5. EDP Catalog
With the foundation we built in the previous chapters, you’re ready to start investigating the first portion of the EDP Catalog presented in the remainder of this book. The first sixteen patterns presented are the four fundamental object-oriented programming patterns followed by the twelve method-call EDPs. You’ve been introduced to eleven of them so far, and there are five more for you to learn on your own from the included specifications.
The format used to write up a design pattern is fairly standardized. The first popular use was in the original Gang of Four (GoF) text [21], and I follow that form here. Each pattern is written in several sections, starting with the pattern’s name, so that we have something canonical to refer to it by. The Intent section explains the pattern’s purpose. Next, the Motivation section provides background on the problem this pattern solves, and then the Applicability section explains when it should (or should not) be used. A sample structure is provided next as both a UML diagram and, where appropriate, an expanded PINbox. This structure is not ever to be used as a rote recipe, remember, but only as an example. If you need to change the implementation and do so without altering the relationships you’re concerned with, then do it. The concepts will still be there.
The Participants and Collaborations sections follow and address those concepts. The pattern specification continues with the Consequences and Implementation sections. Here, sample code is provided, but, again, it is to be taken only as a guideline. Your implementation language will almost certainly greatly impact how you choose to express a design pattern. Where appropriate, discussions of how these concepts are expressed in different languages are used to highlight just how varied different implementations may look, yet each still can provide the basis for consistent description of the underlying concepts as design patterns. A discussion of related patterns completes each specification.
The EDPs are organized into three main categories: Object Elements, Type Relation, and Method Invocation.
Object Elements are those elemental patterns that deal with the creation and definition of objects: Create Object and Retrieve. Create Object describes when, how, and why we instantiate objects, what makes them special over procedural systems, and why they are not merely syntactic sugar. Retrieve outlines how and why objects are used as data fields inside an enclosing object.
Type Relation contains two simple patterns: Inheritance provides a discussion of the primary method by which typing information and method body definitions are reused effectively in object-oriented systems, and Abstract Interface solves the problem of needing to defer implementations to type definitions that may be created at a later date.
The last group, Method Invocation, contains the final 12 patterns in this chapter, as described in Chapter 2.
The patterns in the collection, while small and precise, are important because of their ubiquity in object-oriented programming and because they are amenable to formalization, unlike most higher abstraction design patterns. Every programmer uses these patterns on a daily basis, usually without conscious effort. Because one purpose of patterns is to bring awareness to that which is subconscious and reflexively seen as useful, these specifications are intended to foster that awareness and facilitate discussion about the basic concepts of our field.
Additionally, the EDPs act as a foundation for better describing and discussing best-practice design patterns that may not be as readily understandable or memorable from the current literature. These EDPs are the building blocks of comprehension, empowering us to reshape our conversations about design patterns in a significant way.
Create Object
Object Creation
Intent
To ensure that newly allocated data structures conform to a set of assertions and preconditions before they are operated on by the rest of the system, and that they can only be operated on in predefined ways.
Also Known As
Instantiation
Motivation
In any executable run on a computer, data must have storage space to be placed in and functions or methods to act on that data. Data without behavior is incapable of action. Behavior without data is incapable of meaningful action. A fundamental talent for any programmer is knowing how to tie together data and functionality in ways that make conceptual sense and facilitate maintainability of the source code. Object instantiation solves two issues: establishing both a default valid state for data and a set of related defined behaviors on that data.
In procedural languages, data and behavior are distinct, with data structures defining the former and functions taking care of the latter. Data is more than just allocated memory: it is a set of assumptions about how to interpret, set, and work with the information in that memory space. In addition, those assumptions define a set of behaviors that are valid to operate on, or operate with, the data.
When data is needed, it requires a block of memory to occupy, which in many languages is simply allocated and handed back to the programmer for use. This data may be associated with a type, or it may be typeless and raw. In most cases, it is uninitialized, meaning that the memory has no default value. A developer must manually fill in the beginning values or risk that whatever random data happened to be in the memory location prior to allocation is still there. This process must be done every time, by every developer. Of course, a reasonable way of encapsulating this initialization behavior is to put it into a function to be called, but doing so only moves the requirement up a level, and now the developer must remember to call the initialization function. Failing to do so means that later functions that operate on that piece of data may be fed invalid or incorrect values, but this requirement is usually not automated or strictly enforced.
Listing 5.1 demonstrates this scenario in C. Assume you’re writing a low-level GUI library for offering windows to an application. An initialization function has been supplied, but before it is called, as in lines 31 and 32, the values in the requested data are essentially random. I say “essentially” because some implementations of C do provide a default value of zero for integers, floats, and such, but this is only some implementations, on some hardware. On other systems, the values are simply whatever was in memory beforehand. Because Listing 5.1 is a complete program, you can run it on your system and see how your particular system behaves.
Listing 5.1. Uninitialized data.
#include <stdio.h>
2 #include <string.h>
#include <stdlib.h>
4
struct WindowData {
6 int xPosition;
int yPosition;
8 int width;
int height;
10 char* title;
};
12
void
14 initializeWindowData( struct WindowData* wd ) {
wd->xPosition = 0;
16 wd->yPosition = 0;
wd->width = 600;
18 wd->height = 800;
// Allocate enough for the string
20 // (Plus 1 for terminating NULL)
wd->title = (char*)malloc(
22 (strlen("Default␣title") + 1) * sizeof(char));
strcpy(wd->title, "Default␣title");
24 };
26 int
main(int argc, char** argv) {
28 struct WindowData wd;
30 // These usually print random data
printf("width:␣%d
", wd.width);
32 printf("title:␣%s
", wd.title);
34 initializeWindowData(&wd);
36 // These *always* print 0 and "Default title"
printf("width:␣%d
", wd.width);
38 printf("title:␣%s
", wd.title);
};
This leads to the second issue involved with working with even well-formed data in well-formed ways: not only may the data be malformed in the beginning, but also there are few, if any, barriers to what functions may operate on it. Functions that were not designed to work on a particular piece of data may behave incorrectly due to a mismatch between assumptions of what is stored in the memory and what is actually there. In addition, a function’s incorrect assumptions about the data may alter the underlying values in an invalid way. What was previously correctly formed data may now be invalid for the data type.
Often, data and a group of related functions are shipped as a library, but a library only provides them as a loosely defined group; nothing actively ties them together in a way that is enforced by the system. As an improvement, it is possible to bundle functions directly with the data they operate on in some procedural languages, provided you have access to some way of incorporating the functions into a data structure.
In C, this can be done with function pointers. A function pointer for each desired function to be associated with a struct is placed directly within that struct and then is carried along with the data.1 This is a good way to indicate which behavior is associated with particular data, but it doesn’t prevent a developer from simply stepping in and fiddling with the data directly.
1. This is what early C++ systems looked like under the hood, when the cfront tool was the primary technique for compiling C++ code. If you’re interested in the boundary between object-oriented and procedural languages, that is a good historical place to start.
To protect the data, we need encapsulation, which hides the data from view while providing a set of well-defined and limited ways to access and manipulate the data. Data hidden by encapsulation is said to be private. Encapsulation prevents a developer from directly manipulating the data and restricts the possible behaviors to the set bundled with the data. It is possible to perform data encapsulation in a procedural language, again, provided you have some lower-level access, such as through pointers. This technique is also called a pointer-to-implementation (pimpl), d-pointer, opaque pointer, or Cheshire cat.
Combining the two techniques results in a decent way of protecting data and providing a consistent set of possible behaviors on that data. The behavior bundling and encapsulation are possible in only some procedural languages, however, and they are quite messy, error prone, and require careful consideration and implementation. Worse yet, they still rely on these techniques being applied as a matter of policy, without automated enforcement by the compiler or language.
Listing 5.2. Fixed default values.
1 struct WindowData {
int xPosition = 0;
3 int yPosition = 0;
int width = 600;
5 int height = 800;
char title[] = "Default␣title";
7 };
An object, on the other hand, is a language-enforced, single, indivisible unit composed of data and applicable methods that are conceptually related, as defined by an object type. The methods chosen to be part of the object type have been determined to have a meaningful association with each other and with the data. The data can easily be protected, we can ensure that this unit is in a specified coherent and well-defined state before we attempt to operate on the object, and we can ensure that only well-defined operations can be performed on the object.
In some procedural languages, while a developer can emulate an object reasonably well for encapsulation and bundled behaviors, they cannot absolutely ensure that the data is always coherent or that the operations on the state of that data are properly restricted. There is almost always some way to subvert the techniques described previously to address these issues.
Also, and critically, the practitioner cannot guarantee at the time of allocation of the record that the record’s contents conform to any specific assertion they may choose to make. Building off of our earlier example, we could provide default values for the members of the WindowData struct, as in Listing 5.2.
Now we don’t have to call initializeWindowData(). Whenever we define a new variable of the WindowData type, it comes prefilled with the appropriate values.
This approach works, provided these default values never need to change. Changing the values requires editing and recompiling the source code. Unfortunately, that’s often not what we need. Consider what happens when you request a new document window in most modern GUI applications. A new window appears slightly to the right and below your current one, if one exists, and usually has the title “Untitled,” but if one with that name already exists and has not been renamed, then the title appends a counter, such as “Untitled 1” and “Untitled 2.” This sort of basic behavior should be offered by the library if possible, so it would be nice to have this information set automatically for when you request a new WindowData.
Listing 5.3. Dynamic initialization
1 void
initializeWindowData( struct WindowData* wd ) {
3 wd->xPosition = currentWindow()->xPosition + 10;
wd->yPosition = currentWindow()->yPosition + 10;
5 wd->width = currentWindow()->width;
wd->height = currentWindow()->height;
7 char * currTitle = currentWindow()->title;
int counter = currentUntitledCounter();
9 if (counter == 0) {
// Set to "Untitled": 8 chars + 1 NULL
11 wd->title =
(char*)malloc(9 * sizeof(char));
13 strcpy(wd->title, "Untitled");
} else {
15 // Add enough chars for a ' ', and two digits
// Limit of 100 Untitled windows at once
17 wd->title =
(char*)malloc(12 * sizeof(char));
19 strcpy(wd->title, "Untitled␣");
char num[3];
21 snprintf(num, 3, "%d", counter + 1);
strcat(wd->title, num);
23 }
};
But we can’t do that. The default settings just described rely on the existing state of the application and its documents, and we can’t possibly know that when we’re writing or compiling the code. We can, of course, put this sort of dynamic information gathering and assignment in a function, as in Listing 5.3, but then we’re right back to requiring the developer to remember to call this function. Using default static values doesn’t solve our problem as well as we’d like.
Having an initializer function would be an effective solution but not an enforceable one. Enforcement relies on policy, documentation, and engineer discipline, none of which have proven to be ultimately accurate or reliable. An engineer is therefore back to the original problem of not being able to guarantee that any given assertion holds true on the newly allocated data. A malicious, careless, or lazy programmer could allocate the structure, and then fail to call the proper initialization procedure, leading to potentially catastrophic consequences.
Object- and class-based systems provide an alternative. When an object is allocated by a runtime environment, it is initialized in a well-formed way that is dependent on the language and environment. All object-oriented environments provide some analogous mechanism as a fundamental part of their implementation. This mechanism is the attachment point at which the implementor can create a function (usually called the initializer or constructor) that performs the appropriate setup on the object. In this way any specific assertion, including those based on information only available at the time of object creation, can be imposed on the data before it is available for use by the rest of the system.2
2. One popular language is a glaring exception to this rule: Objective-C does not enforce both allocation and initialization in one behavior, as most languages do. Instead, it has an alloc-init idiom intended to let developers handle the memory management and data initialization of objects as separate pieces. While it can offer optimization opportunities, as you might expect, it can also lead to developer error.
There is no way for a user of the object to bypass this mechanism; it is enforced by the language and runtime environment. The hypothetical malicious, careless, or lazy programmer is thwarted, and a possible error is avoided. Because this type of missed-initialization error is generally extremely difficult to track down and identify, avoidance is preferred.
This enforcement of best practices in the procedural realm provides a strong policy-enforcement mechanism at the language level and promotes objects above mere syntactic sugar or convenience.
Applicability
Use Create Object when:
• You wish to provide a data representation and enforce that only certain operations can be performed on any particular instance.
• You wish to provide allocated instances of a data representation and ensure that a set of preconditions is met before use.
Structure
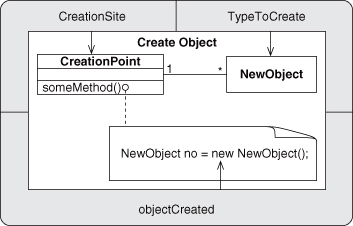
Participants
CreationSite
The object that requests the creation of a new object of type objectCreated.
objectCreated
The object to be created.
TypeToCreate
The type of objectCreated.
Collaborations
An instance of CreationSite requests that a new instance of object, objectCreated, of type TypeToCreate, be created. The exact mechanism for doing so varies among languages, but it generally consists of making the request “of” the object type itself. In reality, the request is given to the runtime environment, with the object type as an argument, but the syntax of most languages creates the appearance that the request is made directly to the object type. This is, as an astute reader will notice, a self-referential definition: you must have an object to be the CreationSite before making a new object. The initial object that kicks off this whole chain comes into play in the runtime mechanism of the language being used. For instance, in Java, the user tells the JVM (Java Virtual Machine) which class to find the main() method in to start the whole system. This is a static method, so it is in the class object for the class, but, still, it’s a class object and satisfies our requirement.
Consequences
Most object-oriented languages do not allow for the creation of data structures using any other method, yet do not require the definition of a developer-supplied initialization routine. A default initialization routine is generally supplied that performs a minimum of setup.
Some languages, although object oriented, allow the creation of nonobject data structures. C++ and Objective-C are two examples, both derived from the imperative C language. Python, Perl 6, and other languages have similar historical reasons for allowing such behavior.
Once an object is created, only the set of methods that were supplied by the developer of the original class are valid operations on that object. See the Inheritance pattern for an example of how to alter this state of affairs.
Objects are disposed of at the end of their useful existence. This deallocation has an analogous function, the deallocator, or destructor, that is called before the storage space of the data is finally released. This function allows any postconditions to be imposed on the data and resources of the object. Although it is also a best practice to have a well-formed and definite deconstruction sequence for objects, it turns out that, from a computational standpoint, deconstruction is a matter of convenience only. With infinite resources at our disposal, objects could continue to exist, unused, for an indefinite amount of time, and we would never accidentally use an old one again. It is only because we have finite resources that destruction of objects is determined essential in most systems. The construction of objects, however, injects them into the working environment so they can be used in computation and is therefore a requirement, not a convenience. Conceptually, some object types may rely on the destruction of objects to enforce certain abstract notions (fixed elements of a set, etc.), but it is a matter for the class designer.
Implementation
In C++:
Listing 5.4 is a basic class showing encapsulation, bundled behaviors, and default state. For excellent advice on creating best practice C++ classes of your own, see Scott Meyers’s Effective C++ [28] and More Effective C++ [29].
Listing 5.4. Create Object Implementation.
class ThreadCount {
2 public:
// Constructors
4 ThreadCount() {
numThreads = getNumberOfRunningThreads();
6 };
ThreadCount(int newData) {
8 numThreads = newData;
};
10
// Accessors
12 int getNumThreads() {
return numThreads;
14 };
ThreadCount setNumThreads(int newData) {
16 if (newData > 1) numThreads = newData; };
};
18 private:
int numThreads;
20 };
22 int
main(int argc, char** argv) {
24 // Instantiate an object
ThreadCount mc;
26
// Already set up and ready to go
28 // Will print out the number of running threads
cout << mc.getPrivateData() << endl;
30
// Won't change the data, value isn't good
32 mc.setPrivateData(-1);
34 // Will change the data, value okay
mc.setPrivateData(100);
36
// Prints out 100
38 cout << mc.getPrivateData() << endl;
};
Related Patterns
Create Object is a core concept in object-oriented programming and as such is found everywhere. Any design pattern that concentrates mainly on the creation or distribution of objects builds off of this EDP. Examples include the Retrieve New and Retrieve Shared patterns in the next chapter and the Creational Patterns found in GoF’s Design Patterns: Abstract Factory, Builder, Factory Method, Prototype, and Singleton [21].
