
Chapter 9. Locking, Performance, and NT6 Enhancements
Chapter 8 introduced synchronization operations and demonstrated their use in some relatively simple examples. Chapter 10 provides more complex but realistic and useful message passing and compound object examples and describes a general model that solves many practical problems and enhances program reliability. This chapter is concerned first with locking performance implications and techniques to minimize the impact. The chapter then describes Windows NT6 (Vista, Server 2008, ...) SRW locks and NT6 thread pools, which provide additional performance improvements and programming conveniences. The chapter ends with a continuation of the parallelism discussion started in Chapter 7.
While thread synchronization is essential, there are some significant performance pitfalls, and we describe some of the major issues, both on single-processor and multiprocessor systems. There are also trade-offs among alternative solutions. For example, CRITICAL_SECTIONs (CSs) and mutexes are nearly identical functionally and solve the same fundamental problem. CSs are generally the most efficient locking mechanism, and SRW locks are even better. In other cases, interlocked operations are sufficient, and it may even be possible to avoid locking synchronization altogether with careful design and implementation.
CS–mutex trade-offs form the first topic, along with multiprocessor implications. CS spin counts, semaphore throttles, and processor affinity are other topics.
Note: Microsoft has implemented substantial performance improvements in NT5 and again in NT6; these improvements are particularly significant when using multiple processors. Consequently, some programming guidelines in this book’s third edition, while appropriate for NT4 and older systems, are now obsolete and often counter productive.
Synchronization Performance Impact
Synchronization can and will impact your program’s performance. There are several reasons for this:
• Locking operations, waiting, and even interlocked operations are inherently time consuming.
• Locking that requires kernel operation and waiting is expensive.
• Only one thread at a time can execute a critical code region, reducing concurrency and having the effect of serializing execution of critical code regions.
• Processor contention for memory and cache access on multiprocessor systems can produce unexpected effects, such as false sharing (described later).
CRITICAL_SECTION–Mutex Trade-offs
The first step is to assess the locking performance impact and compare CRITICAL_SECTIONs to mutexes. Program 9-1 shows statsMX.c, which uses a mutex to lock access to a thread-specific data structure. statsCS.c, not shown but in the Examples file, does exactly the same thing using a CRITICAL_SECTION, and statsIN.c uses interlocked functions. Finally, statsNS.c, also not shown, uses no locking at all; by design, locking is not necessary in this example because each worker accesses its own unique storage. However, see the cautionary note after the bulleted list following the program. The actual programs allow any number of worker threads.
Program 9-1 statsMX: Maintaining Thread Statistics
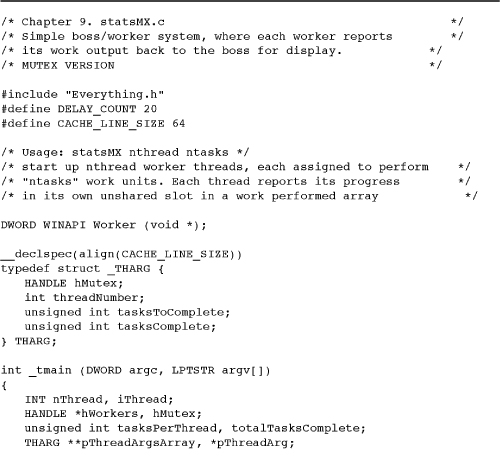

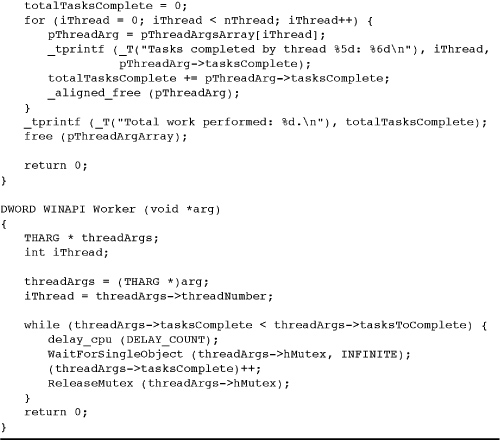
This set of examples not only illustrates the relative performance impact of three types of locking but also shows the following concepts.
• Locking is sometimes avoidable or can be minimized with careful program design. For example, the total amount of work performed is accumulated in the boss after the threads complete, so the example has no locking requirement for this computation. However, if each thread updated the global work completed variable, then the update operation would require a lock.
• The interlocked functions work well in some simple situations, such as incrementing a shared variable, as in Program 9-1.
• CSs are significantly faster than mutexes in most situations.
• A common technique is to specify the thread argument data structure so that it contains state data to be maintained by the thread along with a reference to a mutex or other locking object.
• Program 9-1 carefully aligns the thread argument data structure on cache line boundaries (defined to be 64 bytes in the listing). The alignment implementation uses the __declspec(align) modifier on the structure definition and the _aligned_malloc and _aligned_free memory management calls (all are Microsoft extensions). The cache alignment is to avoid a “false-sharing” performance bug, as described after the program listing.
You can use the timep program from Chapter 6 (Program 6-2) to examine the behavior of the different implementations. Run 9-1a shows the results with 32 threads and 256,000 work units for statsNS (no synchronization), statsIN (interlocked), statsCS (CRITICAL_SECTION), and statsMX (mutex). The test system has four processors.
