
Chapter 5
Define Endpoint Types and Operations
API design affects not only the structure of request and response messages, which we covered in Chapter 4, “Pattern Language Introduction.” It is equally—or even more—important to position the API endpoints and their operations within the architecture of the distributed system under construction (the terms endpoints and operations were introduced in the API domain model in Chapter 1, “Application Programming Interface (API) Fundamentals”). If positioning is done without careful thought, in a hurry, or not at all, the resulting API provider implementation is at risk for being hard to scale and maintain when inconsistencies degrade conceptual integrity; API client developers might find it difficult to learn and utilize the resulting mishmash APIs.
The architectural patterns in this chapter play a central role in our pattern language. Their purpose is to connect high-level endpoint identification activities with detailed design of operations and message representations. We employ a role- and responsibility-driven approach for this transition. Knowing about the technical roles of API endpoints and the state management responsibilities of their operations allows API designers to justify more detailed decisions later and also helps with runtime API management (for instance, infrastructure capacity planning).
This chapter corresponds to the Define phase of the Align-Define-Design-Refine (ADDR) process outlined in the introduction to Part 2 of the book. You do not have to be familiar with ADDR to be able to apply its patterns.
Introduction to API Roles and Responsibilities
Business-level ideation activities often produce collections of candidate API end-points. Such initial, tentative design artifacts typically start from API design goals expressed as user stories (of various forms), event storming output, or collaboration scenarios [Zimmermann 2021b]. When the API realization starts, these interface candidates have to be defined in more detail. API designers seek an appropriate balance between architectural concerns such as granularity of the services exposed by the API (small and specific vs. large and universal) and degree of coupling between clients and API provider implementations (as low as possible, as high as needed).
The requirements for API design are diverse. As explained previously, goals derived from the business-level activities are a primary source of input, but not the only one; for instance, external governance rules and constraints imposed by existing backend systems have to be taken into account as well. Consequently, the architectural roles of APIs in applications and service ecosystems differ widely. Sometimes, API clients just want to inform the provider about an incident or hand over some data; sometimes, they look for provider-side data to continue their processing. When responding to client requests, providers may simply return a data element already available—or may perform rather complex processing steps (including calls to other APIs). Some of the provider-side processing, whether simple or complex, may change the provider state, some might leave this state untouched. Calls to API operations may or may not be part of complex interaction scenarios and conversations. For instance, long-running business processes such as online shopping and insurance claims management involve complex interactions between multiple parties.
The granularity of the operations varies greatly. Small API operations are easy to write, but there might be many, which have to be composed with their invocations being coordinated over time; few large API operations may be self-contained and autonomous, but they can be difficult to configure, test, and evolve. The runtime operations management of many small units also differs from that of a few big ones; there is a flexibility versus efficiency trade-off.
API designers have to decide how to give operations a business meaning (this, for instance, is a principle in service-oriented architectures [Zimmermann 2017]). They also have to decide if and how to manage state; an operation might simply return a calculated response but might also have a permanent mutational effect on the provider-side data stores.
In response to these challenges, the patterns in this chapter deal with endpoint and operation semantics in API design and usage. They carve out the architectural role of API endpoints (emphasis on data or activity?) and the responsibilities of operations (read and/or write behavior?).
Challenges and Desired Qualities
The design of endpoints and operations, expressed in the API contract, directly influences the developer experience in terms of function, stability, ease of use, and clarity.
Accuracy: Calling an API rather than implementing its features oneself requires a certain amount of trust that the called operation will deliver correct results reliably; in this context, accuracy means the functional correctness of the API implementation with regard to its contract. Such accuracy certainly helps building trust. Mission-critical functionality deserves particular attention. The more important the correct functioning of a business process and its activities is, the more effort should be spent on their design, development, and operations. Preconditions, invariants, and postconditions of operations in the API contract communicate what clients and providers expect from each other in terms of request and response message content.
Distribution of control and autonomy: The more work is distributed, the more parallel processing and specialization become possible. However, distribution of responsibilities and shared ownership of business process instances require coordination and consensus between API client and provider; integrity guarantees have to be defined, and consistent activity termination must be designed. The smaller and more autonomous an endpoint is, the easier it becomes to rewrite it; however, many small units often have a lot of dependencies among each other, making an isolated rewrite activity risky; think about the specification of pre-and postconditions, end-to-end testing, and compliance management.
Scalability, performance, and availability: Mission-critical APIs and their operations typically have demanding SERVICE LEVEL AGREEMENTS that go along with the API DESCRIPTION. Two examples of mission-critical components are day trading algorithms at a stock exchange and order processing and billing in an online shop. A 24/7 availability requirement is an example of a highly demanding, often unrealistic quality target. Business processes with many concurrent instances, implemented in a distributed fashion involving a large number of API clients and involving multiple calls to operations, can only be as good as their weakest component in this regard. API clients expect the response times for their operations calls to stay in the same order of magnitude when the number of clients and requests increases. Otherwise, they will start to question the reliability of the API.
Assessing the consequences of failure or unavailability is an analysis and design task in software engineering but also a business leadership and risk management activity. An API design exposing business processes and their activities can ease the recovery from failures but also make it more difficult. For example, APIs might provide compensating operations that undo work done by previous calls to the same API; however, a lack of architectural clarity and request coordination might also lead to inconsistent application state within API clients and providers.
Manageability: While one can design for runtime qualities such as performance, scalability, and availability, only running the system will tell whether API design and implementation are adequate. Monitoring the API and its exposed services is instrumental in determining its adequacy and what can be done to resolve mismatches between stated requirements and observed performance, scalability, and availability. Monitoring supports management disciplines such as fault, configuration, accounting, performance, and security management.
Consistency and atomicity: Business activities should have an all-or-nothing semantics; once their execution is complete, the API provider finds itself in a consistent state. However, the execution of the business activity may fail, or clients may choose to explicitly abort or compensate it (here, compensation refers to an application-level undo or other follow-up operation that resets the provider-side application state to a valid state).
Idempotence: Idempotence is another property that influences or even steers the API design. An API operation is idempotent if multiple calls to it (with the same input) return the same output and, for stateful operations, have the same effect on the API state. Idempotence helps deal with communication errors by allowing simple message retransmission.
Auditability: Compliance with the business process model is ensured by audit checks performed by risk management groups in enterprises. All APIs that expose functionality that is subject to be audited must support such audits and implement related controls so that it is possible to monitor business activities execution with logs that cannot be tampered with. Satisfying audit requirements is a design concern but also influences service management at runtime significantly. The article “Compliance by Design—Bridging the Chasm between Auditors and IT Architects,” for instance, introduces “Completeness, Accuracy, Validity, Restricted Access (CAVR)” compliance controls and suggests how to realize such controls, for instance in service-oriented architectures [Julisch 2011].
Patterns in this Chapter
Resolving the preceding design challenges is a complex undertaking; many design tactics and patterns exist. Many of those have already been published (for instance, in the books that we list in the preface). Here, we present patterns that carve out important architectural characteristics of API endpoints and operations; doing so simplifies and streamlines the application of these other tactics and patterns.
Some of the architectural questions an API design has to answer concern the input to operations:
What can and should the API provider expect from the clients? For instance, what are its preconditions regarding data validity and integrity? Does an operation invocation imply state transfer?
The output produced by API implementations when processing calls to operations also requires attention:
What are the operation postconditions? What can the API client in turn expect from the provider when it sends input that meets the preconditions? Does a request update the provider state?
In an online shopping example, for instance, the order status might be updated and can be obtained in subsequent API calls, with the order confirmation containing all (and only) the purchased products.
Different types of APIs deal with these concerns differently. A key decision is whether the endpoint should have activity- or data-oriented semantics. Hence, we introduce two endpoint roles in this chapter. These types of endpoints correspond to architectural roles as follows:
The pattern PROCESSING RESOURCE can help to realize activity-oriented API endpoints.
Data-oriented API endpoints are represented by INFORMATION HOLDER RESOURCES.
The section “Endpoint Roles” covers PROCESSING RESOURCE and INFORMATION HOLDER RESOURCE. Specialized types of INFORMATION HOLDER RESOURCES exist. For instance, DATA TRANSFER RESOURCE supports integration-oriented APIs, and LINK LOOKUP RESOURCE has a directory role. OPERATIONAL DATA HOLDERS, MASTER DATA HOLDERS, and REFERENCE DATA HOLDERS differ concerning the characteristics of data they expose in terms of data lifetime, relatedness, and mutability.
The four operation responsibilities found in these types of endpoints are COMPUTATION FUNCTION, RETRIEVAL OPERATION, STATE CREATION OPERATION, and STATE TRANSITION OPERATION. These types are covered in the section “Operation Responsibilities.” They differ in terms of client commitment (preconditions in API contract) and expectation (postconditions), as well as their impact on provider-side application state and processing complexity.
Figure 5.1 summarizes the patterns in this chapter.
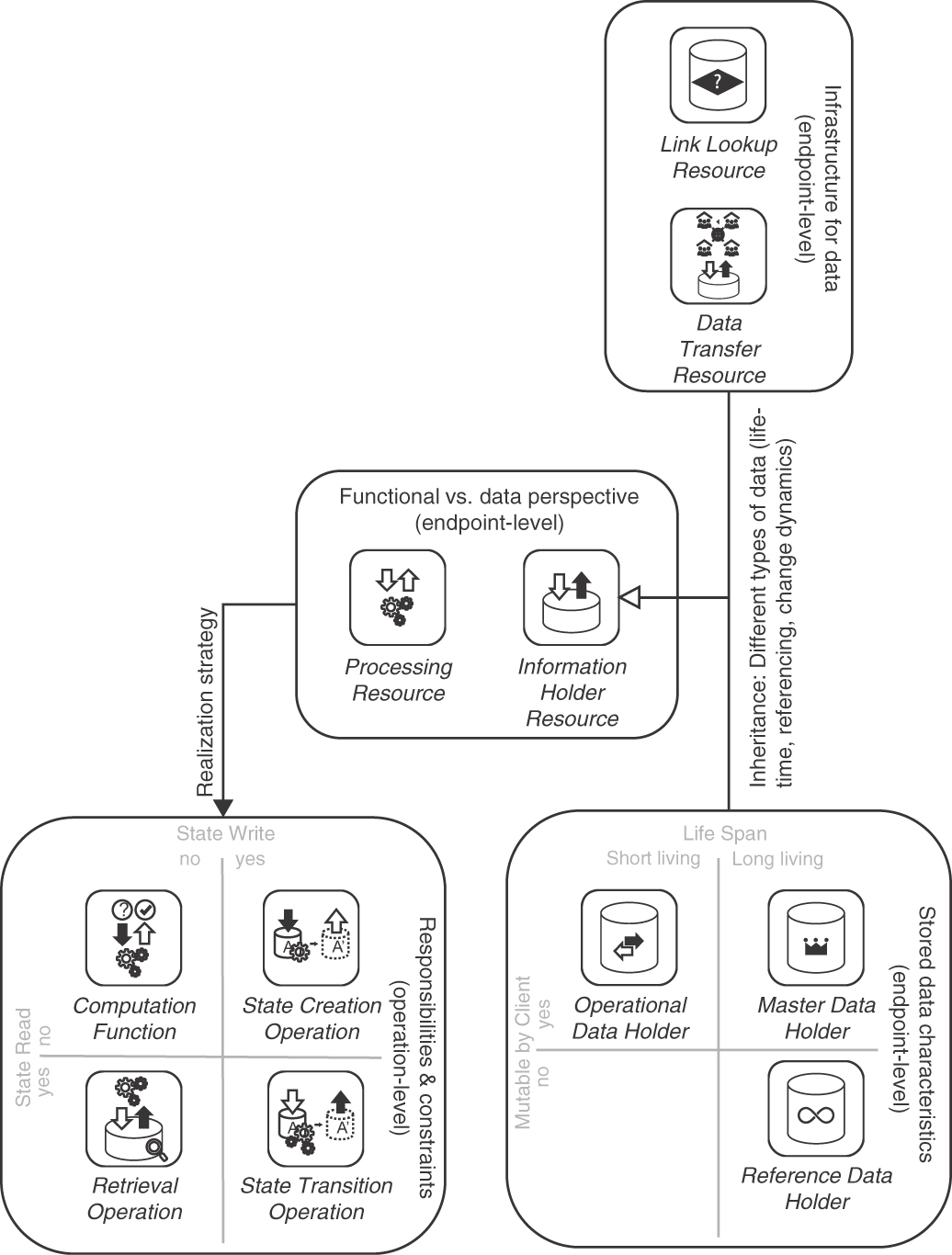
Figure 5.1 Pattern map for this chapter (endpoint roles and operations responsibilities)
Endpoint Roles (aka Service Granularity)
Refining the pattern map for this chapter, Figure 5.2 shows the patterns representing two general endpoint roles and five types of information holders.
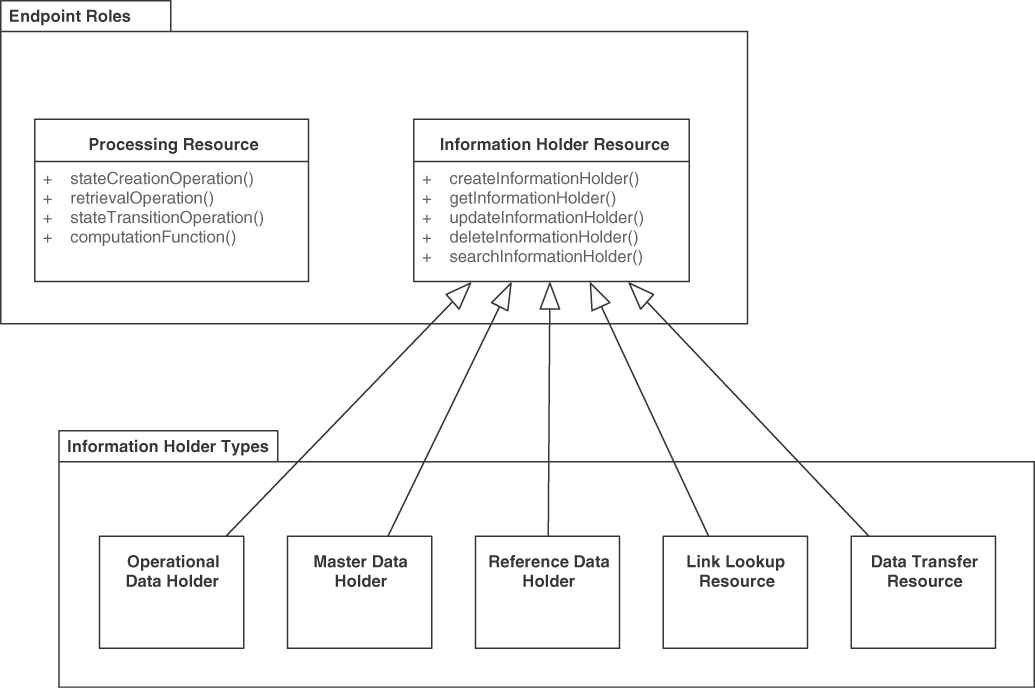
Figure 5.2 Patterns distinguishing endpoint roles
The two general endpoint roles are PROCESSING RESOURCE and INFORMATION HOLDER RESOURCE. They may expose different types of operations that write, read, read-write, or only compute. There are five INFORMATION HOLDER RESOURCE specializations, answering the following question differently:
How can data-oriented API endpoints be classified by data lifetime, link structure, and mutability characteristics?
Let us cover PROCESSING RESOURCE first, followed by INFORMATION HOLDER RESOURCE and its five specializations.
 Pattern: PROCESSING RESOURCE
Pattern: PROCESSING RESOURCE
When and Why to Apply
The functional requirements for an application have been specified, for instance, in the form of user stories, use cases, and/or analysis-level business process models. An analysis of the functional requirements suggests that something has to be computed or a certain activity is required. This cannot or should not be done locally; remote FRONTEND INTEGRATION and/or BACKEND INTEGRATION APIs are required. A preliminary list of candidate API endpoints might have been collected already.
How can an API provider allow its remote clients to trigger actions in it?
Such actions may be short-lived, standalone commands and computations (application-domain-specific ones or technical utilities) or long-running activities in a business process; they may or may not read and write provider-side state.
We can ask more specifically:
How can clients ask an API endpoint to perform a function that represents a business capability or a technical utility? How can an API provider expose the capability of executing a command to its clients that computes some output from the client’s input and, possibly, from the provider’s own state?
When invoking provider-side processing upon request from remote clients, general design concerns are as follows:
Contract expressiveness and service granularity (and their impact on coupling): Ambiguities in the invocation semantics harm interoperability and can lead to invalid processing results (which in turn might cause bad decisions to be made and consequently other harm). Hence, the meaning and side effects of the invoked action (such as a self-contained command or part of a conversation), including the representations of the exchanged messages, must be made clear in the API DESCRIPTION. The API DESCRIPTION must be clear in what end-points and operations do and do not do; preconditions, invariants, and postconditions should be specified. State changes, idempotence, transactionality, event emission, and resource consumption in the API implementation should also be defined. Not all of these properties have to be disclosed to API clients, but they still must be described in the provider-internal API documentation.
API designers have to decide how much functionality each API endpoint and its operations should expose. Many simple interactions give the client a lot of control and can make the processing highly efficient, but they also introduce coordination effort and evolution challenges; few rich API capabilities can promote qualities such as consistency but may not suit each client and therefore may waste resources. The accuracy of the API DESCRIPTION matters as much as that of its implementation.
Learnability and manageability: An excessive number of API endpoints and operations leads to orientation challenges for client programmers, testers, and API maintenance and evolution staff (which might or might not include the original developers); it becomes difficult to find and choose the ones appropriate for a particular use case. The more options available, the more explanations and decision-making support have to be given and maintained over time.
Semantic interoperability: Syntactic interoperability is a technical concern for middleware, protocol, and format designers. The communication parties must also agree on the meaning and impact of the data exchanged before and after any operation is executed.
Response time: Having invoked the remote action, the client may block until a result becomes available. The longer the client has to wait, the higher the chances that something will break (either on the provider side or in client applications). The network connection between the client and the API may time out sooner or later. An end user waiting for slow results may click refresh, thus putting additional load on an API provider serving the end-user application.
Security and privacy: If a full audit log of all API invocations and resulting server-side processing has to be maintained (for instance, because of data privacy requirements), statelessness on the provider side is an illusion even if application state is not required from a functional requirement point of view. Personal sensitive information and/or otherwise classified information (for example, by governments or enterprises) might be contained in the request and response message representations. Furthermore, in many scenarios one has to ensure that only authorized clients can invoke certain actions (that is, commands, conversation parts); for instance, regular employees are usually not permitted to increase their own salary in the employee management systems integrated via COMMUNITY APIS and implemented as microservices. Hence, the security architecture design has to take the requirements of processing-centric API operations into account—for instance in its policy decision point (PDP) and policy enforcement point (PEP) design and when deciding between role-based access control (RBAC) and attribute-based access control (ABAC). The processing resource is the subject of API security design [Yalon 2019] but also is an opportunity to place PEPs into the overall control flow. The threat model and controls created by security consultants, risk managers, and auditors also must take processing-specific attacks into account, for instance denial-of-service (DoS) attacks [Julisch 2011].
Compatibility and evolvability: The provider and the client should agree on the assumptions concerning the input/output representations as well as the semantics of the function to be performed. The client expectations should match what is offered by the provider. The request and response message structures may change over time. If, for instance, units of measure change or optional parameters are introduced, the client must have a chance to notice this and react to it (for instance, by developing an adapter or by evolving itself into a new version, possibly using a new version of an API operation). Ideally, new versions are forward and backward compatible with existing API clients.
These concerns conflict with each other. For instance, the richer and the more expressive a contract is, the more has to be learned, managed, and tested (with regard to interoperability). Finer-grained services might be easier to protect and evolve, but there will be many of them, which have to be integrated. This adds performance overhead and may raise consistency issues [Neri 2020].
A “Shared Database” [Hohpe 2003] that offers actions and commands in the form of stored procedures could be a valid integration approach (and is used in practice), but it creates a single point of failure, does not scale with a growing number of clients, and cannot be deployed or redeployed independently. Shared Databases containing business logic in stored procedures do not align well with service design principles such as single responsibility and loose coupling.
How It Works
Add a PROCESSING RESOURCE endpoint to the API exposing operations that bundle and wrap application-level activities or commands.
For the new endpoint, define one or more operations, each of which takes over a dedicated processing responsibility (“action required”). COMPUTATION FUNCTION, STATE CREATION OPERATION, and STATE TRANSITION OPERATION are common in activity-oriented PROCESSING RESOURCES. RETRIEVAL OPERATIONS mostly are limited to mere status/state checks here and are more commonly found in data-oriented INFORMATION HOLDER RESOURCES. For each of these operations, define a “Command Message” for the request. Add a “Document Message” for the response when realizing an operation as a “Request-Reply” message exchange [Hohpe 2003]. Make the endpoint remotely accessible for one or more API clients by providing a unique logical address (for instance, a Uniform Resource Identifier [URI] in HTTP APIs).
Figure 5.3 sketches this endpoint-operation design in a UML class diagram.
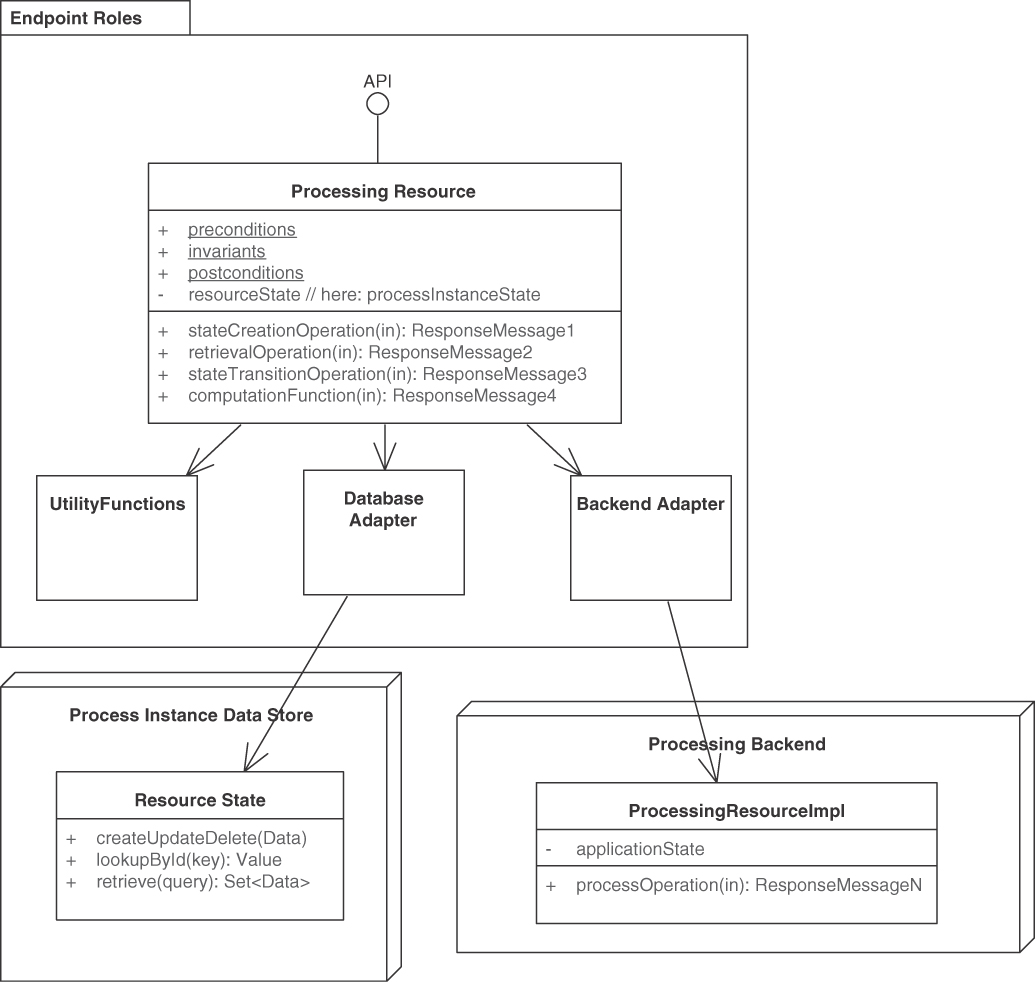
Figure 5.3 PROCESSING RESOURCES represent activity-oriented API designs. Some operations in the endpoint access and change application state, others do not. Data is exposed only in request and response messages
The request message should make the performed action explicit and allow the API endpoint to determine which processing logic to execute. These actions might represent a general-purpose or an application-domain-specific functional system capability (implemented within the API provider or residing in some backend and accessed via an outbound port/adapter) or a technical utility.