Retrieve
Object Structural
Intent
To use an object from another nonlocal source in the local scope, thereby creating a relationship and a connection between the local scoping object and the nonlocal source.
Motivation
Objects are an established and well-understood mechanism for encapsulating common data and methods and enforcing policy, as shown in Create Object. Singular objects, however, are of extremely limited utility. In fact, if there were only one object in a system, and nothing external to it, it could be considered a procedural program—all data and methods are local and fully exposed to one another. Nonobject data types can be faked in any object-oriented system that supports the use of function objects and methodless classes. It is therefore critical that a well-formed methodology be put into place for transporting objects across object boundaries. There are two situations in which this methodology is necessary, and they differ only slightly. The simplest case is when an external object has an exposed field that is being accessed. The more complex case is when an external object has a method that is called, and the return value of that method is being used in the internal scope.
The simplest form is shown in Listing 5.5, using Java as the example language.
Listing 5.5. Retrieve with an update.
1 public class SoundSettings {
public int volume;
3 // A player specific offset to adjust volume
public int offset;
5 };
7 public class MusicPlayer {
public void setVolume( SoundSettings ss ) {
9 // This is an instance of Retrieve
this.settings.volume = ss.volume;
11 };
private SoundSettings settings;
13 };
If the use of the external data is at the middle of a temporary expression, as in method adjustVolume1 of Listing 5.6, then an equivalent can be considered, as in method adjustVolume2.
Listing 5.6. Retrieve in a temporary variable.
1 public class MusicPlayer {
public void adjustVolume1( SoundSettings ss ) {
3 // This is also a Retrieve
this.settings.volume =
5 this.settings.offset + ss.volume;
};
7 public void adjustVolume2( SoundSettings ss ) {
// Here the Retrieve is explicit
9 int tempVar = ss.volume;
this.settings.volume =
11 this.settings.offset + tempVar;
};
13 };
Applicability
Use Retrieve when:
• A nonlocal object provides access to an object that is required for local computation and the required object is either:
– provided by a method call’s return value or
– provided by an exposed field object.
Structure
Note that selected could be either a method or a public field.
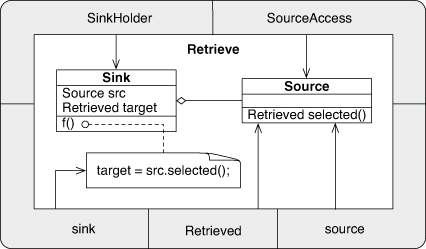
Participants
SourceAccess
The object (or class) type that contains selected.
SinkHolder
The object (or class) type that includes the item, target, to be given a new value.
Retrieved
The type of the value to be updated and the value that is returned.
sink
The field that is given a new value.
source
The method or field that produces the new value.
Collaborations
This simple relationship consists of two objects and two methods. The distinguishing factors are the transferral of a return value into the local object space and an update to a local field using that retrieved object. The local field may be a defined field, or it could be a temporary value in the middle of an expression.
Consequences
Tying two objects and/or types like this is an everyday occurrence, but it should not be done without thought. Any time you bind two objects in this manner, you are introducing a dependency: the target object now relies on the source object. Make sure it’s what you need to do.
In languages with dynamic typing, such as Python, Ruby, or JavaScript, the type roles of SourceAccess, SinkHolder, and Retrieved may not be explicitly shown in all cases. Also, a developer may or may not provide strong typing.
Implementation
In C++:
1 class SourceAccess {
public:
3 Retrieved source();
};
5
class SinkHolder {
7 Retrieved sink;
SourceAccess srcobj;
9 public:
void operation() { sink = srcobj.source(); }
11 };
In Java:
1 public class SourceAccess {
public Retrieved source();
3 };
5 public class SinkHolder {
private Retrieved sink;
7 private SourceAccess srcobj;
public void operation() {
9 sink = srcobj.source();
};
11 };
In Python (note dynamic typing):
1 class SourceAccess(object):
def source(self):
3 pass // Return value here
5 class SinkHolder(object):
def void operation(self):
7 self.sink = self.srcobj.source()
Related Patterns
Retrieve is a fundamental EDP and is found with any other pattern that involves two or more objects, where those objects are brought together at runtime. See the Retrieve New and Retrieve Shared patterns in Chapter 6 for variations on this EDP where object ownership and instantiation are involved.
Inheritance
Type Relation
Intent
To reuse another class’s interface, implementation, and behavior with additions to or alterations of each.
Also Known As
IsA, Type Reuse
Motivation
Often, an existing class provides an excellent start for producing a new class type. The interface may be almost exactly what you are looking for, the existing methods may provide almost what you need for your new class, or, at the very least, the existing class may be conceptually close to what you wish to accomplish.
In such cases, it is useful and efficient to reuse the existing class instead of rewriting everything from scratch. One way of doing so is by copying and pasting the code into a new class. This technique is done quite often, but it has many drawbacks. If a bug is found in the original code, you now have two places to track and maintain the fix. If an enhancement is made to one copy of the code, anyone working on the other code location must be explicitly told that it exists. Copy and paste seems like a quick and easy approach in the beginning, but it doesn’t just tie the copies of code together, it ties the development teams together. In addition, in many cases, you won’t have the source code to copy at all, such as when using a vendor’s development API.
A better way to accomplish this reuse is through the Inheritance pattern. Every object-oriented language supports this approach of code reuse, and it is usually a core primitive of such a language.
At its most basic level, this pattern offers a relationship between a superclass or base class, and a subclass or derived class. The superclass (let’s call it Superclass) is an existing class in the system, one that provides at a minimum an interface of concepts for methods and/or data structures. A second class can be defined as being derived from Superclass; let’s call it Subclass. The Subclass class inherits the interface and implementations of all methods and fields of Superclass, and this provides a starting point for a programmer to begin work on Subclass.
Assume that you are writing a library to display shapes in a graphical interface, such as might be at the core of a game engine. Every shape is going to have some basic information, regardless of what kind of shape it is. It will have a position on the screen, it will have a color, the line that draws its border will have a thickness, and so on. You could add this information, and implement the methods to work with the data, to each and every class that represents a shape. Or, you could use Inheritance as in Listing 5.7. The Shape class sets up the basic information for any shape in the system and provides a basic set of method implementations for working with that data.
You may notice that in the Square class we re-declared the instance method setWidth:andHeight. This is an example of overriding and is a behavior that commonly goes along with Inheritance. Overriding lets you customize certain methods from a base class by providing a new definition of the method. You can use it to change the behavior of an existing method, either by completely replacing it or by augmenting it in new ways. Listing 5.8 demonstrates overriding with Square. We’d like to let clients of both Square and Rectangle still use the setWidth:andHeight interface, since a square is just a special kind of rectangle, but now we have to make sure the sides are the same size. We add a check on the data, and then call the preexisting method from our superclass. There’s no need to completely replace the implementation because we’re just wrapping it in a validity check.3
3. By the way, this calling of the superclass’s version of the same method is an example of the Extend Method EDP. You can read that entry for a more thorough discussion.
Listing 5.7. Basic inheritance example in Objective-C.
1 @interface Shape
{
3 int xPos;
int yPos;
5 int lineWidth;
Color* fillColor;
7 }
- (void) setPosWithX: (int) x andY: (int) y;
9 - (void) setColor: (Color*) c;
- (void) setLineWidth: (int) lw;
11 @end
13 @interface Circle : Shape
{
15 int radius;
}
17 - (void) setRadius: (int) r;
@end
19
@interface Rectangle : Shape
21 {
int width;
23 int height;
}
25 - (void) setWidth: (int) w andHeight: (int) h;
@end
27
@interface Square : Rectangle
29 {
}
31 - (void) setWidth: (int)w andHeight: (int) h;
- (void) setSize: (int) s;
33 @end
Listing 5.8. Overriding an implementation.
1 @implementation Square
- (void) setWidth: (int) w andHeight: (int) h
3 {
if (w == h) {
5 [super setWidth: w andHeight: h];
} else {
7 printf("ERR:␣Width␣!=␣height
");
}
9 }
- (void) setSize: (int) s
11 {
[self setWidth: s andHeight: s];
13 }
@end
Sometimes you need to keep intact the original behavior for code that relies on it, but you want to provide a fixed version moving forward for new code. You can do this by creating a new class that inherits from the original but overrides the broken method and provides a fixed version. Existing code can then continue to use the base class, complete with the bug that it may be working around, but new code can take advantage of the fixed version. As the old code is inspected and tested, it can be migrated to the new version as well.
For instance, assume you have a piece of Java code such as in Listing 5.9. This is a totally artificial example to demonstrate what is commonly called the fencepost error. If you have a fence that’s 100 feet long, with a fencepost every 10 feet, how many fenceposts are you going to need? If you said 10, you’re in good company. Many people forget that there’s an extra fencepost at the zero mark on the fence as well. It is a surprisingly common bug, also known as an off-by-one error. The implementation for fencepostHeights simply returns the height of the requested fencepost. The problem is, the array of heights is zero-based in Java. This means that the first element has an index of 0, the second element has an index of 1, and so on. The problem is that most people don’t think of fences in this way. Assume that client code asks the user which fencepost he or she wants the height of, and then passes the entry to a fence, as in fence.getHeightOfPost(p). The client code must adjust the value of p by subtracting 1 before sending it in, or the result will be the height of the post after the one the user expects. The client code must work around this problem. By the way, it’s easy to argue that an off-by-one error isn’t a bug, that it is how Java arrays work. That much is true. It is also how C and C++ arrays work. The bug isn’t in the code; it is in the miscommunication of intent between the class implementer and the developers who use the class. The developer who implemented the class did so with reasonable assumptions. The client using the class also has reasonable assumptions. They’re just not the same set of assumptions.
Listing 5.9. Implementation assumption mismatch.
public class Fence {
2 int[] fencepostHeights;
public int getHeightOfPost( int post ) {
4 return fencepostHeights[post];
};
6 };
8 ...
Fence fence;
10 // Fence gets filled in at some point
...
12 Scanner scanner = new Scanner (System.in);
System.out.println(
14 "Enter␣fence␣post␣to␣get␣height␣of:");
int p = scanner.nextInt ();
16 System.out.format("Post␣#%d␣has␣height␣of:␣%d%n",
p, fence.getHeightOfPost(p - 1));
18 // Workaround for error ^^^^
Starting with Listing 5.9, what happens when someone realizes the mismatch and decides to fix fencepostHeights (Listing 5.10)?
Listing 5.10. Obvious fix—but likely not feasible.
public class Fence {
2 int[] fencepostHeights;
public int getHeightOfPost( int post ) {
4 return fencepostHeights[post - 1];
// Bug fix for off-by-one ^^^^
6 };
};
Listing 5.11. Fixing a bug while leaving old code in place.
1 public class MendedFence extends Fence {
public int getHeightOfPost( int post ) {
3 return fencepostHeights[post - 1];
};
5 };
This obvious, straightforward, and simple fix just broke every piece of client code that was adjusting the value sent in to getHeightOfPost. Now the client code will be using the height of the post to the left of the expected one. This is probably not as helpful a fix as was intended. If there is a large number of clients, or if they are on different schedules—which is almost always the case—then it’s nearly impossible to coordinate all teams to incorporate the fix at once. The usual outcome in these cases is that the bug perpetuates, and the workaround must be incorporated into every client. This solution is fragile and prone to error.4
4. It also resulted in one of my favorite vanity plates. It was a mid-60s VW Beetle in Seattle with the license plate FEATURE. Because any bug, if left long enough, eventually becomes a feature that someone, somewhere, is relying on.
A better way to fix this is to provide a fixed version of the Fence class that can be used by new clients and to allow old clients to migrate to it on their own schedule. The fix is shown in Listing 5.11, based on the original Fence class in Listing 5.9. Newly developed code can use this version instead. It is cleaner and doesn’t need to remember to adjust the post number. Old client code can continue using the old code until it has time to move to the new MendedFence class. Once all client code is using the new class, it and the old one can be merged into one class for everyone. Note that this fix can also work when the source code for Fence isn’t available. This is common when you’re using a library from another developer.
Applicability
Use Inheritance when:
• An existing class provides an interface, implementation, and data storage that is almost, but not quite, what is needed for a new class.
• Copying and pasting the code from the original class is either undesirable for maintenance reasons or not possible because the original source code is unavailable.
Structure
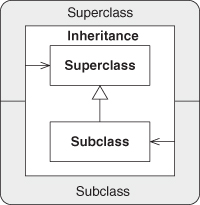
Participants
Superclass
An existing class in a system that is used as a basis for producing a further class.
Subclass
The secondary class that relies on the first for its basic interface and implementation.
Collaborations
The Superclass class creates a basic set of method interfaces with any accompanying optional method implementations. Subclass inherits all the interface elements of Superclass, and, by default, all of the implementations as well, which it may choose to override with new implementations.
Consequences
Inheritance is a powerful mechanism that has some interesting limitations and consequences. For one thing, due to a bit of subtlety at the heart of object-oriented programming theory, a subclass may not remove a method or data field. It can be stated informally, however, that inheritance creates what is called an IsA relationship between the subclass and the superclass. The subclass literally “Is A” specialized version of the superclass. The interface is what constitutes the definition of what the class is, so saying what the superclass is by defining an interface, and then turning around and removing portions of that interface in a subclass, means that the subclass no longer is everything the superclass is. Yes, it’s all rather existential, but that’s object-oriented theory for you. Best to stick with the simpler concept: If the subclass cannot be described without reservation as an instance of the superclass, then do not subclass.
Many languages offer multiple inheritance, allowing a subclass to have multiple superclasses. This effectively allows a subclass to be described as each of the superclasses in turn. For instance, milk is both a fluid and a foodstuff. If a class Milk were to inherit from Fluid, then it could be described by the properties of a Fluid, such as viscosity and freezing point. If Milk also inherited from FoodItem, then you could discuss its nutritional content or expiration date. There are issues to be considered in such situations, however, and many languages reject multiple inheritance in favor of the simpler single-inheritance model.
In some languages, a subclass may hide a method by making it private, but this is not universal. In all languages, a subclass may override a method and simply provide an empty implementation, effectively erasing the behavior while the interface remains the same.
It may seem that overriding is a waste of good code in the base class, and this is true in many cases. The Extend Method pattern solves this problem by overriding a method while still using it.
In some cases, you may not wish to inherit an entire existing class and its interface but instead to inherit only small pieces of functionality. You may lack confidence in the implementations of the method bodies if the original source code is unavailable, you may be reluctant to absorb the cost of integrating a large class into the current system when only a small segment of that class is needed, or you may have a variety of other reasons for using only part of the existing class.
Consider using the Redirection pattern when you wish to retain some, but not all, of an interface. An instance of the class you wish to reuse is placed in the new class using Create Object, and the portion of the interface you want to retain is replicated, as in Listing 5.12. Here, the Square class has effectively removed the setWidth:andHeight method that had to be worked around before. The downside is that you have to implement wrappers for every method you wish to retain, all the way back up the inheritance hierarchy. For instance, Listing 5.12 wraps methods from Shape in Redirection instances.5 You are effectively erasing the unused methods of the original class, but you do not get to take advantage of polymorphism in statically typed languages when you do so. Dynamically typed languages, particularly those that allow for runtime determination of method availability, such as Objective-C and JavaScript, let you play with the typing a bit more loosely, having effective polymorphism among types not in a subclassing relationship. Languages based on prototyping, such as JavaScript, Self, and Lua, offer dynamic typing almost universally and allow ad hoc polymorphism without penalty.
5. You can even say that, as far as the interface is concerned, Inheritance can be considered a gathering together of multiple Redirection pattern instances, with one Redirect object being shared among them.
Listing 5.12. Using Redirection to hide part of an interface.
