
Active Record associations let you declaratively express relationships between model classes. The power and readability of the Associations API is an important part of what makes working with Rails so special.
This chapter covers the different kinds of ActiveRecord associations available while highlighting use cases and available customizations for each of them. We also take a look at the classes that give us access to relationships themselves.
Associations typically appear as methods on ActiveRecord model objects. For example, the method timesheets might represent the timesheets associated with a given user.
>> user.timesheets
However, people might get confused about the type of objects that are returned by association with these methods. This is because they have a way of masquerading as plain old Ruby objects and arrays (depending on the type of association we’re considering). In the snippet, the timesheet method may appear to return an array of project objects.
The console will even confirm our thoughts. Ask any association collection what its return type is and it will tell you that it is an Array:
>> obie.timesheets.class => Array
It’s actually lying to you, albeit very innocently. Association methods for has_many associations are actually instances of HasManyAssociation, shown within its class hierarchy in Figure 7.1.
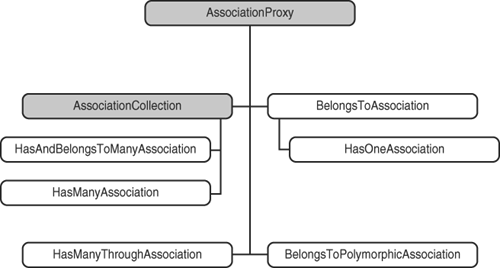
The parent class of all associations is AssociationProxy. It contains the basic structure and functionality of all assocation proxies. If you look near the top of its source code excerpted in Listing 7.1, you’ll notice that it undefines a bunch of methods.
As a result, most normal instance methods aren’t actually defined on the proxy anymore, but are instead delegated to the target of the proxy via method_missing. That means that a call to timesheets.class returns the class of the underlying array rather than the proxy. You can prove that timesheet is actually a proxy by asking it if it responds to one of AssociationProxy’s public methods, such as proxy_owner:
>> obie.timesheets.respond_to? :proxy_owner => true
Fortunately, it’s not the Ruby way to care about the actual class of an object. What messages an object responds to is a lot more significant. That’s why I think it would be a mistake to make your code depend on working with an array instead of an association proxy. If absolutely necessary, you can always call to_a to get an actual Array object:
>> obie.timesheets.to_a # make absolutely sure we're working with an Array => []
The parent class of all has_many associations is AssociationCollection and most of the methods that it defines work similarly regardless of the options declared for the relationship. Before we get much further into the details of the association proxies, let’s delve into the most fundamental type of association that is commonly used in Rails applications: the has_many / belongs_to pair.
In our recurring sample application, an example of a one-to-many relationship is the association between the User, Timesheet, and ExpenseReport classes:
class User < ActiveRecord::Base has_many :timesheets has_many :expense_reports end
Timesheets and expense reports should be linked in the opposite direction as well, so that it is possible to reference the user to which a timesheet or expense report belongs.
class Timesheet < ActiveRecord::Base belongs_to :user end class ExpenseReport < ActiveRecord::Base belongs_to :user end
When these relationship declarations are executed, Rails uses some metaprogramming magic to dynamically add code to your models. In particular, proxy collection objects are created that let you manipulate the relationship easily.
To demonstrate, let’s play with these relationships in the console. First, I’ll create a user.
>> obie = User.create :login => 'obie', :password => '1234', :password_confirmation => '1234', :email => '[email protected]' => #<User:0x2995278 ...}>
Now I’ll verify that I have collections for timesheets and expense reports.
>> obie.timesheets ActiveRecord::StatementInvalid: SQLite3::SQLException: no such column: timesheets.user_id: SELECT * FROM timesheets WHERE (timesheets.user_id = 1) from /.../connection_adapters/abstract_adapter.rb:128:in `log'
As David might say, “Whoops!” I forgot to add the foreign key columns to the timesheets and expense_reports tables, so in order to go forward I’ll generate a migration for the changes:
$ script/generate migration add_user_foreign_keys
exists db/migrate
create db/migrate/004_add_user_foreign_keys.rbThen I’ll open db/migrate/004_add_user_foreign_keys.rb and add the missing columns.
class AddUserForeignKeys < ActiveRecord::Migration
def self.up
add_column :timesheets, :user_id, :integer
add_column :expense_reports, :user_id, :integer
end
def self.down
remove_column :timesheets, :user_id
remove_column :expense_reports, :user_id
end
endRunning rake db:migrate applies the changes:
$ rake db:migrate (in /Users/obie/prorails/time_and_expenses) == AddUserForeignKeys: migrating ============================================== -- add_column(:timesheets, :user_id, :integer) -> 0.0253s -- add_column(:expense_reports, :user_id, :integer) -> 0.0101s == AddUserForeignKeys: migrated (0.0357s) ==============================================
Now I should be able to add a new blank timesheet to my user and check timesheets again to make sure it’s there:
>> obie = User.find(1)
=> #<User:0x29cc91c ... >
>> obie.timesheets << Timesheet.new
=> [#<Timesheet:0x2147524 @new_record=true, @attributes={}>]
>> obie.timesheets
=> [#<Timesheet:0x2147524 @new_record=true, @attributes={}>]According to the Rails documentation, adding an object to a has_many collection automatically saves that object, unless the parent object (the owner of the collection) is not yet stored in the database. Let’s make sure that’s the case using ActiveRecord’s reload method, which re-fetches the attributes of an object from the database:
>> obie.timesheets.reload
=> [#<Timesheet:0x29b3804 @attributes={"id"=>"1", "user_id"=>"1"}>]There it is. The foreign key, user_id, was automatically set by the << method.
The << method takes one or more association objects to add to the collection, and since it flattens its argument list and inserts each record, push and concat behave identically.
In the blank timesheet example, I could have used the create method on the association proxy, and it would have worked essentially the same way:
>> obie.timesheets.create => #<Timesheet:0x248d378 @new_record=false ... >
However, be careful when deciding between << and create!. Even though at first glance << and create do the same thing, there are several very important differences in how they’re implemented and you need to be aware of them (see the next sub-section “AssociationCollection Methods” for more information).
As illustrated in Figure 7.1, AssociationCollection has the following subclasses: HasManyAssociation and HasAndBelongsToManyAssociation. The following methods are inherited by and available to both of these subclasses. (HasManyThroughAssociation defines its own very similar set methods, covered later in the chapter.)
In Rails 1.2.3 and earlier versions, the first thing that the << method did was to load the entire contents of the collection from the database, an operation that could be very expensive! On the other hand, create simply invoked its counterpart on the association’s model class, passing along the value of the foreign key, so that the link is established in the database. Thankfully, Rails 2.0 corrects the behavior of << in that it doesn’t load the entire collection, making it similar in function to create.
However, this is an area of Rails where you can really hurt yourself if you’re not careful. For instance, both methods will add either a single associated object or many, depending on whether you pass them an array or not. However, << is transactional, and create is not.
Yet another difference has to do with association callbacks (covered in this chapter’s options section for has_many). The << method triggers the :before_add and :after_add callbacks, but the create method does not.
Finally, the return value behavior of both methods varies wildly. The create method returns the new instance created, which is what you’d expect given its counterpart in ActiveRecord::Base. The << method returns the association proxy (ever masquerading as an array), which allows chaining and is also natural behavior for a Ruby array.
However, << will return false and not itself if any of the records being added causes the operation to fail. Therefore you shouldn’t really depend on its return value being an array that you can continue operating on in a chained fashion.
Removes all records from this association by clearing the foreign key field (see delete). If the association is configured with the :dependent option set to :delete_all, then clear iterates over all the associated objects and invokes destroy on each one.
The clear method is transactional.
The delete and delete_all methods are used to sever specified associations, or all of them, respectively. Both methods operate transactionally.
It’s worth noting, for performance reasons, that calling delete_all first loads the entire collection of associated objects into memory in order to grab their ids. Then it executes a SQL UPDATE that sets foreign keys for all currently associated objects to nil, effectively disassociating them from their parent. Since it loads the entire association into memory, it would be ill-advised to use this method with an extremely large collection of associated objects.
