
Chapter 17
Provision Azure SQL Database
This chapter delves into Azure SQL Database, a cloud database service that provides SQL Server relational Database Engine. Azure SQL Database is a platform as a service (PaaS) offering designed for cloud applications to take advantage of relational database services, without most of the overhead of managing the Database Engine. Azure SQL Database is also designed to meet various requirements, from hosting a single database associated with an organization’s line-of-business application to hosting thousands of databases for a global software as a service (SaaS) offering. This chapter looks at Azure SQL Database concepts and how to provision and manage databases.
 For an overview of cloud concepts and an introduction to the different SQL Server offerings in Microsoft Azure, see Chapter 16, “Design and implement hybrid and Azure database infrastructure.” Azure SQL Managed Instance is covered in Chapter 18, “Provision Azure SQL Managed Instance.”
For an overview of cloud concepts and an introduction to the different SQL Server offerings in Microsoft Azure, see Chapter 16, “Design and implement hybrid and Azure database infrastructure.” Azure SQL Managed Instance is covered in Chapter 18, “Provision Azure SQL Managed Instance.”
In this chapter, you’ll learn how to create your first server and database, with thorough coverage of the available options and why each one matters. Next, this chapter explains how to create and manage elastic pools.
Security must be on your checklist when deploying any database, and perhaps even more so in the cloud. This chapter includes coverage of the security features specific only to Azure SQL Database. Finally, this chapter reviews features designed to prepare your cloud-hosted database for disaster recovery.
- For security features common to SQL Server, refer to Chapter 12, “Administer instance and database security and permissions,” and Chapter 13, “Protect data through classification, encryption, and auditing.”
Throughout this chapter, you will find many PowerShell samples to complete tasks. This is important because the flexibility of cloud computing offers quick setup and teardown of resources. Automation through scripting becomes a must-have skill—unless you prefer to work overtime in the web GUI.
- If you need an introduction to PowerShell 7, we discussed it in the previous chapter. Also refer to https://github.com/PowerShell/PowerShell/tree/master/docs/learning-powershell.
The scripts for this book are all available for download at https://www.MicrosoftPressStore.com/SQLServer2022InsideOut/downloads.
Provision an Azure SQL Database logical server
The Azure SQL Database service introduces a concept called an Azure SQL logical server (note the lowercase server). This server is quite different from what you might be used to on-premises. A logical server is best described as a connection endpoint rather than an instance. For example, the Azure SQL logical server (just called logical server or just server from here on) does not provide compute or storage resources. It does not provide much configuration. And although there is a virtual master database, there is no model, tempdb, or msdb database—those are abstracted away. In addition to missing several features of an on-premises SQL Server, there are also features that are unique to logical SQL servers: firewall configuration and elastic pools to name just two.
- You can find more information about firewall configuration later in this chapter. We covered elastic pools in Chapter 16.
You should consider that your server determines the geographic region where your data will be stored. When a single logical server hosts multiple databases, these databases are collocated in the same Azure region, but they might not be hosted on the same hardware. That is of no consequence to you when using the databases, but the point serves to illustrate the purely logical nature of logical servers.
Creating a logical server is the first step in the process of deploying a database. The logical server determines the region that will host the database(s), provides the basis for access control and security configuration (more on that later), and provides the fully qualified domain name (FQDN) of the endpoint.
Note
Using the Azure portal, it is possible to provision a new logical server while creating a new database. All other methods require two separate steps or commands, so for consistency, we will discuss each separately in this chapter. This will allow the focus to remain on each distinct element (server and database) of your provisioning process.
You might be interested to know that provisioning a logical server does not incur usage charges. Azure SQL Database is billed based on the resources assigned to each database or elastic pool. The logical server acts only as a logical container for databases and provides the connection endpoint. This is also why there are no performance or sizing specifications attached to a logical server.
Create an Azure SQL Database server using the Azure portal
To provision a server using the Azure portal, use the search feature to find SQL Database and then use the Create SQL Database Server page. You must provide the following information to create a server:
Subscription. The subscription in which you create the server determines which Azure account will be associated with databases on this server. Database usage charges are billed to the subscription.
Resource group. The resource group where this server will reside. Review the section “Azure governance” in Chapter 16 to learn about the importance of resource groups.
Server name. The logical server name becomes the DNS name of the server. The domain name is fixed to database.windows.net. This means your logical server name must be globally unique and lowercase. There are also restrictions as to which characters are allowed, though these restrictions are comparable to on-premises server names.
Location. The Azure region where any databases are physically located. Azure SQL Database is available in most regions worldwide. You should carefully consider the placement of your servers and, by consequence, your databases. Your data should be in the same region as the compute resources (Azure Web Apps, for example) that will read and write the data. When you locate the applications that connect to the server in the same region, you can expect latency in the order of single-digit milliseconds. Another consequence of locating resources in other regions is that you might end up paying per gigabyte for the egress from the region where the data is located. Not all services incur these charges, but you must be aware before going this route.
Authentication method. You have the option to use only SQL Authentication, only Azure AD Authentication, or both SQL and Azure AD Authentication.
Server admin login. This username is best compared to the
saaccount in a SQL Server. However, you cannot usesaor other common SQL Server identifiers for this username; they are reserved for internal purposes. You should choose a generic name rather than one derived from your name because you cannot change the server admin login later.Password. The password associated with the server admin login. It is required only when you choose to use SQL Authentication. The admin password should be very strong and carefully guarded—ideally stored in Microsoft Azure Key Vault. Unlike the login itself, Azure users with specific roles can change it.
Azure AD Admin. If you choose to use Azure AD Authentication on the logical server, you must specify an Azure AD user or group as the Azure AD Admin.
- You can read more about applying role-based access control (RBAC) to your Azure SQL Database resources later in this chapter.
When you create a new SQL Database logical server using the Azure portal, you can enable the new server’s firewall to accept connections from all Azure resources. Before deploying any databases, we recommend that you either use a virtual network (VNet) service endpoint or configure the firewall to only allow connections from known IP addresses, as described in Chapter 16.
- You can read more about the firewall in the section “Server- and database-level firewall” later in this chapter.
Another decision you’ll make at the server level is whether to enable Microsoft Defender for SQL, which is covered later in this chapter.
As with all Azure resources, you can add tags to the Azure SQL logical server resource, as well as the databases, SQL elastic pools, storage accounts, and so on. Tags are name-value pairs that enable you to categorize and view resources for billing or administrative purposes. Tags are highly recommended for your own enterprise organization, and they can also be used in reporting. Most commonly, you’ll want to add a “Created By” tag, so that others in your environment know who created the resource.
There are other settings you might want to configure when you create a server, but they are found on the resource page after the server has been provisioned. For example, you can choose to use a service-managed key or a customer-managed key for transparent data encryption (TDE). You might also want to enable the system-assigned managed identity (SMI), which is useful for allowing the server to access other resources such as an Azure Key Vault. You can also create user-assigned managed identities (UMIs). These options are all covered later in this chapter.
Create a server using PowerShell
To provision a server using PowerShell, use the New-AzSqlServer cmdlet, as demonstrated in the following code example. You must modify the values of the variables in lines 1 through 6 to fit your needs. These commands assume the following objects already exist:
A resource group with the name
SSIO2022An Azure Key Vault with a secret named
SQLAdminPwd
The server will be created in the active Azure tenant and subscription, so be sure to set your context appropriately before creating your server.
$resourceGroupName = "SSIO2022"
$location = "southcentralus"
$serverName = "ssio2022"
$adminSqlLogin = "SQLAdmin"
$adminSqlSecret = Get-AzKeyVaultSecret -VaultName 'SSIO-KV' -Name 'SQLAdminPwd'
$cred = $(New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList
$adminSqlLogin, $($adminSqlSecret.SecretValue) )
$tags = @{"CreatedBy"="Kirby"; "Environment"="Dev"}
New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Location $location `
-SqlAdministratorCredentials $cred `
-AssignIdentity `
-IdentityType "SystemAssigned" `
-Tags $tagsThe New-AzSqlServer PowerShell cmdlet allows you to create managed identities, specify the key to be used for TDE, specify the minimum TLS version, and disable public network access while provisioning the server.
The preceding script creates a server with the (SQL Authentication) server administrator specified. You might also want to specify the Azure AD admin as well.
In this script, the Get-AzKeyVaultSecret cmdlet is used to obtain the password for the SQLAdmin server administrator. This cmdlet retrieves the secret object from the key vault. Then the secret value is used to create a PowerShell credential object. The secret value is a secure string, so the plain text password is never exposed by the script. All values needed to create a server are provided as parameters to the New-AzSqlServer cmdlet. The script also creates a system-assigned managed identity for the server.
Note
All the sample Azure PowerShell scripts throughout this chapter build on the existence of an Azure SQL Database logical server named ssio2022 in a resource group named SSIO2022. You must choose your own server name because it must be globally unique. The sample scripts available for download are all cumulative and define the value just once, which makes it easy to make a single modification and run all the sample scripts.
Establish a connection to your server
With a server created, you can establish a connection. Azure SQL Database supports only one protocol for connections: TCP. In addition, you have no control over the TCP port number; it is always 1433.