Run 9-1a statsXX: Performance with Different Locking Techniques
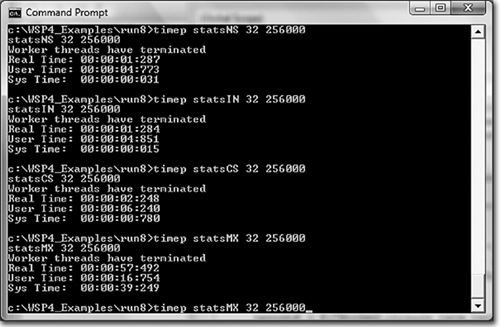
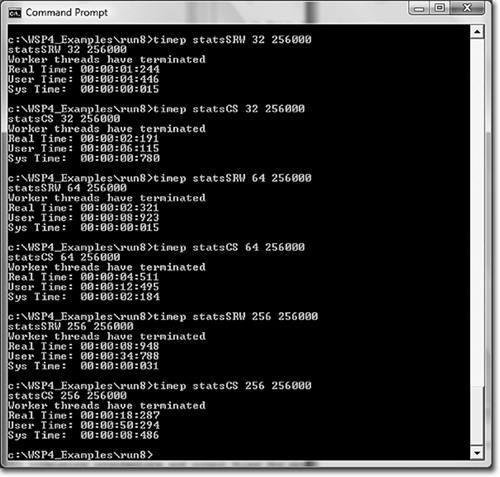
Additional tests performed on otherwise idle systems with 256,000 work units and 1, 2, 4, 8, 16, 32, 64, and 128 worker threads show similar results, as follows:
• The NS (no synchronization) and IN (interlocked functions) versions are always fastest, as is to be expected, and they really cannot be distinguished in this example. The CS version is noticeably slower, by a factor of 2 or more compared to IN, showing a typical synchronization slowdown. The MX (mutex) version, however, can take 2 to 30 times longer to execute than CS.
• Prior to NT5, CS performance did not always scale with the number of threads when the thread count exceeded 4. CS scalability is a significant NT5 improvement.
• NT6 SRW locks (later in this chapter) generally have performance between the interlocked functions and CSs.
• NT6 thread pools (later in this chapter) provide slight additional performance gains.
• Any type of locking, even interlocked locking, is expensive compared to no locking at all, but, of course, you frequently need locking. This example was deliberately designed so that locking is not required so as to illustrate locking costs.
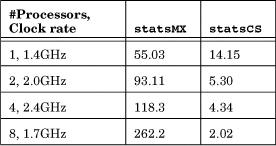
• Mutexes are very slow, and unlike the behavior with CSs, performance degrades rapidly as the processor count increases. For instance, Table 9-1 shows the elapsed statsMX and statsCS times (seconds) for 64 threads and 256,000 work units on 1-, 2-, 4-, and 8-processor systems. Table C-5 (Appendix C) contains additional data. CS performance, however, improves with processor count and clock rate.
Table 9-1 Mutex and CS Performance with Multiple Processors
False Sharing
The pThreadArgsArray array deliberately uses integers in cache-line aligned THARG structures to avoid the potential performance degradation caused by “false-sharing” cache contention (see Figure 8-2) on multiprocessor systems. The false-sharing problem can occur when:
• Two or more threads on different processors concurrently modify adjacent (that is, on the same cache line) task counts or other variables, making the modification in their respective cache lines.
• At the next memory barrier, the system would need to make the cache lines consistent, slowing the program.
False-sharing prevention requires that each thread’s working storage be properly separated and aligned according to cache line size, as was done in Program 9-1, at some cost in program complexity and memory.
A Model Program for Performance Experimentation
The Examples file includes a project, TimedMutualExclusion, that generalizes Program 9-1 and enables experimentation with different boss/worker models, application program characteristics, and Windows locking and threading mechanisms (not all of which have been described yet). Program features, controlled from the command line, include the following:
• The lock type (CS, mutex, or SRW lock).
• The lock holding time, or delay, which models the amount of work performed in the critical code section.
• The number of worker threads, limited only by system resources.
• Thread pool usage, if any.
• The number of sleep points where a worker yields the processor, using Sleep(0), while owning the lock. Sleep points model a worker thread that waits for I/O or an event, while the delay models CPU activity.
The delay and sleep point parameters significantly affect performance because they affect the amount of time that a worker holds a lock, preventing other workers from running.
The program listing contains extensive comments explaining how to run the program and set the parameters. Exercise 9–1 suggests some experiments to perform on as wide a variety of systems as you can access. A variation, TimedMutualExclusionSC, supports spin counts, as explained in the next section.
Note: TimedMutualExclusion is a simple model that captures many worker thread features. It can often be tuned or modified to represent a real application, and if the model shows performance problems, the application is at risk for similar problems. On the other hand, good performance in the model does not necessarily indicate good performance in the real application, even though the model may assist you in application performance tuning.
Tuning Multiprocessor Performance with CS Spin Counts
CRITICAL_SECTION locking (enter) and unlocking (leave) are efficient because CS testing is performed in user space without making the kernel system call that a mutex makes. Unlocking is performed entirely in user space, whereas ReleaseMutex requires a system call. CS operation is as follows.
• A thread executing EnterCriticalSection tests the CS’s lock bit. If the bit is off (unlocked), then EnterCriticalSection sets it atomically as part of the test and proceeds without ever waiting. Thus, locking an unlocked CS is extremely efficient, normally taking just one or two machine instructions. The owning thread identity is maintained in the CS data structure, as is a recursion count.
• If the CS is locked, EnterCriticalSection enters a tight loop on a multiprocessor system, repetitively testing the lock bit without yielding the processor (of course, the thread could be preempted). The CS spin count determines the number of times EnterCriticalSection repeats the loop before giving up and calling WaitForSingleObject. A single-processor system gives up immediately; spin counts are useful only on a multiprocessor system where a different processor could change the lock bit.
• Once EnterCriticalSection gives up testing the lock bit (immediately on a single-processor system), EnterCriticalSection enters the kernel and the thread goes into a wait state, using a semaphore wait. Hence, CS locking is efficient when contention is low or when the spin count gives another processor time to unlock the CS.
• LeaveCriticalSection is implemented by turning off the lock bit, after checking that the thread actually owns the CS. LeaveCriticalSection also notifies the kernel, using ReleaseSemaphore, in case there are any waiting threads.
Consequently, CSs are efficient on single-processor systems if the CS is likely to be unlocked, as shown by the CS version of Program 9-1. The multiprocessor advantage is that the CS can be unlocked by a thread running on a different processor while the waiting thread spins.
