
Chapter 8. C# 4.0 Features
Goals of this chapter:
• Define new C# 4.0 language features.
• Demonstrate the new language features in the context of LINQ to Objects.
C# is an evolving language. This chapter looks at the new features added into C# 4.0 that combine to improve code readability and extend your ability to leverage LINQ to Object queries over dynamic data sources. The examples in this chapter show how to improve the coding model for developers around reading data from various sources, including text files and how to combine data from a COM-Interop source into a LINQ to Objects query.
Evolution of C#
C# is still a relatively new language (circa 2000) and is benefiting from continuing investment by Microsoft’s languages team. The C# language is an ECMA and ISO standard. (ECMA is an acronym for European Computer Manufacturers Association, and although it changed its name to Ecma International in 1994, it kept the name Ecma for historical reasons.1) The standard ECMA-334 and ISO/IEC 23270:2006 is freely available online at the Ecma International website2 and describes the language syntax and notation. However, Microsoft’s additions to the language over several versions take some time to progress through the standards process, so Microsoft’s release cycle leads Ecma’s acceptance by at least a version.
Each version of C# has a number of new features and generally a major theme. The major themes have been generics and nullable types in C# 2.0, LINQ in C# 3.0, and dynamic types in C# 4.0. The major features added in each release are generally considered to be the following:
• C# 2.0—Generics (.NET Framework support was added, and C# benefited from this); iterator pattern (the yield keyword); anonymous methods (the delegate keyword), nullable types, and the null coalescing operator (??).
• C# 3.0—Anonymous types, extension methods, object initializers, collection initializers, implicitly typed local variables (var keyword), lambda expressions (=>), and the LINQ query expression pattern.
• C# 4.0—Optional Parameters and Named Arguments, Dynamic typing (dynamic type), improved COM-Interop, and Contra and Co-Variance.
The new features in C# 3.0 that launched language support for LINQ can be found in Chapter 2, “Introducing LINQ to Objects,” and this chapter documents each of the major new features in C# 4.0 from the perspective of how they impact the LINQ story.
Optional Parameters and Named Arguments
A long-requested feature for C# was to allow for method parameters to be optional. Two closely related features in C# 4.0 fulfill this role and enable us to either omit arguments that have a defined default value when calling a method, and to pass arguments by name rather than position when calling a method.
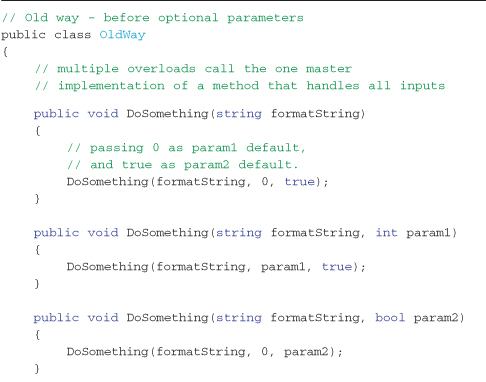
The main benefit of these features is to improve COM-Interop programming (which is covered shortly) and to reduce the number of method overloads created to support a wide range of parameter overloads. It is a common programming pattern to have a master method signature containing all parameters (with the actual implementation) chained to a number of overloaded methods that have a lesser parameter signature set calling the master method with hard-coded default values. This common coding pattern becomes unnecessary when optional parameters are used in the definition of the aforementioned master method signature, arguably improving code readability and debugging by reducing clutter. (See Listing 8-2 for an example of the old and new way to create multiple overloads.)
There has been fierce debate on these features on various email lists and blogs. Some C# users believe that these features are not necessary and introduce uncertainty in versioning. For example if version 2 of an assembly changes a default parameter value for a particular method, client code that was assuming a specific default might break. This is true, but the existing chained method call pattern suffers from a similar issue—default values are coded into a library or application somewhere, so thinking about when and how to handle these hard-coded defaults would be necessary using either the existing chained method pattern or the new optional parameters and named arguments. Given that optional parameters were left out of the original C# implementation (even when the .NET Runtime had support and VB.NET utilized this feature), we must speculate that although this feature is unnecessary for general programming, coding COM-Interop libraries without this feature is unpleasant and at times infuriating—hence, optional parameters and specifying arguments by name has now made its way into the language.
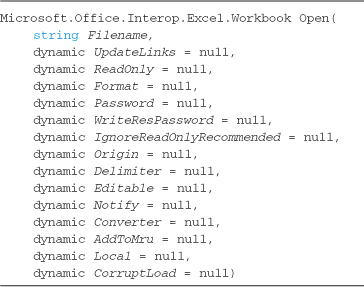
COM-Interop code has always suffered due to C#’s inability to handle optional parameters as a concept. Many Microsoft Office Component Object Model (COM) libraries, like those built to automate Excel or Word for instance, have method signatures that contain 25 optional parameters. Previously you had no choice but to pass dummy arguments until you reached the “one” you wanted and then fill in the remaining arguments until you had fulfilled all 25. Optional parameters and named arguments solve this madness, making coding against COM interfaces much easier and cleaner. The code shown in Listing 8-1 demonstrates the before and after syntax of a simple Excel COM-Interop call to open an Excel spreadsheet. It shows how much cleaner this type of code can be written when using C# 4.0 versus any of its predecessors.
Listing 8-1. Comparing the existing way to call COM-Interop and the new way using optional parameters