Note
Some corporate networks might block connections to Internet IP addresses with a destination port of 1433. If you have trouble connecting, check with your network administrators.
Figure 17-1 shows the different values entered in the Connect to Server dialog box after you use SQL Server Management Studio (SSMS) to connect to the newly created server. When you first establish the connection, SSMS prompts you to create a firewall rule to allow this connection (see Figure 17-2). You must sign in with your Azure account to create the firewall rule.
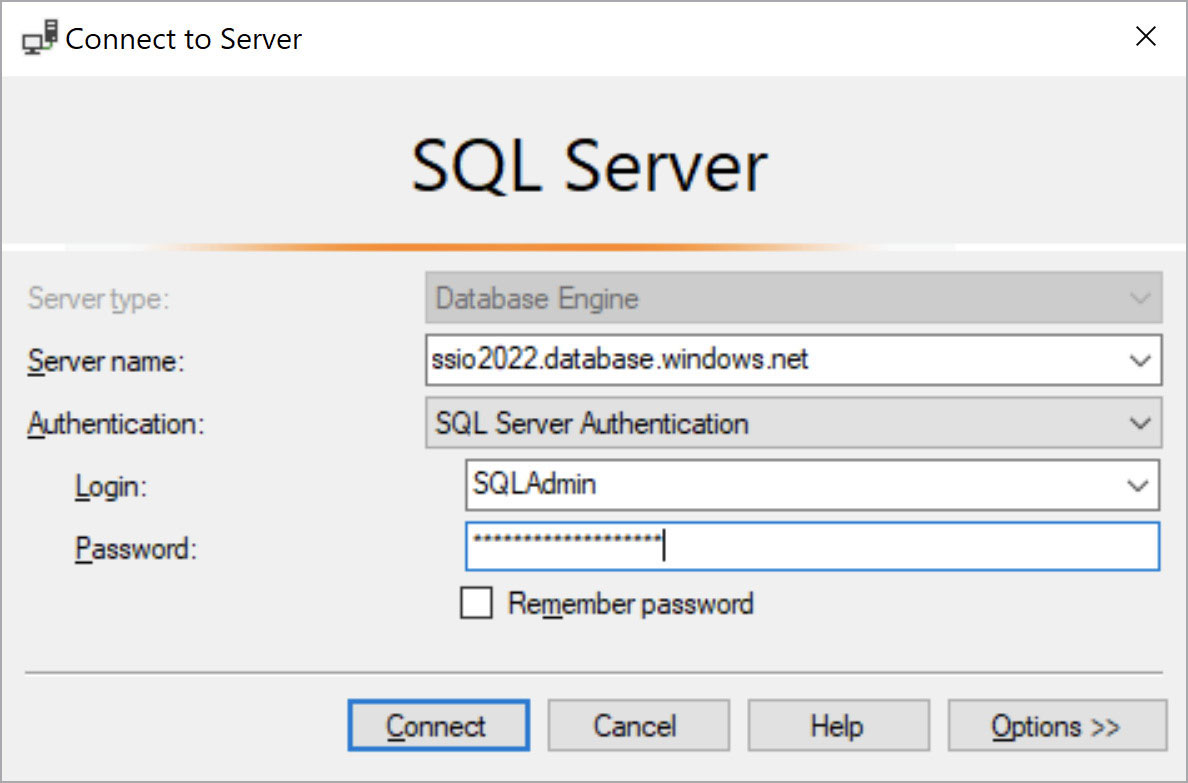
Figure 17-1 The Connect to Server dialog box, showing values to connect to the newly created Azure SQL Database logical server.
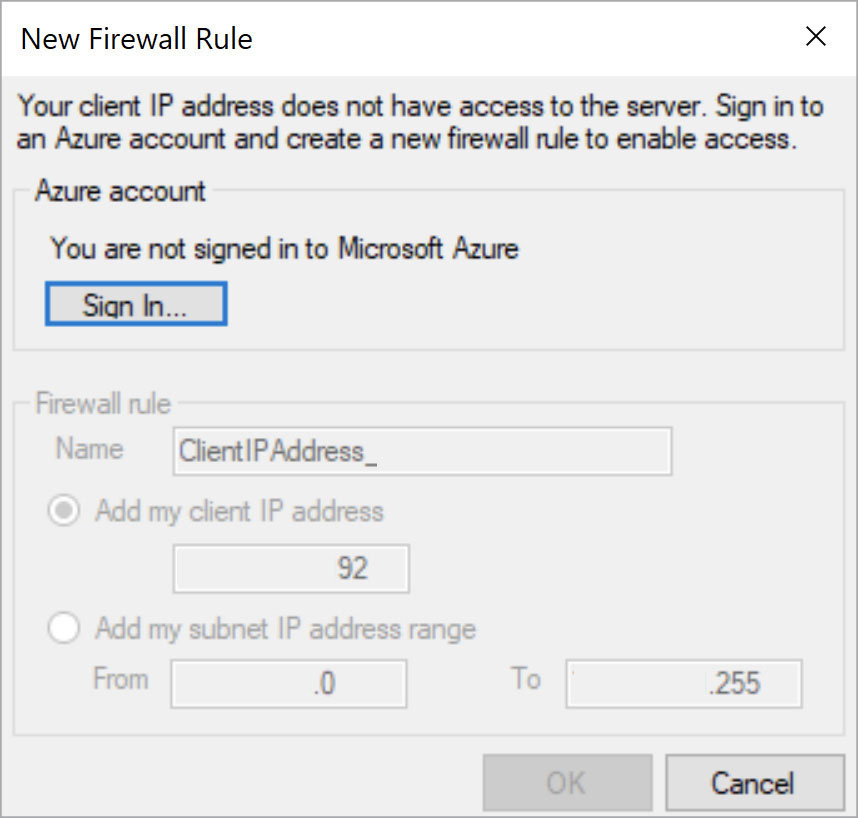
Figure 17-2 The New Firewall Rule dialog box that opens if the IP address attempting to connect is not included in any existing firewall rule.
Connections to Azure SQL Database are always encrypted, even if this is not specified in the connection string. For older client libraries, you might need to specify encryption explicitly in the connection string because these libraries might not support the automatic upgrade of the connection. If you neglect to specify it explicitly when using these older client libraries, you might receive an error message. Use Encrypt=True in the connection string if needed to successfully connect.
You might be tempted to look up the IP address of your server and use the IP address instead of the FQDN to connect. This is not recommended because the IP address for the server is really the IP address of a connection gateway. This IP address is subject to change at any time as the Azure infrastructure conducts updates or failovers.
Note
During Azure upgrade windows or infrastructure failures, you might experience a brief period of connectivity loss while the DNS infrastructure and your client(s) retain the cached IP address. The downtime after a maintenance operation is typically under 10 seconds, but you might have to wait up to 2 minutes for DNS records to be updated and clients to clear cached IP addresses.
Delete a server
Deleting a server is a permanent, irreversible operation. You should delete a server only if the following conditions are true:
You no longer need that server’s name.
You are confident that you will not need to restore any databases that are or were hosted on it.
You are approaching the limit of servers permitted in a subscription.
Note
As of this writing, the default maximum number of servers in a single subscription is 20 in a single region. You can request an increase up to 250 servers per subscription in a single region by contacting Azure Support.
Provision a database in Azure SQL Database
After provisioning a server, you are ready to provision your first database. Provisioning a database incurs charges associated with the service tier that you select. As a reminder, pricing for Azure SQL Database is per database or elastic pool, not per logical server.
The sections that follow discuss the process of provisioning a database using the Azure portal, PowerShell, Azure CLI, and Transact-SQL (T-SQL).
Note
You can provision a new Azure SQL Database logical server while provisioning a new database only by using the Azure portal. All other methods require two separate steps or commands.
Create a database using the Azure portal
There are several ways to create a new database in Azure SQL Database using the Azure portal. One is to start from the Overview pane of an existing server. You can also start from the Create New Service pane. The method you choose determines which values you must provide:
Subscription. Select the subscription that will be used to bill the charges for this database. The subscription you select here will narrow down the list of server choices later. This parameter is not shown when the process is started from a server.
Resource Group. Choose to create a new resource group or use an existing one. If you choose to create a new resource group, you must also create a new server. Choosing an existing resource group does not narrow the list of server choices later.
Database Name. The database name must be unique within the server and meet all requirements for a database name in SQL Server.
Server. You can select an existing logical server in the selected subscription or create a new one. If you select a server in a different resource group from the one you selected, the resource group value will be updated automatically to reflect the correct selection. This is because the life cycle of a database is tied to the life cycle of the server, and the life cycle of the server is tied to the resource group. Therefore, a database cannot exist in a different resource group than its server. This server value is locked when the process is started from a logical server.
Elastic Database Pool. We discuss elastic pools in detail in the “Provision an elastic pool” section later in this chapter. From the Create SQL Database pane, you can select an existing elastic pool or create a new one.
Backup Storage Redundancy. This affects how your point-in-time restore and long-term retention backups are replicated. As of this writing, you can choose locally redundant, zone-redundant, or geo-redundant backup storage.