The request and response messages possibly can be structured according to any of the four structural representation patterns ATOMIC PARAMETER, ATOMIC PARAMETER LIST, PARAMETER TREE, and PARAMETER FOREST. The API DESCRIPTION has to document the syntax and semantics of the PROCESSING RESOURCE (including operation pre- and postconditions as well as invariants).
The PROCESSING RESOURCE can be a “Stateful Component” or a “Stateless Component” [Fehling 2014]. If invocations of its operations cause changes in the (shared) provider-side state, the approach to data management must be designed deliberately; required decisions include strict vs. weak/eventual consistency, optimistic vs. pessimistic locking, and so on. The data management policies should not be exposed in the API (which would make them visible to the API client), but open and close (or commit, rollback) system transactions be placed inside the API implementation, preferably at the operation boundary. Application-level compensating operations should be offered to handle things that cannot be undone easily by system transaction managers. For instance, an email that is sent in an API implementation cannot be taken back once it has left the mail server; a second mail, “Please ignore the previous mail,” has to be sent instead [Zimmermann 2007; Richardson 2018].
Example
The Policy Management backend of the Lakeside Mutual case contains a stateful PROCESSING RESOURCE InsuranceQuoteRequestCoordinator that offers STATE TRANSITION OPERATIONS, which move an insurance quotation request through various stages. The resource is implemented as an HTTP resource API in Java and Spring Boot:
@RestController@RequestMapping("/insurance-quote-requests")public class InsuranceQuoteRequestCoordinator {@Operation(summary = "Updates the status of an existing " +"Insurance Quote Request")@PreAuthorize("isAuthenticated()")@PatchMapping(value = "/{id}")public ResponseEntity<InsuranceQuoteRequestDto>respondToInsuranceQuote(Authentication,@Parameter(description = "the insurance quote " +"request's unique id", required = true)@PathVariable Long id,@Parameter(description = "the response that " +"contains the customer's decision whether " +"to accept or reject an insurance quote",required = true)@Valid @RequestBodyInsuranceQuoteResponseDto insuranceQuoteResponseDto) {
The Lakeside Mutual application services also contain RiskComputation-Service, a stateless PROCESSING RESOURCE that implements a single COMPUTATION FUNCTION called computeRiskFactor:
@RestController@RequestMapping("/riskfactor")public class RiskComputationService {@Operation(summary = "Computes the customer's risk factor.")@PostMapping(value = "/compute")public ResponseEntity<RiskFactorResponseDto>computeRiskFactor(@Parameter(description = "the request containing " +"relevant customer attributes (e.g., birthday)",required = true)@Valid @RequestBodyRiskFactorRequestDto riskFactorRequest) {int age = getAge(riskFactorRequest.getBirthday());String postalCode = riskFactorRequest.getPostalCode();int riskFactor = computeRiskFactor(age, postalCode);return ResponseEntity.ok(new RiskFactorResponseDto(riskFactor));}
Discussion
Business activity- and process-orientation can reduce coupling and promote information hiding. However, instances of this pattern must make sure not to come across as remote procedure call (RPC) tunneled in a message-based API (and consequently be criticized because RPCs increase coupling, for instance, in the time and format autonomy dimensions). Many enterprise applications and information systems do have “business RPC” semantics, as they execute a business command or transaction from a user that must be triggered, performed, and terminated somehow. According to the original literature and subsequent collections of design advice [Allamaraju 2010], an HTTP resource does not have to model data (or only data), but can represent such business transactions, long-running ones in particular.1 Note that “REST was never about CRUD” [Higginbotham 2018]. The evolution of PROCESSING RESOURCES is covered in Chapter 8.
1. Note that HTTP is a synchronous protocol as such; hence, asynchrony has to be added on the application level (or by using QoS headers or HTTP/2) [Pautasso 2018]. The DATA TRANSFER RESOURCE pattern describes such design.
A PROCESSING RESOURCE can be identified when applying a service identification technique such as dynamic process analysis or event storming [Pautasso 2017a]; this has a positive effect on the “business alignment” tenet in service-oriented architectures. One can define one instance of the pattern per backend integration need becoming evident in a use case or user story; if a single execute operation is included in a PROCESSING RESOURCE endpoint, it may accept self-describing action request messages and return self-contained result documents. All operations in the API have to be protected as mandated by the security requirements.
In many integration scenarios, activity- and process-orientation would have to be forced into the design, which makes it hard to explain and maintain (among other negative consequences). In such cases, INFORMATION HOLDER RESOURCE is a better choice. It is possible to define API endpoints that are both processing- and data-oriented (just like many classes in object-oriented programming combine storage and behavior). Even a mere PROCESSING RESOURCE may have to hold state (but will want to hide its structure from the API clients). Such joint use of PROCESSING RESOURCE and INFORMATION HOLDER RESOURCE is not recommended for microservices architectures due to the amount of coupling possibly introduced.
Different types of PROCESSING RESOURCES require different message exchange patterns, depending on (1) how long the processing will take and (2) whether the client must receive the result immediately to be able to continue its processing (otherwise, the result can be delivered later). Processing time may be difficult to estimate, as it depends on the complexity of the action to be executed, the amount of data sent by the client, and the load/resource availability of the provider. The Request-Reply pattern requires at least two messages that can be exchanged via one network connection, such as one HTTP request-response pair in an HTTP resource API. Alternatively, multiple technical connections can be used, for instance, by sending the command via an HTTP POST and polling for the result via HTTP GET.
Decomposing the PROCESSING RESOURCE to call operations in other API end-points should be considered (it is rather common that no single existing or to-be-constructed system can satisfy all processing needs, due to either organizational or legacy system constraints). Most of the design difficulty lies in how to decompose a PROCESSING RESOURCE to a manageable granularity and set of expressive, learnable operations. The Stepwise Service Design activity in our Design Practice Reference (DPR) [Zimmermann 2021b] investigates this problem set.
Related Patterns
This pattern explains how to emphasize activity; its INFORMATION HOLDER RESOURCE sibling focuses on data orientation. PROCESSING RESOURCES may contain operations that differ in the way they deal with provider-side state (stateless services vs. stateful processors): STATE TRANSITION OPERATION, STATE CREATION OPERATION, COMPUTATION FUNCTION, and RETRIEVAL OPERATION.
PROCESSING RESOURCES are often exposed in COMMUNITY APIS, but also found in SOLUTION-INTERNAL APIS. Their operations are often protected with API KEYS and RATE LIMITS. A SERVICE LEVEL AGREEMENT that accompanies the technical API contract may govern their usage. To prevent technical parameters from creeping into the payload in request and response messages, such parameters can be isolated in a CONTEXT REPRESENTATION.
The three patterns “Command Message,” “Document Message,” and “Request-Reply” [Hohpe 2003] are used in combination when realizing this pattern. The “Command” pattern in [Gamma 1995] codifies a processing request and its invocation data as an object and as a message, respectively. PROCESSING RESOURCE can be seen as the remote API variant of the “Application Service” pattern in [Alur 2013]. Its provider-side implementations serve as “Service Activators” [Hohpe 2003].
Other patterns address manageability; see our evolution patterns in Chapter 8, “Evolve APIs,” for design-time advice and remoting patterns books [Voelter 2004; Buschmann 2007] for runtime considerations.
More Information
PROCESSING RESOURCES correspond to “Interfacers” that provide and protect access to service providers in responsibility-driven design (RDD) [Wirfs-Brock 2002].
Chapter 6 in SOA in Practice [Josuttis 2007] is on service classification; it compares several taxonomies, including the one from Enterprise SOA [Krafzig 2004]. Some of the examples in the process services type/category in these SOA books qualify as known uses of this pattern. These two books include project examples and case studies from domains such as banking and telecommunications.
“Understanding RPC vs REST for HTTP APIs” [Sturgeon 2016a] talks about RPC and REST, but taking a closer look, it actually (also) is about deciding between PROCESSING RESOURCE and INFORMATION HOLDER RESOURCE.
The action resource topic area/category in the API Stylebook [Lauret 2017] provides a (meta) known use for this pattern. Its “undo” topic is also related because undo operations participate in application-level state management.
 Pattern: INFORMATION HOLDER RESOURCE
Pattern: INFORMATION HOLDER RESOURCE
When and Why to Apply
A domain model, a conceptual entity-relationship diagram, or another form of glossary of key application concepts and their interconnections has been specified. The model contains entities that have an identity and a life cycle as well as attributes; entities cross reference each other.
From this analysis and design work, it has become apparent that structured data will have to be used in multiple places in the distributed system being designed; hence, the shared data structures have to be made accessible from multiple remote clients. It is not possible or is not easy to hide the shared data structures behind domain logic (that is, processing-oriented actions such as business activities and commands); the application under construction does not have a workflow or other processing nature.
How can domain data be exposed in an API, but its implementation still be hidden?
More specifically,
How can an API expose data entities so that API clients can access and/or modify these entities concurrently without compromising data integrity and quality?
Modeling approach and its impact on coupling: Some software engineering and object-oriented analysis and design (OOAD) methods balance processing and structural aspects in their steps, artifacts, and techniques; some put a strong emphasis on either computing or data. Domain-driven design (DDD) [Evans 2003; Vernon 2013], for instance, is an example of a balanced approach. Entity-relationship diagrams focus on data structure and relationships rather than behavior. If a data-centric modeling and API endpoint identification approach is chosen, there is a risk that many CRUD (create, read, update, delete) APIs operating on data are exposed, which can have a negative impact on data quality because every authorized client may manipulate the provider-side data rather arbitrarily. CRUD-oriented data abstractions in interfaces introduce operational and semantic coupling.
Quality attribute conflicts and trade-offs: Design-time qualities such as simplicity and clarity; runtime qualities such as performance, availability, and scalability; as well as evolution-time qualities such as maintainability and flexibility often conflict with each other.
Security: Cross-cutting concerns such as application security also make it difficult to deal with data in APIs. A decision to expose internal data through an API must consider the required data read/write access rights for clients. Personal sensitive information and/or information classified as confidential might be contained in the request and response message representations. Such information has to be protected. For example, the risk of the creation of fake orders, fraudulent claims, and so on, has to be assessed and security controls introduced to mitigate it [Julisch 2011].
Data freshness versus consistency: Clients desire data obtained from APIs to be as up-to-date as possible, but effort is required to keep it consistent and current [Helland 2005]. Also, what are the consequences for clients if such data may become temporarily or permanently unavailable in the future?
Compliance with architectural design principles: The API under construction might be part of a project that has already established a logical and a physical software architecture. It should also play nice with respect to organization-wide architectural decisions [Zdun 2018], for instance, those establishing architectural principles such as loose coupling, logical and physical data independence, or microservices tenets such as independent deployability. Such principles might include suggestive or normative guidance on whether and how data can be exposed in APIs; a number of pattern selection decisions are required, with those principles serving as decision drivers [Zimmermann 2009; Hohpe 2016]. Our patterns provide concrete alternatives and criteria for making such architectural decisions (as we discussed previously in Chapter 3).
One could think of hiding all data structures behind processing-oriented API operations and data transfer objects (DTOs) analogous to object-oriented programming (that is, local object-oriented APIs expose access methods and facades while keeping all individual data members private). Such an approach is feasible and promotes information hiding; however, it may limit the opportunities to deploy, scale, and replace remote components independently of each other because either many fine-grained, chatty API operations are required or data has to be stored redundantly. It also introduces an undesired extra level of indirection, for instance, when building data-intensive applications and integration solutions.
Another possibility would be to give direct access to the database so that consumers can see for themselves what data is available and directly read and even write it if allowed. The API in this case becomes a tunnel to the database, where consumers can send arbitrary queries and transactions through it; databases such as CouchDB provide such data-level APIs out-of-the-box. This solution completely removes the need to design and implement an API because the internal representation of the data is directly exposed to clients. Breaking basic information-hiding principles, however, it also results in a tightly coupled architecture where it will be impossible to ever touch the database schema without affecting every API client. Direct database access also introduces security threats.
How It Works
Add an INFORMATION HOLDER RESOURCE endpoint to the API, representing a data-oriented entity. Expose create, read, update, delete, and search operations in this endpoint to access and manipulate this entity.
In the API implementation, coordinate calls to these operations to protect the data entity.
Make the endpoint remotely accessible for one or more API clients by providing a unique logical address. Let each operation of the INFORMATION HOLDER RESOURCE have one and only one of the four operation responsibilities (covered in depth in the next section): STATE CREATION OPERATIONS create the entity that is represented by the INFORMATION HOLDER RESOURCE. RETRIEVAL OPERATIONS access and read an entity but do not update it. They may search for and return collections of such entities, possibly filtered. STATE TRANSITION OPERATIONS access existing entities and update them fully or partially; they may also delete them.
For each operation, design the request and, if needed, response message structures. For instance, represent entity relationships as LINK ELEMENTS. If basic reference data such as country codes or currency codes are looked up, the response message typically is an ATOMIC PARAMETER; if a rich, structured domain model entity is looked up, the response is more likely to contain a PARAMETER TREE that represents the data transfer representation (a term from the API domain model introduced in Chapter 1) of the looked-up information. Figure 5.4 sketches this solution.
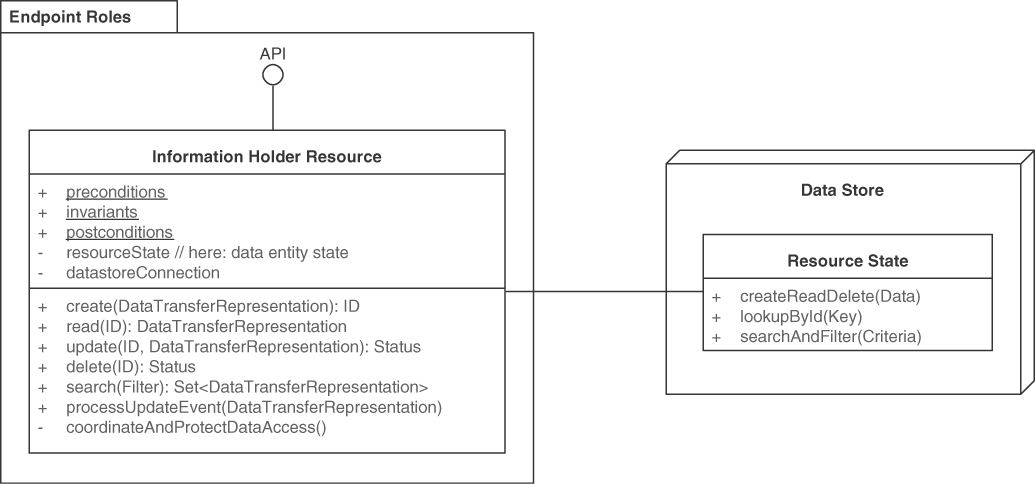
Figure 5.4 INFORMATION HOLDER RESOURCES model and expose general data-oriented API designs. This endpoint role groups information-access-oriented responsibilities. Its operations create, read, update, or delete the data held. Searching for data sets is also supported
Define operation-level pre- and postconditions as well as invariants to protect the resource state. Decide whether the INFORMATION HOLDER RESOURCE should be a “Stateful Component” or a “Stateless Component,” as defined in [Fehling 2014]. In the latter case, there still is state (because the exposed data has to be held somewhere), but the entire state management is outsourced to a backend system. Define the quality characteristics of the new endpoint and its operation, covering transactionality, idempotence, access control, accountability, and consistency:
Introduce access/modification control policies. API KEYS are a simple way of identifying and authorizing clients, and more advanced security solutions are also available.
Protect the concurrent data access by applying an optimistic or a pessimistic locking strategy from the database and concurrent programming communities. Design coordination policies.
Implement consistency-preserving checks, which may support “Strict Consistency” or “Eventual Consistency” [Fehling 2014].
Five patterns in our language refine this general solution to data-oriented API endpoint modeling: OPERATIONAL DATA HOLDER, MASTER DATA HOLDER, REFERENCE DATA HOLDER, DATA TRANSFER RESOURCE, and LINK LOOKUP RESOURCE.
Example
The Customer Core microservice in the Lakeside Mutual sample exposes master data. The semantics and its operations (for example, changeAddress(...)) of this service are data- rather than action-oriented (the service is consumed by other microservices that realize the PROCESSING RESOURCE pattern). Hence, it exposes a CustomerInformationHolder endpoint, realized as an HTTP resource:
@RestController@RequestMapping("/customers")public class CustomerInformationHolder {@Operation(summary = "Change a customer's address.")@PutMapping(value = "/{customerId}/address")public ResponseEntity<AddressDto> changeAddress(@Parameter(description = "the customer's unique id",required = true)@PathVariable CustomerId,@Parameter(description = "the customer's new address",required = true)@Valid @RequestBody AddressDto requestDto) {[...]}@Operation(summary = "Get a specific set of customers.")@GetMapping(value = "/{ids}")public ResponseEntity<CustomersResponseDto>getCustomer(@Parameter(description ="a comma-separated list of customer ids",required = true)@PathVariable String ids,@Parameter(description ="a comma-separated list of the fields" +"that should be included in the response",required = false)@RequestParam(value = "fields", required = false,defaultValue = "")String fields) {[...])}
This CustomerInformationHolder endpoint exposes two operations, a read-write STATE TRANSITION OPERATION changeAddress (HTTP PUT) and a read-only RETRIEVAL OPERATIONS getCustomer (HTTP GET).
Discussion
INFORMATION HOLDER RESOURCES resolve their design forces as follows:
Modeling approach and its impact on coupling: Introducing INFORMATION HOLDER RESOURCES often is the consequence of a data-centric approach to API modeling. Processing will typically shift to the consumer of the INFORMATION HOLDER RESOURCE. The INFORMATION HOLDER RESOURCE then is solely responsible for acting as a reliable source of linked data. The resource may serve as a relationship sink, source, or both.
It depends on the scenario at hand and the project goals/product vision whether such an approach is adequate. While activity- or process-orientation is often preferred, it simply is not natural in a number of scenarios; examples include digital archives, IT infrastructure inventories, and server configuration repositories. Data-oriented analysis and design methods are well suited to identify INFORMATION HOLDER endpoints but sometimes go too far, for instance, when tackling system behavior and logic.2
2. One of the classic cognitive biases is that every construction problem looks like a nail if you know how to use a hammer (and have one at hand). Analysis and design methods are tools made for specific purposes.
Quality attribute conflicts and trade-offs: Using an INFORMATION HOLDER RESOURCE requires carefully considering security, data protection, consistency, availability, and coupling implications. Any change to the INFORMATION HOLDER RESOURCE content, metadata, or representation formats must be controlled to avoid breaking consumers. Quality attribute trees can steer the pattern selection process.
Security: Not all API clients may be authorized to access each INFORMATION HOLDER RESOURCE in the same way. API KEYS, client authentication, and ABAC/RBAC help protect each INFORMATION HOLDER RESOURCE.
Data freshness versus consistency: Data consistency has to be preserved for concurrent access of multiple consumers. Likewise, clients must deal with the consequences of temporary outages, for instance, by introducing an appropriate caching and offline data replication and synchronization strategy. In practice, the decision between availability and consistency is not as binary and strict as the CAP theorem suggests, which is discussed by its original authors in a 12-year retrospective and outlook [Brewer 2012].
If several fine-grained INFORMATION HOLDERS appear in an API, many calls to operations might be required to realize a user story, and data quality is hard to ensure (because it becomes a shared, distributed responsibility). Consider hiding several of them behind any type of PROCESSING RESOURCE.
Compliance with architectural design principles: The introduction of INFORMATION HOLDER RESOURCE endpoints may break higher-order principles such as strict logical layering that forbids direct access to data entities from the presentation layer. It might be necessary to refactor the architecture [Zimmermann 2015]—or grant an explicit exception to the rule.
INFORMATION HOLDER RESOURCES have the reputation for increasing coupling and violating the information-hiding principle. A post in Michael Nygard’s blog calls for a responsibility-based strategy for avoiding pure INFORMATION HOLDER RESOURCES, which he refers to as “entity service anti-pattern.” The author recommends always evolving away from this pattern, because it creates high semantic and operational coupling, and rather “focus[ing] on behavior instead of data” (which we describe as PROCESSING RESOURCE) and “divid[ing] services by life cycle in a business process” [Nygard 2018b] (which we see as one of several service identification strategies). In our opinion, INFORMATION HOLDER RESOURCES do have their place both in service-oriented systems and in other API usage scenarios. However, any usage should be a conscious decision justified by the business and integration scenario at hand—because of the impact on coupling that is observed and criticized. For certain data, it might be better indeed not to expose it at the API level but hide it behind PROCESSING RESOURCES.
Related Patterns
“Information Holder” is a role stereotype in RDD [Wirfs-Brock 2002]. This general INFORMATION HOLDER RESOURCE pattern has several refinements that differ with regard to mutability, relationships, and instance lifetimes: OPERATIONAL DATA HOLDER, MASTER DATA HOLDER, and REFERENCE DATA HOLDER. The LINK LOOKUP RESOURCE pattern is another specialization; the lookup results may be other INFORMATION HOLDER RESOURCES. Finally, DATA TRANSFER RESOURCE holds temporary shared data owned by the clients. The PROCESSING RESOURCE pattern represents complementary semantics and therefore is an alternative to this pattern.
STATE CREATION OPERATIONS and RETRIEVAL OPERATIONS can typically be found in INFORMATION HOLDER RESOURCES, modeling CRUD semantics. Stateless COMPUTATION FUNCTIONS and read-write STATE TRANSITION OPERATIONS are also permitted in INFORMATION HOLDER RESOURCES but typically operate on a lower level of abstraction than those of PROCESSING RESOURCES.
