
HTTP (HyperText Transfer Protocol) is the “language” in which the client and the server of a web application speak to each other. It was initially defined in 1996[1], and the simplicity and versatility of its design are, to an extent, responsible for the success and expansion of the web and the Internet as a whole.
Although it is still valid in traditional web scenarios, there are others, such as real-time applications or services, for which it is quite limited.
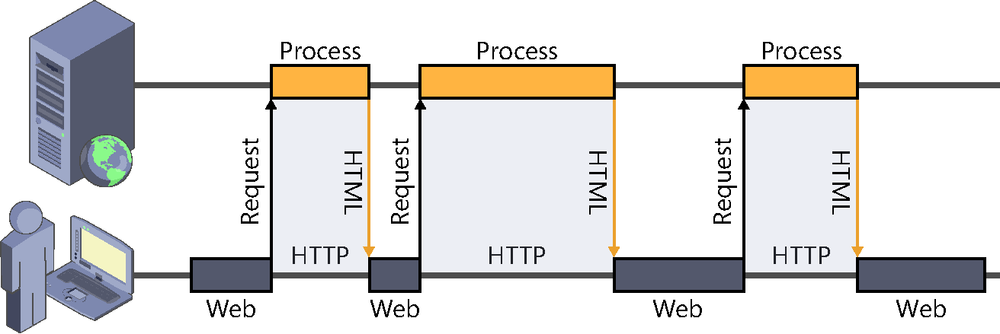
An HTTP operation is based on a request-response schema, which is always started by the client. This procedure is often referred to as the pull model: When a client needs to access a resource hosted by a server, it purposely initiates a connection to it and requests the desired information using the “language” defined by the HTTP protocol. The server processes this request, returns the resource that was asked for (which can be the contents of an existing file or the result of running a process), and the connection is instantly closed.
If the client needs to obtain a new resource, the process starts again from the beginning: a connection to the server is opened, the request for the resource is sent, the server processes it, it returns the result, and then the connection is closed. This happens every time we access a webpage, images, or other resources that are downloaded by the browser, to name a few examples.
As you can guess by looking at Figure 2-1, it is a synchronous process: after sending the request to the server, the client is left to wait, doing nothing until the response is available.
Although this operation is a classic in web systems, the HTTP protocol itself can support the needs for asynchrony of modern applications, owing to the techniques generally known as AJAX (Asynchronous JavaScript And XML).
Using AJAX techniques, the exchange of information between the client and the server can be done without leaving the current page. At any given moment, as shown in Figure 2-2, the client can initiate a connection to the server by using JavaScript, request a resource, and process it (for example, updating part of the page).
What is truly advantageous and has contributed to the emergence of very dynamic and interactive services, such as Facebook or Gmail, is that these operations are carried out asynchronously—that is, the user can keep using the system while the latter communicates with the server in the background to send or receive information.
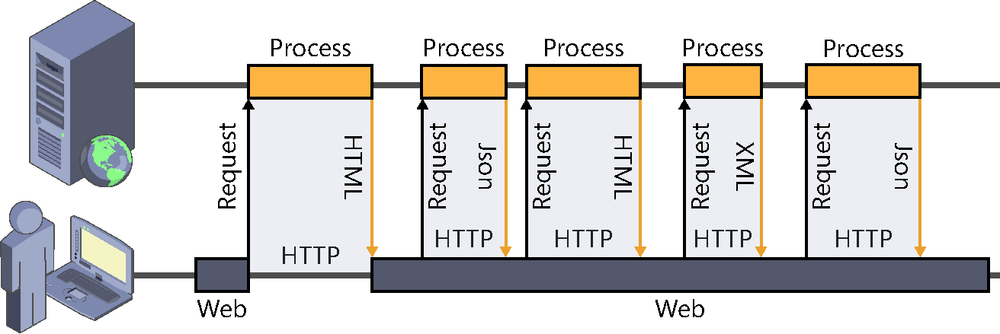
This operating schema continues to use and abide by the HTTP protocol and the client-driven request-response model. The client is always the one to take the initiative, deciding when to connect to the server.