1 @interface Square
{
3 Rectangle rect;
}
5 - (void) setPosWithX: (int) x andY: (int) y;
- (void) setColor: (Color) c;
7 - (void) setLineWidth: (int) lw;
- (void) setSize: (int) s;
9 @end
11 @implementation Square
- (void) setPosWithX: (int) x andY: (int) y
13 {
[rect setPosWithX: x andY: y];
15 }
- (void) setColor: (Color) c
17 {
[rect setColor: c];
19 }
- (void) setLineWidth: (int) lw
21 {
[rect setLineWidth: lw];
23 }
- (void) setSize: (int) s
25 {
[rect setWidth: s andHeight: s];
27 }
@end
Compare this situation with one in which you want to reuse the implementation and/or data storage of a class but are unsatisfied with the interface and wish to provide a new one. In this situation, you can use an object instance in the new class, much like was done in the Redirection example but access it via the Delegation EDP. Now you are erasing the original interface and providing a new one while still using the underlying data storage and implementation of behaviors. This feature is common in classes that are to be used as facades, those that adapt between interfaces or APIs.
These techniques to work around limitations of Inheritance using a combination of Redirection and Delegation are so common that some languages provide native support for the feature, such as with C#’s delegate keyword.
Implementation
The mechanism for creating an inheritance relationship varies from language to language, but statically typed languages almost always provide clear syntax for doing so. Dynamically typed or prototype-based languages may not always make the relationship explicit.
In C++:
class Superclass {
2 public:
Superclass( );
4 };
6 class Subclass : public Superclass {
public:
8 Subclass( );
};
In Python:
1 class Superclass(object):
def __init__(self):
3 pass
5 class Subclass(Superclass):
def __init__(self):
7 Superclass.__init__(self)
Related Patterns
Inheritance is ubiquitously used. It is a core component of any EDP that uses object type similarities of Subtype or Sibling. In particular, see Trusted Delegation, Deputized Delegation, Trusted Redirection, Deputized Redirection, Revert Method, and Extend Method. In addition, Inheritance is used in the Fulfill Method pattern. Because each of these patterns is fundamental to many other composed patterns, Inheritance is an EDP you should make sure you understand thoroughly.
Also see Delegation and Redirection for further information on how to use those patterns to work around some limitations of Inheritance.
Abstract Interface
Type Relation
Intent
To provide a common interface for applying a behavior in a family of object types but without providing an implementation of the actual operation. In this scenario, subclasses are forced to provide a proper implementation of their own because no default method exists.
Also Known As
Virtual Method, Polymorphism, Defer Implementation
Motivation
Often, when we have a hierarchy of classes using the Inheritance pattern that conforms to our conceptual design, we run into a situation where we simply cannot provide a meaningful method implementation at the root of the class hierarchy. We know what we want to do conceptually, but we are not entirely sure how to go about doing it.
Assume that we are modeling animals. Animals all, roughly speaking, have certain behaviors and needs. They eat, they age, and they (usually) move. What they eat depends on the species, but eating is almost always an act of ingestion of some sort. Some animals may not actually ingest food, but they are rare and special cases. Animals pass through a number of phases as they mature, such as gestation, juvenile, and adult. The details and timing of each stage vary across species, but at least a broad default process of aging can be modeled.
Movement, however, is a bit trickier. We can give a destination location for the animal to move to, but implementing this behavior is a more complex task: fish, birds, and terrestrial animals all have very different modes of locomotion and kinds of locations that they can get to. There’s no overly broad behavior that we can really model here, at least not without requiring a lot of special cases immediately from the beginning. However we choose to implement a moveTo method, we’re going to end up overriding and replacing the implementation more or less completely in most of the subclasses. We’re likely going to end up with something such as in Listing 5.13.
This tells us that perhaps we shouldn’t offer an implementation at all, because no matter what we choose, it’s almost certainly going to be wrong. We want to ensure that every Animal, no matter which subclass describes it, can be asked to move, but we can’t come up with a reasonable default for how to move that would apply to all or even most animals. We want to provide an interface—a defined way of invoking the behavior—but no implementation to define the behavior itself.
Listing 5.13. Animals almost all move but in very different ways.
1 public class Animal {
public void eatFood( FoodItem f ) {
3 this.ingest(f);
this.digest(f);
5 };
public void matureTo ( TimeDuration age ) {
7 if (age > gestation) {
this.beAJuvenile(age);
9 } else if (age > maturation) {
this.beAnAdult(age);
11 } else if (age > longevity) {
this.die();
13 }
};
15 public void moveTo( Location dest ) {
// Um... what to put here?
17 };
};
Recall from the discussion in Inheritance that behaviors in types are provided by the methods that are defined on a type. Therefore, to provide the behavior evenly across all the subclasses, we should provide a method definition, but we’re then stuck because we have no implementation to define the method with.
If we provide an empty implementation body as in Listing 5.13, then we’ve provided a default implementation that simply does nothing. If a subclass fails to override this method, then the poor animal being modeled by that class won’t be able to move at all. Although there are some truly stationary animals, they are the exceptions. Therefore, in cases such as this, we would also like to ensure that the implementors of subclasses are reminded to define a proper implementation, even though we can’t. The solution is to create an Abstract Interface for that method.
Applicability
Use Abstract Interface when:
• Implementation of a method either is not known at class definition time or no reasonable default implementation can be determined.
• The interface for that method can be determined.
• You expect subclasses to handle the functionality of the method according to their special needs.
Structure
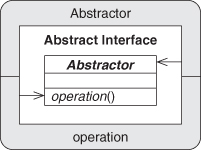
Participants
Abstractor
The class type that declares an interface for operation.
operation
The method being abstracted out: no method definition can be given.
Collaborations
Abstractor defines an interface for a method that all subclasses will implement. (An implicit collaboration occurs between Abstractor and an as-yet unknown subclass here.)
Consequences
The Create Object pattern lets us instantiate objects, and the Retrieve pattern shows how to fill in the fields of that newly created object. Abstract Interface is unusual in that it indicates the absence of a method implementation; instead of showing us how to fill in the method, it shows us how to defer the method definition until another point in the design. See the related Fulfill Method pattern for the rest of the solution.
In this case, the method is declared in order to define the proper interface for our conceptual needs, yet the method body is left undefined. This does not mean that we simply define an empty method, one that does nothing; the method has no definition at all. This is a critical point, and one that is often missed by programmers new to object-oriented languages. How it is done varies from language to language, as you can see from the examples in the Implementation section.
Different languages have different uses of this pattern as well. C++, for instance, asserts that any class type with even a single method that is an Abstract Interface is an abstract class and therefore incapable of being instantiated directly. Only subclasses that provide a definition for the abstract method via the Fulfill Method pattern may be instantiated into objects using Create Object.
Java takes it even further. As with C++, a class may contain one or more abstract methods, making the class abstract. If it contains nothing but abstract methods, however, Java offers the interface construct instead. The term interface here refers to a classlike entity collecting many abstract methods, not the interface of a single method. Like an abstract class, a Java interface cannot be instantiated. Unlike abstract classes, which can have both defined and abstract methods, a Java interface is not allowed to have any defined methods at all. Classes should have at least one defined method, and interfaces are composed of only abstract methods. Although Java has only single inheritance of classes, it offers multiple inheritance of interfaces to allow the composition of new class interfaces at a very fine granularity. See Inheritance for more information on inheritance models.
Python added support for abstract methods only in version 2.6 of the library as a standard library addition in the abc module, which stands for abstract base class. Python 3.0 introduced a slightly more straightforward notation, which you will see in the Implementation section. Unlike Java or C++, Python’s approach allows for a default implementation, which can be called by subclasses, most often using the Extend Method EDP. Subclasses, however, still must override the method and provide their own implementation.
Implementation
In C++ the method is set equal to zero and called a pure virtual method:
class AbstractOperations {
2 public:
virtual void operation() = 0;
4 };
6 class DefinedOperations :
public AbstractOperations {
8 public:
void operation();
10 };
12 void
DefinedOperations::operation() {
14 // Perform the appropriate work
};
In Java the method is included in an interface or is in an abstract class:
1 public interface AbstractOperations {
public void operation();
3 };
5 public abstract class SemiDefinedOperations {
public abstract void operation2();
7 public void operation3() {};
};
9
public class DefinedOperations
11 extends SemiDefinedOperations
implements AbstractOperations {
13 public void operation() {
// Perform the appropriate work
15 }
public void operation2() {
17 // Perform the appropriate work
}
19 };
In Python 3.x:
1 class AbstractOperations(metaclass=ABCMeta):
@abstractmethod
3 def operation(self, ...):
// Default implementation allowed
5 return
7 class DefinedOperations(AbstractOperations):
def operation(self, ...):
9 // Perform the appropriate work
pass
Related Patterns
Inheritance will obviously be used in conjunction with this EDP to set up the subclass that will provide an implementation for the method used in Abstract Interface. See the Fulfill Method pattern in Chapter 6 for the complete story on how to go about doing so.
Delegation
Object Behavioral
Intent
To parcel out, or delegate, a portion of the current work to another method in another object.
Also Known As
Messaging, Method Invocation, Calls, The Executive
Motivation
In the course of working with objects, the situation often arises that “some other object” can provide a piece of functionality we want to have. Delegation embodies the most general form of a method call from one object to another, allowing one object to send a message to another, to perform some bit of work. The receiving object may or may not send back data as a result.
As a real-world example, consider how a corporation works. The CEO’s goal is to successfully run a company. She assigns subordinates to handle different parts of it, and rarely are any two subordinates in charge of the same part of the operation. The vice president of finance, for instance, ensures that the financial reporting meets government standards, the CTO makes sure the technology needs of the company are addressed, and so on. Each job is discrete and differs greatly from the others as well as from the responsibilities of the CEO, but the success of the company as a whole relies on the synergy of all of its parts. Listing 5.14 shows a bit of code that models this approach.
Listing 5.14. CEO delegates out responsibilities.
public class CEO {
2 FinanceExec vpFinance;
ResearchExec vpResearch;
4 TechnologyExec cto;
public void runCompany () {
6 vpFinance.ensureFinancialCompliance();
vpResearch runResearchDivision();
8 cto.manageTechnology();
};
10 };
One interesting point to make here is that the routine in Listing 5.14 is an example of synchronous method calling. In this Java code, when runCompany is invoked, the vice president of finance is asked to manage the finances, and only when he is finished reporting is the vice president of research asked to start his task. The tasks are synchronized by the calling task. First one, then the other, and execution is done in a specific order.
In real life, of course, this isn’t how the CEO performs her job. She asks all the executives to go do their jobs and to do them at the same time. Then, when each is done, he or she reports back on his or her own schedule. This is an example of asynchronous execution. The delegates are told to go off and do their own thing, in parallel.
Such asynchronous, or parallel, processing is not a simple feature to perform in most object-oriented languages, although some do offer threading libraries, such as Java’s FutureTask API, to fulfill this need. Other languages, particularly functional languages such as Go and Erlang, have native support for concurrency and parallel features via asynchronous calls, but their syntax is, as you might expect, radically different. Whether it is referred to as asynchronous calling, concurrent programming, or parallel programming, it is an entire discipline beyond the scope of this book. Note, however, that every EDP described in this text is applicable as an asynchronous call.
Delegation is a common enough component of design and functionality that C# offers the delegate keyword. This language feature encapsulates a function in an object such that it can be passed around as if it were a regular object. This delegate object then becomes callable as a regular method would be. The enclosing object is essentially invisible.6 The point here is that this feature makes no assertions and imposes no restrictions on the method being wrapped other than that it match a predefined set of types for the arguments and return value. The delegate object being called upon is obviously dissimilar from the calling object, the object types have nothing to do with one another, and the method being wrapped may or may not be named anything like the method doing the calling. This truly is the most general possible case and an example of Delegation.
6. C++ offers something similar in the functor concept using operator() as the calling mechanism, but C# takes the next step to allow for ad hoc wrapping of preexisting methods for passing around in this manner.
Applicability
Use Delegation when:
• Another object can perform some work that your current method body wishes to have done.
• The other object does not need access to the private data in the current object to complete the task.
• There is no known relevant type relationship between the two objects.
Structure
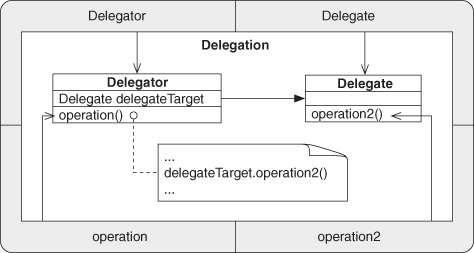
Participants
Delegator
The object type sending the message to the Delegate.
operation
The method within the Delegator that is currently being executed when the message is sent—the point of invocation of the operation2 method call.
Delegate
The object type receiving the message, with an appropriate method to be invoked.
operation2
The method being invoked from the call site.
Collaborations
This is a simple binary relationship: one method calls another, just as in procedural systems, and with the same sorts of caveats and requirements. Because we are working in an object-oriented realm, however, we have a couple of additional needs. We require the object being called to be visible at the point of invocation, whether by being a locally scoped object variable, or by access through Retrieve. Also, obviously, the method being called must be visible to other objects.
Consequences
All operations between any two objects can be described as an instance of the Delegation pattern, but being able to describe further attributes of the relationship is much more useful. See the remaining Method Invocation EDPs for refinements of Delegation that are better suited to specific tasks and needs. This generalized form of a method call, however, is a crucial concept in some of the higher abstractions such as Bridge, or Adapter in its object-variant form, where the point is to create a well-formed and effective translation between two interfaces that are otherwise unrelated. If the interfaces are related in a methodical manner, then these patterns are not necessarily the right ones to use. The lack of relation between the interfaces and types is a required trait, therefore, and Delegation fulfills that need.
Implementation
The most generalized and basic style of method invocation in object-oriented programming, Delegation describes how two objects communicate with each other, as the sender and receiver of messages, performing work and returning values.
In C++:
class Delegator {
2 public:
Delegatee target;
4 void operation() {
// Work may be done before...
6 target.operation2();
// Work may be done after...
8 };
};
10
class Delegatee {
12 public:
void operation2();
14 };
Related Patterns
Delegation is ubiquitous in object-oriented programming. If no other Method Invocation EDP applies, this is the most general form that will be the default. Immediately related EDPs include those reached through minor changes to Delegation. By altering the method similarity to similar, you arrive at Redirection. Changing the object type similarity to similar gives you Delegated Conglomeration. Modifying only the object similarity doesn’t give us anything particularly meaningful, because it would result in a single object having two dissimilar types imposed on it simultaneously. Delegation is often found in conjunction with Retrieve, which provides the object to be called upon.
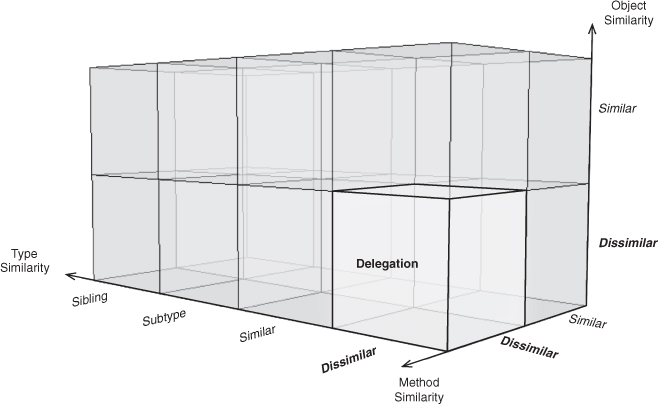
Method Call Classification
Object: Dissimilar
Object Type: Dissimilar
Method: Dissimilar
Redirection
Object Behavioral
Intent
To request that another object perform a tightly related subtask to the task at hand, perhaps performing the basic work.
Also Known As
Tom Sawyer, Shop Foreman
Motivation
A small refinement to Delegation, Redirection takes into consideration that methods performing similar tasks are often named similarly. We can take advantage of this to clarify the intent of this pattern over the more general form and show cases where it is applicable.
An example for this pattern is Tom Sawyer, a literary figure who was famous for convincing other people to do his tasks for him [39]. Unlike the Executive alias of Delegation, Tom generally sought to have others do exactly the task he was asked to do. The common anecdote involves Tom being asked to paint his aunt’s fence. He didn’t want to do the work himself, so he convinced a group of friends to do it for him. He could have had one friend handle paint buckets, another prep the fence, and so on, and the workflow would have looked a lot like that of an executive. Instead, he decided the best way of dividing the work was to have each friend perform the same task: paint the fence. Tom made sure that each person had the right tools and enough paint and that the task was completed, but he did not perform the task himself. Those he asked to paint the fence each did the same task Tom was asked to do—they just did smaller portions of it.