Implementations of this pattern can be seen as the API pendant to the “Repository” pattern in DDD [Evans 2003], [Vernon 2013]. An INFORMATION HOLDER RESOURCE is often implemented with one or more “Entities” from DDD, possibly grouped into an “Aggregate.” Note that no one-to-one correspondence between INFORMATION HOLDER RESOURCE and Entities should be assumed because the primary job of the tactical DDD patterns is to organize the business logic layer of a system, not a (remote) API “Service Layer” [Fowler 2002].
More Information
Chapter 8 in Process-Driven SOA is devoted to business object integration and dealing with data [Hentrich 2011]. “Data on the Outside versus Data on the Inside” by Pat Helland explains the differences between data management on the API and the API implementation level [Helland 2005].
“Understanding RPC vs REST for HTTP APIs” [Sturgeon 2016a] covers the differences between INFORMATION HOLDER RESOURCES and PROCESSING RESOURCES in the context of an RPC and REST comparison.
Various consistency management patterns exist. “Eventually Consistent” by Werner Vogels, the Amazon Web Services CTO, addresses this topic [Vogels 2009].
 Pattern: OPERATIONAL DATA HOLDER
Pattern: OPERATIONAL DATA HOLDER
When and Why to Apply
A domain model, an entity-relationship diagram, or a glossary of key business concepts and their interconnections has been specified; it has been decided to expose some of the data entities contained in these specifications in an API by way of INFORMATION HOLDER RESOURCE instances.
The data specification unveils that the entity lifetimes and/or update cycles differ significantly (for instance, from seconds, minutes, and hours to months, years, and decades) and that the frequently changing entities participate in relationships with slower-changing ones. For instance, fast-changing data may act mostly as link sources, while slow-changing data appears mostly as link targets.3
3. The context of this pattern is similar to that of its sibling pattern MASTER DATA HOLDER. It acknowledges and points out that the lifetimes and relationship structure of these two types of data differ (in German: Stammdaten vs. Bewegungsdaten; see [Ferstl 2006; White 2006]).
How can an API support clients that want to create, read, update, and/or delete instances of domain entities that represent operational data that is rather short-lived, changes often during daily business operations, and has many outgoing relations?
Several desired qualities are worth calling out, in addition to those applying to any kind of INFORMATION HOLDER RESOURCE.
Processing speed for content read and update operations: Depending on the business context, API services dealing with operational data must be fast, with low response time for both reading and updating its current state.
Business agility and schema update flexibility: Depending on the business context (for example, when performing A/B testing with parts of the live users), API endpoints dealing with operational data must also be easy to change, especially when the data definition or schema evolves.
Conceptual integrity and consistency of relationships: The created and modified operational data must meet high accuracy and quality standards if it is business-critical. For instance, system and process assurance audits inspect financially relevant business objects such as invoices and payments in enterprise applications [Julisch 2011]. Operational data might be owned, controlled, and managed by external parties such as payment providers; it might have many outgoing relations to similar data and longer-lived, less frequently changing master data. Clients expect that the referred entities will be correctly accessible after the interaction with an operational data resource has successfully completed.
One could think of treating all data equally to promote solution simplicity, irrespective of its lifetime and relationship characteristics. However, such a unified approach might yield only a mediocre compromise that meets all of the preceding needs somehow but does not excel with regard to any of them. If, for instance, operational data is treated as master data, one might end up with an overengineered API with regard to consistency and reference management that also leaves room for improvement with regard to processing speed and change management.
How It Works
Tag an INFORMATION HOLDER RESOURCE as OPERATIONAL DATA HOLDER and add API operations to it that allow API clients to create, read, update, and delete its data often and fast.
Optionally, expose additional operations to give the OPERATIONAL DATA HOLDER domain-specific responsibilities. For instance, a shopping basket might offer fee and tax computations, price update notifications, discounting, and other state-transitioning operations.
The request and response messages of such OPERATIONAL DATA HOLDERS often take the form of PARAMETER TREES; however, the other types of request and response message structure can also be found in practice. One must be aware of relationships with master data and be cautious when including master data in requests to and responses from OPERATIONAL DATA HOLDERs via EMBEDDED ENTITY instances. It is often better to separate the two types in different endpoints and realize the cross references via LINKED INFORMATION HOLDER instances.
Figure 5.5 sketches the solution. A System of Engagement is used to support everyday business and typically holds operational data; related master data can be found in a System of Record. The API implementation might also keep its own Data Stores in addition to integrating with such backend systems, which may hold both operational data and master data.
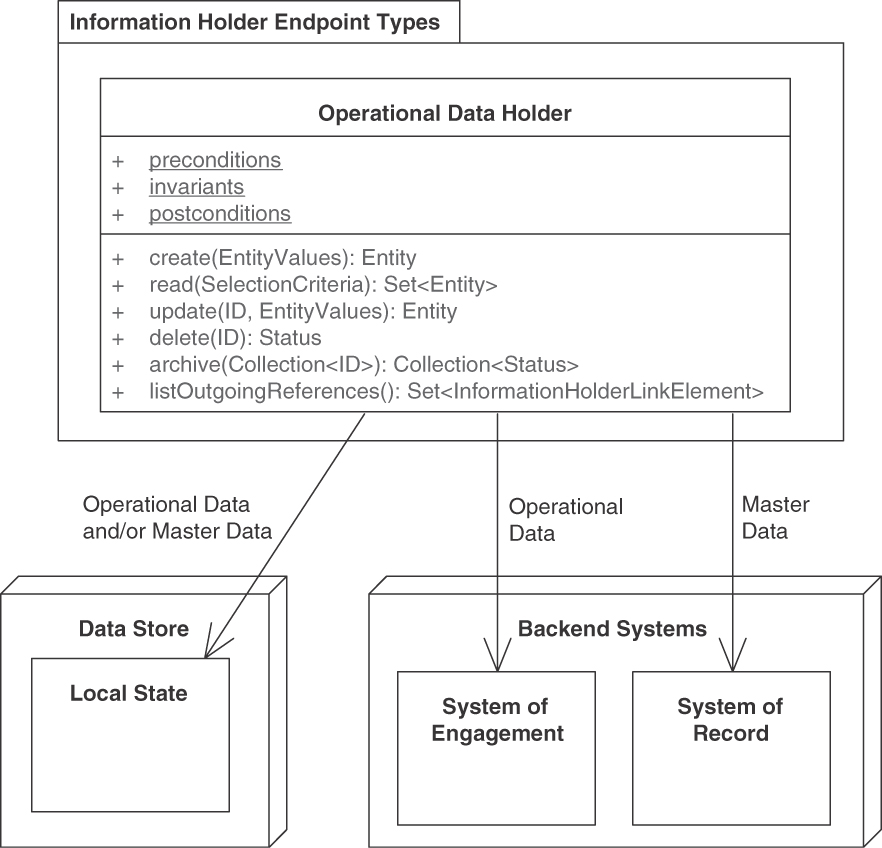
Figure 5.5 OPERATIONAL DATA HOLDER: Operational data has a short to medium lifetime and may change a lot during daily business. It may reference master data and other operational data
OPERATIONAL DATA HOLDERS accessed from multiple concurrent clients should provide transactional guarantees in terms of isolation and atomicity so that multiple clients may attempt to access the same data items at the same time while keeping its state consistent. If failures occur during the interaction with a specific client, the state of the OPERATIONAL DATA HOLDER should be reverted back to the last known consistent state. Likewise, update or creation requests being retried should be de-duplicated when not idempotent. Closely related OPERATIONAL DATA HOLDERS should also be managed and evolved together to assure their clients that references across them will remain valid. The API should provide atomic update or delete operations across all related OPERATIONAL DATA HOLDERS.
OPERATIONAL DATA HOLDERS are good candidates for event sourcing [Stettler 2019] whereby all state changes are logged, making it possible for API clients to access the entire history of state changes for the specific OPERATIONAL DATA HOLDER. This may increase the API complexity, as consumers may want to refer to or retrieve arbitrary snapshots from the past as opposed to simply querying the latest state.
Example
In an online shop, purchase orders and order items qualify as operational data; the ordered products and the customers placing an order meet the characteristics of master data. Hence, these domain concepts are typically modeled as different “Bounded Context” instances (in DDD) and exposed as separate services, as shown in Figure 5.6.
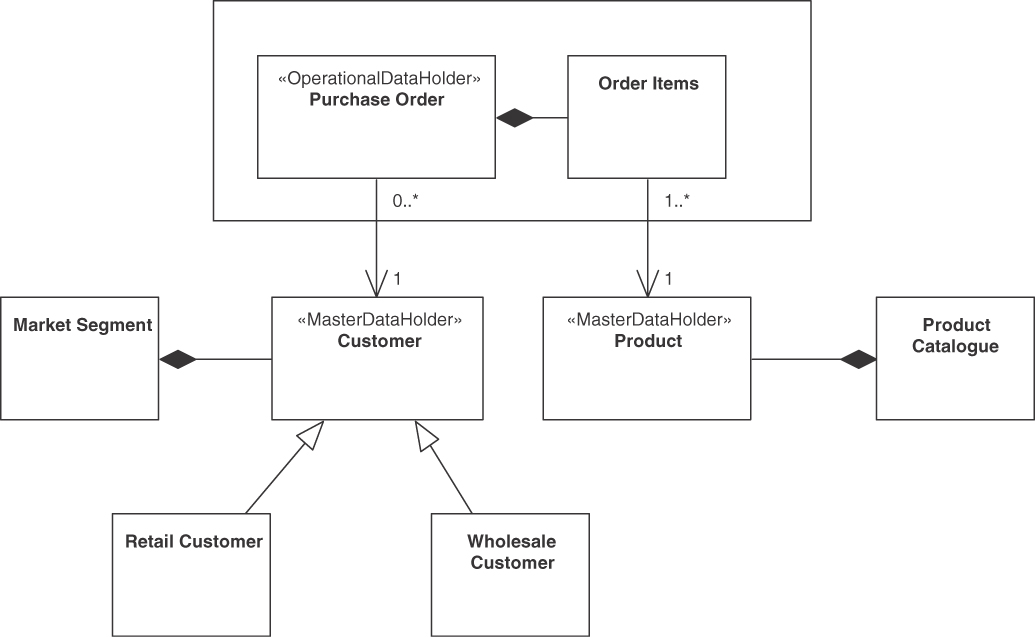
Figure 5.6 Online shop example: OPERATIONAL DATA HOLDER (Purchase Order) and MASTER DATA HOLDERS (Customer, Product) and their relations
Lakeside Mutual, our sample application from the insurance domain, manages operational data such as claims and risk assessments that are exposed as Web services and REST resources (see Figure 5.7).
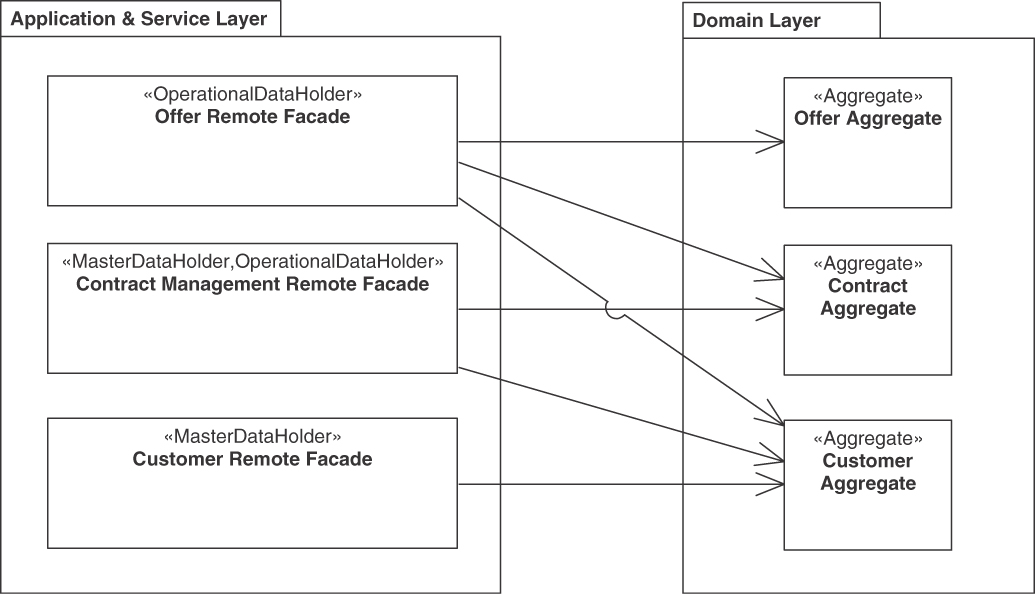
Figure 5.7 Examples of combining OPERATIONAL DATA HOLDER and MASTER DATA HOLDER: Offers reference contracts and customers, contracts reference customers. In this example, the remote facades access multiple aggregates isolated from each other. The logical layer names come from [Evans 2003] and [Fowler 2002]
Discussion
The pattern primarily serves as a “marker pattern” in API documentation, helping to make technical interfaces “business-aligned,” which is one of the SOA principles and microservices tenets [Zimmermann 2017].
Sometimes even operational data is kept for a long time: in a world of big data analytics and business intelligence insights, operational data is often archived for analytical processing, such as in data marts, data warehouses, or semantic data lakes.
The fewer inbound dependencies an OPERATIONAL DATA HOLDER has, the easier to update it is. A limited lifetime of data and data definitions makes API evolution less challenging; for instance, backward compatibility and integrity management become less of an issue. It might even be possible to rewrite OPERATIONAL DATA HOLDERS rather than maintain older versions of them [Pautasso 2017a]. Relaxing their consistency properties from strict to eventual [Fehling 2014] can improve availability.
The consistency and availability management of OPERATIONAL DATA HOLDERS may prioritize the conflicting requirements differently than MASTER DATA HOLDERS (depending on the domain and scenario). Business agility, schema update flexibility, and processing speed are determined by the API implementation.
The distinction between master data and operational data is somewhat subjective and dependent on application context; data that is needed only temporarily in one application might be a core asset in another one. For instance, think about purchases in an online shop. While the shopper cares about the order only until it is delivered and paid for (unless there is a warranty case or the customer wants to return the good or repeat the same order in the future), the shop provider will probably keep all details forever to be able to analyze buying behavior over time (customer profiling, product recommendations, and targeted advertisement).
The OPERATIONAL DATA HOLDER pattern can help to satisfy regulatory requirements expressed as compliance controls. An example of such requirement and compliance control is “all purchase orders reference a customer that actually exists in a system of record and in the real world.” Enforcing this rule prevents (or finds) cases of fraud [Julisch 2011].
Related Patterns
Longer-living information holders with many incoming references are described by the patterns MASTER DATA HOLDER (mutable) and REFERENCE DATA HOLDER (immutable via the API). An alternative, less data- and more action-oriented pattern is PROCESSING RESOURCE. All operation responsibilities patterns, including STATE CREATION OPERATION and STATE TRANSITION OPERATION, can be used in OPERATIONAL DATA HOLDER endpoints.
Patterns from Chapters 4, 6, and 7 are applied when designing the request and response messages of the operations of the OPERATIONAL DATA HOLDER. Their suitability heavily depends on the actual data semantics. For instance, entering items into a shopping basket might expect a PARAMETER TREE and return a simple success flag as an ATOMIC PARAMETER. The checkout activity then might require multiple complex parameters (PARAMETER FOREST) and return the order number and the expected delivery date in an ATOMIC PARAMETER LIST. The deletion of operational data can be triggered by sending a single ID ELEMENT and might return a simple success flag and/or ERROR REPORT representation. PAGINATION slices responses to requests for large amounts of operational data.
The “Data Type Channel” pattern in [Hohpe 2003] describes how to organize a messaging system by message semantics and syntax (such as query, price quote, or purchase order).
OPERATIONAL DATA HOLDERS referencing other OPERATIONAL DATA HOLDERS may choose to include this data in the form of an EMBEDDED ENTITY. By contrast, references to MASTER DATA HOLDERS often are not included/embedded but externalized via LINKED INFORMATION HOLDER references.
More Information
The notion of operational (or transactional) data has its roots in the database and information integration community and in business informatics (Wirtschaftsinfor-matik) [Ferstl 2006].
 Pattern: MASTER DATA HOLDER
Pattern: MASTER DATA HOLDER
When and Why to Apply
A domain model, an entity-relationship diagram, a glossary, or a similar dictionary of key application concepts has been specified; it has been decided to expose some of these data entities in an API by way of INFORMATION HOLDER RESOURCES.
The data specification unveils that the lifetimes and update cycles of these INFORMATION HOLDER RESOURCE endpoints differ significantly (for instance, from seconds, minutes, and hours to months, years, and decades). Long-living data typically has many incoming relationships, whereas shorter-living data often references long-living data. The data access profiles of these two types of data differ substantially.4
4. The context of this pattern is similar to that of its alternative pattern OPERATIONAL DATA HOLDER. It emphasizes that the lifetimes and relationship structure of these two types of data differ. Here we are interested in master data, often contrasted with operational data, also called transactional data (in German, Stammdaten vs. Bewegungsdaten; see Ferstl [2006], White [2006]).
How can I design an API that provides access to master data that lives for a long time, does not change frequently, and will be referenced from many clients?
In many application scenarios, data that is referenced in multiple places and lives long has high data quality and data protection needs.
Master data quality: Master data should be accurate because it is used directly, indirectly, and/or implicitly in many places, from daily business to strategic decision making. If it is not stored and managed in a single place, uncoordinated updates, software bugs, and other unforeseen circumstances may lead to inconsistencies and other quality issues that are hard to detect. If it is stored centrally, access to it might be slow due to overhead caused by access contention and backend communication.
Master data protection: Irrespective of its storage and management policy, master data must be well protected with suitable access controls and auditing policies, as it is an attractive target for attacks, and the consequences of data breaches can be severe.
Data under external control: Master data may be owned and managed by dedicated systems, often purchased by (or developed in) a separate organizational unit. For instance, there is an application genre of master data management systems specializing in product or customer data. In practice, external hosting (strategic outsourcing) of these specialized master data management systems happens and complicates system integration because more stakeholders are involved in their evolution.
Data ownership and audit procedures differ from those of other types of data. Master data collections are assets with a monetary value appearing in the balance sheets of enterprises. Therefore, their definitions and interfaces often are hard to influence and change; due to external influences on its life cycle, master data may evolve at a different speed than operational data that references it.
One could think of treating all entities/resources equally to promote solution simplicity, irrespective of their lifetime and relationship patterns. However, such an approach runs the risk of not satisfactorily addressing the concerns of stakeholders, such as security auditors, data owners, and data stewards. Hosting providers and, last but not least, the real-world correspondents of the data (for instance, customers and internal system users) are other key stakeholders of master data whose interests might not be fulfilled satisfactorily by such an approach.
How It Works
Mark an INFORMATION HOLDER RESOURCE to be a dedicated MASTER DATA HOLDER endpoint that bundles master data access and manipulation operations in such a way that the data consistency is preserved and references are managed adequately. Treat delete operations as special forms of updates.
Optionally, offer other life-cycle events or state transitions in this MASTER DATA HOLDER endpoint. Also optionally, expose additional operations to give the MASTER DATA HOLDER domain-specific responsibilities. For instance, an archive might offer time-oriented retrieval, bulk creations, and purge operations.
A MASTER DATA HOLDER is a special type of INFORMATION HOLDER RESOURCE. It typically offers operations to look up information that is referenced elsewhere. A MASTER DATA HOLDER also offers operations to manipulate the data via the API (unlike a REFERENCE DATA HOLDER). It must meet the security and compliance requirements for this type of data.
Figure 5.8 shows its specific design elements.
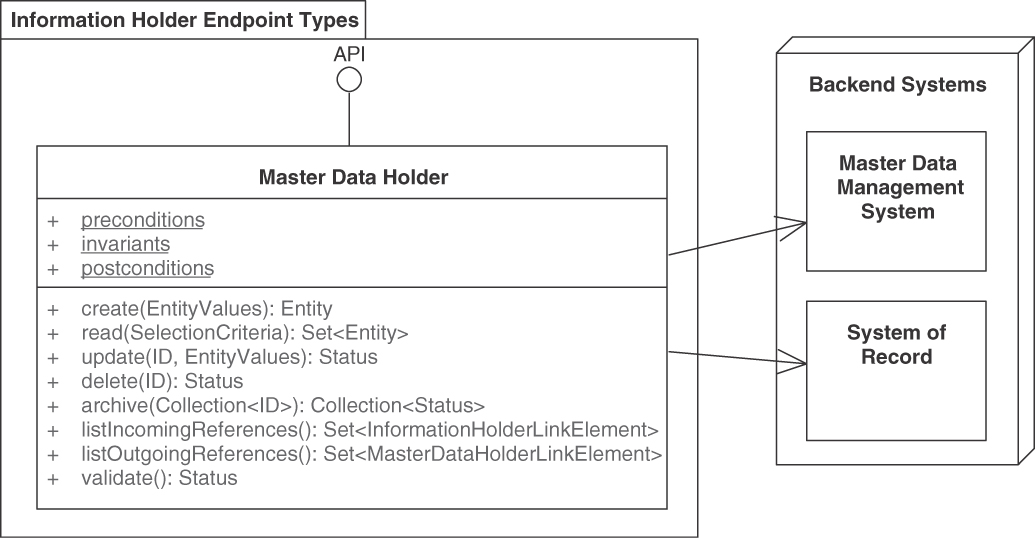
Figure 5.8 MASTER DATA HOLDER. Master data lives long and is frequently referenced by other master data and by operational data. It therefore faces specific quality and consistency requirements
The request and response messages of MASTER DATA HOLDERS often take the form of PARAMETER TREES. However, more atomic types of request and response message structure can also be found in practice. Master data creation operations typically receive a simple to medium complex PARAMETER TREE because master data might be complex but is often created in one go, for instance, when being entered completely by a user in a form (such as an account creation form). They usually return an ATOMIC PARAMETER or an ATOMIC PARAMETER LIST to report the ID ELEMENT or LINK ELEMENT that identifies the master data entity uniquely/globally and reports whether or not the creation request was successful (for instance, using the ERROR REPORT pattern). Reasons for failure can be duplicate keys, violations of business rules and other invariants, or internal server-side processing errors (for instance, temporary unavailability of backend systems).
A master data update may come in two forms:
Coarse-grained full update operation that replaces most or all attributes in a master data entity such as customer or product. This form corresponds to the HTTP PUT verb.
Fine-grained partial update operation that updates only one or a few of the attributes in a master data entity, for instance, the address of a customer (but not its name) or the price of a product (but not its supplier and taxation rules). In HTTP, the verb PATCH has such semantics.
Read access to master data is often performed via RETRIEVAL OPERATIONS that offer parameterized search-and-filter query capabilities (possibly expressed declaratively).
Deletion might not be desired. If supported, delete operations on master data sometimes are complicated to implement due to legal compliance requirements. There is a risk of breaking a large number of incoming references when removing master data entirely. Hence, master data often is not deleted at all but is set into an immutable state “archived” in which updates are no longer possible. This also allows keeping audit trails and historic data manipulation journals; master data changes are often mission-critical and thus must be nonrepudiable. If deletion is indeed necessary (and this can be a regulatory requirement), the data may actually be hidden from (some or all) consumers but still preserved in an invisible state (unless yet another regulatory requirement forbids this).
