
Chapter 5. Information Systems Hardware and Architecture
This chapter helps you prepare for the Certified Information Systems Auditor (CISA) exam by covering the following ISACA objectives, which include understanding system hardware and the architecture of operating systems and databases. This includes items such as the following:
Tasks
Evaluate service level management practices to ensure that the level of service from internal and external service providers is defined and managed.
Evaluate operations management to ensure that IT support functions effectively meet business needs.
Evaluate data administration practices to ensure the integrity and optimization of databases.
Evaluate change, configuration, and release management practices to ensure that changes made to the organization’s production environment are adequately controlled and documented.
Evaluate the functionality of the IT infrastructure (e.g., network components, hardware, system software) to ensure that it supports the organization’s objectives.
Knowledge Statements
Knowledge of service-level management practices
Knowledge of operations management best practices (e.g., workload scheduling, network services management, preventive maintenance)
Knowledge of database administration practices
Knowledge of the functionality of system software, including operating systems, utilities, and database management systems
Knowledge of capacity planning and monitoring techniques
Knowledge of processes for managing scheduled and emergency changes to the production systems and/or infrastructure, including change, configuration, release, and patch management practices
Knowledge of incident/problem management practices (e.g., help desk, escalation procedures, tracking)
Knowledge of software licensing and inventory practices
Knowledge of system resiliency tools and techniques (e.g., fault tolerant hardware, elimination of single point of failure, clustering)
Computer Configurations and Roles
Radio Frequency Identification
Hardware Monitoring and Capacity Management
Information Systems Architecture and Software
This chapter addresses information you need to review about computer hardware, operating systems, and related issues. A CISA must understand the technical environment to successfully perform the job tasks. A CISA candidate should review the following primary topics for the exam:
![]() Understand service-level management best practices
Understand service-level management best practices
![]() Know what lights-out processes are
Know what lights-out processes are
![]() Understand databases, their structure, and database-management systems
Understand databases, their structure, and database-management systems
![]() Know the differences between distributed and centralized architectures
Know the differences between distributed and centralized architectures
![]() Understand operation-management best practices
Understand operation-management best practices
![]() Describe the change-control and change-management best practices
Describe the change-control and change-management best practices
Introduction
In this chapter, you review information systems operations. This topic involves issues dealing with resource use monitoring, the help desk, and the issues of security involving programming code. Programming code must be handled carefully, and controls must be used to protect the integrity of source code and production applications. This chapter also discusses information systems hardware. This chapter reviews different types of computers, as well as the roles that computers fulfill, such as clients or servers. It also reviews components such as memory, storage, and interfaces. Hardware represents just one part of computer operations; software is another big piece. Computers cannot run without operating systems and software. The design of the operation system plays a big part in how easily controls can be implemented. This also holds true for databases, which hold sensitive information; the auditor must understand the architecture, structure, and controls.
Information Systems Operation
Tasks
![]() Evaluate service level management practices to ensure that the level of service from internal and external service providers is defined and managed.
Evaluate service level management practices to ensure that the level of service from internal and external service providers is defined and managed.
![]() Evaluate operations management to ensure that IT support functions effectively meet business needs.
Evaluate operations management to ensure that IT support functions effectively meet business needs.
![]() Evaluate change, configuration, and release management practices to ensure that changes made to the organization’s production environment are adequately controlled and documented.
Evaluate change, configuration, and release management practices to ensure that changes made to the organization’s production environment are adequately controlled and documented.
Knowledge Statements
![]() Knowledge of service level management practices
Knowledge of service level management practices
![]() Knowledge of operations management best practices (e.g., workload scheduling, network services management, preventive maintenance)
Knowledge of operations management best practices (e.g., workload scheduling, network services management, preventive maintenance)
![]() Knowledge of capacity planning and monitoring techniques
Knowledge of capacity planning and monitoring techniques
![]() Knowledge of processes for managing scheduled and emergency changes to the production systems and/or infrastructure, including change, configuration, release, and patch management practices
Knowledge of processes for managing scheduled and emergency changes to the production systems and/or infrastructure, including change, configuration, release, and patch management practices
![]() Knowledge of incident/problem management practices (e.g., help desk, escalation procedures, tracking)
Knowledge of incident/problem management practices (e.g., help desk, escalation procedures, tracking)
Information systems (IS) management has responsibility for IS operations and must develop policies and procedures to ensure that operations comply with management’s strategy. Management must also allocate resources to ensure that resources are available to meet the needs of the organization. This requires deploying systems to monitor IS processes. Monitoring enables management to detect problems, measure the effectiveness of existing systems, and plan for upgrades as needed. Table 5.1 lists and describes the control functions for which IS operations are responsible.
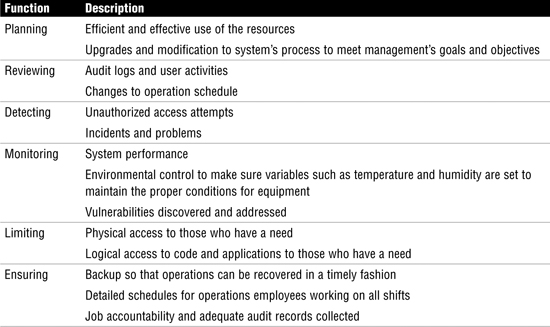
In many ways, IS operations is a service organization because it provides services to its users. Many IS departments have mission statements in which they publicly identify the level of service they agree to provide to their customers. When IS services are outsourced, this becomes an even bigger concern. The issue of service is usually addressed by means of a service level agreement (SLA). SLAs define performance targets for hardware and software. Some common types of SLAs include the following:
![]() Uptime agreements (UAs)—UAs are one of the most well-known type of SLA. UAs detail the agreed-on amount of uptime. As an example, these can be used for network services, such as a WAN link or equipment-like servers.