So it is with Redirection. Use Redirection when a job can be broken down into smaller subtasks that have the same basic motivation and intent as the main task. Note that the behavior may be radically different across the methods but that intent is the same. Tom didn’t paint—he handed out paint and brushes—but his intent was to get the fence painted. Likewise, the people working for him intended to paint the fence—they were just concerned with smaller sections of it. Listing 5.15 shows an example in Java: Tom directs each of his friends to paint the fence when he’s asked to do it.
Listing 5.15. Tom paints the fence with help.
public class Friend {
2 public void paintTheFence(int beg, int end) {
// Do the painting
4 };
};
6
public class TomSawyer {
8 // Friends are collected elsewhere
java.util.ArrayList<Friend> friends;
10
// Paint the fence from beg to end
12 public void paintTheFence(int beg, int end) {
int fenceLength = end - beg;
14 int subfence = fenceLength / friends.size();
int friendBeg = beg;
16 for (Friend f : friends) {
int friendEnd = friendBeg + subfence - 1;
18 f.paintTheFence(friendBeg, friendEnd);
// ^--- Redirect
20 friendBeg = friendEnd + 1;
}
22 };
};
This setup is similar to what we saw back in Chapter 2, Section 2.2.4, with the shop foreman painting cars. Notice that in neither case is the calling method actually doing the work requested, although it certainly is possible. Whether the calling method is acting purely as a router, a foreman, or a manager, or whether it is involved in actually performing the task is immaterial.
At other times, the caller may have a slightly different idea of what the task to be completed is and ask someone else to do the bulk of the work, and the caller will then either perform prep work or do cleanup afterwards. If you’re painting a room, there are two ways you can go about doing it. You can either dive in and start painting with a brush—and hope you don’t slop too much paint on lightswitches, molding, outlets, and the like—or you can take time to carefully prepare the room by laying down tarps properly taped to the baseboards, removing the lightswitch and outlet plates, taping all the molding edges, and carefully replacing everything and removing the tape and tarps afterwards.
Someone who is lightning fast and good at applying a coat of paint isn’t necessarily going to be the person who is careful and methodical about prep work and cleanup. They’re both painting the room, but one person’s concept of how to go about doing it is to maximize speed, while the other person’s focus is on quality. It would be great to do both where you can. In cases such as this, you can have the careful person perform the prep work and cleanup, and then that person can ask someone else to do the actual painting for speed. Now the prep and cleanup person is free to go prep another room while the first one is being painted. This process can be modeled synchronously as something like Listing 5.16.
Listing 5.16. Prep work and cleanup are important.
1 class SloppyFastPainter {
public:
3 void paintRoom( Room r ) {
// Paint the walls
5 };
};
7
class CarefulPainter {
9 SloppyFastPainter sloppy;
public:
11 void paintRoom( Room r ) {
// Laydown tarps in room
13 // Remove hardware from room
sloppy.paintRoom( r ); // Redirect
15 // Replace hardware in room
// Clean up room
17 };
};
Unfortunately, there is an opportunity for confusion here. Used in the general sense, the word delegate simply means to hand off part of a workload to someone else. That most general sense is what the Delegation EDP defines. Every method-call EDP is a specialization of delegation, but Redirection is the most likely one to be mistakenly described as Delegation. This confusion is quite understandable, as the term delegation is used in a number of ways in software engineering. Just remember that even C# has adopted the term delegate for the most general case, using it as a keyword wrapping a method to be passed around while leaving open all three of the similarity axes we defined in this text. Delegation is used for handing off to any other method, while using Redirection is a bit more specific.
Applicability
Use Redirection when:
• Another object can perform some work that your current method body wishes to have done.
• The other object does not need access to the private data in the current object to complete the task.
• There is no known relevant type relationship between the two objects.
• That target object has a method that has a similar intent, expressed through its signature name after Kent Beck’s Intention Revealing Selector pattern.
Structure

Participants
Redirector
The originating site of the method call contains a method named operation, which has a subtask to be parceled out to another object. This object, redirectTarget, is a field element of type Redirectee.
Redirectee
The type of the receiver of the message, which performs the subtask asked of it.
operation
Redirector’s operation calls redirectTarget. operation to perform a portion of its work, and thereby invokes Redirectee’s version of operation.
Collaborations
As with Delegation (and indeed all the Method Invocation EDPs), Retrieve describes a binary relationship between two objects and their enclosed methods. In this case, it defines a relationship between two dissimilar objects of dissimilar types, using a call between similar methods. The similarity of the naming, and therefore assumed intent, provides a clue to the nature of their relationship.
Consequences
Even though Retrieve is almost identical to the Delegation pattern, the seemingly small additional requirement that the methods be similar has some far-reaching effects. We will see in later patterns that when this pattern is combined with other EDPs and typing information, complex interactions can quickly be formed and described simply.
By leveraging the facts that both methods have the same name and that this is a common way of declaring the intent of a method, we can deduce that the two methods have a common functional intent. Furthermore, it becomes obvious that this is an appropriate way to indicate that our originating call-site method is requesting the invoked method to do some portion of work, and that work is tightly related to the core functionality of the original method.
The object being called upon may reside in or be owned by the calling method, the object enclosing the calling method, or it may come from elsewhere via a use of Retrieve. The Implementation section shows multiple forms.
If done carefully, this behavior can be used to form an ad hoc variant of Inheritance by stitching one object to another with the same (or very similar) interface using multiple Redirection instances with a single target object. The calling methods may just pass through to the Redirectee, mimicking an inherited implementation, or they may provide their own method body, mimicking the overriding of an inherited implementation, but breaking the Redirection. If they both provide their own method body, and in that body call the appropriate target method in the Redirectee, then not only is this a Redirection, but it is also an ad hoc form of the related Extend Method.
Implementation
In Java:
public class Foo {
2 public void operation();
};
4
public class Bar {
6 Foo f;
public void operation() {
8 Foo f2;
f.operation(); // Redirect
10 f2.operation(); // Redirect
};
12 };
In Objective-C, illustrating the use of Retrieve to get the reference to the Redirectee:
@interface Foo
2 {
}
4 -(void) operation;
@end
6
@implementation Foo
8 -(void) operation {
// Do work
10 };
@end
12
@interface Goo
14 {
Foo* f;
16 }
-(Foo*) getFoo;
18 @end
20 @implementation Goo
-(Foo*) getFoo {
22 return f;
};
24 @end
26 @interface Bar
{
28 Goo* g;
}
30 -(void) operation;
@end
32
@implementation Bar
34 -(void) operation {
[[g getFoo] operation]; // Redirect on Retrieve
36 }
@end
Related Patterns
Redirection is another very general EDP. It differs from Delegation only in that the methods now have a similarity of intent and naming. Alter that similarity, and you’re back to Delegation. Also see Retrieve for advice on how to let the target object vary at runtime by tightening the object type similarity. As with Delegation, changing just the object similarity to similar while leaving the object type similarity as dissimilar results in an unknown state.
Method Call Classification
Object: Dissimilar
Object Type: Dissimilar
Method: Similar

Conglomeration
Object Behavioral
Intent
To bring together, or conglomerate, diverse operations and behaviors in order to complete a more complex task within a single object.
Also Known As
Decomposing Message, Helper Methods
Motivation
An object is often asked to perform a task that is too large or unwieldy to be performed within a single method. Usually, it makes conceptual sense to break the task into smaller parts to be handled individually as discrete methods, and then build them back into a whole result by the method responsible for the larger task. Kent Beck refers to this as the Decomposing Message pattern [5]. It may also happen that related subtasks can be unified into single methods, resulting in the reuse of code inside a single object.
The recomposition of smaller actions by Conglomeration has several benefits. It refines the granularity of actions that can be triggered by having each method perform less work. This can improve maintainability by allowing these methods to be reused in multiple places without copying and pasting the code in several places. Additionally, other objects may be able to use portions of the behavior in new ways if these fine-grained methods are made publicly visible.
Consider the example in Listing 5.17, which builds on one of the code examples from Redirection. We recognized that the method for painting a room is simply too long; there are too many steps to be taken, and the code is easier to read if it is broken up into smaller tasks. We make the subtask methods publicly available because it becomes obvious that the actions of setting up and cleaning up a room are valuable and can be requested independently of the act of painting a room. Now, the CarefulPainter can do the preparation before a ceiling refinisher or a drywall sander comes in and can also perform the cleanup afterwards. What was once inextricably part of the paintRoom behavior is now broken out into useful smaller actions.
Listing 5.17. Prep work and cleanup are decomposable.
1 class SloppyFastPainter {
public:
3 void paintRoom( Room r ) {
// Paint the walls
5 };
};
7
class CarefulPainter {
9 SloppyFastPainter sloppy;
Room currentTarpRoom;
11 Room currentHardwareRoom;
public:
13 void paintRoom( Room r ) {
this->laydownTarps( r ); // Conglomeration
15 this->removeHardware( r ); // Conglomeration
sloppy.paintRoom( r );
17 this->replaceHardware();// Conglomeration
this->cleanUp(); // Conglomeration
19 };
void laydownTarps( Room r ) {
21 this->currentTarpRoom = r;
// Laydown tarps
23 };
void cleanUp() {
25 // Clean currentTarpRoom
// Relinquish currentTarpRoom
27 };
void removeHardware( Room r ) {
29 this->currentHardwareRoom = r;
// Remove hardware
31 };
void replaceHardware() {
33 // Replace hardware in currentHardwareRoom
// Relinquish currentHardwareRoom
35 };
};
In doing so, we had a decision to make. We could have allowed the room to be sent along as a parameter to each and every of the subtasks. This allows for the greatest flexibility, but let’s assume for a moment that there are employer and union regulations at work here, and one is that, for accountability reasons, the same person must perform the preparation and finalization tasks. This prevents, say, hardware lost during removal from being blamed on the person replacing it, and so on. Each person finishes the job he or she initiated. Not properly tracking this data can, however, lead to confusion.
If an unorganized site manager had several CarefulPainters running around and was responsible for telling them which room to go do each step in, they could accidentally send one to clean up a room that another had prepped. Instead, we choose to make the room information private to each CarefulPainter. Think of this as if the site manager tells a worker to go laydownTarps and hands him or her a chit with the room number. The chit is kept in the worker’s pocket, and when told to cleanUp, he or she simply refers to the chit to make sure the right room gets cleaned up. Once completed, the worker relinquishes the chit and is ready for another room. The data the chit represents is private to the worker and ties together separate tasks that worker can be asked to do.
Conglomeration is powerful, but it can cause issues if taken too far. The illogical conclusion would be to place every statement within its own method, but it should be obvious why that’s a bad idea. Any time Conglomeration is applied, a balance must be struck between the necessity for fine granularity and the simplification and efficiency of directly expressed code. Finding the proper “atomic behavior” requires knowing how large your atoms must be.
Applicability
Use Conglomeration when:
• A large task can be broken into smaller subtasks.
• The subtasks must be performed on a single object instance, usually due to shared private data or state.
• Several subtasks may be unified into a single method body.
Structure
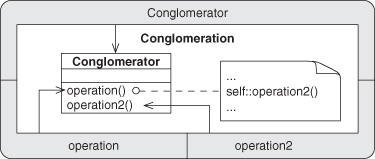
Participants
Conglomerator
Enclosing object type.
operation
Master controlling method that parcels out subtasks.
Subservient method performing a particular subtask.
Collaborations
In a specialization of Delegation, the object calls a method of itself. The calling site is operation, and the method being called is operation2.
Consequences
As with Delegation, this pattern ties two methods into a reliance relationship in which operation relies on the behavior and implementation of operation2. In this case, unlike Delegation, there may be immediate side effects on shared data within the confines of the object that they share.
Implementation
In Java:
public class Conglomerate {
2 public void operation() {
// Optional prep work
4 operation2();
// Optional finish work
6 };
public void operation2() {};
8 }
In Python:
class Conglomerate:
2 def operation(self):
# Optional prep work
4 self.operation2();
# Optional finish work
6 def operation2(self):
# Requested behavior
8 pass
Related Patterns
Conglomeration ties methods within a single object together and therefore is the first EDP we’ve seen that doesn’t have a form that relies on Retrieve. Modifying the object similarity so that the call is to another object, while retaining the same object type similarity, results in a use of Delegated Conglomeration. Reversing this to retain the object similarity, and changing the object type similarity to a subtyping relationship leads to Revert Method. This may sound a bit bizarre—having the same object but not the same type—but read the Revert Method specification for why this is not only possible but also highly useful. On the other hand, keeping the object similarity but changing the object type similarity to completely dissimilar is, at this juncture, ill formed. Finally, changing the method similarity such that the call is to a similar method results in Recursion.
Conglomeration will appear anywhere that an object is breaking down a task internally, but for a rather unique use of this EDP, see Template Method in Chapter 7.
Method Call Classification
Object: Similar
Object Type: Similar
Method: Dissimilar
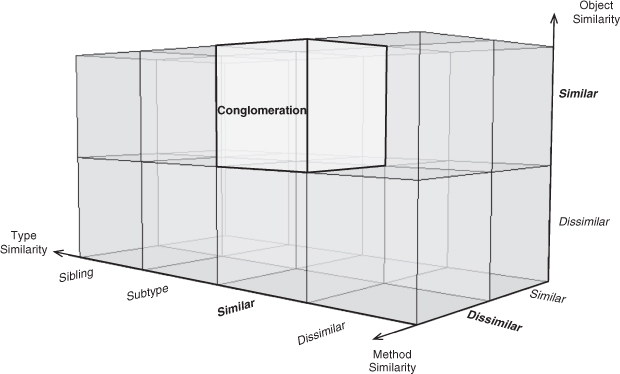
Recursion
Object Behavioral
Intent
To accomplish a larger task by performing many smaller and similar tasks while using the same object state.
Motivation
Sometimes, after consideration, we find that a problem can be broken down into subtasks that are identical to the original task, except on a smaller scale. Sorting an array of items using the merge sort algorithm is one such example. Merge sort takes an array and divides it into halves, sorting each individually, and then merges the two sorted arrays into a unified whole. The two half-problems are also sorted using merge sort, so they are subject to the same halving of the problem, and so on. Eventually, arrays of a single item are reached, at which point the merging begins.
The process by which a method calls itself is known as recursion, and it is ubiquitous in general programming. The same principle applies in object-oriented programming, but we have the additional requirement that the object must be calling on itself through implicit or explicit use of self. You’re almost certainly familiar with this concept, but it has a specific placement and context within the EDP catalog.
Generally speaking, recursion is a way of folding a large amount of computation into a small conceptual space. Assume we want to sort an array, and we decide that a simple way to sort a large array is to split it into two arrays of similar size and then merge the two subarrays after they are individually sorted. The merging will be easy: if the head of array A is less than the head of array B, then the head of A is copied to the new, larger array; otherwise, the head of B is copied. The copied item is removed from the appropriate array, and the process is repeated until both arrays are merged.
Because the merge sort scheme relies on the proper sorting of the sub-arrays, we correctly surmise that we can perform the sort algorithm on the two subarrays by splitting, sorting, and then merging each in turn. We are again faced with the same sorting problem, so we continue in the same manner until we reach the smallest indivisible array: a single item. At that point, the process of merging the sorted subarrays at each step can begin.