However, there are scenarios in which HTTP is not very efficient. With this protocol, it is not easy to implement instant-messaging applications or chat rooms, collaboration tools, multiuser online games, or real-time information services, even when using asynchrony.
The reason is simple: HTTP is not oriented to real time. There are other protocols, such as the popular IRC[2], which are indeed focused on achieving swifter communication to offer more dynamic and interactive services than the ones we can obtain using pull. In those, the server can take the initiative and send information to the client at any time, without waiting for the client to request it expressly.
As web developers, when we face a scenario in which we need the server to be the one sending information to the client on its own initiative, the first solution that intuitively comes to our minds is to use the technique known as polling. Polling basically consists in making periodic connections from the client to check whether there is any relevant update at the server, as shown in Figure 2-3.
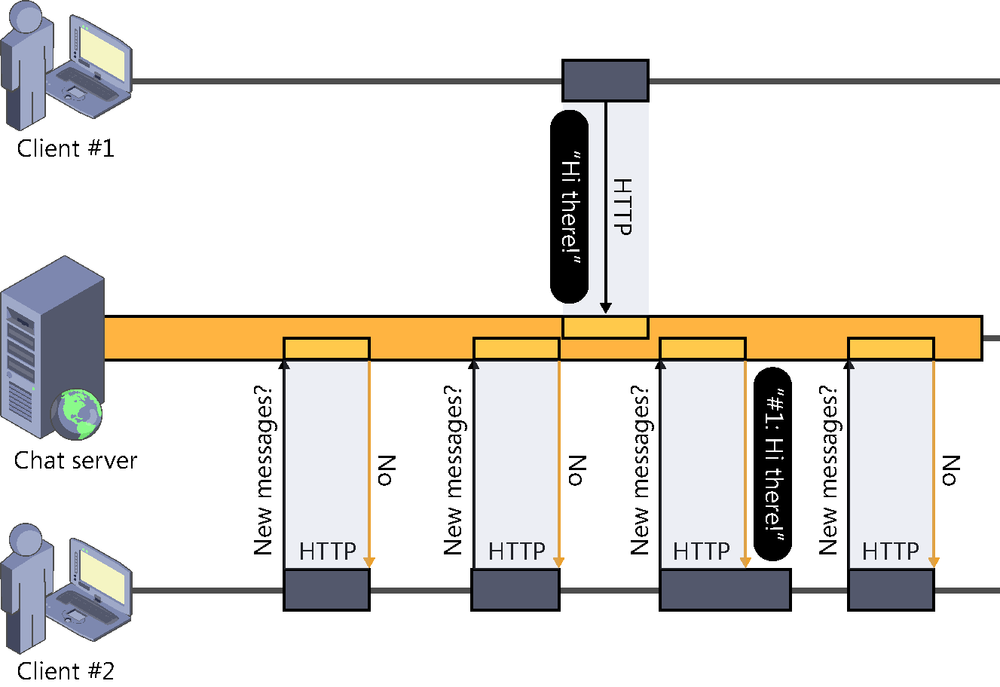
The main advantages of this solution are, first, its easy implementation and, second, its universal application: it works in every case, with all browsers and with all servers, because it does nothing more than use the standard features of HTTP. And, of course, we still use the pull model.
However, sometimes the price of polling is too high. Constant connections and disconnections have a high cost in terms of bandwidth and processing at both ends of communication. The worst part is that this cost increases proportionally to our need for faster updates and the number of clients making use of the service at a given time. In an application providing real-time updates, it is easy to imagine the load that a server has to bear when it has thousands of users connected, requesting several updates per second.
There are techniques to mitigate these problems insofar as possible. One of them is to use adaptive intervals so that the interval between queries regularly adapts to the current system load or to the probability of new updates. This solution is quite easy to implement and can significantly improve resource consumption in some scenarios.
There is a more conservative variant of polling, but it degrades user experience. It is the technique called piggy backing, which consists in not making deliberate queries from the client and, instead, taking advantage of any interaction between the user and the system to update any necessary information. To illustrate this, consider a web mail service: instead of making periodic queries to check for the arrival of new messages, those checks would be performed each time the user accessed a page, an email, or any other feature. This can be useful in scenarios that do not require great immediacy and in which the features of the system itself mean that we can be sure that the user will interact with the application frequently.