The next steps show how to set spin counts and how to tune an application by determining the best spin count value. Again, spin counts are useful only on multiprocessor systems; they are ignored on single-processor systems.
Setting the Spin Count
You can set CS spin counts at CS initialization or dynamically. In the first case, replace InitializeCriticalSection with InitializeCriticalSectionAndSpinCount, where there is an additional count parameter. There is no way to read a CS’s spin count.
You can change a spin count at any time.
![]()
MSDN mentions that 4,000 is a good spin count for heap management and that you can improve performance with a small spin count when a critical code section has short duration. The best value is, however, application specific, so spin counts should be adjusted with the application running in a realistic multiprocessor environment. The best values will vary according to the number of processors, the nature of the application, and so on.
TimedMutualExclusionSC is in the Examples file. It is a variation of the TimedMutualExclusion program, and it includes a spin count argument on the command line. You can run it on your host processor to find a good value for this particular test program on your multiprocessor systems, as suggested in Exercise 9–2.
NT6 Slim Reader/Writer Locks
NT6 supports SRW locks.1 As the name implies, SRWs add an important feature: they can be locked in exclusive mode (“write”) and shared mode (“read”), and they are light weight (“slim”). Exclusive mode is comparable to CRITICAL_SECTION and mutex locking, and shared mode grants read-only access. The locking logic is similar to file locking (Chapter 3), as are the benefits.
1 Some writers use the term “Vista SRW locks” because Vista was the first Windows release to support this feature.
SRWs have several features that are different from CRITICAL_SECTIONs.
• An SRW lock can be acquired in either mode, but you cannot upgrade or downgrade the mode between shared and exclusive.
• SRW locks are light weight and small, the size of a pointer (either 32 or 64 bits). Also, there is no associated kernel object for waiting, thus SRW locks require minimal resources.
• SRW locks do not support recursion because there is insufficient state information in the lock.
• You cannot configure or adjust the spin count; Microsoft implemented a spin count value that they determined to provide good results in a wide variety of situations.
• While you do need to initialize an SRW lock, there is no need to delete it.
• There is no nonblocking call equivalent to TryEnterCriticalSection.
• Both CSs and SRW locks can be used with Windows condition variables (Chapter 10).
With this CRITICAL_SECTION comparison, the API is self-explanatory, using the SRWLOCK and PSRWLOCK types. The initialization function (there is no delete function) is:
There are two SRW acquisition and release functions, corresponding to the two modes. SRWs use the terms “acquire” and “release,” as opposed to “enter” and “leave.” You need to release a lock with the function corresponding to the acquistion. The functions for shared, or read, mode are:

The two corresponding functions for exclusive, or write, mode are:

There is one additional SRW function, SleepConditionVariableSRW, which Chapter 10 describes along with condition variables.
You can now use SRW locks in exclusive mode the same way that you use CSs, and you can also use shared mode if the critical code region does not change the guarded state variables. The advantage of shared mode is that multiple threads can concurrently own an SRW in shared mode, which can improve concurrency in many applications.
In summary, SRWs provide improved locking performance compared to mutexes and CSs for three principal reasons:
• SRWs are light weight, both in implementation and in resource requirements.
• SRWs allow shared mode access.
• SRWs do not support recursion, simplifying the implementation.
To test SRW locks, there is an SRW version of statsMX called statsSRW. TimedMutualExclusion also has an option to use SRWs, and there is also an exclusive/shared parameter that specifies the percentage of shared acquisitions. See the code comments. Program 9-2 uses both an SRW lock and a thread pool (see the next section).
Program 9-2 statsSRW_VTP: Thread Performance with a Thread Pool
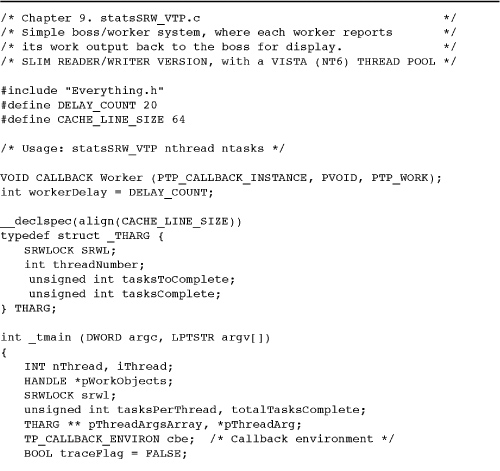



Run 9-1b compares statsSRW and statsCS performance for several thread count values, running on the same four-processor system used in Run 9-1a.
Run 9-1b statsXX: Comparing SRW and CS Performance
The experimental results confirm that SRW locks, used in exclusive mode (the worst case), are faster than CSs (by a factor of 2 in this case). Appendix C shows timing results on several machines under a variety of circumstances. An exercise suggests testing a situation in which CSs can be more competitive.
Thread Pools to Reduce Thread Contention
Programs with numerous threads can cause performance problems beyond locking issues. These problems include:
• Each thread has a distinct stack, with 1MB as the default stack size. For instance, 1,000 threads consume 1GB of virtual address space.
• Thread context switching is time consuming.
• Thread context switches can cause page faults during stack access.
Nonetheless, it is very natural to use multiple threads, where each thread represents a distinct activity, such as a worker processing its own work unit. It is difficult, and often self-defeating, to attempt to multiplex user-created worker threads. For example, an application cannot effectively determine how to load-balance tasks among the worker threads; this is a problem for the kernel’s scheduler to solve. Furthermore, reducing the number of threads has the effect of serializing activities that are inherently parallel.
Several useful techniques and Windows features can help address this problem:
• Semaphore throttles, a simple programming technique that is still useful on NT4 and, to a lesser extent, on NT5 and NT6. The next section has a brief description.
• I/O completion ports, which are described and illustrated in Chapter 14, with a very brief description in a following section.