In an HTTP resource API, the address (URI) of a MASTER DATA HOLDER resource can be widely shared among clients referencing it, which can access it via HTTP GET (a read-only method that supports caching). The creation and update calls make use of POST, PUT, and PATCH methods, respectively [Allamaraju 2010].
Please note that the discussion of the words create, read, update, and delete in the context of this pattern should not indicate that CRUD-based API designs are the intended or only possible solution for realizing the pattern. Such designs quickly lead to chatty APIs with bad performance and scalability properties, and lead to unwanted coupling and complexity. Beware of such API designs! Instead, follow an incremental approach during resource identification that aims to first identify well-scoped interface elements such as Aggregate roots in DDD, business capabilities, or business processes. Even larger formations, such as Bounded Contexts, may serve as starting points. In infrequent cases, domain Entities can also be considered to supply endpoint candidates. This inevitably will lead to MASTER DATA HOLDER designs that are semantically richer and more meaningful—and with a more positive impact on the mentioned qualities. In DDD terms, we aim for a rich and deep domain model, as opposed to an anemic domain model [Fowler 2003]; this should be reflected in the API design. In many scenarios, it makes sense to identify and call out master data (as well as operational data) in the domain models so that later design decisions can use this information.
Example
Lakeside Mutual, our sample application from the insurance domain, features master data such as customers and contracts that are exposed as Web services and REST resources, thus applying the MASTER DATA HOLDER pattern. Figure 5.9 illustrates two of these resources as remote facades.
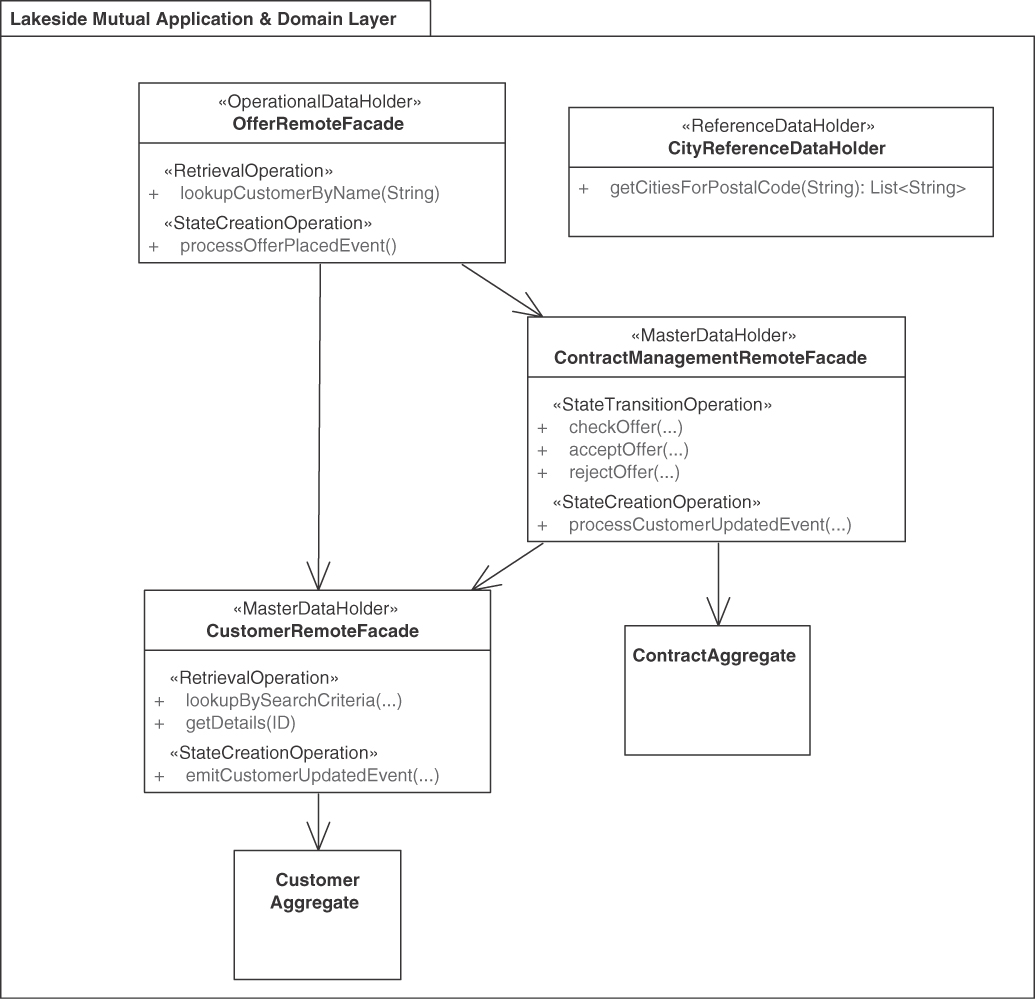
Figure 5.9 Example of OPERATIONAL DATA HOLDER and MASTER DATA HOLDER interplay. Operational data references master data, but not vice versa. An application of the REFERENCE DATA HOLDER pattern is also shown
In this example, the remote facades (offer, contract, customer) access each other and two domain-layer aggregates in the API implementation.
Discussion
Tagging an API endpoint as a MASTER DATA HOLDER can help achieve the required focus on data quality and data protection.
Master data by definition has many inbound dependencies and might also have outbound ones. Since such data is often under external control, tagging an API end-point as MASTER DATA HOLDER also helps to control and limit where such external dependency is introduced. This way, there will be only one API providing fresh access to a specific master data source in a consistent way.
Master data often is a valuable company asset that is key to success in the market (it might even turn a company into an acquisition target). Hence, when exposed as part of the API, it is particularly important to plan its future evolution in a roadmap that respects backward compatibility, considers digital preservation, and protects the data from theft and tampering.
Related Patterns
The MASTER DATA HOLDER pattern has two alternatives: REFERENCE DATA HOLDER (with data that is immutable via the API) and OPERATIONAL DATA HOLDER (exposing shorter-lived data with less incoming references).
More Information
The notion of master data versus operational data comes from literature in the database community (more specifically, information integration) and in business informatics (Wirtschaftsinformatik in German) [Ferstl 2006]. It plays an important role in online analytical processing (OLAP), data warehouses, and business intelligence (BI) efforts [Kimball 2002].
 Pattern: REFERENCE DATA HOLDER
Pattern: REFERENCE DATA HOLDER
When and Why to Apply
A requirements specification unveils that some data is referenced in most if not all system parts, but it changes only very rarely (if ever); these changes are administrative in nature and are not caused by API clients operating during everyday business. Such data is called reference data. It comes in many forms, including country codes, zip codes, geolocations, currency codes, and units of measurement. Reference data often is represented by enumerations of string literals or numeric value ranges.
The data transfer representations in the request and response messages of API operations may either contain or point at reference data to satisfy the information needs of a message receiver.
How should data that is referenced in many places, lives long, and is immutable for clients be treated in API endpoints?
How can such reference data be used in requests to and responses from PROCESSING RESOURCES or INFORMATION HOLDER RESOURCES?
Two desired qualities are worth calling out (in addition to those applying to any kind of INFORMATION HOLDER RESOURCE).
Do not repeat yourself (DRY): Because reference data rarely changes (if ever), there is a temptation to simply hardcode it within the API clients or, if using a cache, retrieve it once and then store a local copy forever. Such designs work well in the short run and might not cause any immanent problems—until the data and its definitions have to change.5 Because the DRY principle is violated, the change will impact every client, and if clients are out of reach, it may not be possible to update them.
5. For instance, it was sufficient to use two digits for calendar years through 1999.
Performance versus consistency trade-off for read access: Because reference data rarely changes (if at all), it may pay off to introduce a cache to reduce round-trip access response time and reduce traffic if it is referenced and read a lot. Such replication tactics have to be designed carefully so that they function as desired and do not make the end-to-end system overly complex and hard to maintain. For instance, caches should not grow too big, and replication has to be able to tolerate network partitions (outages). If the reference data does change (on schema or on content level), updates have to be applied consistently. Two examples are new zip codes introduced in a country and the transition from local currencies to the Euro (EUR) in many European countries.
One could treat static and immutable reference data just like dynamic data that is both read and written. This works fine in many scenarios but misses opportunities to optimize the read access, for instance, via data replication in content delivery networks (CDNs) and might lead to unnecessary duplication of storing and computing efforts.
How It Works
Provide a special type of INFORMATION HOLDER RESOURCE endpoint, a REFERENCE DATA HOLDER, as a single point of reference for the static, immutable data. Provide read operations but no create, update, or delete operations in this endpoint.
Update the reference data elsewhere if required, by directly changing back-end assets or through a separate management API. Refer to the REFERENCE DATA HOLDER endpoint via LINKED INFORMATION HOLDERS.
The REFERENCE DATA HOLDER may allow clients to retrieve the entire reference data set so that they can keep a local copy that can be accessed multiple times. They may want to filter its content before doing so (for instance, to implement some auto-completion feature in an input form in a user interface). It is also possible to look up individual entries of the reference data only (for instance, for validation purposes). For example, a currency list can be copy-pasted all over the place (as it never changes), or it can be retrieved and cached from the REFERENCE DATA HOLDER API, as described here. Such API can provide a complete enumeration of the list (to initialize and refresh the cache) or feature the ability to project/select the content (for instance, a list of European currency names), or allow clients to check whether some value is present in the list for client-side validation (“Does this currency exist?”).
Figure 5.10 sketches the solution.
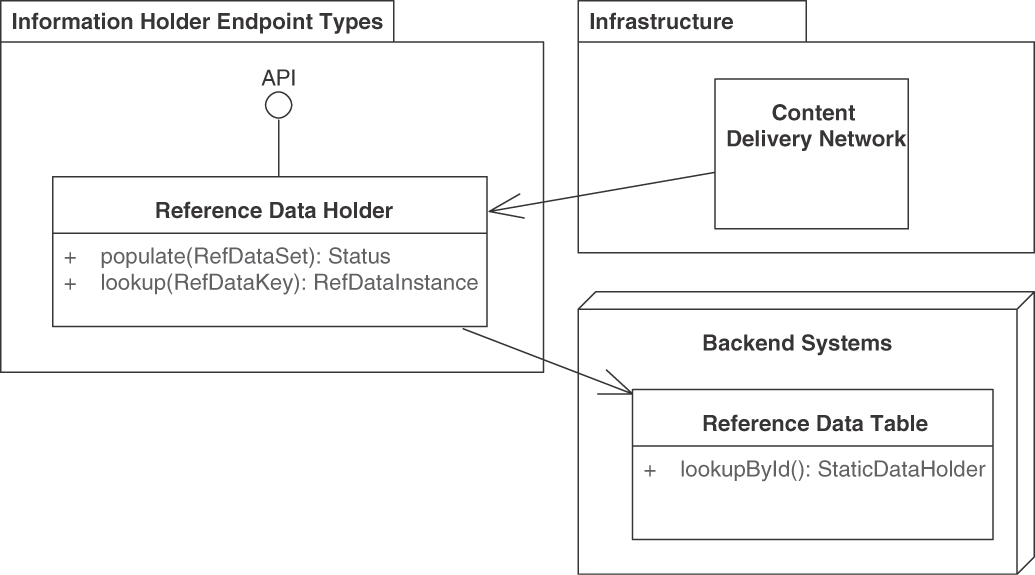
Figure 5.10 REFERENCE DATA HOLDER. Reference data lives long but cannot be changed via the API. It is referenced often and in many places
The request and response messages of REFERENCE DATA HOLDERS often take the form of ATOMIC PARAMETERS or ATOMIC PARAMETER LISTS, for instance, when the reference data is unstructured and merely enumerates certain flat values.
Reference data lives long but hardly ever changes; it is referenced often and in many places. Hence, the operations of REFERENCE DATA HOLDERS may offer direct access to a reference data table. Such lookups can map a short identifier (such as a provider-internal surrogate key) to a more expressive, human-readable identifier and/or entire data set.
The pattern does not prescribe any type of implementation; for instance, a relational database might come across as an overengineered solution when managing a list of currencies; a file-based key-value store or indexed sequential access method (ISAM) files might be sufficient. Key-value stores such as a Redis or a document-oriented NoSQL database such as CouchDB or MongoDB may also be considered.
Example
Figure 5.11 shows an instance of the pattern that allows API clients to look up zip codes based on addresses, or vice versa.
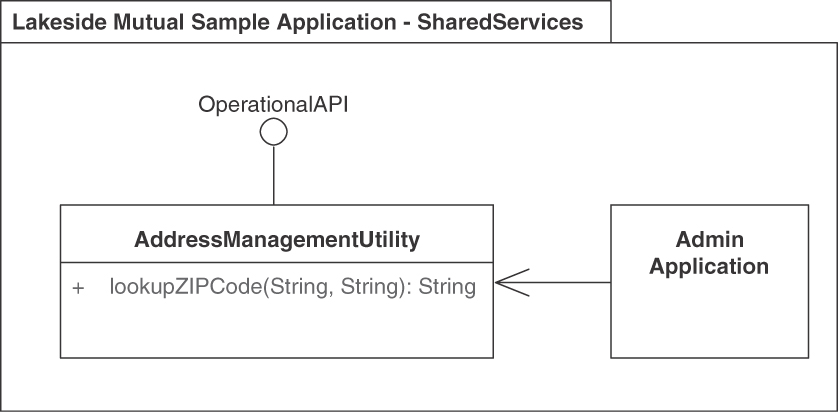
Figure 5.11 REFERENCE DATA HOLDER: Zip code lookup
Discussion
The most common usage scenario for this pattern is the lookup of simple text data whose value ranges meet certain constraints (for example, country codes, currency codes, or tax rates).
Explicit REFERENCE DATA HOLDERS avoid unnecessary repetition. The purpose of a REFERENCE DATA HOLDER is to give a central point of reference for helping disseminate the data while keeping control over it. Read performance can be optimized; immutable data can be replicated rather easily (no risk of inconsistencies as long as it never changes).
Dedicated REFERENCE DATA HOLDERS have to be developed, documented, managed, and maintained. This effort will still be less than that required to upgrade all clients if such reference data gets hardcoded in them.
DRY: Clients no longer have to implement reference management on their own, at the expense of introducing a dependency on a remote API. This positive effect can be viewed as a form of data normalization, as known from database design and information management.
Performance versus consistency trade-off for read access: The pattern hides the actual data behind the API and therefore allows the API provider to introduce proxies, caches, and read-only replicas behind the scenes. The only effect that is visible to the API clients is an improvement (if done right) in terms of quality properties such as response times and availability, possibly expressed in the SERVICE LEVEL AGREEMENT that accompanies the functional API contract.
A standalone REFERENCE DATA HOLDER sometimes turns out to cause more work and complexity than it adds value (in terms of data normalization and performance improvements). In such cases, one can consider merging the reference data with an already existing, more complex, and somewhat more dynamic MASTER DATA HOLDER endpoint in the API by way of an API refactoring [Stocker 2021a].
Related Patterns
The MASTER DATA HOLDER pattern is an alternative to REFERENCE DATA HOLDER. It also represents long-living data, which still is mutable. OPERATIONAL DATA HOLDERS represent more ephemeral data.
The section “Message Granularity” in Chapter 7, “Refine Message Design for Quality,” features two related patterns, EMBEDDED ENTITY and LINKED INFORMATION HOLDER. Simple static data is often embedded (which eliminates the need for a dedicated REFERENCE DATA HOLDER) but can also be linked (with the link pointing at a REFERENCE DATA HOLDER).
More Information
“Data on the Outside versus Data on the Inside” introduces reference data in the broad sense of the word [Helland 2005]. Wikipedia provides links to inventories/directories of reference data [Wikipedia 2022b].
 Pattern: LINK LOOKUP RESOURCE
Pattern: LINK LOOKUP RESOURCE
When and Why to Apply
The message representations in request and response messages of an API operation have been designed to meet the information needs of the message receivers. To do so, these messages may contain references to other API endpoints (such as INFORMATION HOLDER RESOURCES and/or PROCESSING RESOURCES) in the form of LINK ELEMENTS. Sometimes it is not desirable to expose such endpoint addresses to all clients directly because this adds coupling and harms location and reference autonomy.
How can message representations refer to other, possibly many and frequently changing, API endpoints and operations without binding the message recipient to the actual addresses of these endpoints?
Following are two reasons to avoid an address coupling between communication participants:
API providers want to be able to change the destinations of links freely when evolving their APIs while workload grows and requirements change.
API clients do not want to have to change code and configuration (for example, application startup procedures) when the naming and structuring conventions for links change on the provider side.
The following design challenges also have to be addressed:
Coupling between clients and endpoints: If clients use the address of an end-point to reference it directly, a tight link is created between these parties. The client references can break for many reasons, such as if the endpoint address changes or the endpoint is down temporarily.
Dynamic endpoint references: API designs often bind references to endpoints at design or deployment time, for instance, hardcoding references in the clients (while more sophisticated binding schemes exist as well). Sometimes this is not flexible enough; dynamic changes to endpoint references at runtime are required. Two examples are endpoints that are taken offline for maintenance and load balancers working with a dynamic number of endpoints. Another usage scenario involves intermediaries and redirecting helpers that help overcome formatting differences after new API versions have been introduced.
Centralization versus decentralization: Providing exactly one INFORMATION HOLDER RESOURCE per data element in the Published Language that is referenced in requests and responses to other API endpoints via hardcoded addresses leads to highly decentralized solutions. Other API designs could centralize the registration and binding of endpoint addresses instead. Any centralized solution is likely to receive more traffic than a partially autonomous, distributed one; decentralized ones are easy to build but might become hard to maintain and evolve.
Message sizes, number of calls, resource use: An alternative solution to consider for any form of references used in clients is to avoid them, following the EMBEDDED ENTITY pattern. However, this increases message sizes. Any solutions for managing references to endpoints in clients generally cause additional API calls. All these considerations influence the resource use in terms of provider-side processing resources and network bandwidth.
Dealing with broken links: Clients following references will assume these references point at the right existing API endpoints. If such references no longer work because an API endpoint has been moved, existing clients that do not know about this may fail (as they are no longer able to connect to the API) or, even worse, run the risk of receiving out-of-date information from a previous endpoint version.
Number of endpoints and API complexity: The coupling problem could be avoided by having a specific endpoint only for getting the address of another endpoint. But in the extreme case that all endpoints require such functionality, this tactic would double the number of endpoints, which would make API maintenance more difficult and increase the API complexity.
A simple approach could be to add lookup operations, which are special types of RETRIEVAL OPERATIONS that return LINK ELEMENTS to already existing endpoints. This solution is workable but compromises cohesion within the endpoints.
How It Works
Introduce a special type of INFORMATION HOLDER RESOURCE endpoint, a dedicated LINK LOOKUP RESOURCE that exposes special RETRIEVAL OPERATION operations. These operations return single instances or collections of LINK ELEMENTS that represent the current addresses of the referenced API endpoints.
These LINK ELEMENTS may point at action-oriented PROCESSING RESOURCES as well as data-oriented INFORMATION HOLDER RESOURCES endpoints (or any of its refinements dealing with operational data, master data, reference data, or serving as a shared data exchange space).
The most basic LINK LOOKUP RESOURCE uses a single ATOMIC PARAMETER for the request message to identify the lookup target by its primary key, such as a plain/flat but globally unique ID ELEMENT . Such unique identifiers are also used to create API KEYS. On the next level of client convenience, an ATOMIC PARAMETER LIST can be used if multiple lookup options and query parameters exist (this way, the lookup mode can/has to be specified by the client). The LINK LOOKUP RESOURCE returns global, network-accessible references to the held information (each taking the form of a LINK ELEMENT, possibly amended with METADATA ELEMENTS that disclose the link type).
If the network addresses of instances of the different types of INFORMATION HOLDER RESOURCE are returned, the client can access these resources subsequently to obtain attributes, relationship information, and so on. Figure 5.12 sketches this solution.
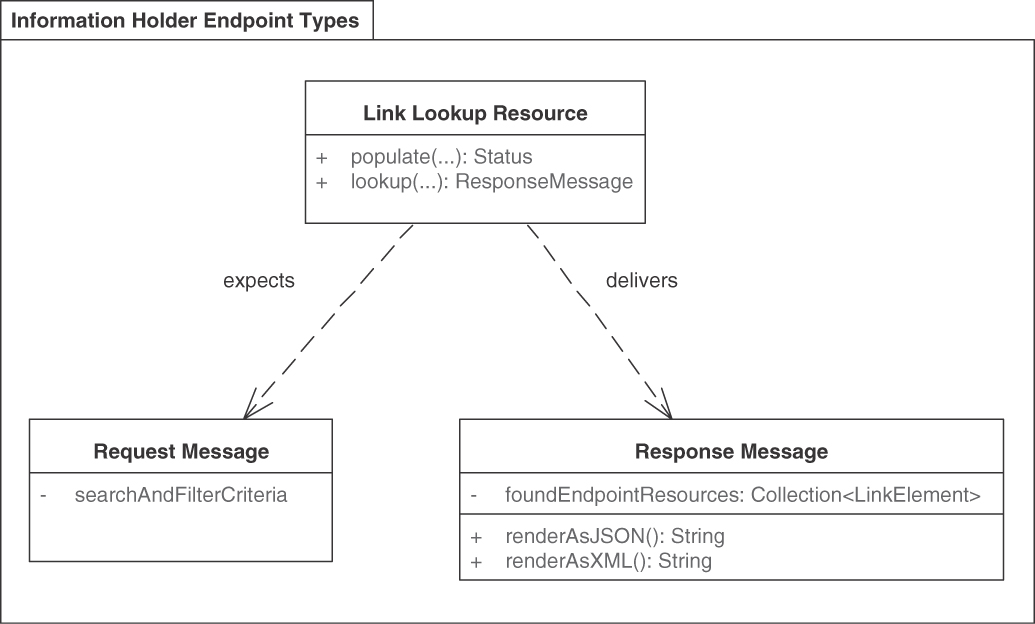
Figure 5.12 A LINK LOOKUP RESOURCE is an API endpoint that merely holds information about other ones
The link information may come in different forms. Many notations have been proposed to represent hyperlinks in messages, including JSON-LD [W3C 2019], HAL [Kelly 2016], WS-Addressing (XML) [W3C 2004].
Variant When the LINK ELEMENTS point at PROCESSING RESOURCES rather than INFORMATION HOLDER RESOURCES, a variant of this pattern is constituted: Hypertext as the Engine of Application State (HATEOAS) is one of the defining characteristics of truly RESTful Web APIs, according to the definitions of the REST style [Webber 2010; Erl 2013]. Note that the links in HATEOAS are also referred to as hypermedia controls.
The addresses of a few root endpoints (also called home resources) are published (that is, communicated to prospective API clients); the addresses of related services can then be found in each response. The clients parse the responses to discover the URIs of resources to be called subsequently. If a PROCESSING RESOURCE is referenced this way, the control flow and application state management become dynamic and highly decentralized; the operation-level pattern STATE TRANSITION OPERATION covers this REST principle in detail. RESTful INFORMATION HOLDER RESOURCES may support the slicing or partitioning of large, complex data.