Data Source. You select one of three values that match the previously mentioned options: Blank Database, Sample, or Backup. You can create a database from one of three sources:
Blank. A blank database is just that: There are no user database objects.
Sample. The new database will have the lightweight Adventure Works schema and data.
Backup. You can restore the most recent daily backup of another Azure SQL Database in the subscription.
Collation. The collation selected here becomes the database’s default collation. Unlike on-premises, there is no GUI to set the new database’s collation name. You can type the collation name from memory or use a basic UI to search the list of valid SQL Server collation names.
Backup. You are prompted to provide this only if you select Backup as the data source. The database you select will be restored to its most recent daily backup, which means it might be up to 24 hours old.
- You can read more about options for restoring database backups in the “Understand default disaster recovery features” section later in this chapter.
Service and Compute Tier. When creating a standalone database, you must select a service tier and a compute tier. The service tier determines the hourly usage charges and several architectural aspects of your database. (Chapter 16 discusses service tiers and compute tiers.) It is possible to mix service tiers of databases within a logical server, underscoring the fact that the server is merely a logical container for databases and has no relationship to any performance aspects. The compute tier specifies whether you want a serverless or provisioned database. When selecting the service and compute tier, you can also set a maximum database size. Your database will not be able to run
INSERTorUPDATET-SQL statements when the maximum size is reached.Maintenance Window. When creating a standalone database, you might have the option to change the maintenance window while creating the database. Although the drop-down is always present in the Azure portal, the maintenance windows available depend on the region in which you are provisioning your database, which itself depends on your logical server’s region.
Create a database using PowerShell
The following script illustrates how to create a new general purpose standalone database with two vCores on an existing server named ssio2022. The database collation is set to Latin1_General_CI_AS. The -Vcore, -ComputeGeneration, -ComputeMode, -CollationName, and -Edition parameters are optional. We show them here as an example of a commonly specified configuration. The default collation for Azure SQL Database is SQL_Latin1_General_CP1_CI_AS, which might not be desirable.
- Collation is discussed in detail in Chapter 4, “Install and configure SQL Server instances and features.”
Pay attention to the server name. It is lowercase because the parameter value must match exactly. Logical server names cannot contain uppercase characters.
$resourceGroupName = "SQL2022"
$serverName = "ssio2022"
$databaseName = "Contoso4"
$tags = @{"CreatedBy"="Kirby"; "Environment"="Dev"}
New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Edition "GeneralPurpose" `
-Vcore 2 `
-ComputeGeneration "Gen5" `
-ComputeMode "Provisioned" `
-CollationName "Latin1_General_CI_AS" `
-DatabaseName $databaseName `
-Tags $tagsOther optional parameters include the following:
CollationName. Similar to the database collation in SQL Server, this is the collation for the SQL database user data.
CatalogCollation. This parameter determines the collation of character data in the database’s metadata catalog. Note that you cannot set this database property in the GUI. This value defaults to
SQL_Latin1_General_CP1_CI_AS. The catalog collation, used for system metadata, cannot be changed. This is a concept specific to Azure SQL Database and not SQL Server. This is a multitenancy feature, allowing you to have a consistent collation for schema but client-specific collations for user data.ElasticPoolName. When specified, this database will be added to the existing elastic pool on the server. Elastic pools are covered later in this chapter.
MaxSizeBytes. Sets the maximum database size in bytes. You cannot set just any value here; there is a list of supported maximum sizes. The available maximum sizes depend on the selected service tier.
SampleName. Specify
AdventureWorksLTif you want the database to have the available sample schema and data.LicenseType. Use this parameter to take advantage of Azure Hybrid Benefit discounted pricing.
Tags. This parameter is common to many Azure cmdlets. You can use it to specify an arbitrary number of name-value pairs. Tags are used to add custom metadata to Azure resources. You can use both the Azure portal and PowerShell to filter resources based on tag values. You can also obtain a consolidated billing view for resources with the same tag values. An example is
-Tags @{"Tag1"="Value 1";"Tag 2"="Value 2"}, which associates two name-value pairs with the database. The name of the first tag isTag1withValue 1, and the name of the second tag isTag 2withValue 2.
After creating the database, you can retrieve information about it by using the Get-AzSqlDatabase cmdlet, as shown here:
$resourceGroupName = "SSIO2022"
$serverName = "ssio2022"
$databaseName = "Contoso"
Get-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseNameCreate a database using Azure CLI
The Azure CLI enables you to use the same set of commands to manage Azure resources regardless of the platform of your workstation: Windows, macOS, Linux, and even using the Azure portal’s Cloud Shell.
Note
Installing the Azure CLI on different operating systems is not covered in this text. Guidance for each OS is available at https://learn.microsoft.com/cli/azure/install-azure-cli.
The following Azure CLI command creates a database with the same parameters as those found in the preceding PowerShell script. After creating the database, the new database’s properties are retrieved.
- You can find the full list of supported CLI commands for Azure SQL Database at https://learn.microsoft.com/cli/azure/sql/db.
az sql db create
--resource-group SSIO2022
--server ssio2022
--name Contoso
--collation Latin1_General_CI_AS
--edition GeneralPurpose
--capacity 2
--family Gen5
--compute-model Provisioned
--tags Environment=Dev CreatedBy=Kirby
az sql db show --resource-groupSIO2022 --server ssio2022 --name ContosoNote
For clarity, long parameter names are used in the preceding example. Many parameters for the az command also have a shorthand version. For example, instead of using --resource-group, you can use -g. The --help (shorthand: -h) parameter shows both the long and shorthand parameter names, if a shorthand version is available. As with PowerShell, we recommend using the long parameter names to aid maintenance and understanding.
Create a database using T-SQL
The following T-SQL script creates a new Azure SQL database with the same properties as in both previous examples. To create a new database, connect to the server on which the new database will reside—for example, using SSMS or Azure Data Studio:
CREATE DATABASE Contoso COLLATE Latin1_General_CI_AS
(EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_Gen5_2');Because the T-SQL command is run in the context of a server, you do not need to, nor can you, provide a server name or resource group name. You cannot use T-SQL to create a database based on the AdventureWorksLT sample, but you can use it to restore a database backup from a database on the same or a different server using the AS COPY OF clause, as shown here:
CREATE DATABASE Contoso_copy AS COPY OF Server1.Contoso;Scale up or down
Azure SQL Database scale operations are conducted with minimal disruption to the availability of the database. A scale operation is performed by the service using a replica of the original database at the new service level. When the replica is ready, connections are switched over to the replica. Although this does not cause data loss and is completed in a time frame measured in seconds, active transactions might be rolled back. The application should be designed to handle such events and to retry the operation.
Scaling down might not be possible if the database size exceeds the maximum allowed size for the lower service objective or service tier. If you know you will likely scale down your database, you should set the current maximum database size to a value equal to or less than the future maximum database size for the service objective to which you might scale down.
In most tiers, scaling is initiated by an administrator. Only the serverless tier supports autoscaling. If the serverless tier does not meet your needs, you can consider deploying databases to an elastic pool (discussed shortly) to automatically balance resource demands for a group of databases. Another option to scale without administrator intervention is to use Azure Automation to monitor resource usage and initiate scaling when a threshold has been reached. You can use the PowerShell Set-AzSqlDatabase cmdlet to set a new service tier with the -Edition parameter, and a new service objective with the -RequestedServiceObjectiveName parameter.
Provision a named replica for a Hyperscale database
In June 2022, the named replica feature for Azure SQL Database Hyperscale became generally available. Named replicas enable you to scale out read-only workloads to up to 30 replicas. Named replicas share the same storage, but not compute. Each replica can have a different service-level objective (compute size). Named replicas allow isolated access, where a user can be granted read-only access to a specific replica without being granted access to the primary or other replicas.
- See Chapter 16 for more information on the Hyperscale tier of Azure SQL Database.
- For more information on use cases for Azure SQL Database Hyperscale named replicas, see this post on the Azure SQL blog: https://techcommunity.microsoft.com/t5/azure-sql-blog/azure-sql-database-hyperscale-named-replicas-feature-is/ba-p/3455674.
Named replicas allow for several differences from the primary replica that are not supported in normal high availability replicas, including the following:
They can have a different database name from the primary replica.
They can be located on a different logical server from the primary replica, as long as they are in the same region.
You can configure different authentication for each named replica by creating different logins on logical servers hosting named replicas.
Unlike high availability (HA) replicas, named replicas appear as regular databases in the Azure portal and REST API. They cannot be used as a failover target.
To create a named replica using the Azure portal, locate the existing Hyperscale database. Then, in the Data Management section in the left menu, choose Replicas. Next, on the Replicas page, choose Create Replica. (See Figure 17-3.) Be sure to select Named Replica for the replica type on the Basics page of the wizard that starts.