Note
The names of the delete and delete_all methods can be misleading. By default, they don’t delete anything from the database—they only sever associations by clearing the foreign key field of the associated record. This behavior is related to the :dependent option, which defaults to :nullify. If the association is configured with the :dependent option set to :delete_all or :destroy, then the associated records will actually be deleted from the database.
The destroy_all method takes no parameters; it’s an all or nothing affair. When called, it begins a transaction and invokes destroy on each object in the association, causing them all to be deleted from the database with individual DELETE SQL statements. Again, there are load issues to consider if you plan to use this method with large association collections, since many objects will be loaded into memory at once.
Returns the size of the collection by loading it and calling size on the array. If you want to use this method to check whether the association collection is empty, use length.zero? instead of just empty?. It’s more efficient.
Replaces the collection with other_array. Works by deleting objects that exist in the current collection, but not in other_array and inserting (using concat) objects that don’t exist in the current collection, but do exist in other_array.
If the collection has already been loaded, the size method returns its size. Otherwise a SELECT COUNT(*) query is executed to get the size of the associated collection without having to load any objects.
When starting from an unloaded state where it’s likely that the collection is not actually empty and you will need to load the collection no matter what, it’ll take one less SELECT query if you use length.
The :uniq setting, which removes duplicates from association collections, comes into play when calculating size—basically it will force all objects to be loaded from the database so that Rails can remove duplicates in Ruby code.
Calculates a summed value in the database using SQL. The first parameter should be a symbol identifying the column to be summed. You have to provide a :group option, so that a summation actually takes place.
total = person.accounts.sum(:credit_limit, :group => 'accounts.firm_id')
Depending on the way your association is structured, you may need to disambiguate the query by prefixing the name of the table to the value you pass to :group.
The belongs_to class method expresses a relationship from one ActiveRecord object to a single associated object for which it has a foreign key attribute. The trick to remembering whether a class “belongs to” another one is determining where the foreign key column will reside.
Assigning an object to a belongs_to association will set its foreign key attribute to the owner object, but will not save the record to the database automatically, as in the following example:
>> timesheet = Timesheet.create
=> #<Timesheet:0x248f18c ... @attributes={"id"=>1409, "user_id"=>nil,
"submitted"=>nil} ...>
>> timesheet.user = obie
=> #<User:0x24f96a4 ...>
>> timesheet.user.login
=> "obie"
>> timesheet.reload
=> #<Timesheet:0x248f18c @billable_weeks=nil, @new_record=false,
@user=nil...>Defining a belongs_to relationship on a class establishes an attribute of the same name on instances of that class. As mentioned earlier, the attribute is actually a proxy to the related ActiveRecord object and adds capabilities useful for manipulating the relationship.
Just invoking the attribute will query the database (if necessary) and return an instance of the related object. The accessor method actually takes a force_reload parameter that tells ActiveRecord whether to reload the related object, if it happens to have been cached already by a previous access.
In the following capture from my console, I look up a timesheet and take a peek at the object_id of its related user object. Notice that the second time I invoke the association via user, the object_id remains the same. The related object has been cached. However, passing true to the accessor reloads the relationship and I get a new instance.
>> ts = Timesheet.find :first
=> #<Timesheet:0x3454554 @attributes={"updated_at"=>"2006-11-21
05:44:09", "id"=>"3", "user_id"=>"1", "submitted"=>nil,
"created_at"=>"2006-11-21 05:44:09"}>
>> ts.user.object_id
=> 27421330
>> ts.user.object_id
=> 27421330
>> ts.user(true).object_id
=> 27396270The belongs_to method does some metaprogramming and adds factory methods for creating new instances of the related class and attaching them via the foreign key automatically.
The build_association method does not save the new object, but the create_association method does. Both methods take an optional hash of attribute parameters with which to initialize the newly instantiated objects. Both are essentially one-line conveniences, which I don’t find particularly useful, because it just doesn’t usually make sense to create instances in that direction!
To illustrate, I’ll simply show the code for building a User from a Timesheet or creating a Client from a BillingCode, neither of which would ever happen in real code because it just doesn’t make sense to do so:
>> ts = Timesheet.find :first
=> #<Timesheet:0x3437260 @attributes={"updated_at"=>"2006-11-21
05:44:09", "id"=>"3", "user_id"=>"1", "submitted"=>nil, "created_at"
=>"2006-11-21 05:44:09"}>
>> ts.build_user
=> #<User:0x3435578 @attributes={"salt"=>nil, "updated_at"=>nil,
"crypted_password"=>nil, "remember_token_expires_at"=>nil,
"remember_token"=>nil, "login"=>nil, "created_at"=>nil, "email"=>nil},
@new_record=true>
>> bc = BillingCode.find :first
=> #<BillingCode:0x33b65e8 @attributes={"code"=>"TRAVEL", "client_id"
=>nil, "id"=>"1", "description"=>"Travel expenses of all sorts"}>
>> bc.create_client
=> #<Client:0x33a3074 @new_record_before_save=true,
@errors=#<ActiveRecord::Errors:0x339f3e8 @errors={},
@base=#<Client:0x33a3074 ...>>, @attributes={"name"=>nil, "code"=>nil,
"id"=>1}, @new_record=false>You’ll find yourself creating instances of belonging objects from the has_many side of the relationship much more often.
The following options can be passed in a hash to the belongs_to method.
Assume for a moment that we wanted to establish another belongs_to relationship from the Timesheet class to User, this time modeling the relationship to the approver of the timesheet. You might start by adding an approver_id column to the timesheets table and an authorized_approver column to the users table:
class AddApproverInfo < ActiveRecord::Migration
def self.up
add_column :timesheets, :approver_id, :integer
add_column :users, :authorized_approver, :boolean
end
def self.down
remove_column :timesheets, :approver_id
remove_column :users, :authorized_approver
end
endThen you would add a belongs_to that looks like the following:
class Timesheet < ActiveRecord::Base belongs_to :approver ...
The thing is that Rails can’t figure out what class you’re trying to connect to with just the information provided, because you’ve (legitimately) acted against the Rails convention of naming a relationship according to the related class. It’s time for a :class_name parameter.
class Timesheet < ActiveRecord::Base belongs_to :approver, :class_name => 'User' ...
What about adding conditions to the belongs_to association? Rails allows us to add conditions to a relationship that must be satisfied in order for it to be valid. The :conditions option allows you to do just that, with the same syntax that is used when you add conditions to a find invocation.
In the last migration, I added an authorized_approver column to the users table and we’ll make use of it here:
class Timesheet < ActiveRecord::Base
belongs_to :approver,
:class_name => 'User',
:conditions => ['authorized_approver = ?', true]
...
endNow in order for the assignment of a user to the approver field to work, that user must be authorized. I’ll go ahead and add a test that both indicates the intention of my code and shows it in action.
First I need to ensure that my users fixture (users.yml) makes an authorized approver available to my test methods. For good measure, I go ahead and add a non-authorized user too. The following markup appears at the bottom of test/fixtures/users.yml:
approver: id: 4 login: "manager" authorized_approver: true joe: id: 5 login: "joe" authorized_approver: false
Then I turn my attention to test/unit/timesheet_test.rb, where I add a test to make sure that my application code works and is correct:
require File.dirname(__FILE__) + '/../test_helper'
class TimesheetTest < Test::Unit::TestCase
fixtures :users
def test_only_authorized_user_may_be_associated_as_approver
sheet = Timesheet.create
sheet.approver = users(:approver)
assert_not_nil sheet.approver, "approver assignment failed"
end
endIt’s a good start, but I also want to make sure something happens to prevent the system from assigning a nonauthorized user to the approver field, so I add another test:
def test_non_authorized_user_cannot_be_associated_as_approver sheet = Timesheet.create sheet.approver = users(:joe) assert sheet.approver.nil?, "approver assignment should have failed" end
I have my suspicions about the validity of that test, though, and as I half-expected, it doesn’t really work the way I want it to work:
1) Failure: test_non_authorized_user_cannot_be_associated_as_approver(TimesheetTest ) [./test/unit/timesheet_test.rb:16]: approver assignment should have failed. <false> is not true.