Uptime agreements (UAs)—UAs are one of the most well-known type of SLA. UAs detail the agreed-on amount of uptime. As an example, these can be used for network services, such as a WAN link or equipment-like servers.
![]() Time service factor (TSF)—The TSF is the percentage of help desk or response calls answered within a given time.
Time service factor (TSF)—The TSF is the percentage of help desk or response calls answered within a given time.
![]() Abandon rate (AR)—The AR is the number of callers that hang up while waiting for a service representative to answer.
Abandon rate (AR)—The AR is the number of callers that hang up while waiting for a service representative to answer.
![]() First call resolution (FCR)—The FCR is the number of resolutions that are made on the first call and that do not require the user to call back to the help desk to follow up or seek additional measures for resolution.
First call resolution (FCR)—The FCR is the number of resolutions that are made on the first call and that do not require the user to call back to the help desk to follow up or seek additional measures for resolution.
IS operations are responsible for monitoring resources, incident/problem handling, infrastructure operations, help desk and support, and change management. The following sections examine each of these functions in more detail.
Note
Lights-Out Operations Lights-out operations can take place without human interaction. These include job scheduling, report generation, report balancing, and backup.
Monitoring Resource Usage
Computer resources are considered a limited commodity because the company provides them to help meet its overall goals. Although many employees would never dream of placing all their long-distance phone calls on a company phone, some of those same individuals have no problem using computer resources for their own personal use. Consider these statistics from http://www.connections-usa.com: One-third of time spent online at work is non–work related, 70% of porn is downloaded between 9 a.m. and 5 p.m., and more than 75% of streaming radio downloads occurs between 5 a.m. and 5 p.m. This means that the company must have an effective monitoring program. Accountability should be maintained for computer hardware, software, network access, and data access. Other resources such as VoIP and email must also be monitored and have sufficient controls in place to prevent its misuse. In a high-security environment, the level of accountability should be even higher and users should be held responsible by logging and auditing many types of activities.
If there is a downside to all this logging, it is that all the information must be recorded and reviewed. Reviewing it can be expedited by using audit reduction tools. These tools parse the data and eliminate unneeded information. Another useful tool for an auditor is a variance detection tool, which looks for trends that fall outside the realm of normal activity. As an example, if an employee normally enters the building around 8 a.m. and leaves about 5 p.m., but now is seen entering the building at 3 a.m., a variance detection tool can detect this abnormality.
Note
Keystroke Monitoring Capturing a user’s keystrokes for later review is an example of monitoring. Users need to be made aware of such activities through acceptable use policies and warning banners.
This exercise has you review the application log in Event Viewer on a Windows computer.
1. Click Start, Settings, Control Panel, Administrative Tools, Event Viewer.
2. On the left side of the screen under Tree, select the System Log. Figure 5.1 illustrates where the logs can be seen on the right side of the dialog box.

3. Choose an event to examine by double-clicking it.
4. After double-clicking the event, scroll down to the bottom of the Description box where you will find a URL that you can click on that takes you directly to the page on Microsoft’s site (after you approve sending the information over the Internet, of course) that provides the explanation, possible causes, and recommended user action.
5. Repeat the process for another event ID and review the results.
Incident Handling
Things will go wrong, and technology does not always work as planned. Part of the process of monitoring is to verify that nothing out of the ordinary has occurred. If unusual activity is discovered, a method of handling the situation needs to be followed. This means that an incident-handling process must be established. Incident handling should follow a structured methodology that has smaller, manageable steps so that incidents can be dealt with in a logical fashion. This process starts with policies, procedures, and guidelines that should be developed before incidents occur. Although incident handling might seem to be a reactive process, it should be based on a proactive plan.
A big part of the plan should address priority. As an example, if the CEO calls about a printer problem and a production server crashes at the same time, parameters need to be established to determine what incidents are addressed first. The time between when an incident occurs and when it is addressed is called the delay window. Incident handling should look at ways to reduce the delay window to the smallest value possible. As an example, adding two extra people to the help desk might reduce the delay window from two minutes to under one minute of wait time. Incidents are typically caused by an underlying problem, which is the next topic for discussion.
Problem Management
A problem can be defined as an underlying cause of one or more incidents. Problem management is about more than mitigating an immediate incident; it’s about preventing future problems and incidents.
When an incident is confirmed and the underlying problem is determined, the process moves into the known error state. Problem management follows a known process, as outlined in Figure 5.2.
Figure 5.2 Typical problem-management process.
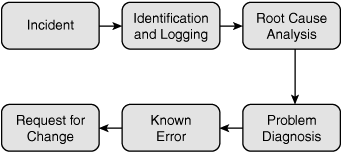
Note that the goal of the problem-management process is to find the root cause of problems and institute change management. Identifying problems and instituting change allows for the improvement of service and the reduction of problems. The department responsible for this process should track incidents, response time, and final resolution. These items are discussed in more detail next.