Assume we have an Array class that contains the usual methods of add and remove. If the length of the beginning array was 4 items, then we could hardcode the entire sorting as in the following pseudocode, remembering that in an object-oriented system we should have an enclosing class or object by default.
class ArrayOfLength4Library {
2 Array sort_merge(Array a) {
Element a11 = a[0];
4 Element a12 = a[1];
Element a21 = a[2];
6 Element a22 = a[3];
Array a1, a2, res;
8 // Sort first half
if (a11 < a12) {
10 a1.add(a11);
a1.add(a12);
12 } else {
a1.add(a12);
14 a1.add(a11);
}
16 // Sort second half
if (a21 < a22) {
18 a2.add(a21);
a2.add(a22);
20 } else {
a2.add(a22);
22 a2.add(a21);
}
24 // Merge
if (a1[0] < a2[0]) {
26 res.add(a1[0]);
a1.remove(0);
28 } else {
res.add(a2[0]);
30 a2.remove(0);
}
32 if (a1[0] < a2[0]) {
res.add(a1[0]);
34 a1.remove(0);
} else {
36 res.add(a2[0]);
a2.remove(0);
38 }
if (a1.length == 0) {
40 res.add(a2[0]);
res.add(a2[1]);
42 }
if (a2.length == 0) {
44 res.add(a1[0]);
res.add(a1[1]);
46 }
if (a1.length == 1 && a2.length == 1) {
48 res.add(a1[0]);
res.add(a2[0]);
50 }
return a;
52 };
};
While highly efficient, this solution has an obvious drawback: it is limited to only working for arrays of length 4. A much more flexible version is one using looping. Here we illustrate a for loop implementation, assuming for simplicity that the length of the array is a power of 2:
1 class ArrayOfPower2LengthLibrary {
Array sort_array(Array a) {
3 // Slice a into subarrays
subarray[0][0] = a;
5 for (i = 1 to log_2(a.length())) {
for (j = 0 to 2^i) {
7 prevarray = subarray[i-1][floor(j/2)]
subarray[i][j] = prevarray.slice(
9 ((j mod 2) *
(prevarray.length() / 2)),
11 ((j mod 2) + 1) *
(prevarray.length() / 2))
13 }
}
15 // Sort subarrays and merge
for (i = log_2(a.length()) to 1) {
17 for (j = 2^i to 0) {
subarray[i-1][j] =
19 max(subarray[i][j],
subarray[j][i]);
21 }
}
23 return subarray[0][0];
};
This solution succeeds in making our algorithm much more flexible, but at a cost of making it almost unreadable because of the overhead mechanisms. Note that we are looping inward to the base case (length of array is a single unit), storing state at every step, then looping outward using the state previously stored. This process of enter, store, use store, and unroll is precisely what a function call accomplishes. We can use this fact to vastly simplify our implementation using Recursion:
class ArrayLibrary {
2 Array sort (Array a) {
return sort_array(a,
4 a.begIndex(), a.endIndex());
}
6 Array sort_merge(Array a, int beg, int end) {
if (a.length() > 1) {
8 Array firstHalf =
sort_array(a, beg, end-beg/2);
10 // ^--- Recursion (implicit self)
Array secondHalf =
12 this->sort_array(a,
(end-beg/2) + 1, end);
14 // ^--- Recursion (explicit self)
return merge(firstHalf, secondHalf);
16 } else {
return a;
18 }
};
20
Array merge(Array a, Array b) {
22 Array res;
while (b.length() > 1 || a.length() > 1) {
24 // If a or b is empty, then a[0] or b[0]
// returns a min value
26 if (a[0] < b[0]) {
res.add(a[0]);
28 a.delete(0);
} else {
30 res.add(b[0]);
b.delete(0);
32 }
}
34 return res;
};
36 };
This version is conceptually cleaner and performs the same task as our looping variation. We allow the runtime of the language to handle the overhead for us. As a bonus, we’re no longer limited to certain lengths. Not only is the code cleaner, it is highly generalized.
There are times, such as in a high-performance embedded system, when that manner of overhead handling may be excessive for our needs. In such cases, optimizing away the recursion into loops, or further into linear code, is a possibility. These instances are extreme, however, and tend to be highly specialized. In most cases, the benefits of Recursion—conceptual cleanliness and simple code—greatly outweigh the small loss of speed.
Applicability
Use Recursion when:
• A task can be divided into highly similar subtasks.
• The subtasks must be, or are preferred to be, performed by the same object, usually because of a need for access to common stored state by both the calling and called methods.
• A small loss of efficiency is overshadowed by the resulting gain in simplicity.
Participants
Recursor
Recursor has a method that calls back on itself within the same instantiation.
operation is the method that calls itself, through self.operation(), whether implicitly or explicitly.
Structure
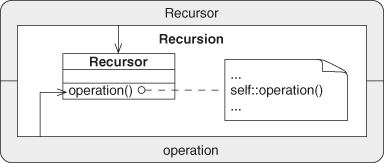
Collaborations
Recursor’s method operation collaborates with itself, requesting that smaller and smaller tasks be performed at each step, until a base case is reached, at which point results are gathered into a final result.
Consequences
The reliance of Recursion on a properly formed base case for termination of the recursion stack is the weakest point of this pattern. It is nearly impossible in most modern systems to wantonly consume all available resources, but recursion can do it easily by having a malformed base case that is never satisfied.
Implementation
In Java:
1 public class Recursor {
public void operation() {
3 // Optional prior work
self.operation();
5 // Optional finish work
};
7 }
Related Patterns
Recursion is perhaps the least general method-call EDP, in that it specifies that object, object type, and method similarity are all set to similar. Each can be relaxed to reach new EDPs. Conglomeration is achieved by using other methods within the same object and object type while using methods that are dissimilar to the caller. (The final sort_merge example from earlier contains instances of Conglomeration, including the call from sort to sort_merge and the call from sort_merge to merge.) Retaining the method similarity but allowing the call to occur to other instances of the same object type results in a Redirected Recursion, a concept commonly seen in chains of objects. Perhaps the most interesting neighbor EDP of Recursion is Extend Method, which is encountered when the method and object similarity are preserved but the object type similarity is set to a subtyping relationship.
Finally, there is a specialized use of Delegation: when two objects mutually call each other via two different methods to work through a task together, but with separated private data. Object A’s method f() calls method g() on object B, and in turn g() calls method f() on object A. This is known as mutual recursion because each method calls itself indirectly. While not a true example of Recursion, it is conceptually similar enough to warrant mentioning.
Method Call Classification
Object: Similar
Object Type: Similar
Method: Similar
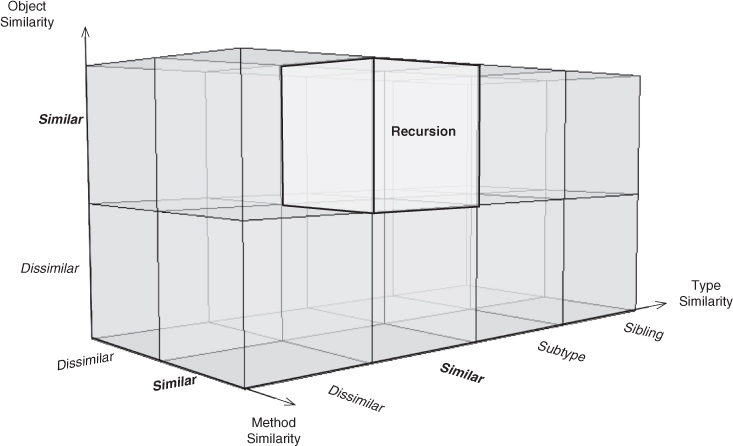
Revert Method
Object Behavioral
Intent
Bypass the current class’s implementation of a method, and use the superclass’s implementation instead, reverting to less specialized method body.
Motivation
Polymorphism sometimes works against us. In the pattern specification for Inheritance, you learned how reducing maintenance issues during reuse of an implementation is a driving factor for that pattern. Fixes applied to the base implementation for a method are auto applied to subclasses, but subclasses are allowed either to override existing methods or add new functionality through Extend Method. We don’t always want fixes to be propagated automatically, however, and we’re not always calling a similar method. Sometimes we need to use prior implementations of a method from higher up our inheritance tree instead of the one local to our class definition.
One such instance is when providing multiple versions of classes for simultaneous use within a system. Imagine a library of classes for an Internet data transfer protocol. A base library is shipped as 1.0. With the 1.1 library, changes to the underlying protocol are made, and an application using the 1.1 protocol must be able to fall back to the 1.0 protocol when it detects that the application at the other end of the connection is only 1.0 enabled.
One approach would be to use polymorphism directly and define a base class that abstractly provides the protocol’s methods, as in Figure 5.1, and create the proper class item on protocol detection. Unfortunately, this approach does not offer a lot of dynamic flexibility and would not allow a protocol to adapt on the fly to changing demands.
Figure 5.1. Polymorphic approach
Although it makes setting up a connection with client using the older protocol simple, it makes graceful degradation of the connection in case of an error more problematic. Let’s say you’re transmitting a video stream, and if network conditions are good and latency is low, then a new processor-intensive compression algorithm for the data can be brought to bear. If latency is high, however, then the CPU time needed for decompression at the other end would cause skipping. If you notice that the network is congested, you drop down to the older compression system.
You could instantiate objects of each protocol type and swap to earlier versions as needed, but protocol state issues might arise and be troublesome. Converting from one protocol handler class to another would require instantiating a new object of the new class and then copying over any private data each and every time a possible protocol shift was needed. Hopefully this data can be held exclusively in the ProtocolBase class, but even then there has to be a breaking of strict encapsulation of the private data to accomplish the copy. Further, this splits the protocol knowledge between the Protocol classes and the Controller class, as shown in Listing 5.18. The former classes implement that actual behavior, but the latter has to know when each behavior is appropriate.
Listing 5.18. Instance swapping for protocol fallback in C++.
1 class CommonData{};
class RawData{};
3 class Video{};
5 class Connection{
public:
7 bool lowLatency(); // is network in good shape?
void transmit(RawData);
9 };
11 class RemoteEnd {
public:
13 int protocolVersion();
};
15
// Protocol handler classes:
17 class ProtocolBase {
protected:
19 CommonData data;
int d_version;
21 Connection connection;
public:
23 virtual
Connection initConnection(RemoteEnd otherSide);
25 Connection getConnection() {
return connection;
27 };
virtual void sendData(Video vid) {
29 connection.transmit(compress(vid));
};
31 int version() { return d_version; };
CommonData getData() { return data; };
33 virtual RawData compress(Video vid) = 0;
};
35
class Protocol1dot0 : public ProtocolBase {
37 public:
Protocol1dot0() {
39 d_version = 1.0;
};
41 Protocol1dot0(ProtocolBase* base) {
d_version = 1.0;
43 this->data = base->getData();
};
45 RawData compress(Video vid);
};
47
class Protocol1dot1 : public ProtocolBase {
49 public:
Protocol1dot1() {
51 d_version = 1.1;
};
53 Protocol1dot1(ProtocolBase* base) {
d_version = 1.1;
55 this->data = base->getData();
}
57 RawData compress(Video vid);
};
59
class Controller {
61 ProtocolBase* handler;
public:
63 void setupConnection(RemoteEnd otherSide) {
if (otherSide.protocolVersion() == 1.0) {
65 handler = new Protocol1dot0();
} else {
67 handler = new Protocol1dot1();
}
69 handler->initConnection(otherSide);
};
71 void sendData(Video vid) {
bool networkGood =
73 handler->getConnection().lowLatency();
if (networkGood &&
75 handler->version() == 1.0) {
// fall forward
77 handler = new Protocol1dot1(handler);
} else if (!networkGood &&
79 handler->version() == 1.1) {
// fall back
81 handler = new Protocol1dot0(handler);
}
83 handler->sendData(vid);
};
85 };
This is a tremendous amount of overhead being placed in each of the methods in Controller. We could have tried to put all of this controller logic in to the ProtocolBase class, and at first glance that looks like it could work. However, it requires that the ProtocolBase class know about all of the subclasses, which is fairly poor design in general. It also means that ProtocolBase must be updated anytime a new protocol is defined. If this class is shipped in a precompiled library for clients to use, then the clients cannot extend the library for new protocol versions.
In addition, this approach doesn’t easily allow for code reuse for the actual implementation. If Protocol 1.1 is just a small tweak off of Protocol 1.0, then it would be nice if we could reuse 1.0’s behavior, which would probably be done by hoisting the common code into the base class and allowing it to be called from each subclass. This approach is likely to work well for two subclasses. Once we start getting into more subclasses, protocol versions, and special cases, however, it is likely to become cumbersome. The likelihood of a common core of code being definable goes down quickly.
It fast becomes apparent that graceful dynamic fallback and fallfoward is not well supported by this approach.
Instead, we can have each new protocol version subclass from the prior protocol version so that only the necessary changes to the protocol need to be implemented. This lets us have only a single class to deal with when we first figure out the best possible protocol that each end might be able to support, but we still need to be able to revert to the previous version. Figure 5.2 shows an extended variant of this approach, including several versions.

Figure 5.2. Subclassing approach
An example of this approach is shown in Listing 5.19 with just two classes. The supporting classes are as in Listing 5.18. In this case, we can instantiate an object of just the last class in the chain, and conditional statements in the code will pass the protocol handling back up the chain to the appropriate version if needed. This vastly simplifies further maintenance of the code that supports this protocol because only the instance(s) of the protocol-handling object need to be changed to the latest version anytime a new update to the library comes out, and all the graceful degradation is therefore handled automatically.
Listing 5.19. Auto fallback/forward using Revert Method.
1 class Protocol1dot0 {
public:
3 virtual
void initConnection(RemoteEnd otherSide) {
5 connection = otherSide.connect(1.0);
};
7 virtual
void sendData(Video vid) {
9 RawData rawData = compress(vid);
connection.transmit(rawData);
11 };
protected:
13 virtual
RawData compress(Video);
15 Connection connection;
CommonData data;
17 };
19 class Protocol1dot1 : public Protocol1dot0 {
public:
21 virtual
void initConnection(RemoteEnd otherSide) {
23 connection = otherSide.connect(1.1);
};
25 virtual
void sendData(Video vid) {
27 RawData rawData;
if (connection.lowLatency()) {
29 rawData = compress(vid);
} else {
31 rawData = Protocol1dot0::compress(vid);
// ^--- Revert Method
33 }
connection.transmit(rawData);
35 };
protected:
37 virtual
RawData compress(Video);
39 };
Now we have eliminated the need for the Controller and ProtocolBase classes. Any client only needs to instantiate the newest version that it is capable of working with, and any fallback or fallforward happens automatically. The code is considerably cleaner and more directly expresses the intent of the developer.
Applicability
Use Revert Method when:
• A class wishes to reenable a superclass’s implementation of a method that it has overridden in order to use the original behavior.
Structure
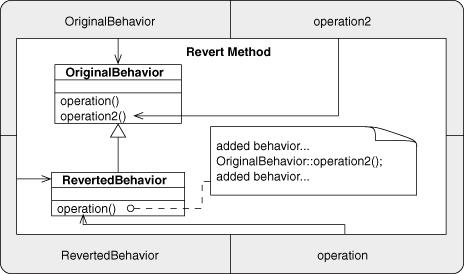
Participants
OriginalBehavior
A base class defining at least the method operation2.
operation
operation is the method in which the call takes place and is defined in at least the RevertedBehavior class.
operation2
operation2 is the method being called and is defined in at least the OriginalBehavior class. If must also be defined in a subclass of OriginalBehavior, either in RevertedBehavior or in a class defined between them in the class hierarchy. This second definition masks the implementation in OriginalBehavior from being the default within RevertedBehavior and forcing the selection of the reverted implementation.
A subclass of OriginalBehavior, with operation defined and operation2 overridden. operation calls the Original-Behavior implementation of operation2 when we would normally expect it to call its own implementation of that method.
Collaborations
In most cases, a subclass overrides a parent class’s method to replace its functionality, but the two method definitions can work together to allow an extension of the behavior. RevertedBehavior relies on OriginalBehavior for a core implementation.
Consequences
There is a conceptual disconnect between the overriding of a base class’s method and the utilization of that same method that can be confusing to some students and practitioners. Overriding a method does not erase the old method; it merely hides the old method from public view for objects of the subclass. The object still has knowledge of its parent’s methods and can invoke them internally without exposing this knowledge to the external world.
Revert Method is a form of Conglomeration to which the knowledge of a superclass’s implementation and the ability to access it directly have been added.
