
Chapter 7. A System-Oriented Perspective
The serious problems of life
are never fully solved. If ever
they should appear to be so, it
is a sure sign that something
has been lost. The meaning
and purpose of a problem
seem to lie not in its solution
but in our working at
it incessantly.
C.G. JUNG
7.1 The Not-So-Accidental Holist: A System View
Think of the small as large and the few as many.
LAO TSE, TAO TE CHING, 631
We consider here the importance of an overall systems viewpoint in avoiding computer-related risks. A system is a regularly interacting or interdependent group of items forming a unified whole. In computer systems, one person’s components may be another person’s system, and one person’s system may in turn be one of another person’s components. That is, each layer of abstraction may have its own concept of a system. We speak of a memory system, a multiprocessor system, a distributed system, a multisystem system, a networked system, and so on. A system design can most effectively be considered as a unified whole when it is possible to analyze the interdependent subsystems individually, and then to evaluate, reason about, and test the behavior of the entire system based on the interactions among the subsystems. This system view is particularly true of distributed systems that mask the presence of distributed storage, processing, and control. At each layer of abstraction, it is desirable to design (sub)systems that are context-free; in reality, however, there may be subtle interactions that must be accommodated—particularly those involving the operating environment.
One of the problems that we encounter throughout research, development, and indeed life is that we tend to compartmentalize our endeavors, with individuals becoming specialists in relatively narrow areas, with the result that they often fail to see the bigger picture. There is a great need at certain crucial times in many system developments to bring together the different communities, such as people who fully understand hardware, software, networks, and the intended applications, as well as people who understand the importance of the human interface. In too many cases, these folks have not communicated with one another, resulting in system glitches that illustrate Conway’s Law:
The organization of a system directly imitates the organization of the people developing the system.
For example, weaknesses in human communication typically beget analogous weaknesses in computer communication in corresponding system manifestations. This problem can be particularly severe in distributed systems in which various components have been developed by different people. In many cases, it is only after the occurrence of an accident or system failure that there is awareness of certain hitherto invisible system interactions and of the latent flaws that these interactions may trigger.
7.1.1 Risks of Nonholistic Views
The cases enumerated here include many in which a failure to consider the whole system resulted directly or indirectly in serious consequences.
Absence of end-to-end testing
In the development of the Hubble Space Telescope, no overall system tests were performed—only subassembly tests were done, and they succeeded because they satisfied an erroneous monitoring program that tolerated a 1-millimeter error in the polishing process. In addition to mirror imperfections, there were also sensors that were misdirected because of a wrong sign on the precession relating to star data, the motion of the second antenna was limited by a misplaced cable, and the motion of the first antenna was limited by a software mistake.2 In a remarkable and successful rescue effort, the astronauts aboard the shuttle Endeavour (STS-61) (launched on December 2, 1993) were able to replace a damaged solar panel with new solar arrays, replace two sets of faulty gyroscopes, and install corrective mirrors to improve the precision. Finally, correcting a misaligned antenna resolved what earlier had appeared to be a computer-system problem.
Multiple causes
Both the 1980 ARPAnet collapse and the 1990 AT&T long-distance slowdown (discussed in Section 2.1) involved a confluence of hardware and software problems that had not been adequately anticipated. Further telephone problems in June 1991 continued to demonstrate the intrinsic difficulties in making highly distributed systems robust and efficient.
Multiprocessor incompatibilities
In the first shuttle launch, the 2-day launch delay (Section 2.2.1) resulted from a multicomputer clock synchronization problem that could not be detected locally.
Security problems
Many system and network penetrations (Section 5.1) have resulted from a lack of a suitable system perspective on the part of developers, administrators, and users.
Environmental influences
The Challenger disaster and many other cases (including the squirrelcides of Section 2.10) remind us that the physical environment is a vital part of the system.
Poor human interfaces
See Section 7.2 for a discussion of how the interfaces for users, operators, and maintenance personnel can be particularly critical.
7.1.2 Introduction to a System Perspective
There is a pressing need to integrate what is known about different disciplines. In some cases it is vital to accommodate different requirements, such as reliability, availability, confidentiality, integrity, human safety, real-time performance, and massive throughput, and to do so simultaneously and dependably. We recognize that sometimes these requirements are in conflict with one another, in which case sound engineering judgments become essential. In such cases, development methodologies, design languages, and good programming practices cannot overcome the need for sage individuals with a suitably holistic system perspective. These concepts are explored further in the remainder of this chapter.
7.2 Putting Your Best Interface Forward
Human interfaces to computer-based systems have been a source of serious difficulties. Blame for resulting disasters has often fallen on users, operators, and maintainers, but can generally be traced back at least in part to the original system developers. Problems can arise on both input and output. Some interfaces are oversimplified, whereas others are overly complex and difficult to use; many contain high-risk ambiguities. Each of these situations has led to harmful system behavior, with several cases revisited here.
Accident-prone conventions
We noted in Section 5.7 a high-rolling group that always dealt with wire transfers in multiples of thousands, whereas the other groups within the same organization used the actual amount, the result being a $500,000 Federal Reserve transaction converted into $500,000,000 (SEN 10, 3, 9-10).
That case is reminiscent of when the shuttle Discovery (STS-18) was positioned upside down in attempting to conduct a Star Wars-type laser-beam missile-defense experiment. The computer system had been given the number +10,023, with the expectation that a mirror would be positioned (downward) toward a point +10,023 feet above sea level—that is, at a laser beam on top of Mona Kea; however, the input was supposed to be in nautical miles, so that the mirror was actually aimed upward (SEN 10, 3, 10).
Unintended interface puns
Ambiguities in the human interface are common. The next two cases illustrate harmful input sequences that might be called computer puns, because each has a double meaning, depending on context.3
BRAVO editor
Jim Horning reported on a lurking danger in getting into edit mode in Xerox PARC’s pioneering WYSIWYG (What You See Is What You Get) editor BRAVO. If the user accidentally typed edit when the BRAVO was already in edit mode, BRAVO interpreted the character sequence edit as “Everything Deleted Insert t” and did exactly as instructed—it transformed the contents of the file into the single letter t. After the first two characters, it was still possible to undo the ed; however, once the i was typed, the only remaining fallback was to replay the recorded keystroke log from the beginning of the editing session (except for the edit sequence) against the still-unaltered original file. (This type of recovery would not have been possible in many other systems.)
Univac line editor
A similar example was reported to me by Norman Cohen of SofTech. He had been entering text using the University of Maryland line editor on the Univac 1100 for an hour or two, when he entered two lines that resulted in the entire file being wiped out. The first line contained exactly 80 characters (demarcated by a final carriage return); the second line began with the word about.
Because the first line was exactly 80 characters long, the terminal handler inserted its own carriage return just before mine, but I started typing the second line before the generated carriage return reached the terminal. When I finished entering the second line, a series of queued output lines poured out of the terminal. It seems that, having received the carriage return generated by the terminal handler, the editor interpreted my carriage return as a request to return from input mode to edit mode. In edit mode, the editor processed the second line by interpreting the first three letters as an abbreviation for abort and refusing to be bothered by the rest of the line. Had the editing session been interrupted by a system crash, an autosave feature would have saved all but the last 0 to 20 lines I had entered. However, the editor treated the abort request as a deliberate action on my part, and nothing was saved.
Complicated interfaces
The Iranian Airbus shot down by the Vincennes was being tracked by an Aegis system, whose complicated user interface was determined to be a contributing cause (see Section 2.3). The Stark’s inability to cope with the Iraqi Exocets was also partly attributable to the human-machine interface (SEN 12, 3, 4). Lack of familiarity with a new interface replacing a conventional throttle may have contributed to the 1989 crash of a 737-400 on an under-powered takeoff from LaGuardia Airport in New York (SEN 15, 1). Three Mile Island and Chernobyl are further examples of complicated interfaces that contributed to disasters.
Flaky interfaces
Automatic speech recognition and handwriting recognition are intrinsically unreliable when used for purposes of contextual understanding rather than just for user identification. Variations in dialect among different people and variations in speech by the same person both tend to make speech recognition difficult. Handwriting recognition is similarly risky. The handwriting interface to Apple’s Newton was described by Ken Siegman4 as being flaky, slow, poorer for left-handed writers, and strictly limited to a 10,000-word dictionary. Ken (whose name Newton interpreted as “Rick 5 Jeffries”) cited the following firsthand example: “Hello, this is Ken, writing this message to test the fax on Newton. So far it’s useless.” The result he got was this: “Hello, thisis ken irrit nj to test the fax on xiewwtoz. Sofar itf lervgelj.” Similar examples have been noted elsewhere, including in the Doonesbury comic strip.
Nonatomic transactions
Section 2.9.1 discusses the Therac-25, a therapeutic linear accelerator in which a supposedly atomic transaction had an unsafe intermediate state that should have been prevented by the hardware and the software. In addition, the command language presented an extremely low and error-prone level of abstraction. (The temporary fix of removing the key cap from the edit key on the Therac-25 control console was clearly an attempt to hinder low-level operator-command hacking, but ducked the deeper issues.)
Dehumanizing the loop
In fly-by-wire aircraft in which critical operations are completely controlled by computer, there is no longer sufficient time for pilots to respond in emergencies. In such cases, leaving the human in the loop could be dangerous. However, taking the human completely out of the loop can also be dangerous, especially if there are unrecognized flaws in the computer system or if the environment presents operating conditions that had not been anticipated adequately by the designers.
Much more care needs to be devoted to human-visible machine interfaces. In general, interface design must be considered as a fundamental part of the overall system design. Superficially, explicit prompting and confirmation can be helpful, with insistence on self-defining inputs and outputs where ambiguities might otherwise arise. Some interfaces are intrinsically risky, however, and patching up the interface may only increase the risks. Consistent use of abstraction, information hiding, parameterization, and other aspects of good software-engineering practice should be applied to human interfaces as well as internally, throughout system design and development. Peter Denning suggested that some of the best interface design work has been done by teams consisting of experts in the domain, experts in graphics, and experts in computation, as in the “cockpit of the future” project at NASA Ames.
A possible moral is that you have to know when to scrub your interface; in some cases, cosmetic palliatives are inadequate, and a better interface and system design would be preferable.
Newer systems have lurking dangers comparable to earlier systems, but with even more global effects. In user interfaces, there are many cases in which a slight error in a command had devastating consequences. In software, commands typed in one window or in one directory may have radically different effects in other contexts. Programs are often not written carefully enough to be independent of environmental irregularities and of less-than-perfect users. Search paths provide all sorts of opportunities for similar computer puns (including the triggering of Trojan horses). Accidental deletion is still a common problem, although many systems and applications provide a form of undelete operation that can reverse the effects of a delete operation, until the occurrence of a particular time or event, at which point the deletion becomes permanent. In hardware, various flaws in chip designs have persisted into delivery.
I offer a few observations relating to human-machine interfaces.
• Although systems, languages, and user interfaces have changed dramatically, and we have learned much from experience, similar problems continue to arise—often in new guises.
• Designers of human interfaces should spend much more time anticipating human foibles.
• Manual confirmations of unusual commands, crosschecking, and making backups are ancient techniques, but still helpful.
• Computers do not generally recognize, understand, or appreciate puns and other ambiguities.5
7.3 Distributed Systems
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
LESLIE LAMPORT
As we evolve more and more toward distributed systems, we must recognize that certain design decisions must be fundamentally altered, and in particular that we must not rely on weak-link centralized servers.6
In this section, we summarize briefly problems that are generic to computer systems. Of particular interest are those problems that are intensified by the development and use of distributed systems, in which there may be geographical dispersion of hardware, logical distribution of control among coordinating computers, and both logical and physical distribution of data. Various requirements are considered collectively, to emphasize the interactions among them. A generalized notion of trustworthiness is used to imply system dependability with respect to whichever set of requirements is to be enforced. Thus, we speak of the trustworthinessof a system, of a subsystem, or of people who are expected to live up to certain assumptions about their behavior.
Distributed systems obviously have great intuitive appeal. People can have greater control over their own facilities. Workstations and computing engines can be integrated to provide enormous computing power. Systems can be configured to provide hardware fault tolerance, reliable communications, high availability, and physical isolation where desired. The benefits of central file servers can still be achieved. However, the simplicity of those arguments sweeps under the rug serious problems of security and controllability that arise when the sharing of data and distributed processing are permitted.