Tracking Abnormal Events
Audit logs help detect misuse, but a method of reporting and tracking abnormal events must be in place. IS operations are highly complex; when various types of hardware, software, and operating systems are combined, things are bound to occasionally go wrong and/or abnormal events are bound to occur. It’s important to be able to track these events and document their occurrence. A manual log or an automated process can be used to perform this tracking activity. Recorded items should include errors caused by the following:
![]() Systems
Systems
![]() Operators
Operators
![]() Networks
Networks
![]() Hardware
Hardware
![]() Telecommunications systems
Telecommunications systems
The contents of the log should be restricted. Only authorized individuals should be able to update items or post the final resolution. Separation of duties should be practiced so that the same person who can create log entries cannot close a log entry. Table 5.2 shows an example of what should be found in a log.

The problem management’s log should be reviewed periodically to ensure that problems are being addressed and that resolution is occurring in a timely manner. Problems that are not resolved within a reasonable period of time should be escalated. The mechanisms by which this happens should be detailed in policy and be thoroughly documented. Problem escalation should include the following information:
![]() Who can address the problem
Who can address the problem
![]() Lists of problems that require immediate response
Lists of problems that require immediate response
![]() Types of problems that should be addressed only during normal working hours
Types of problems that should be addressed only during normal working hours
Exam Alert
Auditing Problem Reports The auditor should know to review the problem log to verify that problems are being resolved. Auditors must also check to see that the most appropriate department or individual is handling the problems.
Help Desk and Support
The help desk has the responsibility of providing technical support to the organization and its employees. The help desk is typically charged with identifying problems, performing root cause analysis, and tracking change management or problem resolution. Many companies provide help desk functionality by means of toll-free phone numbers, websites, or email. After a user contacts the help desk, he is issued a trouble ticket. Figure 5.3 shows an example of a web-based trouble ticket.
Figure 5.3 Example of a web-based trouble ticket.
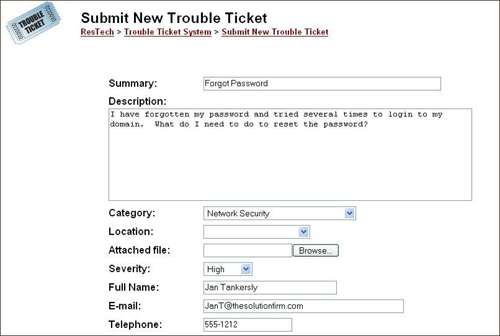
Trouble tickets are assigned unique IDs, which are used to track the time of entry, response, and resolution. The trouble ticket is typically assigned a level of priority at the time it is created. As an example, most companies use a Level 1 help desk priority to answer common questions and easy-to-address problems. Level 1 help desk employees typically use a script or decision tree to step through possible problems and solutions. An example of a Level 1 connectivity script is shown here:
5.1 Troubleshooting Connectivity Problems
1. Do you have connectivity to the web? Can you access the company webserver at http://192.168.1.254?
2. Can you ping 192.168.1.254? (Yes/No)
3. Can you verify that the network cable is attached to your computer and is connected to the wall jack? (Yes/No)
4. Open a command prompt and enter ipconfig/all. Can you please read off the settings? (Yes/No)
5. Click Start, Settings, Control Panel, Network Connections, Local Area Network Connection. Next select the Properties button. Now double-click on Internet Protocol. Please read off the values listed in each field. Are these correct? (Yes/No)
6. All obvious checks have been completed and the problem has not been resolved. Refer problem to Level 2 response.
Problems that cannot be resolved by Level 1 are escalated to Level 2 response. Level 2 help desk analysts handle the most difficult calls. Small organizations might have help desk analysts who answer all types of calls; however, many larger companies separate calls by the nature of the problem. Common teams include the following:
![]() Deskside team—Responsible for desktops and laptops
Deskside team—Responsible for desktops and laptops
![]() Network team—Responsible for network issues
Network team—Responsible for network issues
![]() Application software team—Responsible for application issues
Application software team—Responsible for application issues
![]() Printer team—Responsible for printers and printer-related problems
Printer team—Responsible for printers and printer-related problems
![]() Telecom team—Responsible for VoIP systems, PBX, voice mail, modems, and fax machines
Telecom team—Responsible for VoIP systems, PBX, voice mail, modems, and fax machines
Note
Crossover Responsibilities In real life it can sometimes be a challenge to find out who is really responsible, as there can be some crossover within technologies and duties. For example, the Telecom team works the PBX, but the PBX has a VoIP firewall that the Network team administers.
Regardless of how the team is structured, it has several responsibilities:
![]() Document problems
Document problems
![]() Prioritize issues
Prioritize issues
![]() Follow up on unresolved problems
Follow up on unresolved problems
![]() Close out problems
Close out problems
![]() Document results
Document results
The next section shifts the topic focus to change management and how it’s related to help desk and problem management.
Change-Management Process
Change management is a formalized process whose purpose is to control modifications made to systems and programs. Without effective change-management procedures, situations can arise where unauthorized changes occur, potentially endangering the security of the organization or leading to operations being performed in an untested or unknown state. These questions must be asked during the change-management process:
![]() Time scale—How quickly is the change needed?
Time scale—How quickly is the change needed?
![]() Scope—How big of a change is needed?
Scope—How big of a change is needed?
![]() Capability—Does the company have the in-house skills and capability to implement change?
Capability—Does the company have the in-house skills and capability to implement change?
![]() Cost—What is the cost of the change?
Cost—What is the cost of the change?
![]() Time completion—What is the time frame to make the change?
Time completion—What is the time frame to make the change?
![]() Approval—Who must approve the change and what is the approval process?
Approval—Who must approve the change and what is the approval process?