Implementation
In C#:
1 public class OriginalBehavior {
// Optional definition of operation()
3 public virtual void operation() {};
public virtual void operation2() {};
5 };
7 public class RevertedBehavior : OriginalBehavior {
public override void operation() {
9 // Optional work priot
if (oldBehaviorNeeded) {
11 OriginalBehavior::operation2();
} else {
13 operation2();
}
15 // Optional work after
};
17 // If this were not overridden, there would be
// no need to revert to superclass's version
19 public override void operation2();
};
Related Patterns
As noted earlier, Revert Method is closely related to Conglomeration except that it uses a supertype’s implementation of the method to be conglomerated. If the similar method is to be called, then you have an example of Extend Method. If the behavior is being provided by the other objects of the supertype defined by OriginalBehavior, then that is an instance of Trusted Delegation.
Method Call Classification
Object: Similar
Object Type: Subtype
Method: Dissimilar
Extend Method
Object Behavioral
Intent
Supplement, not replace, behavior in a method of a superclass while reusing existing code.
Also Known As
Extending Super
Motivation
Two of the most common tasks in software production and maintenance are to fix bugs or add new features. The most straightforward way of doing so is to alter the code directly. Where the bug exists, fix it. Where the new feature is needed, add it.
This isn’t always possible, however. Often the code that needs fixing or enhancing is not available in source form because it has been provided as a library. Other times, the original code and behavior must be preserved for use by legacy code. In either case, there will be times when the original method cannot be changed.
If the original source is available, of course, we can just copy and paste the old code into the new method. As shown in the specification for Inheritance, however, this presents a host of problems, including inconsistency of methods, and results in a potential maintenance morass. A much less error-prone approach is to have any implementation defined at only a single point and then reuse the existing code, tweaking the input or results as needed. Data can be massaged before being passed to the original implementation, or the results of the original implementation can be used to perform additional steps. Adhering to this principle is a simple way to reduce maintenance complexity and produce clear code.
If the original source is not available, then we’re prevented from copying and pasting code in any case and have to find another way to reuse the existing code. It is possible, of course, to create a reference to a delegate object with the original behavior and call into it when needed. This is the approach taken in Redirection, but this approach breaks down quickly in certain cases, as shown in Listing 5.20. If the added behavior needs to have access to data that was encapsulated as private by the original code, and the code does not expose it for use or manipulation by outside clients, then this tactic simply isn’t possible. Even when it is possible, it may not be clear what the new code is doing and that its relationship to the original code is quite close.
Listing 5.20. Using Redirection in Python to add behavior.
class OriginalBehavior:
2 __privateData = True
# Prepend __ for a private attribute
4 def desiredBehavior(self, data):
# Do something interesting
6 return data
8 class NewBehavior:
def addMoreBehavior(self, data):
10 # Perform any necessary pre-call setup
# Cannot access __privateData of ob
12 ob = OriginalBehavior()
val = ob.desiredBehavior(data)
14 # Post-call cleanup or more functionality
The solution to these problems is to use Extend Method, as in Listing 5.21. We implement a new class that subclasses off of the class containing the original desired behavior using Inheritance because it provides the mechanisms for reuse of the original code. We then override the original method, adding what implementation of the method we need, but make a call back to the superclass’s implementation of the method when we need its behavior to be executed. This provides us with simple maintenance, reuse, and encapsulation of the altered behavior.
Listing 5.21. Using Extend Method to add behavior.
class OriginalBehavior:
2 __privateData = True
# Prepend __ for a private attribute
4 def desiredBehavior(self, data):
# Do something interesting
6 return data
8 class NewBehavior(OriginalBehavior):
def desiredBehavior(self, data):
10 # Perform any necessary pre-call setup
# Can access __privateData!
12 superDelegate = super(NewBehavior, self)
superDelegate.desiredBehavior(data)
14 # ^--- Extend Method
# Post-call cleanup or more functionality
Applicability
Use Extend Method when:
• Existing behavior of a method needs to be extended but not replaced.
• Reuse of code is preferred or necessitated by lack of source code.
• Using Redirection is not possible or optimal because the new behavior needs access to data that is private to the original implementation.
Structure
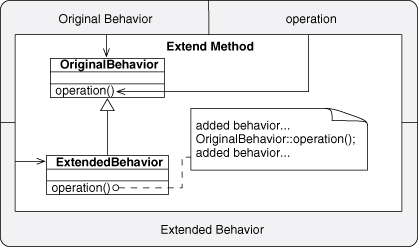
Participants
Original Behavior
Defines interface and contains an implementation of the method operation with the desired core functionality.
operation
Defined by OriginalBehavior to provide basic behavior. Overridden in ExtendedBehavior to provide a new implementation that makes use of the original implementation.
Extended Behavior
Uses interface of OriginalBehavior, then reimplements the operation method to include a call to the base class code surrounded by added code and/or behavior.
Collaborations
In most cases when a subclass overrides a parent class’s method, the purpose is to replace the functionality of that original method. The two method definitions, however, can work together to allow an extension of the behavior of the parent class instead of a replacement. ExtendedBehavior relies on OriginalBehavior for both interface and core implementation.
Consequences
As with Revert Method, the concept of calling an overridden version of a method can be confusing. In Extend Method, it can be even more confusing because the calling method seems to be invoking a ghost method. Using this pattern optimizes code reuse, but the method operation in OriginalBehavior becomes somewhat fragile—its behavior is now relied on by ExtendedBehavior::Operation to be invariant over time. Behavior is extended polymorphically and transparently to clients of OriginalBehavior.
Implementation
In Java:
1 public class OriginalBehavior {
public void operation() {
3 // Do core behavior
};
5 };
public class ExtendedBehavior
7 extends OriginalBehavior {
public void operation() {
9 // Optional work before
super.operation();
11 // Optional work after
};
13 };
In C++:
1 class OriginalBehavior {
public:
3 virtual void operation() {
// Do core behavior
5 };
};
7 class ExtendedBehavior : public OriginalBehavior {
public:
9 void operation() {
// Optional work before
11 OriginalBehavior::operation();
// Optional work after
13 };
};
Related Patterns
Extend Method, like Recursion, is defined using a single object. Converting this object similarity to distinct dissimilar objects results in an instance of Trusted Redirection, which uses polymorphism to traverse a cluster of trusted related classes for functionality. Relaxing the method similarity to call a different method of the superclass results in Revert Method. Because Revert Method is a superclass-aware variation of Conglomeration, Extend Method is a superclass-aware version of Recursion, even though the resulting behavior is quite different. Recursion can be reached by simply removing that superclass access and invoking the current type’s implementation.
Method Call Classification
Object: Similar
Object Type: Super
Method: Similar

Delegated Conglomeration
Object Behavioral
Intent
When multiple objects of the same type must work in concert to complete a task, with each performing different behaviors.
Motivation
Objects of the same type often work in concert to perform tasks. Homogeneous data environments with heterogeneous behavior are frequently coded as a collection of like objects collaborating to produce a larger functionality.
Listing 5.22 presents an example using a social networking site. Each user’s account has a list of friends, and one action users are likely to want to do is invite other friends to an event. Users can set their own notification preferences, including the email address they want to be contacted at when they get an invitation.
Listing 5.22. Inviting friends naively in Java.
import java.util.Vector;
2 import java.lang.String;
4 public class UserAccount {
Vector<UserAccount> allMyFriends;
6 public String notificationEmail;
8 public void inviteToEvent (
Vector<UserAccount> friends, String msg) {
10 for (UserAccount friend : friends) {
String email = friend.notificationEmail;
12 // send email
}
14 }
};
This solution works, but it requires each account to expose its email information publicly. Most users do not want to expose their email address on a networking site. To keep this information slightly more private, event planners can request emails from friends, and friends can provide those emails if they wish to, as shown in Listing 5.23.
Listing 5.23. A slightly better approach for inviting friends.
1 import java.util.Vector;
import java.lang.String;
3
public class UserAccount {
5 Vector<UserAccount> allMyFriends;
public String notificationEmail;
7
public void inviteToEvent (
9 Vector<UserAccount> friends, String msg) {
for (UserAccount friend : friends) {
11 String email = friend.getEmail(this);
// send email
13 }
}
15
public String getEmail (UserAccount requester) {
17 String returnVal = "";
if (allMyFriends.contains(requester)) {
19 returnVal = notificationEmail;
}
21 return returnVal;
};
23 };
This approach still requires users to provide their email address to anyone on their friends list who requests it. Again, most users would probably just like to receive an invitation without having to share their email address. Visibility of an email address can be separated from the capability to receive invitations by use of Delegated Conglomeration, as in Listing 5.24. Now when users invite friends, they don’t see or access their friends’ email information directly. Instead, they send a notification request to their friends’ accounts, which ensures the invitation is delivered without exposing the email addresses.
Listing 5.24. Delegated Conglomeration in Java.
1 import java.util.Vector;
import java.lang.String;
3
public class UserAccount {
5 Vector<UserAccount> allMyFriends;
public String notificationEmail;
7
public void inviteToEvent (
9 Vector<UserAccount> friends, String msg) {
for (UserAccount friend : friends) {
11 friend.notify(this, msg);
// ^--- Delegated Conglomeration
13 }
}
15
public boolean notify (UserAccount inviter,
17 String msg) {
// Send email to notificationEmail
19 return true;
};
21 };
Listings 5.23 and 5.24 are technically instances of Delegated Conglomeration, but the latter shows a much better justification and clearer use case. Listing 5.23 selectively exposes private data based on who requests it; Listing 5.24 shows that Delegated Conglomeration can be used to completely hide private data such that it is never shared. The second object is given the sole responsibility to perform a task with private data.
Applicability
Use Delegated Conglomeration when:
• A task can be broken into subtasks that are properly handled by the same object type.
• Many objects of the same type work in concert to complete a task.
• A single object cannot complete the task alone.
• The task requires data that is kept private by the other objects.
Structure
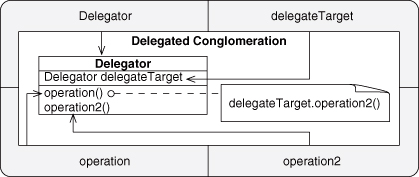
Participants
Delegator
The object type that contains references to other instances of its own type.
delegateTarget
The enclosed instance that is called upon to perform a task.
The calling point within the first object.
operation2
The subtask to be completed by the second object.
Collaborations
Only one object type, Delegator, is involved in this pattern, but there are two distinct instances of that type. One object relies on the other to perform some part of the task, as with Delegation, and that subtask is not directly associated with the current request, as with Conglomeration.
Consequences
As with Redirected Recursion, this pattern offers the ability to distribute tasks among a number of objects. Unlike its cousin, however, Delegated Conglomeration offers a clear decision-making point, separating the behavior-determining logic from the behavior implementation.
Implementation
In C++:
1 class Delegator {
Delegator* delegateTarget;
3 public:
void operation() {
5 // Optional work prior
delegateTarget->operation2();
7 // Optional work after
};
9 void operation2() {
// Do something useful
11 };
}
In Objective-C:
@interface Delegator
2 {
Delegator* delegateTarget;
4 }
- (void) operation;
6 - (void) operation2;
@end
8
@implementation Delegator
10 - (void) operation
{
12 // Optional work prior
[delegateTarget operation2];
14 // Optional work after
}
16 - (void) operation2
{
18 // Do something useful
}
20 @end
Related Patterns
Obviously, Delegated Conglomeration can be converted either to Delegation, by relaxing the typing relationship between the objects, or to Conglomeration, by having the object call back into itself. If the type similarity is changed to subtyping, it means the object is calling into a family of trusted classes, resulting in Trusted Delegation. Keeping the type similarity the same and retaining the distinct objects, but instead having the method call into its similar counterpart in the other object to invoke the same behavior, brings us to Redirected Recursion.
Method Call Classification
Object: Dissimilar
Object Type: Similar
Method: Dissimilar
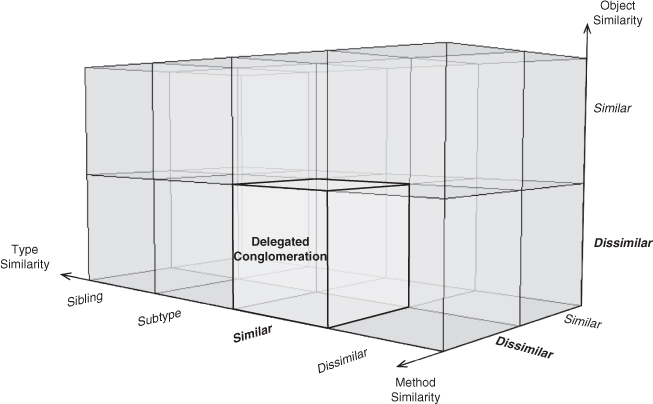
Redirected Recursion
Object Behavioral
Intent
To perform a singular action on multiple objects and have the objects be responsible for distribution and invocation of that action.
Motivation
Often we wish to perform the same action on a lot of data in a system. Sometimes that data is best organized by an external container, and the data can be considered “dumb,” with no responsibility for its own organization; it is acted on only by an external entity traversing the container. Iterating over a container and performing an action on each item contained in it is an example of this process. It requires that the structure of the data be imposed from outside and that the flow of invocation of the behavior also be controlled externally. A simple example is provided in Listing 5.25.
Listing 5.25. Traditional iteration and invocation in C.
#include <stdio.h>
2 #define LENGTH 4
int data[LENGTH] = {1, 2, 3, 4};
4 void printAll() {
int i;
6 for(i = 0; i < LENGTH; i++) {
printf("%d
", data[i]);
8 }
};
This solution is a common way of solving the original problem, but it can be improved on. First, data in an object-oriented system doesn’t have to be dumb. It can perform its own actions when requested. We can instead do something more like what is shown in Listing 5.26.
Listing 5.26. Object-oriented iteration and invocation in C++.
1 #include <cstdio>
3 class DataItem {
int data;
5 public:
DataItem(int val) : data(val) {};
7 void print() {
printf("%d
", data);
9 };
};
11
#define LENGTH 4
13 DataItem data[LENGTH] =
{DataItem(1), DataItem(2),
15 DataItem(3), DataItem(4)};
17 void printAll() {
int i;
19 for(i = 0; i < LENGTH; i++) {
data[i].print();
21 }
};
Now the data is responsible for doing the printing. The printAll() function doesn’t have to know anything about the data, how it is encoded, or even how it is printed. It just has to know how to traverse the organizing container and invoke print() on each object.
This solution is better, but we can take it a step further. Instead of an array, the data may be best represented by a graph or a balanced tree. As it currently stands, any piece of code that wishes to perform an operation on each element in the above array would have to be modified to now traverse the new organizational structure. In a large system, this can be a huge undertaking. Because objects can contain references to other objects through the use of Retrieve, however, we can have the objects also take care of their own organization, leading us to something like Listing 5.27.
Listing 5.27. Basic Redirected Recursion in C++.
#include <cstdio>
2
class DataItem {
4 int data;
DataItem* next;
6 public:
DataItem(int val) : data(val), next(NULL) {};
8 DataItem(int val, DataItem* next) :
data(val), next(next) {};
10 void print() {
printf("%d
", data);
12 if (next) {
next->print();
14 // ^--- Redirected Recursion
}
16 };
};
18
DataItem data =
20 {DataItem(1,
new DataItem(2,
22 new DataItem(3,
new DataItem(4))))};
24
void printAll() {
26 data.print();
};
Now responsibility not only for the printing behavior but also for how to find the next piece of data has been handed over to the data object. Because the data is now responsible for its own organization, it can also be responsible for its own invocation ordering. If the DataItem class decides to change its implementation and store its partner objects as a red-black tree, a hashmap, or any other manner of data structure, it is free to do so, and the code in printAll() doesn’t need to change. This isn’t always the right approach to take, but it can be powerful in the right circumstances when objects that a system is dealing with can be trusted to be self-organizing and only need a trigger to initiate a complex sequence of events in tandem.
Imagine, for example, a line of paratroopers getting ready for a jump. Space is tight, so the commander cannot walk down the line to indicate to each trooper to jump individually. Instead, he stands at the back of the line, and when the drop time comes, he taps the last trooper on the shoulder. That trooper knows to tap the shoulder of the trooper in front of him and to jump after that soldier has jumped. This can continue down a line of arbitrary length, from 2 to 200 troopers. The paratroopers’ only tasks are to, when they feel a tap on their shoulder, tap the next person in line; wait; shuffle forward as space is available; and when they see the soldier in front of them go, jump next. The commander issues one order instead of one to each soldier. A sample coding of this might look like Listing 5.28.
