
Chapter 2. Implement Policies for Monitoring
My first college apartment had a terrible cockroach problem. Upon returning from a date one evening, I was shocked to see dozens of them scatter away from an empty pizza box when I turned on the lights. After that, it was tough to push away the idea that cockroaches were everywhere—I expected to see them in every corner of the apartment. The first time I fired up Snort I was reminded of that experience; suddenly I could see what was crawling through the network, and I wanted to fix it all at once.
It’s easy to get sucked into bug stomping: once you see what’s on the network, you have the urge to fix and explain every security event you discover. Here’s where the analogy ends, though, for not everything on the wire is a cockroach. Much of the traffic is perfectly fine, if ugly. Once you understand that its ugliness is not a security threat, you can safely let it through. By narrowing your focus to the truly threatening traffic, you can turn your full attention to stomping it out.
Historically, security monitoring tools have demonstrated their worth by showing the cockroaches: they illuminate the dark corners to show you how well they’re performing their task. Once you’re convinced of a cockroach problem, you need a plan for dealing with the problem, and that plan will likely involve prevention and detection.
A security guard could easily be fooled if his practice was to investigate every movement detected by security cameras. He must work from a plan—when to investigate, when to log activity for further analysis, and when to ignore something as normal or insignificant. To organize his response, he must choose from a combination of the following approaches:
- Blacklisting
Enumerate threatening events and document preparations to detect and address them. For example, the plan might enumerate threatening actors (such as people with weapons and ski masks) and prevent them from entering the premises. Signs forbidding specific items or activities, such as the one in Figure 2-1, are implementing a blacklist.
- Anomaly monitoring
Enumerate events considered normal, such as the general work schedule and how employees are expected to dress. Watch for events that fall outside of what’s normal. Signs such as the suspicious mail alert highlighted in Figure 2-2 implement examples of anomaly monitoring.
- Policy monitoring
Enumerate a set of discernible criteria from which you can evaluate each person or vehicle approaching the premises to determine the response. Signs forbidding entry by all but authorized personnel, as shown in Figure 2-3, are examples of such monitoring in action.



Blacklist Monitoring
Creating a list of prohibited events or items (commonly called a blacklist) is the most straightforward method of security monitoring. With the blacklist in hand, you can deploy tools to detect prohibited items, and build procedures for remediating them. This technique is most effective under the following conditions:
- You can reliably and accurately identify signs of dangerous or malicious behavior
Some signs are accurate indications that something is wrong: an airport security checkpoint screens for the presence of banned items such as weapons and bomb chemicals. If the items you’re screening for, however, are not accurate signs of trouble, it will bog down the monitoring process as your staff must take the time to weed out the false positives. For example, because the Transportation Safety Administration (TSA) was unable to identify only dangerous liquids at security checkpoints, it chose to ban all liquids (see Figure 2-4). This presented a problem because many liquids were perfectly safe and necessary, such as baby formula.
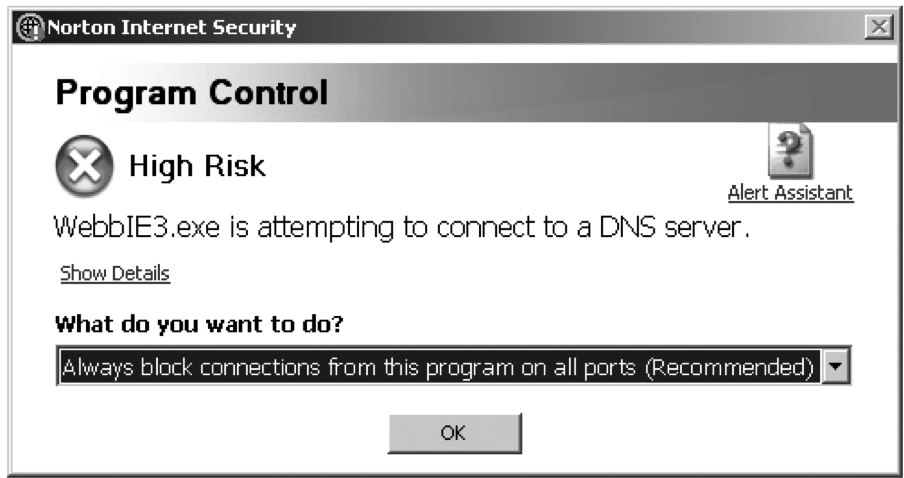
The blacklist must also be limited to items that can be reliably identified. Software firewalls running on desktops have historically been very poor at this; they block traffic or prompt the user for harmless connections in an effort to demonstrate that they’re still on the job (see Figure 2-5). Unfortunately, this conditions Aunt Mary into answering OK or Allow to every prompt without considering the danger of doing so, negating the firewall’s purpose. If a blacklisted item can be obscured in some fashion, it cannot be reliably identified and will sail past detection and prevention tools.