Companies typically customize the change-management process for their particular environment. The change-management process should be designed to ensure that the benefits of any potential change are properly analyzed and that changes to a system are made in a structured manner. On a higher level, change management consists of three stages, as illustrated in Figure 5.4.
Figure 5.4 General change-management process.
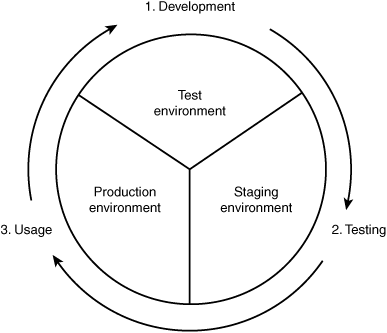
Changes should be looked at closely to make sure that no proposed change affects the process negatively or reduces the quality of service. The change-management process should include steps for change development, testing, and usage. Change management should have an escape path so that changes can be backed out if the change is unsuccessful.
Program Library Systems
Change management is especially critical for program library systems, which typically control all applications, including accessing code and compiling it to an executable program. Program library systems should also contain an audit function so that the date, time, or name of a specific programmer that accessed the library can be identified. Accountability must be maintained so that the auditor can trace any changes to code or compiled programs. Specifically, these systems should prevent programmers from directly accessing production source code and object libraries. If a programmer needs the code, it should be released only through a third-party control group that has the capability to copy it to the programmer’s library. If compiled code is to be placed back into production again, the programmer should not be able to do this directly. The programmer should again go through the control group and have it place the approved code back into the production library. Sufficient controls should be in place to prevent nonproduction code from inadvertently being executed in the production environment. Ensuring that these requirements are met is a complicated task that can be made easier by verifying that the program library system has certain capabilities:
![]() Integrity—Each piece of source code should be assigned a unique ID and version number. Security should be maintained through password-controlled directories, encryption, and regular backups.
Integrity—Each piece of source code should be assigned a unique ID and version number. Security should be maintained through password-controlled directories, encryption, and regular backups.
![]() Update—Any changes or modification to source code should be tracked and an audit trail should be produced.
Update—Any changes or modification to source code should be tracked and an audit trail should be produced.
![]() Reporting—Controls should be in place to report changes to code or any modification.
Reporting—Controls should be in place to report changes to code or any modification.
![]() Interface—Library-management systems need to interface with the OS, access-control system, audit, and access-control mechanisms.
Interface—Library-management systems need to interface with the OS, access-control system, audit, and access-control mechanisms.
Auditors might be asked to verify existing source code at some point. If so, the auditor might want to use source code comparison software. This software compares a previously obtained copy of the source code to a current copy and can identify any changes. Although this is somewhat effective, it should be noted that after changes are entered into the code and then removed, they cannot be detected. As an example of this shortcoming, suppose that a programmer adds code to the accounting software to shave off a few cents from each transaction and then adds them to a secret account that he has set up. After compiling the code and placing it in production, the programmer removes the added lines of code from the source and returns it to its original state. The source code comparison software would not detect this.
Exam Alert
Source Code Comparison A CISA candidate should be aware that source code comparison does have its limitations. As an example, it cannot detect a change in source code that has been changed and restored between checks. Compiled code must also be examined. The test might review these types of items.
These issues emphasize the fact that executable code must also be examined. Items such as time stamps and integrity checks can be examined on compiled code to make sure that nonvalidated programs are not in production. At no time should the programmer or developer have direct access to the production libraries. In some environments, users might create their own programs. This can be particularly challenging to the auditor because there are few controls in place. More than one user can use these programs, and, without the guidance of professional programmers, these programs might be flawed. Such programs can easily introduce flaws into data files.
Release Management
Release management is the discipline within software management of controlling the release of software to end users. Released software is software that has been approved for release to users. Releases can be divided into one of several categories:
![]() Emergency fix—These are updates that must be done quickly, sometimes referred to as a patch. An emergency fix is designed to fix a small number of known problems. These can be dangerous because they can introduce additional errors into the program.
Emergency fix—These are updates that must be done quickly, sometimes referred to as a patch. An emergency fix is designed to fix a small number of known problems. These can be dangerous because they can introduce additional errors into the program.
![]() Minor release—Minor releases contain small enhancements or fixes that supersede an emergency fix. Minor releases are used to improve performance, reliability, or security.
Minor release—Minor releases contain small enhancements or fixes that supersede an emergency fix. Minor releases are used to improve performance, reliability, or security.
![]() Major release—Major releases supersede minor releases and emergency fixes. They are designed to provide a significant improvement to the program. Major releases are usually scheduled to be released at predetermined times, such as quarterly, biannually, or yearly.
Major release—Major releases supersede minor releases and emergency fixes. They are designed to provide a significant improvement to the program. Major releases are usually scheduled to be released at predetermined times, such as quarterly, biannually, or yearly.
Updates to programs are also sometimes referred to as patches. A patch is an additional piece of code designed to remedy an existing bug or problem. As an example, Microsoft releases patches in three formats:
![]() Hotfixes—These updates address a single problem or bug encountered by a customer.
Hotfixes—These updates address a single problem or bug encountered by a customer.
![]() Roll-ups—A roll-up fix combines the updates of several hotfixes into a single update file.
Roll-ups—A roll-up fix combines the updates of several hotfixes into a single update file.
![]() Service packs—These are a collection of all hotfixes released since the application’s release, including hotfixes released in previous service pack versions.
Service packs—These are a collection of all hotfixes released since the application’s release, including hotfixes released in previous service pack versions.