• Asynchronous I/O (overlapped and extended), also covered in Chapter 14. Generally, asynchronous I/O is difficult to program and does not provide performance advantages until NT6. Extended I/O, but not overlapped I/O, gives excellent performance on NT6 (Vista, Server 2008, ...) and can be worth the programming effort.
• NT6 thread pools, where the application submits callback functions to a thread pool. The kernel executes the callback functions from worker threads. Typically, the number of worker threads is the same as the number of processors, although the kernel may make adjustments. We describe thread pools after the semaphore throttle section.
• Asynchronous procedure calls (APC), which are important in the next chapter.
• A parallelization framework, such as OpenMP, Intel Thread Building Blocks, or Cilk++. These frameworks are language extensions that express program parallelism; as language extensions, they are out of scope for this book. Nonetheless, there’s a (very) brief overview at the end of this chapter.
Before proceeding to NT6 thread pools, there are short descriptions of semaphore throttles and I/O completion ports. These descriptions help to motivate NT6 thread pools.
Semaphore “Throttles” to Reduce Thread Contention
Semaphores give a natural way to retain a simple threading model while still minimizing the number of active, contending threads. The solution is simple conceptually and can be added to an existing application program, such as the statsMX and TimedMutualExclusion examples, very quickly. The solution, called a semaphore throttle, uses the following techniques. We’ll assume that you are using a mutex, some other kernel object, or file locks and have a good reason for doing so.
• The boss thread creates a semaphore with a small maximum value, such as 4, which represents the maximum number of active threads, possibly the number of processors, compatible with good performance. Set the initial count to the maximum value as well. This number can be a parameter and tuned to the best value after experimentation, just as spin lock counts can be tuned.
• Each worker thread waits on the semaphore before entering its critical code section. The semaphore wait can immediately precede the mutex or other wait.
• The worker thread should then release the semaphore (release count of 1) immediately after leaving the critical code section.
• If the semaphore maximum is 1, the mutex is redundant.
• Overall CS or mutex contention decreases as the thread execution is serialized with only a few threads waiting on the mutex or CS.
The semaphore count simply represents the number of threads that can be active at any one time, limiting the number of threads contending for the mutex, CS, processors, or other resource. The boss thread can even throttle the workers and dynamically tune the application by waiting on the semaphore to reduce the count if the boss determines that the workers are running too slowly (for example, the boss could monitor exit flags maintained by each worker, as in Program 8-1), and it can release semaphore units to allow more workers to run. Note, however, that the maximum semaphore count is set at create time and cannot be changed.
The following code fragment illustrates a modified worker loop with two semaphore operations.

There is one more variation. If a particular worker is considered to be “expensive” in some sense, it can be made to wait for several semaphore units. As noted in the previous chapter, however, two successive waits can create a deadlock. An exercise in the next chapter shows how to build an atomic multiple-wait compound semaphore object.
TimedMutualExclusion, the familiar example, adds a sixth parameter that is the initial throttle semaphore count for the number of active threads. You can experiment with this count as suggested in one of the exercises.
Comment: As mentioned previously, this technique is useful mostly on older Windows releases with multiple processors, before NT5. NT5 and NT6 have improved synchronization performance, so you should experiment carefully before deploying a semaphore throttle solution. Nonetheless:
• Throttles are still useful in some NT5 and NT6 systems when using mutexes and multiple processors (see Run 9-1c and Table 9-1, later in this chapter).
Run 9-1c statsMX: Using a Semaphore Throttle
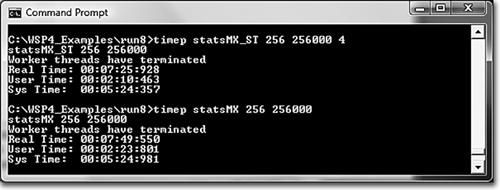
• I’ve also found semaphore throttles useful to limit concurrent access to other resources, such as files and memory. Thus, if multiple threads all have large, thread-specific memory requirements, limiting the number of active threads can reduce page faults and thrashing.
• You can add a semaphore throttle very easily to an existing program, and you do not need to depend on the Windows version or new functionality, such as thread pools.
Run 9-1c compares statsMX and statsMX_ST (the semaphore throttle version) for a large number of threads (256). statsMX_ST is slightly but consistently faster (about 24 seconds faster over nearly 8 minutes).
I/O Completion Ports
Chapter 14 describes I/O completion ports, which provide another mechanism to avoid thread contention by limiting the number of threads. I/O completion ports allow a small number of threads to manage a large number of concurrent I/O operations. Individual I/O operations are started asynchronously so that the operation is, in general, not complete when the read or write call returns. However, as outstanding operations complete, data processing is handed off to one of a small number of worker threads. Chapter 14 has an example using a server communicating with remote clients (Program 14-4).
NT6 Thread Pools
NT6 thread pools are easy to use, and it’s also simple to upgrade an existing program to use a thread pool rather than threads. The major thread pool features are as follows:
• The application program creates “work objects” rather than threads and submits the work objects to the thread pool. Each work object is a callback function and a parameter value and is identified by handle-like (but not a HANDLE) structure that identifies the work object.
• The thread pool manages a small number of “worker threads” (not to be confused with the application worker threads in preceding examples). Windows then assigns work objects to worker threads, and a worker thread executes a work object by calling the callback function with the work object’s parameter.
• When a work object completes, it returns to the Windows worker thread, which can then execute another work object. Notice that a callback function should never call ExitThread or _endthreadex, as that would terminate the Windows worker thread. A work object can, however, submit another work object, which could be itself, requesting that the same work object be executed again.
• Windows can adjust the number of worker threads based on application behavior. The application can, however, set upper and lower bounds on the number of worker threads.
• There is a default thread pool, but applications can create additional pools. However, the pools will all contend for the same processor resources, so the examples use the default pool.
Thread pools allow the Windows kernel to exploit sophisticated techniques to determine how many worker threads to create and when to call the work objects. Furthermore, invoking a callback function avoids the overhead of thread context switching, and this is most effective when the work item callback functions are short.
