
Chapter 2. Reliability and Safety Problems
If anything can go wrong,
it will (and at the worst
possible moment).
A VARIANT OF MURPHY’S LAW
ONE OF THE MOST IMPORTANT CHALLENGES in the design of computer-related systems is to provide meaningful assurances that a given system will behave dependably, despite hardware malfunctions, operator mistakes, user mistakes, malicious misuse, and problems in the external environment—including lightning strikes and power outages that affect system performance, as well as circumstances outside the computer systems relating to processes being controlled or monitored, such as a nuclear meltdown.
With respect to reliability issues, a distinction is generally made among faults, errors, and failures in systems. Basically, a fault is a condition that could cause the system to fail. An error is a deviation from expected behavior. Some errors can be ignored or overcome. However, a failure is an error that is not acceptable. A critical failure is a failure that can have serious consequences, such as causing damage to individuals or otherwise undermining the critical requirements of the system.
The following 11 sections of this chapter present past events that illustrate the difficulties in attaining reliability and human safety. These events relate to communication systems and computers used in space programs, defense, aviation, public transit, control systems, and other applications. Many different causes and effects are represented. Each application area is considered in summary at the end of the section relating to that area.
It is in principle convenient to decouple reliability issues from security issues. This chapter considers reliability problems, whereas security is examined in Chapters 3 and 5. In practice, it is essential that both reliability and security be considered within a common framework, because of factors noted in Chapter 4. Such an overall system perspective is provided in Chapter 7. In that chapter, a discussion of how to increase reliability is given in Section 7.7.
2.1 Communication Systems
Communications are required for many purposes, including for linking people, telephones, facsimile machines, and computer systems with one another. Desirable requirements for adequate communications include reliable access and reliable transmission, communication security, privacy, and availability of the desired service.
2.1.1 Communications Reliability Problems
This section considers primarily cases in which the reliability requirements failed to be met for communications involving people and computers. Several security-related communications problems are considered in Chapter 5.
The 1980 ARPAnet collapse
In the 1970s, the ARPAnet was a network linking primarily research computers, mostly within the United States, under the auspices of the Advanced Research Projects Agency (ARPA) of the Department of Defense (DoD). (It was the precursor of the Internet, which now links together many different computer networks worldwide.) On October 27, 1980, the ARPAnet experienced an unprecedented outage of approximately 4 hours, after years of almost flawless operation. This dramatic event is discussed in detail by Eric Rosen [139], and is summarized briefly here.
The collapse of the network resulted from an unforeseen interaction among three different problems: (1) a hardware failure resulted in bits being dropped in memory; (2) a redundant single-error-detecting code was used for transmission, but not for storage; and (3) the garbage-collection algorithm for removing old messages was not resistant to the simultaneous existence of one message with several different time stamps. This particular combination of circumstances had not arisen previously. In normal operation, each net node broadcasts a status message to each of its neighbors once per minute; 1 minute later, that message is then rebroadcast to the iterated neighbors, and so on. In the absence of bogus status messages, the garbage-collection algorithm is relatively sound. It keeps only the most recent of the status messages received from any given node, where recency is defined as the larger of two close-together 6-bit time stamps, modulo 64. Thus, for example, a node could delete any message that it had already received via a shorter path, or a message that it had originally sent that was routed back to it. For simplicity, 32 was considered a permissible difference, with the numerically larger time stamp being arbitrarily deemed the more recent in that case. In the situation that caused the collapse, the correct version of the time stamp was 44 [101100 in binary], whereas the bit-dropped versions had time stamps 40 [101000] and 8 [001000]. The garbage-collection algorithm noted that 44 was more recent than 40, which in turn was more recent than 8, which in turn was more recent than 44 (modulo 64). Thus, all three versions of that status message had to be kept.
From then on, the normal generation and forwarding of status messages from the particular node were such that all of those messages and their successors with newer time stamps had to be kept, thereby saturating the memory of each node. In effect, this was a naturally propagating, globally contaminating effect. Ironically, the status messages had the highest priority, and thus defeated all efforts to maintain the network nodes remotely. Every node had to be shut down manually. Only after each site administrator reported back that the local nodes were down could the network be reconstituted; otherwise, the contaminating propagation would have begun anew. This case is considered further in Section 4.1. Further explanation of the use of parity checks for detecting any arbitrary single bit in error is deferred until Section 7.7.
The 1986 ARPAnet outage
Reliability concerns dictated that logical redundancy should be used to ensure alternate paths between the New England ARPAnet sites and the rest of the ARPAnet. Thus, seven separate circuit links were established. Unfortunately, all of them were routed through the same fiber-optic cable, which was accidentally severed near White Plains, New York, on December 12, 1986 (SEN 12, 1, 17).1
The 1990 AT&T system runaway
In mid-December 1989, AT&T installed new software in 114 electronic switching systems (Number 4 ESS), intended to reduce the overhead required in signaling between switches by eliminating a signal indicating that a node was ready to resume receiving traffic; instead, the other nodes were expected to recognize implicitly the readiness of the previously failed node, based on its resumption of activity. Unfortunately, there was an undetected latent flaw in the recovery-recognition software in every one of those switches.
On January 15, 1990, one of the switches experienced abnormal behavior; it signaled that it could not accept further traffic, went through its recovery cycle, and then resumed sending traffic. A second switch accepted the message from the first switch and attempted to reset itself. However, a second message arrived from the first switch that could not be processed properly, because of the flaw in the software. The second switch shut itself down, recovered, and resumed sending traffic. That resulted in the same problem propagating to the neighboring switches, and then iteratively and repeatedly to all 114 switches. The hitherto undetected problem manifested itself in subsequent simulations whenever a second message arrived within too short a time. AT&T finally was able to diagnose the problem and to eliminate it by reducing the messaging load of the network, after a 9-hour nationwide blockade.2 With the reduced load, the erratic behavior effectively went away by itself, although the software still had to be patched correctly to prevent a recurrence. Reportedly, approximately 5 million calls were blocked.
The ultimate cause of the problem was traced to a C program that contained a break statement within an if clause nested within a switch clause. This problem can be called a programming error, or a deficiency of the C language and its compiler, depending on your taste, in that the intervening if clause was in violation of expected programming practice. (We return to this case in Section 4.1.)
The Chicago area telephone cable
Midmorning on November 19, 1990, a contractor planting trees severed a high-capacity telephone line in suburban Chicago, cutting off long-distance service and most local service for 150,000 telephones. The personal and commercial disruptions were extensive. Teller machines at some banks were paralyzed. Flights at O’Hare International Airport were delayed because the air-traffic control tower temporarily lost contact with the main Federal Aviation Administration air-traffic control centers for the Chicago area. By midafternoon, Illinois Bell Telephone Company had done some rerouting, although outages and service degradations continued for the rest of the day.3
The New York area telephone cable
An AT&T crew removing an old cable in Newark, New Jersey, accidentally severed a fiber-optic cable carrying more than 100,000 calls. Starting at 9:30 A.M. on January 4, 1991, and continuing for much of the day, the effects included shutdown of the New York Mercantile Exchange and several commodities exchanges; disruption of Federal Aviation Administration (FAA) air-traffic control communication in the New York metropolitan area, Washington, and Boston; lengthy flight delays; and blockage of 60 percent of the long-distance telephone calls into and out of New York City.4
Virginia cable cut
On June 14, 1991, two parallel cables were cut by a backhoe in Annandale, Virginia. The Associated Press (perhaps having learned from the previously noted seven-links-in-one-conduit separation of New England from the rest of the ARPAnet) had requested two separate cables for their primary and backup circuits. Both cables were cut at the same time, because they were adjacent!
Fiber-optic cable cut
A Sprint San Francisco Bay Area fiber-optic cable was cut on July 15, 1991, affecting long-distance service for 3.5 hours. Rerouting through AT&T caused congestion there as well.5
SS-7 faulty code patch
On June 27, 1991, various metropolitan areas had serious outages of telephone service. Washington, D.C. (6.7 million lines), Los Angeles, and Pittsburgh (1 million lines) were all affected for several hours. Those problems were eventually traced to a flaw in the Signaling System 7 protocol implementation, and were attributed to an untested patch that involved just a few lines of code. A subsequent report to the Federal Communications Commission (written by Bell Communications Research Corp.) identified a mistyped character in the April software release produced by DSC Communications Corp. (“6” instead of “D”) as the cause, along with faulty data, failure of computer clocks, and other triggers. This problem caused the equipment and software to fail under an avalanche of computer-generated messages (SEN, 17, 1, 8-9).
Faulty clock maintenance
A San Francisco telephone outage was traced to improper maintenance when a faulty clock had to be repaired (SEN, 16, 3, 16-17).
Backup battery drained
A further telephone-switching system outage caused the three New York airports to shut down for 4 hours on September 17, 1991. AT&T’s backup generator hookup failed while a Number 4 ESS switching system in Manhattan was running on internal power (in response to a voluntary New York City brownout); the system ran on standby batteries for 6 hours until the batteries depleted, unbeknownst to the personnel on hand. The two people responsible for handling emergencies were attending a class on power-room alarms. However, the alarms had been disconnected previously because of construction in the area that was continually triggering the alarms! The ensuing FAA report concluded that about 5 million telephone calls had been blocked, and 1174 flights had been canceled or delayed (SEN 16, 4; 17, 1).
Air-traffic control problems
An FAA report to a House subcommittee listed 114 “major telecommunication outages” averaging 6.1 hours in the FAA network consisting of 14,000 leased lines across the country, during the 13-month period from August 1990 to August 1991. These outages led to flight delays and generated safety concerns. The duration of these outages ranged up to 16 hours, when a contractor cut a 1500-circuit cable at the San Diego airport in August 1991. That case and an earlier outage in Aurora, Illinois, are also noted in Section 2.4. The cited report included the following cases as well. (See SEN 17, 1.)
• On May 4, 1991, four of the FAA’s 20 major air-traffic control centers shut down for 5 hours and 22 minutes. The cause: “Fiber cable was cut by a farmer burying a dead cow. Lost 27 circuits. Massive operational impact.”
• The Kansas City, Missouri, air-traffic center lost communications for 4 hours and 16 minutes. The cause: “Beaver chewed fiber cable.” (Sharks have also been known to chomp on undersea cables.) Causes of other outages cited included lightning strikes, misplaced backhoe buckets, blown fuses, and computer problems.
• In autumn 1991, two technicians in an AT&T long-distance station in suburban Boston put switching components on a table with other unmarked components, and then put the wrong parts back into the machine. That led to a 3-hour loss of long-distance service and to flight delays at Logan International Airport.
• The failure of a U.S. Weather Service telephone circuit resulted in the complete unavailability of routine weather-forecast information for a period of 12 hours on November 22, 1991 (SEN 17, 1).
Problems in air-traffic control systems are considered more generally in Section 2.4, including other cases that did not involve communications difficulties.
The incidence of such outages and partial blockages seems to be increasing, rather than decreasing, as more emphasis is placed on software and as communication links proliferate. Distributed computer-communication systems are intrinsically tricky, as illustrated by the 1980 ARPAnet collapse and the similar nationwide saturation of AT&T switching systems on January 15, 1990. The timing-synchronization glitch that delayed the first shuttle launch (Section 2.2.1) and other problems that follow also illustrate difficulties in distributed systems. A discussion of the underlying problems of distributed systems is given in Section 7.3.
2.1.2 Summary of Communications Problems
Section 2.1 considers a collection of cases related to communications failures. Table 2.1 provides a brief summary of the causes of these problems. The column heads relate to causative factors enumerated in Section 1.2, and are as defined in Table 1.1 in Section 1.5. Similarly, the table entries are as defined in Table 1.1.
Table 2.1 Summary of communications problems

The causes and effects in the cases in this section vary widely from one case to another. The 1980 ARPAnet outage was triggered by hardware failures, but required the presence of a software weakness and a hardware design shortcut that permitted total propagation of the contaminating effect. The 1986 ARPAnet separation was triggered by an environmental accident, but depended on a poor implementation decision. The 1990 AT&T blockage resulted from a programming mistake and a network design that permitted total propagation of the contaminating effect. A flurry of cable cuttings (Chicago, New York area, Virginia, and the San Francisco Bay Area) resulted from digging accidents, but the effects in each case were exacerbated by designs that made the systems particularly vulnerable. The SS-7 problems resulted from a faulty code patch and the absence of testing before that patch was installed. The New York City telephone outage resulted from poor network administration, and was complicated by the earlier removal of warning alarms.
In summary, the primary causes of the cited communications problems were largely environmental, or were the results of problems in maintenance and system evolution. Hardware malfunctions were involved in most cases, but generally as secondary causative factors. Software was involved in several cases. Many of the cases have multiple causative factors.
The diversity of causes and effects noted in these communications problems is typical of what is seen throughout each of the sections of this chapter relating to reliability, as well as in succeeding chapters relating to security and privacy. However, the specific factors differ from one type of application to another. As a consequence, the challenge of avoiding similar problems in the future is itself quite diversified. (See, for example, Chapter 7.)
2.2 Problems in Space
In this section, we consider difficulties that have occurred in space programs, involving shuttles, probes, rockets, and satellites, to illustrate the diversity among reliability and safety problems.
One of the most spectacular uses of computers is in the design, engineering, launch preparation, and real-time control of space vehicles and experiments. There have been magnificent advances in this area. However, in the firm belief that we must learn from the difficulties as well as the successes, this section documents some of the troubles that have occurred.
Section 2.2.1 considers problems that have arisen in the shuttle program, plus a few other related cases involving risks to human lives. Section 2.2.2 considers space exploration that does not involve people on board.
2.2.1 Human Exploration in Space
Despite the enormous care taken in development and operation, the space program has had its share of problems. In particular, the shuttle program has experienced many difficulties. The National Aeronautics and Space Administration (NASA) has recorded hundreds of anomalies involving computers and avionics in the shuttle program. A few of the more instructive cases are itemized here, including several in which the lives of the astronauts were at stake. Unfortunately, details are not always available regarding what caused the problem, which makes it difficult to discuss how that problem could have been avoided, and which may at times be frustrating to both author and reader.
The order of presentation in this section is more or less chronological. The nature of the causes is extremely diverse; indeed, the causes are different in each case. Thus, we begin by illustrating this diversity, and then in retrospect consider the nature of the contributing factors. In later sections of this chapter and in later chapters, the presentation tends to follow a more structured approach, categorizing problems by type. However, the same conclusion is generally evident. The diversity among the causes and effects of the encountered risks is usually considerable — although different from one application area to another.
The first shuttle launch (STS-1)
One of the most often-cited computer-system problems occurred about 20 minutes before the scheduled launch of the first space shuttle, Columbia, on April 10, 1981. The problem was extensively described by Jack Garman (“The ‘Bug’ Heard ‘Round the World” [47]), and is summarized here. The launch was put on hold for 2 days because the backup computer could not be initialized properly.
The on-board shuttle software runs on two pairs of primary computers, with one pair in control as long as the simultaneous computations on both agree with each other, with control passing to the other pair in the case of a mismatch. All four primary computers run identical programs. To prevent catastrophic failures in which both pairs fail to perform (for example, if the software were wrong), the shuttle has a fifth computer that is programmed with different code by different programmers from a different company, but using the same specifications and the same compiler (HAL/S). Cutover to the backup computer would have to be done manually by the astronauts. (Actually, the backup fifth computer has never been used in mission control.)
Let’s simplify the complicated story related by Garman. The backup computer and the four primary computers were 1 time unit out of phase during the initialization, as a result of an extremely subtle 1-in-67 chance timing error. The backup system refused to initialize, even though the primary computers appeared to be operating perfectly throughout the 30-hour countdown. Data words brought in one cycle too soon on the primaries were rejected as noise by the backup. This system flaw occurred despite extraordinarily conservative design and implementation. (The interested reader should delve into [47] for the details.)
A software problem on shuttle (STS-6)
The Johnson Space Center Mission Control Center had a pool of four IBM 370/168 systems for STS mission operations on the ground. During a mission, one system is on-line. One is on hot backup, and can come on-line in about 15 seconds. During critical periods such as launch, reentry, orbit changes, or payload deployment, a third is available on about 15 minutes notice. The third 370 can be supporting simulations or software development during a mission, because such programs can be interrupted easily. Prior to STS-6, the 370 software supported only one activity (mission, simulation, or software development) at a time. Later, the Mature Operations Configuration would support three activities at a time. These would be called the Dual and Triple Mission Software deliveries. STS-6 was the first mission after the Dual Mission Software had been installed. At liftoff, the memory allocated to that mission was saturated with the primary processing, and the module that allocated memory would not release the memory allocated to a second mission for Abort Trajectory calculation. Therefore, if the mission had been aborted, trajectories would not have been available. After the mission, a flaw in the software was diagnosed and corrected (SEN 11, 1).
Note that in a similar incident, Mercury astronauts had previously had to fly a manual reentry because of a program bug that prevented automatic control on reentry (SEN 8, 3).
Shuttle Columbia return delayed (STS-9)
On December 8, 1983, the shuttle mission had some serious difficulties with the on-board computers. STS-9 lost the number 1 computer 4 hours before reentry was scheduled to begin. Number 2 took over for 5 minutes, and then conked out. Mission Control powered up number 3; they were able to restart number 2 but not number 1, so the reentry was delayed. Landing was finally achieved, although number 2 died again on touchdown. Subsequent analysis indicated that each processor failure was due to a single loose piece of solder bouncing around under 20 gravities. Astronaut John Young later testified that, had the backup flight system been activated, the mission would have been lost (SEN 9, 1, 4; 14, 2).
Thermocouple problem on Challenger (STS-19)
On July 29, 1985, 3 minutes into ascent, a failure in one of two thermocouples directed a computer-controlled shutdown of the center engine. Mission control decided to abort into orbit, 70 miles up — 50 miles lower than planned. Had the shutdown occurred 30 seconds earlier, the mission would have had to abort over the Atlantic. NASA has reset some of the binary thermocouple limits via subsequent software changes. (See SEN 14, 2.)
Discovery launch delay (STS-20)
An untimely—and possibly experiment-aborting—delay of the intended August 25, 1985, launch of the space shuttle Discovery was caused when a malfunction in the backup computer was discovered just 25 minutes before the scheduled launch. The resulting 2-day delay caused serious complications in scheduling of the on-board experiments, although the mission was concluded successfully. A reporter wrote, “What was puzzling to engineers was that the computer had worked perfectly in tests before today. And in tests after the failure, it worked, though showing signs of trouble.”6 (Does that puzzle you?)
Arnold Aldrich, manager of the shuttle program at Johnson, was quoted as saying “We’re about 99.5 percent sure it’s a hardware failure.” (The computers were state of the art as of 1972, and were due for upgrading in 1987.) A similar failure of the backup computer caused a 1-day delay in Discovery’s maiden launch in the summer of 1984 (SEN 10, 5).