Each of these patch formats are distributed with release or patch notes which should be reviewed.
What is important about this process is that the organization has a schedule for deploying and updating applications. A rollout plan needs to be established and a system should be in place to test releases and phases of their use within the organization. An organization should also have a rollback plan so that it can back out of the process if something fails. The Quality Assurance group is responsible for overseeing much of this process. Quality Assurance personnel must verify that changes are authorized, tested, and implemented in a structured method. Most Quality Assurance groups follow a Plan-Do-Check-Act (PDCA) approach. This allows Quality Assurance to ensure quality and verify that changes to programs or applications are met and/or exceed customer needs.
Post-Deployment
Many might believe that in post-deployment, the job is complete; however, this is not the case. Programs and the data that programs use require ongoing protection. This means performing periodic vulnerability tests. After major changes, a business must perform an impact analysis, as well as secure certification and accreditation. Other post-deployment issues include these:
![]() Testing backup and recovery
Testing backup and recovery
![]() Ensuring proper controls for data and reports
Ensuring proper controls for data and reports
![]() Verifying that security features cannot be bypassed or disabled
Verifying that security features cannot be bypassed or disabled
![]() Validating the security of system resources and data
Validating the security of system resources and data
Information Systems Hardware
Task
![]() Evaluate the functionality of the IT infrastructure (e.g., network components, hardware, system software) to ensure that it supports the organization’s objectives.
Evaluate the functionality of the IT infrastructure (e.g., network components, hardware, system software) to ensure that it supports the organization’s objectives.
Knowledge Statements
![]() Knowledge of capacity planning and monitoring techniques
Knowledge of capacity planning and monitoring techniques
![]() Knowledge of system resiliency tools and techniques (e.g., fault tolerant hardware, elimination of single point of failure, clustering)
Knowledge of system resiliency tools and techniques (e.g., fault tolerant hardware, elimination of single point of failure, clustering)
This section reviews hardware used in organizations. It begins by reviewing the central processing unit (CPU) and then moves on to look at other components found in a computer.
The Central Processing Unit
At the heart of every computer is the CPU. The CPU is capable of executing a series of basic operations; it can fetch instructions and then process them. CPUs have four basic tasks: fetch, decode, execute, and write back. Because CPUs have very specific designs, the operating system must be developed to work with the CPU. CPUs have two primary components:
![]() The arithmetic logic unit—Computations are performed here, in the brain of the CPU.
The arithmetic logic unit—Computations are performed here, in the brain of the CPU.
![]() The control unit—This unit handles the sequence of operations for the CPU and is also responsible for the retrieval of instructions and data.
The control unit—This unit handles the sequence of operations for the CPU and is also responsible for the retrieval of instructions and data.
CPUs also have different types of registers to hold data and instructions. Together the components are responsible for the recall and execution of programs. CPUs have made great strides, as the timeline in Table 5.3 illustrates.
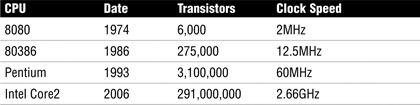
Note
The CPU The CPU consists of the control unit, the arithmetic logic unit, and registers. The arithmetic unit performs computations and is the brain of the CPU.
CPUs can be classified according to several categories, based on their functionality:
![]() Multiprogramming—The CPU can interleave two or more programs for execution at any one time.
Multiprogramming—The CPU can interleave two or more programs for execution at any one time.
![]() Multitasking—The CPU can perform one or more tasks or subtasks at a time.
Multitasking—The CPU can perform one or more tasks or subtasks at a time.
![]() Multiprocessor—The computer has the support for more than one CPU. As an example, Windows 95 does not support the multiprocessor, but Windows Longhorn does.
Multiprocessor—The computer has the support for more than one CPU. As an example, Windows 95 does not support the multiprocessor, but Windows Longhorn does.
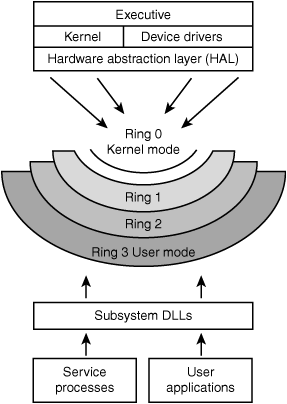
CPUs can operate in user mode or kernel mode. These modes specify what state the CPU is working in. Kernel mode is a privileged or supervisory state, which provides a greater level of protection. As an example, if the CPU is running the Windows operating system (OS) and needs to perform a trusted OS operation, it can do so in kernel mode; yet, if it needs to run an application of unknown origin, it can do so in user mode. This sets up rings of protection, as Figure 5.5 demonstrates. This model provides a level of access control and granularity. As you move toward the outer bounds of the user mode of the model, the ring numbers increase and the level of trust decreases. User mode is also sometimes called the general user state because this is the level in which most users operate.
Figure 5.5 CPU operating modes.
Note
The CISA Exam Is Vendor Neutral No vendor-specific hardware or technology is included on the exam. If it is mentioned in this chapter, it is to better illustrate concepts or techniques.