NT5 supports thread pools, and we use them in later chapters. NT6 introduced a new and more powerful thread pool API, which we use in this chapter. MSDN compares the API functions (search for “thread pool API”).
We convert statsSRW to statsSRW_VTP (for “Vista Thread Pool”) to illustrate the changes. The Examples file also contains wcMT_VTP, a conversion of Chapter 7’s multithreaded wc (word count) utility.
The conversion steps are as follows; function descriptions follow:
• Add an initialization call to InitializeThreadpoolEnvironment and, optionally, modify the environment.
• Create a work object (callback function and argument), which is similar to creating a thread in the suspended state. This creates a work object handle to use with the other functions; note that this is not a HANDLE but a PTP_WORK object.
• Submit the work object using SubmitThreadPoolWork, which is analogous to ResumeThread.
• Replace the thread wait call with calls to WaitForThreadpoolWorkCallbacks. The calling, or boss, thread will block until all calls to the work object complete.
• Replace the thread handle CloseHandle calls with calls to CloseThreadpoolWork.
We describe each function in turn and then show the statsSRW_VTP listing and performance results.
Caution: Be careful using the C library in the callback functions because the Windows executive does not use _beginthreadex. Many functions, such as printf statements, will usually work if you use the multithreaded C library (see Chapter 7). However, some C library functions, such as strtok, could fail in a callback function.
CreateThreadpoolWork
This is the thread pool work object creation function.

Parameters
• pfnwk is the callback function; the function signature is described later.
• pv is optional. The value will be passed as a parameter to every call to the callback function. Notice that every call to the callback function for this work object receives the same value.
• pcbe is an optional TP_CALLBACK_ENVIRON structure. The default is usually sufficient, but see the InitializeThreadpoolEnviroment function to understand the advanced options, and Chapter 14 has more on the thread pool environment.
• The return value is the thread pool work object and is NULL in case of failure.
SubmitThreadpoolWork
Each call to this function posts a work object (that is, a callback function call and parameter) to the thread pool. The Windows executive’s thread pool implementation decides when to call the individual instances. The callbacks can execute in parallel on separate processors.
pwk is the value that CreateThreadpoolWork returned. Assuming that this value is valid, SubmitThreadpoolWork never fails, since all the required resources were allocated previously.
The callback function associated with pwd will be called once for every SubmitThreadpoolWork call. The Windows kernel scheduler determines which of several threads will run a specific call. The programmer does not need to manage threads but still must manage synchronization. Furthermore, a specific callback instance might run on different threads at different points.
WaitForThreadpoolWorkCallbacks
This wait function does not have a time-out and returns when all submitted work objects (callbacks) complete. Optionally, you can cancel callbacks for the work objects that have not started, using the second parameter, but callbacks that have started will run to completion. The first parameter is the thread pool work object.
![]()
CloseThreadpoolWork
All that is required is a valid work object.
The Callback Function
This is our first use of callback functions, although we’ll see them again with extended I/O and timers (Chapter 14) and APCs (Chapter 10). The thread pool will invoke this function once for every SubmitThreadpoolWork invocation.
The callback function replaces the thread function.

Work is the work object, and Context is the pv value from the work object creating CreateThreadpoolWork call. The Instance value identifies this specific callback instance (not the work object, which may have multiple instances), allowing the callback function to provide the Windows executive with information that may help scheduling. Specifically, CallbackMayRunLong informs the executive that the callback instance may execute for a long time so that the executive can attempt to assign an existing or new worker thread to this instance. Normally, callback instances are expected to execute quickly.
Using Thread Pools
Program 9-2 modifies Program 9-1 to use an SRW lock and a thread pool.
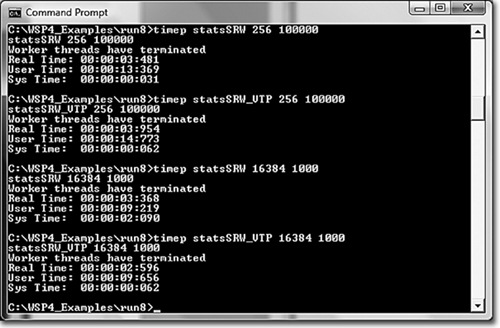
Run 9-2 compares performance for statsSRW, which uses worker threads, and statsSRW_VTP, which uses work objects, on a four-processor system, with the expectation that the second program will be faster.
• First, the two programs are run with large “tasks to complete” values (the second command line argument) for the worker threads (or work objects); this means that the workers are long running. It turns out that the VTP is a bit slower (3.954 seconds instead of 3.481 seconds).
• However, when there is a large number of workers (the first command line argument), each with a small amount of work, the thread pool solution is faster. See the second pair of test runs, where the thread pool version requires 2.596 seconds, and the threads version requires 3.368 seconds.
Run 9-2 statsSRW: Using a Thread Pool, Fast and Slow Workers
If you test statsSRW_VTP, it is interesting to add a call to GetCurrentThreadId from within the worker callback function. You can either print the value or add a field to the thread argument to display within the boss function. You will find that Windows will use a small number of threads, typically one per processor.
Submitting Callbacks to the Thread Pool
TrySubmitThreadpoolCallback is an alternative to the CreateThreadpoolWork, SubmitThreadpoolWork, CloseThreadpoolWork sequence.

The callback function is a different type: PTP_SIMPLE_CALLBACK instead of PTP_WORK_CALLBACK. The work item is omitted because it’s not required.
![]()
The Thread Pool Environment
Both CreateThreadpoolWork and TrySubmitThreadpoolCallback have optional callback environment parameters, which are frequently NULL for the default value. However, the callback environment can be useful, and Chapter 14 describes some advanced thread pool techniques that use the environment.
The wcMT_VTP example in the Examples file illustrates a simple environment use in which the environment is set to indicate that the callback functions are long running. However, in this example, there was no measurable effect on performance, just as with Run 9-2.