- You have a relatively small list
If you have only a few items to watch for, it’s reasonable to keep the list up-to-date with filters that are properly tuned to find the right triggers. If the list is too long, however, it becomes impossible to keep it up-to-date and reliable. For example, the “do not fly” list is reasonably effective only because it represents a tiny percentage of the flying population. If the list doubles or triples in size, it may create chaos at security checkpoints. Antivirus tools have been successful because they can identify a small list of bad files from an infinite list of harmless files.
Most of today’s web content filters, often used by libraries and families to keep out unsavory content, police browsing by checking against a list of “known bad” domain names. This works only because there are only a few thousand sites to filter out, compared to the millions of available websites on the Internet.
- You cannot constrain events to a narrow set of acceptable criteria
If the TSA could restrict baggage to a narrow list of preapproved items, air travel might be much safer, but at an unacceptable cost. To effectively enforce the rule, the agency would have to draft a list of reliably safe items. Passengers would be permitted to wear and carry items from only a small list of choices. Because that is not practical, the agency screens for blacklisted items.
In an enterprise, however, it is possible to catalog all authorized applications and devices on your network. Though it’s a vast task, controlled environments such as data centers allow reasonable limits regarding which items are allowed and expected on the network. On the network perimeter, this doesn’t hold true. You must sort through the traffic flowing through your Internet gateways to determine how best to secure yourself in the thick of it.

Therefore, blacklist monitoring has been traditionally applied to the perimeter due to the large volume of data. Monitoring tools must select a small percentage of traffic upon which to alarm. This type of monitoring can be effective against threats that are reliably identified, detecting them with signature patterns on the wire. It’s becoming increasingly easy for malware authors to evade simple signature-based detection. A single, inconsequential change to a malware binary can throw off the signature pattern, and encoding or placing null bytes in the payload can further obfuscate the malicious traffic.
Anomaly Monitoring
Monitoring for meaningful deviations from normal traffic and events is a promising technique. It’s an emerging area of intrusion detection, and monitoring that uses artificial intelligence and statistical deviations to detect traffic abnormalities. When anomaly detection is initially deployed, the tools must first create a watermark against the traffic that will be measured. Sustained statistical deviations above or below that watermark are triggers for the tool to analyze the traffic further and produce an alert for a network security analyst. Products such as Arbor Peakflow, which provides an early warning of denial-of-service (DoS) traffic and other anomalous patterns, have employed this technique effectively. Intrusion detection systems have a growing set of capabilities to detect anomalies in protocol usage, such as tunneling and nonencrypted traffic over encrypted protocols. They’re also good at detecting volume-based incidents, such as port scans. Still, this technique can elicit a high rate of false positives, and it doesn’t often capture enough detail to conduct meaningful incident response.
Policy Monitoring
The goal of policy monitoring is to compare events discovered on the network to ensure that they are approved and acceptable. For example, in a sensitive environment, a security guard would have a list of those who are permitted to enter the building after business hours (the policy). The guard would have cause to question and detain any nonlisted person entering the building after hours.
A better example of policy monitoring is applied to counterfeit protection. It’s common for retailers to require their cashiers to inspect large bills (say, bills larger than $20 in the United States) before accepting them. Policy-based monitoring is being applied, as the cashier inspects the currency for reliable indications that it is bona fide before accepting it. The only bills legal to create or pass for sale are those minted by the U.S. Treasury. The Treasury designs security features into the currency to help cashiers and others evaluate the bill’s integrity. To prove authenticity, the cashier can evaluate certain hard-to-falsify traits of the bill, such as watermarks, holographic images, color-shifting ink, and security threads. This requires the cashier to know and be able to accurately identify such traits. Success depends on both the currency’s reliable, unique, and falsification-proof security features, and the cashier’s ability to acknowledge these signs.
Policy-based network monitoring is practical where acceptable conditions can be documented as policies. For example, a security colleague once discovered a Windows server in the data center making dozens of connections to sites outside his company’s address space, and determined that those sites were botnet controllers. If his company had applied policy monitoring, the server would have been allowed to initiate connections to only a handful of sites. You can enforce this type of control in a firewall, though some network engineers are reticent to impact network operations or performance by deploying them. When firewalls can’t be applied, the need for policy-based network monitoring is amplified, and would have called out this compromise immediately.