Generic threats to the security of computer systems and networks (such as those enumerated in Section 3.1) are particularly relevant to distributed systems. The requirements of confidentiality, integrity, and prevention of denials of service are the same as for centralized systems, but distributed data and control tend to make global enforcement more difficult.
The analysis of trustworthiness can be significantly more complicated for a distributed system than for centralized systems, although in principle the concepts are the same. Heterogeneous resources and mixed degrees of user and system trustworthiness are characteristically sources of difficulty.
7.3.1 Risks in Distributed Systems
We next identify various potential problem areas in distributed systems.
Untrustworthy computer systems
In a distributed system, it is not always clear what hidden dependencies exist, and which of those involve dependence on less trustworthy systems and networks. In general, it is difficult to avoid such potentially risky dependencies, unless either all components are equally trustworthy or their relative trustworthiness is somehow made explicit and is respected throughout. Trustworthiness must include adequate system security, system integrity, availability, and protection against denials of service. Vulnerabilities in any one system or its network software may lead to penetrations, Trojan horses, or virus attacks on other systems, such as the Internet Worm’s exploitation of send-mail, fingerd, and the .rhosts remote logins, discussed in Section 5.1. Unintentional or unpredicted behavior may also have serious side effects. Of particular importance here are mutually suspicious systems, in which neither can be sure of the trustworthiness of the other; such systems require special care to guard against a wide range of threats.
Untrustworthy networks and communications
Distributed systems are particularly vulnerable to network unreliability and inadequate communication security, both internally and externally. Even with constructive redundancy, breakdowns in communications can isolate subsystems. An example was the 1986 case when New England was cut off from the ARPAnet, because all seven supposedly independent trunk lines went through the same physical conduit—which was severed. Unencrypted local networks and long-haul networks may give rise to loss of confidentiality and integrity, as well as compromised authentication (for example, password capture). Use of “promiscuous” mode in the Ethernet permits eavesdropping on all local network communications, including passwords, authenticators, and other interesting information. In many systems and networks, passwords are transmitted in unencrypted form, in some cases worldwide. Even in the presence of encryption, it may be possible to replay encrypted authenticators unless they are constructively made nonreusable—for example, cryptographically based one-time tokens that incorporate a timestamp to prevent replay attacks.
Untrustworthy users
Distributed systems are particularly vulnerable to users erroneously presumed to be trustworthy or infallible. This problem exists in centralized systems, but can be exacerbated by geographic remoteness and apparent logical independence in distributed systems. Undesirable activities include not only malicious misuse but also accidental misuse.
Identification and authentication
It is often difficult to know the identity of a remote user, user surrogate, or system, particularly in distributed heterogeneous environments. Providing assurances that an identity is genuine—authentication—becomes utterly fundamental to distributed systems. The term user surrogate implies something acting on behalf of a user, directly or indirectly, such as a user process or a daemon process that runs independently of particular users. In some cases, an entire system can act as a user surrogate.
A related authentication problem involves nonrepudiation—that is, providing assurances of genuineness such that a seemingly authentic but possibly forged message cannot subsequently be claimed to be a forgery. Some authentication systems are not strong enough to provide assurances of nonrepudiation.
In addition, distributed systems exacerbate the need for different system components to be able to authenticate one another. For example, an authentication server must be able to authenticate those system components that communicate with it for access requests. Furthermore, the various system components must be able to authenticate the authentication server when updating a user’s authorizations. Techniques such as public-key cryptography hold promise in this area, for example, for distribution of one-time shared keys (sometimes misnamed secret keys!) This problem is made still more difficult by the need for alternative authentication servers, because a single centralized authentication server is vulnerable to denial of service attacks and accidental outages. Adding still further complexity with multiple servers is the need to keep them consistent in spite of network outages and malicious attacks. Techniques for enhancing authentication are given in Section 7.9.2.
Distributed data
There are many benefits of distributed data, including the high availability of data despite system and network outages. This can be achieved by making constructive use of redundant or less recent multiple versions, and by avoiding dependence on less accessible or less reliable sites. These benefits are countered by the problems of consistency and concurrency control, which escalate substantially in widely distributed systems. Data integrity is a potential problem in the presence of untrustworthy sites. Communication confidentiality may also be a problem, along with covert channels (see Section 3.4)—that is, storage channels or timing channels indirectly permitting signaling between cooperating processes, despite direct communications being forbidden.
Fault tolerance and robust algorithms in distributed control
Distributed systems present opportunities for greater algorithmic robustness, particularly in response to unexpected behavior. However, the increased complexity may result in less stability unless carefully controlled. Simplifying assumptions can make algorithms less complex, but also less able to cope with realistic events. The absence of assumptions about what events must be protected against leads to complex algorithms (for example, Byzantine algorithms that can withstand arbitrary combinations of faults, termed Byzantine faults [70]). (A Byzantine clock algorithm is noted in Section 2.11.2.) Byzantine algorithms tend to require extensive confirmations, or time delays, or both. Short-sighted solutions are often risky. A middle ground is needed that is both realistic and practical. In some cases, it is the management of the redundancy itself that is the cause of difficulties, as in the New York area airport shutdowns due to the AT&T internal power problems on September 17, 1991, noted in Section 2.1.7
Backup and recovery
Distributed control and distributed data both exacerbate the problems of recovering from complex fault modes; in a highly distributed system, complete consistency is usually not globally possible, and thus local consistency must suffice. Preserving consistent distributed versions is complicated by the need to protect recent versions and redundant copies from compromise and from subsystem outages. Recovery systems that attempt to overcome system failures are inherently difficult to test adequately, as demonstrated by the AT&T problem of January 15, 1990, noted in Section 2.1.
Optimization, high throughput, and enormous parallelism
Highly parallel systems (with perhaps thousands of processors executing simultaneously) present opportunities for increased performance. However, shortcuts in software-engineering practice may result in optimizations that increase the risks in the long run. Furthermore, the very-high-performance hardware architectures have in general ignored security problems to achieve that performance.
Distributed auditing
Distributed control among heterogeneous systems or among homogeneous systems with different administrative organizations can complicate the problems of audit-trail collection (that is, monitoring) and audit-trail analysis (that is, auditing). In the absence of a suitably global perspective, disruptive activity may go undetected far longer than it would with centralized auditing, simply because events across different system components are difficult to correlate. Careful cooperation is required to ensure that real-time or retrospective analysis can identify the people, processes, and systems involved, without violating confidentiality and privacy requirements.
System administration and use
Distributed control introduces new complexities for system operation. In the absence of centralized control, there is typically no one entity that knows what the global state of the system is, who its users are, what their physical locations are, what the system configurations are, what system components are connected to which networks, what access may be available to gateways, and what possibilities exist for remote accessibility from systems on other networks. Thus, there may be a poorer ability to provide management of the resources. Similarly, users are typically less aware of other people who may have access to the user’s resources and consequently are not sufficiently aware of the vulnerabilities.
Nonlocal side effects
Small effects in one portion of a distributed system can propagate unexpectedly. Hidden fault modes or other vulnerabilities may be lurking, or may be introduced by program changes to a system that has worked properly in the past, even if thought to have no weak links. Three examples of this phenomenon are provided by the first shuttle synchronization failure (Section 2.2.1), the ARPAnet collapse of 1980, and the AT&T collapse of 1990 (Section 2.1).
7.3.2 Distributed Systems as Systems
In each of these areas, the problems are quite broad with respect to, for example, security, integrity, reliability, availability, performance, system configuration control, and administration. External penetrations and misuses by authorized users are part of the problem, as are attainment of confidentiality, integrity, adequacy of service, and sufficient anticipation of accidental events and accidental misuse. System configuration, maintenance, and general evolution add to each of these problems.
Many people believe that distributed systems can make life easier for system developers and users alike. But the risks of hidden pitfalls are significant. Implicit trust may unknowingly be conferred on parts of a system that are inadequately reliable, secure, safe, and so on; people are also error prone. The close resemblance between the 1990 AT&T saturation and the 1980 ARPAnet collapse suggests that intrinsic problems still remain and are likely to recur in different guises.
There is widespread consensus that such events can and will continue to happen, particularly because of the role of people. Reflecting on the telephone outages, Jim Horning somewhat ironically recalled the Congressional testimony of Sol Buchsbaum of AT&T Bell Laboratories, who asserted that a large, robust, and resilient Strategic Defense Initiative (Star Wars) system could be designed and implemented, because it could use the demonstrably sound techniques found in the U.S. public telecommunications network. There was much debate over whether the saturation was a programming-language problem or a programmer problem. Bill Murray stressed the AT&T outage as a system problem rather than just a software problem. He also warned of gratuitous automation. Jonathan I. Kamens quoted Edwin A. Irland, who had noted that “failure to recover from simplex faults is usually a significant source of total outage time.” Gene Spafford warned of increasing technoterrorism in such events being caused intentionally. Lively discussion went on for over 1 month.
Jim Horning added that the 1990 telephone system failure bears a close resemblance to the December 1981 failure of an experimental distributed system, Grapevine. In both cases, the persistence of the recovery code itself caused each node to crash again whenever recovery was attempted. One of the ironies of the Grapevine incident was that it occurred while the principals were presenting Grapevine to the ACM Symposium on Operating Systems Principles [149].
In our modern times, distributed systems need not have so many weak links. There are typically all sorts of hidden dependencies—such as on password servers, file servers, name servers, system logs, and lock managers—whose malfunctions can cause pervasive disturbances. Caveh Jalali noted how timeouts were nested in Sun/OS, ensuring total blockage under certain circumstances. In the research community and in the Tandem world, we know how to reduce drastically the dependence on weak links. It is time that developers of distributed operating systems got the message: Distributed systems are a step forward only if they cannot be totally disabled by simple server failures; ideally, they should be able to survive single failures.
A stand-alone personal computer or totally centralized system works just fine as long as that system is up. The corresponding situation in distributed systems is that a system works wonderfully as long as every component you depend on is working properly. But the likelihood of success is even lower in distributed systems, unless weak links have been avoided by good system design. The problems of designing robust distributed systems are not conceptually difficult, but nevertheless present significant challenges.
7.4 Woes of System Development
Confront the difficult while it is still easy;
accomplish the great task by a series of small acts.
LAO TSE, TAO TE CHING, 638
Complex computer systems are rarely developed on time, within budget, and up to spec. Here are just a few examples from the RISKS archives that suggest how pervasive the problems are. In most cases, details are not readily available regarding what went wrong.
London Stock Exchange Taurus
The London Stock Exchange spent £400 million in the development of Taurus, an automated stock-transaction system. The entire project was scuttled after it became clear that the system was unlikely ever to satisfy its requirements; its complexity had grown beyond manageability. Much of the criticism centered on the system security and the system integration. The chief executive of the exchange resigned.9
Virginia child-support system
The state of Virginia acquired a new system for distributing child-support checks, but experienced massive delays, confusion, lost checks, delayed payments, and improper seizure of tax refunds. Operations costs were expected to be triple the original estimates.10
Bank of America MasterNet
Bank of America spent $23 million on an initial 5-year development of MasterNet, a new computer-based trust accounting and reporting system. After abandoning the old system, BoA spent $60 million more trying to make the new system work—and finally gave up. Departed customer accounts may have exceeded billions of dollars.11
Allstate Insurance automation
In 1982 Allstate Insurance began to build an $8 million computer to automate its business, with Electronic Data Systems providing software. The supposedly 5-year project continued until at least 1993, with a cost approaching $100 million.
Richmond utility system
In 1984 the city of Richmond, Virginia, hired the accounting firm of Arthur Young to develop a $1.2 million billing and information system for its water and gas utilities. After spending almost $1 million, Richmond canceled the contract for nondelivery. Arthur Young retaliated with a $2-million breach of contract suit.
Business Men’s Assurance
Business Men’s Assurance began a 1-year project in 1985 to build a $0.5 million system to help minimize the risk of buying insurance policies held by major insurers. After spending $2 million, the completion date was slipped to 1990.
Oklahoma compensation system
The state of Oklahoma hired a major accounting firm in 1983 to design a $0.5 million system to handle its workers’ compensation claims. Two years and more than $2 million later, the system still did not exist. It was finally finished in 1987, for nearly $4 million.