Of course, these variants can be combined with each other to achieve more efficient usage of resources, offering at the same time a reasonable user experience. For example, to obtain the updates, it would be possible to update the status of a client via piggy backing when the client interacts with the server, using polling with or without adaptive periodicity when there is no such interaction.
In conclusion, polling is a reasonable option despite its disadvantages when we want a solution that is easy to implement and that can be used universally and in scenarios in which a very high update frequency is not required. In fact, it is used a lot in current systems. A real-life example of its application is found in the web version of Twitter, where polling is used to update the timeline every 30 seconds.
We have already said that there are applications where the use of pull is not very efficient. Among them, we can name instant-messaging systems, real-time collaboration toolsets, multiuser online games, information broadcasting services, and any kind of system where it is necessary to send information to the client right when it is generated.
For such applications, we need the server to take the initiative and be capable of sending information to the client exactly when a relevant event occurs, instead of waiting for the client to request it.
This is precisely the idea behind the push, or server push, concept. This name does not make reference to a component, a technology, or a protocol: it is a concept, a communication model between the client and the server where the latter is the one taking the initiative in communications.
This concept is not new. There are indeed protocols that are push in concept, such as IRC, the protocol that rules the operation of classic chat room services, or SMTP, the protocol in charge of coordinating email sending. These were created before the term that identifies this type of communication was coined.
For the server to be able to notify events in real time to a set of clients interested in receiving them, the ideal situation would be to have the ability to initiate a direct point-to-point connection with them. For example, a chat room server would keep a list with the IP addresses of the connected clients and open a socket type connection to each of them to inform them of the arrival of a new message.
However, that is technically impossible. For security reasons, it is not normally possible to make a direct connection to a client computer due to the existence of multiple intermediate levels that would reject it, such as firewalls, routes, or proxies. For this reason, the customary practice is for clients to be the ones to initiate connections and not vice versa.
To circumvent this issue and manage to obtain a similar effect, certain techniques emerged that were based on active elements embedded in webpages (Java applets, Flash, Silverlight apps, and so on). These components normally used sockets to open a persistent connection to the server—that is, a connection that would stay open for as long as the client was connected to the service, listening for anything that the server had to notify. When events occurred that were relevant to the client connected, the server would use this open channel to send the updates in real time.
Although this approach has been used in many push solutions, it is tending to disappear. Active components embedded in pages are being eliminated from the web at a dramatic speed and are being substituted for more modern, reliable, and universal alternatives such as HTML5. Furthermore, long-term persistent connections based on pure sockets are problematic when there are intermediary elements (firewalls, proxies, and so on) that can block these communications or close the connections after a period of inactivity. They can also pose security risks to servers.
Given the need for reliable solutions to cover these types of scenarios, both W3C and IETF—the main organizations promoting and defining protocols, languages, and standards for the Internet—began to work on two standards that would allow a more direct and fluent communication from the server to the client. They are known as WebSockets and Server-Sent Events, and they both come under the umbrella of the HTML5 “commercial name.”
The WebSockets standard consists of a development API, which is being defined by the W3C (World Wide Web Consortium, http://www.w3.org), and a communication protocol, on which the IETF (Internet Engineering Task Force, http://www.ietf.org) has been working.
Basically, it allows the establishment of a persistent connection that the client will initiate whenever necessary and which will remain open. A two-way channel between the client and the server is thus created, where either can send information to the other end at any time, as shown in Figure 2-4.