The problem is that ActiveRecord (for better or worse, probably worse) allows me to make the invalid assignment. The :conditions option only applies during the query to get the association back from the database. I’ll have some more work ahead of me to achieve the desired behavior, but I’ll go ahead and prove out Rails’ actual behavior by fixing my tests:
def test_only_authorized_user_may_be_associated_as_approver sheet = Timesheet.create sheet.approver = users(:approver) assert sheet.save assert_not_nil sheet.approver(true), "approver assignment failed" end def test_non_authorized_user_cannot_be_associated_as_approver sheet = Timesheet.create sheet.approver = users(:joe) assert sheet.save assert sheet.approver(true).nil?, "approver assignment should fail" end
Those two tests do pass. I went ahead and made sure to save the sheet, since just assigning a value to it will not save the record. Then I took advantage of the force_reload parameter to make Rails reload approver from the database, and not just simply give me the same instance I originally assigned to it.
The lesson to learn is that :conditions on relationships never affect the assignment of associated objects, only how they’re read back from the database. To enforce the rule that a timesheet approver must be authorized, you’d need to add a before_save callback to the Timesheet class itself. Callbacks are covered in detail at the beginning of Chapter 9, “Advanced ActiveRecord,” and since I’ve gotten us a little bit off on a tangent, we’ll go back to the list of options available for the belongs_to association.
Specifies the name of the foreign key column that should be used to find the associated object. Rails will normally infer this setting from the name of the association, by adding _id . You can override the inferred foreign key name with this option if necessary.
# without the explicit option, Rails would guess administrator_id belongs_to :administrator, :foreign_key => 'admin_user_id'
Use this option to make Rails automatically update a counter field on the associated object with the number of belonging objects. The option value can be true, in which case the pluralized name of the belonging class plus _count is used, or you can supply your own column name to be used:
:counter_cache => true :counter_cache => 'number_of_children'
If a significant percentage of your association collections will be empty at any given moment, you can optimize performance at the cost of some extra database storage by using counter caches liberally. The reason is that when the counter cache attribute is at zero, Rails won’t even try to query the database for the associated records!
Note
The value of the counter cache column must be set to zero by default in the database! Otherwise the counter caching won’t work at all. It’s because the way that Rails implements the counter caching behavior is by adding a simple callback that goes directly to the database with an UPDATE command and increments the value of the counter.
If you’re not careful, and neglect to set a default value of 0 for the counter cache column on the database, or misspell the column name, the counter cache will still seem to work! There is a magic method on all classes with has_many associations called collection_count, just like the counter cache. It will return a correct count value if you don’t have a counter cache option set or the counter cache column value is null!
Takes a list of second-order association names that should be eager-loaded when this object is loaded. A SELECT statement with the necessary LEFT OUTER JOINS will be constructed on the fly so that all the data needed to construct a whole object graph is queried in one database request.
With judicious use of :include and careful benchmarking, you can sometimes improve the performance of your application dramatically, mostly by eliminating N+1 queries. On the other hand, since doing huge multijoin queries and instantiating large object trees can also get very costly, certain usages of :include can actually make your application perform much more slowly. As they say, your mileage may vary.
Use the :polymorphic option to specify that an object is related to its association in a polymorphic way, which is the Rails way of saying that the type of the related object is stored in the database along with its foreign key. By making a belongs_to relationship polymorphic, you abstract out the association so that any other model in the system can fill it.
Polymorphic associations let you trade some measure of relational integrity for the convenience of implementation in child relationships that are reused across your application. Common examples are models such as photo attachments, comments, notes, line items, and so on.
Let’s illustrate by writing a Comment class that attaches to its subjects polymorphically. We’ll associate it to both expense reports and timesheets. Listing 7.2 has the schema information in migration code, followed by the code for the classes involved. Notice the :subject_type column, which stores the class name of the associated class.
Example 7.2. Comment Class Using Polymorphic belongs_to Relationship
create_table :comments do |t| t.column :subject, :string t.column :body, :text t.column :subject_id, :integer t.column :subject_type, :string t.column :created_at, :datetime end class Comment < ActiveRecord::Base belongs_to :subject, :polymorphic => true end class ExpenseReport < ActiveRecord::Base belongs_to :user has_many :comments, :as => :subject end class Timesheet < ActiveRecord::Base belongs_to :user has_many :comments, :as => :subject end
As you can see in the ExpenseReport and Timesheet classes of Listing 7.2, there is a corresponding syntax where you give ActiveRecord a clue that the relationship is polymorphic by specifying :as => :subject. We haven’t even covered has_many relationships yet, and polymorphic relationships have their own section in Chapter 9. So before we get any further ahead of ourselves, let’s take a look at has_many relationships.
Just like it sounds, the has_many association allows you to define a relationship in which one model has many other models that belong to it. The sheer readability of code constructs such as has_many is a major reason that people fall in love with Rails.
The has_many class method is often used without additional options. If Rails can guess the type of class in the relationship from the name of the association, no additional configuration is necessary. This bit of code should look familiar by now:
class User has_many :timesheets has_many :expense_reports
The names of the associations can be singularized and match the names of models in the application, so everything works as expected.
Despite the ease of use of has_many, there is a surprising amount of power and customization possible for those who know and understand the options available.
Called after a record is added to the collection via the << method. Is not triggered by the collection’s create method, so careful consideration is needed when relying on association callbacks.
Add callback method options to a has_many by passing one or more symbols corresponding to method names, or Proc objects. See Listing 7.3 in the :before_add option for an example.
Called after a record has been removed from the collection with the delete method. Add callback method options to a has_many by passing one or more symbols corresponding to method names, or Proc objects. See Listing 7.3 in the :before_add option for an example.
Specifies the polymorphic belongs_to association to use on the related class. (See Chapter 9 for more about polymorphic relationships.)
Triggered when a record is added to the collection via the << method. (Remember that concat and push are aliases of <<.) Raising an exception in the callback will stop the object from getting added to the collection. (Basically, because the callback is triggered right after the type mismatch check, and there is no rescue clause to be found inside <<.)
Add callback method options to a has_many by passing one or more symbols corresponding to method names, or Proc objects. You can set the option to either a single callback (as a Symbol or Proc) or to an array of them.
Of course, that would have been a lot shorter code using a Proc since it’s a one liner. The owner parameter is the object with the association. The record parameter is the object being added.
has_many :unchangable_posts,
:class_name => "Post",
:before_add => Proc.new {|owner, record| raise "Can't do it!"}One more time, with a lambda, which doesn’t check the arity of block parameters:
has_many :unchangable_posts,
:class_name => "Post",
:before_add => lamda {raise "You can't add a post"}Called before a record is removed from a collection with the delete method. See before_add for more information.
The :class_name option is common to all of the associations. It allows you to specify, as a string, the name of the class of the association, and is needed when the class name cannot be inferred from the name of the association itself.
The :conditions option is common to all of the associations. It allows you to add extra conditions to the ActiveRecord-generated SQL query that bring back the objects in the association.
You can apply extra :conditions to an association for a variety of reasons. How about approval?
has_many :comments, :conditions => ['approved = ?', true]
Plus, there’s no rule that you can’t have more than one has_many association exposing the same two related tables in different ways. Just remember that you’ll probably have to specify the class name too.
has_many :pending_comments, :conditions => ['approved = ?', true],
:class_name => 'Comment'Overrides the ActiveRecord-generated SQL query that would be used to count the number of records belonging to this association. Not necessarily needed in conjunction with the :finder_sql option, since ActiveRecord will automatically generate counter SQL code based on the custom finder SQL statement.