Example
In the Lakeside Mutual sample case, two operations to find INFORMATION HOLDER RESOURCES that represent customers can be specified as follows (notation: MDSL, introduced in Appendix C):
API description LinkLookupResourceExampledata type URI D<string> // protocol, domain, path, parametersendpoint type LinkLookupResourceInterface // sketchexposesoperation lookupInformationHolderByLogicalNameexpecting payload<<Identifier_Element>> "name": IDdelivering payload<<Link_Element>> "endpointAddress": URIoperation lookupInformationHolderByCriteriaexpecting payload {"filter": P // placeholder parameter P}delivering payload {<<Link_Element>> "uri": URI* // 0..m cardinality}API provider CustomerLookupResourceoffers LinkLookupResourceInterface
Discussion
A centralized LINK LOOKUP RESOURCE providing dynamic endpoint references decouples clients and providers in terms of location autonomy. The pattern promotes high cohesion within one endpoint, as the lookup responsibility is separated from the actual processing and information retrieval. As a negative consequence, a LINK LOOKUP RESOURCE causes extra calls and increases the number of endpoints. The pattern increases operational costs; the lookup resource must be kept current. Use of the pattern improves cohesion within endpoints (at the expense of adding additional, specialized ones).
The pattern has a negative impact on the number of calls clients are required to send unless caching is introduced to mitigate this effect and lookup calls are performed only after detecting broken links. The pattern can improve performance only if the overhead for looking up the INFORMATION HOLDER RESOURCE (or other provider-internal data storage) over an API operation boundary (so making two calls) does not exceed the savings achieved by leaner message payloads (of each operation).
If the combination of a LINKED INFORMATION HOLDER with a LINK LOOKUP RESOURCE turns out to add more overhead than performance and flexibility gains, the LINKED INFORMATION HOLDER can be changed to contain a direct link. If the direct linking still leads to overly chatty message exchanges (conversations) between API clients and API providers, the referenced data could be flattened as an instance of EMBEDDED ENTITY.
The added indirection can help to change the system runtime environment more freely. Systems that include direct URIs might be harder to change as server names change. The REST principle of HATEOAS solves this problem for the actual resource names; only hardcoded client-side links are problematic (unless HTTP redirections are introduced). Microservices middleware such as API gateways can be used as well; however, such usage adds complexity to the overall architecture as well as additional runtime dependencies. Using hypermedia to advance the application state is one of the defining constraints of the REST style. One has to decide whether the hypermedia should refer to the resources responsible for provider-side processing (of any endpoint type) directly or whether a level of indirection should be introduced to further decouple clients and endpoints (this pattern).
Related Patterns
Instances of this pattern can return links to any of the endpoint types/roles, often to INFORMATION HOLDER RESOURCES. The pattern uses RETRIEVAL OPERATIONS. For instance, RETRIEVAL OPERATION instances may return ID ELEMENTS pointing at INFORMATION HOLDER RESOURCES indirectly (that in turn return the data); the LINK LOOKUP RESOURCE turns the ID ELEMENT into a LINK ELEMENT.
Infrastructure-level service discovery can be used alternatively. For instance, patterns such as “Service Registry,” “Client-Side Discovery,” and “Self Registration” have been captured by [Richardson 2018].
This pattern is an API-specific version/refinement of the more general “Lookup” pattern described in [Kircher 2004] and [Voelter 2004]. At a more abstract level, the pattern also is a specialization of the Repository pattern described in [Evans 2003], effectively acting as a meta-repository.
More Information
SOA books cover related concepts such as service repositories and registries. In RDD terms, a LINK LOOKUP RESOURCE acts as a “Structurer” [Wirfs-Brock 2002].
If multiple results of the same type are returned, the LINK LOOKUP RESOURCE turns into a “Collection Resource.” Collection Resources can be seen as a RESTful HTTP pendant of this pattern, adding add and remove support. Recipe 2.3 in the RESTful Web Services Cookbook [Allamaraju 2010] features them; Chapter 14 of that book discusses discovery. Collections use links to enumerate their content and allow clients to retrieve, update, or delete individual items. As shown in [Serbout 2021], APIs can feature read-only collections, appendable collections, as well as mutable collections.
 Pattern: DATA TRANSFER RESOURCE
Pattern: DATA TRANSFER RESOURCE
When and Why to Apply
Two or more communication participants want to exchange data. The number of exchange participants might vary over time, and their existence might be known to each other only partially. They might not always be active at the same time. For instance, additional participants may want to access the same data after it has already been shared by its originator.
Participants may also be interested in accessing only the latest version of the shared information and do not need to observe every change applied to it. Communication participants may be constrained in the networking and integration technologies they are permitted to use.
How can two or more communication participants exchange data without knowing each other, without being available at the same time, and even if the data has already been sent before its recipients became known?
Coupling (time dimension): Communication participants may not be able to communicate synchronously (that is, at the same time), as their availability and connectivity profiles may differ and change over time. The more communication participants want to exchange data, the more unlikely it is that all will be ready to send and receive messages at the same time.
Coupling (location dimension): The location of communication participants may be unknown to the other participants. It might not be possible to address all participants directly due to asymmetric network connectivity, making it difficult, for example, for senders to know how to reach the recipients of the data exchange that are hidden behind a Network Address Translation (NAT) table or a firewall.
Communication constraints: Some communication participants may be unable to talk to each other directly. For instance, clients in the client/server architectural style by definition are not capable of accepting incoming connections. Also, some communication participants may not be allowed to install any software required for communication beyond a basic HTTP client library locally (for example, a messaging middleware). In such cases, indirect communication is the only possibility.
Reliability: Networks cannot be assumed to be reliable, and clients are not always active at the same time. Hence, any distributed data exchanges must be designed to be able to cope with temporary network partitions and system outages.
Scalability: The number of recipients may not be known at the time the data is sent. This number could also become very large and increase access requests in unexpected ways. This, in turn, may harm throughput and response times. Scaling up the amount of data can be an issue: the amount of data to be exchanged may grow unboundedly and beyond the capacity limits of individual messages (as defined by the communication and integration protocols used).
Storage space efficiency: The data to be exchanged has to be stored somewhere along its way, and sufficient storage space must be available. The amount of data to be shared must be known, as there may be limits on how much data can be transferred or stored due to bandwidth constraints.
Latency: Direct communication tends to be faster than indirect communication via relays or intermediaries.
Ownership management: Ownership of the exchanged information has to be established to achieve explicit control over its availability life cycle. The initial owner is the participant sharing the data; however, there may be different parties responsible for cleanup: the original sender (interested in maximizing the reach of the shared data), the intended recipient (who may or not want to read it multiple times), or the host of the transfer resource (who must keep storage costs in check).
One could think of using publish-subscribe mechanisms, as offered by message-oriented middleware (MOM) such as ActiveMQ, Apache Kafka, or Rabbit MQ, but then the clients would have to run their own local messaging system endpoint to receive and process incoming messages. MOM needs to be installed and operated, which adds to the overall systems management effort [Hohpe 2003].
How It Works
Introduce a DATA TRANSFER RESOURCE as a shared storage endpoint accessible from two or more API clients. Provide this specialized INFORMATION HOLDER RESOURCE with a globally unique network address so that two or more clients can use it as a shared data exchange space. Add at least one STATE CREATION OPERATION and one RETRIEVAL OPERATION to it so that data can be placed in the shared space and also fetched from it.
Share the address of the transfer resource with the clients. Decide on data ownership and its transfer; prefer client ownership over provider ownership here.
Multiple applications (API clients) can use the shared DATA TRANSFER RESOURCE as a medium to exchange information that is originally created by one of them and then transferred to the shared resource. Once the information has been published in the shared resource, any additional client that knows the URI of the shared resource and is authorized to do so may retrieve it, update it, add to it, and delete it (when the data is no longer useful for any client application). Figure 5.13 sketches this solution.
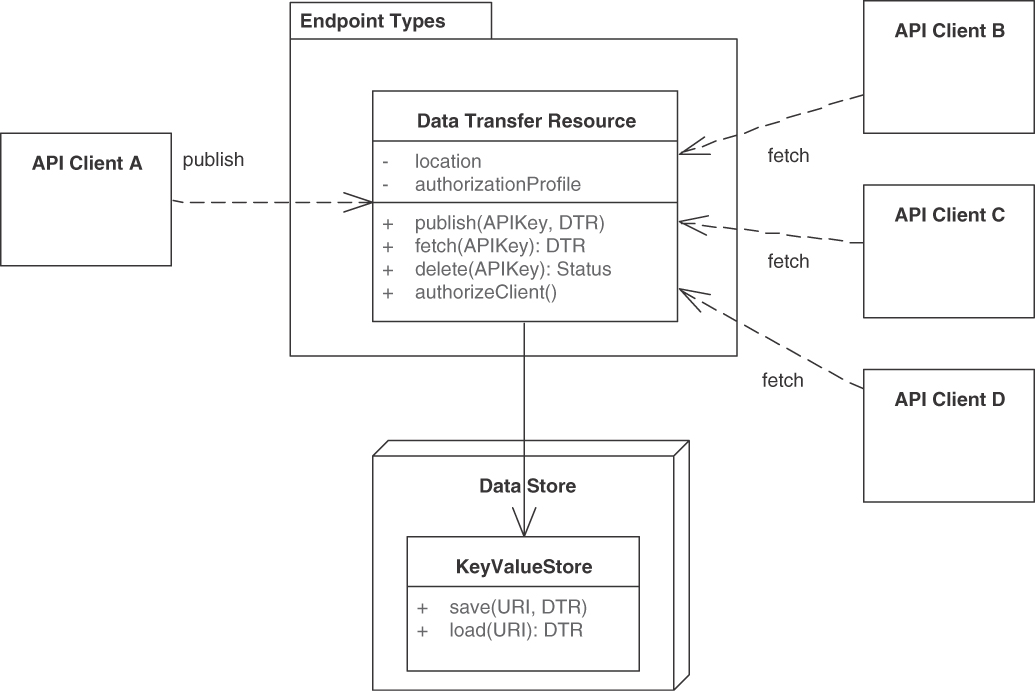
Figure 5.13 DATA TRANSFER RESOURCE. A DATA TRANSFER RESOURCE endpoint holds temporary data to decouple two or more API clients sharing this data. The pattern instance provides a data exchange space between these clients. Data ownership remains with the application clients
The shared DATA TRANSFER RESOURCE establishes a blackboard between its clients, providing them with an asynchronous, virtual data flow channel to mediate all their interactions. As a result, clients can exchange data without having to connect directly to each other, or (perhaps even more important) without having to address each other directly and without being up and running at the same time. Hence, it decouples them in time (they do not have to be available at the same time) and makes their location irrelevant—as long as they all can reach the shared DATA TRANSFER RESOURCE.
How do clients negotiate the URI for the shared resource? Clients may need to agree in advance about the shared resource address, or they may dynamically discover it using a dedicated LINK LOOKUP RESOURCE. Also, it is possible that the first client sets the URI while publishing the original content and informs the others about it via some other communication channel, or, again, by registering the address with a LINK LOOKUP RESOURCE, whose identity has been agreed upon in advance by all clients.
HTTP Support for the Pattern From an implementation perspective, this solution is directly supported in HTTP, whereby Client A first performs a PUT request to publish the information on the shared resource, uniquely identified by a URI, and then Client B performs a GET request to fetch it from the shared resource. Note that the information published on the shared resource does not disappear as long as no clients perform an explicit DELETE request. Client A publishing the information to the shared resource can do so reliably, as the HTTP PUT request is idempotent. Like-wise, if the subsequent GET request fails, Client B may simply retry it to be able to read the shared information eventually. Figure 5.14 illustrates the HTTP realization of the pattern.
Figure 5.14 DATA TRANSFER RESOURCE (HTTP realization)
Clients cannot know whether other clients have retrieved the information from the shared resource. To address this limitation, the shared resource can track access traffic and offer additional metadata about the delivery status so that it is possible to inquire whether and how many times the information has been fetched after it has been published. Such METADATA ELEMENTS exposed by RETRIEVAL OPERATIONS may also help with the garbage collection of shared resources that are no longer in use.
Variants Access patterns and resource lifetimes may differ, which suggests the following variants of this pattern:
Relay Resource: There are two clients only, one that writes and one that reads. Data ownership is shifted from the writer to the reader. Figure 5.15 illustrates this variant.

Figure 5.15 RELAY RESOURCE
Published Resource: One client writes as before, but then a very large, unpredictable number of clients read it at different times (maybe years later), as shown in Figure 5.16. The original writer determines how long the shared resource remains publicly available to its multiple readers. Routing patterns such as “Recipient List” can be supported this way [Hohpe 2003]; streaming middleware may realize this variant.

Figure 5.16 PUBLISHED RESOURCE
Conversation Resource: Many clients read, write, and eventually delete the shared resource (Figure 5.17). Any participant owns the transfer resource (and can therefore both update and delete it).
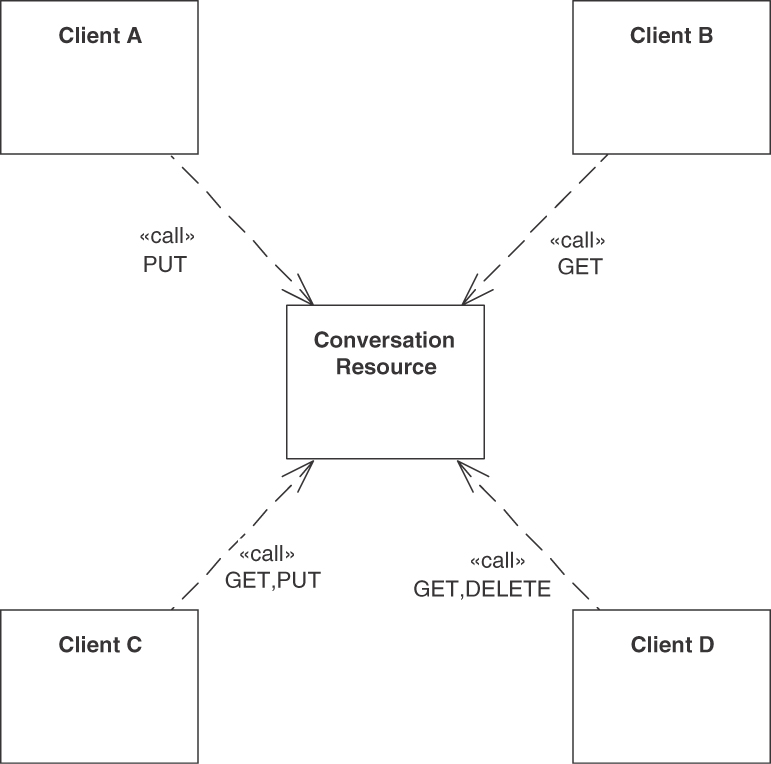
Figure 5.17 CONVERSATION RESOURCE
Example
The example in Figure 5.18 instantiates the pattern for an integration interface in the Lakeside Mutual sample case. The Claim Reception System Of Engagement is the data source, and a Claim Transfer Resource decouples the two data sinks Claim Processing System Of Records and Fraud Detection Archive from it.
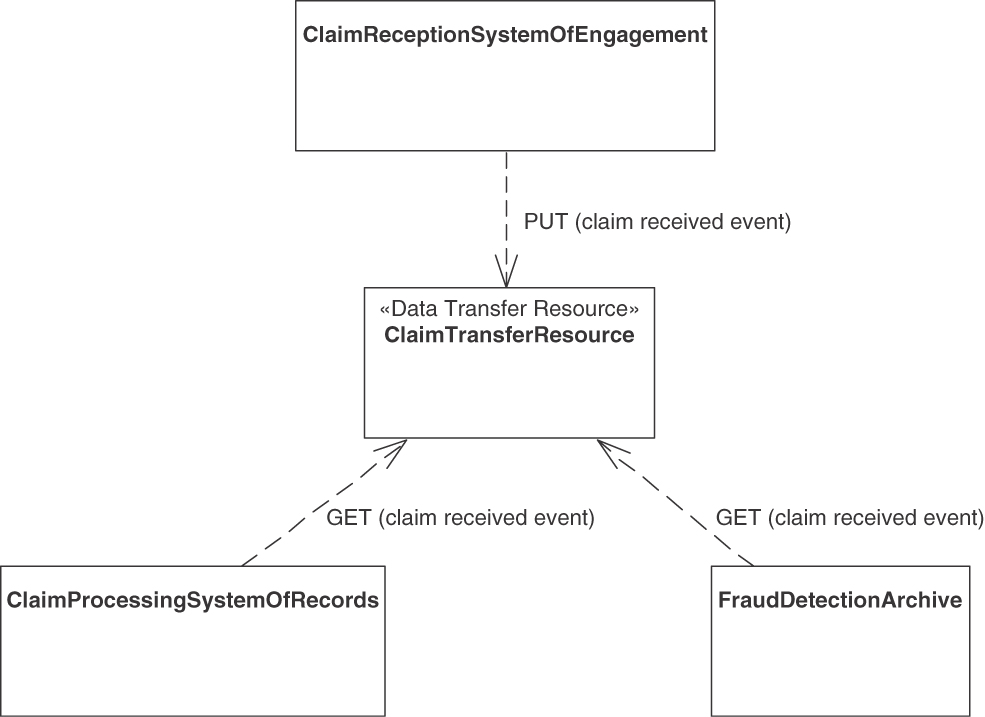
Figure 5.18 Claims management data flow as an example of a DATA TRANSFER RESOURCE
Discussion
The pattern combines the benefits of messaging and shared data repositories: flexibility of data flow and asynchrony [Pautasso 2018]. Let us go through the forces and pattern properties one by one (in the context of HTTP and Web APIs).
Coupling (time and location dimensions): Asynchronous and indirect communication are supported.
Communication constraints: Clients that cannot directly connect use the transfer resource as a shared blackboard. Clients sometimes cannot directly talk to each other for these reasons:
They are clients and therefore are not supposed to receive any incoming requests.
They are running behind a firewall/NAT that allows only outgoing connections.
They are running inside a Web browser, which only allows sending HTTP requests to and receiving responses from a Web server.
They are not running at the same time.
If direct connectivity is impossible, then an indirect route may still work. The shared DATA TRANSFER RESOURCE provides such an intermediary element and can serve as a joint storage space, which is reachable from both clients and remains available even when some of the clients temporarily disappear.
Reliability: When using messaging systems, the connection from the client to the middleware can be a local one (the messaging system broker process then takes care of the remote messaging, guaranteeing message delivery). Such “programming without a call stack” is conceptually harder and more error prone than blocking remote procedure invocations, but it is also more powerful when done properly [Hohpe 2003]. When applying the DATA TRANSFER RESOURCE pattern, the client-to-resource connection always is a remote one. Moreover, HTTP cannot guarantee message delivery. However, the idempotence of the PUT and GET methods in HTTP can mitigate the problem because the sending clients can retry calls to the DATA TRANSFER RESOURCE until the upload or download succeeds. When using such idempotent HTTP methods to access the shared resource, neither the middleware nor the receiver has to detect and remove duplicate messages.
Scalability: The amount of data that can be stored on a Web resource is bound by the capacity of the data storage/file system that underlies the Web server. The amount of data that can be transferred to and from the Web resource within one standard HTTP request/response is virtually unlimited according to the protocol and therefore constrained only by the underlying middleware implementations and hardware capacity. The same constraints also apply for the number of clients.
Storage space efficiency: The DATA TRANSFER RESOURCE provider has to allocate sufficient space.
Latency: Indirect communication requires two hops between participants, which, however, do not have to be available at the same time. In this pattern, the ability to transfer data across large periods and multiple participants takes priority over the performance of the individual transfer.
Ownership management: Depending on the pattern variant, data ownership—the right but also the obligation to ensure the validity of the shared resource content and to clean it up eventually—can stay with the source, be shared among all parties aware of its URI, or be transferred to the DATA TRANSFER RESOURCE. The latter option is adequate if the source originally publishing the data is not expected to be present until all recipients have had a chance to read it.
Once a DATA TRANSFER RESOURCE has been introduced, additional design issues arise:
Access control: Depending on the type of information being exchanged, clients reading from the resource trust that the resource was initialized by the right sources. Therefore, in some scenarios, only authorized clients may be allowed to read from or write to the shared resource. Access may be controlled with an API KEY or more advanced security solutions.
(Lack of) coordination: Clients may read from and write to the shared resource at any time, even multiple times. There is little coordination between writers and readers beyond being able to detect empty (or noninitialized) resources.
Optimistic locking: Multiple clients writing at the same time may run into conflicts, which should be reported as an error and trigger a systems management activity to reconcile.
Polling: Some clients cannot receive notifications when the shared resource state is changed, and they must resort to polling to be able to fetch the most recent version.
Garbage collection: The DATA TRANSFER RESOURCE cannot know whether any client that has completed reading will be the last one; hence, there is a risk of leaking data unless it is explicitly removed. Housekeeping is required: purging DATA TRANSFER RESOURCES that have outlived their usefulness avoids waste of storage resources.
Related Patterns
The pattern differs from other types of INFORMATION HOLDER RESOURCES with respect to data access and storage ownership. The DATA TRANSFER RESOURCE acts both as a data source and a data sink. The DATA TRANSFER RESOURCE exclusively owns and controls its own data store; the only way to access its content is via the published API of the DATA TRANSFER RESOURCE. Instances of other INFORMATION HOLDER RESOURCE types often work with data that is accessed and possibly even owned by other parties (such as backend systems and their non-API clients). A LINK LOOKUP RESOURCE can be seen as a DATA TRANSFER RESOURCE that holds a special type of data, namely addresses (or LINK ELEMENTS).
Patterns for asynchronous messaging are described in Enterprise Integration Patterns [Hohpe 2003]. Some of these patterns are closely related to DATA TRANSFER RESOURCE. A DATA TRANSFER RESOURCE can be seen as a Web-based realization of a “Message Channel,” supporting message routing and transformation, as well as several message consumption options (“Competing Consumers” and “Idempo-tent Receiver”). Queue-based messaging and Web-based software connectors (as described by this DATA TRANSFER RESOURCE pattern) can be seen as two different but related integration styles; these styles are compared in “The Web as a Software Connector” [Pautasso 2018].
“Blackboard” is a POSA 1 pattern [Buschmann 1996], intended to be eligible in a different context but similar in its solution sketch. Remoting Patterns [Voelter 2004] describes the remoting style “Shared Repository”; our DATA TRANSFER RESOURCE can be seen as the API for a Web-flavored shared repository.
More Information
“Interfacer” is a role stereotype in RDD that describes a related but more generic programming-level concept [Wirfs-Brock 2002].
Operation Responsibilities
An API endpoint exposes one or more operations in its contract. These operations show some recurring patterns in the way they work with provider-side state. The four operations responsibility patterns are COMPUTATION FUNCTION, STATE CREATION OPERATION, RETRIEVAL OPERATION, and STATE TRANSITION OPERATION. Figure 5.19 gives an overview of these patterns, including their variants.