A network is a good candidate for policy monitoring if it meets the following two conditions:
- You have reasonable control over deployed systems and services
Most enterprises have standards that restrict the servers and services allowed into data centers. This allows the network monitoring staff to document a relatively small set of expected protocols on the wire. It also allows administrators to restrict allowable protocols so that policy monitoring can succeed. An environment is ready for policy monitoring if administrators can articulate acceptable traffic patterns.
- A malicious payload can be easily disguised
If malevolent traffic can be easily obfuscated so that it slips past your intrusion detection sensors and virus scanners, policy monitoring will allow you to see that traffic in new ways. This can improve the fidelity, accuracy, and timeliness of your blacklist via a hybrid approach.
Monitoring Against Defined Policies
To effectively monitor the enterprise, you must codify acceptable behavior as policies, providing a reference point against which to survey. These policies must be precise and concrete to be successful. When my daughter received her stage one driver’s license, she was allowed to drive only between the hours of 6 a.m. and 9 p.m. To monitor for compliance of such a policy, an officer need only check the license status of a young adult against the time of day when evaluating compliance. The policy was clear and concise, and she knew exactly what was expected of her. Of course, in monitoring for determined threats, you should keep your policy details a closely guarded secret, as a true criminal will disguise traffic to evade detection.
In developing policies against which you can build monitoring procedures, it’s helpful to reference external standards such as those published by the ISO. The Site Security Handbook (RFC 2196) suggests that a solid security policy must have the following characteristics:
It must be capable of being implemented through system administration procedures, publishing of acceptable use guidelines, or other appropriate methods.
It must be enforceable with security tools, where appropriate and with sanctions, where actual prevention is not technically feasible.
It must clearly define the areas of responsibility for the users, administrators, and management.
Management Enforcement
To make policies enforceable, you should base them on a documented “code of conduct” to which all employees are held accountable. Policies may need to be referenced for disciplinary action, so linking them to the code of conduct is a transitive means of enforcing behavior.
The guidelines and rules developed from these policies must be detailed enough to yield rules that can be monitored. For example, a policy requiring employees to use encrypted channels to discuss confidential matters is impossible to monitor and enforce because human context is necessary to determine confidentiality. Context cannot be discovered automatically; it requires detailed analysis. As an alternative, a policy that requires employees to use encryption when sending mail to specific domains is enforceable, as it’s possible to determine encrypted channels for mail protocols and to discover the destination of the traffic.
When selecting policies for monitoring, don’t bother with policies that you know management won’t enforce. For example, your monitoring system may be very adept at uncovering use of peer-to-peer (P2P) applications on the network; it’s well understood that P2P networking is often used to violate copyright law and download illegal material. You may even have a policy, as many companies do, against use of such software on the office network. Management, however, may not be willing to restrict employee freedom by enforcing such rules. Lacking enforcement, detection of P2P networking and other recreational traffic can become a distraction from policy monitoring. Focus instead on detecting policy violations you can assign for action. Once you detect an event, you’ll likely have an information-gathering step that allows you to validate the information and determine further details about the source and destination of the activity. Once that’s complete, you’ll route the case to a support team that can fix the problem.
Employees must be aware of policies, especially those for which you will be taking action. This is best done with an awareness campaign that explains what is expected and how best to comply with the policies. One of the best ways to “bake in” policy is to build tools and configuration guides that implement policy details. When an employee changes a password or configures a web server, the tools and configuration guidance you’ve provided will be readily available to lower resistance to compliance.
Types of Policies
Two types of policies are used for monitoring: regulatory compliance, which involves adherence to externally enforced controls, and employee policies, which govern the security compliance of employees.
Regulatory Compliance Policies
All companies are bound by some form of IT legislation in the countries where they conduct business. This legislation places obligations and restrictions on the company, and compliance with these rules often requires active monitoring. Examples of such laws include the Sarbanes-Oxley Act of 2002 (SOX), which requires demonstration of integrity in accounting; the Health Insurance Portability and Accountability Act of 1996 (HIPAA), which protects the privacy of personal health information; and California’s Senate Bill 1386 (SB1386), which protects the privacy of personal information.
In addition to regulatory compliance, adherence to industry standards is a further necessity, which requires verifiable compliance with sets of best practices. Some may be required by business partners as a means of ensuring data handling, such as the Visa PCI standards.