Blue Cross and Blue Shield
Blue Cross and Blue Shield United of Wisconsin hired EDS in late 1983 to build a $200 million computer system. The system was delivered on time in 18 months, but it did not work correctly; it issued $60 million in overpayments and duplicate checks. By the time it was finished in 1987, Blue Cross had lost 35,000 policyholders.
Surface Mining
The U.S. Office of Surface Mining spent $15 million on a computer system intended to prevent violators of stripmine laws from getting new permits. The system could not keep identities straight, and the Government Accounting Office (GAO) called it a failure.12
L.A. property-tax billing
Thousands of Los Angeles County homeowners were billed retroactively for up to $15,000 in additional property taxes, resulting from a 1988 glitch in an $18 million computer system that was subsequently rewritten from scratch. In addition, the county was unable to collect $10 million that it was owed in taxes.13
Pentagon modernization
Modernization of a Pentagon computer system used for general data processing was running $1 billion over budget and far behind schedule. The congressional report released about this system says that Pentagon computer systems have experienced “runaway costs and years of schedule delays while providing little capability.” Charles A. Bowsher, the head of the General Accounting Office, said that problems with the Pentagon’s accounting system may impede efforts to reduce spending in the Department of Defense because of inaccuracies in the data used to manage the department.14
B-1 bomber
The B-1 bomber required an additional $1 billion to improve its ineffective air-defense software, but software problems prevented it from achieving its goals.
Satellite Tracking Control Facility
The software for the modernization of the Satellite Tracking Control Facility was reportedly about 7 years behind schedule, was about $300 million over budget, and provided less capability than required.
NORAD modernization
The modernization of the software at NORAD headquarters was running $250 million over budget and years late.
ASPJ
The Airborne Self-Protection Jammer (ASPJ), an electronic air-defense system installed in over 2000 Navy fighters and attack planes, was $1 billion over budget, 4 years behind schedule, and only “marginally operationally effective and marginally operationally suitable.”
Software schedules
General Bernard Randolph, commander of the Air Force Systems Command: “We have a perfect record on software schedules—we have never made one yet and we are always making excuses.”
C-17
The C-17 cargo plane being built by McDonnell Douglas had a $500 million overrun because of problems in its avionics software. A GAO report noted that there were 19 on-board computers, 80 microprocessors, and 6 different programming languages. It stated that “The C-17 is a good example of how not to approach software development when procuring a major weapons system.”15 The cost-dispute settlement required the government to pay $348 million and McDonnell Douglas to cover $454 million, although a subsequent GAO report delivered to Congress on April 19, 1994, concluded that the actual out-of-pocket cost to the contractor was only $46 million.
The software development process itself
An important report by James Paul and Simon Gregory16 takes to task the waterfall model (which encompasses the entire system-development cycle) and the system- and software-procurement process. “Software is now the choke point in large systems .... Government policies on everything from budgeting to intellectual property rights have congealed over time in a manner almost perfectly designed to thwart the development of quality software,” James Paul told Science, “The federal procurement system is like a software system with bugs.”17
7.5 Modeling and Simulation
The less we understand a phenomenon, the more variables we require to explain it.
LEWIS BRANSCOMB
Analysis based on system modeling and simulation is always tricky. When it catches a horrendous bug that would have undermined system behavior, it is invaluable. When it fails to detect such a bug, it is a potential source of disaster, especially if its apparent success promotes false credibility. The RISKS archives include examples of both types.
7.5.1 Simulation Testing Successful in Debug
We begin with several cases in which simulation uncovered flaws in a design or a program before any bad effects could occur.
F-16 flipover
Section 2.3 notes two bugs that were caught in simulation—the F-16 program bug that caused the virtual airplane to flip over whenever it crossed the equator, and the F-16 that flew upside down because the program deadlocked over whether to roll to the left or to the right.
Shuttle STS-2 abort problem
Preparing for the second shuttle mission, the astronauts in simulation testing attempted to abort and return to their simulated earth during a particular orbit. They subsequently changed their minds and tried to abort the abort. When they then decided to abort the mission after all on the next orbit, the program got into a two-instruction loop. Apparently the designers had not anticipated that anyone would ever abort twice on the same flight (SEN 8, 3, Jul 1983).
Nuclear simulations
Difficulties with the Shock II model are noted in Section 2.10; they necessitated the closure of five nuclear plants.
7.5.2 Simulation Missed Flaw, Live Testing Found It
We consider next a case in which simulation failed to detect a flaw that was later uncovered by full-scale testing.
Titan IV SRB explosion
On April 1, 1991, a Titan IV upgraded solid rocket booster (SRB) blew up on the test stand at Edwards Air Force Base. The program director noted that extensive three-dimensional computer simulations of the motor’s firing dynamics did not reveal subtle factors that apparently contributed to failure. He added that full-scale testing was essential precisely because computer analyses cannot accurately predict all nuances of the rocket motor dynamics.18
7.5.3 Modeling, Simulation, or Testing Failed
Further cases illustrate problems that could not be detected by modeling, simulation, or testing.
Handley-Page Victor aircraft crash
The Handley-Page Victor aircraft tailplane flutter problem is mentioned in Section 4.1. Each of three independent test methods used in flutter analysis had an error, but coincidentally all came up with seemingly consistent results, each wrong, but for a different reason. First, a wind-tunnel model had an error relating to wing stiffness and flutter; second, the results of a resonance test were erroneously accommodated in the aerodynamic equations; third, low-speed flight tests were incorrectly extrapolated. This congruence of results led to the conclusion that there was no tailplane flutter problem at any attainable speed. The tailplane broke off during the first flight test, killing the crew. (See SEN 11, 2, 12, plus erratum in 11, 3, 25.)
Electra body failures
Structural failures of the Electra aircraft were apparently due to simulation having omitted a dynamic effect (gyroscopic coupling) that had never been significant in piston-engined planes (SEN 11, 5).
Northwest Airlines crash
The crash of Northwest Flight 255 that killed 156 people in 1987 is discussed in Section 2.4. There was a later report that the flight simulator behaved differently from the aircraft. In particular, the warning indicator for the MD-80 aircraft went off as expected in the simulator, but did not do so in the planes. (The FAA’s fix for that was to change the simulator rather than the aircraft, because the warning system was considered “nonessential.”19
Colorado River flooding
In the late spring of 1983, there was serious flooding from the Colorado River. Too much water had been held back prior to spring thaws. There were six deaths, with damages costing millions of dollars. The problem was traced to a bug in the computer program that had modeled the flood process and predicted how much water should be stored. The implications were that any one or all of the model, the program, and the data could have been faulty.20
Salt Lake City shopping mall roof collapses
The collapse of the Salt Lake City shopping mall involved an incorrect model, tests that ignored the extreme conditions, and some bad assumptions. The roof caved in after the first big snowfall of the season—fortunately, before the mall was opened to the public (noted by Brad Davis in SEN 11, 5).
Hartford Civic Center roof collapse
The collapse of the Hartford Civic Center Coliseum’s 2.4-acre roof under heavy ice and snow on January 18, 1978, apparently resulted from the wrong model being selected for beam connection in the simulation program. After the collapse, the program was rerun with the correct model—and the results were precisely what had actually occurred.21
Stars and Stripes skids the grease
In losing the America’s Cup, the racing boat Stars and Stripes was victimized by problems in computer modeling and tank testing of scale models. Three iterations of modeling and tank-testing on supposedly improved designs yielded results that were degrading rather than improving. This counter-productivity led to a startling discovery: The simulation program accidentally included a digital filter left over from an earlier oil-platform test.22
7.5.4 Perspective
Analysis and testing based on modeling and simulation are typically dependent on the accuracy of assumptions, parameters, and programs. We must be suspicious of every detail throughout the overall system engineering. Even end-to-end testing of an entire system is not enough. In discussing the Electra simulation problem, Jim Horning summed up: “Simulations are only as good as the assumptions on which they are based.” In fact, they may not even be that good. Rebecca Mercuri noted that “It is the illusion that the virtual is real and that the system is an expert that creates a false sense of confidence.” The roles of modeling, simulation, and testing all must be considered accordingly.
7.6 Coping with Complexity
Seek simplicity and distrust it.
ALFRED NORTH WHITEHEAD
Everything should be made as simple as possible, but no simpler.
ALBERT EINSTEIN
7.6.1 Factors Affecting Complexity
Coping with complexity is a serious problem in system development, operation, maintenance, and use.23 Here are some relevant observations.
Complexity is in the eye of the beholder. Some people have serious difficulties managing intrinsic complexity, especially in coping with reality. Others thrive on creating monstrous systems where simpler ones would do. Between these extremes are a chosen few whose instincts, experience, and training permit them to manage complexity with relative ease.
There are some people who believe they could successfully create enormously complex, dependable systems meeting arbitrarily stringent requirements (such as in the early conceptions of Star Wars), in the face of copious evidence that very large system-development projects are rife with serious shortcomings and are subject to all sorts of inadequately anticipated events. For the naïve and the optimists, complexity is the eye of the hurricane. Everything seems to be calm, until the development progresses sufficiently far or until something must be changed, with consequent unanticipated disasters.
Complexity will also be increasingly in the eye of the law. If a computer system is implicated in deaths or property loss, the defense may ultimately depend on whether generally accepted system-engineering practices were in use. If a computer audit trail seems to implicate someone as a perpetrator of inside misuse, the defense may depend on whether that audit trail could have been altered. Strangely, the legal implications may encourage generally poor practice rather than better practice.
Complexity is often viewed in the eye of the technologist. Complexity must not be considered solely as a technological problem. It must be regarded in a broader perspective that includes social, economic, and world-political issues. Again, Star Wars comes to mind. The need for global awareness may seem unfortunate to the manager who wishes to circumscribe his responsibilities starkly, but such awareness is absolutely essential. In many cases, complexity is out of control because of nontechnological problems, to which management may be a major contributor. In other cases, the technology itself is not able to overcome the other problems.
Complexity is ubiquitous. Complexity means different things to different people. We use an intuitive notion of “complex” here, roughly equivalent to what we normally think of as “complicated”—difficult to analyze, understand, or explain. We eschew numerical measures that might appear to quantify complexity but that can themselves be risky if they are institutionalized to the point that design decisions are made on the basis of those measures rather than on that of sound judgment.
Complexity has diverse causes. Certain applications are intrinsically complex, no matter how you look at them. Stringent real-time constraints, distributed control, and concurrent execution tend to add complexity in certain ways, but can alternatively be used as forcing functions that demand a conceptual simplicity of the overall system. Systems with elaborate user interfaces are often complex. In a classical tradeoff, the user interface may be simplified at the expense of internal system complexity, or the system may be simplified at the expense of much greater human interaction; however, each of these efforts is likely to be counterproductive unless a suitable balance is struck. Measures to increase reliability (for example, fault tolerance and recovery) can add significant complexity to an otherwise simple system, particularly if the system seriously attempts to anticipate all realistic exception conditions that might somehow arise. In some systems, the code responsible for fault and error handling outweighs everything else. Software tools may create further complexity in their attempts to control it. Overall, complexity tends to grow faster than the size of the system, under any meaningful definition of complexity.
Complexity tends to increase. Combatting complexity is made increasingly difficult by continual demands for larger and more elaborate systems, extensions of existing systems into areas that push the limits of the technology or the limits of the approach, and demands for increased interoperability by linking disparate systems into heterogeneous distributed systems and networks.
Complexity is difficult to control. The development of complex systems is always a challenge, with many obstacles: The requirements are often ill-defined and poorly understood; the interfaces to other subsystems and to the rest of the world are ill-defined; the design is specified (if at all) only after the implementation is mostly well underway; the schedules are often unrealistic and driven by external events; the developers are not ideally matched to the tasks at hand; the funding is inadequate, and so on.
A common simplistic rejoinder is that we can avoid these obstacles simply by “doing it right in the first place.” Unfortunately, the obstacles tend to be pervasive and not easy to avoid, even with wonderful technology and gifted people. The principles of good system development are not easy to employ wisely. Experience shows that motherhood cannot be taken lightly if it is to be done right.
7.6.2 Structural Approaches to Managing Complexity
In light of the existing software practice, it is appropriate to consider constructive approaches to the development of complex systems. We discuss techniques for structuring both the development effort and the system design itself, with significant potential returns on investment, mentally, financially, managerially, and practically.