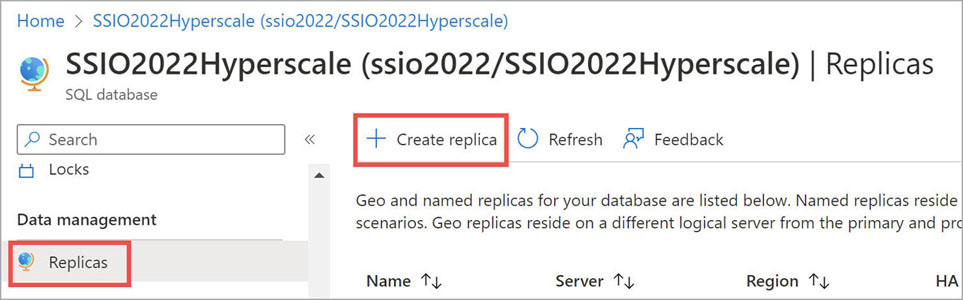
Figure 17-3 Selections in the Azure portal to create a named replica for a Hyperscale database.
- For detailed instructions to create a named replica in the Azure portal, T-SQL, PowerShell, or Azure CLI, review https://learn.microsoft.com/azure/azure-sql/database/service-tier-hyperscale-replicas.
Provision an elastic pool
Chapter 16 discussed the benefits and use cases of elastic database pools. Elastic pools are created per server, and a single server can have more than one elastic pool. The number of eDTUs or vCores available depends upon the service tier, as is the case with standalone databases.
Beyond the differences between tiers described in Chapter 16, which also apply to elastic pools, the relationship between the maximum pool size, and the selected eDTU or vCore and the maximum number of databases per pool, are also different per tier.
You can create elastic pools with the Azure portal, PowerShell, the Azure CLI, or the REST API. After an elastic pool is created, you can create new databases directly in the pool. You also can add existing single databases to a pool and move databases out of pools.
In most of the following sections, no distinction is made between standalone databases and elastic pool databases. Managing standalone databases is similar to managing databases in elastic pools. Also, whether a database is in an elastic pool or standalone makes no difference for establishing a connection.
Use the following PowerShell script to create a new elastic pool on the ssio2022 server and move the existing Contoso database to the pool:
$resourceGroupName = "SIO2022"
$serverName = "ssio2022"
$databaseName = "Contoso"
$poolName = "Contoso-Pool"
# Create a new elastic pool
New-AzSqlElasticPool -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-ElasticPoolName $poolName `
-Edition "GeneralPurpose" `
-Vcore 4 `
-ComputeGeneration Gen5 `
-DatabaseVCoreMin 0 `
-DatabaseVCoreMax 2
# Now move the Contoso database to the pool
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseName `
-ElasticPoolName $poolNameThis script creates a new pool named Contoso-Pool in the general purpose service tier and provides four total vCores. A single database will be assigned no more than two vCores. The parameters -Vcore, -DatabaseVCoreMin, and -DatabaseVCoreMax have a list of valid values depending on the selected tier and each other.
- For more information on the vCore-related PowerShell parameters, see https://learn.microsoft.com/powershell/module/az.sql/set-azsqlelasticpool.
- To understand the possible values for vCore-related PowerShell parameters, refer to https://learn.microsoft.com/azure/azure-sql/database/resource-limits-vcore-elastic-pools.
Manage database space
The Azure SQL Database service manages the growth of data and log files. For log files, the service also manages shrinking the log file. Data files are not automatically shrunk because of the potential impact on performance. Each service tier has an included maximum database size. When your database size approaches that maximum, you can choose to pay for extra storage space (up to a certain limit, again determined by the service tier) or scale your database up.
In some cases, the database data space might be allocated for your database but no longer in use. This effect can be especially significant in elastic pools. If many databases in a single pool have a significant amount of unused space, the pool maximum size might be reached sooner than expected.
- For a discussion on how to determine the amount of unused allocated space for all databases in a pool, visit https://learn.microsoft.com/azure/sql-database/sql-database-file-space-management#understanding-types-of-storage-space-for-an-elastic-pool.
If you don’t expect your databases to need the unused space, you might consider reclaiming that space. Beware of the need to rebuild indexes after shrinking and the fact that rebuilding indexes will cause the data file to grow again to some extent. All other caveats related to shrinking database files and rebuilding indexes apply. If you decide to shrink the database file, use the standard T-SQL statement:
DBCC SHRINKDATABASE ('Contoso');
-- Rebuild all indexes after shrink!- See Chapter 8, “Maintain and monitor SQL Server,” for information on rebuilding indexes.
Note
As with on-premises SQL Server databases, Azure SQL Database supports auto-shrink. There are no valid reasons to enable auto-shrink.
Security in Azure SQL Database
As with many PaaS cloud services, certain security operations are handled for you by the cloud provider. As it relates to security in Azure SQL Database, this includes patching the OS and the database service.
Other aspects of security must be managed by you, the cloud DBA. Some Azure SQL Database security features, such as transparent data encryption (TDE), are shared with on-premises SQL Server. Others are specific to Azure SQL Database and include firewall configuration, access control, and auditing and threat detection. We discuss these features of Azure SQL Database in the upcoming sections. Microsoft’s commitment regarding Azure SQL Database is to not differentiate the service tiers with security features. All the features discussed in this section are available in all service tiers, though some features incur additional charges.
Security features shared with SQL Server 2022
An important security consideration is access control. Azure SQL Database implements the same permission infrastructure that’s available in SQL Server 2022. This means database and application roles are supported, and you can set very granular permissions on database objects and operations using the data control language (DCL) statements GRANT and REVOKE. Refer to Chapter 12 for more information.
TDE is enabled by default for any new database. This hasn’t always been the case, so if your database has been around for a long time, you should verify whether it is enabled. When TDE is enabled for a database, not only are the database files encrypted, but the geo-replicated backups are, too. You will learn more about backups in the “Prepare Azure SQL Database for disaster recovery” section later in this chapter. TDE is covered in Chapter 13.
Other security features shared with SQL Server 2022 are dynamic data masking, row-level security, and Always Encrypted. Chapter 13 looks at these features in detail.
Server- and database-level firewall
A server is accessed using an FQDN, which maps to a public IP address. To maintain a secure environment, you must manage firewall entries to control which IP addresses can connect to the logical server or database.
Note
You can associate a server with a VNet, offering enhanced network security when connecting to other Azure resources in the same VNet. VNets can be used to communicate with on-premises resources as well as other Azure resources. They can be peered with other VNets to allow traffic to flow through. VNets offer a more secure way to connect to databases. However, there might still be times when you must add IP addresses in a firewall rule. This might be because a resource doesn’t have service endpoints or private endpoints, or the rare case when you have a truly customer-facing database. But whenever possible, consider connecting to your database through VNets.
When creating a new server using the Azure portal, you might choose to allow any Azure resource through the server-level firewall. This is convenient, but it leaves the server open to unauthorized connection attempts from an attacker who merely needs to create an Azure service such as a web app. Servers created using other methods—for example, PowerShell—do not have any default firewall rules, which means any connection attempt is refused until at least one firewall rule is created.
Database-level firewall rules take precedence over server firewall rules. After you have created database firewall rules, you can remove the server firewall rule(s) and still connect to the database. However, if one server will be hosting several databases that each need to accept connections from the same IP addresses, keeping the firewall rules at the server level might be more sensible. It is also convenient to keep server-level firewall rules in place for administrative access.
You can find server-level firewall rules in the virtual master database in the sys.firewall_rules catalog view. Database-level firewall rules are in the user database in the sys.database_firewall_rules catalog view. This makes the database more portable, which can be advantageous in combination with contained users. Especially when using geo-replication, discussed in the “Prepare Azure SQL Database for disaster recovery” section later in this chapter, having portable databases avoids unexpected connection issues when failing-over databases to another server.
- Learn more about contained databases in Chapter 12.
Configure the server-level firewall
You can create server-level firewall rules using the Azure portal, PowerShell, Azure CLI, or T-SQL. As seen earlier, SSMS might prompt you to create a firewall rule when establishing a connection, though you would not use this method to create firewall rules for your application’s infrastructure. To create a firewall rule, you provide the following:
Rule Name. This has no impact on the operation of the firewall; it exists only to create a human-friendly reminder about the rule. The rule name is limited to 128 characters. The name must be unique in the server.
Start IP Address. This is the first IPv4 address of the range of allowed addresses.
End IP Address. This can be the same as the start IP address to create a rule that allows connections from exactly one address. The end IP address cannot be lower than the start IP address.
Note
When configuring server-level IP firewall rules, the maximum number allowed is 128. There can be up to 256 database-level IP firewall rules.
Managing firewall rules in a dynamic environment can quickly become error prone and resource intensive. For example, when databases on a server are accessed from numerous Azure Web App instances, which often scale up and down and out and in, the rules must be updated frequently. Rather than resorting to allowing any Azure resource to pass through the server-level firewall, you should consider automating firewall rule management.
The first step in such an endeavor is to create a list of allowed IP addresses. This list could include static IP addresses, such as from your on-premises environment for management purposes, and dynamic IP addresses, such as from Azure Web Apps or Azure virtual machines (VMs). In the case of dynamic IP addresses, you can use the Az PowerShell module to obtain the current IP addresses of Azure resources.
After you build the list of allowed IP addresses, you can apply it by looping through each address, attempting to locate that IP address in the current firewall rule list, and adding it if necessary. In addition, you can remove any IP addresses in the current rule list that are not on your allowed list.
This is not always an option. There are Azure services whose IP addresses are impossible to obtain. In this scenario, you should review if those services can be joined to a VNet where your server has an endpoint. If not available, you must allow access from all Azure services or re-architect your solution to avoid using those services.