Example: COBIT configuration control monitoring
Control Objectives for Information and related Technology (COBIT) is a set of standards that the Information Systems Audit and Control Association (ISACA) and the IT Governance Institute (ITGI) introduced in 1992. IT management may subscribe to the control objectives set forth by COBIT, and require the development of monitoring procedures to maintain compliance. Few of the control objectives can be effectively monitored in real time, but a good example of one that can is Design and Support 9 (DS9), which requires “managing the configuration.” In Section 4 (DS 9.4), the control specifically requires the verification and auditing of configuration information. (COBIT 4.1, ITGI, page 135.) To accomplish this, you must ensure that changes executed on critical systems and network devices have been approved and documented in a change control system.
To monitor for violation of such controls, you must reconcile detected changes to critical systems with the records in your configuration control repository. This requires access to the change logs from the devices, along with elements such as the time of the change, the component changed, and the person who made the change. To reconcile this information, you must have access to the configuration control system.
Consider COBIT configuration monitoring on a company’s routers—some of the most important and sensitive devices on the network. To monitor these devices for unauthorized changes, we must first configure the routers to log a message upon changes to the configuration. On Cisco IOS routers, we can accomplish this by enabling syslog output and sending messages to an external syslog collector for monitoring and analysis.
For example, the following will set up logging to a syslog server at 10.83.4.100:
router> enable Password: router# configure terminal router(config)# logging 10.83.4.100
When it’s configured to enable syslog output, the router must be configured to message upon each configuration change. This will tell us when it was changed, and who changed it:
router(config)# archive router(config-archive)# log config router(config-archive-log-config)# logging enable router(config-archive-log-config)# notify syslog
If it’s set up correctly, the router will be logging to our collector at 10.83.4.100. Let’s take a look at the setup to see whether we did it correctly:
router>show logging
Syslog logging: enabled (12 messages dropped, 83 messages rate-limited,
0 flushes, 0 overruns, xml disabled, filtering disabled)
Console logging: disabled
Monitor logging: level debugging, 0 messages logged, xml disabled,
filtering disabled
Buffer logging: level informational, 118416 messages logged, xml disabled,
filtering disabled
Logging Exception size (4096 bytes)
Count and timestamp logging messages: disabled
No active filter modules.
Trap logging: level informational, 118420 message lines logged
Logging to 10.83.4.100 (udp port 514, audit disabled, link up), 118420
message lines logged, xml disabled,
filtering disabledNow, every time the configuration on that device changes, it will send an alert. Here’s a sampling of the kind of message it will generate upon such changes:
router# show archive log config all
idx sess user@line Logged command
1 1 mnystrom@vty0 | logging enable
2 1 mnystrom@vty0 | logging size 200
3 2 mnystrom@vty0 | hostname rtp2-prodBy forwarding these alerts to our monitoring system, it will receive an alert every time the configuration changes on this device. Figure 2-6 shows an example of such an alert.
Note
To effectively respond to incidents generated by such logs, the information must be complemented by Authentication, Authorization, and Accounting (AAA) records, which correlate employee authentication to such devices.
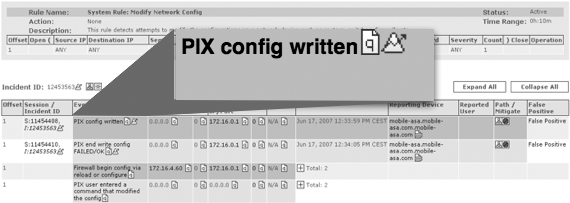
We must reconcile the alert in Figure 2-6 with the configuration management system to determine whether it matches an approved change record for that device. For this device, it must fall within the approved window and have been executed by the approved implementer. If the change is not an approved change, the analyst must engage the user called out in the alert message, to see whether the change can be explained. A problem on the device may have required an administrator to troubleshoot or make temporary changes to the device. Such changes would not be reflected in an approved change request, and should be easy to reference in a trouble ticket documenting the problem. If the change cannot be reconciled, this is a policy violation and a reporting procedure must be executed.
Note
Alerting and responding to unexpected configuration changes is a lot of trouble. To avoid triggering incidents too frequently, tune your alerting with generous exceptions that allow for time surrounding approved change requests, documented outages, and known maintenance windows. You should also notify the support staff that their configuration changes are being monitored, and that they will be required to provide a justification for out-of-policy changes. This is like a security camera in a convenience store—it brings the positive side effect of guiding compliance with policy.