Constructive Approaches
There are many approaches to controlling complexity. First, there is enormous payoff from good management, especially if aided by software-engineering and system-engineering techniques that help to structure the system design and the development effort. In addition, there are great benefits from being able to reuse software and hardware components that have been carefully developed and evaluated. Standards for interfaces, development techniques, programming languages, and tools all may have benefits. To the extent that the mechanisms are demonstrably sound and firmly established, software functionality can migrate into hardware. Also helpful are tools that help to structure the entire development cycle (including requirements, specifications, programming, reviews, walkthroughs, testing, and formal analysis), whether they support the management process or the development itself. For example, it would be helpful to obtain projective views of a system design from differing perspectives, such as from the vantage point of the networking or storage management. Even techniques that merely enable managers to ask more sensible questions can be beneficial. However, managers and technologists must both beware of overendowing tools with supposedly magical Wizard-of-Oz-like powers.
Various approaches have been discussed for structuring the design of a complex system, including those in Dijkstra [37], Parnas [122] and Neumann [107]. (See also [103] for a systems-oriented overview.) Useful techniques include partitioning and modularization, hierarchical abstraction, abstract data types and object-oriented design, strong typing, encapsulation and information hiding, functional isolation, decoupling of policy and mechanism, separation of privileges, allocation of least privilege, and virtualization (such as the invisibility of physical locations, concurrency, replication, hardware fault tolerance, backup, recovery, and distribution of control and data). These techniques are revisited in Section 7.8 in the context of software engineering. There can be significant benefits from the use of higher-level (more abstract) languages in which to express requirements, designs, and implementations, although the existing languages all seem far from ideal. Also of value as structuring concepts are multilevel security (MLS) (for example, no adverse flow of information with respect to sensitivity of information) and multilevel integrity (MLI) (for example, no dependence on less trusted entities). In addition, formal methods (such as specifications based on mathematical logic and reasoning based on mathematical theorem proving) have potential for addressing requirements, specifications, programs, and hardware, possibly including selected formal analyses of consistency or correctness for particularly important properties and components.
Dependence
Among all of the techniques for managing complexity, perhaps the most poorly understood and yet potentially most valuable are those relating to the structuring of a system—for example, into layers of abstraction or into mutually suspicious cooperating subsystems. Parnas [124] defines and discusses the mathematical relation in which one component depends for its correctness on another component. (He also discusses other hierarchical relationships, although the depends-on relation is the most important here.) If one component depends on another, then there need to be adequate assurances that the depended-on component is adequately trust-worthy, or else that its misbehavior would not be harmful. With some care, it is possible to develop trustworthy systems using untrustworthy components, as is the case in fault-tolerant systems. Malicious misbehavior, correlated faults, collusion, and other more obscure modes of misbehavior are referred to as Byzantine fault modes.
Whether Byzantine or more conventional modes are addressed, whenever one component must depend for its correctness on another component, the dependencies must be carefully controlled, respecting varying degrees of trustworthiness inherent in the different components. Correctness may be defined in terms of requirements such as confidentiality, system and data integrity, availability, and performance. The layers of abstraction can profitably reflect the different degrees of criticality of the properties that each layer enforces.
It may be useful to extend the depends-on relation to encompass multilevel integrity (for example, Biba [9]). With such an extension, a component would—to a first approximation—depend on only those other components that are considered at least as trustworthy; in reality, there are typically various cases in which it is necessary to deviate from that strict policy, and in those cases it is necessary that the management of those exceptions themselves be done in a trustworthy way. In some circumstances, the exceptions are so predominant or so nonhierarchical that they become the rule.24
Trusted Computing Bases
The security community has evolved a notion of a trusted computing base (TCB), which completely controls all use of its own operations, and which cannot be tampered with.25 It encapsulates all of its operations, mediating all security-relevant accesses. In distributed systems, a trusted server may be thought of as a TCB for the objects, access to which it mediates.
The essence of trusted computing bases is that security-relevant components are separated from security-irrelevant components, which do not need to be trusted with respect to security. Having made that separation, design effort and analysis for security can focus on the TCB.
The TCB notion may be extended usefully to other properties of complex systems in general. For example, a TCB may be trusted to enforce fundamental properties such as multilevel security or multilevel integrity, and also high-availability processing, basic safety properties, financial soundness of an enterprise, or simply doing the right thing. The Clark-Wilson application integrity properties [25] represent a model for the sound behavior of a transaction-oriented system; an application system ensuring those properties could be a TCB with respect to those properties; however, ensuring those properties in turn requires that the underlying operating system, database-management system, and so on, cannot be compromised.
Structuring a system hierarchically according to dependence on its components according to their trustworthiness can help significantly in managing complexity. This approach is particularly vital in the design of distributed systems, in which some components may be of unknown trustworthiness.
System Engineering
The overall perspective of system engineering is essential for managing complexity. The risks are widely distributed throughout development and operation. Potentially every supposedly minor change could have serious consequences unless the system design and development methodology reflect the decoupling of cause and effect, the need to provide incremental closure on each change (for example, Moriconi and Winkler [95]), and the need for discipline throughout the development process.
Efforts to combat complexity must address not only software but also hardware issues, environmental factors, and the workings of potentially all the people involved as requirements definers, designers, specifiers, implementers, users, administrators, and malefactors, any of whom might wittingly or unwittingly undermine the work of others.
Unfortunately, some of the biggest problems confronting computer system developers stem from the paucity of real and useful systems that have successfully been methodologically developed and carefully documented. Few efforts provide explicit lessons as to how best to manage requirements, the design, the implementation, and the entire development process. Seldom do we find a system development whose design decisions were well documented, individually justified, and subsequently evaluated—explaining how the decisions were arrived at and how effective they were. Clearly, however painful it may be to carry out such an effort, the rewards could be significant.
7.7 Techniques for Increasing Reliability
The most likely way for the world to be destroyed, most experts agree, is by accident. That’s where we come in; we’re computer professionals. We cause accidents.
NATHANIEL BORENSTEIN [15]
An enormous range of techniques exists for increasing system reliability and achieving fault tolerance. Each technique makes assumptions about the potential faults that need to be accommodated, and then attempts to cover those faults adequately. The simplest assumptions involve transient errors that will occur occasionally and then disappear; in such cases, error detection and retry may be adequate. On the other end of the spectrum are the assumptions of essentially unrestrictive failure modes, namely, the Byzantine failures [70]. Transcending Byzantine fault modes generally requires complicated algorithms. As an example, a Byzantine clock is noted in Section 2.11, composed of 3n+1 constituent clocks such that the overall clock will remain within its prescribed accuracy despite arbitrary (accidental or malicious) failures of any n of the constituent clocks.
Fault tolerance
Fault tolerance involves designing a system or subsystem such that, even if certain types of faults occur, a failure will not occur. Many techniques have been used to improve reliability and specifically to provide fault tolerance. These techniques include forward error recovery and backward error recovery, existing at various layers of abstraction in hardware or in software.
Forward error recovery
Forward error recovery implies detecting an error and going onward in time, attempting to overcome the effects of the faults that may have caused the errors. It includes the constructive use of redundancy. For example, error-correcting codes may be used to correct faults in memory, errors in communications, or even errors in arithmetic operations. Sufficient extra information is provided so that the desired information can be reconstructed. Forward recovery also includes hardware-instruction retry, which often is used to overcome transient faults in processing. Forward recovery may involve taking alternative measures in the absence of certain resources. However, the presence of faults can often be masked completely. Results are not made available until correction has been accomplished.
Backward error recovery
Backward error recovery implies detecting an error and returning to an earlier time or system state, whether or not the effects have been observed externally or have otherwise propagated. It includes the use of error-detecting codes, where a fault or error is detected and some alternative action is taken. It also includes rollback to an earlier version of data or an earlier state of the system. It may include fail-safe and fail-stop modes in which degraded performance or less complete functional behavior may occur. The presence of faults is not masked in some cases—for example, when a garbled message is received and a retry is requested.
7.7.1 Error-Detecting and Error-Correcting Codes
We can illustrate the need to avoid weak links by considering the use of error-detecting and error-correcting codes [128, 135], whether for transmission, for storage, or for processing operations (as in the case of codes capable of correcting arithmetic errors). The Hamming distance [56] between two equally long binary words is the number of positions in which those words differ. The minimum Hamming distance of a code is the smallest distance between arbitrary pairs of code words. As we see below, if the minimum Hamming distance is d = 2e + 1, then e independent errors can be corrected.
First, consider uncorrelated errors in which a binary digit (bit) position is altered from 0 to 1 or from 1 to 0. The addition of a parity check bit, so that there is an even number of 1 bits among all of the bit positions, results in the ability to detect any one arbitrary bit position in error. Such a code has minimum Hamming distance 2. Any single-bit alteration converts a word with an even number of 1 bits into a word with an odd number of 1 bits, which is immediately recognized as erroneous.
A code with minimum Hamming distance 4 can correct single errors and also detect arbitrary double errors. This ability is illustrated in Table 7.1 with a trivial 4-bit code consisting of two code words, 0000 and 1111. The presence of an error in a single-bit position is clearly detectable as an apparent single error. The presence of errors in two bit positions is clearly recognizable as an apparent double error. However, the presence of errors in three bit positions of one code word would appear to be a single error in the other code word; if the code were used for single-error correction, the received code word would be miscorrected as though it were a single error. Somewhat more insidiously, quadruple errors would appear to be correct messages, with no error indication. Thus, if triple or quadruple errors are at all likely, it would be desirable to use a code with a larger Hamming distance, or else to find a more reliable communication medium.
Table 7.1 A trivial 4-bit code with Hamming distance 4

Suppose that a code has a minimum Hamming distance of 7. Such a code could be used to correct up to triple errors, or to correct up to double errors and to detect up to quadruple errors, or to correct single errors and to detect up to quintuple errors, or simply to detect sextuple errors. The choice of how to use such a code needs to be made with knowledge of the expected errors. The choice of which code to use also depends on the nature of the expected errors. Deeper knowledge of the entire system is also required, to ascertain the potential damage if the actual errors exceed the capability of the code.
Suppose that the errors are likely to be correlated—for example, that they tend to occur within consecutive bursts during transmission. In such cases, it is possible to use burst-detecting and burst-correcting codes, as long as the burst length is not too long. However, if the noise characteristics of the communication (or storage) medium are high, or if the risks of the consequences of exceeding the fault-tolerance coverage are too great, then physical replication may be desirable—in addition to coding. Alternatively, error detection and retry using an alternative path provide both temporal and spatial redundancy for increased communication reliability, assuming that real-time requirements do not preclude such an approach—as in the case of communications with distant spacecraft.
7.7.2 Applicability and Limitations of Reliability Techniques
In a typical application, each system layer depends on the functionality of lower layers and employs reliability techniques appropriate to that layer. The association of such techniques with the threats at different layers is illustrated in Table 7.2. In essence, this table suggests that the implementation at any layer should be designed such that the layer can be largely responsible for its own reliability, that it may constructively depend on and take advantage of lower-layer techniques, and that higher-layer actions may have to be taken in the event that fault tolerance or recovery cannot be effected at the particular layer.
Table 7.2 Reliability threats and fault-tolerance techniques

Despite efforts to increase reliability, there is always the potential for circumstances in which those efforts break down—for example, in the face of massive faults or subsystem outage or of faults that exceed the coverage of the fault tolerance.
Techniques for achieving hardware-fault tolerance and software recovery are widespread in the literature, and many of those techniques have made their way into commercial off-the-shelf computer systems.26
7.8 Techniques for Software Development
Developing complex systems that must satisfy stringent requirements for reliability, security, human safety, or other forms of application correctness, such as the ability to manage money soundly, requires an extremely principled approach to system development, well beyond what is traditionally experienced in general programming practice. Such an approach is needed especially when the systems are highly dispersed physically or when the control and accountability are distributed. System engineering and software engineering are in essence approaches that seek to manage complexity. However, they must not be invoked blindly because they present pitfalls when applied to complex systems.