As with all custom SQL specifications in ActiveRecord, you must use single-quotes around the entire string to prevent premature interpolation. (That is, you don’t want the string to get interpolated in the context of the class where you’re declaring the association. You want it to get interpolated at runtime.)
has_many :things, :finder_sql => 'select * from t where id = #{id}'Overrides the ActiveRecord-generated SQL statement that would be used to break associations. Access to the associated model is provided via the record method.
All associated objects are deleted in fell swoop using a single SQL command. Note: While this option is much faster than :destroy_all, it doesn’t trigger any destroy callbacks on the associated objects—you should use this option very carefully. It should only be used on associations that depend solely on the parent object.
All associated objects are destroyed along with the parent object, by iteratively calling their destroy methods.
The default behavior for deleting associated records is to nullify, or clear, the foreign key that joins them to the parent record. You should never have to specify this option explicitly, it is only here for reference.
Specifies a module with methods that will extend the association collection proxy. Used as an alternative to defining additional methods in a block passed to the has_many method itself. Discussed in the section “Association Extensions”.
Specifies a complete SQL statement to fetch the association. This is a good way to load complex associations that depend on multiple tables for their data. It’s also quite rare to need to go this route.
Count operations are done with a SQL statement based on the query supplied via the :finder_sql option. If ActiveRecord botches the transformation, it might be necessary to supply an explicit :counter_sql value also.
Overrides the convention-based foreign key name that would normally be used in the SQL statement that loads the association.
Takes an array of second-order association names (as an array) that should be eager-loaded when this collection is loaded. As with the :include option on belongs_to associations, with judicious use of :include and careful benchmarking you can sometimes improve the performance of your application dramatically.
To illustrate, let’s analyze how :include affects the SQL generated while navigating relationships. We’ll use the following simplified versions of Timesheet, BillableWeek, and BillingCode:
class Timesheet < ActiveRecord::Base has_many :billable_weeks end class BillableWeek < ActiveRecord::Base belongs_to :timesheet belongs_to :billing_code end class BillingCode < ActiveRecord::Base belongs_to :client has_many :billable_weeks end
First, I need to set up my test data, so I create a timesheet instance and add a couple of billable weeks to it. Then I assign a billable code to each billable week, which results in an object graph (with four objects linked together via associations).
Next I do a fancy one-line collect, which gives me an array of the billing codes associated with the timesheet:
>> Timesheet.find(3).billable_weeks.collect{ |w| w.billing_code.code }
=> ["TRAVEL", "DEVELOPMENT"]Without the :include option set on the billable_weeks association of Timesheet, that operation cost me the following four database hits (copied from log/development.log, and prettied up a little):
Timesheet Load (0.000656) SELECT * FROM timesheets
WHERE (timesheets.id = 3)
BillableWeek Load (0.001156) SELECT * FROM billable_weeks
WHERE (billable_weeks.timesheet_id = 3)
BillingCode Load (0.000485) SELECT * FROM billing_codes
WHERE (billing_codes.id = 1)
BillingCode Load (0.000439) SELECT * FROM billing_codes
WHERE (billing_codes.id = 2)This is demonstrates the so-called “N+1 select” problem that inadvertently plagues many systems. Anytime I need one billable week, it will cost me N select statements to retrieve its associated records.
Now let’s add :include to the billable_weeks association, after which the Timesheet class looks as follows:
class Timesheet < ActiveRecord::Base has_many :billable_weeks, :include => [:billing_code] end
Simple! Rerunning our test statement yields the same results in the console:
>> Timesheet.find(3).billable_weeks.collect{ |w| w.billing_code.code }
=> ["TRAVEL", "DEVELOPMENT"]But look at how different the generated SQL is:
Timesheet Load (0.002926) SELECT * FROM timesheets LIMIT 1 BillableWeek Load Including Associations (0.001168) SELECT billable_weeks."id" AS t0_r0, billable_weeks."timesheet_id" AS t0_r1, billable_weeks."client_id" AS t0_r2, billable_weeks."start_date" AS t0_r3, billable_weeks."billing_code_id" AS t0_r4, billable_weeks."monday_hours" AS t0_r5, billable_weeks."tuesday_hours" AS t0_r6, billable_weeks."wednesday_hours" AS t0_r7, billable_weeks."thursday_hours" AS t0_r8, billable_weeks."friday_hours" AS t0_r9, billable_weeks."saturday_hours" AS t0_r10, billable_weeks."sunday_hours" AS t0_r11, billing_codes."id" AS t1_r0, billing_codes."client_id" AS t1_r1, billing_codes."code" AS t1_r2, billing_codes."description" AS t1_r3 FROM billable_weeks LEFT OUTER JOIN billing_codes ON billing_codes.id = billable_weeks.billing_code_id WHERE (billable_weeks.timesheet_id = 3)
Rails has added a LEFT OUTER JOIN clause so that billing code data is loaded along with billable weeks. For larger datasets, the performance improvement can be quite dramatic!
It’s generally easy to find N+1 select issues just by watching the log scroll by while clicking through the different screens of your application. (Of course, make sure that you’re looking at realistic data or the exercise will be pointless.) Screens that might benefit from eager loading will cause a flurry of single-row SELECT statements, one for each record in a given association being used.
If you’re feeling particularly daring (perhaps masochistic is a better term) you can try including a deep hierarchy of associations, by mixing hashes into your eager :include array:
Post.find(:all, :include=>[:author, {:comments=>{:author=>:gravatar }}])That example snippet will grab not only all the comments for a Post, but all the authors and gravatar pictures as well. You can mix and match symbols, arrays and hashes in any combination to describe the associations you want to load.
Frankly, deep :includes are not well-documented functionality and are probably more trouble than what they’re worth. The biggest problem is that pulling too much data in one query can really kill your performance. You should always start out with the simplest solution that will work, then use benchmarking and analysis to figure out if optimizations such as eager-loading help improve your performance.
Overrides the ActiveRecord-generated SQL statement that would be used to create associations. Access the associated model via the record method.
Specifies the order in which the associated objects are returned via an “ORDER BY” sql fragment, such as "last_name, first_name DESC".
By default, this is * as in SELECT * FROM, but can be changed if you for example want to add additional calculated columns or “piggyback” additional columns from joins onto the associated object as its loaded.
Used exclusively as additional options to assist in using has_many :through associations with polymorphic belongs_to and is covered in detail later in the chapter.
The :table_name option lets you override the table names (FROM clause) that will be used in SQL statements generated for loading the association.
Creates an association collection via another association. See the section in this chapter entitled “has_many :through” for more information.
The has_many class method creates an association collection proxy, with all the methods provided by AssociationCollection and a few more methods defined in HasManyAssociation.
Instantiates a new object in the associated collection, and links it to the owner by specifying the value of the foreign key. Does not save the new object in the database and the new object is not added to the association collection. As you can see in the following example, unless you capture the return value of build, the new object will be lost:
>> obie.timesheets
=> <timesheets not loaded yet>
>> obie.timesheets.build
=> #<Timesheet:0x24c6b8c @new_record=true, @attributes={"user_id"=>1,
"submitted"=>nil}>
>> obie.timesheets
=> <timesheets not loaded yet>As the online API documents point out, the build method is exactly the same as constructing a new object and passing in the foreign key value as an attribute:
>> Timesheet.new(:user_id => 1)
=> #<Timesheet:0x24a52fc @new_record=true, @attributes={"user_id"=>1,
"submitted"=>nil}>Not much different here than the normal ActiveRecord find method, other than that the scope is constrained to associated records and any additional conditions specified in the declaration of the relationship.
Remember the has_one example shown earlier in the chapter? It was somewhat contrived, since it would have been easier to look up the last modified timesheet using find:.
Associating persistent objects via a join table can be one of the trickier aspects of object-relational mapping to implement correctly in a framework. Rails has a couple of techniques that let you represent many-to-many relationships in your model. We’ll start with the older and simpler has_and_belongs_to_many and then cover the newer has_many :through.
The has_and_belongs_to_many method establishes a link between two associated ActiveRecord models via an intermediate join table. Unless the join table is explicitly specified as an option, Rails guesses its name by concatenating the table names of the joined classes, in alphabetical order and separated with an underscore.