Figure 2-7 provides an example of an approved request.
Note the important elements of Figure 2-7:
Device name
Implementer (user ID)
Time window (Start Time and End Time columns)
Approval status
We can now monitor these elements by watching for device changes that fall outside this time window or were not performed by this authorized user.

Example: SOX monitoring for financial apps and databases
Section 404 of SOX requires IT management to implement controls on applications that are a key part of the company’s financials. This is to mitigate the potential risk of misstating the company’s financial numbers.
To ensure the integrity of financial applications, especially those with direct relevance to SOX controls, you must monitor for data integrity within such applications. A rational policy would prohibit all direct database access for such sensitive applications, except for scheduled administration by administrators (and possibly data maintenance for application changes, archiving, etc.). To be practical, the allowed hosts and users, along with the approved time windows, must be documented in a policy. Security monitoring could employ network traffic analysis to watch for activity that falls outside the approved policy.
Example: Monitoring HIPAA applications for unauthorized activity
Title II of HIPAA addresses security and privacy of health data. Among many other safeguards, it states that “Information systems housing [protected health information] must be protected from intrusion. When information flows over open networks, some form of encryption must be utilized. If closed systems/networks are utilized, existing access controls are considered sufficient and encryption is optional.”
To monitor for compliance with this safeguard, you could position a data capture device, such as a NIDS, on the network to ensure that data leaving the application/system is encrypted before leaving the closed network. Many NIDSs can detect unencrypted data over a supposedly encrypted channel, and could alert on discovery of such data. Tracing this to the source of the connection would allow you to log this as a policy violation.
Example: ISO 17799 monitoring
ISO 17799 (a.k.a. IEC 27002) is an information security code of practice, covering best practice recommendations on information security management for use by those who are responsible for initiating, implementing, or maintaining Information Security Management Systems (ISMSs).[8] An objective of ISO 17799 is section access control, described in Section 8, which requires that you prevent unauthorized access to information systems.
One challenge facing enterprises trying to secure systems from unauthorized access is the generic account. Shared applications such as web servers, application servers, and databases run as a generic user account, typically with limited privileges. Unless they are secured and monitored, these accounts can become weak points in implementing this policy. Administrators may need to occasionally log into these accounts to update applications. Monitoring for unauthorized access will require you to monitor system logs and audit system configurations.
Syslog from the systems you wish to monitor will allow you to detect system access and changes. To detect account access, you should configure the system to detect login and sudo access to the generic accounts. Then, you should reconcile these changes against approved change requests, as described in the previous example.
An auditing technique could involve checking snapshots of device
configurations, specifically, the account registry such as /etc/passwd, to ensure that direct login is
disabled for such accounts and that sudo is appropriately
restricted.
Example: Payment Card Industry Data Security Standard (PCI DSS) monitoring
Major credit card companies developed PCI DSS as a guideline to help organizations that process card payments prevent credit card fraud, hacking, and various other security vulnerabilities and threats. A company processing, storing, or transmitting payment card data must be PCI DSS-compliant or risk losing its ability to process credit card payments.[9]
PCI DSS requires the protection of cardholder data. As an example, Requirement 4 of the standard states that you must “Encrypt transmission of cardholder data across open, public networks.”
To effectively monitor for compliance, an organization could set up a NIDS to detect unencrypted data emanating from the applications used for card processing. For additional protection, additional signatures could implement a regular expression match to find credit card numbers traversing the network. You can use a regex pattern such as this:
^((4d{3})|(5[1-5]d{2}))(-?|�40?)(d{4}(-?|�40?)){3}|^(3[4,7]d{2})
(-?|�40?)d{6}(-?|�40?)d{5}to detect the common numeric pattern used by credit cards. With this regular expression, a NIDS (or any packet capture device with a full copy of network traffic) could catch unencrypted transmission of these card numbers. Should the NIDS detect such a pattern, it’s a likely violation of the encryption policy outlined by Section 4 of PCI DSS.
Employee Policies
Compliance-based policies are developed from without, and drive an organization’s policies, auditing, and monitoring. In contrast, employee policies are typically derived from the company’s ethical standards or code of business conduct, and are often set by human resources, legal, and information security departments. These policies are designed to place some limits on employees to preserve ethical standards, limit financial loss, protect corporate revenue, and maintain a safe working environment.