The addition of object initializer functionality in C# 3.0 took over some of the workload of having numerous constructor overloads by allowing public properties to be set in line with a simpler constructor (avoiding having a constructor for every Select projection needed). Optional parameters and named arguments offer an alternative way to simplify coding a LINQ Select projection by allowing variations of a type’s constructor with a lesser set of parameters. Before diving into how to use these features in LINQ queries, it is necessary to understand the syntax and limitations of these new features.
Optional Parameters
The first new feature allows default parameters to be specified in a method signature. Callers of methods defined with default values can omit those arguments without having to define a specific overload matching that lesser parameter list for convenience.
To define a default value in a method signature, you simply add a constant expression as the default value to use when omitted, similar to member initialization and constant definitions. A simple example method definition that has one mandatory parameter (p1, just like normal) and an optional parameter definition (p2) takes the following form:
public void MyMethod( int p1, int p2 = 5 );
The following invocations of method MyMethod are legal (will compile) and are functionally equivalent as far as the compiler is concerned:
![]()
The rules when defining a method signature that uses optional parameters are:
- Required parameters cannot appear after any optional parameter.
- The default specified must be a constant expression available at compile time or a value type constructor without parameters, or
default(T)whereTis a value type. - The constant expression must be implicitly convertible by an identity (or nullable conversion) to the type of the parameter.
- Parameters with a
reforoutmodifier cannot be optional parameters. - Parameter arrays (
params) can occur after optional parameters, but these cannot have a default value assigned. If the value is omitted by the calling invocation, an empty parameter array is used in either case, achieving the same results.
Valid optional parameter definitions take the following form:

The following method definitions using optional parameters will not compile:

To understand how optional parameters reduce our code, Listing 8-2 shows a traditional overloaded method pattern and the equivalent optional parameter code.
Listing 8-2. Comparing the traditional cascaded method overload pattern to the new optional parameter syntax pattern

Named Arguments
Traditionally, the position of the arguments passed to a method call identified which parameter that value matched. It is possible in C# 4.0 to specify arguments by name, in addition to position. This is helpful when many parameters are optional and you need to target a specific parameter without having to specify all proceeding optional parameters.
Methods can be called with any combination of positionally specified and named arguments, as long as the following rules are observed:
- If you are going to use a combination of positional and named arguments, the positional arguments must be passed first. (They cannot come after named arguments.)
- All non-optional parameters must be specified somewhere in the invocation, either by name or position.
- If an argument is specified by position, it cannot then be specified by name as well.
To understand the basic syntax, the following example creates a System.Drawing.Point by using named arguments. It should be noted that there is no constructor for this type that takes the y-size, x-size by position—this reversal is solely because of named arguments.
![]()
The following method invocations will not compile:

To demonstrate how to mix and match optional parameters and named arguments within method or constructor invocation calls, the code shown in Listing 8-3 calls the method definition for NewWay in Listing 8-2.
Listing 8-3. Mixing and matching positional and named arguments in a method invocation for methods that have optional and mandatory parameters

Using Named Arguments and Optional Parameters in LINQ Queries
Named arguments and optional parameters offer an alternative way to reduce code in LINQ queries, especially regarding flexibility in what parameters can be omitted in an object constructor.
Although anonymous types make it convenient to project the results of a query into an object with a subset of defined properties, these anonymous types are scoped to the local method. To share a type across methods, types, or assemblies, a concrete type is needed, meaning the accumulation of simple types or constructor methods just to hold variations of data shape projections. Object initializers reduce this need by allowing a concrete type to have a constructor without parameters and public properties used to assign values in the Select projection. Object-oriented purists take issue with a parameterless constructor being a requirement; it can lead to invalid objects being created by users who are unaware that certain properties must be set before an object is correctly initialized for use—an opinion I strongly agree with. (You can’t compile using the object initialization syntax unless the type concerned has a parameterless constructor, even if there are other constructors defined that take arguments.)
Optional parameters and named arguments can fill this gap. Data can be projected from queries into concrete types, and the author of that concrete type can ensure that the constructor maintains integrity by defining the default values to use when an argument is omitted. Many online discussions have taken place discussing if this is a good pattern; one camp thinks it doesn’t hurt code readability or maintainability to use optional parameters in a constructor definition, and the other says refactoring makes it an easy developer task to define the various constructors required in a given type, and hence of no value. I see both sides of that argument and will leave it up to you to decide where it should be employed.
To demonstrate how to use named arguments and optional parameters from a LINQ query, the example shown in Listing 8-4 creates a subset of contact records (in this case, contacts from California) but omits the email and phone details. The Console output from this example is shown in Output 8-1.
Listing 8-4. Example LINQ query showing how to use named arguments and optional parameters to assist in projecting a lighter version of a larger type—see Output 8-1


