
As mentioned and proven in a number of previous chapters, digital audio creates large amounts of data to be stored; the need for data compression became clear almost from the start of digital audio, but it also became clear that digital audio compression and data compression as used in PCs was a totally different game. Much research and development needed to be performed before some usable designs were available. One of the most noticeable efforts in this domain was performed by the Fraunhofer Institute in Germany, together with the University of Erlangen, who started to work around 1987 on a perceptual audio coding in the framework of Digital Audio Broadcast. A powerful algorithm to compress the digital data used for audio purposes was standardized.
Based on the compression techniques developed by the Motion Picture Expert Group (MPEG) to compress the amount of data for video purposes, the MPEG audio coding family became reality.
Note that the MPEG theory, which is explained here, closely resembles the theory behind ATRAC, as used in MiniDisc and explained in Chapter 17. For the sake of completeness, and to demonstrate that both methods are indeed derived from the same line of thought, readers should be aware that some feeling of ‘déja-vu’ when reading the psychoacoustics behind MPEG might occur.
Depending on the MPEG layer, the original data are reduced up to 12 times. The basic technique to realize this is to make use of the masking effect and the psychoacoustics of the human ear, and to remove the redundant signals by making use of complex algorithms. The psychoacoustic curve has been set up by means of a group of test persons. By exploring several test tones to this group of persons, a detailed curve of the average human hearing sensitivity could be established. Out of these tests it was found that the human ear is most sensitive for frequencies between 2 and 4 kHz. Figure 20.1 is a representation of the threshold level of human hearing in a quiet room. The average person does not hear sounds from below that line.
The second part of the psychoacoustics is the masking effect or the covering of other signals. Due to a loud sound it can happen that the human ear does not notice weaker sounds. In Figure 20.2, it can be seen that when a tone of 1 kHz is emitted, the nearby frequencies with a lower level are covered. The normal threshold line will change momentarily due to this short burst.
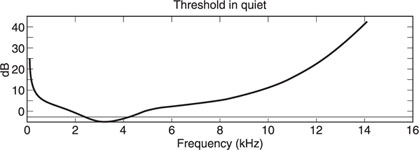
Figure 20.1 Human hearing sensitivity.
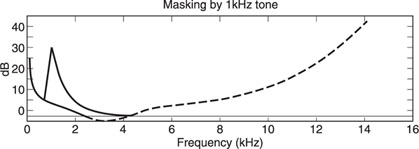
Figure 20.2 Masking effect.
In the same way, a similar threshold line can be made for different test tones (Figure 20.3).
The third part is temporal masking. Right after playing a loud tone of a certain frequency, adjacent frequencies are masked even when the test tone has already stopped.
These items were set up by experiment and are used as a perceptual model to encode the digital information.
The basic idea of MPEG is the division of the incoming audio signal into 32 critical bands. Within these bands, the threshold level will be defined and all information below this threshold will be omitted.
The encoder part analyses the incoming signal and creates a filterbank. This filterbank is compared to the psychoacoustic model to estimate the noise level that can be covered (masked) by the signal. Subsequently, the encoder tries to allocate the available amount of bits (depending on the compression rate) to meet the bit rate and the masking requirements.
Suppose we have the next situation: an audio signal is analysed in the critical bands at the level presented in Figure 20.6. The level in band 8 is 60 dB. This will result in a masking effect of 12 dB in band 7. The level in band 7 is 10 dB, so it will be completely masked and there is no need to encode band 7. The noise level of band 8 is 12 dB, so encoding can be performed with 2 bits (refer to Chapter 3, section on ‘Calculation of theoretical signal-to-noise ratio’ pages 49–50).
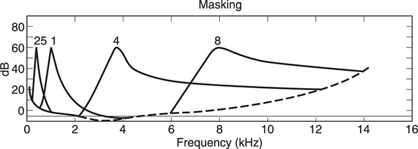
Figure 20.3 Masking effect for different frequencies.
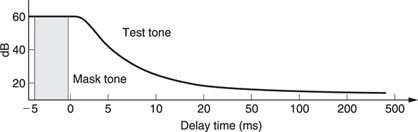
Figure 20.4 Temporal masking.
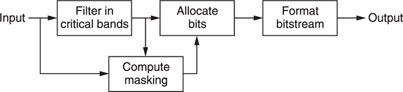
Figure 20.5 Encoder.
![]()
Figure 20.6 Band analysis.
MPEG layer 1 will reduce the amount of data four times, which corresponds with a transfer rate of 384 kbps starting from a 16-bit PCM signal sampled at 44.1 kHz. Layer 2 reduces the data six to eight times. The very popular layer 3 or MP3 reduces the amount of data 10–12 times (corresponds with 128…112 kbps for a stereo signal), without losing the majority of the sound quality.
Obviously, the audio quality will also vary with the compression level; some tradeoff between the amount of compression and audio quality has to be foreseen, although design improvement continuously pushes the limits forward.
Based upon these psychoacoustic theories, and some basic specifications, MPEG audio layers become a kind of applied computer programming, which can be designed appropriately.