For example, if I was using has_and_belongs_to_many (or habtm for short) to establish a relationship between Timesheet and BillingCode, the join table would be named billing_codes_timesheets and the relationship would be defined in the models. Both the migration class and models are listed:
class CreateBillingCodesTimesheets < ActiveRecord::Migration
def self.up
create_table :billing_codes_timesheets, :id => false do |t|
t.column :billing_code_id, :integer, :null => false
t.column :timesheet_id, :integer, :null => false
end
end
def self.down
drop_table :billing_codes_timesheets
end
end
class Timesheet < ActiveRecord::Base
has_and_belongs_to_many :billing_codes
end
class BillingCode < ActiveRecord::Base
has_and_belongs_to_many :timesheets
endNote that an id primary key is not needed, hence the :id => false option was passed to the create_table method. Also, since the foreign key columns are both needed, we pass them a :null => false option. (In real code, you would also want to make sure both of the foreign key columns were indexed properly.)
What about self-referential many-to-many relationships? Linking a model to itself via a habtm relationship is easy—you just have to provide explicit options.
In Listing 7.4, I’ve created a join table and established a link between related BillingCode objects. Again, both the migration and model class are listed:
Example 7.4. Related Billing Codes
class CreateRelatedBillingCodes < ActiveRecord::Migration
def self.up
create_table :related_billing_codes, :id => false do |t|
t.column :first_billing_code_id, :integer, :null => false
t.column :second_billing_code_id, :integer, :null => false
end
end
def self.down
drop_table :related_billing_codes
end
end
class BillingCode < ActiveRecord::Base
has_and_belongs_to_many :related,
:join_table => 'related_billing_codes',
:foreign_key => 'first_billing_code_id',
:association_foreign_key => 'second_billing_code_id',
:class_name => 'BillingCode'
endIt’s worth noting that the related relationship of the BillingCode in Listing 7.4 is not bidirectional. Just because you associate two objects in one direction does not mean they’ll be associated in the other direction. But what if you need to automatically establish a bidirectional relationship?
First let’s write a test for the BillingCode class to prove our solution. We’ll start by writing a couple of sample records to work with in test/fixtures/billing_codes.yml:
travel: code: TRAVEL client_id: id: 1 description: Travel expenses of all sorts development: code: DEVELOPMENT client_id: id: 2 description: Coding, etc
When we add bidirectional, we don’t want to break the normal behavior, so at first my test method establishes that the normal habtm relationship works:
require File.dirname(__FILE__) + '/../test_helper'
class BillingCodeTest < Test::Unit::TestCase
fixtures :billing_codes
def test_self_referential_habtm_association
billing_codes(:travel).related << billing_codes(:development)
assert BillingCode.find(1).related.include?(BillingCode.find(2))
end
endI run the test and it passes. Now I can modify the test method to add proof that the bidirectional behavior that we’re going to add works. It ends up looking very similar to the original method. (Normally I would lean toward only having one assertion per test method, but in this case it makes more sense to keep them together.) The second assert statement checks to see that the newly associated class also has its related BillingCode in its related collection.
require File.dirname(__FILE__) + '/../test_helper'
class BillingCodeTest < Test::Unit::TestCase
fixtures :billing_codes
def setup
@travel = billing_codes(:travel)
@development = billing_codes(:development)
end
def test_self_referential_bidirectional_habtm_association
@travel.related << @development
assert @travel.related.include?(@development)
assert @development.related.include?(@travel)
end
endOf course, the new test fails, since we haven’t added the new behavior yet. I’m not entirely happy with this approach, since it involves bringing hand-coded SQL into my otherwise beautiful Ruby code. However, the Rails way is to use SQL when it makes sense to do so, and this is one of those cases.
To get our bidirectional, we’ll be using the :insert_sql option of has_and_belongs_to_many to override the normal INSERT statement that Rails would use to associate objects with each other.
Here’s a neat trick so that you don’t have to figure out the syntax of the INSERT statement from memory. Just copy and paste the normal INSERT statement that Rails uses. It’s not too hard to find in log/test.log if you tail the file while running the unit test we wrote in the previous section:
INSERT INTO related_billing_codes (`first_billing_code_id`, `second_billing_code_id`) VALUES (1, 2)
Now we just have to tweak that INSERT statement so that it adds two rows instead of just one. You might be tempted to just add a semicolon and a second, full INSERT statement. That won’t work, because it is invalid to stuff two statements into one using a semicolon. Try it and see what happens if you’re curious.
After some quick googling, I found the following method of inserting multiple rows with one SQL statement that will work for Postgres, MySQL, and DB2 databases.[1] It is valid according to the SQL-92 standard, just not universally supported:
:insert_sql => `INSERT INTO related_billing_codes
(`first_billing_code_id`, `second_billing_code_id`)
VALUES (#{id}, #{record.id}), (#{record.id}, #{id})`There are some very important things to remember when trying to get custom SQL options to work. The first is to use single quotes around the entire string of custom SQL. If you were to use double quotes, the string would be interpolated in the context of the class where it is being declared, not at the time of your query like you need it to be.
Also, while we’re on the subject of quotation marks and how to use them, note that when I copied the INSERT query over from my log, I ended up with backtick characters around the column names, instead of single quotes. Trying to use single-quotes around values instead of backtick characters will fail, because the database adapter will escape the quotes, producing invalid syntax. Yes, it’s a pain in the neck—luckily you shouldn’t need to specify custom SQL very often.
Another thing to remember is that when your custom SQL string is interpolated, it will happen in the context of the object holding the association. The object being associated will be made available as record. If you look closely at the code listing, you’ll notice that to establish the bidirectional link, we just added two rows in the related_billing_codes table, one in each direction.
A quick test run confirms that our :insert_sql approach did indeed work. We should also use the :delete_sql option to make sure that the relationship can be broken bidirectionally as well. Again, I’ll drive the implementation in a TDD fashion, adding the following test to BillingCodeTest:
def test_that_deletion_is_bidirectional_too billing_codes(:travel).related << billing_codes(:development) billing_codes(:travel).related.delete(billing_codes(:development)) assert !BillingCode.find(1).related.include?(BillingCode.find(2)) assert !BillingCode.find(2).related.include?(BillingCode.find(1)) end
It’s similar to the previous test method, except that after establishing the relationship, it immediately deletes it. I expect that the first assertion will pass right away, but the second should fail:
$ ruby test/unit/billing_code_test.rb Loaded suite test/unit/billing_code_test Started .F Finished in 0.159424 seconds. 1) Failure: test_that_deletion_is_bidirectional_too(BillingCodeTest) [test/unit/billing_code_test.rb:16]: <false> is not true. 2 tests, 4 assertions, 1 failures, 0 errors
Yep, just as expected. Let’s peek at log/test.log and grab the SQL DELETE clause that we’ll work with:
DELETE FROM related_billing_codes WHERE first_billing_code_id = 1 AND second_billing_code_id IN (2)
Hmph! This might be a little trickier than the insert. Curious about the IN operator, I take a peek inside the active_record/associations/has_and_belongs_to_many_association.rb file and find the following relevant method:
def delete_records(records)
if sql = @reflection.options[:delete_sql]
records.each { |record|
@owner.connection.execute(interpolate_sql(sql, record))
}
else
ids = quoted_record_ids(records)
sql = "DELETE FROM #{@reflection.options[:join_table]}
WHERE #{@reflection.primary_key_name} = #{@owner.quoted_id}
AND #{@reflection.association_foreign_key} IN (#{ids})"
@owner.connection.execute(sql)
end
endThe final BillingCode class now looks like this:
class BillingCode < ActiveRecord::Base
has_and_belongs_to_many :related,
:join_table => `related_billing_codes`,
:foreign_key => `first_billing_code_id`,
:association_foreign_key => `second_billing_code_id`,
:class_name => `BillingCode`,
:insert_sql => `INSERT INTO related_billing_codes
(`first_billing_code_id`,
`second_billing_code_id`)
VALUES (#{id}, #{record.id}), (#{record.id},
#{id})`
endLinking Two Existing Objects Efficiently
Prior to Rails 2.0, the
<<method loads the entire contents of the associated collection from the database into memory—which, depending on how many associated records you have in your database, could take a really long time!