Output 8-1
![]()
Dynamic Typing
The wow feature of C# 4.0 is the addition of dynamic typing. Dynamic languages such as Python and Ruby have major followings and have formed a reputation of being super-productive languages for building certain types of applications.
The main difference between these languages and C# or VB.NET is the type system and specifically when (and how) member names and method names are resolved. C# and VB.NET require (or required, as you will see) that static types be available during compile time and will fail if a member name or method name does not exist. This static typing allows for very rigorous error checking during compile time, and generally improves code performance because the compiler can make targeted optimizations based on exact member name and method name resolution. Dynamic-typed languages on the other hand enable the member and method lookups to be carried out at runtime, rather than compile time. Why is this good? The main identifiable reason is that this allows code to locate members and methods dynamically at runtime and handle additions and enhancements without requiring a recompile of one system or another.
I’m going to stay out of the religious debate as to which is better. I believe there are positives and negatives in both approaches, and C# 4.0 allows you to make the choice depending on the coding problem you need to solve. Dynamic typing allows very clean coding patterns to be realized, as you will see in an upcoming example, where we code against the column names in a CSV file without the need for generating a backing class for every different CSV file format that might need to be read.
Using Dynamic Types
When a variable is defined with the type dynamic, the compiler ignores the call as far as traditional error checking is concerned and instead stores away the specifics of the action for the executing runtime to process at a later time (at execution time). Essentially, you can write whatever method calls (with whatever parameters), indexers, and properties you want on a dynamic object, and the compiler won’t complain. These actions are picked up at runtime and executed according to how the dynamic type’s binder determines is appropriate.
A binder is the code that gets the payload for an action on a dynamic instance type at runtime and resolves it into some action. Within the C# language, there are two paths code can take at this point, depending on the binder being used (the binding is determined from the actual type of the dynamic instance):
• The dynamic type does not implement the IDynamicMetaObjectProvider interface. In this case, the runtime uses reflection and its traditional method lookup and overload resolution logic before immediately executing the actions.
• The dynamic type implements the IDynamicMetaObjectProvider interface, by either implementing this interface by hand or by inheriting the new dynamic type from the System.Dynamic.DynamicObject type supplied to make this easier.
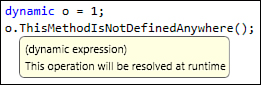
Any traditional type of object can be declared as type dynamic. For all dynamic objects that don’t implement the interface IDynamicMetaObjectProvider, the Microsoft.CSharp.RuntimeBinder is used, and reflection is employed to look up property and method invocations at runtime. The example code shown in Figure 8-1 shows the Intellisense balloon in Visual Studio 2010, which demonstrates an integer type declared as dynamic. (The runtime resolves the type by the initialization expression, just like using the local type inference var keyword.) No compile error occurs at design time or compile time, even though the method call is not defined anywhere in the project. When this code is executed, the runtime uses reflection in an attempt to find and execute the fictitious method ThisMethodIsNotDefinedAnywhere, which of course fails with the exception:
Microsoft.CSharp.RuntimeBinder.RuntimeBinderException: 'int' does not contain a definition for 'ThisMethodIsNotDefinedAnywhere'
Figure 8-1. Any object declared as type dynamic is resolved at runtime. No errors will be reported at compile time.
If that method had been actually declared, it would have been simply invoked just like any traditional method or property call.
The ability to have a type that doesn’t implement the IDynamicObject interface should be rare. The dynamic keyword shouldn’t be used in place of a proper type definition when that type is known at compile time. It also shouldn’t be used in place of the var keyword when working with anonymous types, as that type is known at compile time. The dynamic keyword should only be used to declare IDynamicMetaObjectProvider implementers and for interoperating with other dynamic languages and for COM-Interop.
Specific binders are written to support specific purposes. IronRuby, IronPython, and COM-Interop are just a few of the bindings available to support dynamic language behavior from within C# 4.0. However, you can write your own and consume these types in order to solve some common coding problems, as you will see shortly in an example in which text file data is exposed using a custom dynamic type and this data is used as the source of a LINQ to Objects query.
Using Dynamic Types in LINQ Queries
Initially you might be disappointed to learn that dynamic types aren’t supported in LINQ. LINQ relies exclusively on extension methods to carry out each query expression operation. Extension methods cannot be resolved at runtime due to the lack of information in the compiled assembly. Extension methods are introduced into scope by adding the assembly containing the extension into scope via a using clause, which is available at compile time for method resolutions, but not available at runtime—hence no LINQ support. However, this only means you can’t define collection types as dynamic, but you can use dynamic types at the instance level (the types in the collections being queried), as you will see in the following example.
For this example we create a type that allows comma delimited text files to be read and queried in an elegant way, often useful when importing data from another application. By “elegant” I mean not hard-coding any column name definitions into string literals in our importing code, but rather, allowing direct access to fields just like they are traditional property accessors. This type of interface is often called a fluent interface. Given the sample CSV file content shown in Listing 8-5, the intention is to allow coders to directly reference the data columns in each row by their relevant header names, defined in the first row—that is FirstName, LastName, and State.
Listing 8-5. Comma separated value (CSV) file content used as example content

The first row contains the column names for each row of the file, and this particular implementation expects this to always be the case. When writing LINQ queries against files of this format, referring to each row value in a column by the header name makes for easily comprehensible queries. The goal is to write the code shown in Listing 8-6, and this code compiling without a specific backing class from every CSV file type to be processed. (Think of it like coding against a dynamic anonymous type for the given input file header definition.)
Listing 8-6. Query code fluently reading CSV file content without a specific backing class