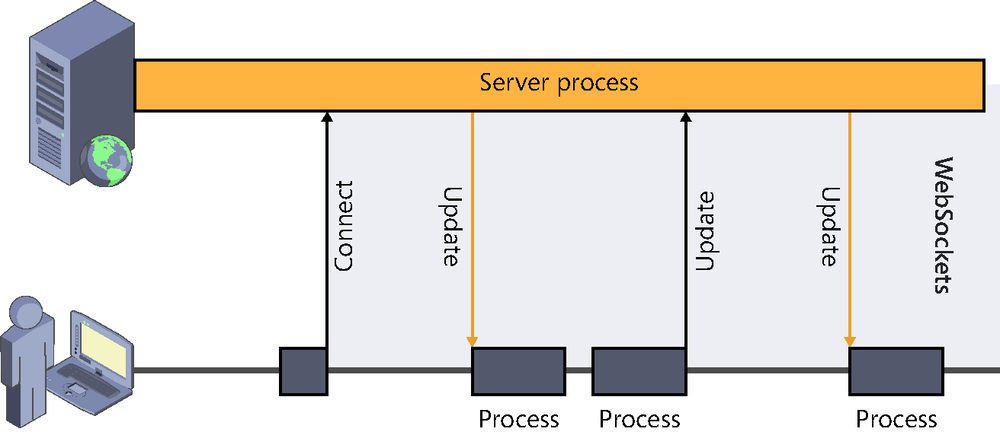
Although at the moment the specifications of both the API and the protocol are quite far advanced, we cannot yet consider this technology to be universally applicable.
We can find implementations of WebSockets in many current browsers, such as Internet Explorer 10, Internet Explorer 11, Chrome, and Firefox. Some feature only partial implementations (Opera mini, Android browser), and in others, WebSockets is simply not available[3].
Aside from the problem of the different implementation levels at the client side, the fact that the standard includes an independent protocol for communication (although initially negotiated on HTTP) means that changes also have to be made on some infrastructural elements, and even on servers, so that connections using WebSockets are accepted.
For example, it has not been possible to use WebSockets easily on Microsoft technologies up until the very latest wave of developments (Internet Explorer 10, ASP.NET 4.5, WCF, IIS 8, and so on), in which it has begun to be supported natively.
From the perspective of a developer, WebSockets offers a JavaScript API that is really simple and intuitive to initiate connections, send messages, and close the connections when they are not needed anymore, as well as events to capture the messages received:
var ws = new WebSocket("ws://localhost:9998/echo");
ws.onopen = function() {
// Web Socket is connected, send data using send()
ws.send("Message to send");
alert("Message is sent...");
};
ws.onmessage = function(evt) {
var received_msg = evt.data;
alert("Message is received...");
};
ws.onclose = function () {
// WebSocket is closed.
alert("Connection is closed...");
};As you can see, the connection is opened simply by instantiating a WebSockets object pointing to the URL of the service endpoint. The URL uses the ws:// protocol to indicate that it is a WebSockets connection.
You can also see how easily we can capture the events produced when we succeed in opening the connection, data are received, or the connection is closed.
Without a doubt, WebSockets is the technology of the future for implementing push services in real time.
Server-Sent Events, also known as API Event Source, is the second standard on which the W3 consortium has been working. Currently, this standard is in candidate recommendation state. But this time, because it is a relatively straightforward JavaScript API and no changes are required on underlying protocols, its implementation and adoption are simpler than in the case of the WebSockets standard.
In contrast with the latter, Server-Sent Events proposes the creation of a one-directional channel from the server to the client, but opened by the client. That is, the client “subscribes” to an event source available at the server and receives notifications when data are sent through the channel, as illustrated in Figure 2-5.