Rails won’t have a problem with you adding as many extra columns as you want to habtm’s join table. The extra attributes will be read in and added onto model objects accessed via the habtm association. However, speaking from experience, the severe annoyances you will deal with in your application code make it really unattractive to go that route.
What kind of annoyances? For one, records returned from join tables with additional attributes will be marked as read-only, because it’s not possible to save changes to those additional attributes.
You should also consider that the way that Rails makes those extra columns of the join table available might cause problems in other parts of your codebase. Having extra attributes appear magically on an object is kind of cool, but what happens when you try to access those extra properties on an object that wasn’t fetched via the habtm association? Kaboom! Get ready for some potentially bewildering debugging exercises.
Other than the deprecated push_with_attributes, methods of the habtm proxy act just as they would for a has_many relationship. Similarly, habtm shares options with has_many; only its :join_table option is unique. It allows customization of the join table name.
To sum up, habtm is a simple way to establish a many-to-many relationship using a join table. As long as you don’t need to capture additional data about the relationship, everything is fine. The problems with habtm begin once you want to add extra columns to the join table, after which you’ll want to upgrade the relationship to use has_many :through instead.
Rails 1.2 documentation advises readers that: “It’s strongly recommended that you upgrade any [habtm] associations with attributes to a real join model.” Use of habtm, which was one of the original innovative features in Rails, fell out of favor once the ability to create real join models was introduced via the has_many :through association.
Realistically, habtm is not going to be removed from Rails, for a couple of sensible reasons. First of all, plenty of legacy Rails applications need it. Second, habtm provides a way to join classes without a primary key defined on the join table, which is occasionally useful. But most of the time you’ll find yourself wanting to model many-to-many relationships with has_many :through.
Well-known Rails guy and fellow cabooser Josh Susser is considered the expert on ActiveRecord associations, even his blog is called has_many :through. His description of the :through association[2], written back when the feature was originally introduced in Rails 1.1, is so concise and well-written that I couldn’t hope to do any better. So here it is:
The
has_many :throughassociation allows you to specify a one-to-many relationship indirectly via an intermediate join table. In fact, you can specify more than one such relationship via the same table, which effectively makes it a replacement forhas_and_belongs_to_many. The biggest advantage is that the join table contains full-fledged model objects complete with primary keys and ancillary data. No morepush_with_attributes; join models just work the same way all your otherActiveRecordmodels do.
To illustrate the has_many :through association, we’ll set up a Client model so that it has many Timesheet objects, through a normal has_many association named billable_weeks.
class Client < ActiveRecord::Base has_many :billable_weeks has_many :timesheets, :through => :billable_weeks end
The BillableWeek class was already in our sample application and is ready to be used as a join model:
class BillableWeek < ActiveRecord::Base belongs_to :client belongs_to :timesheet end
We can also set up the inverse relationship, from timesheets to clients, like this.
class Timesheet < ActiveRecord::Base has_many :billable_weeks has_many :clients, :through => :billable_weeks end
Notice that has_many :through is always used in conjunction with a normal has_many association. Also, notice that the normal has_many association will often have the same name on both classes that are being joined together, which means the :through option will read the same on both sides.
:through => :billable_weeks
How about the join model; will it always have two belongs_to associations? No.
You can also use has_many :through to easily aggregate has_many or has_one associations on the join model. Forgive me for switching to completely nonrealistic domain for a moment—it’s only intended to clearly demonstrate what I’m trying to describe:
class Grandparent < ActiveRecord::Base has_many :parents has_many :grand_children, :through => :parents, :source => :childs end class Parent < ActiveRecord::Base belongs_to :grandparent has_many :childs end
For the sake of clarity in later chapters, I’ll refer to this usage of has_many :through as aggregating.
You can use nonaggregating has_many :through associations in almost the same ways as any other has_many associations. The limitations have to do with handling of unsaved records.
>> c = Client.create(:name => "Trotter's Tomahawks", :code => "ttom") => #<Client:0x2228410...> >> c.timesheets << Timesheet.new ActiveRecord::HasManyThroughCantAssociateNewRecords: Cannot associate new records through 'Client#billable_weeks' on '#'. Both records must have an id in order to create the has_many :through record associating them.
Hmm, seems like we had a hiccup. Unlike a normal has_many, ActiveRecord won’t let us add an object to the the has_many :through association if both ends of the relationship are unsaved records.
The create method saves the record before adding it, so it does work as expected, provided the parent object isn’t unsaved itself.
>> c.save
=> true
>> c.timesheets.create
=> [#<Timesheet:0x2212354 @new_record=false, @new_record_before_save=
true, @attributes={"updated_at"=>Sun Mar 18 15:37:18 UTC 2007,
"id"=>2,
"user_id"=>nil, "submitted"=>nil, "created_at"=>Sun Mar 18 15:37:18
UTC
2007}, @errors=#<ActiveRecord::Errors:0x2211940 @base=
#<Timesheet:0x2212354 ...>, @errors={}>> ]The main benefit of has_many :through is that ActiveRecord takes care of managing the instances of the join model for you. If we call reload on the billable_weeks association, we’ll see that there was a billable week object created for us:
>> c.billable_weeks.reload
=> [#<BillableWeek:0x139329c @attributes={"tuesday_hours"=>nil,
"start_date"=>nil, "timesheet_id"=>"2", "billing_code_id"=>nil,
"sunday_hours"=>nil, "friday_hours"=>nil, "monday_hours"=>nil,
"client_id"=>"2", "id"=>"2", "wednesday_hours"=>nil,
"saturday_hours"=>nil, "thursday_hours"=>nil}> ]The BillableWeek object that was created is properly associated with both the client and the Timesheet. Unfortunately, there are a lot of other attributes (e.g., start_date, and the hours columns) that were not populated.
One possible solution is to use create on the billable_weeks association instead, and include the new Timesheet object as one of the supplied properties.
>> bw = c.billable_weeks.create(:start_date => Time.now,
:timesheet => Timesheet.new)
=> #<BillableWeek:0x250fe08 @timesheet=#<Timesheet:0x2510100
@new_record=false, ...>When you’re using has_many :through to aggregate multiple child associations, there are more significant limitations—essentially you can query to your hearts content using find and friends, but you can’t append or create new records through them.
For example, let’s add a billable_weeks association to our sample User class:
class User < ActiveRecord::Base has_many :timesheets has_many :billable_weeks, :through => :timesheets ...
The billable_weeks association aggregates all the billable week objects belonging to all of the user’s timesheets.
class Timesheet < ActiveRecord::Base belongs_to :user has_many :billable_weeks, :include => [:billing_code] ...
Now let’s go into the Rails console and set up some example data so that we can use the new billable_weeks collection (on User).
>> quentin = User.find :first => #<User id: 1, login: "quentin" ...> >> quentin.timesheets => [] >> ts1 = quentin.timesheets.create => #<Timesheet id: 1 ...> >> ts2 = quentin.timesheets.create => #<Timesheet id: 2 ...> >> ts1.billable_weeks.create(:start_date => 1.week.ago) => #<BillableWeek id: 1, timesheet_id: 1 ...> >> ts2.billable_weeks.create :start_date => 2.week.ago => #<BillableWeek id: 2, timesheet_id: 2 ...> >> quentin.billable_weeks => [#<BillableWeek id: 1, timesheet_id: 1 ...>, #<BillableWeek id: 2, timesheet_id: 2 ...>]
Just for fun, let’s see what happens if we try to create a BillableWeek with a User instance:
>> quentin.billable_weeks.create(:start_date => 3.weeks.ago) NoMethodError: undefined method `user_id=` for #<BillableWeek:0x3f84424>
There you go... BillableWeek doesn’t belong to a user, it belongs to a timesheet, so it doesn’t have a user_id field.