Listing 5.28. Paratroopers implementing Redirected Recursion.
1 class Paratrooper {
bool _hasJumped;
3 Paratrooper* nextTrooper;
public:
5 Paratrooper() : _hasJumped(false) {};
void jump() {
7 if (nextTrooper) {
nextTrooper->jump();
9 // ^--- Redirected Recursion
while (! nextTrooper->hasJumped() ) {
11 shuffleForward();
}
13 }
leap();
15 };
void leap() {
17 _hasJumped = true;
// Enter gravity's sweet embrace
19 };
void shuffleForward() {
21 // Take a step
};
23 bool hasJumped() {
return _hasJumped;
25 };
};
27
class Commander {
29 Paratrooper* backOfLine;
public:
31 void greenLight() {
backOfLine->jump();
33 };
};
The current paratrooper cannot jump until the trooper in front has completed the task, and so on, and so on. Eventually each paratrooper has completed his or her task, in the proper order, and with very little instruction. The order issues down the chain, but the behavior propagates back. The first trooper tapped is the last to jump.
Applicability
Use Redirected Recursion when:
• Recursion is a clean way to break up the task into subparts.
• Multiple objects of the same type must interact to complete the task.
• The objects can be responsible for their own organization among themselves.
Structure
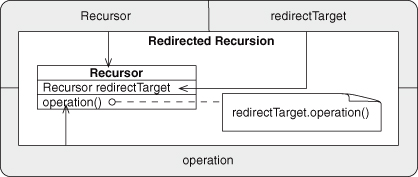
Participants
Recursor
An object type that holds a reference to another instance of its own type.
redirectTarget
The enclosed instance.
operation
A method within Recursor that is recursive on itself but through redirectTarget.
Collaborations
Multiple instances of the same object type interact to complete a task. Each instance knows how to message the next object for its turn.
Consequences
This is a powerful method for shared recursive behavior when using a number of objects, and it is found in many systems. It allows functionality to be split among disparate data sets that can be self-organized, but it constrains the functionality to a particular behavior. It is analogous to single instruction, multiple data (SIMD) computing in hardware such as a graphics processor, except that in this case the data is responsible for passing along the instruction. This can be a highly flexible approach to solving problems that require a divide-and-conquer algorithm, as changing the method’s implementation propagates across all objects equally.
Implementation
In Java:
public class Recursor {
2 Recursor redirectTarget;
public void operation() {
4 // Optional work before...
redirectTarget.operation();
6 // Optional work after...
};
8 };
In Python:
class Recursor:
2 def __init__(self):
__redirectTarget = Recursor()
4
def operation(self):
6 # Optional work before...
redirectTarget.operation();
8 # Optional work after...
Related Patterns
As you might expect from the name, Redirected Recursion can be converted into Redirection by eliminating the method similarity requirement. Similarly, collapsing the distinct object dissimilarity into one object results in simple Recursion. Retaining the object dissimilarity to enforce cooperation between multiple objects while relaxing the method similarity to a method dissimilarity yields Delegated Conglomeration. Finally, Trusted Redirection is achieved by changing the type relationship to one of subtyping, which lets the method call be handled polymorphically through a trusted collection of classes related to the one initiating the call.
Method Call Classification
Object: Dissimilar
Object Type: Similar
Method: Similar
Trusted Delegation
Object Behavioral
Intent
Related classes are often defined as such to perform tasks collectively. In these cases, multiple objects of related types can interact in generalized ways to delegate tasks to one another. If the objects are of related types, the objects can make certain well-formed assumptions about the level of trust they can place in the other object.
Motivation
When objects must act in concert to perform a task, such as in Delegation, they are placing a certain amount of trust in the other object to complete its task. One way to ensure trust, or at least to reduce the risk involved, is to delegate the portion of the task that the calling object knows something about to another object. A common way to share information about objects is for their types to be related, and the simplest form of that is the subtyping relationship.
By passing a task to an object of a supertype of the current object, certain aspects of the receiving object can be known ahead of time. The method signatures are necessarily established before the call can be implemented, and the intent can be assumed from the relationship between the method signatures, as with Delegation. In addition, however, the intent can be known precisely, because the calling object also has that same method. The implementation may differ, but the calling object has inherited the basic conceptual intent as well as the signature. It may even have the same default implementation.
Intent and concept, however, are most important here. The calling object knows that the delegate object is going to have at least the semantics of the superclass. Through polymorphism (where applicable), the delegate object may restrict these semantics to provide specialization, but in general, it is not allowed to relax them. The calling object knows that the delegate object will conform to a certain set of predeterminable guidelines. Although this is technically true in any strongly typed language—because the calling object must have an idea of the type of the delegate object at the calling site—the fact that the type is the calling object’s own supertype offers an entirely different level of knowledge. This additional knowledge enables the calling object to place a higher level of trust in the delegate object.
User interfaces are a familiar type of system in which to find Trusted Delegation and related patterns such as Deputized Delegation, Trusted Redirection, and Deputized Redirection. This pattern allows tasks to be parceled out within a family of classes, often called a class cluster, when the interface and method name are known, but the precise object type and, therefore, method body may not be. It is a form of polymorphic delegation in which the calling object is one of the polymorphic types.
Consider a windowing system that includes slider bars and rotary dials as input controls and text fields and bar graphs as display widgets. An input control is tied to a particular display widget and sends that widget updates of values when the control is adjusted by the user. The input controls don’t need to know precisely what kind of display widget is at the other end; they just need to know that they must call the updateValue method with the appropriate value as a parameter. Because input controls also necessarily display a value, it is possible to programmatically change their adjustment accordingly, so they too need an updateValue method. By our Inheritance pattern, it seems the input controls and display widgets are of the same family and, in fact, we want to make sure that they can all interact, so we create a class hierarchy accordingly, as in Listing 5.29.
Listing 5.29. UI widgets demonstrating Trusted Delegation in C++.
class UIWidget {
2 public:
virtual void updateValue( int newValue );
4 };
6 class InputControl : UIWidget{
UIWidget* target;
8 public:
void userHasSetNewValue(int myNewValue) {
10 target->updateValue(myNewValue);
// ^--- Trusted Delegation
12 }
};
14
class SliderBar : public InputControl {
16 public:
// Moves the slider bar accordingly
18 void updateValue( int newValue );
void acceptUserClick() {
20 // Determine new value, set it
int newVal;
22 // Update the slider bar graphic
this->userHasSetNewValue(newVal);
24 };
};
26
class RotaryKnob : InputControl {
28 public:
// Rotates the knob image accordingly
30 void updateValue( int newValue );
void acceptUserClick() {
32 // Determine new value, set it
int newVal;
34 // Update the knob image
this->userHasSetNewValue(newVal);
36 };
};
38
class GraphicsContext {
40 public:
virtual void render(int);
42 };
44 class DisplayWidget : public UIWidget {
protected:
46 // Each subclass should set the
// GraphicsContext to something
48 // meaningful for its needs
GraphicsContext* gc;
50 public:
void updateValue( int newValue ) {
52 gc->render( newValue );
};
54 };
56 class TextWidget : public DisplayWidget {};
58 class BarGraph : public DisplayWidget {};
In this example, the InputControl and UIWidget classes fulfill the necessary roles in the Trusted Delegation pattern, as shown in Figure 5.3. InputControl has a greater sense of certainty about what the call to updateValue will do, because it knows about and is intimately tied with the UIWidget class through subclassing. If the target object were of some other type, then InputControl would have much less information about what that call to updateValue() would accomplish. Knowing that it is an instance of UIWidget or of one of its subclasses tells InputControl that the delegate object will be involved with the user, just as it is. It can trust that its delegated task will be handled as expected.
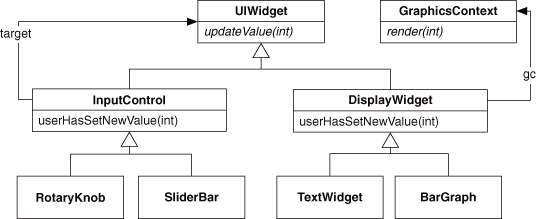
Figure 5.3. UI class cluster showing an instance of Trusted Delegation.
The SliderBar and RotaryKnob objects do not have to know anything about where their value is going and, in fact, they could be tied to each other, with each adjusting the other in sync. You could even have two objects of the same InputControl subclass tied together, such as two SliderBar instances. We have separated the concerns of who is sending what data and who is receiving it. Our only concerns are that the data is being sent to a properly receiving client polymorphically and that the current calling object is of that polymorphic family. This allows for a single, unified interface for many classes that can work in tandem to perform many tasks.
Applicability
Use Trusted Delegation when:
• Delegation is appropriate, with related and/or unrelated subtasks to be performed.
• A level of assumed trust is required in the requirements and/or implementation for the task.
• The actual implementation may not be selectable ahead of time, and polymorphism may be required to properly handle the message request.
• The calling object is of a type in the polymorphic class hierarchy.
Structure
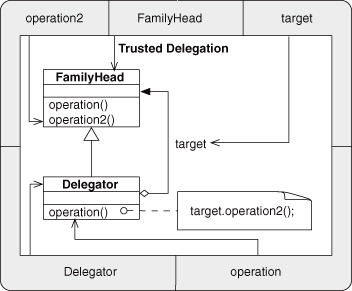
Participants
FamilyHead
The base class for a polymorphic class cluster.
Delegator
A subclass of FamilyHead.
target
A polymorphic instance of FamilyHead that is contained by Delegator.
operation
The calling method that is requesting a trusted delegated task.
operation2
The called method trusted to perform the delegated task.
Collaborations
FamilyHead provides a base interface for Delegator, and an instance of FamilyHead also resides within the Delegator to handle requests. This instance is understood to be polymorphic and may handle a request in a number of different ways. Trusted Delegation differs from Trusted Redirection in that it is a more generalized form and parcels out subtasks that are related to, not refinements of, the initiating method.
Consequences
As with any subtyping relationship, Delegator is tied to the interface of FamilyHead. The implementation of the target method is subject to the particular subclass that it ends up being contained in, via polymorphism. For this reason, Trusted Delegation may set up unintended consequences if another class within the class hierarchy implements its methods in an unexpected way. On the other hand, this is a powerful mechanism for extending functionality by adding classes to the class family. If the possible extensions need to be limited in some way, consider using the Deputized Delegation pattern instead.
Implementation
The target can be defined in either the base class or the subclass; it just needs to be accessible from with the subclass.
In Java, superclass-defined target:
public abstract class FamilyHead {
2 FamilyHead target;
public abstract void operation();
4 public abstract void operation2();
};
6
public class Delegator extends FamilyHead {
8 public void operation() {
// Optional work before...
10 target.operation2();
// ^--- Trusted Delegation
12 // Optional work after...
};
14 public void operation2() {};
};
In Python, subclass-defined target:
1 class FamilyHead:
def operation(self):
3 pass
def operation2(self):
5 pass
};
7
class Delegator(FamilyHead):
9 target = FamilyHead();
def operation(self) {
11 # Optional work before...
target.operation2();
13 # ^--- Trusted Delegation
# Optional work after...
Related Patterns
As you might guess from the name, Trusted Delegation is a specialized version of Delegation, but the delegation is going to an object of a trusted type, by virtue of that type of the delegate object being a supertype of the calling object. Removing this typing relation results in turning this pattern back into a plain Delegation. On the other hand, putting even tighter restrictions on this typing relationship and turning it into a sibling type relationship yields Deputized Delegation. Putting yet tighter restrictions on the type, making it exactly the same as the calling object, creates an instance of Delegated Conglomeration. Keeping the type smiliarity the same but modifying the method similarity such that we’re calling the similar method in the delegate object gets us to Trusted Redirection. Finally, collapsing the objects into the same one, such that we’re calling the supertype implementation of a method on the same object, we arrive at Revert Method.
Method Call Classification
Object: Similar
Object Type: Subtype
Method: Dissimilar
Trusted Redirection
Object Behavioral
Intent
Redirect some portion of a method’s implementation to a possible cluster of classes of which the current class is a member. The classes are considered trustworthy through the typing relationships.
Motivation
Frequently, a hierarchical object structure of related objects is built at runtime, and behavior needs to be distributed among multiple objects operating with differing implementations. This is an effective way to move responsibility for the handling of a request through a number of objects, and it is a core structure in the Chain of Responsibility and Composite patterns [21]. Trusted Redirection can be considered a single link of such chains.
Although we could simply use Redirection in these cases, chains of related behavior assume more stringent requirements than simple method similarity. The intents must be identical, not just similar. Frequently, even the implementations are assumed to have some commonality.
Just as in Trusted Delegation, a level of trust is built between the calling object and the called object, based on the knowledge that the called object is of a very closely related type. With Trusted Redirection, however, that trust is just a little bit stronger.
The use of a Redirection implies that the intent behind the calling method and the target method are similar and that a strong correlation exists between the two methods. By ensuring that the type of the recipient object is a supertype of the current object, a much stronger correlation can be established. Declaring that the target object must be of a type that is, or is derived from, a superclass of the current object’s type, sets up a pool of trusted types. These types are expected to have behavior that is closer in form and intent to the method triggering the call.
For example, in event-handling systems, such as found in GUIs, it is common to have a hierarchy of event-aware elements. Data views and controls are contained within panes, which are composed into windows, which sit in a global UI environment, perhaps with other elements. Any of these elements may be asked to handle a user-generated event such as a mouse-click, but it may be a context-driven handling. A window that is in the background and currently inactive may react differently to mouse events than one in the foreground, for example. If the window is inactive, it will come to the foreground; but if the window is active, it will redirect the click event to its contents, so they can handle it. Those contents could be a tabbed subpane, a control widget, a text box, anything at all. A tabbed subpane may be similarly active or inactive and decide how to react to the click. A text box may, in turn, elect to pass along the click to the text contents if appropriate, based on its state. The text contents can react to the click, drag, or other event internally while letting the text box handle the visual aspects. Not all event handlers have a visual component. All the visual elements are expected be able to handle an event appropriately, but they may not all be asked to handle them the same way at any specific point in time. This temporal dynamicism is a common but not necessary constraint leading to the use of Trusted Redirection.
Example code for an implementation of an event handler could be defined in C++ as in Listing 5.30 and in Figure 5.4.
Figure 5.4. UI class cluster showing an instance of Trusted Redirection.
Listing 5.30. Event handler in C++ showing Trusted Redirection.
#include <vector>
2 using std::vector;
4 class Event {};
class Position {};
6
class MouseEvent : public Event {
8 vector<bool> modifierKeys;
Position position;
10 bool mouseDown;
};
12
class EventHandler {
14 public:
virtual void handle(Event* e) {
16 // do what is needed
};
18 };
20 class TextData : public EventHandler {
// Text storage class
22 };
24 class UIWidget : public EventHandler {
protected:
26 EventHandler* nextHandler;
public:
28 virtual bool isActive();
virtual void handle(Event* e) {
30 // Possible setup...
if ( !(this->isActive()) ) {
32 nextHandler->handle(e);
// ^--- Trusted Redirection
34 } else {
// Handle it myself
36 }
};
38 };
40 class Button : public UIWidget {
// Base class for any clickable button
42 };
44 class TabPane : public UIWidget {
UIWidget* contents;
46 public:
TabPane() {
48 // Setup contents
nextHandler = contents;
50 };
};
52
class TextField : public UIWidget {
54 TextData* text;
public:
56 TextField() {
// Setup text
58 nextHandler = text;
};
60 };
Each visual UI subclass inherits the default behavior from UIWidget, although it can be overridden at any time. In this structure, each subclass uses an instance of EventHandler as the next item to be asked to handle an event in the case that the current object is not suitable. A common alteration to this behavior includes checking to see what type of event has been passed in before making a decision regarding whether to handle it.
Applicability
Use Trusted Redirection when:
• An aggregate structure of related objects is expected to be composed at compile or runtime.