Near-disaster on shuttle Columbia (STS-24)
The space shuttle Columbia came within 31 seconds of being launched without enough fuel to reach its planned orbit on January 6, 1986, after weary Kennedy Space Center workers mistakenly drained 18,000 gallons of liquid oxygen from the craft, according to documents released by the White House panel that probed the shuttle program. Although NASA said at the time that computer problems were responsible for the scrubbed launch, U.S. Representative Bill Nelson from Florida flew on the mission, and said that he was informed of the fuel loss while aboard the spacecraft that day.
According to the appendix [to the panel report], Columbia’s brush with disaster . . . occurred when Lockheed Space Operations Co. workers “inadvertently” drained super-cold oxygen from the shuttle’s external tank 5 minutes before the scheduled launch. The workers misread computer evidence of a failed valve and allowed a fuel line to remain open. The leak was detected when the cold oxygen caused a temperature gauge to drop below approved levels, but not until 31 seconds before the launch was the liftoff scrubbed.7
The Challenger disaster (STS-25)
The destruction of the space shuttle Challenger on January 28, 1986, killed all seven people on board. The explosion was ultimately attributed to the poor design of the booster rockets, as well as to administrative shortcomings that permitted the launch under cold-weather conditions. However, there was apparently a decision along the way to economize on the sensors and on their computer interpretation by removing the sensors on the booster rockets. There is speculation that those sensors might have permitted earlier detection of the booster-rocket failure, and possible early separation of the shuttle in an effort to save the astronauts. Other shortcuts were also taken so that the team could adhere to an accelerating launch schedule. The loss of the Challenger seems to have resulted in part from some inadequate administrative concern for safety—despite recognition and knowledge of hundreds of problems in past flights. Problems with the O-rings — especially their inability to function properly in cold weather—and with the booster-rocket joints had been recognized for some time. The presidential commission found “a tangle of bureaucratic underbrush”: “Astronauts told the commission in a public hearing . . . that poor organization of shuttle operations led to such chronic problems as crucial mission software arriving just before shuttle launches and the constant cannibalization of orbiters for spare parts.” (See the Chicago Tribune, April 6, 1986.)
Shuttle Atlantis computer fixed in space (STS-30).8
One of Atlantis’ main computers failed on May 7, 1989. For the first time ever, the astronauts made repairs — in this case, by substituting a spare processor. It took them about 3.5 hours to gain access to the computer systems by removing a row of lockers on the shuttle middeck, and another 1.5 hours to check out the replacement computer. (The difficulty in making repairs was due to a long-standing NASA decision from the Apollo days that the computers should be physically inaccessible to the astronauts.) (See SEN 14, 5.)
Shuttle Atlantis backup computer on ground delays launch (STS-36)
A scheduled launch of Atlantis was delayed for 3 days because of “bad software” in the backup tracking system. (See SEN 15, 2.)
Shuttle Discovery misprogramming (STS-41)
According to flight director Milt Heflin, the shuttle Discovery was launched on October 6, 1990, with incorrect instructions on how to operate certain of its programs. The error was discovered by the shuttle crew about 1 hour into the mission, and was corrected quickly. NASA claims that automatic safeguards would have prevented any ill effects even if the crew had not noticed the error on a display. The error was made before the launch, and was discovered when the crew was switching the shuttle computers from launch to orbital operations. The switching procedure involves shutting down computers 3 and 5, while computers 1 and 2 carry on normal operations, and computer 4 monitors the shuttle’s vital signs. However, the crew noticed that the instructions for computer 4 were in fact those intended for computer 2. Heflin stated that the problem is considered serious because the ground prelaunch procedures failed to catch it.9
Intelsat 6 launch failed
In early 1990, an attempt to launch the $150 million Intelsat 6 communications satellite from a Titan III rocket failed because of a wiring error in the booster, due to inadequate human communications between the electricians and the programmers who failed to specify in which of the two satellite positions the rocket had been placed; the program had selected the wrong one (Steve Bellovin, SEN 15, 3). Live space rescue had to be attempted. (See the next item.)
Shuttle Endeavour computer miscomputes rendezvous with Intelsat (STS-49)
In a rescue mission in May 1992, the Endeavour crew had difficulties in attempting to rendezvous with Intelsat 6. The difference between two values that were numerically extremely close (but not identical) was effectively rounded to zero; thus, the program was unable to observe that there were different values. NASA subsequently changed the specifications for future flights.10
Shuttle Discovery multiple launch delays (STS-56)
On April 5, 1993, an attempt to launch Discovery was aborted 11 seconds before liftoff. (The engines had not yet been ignited.) (There had been an earlier 1-hour delay at 9 minutes before launch, due to high winds and a temperature-sensor problem.) Early indications had pointed to failure of a valve in the main propulsion system. Subsequent analysis indicated that the valve was operating properly, but that the computer system interpreted the sensor incorrectly—indicating that the valve had not closed. A quick fix was to bypass the sensor reading, which would have introduced a new set of risks had there subsequently been a valve problem.11
This Discovery mission experienced many delays and other problems. Because of the Rube Goldberg nature of the mission, each event is identified with a number referred to in Table 2.2 at the end of the section. (1) The initial attempted launch was aborted. (2) On July 17, 1993, the next attempted launch was postponed because ground restraints released prematurely. (3) On July 24, a steering-mechanism failure was detected at 19 seconds from blastoff. (4) On August 4, the rescheduled launch was postponed again to avoid potential interference from the expected heavy Perseid meteor shower on August 11 (in the aftermath of the reemergence of the comet Swift-Tuttle). (5) On August 12, the launch was aborted when the engines had to be shut down 3 seconds from blastoff, because of a suspected failure in the main-engine fuel-flow monitor. (An Associated Press report of August 13, 1993, estimated the expense of the scrubbed launches at over $2 million.) (6) The Columbia launch finally went off on September 12, 1993. Columbia was able to launch two satellites, although each had to be delayed by one orbit due to two unrelated communication problems. (7) An experimental communication satellite could not be released on schedule, because of interference from the payload radio system. (8) The release of an ultraviolet telescope had to be delayed by one orbit because communication interference had delayed receipt of the appropriate commands from ground control.
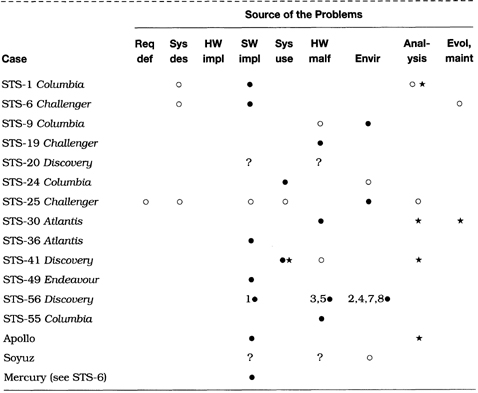
Table 2.2 Summary of space problems

Shuttle Columbia aborted at -3 seconds (STS-55)
On March 22, 1993, Columbia’s main engines were shut down 3 seconds before liftoff, because of a leaky valve. (The mission finally went off on April 26, 1993.)
Columbia launch grounded due to safety software (STS-58)
The planned launch of Columbia on October 14, 1993, had to be scrubbed at the last minute because of a “glitch in the computer system designed to ensure safety on the ground during launches.”12 The launch went off successfully 4 days later.
Apollo: The moon was repulsive
The Apollo 11 software reportedly had a program flaw that resulted in the moon’s gravity appearing repulsive rather than attractive. This mistake was caught in simulation. (See SEN 9, 5, based on an oral report.)
Software mixup on the Soyuz spacecraft
According to Aviation Week (September 12, 1988, page 27), in the second failed reentry of the Soviet Soyuz-TM spacecraft on September 7, 1988, the engines were shut down in the last few seconds due to a computer problem: “Instead of using the descent program worked out for the Soviet-Afghan crew, the computer switched to a reentry program that had been stored in the Soyuz TM-5 computers in June for a Soviet-Bulgarian crew. Soviet officials said . . . that they did not understand why this computer mixup occurred.” Karl Lehenbauer noted that the article stated that the crew was committed to a reentry because they had jettisoned the orbital module that contained equipment that would be needed to redock with the Mir space station. The article also noted that Geoffrey Perry, an analyst of Soviet space activities with the Kettering Group, said “the crew was not flying in the same Soyuz that they were launched in, but instead were in a spacecraft that had been docked with the Mir for about 90 days. Perry said that is about half the designed orbital life of the Soyuz.” (See SEN 13, 4.)
2.2.2 Other Space-Program Problems
The problems itemized in Section 2.2.1 involved risks to human lives (except for the Intelsat 6 launch, which is included because of the rescue mission). Some of these cases necessitated extra-vehicular human actions as well. Next, we examine problems relating to uninhabited space missions.
Atlas-Agena went beserk due to missing hyphen
On what was expected to be the first U.S. spacecraft to do a Venus flyby, an Atlas-Agena became unstable at about 90 miles up. The $18.5 million rocket was then blown up on command from the control center at Cape Kennedy. Subsequent analysis showed that the flight plan was missing a hyphen that was a symbol for a particular formula.13
Mariner I lost
Mariner I was intended to be the first space probe to visit another planet (Venus). Apparent failure of an Atlas booster during launch on July 22, 1962, caused the range officer to destroy the booster rather than to risk its crashing in a populated area. However, in reality, the rocket was behaving correctly, and it was the ground-based computer system analyzing the launch that was in error—as the result of a software bug and a hardware failure. The software bug is noteworthy. The two radar systems differed in time by 43 milliseconds, for which the program supposedly compensated. The bug arose because the overbar had been left out in the handwritten guidance equations in the expression R dot bar sub n. Here R denotes the radius; the dot indicates the first derivative — that is, the velocity; the bar indicates smoothed rather than raw data; and n is the increment. When a hardware fault occurred, the computer processed the track data incorrectly, leading to the erroneous termination of the launch.14
There had been earlier erroneous reports that the problem was due to a comma that had been entered accidentally as a period in a DO statement (which really was a problem with the Mercury software, as noted in the next item). The confusion was further compounded by a report that the missing overbar might have been the interchange of a minus sign and a hyphen, but that was also false (SEN 13, 1). This case illustrates the difficulties we sometimes face in trying to get correct details about a computer failure.
DO I=1.10 bug in Mercury software
Project Mercury’s FORTRAN code had a syntax error something like DO I=1.10 instead of DO I=1,10. The substitution of a comma for a period was discovered in an analysis of why the software did not seem sufficiently accurate, even though the program had been used successfully in previous suborbital missions; the error was corrected before the subsequent orbital and moon flights, for which it might have caused problems. This case was reported in RISKS by Fred Webb, whose officemate had found the flaw in searching for why the program’s accuracy was poor (SEN 15, 1). (The erroneous 1.10 would cause the loop to be executed exactly once.)
Ohmage to an Aries launch
At White Sands Missile Range, New Mexico, a rocket carrying a scientific payload for NASA was destroyed 50 seconds after launch because its guidance system failed. The loss of the $1.5-million rocket was caused by the installation of an improper resistor in the guidance system.15 (The flight was the twenty-seventh since the first Aries was launched in 1973, but was only the third to experience failure.)
Gemini V lands 100 miles off course
Gemini V splashed down off-course by 100 miles because of a programmer’s misguided short-cut. The intended calculation was to compute the earth reference point relative to the sun as a fixed point, using the elapsed time since launch. The programmer forgot that the earth does not come back to the same point relative to the sun 24 hours later, so that the error cumulatively increased each day.16
Titan, Orion, Delta, Atlas, and Ariane failures
The disaster of the space shuttle Challenger (January 28, 1986) led to increased efforts to launch satellites without risking human lives in shuttle missions. However, the Challenger loss was followed by losses of the Titan III (34-D) on April 18, 1986; the Nike Orion on April 25, 1986 (although it was not reported until May 9); and the Delta rocket on May 3, 1986. The Titan III loss was the second consecutive Titan III failure, this launch having been delayed because of an accident in the previous launch during the preceding August, traced to a first-stage turbo-pump. A subsequent Titan IV loss is noted in Section 7.5. A further Titan IV blew up 2 minutes after launch on August 2, 1993, destroying a secret payload thought to be a spy satellite.17 The failure of the Nike Orion was its first, after 120 consecutive successes. The Delta failure followed 43 consecutive successful launches dating back to September 1977. In the Delta-178 failure, the rocket’s main engine mysteriously shut itself down 71 seconds into the flight—with no evidence of why! (Left without guidance at 1400 mph, the rocket had to be destroyed, along with its weather satellite.) The flight appeared normal up to that time, including the jettisoning of the first set of solid rockets after 1 minute out. Bill Russell, the Delta manager, was quoted thus: “It’s a very sharp shutdown, almost as though it were a commanded shutdown.” The preliminary diagnosis seemed to implicate a short circuit in the engine-control circuit. The May 22, 1986, launch of the Atlas-Centaur was postponed pending the results of the Delta investigation, because both share common hardware. The French also had their troubles, when an Ariane went out of control and had to be destroyed, along with a $55 million satellite. (That was its fourth failure out of 18 launches; 3 of the 4 involved failure of the third stage.) Apparently, insurance premiums on satellite launches skyrocketed as a result. (See SEN 11, 3.) Atlas launches in 1991, August 1992, and March 1993 also experienced problems. The first one had to be destroyed shortly after liftoff, along with a Japanese broadcasting satellite. The second went out of control and had to be blown up, along with its cable TV satellite. The third left a Navy communications satellite in a useless orbit, the failure of the $138 million mission being blamed on a loose screw. The losses in those 3 failed flights were estimated at more than $388 million. The first successful Atlas flight in a year occurred on July 19, 1993, with the launch of a nuclear-hardened military communications satellite.18
Voyager missions
Voyager 1 lost mission data over a weekend because all 5 printers were not operational; 4 were configured improperly (for example, off-line) and one had a paper jam (SEN 15, 5).
Canaveral rocket destroyed
In August 1991, an off-course rocket had to be destroyed. A technician had apparently hit a wrong key while loading the guidance software, installing the ground-test version instead of the flight software. Subsequently, a bug was found before a subsequent launch that might have caused the rocket to err, even if the right guidance software had been in place (Steve Bellovin, SEN 16, 4).
Viking antenna problem
The Viking probe developed a misaligned antenna due to an improper code patch. (An orally provided report is noted in SEN 9, 5.)
Phobos 1 and 2
The Soviets lost their Phobos 1 Mars probe after it tumbled in orbit and the solar cells lost power. The tumbling resulted from a single character omitted in a transmission from a ground controller to the probe. The change was necessitated because of a transfer from one command center to another. The omission caused the spacecraft’s solar panels to point the wrong way, which prevented the batteries from staying charged, ultimately causing the spacecraft to run out of power. Phobos 2 was lost on March 27, 1989, because a signal to restart the transmitter while the latter was in power-saver mode was never received.19
Mars Observer vanishes
The Mars Observer disappeared from radio contact on Saturday, August 21, 1993, just after it was ready to pressurize its helium tank (which in turn pressurizes the hydrazine-oxygen fuel system), preparatory to the rocket firings that were intended to slow down the spacecraft and to allow it to be captured by Martian gravity and settle into orbit around Mars. The subsequent request to switch on its antenna again received no response. Until that point, the mission had been relatively trouble free—except that the spacecraft’s instructions had to be revised twice to overcome temporary problems. Speculation continued as to whether a line leak or a tank rupture might have occurred. Glenn Cunningham, project manager at the Jet Propulsion Laboratory, speculated on several other possible scenarios: the Observer’s on-board clock could have stopped, the radio could have overheated, or the antenna could have gone askew. Lengthy analysis has concluded that the most likely explanation is that a change in flight plan was the inadvertent cause. The original plan was to pressurize the propellant tanks 5 days after launch; instead, the pressurization was attempted 11 months into the flight, in hopes of minimizing the likelihood of a leak. Apparently the valves were not designed to operate under the alternative plan, which problem now seems most likely to have been the cause of a fuel-line rupture resulting from a mixture of hydrazine and a small amount of leaking oxidizer.20
Landsat 6
Landsat 6 was launched on October 5, 1993. It was variously but erroneously reported as (1) having gotten into an improper orbit, or (2) being in the correct orbit but unable to communicate. On November 8, 1993, the $228 million Landsat 6 was declared officially missing. The object NASA had been tracking turned out to be a piece of space junk.21
These problems came on the heels of the continued launch delays on another Discovery mission, a weather satellite that died in orbit after an electronic malfunction, and the Navy communications satellite that was launched into an unusable orbit from Vandenburg in March 1993 ($138 million). Shuttle launches were seriously delayed.22
Galileo troubles en route to Jupiter
The $1.4 billion Galileo spacecraft en route to Jupiter experienced difficulties in August 1993. Its main antenna jammed, and its transmissions were severely limited to the use of the low-gain antenna.
Anik E-1, E-2 failures
Canadian Telesat’s Anik E-1 satellite stopped working for about 8 hours on January 21, 1994, with widespread effects on telephones and the Canadian Press news agency, particularly in the north of Canada. Minutes after Anik E-1 was returned to service, Anik E-2 (which is Canada’s main broadcast satellite) ceased functioning altogether. Amid a variety of possible explanations (including magnetic storms, which later were absolved), the leading candidate involved electron fluxes related to solar coronal holes.
Xichaing launchpad explosion
On April 9, 1994, a huge explosion at China’s Xichiang launch facility killed at least two people, injured at least 20 others, and destroyed the $75 million Fengyun-2 weather satellite. The explosion also leveled a test laboratory. A leak in the on-board fuel system was reported as the probable cause.23
Lens cap blocks satellite test
A Star Wars satellite launched on March 24, 1989, was unable to observe the second-stage rocket firing because the lens cap had failed to be removed in time. By the time that the lens was uncovered, the satellite was pointing in the wrong direction (SEN 14, 2).
2.2.3 Summary of Space Problems
Table 2.2 provides a brief summary of the problems cited in Section 2.2. The abbreviations and symbols used for table entries and column headings are as in Table 1.1.
From the table, we observe that there is considerable diversity among the causes and effects, as in Table 2.1, and as suggested at the beginning of Section 2.2.1. However, the nature of the diversity of causes is quite different from that in Table 2.1. Here many of the problems involve software implementation or hardware malfunctions as the primary cause, although other types of causes are also included.
The diversity among software faults is evident. The STS-1 flaw was a subtle mistake in synchronization. The STS-49 problem resulted from a precision glitch. The original STS-56 launch postponement (noted in the table as subcase (1)) involved an error in sensor interpretation. The Mariner I bug was a lexical mistake in transforming handwritten equations to code for the ground system. The Mercury bug involved the substitution of a period for a comma. The Gemini bug resulted from an overzealous programmer trying to find a short-cut in equations of motion.
The diversity among hardware problems is also evident. The multiple STS-9 hardware failures were caused by a loose piece of solder. The STS-19 abort was due to a thermocouple failure. STS-30’s problem involved a hard processor failure that led the astronauts to replace the computer, despite the redundant design. The original STS-55 launch was aborted because of a leaky valve. Two of the STS-56 delays (subcases 3 and 5) were attributable to equipment problems. The Mariner I hardware failure in the ground system was the triggering cause of the mission’s abrupt end, although the software bug noted previously was the real culprit. The mysterious shutdown of the Delta-178 main engine adds still another possible cause.