When you append to a non-aggregating has_many :through association with <<, ActiveRecord will always create a new join model, even if one already exists for the two records being joined. You can add validates_uniqueness_of constraints on the join model to keep duplicate joins from happening.
This is what such a constraint might look like on our BillableWeek join model.
validates_uniqueness_of :client_id, :scope => :timesheet_id
That says, in effect: “There should only be one of each client per timesheet.”
If your join model has additional attributes with their own validation logic, then there’s another important consideration to keep in mind. Adding records directly to a has_many :through association causes a new join model to be automatically created with a blank set of attributes. Validations on additional columns of the join model will probably fail. If that happens, you’ll need to add new records by creating join model objects and associating them appropriately through their own association proxy.
timesheet.billable_weeks.create(:start_date => 1.week.ago)
The options for has_many :through are the same as the options for has_many—remember that :through is just an option on has_many! However, the use of some of has_many’s options change or become more significant when :through is used.
First of all, the :class_name and :foreign_key options are no longer valid, since they are implied from the target association on the join model.
Here are the rest of the options that have special significance together with has_many :through.
The :source option specifies which association to use on the associated class. This option is not mandatory because normally ActiveRecord assumes that the target association is the singular (or plural) version of the has_many association name. If your association names don’t match up, then you have to set :source explicitly.
For example, the following code will use the BillableWeek’s sheet association to populate timesheets.
has_many :timesheets, :through => :billable_weeks, :source => :sheet
The :source_type option is needed when you establish a has_many :through to a polymorphic belongs_to association on the join model.
Consider the following example of clients and contacts:
class Client < ActiveRecord::Base has_many :contact_cards has_many :contacts, :through => :contact_cards end class ContactCard < ActiveRecord::Base belongs_to :client belongs_to :contacts, :polymorphic => true end
The most important fact here is that a Client has many contacts, which can be any kind of model since they are declared polymorphically on the join model, ContactCard. For example purposes, let’s associate people and businesses to contact cards:
class Person < ActiveRecord::Base has_many :contact_cards, :as => :contact end class Business < ActiveRecord::Base has_many :contact_cards, :as => :contact end
Now take a moment to consider the backflips that ActiveRecord would have to perform in order to figure out which tables to query for a client’s contacts. It would theoretically need to be aware of every model class that is linked to the other end of the contacts polymorphic association.
In fact, it can’t do those kinds of backflips, which is probably a good thing as far as performance is concerned:
>> Client.find(:first).contacts ArgumentError: /.../active_support/core_ext/hash/keys.rb:48: in `assert_valid_keys`: Unknown key(s): polymorphic
The only way to make this scenario work (somewhat) is to give ActiveRecord some help by specifying which table it should search when you ask for the contacts collection, and you do that with the source_type option. The value of the option is the name of the target class, symbolized:
class Client < ActiveRecord::Base
has_many :people_contacts, :through => :contact_cards,
:source => :contacts, :source_type => :person
has_many :business_contacts, :through => :contact_cards,
:source => :contacts, :source_type => :business
endAfter the :source_type is specified, the association will work as expected.
>> Client.find(:first).people_contacts.create!
[#<Person:0x223e788 @attributes={"id"=>1}, @errors=
#<ActiveRecord::Errors:0x223dc0c @errors={}, @base=
#<Person: 0x...>>, @new_record_before_save=true, @new_record=false>]The code is a bit longer and less magical, but it works. If you’re upset that you cannot associate people_contacts and business_contacts together in a contacts association, you could try writing your own accessor method for a client’s contacts:
class Client < ActiveRecord::Base
def contacts
people_contacts + business_contacts
end
endOf course, you should be aware that calling that contacts method will result in at least two database requests and will return an Array, without the association proxy methods that you might expect it to have.
The :uniq option tells the association to include only unique objects. It is especially useful when using has_many :through, since two different BillableWeeks could reference the same Timesheet.
>> client.find(:first).timesheets.reload
[#<Timesheet:0x13e79dc @attributes={"id"=>"1", ...}>,
#<Timesheet:0x13e79b4 @attributes={"id"=>"1", ...}>]It’s not extraordinary for two distinct model instances of the same database record to be in memory at the same time—it’s just not usually desirable.
class Client < ActiveRecord::Base has_many :timesheets, :through => :billable_weeks, :uniq => true end
After adding the :uniq option, only one instance per record is returned.
>> client.find(:first).timesheets.reload [#<Timesheet:0x22332ac ...>]
The implementation of uniq on AssociationCollection is a neat little example of how to build a collection of unique values in Ruby, using a Set and the inject method. It also proves that the record’s primary key (and nothing else) is what’s being used to establish uniqueness:
def uniq(collection = self)
seen = Set.new
collection.inject([]) do |kept, record|
unless seen.include?(record.id)
kept << record
seen << record.id
end
kept
end
endOne of the most basic relationship types is a one-to-one object relationship. In ActiveRecord we declare a one-to-one relationship using the has_one and belongs_to methods together. As in the case of a has_many relationship, you call belongs_to on the model whose database table contains the foreign key column linking the two records together.
Conceptually, has_one works almost exactly like has_many does, except that when the database query is executed to retrieve the related object, a LIMIT 1 clause is added to the generated SQL so that only one row is returned.
The name of a has_one relationship should be singular, which will make it read naturally, for example: has one :last_timesheet, has one :primary_account, has one :profile_photo, and so on.
Let’s take a look at has_one in action by adding avatars for our users.
class Avatar < ActiveRecord::Base belongs_to :user end class User < ActiveRecord::Base has_one :avatar # ... the rest of our User code ... end
That’s simple enough. Firing this up in script/console, we can look at some of the new methods that has_one adds to User.
>> u = User.find(:first)
>> u.avatar
=> nil
>> u.build_avatar(:url => '/avatars/smiling')
#<Avatar:0x2266bac @new_record=true, @attributes={"url"=>
"/avatars/smiling", "user_id"=>1}>
>> u.avatar.save
=> trueAs you can see, we can use build_avatar to build a new avatar object and associate it with the user. While it’s great that has_one will associate an avatar with the user, it isn’t really anything that has_many doesn’t already do. So let’s take a look at what happens when we assign a new avatar to the user.
>> u = User.find(:first)
>> u.avatar
=> #<Avatar:0x2266bac @attributes={"url"=>"/avatars/smiling",
"user_id"=>1}>
>> u.create_avatar(:url => '/avatars/frowning')
=> #<Avatar:0x225071c @new_record=false, @attributes={"url"=>
"/avatars/4567", "id"=>2, "user_id"=>1}, @errors=
#<ActiveRecord::Errors:0x224fc40 @base=#<Avatar:0x225071c ...>,
@errors={}>>
>> Avatar.find(:all)
=> [#<Avatar:0x22426f8 @attributes={"url"=>"/avatars/smiling",
"id"=>"1", "user_id"=>nil}>, #<Avatar:0x22426d0
@attributes={"url"=>"/avatars/frowning", "id"=>"2", "user_id"=>"1"}>]The last line from that script/console session is the most interesting, because it shows that our initial avatar is now no longer associated with the user. Of course, the previous avatar was not removed from the database, which is something that we want in this scenario. So, we’ll use the :dependent => :destroy option to force avatars to be destroyed when they are no longer associated with a user.
class User has_one :avatar, :dependent => :destroy end
With some fiddling around in the console, we can verify that it works as intended.