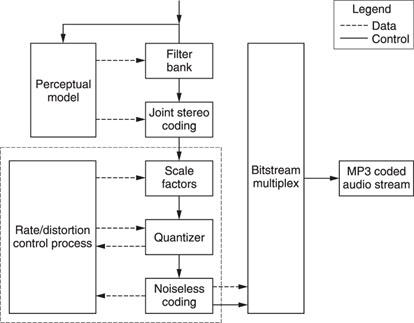
Figure 20.7 MP3 encoder.
Compression for other applications
As already mentioned, Sony improved the existing compression method ‘ATRAC’ that is used in the MiniDisc. By means of complex algorithms, ATRAC version 3 is capable of compressing the data two to four more times. Depending on the compression chosen (in the case of MiniDisc Long Play or MDLP, this is called LP2 or LP4), a bit rate of 132 or 66 kbps can be achieved without losing most of the high-quality sound information.
Basically, ATRAC3 uses a more efficient method of allocating the bits than previous ATRAC versions. More frequency bands are used and more efficient use of the available bits is achieved by several recalculations of the original signal.
Further bit reduction for ATRAC3 and also for MP3 is realized by the adoption of a joint stereo coding scheme, which takes advantage of the similarity of the left and right channels in a stereo signal. In general, the difference between left and right is not very much, so the amount of data needed to encode these differences will be much smaller than the complete signal.
With the further development of multi-channel audio, more powerful compressions were needed for this purpose. Starting with the Dolby AC1 encoding, where the surround channels are multiplexed in the stereo signals, sound quality and coding gain improved over the years. Already in 1992, the first cinema movies were presented with AC3 sound and in 1995 the Dolby AC3 digital compression algorithm was widely accepted to encode 1 to 5.1 channel PCM converted signals into a serial bit stream.
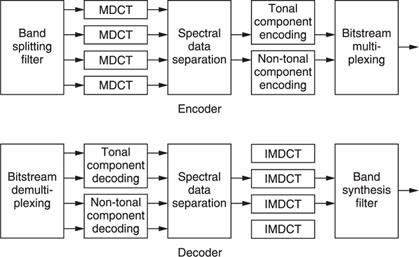
Figure 20.8 ATRAC encoder–decoder.
A block diagram of the AC3 process is shown in Figure 20.9.
Under impulse of the manufacturers that came up with different carriers, different compression techniques were also developed to compress the multi-channel sound information. Most of these compression techniques are based on MPEG-2 Advanced Audio Coding (MPEG-2AAC), which was created by an international cooperation of the Fraunhofer Institute and companies like AT&T, Sony and Dolby. MPEG-2AAC became an international standard at the end of April 1999. For high-quality sound reproduction, compression without loss (DST for SACD and MLP for DVD-Audio) were developed.
In fact, MPEG-2AAC is the further development of the successful ISO/MPEG Audio layer 3. The main difference is that MPEG-2AAC can compress data between one and 48 channels with a sampling frequency between 8 and 96 kHz. The high-quality compression is achieved by some crucial differences to MP3:
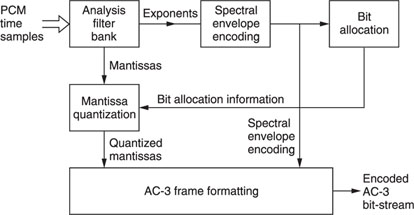
Figure 20.9 AC3 encoder.
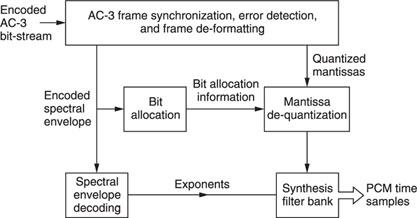
Figure 20.10 AC3 decoder.
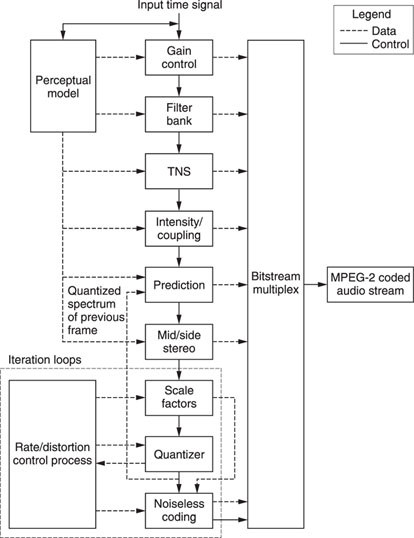
Figure 20.11 MPEG2-2AAC block.
At present, MPEG-2AAC is the most advanced coding technology used as a basis to compress high-quality sound sources and is selected to be used in the Digital Radio Mondiale (DRM). DRM is a world consortium dedicated to form a single world standard for digital broadcasting in AM radio bands below 30 MHz. Its members are broadcasters, network operators, receiver and transmitter manufacturers, research institutes and standardization bodies.
For transportation of high-quality music via the internet, MPEG-2AAC will also play an important role.