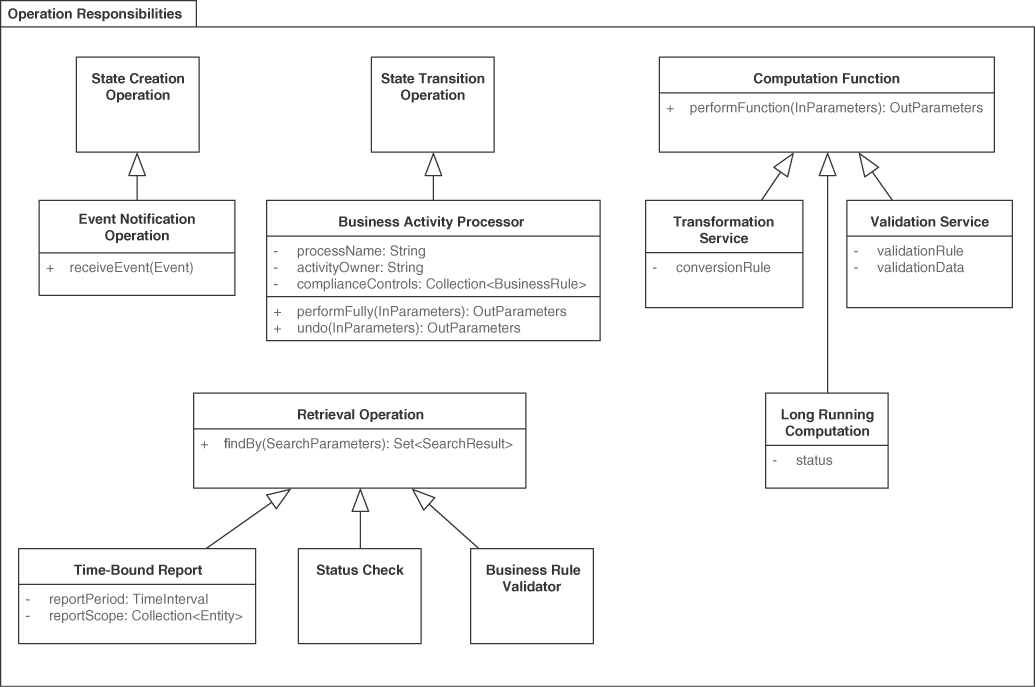
Figure 5.19 Patterns distinguishing operation responsibilities
Note that we call state-preserving API responsibilities functions (as they just get some self-contained work done on behalf of a client) and state-changing responsibilities operations (as they become active because the client hands in some data, which is then processed and stored; it can be retrieved as well).
 Pattern: STATE CREATION OPERATION
Pattern: STATE CREATION OPERATION
When and Why to Apply
An API endpoint has been introduced. The API client has expressed its API wants and needs, for instance, in the form of user stories and/or given-when-then clauses [Fowler 2013]; quality requirements have been elicited as well.
The API client(s) would like to inform the API provider about new client-side incidents without being interested in detailed information about further server-side processing (if any).
The client might want to instruct the API provider to initiate a long-running business transaction (like an order management and fulfillment process) or report the completion of a client-side batch job (like the bulk reinitialization of a product catalog). Such requests cause data to be added to the provider-internal state.
An immediate response can be returned, which might just be a simple “got it” acknowledgment.
How can an API provider allow its clients to report that something has happened that the provider needs to know about, for instance, to trigger instant or later processing?
Coupling trade-offs (accuracy and expressiveness versus information parsimony): To ease processing on the provider side, the incoming incident report should be self-contained so that it is independent of other reports. To stream-line report construction on the client-side, save transport capacities, and hide implementation details, it should contain only the bare minimum of information the API provider is interested in.
Timing considerations: The client-side occurrence of an incident may differ from the moment it is reported and the time when the incident report finally reaches the provider. It may not be possible to determine the sequencing/serialization of incidents happening on different clients.6
6. Time synchronization is a general theoretical limitation and challenge in any distributed system; logi-cal clocks have been invented for that reason.
Consistency effects: Sometimes the provider-side state cannot be read, or should be read as little as possible, when calls to an API arrive. In such cases, it becomes more difficult to validate that the provider-side processing caused by incoming requests does not break invariants and other consistency properties.
Reliability considerations: Reports cannot always be processed in the same order in which they were produced and sent. Sometimes reports get lost or the same report is transmitted and received multiple times. It would be nice to acknowledge that the report causing state to be created has been processed properly.
One could simply add yet another API operation to an endpoint without making its state read-write profile explicit. If this is done, the specific integration needs and concerns described previously still have to be described in the API documentation and usage examples; there is a risk of making implicit assumptions that get forgotten over time. Such an informal, ad hoc approach to API design and documentation can cause undesired extra efforts for client developers and API maintainers when they find out that their assumptions about effects on state and operation pre- and postconditions no longer hold. Furthermore, cohesion within the endpoint might be harmed. Load balancing becomes more complicated if stateful operations and stateless operations appear in the same endpoint. Operations staff must guess where and how to deploy the endpoint implementation (for instance, in certain cloud environments and container managers).
How It Works
Add a STATE CREATION OPERATION sco: in -> (out,S') that has a write-only nature to the API endpoint, which may be a PROCESSING RESOURCE or an INFORMATION HOLDER RESOURCE.
Let such a STATE CREATION OPERATION represent a single business incident that does not mandate a business-level reaction from the provider-side endpoint; it may simply store the data or perform further processing in the API implementation or an underlying backend. Let the client receive a mere “got it” acknowledgment or identifier (for instance, to be able to inquire about the state in the future and to resend the incident report in case of transmission problems).
Such operations might have to read some state, for instance, to check for duplicate keys in existing data before creation, but their main purpose should be state creation. This intent is sketched in Figure 5.20.
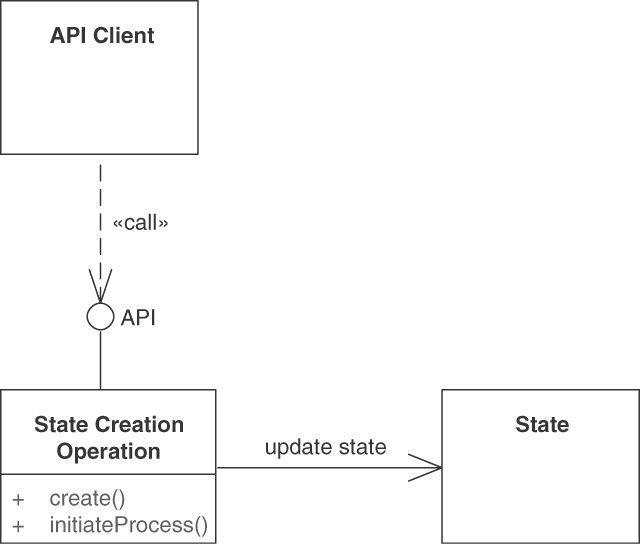
Figure 5.20 A STATE CREATION OPERATION has the responsibility to write to provider-side storage but cannot read from it
Describe the abstract and the concrete syntax as well as the semantics of the incident report (the incoming state creation messages, that is) and the acknowledging response (if any) in the API DESCRIPTION. Express the operation behavior in pre- and postconditions.
STATE CREATION OPERATIONS may or may not have fire-and-forget semantics. In the latter case, give each state item caused by calls to instances of this pattern a unique id (for duplicate detection and removal). Include a timestamp to capture the time when the reported incident happened (according to the client-side clock).
Unless you write to an append-only event store, perform the required write/insert operation in its own system transaction whose boundaries match that of the API operation (but are not visible to the API client). Let the processing of the STATE CREATION OPERATION appear to be idempotent.
The request messages accepted by a STATE CREATION OPERATION contain the full data set that is required to describe the incident that has happened, often in the form of a PARAMETER TREE, possibly including METADATA ELEMENTS that annotate other DATA ELEMENTS. The response message typically contains only a basic and simple “report received” element, for instance, an ATOMIC PARAMETER containing an explicit acknowledgment flag (of Boolean type). Sometimes, an ATOMIC PARAMETER LIST combining an error code with an error message is used, thus forming an ERROR REPORT.
Variant A popular variant of this pattern is Event Notification Operation, notifying the endpoint about an external event without assuming any visible provider-side activity and thus realizing event sourcing [Fowler 2006]. Event Notification Operations can report that data has been created, updated (fully or partially), or deleted elsewhere. Past tense is often used to name events (for example, “customer entity created”). Unlike in most implementations of stateful processing, the incoming event is only stored as-is, but the provider-side application state is not updated instantly. If the most recent state is required later on, all stored events (or all events up to a certain point in time when snapshots are taken) are rather replayed and the application state is calculated in the API implementation. This makes the event reporting fast, at the expense of slowing down the later state lookup. An additional benefit of event sourcing is that time-based queries can be performed, as the entire data manipulation history is available in the event journal. Modern event-based systems such as Apache Kafka support such replays in their event journals and distributed transaction logs.
Events can either contain absolute new values that form full reports or, as delta reports, communicate the changes since the previous event (identified by a “Correlation Identifier” [Hohpe 2003] or indirectly by timestamp and entity identifier).
Event Notification Operations and event sourcing can form the base of event-driven architectures (EDAs). Other pattern languages provide advice for EDA design [Richardson 2016].
A second variant of this pattern is a Bulk Report. The client combines multiple related incident events into one report and sends this report as a REQUEST BUNDLE. The bundle entries may all pertain to the same entity or may refer to different ones, for instance, when creating a snapshot or an audit log from the individual events in the Bulk Report or when passing a journal of events that occurred in a certain period on to a data warehouse or data lake.
Examples
In the online shopping scenario, messages such as “new product XYZ created” sent from a product management system or “customer has checked out order 123” from an online shop qualify as examples.
Figure 5.21 gives an example in the Lakeside Mutual case. The events received by the STATE CREATION OPERATION report that a particular customer has been contacted, for instance by a sales agent.
Figure 5.21 Example of a STATE CREATION OPERATION: EVENT NOTIFICATION OPERATION
Discussion
Loose coupling is promoted because client and provider do not share any application state; the API client merely informs the provider about incidents on its side. Provider-side consistency checks might be difficult to implement because state reads are supposed to be avoided in STATE CREATION OPERATIONS (for instance, if scaling APIs and their endpoints up and out is desired). Hence, consistency cannot always be fully ensured when operations are defined as write-only (for instance, how should events reporting contradictory information be dealt with?). Time management remains a difficult design task for the same reason. Reliability might suffer if no acknowledgment or state identifier is returned; if it is returned, the API client has to make sure to interpret it correctly (for instance, to avoid unnecessary or premature resending of messages).
Exposing write-only API operations with business semantics that report external events is a key principle of EDAs; we discussed it in the context of the Event Notification Operation variant. In replication scenarios, events represent state changes that have to be propagated among the replicas.
The pattern leaves some room for interpretation when implementing it:
What should be done with arriving reports: should they be simply stored locally, processed further, or passed on? Does provider-side state have to be accessed, even if it is not desired, for instance, to check the uniqueness of keys?
Does the report processing change the behavior of future calls to other operations in the same endpoint?
Is operation invocation idempotent? Events can get lost, for instance, in the case of unreliable network connections or temporary server outages, and might be transmitted multiple times if the client attempts to resend unacknowledged ones. How is consistency ensured in such situations? Strict and eventual consistency are two of the options here [Fehling 2014].
STATE CREATION OPERATIONS are sometimes exposed in PUBLIC APIS; if this is done, they must be protected, for instance, with an API KEY and RATE LIMITS.
This pattern covers scenarios in which an API client notifies a known API provider about an incident. An API provider notifying its clients via callbacks and publish-subscribe mechanisms is another approach covered in other pattern languages and middleware/distributed systems books [Hohpe 2003; Voelter 2004; Hanmer 2007].
Related Patterns
The endpoint role patterns PROCESSING RESOURCE and INFORMATION HOLDER RESOURCE typically contain at least one STATE CREATION OPERATION (unless they are mere compute resources or view providers). Other operation responsibilities are STATE TRANSITION OPERATION, COMPUTATION FUNCTION, and RETRIEVAL OPERATION. A STATE TRANSITION OPERATION usually identifies a provider-side state element in its request message (for instance, an order id or a serial number of a staff member); STATE CREATION OPERATIONS do not have to do this (but might).
“Event-Driven Consumer” and “Service Activator” [Hohpe 2003] describe how to trigger message reception and operation invocation asynchronously (all four operation responsibilities can be combined with these patterns). Chapter 10 in Process-Driven SOA features patterns for integrating events into process-driven SOAs [Hentrich 2011].
“The Domain Event” pattern in DDD [Vernon 2013] can help identify STATE CREATION OPERATIONS, specifically but not limited to the Event Notification Operation variant.
More Information
Instances of this pattern may trigger long-running and therefore stateful conversations [Hohpe 2007; Pautasso 2016]. The STATE TRANSITION OPERATION pattern covers this usage scenario.
Martin Fowler describes “Command Query Responsibility Segregation” (CQRS) [Fowler 2011] and event sourcing [Fowler 2006]. The Context Mapper DSL and tools support DDD and event modeling, model refactoring, as well as diagram and service contract generation [Kapferer 2021].
DPR features a seven-step service design method to carve out API endpoints and their operations [Zimmermann 2021b].
 Pattern: RETRIEVAL OPERATION
Pattern: RETRIEVAL OPERATION
When and Why to Apply
A PROCESSING RESOURCE or INFORMATION HOLDER RESOURCE endpoint has been identified as required; functional and quality requirements for it have been specified. The operations of these resources do not yet cover all required capabilities—the API consumer(s) also demand read-only access to data, possibly large amounts of repetitive data in particular. This data can be expected to be structured differently than in the domain model of the underlying API implementation; for instance, it might pertain to a particular time period or domain concept (like a product category or customer profile group). The information need arises either ad hoc or regularly, for instance, at the end of a certain period (such as week, month, quarter, or year).
How can information available from a remote party (the API provider, that is) be retrieved to satisfy an information need of an end user or to allow further client-side processing?
Processing data in context turns it into information, interpreting it in context creates knowledge. Related design issues are as follows:
How can data model differences be overcome, and how can data be aggregated and combined with information from other sources?
How can clients influence the scope and the selection criteria for the retrieval results?
How can the timeframe for reports be specified?
Veracity, Variety, Velocity, and Volume: Data comes in many forms, and client interest in it varies in terms of volume, required accuracy, and processing speed. The variability dimensions include frequency, breadth, and depth of data access. Data production on the provider side and its usage on the client side also change over time.
Workload Management: Data processing takes time, especially if the data volume is big and the processing power is limited. Should clients download entire databases so that they can process their content at will locally? Should some of the processing be performed on the provider-side instead so that the results can be shared and retrieved by multiple clients?
Networking Efficiency versus Data Parsimony (Message Sizes): The smaller messages are, the more messages have to be exchanged to reach a particular goal. Few large messages cause less network traffic but make the individual request and response messages harder to prepare and process in the conversation participants.
It is hard to imagine a distributed system that does not require some kind of retrieval and query capability. One could replicate all data to its users “behind the scenes” periodically, but such an approach has major deficiencies with regard to consistency, manageability, and data freshness, not to mention the coupling of all clients to the fully replicated, read-only database schema.
How It Works
Add a read-only operation ro: (in,S) -> out to an API endpoint, which often is an INFORMATION HOLDER RESOURCE, to request a result report that contains a machine-readable representation of the requested information. Add search, filter, and formatting capabilities to the operation signature.
Access the provider-side state in read-only mode. Make sure that the pattern implementation does not change application/session state (except for access logs and other infrastructure-level data), as shown in Figure 5.22. Document this behavior in the API DESCRIPTION.
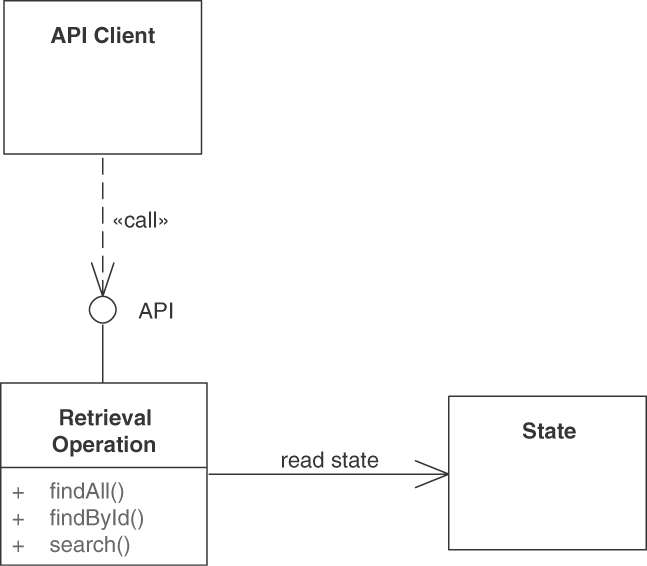
Figure 5.22 A RETRIEVAL OPERATION reads from but does not write to provider-side storage. Searching (and filtering) may be supported
For simple retrievals, one can use an ATOMIC PARAMETER LIST to define the query parameters for the report and return the report as a PARAMETER TREE or PARAMETER FOREST. In more complex scenarios, a more expressive query language (such as GraphQL [GraphQL 2021] with its hierarchical call resolvers or SPARQL [W3C 2013], used for big data lakes) can be introduced; the query then describes the desired output declaratively (for instance, as an expression formulated in the query language); it can travel as an ATOMIC PARAMETER string. Such an expressive, highly declarative approach supports the “variety” V (one of the four Vs introduced earlier).
Adding support for PAGINATION is common and advised if result collections are large (the “volume” V of the four big data Vs). Clients can shape and streamline the responses when providing instances of WISH LIST or WISH TEMPLATE in their retrieval requests.
Access control might be required to steer what API client are permitted to ask for. Data access settings (including transaction boundaries and isolation level) may have to be configured in the operation implementation.
Examples
In an online shopping example, an analytic RETRIEVAL OPERATION is “show all orders customer ABC has placed in the last 12 months.”
In the Lakeside Mutual case, we can define multiple operations to find customers and retrieve information about them as illustrated in Figure 5.23. The allData parameter is a primitive yes/no WISH LIST. When set to true, an EMBEDDED ENTITY containing all customer data is included in the response; when false, a LINKED INFORMATION HOLDER pointing at this data is returned instead.
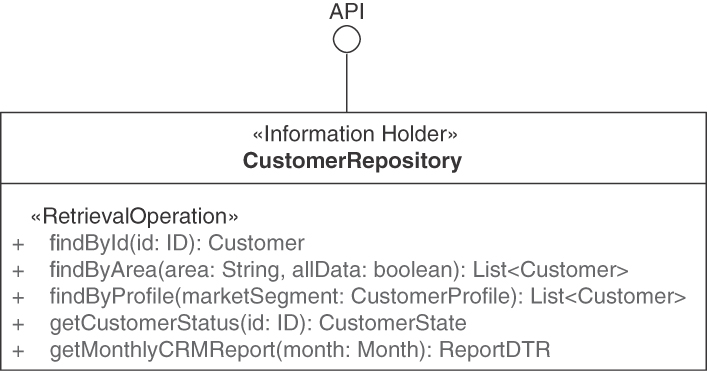
Figure 5.23 Examples of RETRIEVAL OPERATIONS: Search, filter, direct access
In the Lakeside Mutual implementation, we find many Web-based retrieval operations (HTTP GETs), which can be called with curl on the command line. An example is listClaims:
curl –X GET http://localhost:8080/claims?limit=10&offset=0The command arrives at this API endpoint operation (Java Spring):
@GETpublic ClaimsDTO listClaims(@QueryParam("limit") @DefaultValue("3") Integer limit,@QueryParam("offset")@DefaultValue("0") Integer offset,@QueryParam("orderBy") String orderBy) {List<ClaimDTO> result = […]return new ClaimsDTO(limit, offset, claims.getSize(), orderBy, result);}
Variants Several variants of this pattern exist, for instance, Status Check (also known as Progress Inquiry, Polling Operation), Time-Bound Report, and Business Rule Validator.
A Status Check has rather simple in and out parameters (for example, two ATOMIC PARAMETER instances): an id (for instance, a process or activity identifier) is passed in and a numeric status code or a state name (defined in an enumeration type) is returned.
A Time-Bound Report typically specifies the time interval(s) as an additional query parameter (or set of parameters); its responses then contain one PARAMETER TREE per interval.
A Business Rule Validator is similar to the Validation Service variant of a COMPUTATION FUNCTION. However, it does not validate data that is passed on but retrieves this data from the provider-side application state. A list of identifiers of entities already present in the API implementation (validation target) might be included in the request. One example of a Business Rule Validator is a check whether the provider will be able to process this business object in the current state of the conversation with the client. Such a validator can be invoked prior to a call to a STATE TRANSITION OPERATION that primarily works on the business object that is passed in. The validation may also include provider-side application state into the checking process. In an online shopping example, “check whether all order items point to existing products that are currently in stock” is an example of such a validator. This Business Rule Validator helps catch errors early, which can reduce workload.
Discussion
With respect to workload management, RETRIEVAL OPERATIONS can scale out by replicating data. This is simplified by their read-only nature. RETRIEVAL OPERATIONS may also become a performance bottleneck, for instance, if user information needs and query capabilities do not match and many complex calculations are required to match information demand and supply. Network efficiency is at risk.
PAGINATION is commonly used to address the “volume” aspect and to reduce message sizes. The “velocity” aspect cannot be easily supported with standard request-reply retrievals; the introduction of streaming APIs and stream processing (which is out of our scope here) can be considered instead.
From a security point of view, the request message often has low to medium data protection needs in case of aggregated data retrieval; however, the request may contain secure credentials to authorize access to sensitive information and has to avoid DoS attacks. The response message protection requirements might be more advanced, as returned data reports might contain business performance data or sensitive personal information.7
7. OWASP has published an API Security Top 10 [Yalon 2019] that any API should respect, especially those dealing with sensitive and/or classified data.
RETRIEVAL OPERATION instances are commonly exposed in PUBLIC APIS, such as those of open data [Wikipedia 2022h] and open government data scenarios. If this is done, they often are protected with an API KEY and RATE LIMITS.
Time-Bound Report services can use denormalized data replicas and apply the extract-transform-load staging commonly used in data warehouses. Such services are common in COMMUNITY APIS and SOLUTION-INTERNAL APIS, for example, those supporting data analytics solutions.
Related Patterns
The endpoint pattern PROCESSING RESOURCE and all types of INFORMATION HOLDER RESOURCES may expose RETRIEVAL OPERATIONS. The PAGINATION pattern is often applied in RETRIEVAL OPERATIONS.
If query responses are not self-explanatory, METADATA ELEMENTS can be introduced to reduce the risk of misinterpretations on the consumer side.
The sibling patterns are STATE TRANSITION OPERATION, STATE CREATION OPERATION, and COMPUTATION FUNCTION. A STATE CREATION OPERATION pushes data from the client to the API provider, whereas a RETRIEVAL OPERATION pulls data; COMPUTATION FUNCTION and STATE TRANSITION OPERATION can support both unidirectional data flows and bidirectional ones.
More Information
Chapter 8 in the RESTful Web Services Cookbook [Allamaraju 2010] discusses queries (in the context of HTTP APIs). There is a large body of literature on database design and information integration, including data warehouses [Kimball 2002].
Implementing Domain-Driven Design [Vernon 2013] talks about Query Models in Chapter 4 in the section on CQRS. Endpoints that expose only RETRIEVAL OPERATIONS form the Query Model in CQRS.
 Pattern: STATE TRANSITION OPERATION
Pattern: STATE TRANSITION OPERATION
When and Why to Apply
A PROCESSING RESOURCE or an INFORMATION HOLDER RESOURCE exists in an API. Its functionality should be decomposed into multiple activities and entity-related operations, whose execution state should be visible in the API so that clients can advance it.