In PowerShell, the New-AzSqlServerFirewallRule cmdlet provides the -AllowAllAzureIPs parameter as a shortcut to create a rule to allow all Azure services. You do not need to provide a rule name, start, or end IP address. Using the CLI to achieve the same outcome, you create a rule with 0.0.0.0 as both the start and end IP address. You must provide a rule name for the command to work, but you’ll find that in the Azure portal, the rule is not shown. Instead, the toggle switch is in the on position.
Note
When SSMS offers to create a server-level firewall rule, you must sign in with an Azure AD user account whose default directory matches the directory associated with the subscription where the logical server exists. Otherwise, the creation of the firewall rule will fail with an HTTP status code 401 error.
Configure the database-level firewall
To configure database-level firewall rules, you must have already established a connection to the database. This means you must at least temporarily create a server-level firewall rule to create database-level firewall rules. You can create and manage database-level firewall rules only using T-SQL. Azure SQL Database provides the following stored procedures to manage the rules:
sp_set_database_firewall_rule. Creates a new database-level firewall rule or updates an existing firewall rule.
sp_delete_database_firewall_rule. Deletes an existing database-level firewall rule using the name of the rule.
The following T-SQL script creates a new database-level firewall rule allowing a single (fictitious) IP address, updates the rule by expanding the single IP address to a range of addresses, and finally deletes the rule:
EXEC sp_set_database_firewall_rule N'Headquarters', '1.2.3.4', '1.2.3.4';
EXEC sp_set_database_firewall_rule N'Headquarters', '1.2.3.4', '1.2.3.6';
SELECT * FROM sys.database_firewall_rules;
EXEC sp_delete_database_firewall_rule N'Headquarters';Integrate with virtual networks
Azure SQL Database can be integrated with one or more VNet subnets. By integrating a logical server with a VNet subnet, other resources in that subnet can connect to the server without requiring a firewall rule.
In addition to removing the need to create firewall rules, the traffic between these resources stays within the Azure backbone and does not go across public Internet connections at all, thereby providing further security and latency benefits.
VNet integration and the public endpoint of the Azure SQL server can be used simultaneously.
- Chapter 16 discusses VNets in more detail.
Azure Private Link for Azure SQL Database
Azure SQL Database now supports the Azure Private Link feature, which creates a private endpoint for use by various Azure services. This private endpoint becomes an IP address that can only be used by certain services within Azure, including a VNet.
By using Private Link endpoints, you can further reduce the network surface area of an Azure SQL Database. You should make an effort to eliminate all public access to your Azure SQL Database that is secured by only a username and password. A Private Link’s network traffic uses only the Microsoft infrastructure network and not the public Internet.
Azure SQL Database integration with Private Link continues. For more on the features and capabilities possible, visit https://learn.microsoft.com/azure/azure-sql/database/private-endpoint-overview.
- For more information, see the “Networking in Azure” section in Chapter 16.
Control access using Azure AD
To set up single sign-on (SSO) scenarios, easier login administration, and secure authentication for application identities, you can enable Azure AD Authentication. When Azure AD Authentication is enabled for a server, an Azure AD user or group is given the same permissions as the server admin login. In addition, you can create contained users referencing Azure AD principals. So, user accounts and groups in an Azure AD domain can authenticate to the databases without needing a SQL Authentication login.
For cases in which the Azure AD domain is federated with an Active Directory Domain Services (AD DS) domain, you can achieve true SSO comparable to an on-premises experience. The latter case excludes any external users or Microsoft accounts that have been added to the directory; only federated identities can take advantage of this. Furthermore, it also requires a client that supports it.
Note
The principal you set as the Azure AD admin for the server must reside in the directory associated with the subscription where the server resides. The directory associated with a subscription can be changed, but this might have effects on other configuration aspects, such as role-based access control (RBAC), which we describe in the next section. If users from other directories need to access your SQL Server, add them as guest users in the Azure AD domain backing the subscription.
To set an Azure AD admin for a server, you can use the Azure portal, PowerShell, or Azure CLI. You use the PowerShell Set-AzSqlServerActiveDirectoryAdministrator cmdlet to provision the Azure AD admin. The -DisplayName parameter references the Azure AD principal. When you use this parameter to set a user account as the administrator, the value can be the user’s display name or user principal name (UPN). When setting a group as the administrator, only the group’s display name is supported.
If the group you want to designate as administrator has a display name that is not unique in the directory, the -ObjectID parameter is required. You can retrieve the ObjectID value from the group’s properties in the Azure portal or via PowerShell using the Get-AzADGroup cmdlet.
Note
If you decide to configure an Azure AD principal as server administrator, it’s always preferable to designate a group instead of a single user account.
After you set an Azure AD principal as the Azure AD admin for the server, you can create contained users in the server’s databases. Contained users for Azure AD principals must be created by other Azure AD principals. Users authenticated with SQL Authentication cannot validate the Azure AD principal names, and, as such, even the server administrator login cannot create contained users for Azure AD principals.
Contained users are created by using the T-SQL CREATE USER statement with the FROM EXTERNAL PROVIDER clause. The following sample statements create an external user for an Azure AD user account with UPN [email protected] and for an Azure AD group Sales Managers:
CREATE USER [[email protected]] FROM EXTERNAL PROVIDER;
CREATE USER [Sales Managers] FROM EXTERNAL PROVIDER;By default, these newly created contained users will be members of the public database role and will be granted CONNECT permission. You can add these users to additional roles or grant them additional permissions directly like any other database user. Azure B2B users can be added as contained users with the same CREATE statement used for users whose default directory is the same directory tied to the Azure subscription containing the database and server. For guest users, use their UPN in their default tenant as the username. For example, suppose Earl is a user in the ProseWare, Inc. tenant with UPN [email protected]. To grant access to the Contoso database, first make sure the user has been added as a guest user in the Contoso tenant, then create the user [email protected] in the Contoso database. Chapter 12 has further coverage of permissions and roles.
Grant access to Azure AD managed identities
Most Azure resources have a system-assigned managed identity (SMI or SAMI) and can also be assigned a user-assigned managed identity (UMI or UAMI). A managed identity is a special type of service principal that can only be used with a specific Azure resource. When the managed identity is deleted, the corresponding service principal is automatically removed. With a managed identity, there is no need to manage credentials—you have no access to the password. Managed identities can be used to access other Azure resources. By default, a new SMI is created and enabled, but you can additionally configure one or more UMIs.
UMIs can serve as service identity for one or more Azure SQL databases or SQL managed instances. When you create a UMI, you can choose to disable the SMI.
A user interface update in September 2022 to the Azure portal displays the SMI for the Azure SQL logical server in the Properties page.
- For more on SMIs vs UMIs, including how to get and set them, see https://learn.microsoft.com/azure/azure-sql/database/authentication-azure-ad-user-assigned-managed-identity.
Services such as Azure Data Factory, Azure Machine Learning Services, Azure Synapse Link for Azure SQL Database, and Azure Automation support authentication via managed identities. Contained users can be created in an Azure SQL database for these managed identities. From there, you can add these users to built-in or custom roles or directly grant permissions, just as you would any other user account.
To create a user in a database for a managed identity, you need the display name of the managed identity. For system-assigned managed identities, this is the name of the resource to which it belongs. The following example creates an external user for the system-assigned managed identity that is associated with an Azure Data Factory named MyFactory.
CREATE USER [MyFactory] FROM EXTERNAL PROVIDER;Caution
Different resource types have different scopes within which the resource name is required to be unique. For example, data factories must be globally unique across all of Azure, but logic apps only have to be unique within the resource group. Be careful when granting access to managed identities when there are multiple service principals with the same display name. If you have three logic apps with the same name in the same tenant as your database, you will encounter problems when trying to grant database access to the managed identity for one of the logic apps.
- For recommendations for Azure resource naming conventions in Microsoft’s Cloud Adoption Framework for Azure, visit https://learn.microsoft.com/azure/cloud-adoption-framework/ready/azure-best-practices/naming-and-tagging.
Use Azure role-based access control
All operations discussed thus far have assumed that your user account has permission to create servers, databases, and pools, and can then manage these resources. If your account is the service administrator or subscription owner, no restrictions are placed on your ability to add, manage, and delete resources. Most enterprise deployments, however, require more fine-grained control over permissions to create and manage resources. Using Azure role-based access control (RBAC), administrators can assign permissions to Azure AD users, groups, or service principals at the subscription, resource group, or resource level.
RBAC includes several built-in roles to which you can add Azure AD principals. The built-in roles have a fixed set of permissions. You also can create custom roles if the built-in roles do not meet your needs.
- For a comprehensive list of built-in roles and their permissions, visit https://learn.microsoft.com/azure/active-directory/role-based-access-built-in-roles.
Three built-in roles relate specifically to Azure SQL Database:
SQL DB Contributor. This role can primarily create and manage Azure SQL databases, but not change security-related settings. For example, this role can create a new database on an existing server and create alert rules.
SQL Security Manager. This role can primarily manage security settings of databases and servers. For example, it can create auditing policies on an existing database but cannot create a new database.