The Process Thread Pool
Each process has a dedicated thread pool. When you use CreateThreadpoolWork, SubmitThreadpoolWork, and TrySubmitThreadpoolCallback, the callback functions are all executed using the process thread pool. Therefore, several distinct callback functions could contend for this pool, and this is normally the desired behavior because it allows the executive to schedule work objects with the available resources.
Our examples (statsSRW_VTP and wcMT_VTP) both share the property that there is only one callback function, and the callback functions dominate execution time.
You can, however, create additional thread pools with CreateThreadPool; however, test carefully to see if this provides any benefit or if it degrades performance.
Other Threadpool Callback Types
CreateThreadpoolWork associates a work callback function with a TP_WORK structure. In the examples here, the work function performs computation and possibly I/O (see the wcMT_VTP example in the Examples file). There are, however, other callback types that can be associated with the process thread pool.
• CreateThreadpoolTimer specifies a callback function to execute after a time interval and possibly periodically after that. The callback will execute on a thread in the pool. Chapter 14 has an example, TimeBeep_TPT.
• CreateThreadpoolIo specifies a callback function to execute when an overlapped I/O operation completes on a HANDLE. Again, see Chapter 14.
• CreateThreadpoolWait specifies a callback function to execute when an object, specified by SetThreadpoolWait, is signaled.
Summary: Locking Performance
We now have four locking mechanisms as well as thread pools and the possibility of no locking. The seven stats program variations (including statsMX_ST) illustrate the relative performance, although, as with any statement about performance, results may vary depending on a wide variety of software and hardware factors. Nonetheless, as a generalization, the mechanisms, from fastest to slowest, are:
• No synchronization, which is possible in some situations.
• Interlocked functions.
• SRW locks with a worker thread pool (NT6 only). The locks are exclusive mode. A mix of shared and exclusive locking could improve performance.
• SRW locks with conventional thread management (NT6 only).
• Critical sections, which can be optimized with spin count tuning.
• Mutexes, which can be dramatically slower than the alternatives, especially with multiple processors. A semaphore throttle can be marginally useful in some cases with a large number of threads.
Appendix C gives additional results, using other systems and different parameter values.
Parallelism Revisited
Chapter 7 discussed some basic program characteristics that allow application threads to run in parallel, potentially improving program performance, especially on multiprocessor systems.
Parallelism has become an important topic because it is the key to improving application performance, since processor clock rates no longer increase regularly as they have in the past. Most systems today and in the foreseeable future, whether laptops or servers, will have clock rates in the 2–3GHz range. Instead, chip makers are marketing multicore chips with 2, 4, or more processors on a single chip. In turn, system vendors are installing multiple multicore chips in their systems so that systems with 4, 8, 16, or more total processors are common.2
2 Nearly all desktop systems, most laptops, and many notebooks sold today have multiple processors and cost less than single-processor systems sold a few years ago. The “Additional Reading” section suggests references for parallelism and the appropriate technology trends.
Therefore, if you want to increase your application’s performance, you will need to exploit its inherent parallelism using threads, NT6 thread pools, and, possibly, parallelism frameworks (which this section surveys). We’ve seen several simple examples, but these examples give only a partial view of what can be achieved:
• In most cases, such as wcMT and grepMT, the parallel operations are straightforward. There is one thread per file.
• sortMT is more complex, as it divides a single data structure, an array, into multiple parts, sorts them, and merges the results. This is a simplistic use of the divide and conquer strategy.
• cciMT (Chapter 14) divides the file into multiple segments and works on them independently.
In each case, the maximum potential speedup, compared to a single-threaded implementation or running on a single processor, is easy to determine. For example, the speedup for wcMT and grepMT is limited by the minimum of the number of processors and the number of files.
A Better Foundation and Extending Parallel Program Techniques
The previous parallelism discussion was very informal and intuitive, and the implementation, such as wcMT, are all boss/worker models where the workers are long-lived, executing for essentially the entire duration of the application execution.
While a formal discussion is out of scope for this book, it’s important to be aware that parallelism has been studied extensively, and there is a solid theoretical foundation along with definitions for important concepts. There are also analytical methods to determine algorithmic complexity and parallelism. Interested readers will find several good treatments; for example, see Chapter 27 of Cormen, Leiserson, Rivest, and Stein, Introduction to Algorithms, Third Edition.
Furthermore, parallel programming techniques are far more extensive than the boss/worker examples used here. For example:
• Parallel sort-merge can be made far more effective than sortMT’s rudimentary divide and conquer design.
• Recursion and divide and conquer techniques are important for exploiting finer-grained program parallelism where parallel tasks can be short-lived relative to total program duration.
• Computational tasks that are amenable to parallel programming include, but are hardly limited to, matrix multiplication, fast Fourier transformations, and searching. Usually, a new thread is created for every recursive function call.
• Games and simulations are other application types that can often be decomposed into parallel components.
In short, parallelism is increasingly important to program performance. Our examples have suggested the possibilities, but there are many more that are beyond this book’s scope.
Parallel Programming Alternatives
Once you have identified the parallel components in your program, the next issue is to determine how to implement the parallelism. There are several alternatives; we’ve been using the first two, which Windows supports well.
• The most direct approach is to “do it yourself” (DIY), as in some of the examples. This requires direct thread management and synchronization. DIY is manageable and effective for smaller programs or programs with a simple parallel structure. However, DIY can become complex and error prone, but not impossible, when implementing recursion.
• Thread pools, both legacy and NT6 thread pools, enable advanced kernel scheduling and resource allocation methods that can enhance performance. Be aware, however, that the NT6 thread pool API is limited to that kernel; this should become less of an issue in coming years.
• Use a parallelism framework, which extends the programming language to help you express program parallelism. See the next section.
Parallelism Frameworks
Several popular “parallelism frameworks” offer alternatives to DIY or thread pools. Framework properties include:
• Programming language extensions that express program parallelism. The two most common extensions are to express loop parallelism (that is, every loop iteration can execute concurrently) and fork-join parallelism (that is, a function call can run independently from the calling program, which eventually must wait for the called function to complete). The language extensions may take the form of compiler directives or actual extensions that require compiler front ends.