Memory
A computer is not just a CPU—memory is also an important component. When a CPU processes instructions, the results must be stored, most likely in random access memory (RAM). RAM is considered volatile memory because if power is lost, data is destroyed. RAM can be static because it uses circuit latches to represent binary data, or it can be dynamic. Dynamic RAM (DRAM) must be periodically refreshed every few milliseconds. RAM is not the only memory type; read-only memory (ROM) is a second type. ROM is used to permanently hold data so that even if the computer is turned off, the information remains; thus, it is considered nonvolatile. ROM is typically used to load and store firmware. Some common types of ROM include the following:
![]() Erasable Programmable Read-Only Memory (EPROM)
Erasable Programmable Read-Only Memory (EPROM)
![]() Electrically Erasable Programmable Read-Only Memory (EEPROM)
Electrically Erasable Programmable Read-Only Memory (EEPROM)
![]() Flash memory
Flash memory
![]() Programmable logic devices (PLD)
Programmable logic devices (PLD)
A longer form of storage is secondary storage, also considered nonvolatile. Hard disk drives are an example of secondary storage. Hard drives have a series of platters, read/write heads, motors, and drive electronics contained within a case designed to prevent contamination. Floppies, or diskettes, are also considered secondary storage. The data on diskettes is organized in tracks and sectors. Tracks are narrow concentric circles on the disk. Sectors are pie-shaped slices of the disk. The disk is made of a thin plastic material coated with iron oxide. This is much like the material found in a backup tape or cassette tape. As the disk spins, the disk drive heads move in and out to locate the correct track and sector. It then reads or writes the requested track and sector.
Compact discs (CDs) are a type of optical media that use a laser/optoelectronic sensor combination to read or write data. A CD can be read-only, write once, or rewriteable. CDs can hold up to around 800 MB on a single disk. A CD is manufactured by applying a thin layer of aluminum to what is primarily hard, clear plastic. During manufacturing, or whenever a CD/R is burned, small bumps or, pits, are placed in the surface of the disk. These bumps, or pits, are converted into binary ones or zeros. Unlike the tracks and sectors of a floppy, a CD consists of one long spiral track that begins at the inside of the disk and continues toward the outer edge. Digital video discs (DVDs) are similar to a CD because both are a type of optical medium, but DVDs hold more data. The data capacity of DVDs ranges from 4.7 to 17.08 GB, depending on type—R, RW, RAM, 5, 9, 10, or 18. One contender for the next generation of optical storage is the Blu-ray Disc. These optical disks can hold 50 GB or more of data.
Memory cards and sticks are another form of storage. The explosion of PDAs, digital cameras, and other computerized devices has fueled their growth. One of the most well-known is the PC memory card that came out in the 1980s, originally called the Personal Computer Memory Card International Association (PCMCIA) card. Newer but smaller versions, such as a smart media card and multimedia cards, are not much bigger than a postage stamp. Since the late 1990s, USB memory drives have become increasingly popular. These floppy disk killers are nothing more than a Universal Serial Bus (USB) connector with a Flash memory chip. These devices can easily be found in 2 GB format and up. Many companies have become increasingly worried about such devices because they can hold such a large amount of information and can be easily moved in and out of the company’s facility in someone’s pocket or purse.
I/O Bus Standards
From a CPU point of view, the various adaptors plugged into the computer are external devices. These connectors and the bus architecture used to move data to the devices have changed over time. Some common bus architectures follow:
![]() The ISA bus—The Industry Standard Architecture (ISA) bus started as an 8-bit bus designed for IBM PCs. It is now obsolete.
The ISA bus—The Industry Standard Architecture (ISA) bus started as an 8-bit bus designed for IBM PCs. It is now obsolete.
![]() The PCI bus—The Peripheral Component Interface (PCI) bus was developed by Intel and served as a replacement for the ISA and other bus standards.
The PCI bus—The Peripheral Component Interface (PCI) bus was developed by Intel and served as a replacement for the ISA and other bus standards.
![]() The SCSI bus—The Small Computer Systems Interface (SCSI) bus allows a variety of devices to be daisy-chained off a single controller. Many servers use the SCSI bus for their preferred hard drive solution.
The SCSI bus—The Small Computer Systems Interface (SCSI) bus allows a variety of devices to be daisy-chained off a single controller. Many servers use the SCSI bus for their preferred hard drive solution.
Two serial bus standards have also gained wide market share, USB and FireWire. USB overcame the limitations of traditional serial interfaces. USB devices can communicate at speeds up to 480 Mbps. Up to 127 devices can be chained together. USB is used for Flash memory, cameras, printers, and even iPods. One of the fundamental designs of the USB is that it has such broad product support, and many devices are immediately recognized when connected. The competing standard for USB is FireWire, or IEEE 1394. This design is found on many Apple computers and also on digital audio and video equipment. Because of licensing fees, FireWire has not gained the market share that USB has. Figure 5.6 shows USB and FireWire adaptors.
Figure 5.6 USB and FireWire adaptors.

Caution
Open USB and FireWire Ports Open USB and FireWire ports can present a big security risk. Organizations should consider disabling ports or using a software package to maintain some type of granular control. New U3 memory sticks enable users to autoexecute programs, whether legitimate or malicious. This is an issue of growing concern.
Computer Types
Computers can be categorized by the role they play in the organization, their amount of processing power, and their architecture or design. Common types include servers, supercomputers, mainframes, client desktops, laptops, and PDAs, as described in Table 5.4.

Computer Configurations and Roles
Most companies today have their computers configured in one of two configurations: peer-to-peer or client/server. In a peer-to-peer network, each system is both a server and a client. Peer-to-peer systems split their time between these two duties. Peer-to-peer networks are usually found only in small networks because of the following concerns:
![]() Desktop systems are not optimized to be servers and usually cannot handle a large traffic load.
Desktop systems are not optimized to be servers and usually cannot handle a large traffic load.