Example: Unique login for privileged operations
To maintain accountability, an organization must be able to correlate activity to an individual employee. For the organization to do this effectively, it must require employees to use unique logins when accessing shared resources. Especially when performing privileged operations, employers must ensure that sensitive operations are attributable to an individual. To accomplish this task, an employer needs policies that require employees to use their individually assigned accounts when accessing shared resources such as Unix servers, database servers, and so on.
When employees are performing privileged operations, employers
should direct the employees to first log in with their individual
accounts before “switching user” for privileged operations. On Unix,
sudo is the recommended command for
users executing privileged operations; on an Oracle database, a user
can connect as a privileged account
(such as SYSTEM). Upon examining the log messages, the security
analyst can trace the actions directly to the individual executing the
commands. Shared accounts should never be accessible directly, as they
obscure the true identity of the individual.
On a Unix server, a simple method for monitoring violations of this policy requires only that the server record each login via syslog. The monitoring application or staff must then screen for instances of the user “root” directly logging into the system, as shown in the following code snippet, and conduct further investigation about the activity:
Mar 28 16:19 bw-web1 sshd(pam_unix)[13698]: session opened for user root by (uid=0)Note
Should you require security logs to investigate a malicious incident, activity will likely correlate the most damaging events to the privileged user (root or Administrator). Tracing the activity back to an individual will require that backtracking through the logs to correlate it with a login by a unique user. If the privileged user logged in directly, the investigation must take on much more complexity.
Example: Rogue wireless devices
The insecure wireless network at a Marshall’s discount clothing store near St. Paul, Minnesota, may have allowed high-tech attackers to gain a beachhead in retail giant TJX Companies’ computer network, resulting in the theft of information on at least 45.6 million credit and debit cards, according to the Wall Street Journal.[10]
Though it’s not clear whether the problem at Marshall’s was a rogue wireless device or just a poorly configured wireless deployment, it’s clear that wireless technology extends enterprise networks well beyond the guarded perimeter. Wireless access points are cheap, are easy to connect, and can create a dangerous back door into the organization if they are not properly configured. Security professionals must vigilantly drive rogue wireless devices out of the corporate network. Technologies now exist to allow the wireless infrastructure to defend itself by denying access to rogue wireless devices. Reliably finding and blocking rogue devices from the network requires sophisticated infrastructure. Corporate policy must require wireless devices to be properly configured and deployed, and only by the IT staff. A standard should provide details for secure configuration, and the key to successful monitoring is to watch for wireless devices that do not meet this standard. Several Wireless Intrusion Detection Systems (WIDSs) are available, which use an overlay network of RF detectors to discover wireless access points. These can be correlated to network location, allowing the network security monitor to compare the network location with those of approved wireless access points. Effective use of this solution requires a “registration” of approved wireless access points. Documenting approved, supported services, and their network location is a vital part of making policy monitoring work, and we cover it in greater depth in Chapter 3.
Note
WIDSs store a database of authorized access points as a basis for detection of rogue devices. WIDSs use a variety of means to identify access points, including MAC addresses, IP addresses, and RF fingerprints. The technology to detect a unique RF signature was developed at Carleton University in Ottawa, Canada, in 2006.
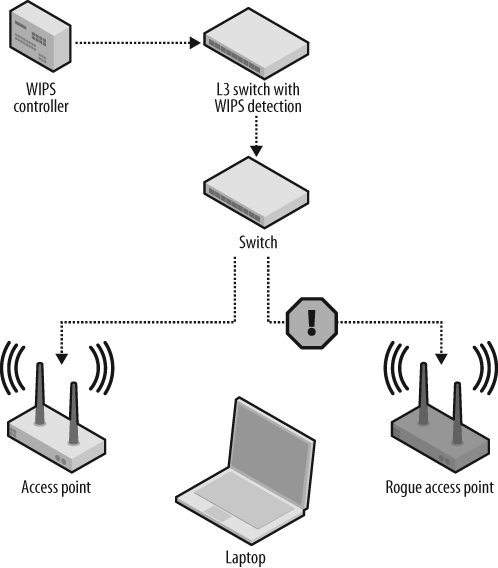
In Figure 2-8, the WIPS controller (a.k.a. WIDS controller; the P stands for prevention) maintains a database of authorized access points. The L3 switch has software to read the reported access point fingerprints via the connected access points. These fingerprints are stored and analyzed in the WIPS controller, which will tell the L3 switch to deny IP connectivity to the rogue access point.