SQL Server Contributor. This role can primarily create and manage servers, but not databases or security-related settings.
Permissions do not relate to server or database access; instead, they relate to managing Azure resources. Indeed, users assigned to these RBAC roles are not granted any permissions in the database—not even the CONNECT permission.
Note
An Azure AD user in the SQL Server Contributor role can create a server and thus define the server administrator login’s username and password. Yet, the user’s Azure AD account does not obtain any permissions in the database at all. If you want the same Azure AD user to have permissions in the database, including creating new users and roles, you must use the steps in this section to set up Azure AD integration and create an external database user for that Azure AD account.
Audit database activity
Microsoft Defender for SQL provides auditing and threat-detection for Azure SQL Database, allowing you to monitor database activity using Azure tools. In on-premises deployments, Extended Events are often used for monitoring. SQL Server builds on Extended Events for its SQL Server Audit feature (discussed in Chapter 13). This feature is not present in Azure SQL Database in the same form, but a large subset of Extended Events is supported in Azure SQL Database.
- You can find more details about support for Extended Events at https://learn.microsoft.com/azure/sql-database/sql-database-xevent-db-diff-from-svr.
Azure SQL Database auditing creates a record of activities that have taken place in the database. The types of activities that can be audited include permission changes, T-SQL batch execution, and auditing changes themselves.
- Audit actions are grouped in audit action groups. A list of audit action groups is available in the PowerShell reference for the
Set-AzSqlDatabaseAuditcmdlet at https://learn.microsoft.com/powershell/module/az.sql/set-azsqldatabaseaudit#parameters.
Note
By default, all actions are audited. The Azure portal does not provide a user interface for selecting which audit action groups are included. Customizing audited events requires the use of the PowerShell cmdlet or the REST API.
Auditing and advanced threat protection are separate but related features. Investigating alerts generated by advanced threat protection is easier if auditing is enabled. Auditing is available at no initial charge, but there is a monthly fee per server for activating Microsoft Defender for SQL, which contains the Advanced Threat Protection functionality. There are also charges for writing and storing logs in a storage account or a Log Analytics workspace.
You can enable auditing at the server and database level. When auditing is enabled at the server level, all databases hosted on that server are audited. After you enable auditing on the server, you can still turn it on at the database level as well. This does not override any server-level settings; rather, it creates two separate audits. This is not usually desired, though in environments with specific compliance requirements that only apply to one or a few databases on a single server, it can make sense. These compliance requirements might include longer retention periods or additional action groups that must be audited.
In addition to auditing normal operations on the databases and server, you can also enable auditing of Microsoft Support operations for Azure SQL Server. This allows you to audit Microsoft support engineers’ operations when they need to access your server during a support request.
Auditing events are stored in an Azure Storage account or sent to a Log Analytics workspace or Event Hub. The configuration of Event Hubs is beyond the scope of this book. The other two options are covered later in this chapter.
Configure auditing to a storage account
When configuring auditing in the Azure portal, the target storage account must be in the same region as the server. This limitation does not exist when configuring auditing using PowerShell, Azure CLI, or the REST API. Be aware that you might incur data transfer charges for audit data or deal with latency if you choose a storage account in a different region from the server. Many types of storage accounts are supported, but Premium page blobs are not.
You can configure the storage account to require storage account keys or managed identity for access. If you choose to use managed identity, the Allow trusted Microsoft services to access this storage account setting will be enabled, and the server’s managed identity will be assigned the Storage Blob Data Contributor RBAC role.
To configure auditing, you must create or select an Azure Storage account. We recommend that you aggregate logging for all databases in a single storage account. When all auditing is done in a single storage account, you will benefit from having an integrated view of audit events.
You also must decide on an audit log retention period. You can choose to keep audit logs indefinitely or you can select a retention period. The retention period can be at most 3,285 days, or about 9 years.
The following PowerShell script sets up auditing for the Contoso database on the ssio2022 server:
$resourceGroupName = "SSIO2022"
$location = "southcentralus"
$serverName = "ssio2022"
$databaseName = "Contoso"
# Create your own globally unique name here
$storageAccountName = "azuresqldbaudit"
# Create a new storage account
$storageAccount = New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName -Location $location -Kind Storage `
-SkuName Standard_LRS -EnableHttpsTrafficOnly $true
# Use the new storage account to configure auditing
$auditSettings = Set-AzSqlDatabaseAudit `
-ResourceGroupName $resourceGroupName `
-ServerName $serverName -DatabaseName $databaseName `
-StorageAccountResourceId $storageAccount.Id -StorageKeyType Primary `
-RetentionInDays 365 -BlobStorageTargetState EnabledThe first cmdlet in the script creates a new storage account with the name azuresqldbaudit. Note that this name must be globally unique, so you must update the script with a name of your choosing before running the script. Storage account names can contain only lowercase letters and digits.
- For more details on the
New-AzStorageAccountcmdlet, see https://learn.microsoft.com/powershell/module/az.storage/new-azstorageaccount.
The second cmdlet, Set-AzSqlDatabaseAudit, configures and enables auditing on the database using the newly created storage account. The audit log retention period is set to 365 days.
Note
To set auditing at the server level, use the Set-AzSqlServerAudit cmdlet. This cmdlet uses the same parameters, except you’ll omit the -DatabaseName parameter.
View audit logs from a storage account
There are several methods you can use to access the audit logs. Which method you use largely depends on your preferences and the tools you have available on your workstation. This section discusses some of these methods in no particular order.
If your goal is to quickly review recent audit events, you can see the audit logs in the Azure portal. In the Auditing pane for a database, select View Audit Logs to open the Audit records pane. This pane shows the most recent audit logs, which you can filter to restrict the events shown by, say, the latest event time or to only show suspect SQL injection audit records, for example. This approach is rather limited because you cannot aggregate audit logs from different databases, and the filtering capabilities are minimal.
A more advanced approach is to use SQL Server Management Studio (SSMS). SSMS 17 introduced support for opening audit logs directly from Azure Storage. Alternatively, you can use Azure Storage Explorer to download audit logs and open them using older versions of SSMS or third-party tools.
Audit logs are stored in the sqldbauditlogs blob container in the selected storage account. The container follows a hierarchical folder structure: logicalservernameDatabaseNameSqlDbAuditing_AuditNameyyyymmdd. The blobs within the date folder are the audit logs for that date, in Coordinated Universal Time (UTC). The blobs are binary Extended Event files (.xel).
Note
Azure Storage Explorer is a free and supported tool from Microsoft. You can download it from https://azure.microsoft.com/features/storage-explorer/.
After you obtain the audit files, you can open them in SSMS. On the File menu, select Open, and select Merge Audit Files to open the Add Audit Files dialog box, shown in Figure 17-4.
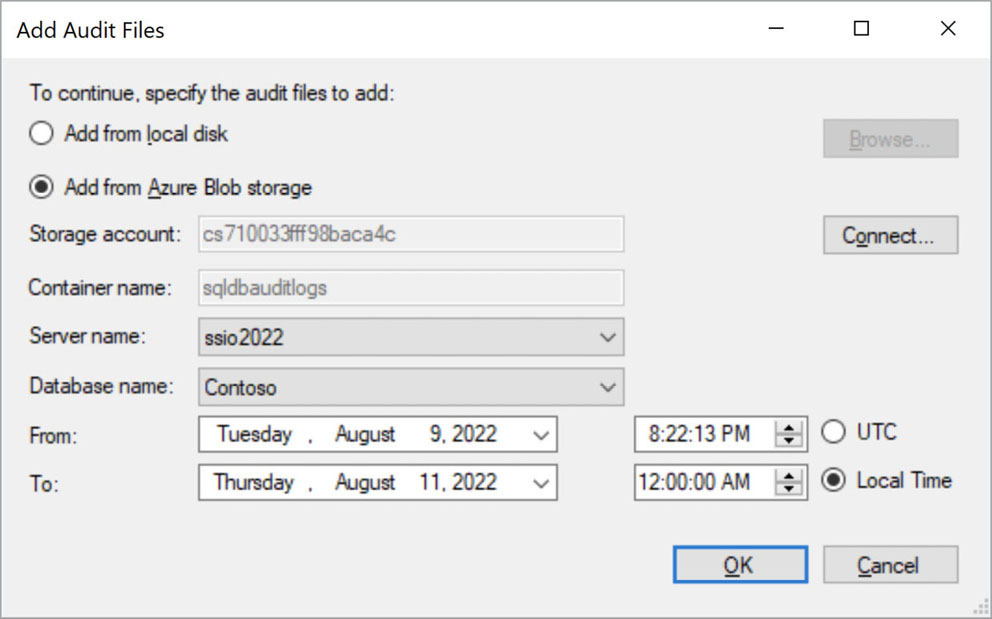
Figure 17-4 SSMS 17 introduced support for opening and merging multiple Azure SQL Database audit files directly from an Azure Storage account.