Several cases of operational human mistakes are also represented. STS-24 involved a human misinterpretation of a valve condition. STS-41 uncovered incorrect operational protocols. The Atlas-Agena loss resulted from a mistake in the flight plan. Voyager gagged on output data because of an erroneous system configuration. The loss of Phobos 1 was caused by a missing character in a reconfiguration command.
The environmental causes include the cold climate under which the Challenger was launched (STS-25), weightlessness mobilizing loose solder (STS-9), and communication interference that caused the delays in Discovery’s placing satellites in orbit (STS-56, subcases 7 and 8).
Redundancy is an important way of increasing reliability; it is considered in Section 7.7. In addition to the on-board four primary computers and the separately programmed emergency backup computer, the shuttles also have replicated sensors, effectors, controls, and power supplies. However, the STS-1 example shows that the problem of getting agreement among the distinct program components is not necessarily straightforward. In addition, the backup system is intended primarily for reentry in an emergency in which the primary computers are not functional; it has not been maintained to reflect many of the changes that have occurred in recent years, and has never been used. A subsystem’s ability to perform correctly is always dubious if its use has never been required.
In one case (Apollo), analytical simulation uncovered a serious flaw before launch. In several cases, detected failures in a mission led to fixes that avoided serious consequences in future missions (STS-19, STS-49, and Mercury).
Maintenance in space is much more difficult than is maintenance in ground-based systems (as evidenced by the cases of STS-30 and Phobos), and consequently much greater care is given to preventive analysis in the space program. Such care seems to have paid off in many cases. However, it is also clear that many problems remain undetected before launch.
2.3 Defense
Some of the applications that stretch computer and communication technology to the limits involve military systems, including both defensive and offensive weapons. We might like to believe that more money and effort therefore would be devoted to solving problems of safety and lethality, system reliability, system security, and system assurance in defense-related systems than that expended in the private sector. However, the number of defense problems included in the RISKS archives suggests that there are still many lessons to be learned.
2.3.1 Defense Problems
In this section, we summarize a few of the most illustrative cases.
Patriot clock drift
During the Persian Gulf war, the Patriot system was initially touted as highly successful. In subsequent analyses, the estimates of its effectiveness were seriously downgraded, from about 95 percent to about 13 percent (or possibly less, according to MIT’s Ted Postol; see SEN 17, 2). The system had been designed to work under a much less stringent environment than that in which it was actually used in the war. The clock drift over a 100-hour period (which resulted in a tracking error of 678 meters) was blamed for the Patriot missing the scud missile that hit an American military barracks in Dhahran, killing 29 and injuring 97. However, the blame can be distributed—for example, among the original requirements (14-hour missions), clock precision, lack of system adaptability, extenuating operational conditions, and inadequate risks analysis (SEN, 16, 3; 16, 4). Other reports suggest that, even over the 14-hour duty cycle, the results were inadequate. A later report stated that the software used two different and unequal versions of the number 0.1—in 24-bit and 48-bit representations (SEN 18, 1, 25). (To illustrate the discrepancy, the decimal number 0.1 has as an endlessly repeating binary representation 0.0001100110011 . . . . Thus, two different representations truncated at different lengths are not identical—even in their floating-point representations.) This case is the opposite of the shuttle Endeavour problem on STS-49 noted in Section 2.2.1, in which two apparently identical numbers were in fact representations of numbers that were unequal!
Vincennes Aegis system shoots down Iranian Airbus
Iran Air Flight 655 was shot down by the USS Vincennes’ missiles on July 3, 1988, killing all 290 people aboard. There was considerable confusion attributed to the Aegis user interface. (The system had been designed to track missiles rather than airplanes.) The crew was apparently somewhat spooked by a previous altercation with a boat, and was working under perceived stress. However, replay of the data showed clearly that the airplane was ascending—rather than descending, as believed by the Aegis operator. It also showed that the operator had not tracked the plane’s identity correctly, but rather had locked onto an earlier identification of an Iranian F-14 fighter still on the runway. Matt Jaffe [58] reported that the altitude information was not displayed on the main screen, and that there was no indication of the rate of change of altitude (or even of whether the plane was going up, or going down, or remaining at the same altitude). Changes were recommended subsequently for the interface, but most of the problem was simplistically attributed to human error. (See SEN 13, 4; 14, 1; 14, 5; 14, 6.) However, earlier Aegis system failures in attempting to hit targets previously had been attributed to software (SEN 11, 5).
“Friendly Fire”—U.S. F-15s take out U.S. Black Hawks
Despite elaborate precautions designed to prevent such occurrences, two U.S. Army UH-60 Black Hawk helicopters were shot down by two American F-15C fighter planes in the no-fly zone over northern Iraq on April 14, 1994, in broad daylight, in an area that had been devoid of Iraqi aircraft activity for many months. One Sidewinder heat-seeking missile and one Amraam radar-guided missile were fired. The fighters were operating under instructions from an AWACS plane, their airborne command post. The AWACS command was the first to detect the helicopters, and instructed the F-15s to check out the identities of the helicopters. The helicopters were carrying U.S., British, French, and Turkish officers from the United Nations office in Zakho, in northern Iraq, and were heading eastward for a meeting with Kurdish leaders in Salahaddin. Both towns are close to the Turkish border, well north of the 26th parallel that delimits the no-fly zone. All 26 people aboard were killed.
After stopping to pick up passengers, both helicopter pilots apparently failed to perform the routine operation of notifying their AWACS command plane that they were underway. Both helicopters apparently failed to respond to the automated “Identification: Friend or Foe” (IFF) requests from the fighters. Both fighter pilots apparently did not try voice communications with the helicopters. A visual flyby apparently misidentified the clearly marked (“U.N.”) planes as Iranian MI-24s. Furthermore, a briefing had been held the day before for appropriate personnel of the involved aircraft (F-15s, UH-60s, and AWACS).
The circumstances behind the shootdowns remained murky, although a combination of circumstances must have been present. One or both helicopter pilots might have neglected to turn on their IFF transponder; one or both frequencies could have been set incorrectly; one or both transponders might have failed; the fighter pilots might not have tried all three of the IFF modes available to them. Furthermore, the Black Hawks visually resembled Russian helicopters because they were carrying extra external fuel tanks that altered their profiles. But the AWACS plane personnel should have been aware of the entire operation because they were acting as coordinators. Perhaps someone panicked. An unidentified senior Pentagon offical was quoted as asking “What was the hurry to shoot them down?” Apparently both pilots neglected to set their IFF transponders properly. In addition, a preliminary Pentagon report indicates that the controllers who knew about the mission were not communicating with the controllers who were supervising the shootdown.24
“Friendly fire” (also called fratricide, amicicide, and misadventure) is not uncommon. An item by Rick Atkinson25 noted that 24 percent of the Americans killed in action—35 out of 146—in the Persian Gulf war were killed by U.S. forces. Also, 15 percent of those wounded—72 out of 467—were similarly victimized by their colleagues. During the same war, British Warrior armored vehicles were mistaken for Iraqi T-55 tanks and were zapped by U.S. Maverick missiles, killing 9 men and wounding 11 others. Atkinson’s article noted that this situation is not new, citing a Confederate sentry who shot his Civil War commander, Stonewall Jackson, in 1863; an allied bomber that bombed the 30th Infantry Division after the invasion of Normandy in July 1944; and a confused bomber pilot who killed 42 U.S. paratroopers and wounded 45 in the November 1967 battle of Hill 875 in Vietnam. The old adage was never more appropriate: With friends like these, who needs enemies?
Gripen crash
The first prototype of Sweden’s fly-by-wire Gripen fighter plane crashed on landing at the end of its sixth flight because of a bug in the flight-control software. The plane is naturally unstable, and the software was unable to handle strong winds at low speeds, whereas the plane itself responded too slowly to the pilot’s controls (SEN 14, 2; 14, 5). A second Gripen crash on August 8, 1993, was officially blamed on a combination of the pilot and the technology (SEN 18, 4, 11), even though the pilot was properly trained and equipped. However, pilots were not informed that dangerous effects were known to be possible as a result of large and rapid stick movements (SEN 19, 1, 12-13).
F-111s bombing Libya jammed by their own jamming
One plane crashed and several others missed their targets in the 1986 raid on Libya because the signals intended to jam Libya’s antiaircraft facilities were also jamming U.S. transmitters (SEN 11, 3; 15, 3).
Bell V22 Ospreys
The fifth of the Bell-Boeing V22 Ospreys crashed due to the cross-wiring of two roll-rate sensors (gyros that are known as vyros). As a result, two faulty units were able to outvote the good one in a majority-voting implementation. Similar problems were later found in the first and third Ospreys, which had been flying in tests (SEN 16, 4; 17, 1). Another case of the bad outvoting the good in flight software is reported by Brunelle and Eckhardt [18], and is discussed in Section 4.1.
Tornado fighters collide
In August 1988, two Royal Air Force Tornado fighter planes collided over Cumbria in the United Kingdom, killing the four crewmen. Apparently, both planes were flying with identical preprogrammed cassettes that controlled their on-board computers, resulting in both planes reaching the same point at the same instant. (This case was reported by Dorothy Graham, SEN 15, 3.)
Ark Royal
On April 21, 1992, a Royal Air Force pilot accidentally dropped a practice bomb on the flight deck of the Royal Navy’s most modern aircraft carrier, the Ark Royal, missing its intended towed target by hundreds of yards. Several sailors were injured. The cause was attributed to a timing delay in the software intended to target an object at a parametrically specified offset from the tracked object, namely the carrier. 26
Gazelle helicopter downed by friendly missile
On June 6, 1982, during the Falklands War, a British Gazelle helicopter was shot down by a Sea Dart missile that had been fired from a British destroyer, killing the crew of four (SEN 12, 1).
USS Scorpion
The USS Scorpion exploded in 1968, killing a crew of 99. Newly declassified evidence suggests that the submarine was probably the victim of one of its own conventional torpedoes, which, after having been activated accidentally, was ejected. Unfortunately, the torpedo became fully armed and sought its nearest target, as it had been designed to do.27
Missiles badly aimed
The U.S. guided-missile frigate George Philip fired a 3-inch shell in the general direction of a Mexican merchant ship, in the opposite direction from what had been intended during an exercise in the summer of 1983 (SEN 8, 5). A Russian cruise missile landed in Finland, reportedly 180 degrees off its expected target on December 28, 1984 (SEN 10, 2). The U.S. Army’s DIVAD (Sgt. York) radar-controlled antiaircraft gun reportedly selected the rotating exhaust fan in a latrine as a potential target, although the target was indicated as a low-priority choice (SEN 11, 5).
Air defense
For historically minded readers, there are older reports that deserve mention. Daniel Ford’s book The Button28 notes satellite sensors being overloaded by a Siberian gas-field fire (p. 62), descending space junk being detected as incoming missiles (p. 85), and a host of false alarms in the World-Wide Military Command and Control System (WWMCCS) that triggered defensive responses during the period from June 3 to 6, 1980 (pp. 78-84) and that were eventually traced to a faulty integrated circuit in a communications multiplexor. The classical case of the BMEWS defense system in Thule, Greenland, mistaking the rising moon for incoming missiles on October 5, 1960, was cited frequently.29 The North American Air Defense (NORAD) and the Strategic Air Command (SAC) had 50 false alerts during 1979 alone—including a simulated attack whose outputs accidentally triggered a live scramble/alert on November 9, 1979 (SEN 5, 3).
Early military aviation problems
The RISKS archives also contain a few old cases that have reached folklore status, but that are not well documented. They are included here for completeness. An F-18 reportedly crashed because of a missing exception condition if . . . then . . . without the else clause that was thought could not possibly arise (SEN 6, 2; 11, 2). Another F-18 attempted to fire a missile that was still clamped to the plane, resulting in a loss of 20,000 feet in altitude (SEN 8, 5). In simulation, an F-16 program bug caused the virtual plane to flip over whenever it crossed the equator, as the result of a missing minus sign to indicate south latitude.30 Also in its simulator, an F-16, flew upside down because the program deadlocked over whether to roll to the left or to the right (SEN 9, 5). (This type of problem has been investigated by Leslie Lamport in an unpublished paper entitled “Buridan’s Ass”—in which a donkey is equidistant between two points and is unable to decide which way to go.)
2.3.2 Summary of Defense Problems
Table 2.3 provides a brief summary of the causative factors for the cited problems. (The abbreviations and symbols are given in Table 1.1.)
Table 2.3 Summary of defense problems
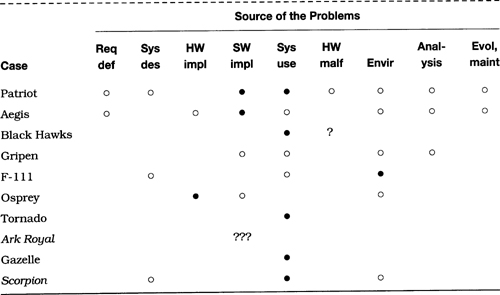
The causes vary widely. The first six cases in the table clearly involve multiple causative factors. Although operator error is a common conclusion in such cases, there are often circumstances that implicate other factors. Here we see problems with system requirements (Patriot), hardware (Osprey), software (lack of precision in the Patriot case, a missing exception condition in the F-18, and a missing sign in the F-16), and the user interface (Aegis). The Black Hawk shootdown appears to have been a combination of errors by many different people, plus an overreliance on equipment that may not have been turned on. The environment also played a role—particularly electromagnetic interference in the F-111 case.
2.4 Civil Aviation
This section considers the basic problems of reliable aviation, the risks involved, and cases in which reliability and safety requirements failed to be met. The causes include human errors and computer-system failures. The effects are serious in many of the cited cases.
2.4.1 Risks in Automated Aviation
Section 2.4.1 originally appeared as a two-part Inside Risks column, CACM 37, 1 and 2, January and February 1994, written by Robert Dorsett—who is the author of a Boeing 727 systems simulator and TRACON II for the Macintosh.
The 1980s saw a tremendous increase of the use of digital electronics in newly developed airliners. The regulatory requirement for a flight engineer’s position on larger airplanes had been eased, such that only two pilots were then required. The emerging power of advanced technology has resulted in highly automated cockpits and in significant changes to flight management and flight-control philosophies.
Flight management
The Flight Management System (FMS) combines the features of an inertial navigation system (INS) with those of a performance-management computer. It is most often used in conjunction with screen-based flight instrumentation, including an artificial horizon and a navigation display. The crew can enter a flight plan, review it in a plan mode on the navigation display, and choose an efficiency factor by which the flight is to be conducted. When coupled with the autopilot, the FMS can control virtually the entire flight, from takeoff to touchdown. The FMS is the core of all modern flight operations.
Systems
As many functions as possible have been automated, from the electrical system to toilet-flush actuators. System states are monitored by display screens rather than more than 650 electromechanical gauges and dials. Most systems’ data items are still available via 10 to 15 synoptic pages, on a single systems display. It is not feasible for the pilots to monitor long-term changes in any onboard system; they must rely on an automatic alerting and monitoring system to do that job for them. Pilots retain limited control authority over on-board systems, if advised of a problem.
Flight control
In 1988, the Airbus A320 was certified; it was the first airliner to use a digital fly-by-wire flight-control system. Pilots control a conventional airliner’s flight path by means of a control column. The control column is connected to a series of pulleys and cables, leading to hydraulic actuators, which move the flight surfaces. Fly-by-wire control eliminates the cables, and replaces them with electrical wiring; it offers weight savings, reduced complexity of hardware, the potential for the use of new interfaces, and even modifications of fundamental flight-control laws — resulting from having a computer filter most command inputs.
Communications
All new airliners offer an optional ARINC Communication and Reporting System (ACARS). This protocol allows the crew to exchange data packets, such as automatically generated squawks and position reports, with a maintenance or operations base on the ground. Therefore, when the plane lands, repair crews can be ready, minimizing turnaround time. ACARS potentially allows operations departments to manage fleet status more efficiently, in real time, worldwide, even via satellite.
Similar technology will permit real-time air-traffic control of airliners over remote locations, such as the Pacific Ocean or the North Atlantic, where such control is needed.
Difficulties
Each of the innovations noted introduces new, unique problems. The process of computerization has been approached awkwardly, driven largely by market and engineering forces, less by the actual need for the features offered by the systems. Reconciling needs, current capabilities, and the human-factors requirements of the crew is an ongoing process.
For example, when FMSs were introduced in the early 1980s, pilots were under pressure to use all available features, all the time. However, it became apparent that such a policy was not appropriate in congested terminal airspace; pilots tended to adopt a heads-down attitude, which reduced their ability to detect other traffic. They also tended to use the advanced automation in high-workload situations, long after it clearly became advisable either to hand-fly or to use the autopilot in simple heading- and altitude-select modes. By the late 1980s, airlines had started click-it-off training. Currently, many airlines discourage the use of FMSs beneath 10,000 feet.
Increased automation has brought the pilot’s role closer to that of a manager, responsible for overseeing the normal operation of the systems. However, problems do occur, and the design of modern interfaces has tended to take pilots out of the control loop. Some research suggests that, in an emergency situation, pilots of conventional aircraft have an edge over pilots of a modern airplane with an equivalent mission profile, because older airplanes require pilots to participate in a feedback loop, thus improving awareness. As an example of modern philosophies, one manufacturer’s preflight procedure simply requires that all lighted buttons be punched out. The systems are not touched again, except in abnormal situations. This design is very clever and elegant; the issue is whether such an approach is sufficient to keep pilots in the loop.
Displays
The design of displays is an ongoing issue. Faced with small display screens (a temporary technology limitation), manufacturers tend to use tape formats for airspeed and altitude monitoring, despite the cognitive problems. Similarly, many systems indications are now given in a digital format rather than in the old analog formats. This display format can result in the absence of trend cues, and, perhaps, can introduce an unfounded faith in the accuracy of the readout.
Control laws
Related to the interface problem is the use of artificial control laws. The use of unconventional devices, such as uncoupled sidesticks, dictates innovations in control to overcome the device’s limitations; consequently, some flight-control qualities are not what experienced pilots expect. Moreover, protections can limit pilot authority in unusual situations. Because these control laws are highly proprietary—they are not standardized, and are not a simple consequence of the natural flying qualities of the airplane—there is potential for significant training problems as pilots transition between airplane types.
Communications
The improvement of communications means that ground personnel are more intimately connected with the flight. The role of an airliner captain has been similar to that of a boat captain, whose life is on the line and who is in the sole position to make critical safety judgments—by law. With more real-time interaction with company management or air-traffic control, there are more opportunities for a captain to be second-guessed, resulting in distributed responsibility and diminished captain’s authority. Given the increasingly competitive, bottom-line atmosphere under which airlines must operate, increased interaction will help diminish personnel requirements, and may tend to impair the safety equation.