![]() A large number of requests will most likely degrade system performance.
A large number of requests will most likely degrade system performance.
![]() Peer-to-peer systems leave each user in charge of his own security, so many users are in charge, not one central body or department.
Peer-to-peer systems leave each user in charge of his own security, so many users are in charge, not one central body or department.
Exam Alert
Peer-to-Peer Peer-to-peer networks do not scale well and are not efficient for large organizations. Peer-to-peer networks also suffer from security concerns that make them a poor choice for larger companies.
Client/server networks are configured in such a way that clients make requests and servers respond. Examples of client/server systems include Microsoft 2003 server and Novell NetWare. Client/server networks have the following characteristics:
![]() Servers are loaded with dedicated server software.
Servers are loaded with dedicated server software.
![]() Servers are designed for specific needs.
Servers are designed for specific needs.
![]() User accounts and access privileges are configured on the server.
User accounts and access privileges are configured on the server.
![]() Client software is loaded on the client’s computer.
Client software is loaded on the client’s computer.
![]() Clients don’t service other clients.
Clients don’t service other clients.
Within a client/server network, a server holds some basic defined roles. These are some of the most common configurations:
![]() Print server—Print servers are usually located close to printers and enable many users to access the printer and share its resources.
Print server—Print servers are usually located close to printers and enable many users to access the printer and share its resources.
![]() File server—File servers give users a centralized site for storing files. This provides an easier way to back up a network because only one file server needs to be backed up, not all individual workstations.
File server—File servers give users a centralized site for storing files. This provides an easier way to back up a network because only one file server needs to be backed up, not all individual workstations.
![]() Program server—Program servers are also known as application servers. This service enables users to run applications that are not installed on the end user’s system. This is a very popular concept in thin client environments. Licensing is an important consideration.
Program server—Program servers are also known as application servers. This service enables users to run applications that are not installed on the end user’s system. This is a very popular concept in thin client environments. Licensing is an important consideration.
![]() Web server—Web servers provide web services to internal and external users via web pages. An example of a web address or uniform resource locator (URL) is www.thesolutionfirm.com.
Web server—Web servers provide web services to internal and external users via web pages. An example of a web address or uniform resource locator (URL) is www.thesolutionfirm.com.
![]() Database server—Database servers store and access data. This includes information such as product inventory, price lists, customer lists, and employee data. Databases hold sensitive information and require well-designed security controls.
Database server—Database servers store and access data. This includes information such as product inventory, price lists, customer lists, and employee data. Databases hold sensitive information and require well-designed security controls.
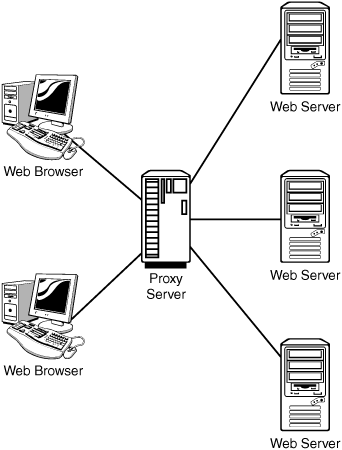
![]() Proxy server—Proxy servers stand in place of the client and provide indirect access. Proxy servers can provide caching services and improve security. Figure 5.7 shows an example of a proxy server.
Proxy server—Proxy servers stand in place of the client and provide indirect access. Proxy servers can provide caching services and improve security. Figure 5.7 shows an example of a proxy server.
Figure 5.7 Proxy server for connection to website.
Most networks have some common hardware elements. These are discussed in depth in Chapter 6, “Information Systems Used for IT Delivery and Support,” but Table 5.5 introduces them.
Table 5.5 Common Hardware Elements Used for IT Delivery

Radio Frequency Identification
Radio frequency identification (RFID) tags are extremely small electronic devices that consist of a microchip and antenna. These devices send out small amounts of information when activated. Companies are excited about this technology because it means they can forget about bar-code scanning and improve product management. As an example, employees can quickly scan an entire pallet of goods and record the information. An RFID tag can be designed in one of several different ways:
![]() Active—Active tags have a battery or power source that is used to power the microchip.
Active—Active tags have a battery or power source that is used to power the microchip.
![]() Passive—These devices have no battery; the RFID reader powers them. The reader generates an electromagnetic wave that induces a current in the RFID tag.
Passive—These devices have no battery; the RFID reader powers them. The reader generates an electromagnetic wave that induces a current in the RFID tag.
![]() Semipassive—These hybrid devices use a battery to power the microchip, but they transmit by harnessing energy from the reader.
Semipassive—These hybrid devices use a battery to power the microchip, but they transmit by harnessing energy from the reader.
Passive RFID tags can hold about 2 KB of data, which is enough to hold more information than a bar code. Active RFID tags can hold even more information. Both types offer companies a wealth of information. If development of this technology proceeds as planned, RFID tags could someday allow retailers to add up the price of purchased goods as shoppers leave the store and deduct the charges directly from the customer’s credit card. Another use for RFID tags is in the inventory and audit process. Current technology requires each item to be counted by hand. However, in the future, RFID readers strategically placed throughout the store would automatically determine the amount and type of a product sitting on the store’s shelves.
Using RFID tags on animals and people has even been proposed. Some individuals have already implanted RFID tags. In response to a growing rabies problem, Portugal has passed a law that all dogs must be embedded with RFID devices. Government officials have advocated that these devices become a standard issue for individuals who work as firemen, policemen, or emergency rescue workers whose jobs place them in situations in which their identifications could become lost or destroyed.