A third way of examining audit logs is by querying the sys.fn_get_audit_file system function with T-SQL. You can use this to perform programmatic evaluation of the audit logs. The function works with locally downloaded files or you can obtain files directly from the Azure Storage account. To obtain logs directly from the Azure Storage account, you run the query using a connection to the database whose logs are being accessed. The following T-SQL script example queries all audit events logged to the azuresqldbaudit storage account from October 16, 2022, for the Contoso database on the ssio2022 server:
SELECT * FROM sys.fn_get_audit_file ('https://azuresqldbaudit.blob.core.windows.net/
sqldbauditlogs/ssio2022/Contoso/SqlDbAuditing_Audit/2022-10-16/', default, default);- Find more information on
sys.fn_get_audit_fileat https://learn.microsoft.com/sql/relational-databases/system-functions/sys-fn-get-audit-file-transact-sql.
The output from the system function can be visualized and analyzed using Power BI. To get started, a sample Power BI dashboard template is available for download from the Microsoft Tech Community. Using the template, you only need to provide the server name, storage account name, and credentials. You can use the template as is or customize it. The template can be used directly in the free Power BI Desktop tool. You might also choose to publish it to your organization’s Power BI service.
- The template and a walkthrough on using it are available from the Microsoft Tech Community at https://techcommunity.microsoft.com/t5/Azure-Database-Support-Blog/SQL-Azure-Blob-Auditing-Basic-Power-BI-Dashboard/ba-p/368895.
Configure auditing to a Log Analytics workspace
When configuring audit events to be sent to a Log Analytics workspace using the Azure portal, the Log Analytics workspace must be in the same subscription as the SQL server and database. The workspace must exist before you configure the database audit because the Azure portal does not offer you the ability to create a new workspace while configuring auditing.
There are additional logs and metrics that can be configured to be sent to the Log Analytics workspace (or archived in Azure Blob Storage). You configure these by adding a diagnostic setting. Information that can be captured in a diagnostic setting includes the following:
SQL insights
Automatic tuning
Query Store runtime statistics
Query Store wait statistics
Database wait statistics
Timeouts
Blocks
Deadlocks
SQL security audit events
Metrics
View audit logs in a Log Analytics workspace
There are several ways to access audit logs stored in a Log Analytics workspace. You can access the logs for a single database or server in the Azure portal on the Logs pane for the resource. You can also go to the Logs pane for the Log Analytics workspace in the Azure portal. Or you can go to the Auditing pane for the resource and select View Audit Logs.
One advantage of using a Log Analytics workspace is that you can send the logs for many SQL servers and databases to one workspace to spot trends and outliers across resources. You can also send logs from many different types of resources to the same workspace and track an issue or security event across your tech stack. Log Analytics also allows you to create dashboards from data stored in a workspace.
To query a Log Analytics workspace, you must use a Kusto query. Kusto Query Language (KQL) uses schema entities organized in a hierarchy similar to SQL: databases, tables, and columns. The following sample Kusto query requests the count of database authentication failures grouped by client IP address.
AzureDiagnostics
|where action_name_s == 'DATABASE AUTHENTICATION FAILED'
|summarize count() by client_ip_s- For a KQL quick start guide, visit https://learn.microsoft.com/azure/data-explorer/kql-quick-reference.
Microsoft Defender for SQL
As discussed in Chapter 13, Microsoft Defender for SQL is the collective name for two services that are enabled at the logical server level and apply to all databases on that server. These services are:
Vulnerability assessment. Assesses your database against security best practices
Advanced Threat Protection. Provides alerts when potentially malicious activity is detected in the database
Understand vulnerability assessment
Vulnerability assessment consists of a set of rules that are evaluated against one or more databases on the server. Optionally, you can schedule weekly automatic scans of all databases on the server. Unfortunately, at the time of this writing, the schedule for these weekly scans is not customizable. This means the vulnerability scan might run at a time when your database is under heavy load. Fortunately, though the impact on compute utilization is measurable, the scan completes quickly.
Because one size does not fit all when it comes to best practices, many rules can be configured with a custom baseline. If your environment uses user-defined roles, you must review the current configuration and approve it as a baseline. Then, during the next scan, the rule will fail only if the membership is different from the baseline.
The value of vulnerability assessment is further enhanced by the actionable steps and, when appropriate, T-SQL scripts provided to remediate the failure. A scan itself will not modify the database or server automatically; the scan is read-only. However, with a single tap, the suggested remediation script can be opened in the Azure portal’s online query editor.
- For directions on how to use SSMS to run a vulnerability assessment scan, see https://learn.microsoft.com/sql/relational-databases/security/sql-vulnerability-assessment.
Configure Advanced Threat Protection
Advanced Threat Protection examines the database activity for anomalies. If an anomaly is detected, it then alerts Azure service administrators and co-administrators or a list of configured email addresses. As of this writing, there are more than a dozen different alerts for SQL Database, including:
A possible vulnerability to SQL injection
Attempted logon by a potentially harmful application
Login from a principal user not seen in 60 days
Login from a suspicious IP
Potentially unsafe action
Potential SQL brute force attempt
Unusual export location
- Additional information about these threats is at https://learn.microsoft.com/azure/sql-database/sql-database-threat-detection-overview#advanced-threat-protection-alerts.
You can disable each threat type individually if you do not want to detect it.
The configuration of Advanced Threat Protection allows the DBA to specify one or more email addresses that should receive alerts. Optionally, subscription administrators and owners can also receive alerts via email. DBAs should consider including the enterprise security team’s alert address in the list for rapid triage and response.
- For elementary guidance on using the Azure Security Center for incident response, visit https://learn.microsoft.com/azure/security-center/security-center-incident-response.
Advanced Threat Protection does not require auditing to be enabled for the database or server, but auditing records will provide for a better experiencing investigating detected threats. Audit records are used to provide context when Advanced Threat Protection raises an alert.
To effectively analyze detected threats, the following audit action groups are recommended:
BATCH_COMPLETED_GROUPSUCCESSFUL_DATABASE_AUTHENTICATION_GROUPFAILED_DATABASE_AUTHENTICATION_GROUP
Enabling these groups will provide details about the events that triggered the threat detection alert.
Prepare Azure SQL Database for disaster recovery
Hosting your data on Microsoft’s infrastructure does not excuse you from preparing for disasters. Even though Azure has high levels of availability, your data can still be at risk due to human error and significant adverse events. Azure SQL Database provides default and optional features that will ensure high availability (HA) for your databases when properly configured.
Understand default disaster recovery features
Without taking any further action after provisioning a database, the Azure infrastructure takes care of several basic disaster recovery (DR) preparations. First among these is the replication of data files across fault and upgrade domains within the regional datacenters. This replication is not something you see or control, but it is there. This is comparable to the on-premises use of availability groups or storage tier replication. The exact method of replication of the database files within a datacenter depends on the chosen tier. As Azure SQL Database evolves, the methods Microsoft employs to achieve local HA are of course subject to change.
Regularly scheduled backups are also configured by default. A full backup is scheduled weekly, differential backups take place every few hours, and transaction log backups every 5 to 10 minutes. The exact timing of backups is managed by the Azure fabric based on overall system workload and the database’s activity levels. These backups are retained for a period of 7 days (by default, and the maximum for the Basic service tier) to 35 days (maximum).
You can use backups to restore the database to a point-in-time within the retention period. You also can restore a database that was accidentally deleted to the same server from which it was deleted. Remember: Deleting a server irreversibly deletes all databases and backups. You should generally not delete a server until the backup-retention period has expired, just in case. After all, if Microsoft Defender for SQL is disabled, there is no cost associated with a server without databases.
You also can restore databases to another Azure region. This is referred to as a geo-restore. This restores databases from backups that are geo-replicated to other regions using Azure Storage replication. If your database has TDE enabled, the backups are also encrypted.
Although these default features provide valuable DR options, they are likely not adequate for production workloads. For example, the estimated recovery time (ERT) for a geo-restore is less than 12 hours, with a recovery point objective (RPO) of less than 1 hour. Further, the maximum backup retention period is 35 days for the Standard and Premium tiers, and only 7 days for the Basic tier. Some of these values are likely unsuitable for mission-critical databases, so you should review the optional DR features covered in the next sections and configure them as needed to achieve an acceptable level of risk for your environment.
Manually export database contents
In addition to the automatic, built-in backup discussed in the preceding section, you might need to export a database. This could be necessary if you need to restore a database in an on-premises or infrastructure as a service (IaaS) environment. You might also need to keep database backups for longer than the automatic backups’ retention period, though we encourage you to read the “Use Azure Backup for long-term backup retention” section later in this chapter to understand all options for long-term archival.
The term backup is inappropriate when referring to a BACPAC file. (You can read more about BACPAC files in Chapter 6, “Provision and configure SQL Server databases.”) A significant difference between a database backup and an export is that the export is not transactionally consistent. During the data export, data manipulation language (DML) statements in a single transaction might have completed before and after the data in different tables that were extracted. This can have unintended consequences and can even prevent you from restoring the export without dropping foreign key constraints.
Databases can be exported via the Azure portal, PowerShell, Azure CLI, the SQLPackage utility, SSMS, or Azure Data Studio. The SQLPackage utility might complete and export more quickly, as it allows you to run multiple sqlpackage.exe comments in parallel for subsets of tables to speed up export operations.