Dynamic typing enables us to do just that and with remarkably little code. The tradeoff is that any property name access isn’t tested for type safety or existence during compile time. (The first time you will see an error is at runtime.) To fulfill the requirement of not wanting a backing class for each specific file, the line type shown previously must be of type dynamic. This is necessary to avoid the compile-time error that would be otherwise reported when accessing the State and LastName properties, which don’t exist.
To create our new dynamic type, we need our type to implement IDynamicMetaObjectProvider, and Microsoft has supplied a starting point in the System.Dynamic.DynamicObject type. This type has virtual implementations of the required methods that allow a dynamic type to be built and allows the implementer to just override the specific methods needed for a given purpose. In this case, we need to override the TryGetMember method, which will be called whenever code tries to read a property member on an instance of this type. We will process each of these calls by returning the correct text out of the CSV file content for this line, based on the index position of the passed-in property name and the header position we read in as the first line of the file.
Listing 8-7 shows the basic code for this dynamic type. The essential aspects to support dynamic lookup of individual CSV fields within a line as simple property access calls are shown in this code. The property name is passed to the TryGetMember method in the binder argument, and can be retrieved by binder.Name, and the correct value looked up accordingly.
Listing 8-7. Class to represent a dynamic type that will allow the LINQ code (or any other code) to parse a single comma-separated line and access data at runtime based on the names in the header row of the text file

To put in the plumbing required for parsing the first row, a second type is needed to manage this process, which is shown in Listing 8-8, and is called CsvParser. This is in place to determine the column headers to be used for access in each line after that and also the IEnumerable implementation that will furnish each line to any query (except the header line that contains the column names).
The constructor of the CsvParser type takes the CSV file content as a string and parses it into a string array of individual lines. The first row (as is assumed in this implementation) contains the column header names, and this is parsed into a List<string> so that the index positions of these column names can be subsequently used in the CsvLine type to find the correct column index position of that value in the data line being read. The GetEnumerator method simply skips the first line and then constructs a dynamic type CsvLine for each line after that until all lines have been enumerated.
Listing 8-8. The IEnumerable class that reads the header line and returns each line in the content as an instance of our CsvLine dynamic type

Listing 8-9 shows the LINQ query that reads data from a CSV file and filters based on one of the column values. The important aspects of this example are the dynamic keyword in the from clause, and the ability to directly access the properties State, FirstName, and LastName from an instance of our CsvLine dynamic type. Even though there is no explicit backing type for those properties, they are mapped from the header row in the CSV file itself. This code will only compile in C# 4.0, and its output is all of the rows (in this case just one) that have a value of “WA” in the third column position (State), as shown in Output 8-2.
Listing 8-9. Sample LINQ query code that demonstrates how to use dynamic types in order to improve code readability and to avoid the need for strict backing classes—see Output 8-2

Output 8-2
![]()
As this example has shown, it is possible to mix dynamic types with LINQ. The key point to remember is that the actual element types can be dynamic, but not the collection being queried. In this case, we built a simple enumerator that reads the CSV file and returns an instance of our dynamic type. Any CSV file, as long as the first row contains legal column names (no spaces or special characters that C# can’t resolve as a property name), can be coded against just as if a backing class containing those columns names was created by code.
COM-Interop and LINQ
COM interoperability has always been possible within C# and .NET; however, it was often less than optimal in how clean and easy the code was to write (or read). Earlier in this chapter, named arguments and optional parameters were introduced, which improve coding against COM objects. And with the additional syntax improvements offered by the dynamic type, the code readability and conciseness is further improved.
To demonstrate how COM-Interop and LINQ might be combined, the following example shows a desirable coding pattern to read the contents of a Microsoft Excel spreadsheet, and use that data as a source for a LINQ to Objects query.

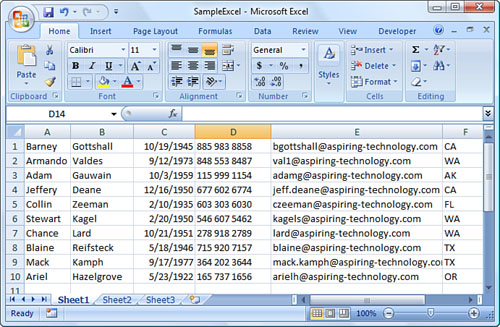
This query returns rows where the State column equals “WA” from the spreadsheet data shown in Figure 8-2. Microsoft Excel is often used as the source for importing raw data, and although there are many ways to import this data using code, the ability to run LINQ queries over these spreadsheets directly from C# is useful.
Figure 8-2. Sample Microsoft Excel spreadsheet to query using LINQ.
The strategy used to implement the Microsoft Excel interoperability and allow LINQ queries over Excel data is:
- Add a COM-Interop reference to the Microsoft Excel library in order to code against its object model in C#.
- Return the data from a chosen spreadsheet (by its filename) into an
IEnumerablecollection (row by row) that can be used as a source for a LINQ query.
Adding a COM-Interop Reference
COM-Interop programming in C# 4.0 is greatly improved in one way because of a new style of interop backing class that is created when you add a COM reference to a project. The improved backing class makes use of optional parameters and named arguments and the dynamic type features that were introduced earlier this chapter. Listing 8-10 demonstrates the old code required to access an Excel spreadsheet via COM, and contrasts it with the new programming style.
Listing 8-10. Comparing the existing way to call COM-Interop and the new way using the improved COM reference libraries