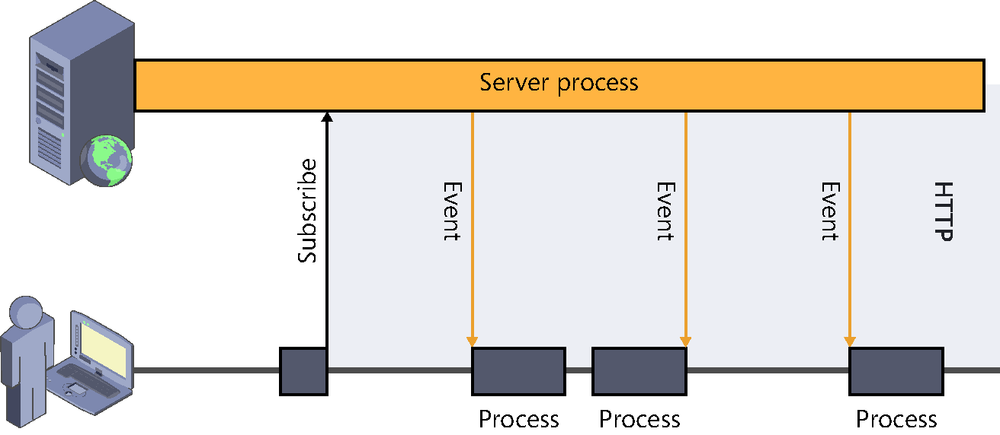
All communication is performed on HTTP. The only difference with respect to a more traditional connection is the use of the content-type text/event-stream in the response, which indicates that the connection is to be kept open because it will be used to send a continuous stream of events—or messages—from the server.
Implementation at the client is even simpler than the one we saw earlier for WebSockets:
var source = new EventSource('/getevents'),
source.onmessage = function(event) {
alert(event.data);
};As you can guess, instantiating the EventSource object initiates the subscription of the client to the service whose URL is provided in the constructor, and the messages will be processed in the callback function specified to that effect.
Currently, almost all browsers support this standard except for Internet Explorer and some mobile-specific browsers, and this limits its use in real applications. Also, if we look at it from an infrastructural point of view, we find that although being based on HTTP greatly simplifies its generalization, it requires the aid of proxies or other types of intermediaries, which must be capable of interpreting the content-type used and not processing the connections in the same way as the traditional ones—for example, avoiding buffering responses or disconnections due to time-out.
It is also important to highlight the limitations imposed by the fact that the channel established for this protocol is one-directional from the server to the client: if the client needs to send data to the server, it must do so via a different connection, usually another HTTP request, which involves, for example, having greater resource consumption than if WebSockets were used in this same scenario.
As we have seen, standards and browsers are both getting prepared to solve the classic push scenarios, although we currently do not have enough security to use them universally.
Nevertheless, push is something that we need right now. Users demand ever more interactive, agile, and collaborative applications. To develop them, we must make use of techniques allowing us to achieve the immediacy of push but taking into account current limitations in browsers and infrastructure. At the moment, we can obtain that only by making use of the advantages of HTTP and its prevalence.
Given these premises, it is easy to find multiple conceptual proposals on the Internet, such as Comet, HTTP push, reverse AJAX, AJAX push, and so on, each describing solutions (sometimes coinciding) to achieve the goals desired. In the same way, we can find different specific techniques that describe how to implement push on HTTP more or less efficiently, such as long polling, XHR streaming, or forever frame.
We will now study two of them, long polling and forever frame, for two main reasons. First, because they are the most universal ones (they work in all types of client and server systems), and second, because they are used natively by SignalR, as we shall see later on. Thus we will move toward the objectives of this book.
This push technique is quite similar to polling, which we already described, but it introduces certain modifications to improve communication efficiency and immediacy.
In this case, the client also polls for updates, but, unlike in polling, if there is no data pending to be received, the connection will not be closed automatically and initiated again later. In long polling, the connection remains open until the server has something to notify, as shown in Figure 2-6.