How can a client initiate a processing action that causes the provider-side application state to change?
For instance, functionality that is part of a longer-running business process might call for incremental updates of entities and coordination of application state transitions to move process instances from initiation to termination in a decentralized, stepwise fashion. The process behavior and interaction dynamics might have been specified in a use case model and/or set of related user stories. An analysis-level business process model or entity-centric state machine might have been specified as well.
How can API clients and API providers share the responsibilities required to execute and control business processes and their activities in a distributed approach to business process management?
In this process management context, frontend business process management (BPM) and BPM services can be distinguished:
How can API clients ask an API provider to take over certain functions that represent business activities of varying granularities, from atomic activities to subprocesses to entire processes, but still own the process state?
How can API clients initiate, control, and follow the asynchronous execution of remote business processes (including subprocesses and activities) exposed and owned by an API provider?
The process instances and the state ownership can lie with the API client (frontend BPM) or the API provider (BPM services), or they can be shared responsibilities.
A canonical example process from the insurance domain is claim processing, with activities such as initial validation of a received claim form, fraud check, additional customer correspondence, accept/reject decision, payment/settlement, and archiving. Instances of this process can live for days to months or even years. Process instance state has to be managed; some parts of the processing can run in parallel, whereas others have to be executed one by one sequentially. When dealing with such complex domain semantics, the control and data flow depends on a number of factors. Multiple systems and services may be involved along the way, each exposing one or more APIs. Other services and application frontends may act as API clients.
The following forces have to be resolved when representing business processes and their activities as API operations or, more generally speaking, when updating provider-side application state: service granularity; consistency; dependencies on state changes being made beforehand, which may collide with other state changes; workload management; and networking efficiency versus data parsimony. Time management and reliability also qualify as forces of this pattern; these design concerns are discussed in the pattern STATE CREATION OPERATION.
Service granularity: Large business services may contain complex and rich state information, updated only in a few transitions, while smaller ones may be simple but chatty in terms of their state transitions. It is not clear per se whether an entire business process, its subprocesses, or its individual activities should be exposed as operations of a PROCESSING RESOURCE. The data-oriented services provided by INFORMATION HOLDER RESOURCES also come in different granularities, from simple attribute lookups to complex queries and from single-attribute updates to bulk uploads of rich, comprehensive data sets.
Consistency and auditability: Process instances are often subject to audit; depending on the current process instance state, certain activities must not be performed. Some activities have to be completed in a certain time window because they require resources that have to be reserved and then allocated. When things go wrong, some activities might have to be undone to bring the process instance and backend resources (such as business objects and database entities) back into a consistent state.
Dependencies on state changes being made beforehand: State-changing API operations may collide with state changes already initiated by other system parts. Examples of such conflicting changes are system transactions triggered by other API clients, by external events in downstream systems, or by provider-internal batch jobs. Coordination and conflict resolution might be required.
Workload management: Some processing actions and business process activities may be computationally or memory intensive, run for a long time, or require interactions with other systems. High workload may affect the scalability of the provider and make it difficult to manage.
Networking efficiency versus data parsimony: One can reduce the message size (or the weight of the message payload) and only send the difference with regard to a previous state (an incremental approach). This tactic makes messages smaller; another option is to always send complete and consistent information, which leads to larger messages. The number of messages exchanged can be reduced by combining multiple updates into a single message.
One could decide to ban provider-side application state entirely. This is only realistic in trivial application scenarios such as pocket calculators (not requiring any storage) or simple translation services (working with static data). One could also decide to expose stateless operations and transfer state to and from the endpoint every time. The “Client Session State” pattern [Fowler 2002] describes the pros and cons of this approach (and the REST principle of “hypertext as the engine of application state” promotes it). It scales well but may introduce security threats with non-trusted clients and, if state is large, cause bandwidth problems. Client programming, testing, and maintenance become more flexible but also more complex and riskier. Auditability suffers; for instance, it is not clear how to guarantee that all execution flows are valid. In our order cancellation example, a valid flow would be “order goods → pay → deliver → return goods → receive refund,” whereas “order goods → deliver → refund” is an invalid, possibly fraudulent sequence.
How It Works
Introduce an operation in an API endpoint that combines client input and current state to trigger a provider-side state change sto: (in,S) -> (out,S'). Model the valid state transitions within the endpoint, which may be a PROCESSING RESOURCE or an INFORMATION HOLDER RESOURCE, and check the validity of incoming change requests and business activity requests at runtime.
Pair a “Command Message” with a “Document Message” [Hohpe 2003] to describe the input and the desired action/activity and receive an acknowledgment or result. In a business-process-like context, such as claims processing or order management, a STATE TRANSITION OPERATION may realize a single business activity in a process or even wrap the complete execution of an entire process instance on the provider side.
The basic principle is shown in Figure 5.24. The update() and replace() operations are entity-centric and primarily found in data-centric INFORMATION HOLDER RESOURCES; processActivity() operations are at home in action-oriented PROCESSING RESOURCES. Calls to such STATE TRANSITION OPERATIONS trigger one or more instances of the “Business Transaction” pattern described in Patterns of Enterprise Application Architecture [Fowler 2002]. When multiple STATE TRANSITION OPERATIONS are offered by a PROCESSING RESOURCE, the API hands out explicit control to the internal processing states so that the client may cancel the execution, track its progress, and influence its outcome.
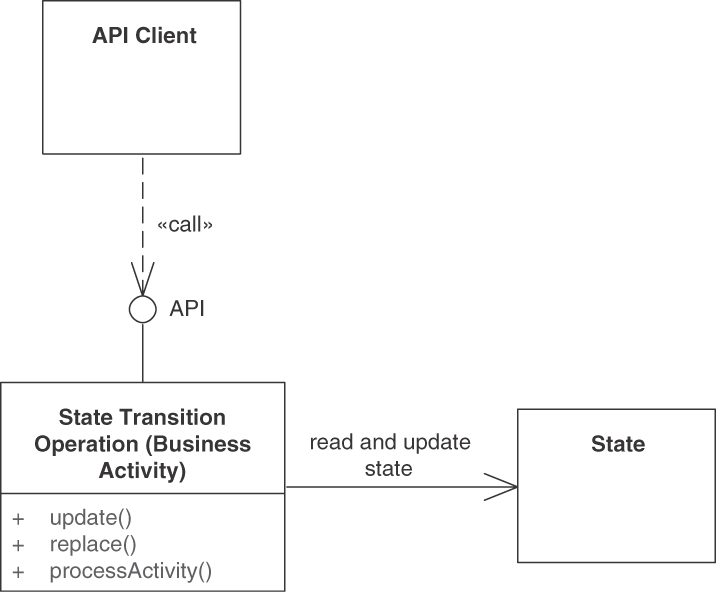
Figure 5.24 STATE TRANSITION OPERATIONS are stateful, both reading and writing provider-side storage
There are two quite different types of update, full overwrite (or state replacement) and partial change (or incremental update). Full overwrites often can be processed without accessing the current state and then can be seen as instances of STATE CREATION OPERATIONS. Incremental change typically requires read access to state (as described in this pattern). Upsert (update + insert) is a special case combining both themes: attempting to replace a nonexisting entity results in creating a new one (with the identifier provided in the request message) [Higginbotham 2019]. With HTTP-based APIs, full overwrite is typically exposed with the PUT method, while partial change can be achieved with PATCH.
From a message representation structure point of view, the request and response messages of STATE TRANSITION OPERATION instances can be fine-grained (in the simplest case, a single ATOMIC PARAMETER) as well as coarse-grained (nested PARAMETER TREES). Their request message representations vary greatly in their complexity.
Many STATE TRANSITION OPERATIONS are transactional internally. Operation execution should be governed and protected by a transaction boundary that is identical to the API operation boundary. While this should not be visible to the client on the technical level, it is okay to disclose it in the API documentation due to the consequences for composition. The transaction can either be a system transaction following the atomicity, consistency, isolation, and durability (ACID) paradigm [Zimmermann 2007] or a saga [Richardson 2018], roughly corresponding to compensation-based business transactions [Wikipedia 2022g]. If ACID is not an option, the BASE principles or try-cancel-confirm (TCC) [Pardon 2011] can be considered; a conscious decision between strict and eventual consistency [Fehling 2014] is required, and a locking strategy also has to be decided upon. The transaction boundaries have to be chosen consciously; long-running business transactions usually do not fit into a single database transaction with ACID properties.
The processing of the STATE TRANSITION OPERATION should appear to be idempotent, for instance, by preferring absolute updates over incremental ones. For example, “set value of x to y” is easier to process with consistent results than is “increase value of x by y,” which could lead to data corruption if the action request gets duplicated/resent. “Idempotent Receiver” in Enterprise Integration Patterns [Hohpe 2003] provides further advice.
It should be considered to add compliance controls and other security means such as ABAC, for instance, based on an API KEY or a stronger authentication token, to the entire API endpoint or individual STATE TRANSITION OPERATIONS. This may degrade performance caused by extra computations and data transfers.
Variant A Business Activity Processor is a variant of this pattern that can support frontend BPM scenarios and realize BPM services as well (Figure 5.25). Note that we use the term activity in a general sense here; activities might be rather fine-grained and participate in larger processes (for example, accept or reject claim or proceed to checkout in our sample scenarios) but might also be rather coarse grained (for instance, process claim or shop online).
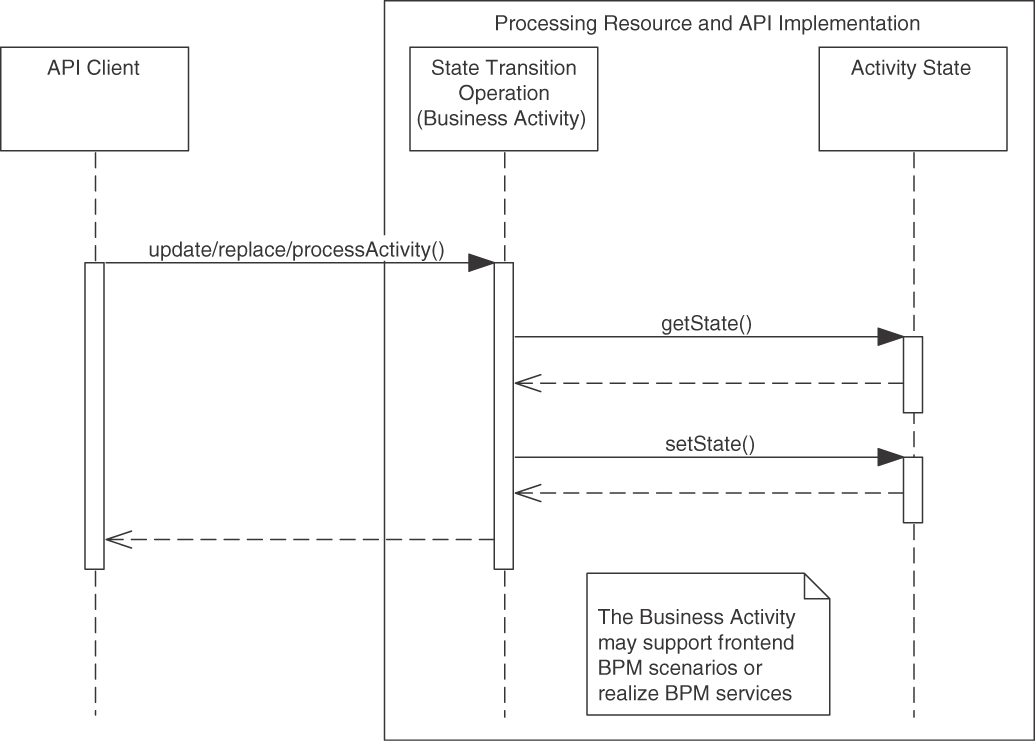
Figure 5.25 STATE TRANSITION OPERATION in a PROCESSING RESOURCE (here: Business Activity Processor variant)
Single activities can be responsible for any of the following fine-grained action primitives providing process control: prepare, start, suspend/resume, complete, fail, cancel, undo, restart, and cleanup. Given an asynchronous nature of the business activity execution and, in the frontend BPM case, client-side process ownership, it should also be possible to receive the following events via STATE TRANSITION OPERATIONS: activity finished, failed, or aborted; and state transition occurred.
Figure 5.26 assembles the action primitives and states into a generic state machine modeling the behavior of PROCESSING RESOURCES and their STATE TRANSITION OPERATIONS in the Business Activity Processor variant. Depending on the complexity of their behavior, instances of INFORMATION HOLDER RESOURCES can also be specified, implemented, tested, and documented this way.
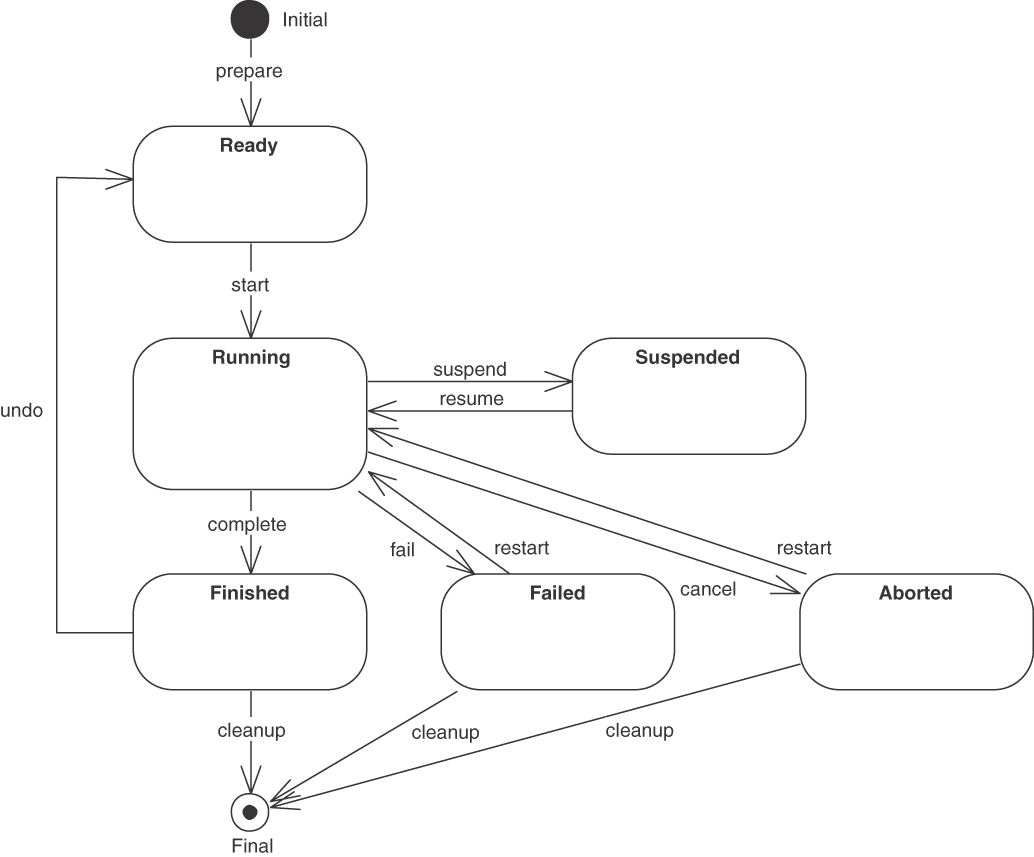
Figure 5.26 A state machine featuring common action primitives as transitions
Domain-specific API endpoints and their STATE TRANSITION OPERATIONS should refine and customize this generic state machine for their particular business scenario and API use cases; each required primitive becomes one API operation (or an option of a coarser-grained operation, selected by an ID ELEMENT parameter in the request message representation). API implementation, pre- and postconditions in the API documentation and test cases then can be organized according to the resulting API-specific state machine, which should be documented in the API DESCRIPTION.
The semantics of the states and state transitions in Figure 5.26 are as follows:
Prepare (or initialize): This primitive allows clients to prepare the execution of a state-changing activity by transferring the input prior to the actual activity, for instance, for validation purposes. Depending on the complexity of such information, an initialization may involve a single call or a more complex conversation. Once all information has been provided, the activity is “Ready” to start and an activity identifier is assigned. This primitive can be seen as an instance of the sibling pattern STATE CREATION OPERATION.
Start: This primitive allows clients to explicitly start the execution of an activity, which has been initialized and is ready to start. The state of the activity becomes “Running.”
Suspend/resume: These two primitives allow clients to pause and later continue the execution of a running activity. Suspending a running activity may free execution resources within the API endpoint.
Complete: This primitive transitions the activity state from “Running” to “Finished” to indicate that the activity ended successfully.
Fail: This activity transitions the state from “Running” to “Failed,” possibly explained in an ERROR REPORT.
Cancel: This primitive allows clients to interrupt the execution of the activity and “Abort” it in case they are no longer interested in its results.
Undo: This primitive allows compensating the actions performed by the activity, effectively reverting the state of the API endpoint back to its original one, before the activity was started. It may not always be possible to do so, especially when activities provoke side effects that impact the outside of the API provider. An example is an email that is sent and cannot be recalled. Note that we assume compensation can be done within the undo transition. In some cases, it may require to set up a separate activity (with its own state machine).
Restart: This primitive allows clients to retry the execution of a failed or aborted activity. The activity state goes back to “Running”.
Cleanup: This primitive removes any state associated with finished, failed, or aborted activities. The activity identifier is no longer valid and the activity state transitions to “Final.”
In frontend BPM, API clients own the process instance state. They may inform the API provider about the following two types of events (when exposing BPM services, such event notifications may travel in the other direction, from the service provider to its clients):
Activity finished, failed, or aborted: Once the execution of the activity completes, affected parties should be notified of its successful or failed completion so that they can retrieve its output. This may happen via a call to a STATE CREATION OPERATION pattern (in its Event Notification Operation variant). It may also be realized differently, for instance, via server-sent events or callbacks.
State transition occurred: For monitoring and tracking the progress of the activity, affected parties might want to learn about the current state of an activity and changes to it; they want to be notified when a state transition occurs. Realization options for this type of event, that follow a push model, include event streaming, server-sent events, and callbacks. Following a pull model, state lookups can be realized as instances of the RETRIEVAL OPERATION pattern.
Multiple STATE TRANSITION OPERATIONS, often located in the same API endpoint, can be composed to cover subprocesses or entire business processes. It has to be decided consciously where to compose: frontend BPM often uses a Web frontend as API client; BPM services yield composite PROCESSING RESOURCES exposing rather coarse-grained STATE TRANSITION OPERATIONS, effectively realizing the “Process Manager” pattern from [Hohpe 2003]. Other options are to (1) introduce an API Gateway [Richardson 2018] as a single integration and choreography coordination point or (2) choreograph services in a fully decentralized fashion via peer-to-peer calls and/or event transmission.
Executing these activities, STATE TRANSITION OPERATIONS change the business activity state in the API endpoint; the complexity of their pre- and postconditions as well as invariants varies, depending on the business and integration scenario at hand. Medium to high complexities of these rules are common in many application domains and scenarios. This behavior must be specified in the API DESCRIPTION; the transition primitives and state transitions should be made explicit in it.
When realizing the pattern and its Business Activity Processor variant in HTTP, suitable verbs (POST, PUT, PATCH, or DELETE) should be picked from the uniform REST interface options. Process instance and activity identifiers typically appear in the URI as an ID ELEMENT. This makes it easy to retrieve status information via HTTP GET. Each action primitive can be supported by a separate STATE TRANSITION OPERATION; alternatively, the primitive can be provided as an input parameter to a more general process management operation. In HTTP resource APIs, process identifier and primitive name often are transported as path parameters; the same holds for the activity identifier. LINK ELEMENTS and URIs then advance the activity state and inform affected parties about subsequent and alternative activities, compensation opportunities, and so on.
Example
The activity “proceed to checkout and pay” in an online shop illustrates the pattern in an order management process. “Add item to shopping basket” is an activity in the “product catalog browsing” subprocess. These operations do change provider-side state, they do convey business semantics, and they do have nontrivial pre- and postconditions as well as invariants (for instance, “do not deliver the goods and invoice the customer before the customer has checked out and confirmed the order”). Some of these might be long running too, thus requiring fine-grained activity status control and transfer.
The following example from the Lakeside Mutual case, shown in Figure 5.27, illustrates the two extremes of activity granularity. Offers are created in a single-step operation; claims are managed step by step, causing incremental state transitions on the provider side. Some of the primitives from Figure 5.26 can be assigned to STATE TRANSITION OPERATIONS in the example; for instance, createClaim() corresponds to the start primitive, and closeClaim() completes the business activity of claim checking. The fraud check might be long running, which indicates that the API should support the suspend and resume primitives in the corresponding STATE TRANSITION OPERATIONS of the PROCESSING RESOURCE for claims management.
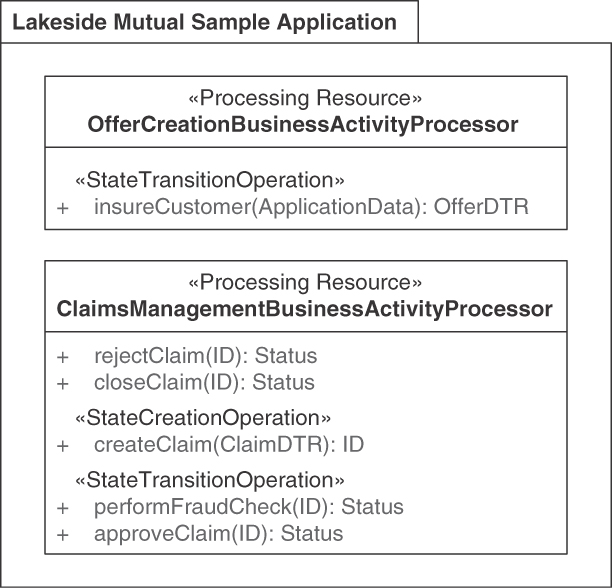
Figure 5.27 Two examples of STATE TRANSITION OPERATIONS: Coarse-grained BPM service and fine-grained frontend BPM process execution
Discussion
The design forces are resolved as follows:
Service granularity: PROCESSING RESOURCES and their STATE TRANSITION OPERATIONS can accommodate both smaller and larger “service cuts” [Gysel 2016] and therefore promote agility and flexibility. INFORMATION HOLDER RESOURCES come in different sizes too. The impact of the endpoint sizing decisions on coupling and other qualities was discussed previously in these two patterns. The fact that such states are explicitly modeled as part of the API DESCRIPTION makes it possible to track them in the first place.
Consistency and auditability: STATE TRANSITION OPERATIONS can and must handle business and system transaction management internally in the API implementation; the chosen design options, discussed previously, and their realization determine whether the pattern instance is able to resolve these forces and meet its requirements. Similarly, API implementation-internal logging and monitoring support auditability.
Dependencies on state changes made beforehand: State changes may collide with each other. The API providers should check the validity of a requested state transition, and clients should expect that their state transition requests might be denied due to their out-of-date assumptions about the current state.