Complexity
The effect of software complexity on safety is an open issue. Early INSs had about 4 kilobytes of memory; modern FMSs are pushing 10 megabytes. This expansion represents a tremendous increase in complexity, combined with a decrease in pilot authority. Validating software to the high levels of reliability required poses all but intractable problems. Software has allowed manufacturers to experiment with novel control concepts, for which the experience of conventional aircraft control gathered over the previous 90 years provides no clear guidance. This situation has led to unique engineering challenges. For example, software encourages modal thinking, so that more and more features are context-sensitive.
A Fokker F.100 provided a demonstration of such modality problems in November 1991. While attempting to land at Chicago O’Hare, the crew was unable to apply braking. Both the air and ground switches on its landing gear were stuck in the air position. Since the computers controlling the braking system thought that the plane was in the air, not only was the crew unable to use reverse thrust, but, more controversially, they also were unable to use nosewheel steering or main gear braking—services that would have been available on most other airliners in a similar situation.
As another example, the flight-control laws in use on the Airbus A320 have four distinct permutations, depending on the status of the five flight-control computers. Three of these laws have to accommodate individual-component failure. On the other hand, in a conventional flight-control system, there is but one control law, for all phases of flight.
Regulation
The regulatory authorities are providing few direct standards for high-tech innovation. As opposed to conventional aircraft, where problems are generally well understood and the rules codified, much of the modern regulatory environment is guided by collaborative industry standards, which the regulators have generally approved as being sound. Typically a manufacturer can select one of several standards to which to adhere. On many issues, the position of the authorities is that they wish to encourage experimentation and innovation.
The state of the industry is more suggestive of the disarray of the 1920s than of what we might expect in the 1990s. There are many instances of these emerging problems; Boeing and Airbus use different display color-coding schemes, not to mention completely different lexicons to describe systems with similar purposes. Even among systems that perform similarly, there can be significant discrepancies in the details, which can place tremendous demands on the training capacity of both airlines and manufacturers. All of these factors affect the safety equation.
2.4.2 Illustrative Aviation Problems
There have been many strange occurrences involving commercial aviation, including problems with the aircraft, in-flight computer hardware and software, pilots, air-traffic control, communications, and other operational factors. Several of the more illuminating cases are summarized here. A few cases that are not directly computer related are included to illustrate the diversity of causes on which airline safety and reliability must depend. (Robert Dorsett has contributed details that were not in the referenced accounts.)
Lauda Air 767
A Lauda Air 767-300ER broke up over Thailand, apparently the result of a thrust reverser deploying in mid-air, killing 223. Of course, this event is supposed to be impossible in flight.31 Numerous other planes were suspected of flying with the same defect. The FAA ordered changes.
757 and 767 autopilots
Federal safety investigators have indicated that autopilots on 757 and 767 aircraft have engaged and disengaged on their own, causing the jets to change direction for no apparent reason, including 28 instances since 1985 among United Airlines aircraft. These problems have occurred despite the autopilots being triple-modular redundant systems.32
Northwest Airlines Flight 255
A Northwest Airlines DC-9-82 crashed over Detroit on August 17, 1987, killing 156. The flaps and the thrust computer indicator had not been set properly before takeoff. A computer-based warning system might have provided an alarm, but it was not powered up—apparently due to the failure of a $13 circuit breaker. Adding to those factors, there was bad weather, confusion over which runway to use, and failure to switch radio frequencies. The official report blamed “pilot error.” Subsequently, there were reports that pilots in other aircraft had disabled the warning system because of frequent false alarms.33
British Midland 737 crash
A British Midland Boeing 737-400 crashed at Kegworth in the United Kingdom, killing 47 and injuring 74 seriously. The right engine had been erroneously shut off in response to smoke and excessive vibration that was in reality due to a fan-blade failure in the left engine. The screen-based “glass cockpit” and the procedures for crew training were questioned. Cross-wiring, which was suspected—but not definitively confirmed—was subsequently detected in the warning systems of 30 similar aircraft.34
Aeromexico crash
An Aeromexico flight to Los Angeles International Airport collided with a private plane, killing 82 people on August 31, 1986 — 64 on the jet, 3 on the Piper PA-28, and at least 15 on the ground. This crash occurred in a government-restricted area in which the private plane was not authorized to fly. Apparently, the Piper was never noticed on radar (although there is evidence that it had appeared on the radar screen), because the air-traffic controller had been distracted by another private plane (a Grumman-Yankee) that had been in the same restricted area (SEN 11, 5). However, there were also reports that the Aeromexico pilot had not explicitly declared an emergency.
Collisions with private planes
The absence of technology can also be a problem, as in the case of a Metroliner that collided with a private plane that had no altitude transponder, on January 15, 1987, killing 10. Four days later, an Army turboprop collided with a private plane near Independence, Missouri. Both planes had altitude transponders, but controllers did not see the altitudes on their screens (SEN 12, 2).
Air France Airbus A320 crash
A fly-by-wire Airbus A320 crashed at the Habsheim airshow in the summer of 1988, killing 3 people and injuring 50. The final report indicates that the controls were functioning correctly, and blamed the pilots. However, there were earlier claims that the safety controls had been turned off for a low overflight. Dispute has continued to rage about the investigation. One pilot was convicted of libel by the French government for criticizing the computer systems (for criticizing “public works”), although he staunchly defends his innocence [6]. There were allegations that the flight-recorder data had been altered. (The flight recorder showed that the aircraft hit trees when the plane was at an altitude of 32 feet.) Regarding other A320 flights, there have been reports of altimeter glitches, sudden throttling and power changes, and steering problems during taxiing. Furthermore, pilots have complained that the A320 engines are generally slow to respond when commanded to full power.35
Indian Airlines Airbus A320 crash
An Indian Airlines Airbus A320 crashed 1000 feet short of the runway at Bangalore, killing 97 of the 146 passengers. Some similarities with the Habsheim crash were reported. Later reports said that the pilot was one of the airline’s most experienced and had received “excellent” ratings in his Airbus training. Airbus Industrie apparently sought to discredit the Indian Airlines’ pilots, whereas the airlines expressed serious apprehensions about the aircraft. The investigation finally blamed human error; the flight recorder indicated that the pilot had been training a new copilot (SEN 15, 2; 15, 3; 15, 5) and that an improper descent mode had been selected. The crew apparently ignored aural warnings.
French Air Inter Airbus A320 crash
A French Air Inter Airbus A320 crashed into Mont Sainte-Odile (at 2496 feet) on automatic landing approach to the Strasbourg airport on a flight from Lyon on January 20, 1992. There were 87 people killed and 9 survivors. A combination of human factors (the integration of the controller and the human-machine interface, and lack of pilot experience with the flightdeck equipment), technical factors (including altimeter failings), and somewhat marginal weather (subfreezing temperature and fog) was blamed. There was no warning alarm (RISKS 13, 05; SEN 17, 2; 18, 1, 23; 19, 2, 11).
Lufthansa Airbus A320 crash
A Lufthansa Airbus A320 overran the runway after landing at Warsaw Airport, killing a crew member and a passenger, and injuring 54 (70 people were aboard). There was a delay after the pilot attempted to actuate the spoilers and reverse thrust, apparently due to supposedly protective overrides in the safety system. Peter Ladkin suggested that this delay was most likely due to an improper requirements specification that prevented the pilot from taking the proper action. There was also a serious problem in the reporting of surface wind, which was given orally and which was updated only every 3 minutes. A strong tailwind existed, which had shifted by 120 degrees and doubled in speed since the previous report.36 Lufthansa later concluded there had been a problem with the braking logic, the fix to which was to change the recommended landing configuration (SEN 19, 2, 11).
Ilyushin II-114 crash
A prototype Ilyushin II-114 regional turboprop crashed on July 5, 1993, when the digital engine-control system inadvertently commanded one propeller to feather just after takeoff. The pilots could not compensate for the resultant yaw.37
Korean Airlines Flight 007 off-course
Korean Airlines 007 was shot down on September 1, 1983, as it was leaving Soviet airspace, about 360 miles off course; all 269 people aboard were killed. The most plausible explanation was that the autopilot was not switched to inertial navigation when the plane passed over the checkpoint on its heading 246 outbound from Anchorage. This explanation now seems to have been confirmed, based on the blackbox flight recorder that the Russians recovered and disclosed, and analysis of the limitations of the inertial navigation system—which has now been improved.38 There were reports that Arctic gales had knocked out key Soviet radars, and that Sakhalin air defense forces were trigger-happy following earlier U.S. Navy aircraft overflight incursions. There were also various contrary theories regarding intentional spying that took the plane over Sakhalin at the time of a planned Soviet missile test—which was scrubbed when the flight was detected.
Air New Zealand crash
On November 28, 1979, an Air New Zealand plane crashed into Mount Erebus in Antarctica, killing 257. A critical error in the on-line course data had been detected the day before, but had not been reported to the pilots of the excursion trip—which wound up many miles off course. Unfortunately, this was the first flight in that area under instrument controls (SEN 6, 3; 6, 5).
Autopilot malfunction breaks off two engines
A Boeing KC-135 had two engines break off during Desert Storm operations. An autopilot malfunction apparently put the plane into a roll that overstressed the airframe.39
Three engines failed on a DC-8
Responding to a discussion on the unlikeliness of two engines having failed (in connection with the British Midlands crash noted previously), a Transamerica Airlines pilot reported that three of the four engines of his DC-8/73 had failed simultaneously on a military flight to the Philippines. He was able to restart them during descent, but the fourth one failed after landing. The cause was attributed to the specific-gravity adjustments on the fuel controls having been set improperly for the fuel being used.40
Birds in flight
Birds colliding with an Ethiopian Airlines 737 were responsible for a crash that killed 31 people (SEN 14, 2).
Lightning strikes
A Boeing 707 at 5000 feet over Elkton, Maryland, was hit by lightning in 1963; a wing fuel tank exploded, killing all passengers (SEN 15, 1).
Traffic Collision Avoidance System (TCAS)
TCAS is a system intended to prevent mid-air collisions. There have been various problems, including the appearance of ghost aircraft41 and misdirected avoidance maneuvers. On February 3, 1994, two commercial planes came within 1 mile of each other over Portland, Oregon. Instead of moving apart, they apparently came closer to each other because of their reactions to the TCAS warning (SEN 19, 2, 12).
Communication outages that seriously affected air traffic
As noted in Section 2.1, telephone-system outages have resulted in air-traffic control system outages and major airport shutdowns—in Chicago, New York, San Diego, Kansas City (cable cuts), New York again (due to power problems), and Boston (due to a maintenance mistake that interchanged unmarked components). The FAA reported that, during a 12-month period in 1990 and 1991, there were 114 major telecommunications outages affecting air traffic, including 20 air-traffic control centers that were downed by a single fiber cable cut on May 4, 1991 (SEN 17, 1). There was an earlier problem in Aurora, Illinois, where a cable cut prevented radar data from reaching the air-traffic control (ATC) center, which resulted in several close calls (SEN 10, 5).
Other air-traffic control problems
We include here only a sampling of other items from the RISKS archives relating to air-traffic control problems. During the software-triggered AT&T long-distance telephone outage of January 15, 1990 (discussed in Section 2.1), air travel was essentially crippled (SEN 17, 1). The FAA has reported many other ATC center outages (for example, SEN 5, 3; 11, 5) and near-misses—some that were reported officially and others that were not (SEN 10, 3). Causes included lightning strikes, blown fuses, and computer problems (SEN 17, 1). There have been numerous reports of ghost aircraft on controller screens (for example, SEN 12, 4; 16, 3). In addition, a software bug brought down the Fremont, California, ATC Center for 2 hours on April 8, 1992; shortly afterward, on April 17, 1992, 12 of 50 of their radio frequencies stopped working, for unspecified reasons (SEN 17, 3). The installation of a new air-traffic control system in Canada was beset with frozen radar screens, jets appearing to fly backward, and blackouts of radar data (SEN 17, 4). There were earlier reports of flawed ATC radars, with planes mysteriously disappearing from the display screens (SEN 12, 1). O’Hare Airport in Chicago reported a near-miss of two American Airlines’ planes due to controller errors resulting from the assignment of an incorrect plane designator (SEN 12, 3). Two planes had a near-miss over Cleveland on August 24, 1991, due to a controller accidentally assigning the wrong frequency that blocked contact with one of the planes (SEN 16, 4). Delta and Continental planes missed colliding by about 30 feet on July 8, 1987; the Delta plane was 60 miles off course, reportedly because of a miskeyed navigation heading (similar to the KAL 007?), but also because previously recommended safety measures had been ignored (SEN 12, 4). There were also various reports of near-misses on the ground — for example, 497 in 1986 alone.42 In light of all these troubles, it is wonderful that air travel works as well as it does. On the other hand, most of us have experienced the long delays caused by the necessity of using manual or semiautomatic backup systems. The concept of fail-safe operation is clearly important here.
Air-traffic control impersonations
Two other cases are worth reporting, because they involved bypasses of the air-traffic control systems. A radio operator with a “bizarre sense of humor” masqueraded as an air-traffic controller using an approach channel for the Miami International Airport; he transmitted bogus instructions to pilots on at least two occasions, one triggering a premature descent (SEN 12, 1). Similar events occurred in Virginia, in 1994, when a phony controller referred to as the “Roanoake Phantom” instructed pilots to abort landings and to change altitudes and direction.
2.4.3 Summary of Aviation Problems
Table 2.4 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
Table 2.4 Summary of aviation problems
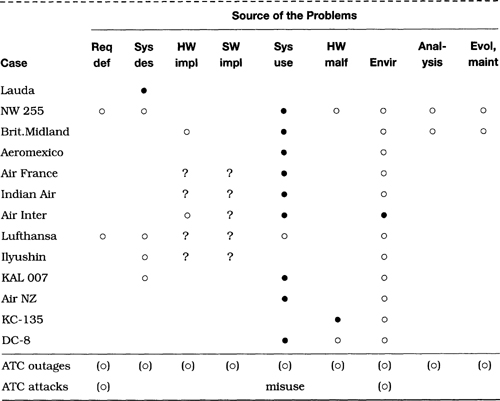
The table suggests that the pilots and their interactions with their environment are the predominant targets of blame attributed in the civil aviation problems included here. Hardware and software problems are also involved or suspected in several cases. In the A320 cases, for example, blame has been officially placed on the pilots; however, serious questions remain about the influence of software and interface problems. Unfortunately, there are cases in which examination of the flight recorders and subsequent investigations cannot resolve the residual ambiguities completely.
Any system whose design requires almost perfect performance on the part of its human operators and air-traffic controllers is clearly risky. The cases collected here suggest that there are still too many weak links, even in redundant systems, and that people are often the weakest link—even when they have had ample training and experience. Much greater effort is needed to make the systems more robust and less susceptible to failure, irrespective of the sources of difficulties (the systems, the people, or the environments). Air-traffic-control outages, birds, and lightning are not unusual events, and must be anticipated. Under normal conditions, however, flying commercial airlines is significantly safer per passenger mile than is driving on the highways and back roads.
2.5 Trains
Sic transit gloria mundi43
2.5.1 Transit Problems
Public transportation is a valuable cog in the mobility of a modern civilization, ideally reducing traffic congestion, pollution levels, and stress levels. A few cases illustrating the difficulties of maintaining reliable rail-transportation systems are noted in this section. Problems at sea are noted in Section 2.6. (Air travel is discussed in Section 2.4.)
Southern Pacific Cajon crash
A Southern Pacific potash unit train lost its brakes on May 11, 1989, while descending the Cajon Pass near San Bernardino in California. The train reached 90 miles per hour before jumping the track. Three people were killed, and eight were injured; 11 homes were destroyed. Apparently, the tonnage had been calculated incorrectly at 6150 instead of 8950, which resulted in an incorrect estimation of the effort required to brake. However, faulty dynamic brakes were later detected on the four lead engines and on one of the two pushers.44
Train wreck in Canada despite computer controls
In Canada, on February 8, 1986, an eastbound freight train had a head-on collision with a westbound transcontinental passenger train carrying about 120 people. Approximately 26 people were killed. Despite fail-safe computer safety controls (which worked correctly), the freight train had just left a parallel-track section and was 75 yards into the single-track section. Human operations were blamed.45
42 die in Japanese train crash under manual standby operation
In Japan, on May 14, 1991, a head-on collision of two trains killed 42 people and injured 415, 1.5 miles from a siding on which the trains were supposed to have passed each other. Hand signals were being used because of a malfunction in the automatic signaling system.46
Chinese train accident; failing safety systems not blamed
On November 15, 1991, in China, the express train Freedom rammed into the side of another express train that was switching to a siding in preparation for being passed; 30 people were killed, and more than 100 were injured. The subsequent investigation showed that Freedom’s driver was 1 minute early, and had mistakenly sped up in response to a signal to slow down. Freedom’s automatic warning system and automatic brakes were both known to be faulty before the accident, and yet were not blamed. Sloppy administrative practice was seemingly ignored by the report of the investigation.47
Head-on train collision in Berlin
At 2:23 P.M. on April 9, 1993 (Good Friday), an Intercity train leaving Berlin collided head-on with a train approaching Berlin just outside the city limits, near Wannsee. During the workweek, only one track was being used, while the other track was under construction to electrify this section of the tracks. Consequently, the trains were going only 30 kilometers per hour. However, on this day—a holiday—both tracks were supposedly in use. Unfortunately, the Fahrdienstleiter (the supervisor in charge of setting the switches and overseeing the signals) set the switch improperly—to one-way traffic (workday) instead of two-way traffic (holiday). The computer reacted properly by setting the outbound signal to halt. The supervisor believed that this event was a defect in the system, and overrode the signal by setting the temporary extra signal (which is for use precisely when the track is under construction) to proceed without telephoning anyone to investigate the supposed signal error. The supervisor overlooked the fact that a nonregularly scheduled train was approaching the switch, and believed that the track was free. Both engineers in the other train and a passenger were killed, and over 20 people were injured.48
London train crashes into dead end
One man was killed and 348 were injured when a packed rush-hour train ran into the end-of-track buffer at 5 miles per hour, at the Cannon Street Station in London on January 8, 1991. Blame was placed on brake failure and on the fact that the train equipment was 30 to 40 years old (SEN 16, 2).
Automatic London trains crash
Two Docklands Light Railway trains equipped for automatic control crashed on March 10, 1987, with one train hanging off the end of the track 30 feet above ground. The train that was crashed into had been running under manual control because of previous failures. There were no injuries. The blame was placed on “unauthorized tests” having been conducted prior to required modifications. (See SEN 12, 4; 16, 3.)
British Rail Clapham train crash due to loose wire
One commuter train plowed into the back of another on December 12, 1988, at Clapham Junction in south London, killing 35 and injuring almost 100. An earlier installation error was blamed, leaving a wire from an old switch that came into contact with the new electromagnetic signaling system. The fail-safe design had been expected to result in a red light in case of a short. The worker originally responsible for leaving the loose wire testified that he had worked for 12 hours on that day with only a 5-minute break.49
British Rail trains disappear; signaling software problem
Computer software problems in the British Rail signaling center at Wimbledon (controlling the Clapham Junction area) left operators “working blind” after train movements were wiped off control screens on at least one occasion. The problem was attributed to two different faults. Discovery of this problem led to all trains in the area being halted.50
London Underground tragedy: Man trapped in door
On February 3, 1991, a passenger attempting to get on a Northern Line Underground train to stay with his friends opened the door of a departing train by using a mechanism (“butterfly clasp”) normally used only in emergency circumstances. Use of the clasp triggers no alarms. The man’s arm was caught in the door and he was killed when his body hit the tunnel wall and was swept under the train (Peter Mellor, reporting in SEN 16, 2).
