutive calls, the total communication time typically speeds up, as less network communication is required. The coordination effort might make the service provider stateful, which is considered harmful in microservices and cloud environments due to its negative impact on scalability. That is, it becomes more difficult to scale out horizontally when workload increases because the microservices middleware or the cloud provider infrastructure may contain load balancers that now have to make sure that subsequent requests reach the right instances and that failover procedures recreate state in a suited fashion. It is not obvious whether the bundle or its elements should be the units of scaling.
Related Patterns
The request and response messages of a REQUEST BUNDLE form PARAMETER FORESTS or PARAMETER TREES. Additional information about the structure and information that identifies individual requests comes as one or more ID ELEMENTS or METADATA ELEMENTS. Such identifiers might realize the “Correlation Identifier” pattern [Hohpe 2003] to trace responses back to requests.
A REQUEST BUNDLE can be delivered as a CONDITIONAL REQUEST. The pattern can also be combined with a WISH LIST or a WISH TEMPLATE. It must be carefully analyzed if enough gains can be realized to warrant the complexity of a combination of two or even three of those patterns. If the requested entities are of the same kind (for instance, several people in an address book are requested), PAGINATION and its variants can be applied instead of REQUEST BUNDLE.
Using a REQUEST BUNDLE has a positive influence on staying within a RATE LIMIT that counts operation invocations because fewer messages are exchanged when the pattern is used. This pattern goes well with explicit ERROR REPORTS because it is often desirable to report the error status or success per bundle element and not only for the entire REQUEST BUNDLE.
REQUEST BUNDLE can be seen as an extension of the general “Command” design pattern: each individual request is a command according to terminology from [Gamma 1995]. “Message Sequence” [Hohpe 2003] solves the opposite problem: to reduce the message size, messages are split into smaller ones and tagged with a sequence ID. The price for this is a higher number of messages.
More Information
Recipe 13 in Chapter 11 of the RESTful Web Services Cookbook [Allamaraju 2010] advises against providing a generalized endpoint to tunnel multiple individual requests.
Coroutines can improve performance when applying the REQUEST BUNDLE pattern in the context of batch processing (aka chunking). “Improving Batch Performance when Migrating to Microservices with Chunking and Coroutines” discusses this option in detail [Knoche 2019].
Summary
This chapter presented patterns concerned with API quality, specifically, finding the sweet spot between API design granularity, runtime performance, and the ability to support many diverse clients. It investigated whether many small or few large messages should be exchanged.
Applying the EMBEDDED ENTITY pattern makes the API exchange self-contained. LINKED INFORMATION HOLDER leads to smaller messages that can refer to other API endpoints and, therefore, will lead to multiple round-trips to retrieve the same information.
PAGINATION lets clients retrieve data sets piecewise, depending on their information needs. If the exact selection of details to be fetched is not known at design time, and clients would like the API to satisfy all of their desires, then WISH LISTS and WISH TEMPLATES offer the required flexibility.
Bulk messages in a REQUEST BUNDLE require only one interaction. While performance can be carefully optimized by sending and receiving payloads with the right granularity, it also helps to introduce CONDITIONAL REQUESTS and avoid resending the same information to clients who already have it.
Note that performance is hard to predict in general and in distributed systems in particular. Typically, it is measured under steady conditions as a system landscape evolves; if a performance control shows a negative trend that runs the risk of violating one or more formally specified SERVICE LEVEL AGREEMENTS or other specified runtime quality policies, the API design and its implementation should be revised. This is a broad set of important issues for all distributed systems; it becomes even more severe when a system is decomposed into small parts, such as microservices to be scaled and evolved independently of each other. Even when services are loosely coupled, the performance budget for meeting the response-time requirements of an end user performing a particular business-level function can be evaluated only as a whole and end-to-end. Commercial products and open-source software for load/performance testing and monitoring exist. Challenges include the effort required to set up an environment that has the potential to produce meaningful, reproducible results as well as the ability to cope with change (of requirements, system architectures, and their implementations). Simulating performance is another option. There is a large body of academic work on predictive performance modeling of software systems and software architectures (for example, “The Palladio-Bench for Modeling and Simulating Software Architectures” [Heinrich 2018]).
Next up is API evolution, including approaches to versioning and life-cycle management (Chapter 8, “Evolve APIs”).