>> u = User.find(:first)
>> u.avatar
=> #<Avatar:0x22426d0 @attributes={"url"=>"/avatars/frowning",
"id"=>"2", "user_id"=>"1"}>
>> u.avatar = Avatar.create(:url => "/avatars/jumping")
=> #<Avatar:0x22512ac @new_record=false,
@attributes={"url"=>"avatars/jumping", "id"=>3, "user_id"=>1},
@errors=#<ActiveRecord::Errors:0x22508e8 @base=#<Avatar:0x22512ac
...>,
@errors={}>>
>> Avatar.find(:all)
=> [#<Avatar:0x22426f8 @attributes={"url"=>"/avatars/smiling", "id"
=>"1", "user_id"=>nil}>, #<Avatar:0x2245920 @attributes={"url"=>
"avatars/jumping","id"=>"3", "user_id"=>"1"}>]As you can see, adding :dependent => :destroy got rid of the frowning avatar, but not the smiling avatar. Rails only destroys the avatar that was just removed from the user, so bad data that is in your database from before will still remain. Keep this in mind when you decide to add :dependent => :destroy and remember to manually clear any bad data from before.
As I alluded to earlier, has_one is often used to single out one record of significance alongside an already established has_many relationship. For instance, let’s say we want to easily be able to access the last timesheet a user was working on:
class User < ActiveRecord::Base has_many :timesheets has_one :latest_timesheet, :class_name => 'Timesheet' end
I had to specify a :class_name, so that ActiveRecord knows what kind of object we’re associating. (It can’t figure it out based on the name of the association, :latest_timesheet.)
When adding a has_one relationship to a model that already has a has_many defined to the same related model, it is not necessary to add another belongs_to method call to the target object, just for the new has_one. That might seem a little counterintuitive at first, but if you think about it, the same foreign key value is being used to read the data from the database.
What happens when you replace an existing has_one target object with another? A lot depends on whether the newly related object was created before or after the object that it is replacing, because ActiveRecord doesn’t add any additional ordering parameters to its has_one query.
The options for has_one associations are similar to the ones for has_many.
Allows you to set up a polymorphic association, covered in Chapter 9.
Allows you to specify the class this association uses. When you’re doing has_one :latest_timesheet, :class_name => 'Timesheet', :class_name => 'Timesheet' specifies that latest_timesheet is actually the last Timesheet object in the database that is associated with this user. Normally, this option is inferred by Rails from the name of the association.
Allows you to specify conditions that the object must meet to be included in the association. The conditions are specified the same as if you were using ActiveRecord#find.
class User
has_one :manager,
:class_name => 'Person',
:conditions => ["type = ?", "manager"]
endHere manager is specified as a person object that has type = "manager". I tend to almost always use :conditions in conjunction with has_one. When ActiveRecord loads the association, it’s grabbing one of potentially many rows that have the right foreign key. Absent some explicit conditions (or perhaps an order clause), you’re leaving it in the hands of the database to pick a row.
The :dependent option specifies how ActiveRecord should treat associated objects when the parent object is deleted. There are a few different values that you can pass and they work just like the :dependent option of has_many.
If you pass :destroy to it, you tell Rails to destroy the associated object when it is no longer associated with the primary object. Passing :delete will destroy the associated object without calling any of Rails’ normal hooks. Finally, the default (:nullify) will simply set the foreign key values to null so that the connection is broken.
Allows you to “eagerload” additional association objects when your associated object is loaded. See the :include option of the has_many and belongs_to associations for more details.
You can manipulate objects and associations before they are saved to the database, but there is some special behavior you should be aware of, mostly involving the saving of associated objects. Whether an object is considered unsaved is based on the result of calling new_record?
Assigning an object to a has_one association automatically saves that object and the object being replaced (if there is one), so that their foreign key fields are updated. The exception to this behavior is if the parent object is unsaved, since that would mean that there is no foreign key value to set.
If save fails for either of the objects being updated (due to one of them being invalid) the assignment operation returns false and the assignment is cancelled. That behavior makes sense (if you think about it), but it can be the cause of much confusion when you’re not aware of it. If you have an association that doesn’t seem to work, check the validation rules of the related objects.
If you happen to want to assign an object to a has_one association without saving it, you can use the association’s build method:
user.profile_photo.build(params[:photo])
Assigning an object to a belongs_to association does not save the parent or the associated object.
Adding an object to has_many and has_and_belongs_to_many collections automatically saves it, unless the parent object (the owner of the collection) is not yet stored in the database.
If objects being added to a collection (via << or similar means) fail to save properly, then the addition operation will return false. If you want your code to be a little more explicit, or you want to add an object to a collection without automatically saving it, then you can use the collection’s build method. It’s exactly like create, except that it doesn’t save.
Members of a collection are automatically saved (or updated) when their parent is saved (or updated).
The proxy objects that handle access to associations can be extended with your own application code. You can add your own custom finders and factory methods to be used specifically with a particular association.
For example, let’s say you wanted a concise way to refer to an account’s people by name. You might wrap the find_or_create_by_first_name_and_last_name method of a people collection in the following neat little package as shown in Listing 7.5.
Now we have a named method available to use on the people collection.
person = Account.find(:first).people.named("David Heinemeier Hansson")
person.first_name # => "David"
person.last_name # => "Heinemeier Hansson"If you need to share the same set of extensions between many associations, you can use specify an extension module, instead of a block with method definitions.
Here is the same feature shown in Listing 7.5, except broken out into its own Ruby module:
module ByNameExtension
def named(name)
first_name, last_name = name.split(" ", 2)
find_or_create_by_first_name_and_last_name(first_name, last_name)
end
endNow we can use it to extend many different relationships, as long as they’re compatible. (Our contract in the example consists of the find_or_create_by_first_name_and_last_name method.)
class Account < ActiveRecord::Base has_many :people, :extend => ByNameExtension end class Company < ActiveRecord::Base has_many :people, :extend => ByNameExtension end
If you need to use multiple named extension modules, you can pass an array of modules to the :extend option instead of a single module, like this:
has_many :people, :extend => [ByNameExtension, ByRecentExtension]
In the case of name conflicts, methods contained in modules added later in the array supercede those earlier in the array.
AssociationProxy, the parent of all association proxies (refer to Figure 7.1 if needed), contributes a number of useful methods that apply to most kinds of associations and can come into play when you’re writing association extensions.
The reset method puts the association proxy back in its initial state, which is unloaded (cached association objects are cleared). The reload method invokes reset, and then loads associated objects from the database.
References to the internal owner, reflection, and target attributes of the association proxy, respectively.
The proxy_owner method provides a reference to the parent object holding the association.
The proxy_reflection object is an instace of ActiveRecord::Reflection::AssociationReflection and contains all of the configuration options for the association. That includes both default settings and those that were passed to the association method when it was declared.[3]
The proxy_target is the associated array (or associated object itself in the case of belongs_to and has_one).
It might not appear sane to expose these attributes publicly and allow their manipulation. However, without access to them it would be much more difficult to write advanced association extensions. The loaded?, loaded, target, and target= methods are public for similar reasons.
The following code sample demonstrates the use of proxy_owner within a published_prior_to extension method contributed by Wilson Bilkovich:
class ArticleCategory < ActiveRecord::Base
acts_as_tree
has_many :articles do
def published_prior_to(date, options = {})
if proxy_owner.top_level?
Article.find_all_published_prior_to(date, :category =>
proxy_owner)
else
# self is the 'articles' association here so we inherit its
scope
self.find(:all, options)
end
end
end # has_many :articles extension
def top_level?
# do we have a parent, and is our parent the root node of the tree?
self.parent && self.parent.parent.nil?
end
endThe acts_as_tree ActiveRecord plugin extension creates a self-referential association based on a parent_id column. The proxy_owner reference is used to check if the parent of this association is a “top-level” node in the tree.
The ability to model associations is what make ActiveRecord more than just a data-access layer. The ease and elegance with which you can declare those associations are what make ActiveRecord more than your ordinary object-relational mapper.
In this chapter, we covered the basics of how ActiveRecord associations work. We started by taking a look at the class hierarchy of associations classes, starting with AssociationProxy. Hopefully, by learning about how associations work under the hood, you’ve picked up some enhanced understanding about their power and flexibility.
Finally, the options and methods guide for each type of association should be a good reference guide for your day-to-day development activities.
| 1. | |
| 2. | http://blog.hasmanythrough.com/articles/2006/02/28/association-goodness |
| 3. | To learn more about how the reflection object can be useful, including an explanation on how to establish |