Another London Underground problem: Fail-safe doors stay open
On March 12, 1990, the double doors on a London Underground train remained open while the train traveled between four consecutive stations. The supposedly “fail-safe” door-control system failed, and the driver was given no indication that the doors were open.51
London Underground wrong-way train in rush hour
A confused driver drove an empty London Underground train northbound on south-bound tracks on the Piccadilly Line out of Kings Cross during the evening rush hour on March 12, 1990. Seeing the oncoming train, the driver of a stationary train with 800 passengers managed to reach out and manually short the circuit, thereby averting the crash. New warning lights have now been added.52
London Underground train leaves station without its driver
On April 10, 1990, an Underground train driver broke the golden rule of never leaving the cab of a fully automated train; he was checking a door that had failed to close properly. The door finally shut, and the train automatically took off without him — although there was no one to open the doors at the next station. (He took the next train.) As it turned out, the driver had taped down the button that started the train, relying instead on the interlock that prevented the train from starting when the doors were open. Indeed, the risks of this shortcut were probably not evident to him.53
A very similar event was reported on December 2, 1993, when a driver improperly left his Picadilly Line train when the doors did not close. The train took off with 150 passengers, and went through the Caledonian Road station without stopping. The train finally stopped automatically at a red light, and was boarded by personnel following in the next train. (Martyn Thomas, SEN 19, 2, 2).
Autumn leaves British Rail with signal failure
British Rail installed a new Integrated Electronic Control Centre (ICC), with three independent safety systems, intended to overcome problems with the old electromechanical processes. Unfortunately, the ICC worked properly only when the tracks were clear of debris. This fault mode was discovered in November 1991, during the system’s first autumn, when leaves formed an insulating paste that prevented the wheels from making contact with sensors, causing the trains to disappear from the computer system. The problem was created by external clutch brakes having been replaced with disc brakes, which make less contact with the tracks. The temporary fix was to have each train include one car with the old brakes.54
Removal of train’s dead-man switch leads to new crash cause
Four standing train engines rolled downhill for about 25 miles, with top speed of 75 miles per hour, crashing into a parked train. The engineer had fallen from the train and lost consciousness. The intelligent-system electrical replacements for the old dead-man’s switch failed, apparently because they were designed to work only when there was an engineer on board.55
British Rail Severn Tunnel crash under backup controls
Subsequent to earlier problems with the signals that caused control to revert to a backup system on December 7, 1991, a British Rail train went through the Severn Tunnel at a slow pace (20 miles per hour), after having received a proceed-with-caution signal. The train was struck by another train running behind it at higher speed. The question of what kind of a signal the second train had received was not answered.56
Bay Area Rapid Transit: Murphy rides the rails
On November 20, 1980, the San Francisco BART system had a terrible day. Six different trains experienced serious malfunctions within a few hours. These problems were, in order, (1) doors that would not close, (2) failure of automatic controls, (3) brake failure on a train that then got stuck in a switch en route to the yards, (4) another brake failure, (5) smoking brakes, and (6) overheated brakes. During the same period, the controlling computer crashed, grinding the entire network to a halt for almost ½ hour, while waiting for cutover to the backup system. The morning rush hour on December 8, 1980, saw another set of problems. Both the main computer and the backup failed, and lights went out in the control center (apparently due to a faulty power supply) (SEN 6, 1). Early in BART’s life, there were reports of doors automatically opening in the middle of the cross-bay tunnel, because the station-to-station distance on that leg was longer than had been programmed into the control system (noted by Bill Park, in SEN 8, 5).
BART power outage; breakers break in Bay-to-Breakers
On May 17, 1987, BART had a power failure in which 17 switches kicked open in the rush to get runners to the Bay-to-Breakers race. A train was stalled in a tunnel beneath 7th Street in Oakland, and 150 passengers had to walk for 20 minutes to get out. Engineers could not identify the cause and were unable to restore power in the computer-controlled system. Five hours later, the switches suddenly closed again, just as mysteriously as they had opened (SEN 12, 3). On July 7, 1987, BART finally announced that the cause had been identified — a faulty switch and a short circuit caused by the use of a battery charger.57
San Francisco Muni Metro ghost trains
The San Francisco Muni Metro under Market Street was plagued with gremlins for many years, including a ghost-train problem in which the signaling system insisted that there was a train outside the Embarcadero Station blocking a switch. Although there was no such train, operations had to be carried on manually—resulting in increasing delays until finally passengers were advised to stay above ground. This situation lasted for almost 2 hours during the morning rush hour on May 23, 1983, at which point the nonexistent train vanished as mysteriously as it had appeared in the first place. (The usual collection of mechanical problems also has been reported, including brakes catching fire, brakes locking, sundry coupling problems, and sticky switches. There is also one particular switch, the frog switch, that chronically causes troubles, and unfortunately it is a weakest-link single point of failure that prevents crossover at the end of the line.) (See SEN 9, 3.) On December 9, 1986, the ghost-train problem reappeared, again involving the Embarcadero station from 6 A.M. until 8:14 A.M. On the very same day, BART had another horrible series of problems; “doors, signals, switches, brakes, and even a speedometer broke.”58
Muni Metro crash; operator disconnected safety controls
On April 6, 1993, a San Francisco Municipal Railway car was headed for the car barns when it crashed into the rear of another car that had stalled in the Twin Peaks Tunnel. Fifteen people were hospitalized. The investigation showed that the operator had disabled the safety controls, permitting him to run the car faster than the control limits dictated.59
Water seepage stops computer-controlled monorail
In August 1988, water seeped into the programmable-logic controller of Sydney’s new automated monorail and halted the system. One breakdown trapped dozens of passengers in a sealed environment for over 2 hours.60
Roller-coaster accidents blamed on computers
At Worlds of Fun in Kansas City, Missouri, one train rear-ended another on the season’s opening day, March 31, 1990, on the 1-year-old computer-controlled roller coaster, Timber Wolf; 28 people were injured. The fix was to run with only one train until new sensors and redundant controls could be installed.61
A remarkably similar accident occurred on July 18, 1993, at Pennsylvania’s Dorney Park. An occupied train on the Hercules roller coaster ran into an empty train outside the loading platform, injuring 14 passengers. The trains operate with no brakes for the 1-minute, 50-second ride; once they leave the station, they are free-wheeling (except when being towed uphill). A faulty sensor was blamed, which was supposed to detect the train leaving the station, which in turn would enable the computer system to release the restraints on the empty train so that it could move into the loading area. The temporary fix was to run with only one train, until three new safety measures could be added: a backup sensor, where the first one failed; a control-panel modification that displays all trains on the track; and a manually deployable brake on each train. Strangely, the sensor that failed was the only one that did not have a backup.62 Gary Wright observed that Timber Wolf and Hercules were both built in 1989 and designed by the same firm, Curtis D. Summers, Inc. The same construction company may have been used as well.
Section 5.5 notes another roller-coaster crash in which 42 people were killed, attributed to electromagnetic interference.
2.5.2 Summary of Train Problems
Table 2.5 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
Table 2.5 Summary of railroad problems
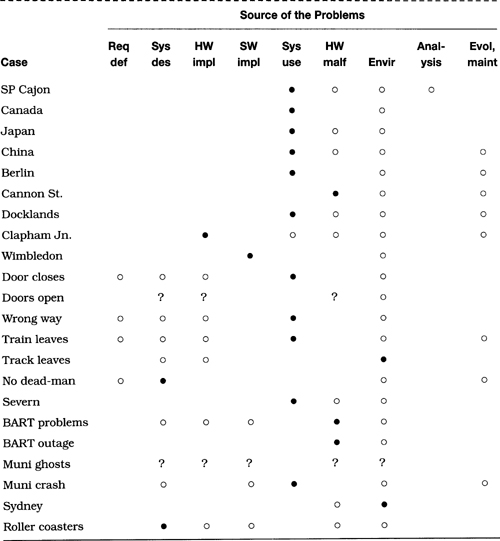
Operational problems predominate, including several in handling single-track sections and sidings. Quite a few cases are attributed to operator mistakes. However, there are also system-design problems (as in the roller-coaster crashes) and equipment problems (brake failures in the Cajon Pass, Cannon Street, and BART cases). Software was a critical factor in the Wimbledon signaling center screen vanishings. As usual, there are also a few cases in which the cause is not clear, even after detailed analysis. For example, whoo (!) knows what caused the Muni Metro ghost trains? Gremlins?
2.6 Ships
Whereas trains tend to operate in a one-dimensional environment (except at switches and crossings, where many problems occur), and planes tend to operate in a three-dimensional environment, ships for the most part operate in a two-dimensional space — except for swells and sinking. Nevertheless, many of the types of control problems experienced with trains and planes also appear in ship control.
2.6.1 Ship Problems
Here are a few examples of problems with ships.
Tempest Puget, or The Sound and the Ferries
In the 1980s, there were at least a dozen dock crashes in the Puget Sound ferry system (the largest such system in the United States) that were attributable to on-board computer failures. The damages for one crash alone (September 12, 1986) cost an estimated $750,000 in repairs to the Whidbey Island dock. The $17 million mid-sized Issaquah ferries (100 cars, 1200 passengers) came on board in 1980 with the slogan “Computerized propeller systems make the ferries more fuel efficient.” The state sued the ferry builder (the now bankrupt Marine Power & Equipment of Seattle), which agreed to pay $7 million over 10 years. The state’s recommendation was to spend an extra $3 million cutting the six ferries over to manual controls.63
It may seem disappointing that the fix was to bypass the computer systems rather than to make them work. Nevertheless, accepting reality is clearly a good idea. Although they did not have a gift horse in whose mouth to look, perhaps Seattle still believes in the truth ferry.
The QE2 hits a shoal
In August 1992, the ocean liner Queen Elizabeth 2 had its hull damaged while cruising off the island of Cuttyhunk, not far from Martha’s Vineyard, Massachusetts. The nautical charts had not been updated since they were made in 1939, and showed a shoal at 39 feet in the midst of deeper waters. The ship’s draw was supposedly 32 feet, although it was reported in the Vineyard Gazette that the ship may have been traveling faster than normal, which would have increased its draw. The entire area has been known as a dangerous one for ships for centuries. Nevertheless, the QE2 was in a standard navigation channel, heading for New York. Felicity Barringer in The New York Times noted that “at least two of the ship’s three electronic navigational systems were operating at the time” of the accident. Divers later found the rocks and paint chips from the QE2. What is the technology connection? Reliance on old data? Inability of the detection equipment? Failure of technology by itself was not the cause. The pilot was a local-area expert.64
Exxon Valdez
The Exxon Valdez accident in early April 1989 was apparently the result of an erroneous autopilot setting and human negligence. The crash onto Bligh Reef and subsequent oil spill (the worst in U.S. history) were blamed alternatively on the captain (who was absent and allegedly drunk), the third mate, the helmsman, and the “system” — Exxon’s bottom line. Further assessment of the blame is considered in Section 8.2. (See SEN 14, 5.)
Sensitive coral reef ruined by reverse-logic steering?
Zdravko Beran, the captain of a ship that ran aground in 1989 on an environmentally sensitive live coral reef off the Fort Jefferson National Monument in Florida, attributed the accident to a confused officer and to a bad user interface. Apparently, an officer, Zvonko Baric, incorrectly changed course because the steering mechanism on the ship operated in the opposite fashion from most such controls. Irrespective of whether the control system was computer based, this case demonstrates dramatically the potential dangers of inconsistent or nonstandard user interfaces (contributed by Jim Helman, in SEN 15, 1).
Submarine sinks the trawler Antares
Four Scottish fishermen were killed when a submarine hit a Scottish trawler, Antares, in the Firth of Clyde. The submarine commander claimed that the submarine’s computer had indicated a 3-mile separation between the vessels.65
Ship lists despite computer-controlled ballast tanks
The Dona Karen Marie, a fish-processing ship lying in a Seattle drydock, was listing toward port on August 4, 1992, until an engineer came to attempt to correct the problem. His adjustment resulted in the ship leveling, and then listing to starboard. A problem in the computer control of the ballast tanks was blamed.66
2.6.2 Summary of Ship Problems
Table 2.6 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
Table 2.6 Summary of ship problems

Again, the cases considered exhibit considerable diversity of causes and effects. Operator problems are evident in the Exxon Valdez and coral-reef cases, although in the latter case the system interface contributed. System design and implementation issues were clearly implicated in the Puget Sound ferry problems. In the majority of cited cases, uncertainties remain as to the exact nature of the causes (as indicated by the proliferation of question marks in the table).
2.7 Control-System Safety
This section considers various problems in computer-related control systems used in specific applications, such as chemical processes, elevators, retractable stadium domes, and drawbridges. In many of these cases, the requirements for reliability and safety failed to be met. Closely related cases involving robotic systems are considered separately in Section 2.8.
2.7.1 Chemical Processes
Various problems in chemical plants have involved computers.
Union Carbide: I thought you told me that could not happen here!
After the December 3, 1984, chemical leak of methyl isocyanate that killed at least 2000 people at a Union Carbide plant in Bhopal, India, various spokespeople for Union Carbide said it could not possibly happen at the sister plant in South Charleston, West Virginia. On March 7, 1985, the West Virginia plant had a leak of 5700 pounds of a mixture that included about 100 pounds of poisonous mesityl oxide, a bigger leak than had ever occurred previously at that plant (there were no deaths). Although neither Bhopal nor the West Virginia case was computer related, both illustrate a common head-in-the-sand problem, sometimes also known as “nothing can go wrong [click] go wrong [click] go wrong . . . .”
Union Carbide: Another toxic leak due to a database problem
In August 1985, another Union Carbide leak (causing 135 injuries) resulted from a computer program that was not yet programmed to recognize aldicarb oxime, compounded by human error when the operator misinterpreted the results of the program to imply the presence of methyl isocyanate (as in Bhopal). A 20-minute delay in notifying the county emergency authorities exacerbated the problem.67
British watchdog systems bark their shins
Watchdog equipment is often used to monitor chemical plants for the occurrence of undesirable events. Two cases are identified here, and numbered for reference in Table 2.7 at the end of the section.
1. In one case, a failure in the watchdog circuitry caused valves to be opened at the wrong time; several tons of hot liquid were spilled.68
2. In another case, a pump and pipelines were used for different purposes in handling methanol, but switching from one mode to another resulted in spillage. Apparently, the watchdog was not designed to monitor mode switching.69
Table 2.7 Summary of control-system problems
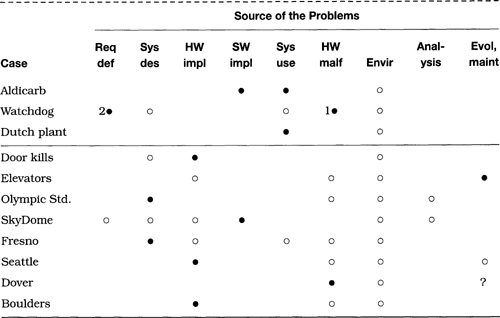
Dutch chemical plant explodes due to typing error
At a Dutch chemical factory, a heavy explosion caused the death of 3 firefighters of the factory fire brigade, and injured 11 workers, including 4 firefighters. The severe damage was estimated at several tens of millions NL guilders; fragments from the explosion were found at a distance of 1 kilometer. The accident was the result of a typing error made by a laboratory worker in preparing a recipe. Instead of tank 632, he typed tank 634. Tank 632 contained resin feed classic (UN-1268), normally used in the batch process. Tank 634 contained dicyclopentadiene (DCDP). The operator, employed for only 3 months and still in training, forgot to check whether the tank contents were consistent with the recipe, and thus filled the reactor with the wrong chemicals. The fire brigade was called by an overheat alarm before the explosion, but was apparently unprepared for the particular chemical reaction. In court, a judge ruled that the management of the company had paid insufficient attention to safety, and the company was fined 220,000 NL Guilders.70
2.7.2 Openings and Closings, Ups and Downs
The next group of cases involves doors, elevators, roofs, drawbridges, and other entities controlled by computer.
Computer-room door kills woman
A South African woman was killed on December 27, 1988, in a freak computer-room accident. The death occurred when 1.5-ton steel doors closed on the woman as she stood in their path but out of sight of optical sensors intended to detect obstructions. The accident took place at the computer facilities of Liberty Life in Johannesburg as the 23-year-old woman was handing a document to a colleague in the course of her employment.71
Elevator deaths in Ottawa
On April 1, 1989, a 13-year-old girl was killed by the doors of an Ottawa elevator (which had been serviced just hours before). At the end of May 1989, another person was killed after having been caught in the doors while entering the elevator (again serviced just hours before) and being dragged along. Both problems were apparently due to a flaw in the interlock circuits that permitted the elevator to move with only one door closed. Subsequent investigation showed that the flaw had been reported by the manufacturer (Otis) in 1978, along with a one-wire fix. The building then changed ownership in 1980, the maintenance company changed in 1988, and the fix was never installed — until after the second accident. Furthermore, no maintenance records were kept.72
Olympic stadium roof tears
The roof of the Olympic Stadium in Montreal developed tears during different tests of the automatic retracting and closing mechanism, one case occurring on September 8, 1989. In another case, a faulty winch apparently placed uneven tension on the roof. The roof was 12 years late, and its cost all by itself reportedly was equal to that of a completely covered stadium.73
SkyDome, Release 0.0
In summer 1989, the 54,000-seat Toronto Sky-Dome became the world’s largest stadium with a retractable roof using rigid segments. (Melbourne already had a similar one, seating only 15,000.) However, the roof was able to operate at only one-third speed, taking 1 hour to open, because the computer programs to work it were not ready.74 Michael Wagner reported that an architect client of his claimed that the stress from repeated openings and closings had been seriously miscalculated, and that three or four times a year would be possible, rather than the estimated 30 or 40, as otherwise the system would be overly stressed. (The problems now seem to have been largely overcome.)