• The supported languages almost always include C and C++, often C# and Java, and Fortran for scientific and engineering applications.
• There is run-time support for efficient scheduling, locking, and other tasks.
• There is support for result “reduction” where the results from parallel tasks are combined (for instance, word counts from individual files are summed), and there is care to minimize locking.
• Parallel code can be serialized for debugging and produces the same results as the parallel code.
• The frameworks frequently contain tools for race detection and identifying and measuring parallelism during program execution.
• The frameworks are sometimes open source and portable to UNIX and Linux.
Popular parallelism frameworks include:3
3 Wikipedia covers all of these, and a Web search will yield extensive additional information. This list is not complete, and it will take time for one or more frameworks to become dominant.
• OpenMP is open source, portable, and scalable. Numerous compilers and development environments, including Visual C++, support OpenMP.
• Intel Thread Building Blocks (TBB) is a C++ template library. The commercial release is available on Windows as well as many Linux and UNIX systems.
• Intel’s Cilk++ supports C and C++. Cilk++ is available on Windows and Linux and provides a simple language extension with three key words along with a run-time library for “work stealing” scheduling. Cilk++ also provides flexible reduction templates.
• .NET Framework 4’s Task Parallel Library (TPL), not yet available, will simplify creating applications with parallelism and concurrency.
Do Not Forget the Challenges
As stated previously, this book takes the point of view that multithreaded programming is straightforward, beneficial, and even enjoyable. Nonetheless, there are numerous pitfalls, and we’ve provided numerous guidelines to help produce reliable multithreaded programs; there are even more guidelines in the next chapter. Nonetheless, do not overlook the challenges when developing multithreaded applications or converting legacy systems. These challenges are daunting even when using a parallelism framework. Here are some of the notable challenges that you can expect and that have been barriers to successful implementations:
• Identifying the independent subtasks is not always straightforward. This is especially true for legacy applications that may have been developed with no thought toward parallelism and threading.
• Too many subtasks can degrade performance; you may need to combine smaller subtasks.
• Too much locking can degrade performance, and too little can cause race conditions.
• Global variables, which are common in large, single-threaded applications, can cause races if independent subtasks modify global variables. For example, a global variable might contain the sum or other combination of results from separate loop iterations; if the iterations run in parallel, you will need to find a way to combine (“reduce”) the independent results to produce a single result without causing a data race.
• There can be subtle performance issues due to the memory cache architecture and the combination of multiple multicore chips.
Processor Affinity
The preceding discussion has assumed that all processors of a multiprocessor system are available to all threads, with the kernel making scheduling decisions and allocating processors to threads. This approach is simple, natural, consistent with multiprocessors, and almost always the best approach. It is possible, however, to assign threads to specific processors by setting processor affinity. Processor affinity can be used in several situations.
• You can dedicate a processor to a small set of one or more threads and exclude other threads from that processor. This assumes, however, that you control all the running applications, and even then, Windows can schedule its own threads on the processor.
• You can assign a collection of threads to a processor pair sharing L2 cache (see Figure 8-2) to minimize the delay caused by memory barriers.
• You may wish to test a processor. Such diagnostic testing, however, is out of scope for this book.
• Worker threads that contend for a single resource can be allocated to a single processor.
You may wish to skip this section, considering the specialized nature of the topic.
System, Process, and Thread Affinity Masks
Each process has its own process affinity mask, which is a bit vector. There is also a system affinity mask.
• The system mask indicates the processors configured on this system.
• The process mask indicates the processors that can be used by the process’s threads. By default, its value is the same as the system mask.
• Each individual thread has a thread affinity mask, which must be a subset of the process affinity mask. Initially, a thread’s affinity mask is the same as the process mask.
• Affinity masks are pointers (either 32 or 64 bits). Win32 supports up to 32 processors. Consult MSDN if you need to deal with more than 64 processors on Win64.
There are functions to get and set the masks, although you can only read (get) the system mask and can only set thread masks. The set functions use thread and process handles, so one process or thread can set the affinity mask for another, assuming access rights, or for itself. Setting a mask has no effect on a thread that might already be running on a processor that is masked out; only future scheduling is affected.
A single function, GetProcessAffinityMask, reads both the system and process affinity masks. On a single-processor system, the two mask values will be 1.
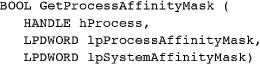
The process affinity mask, which will be inherited by any child process, is set with SetProcessAffinityMask.
![]()
The new mask must be a subset of the values obtained from GetProcessAffinityMask. It does not, however, need to be a proper subset. Such a limitation would not make sense because you would not be able to restore a system mask to a previous value. The new value affects all the threads belonging to this process.
Thread masks are set with a similar function.
![]()
These functions are not designed consistently. SetThreadAffinityMask returns a DWORD with the previous affinity mask; 0 indicates an error. SetThreadAffinityMask, however, returns a BOOL and does not return the previous value.
SetThreadIdealProcessor is a variation of SetThreadAffinityMask. You specify the preferred (“ideal”) processor number (not a mask), and the scheduler will assign that processor to the thread if possible, but it will use a different processor if the preferred processor is not available. The return value gives the previous preferred processor number, if any.
Finding the Number of Processors
The system affinity mask does indicate the number of processors on the system; all that is necessary is to count the number of bits that are set. It is easier, however, to call GetSystemInfo, which returns a SYSTEM_INFO structure whose fields include the number of processors and the active processor mask, which is the same as the system mask. A simple program and project, version, in the Examples file, displays this information along with the Windows version. See Exercise 6–12 for version output on the system used for the run screenshots in this chapter.
Performance Guidelines and Pitfalls
Multiple threads can provide significant programming advantages, including simpler programming models and performance improvement. However, there are several performance pitfalls that can have drastic and unexpected negative performance impact, and the impact is not always consistent on different computers, even when they are running the same Windows version. Some simple guidelines, summarizing the experience in this chapter, will help you to avoid these pitfalls. Some of these guidelines are adapted from Butenhof’s Programming with POSIX Pthreads, as are many of the designing, debugging, and testing hints in the next chapter.