Example: Direct Internet connection from production servers
In Richard Bejtlich’s book, Extrusion Detection (Addison-Wesley Professional), Bejtlich describes the importance of watching outbound traffic, that is, connections initiated from inside the company toward the Internet. Doing so, he argues, allows the network security monitoring staff to watch for communications with known command and control servers, a sure sign of a compromised asset.
Bejtlich argues that production servers should be watched closely for their connections:
In some cases, detecting any outbound connection at all is a sign of compromise. For example, a properly administered web server should never have to make an outbound connection to any foreign host. (By ‘foreign,’ I mean a machine not associated with the local organization.) DNS queries should be sent to the local DNS server. Updates should be pushed to the system from a local patch or package builder, or pulled from the local patch or package builder.[11]
Connections to the Internet from production servers should be rare and well documented. Software updates can be staged on local servers, and administrators should use personal systems to check mail or research techniques to fix problems. If a production server has been compromised, it will soon begin to shuttle information to a server under the hacker’s control.
Server policy should therefore forbid production servers from initiating Internet connections. Once network security monitoring is in place, you can set it up to catch any such activity. Initially, many of the discovered incidents will prove to be accidental usage, and can be mitigated accordingly as policy violations. Once monitoring is fully implemented, it will prove to be an early warning system for catching compromised servers and will be a surprisingly easy and effective tool for securing systems.
Session data records such as NetFlow provide the perfect tool for such monitoring, and we cover them in more detail in Chapter 3. For now, think of NetFlow as being similar to a phone bill; it lists connections between IP addresses and ports, with a record of when and for how long they occurred (see Figure 2-9). You can analyze NetFlow recorded at perimeter gateways to discover data center subnets initiating connections to Internet addresses. A single connection is a clear policy violation, and you can investigate and mitigate it accordingly.

Example: Tunneled traffic
Internet Relay Chat (IRC) was developed in 1988 as an Internet chat program. IRC servers allow for many simultaneous conversations and groups via the use of channels. Since servers and channels are long-lived, users can connect and disconnect at will, and can participate in a never-ending conversation with other users on the channel. In recent years, IRC has become a popular tool for teams to communicate, as all conversation is open and readable by all users on the channel.
Because of its server/channel design and support for programmatic access, IRC has become the de facto application for hackers to remotely control their compromised systems. Commonly used for controlling botnets, IRC is widely used as the control channel for progressively sophisticated application programming interfaces (APIs). Due to its common use as a hacker control plane, default IRC network ports are commonly blocked by firewalls and reliably discovered by NIDS sensors. To circumvent these controls, hackers have begun to disguise and even encrypt the traffic. Security researcher Dan Kaminsky has famously written and spoken on the topic of tunneling information over DNS several times in the past few years, and has introduced tools such as OzymanDNS to make it easy.
Botnet IRC traffic usually has an instantly recognizable format. It contains randomly generated usernames with embedded numeric identifiers, along with an indication of geographic location. The format looks like this:
PASS letmein NICK [M00|JOR|05786] USER XP-4132 * 0 :owned-host MODE [M00|JOR|05786] -ix JOIN #
The botnet controller uses this information to identify and command his bots. In contrast, user-directed IRC traffic will contain more human-readable usernames and hostnames. If you have business needs that require access to IRC servers on the Internet (which prevent you from blocking IRC traffic altogether), you can deploy intrusion detection techniques to detect these patterns and block the IRC botnet traffic. This, of course, requires analysis and monitoring procedures to discern between malicious and benign traffic.
Tools that inspect network traffic can discover telltale signs of tunneling, normally by checking the traffic against the expected structure for the protocol assigned to that port. You also can apply policy-based monitoring to discover this traffic. One means for discovering such tunneling is to detect DNS requests originating from locations other than the DNS servers in the enterprise. By way of policy, clients should only use internal DNS servers for name resolution. Internet-bound DNS traffic originating from hosts other than these DNS servers would be a policy violation, and a possible sign of tunneled traffic. Upon detecting this traffic, you could then analyze it to determine whether it’s truly dangerous or is an anomaly that requires further tuning of network monitors.
Here’s an example of a Snort alert indicating potential DNS tunneling, requiring further investigation:
Apr 2818:34:15 [**] snort[1000001]: Potential DNS Tunneling [**] [Classification: Potentially Bad Traffic] [Priority: 2] (UDP) 31.33.73.57:22652 ->10.13.55.7:53
Policies for Blanco Wireless
The fictitious company Blanco Wireless will serve as a platform to illustrate the stages and techniques of implementing policy monitoring. As part of account administration, Blanco must store sensitive information such as Social Security numbers and direct billing details. Due to the sensitive nature of such information, Blanco has developed several policies to protect itself and its customers’ data.