Computer glitch causes Fresno water mains to rupture
A computer-based system controlling 106 water pumps and wells and 877 miles of pipes in Fresno, California, crashed three times within 1.5 hours on November 14, 1988. The malfunction was attributed to a burglar alarm in one of the pumps that sent confusing signals to the computer system, temporarily shutting down the pumps. The automatic restart that shifted to manual control sent water pressure levels up to 75 pounds per square inch (instead of 40 to 45) through the pipes, rupturing water mains (particularly the older ones) and damaging 50 residential plumbing systems. It also triggered 24 automatic fire alarms. The manual default settings were apparently improper.75
Drawbridge opens without warning in rush-hour traffic
The Evergreen Point Floating Bridge in Seattle opened unexpectedly on December 22, 1989. Cars crashed into the rising span, killing one driver and injuring five others in the morning rush hour. Subsequent analysis discovered a screw driven into one wire and a short in another wire. The two shorted wires, one on the east drawspan and one on the west drawspan, combined to send current around safety systems and to lift the west section of the drawspan.76
Drawbridge controls halt traffic
The computer that controls the Route 37 drawbridge in Dover, Delaware, failed on August 29, 1992, preventing the barrier gates from reopening for 1 hour on a hot afternoon. The manual controls to override the computer system also did not work.77
Bit-dropping causes boulder-dropping
A cement factory had a state-of-the-art 8080-based process-control system controlling the conveyors and the rock crusher used in making cement. Apparently defective MOSTEK RAM (random-access memory) chips tended to drop bits (in the absence of error-detecting or -correcting codes), which on this occasion caused the second of a series of three conveyors to switch off, which in turn stacked up a large pile of boulders (about 6 to 8 feet in diameter) at the top of the conveyor (about 80 feet up) until they fell off, crushing several cars in the parking lot and damaging a building.78
2.7.3 Summary of Control-System Problems
Table 2.7 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
In these cases, the primary causes are quite diverse, with all but two columns of the table represented by at least one case (•). Human errors played a smaller role than did system problems (including both hardware and software), in both design and implementation. Not surprisingly, the physical environment contributed in every case, as a secondary cause.
2.8 Robotics and Safety
We introduce this section by considering Asimov’s Laws of Robotics. Most of Isaac Asimov’s robot-related science fiction observes his Three Laws of Robotics [4]. His final novel [5] adds a Zeroth Law, to establish a precedence over the other laws. The four laws are as follows, in their presumed order, and adapted for consistency (by means of the parenthesized emendations that presumably would have been specified by Asimov had he made the prepending of the Zeroth Law explicit).
• Law 0. A robot may not harm humanity as a whole.
• Law 1. A robot may not injure a human being or, through inaction, allow a human being to come to harm (except where it would conflict with the Zeroth Law).
• Law 2. A robot must obey the orders given it by human beings, except where such orders conflict with (the Zeroth Law or) the First Law.
• Law 3. A robot must protect its own existence unless such protection conflicts with (the Zeroth Law or) the First or Second Law.
Asimov’s Laws of Robotics serve well as an aid in writing science fiction (see The Robots of Dawn); they also provide a first approximation (albeit simplistic) of a set of requirements for designers of robotic systems. Thus, for example, the First Law would force greater attention to be paid to fail-safe mechanisms.
2.8.1 Robotic Safety
Robots are finding increasingly wide use. Here are a few cases in which human safety was an issue and robots did not live up to expectations.
Death in Japan caused by industrial robot
A worker was killed by an industrial robot on July 4, 1981, in the Kawasaki Heavy Industries plant in Hyogo, Japan. The robot was designed by Unimation in Connecticut, and was manufactured under a licensing arrangement by Kawasaki. Kenji Urata “was pinned by the robot’s claw against a machine for processing automobile gears after entering an off-limits area to repair an[other] apparently malfunctioning robot.” Opening a fence surrounding the robot would have shut off its power supply, but instead the worker jumped over the fence and set the machine on manual control. One report79 implied that the man was actually pinned by the second robot, which was delivering parts for the production-line activity. Subsequent reports noted possibly as many as 19 more robot-related deaths in Japan (SEN 11, 1), six of which were later suspected of being triggered by stray electromagnetic interference affecting the robots (SEN 12, 3).
Death in Michigan caused by robot
The national Centers for Disease Control in Atlanta reported “the first documented case of a robot-related fatality in the United States.” Working in a restricted area with automated die-casting machinery on July 21, 1984, a Michigan man was pinned between the back end of a robot and a steel pole. He suffered cardiac arrest and died 5 days later.80
Risks of automated guided vehicles: ALCOA worker killed
A 24-year-old Madisonville, Tennessee, electrician employed by ALCOA died on September 8, 1990, at the University of Texas Hospital following an accident at ALCOA’s North Plant. He had been working on an overhead crane that was not operating when the crane’s tray grab (the part that hangs down and lifts trays of coils of aluminum sheet) was struck by the top of a coil being transported at ground level by an automated guided vehicle. The impact caused the crane to move toward him, and he was crushed between an access platform on the crane and the personnel lift he had used to reach the crane.81
Roboflops
Ron Cain noted two close calls in his welding lab. In one case, an error in a 68000 processor caused an extraneous transfer to a robot move routine, accidentally destroying a small jack. In another, some drive-motor cards in a Cincinnati-Milacron unit failed, causing two robot joints to jerk wildly. In each case, manual use of the kill button was able to stop the action. Ron added that these cases were “worth keeping in mind the next time you stand near a robot.”82
Robotic waiter runs amok
In Edinburgh, Scotland, a robot was dressed in a black hat and bow tie, supposedly helping to serve wine in a restaurant. During its first hour on the job, it knocked over furniture, frightened customers, and spilled a glass of wine. Eventually its head fell into a customer’s lap. When it appeared in court the next day (responding to unspecified charges—presumably disturbing the peace), it was still out of control.83
Robotic aide stumbles at Stanford Hospital
At Stanford University Hospital, Cookie, one of three robots (the other two are Flash and Maxwell) designed to help deliver patients’ meals, X-ray films, equipment, and documents, veered off course (after performing its meal delivery), and fell down a set of stairs. The cause of the malfunction was not specified. The robots are no longer delivering food to patients, because the food was too often cold by the time it arrived.84
Rambling robot disrupts NBC evening news broadcast
On a Saturday evening, while anchoring a weekend news program, Connie Chung was reading an urgent story about the Middle East. Suddenly, she began to disappear from the screen as the camera moved away from her and ran into the stage manager. The usual camera operators had been replaced by a robotic camera crew in an NBC cost-cutting move (three robots at a cost of “less than $1 million together”).85
Budd Company robot accidentally dissolves its own electronics
A Budd Company assembly robot was programmed to apply a complex bead of fluid adhesive, but the robot “ignored the glue, picked up a fistful of highly active solvent, and shot itself in its electronics-packed chest.” Its electronics were disabled.86
Tempo AnDante? No, not moving at all
A robot (Dante) descending for exploration inside the Mount Erebus volcano had its fiber-optic control cable snap only 21 feet from the top of the volcano, immobilizing the robot.87 A new effort by a team at Carnegie-Mellon University is underway to have Dante descend into the Mount Spurr Volcano in Alaska, using wireless communications.88
2.8.2 Summary of Robotic Problems
Table 2.8 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.) Numerous questions remain unanswered at this time.
Table 2.8 Summary of robotics-system problems
Hardware malfunction occurred in several cases, suggesting that inadequate attention was paid to fault tolerance. In other cases, some sort of system problem was evident, but whether it was in hardware or software is not known.
2.9 Medical Health and Safety
Microprocessors, minicomputers, and large-scale computers are increasingly being used in medical applications. Various computer-related accidents related to medical and health issues are considered here.
2.9.1 Therac-25
The most prominently reported risk-related cases in medical electronics were undoubtedly those involving the Therac-25, a computer-based electron-accelerator radiation-therapy system. The Therac-25 was involved in six known accidents, including three deaths directly attributable to radiation overdoses (with one additional death presumably from terminal cancer rather than radiation).
This section is based on a thorough investigation of the Therac-25 by Nancy Leveson and Clark Turner [83]. Their study took several years of detective work and analysis of a mass of documentation. Their results are particularly important, because many of the previous media accounts and papers have been incomplete, misleading, or just plain wrong.
Eleven Therac-25 systems were installed, five in the United States, six in Canada. Six accidents involved massive overdoses between 1985 and 1987, when the machines were finally recalled:
• Marietta, Georgia, June 3, 1985. A 61-year-old woman received severe radiation burns from 15,000 to 20,000 rads (whereas the normal dose was 200 rads). She lost shoulder and arm functionality. Breast removal was required because of the burns.
• Hamilton, Ontario, Canada, July 26, 1985. A 40-year-old woman received between 13,000 and 17,000 rads in treatment of cervical cancer, and would have required a hip replacement as a result of the overdose—except that she died of cancer on November 3, 1985.
• Yakima, Washington, December 1985. A woman received an overdose that caused erythema (abnormal redness) on her right hip.
• Tyler, Texas, March 21, 1986. A man received between 16,500 and 25,000 rads in less than 1 second, over an area of about 1 centimeter. He lost the use of his left arm, and died from complications of the overdose 5 months later.
• Tyler, Texas, April 11, 1986. A man received at least 4000 rads in the right temporal lobe of his brain. The patient died on May 1, 1986, as a result of the overdose.
• Yakima, Washington, January 1987. A patient received somewhere between 8000 and 10,000 rads (instead of the prescribed 86 rads). The patient died in April 1987 from complications of the overdose.
Blame was placed at various times on operator error, software failure, and poor interface design. The identification of the software and interface problems was a harrowing process, particularly because tests after each accident indicated that nothing was wrong. In particular, three flaws were identified. One was the ability of the operator to edit a command line to change the state of the machine such that the execution of the radiation commands took place before the machine state had been completely changed (that is, to low-intensity operation). The second flaw involved the safety checks inadvertently being bypassed whenever a particular 6-bit program counter reached zero (once every 64 times). The third problem was that certain hardware safety interlocks in the Therac-20 (which was not computer controlled) had been removed from the Therac-25, because those interlocks were supposed to be done in software.
The detailed analysis of Leveson and Turner is quite revealing. A quote from the end of [83] is appropriate here:
Most previous accounts of the Therac-25 accidents have blamed them on software error and stopped there. This is not very useful and, in fact, can be misleading and dangerous: If we are to prevent such accidents in the future, we must dig deeper. Most accidents involving complex technology are caused by a combination of organizational, managerial, technical and, sometimes, sociological or political factors; preventing accidents requires paying attention to all the root causes, not just the precipitating event in a particular circumstance.
Accidents are unlikely to occur in exactly the same way again. If we patch only the symptoms and ignore the deeper underlying causes or we fix only the specific cause of one accident, we are unlikely to have much effect on future accidents. The series of accidents involving the Therac-25 is a good example of exactly this problem: Fixing each individual software flaw as it was found did not solve the safety problems of the device. Virtually all complex software will behave in an unexpected or undesired fashion under some conditions (there will always be another software ‘bug’). Instead, accidents need to be understood with respect to the complex factors involved and changes made to eliminate or reduce the underlying root causes and contributing factors that increase the likelihood of resulting loss associated with accidents.
Although these particular accidents occurred in software controlling medical devices, the lessons to be learned apply to all types of systems where computers are controlling dangerous devices. In our experience, the same types of mistakes are being made in nonmedical systems. We must learn from our mistakes so that they are not repeated.
These conclusions are relevant throughout this book.
2.9.2 Other Medical Health Problems
The Therac-25 is the most widely known of the computer-related medical problems. However, several others are noteworthy.
Zaragoza overdoses
The Sagitar-35 linear accelerator in the hospital in Zaragoza, Spain, may have exposed as many as 24 patients to serious radiation overdoses over a period of 10 days. At least 3 people died from the excessive radiation. Apparently, this machine has no computer control, but was left in a faulty state following repair of an earlier fault (SEN 16, 2).
North Staffordshire underdoses
Nearly 1000 cancer patients in the United Kingdom were given radiation doses between 10 percent and 30 percent less than prescribed over a period of 10 years. The error was attributed to a physicist who introduced an unnecessary correction factor when the planning computer was originally installed in 1982 (SEN 17, 2).
Plug-compatible electrocutions
A 4-year-old girl was electrocuted when a nurse accidentally plugged the heart-monitoring line into an electrical outlet at Children’s Hospital in Seattle, Washington (Associated Press, December 4, 1986; SEN 12, 1). Seven years later, the same problem recurred. A 12-day-old baby in a Chicago hospital was electrocuted when the heart-monitor cables attached to electrodes on his chest were plugged directly into a power source instead of into the heart-monitor system.89 (See Challenge 2.1.)
Risks in pacemakers
Three cases are considered here and numbered for reference in Table 2.9 at the end of the section. (1) A 62-year-old man “being treated for arthritis with microwave heating died abruptly during the treatment. Interference from the therapeutic microwaves had reset his pacemaker, driving his already injured heart to beat 214 times a minute. It couldn’t do it.”90 (2) Another man died when his pacemaker was reset by a retail-store antitheft device (SEN 10, 2). (3) In a third case, a doctor accidentally set a patient’s pacemaker into an inoperative state while attempting to reset it (see SEN 11, 1, 9, reported by Nancy Leveson from a discussion with someone at the Food and Drug Administration).91
Table 2.9 Summary of health and safety problems

Defibrillators
Doctors were warned about surgically implanted cardioverter-defibrillators that can be deactivated by strong magnets such as are found in stereo speakers (SEN 14, 5).
Other interference problems
There was a report of a hospital in London where alarms were repeatedly triggered by walkie-talkies operating in the police band (440 to 470 MHz). At another hospital, a respirator failed because of interference from a portable radio (SEN 14, 6). Further problems involving interference are considered in Section 5.5.
Side effects of radiation and environmental contamination
Electromagnetic radiation from various sources, including video display terminals (VDTs), has long been considered a potential source of health-related problems.92 Dermatological problems have been associated with VDT use, including rosacea, acne, seborrheic dermatitis, and poikiloderma of Civatte. (See SEN 13, 4 for references.) Deterioration of eye focusing is reported (SEN 13, 4). Higher miscarriage rates among women working in computer-chip manufacturing have been noted (SEN 12, 2).
Other health risks of using computers
Various stress-related problems are associated with computer use, including carpal tunnel syndrome and ulnar nerve syndrome, as well as stress resulting from increased noise, apparently especially noticeable in women (SEN 15, 5). There was also a report of a Digital Equipment Corporation DEC 11/45 computer falling on a man’s foot (Anthony A. Datri in SEN 12, 4).
Risks in medical databases
A woman in Düsseldorf, Germany, told the court that she had been erroneously informed that her test results showed she had incurable syphillis and had passed it on to her daughter and son. As a result, she strangled her 15-year-old daughter and attempted to kill her son and herself. She was acquitted. The insurance company said the medical information had been based on a computer error—which could have been a lame excuse for human error!93
Software developed by Family Practitioner Services in Exeter, England, failed to identify high-risk groups of women being screened for cervical and breast cancer.94
Other automated hospital aids
Walter Reed Army Medical Center reportedly spent $1.6 billion on a new computer system intended to streamline its health-care delivery. That system apparently bungled pharmacy orders, patient-care records, and doctors’ orders. There were complaints that the access to narcotics was not properly controlled. In addition, doctors complained that their workloads had increased dramatically because of the computer system (SEN 17, 3).95
A physician reported that a 99-year-old man in the emergency room had a highly abnormal white-blood-cell count, which the computer reported to be within normal limits. The computer was reporting values for a infant child, having figured that the year of birth, entered as 89, was 1989, not 1889.96
London Ambulance Service
As many as 20 deaths may be attributable to the London Ambulance Service’s inability to dispatch ambulances in response to emergencies. After severe difficulties in system development, including repeated test failures, the system was finally placed in operation. The system then collapsed completely, including worst-case delays of 11 hours. “An overcomplicated system and incomplete training for control staff and ambulance crews are the likely causes of the collapse of London’s computerised ambulance dispatch service . . . . One software company says that the London Ambulance Service (LAS) underestimated the pressure placed on staff at the control center, and that it makes working there like a wartime action room.’”97
Emergency dispatch problems
Numerous problems with emergency telephone lines have been reported, including the death of a 5-year-old boy due to the failure of the 911 computer-terminal operator in San Francisco (SEN 12, 2), and the death of a man because the system truncated the last digit in his street number. A woman in Norfolk, Virginia, died while waiting over ½ hour for an ambulance to be dispatched; the delay was blamed on the software developer’s failure to install a message-tracking program (SEN 16, 1). In Chicago, a computer program rejected the calling telephone number at its correct address because the address of the previous possessor of that telephone number was also listed. Two people died in the fire (SEN 17, 1).
2.9.3 Summary of Medical Health Problems
Table 2.9 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
System use was implicated in one way or another in each of these cases. In the Therac-25 accidents, it is clear that a range of factors contributed, including various system problems. The argument has been made that the people who died or were injured because of excessive radiation were terminally ill patients anyway, so the failure was not really that important. However, that argument should never be used to justify bad software practice and poorly designed system interfaces.
The first electrocution caused by a heart-monitoring device was the result of a bad mistake. The second similar electrocution is certainly disheartening, indicating a serious lack of awareness. (See Challenge C2.1 at the end of the chapter.)
The pacemaker problems are typical of both repetitiveness and diversity within a single type of device. The first case involved electromagnetic interference from a therapy device within the purview of the medical facility. The second case involved interference from an antitheft device, with no warning of potential effects. However, the basic problem was the same—namely, that pacemakers may be affected by interference. The third case resulted from a doctor’s mistake using an interface that was not fail-safe. The three cases together suggest that these devices deserve greater care in development and operation.98
2.10 Electrical Power
This section considers difficulties in power systems, both nuclear and conventional. The causes and effects both vary widely.
2.10.1 Nuclear Power
Nuclear-power systems require exceedingly critical reliability to maintain stability. Computer systems are being used in various automatic shutdown systems—for example, by Ontario Hydro—and in control systems as well. Nevertheless, the nuclear-power industry could make better use of computers — at least in reporting and analysis of status information—in avoiding problems such as those noted here.
Early nuclear-power problems
To indicate the extent of nuclear-power problems, we give here a terse chronology of the more significant early nuclear-power accidents.99
• December 2, 1952, Chalk River, Canada. One million gallons of radioactive water built up, and took 6 months to clean up. Human error was blamed.
• November 1955, EBR-1 experimental breeder, Idaho Falls. A misshapen-rod mishap was blamed on human error.
• October 7 to 10, 1957, Windscale Pile 1, on the English coast of the Irish Sea. This case was at the time the largest known release of radioactive gases (20,000 curies of iodine). Fire broke out. One-half million gallons of milk had to be destroyed. The plant was permanently shut down.
• Winter 1957-58, Kyshtym, USSR. Radiation contamination ranged over a 400-mile radius. Cities were subsequently removed from Soviet maps. Details are apparently still not available.
• May 23, 1958, Chalk River, Canada, again. A defective rod overheated during removal. Another long cleanup ensued.
• July 24, 1959, Santa Susana, California. A leakage occurred and was contained, although 12 of 43 fuel elements melted.
• January 3, 1961, SL-1 Idaho Falls (military, experimental). Three people were killed when fuel rods were mistakenly removed.
• October 5, 1966, Enrico Fermi, Michigan. A malfunction melted part of the core, although the damage was contained. The plant was closed in 1972.
• June 5, 1970, Dresden II in Morris, Illinois. A meter gave a false signal. The release of iodine was 100 times what was permissible, although the leakage was contained.
• November 19, 1971, Monticello, Minnesota. Fifty-thousand gallons of radioactive waste spilled into the Mississippi River, some of which got into the St. Paul water supply.