7.8.1 System-Engineering and Software-Engineering Practice
As noted in Section 7.1, the need for an overall system perspective is fundamental to the development of secure and reliable systems making extensive use of computers and communications. Beginning with system conceptualization and carrying through requirements definition, design, specification, implementation, and on into system configuration and initialization, maintenance, and long-term system evolution, it is essential never to lose sight of that overall perspective. In addition, continued evaluation is meaningful throughout the development (and redevelopment) process, with respect to the concepts, requirements, design, specification, implementation, and ensuing evolution. Part of that evaluation involves assessing the extent to which the desired criteria have been met.
Good system-engineering and software-engineering practice can add significantly to such system developments. As we can observe from the attack methods enumerated in Section 3.1, many characteristic security-vulnerability exploitations result directly because of poor system and software engineering; such opportunistic attacks occur particularly in trapdoor attacks and other ways of defeating authorization mechanisms, and in both active and passive forms of misuse. Similarly, modes of unreliable system behavior often arise because of poor engineering practice. Unfortunately, many past and existing software system-development efforts—operating systems, database-management systems, and applications—have failed to take adequate advantage of good engineering practice, particularly those systems with stringent requirements for security, reliability, and safety.
Being weak-link phenomena, security, reliability, and human safety depend on sound practice throughout the entire development process. Although human errors made in the early stages of development can sometimes be caught in later stages, those errors that are not caught are typically the most insidious. Thus, each stage noted in the following discussion is important in its own right in the development of reliable, secure, high-performance systems. For each stage, illustrations are included of problems that might have been avoided, referring specifically to incidents discussed in preceding chapters.
Concept formation
Developers must wrestle from the outset with the real goals of the intended system, application, or (in some cases) the entire enterprise, and must anticipate which system problems will potentially be critical later in the development. Sometimes, problems arise because a system is expected to perform a service that could not realistically be implemented, as in the case of the original Star Wars concept. In some cases, design and implementation complications arise because of overspecificity in the original concept, and prevent the development of a system that might have more general applicability. Serious effort must be expended at the outset of a development to ensure that the system conceptualization is sound, realistic, effective, and efficiently implementable. The personal-computer operating-system industry provides a horrible example of a short-sighted concept, where it was never realized that an operating system sometimes needs to be able to protect itself.
Criteria for system evaluation
Explicit criteria need to be established consensually in advance, providing realistic constraints that systems and system developments must satisfy, and against which the completed systems can be evaluated. Various criteria exist for secure systems, such as the U.S. Department of Defense Trusted Computer Security Evaluation Criteria (TCSEC)—for example, the Orange Book [101] and Red Book [100], and the European and Canadian guidelines, as well the many U.S. National Institute of Standards and Technology federal information processing standards on security. A set of criteria for evaluating system safety is in use in the United Kingdom [169, 170].
Requirements definition
The people and organizations that develop system requirements must anticipate all of those problems that should already have become evident in concept formation, as well as other problems that arise in design and implementation. The result should provide specific and realistic requirements for the resulting systems, as well as requirements for the development process itself. As noted throughout this book, developers must address not only the security requirements but also those requirements that interact with security, such as reliability, throughput, real-time performance, and reusability. Fundamental mistakes in requirements definition tend to permeate the entire development effort, even if caught later on. Serious effort must be expended to ensure that the requirements are sound and consistent with the overall system conceptualization. Whenever security is encapsulated into a kernel or trusted computing base, care must be taken to characterize the privileged exceptions. With respect to the security requirements, and to some of the other requirements that interact with security such as reliability and performance, formal definitions of those requirements can be helpful in smoking out ambiguities and inconsistencies in the requirements. A priori requirements definition is vital within a total systems context (for example, see [104]), but is nevertheless often given inadequate attention. Requirements should include aspects of security and reliability, but should also declare what is needed with regard to the human interface, ease of use, generality, flexibility, efficiency, portability, maintainability, evolvability, and any other issues that might later come home to roost if not specified adequately. Whether or not the Patriot requirements for only 14-hour consecutive operation were appropriate, they were not respected by the operational practice. (On the other hand, the clock-drift problem was the result of serious underengineering, and apparently undermined even operations within the 14-hour window.)
System design
The system-design process is typically the source of many system flaws. Particularly annoying are those flaws that remain undetected, because they can be difficult and expensive to fix—especially if they are detected much later. Practical design issues include deciding on the extent to which a system can be built out of already existing or easily modifiable components. Design issues in the large include deciding on the nature of distribution to be used (control, data, etc.), the extent to which the system needs to be fault tolerant and which types of reliability techniques should be employed, the type of communication mechanisms (interprocess communication, message passing, and remote procedure calls), system structuring, layering, and decoupling of subsystems, the role of trusted computing bases as building blocks, and the extent to which good software-engineering practice should pervasively affect the development effort. Design issues in the small relate to specific subsystems, components, and modules, and include the use of abstraction and encapsulation within components, and types of protocols and mechanisms for intercommunication and synchronization. Use of the object-oriented paradigm in the system design itself may be beneficial (particularly with respect to system integrity)—for example, creating a layered system in which each layer can be looked on as an object manager.
The object-oriented paradigm combines four principles of good software engineering—abstraction, encapsulation, polymorphism, and inheritance. Abstraction takes many forms; in the present context, it implies the removal of unnecessary details from the representation of a particular system component. Encapsulation with respect to a particular interface involves the protection of internal mechanisms from tampering and the protection of internal data structures from disclosure. Polymorphism is the notion that a computational resource can accept arguments of different types at different times and still remain type safe; it enhances programming generality and software reuse. Inheritance is the notion that related classes of objects behave similarly, and that subclasses should inherit the proper behavior of their ancestors; it allows reusability of code across related classes. Choice of a design methodology can have a considerable influence on the ensuing development. Arguments over which methodology is best are often second-order; use of any methodology can be beneficial if that methodology is reasonably well defined, is well understood, and has been used previously with success. In any particular development, some methods may be more effective than others, depending on the requirements, the nature of the application, and the composition of the development team. Careful design specification is beneficial throughout the development process, and should be considered as an integral part of the design rather than as an afterthought.
Overt design flaws are a significant source of problems in the design process; they can be combatted somewhat by consistent use of the good design principles emphasized here. Examples of situations cited here that might have been avoided through such practice include the 1980 ARPAnet collapse (Section 2.1), the first shuttle backup-computer clock synchronization problem (Section 2.2.1), the Aegis and Patriot-missile problems (Section 2.3), the Therac-25 (Section 2.9.1), and the design of nonsecure computer operating systems (Chapters 3 and 5), to name a few.
Consistency
Evaluation of the consistency of a design with respect to its design criteria and requirements should be done with considerable care prior to any implementation, determining the extent to which the design specifications are consistent with the properties defined by the requirements. It should also be possible at this stage to do a preliminary assessment of the system design with respect to the intended evaluation criteria. Such an evaluation was clearly lacking in many of the cases discussed here. Much greater emphasis could be placed on analytic processes and tools that could aid in early system evaluations.
Implementation
Some developers view system implementation as an anticlimax following the seemingly successful completion of the previous stages: Given a design, you simply write the code. Unfortunately, the intricacies of the implementation process are often given short shrift, and the pitfalls are ignored:
• The choice of programming language (or languages) is fundamental. Security-critical subsystems may sometimes necessitate the use of a different language from that used in applications when greater discipline is required, or possibly more stringently enforced conventions in the use of the same language. Of particular importance in the choice of programming language are issues concerning modularization, encapsulation, use of types and strong type checking, program definable extensions, initialization and finalization, synchronization, aliasing, control of argument passing, handling of exceptions, and run-time libraries. In weaker programming languages, each of these facilities can lead to serious security compromises. Furthermore, use of lower-level programming languages is typically more error-prone than is use of higher-level programming languages of comparable sophistication.
• Good programming discipline is essential. Choice of an untyped free-wheeling language (such as C) may be effective with disciplined programmers, but disastrous otherwise. Choice of a discipline-demanding language (such as C++, Modula-2+, or Modula-3) may potentially produce a sounder system, but requires disciplined programmers; besides, each of those languages has some severe limitations. C++ is a low-level language, although it does contain certain modern features. Modula-3 has considerable potential, but is in its infancy in terms of widespread availability of practical compilers. Ada, despite its strong advocates, presents difficulties. All of these languages are deficient when it comes to real-time and asynchronous programming (including Ada’s inherently synchronous attempt at asynchrony—that is, its rendezvous mechanism). Estelle and Real-Time Euclid are candidates for developing real-time systems, but are also deficient. Besides, even the best programming language can be misused. Object-oriented programming may fit naturally, particularly if the system design follows the object-oriented paradigm. Object-oriented programming languages include C++, Modula-3, Eiffel, Simula, and Smalltalk. Note that the object-oriented paradigm has also been studied relative to multilevel secure systems and databases [43, 114, 65, 85, 172].
The synchronization problem in the first shuttle was partly a design error and partly a programming flaw. The Patriot clock-drift problem was largely attributable to a programming error, using two different and nonequal representations for the same number. A lack of type checking was certainly evident in the Mercury Fortran program statement with DO 1.10 instead of DO 1,10. The lack of bounds checking on the length of the typed password was partly to blame for the master-password flaw noted in Section 3.1.
Correctness of the implementation
Evaluation of the implementation with respect to its design must be done to determine whether the source code and ultimately the object code are consistent with the system specification. Concepts carefully enforced by a design may be undermined by the implementation. For example, a design that carefully adheres to modular separation and encapsulation may be compromised by overzealous optimization or inadequate hardware protection. Also, a poor choice of the underlying hardware can completely undermine the security requirements. Formal or semiformal techniques may be desirable in ensuring consistency. Formal analysis of code-spec consistency can be greatly simplified through the use of a discipline-requiring programming language, if the semantics of that language have been suitably axiomatized. Although testing is never completely satisfactory, its absence is a serious deficiency, as in the case of the untested code patch in Signaling System 7 that led to the telephone system outages of June 27, 1991, noted in Section 2.1. Simulations successfully detected several problems in the shuttle program and in airplane controls—as in the F-16 that would have flipped over each time it crossed the equator, noted in Section 2.3. Analytical processes and tools can be beneficial—for example, with respect to system security, reliability, and safety.
Evaluation
Careful evaluation of the overall system is necessary throughout the development process rather than just at the end. Note that each stage of development has a corresponding assessment of conceptual soundness, requirement appropriateness, criteria compatibility, verification, validation, and so on, at various layers of abstraction. In case of verification, formal reasoning may be appropriate for demonstrating consistency of specifications with requirements and consistency of code with specifications. In any case, overall system testing is essential. (Lack of end-to-end testing was clearly unfortunate in the Hubble Space Telescope.)
Management of development
Managing the development of a system is generally a complex task. Increasingly, managers of system development efforts need to understand the technology and its limitations. Constructive use of management tools and computer-aided software-engineering (CASE) tools can be beneficial, but can also be misleading. If programmers and managers optimize the development only to satisfy the tools, they may be in for major surprises later on—for example, if it is discovered that the code solves the wrong problems, or is hopelessly inefficient, or does not easily integrate with anything else, or that the tools are checking for the wrong properties. Many problems noted here had as contributing factors poor management throughout system development.
Management of the system build
Given an implemented system, there is a remaining step to configure the system for a particular installation. This step is itself a potential source of serious vulnerabilities, including the introduction of security flaws and Trojan horses, mishandling of privileged exceptions in the trusted computing base, and erroneous tailoring of the system to the given application. One view of controlling certain aspects of this phase of the development cycle is given in [2]; it is referred to as trust engineering, which attempts to ensure that the potential for system security is not compromised by the installation. Configuration control is vital, but widely ignored, especially in personal computer systems—where viruses are a problem primarily because there are often no such controls.
System operations
Anticipation of operational needs is also an important part of system design, requiring vision as to the intended uses of the system, experience with human interfaces, and understanding of human limitations. The implications must be addressed throughout the design rather than being merely tacked on at the end. With respect to security, the system operator functions should respect the principles noted in Section 7.6.2, particularly separation of concerns and separation of duties, least privilege, and least common mechanism. With respect to reliability, the Patriot comes to mind again.