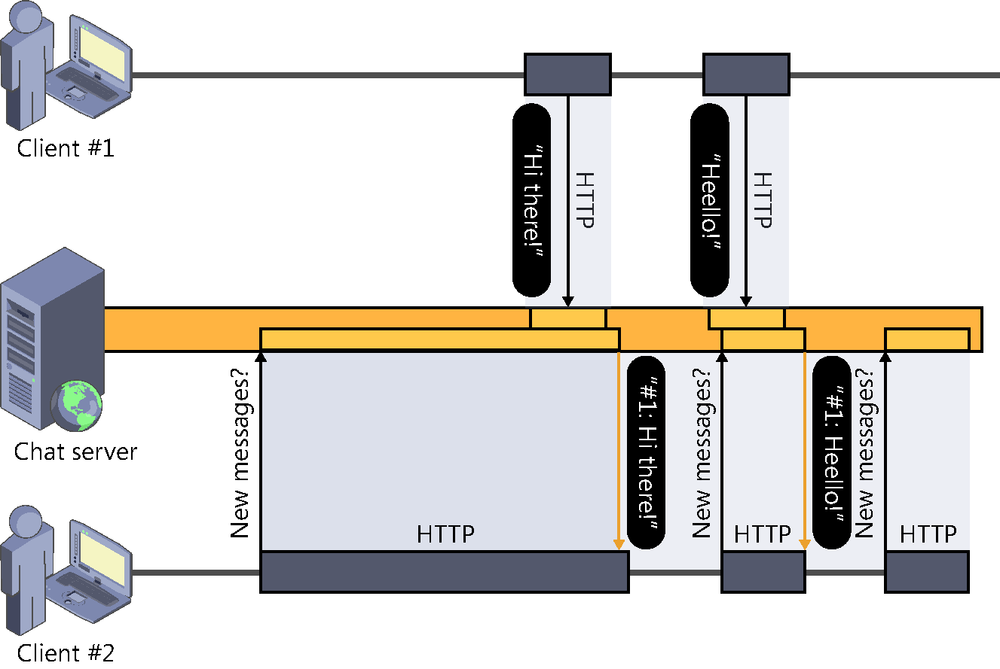
The connection, which is always initiated by the client, can be closed because of only two things:
The server sends data to the client through the connection.
A time-out error occurs due to lack of activity on the connection.
In both cases, a new connection would be immediately established, which would again remain waiting for updates.
This connection is used exclusively to receive data from the server, so if the client needs to send information upward, it will open an HTTP connection in parallel to be used exclusively for that purpose.
The main advantage of long polling is the low delay in updating the client, because as soon as the server has data to update the state of the client, it will be sent through the channel that is already open, so the other end will receive it in real time.
Also, because the number of connection openings and closures is reduced, resource optimization at both ends is much higher than with polling.
Currently, this is a widely used solution due to its relatively simple implementation and the fact that it is completely universal. No browser-specific feature is used—just capabilities offered by HTTP.
Resource consumption with long polling is somewhat higher than with other techniques where a connection is kept open. The reason is that there are still many connection openings and closures if the rate of updates is high, not forgetting the additional connection that has to be used when the client wants to send data to the server. Also, the time it takes to establish connections means that there might be some delay between notifications. These delays could become more evident if the server had to send a series of successive notifications to the client. Unless we implemented some kind of optimization, such as packaging several messages into one same HTTP response, each message would have to wait to be sent while the client received the previous message in the sequence, processed it, and reopened the channel to request a new update.
The other technique that we are going to look at is called forever frame and uses the HTML <IFRAME> tag cleverly to obtain a permanently open connection. In a way, this is very similar to Server-Sent Events.
Broadly, it consists in entering an <IFRAME> tag in the page markup of the client. In the source of <IFRAME>, the URL where the server is listening is specified. The server will maintain this connection permanently open (hence the “forever” in its name) and will use it to send updates in the form of calls to script functions defined at the client. In a way, we might say that this technique consists in streaming scripts that are executed at the client as they are received.
Because the connection is kept open permanently, resources are employed more efficiently because they are not wasted in connection and disconnection processes. Thus we can practically achieve our coveted real time in the server-client direction.
Just like in the previous technique, the use of HTML, JavaScript, and HTTP makes the scope of its application virtually universal, although it is obviously very much oriented towards clients that support those technologies, such as web browsers. That is, the implementation of other types of clients, such as desktop applications, or other processes acting as consumers of those services would be quite complex, as shown in Figure 2-7.