• March 22, 1975, Brown’s Ferry, Decatur, Alabama. Insulation caught fire, and disabled safety equipment. The cleanup cost $150 million.
• March 28, 1979, Three Mile Island II, Pennsylvania. The NRC said that the situation was “within 1 hour of catastrophic meltdown.” There were four equipment malfunctions, human errors, and inadequate control monitors. (This case is considered further, after this enumeration.)
• February 11, 1981, Sequoyah I, Tennessee. Eight workers were contaminated when 110,000 gallons of radioactive coolant leaked.
• January 25, 1982, Ginna plant, Rochester, New York. A steam-generator tube ruptured.
• February 22 and 25, 1983, Salem I, New Jersey. The automatic shutdown system failed twice, but manual shutdown was successful.
• April 19, 1984, Sequoyah I, again. A radiation leak was contained.
• June 9, 1985, Davis-Besse, Oak Harbor, Ohio. A number of pieces of equipment failed, and at least one wrong button was pushed by an operator. Auxiliary pumps saved the day. (This case is considered further, later in this section.)
• Several months after Davis-Besse, a nuclear plant in San Onofre, California, experienced violent shaking in the reactor piping when five check valves failed. There was a leak of radioactive steam, and damage to the pipe surrounds resulted.
Three Mile Island 2: Dangers of assuming too much
The temperature of the fuel rods at Three Mile Island II increased from the normal 600 degrees to over 4000 degrees during the accident on March 28, 1979, partially destroying the fuel rods. The instruments to measure core temperatures were not standard equipment in reactors. Thermocouples had been installed to measure the temperature as part of an experiment on core performance, and were capable of measuring high temperatures. However, whenever the temperature rose above 700 degrees, the system had been programmed to produce a string of question marks on the printer—rather than the measured temperature.100 Furthermore, intended rather than actual valve settings were displayed. (The venting of tritium-contaminated water and removal of radioactive waste to the Hanford waste-disposal site were not completed until August 12, 1993.)
Davis-Besse nuclear-power plant
The Davis-Besse nuclear-power plant had an emergency shutdown on June 9, 1985. A report101 included the following quote:
Davis-Besse came as close to a meltdown as any U.S. nuclear plant since the Three Mile Island accident of 1979. Faced with a loss of water to cool the reactor and the improbable breakdown of fourteen [emphasis added] separate components, operators performed a rescue mission noted both for skill and human foible: They pushed wrong buttons, leaped down steep stairs, wended their way through a maze of locked chambers and finally saved the day . . . by muscling free the valves and plugging fuses into a small, manually operated pump not designed for emergency use.
The lack of a backup pump had been identified much earlier as an intolerable risk, but was met with “prior power-company foot dragging and bureaucratic wrangling.”
Nuclear Regulatory Commission documents compiled in a Public Citizen report reveal that over 20,000 mishaps occurred in the United States between the 1979 meltdown at Three Mile Island and early 1986; at least 1000 of these were considered to be “particularly significant.” (In addition, there were large radiation emissions from Hanford in its early days that were not considered as dangerous at the time. It was only afterward, when the maximum permitted levels were reduced by two orders of magnitude, that the danger of the routine emissions was realized. The cancer rate in that area is now four times normal.)102
Soviet Navy
There were at least 12 serious radiation accidents in the Soviet Union’s atomic-powered Navy prior to 1986, including these:103
• 1966 or 1967. The Icebreaker Lenin had a reactor meltdown, killing approximately 30 people.
• 1966. A radiation leak in the reactor shielding of a nuclear submarine near Polyarnyy caused untold deaths.
• April 11, 1970. There was an unspecified casualty resulting from the nuclear propulsion system of an attack submarine.
• Late 1970s. A prototype Alfa-class submarine experienced a meltdown of the core, resulting in many deaths.
• December 1972. A radiation leakage resulted from a nuclear torpedo.
• August 1979. The propulsion system failed in a missile submarine.
• September 1981. The rupture of a nuclear reactor system in a submarine resulted in an unspecified number of deaths.
Chernobyl
The Chernobyl disaster of April 27, 1986, apparently surprised a lot of people who previously had soft-pedaled risks inherent in nuclear-power plants. At least 92,000 people were evacuated from the surrounding area, and 250,000 children were sent off to summer camp early. High radiation levels were detected in people, animals, meat, produce, dairy products, and so on, within the Soviet Union and in Italy, France, Germany, and Scandinavia, among other countries. The town of Chernobyl has been essentially dismantled. Thirty-one deaths were noted at the time, although the death toll continues to mount. Vladimir Chernousenko, the director of the exclusion zone, has estimated that there have been nearly 10,000 deaths among the clean-up crew. At least 0.5 million people have been contaminated, including 229,000 in the clean-up crew alone—roughly 8500 of whom were dead as of early 1991.104
Some details have been provided by the official Soviet report, confirming what was suggested by early statements that an experiment went awry:
The Soviet Union was conducting experiments to check systems at Chernobyl’s fourth nuclear reactor when a sudden surge of power touched off the explosion. . . . Soviet officials have said that the explosion happened when heat output of the reactor suddenly went from 6 or 7 percent to 50 percent of the plant’s capacity in 10 seconds. The power had been reduced for a prolonged period in preparation for a routine shutdown. . . . “We planned to hold some experiments, research work, when the reactor was on this level,” Sidorenko [deputy chairman of the State Committee for Nuclear Safety] said [May 21, 1986]. “The accident took place at the stage of experimental research work.”105
The official Soviet report says that four different safety systems were all turned off so that researchers could conduct an experiment on the viability of emergency power for cooling—including the emergency cooling system, the power-regulating system, and the automatic shutdown system. The report primarily blames human errors—only one-fourth of the control rods were inserted properly (there were not enough, and they were not deep enough), and too much coolant was added.106
A subsequent report from the Soviet Foreign Ministry107 indicated that the experiments had been intended to show how long Chernobyl 4 could continue to produce electricity in spite of an unexpected shutdown. They were testing to see whether turbine generators could provide enough power to keep the cooling systems going for up to 45 minutes. Incidentally, Chernobyl 3 shared various resources with Chernobyl 4, and consequently its reopening was also affected. (Chernobyl 1 was restarted on September 30, 1986.)
The Chernobyl reactors were intrinsically difficult to operate and to control adequately—they represent an early design that uses graphite (which is flammable) to trap neutrons in producing the desired chain reaction, and uses water as a coolant. However, if the computer controls are inadequate, and the reactor process inherently unstable, the problems lie much deeper in the process than with the operators. Various American scientists were cited as saying that “most Soviet reactors were so difficult to operate and so complex in design that mistakes were more likely than with other reactor designs.”108
Human error blamed for Soviet nuclear-plant problems
Human error caused 20 of the 59 shutdowns at Soviet nuclear-power plants in the first 6 months of 1991 (Trud, July 24, 1991). “It is not the first time that we have to admit the obvious lack of elementary safety culture in running reactors,” Anatoly Mazlov, the government’s head of nuclear safety, said. Mazlov reported that Soviet nuclear-power plants worked at only 67-percent capacity during that 6-month period.109
In RISKS, Tom Blinn noted that the Soviet nuclear engineer and scientist Medvedev’s book on the Chernobyl disaster reported on the root causes—basically, human error. Ken Mayer cautioned against blaming people when the human interface is poorly designed. His theme recurs in many cases throughout.
Distributed system reliability: Risks of common-fault modes
Jack Anderson110 contrasted Chernobyl with the nuclear-power situation in the United States, giving another example of the it-couldn’t-happen-here syndrome. (See also SEN 11, 3.)
We have learned that, since the hideous accident in the Ukraine, the Nuclear Regulatory Commission staff called in the inspectors and informed them that new, more lenient interpretations of the fire-safety regulations had been approved by the commissioners over the inspectors’ vehement protests. . . . Incredibly, the new guidelines let nuclear-plant operators sidestep the protection of redundant control systems by planning fire safety for the first set of controls only. The guidelines permit partial fire barriers between the first control system and the backup system, which can be in the same room. This means that a fire could short-circuit both systems.
Flaw in the earthquake-simulation model Shock II closes five nuclear plants
Following the discovery of a program error in a simulation program used to design nuclear reactors to withstand earthquakes, five nuclear-power plants were shut down in March 1979: Duquesne Light’s Shippingport (Pennsylvania), Wiscasset (Maine), James Fitzpatrick (Scriba, New York), and two at Surry (Virginia). Three types of problems are worth noting here — program bugs (in simulations, analyses, real-time control, and operating systems), fundamental inaccuracies in the underlying requirements and models, and the intrinsic gullibility of the computer neophyte — including administrators, engineers, and laypersons.
The programmed model relating to prediction of effects of earthquakes on nuclear-power plants is known as Shock II. The results of the program were found to differ widely from previous results — and there were indications that the results were not even superficially reproducible! (Actually, only one subroutine was implicated! Apparently, the arithmetic sum of a set of numbers was taken, instead of the sum of the absolute values. The fix was to take the square root of the sum of the squares — such deep mathematical physics!) The reported conclusion reached on discovery of the errors was that the five reactors might not actually survive an earthquake of the specified strength, contrary to what had been asserted previously. Government regulations require reactors to be able to withstand an earthquake as strong as the strongest ever recorded in the area. All four states have had significant earthquakes in recorded history, although they have had only minor ones in recent years.
Accurate live testing of reactors for earthquake damage is difficult in the absence of live earthquakes (but is very dangerous in their presence). Thus, the burden falls on the testing of the computer model as a concept, and then on the testing of the programs that implement it. (At least, that would seem to be good software methodology!). The model for the five reactors is used by the Boston firm that designed the plants, Stone and Webster. The relevant part of the model deals with the strength and structural support of pipes and valves in the cooling systems. A problem was initially discovered in the secondary cooling system at the Shippingport plant. Recalculations showed stresses far in excess of allowable tolerances.
As a result, the model underwent further analysis, and changes were made to the reactors to try to correct the situation. However, this incident brought to light two key factors in critical systems — namely, the correctness of computer programs and the appropriateness of the underlying requirements. As the use of computers increases in the design and operation of life-critical environments and systems, the problem posed by these factors will become both more widespread and more important.
There are many difficulties in modeling such activities. Usually, a set of mathematical equations exists that approximately constitutes the model. However, various programming decisions and other assumptions must often be made in implementing a model, some of which may reveal a fundamental incompleteness of the model. Thus, after a while, the program tends to define the model rather than the other way around. At present, validating such a model is itself a highly nonintuitive and nonformal process. A complete nonprocedural formal specification of the model would be helpful, but that approach has only begun to be taken recently in shutdown systems.111
Crystal River, Florida
A short circuit in the controls caused the coolant temperature to be misread in the Crystal River nuclear plant in Florida. Detecting an apparent drop in temperature, the computer system sped up the core reaction. This overheated the reactor, causing an automatic shutdown. The pressure relief valve was opened (and mistakenly left open) under computer control. As a result, the high-pressure injection was turned on, flooding the primary coolant loop. A valve stuck, and 43,000 gallons of radioactive water poured onto the floor of the reactor building. Finally an operator realized what had happened, and closed the relief valve.112
Nuclear computer-safety fears for Sizewell B
Software engineers close to the design of the software intended to protect the Sizewell B nuclear reactor from serious accidents expressed fears that the system is too complex to check, and have suggested that the system be scrapped. Sizewell B is the first nuclear-power station in the United Kingdom to rely heavily on computers in its primary protection system. A computer-controlled safety system was seen as superior to one operated by people because it would diminish the risk of human error. But Nuclear Electric told The Independent that the system for Sizewell B, based on 300 to 400 microprocessors, is made up of modules that constitute more than 100,000 lines of code.113
Sellafield safety problems
Britain’s nuclear watchdog has launched a full-scale investigation into the safety of computer software at nuclear installations, following an incident at the Sellafield reprocessing plant in which computer error caused radiation safety doors to be opened accidentally.114
The £240-million Sellafield plant was expected to help British Nuclear Fuels to return waste to the country of origin. The plant encases high-level waste in glass blocks for transport and storage, using a process that is known as vitrification.
In mid-September 1991, a bug in the computer program that controlled the plant caused radiation-protection doors to open prematurely while highly radioactive material was still inside one chamber. Nobody was exposed to radiation and the plant has since been shut down, but the incident rang alarm bells within the nuclear inspectorate. The inspectorate originally judged as acceptable the computer software that controls safety—partly because the software consisted of only a limited amount of computer code. However, the computer program was later amended with a software patch that is thought to have caused the doors to open too soon.
Software error at Bruce nuclear station
A computer software error caused thousands of liters of radioactive water to be released at the Bruce nuclear station at Kincardine, near Owen Sound in Canada. The reactor remained down for at least 6 weeks.115
PWR reactor system “abandoned owing to technical problems.”
Electricité de France (EDF) decided in principle to abandon the Controbloc P20 decentralized plant supervisory computer system developed by Cegelec for their N4 Pressurized Water Reactor (PWR) series, because of major development difficulties.116
Neutron reactor lands in hot water
A nuclear reactor at one of Europe’s leading physics research centers was shut down by French safety authorities following the discovery that it had been running at 10 percent over its permitted power output for almost 20 years, ever since it came into operation in the early 1970s. The extra power went unnoticed because the instrument used to measure the output of the reactor at the Institut Laue-Langevin (ILL) at Grenoble in France was calibrated with ordinary water, whereas the reactor uses heavy water.117
Trojan horse in Lithuanian atomic power plant
A worker in a nuclear-power plant in Ignalina, Lithuania, attempted to plant a Trojan horse in the nonnuclear part of the reactor controls. His intent was to be paid for repairing the damage, but his efforts were detected and were undone by plant managers.118 (Many other cases of malicious Trojan horse activities are given in Chapter 5; this one is included here to illustrate that some reliability problems are attributable to malicious causes.)
Nine Mile Point 2
The Nine Mile Point 2 nuclear-power plant near Oswego, New York, has had various problems. The Nuclear Regulatory Commission noted that Nine Mile Point’s two reactors “ranked among the worst of the 111 licensed nuclear reactors in the United States.”119 Two relevant cases are included here and numbered for reference in Table 2.10 at the end of the section.
1. NMP-2 reactor knocked offline by two-way radio in control room. The up-again down-again Nine Mile Point 2 was back on line on April 25, 1989, following a shutdown over the weekend of April 22 and 23 that “shouldn’t have happened,” according to a federal official. An employee accidentally keyed a hand-held two-way radio near circuitry for the turbine-generator monitoring system Saturday night. The transmission shut down the system, which in turn triggered an automatic shutdown of the entire facility. A section chief of the NRC region 1 office said that he had never heard of a similar accident, but that most plants are sensitive and there are strict rules to prevent such an occurrence. Replacement fuel costs $350,000 per day when the 1080 MW plant is down. The plant had been up less than 1 week after an earlier shutdown caused by corrosion and loose wiring in a meter.120
2. NMP-2 reactor shut down by a power surge. Nine Mile Point 2 was shut down again on August 13, 1991, because of a transformer failure. A site area emergency was declared for only the third time in American history, although it was reported that there was “no danger” (SEN 16, 4).
Table 2.10 Summary of electrical-power problems
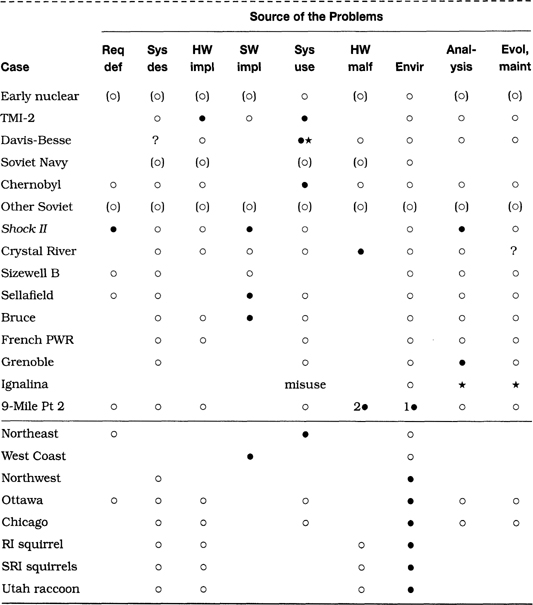
2.10.2 Conventional Power
Nonnuclear power systems are also increasingly computer controlled. The first three cases involve propagation effects reminiscent of the 1980 ARPAnet collapse and the 1990 AT&T long-distance slowdown.
The northeastern U.S. blackout
The great northeast power blackout in the late 1960s was blamed on a power-level threshold having been set too low and then being exceeded, even though the operating conditions were still realistic. (There was also a lack of adequate isolation among the different power grids, because such a propagation effect had never before occurred on that scale.)
Blackout on west coast blamed on computer error
The power failure that blacked out millions of utility customers in 10 western states for up to an hour on October 2, 1984, was traced to a computer error in an Oregon substation. Equipment in Malin, Oregon, misread a power loss from a Pacific Gas and Electric line. The computer system thus thought that the electrical loss on a 2500-kilovolt link between Oregon and California was twice as big as it actually was, somehow setting off a network chain reaction. This event was apparently considered to be a routine occurrence that the computer system should have handled with no difficulty rather than propagating.121 It is intriguing that electrical power-grid isolation may actually prevent such occurrences from happening electrically, but this example of the computer-based propagation of a bogus event signal is similar to the ARPAnet collapse (Section 2.1).
Los Angeles earthquake affects the Pacific Northwest
The Los Angeles earthquake of January 17, 1994, knocked out power to the entire Los Angeles basin. Grid interdependencies caused power outages as far away as Alberta and Wyoming; in Idaho, 150,000 people were without power for 3 hours.122
Ottawa power failure
A brief fire at Ottawa Hydro’s Slater Street station on the morning of August 7, 1986, resulted in a loss of power to a substantial section of the downtown area. Even after 48 hours of work, sections of the city were still without power, causing officials to reexamine their long-accepted system-reliability standards.
Ottawa Hydro engineering manager Gordon Donaldson said “the system is built to be 99.99 percent reliable . . . now we will be looking at going to another standard of reliability—99.999 percent.” He also said that the cost would be huge—many times the $10 million cost of the Slater Street station — and Hydro customers may not be prepared to accept the cost . . . . The Slater station is the biggest and was considered the most reliable of the 12 across the city. It has three units, each of which is capable of carrying the whole system in an emergency. But all three were knocked out. . . . The culprit, an Ontario Hydro control board [called a “soupy board”] that monitors the equipment at the substation, didn’t even have anything directly to do with providing power to the thousands of people who work and live in the area. . . . its job is to make the system safer, cheaper and more reliable . . . . The board is considered so reliable that it doesn’t have its own backup equipment. [!]
Automatic teller machines (ATMs) as far as 100 miles distant from Ottawa were knocked out of commission—the central computer that controls them was in the area of outage. Many traffic signals were out for days, as were a number of businesses.