Policies
Blanco employs the following policies to maintain compliance with government regulations, safeguard its most sensitive data, and provide investigative support should any of the data be compromised. These are, of course, not exhaustive. Rather, they serve as illustrations for how to apply policy monitoring.
Data Protection Policy
In keeping with California law and Blanco Wireless’s commitment to customer privacy, employees are required to maintain strict confidentiality of all personally identifiable information (PII):
- Scope
This applies to all PII stored on production servers in the Blanco Wireless network.
- Configuration requirements
- Storage
PII must be encrypted in storage and transmitted only over encrypted network connections.
- Access
Databases containing PII must be accessed only via an approved method:
An application whose purpose is to broker such access.
An approved database management server. Direct database access via desktop programs such as TOAD is strictly prohibited.
- Database security
Databases storing PII must be configured according to Blanco Wireless’s Database Configuration Guide, which prescribes the application of all severity 1 and 2 directives contained within Pete Finnigan’s Oracle Database Security Checklist.[12]
Server Security Policy
The purpose of the Server Security Policy is to establish standards for the base configuration of internal server equipment that Blanco Wireless owns and/or operates. Effective implementation of this policy will minimize unauthorized access to Blanco’s proprietary information and technology:
- Scope
This policy applies to all production servers at Blanco Wireless, including web, application, and database servers.
- Configuration requirements
The following directives are required of all servers at Blanco, and should be detailed in every configuration or “hardening” guide used by administrators:
- Outbound connections
Production servers deployed into Blanco data centers may initiate connections only to other production servers within the Blanco enterprise. Connections may never be initiated from production servers to the Internet. If deployed into an approved DMZ, servers may only respond to requests in accordance with their deployed function.
- Network services
Servers in the data center must register their hosted network services in the Blanco Enterprise Management System prior to deployment. Registration is not required for approved management services such as SSH and syslog, which are necessary for administration and monitoring.
- Accounts
Servers must be configured to limit available accounts to those who have direct, administrative responsibility on each specific server. Servers must never allow direct login by nonadministrative personnel such as development support staff members or end users. Those with a need to affect application or data configuration should use the IT-supported deployment applications to effect needed changes on the servers.
- Privileged access
Direct login to the system must occur through individually assigned account IDs. Access to privileged accounts, such as root, must be permitted only via “switch user” commands such as
sudoorsuupon successful login. Direct login as a generic privileged account such as root is strictly prohibited.- Administration
Remote administration must be performed only over cryptographically secured, encrypted network connections. Administrative interfaces must never be exposed directly to the Internet, but must be available only to those who have properly authenticated into the Blanco Wireless network.
- Logging
The following events must be logged to a separate log server to support investigations and monitoring:
Login
Privileged operations, including
sudoandsuStatus change for networked services (start/stop)
Implementing Monitoring Based on Policies
In the next few chapters, we will detail a method for analyzing and documenting Blanco’s network, find the best areas to target our monitoring, and provide practical guidance on how to deploy monitoring specifically to watch for policy violations.
Based on the Blanco policies outlined in this chapter, here are the specific items we will monitor to effect policy monitoring:
- Storage/transmission of PII
We will monitor data center gateways to watch for signs that Social Security numbers are being transmitted over unencrypted links.
- Data access
We will monitor for unauthorized SQL*Net connections into our sensitive databases.
- Outbound connections
We will monitor for connections initiated from sensitive servers to ensure that they are approved exceptions.
- Database security
We will audit TNS listeners to ensure that they meet hardening criteria.
- Network services
We will audit open ports on servers to ensure that they are registered as required by the Server Security Policy, referenced in the preceding section.
- Accounts
We will monitor syslog for account logins and compare them against a database of system administrators to ensure that logins are proper and authorized.
- Privileged access
We will monitor syslog for direct privileged logins to servers, and monitor SQL*Net connections for direct system login to databases.
- Administration
We will audit production servers from outside the company to uncover any remote administration protocols (such as SSH, VNC, and Remote Desktop), a violation of the Server Security Policy.
Conclusion
There are a wide variety of approaches for selecting the policies to monitor. Once policies are selected, you must determine the setting—the environment in which these policies are to be applied. You’ll need a reliable map of your network, one that highlights the underlying functions, applications, and users. In the next chapter, we’ll explain how to develop and document a contextual understanding of your own network.