Workload management: Stateful STATE TRANSITION OPERATIONS cannot scale easily, and endpoints featuring such operations cannot be relocated to other compute nodes (hosting servers) seamlessly. This is particularly relevant when deploying to clouds because cloud features such as elasticity and autoscaling can be leveraged only if the deployed application is designed for them. Managing process instance state is delicate by design; its intricacies do not necessarily suggest that it is easy to feel at home in a cloud.8
8. Serverless cloud functions, for instance, seem to be better suited for other usage scenarios.
Networking efficiency versus data parsimony: A RESTful API design of frontend BPM and BPM services can use state transfers from clients to providers and resource designs to come up with a suitable balance between expressiveness and efficiency. The choice between incremental updates (small, nonidempotent messages) or replacement updates (larger but idempotent messages) influences the message sizes and exchange frequency.
Idempotence is good for fault resiliency and scalability, as mentioned earlier. While the concept is easy to understand in textbooks and basic examples, it is often not clear how to achieve idempotence in more complex real-world scenarios—nor is it an easy task. For instance, a recommendation to send a “new value is n” message rather than “value of x has increased by one” is easy to give and take, but the picture gets more complex in advanced business scenarios such as order management and payment processing in which multiple related implementation-level entities are modified by a single API call. The concept is covered in depth in Cloud Computing Patterns [Fehling 2014] and Enterprise Integration Patterns [Hohpe 2003].
When STATE TRANSITION OPERATIONS are exposed in PUBLIC APIS or COMMUNITY APIS, they typically must be protected against security threats. For instance, some actions and activities may require authorization so that only certain authenticated clients can trigger state transitions; furthermore, the validity of state transitions might depend on the message content as well. A deeper discussion of security requirements and designs responding to them is out of scope here.
Performance and scalability are primarily driven by the technical complexity of the API operation. The amount of backend processing required in API implementations, concurrent access to shared data, and the resulting IT infrastructure workload (remote connections, computations, disk I/O, CPU energy consumption) differ widely in practice. From a reliability point of view, single points of failure should be avoided, and a centralized approach to process management in the API implementation may turn into one.
Related Patterns
The pattern differs from its siblings as follows: A COMPUTATION FUNCTION does not touch the provider-side application state (read or write) at all; a STATE CREATION OPERATION only writes to it (in append mode). Instances of RETRIEVAL OPERATION read but do not write to it; STATE TRANSITION OPERATION instances both read and write the provider-side state. RETRIEVAL OPERATION pulls information from the provider; STATE CREATION OPERATIONS push updates to the provider. STATE TRANSITION OPERATIONS may push and/or pull. A STATE TRANSITION OPERATION may refer to a provider-side state element in its request message (for instance, an order id or a serial number of a staff member); STATE CREATION OPERATIONS usually do not do this (except for technical reasons such as preventing usage of duplicate keys or updating audit logs). They often return ID ELEMENTS for later access.
STATE TRANSITION OPERATIONS can be seen to trigger and/or realize “Business Transactions” [Fowler 2002]. Instances of this pattern may participate in long-running and therefore stateful conversations [Hohpe 2007]. If this is done, context information necessary for logging and debugging often has to be propagated—for instance, by introducing an explicit CONTEXT REPRESENTATION. STATE TRANSITION OPERATIONS can use and go along with one or more of the RESTful conversation patterns from “A Pattern Language for RESTful Conversations” [Pautasso 2016].
For instance, one may want to consider factoring out the state management and the computation parts of a process activity into separate services. Conversation patterns or choreographies and/or orchestrations may then define the valid combinations and execution sequences of these services.
STATE TRANSITION OPERATIONS are often exposed in COMMUNITY APIS; Chapter 10, “Real-World Pattern Stories,” features such a case in depth. Services-based systems expose such operations in SOLUTION-INTERNAL APIS as well. An API KEY typically protects external access to operations that write to the provider-side state, and a SERVICE LEVEL AGREEMENT may govern their usage.
More Information
There is a large body of literature on BPM(N) and workflow management that introduces concepts and technologies to implement stateful service components in general and STATE TRANSITION OPERATIONS in particular (for instance, [Leymann 2000; Leymann 2002; Bellido 2013; Gambi 2013]).
In RDD [Wirfs-Brock 2002], STATE TRANSITION OPERATIONS correspond to “Coordinators” and “Controllers” that are encapsulated as “Service Providers” made accessible remotely with the help of an “Interfacer.” Michael Nygard suggests many patterns and recipes that improve reliability in Release It! [Nygard 2018a].
The seven-step service design method in DPR suggests calling out endpoint roles and operation responsibilities such as STATE TRANSITION OPERATION when preparing candidate endpoint lists and refining them [Zimmermann 2021b].
 Pattern: COMPUTATION FUNCTION
Pattern: COMPUTATION FUNCTION
When and Why to Apply
The requirements for an application indicate that something has to be calculated. The result of this calculation exclusively depends on its input. While the input is available in the same place that requires the result, the calculation should not be run there—for instance, for cost, efficiency, workload, trust, or expertise reasons.
An API client, for example, might want to ask the API endpoint provider whether some data meets certain conditions or might want to convert it from one format to another.
How can a client invoke side-effect-free remote processing on the provider side to have a result calculated from its input?
Reproducibility and trust: Outsourcing work to a remote party causes a loss of control, which makes it harder to guarantee that the results are valid. Can the client trust the provider to perform the calculation correctly? Is it always available when needed, and is there a chance that it might be withdrawn in the future? Local calls can be logged and reproduced rather easily. While this is possible over remote connections too, more coordination is required, and an additional type of failure may happen when debugging and reproducing remote executions.9
9. These observations hold when shifting calculations from a client to an API provider in a PROCESSING RESOURCE but also when outsourcing data management to an INFORMATION HOLDER RESOURCE.
Performance: Local calls within a program are fast. Remote calls between system parts incur delays due to network latency, message serialization and deserialization, as well as the time required to transfer the input and output data, which depends on the message sizes and the available network bandwidth.
Workload management: Some computations might require many resources, such as CPU time and main memory (RAM), which may be insufficient on the client side. Some calculations may run for a long time due to their computational complexity or the large amount of input to be processed. This may affect the scalability of the provider and its ability to meet the SERVICE LEVEL AGREEMENT.
One could perform the required calculation locally, but this might require processing large amounts of data, which in turn might slow down clients that lack the necessary CPU/RAM capacity. Eventually, such a nondistributed approach leads to a monolithic architecture, which will require reinstalling clients every time the calculation has to be updated.
How It Works
Introduce an API operation cf with cf: in -> out to the API endpoint, which often is a PROCESSING RESOURCE. Let this COMPUTATION FUNCTION validate the received request message, perform the desired function cf, and return its result in the response.
A COMPUTATION FUNCTION neither accesses nor changes the server-side application state, as shown in Figure 5.28.
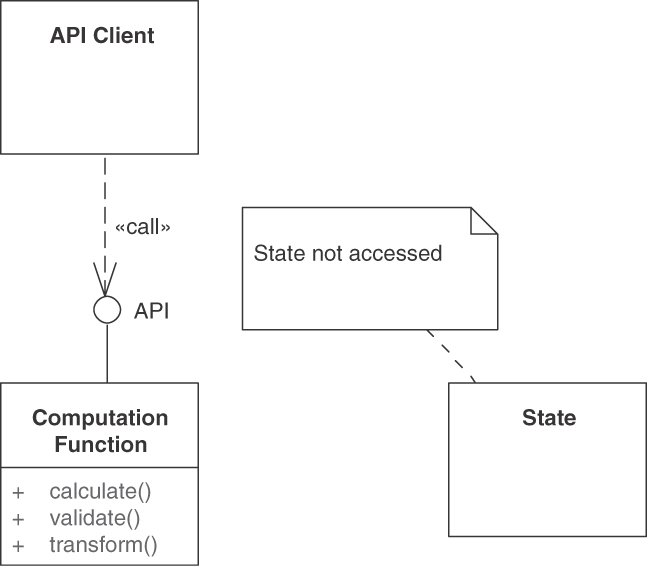
Figure 5.28 A COMPUTATION FUNCTION is stateless, neither reading nor writing to provider-side storage
Design request and response message structures that fit the purpose of the COMPUTATION FUNCTION. Include the COMPUTATION FUNCTION in the API DESCRIPTION (in the context of the endpoint it is added to). Define at least one explicit precondition that references the elements in the request message and one or more postconditions that specify what the response message contains. Explain how this data should be interpreted.
There is no need to introduce transaction management in the API implementation because a mere COMPUTATION FUNCTION is stateless by definition.
Variants The general, rather simple COMPUTATION FUNCTION pattern has several variants, Transformation Service and Validation Service as well as Long Running Computation (which is more challenging technically than the general case). Each variant requires different request/response message representations.
A Transformation Service implements one or more of the message translation patterns from Enterprise Integration Patterns [Hohpe 2003] in a network-accessible form. A Transformation Service does not change the meaning of the data that it processed, but alters its representation. It might convert from one representation structure to another format (for example, customer record schemas used in two different subsystems) or from one notation to another (for example, XML to JSON, JSON to CSV). Transformation Services typically accept and return PARAMETER TREES of varying complexity.
Validation Service is also known as (Pre-)Condition Checker. To deal with potentially incorrect input, the API provider should always validate it before processing it and make it explicit in its contract that the input may be rejected. It may be useful for clients to be able to test their input validity explicitly and independently from the invocation of the function for processing it. The API thus breaks down into a pair of two operations, a Validation Service and another COMPUTATION FUNCTION:
An operation to validate the input without performing the computation
An operation to perform the computation (which may fail due to invalid input unless this input has been validated before)
The Validation Service solves the following problem:
How can an API provider check the correctness/accuracy of incoming data transfer representations (parameters) and provider-side resources (and their state)?
The solution to this problem is to introduce an API operation that receives a DATA ELEMENT of any structure and complexity and returns an ATOMIC PARAMETER (for example, a Boolean value or integer) that represents the validation result. The validation primarily pertains to the payload of the request. If the API implementation consults the current internal state during the validation, the Validation Service becomes a variant of a RETRIEVAL OPERATION (for instance, to look up certain values and calculation rules), as shown in Figure 5.29.

Figure 5.29 Validation Service variant: Arbitrary request data, Boolean response (DTR: data transfer representation)
Two exemplary requests are “Is this a valid insurance claim?” and “Will you be able to accept this purchase order?” invoked prior to a call to a STATE TRANSITION OPERATION in our sample scenarios. In case of such “pre-activity validation,” the parameter types can be complex (depending on the activity to be prevalidated); the response might contain suggestions on how to correct any errors that were reported.
There are many other types of conditions and items worth validating, ranging from classifications and categorizations such as isValidOrder(orderDTR) and status checks such as isOrderClosed(orderId) to complex compliance checks such as has4EyesPrinicipleBeenApplied(...). Such validations typically return rather simple results (such as a success indicator and possibly some additional explanations); they are stateless and operate on the received request data exclusively, which makes them easy to scale and move from one deployment node to another.
The third variant is Long Running Computation. A simple function operation may be sufficient under the following assumptions:
The input representation is expected to be correct.
The expected function execution time is short.
The server has enough CPU processing capacity for the expected peak workload.
However, sometimes the processing will take a noticeable amount of time, and sometimes it cannot be assured that the processing time of a computation will be short enough (for instance, due to unpredictable workload or resource availability on the API provider side or due to varying sizes of input data sent by the client). In such cases, clients should be provided some form of asynchronous, nonblocking invocation of a processing function. A more refined design is needed for such Long Running Computations, which may receive invalid input and may require investing a significant amount of CPU time to execute.
There are different ways of implementing this pattern variant:
Call over asynchronous messaging. The client sends its input via a request message queue, and the API provider puts the output on a response message queue [Hohpe 2003].
Call followed by callback. The input is sent via a first call, and the result is sent via a callback, which assumes that clients support callbacks [Voelter 2004].
Long-running request. The input is posted, and a LINK ELEMENT informs where the progress can be polled via RETRIEVAL OPERATIONS. Eventually, the result is published at its own INFORMATION HOLDER RESOURCE—there is an optional but useful opportunity to use the link to cancel the request and clean up the result when no longer needed (such stateful request processing is further detailed in the Business Activity Processor variant of the STATE TRANSITION OPERATION pattern). This implementation option is often chosen in Web APIs [Pautasso 2016].
Examples
A simple, rather self-explanatory example of a Transformation Service is shown in Figure 5.30.
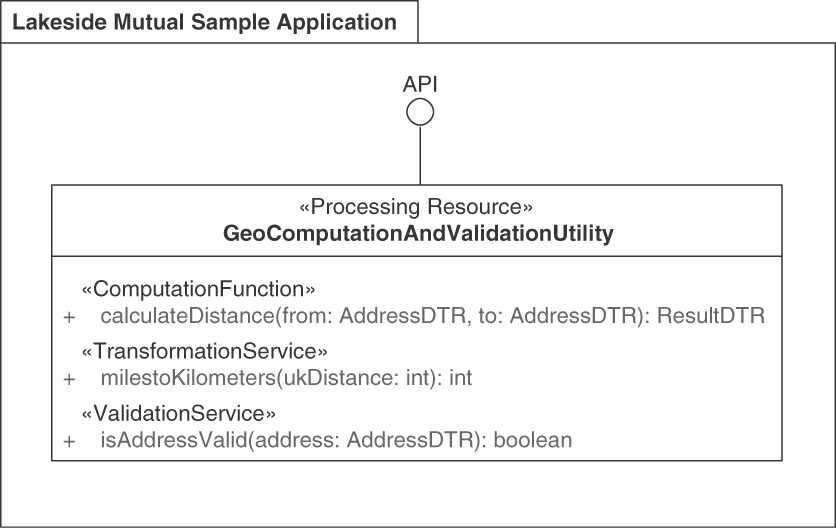
Figure 5.30 A PROCESSING RESOURCE providing Transformation Services
An operation to find out about the health of a service is called heartbeat. Such a test message is an example of a simple command exposed remotely within a PROCESSING RESOURCE endpoint (see Figure 5.31).
Figure 5.31 Examples of Validation Services: Health check operations
“I am alive” operations, sometimes called “application-level ping,” accept and respond to test messages. They are often added to mission-critical API implementations as part of a systems management strategy (here, fault and performance management). Its pre- and postconditions are simple; its API contract is sketched in the preceding UML snippet.
Neither system transactions nor business-level compensation (undo) are required in these simple examples of the pattern and its variants.
Discussion
Reproducibility and trust suffer because an external dependency is introduced that cannot be controlled by the client; it has to trust the provider that multiple subsequent calls will be answered coherently. The decision to outsource functionality must be compliant with legislation and inhouse policies, for instance, those about data protection and software licensing.
Performance is negatively impacted due to the network latency. Message sizes might increase because stateless servers cannot retrieve any intermediate results from their own data stores. Still, it may also occur that for the given computation, the performance penalty due to the network may be compensated by the faster computation time on the provider side and thus make it worthwhile to offload the computation from the client. If exposing a transformation or validation operation as a remote service is too costly, a local library-based API is a cheaper alternative.
Caching makes sense only under certain conditions. More than one client has to request the same computation over the same input, and the result has to be deterministic. Furthermore, the provider must have enough storage capacity. Only then may it be worthwhile to invest in caching results so that they can be shared across multiple clients.
From a security point of view, the protection needs of the request and response messages depend on the sensitivity of the message content. For example, the response message of a Validation Service might have low protection needs if the result alone is hard to interpret without its invocation context. DoS attacks are a threat for all remote API operations; suitable countermeasures and risk management are required.
Workload management is simplified because stateless operations can be moved freely. By definition, implementations of the pattern do not change application state on the provider side (possibly except for access logs and temporary or permanent storage of validation results, if/as needed to meet security requirements such as non-repudiation). They are therefore easy to scale and move, which makes them eligible to cloud deployments.
Maintenance of the COMPUTATION FUNCTION implementation is separated from client updates, as long as the COMPUTATION FUNCTION interface does not change. If the API implementation is deployed to a cloud, the cost of renting the cloud service offering has to be taken into account.
If the computation is resource-intense (CPU, RAM), algorithm and distribution design might have to be rethought to avoid bottlenecks and single points of failure. The conversation pattern “Long-Running Request” [Pautasso 2016] covers this topic. While not directly observable in the functional API contract, this is critical for the API design because it may affect the ability to meet the SERVICE LEVEL AGREEMENT for the API. CPU and RAM workload also affect the components implementing the API; it becomes more challenging to scale the function implementation. Caching computation results and computing some results before they are even requested (anticipating what clients want based on what they requested previously) are two performance and workload management tactics eligible here.
Related Patterns
The “Service” pattern in DDD covers similar semantics (but is broader and targets the business logic layer of an application). It can help identify Computation Function candidates during endpoint identification [Vernon 2013].
Serverless computing lambdas, deployed to public clouds such as AWS or Azure, may be seen as COMPUTATION FUNCTIONS unless they are backed by cloud storage offerings, which makes them stateful.
More Information
Service types are a topic covered by SOA literature from the early 2000s, such as Enterprise SOA [Krafzig 2004] and SOA in Practice [Josuttis 2007]. While the service type taxonomies in these books are more focused on the overall architecture, some of the basic services and utility services have responsibilities that do not require read or write access to provider/server state and therefore qualify as instances of this pattern and its variants.
The design-by-contract approach in the object-oriented programming method and language Eiffel [Meyer 1997] includes validation into the codification of business commands and domain methods and automates pre- and postcondition checking. This program-internal approach can be seen as an alternative to external Validation Services (but also as a rather advanced known use of it).
A lot of online resources on serverless computing exist. One starting point is Jeremy Daly’s Web site and blog Serverless [Daly 2021].
Summary
This chapter presented patterns that address API architectural concerns. We specified endpoint roles and operation responsibilities in the early steps of an API design such as those in the Define phase of the ADDR process.
The roles and responsibilities help clarify the architectural significance of these API design elements and serve as input to the following phases. Chapter 3, “API Decision Narratives,” covered the questions, options, and criteria eligible when designing endpoints and operations in a role- and responsibility-driven way; complementary to that discussion, this chapter provided the full pattern texts.
Following the pattern template introduced in Chapter 4, we covered data-oriented API endpoint roles:
One specific kind of INFORMATION HOLDER RESOURCE is DATA TRANSFER RESOURCE, eligible when multiple clients want to share information without becoming coupled with each other directly.
Other kinds that differ in terms of their lifetime, relations, and changeability are MASTER DATA HOLDER, OPERATIONAL DATA HOLDER, and REFERENCE DATA HOLDER. Master data is changeable, lives long, and has many incoming references. Operational data is short-lived and can be changed by clients as well. Reference data also lives long and is immutable.
A LINK LOOKUP RESOURCE can decouple API clients and API provider further (in terms of endpoint references in request and response message payload).
We modeled activity-oriented API endpoints as stateless or stateful PROCESSING RESOURCES. A Business Activity Processor is an important variant of PROCESSING RESOURCE, supporting two scenarios, frontend BPM and BPM services.
The runtime concerns of INFORMATION HOLDER RESOURCES and PROCESSING RESOURCES are different, and the architectural significance of a mere lookup often is different from that of a data transfer. Such considerations provide good reasons to call out these endpoint roles and the operation responsibilities and possibly to separate them by introducing multiple endpoints. These role-driven endpoints are designed and then operated differently at runtime. For instance, a dedicated MASTER DATA HOLDER management policy regarding data retention and protection might differ from the data management rules employed for PROCESSING RESOURCES that work with transient, short-lived data only.
We used the following role stereotypes from RDD [Wirfs-Brock 2002]: information holder (for data-oriented endpoints) and controller/coordinator (as roles taken by our PROCESSING RESOURCE pattern). Both endpoint patterns also qualify as inter-facer and service provider.
Data-oriented holder resources and activity-oriented processors also have different characteristics in terms of their semantics, structure, quality, and evolution. For example, while an API may offer access to several individual data stores separately, clients may want to perform activities touching multiple backend/implementation resources in a single request. The API may therefore include a dedicated PROCESSING RESOURCE, playing the role of an RDD controller operating on top of (and/or processing data from) multiple, fine-grained INFORMATION HOLDER RESOURCES.10
10. The RESTful Web Services Cookbook mentions such controller resources explicitly [Allamaraju 2010].
We defined four types of operation responsibilities for endpoint resources. The four operation responsibilities differ in the way they read and write provider-side application state, as shown in Table 5.1.
Table 5.1 Operation Impact on State by Responsibility Pattern
| No Read | Read |
|---|---|---|
No Write | COMPUTATION FUNCTION | RETRIEVAL OPERATION |
Write | STATE CREATION OPERATION | STATE TRANSITION OPERATION |
The patterns in this section compare to each other as follows:
Just like a RETRIEVAL OPERATION, a COMPUTATION FUNCTION does not change the application state (but delivers nontrivial data to the client); it receives all required input from the client, whereas a RETRIEVAL OPERATION consults provider-side application state (in read-only mode).
Both STATE CREATION OPERATIONS instances and COMPUTATION FUNCTIONS receive all required data from the client; a STATE CREATION OPERATION changes the provider-side application state (write access), whereas a COMPUTATION FUNCTION preserves it (no access).
A STATE TRANSITION OPERATION also returns nontrivial data (like RETRIEVAL OPERATION and COMPUTATION FUNCTION), but it also changes the provider-side application state. Input comes from the client but also from the provider-side application state (read-write access).
Many COMPUTATION FUNCTIONS and STATE CREATION OPERATIONS can be designed to be idempotent. This also holds for most instances of RETRIEVAL OPERATIONS; some of these may be more difficult to make idempotent (for example, those using advanced caches or an implementation of the PAGINATION pattern using “Server Session State” [Fowler 2002]; note that this usually is not recommended for this reason). Some types of STATE TRANSITION OPERATIONS cause inherent state changes, for instance, when calls to the operations contribute to managing business process instances; idempotence is not always achievable in such cases. For instance, starting an activity is not idempotent if every start request may initiate a separate concurrent activity instance. Canceling a particular started activity instance, by contrast, is idempotent.
All operations, whether they realize any of the patterns presented in this chapter or not, communicate via request and response messages whose structure often is a PARAMETER TREE (a pattern from Chapter 4). The header and payload content of these messages can be designed—and then progressively improved to achieve certain qualities—with the help of the patterns in Chapters 6 and 7. Endpoints and entire APIs are usually versioned, and clients expect a lifetime and support guarantee for them (as discussed in Chapter 8). These guarantees and the versioning policy may differ by endpoint role; for instance, instances of the MASTER DATA HOLDER pattern live longer and change less frequently than OPERATIONAL DATA HOLDER instances (not only in terms of content and state, but also in terms of API and data definitions).
The roles and responsibilities of endpoints and their operations should be documented. They impact the business aspects of APIs (patterns in Chapter 9, “Document and Communicate API Contracts”): the API DESCRIPTION should specify when an API can be called and what the client can expect to be returned (assuming that a response is sent).
Software Systems Architecture: Working with Stakeholders Using Viewpoints and Perspectives [Rozanski 2005] has an information viewpoint. “Data on the Outside versus Data on the Inside” [Helland 2005] explains design forces and constraints for data exposed in APIs and application-internal data. While not specific to APIs and service-oriented systems, Release It! captures a number of patterns that promote stability (including reliability and manageability). Examples include “Circuit Breaker” and “Bulkhead” [Nygard 2018a]. Site Reliability Engineering [Beyer 2016] reports how Google runs production systems.
Next up are the responsibilities of message representations elements—and their structure (Chapter 6, “Design Request and Response Message Representations”).