The economic costs of the power failure were expected to be in the millions of dollars. Recalling the aftereffects of the evening power failure in the northeastern United States, it was deemed unlikely that the Ottawa birthrate would increase. As columnist Charles Lynch noted: “The Ottawa power failure took place during the breakfast hour, not normally a time when Ottawans are being polite to one another, let alone intimate.”123
The Chicago Loop single point of failure
On April 13, 1992, Chicago experienced the closest thing to the “Chicago Fire” this century. The 40 to 60 miles of century-old freight tunnels underneath the Chicago Loop (the main downtown area) were flooded. The flooding appears to have been caused by a newly installed bridge piling that breached the tunnel where it passes under the Chicago River. When built, these tunnels were used for transporting coal, newsprint, and many other items on an electric railway.
The risks to computing were and are significant. Although no longer used to transport freight, these tunnels are now used as conduits for communication cables that connect together the city’s main business district. Even more damaging, the tunnels connect the basements of numerous buildings that were flooded. These flooded basements are home to telephone and electrical equipment, most of which was disabled for days. The loss to the city was expected to exceed $1 billion. Indeed, the city of Chicago had a single weak link.124
Computers go nuts for insurgent squirrel
A squirrel caused a short-circuit in a transformer, causing a power surge in Providence, Rhode Island, on October 29, 1986. The surge affected numerous computers, although the backup transformer prevented a power outage.125
More kamikaze squirrels
There have been at least three times in my years at SRI International (since 1971) that a squirrel blacked out the entire institute. After the second squirrelcide (which downed my laboratory’s primary computer system for 4 days), SRI established a cogeneration plant that was supposed to guarantee uninterruptible power, with appropriate isolation between the standby generators and the local power utility. As usual, nothing is guaranteed. That the “no-single-point-of-failure” power system had a single point of failure was demonstrated on May 29, 1989, during the Memorial Day holiday, by the feet of a squirrel who managed to short out the isolation point. The power was off for approximately 9 hours, and many computers remained down after that—some with their monitors burned out.126
Raccoons, power, and cold-fusion experiments
A raccoon electrocuted itself at the University of Utah, causing a 20-second power outage that resulted in a loss of data on the computers being used by Fleischmann and Pons in trying to verify their cold-fusion experiments. Raccoons managed to cripple the Jet Propulsion Laboratory more than once in the past. The latest one survived, and went on to became a local celebrity.127 Evidently, animals pose a threat to installations with single-point-of-failure power systems.
2.10.3 Summary of Electrical-Power Problems
Table 2.10 provides a brief summary of the causes of the cited problems. (The abbreviations and symbols are given in Table 1.1.)
This table is one of the densest in the chapter, with many problems relating to inadequacies in system design, implementation, and use. There are risks inherent in systems that require significant training of operators and constant vigilance under circumstances when normally nothing goes wrong. Problems in analysis (particularly in the Shock II simulation model and the Grenoble case) and evolution and maintenance are also implicated. The environmental peculiarities of nuclear and conventional power systems contribute to the overall effects of each problem as well—including the single-point failure modes attributable to squirrels and a raccoon.
2.11 Computer Calendar Clocks
In this section, we consider time- and date-related problems. To emphasize the intrinsic nature of calendar-clock problems and how they depend on computer representations of dates and times, we use (in this section only) a mathematically natural format for clock-related dates: year-month-day. This format illustrates the natural numerical order in which carries propagate (upward) from seconds to minutes to hours to days to months to years, and it serves to underlie the nature of those cases in which carries and overflows are not properly handled. Note that the American representation of month-day-year and the European representation of day-month-year are both mathematically unnatural, although the latter is at least logically ordered. In addition, there are often ambiguities between and within the two forms, as in 11/12/98, which could be November 12 or 11 December; furthermore, the year could be 1898 or 1998, for example. We can expect many new ambiguities when we reach 1/1/00 and 1/2/00.
2.11.1 Dependence on Clocks
We consider first a few problems related to dependence on computer clocks.
Dependence on remote clocks
In Colorado Springs, one child was killed and another was injured at a traffic crossing; the computer controlling the street crossing did not properly receive the time transmitted by the atomic clock in Boulder, which affected the system’s ability to vary the controls according to the school schedule. In all, 22 school crossings were affected (SEN 14, 2).
SRI’s Computer Science Laboratory computer system once used a then-common eleven-clock averaging algorithm to reset the local clock automatically on reboot after a crash. Unfortunately, at the moment of reboot, a clock at the University of Maryland was off by 12 years, based on which the CSL clock was initialized to be off by 15 months. (Yes, the new algorithms now discard extreme values, and rely on systems with more dependable clocks.)
Byzantine clocks
Algorithms for making a reliable clock out of less reliable clocks are potentially nontrivial. The old three-clock algorithms (such as taking the median of three values) break down if one clock can report different values to its neighbors at any one time—whether maliciously or accidentally. In that case, it can be shown that four clocks are both necessary and sufficient. Furthermore, if n clocks can be potentially untrustworthy, then 3n+1 clocks are required to provide a Byzantine clock—namely, one that can withstand arbitrary errors in any n clocks [70, 142].
Year ambiguities
In 1992, Mary Bandar received an invitation to attend a kindergarten in Winona, Minnesota, along with others born in ’88. However, Mary was 104 at the time. The person making the database query had typed 1988, but the software kept only the last two digits (as noted by Ed Ravin in SEN 18, 3, A-3).
G.C. Blodgett’s auto-insurance rate tripled when he turned 101; he was the computer program’s first driver over 100, and his age was interpreted as 1, which fit into the program’s definition of a teenager—namely, someone under 20 (noted by Lee Breisacher in SEN 12, 1, 19).
In Section 2.9 we observed the case of the almost-100-year-old man whose white-blood-cell count was interpreted as normal because the program interpreted his birthyear (input 89) as 1989 rather than as 1889 (SEN 15, 2). This kind of problem will certainly be exacerbated as we approach and pass the turn of the century, and as more people become centenarians.
3.11.2 Dates and Times
We next consider problems relating specifically to calendar-clock arithmetic.
Overflows
The number 32,768 = 215 has caused all sorts of grief that resulted from the overflow of a 16-bit word. A Washington, D.C., hospital computer system collapsed on 1989 Sep 19, 215 days after 1900 Jan 01, forcing a lengthy period of manual operation. Brian Randell reported that the University of Newcastle upon Tyne, England, had a Michigan Terminal System (MTS) that crashed on 1989 Nov 16, 215 days after 1900 Mar 01. Five hours later, MTS installations on the U.S. east coast died, and so on across the country—an example of a genuine (but unintentional) distributed time bomb.
John McLeod noted that COBOL uses a two-character year field, and warned about having money in the bank on 1999 Dec 31 at midnight. Robert I. Eachus noted that the Ada time_of_year field blows up after 2099, and MS-DOS bellies up on 2048 Jan 01.
Don Stokes noted that Tandem CLX clocks struck out on 1992 Nov 1 at 3 P.M. in New Zealand, normally the first time zone to be hit, where the program deficiency attacked Westpac’s automatic teller machines and electronic funds transfer point-of-sale terminals (EFTPOSs). For each of the next 4 hours thereafter, similar problems appeared in succeeding time zones, until a microcode bug could be identified and a fix reported. Thus, the difficulties were overcome before they could reach Europe. In some cases, the date was converted back to December 1983, although the bug affected different applications in different ways. Some locations in later time zones avoided 3 P.M. by shifting past it; others set their clocks back 2 years. Fortunately, the day was a Sunday, which decreased the effect.
The linux term program, which allows simultaneous multiple sessions over a single modem dialup connection, died worldwide on 1993 Oct 26. The cause of an overflow was an integer variable defined as int rather than unsigned int.128
Year-end roundup
The Pennsylvania Wild Card Lotto computer system failed on 1990 Jan 01. The winners of the lottery could not be determined until the software had been patched, 3 days later.
Summer Time, and the livin’ is queasy
The U.S. House of Representatives passed a bill in April 1989 that would have delayed the end of Pacific daylight time in presidential election years until after the November election, with the intent of narrowing the gap between when the predictions from the rest of the continental United States start pouring in and when the polls close in California. The bill was never signed, but the option of “US/Pacific-New” was inserted into Unix systems to be used in the event it passed. As a consequence, several administrators on the west coast chose that option, and their systems failed to make the conversion to Pacific standard time on 1992 Oct 26 00:00 (SEN 18, 1).
The end-April 1993 cutover to summer time in Germany resulted in a steel production line allowing molten ingots to cool for 1 hour less than intended. To simplify programming, a German steel producer derived its internal computer clock readings from the Braunschweig radio time signal, which went from 1:59 A.M. to 3:00 A.M. in 1 minute. When the process controller thought the cooling time had expired (1 hour too early), his resulting actions splattered still-molten steel, damaging part of the facility.129
On the same night, the Bavarian police computer system stopped working at 3:00 A.M., blocking access to all of its databases (Debora Weber-Wulff, in SEN 18, 3, A-4).
Arithmetic errors
John Knight found an item in the October 1990 Continental Airlines magazine, while flying home from the 1990 Las Cruces safety workshop. The note described how the airline rented aircraft by the entire day, even if the plane was used only for a few hours. The billing for rentals was consistently 1 day too little, because the billing program merely subtracted the begin and end dates. This example exhibits the classical off-by-one error, which is a common type of programming mistake.
Nonportable software
The National Airspace Package, a program developed in the United States for modeling controlled airspace, failed to work when it was tried in the United Kingdom—the program had ignored longitudes east of Greenwich.130
2.11.3 Leap-Year Problems
Astoundingly, each leap-year or leap-second brings a new set of problems.
Leaping forward
John Knight reported that a Shuttle launch scheduled to cross the end-of-year 1989 was delayed, to avoid the software risks of both the year-end rollover and a leap-second correction that took place at the same time.
Not-making ends meat!
Shortly after 1988 Feb 29, the Xtra supermarket was fined $1000 for having meat around 1 day too long, because the computer program did not make the adjustment for leap-year.
Leap-day 1992
The date of 1992 Feb 29 brought its own collection of problems. The following episodes are worth relating, all of which stem from 1992 and were described in SEN 17, 2, 10-12.
Paul Eggert’s contribution for International Software Calendar Bug Day observed that Prime Computer’s MAGSAV failed at midnight on leap-day. However, Prime’s 800 number is not answered on Saturdays, so they probably did not get as many complaints as might have occurred on a weekday. G.M. Lack noted that MAGSAV probably failed on leap-day because it tried to increment the year by one to set a tape label expiration date, and the resulting nonexistent date 1993 Feb 29 threw it for a loop.
Jaap Akkerhuis reported that Imail caused systems to crash worldwide on leap-day 1992, because the mail handlers did not recognize the date.
Roger H. Goun reported that the PC MS-DOS mail system UUPC/extended hung the PC on leap-day 1992.
Drew Derbyshire, the author of UUPC, traced the problem to a bug in the mktime() library function in Borland C++ 2.0, which converts a time to calendar format. Drew demonstrated that mktime() will hang a PC on leap-day, and reported the problem to Borland. As distributed, UUPC is compiled with Borland C++ 2.0, though source code is available for do-it-yourselfers . . . . Drew tried to warn UUPC users by mail after discovering the problem on Saturday. Ironically, many did not get the message until Sunday or Monday, when they found their PCs hung in uupoll.
Rhys Weatherley noted that a Windows 3.0 newsreader using Borland C++ 2.0 locked up, due to a bug in mktime converting to Unix date/time formats, although the problem may have been due to the run-time library.
Douglas W. Jones noted that all liquor licenses in Iowa expired on 1992 Feb 28, and the new licenses were not in force until 1992 Mar 1. The state announced that this gap was due to a computer error and promised not to enforce the law on leap-day for establishments caught in the interim. (I suppose there might have been a headline somewhere such as “A glitch in time shaves fine.”)
Tsutomu Shimomura parked on leap-day at the San Diego off-airport parking lot, and was given a time_in ticket dated 1992 Feb 30; returning on 1992 Mar 6, he was presented with a demand for $3771 (for 342 days @ $11/day and 9 hours @ $1/hour). It is intriguing to contemplate why the computer program used 1991 Mar 30 as the time in; it apparently kept the 30, but propagated a carry from Feb to Mar!
It ain’t over ’til it’s over
A leap-year bug in an ATM program did not hit until midnight on 1992 Dec 31, causing several thousand ASB regional bank customer transactions to be rejected. Each magnetic stripe was corrupted during the period from midnight to 10 A.M., and anyone trying a second transaction was blocked.131 The same phenomenon also was reported for 1500 TSB regional bank customers in Taranaki, from midnight until after noon.132 Both banks used National Cash Register (NCR) ATM systems. This case was another example of New Zealand bringing in the new day first—serving as the king’s taster for clock problems (Conrad Bullock, in SEN 18, 2, 11) — as in the Tandem Westpac case noted previously. NCR got a fix out fairly quickly, limiting the effect further west.
2.11.4 Summary of Clock Problems
Table 2.11 provides a highly simplified summary of the causes of the cited problems. It suggests simply that all of the potential sources of difficulty have manifested themselves. (The abbreviations and symbols are given in Table 1.1.)
Table 2.11 Summary of clock and date problems

Many of these problems stem from the absence of a requirement that the system be able to continue to work in the more distant future, and from the presence of short-sighted programming practice.
As elsewhere, there is a serious lack of system sense and consistent software practice with respect to date and time arithmetic. Obvious problems created by limitations on leap-year and date-time representations tend not to be anticipated adequately. Perhaps no one ever dreamed that FORTRAN and COBOL would still be around into the next century. The lessons of this section seem to be widely ignored. New systems continue to fall victim to old and well-known problems.
You might think that the leap-day problems would be anticipated adequately by now. Getting clock arithmetic correct might seem to be a conceptually simple task—which is perhaps why it is not taken seriously enough. But even if earlier leap-year problems were caught in older systems, they continue to recur in newer systems. So, every 4 years, we encounter new problems, giving us 4 more years to develop new software with old leap-year bugs, and perhaps even to find some creative new bugs!133
Many computer programmers are concerned about the coming millenium, and speculations on what might happen are rampant. There are many lurking problems, some of which are suggested here.
The maximum-field-value problem would seem to be obvious enough that it would have been better anticipated; however, it keeps recurring. Distributed system clocks are a potential source of serious difficulties, as illustrated by the synchronization problem that caused postponement of the first Shuttle launch (Section 2.2.1). Defensive design is particularly appropriate.
Planning for the future is always important. It is high time that we looked far ahead. We still have time to think about the millenial problems, analyzing existing programs and developing standard algorithms that can help us to avoid alarming consequences. Events on 2000 Jan 01 should indeed be interesting, particularly because 2000 will be a leap-year, following the rule that 100-multiples are not leap-years — except for the 400-multiples. Because there were no clock and date programs in 1900, problems caused by this particular rule may not arise until 2100 (or 2400).
2.12 Computing Errors
We conclude this collection of reliability problems with a few miscellaneous software and hardware cases relating to unexpected computational results.
Floating-point accuracy
A fascinating article by Jean-Francois Colonna134 observes that five algebraically equivalent computational formulae for computing Verhulst dynamics based on the iterative equation
![]()
produce wildly different results even for fairly innocuous values of R and n. The paper considers five corresponding programs in C, each run on both IBM ES9000 and IBM RS6000, with R = 3 and X1 = 0.5. Although the results are quite close to each other for values of X40, they differ by a factor of over 1000 for the smallest and largest value of X60. The same rather startling effect occurs for other programming languages and for other machines.
Risks of FORTRAN in German
Bertrand Meyer (SEN 17, 1) related that some FORTRAN compilers permit writing to a unit as well as to a device. Writing to unit 6 gives standard output, whereas writing to device 6 overwrites the disk. Apparently many German-speaking programmers (for whom both “unit” and “device” are translated as Einheit) were victimized by undesired disk deletions.
Bugs in Intel 486 and AMD 29000 RISC chips
Compaq discovered a flaw in the trigonometric functions when testing the new Intel 486 chip. This flaw was corrected in later versions. Three flaws were also detected in a version of the Advanced Micro Devices 32-bit RISC processor 29000, although workarounds were available (SEN 15, 1).
Harvard Mark I
A wiring mistake in the Harvard Mark I lay dormant for many years until it was finally detected. This case is discussed in Section 4.1.
2.13 Summary of the Chapter
The range of problems relating to reliability is incredibly diverse, even within each type of causal factor summarized by the tables. Referring back to the causes itemized in Section 1.2, almost all of the basic types of problems arising in system development (Section 1.2.1) and in operation and use (Section 1.2.2) are represented in this chapter. Two cases of malicious misuse are included (see Tables 2.4 and 2.10), although that class of causes is the primary subject of Chapters 3 and 5. Similarly, the effects observed in the cases discussed in this chapter encompass many of the effects noted in Section 1.3.
In general, it is a mistake to attempt to oversimplify the identification of the relevant modes of causality, partly because they occur so diversely and partly because each application area has its own peculiarities—but also because multiple factors are so often involved. (The issue of assigning blame is reconsidered in Section 9.1.)
The differences among causes and effects that vary according to the application area are illustrated throughout the chapter. People are a significant factor in many of the cases. There are numerous cases of system problems relating to software and hardware, as well as to environmental problems. The other causalities included in the section-ending table columns are also amply represented.
In principle, many techniques exist whose consistent use might have avoided the problems noted in this chapter (such as those summarized in Table 7.2). In practice, however, it is difficult to eliminate all such problems, as discussed in Chapter 7.
As we discuss in Section 4.1, reliability is a weak-link problem. Although a system may be designed such that it has far fewer weak links than it would if it were not designed defensively, the presence of residual vulnerabilities seems to be unavoidable. In some cases, it may take multiple causative factors to trigger a serious effect; however, the cases discussed in this chapter suggest that such a combination of factors may indeed occur. (This point is amplified in Chapter 4.1.)
John Gall’s Systemantics: How Systems Work and Especially How They Fail [46] has several suggestions from 1975 that are still relevant here:
• In general, systems work poorly or not at all.
• New systems mean new problems.
• Complex systems usually operate in failure mode.
• When a fail-safe system fails, it fails by failing to fail safe.
Challenges
C2.1 Consider the electrocutions of heart-monitor patients noted in Section 2.9.2. What is the simplest countermeasure you can think of that would completely prevent further recurrences? What is the most realistic solution you can think of? Are they the same?
C2.2 For any event summarized in this chapter (other than that mentioned in C2.1), speculate on how the causative factors could have been avoided or substantially reduced in severity. Perfect hindsight is permitted. (Reading the rest of the book may help you to reduce the amount of speculation that you need to apply in some cases. However, this exercise is intended as an anticipatory analysis.)
C2.3 Similarities between the 1980 ARPAnet collapse and the 1990 AT&T long-distance slowdown have been noted in Section 2.1. Identify and discuss three other pairs of problems noted in this chapter for which identical or almost-identical modalities caused similar results.
C2.4 Design a simple alarm system that will continue to work despite the loss of electrical power or the loss of standby battery power or malfunction of a single sensor whose sole purpose is to detect the situation for which the alarm is expected to trigger. (You may use multiple sensors.) Try to identify circumstances under which your design might fail to operate properly. Can you overcome those vulnerabilities? Are there any single-point sources of failure?