System maintenance
The needs of short-term system maintenance and long-term system evolution must be anticipated throughout system development, beginning with the initial system conception. Very few system developments are ever completely finished; instead, they tend to continue indefinitely, to adapt to changing requirements and to remove detected flaws. Yogi Berra’s dictum is particularly appropriate here: “It ain’t over ‘til it’s over.” The moral of the development story is that difficult problems must be wrestled with early; otherwise, they will continue to plague you. Another Berra saying is also relevant: “It gets late early.” Too often, difficult problems are deferred until later, in which case maintenance and evolution become not only burdensome but also extremely difficult. Unless evolvability and ease of maintenance are design goals from the beginning of system development, the task tends to become even harder as the development progresses. System redevelopment should permit incremental closure of the entire analytic process, following any changes to code, specifications, design, or even requirements—each necessitating iteration. The loss of the Phobos 1 mission (Section 2.2.2) is a poignant example of the criticality of maintenance.
From a security viewpoint, it is important that the mechanisms for maintenance and evolution adhere to the basic system security and integrity controls, insofar as possible. Clearly, part of the process of system bootloading and physical reconfiguration may be beyond the control of the system control mechanisms. However, to the extent possible, the directories used for the system source- and object-code files should be completely subjected to the system-control mechanisms. The same is true for the hardware and software responsible for bootloading. The problem of overly powerful processes in maintenance is similar to the superuser problem noted in Section 3.1. It is startling to realize how many systems (telephone systems, control systems, and computer systems generally) can be brought to their knees through misuse of the maintenance interface.
Overview
Good system- and software-engineering practices can influence the entire system-development effort, offering many contributions toward the satisfaction of stringent requirements, such as security, reliability, and performance. These good practices are reflected inadequately in the existing criteria sets. In addition, good management practice is essential throughout system development, as is the incisive vision to anticipate and avoid development problems that otherwise might have a serious negative effect on the development. For an interesting historical perspective of system development, see F.J. Corbató’s 1991 Turing Address lecture [28].
Implications of the software-development practice are discussed next.
7.8.2 Benefits of Software Engineering
Satisfaction of each relevant property requires assiduous adherence to various software-engineering principles. Such principles include abstraction, hierarchical layering of abstractions, formal specification [123], encapsulation, information hiding (for example, Parnas [122]), abstract data types and strong typing, trusted computing bases, strict isolation as in virtual machine monitors that share no resources, separation of concerns in design such as distinguishing among different layers of trustworthiness or different layers of protection, along with allocation of least privilege, separation of duties (for example, Clark and Wilson [25]), client-server architectures, least common mechanism, and avoidance of aliases. Although usually lacking in software-engineering efforts, good documentation is fundamental. It can also be a basis for formal analysis, as in the recent work of Parnas.
Trusted computing bases (TCBs) are a manifestation of information hiding and encapsulation, with several desiderata: all accesses to the objects of the abstract type must be mediated by the TCB; the TCB must be tamperproof; and the TCB must be small enough to permit rigorous analysis. These requirements by themselves are not sufficient to imply noncompromisibility from above. As defined here, a TCB may enforce any set of properties P, not just a security property such as multilevel security. The basic MLS property is that information shall never be visible to security levels that are not at least as trusted.
One of the most fundamental concepts is that of abstraction—for example, defining a particular entity in its own terms rather than in terms of its implementation. An abstract representation of a directory might be in terms of operations on sets of symbolically named entries rather than (say) on list-linked collections of secondary-storage addresses and other preferably hidden information. There are various forms of abstraction, principally procedure abstraction with encapsulation and data abstraction with information hiding (invisibility), both of which are addressed by the object-oriented paradigm noted in Section 7.8.1. These include virtualized resources, such as virtualized data location and virtual memory, with the hiding of physical memory addresses; virtualized flow of control, with reentrant or recursive code and remote procedure calls (RPCs); virtualized caching, masking the mere existence of performance-oriented cache memories; virtualized networking, as in network file servers and hiding the remoteness of data; virtualized remote execution; virtualized transaction management, in which logically atomic actions are indeed implemented indivisibly; virtualized concurrency management, particularly in distributed systems and networks; virtualized replication, hiding the existence of multiple versions; virtualized recovery; and other general forms of fault tolerance, in which faults are either masked or recovered from. Note that there are arguments for and against virtualization with respect to any resource, depending on the context (for example, [168, 54]), sometimes both valid simultaneously.
Of particular interest here are the problems of addressing the different requirements, observing the most useful principles, and developing robust systems that can dependably and simultaneously satisfy all of the requirements, including when operating under recovery and other emergency conditions. Distributed systems and networks are of special concern, because many of the problems are less controllable, and enforcement of proper hierarchical ordering is more difficult [109]. For example, workstations that do not implement adequate reliability, security, and system integrity greatly complicate the attainment of an overall dependable system; in particular, a Byzantine system design that assumes that workstations are completely untrustworthy (for example, with respect to confidentiality, integrity, and availability) is inherently complex. Furthermore, many existing designs are based on unreasonable assumptions, such as that certain weak-link components have to be perfectly reliable, or that certain subordinate transactions are always atomic, or that faults may occur only one at a time within a given time interval during which fault recovery occurs. In such systems, the invalidation of any such assumption could have disastrous effects, particularly if the system design has not considered the resulting consequences. Furthermore, in the extreme, optimization of an implementation can often negatively affect the design goals if the design is flawed or poorly implemented: The problem of untrustworthy optimization is noted in the earlier paragraph on implementation correctness; it results from the possibility of blurring or eliminating distinctions carefully made in the design. Thus, the challenges are to develop a framework that respects the real world, and to make rigorous the assumptions of dependence on components of unknown or limited trustworthiness.
7.8.3 Integrity
One illustration of a set of application-layer properties that need to be enforced by the application software is provided by the integrity model of Clark and Wilson [25]. Their model establishes a set of application-layer integrity properties generally based on good business accounting practice, but which are subliminally merely good software-engineering practice in disguise. These properties are summarized in Table 7.3, couched not in terms of their original Clark-Wilson formulation but rather in terms of their familiar software-engineering equivalents, relating to abstract data types and their proper encapsulation, atomic transactions, and various forms of consistency. It thus becomes clear that good software-engineering practice can contribute directly to the enforcement of the Clark-Wilson properties and to other generalized forms of system integrity.
Table 7.3 Summary of Clark-Wilson integrity properties

Unless a Clark-Wilson type of application is implemented directly on hardware with no underlying operating system, the sound enforcement of the Clark-Wilson properties will typically depend on lower-layer integrity properties. Sound implementation is considered by Karger [63] using a secure capability architecture (SCAP [64]) and by Lee [78] and Shockley [156] employing an underlying MLS/MLI trusted computing base that uses the notion of “partially trusted subjects.” Multilevel integrity is a dual of multilevel security. The basic MLI property is that no entity shall depend on another entity (for example, process, program, or data) whose integrity level is not at least as trusted for integrity.
A useful report analyzing Clark-Wilson integrity is found in [1].
7.8.4 Summary of Software-Development Principles
Table 7.4 summarizes the ways in which software engineering can potentially contribute to the prevention and detection of the misuse techniques of Table 3.1, and to the avoidance of or recovery from unreliability modes (through reliability and fault tolerance mechanisms). In the table, a plus sign indicates a positive contribution, whereas a minus sign indicates a negative effect; square brackets indicate that the contribution (positive or negative) is a second-order effect or a potential effect.
Table 7.4 Software-engineering principles and their potential effects
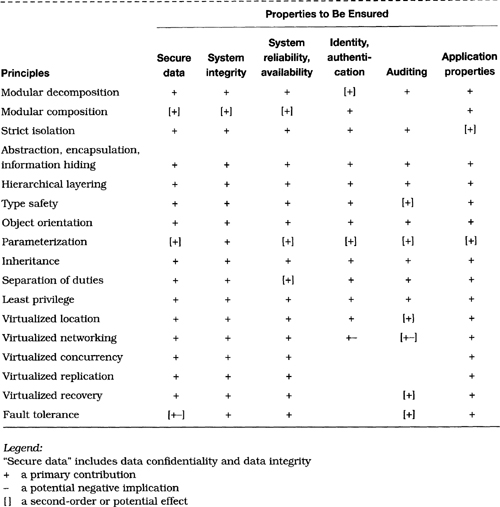
The table illustrates in overview that good software engineering can contribute significantly to system security and integrity, as well as to system reliability and human safety, with respect to the underlying systems and to the applications. However, the mere presence of a technique is not sufficient. All of these techniques are frequently touted as magical answers, which they certainly are not. Each can be badly misused.
Software engineers may find it an interesting challenge to explore the implications of individual table entries.
7.9 Techniques for Increasing Security
Security in computer systems and networks requires enormous attention throughout the requirements, design, and implementation stages of development, and throughout potentially every aspect of system operation and use. Because it is a weak-link phenomenon, considerable effort must be invested in avoiding the vulnerabilities discussed in Chapter 3. Easy answers are almost never available in the large, although occasionally an isolated problem may have a simple solution in the small.
Appropriate techniques for increasing security include the structuring approaches noted in Section 7.6.2, especially those that apply the principle of separation of concerns (duties, privileges, etc.). They also include essentially all of the techniques of system and software engineering, as suggested by Table 7.4. But perhaps most important is an awareness throughout of the types of vulnerabilities that must be avoided, of which this book provides copious examples.
The following subsection addresses a portion of the general problem of increasing security by considering a particular application: computer-based voting. Although that application is not completely representative, it serves to provide specific focus. After that, the section concludes with general considerations and a discussion on authentication.
7.9.1 An Example: Computer-Based Voting Systems
We begin by reconsidering the problems of attaining reliability, security, and integrity in computer-based voting, summarized in Section 5.8.27 These problems are, in many respects, illustrative of the more general security and reliability problems illustrated in this book. Thus, we can derive considerable insight from taking a specific application such as voting and attempting to characterize approaches to avoiding or minimizing the problems.
Criteria for Computer-Based Voting
At present, there is no generally accepted standard set of criteria that voting systems are required to satisfy. Previous attempts to define criteria specifically for voting systems, such as [143, 152], the Federal Election Commission voluntary guidelines, and the New York City requirements,28 are inadequate, because they fail to encompass many of the possible risks that must ultimately be addressed. Indeed, existing security criteria such as the U.S. TCSEC (the Orange Book, TNI, TDI, etc.), the European ITSEC, the Canadian CTCPEC, and the draft U.S. Federal Criteria are also inadequate, for the same reason. Furthermore, essentially all existing voting systems would fail to satisfy even the simplest of the existing criteria. The risks lie not only in the inherent incompleteness of those criteria but also in the intrinsic unrealizability of such criteria. Nevertheless, such criteria are important.
Generic criteria for voting systems are suggested here as follows.
• System integrity. The computer systems (in hardware and system software) must be tamperproof. Ideally, system changes must be prohibited throughout the active stages of the election process; once certified, the code, initial parameters, and configuration information must remain static. No run-time self-modifying software can be permitted. End-to-end configuration control is essential. System bootload must be protected from subversion that could otherwise be used to implant Trojan horses. (Any ability to install a Trojan horse in the system must be considered as a potential for subverting an election.) Above all, vote counting must produce reproducibly correct results.
• Data integrity and reliability. All data involved in entering and tabulating votes must be tamperproof. Votes must be recorded correctly.
• Voter authenticity. In the context of today’s voting systems, questions of voter authenticity are typically handled procedurally, initially by presentation of a birth certificate or other means of supposed identification, and later by means of a written verifying signature. In future systems in which remote voting will be possible, some sort of electronic or biometric authentication may be required.
• Voter anonymity and data confidentiality. The voting counts must be protected from external reading during the voting process. The association between recorded votes and the identity of the voter must be completely unknown within the voting systems.
• Operator authentication. All people authorized to administer an election must gain access with nontrivial authentication mechanisms. Fixed passwords are generally not adequate. There must be no trapdoors—for example, for maintenance and setup—that could be used for operational subversions.
• System accountability. All internal operations must be monitored, without violating voter confidentiality. Monitoring must include votes recorded and votes tabulated and all system programming and administrative operations such as pre- and post-election testing. All attempted and successful changes to configuration status (especially those in violation of the static system integrity requirement) must be noted. This capability is similar to that of an aircraft flight recorder, from which it is possible to recover all important information. Furthermore, monitoring must be nonbypassable—it must be impossible to turn off or circumvent. Monitoring and analysis of audit trails must themselves be nontamperable. All operator authentication operations must be logged. (Greenhalgh [55] analyzes accountability further in this context.)