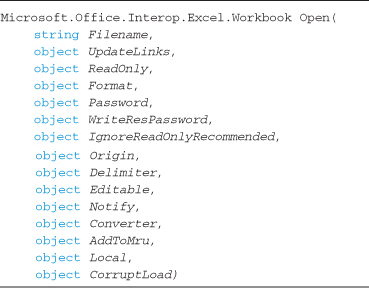
When a reference is added to a COM component using Visual Studio, a backing class is generated to allow coding against that model. Listing 8-11 shows one method of the Excel COM programming model generated by Visual Studio 2008. With no optional parameters, all arguments must be passed when calling these methods.
Listing 8-11. Old style COM-Interop backing class added by Visual Studio 2008 for part of the Microsoft Excel 12 Object Library
Listing 8-12 shows the Visual Studio 2010 COM-Interop backing class. The addition of the default values turned all but one of the parameters (the Filename argument) into optional parameters; therefore, all but the filename can be omitted when this method is called, allowing the simplification shown in Listing 8-10.
Listing 8-12. New style COM-Interop backing class added by Visual Studio 2010—notice the optional parameters and the dynamic types
Adding a COM reference is painless in Visual Studio. The step-by-step process is:
- Open the Visual Studio C# project that the COM reference is being added to.
- Choose
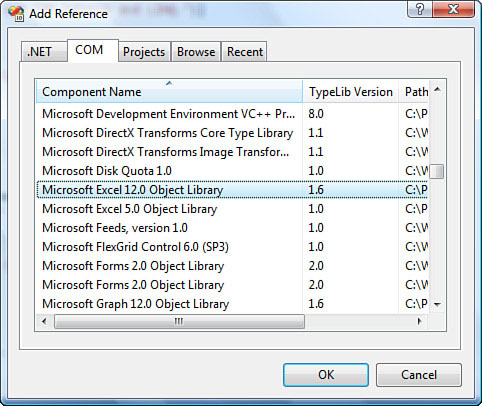
Project-Add Reference...from the main menu (or right-click the References icon in the Solution Explorer and clickAdd Reference...). - Click the COM tab and find the COM Object you want to reference from within your project, as seen in Figure 8-3.
Figure 8-3. The Add Reference dialog box in Visual Studio 2010.
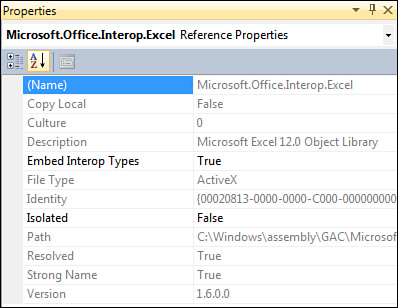
- Click the OK button for the Add Reference dialog box.
Figure 8-4. Set the Embed Interop Types to control whether the no-PIA feature is used (the default behavior, true) or the previous Visual Studio behavior is used (false).
Building the Microsoft Excel Row Iterator
To expose Microsoft Excel in a way that supports LINQ queries, an iterator must be built that internally reads data from an Excel spreadsheet and exposes this data as an IEnumerable collection, row by row. The skeleton of the Excel row iterator, without implementation is:

This iterator declaration takes arguments of a fully qualified filename to an Excel spreadsheet and a worksheet index as a one-based number and returns the values in each row (with each column’s value as an item in a List<dynamic> collection) from the chosen worksheet in the selected Excel file. The full implementation of this algorithm is shown in Listing 8-13.
This implementation isn’t the strategy to be used for extremely large spreadsheets because it buffers the entire dataset into an in-memory array with a single call and then builds the row results from this array of values. This technique, however, is the fastest way to access data from Excel using COM-Interop because it avoids single cell or row access and keeps Excel open (a large executable memory footprint) for as short a time as possible. If an application is required to read a massive spreadsheet of data, experiment with alternative value access strategies supported by Excel’s extensive object model, row by row perhaps, to avoid completely loading the entire array into memory upfront. This implementation is fine in performance and memory usage for most purposes.
The using Declaration for the Following Examples
To avoid having to prefix all calls to the Interop library with long namespaces, I added the following using declaration at the top of my class file:
![]()
This simplified the code declarations and allowed me to use Excel.Application, Excel.Workbook (and others) rather than Microsoft.Office.Interop.Excel.Application, Microsoft.Office.Interop.Excel.Workbook, and so on.
Listing 8-13. Full code listing for an Excel row enumerator. Calling this method enumerates the values of a row in an Excel spreadsheet.

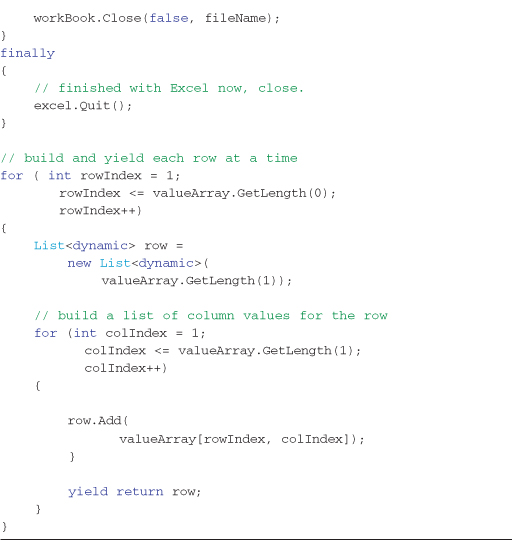
Writing LINQ queries against Microsoft Excel data, like that shown in Figure 8-2, can be written in the code form shown in Listing 8-14. Output 8-3 shows the three rows returned from this code, which is all rows that have a State value of ‘WA.’
Listing 8-14. Example code for reading the data from an Excel spreadsheet and running a LINQ query over its contents—see Output 8-3

Output 8-3

The return type of the row values is declared as type List<dynamic>. It easily could have been declared as type List<object>. The downside of declaring the values as type of object rather than dynamic comes down to the ability to treat the value members as the underlying type. For example, in Listing 8-14 the statement row[lastNameCol].ToUpper() would fail if the element types were declared as object. The object type doesn’t have a method called ToUpper, even though the underlying type it is representing is a string. And to access that method a type cast needs to be added, bloating the code out to ((string)row[lastNameCol]).ToUpper(). Declaring the element type as dynamic in the collection allows the runtime to look up method names using reflection on the underlying type at runtime, however the particular type of that column value is declared as in Excel (in this case a string, but some columns are DateTime and double). The removal of the type casting when calling methods or properties on object types simplifies and improves code readability, at the expense of performance.
The GetExcelRowEnumerator method could be enhanced by combining the header row reading and accessibility in a similar fashion to that used by dynamic lookup in Listing 8-7, which would eliminate the need to hardcode the column index positions and allow the row data to be accessed by column header name using simple property access syntax.
Summary
This chapter introduced the new language features of C# 4.0 and demonstrated how they can be combined to extend the LINQ to Objects story. The examples provided showed how to improve the coding model around reading data from CSV text file sources and how to combine data from Microsoft Excel using COM-Interop into LINQ to Object queries.
References
1. Ecma International History from the Ecma International website hosted at http://www.ecma-international.org/memento/history.htm.
2. Ecma-334—C# Language Specification from the Ecma International website at http://www.ecma-international.org/publications/standards/Ecma-334.htm.