• Behavior should be decomposed to the various member objects.
• The structure of the aggregate objects is not known ahead of time.
• Polymorphic behavior is expected but not enforced.
Structure
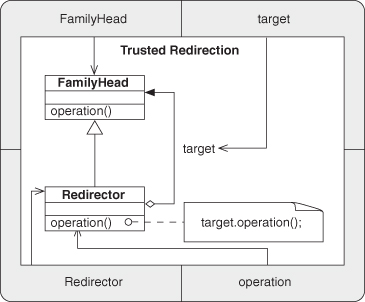
Participants
FamilyHead
Defines interface and contains a method to be possibly overridden.
Redirector
Uses interface of FamilyHead and redirects internal behavior back to an instance of FamilyHead to gain polymorphic behavior over an amorphous object structure.
target
The object that is being requested to perform the redirected work.
Indicates the intended task to be completed in both the calling and called objects.
Collaborations
Redirector relies on the class FamilyHead for an interface and an instance of the same for an object-recursive implementation. The Redirection relationship is a critical part of this pattern because it drives the concept of “do the same as I was asked to do.” The trusted aspect comes in from redirecting the work to a supertype of the current object for polymorphic handling.
Consequences
Redirector is reliant on FamilyHead for its interface, but it falls to the entirety of the class hierarchy to provide the various implementations. For this reason, other classes in the hierarchy may exhibit unexpected behavior. If unexpected behavior is occurring, consider instead using the Deputized Redirection pattern to restrict the possibilities to a manageable set.
Implementation
In C++:
class FamilyHead {
2 public:
virtual void operation();
4 };
6 class Redirector : public FamilyHead {
public:
8 void operation();
FamilyHead* target;
10 };
12 void
Redirector::operation() {
14 // Optional work before...
target->operation();
16 // Optional work after...
}
Related Patterns
Trusted Redirection is a specialization of Redirection such that the possible targets of the redirected task are from a trusted cluster of classes defined as mutual subclasses of a the target type. As such, relaxing that trust lets you go back to that simpler, more general EDP. Further restricting that trust to a subset of the sibling subclasses of the superclass results in Deputized Redirection. If the exact same type of target object is required with no variability, then look to Redirected Recursion for how to work with object type similarity set to the same type. Retaining the subtyping relationship but coalescing the calling and target objects into one object gives rise to Extend Method. Simply breaking the method similarity moves us to Trusted Delegation.
Method Call Classification
Object: Similar
Object Type: Subtype
Method: Similar
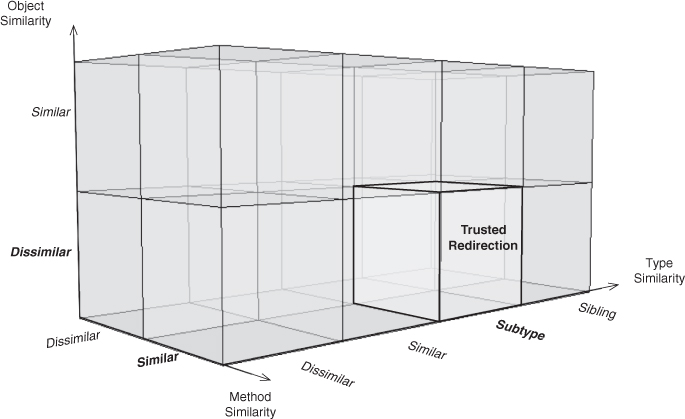
Deputized Delegation
Object Behavioral
Intent
When we need the trusted delegation behavior of Trusted Delegation but find it too generalized, it is necessary to preselect a subtree of the class hierarchy for a restricted polymorphism.
Motivation
Static typing is a way to preselect types from a well-defined pool and form more concrete notions of an object’s type before the invocation of a system at runtime. This preselection is a way of adding type safety—we know precisely what capabilities an object will have when used during execution. Polymorphism, on the other hand, is a technique for abstracting out typing information until runtime. We purposefully obfuscate many details of the underlying type of the object, providing flexibility at the cost of type safety. Sometimes we need a balance of the two.
Consider the driving example from Trusted Delegation. A common data-input control is missing, one to enter text. The way things are set up, a TextInput class that subclassed from InputControl would be able to alter the value of a BarGraph showing numeric values, and this may not be what the designer wants.7 The design from Trusted Delegation can be fine-tuned by adding the classes and changes shown in Listing 5.31.
7. A good argument can be made that having a text input widget control a numeric display does make rational design sense, assuming a numeric input control that was restricted to numerics only, but there are UI toolkits that went the other way.
Listing 5.31. UI widgets demonstrating Deputized Delegation in C++.
1 class UIWidget {
public:
3 virtual void updateValue( int newValue );
};
5
class InputControl : UIWidget{
7 UIWidget* target;
public:
9 void userHasSetNewValue(int myNewValue) {
target->updateValue(myNewValue);
11 }
};
13
class SliderBar : InputControl {
15 public:
// Moves the slider bar accordingly
17 void updateValue( int newValue );
void acceptUserClick() {
19 // Determine new value, set it
int newVal;
21 // Update the slider bar graphic
this->userHasSetNewValue(newVal);
23 };
};
25
class RotaryKnob : InputControl {
27 public:
// Rotates the knob image accordingly
29 void updateValue( int newValue );
void acceptUserClick() {
31 // Determine new value, set it
int newVal;
33 // Update the knob image
this->userHasSetNewValue(newVal);
35 };
};
37
class GraphicsContext {
39 public:
virtual void render(int);
41 };
43 class DisplayWidget : public UIWidget {
protected:
45 // Each subclass should set the
// GraphicsContext to something
47 // meaningful for its needs
GraphicsContext* gc;
49 public:
void updateValue( int newValue ) {
51 gc->render( newValue );
};
53 };
55 class TextWidget : public DisplayWidget {};
57 class BarGraph : public DisplayWidget {};
59 // New class to support Deputized Delegation
class TextInputControl : public InputControl {
61 TextWidget* textTarget;
public:
63 void userHasSetNewValue(int myNewValue) {
textTarget->updateValue(myNewValue);
65 // ^--- Deputized Delegation
};
67 };
Now the TextInputControl is available for altering instances of the TextField class, but it will not be able to alter instances of Bar-Graph or other nontext display items. SliderBar and RotaryKnob could similarly be limited to a class hierarchy based on a NumericWidget, for example. This may be easier to see in Figure 5.5.
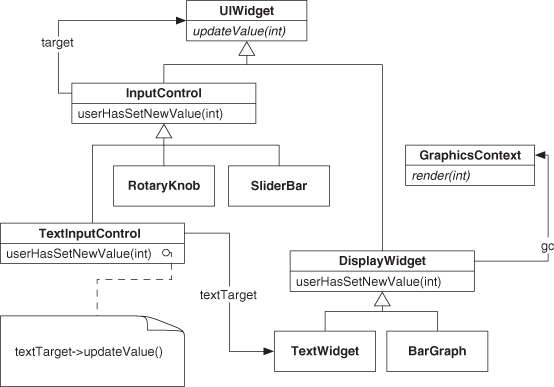
Figure 5.5. UI class cluster showing an instance of Deputized Delegation.
Applicability
Use Deputized Delegation when:
• Trusted Delegation is the appropriate general pattern.
• Greater control over the possible types of objects is required.
• The types to be delegated to do not include the calling object’s type.
Participants
FamilyHead
The base class for a polymorphic class cluster, which establishes the basic generalized interface and semantics.
Delegator
A subclass of FamilyHead that requires a subtask to be delegated to a trusted delegate.
DelegateSibling
Another subclass of FamilyHead that has the appropriate semantics for the subtask.
An instance of DelegateSibling that is contained by Delegator and will be asked to perform the subtask.
operation
The calling method sending the request for the subtask to be performed.
operation2
The called method being asked to perform the subtask.
Structure
Collaborations
In addition to the collaborations involved in Trusted Delegation, this pattern adds the DelegateSibling class as the target for the operation implementation. By doing so, it limits the possible behavior to a subclass of the common ancestor class and therefore to select refined semantics.
Consequences
This pattern differs from its cousin, Trusted Delegation, in that a design decision is made to limit the polymorphism statically to a subtree of the original class family. It can provide large benefits in containing complexity, but it can also lead to issues later if, for example, the chosen sibling class is determined to be too limiting. Although the syntactic change to the code is minimal, the addition of a broader set of possible classes and behaviors can have far-reaching effects that should be carefully considered. Also note that unlike Trusted Delegation, the target cannot be a member of the shared superclass, because the superclass would have to have prior knowledge of one of its subclasses. Although some languages can pull off this particular bit of trickery, it’s not a robust design decision and should be avoided whenever possible.
Implementation
In C++:
1 class FamilyHead {
protected:
3 void operation();
void operation2();
5 };
7 class DelegateSibling : public FamilyHead {
void operation2();
9 };
11 class Delegator : public FamilyHead {
DelegateSibling* target;
13 void operation() {
// Optional work prior
15 target->operation2();
// ^--- Deputized Delegation
17 // Optional work after
};
19 };
Related Patterns
Deputized Delegation is rather specialized and can only lead to a couple of more general EDPs. If the criteria of using a trusted class cluster is relaxed slightly such that the object type similarity is set to subtyping, we get back to Trusted Delegation. If the method being invoked is changed to one that is similar to the caller, then we slide over to Deputized Redirection. This is one case where collapsing the calling and delegate objects into one doesn’t make much sense, and we end up with ill-formed EDP design space positions.
Method Call Classification
Object: Dissimilar
Object Type: Sibling
Method: Dissimilar
Deputized Redirection
Object Behavioral
Intent
When we need the trusted redirection behavior of Trusted Redirection but find it still too generalized, it is necessary to preselect a subtree of the class hierarchy for a restricted polymorphism. This selected subtree of classes will not include the class originating the redirection.
Motivation
Static typing is a way to preselect types from a well-defined pool and form more concrete notions of an object’s type before the invocation of a system at runtime. This preselection is a way of adding type safety—we know precisely what capabilities an object will have when used during execution. Polymorphism, on the other hand, is a technique for abstracting out typing information until runtime. We purposefully obfuscate many details of the underlying type of the object, providing flexibility at the cost of type safety. Sometimes we need a balance of the two.
In the driving example for Trusted Redirection, the code provided a very general event-handling system. Such an open-ended type hierarchy, however, is not appropriate for all cases. For instance, a slider bar is only going to respond to mouse events, and not, except in special circumstances, to keystrokes. Likewise, a text field will respond to both mouse events and keystrokes, but the handling of keystrokes may be best taken care of by an underlying text data object. Entire classes of events can therefore be eliminated from consideration at runtime by a simple refinement. Starting with the code in Listing 5.30 from Trusted Redirection, we can alter it to look like the code in Listing 5.32.
Listing 5.32. UI widgets demonstrating Deputized Redirection in C++.
1 #include <vector>
using std::vector;
3
class Position {};
5 class Key {};
class Event {
7 public:
virtual int getID();
9 };
11 class MouseEvent : public Event {
vector<bool> modifierKeys;
13 Position position;
bool mouseDown;
15 };
17 class KeyEvent : public Event {
vector<bool> modifierKeys;
19 Key key;
bool keyDown;
21 };
23 class EventHandler {
public:
25 virtual void handle(Event* e) {
// do what is needed
27 };
};
29
class TextData : public EventHandler {
31 public:
// Text storage class
33 virtual void handle(KeyEvent* e) {
// do what is needed
35 };
};
37
class UIWidget : public EventHandler {
39 protected:
EventHandler* nextHandler;
41 public:
bool isActive();
43 virtual void handle(Event* e) {
// Possible setup...
45 if ( !(this->isActive()) ) {
nextHandler->handle(e);
47 } else {
// Handle it myself
49 }
};
51 };
53 class Button : public UIWidget {
// Base class for any clickable button
55 };
57 class TabPane : public UIWidget {
UIWidget* contents;
59 public:
TabPane() {
61 // Setup contents
nextHandler = contents;
63 };
};
65
class TextField : public UIWidget {
67 TextData* text;
public:
69 TextField() {
// Setup text
71 nextHandler = text;
};
73 virtual void handle(Event* e) {
// Is e a KeyEvent or subclass?
75 if (dynamic_cast<KeyEvent*>(e)) {
// Optional work before
77 text->handle(dynamic_cast<KeyEvent*>(e));
// ^--- Deputized Redirection
79 // Optional work after
} else {
81 // Handle MouseEvents
}
83 };
};
The new structure is shown in Figure 5.6. We added the KeyEvent class, and TextField now overrides handle(). It handles instances of MouseEvent on its own, but previously it simply set the next-Handler to the TextData instance text. There was the chance that a MouseEvent could slip through via a bug and trip up TextData’s implementation of handle(), but this way the only events handed to TextData are those of KeyEvent. TextField and TextData have a higher level of trust than do TextField and other subclasses of Event-Handler.

Figure 5.6. UI class cluster showing an instance of Deputized Redirection.
Now, TextField ensures that it handles the MouseEvents while the underlying TextData only handles raw text interactions. TextData is trusted to handle the KeyEvent events, because TextField knows more precisely what to expect TextData will do with them. In addition, TextField is specifically not including itself as the type of the possible recipient, as is the case in Trusted Redirection. TextField is insisting that someone else it is related to take care of that portion of the job.
Applicability
Use Deputized Redirection when:
• Trusted Redirection is the appropriate general pattern.
• Greater control over the possible types of objects is required.
• The types to be redirected to do not include the calling object’s type.
Participants
FamilyHead
Defines interface, contains a method possibly to be overridden, and is the base class for both Redirector and RedirectSibling.
Redirector
Uses interface of FamilyHead; redirects internal behavior back to an instance of RedirectSibling to gain polymorphic behavior over an amorphous but limited-in-scope object structure.
RedirectSibling
The head of a new class tree for polymorphic behavior.
target
A polymorphic instance of RedirectSibling that is contained by Redirector.
operation
The calling site.
Structure
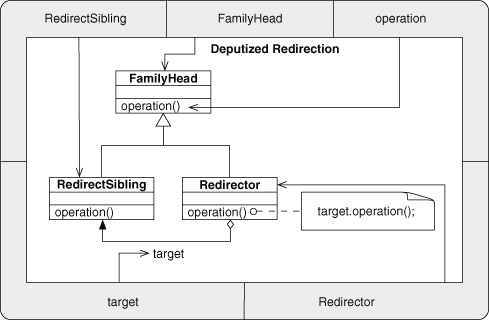
Collaborations
As with Trusted Redirection, Redirector and FamilyHead are tied by interface and intent. The RedirectSibling provides a conceptual starting point for a particular type of implementation. In this case, Redi-rector specifically reduces the set of possible classes that can be polymorphic targets of the request to either classes or subclasses of Redirect-Sibling. The fact that Redirector and RedirectSibling have a common base class in FamilyHead means that each may make stronger assumptions about the other.
Consequences
This pattern differs from its cousin Trusted Redirection in that a design decision has been made to limit the polymorphism statically to a subtree of the original class family. It can provide large benefits in containing complexity, but it can also lead to issues later if, for example, the chosen sibling class is determined to be too limiting. Although the syntactic change to the code is minimal, the addition of a broader set of possible classes and behaviors can have far-reaching effects that should be carefully considered.
Implementation
In C++:
class FamilyHead {
2 protected:
virtual void operation();
4 };
6 class RedirectSibling : public FamilyHead {
void operation();
8 }
10 class Redirector : public FamilyHead {
public:
12 RedirectSibling* target;
void operation() {
14 // Optional work prior
target->operation();
16 // ^--- Deputized Redirection
// Optional work after
18 };
};
Related Patterns
Because Deputized Redirection is a specialization of Trusted Redirection, we can return to that EDP if we relax the trust a bit by changing the type similarity from a sibling relationship back to the more general subtyping relationship. Or, we can change the method similarity to call a dissimilar method and arrive at Deputized Delegation. Finally, it should be noted that attempting to change the object similarity to be similar makes no sense in this case, and we arrive at one of our undefined coordinates in the EDP design space.
Method Call Classification
Object: Dissimilar
Object Type: Sibling
Method: Similar