• System disclosability. The system software, hardware, microcode, and any custom circuitry must be open for random inspections (including examination of the documentation) by appropriate evaluators, despite cries for secrecy from the system vendors.
• System availability. The system must be protected against both accidental and malicious denials of service, and must be available for use whenever it is expected to be operational.
• System reliability. System development (design, implementation, maintenance, etc.) should attempt to minimize the likelihood of accidental system bugs and malicious code.
• Interface usability. Systems must be amenable to easy use by local election officials, and must not be so complicated that they encourage the use of external personnel (such as vendor-supplied operators). The interface to the system should be inherently fail-safe, foolproof, and overly cautious in defending against accidental and intentional misuse.
• Documentation and assurance. The design, implementation, development practice, operational procedures, and testing procedures must all be unambiguously and consistently documented. Documentation must also describe what assurance measures have been applied to each of those system aspects.
• Other lower-level criteria. Further criteria elements are also meaningful, such as the TCSEC trusted paths to the system, trusted facility management, trusted recovery, and trusted system distribution. All of these criteria require technological measures and some administrative controls for fulfillment.
• Personnel integrity. People involved in developing, operating, and administering electronic voting systems must be of unquestioned integrity. For example, convicted felons and gambling entrepreneurs may be considered inherently suspect.29 Satisfaction of this requirement involves primarily nontechnological factors.
• Other factors. This skeletal criteria set is by no means complete. There are many other important attributes that election computing systems need to satisfy operationally. For example, Roy Saltman [143] notes that voting systems must conform with whatever election laws may be applicable, the systems must not be shared with other applications running concurrently, ballot images must be retained in case of challenges, pre- and postelection testing must take place, warning messages must occur during elections whenever appropriate to reflect unusual circumstances, would-be voters must be properly authorized, handicapped voters must have equal access, it must be possible to conduct recounts manually, and adequate training procedures must exist.
Realizability of Criteria
No set of criteria can completely encompass all the possible risks. However, even if we ignore the incompleteness and imprecision of the suggested criteria, numerous intrinsic difficulties make such criteria unrealizable with any meaningful assurance.
System Trustworthiness
System trustworthiness depends on design, implementation, and operation.
Security vulnerabilities are ubiquitous in existing computer systems, and also inevitable in all voting systems—including both dedicated and operating-system-based applications. Vulnerabilities are particularly likely in voting systems developed inexpensively enough to find widespread use. Evidently, no small kernel can be identified that mediates security concerns, and thus potentially the entire system must be trustworthy.
System operation is a serious source of vulnerabilities, with respect to integrity, availability, and, in some cases, confidentiality—even if a system as delivered appears to be in an untampered form. A system can have its integrity compromised through malicious system operations—for example, by the insertion of Trojan horses or trapdoors. The presence of a superuser mechanism presents many opportunities for subversion. Furthermore, Trojan horses and trapdoors are not necessarily static; they may appear for only brief instants of time, and remain totally invisible at other times. In addition, systems based on personal computers are subject to spoofing of the system bootload, which can result in the seemingly legitimate installation of bogus software. Even in the presence of cryptographic checksums, a gifted developer or subverter can install a flaw in the system implementation or in the system generation. Ken Thompson’s Turing Lecture stealthy Trojan horse technique [167] illustrates that such perpetrations can be done without any modifications to source code.
System integrity can be enhanced by the use of locally non-modifiable read-only and once-writable memories, particularly for system programs and preset configuration data, respectively.
Data confidentiality, integrity, and reliability can be subverted as a result of compromises of system integrity. Nonalterable (for example, once-writable) media may provide assistance in ensuring integrity, but not if the system itself is subvertible.
Voter anonymity can be achieved by masking the identity of each voter so that no reverse association can be made. However, such an approach makes accountability much more difficult. One-way hashing functions or even public-key encryption may be useful for providing later verification that a particular vote was actually recorded as cast, but no completely satisfactory scheme exists for guaranteeing voter anonymity, consistency of the votes tabulated with respect to those cast, and correct results. Any attempt to maintain a bidirectional on-line association between voter and votes cast is suspect because of the inability to protect such information in this environment.
Operator authentication that relies on sharable fixed passwords is too easily compromised, in a wide variety of ways such as those noted in Section 3.3.2. Some other type of authentication scheme is desirable, such as a biometric or token approach, although even those schemes themselves have recognized vulnerabilities.
System accountability can be subverted by embedded system code that operates below the accounting layers or by other low-layer trapdoors. Techniques for permitting accountability despite voter anonymity must be developed, although they must be considered inherently suspect. Read-only media can help to ensure nontamperability of the audit trail, but nonbypassability requires a trusted system for data collection. Accountability can be subverted by tampering with the underlying system, below the layer at which auditing takes place. (See also [55].)
System disclosability is important because proprietary voting systems are inherently suspect. However, system inspection is by itself inadequate to prevent stealthy Trojan horses, run-time system alterations, self-modifying code, data interpreted as code, other code or data subversions, and intentional or accidental discrepancies between documentation and code.
System Robustness
System robustness depends on many factors.
System availability can be enhanced by various techniques for increasing hardware-fault tolerance and system security. However, none of these techniques is guaranteed.
System reliability is aided by properly used modern software-engineering techniques, which can result in fewer bugs and greater assurance. Analysis techniques such as thorough testing and high-assurance methods can contribute. Nevertheless, some bugs are likely to remain.
Use of redundancy can in principle improve both reliability and security. It is tempting to believe that checks and balances can help to satisfy some of the criteria. However, we rapidly discover that the redundancy management itself introduces further complexity and further potential vulnerabilities. For example, triple-modular redundancy could be contemplated, providing three different systems and accepting the results if two out of three agree. However, a single program flaw or a Trojan horse can compromise all three systems. Similarly, if three separately programmed systems are used, it is still possible for common-fault-mode mistakes to be made (there is substantial evidence for the likelihood of that occurring) or for collusion to compromise two of the three versions. Furthermore, the systems may agree with one another in the presence of bogus data that compromises all of them. Thus, both reliability and security techniques must provide end-to-end protection, and must check on each other.
In general, Byzantine algorithms can be constructed that work adequately even in the presence of arbitrary component failures (for example, due to malice, accidental misuse, or hardware failure). However, such algorithms are expensive to design, implement, and administer, and introduce substantial new complexities. Even in the presence of algorithms that are tolerant of n failed components, collusion among n+1 components can subvert the system. However, those algorithms may be implemented using systems that have single points of vulnerability, which could permit compromises of the Byzantine algorithm to occur without n failures having occurred; indeed, one may be enough. Thus, complex systems designed to tolerate certain arbitrary threats may still be subvertible through exploitation of other vulnerabilities.
Interface usability is a secondary consideration in many fielded systems. Complicated operator interfaces are inherently risky, because they induce accidents and can mask hidden functionality. However, systems that are particularly user friendly could be even more amenable to subversion than those that are not.
Correctness is a mythical beast. In reliable systems, a probability of failure of 10−4 or 10−9 per hour may be required. However, such measures are too weak for voting systems. For example, a 1-bit error in memory might result in the loss or gain of 2k votes (for example, 1024 or 65,536). Ideally, numerical errors attributable to hardware and software must not be tolerated, although a few errors in reading cards may have to be acceptable within narrow ranges—for example, because of hanging chaff. Efforts must be made to detect errors attributable to the hardware through fault-tolerance techniques or software consistency checks. Any detected but uncorrectable errors must be monitored, forcing a controlled rerun. However, a policy that permits any detected inconsistencies to invalidate election results would be dangerous, because it might encourage denial-of-service attacks by the expected losers. Note also that any software-implemented fault-tolerance technique is itself a possible source of subversion.
System Assurance
High-assurance systems demand discipline and professional maturity not previously found in commercial voting systems (and, indeed, not found in most commercial operating systems and application software). High-assurance systems typically cost considerably more than conventional systems in the short term, but have the potential for payoff in the long term. Unless the development team is exceedingly gifted, high-assurance efforts may be disappointing. As a consequence, there are almost no incentives for any assurance greater than the minimal assurance provided by lowest-common-denominator systems. Furthermore, even high-assurance systems can be compromised, via insertion of trapdoors and Trojan horses and operational misuse.
Conclusions on Realizability
The primary conclusion from this discussion of realizability is that certain criteria elements are inherently unsatisfiable because assurance cannot be attained at an acceptable cost. Systems could be designed that will be operationally less amenable to subversion. However, some of those will still have modes of compromise without any collusion. Indeed, the actions of a single person may be sufficient to subvert the process, particularly if preinstalled Trojan horses or operational subversion can be used. Thus, whereas it is possible to build better systems, it is also possible that those better systems can also be subverted. Consequently, there will always be questions about the use of computer systems in elections. In certain cases, sufficient collusion will be plausible, even if conspiracy theories do not always hold.
There is a serious danger that the mere existence of generally accepted criteria coupled with claims that a system adheres to those criteria might give the naïve observer the illusion that an election is nonsubvertible. Doubts will always remain that some of the criteria have not been satisfied with any realistic measure of assurance and that the criteria are incomplete:
• Commercial systems tend to have lowest common denominators, with potentially serious security flaws and operational deficiencies. Custom-designed voting systems may be even more risky, especially if their code is proprietary.
• Trojan horses, trapdoors, interpreted data, and other subversions can be hidden, even in systems that have received extensive scrutiny. The integrity of the entire computer-aided election process may be compromisible internally.
• Operational misuses can subvert system security even in the presence of high-assurance checks and balances, highly observant poll watchers, and honest system programmers. Registration of bogus voters, insertion of fraudulent absentee ballots, and tampering with punched cards seem to be ever-popular low-tech techniques. In electronic voting systems, dirty tricks may be indistinguishable from accidental errors. The integrity of the entire computer-aided election process may be compromisible externally.
• The requirement for voter confidentiality and the requirement for nonsubvertible and sufficiently complete end-to-end monitoring are conceptually contradictory. It is essentially impossible to achieve both at the same time without resorting to complicated mechanisms, which themselves may introduce new potential vulnerabilities and opportunities for more sophisticated subversions. Monitoring is always potentially subvertible through low-layer Trojan horses. Furthermore, any technique that permitted identification and authentication of a voter if an election were challenged would undoubtedly lead to increased challenges and further losses of voter privacy.
• The absence of a physical record of each vote is a serious vulnerability in direct-recording election systems; the presence of an easily tamperable physical record in paper-ballot and card-based systems is also a serious vulnerability.
• Problems exist with both centralized control and distributed control. Highly distributed systems have more components that may be subverted, and are more prone to accidental errors; they require much greater care in design. Highly centralized approaches in any one of the stages of the election process violate the principle of separation of duties, and may provide single points of vulnerability that can undermine separation enforced elsewhere in the implementation.
Finally, a fundamental dilemma must be addressed. On one hand, computer systems can be designed and implemented with extensive checks and balances intended to make accidental mishaps and fraud less likely. As an example pursuing that principle, New York City is embarking on a modernization program that will attempt to separate the processes of voting, vote collection, and vote tallying from one another, with redundant checks on each. The New York City Election Project hopes to ensure that extensive collusion would be required to subvert an election, and that the risks of detection would be high. However, that effort permits centralized vote tallying, which has the potential for compromising the integrity of the earlier stages.
On the other hand, constraints on system development efforts and expectations of honesty and altruism on the part of system developers seem to be generally unrealistic; the expectations on the operational practice and human awareness required to administer such systems also may be unrealistic.
We must avoid the lowest-common-denominator systems and instead try to approach the difficult goal of realistic, cost-effective, reasonable-assurance, fail-safe, and nontamperable election systems.
Vendor-embedded Trojan horses and accidental vulnerabilities will remain as potential problems, for both distributed and centralized systems. The principle of separation is useful, but must be used consistently and wisely. The use of good software engineering practice and extensive regulation of system development and operation are essential. In the best of worlds, even if voting systems were produced with high assurance by persons of the highest integrity, the operational practice could still be compromisible, with or without collusion. Vigilance throughout the election process is simply not enough to counter accidental and malicious efforts that can subvert the process. Residual risks are inevitable.
Although this section considers election systems, many of the concepts presented here are applicable to secure computer systems in general.
7.9.2 Criteria for Authentication
The example of electronic voting machines is not entirely representative of the fully general security problem in several respects. For example, the “end-users” (the voters) normally do not have direct access to the underlying systems, and the system operators are generally completely trusted. Nevertheless, the example demonstrates the need for overcoming many of the vulnerabilities noted in Chapter 3.