Enable zone-redundant configuration
Applicable only to the general purpose, premium, and business critical (with Gen5 or newer hardware) service tiers, zone-redundant configuration is an optional setting that distributes the default HA nodes between different datacenters in the same region. Zone-redundant configuration provides fault tolerance for several classes of failures that would otherwise require handling by geo-replication. Zone redundancy places multiple replicas within an Azure datacenter but in different availability zones within the physical infrastructure. Availability zones are physically discrete from each other and more tolerant to localized disasters affecting the datacenter. They’re a low cost and fast way to increase survivability without geo-replication.
Unlike geo-replication, which is discussed in the next section, there is no change to the connection string required if a single datacenter suffers an outage.
There is no additional cost associated with this feature, so your decision to enable it is entirely based on the workload’s ability to accept a few extra milliseconds of latency before transactions commit.
- For additional information about zone-redundant configuration, visit https://learn.microsoft.com/azure/sql-database/sql-database-high-availability#zone-redundant-configuration.
Zone-redundant deployments increase the service-level agreement’s (SLA’s) availability guarantee from the normal 99.99 percent to at least 99.995 percent.
Configure geo-replication
If your DR needs are such that your data cannot be unavailable for a period of up to 12 hours, you will likely need to configure geo-replication. When you geo-replicate a database, all transactions are replicated to one or more active secondary databases. Geo-replication takes advantage of the availability groups feature also found in on-premises SQL Server.
You can configure geo-replication in any service tier and any region. To configure geo-replication, you must provision a server in another region, though you can do this as part of the configuration process if you are using the Azure portal.
In the event of a disaster, you are alerted via the Azure portal of reliability issues in the datacenter hosting your primary database. You then need to manually fail over to a secondary database. Using geo-replication only, there is no automatic failover (but keep reading to learn about failover groups, which do provide automatic failover capability). Failover is accomplished by selecting (one of) the secondary database(s) to be the primary.
Because the replication from primary to secondary is asynchronous, an unplanned failover can lead to data loss. The RPO for geo-replication, which is an indicator of the maximum amount of data loss expressed as a unit of time, is 5 seconds. Although no more than 5 seconds of data loss during an actual disaster is a sound objective, when conducting DR drills, no data loss is acceptable. A planned change to another region, such as during a DR drill or to migrate to another region permanently, can be initiated as a planned failover. A planned failover will not lead to data loss because the selected secondary will not become primary until replication is completed.
Unfortunately, a planned failover cannot be initiated from the Azure portal. However, the Set-AzSqlDatabaseSecondary PowerShell cmdlet with the -Failover parameter and without the -AllowDataLoss parameter will initiate a planned failover. If the primary is not available due to an incident, you can use the portal or PowerShell to initiate a failover with the potential for some data loss, as just described. If you have multiple secondaries, after a failover, the new primary will begin replicating to the remaining available secondaries without a need for further manual configuration.
Note
When you first configure geo-replication using the Azure portal, it informs you of the recommended region for the geo-replicated database. You are not required to configure the secondary in the recommended region, but doing so will provide optimal performance for the replication between regions. The recommendation is based on Microsoft’s knowledge of connectivity between its datacenters in different regions.
For each secondary database, you are charged the same hourly rate as for a primary database, with the same service tier and service objective. A secondary database must have the same service tier as its primary, but it does not need to have the same service objective or performance level. For example, a primary database in the Standard tier with service objective S2 can be geo-replicated to a secondary database in the Standard tier with service objective S1 or S3, but it cannot be geo-replicated to a secondary in the Basic or Premium tier.
To decide whether your service objective for secondaries can be lower than that of the primary, you must consider the read-write activity ratio. If the primary is write-heavy—that is, most database operations are writes—the secondary will likely need the same service objective to be able to keep up with the primary. However, if the primary’s utilization is mostly toward read operations, you could consider lowering the service objective for the secondary. You can monitor the replication status in the Azure portal or use the PowerShell Get-AzSqlDatabaseReplicationLink cmdlet to ensure that the secondary can keep up with the primary.
Caution
If one or more secondary databases cannot keep up with the rate of change at the primary database, the primary database will be throttled to allow all secondaries to catch up.
As of this writing, geo-replication introduces a limitation on the scalability of databases. When a primary database is in a geo-replication relationship, its service tier cannot be upgraded (for example, from Standard to Premium) without first upgrading all secondaries. To downgrade, you must downgrade the primary before any secondaries can be downgraded. As a best practice, when scaling up or down, you should ensure that the secondary database has the higher service objective longer than the primary. In other words, when scaling up, scale up secondary databases first; when scaling down, scale down secondary databases second.
Set up failover groups
As discussed in the previous section, geo-replication represents a very capable option for DR planning. Geographically distributing relational data with an RPO of 5 seconds or less is a goal that few on-premises environments can achieve. However, the lack of automatic failover and the need to configure failover on each database individually creates overhead in any deployment, whether it has a single database in an organization with a single DBA or many hundreds or thousands of databases. Further, because a failover causes the writable database to be hosted on a different logical server with a different DNS name, connection strings must be updated, or the application must be modified to try a different connection.
Failover groups build on geo-replication to address these shortcomings. Configured at the server level, a failover group can include one, multiple, or all databases hosted on that server. All databases in a group are recovered simultaneously. By default, failover groups are set to automatically recover the databases in case of an outage, though you can disable this. With automatic recovery enabled, you must configure a grace period. This grace period offers a way to direct the Azure infrastructure to emphasize either availability or data guarantees. By increasing the grace period, you emphasize data guarantees, because the automatic failover does not occur if it will result in data loss until the outage has lasted as long as the grace period. By decreasing the grace period, you emphasize availability. In practical terms, this means that if the secondary database in the failover group is not up to date after the grace period expires, the failover will occur, resulting in data loss.
When you configure a failover group, two new DNS CNAME records are created:
The first
CNAMErecord refers to the read-write listener and it points to the primary server. During a failover, this record is updated automatically so it always points to the writable replica. The read-write listener’s FQDN is the name of the failover group prepended to database.windows.net. This means your failover group name must be globally unique.The second
CNAMErecord points to the read-only listener, which is the secondary server. The read-only listener’s DNS name is the name of the failover group prepended to secondary.database.windows.net. If the failover group name is ssio2022, the FQDN of the read-write listener will be ssio2022.database.windows.net and the FQDN of the secondary will be ssio2022.secondary.database.windows.net.Note
As of this writing, a failover group can have only one secondary. For high-value databases, you should still configure additional secondaries to ensure HA isn’t lost in case of a failover.
You can create failover groups with existing geo-replication already in place. If the failover group’s secondary server is in the same region as an existing geo-replication secondary, the existing secondary will be used for the failover group. If you select a region for the failover secondary server where no replica is configured yet, a new secondary server and database will be created during the deployment process. If a new secondary database is created, it will be created in the same tier and with the same service objective as the primary. (Recall that these replicas incur service charges.)
Unlike with geo-replication, the Azure portal supports the initiation of a planned failover for failover groups. You can also initiate a planned failover by using PowerShell. Planned failovers do not cause data loss. Both interfaces also support the initiation of a forced failover, which, as with geo-replication’s unplanned failover, can lead to data loss within the 5-second RPO window.
Note
DR and business-continuity planning should not just consider Azure SQL Database resources, but also other Azure services your application uses. These might include Azure Web Apps, VMs, DNS, storage accounts, and more. For more information on designing HA services that include Azure SQL Database, see https://learn.microsoft.com/azure/sql-database/sql-database-designing-cloud-solutions-for-disaster-recovery.
Use Azure Backup for long-term backup retention
To meet compliance and regulatory requirements, you might need to maintain a series of long-term database backups. Azure SQL Database can provide a solution using long-term retention (LTR). You can elect to retain full backups for a maximum of 10 years. Retained backups are stored in Azure Blob Storage, which is created for you; you don’t need to provide a storage account.
Long-term backup retention is configured at the server level, but databases on the server can be selectively included or excluded. To begin, you create a retention policy. As its name indicates, the retention policy determines how long the backups are retained. After you configure retention, the next full backups that meet the criteria for weekly, monthly, or yearly will be retained. In other words, existing backups are not included in the long-term retention. A different retention period can be specified for weekly, monthly, and yearly full backups. You can also choose a simpler configuration, to keep only some of the backups.
- For more information on creating a vault as well as step-by-step guidance, see https://learn.microsoft.com/azure/sql-database/sql-database-long-term-backup-retention-configure.
When a database is deleted, you will continue to be charged for the backup’s contents; however, the charges will decrease over time as backup files older than the retention period are deleted.
You can configure long-term backup retention by using the Azure portal or PowerShell. Although only primary or standalone databases are backed up and will therefore be the only databases that have backups added to storage, you should also configure long-term backup retention on geo-replicated secondaries. This ensures that in case of a failover, backups from the new primary database will be added to its vault, without further intervention. After a failover, a full backup is immediately taken, and that backup is added to long-term storage. Until a failover takes place, no additional costs are incurred for configuring retention on the secondary server.
Note
When the server hosting a database is deleted, the database backups are immediately and irrevocably lost. This does not apply to long-term backup retention. If you configured LTR for a database, the LTR backups can be used to restore databases to a different server in the same subscription.