In all cases, of course, it’s essential to maintain program correctness. For example, while the statsXX programs, as written, can run without locking, that is not the case in general. Likewise, when you make a critical code section as small as possible, be sure not to move critical code out of the code section. Thus, if the critical code section adds an element to a search tree, all the code required for the insertion operation must be in the critical code section.
• Beware of conjecture and theoretical arguments about performance, which often sound convincing but can be wrong in practice. Test the conjecture with a simple prototype, such as TimedMutualExclusion, or with alternative implementations of your application.
• Test application performance on as wide a variety of systems as are available to you. It is helpful to run with different memory configurations, processor types, Windows versions, and number of processors. An application may perform very well on one system and then have extremely poor performance on a similar one; see the discussion after Program 9-1.
• Locking is expensive; use it only as required. Hold (own) a lock, regardless of the type, only as long as required and no longer (see earlier comment). As an additional example, consider the message structures used in simplePC (Program 8-1). The critical code section incudes everything that modifies the message structure, and nothing else, and the invariant holds everywhere outside the critical code section.
• Use distinct locks for distinct resources so that locking is as granular as possible. In particular, avoid global locks.
• High lock contention hinders good performance. The greater the frequency of thread locking and unlocking, and the larger the number of threads, the greater the performance impact. Performance degradation can be drastic and is not just linear in the number of threads. Note, however, that this guideline involves a trade-off with fine-grained locking, which can increase locking frequency.
• CSs provide an efficient, lightweight locking mechanism. When using CSs in a performance-critical multiprocessor application, tune performance with the CS spin counts. SRW locks are even more efficient but do not have adjustable spin counts.
• Semaphores can reduce the number of active contending threads without forcing you to change your programming model.
• Multiprocessors can cause severe, often unexpected, performance impacts in cases where you might expect improved performance. This is especially true when using mutexes. Reducing contention and using thread affinity are techniques to maintain good performance.
• Investigate using commercially available profiling and performance analysis tools, which can help clarify the behavior of the threads in your program and locate time-consuming code segments.
Summary
Synchronization can impact program performance on both single-processor and multiprocessor systems; in some cases, the impact can be severe. Careful program design and selection of the appropriate synchronization objects can help assure good performance. This chapter discussed a number of useful techniques and guidelines and illustrated performance issues with a simple test program that captures the essential characteristics of many real programming situations.
Looking Ahead
Chapter 10 shows how to use Windows synchronization in more general ways, particularly for message passing and correct event usage. It also discusses several programming models, or patterns, that help ensure correctness and maintainability, as well as good performance. Chapter 10 creates several compound synchronization objects that are useful for solving a number of important problems. Subsequent chapters use threads and synchronization as required for applications, such as servers. There are also a few more basic threading topics; for example, Chapter 12 illustrates and discusses thread safety and reentrancy in DLLs.
Additional Reading
Chapter 10 provides information sources that apply to this chapter as well. Duffy’s Concurrent Programming on Windows, in addition to covering the synchronization API, also gives insight into the internal implementation and performance implications and compares the Windows features with features available in .NET. In particular, see Chapter 6 for synchronization and Chapter 7 for thread pools.
Chapter 27 of Cormen, Leiserson, Rivest, and Stein, Introduction to Algorithms, Third Edition, is invaluable for understanding parallelism and effective parallel algorithm design.
The Wikipedia “Multi-core” entry gives a good introduction to the commercial and technical incentives as well as long-term trends for multicore systems.
Exercises
9–1. Experiment with the statsXX variations on your own system and on as many different systems (both hardware and Windows versions) as are available to you. Do you obtain similar results as those reported in this chapter and in Appendix C?
9–2. Use TimedMutualExclusionSC, included in the Examples file, to experiment with CRITICAL_SECTION spin counts to see whether adjusting the count can improve and tune multiprocessor performance when you have a large number of threads. Results will vary from system to system, and I have found approximately optimal points ranging from 2,000 to 10,000. How do the best results compare with exclusive-mode SRW locks?
9–3. Experiment with the statsXX variations by modifying the delay time in the worker function. For example, increasing the delay should increase the total elapsed time for all variations, but the relative impact of the locking model could be less.
9–4. Use TimedMutualExclusion to experiment with delay and sleep point counts.
9–5. TimedMutualExclusion also uses a semaphore throttle to limit the number of running threads. Experiment with the count on both single-processor and multiprocessor systems. If an NT4 system is available, compare the results with NT5 and NT6.
9–6. Do the seven statsXX variations all operate correctly, ignoring performance, on multiprocessor systems? Experiment with a large number of worker threads. Run on a multiprocessor Windows 2003 or 2008 server. Can you reproduce the “false-sharing” performance problem described earlier?
9–7. Enhance Program 9-2 (statsSRW_VTP) to display the thread number as suggested after the program listing.
9–8. What is the effect of using an NT6 thread pool with a CS or mutex? Suggestion: Modify statsSRW_VTP. What is the effect of using a semaphore throttle with a CS (modify statsMX_ST)?
9–9. Rewrite statsSRW_VTP to use TrySubmitThreadpoolCallback. Compare the results and ease of programming with statsSRW_VTP.
9–10. Use processor affinity as a possible performance-enhancement technique by modifying this chapter’s programs.
9–11. Run 9-1b compared SRWs with CSs, and SRWs were always considerably faster. Modify the statsXX programs so that they each use a pair of locks (be careful to avoid deadlocks!), each guarding a separate variable. Are CSs more competitive in this situation?
9–12. The statsXX programs have an additional command line parameter, not shown in the listings, that controls the delay time in the worker threads. Repeat the comparisons in Runs 9-1a and 9-1b with larger and smaller delays (changing the amount of contention). What is the effect?