One type of vulnerability at present specifically not within the purview of computer systems in the voting application is the general problem of authenticating users and systems. In this section, we consider techniques for user authentication in the broad context of distributed and networked open systems, such as all of those systems connected to the Internet or otherwise available by dialup connections.
Section 3.3.2 considers risks inherent in reusable passwords. We consider here alternatives that considerably reduce those risks. We also characterize the overall system requirements for authentication, including the mechanisms and their embedding into systems and networks.
Various approaches and commercially available devices exist for nonsubvertible one-time passwords, including smart-cards, randomized tokens, and challenge-response schemes. For example, a hand-held smart-card can generate a token that can be recognized by a computer system or authentication site, where the token is derived from a cryptographic function of the clock time and some initialization information, and where a personal identification number (PIN) is required to complete the authentication process. Some devices generate a visually displayed token that can be entered as a one-time password, while others provide direct electronic input. These devices typically use one-key symmetric cryptographic algorithms such as the Digital Encryption Standard (DES) or two-key asymmetric algorithms such as the RSA public-key algorithm (noted at the end of Section 3.5), with public and private keys. Less high-tech approaches merely request a specified item in a preprinted codebook of passwords.
Following is a basic set of idealized requirements relating to secure authentication.
• User authenticity and nonrepudiation. Authentication compromises such as those noted in Section 3.3.2 must be prevented. For example, guessing and enumeration must be practically hopeless. Capturing and (p)replaying either a token or a PIN must not be successful. Non-repudiation is also necessary, preventing the authenticatee from later proving that the authentication had been subverted by a masquerader. (Public-key systems have an advantage over one-key systems, because shared-key compromise can lead to repudiation.)
• Ease of use. Authentication must be easy for the authenticatee, with system operation as invisible as possible. The human interfaces to computer systems and token-generating devices should be inherently fail-safe, fool-proof, overly cautious in defending against accidental and intentional misuse, and unobtrusive.
• Device integrity and availability. Ideally, the security of the system should not depend on the secrecy of its cryptographic algorithms. The design of a token-generating device should make it difficult for anyone to determine the internal parameters and nonpublic encryption keys. The device should be nontamperable. Reinitialization following battery or circuit failure must not permit any security bypasses.
• System integrity and reliability. Systems that provide authentication must be resistant to tampering, with no bypasses and no Trojan horses that can subvert the authentication or simulate its acceptance of a password. System development (design, implementation, maintenance, etc.) should minimize the likelihood of accidental system bugs and installed malicious code.
• Network integrity. Networks generally do not need to be trusted for confidentiality if the encryption used in generating the token is strong enough, which can hinder replay attacks. However, denials of service can result from encrypted tokens corrupted in transit.
• System accountability. All security-relevant operations and configuration changes must be nonbypassably and nontamperably monitored.
• Emergency overrides. Many systems provide intentional trapdoors in case of failures of the authentication mechanism or loss of ability to authenticate. Such trapdoors should be avoided, and if unavoidable must be audited nonbypassably. Unusual operator actions must also be audited. All persons authorized to perform system-administration functions must be nontrivially authenticated (not to mention that they must be well trained and experienced!), with no exceptions.
These requirements must be satisfied by systems involved in authentication. They are applicable to one-time passwords. They are also generally applicable to biometric authentication techniques, such as matching of fingerprints, handwriting, voiceprints, retina patterns, and DNA. However, even if these requirements are completely satisfied, some risks can still remain; weak links in the computer systems or in personal behavior can undermine even the most elaborate authentication methods. In any event, we need much more stringent authentication than that provided by reusable passwords.30
7.10 Risks in Risk Analysis
Section 7.10 originally appeared as an Inside Risks column, CACM, 34, 6, 106, June 1991, and was written by Robert N. Charette of ITABHI Corp., Springfield, Virginia.
The application of risk analysis and management to software development is gaining increasing interest and attention in the software community. The numbers of articles, books, and conferences on the subject are increasing rapidly. The benefits of applying risk analysis and management are obvious, but their hazards are often hidden. The Gulf War and the erroneous conclusions drawn in many of the risk assessments—such as those concerning enemy strength, potential battle casualties, possible chemical attack, and Arab and other Moslem countries’ reactions to the American presence, serve to highlight this often-interlocked issue and make it appropriate to discuss a few of the risks inherent in risk analysis.
As the Gulf War aptly demonstrated, the premier risk in doing any risk analysis is that the recommendations for the management of the risks are inaccurate. Minor inaccuracy is usually tolerable, but significant inaccuracy can hurt in many ways.
On one hand, if the analysis overestimates the risk, it can cause an excessive amount of mitigation effort to be expended in overcoming the perceived risk, compared to the effort that was truly required. This overreaction can cause substantial side effects, such as the withholding of assets from other key problem areas that could have made the endeavor a (greater) success, or missing the chance to exploit a new opportunity.
On the other hand, if the analysis underestimates the risk, it can result in surprise that the problem has indeed occurred. More often than not, a secondary consequence is management panic about what to do next, because the problem was not planned for, the analysis having led to a false sense of security (itself another risk of risk analysis). Instead of being proactive, management then finds itself reacting to events.
In either case, the next time an analysis is required or performed, there is an increased skepticism at either the need for an analysis or the validity of the recommendations, regardless of circumstance.
Perversely, the second major risk with risk analysis occurs if the analysis is too accurate. In this case, we often cannot later show the true value of the analysis, because by the recommendation of the analysis, the risk was avoided. Since nothing went awry, the analysis is seen as not contributing anything beneficial, and is viewed as an unjustifiable cost. Thus, the next time an analysis is required, it may not be performed. It is like terrorism prevention. If terrorism does not occur, it is hard to prove that terrorism was stopped by the preventive actions rather than by other, unrelated, events.
Another type of risk is that risk analysis frequently can be used as a form of organizational snag hunting, meant to keep the status quo, to stifle innovation or change. Another form of this risk occurs when risk analysis becomes blame analysis, and thus becomes a means of intimidation instead of a means to improve the situation for the better.
A fourth major risk is that risk analysis often overrelies on producing numbers and relies insufficiently on human analysis and common sense to interpret the results. Similarly, if competing analyses exist, arguments over the analysis techniques usually ensue, rather than arguments over what the results may be indicating.
A fifth risk is performing the risk analysis itself may impede project success. One reason is that performing a risk analysis is not cost free, and will take up resources that might better be applied to the endeavor at hand. The other reason is psychological. If risk is viewed as “bad” within an endeavor, especially by management, then the fact of conducting a risk analysis may stigmatize the endeavor as one that is in trouble and should be avoided. This attitude can lead to a self-fulfilling prophecy.
The final risk with risk analysis is that there is no quality control on risk analyses themselves. Risks are only that—that is, potential events. They are not certainties. Only afterward can the value of the analysis be ascertained.
When dealing with risk analyses, we should always remember the physician’s motto: “First, do no harm.” However, by understanding the risks in risk analysis, you can ultimately increase the value of the analysis.31
7.11 Risks Considered Global(ly)
[E]very change, any change, has myriad side effects that can’t always be allowed for. If the change is too great and the side effects too many, then it becomes certain that the outcome will be far removed from anything you’ve planned and that it would be entirely unpredictable.
DORS VENABILI32
In this section, we examine problems in assessing risks, continuing the thread begun in Section 7.1, which considers the importance of an overall system perspective in avoiding risks, and continued in Section 7.10, which deals with risks inherent in risk analysis itself.
As noted throughout this book, it is essential to understand the vulnerabilities and the threats before we can undertake a meaningful analysis of the risks. It is clear that risk analysis is important; it is also clear that it can be highly speculative.
Whether quantitative or qualitative, risk assessment is much like statistics; it can demonstrate almost any conclusion, depending on the assumptions and the frame of reference. In the small, it may emphasize the likelihood and consequences of death, loss of funds, or system failure. In the large, it may factor in global considerations such as environmental hazards and world economic implications. It may also be used for devious purposes, with parameters or interpretations influenced by politics, ideologies, greed, or special-interest constituencies. Occasionally, controverting evidence (sometimes in the form of a disaster) may expose invalid assumptions on which earlier risk analyses were based. In a few cases, retrospective attempts at corrective risk analyses have been hindered by uncertainty as to what really went wrong, as in the case of a damaged aircraft flight recorder or a subverted audit trail.
Several risky situations in recent years spring to mind, in defense systems, Chernobyl, and the savings and loan fiascoes.
• In the defense systems considered in Section 2.3, numerous cases are recorded of systems for which the risks were high or where disasters occurred.
• Ideally, nuclear power seems attractive, economical, and clean. In a global, practical sense (including waste-disposal problems, worldwide health issues, and infrastructure and decommissioning costs, for example), it is potentially much more expensive and risky when all of its implications are considered.
• Financial planning and management lead to wildly differing strategies, depending on whether you are optimizing your own gain or the stability of a bank, a state, a nation, or indeed the world economy. The selfish individual and the global altruist often have diametrically opposed views. (In the savings and loan cases, various accounting firms were also implicated.)
There are enormous potential benefits from using advanced software-development practices and sound system infrastructure. However, the extent to which a development effort or an operational application is willing to invest in such approaches tends to vary dramatically, depending on how extensively longterm considerations are factored into realistic analyses of costs, benefits, and risks. For example, security, reliability, and real-time performance requirements must be thoroughly anticipated if they are to be realized effectively in any complex system. Furthermore, operational requirements must all be carefully established from the outset and adhered to throughout, including day-to-day system maintainability, long-term system evolvability in response to changing needs, system portability and subsystem reusability, the need for robust distributed-system implementations, flexible networkability, and facile interoperability. Such requirements tend not to be satisfied by themselves, with benign neglect, and are generally difficult to retrofit unless planned in advance.
In all of these factors on which risks may depend, it is essential to consider a priori the risks that would result if the requirements were not satisfied or—worse yet—if the requirements were not even stated. However, in most situations, short-term considerations tend to drive the decision-making process away from long-term benefits (for example, by overemphasizing immediate cost effects). The resulting long-term deficiencies often subsequently come back to haunt us; furthermore, those deficiencies are usually difficult to overcome a posteriori. Therefore, we must use risk analysis with great care, and must be sure that it is as realistic, as global, and as far-sighted as possible. Failure to do so can easily result in major disasters. The numerous examples in this book provide ample illustrations of the importance of global thinking.
7.12 Summary of the Chapter
An overall system perspective is essential with respect to subsystems, systems, networks, networks of networks, and applications. Risk analysis is important, but difficult to do wisely. There are many pitfalls throughout system development and use; the avoidance of those pitfalls requires the broadest possible system sense as well as meticulous attention to detail.33
Challenges
C7.1 Identify events described in this book that arose primarily because of an inadequate system perspective. Explore what could have been done differently—for example, with respect to system conceptualization, requirement definition, design, implementation, operation, use, and evolution.
C7.2 From your experience as a system user or developer, identify and describe at least one case in which the user interface was poorly conceived and was itself a source of risks.
C7.3 Consider the computer-based voting problems of Section 5.8. How relevant do you think are the techniques noted in this chapter for increasing the reliability and security of voting systems? Can you identify and isolate the functionality that must be trusted and the people who must be trusted?
C7.4 Can you describe a voting system that would meet all of the criteria given in Section 7.9.1 and still be subvertible? Explain your answer.
C7.5 Consider direct-recording equipment, in which votes are entered directly into a computer system without any physical evidence. How might the absence of physical evidence affect the assurance that election results are correct and untampered? In what ways does it make the security and reliability problems either easier or more difficult?
C7.6 Carry out the conceptual design of a voting system that is intended to satisfy criteria in Section 7.9.1. What residual vulnerabilities remain?
C7.7 (Project) For any application area that is of particular interest to you (other than electronic voting machines in Challenges C7.3 through C7.6), contemplate a set of requirements that includes both reliability and security. For those requirements, outline applicable criteria. Then sketch the design of a system that would meet those requirements subject to those criteria. Then choose at least three types of problems in this book that are relevant to your application and that would not have been avoided by your design. Can you refine your requirements to cover these cases? Can you improve your design to accommodate these problems, or are these problems intrinsic?