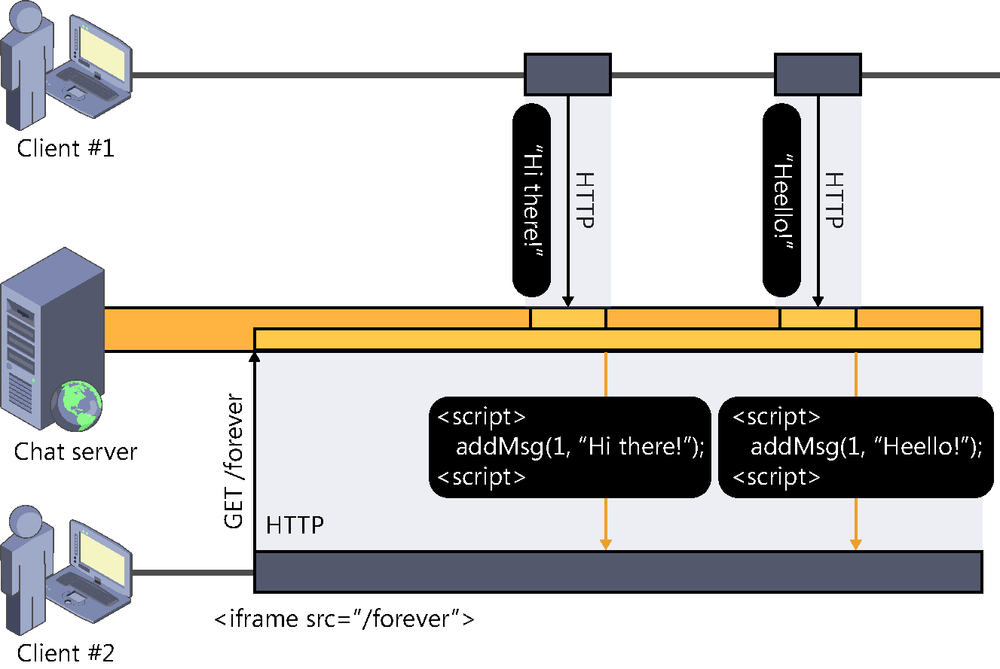
This technique is not exempt from disadvantages either. In its implementation, it is necessary to take into account that there might be time-outs caused by the client, the server, or an intermediary element (such as proxies and firewalls). Also, to obtain the best real-time experience, responses must be sent to the client immediately and not withheld in buffers or caches. And, because the responses would accumulate inside the iframe, in client memory, we might end up taking up too much RAM, so we have to “recycle” or eliminate contents periodically.
Finally, the fact that the connection is used only to send data from the server to the client makes it necessary to use an additional connection when we want to send it in the opposite direction—that is, from the client to the server.
Until now, we have seen techniques that allow us to achieve push; that is, they allow the server to be able to send information to the client asynchronously as it is generated. We have given the initiative to an element that would normally assume a passive role in communications with the client.
However, in the context of asynchronous, multiuser, and real-time applications, push is but one of the aspects that are indispensable. To create these always surprising systems, we need many more capabilities. Here we list a few of them:
Managing connected users. The server must always know which users are connected to the services, which ones disconnect, and, basically, it must control all the aspects associated with monitoring an indeterminate number of clients.
Managing subscriptions. The server must be capable of managing “subscriptions,” or grouping clients seeking to receive specific types of messages. For example, in a chat room service, only the users connected to a specific room should receive the messages sent to that room. This way, the delivery of information is optimized and clients do not receive information that is not relevant to them, minimizing resource waste.
Receiving and processing actions. The server be capable not only of sending information to clients in real time but also of receiving it and processing it on the fly.
Monitoring submissions. Because we cannot guarantee that all clients connect under the same conditions, there might be connections at different speeds, line instability, or occasional breakdowns, and this means that it is necessary to provide for mechanisms capable of queuing messages and managing information submissions individually to ensure that all clients are updated.
Offering a flexible API, capable of being consumed easily by multiple clients. This is even truer nowadays, when there are a wide variety of devices from which we can access online services.
We could surely enumerate many more, but these examples are more than enough to give you an idea of the complexity inherent in developing these types of applications.
Enter SignalR….
[1] Specification of HTTP 1.0: http://www.w3.org/Protocols/HTTP/1.0/spec.html
[2] Internet Relay Chat (IRC) protocol: http://www.ietf.org/rfc/rfc1459.txt
[3] Source: http://caniuse.com/WebSockets