Security concerns are based on the fact that some of these devices are less than half the size of a grain of rice, so their placement possibilities are endless. If these devices are used in retail services, some have expressed concern that such devices might not be disabled when the products are taken home. Some even fear that high-tech thieves might someday be able to park outside your home and scan to determine what valuables are worth stealing.
Note
RFID Passports In 2006, the United States and many European countries began using RFID passports. Although some envision this technology as a way to hold biometric information and better guard the nation’s borders, others fear potential vulnerabilities. One such vulnerability was realized in August 2006 when German hackers succeeded in cloning a Dutch RFID e-passport. Because of this event and other potential vulnerabilities, the United States has decided to place a metallic lining inside RFID passport covers in an attempt to prevent RFID passports from being scanned or snooped when closed.
Hardware Maintenance Program
Just as your car requires periodic oil changes and maintenance, hardware and equipment requires maintenance. It is usually much cheaper to maintain a piece of equipment than it is to repair it. Computers have a habit of trapping a large amount of dust that, over a period of time, coats all the inner components and acts as a thermal blanket. This layer of dust raises the operating temperature and reduces the lifespan of the equipment.
Internal employees might maintain some types of equipment, while vendors might service others. Regardless of who performs the maintenance, it should be documented and recorded. When performing an audit, the auditor should examine the existing procedures to make sure that a maintenance program has been developed, performed, and documented. If outside vendors are given access to sensitive areas, it should be verified that they are properly cleared before receiving access.
Note
Tape-Management Systems Automated tape-management systems reduce errors and speed load time by automatically locating and loading tape volumes as needed.
Hardware Monitoring and Capacity Management
The best way to prevent problems is to monitor current activity. Monitoring should include the following:
![]() Availability reports—These reports indicate availability. The key to these reports is determining when and why resources are unavailable.
Availability reports—These reports indicate availability. The key to these reports is determining when and why resources are unavailable.
![]() Hardware error reports—These reports indicate hardware problems and can be used to look for recurring problems.
Hardware error reports—These reports indicate hardware problems and can be used to look for recurring problems.
![]() Utilization reports—These reports look at overall usage and can be used to help plan needed upgrades to the infrastructure.
Utilization reports—These reports look at overall usage and can be used to help plan needed upgrades to the infrastructure.
Exam Alert
Utilization CISA candidates should know that utilization rates above 95% require attention to determine needed upgrades and that short-term fixes might include countermeasures such as reducing unneeded activities or shifting schedules so that some activities take place at less demanding times, such as the late-night or second shift.
Capacity management provides the capability to monitor and measure usage in real time and forecast future needs before they are required. Capacity management requires analyzing current utilization, past performance, and capacity changes. Table 5.6 outlines the indicators for capacity-management issues.
Table 5.6 Capacity-Management Issues

Review Break
Table 5.7 provides a comparison of various types of computer hardware and equipment. These are terms that the CISA should be familiar with. Each item in the table is followed by an attribute that offers an inherent quality or chacteristic that is worth noting.
Table 5.7 Comparison of Computer Hardware

Information Systems Architecture and Software
Task
![]() Evaluate data administration practices to ensure the integrity and optimization of databases.
Evaluate data administration practices to ensure the integrity and optimization of databases.
Knowledge Statements
![]() Knowledge of database administration practices
Knowledge of database administration practices
![]() Knowledge of the functionality of system software, including operating systems, utilities, and database management systems
Knowledge of the functionality of system software, including operating systems, utilities, and database management systems
![]() Knowledge of software licensing and inventory practices
Knowledge of software licensing and inventory practices
Software differs from hardware: It is the code that runs on computer platforms. Software is loaded into RAM and executed by the CPU. Software can be used for an operating system, a database, access control, file transfer, a user application, and even network management. Before discussing operating systems and databases, you should review the different ways in which software can be developed and learn about some of its common attributes.
Software Development
At the core of systems architecture is computer hardware, which requires programs or code to operate. Programs can be hard-coded instruction or firmware, or can be executed by a higher-layer process. Regardless of the format, code must be translated into a language that the computer understands. The three most common methods of conversion are as follows:
![]() Assembler—An assembler is a program that translates assembly language into machine language.
Assembler—An assembler is a program that translates assembly language into machine language.
![]() Compiler—A compiler translates a high-level language into machine language.
Compiler—A compiler translates a high-level language into machine language.
![]() Interpreter—An interpreter does not assemble or compile; it translates the program line by line. Interpreters fetch and execute.
Interpreter—An interpreter does not assemble or compile; it translates the program line by line. Interpreters fetch and execute.
One big hurdle that software developers face is that computers and humans speak very different languages. As an example, computers work well with assembly language, as demonstrated here:
mov al, 061h
ld length,%
mov bl, 10 ; hex=0ah or bin=00001010b
Humans work well with English and other high-level languages. To bridge this gap, many programming languages have been developed over the years—in fact, they date back to before the computer era. Programming languages are used to convert sets of instructions into a vocabulary, such as the assembly that a computer can understand. The goal is to convert instructions into a format that allows the computer to complete a specific task. Examples of common programming languages include the following:
![]() COBOL—Common Business-Oriented Language is a third-generation programming language used for business finance and administration.
COBOL—Common Business-Oriented Language is a third-generation programming language used for business finance and administration.
![]() C, C-Plus, C++—The C programming language replaced B and was designed by Dennis Ritchie. C was originally designed for UNIX; it is popular and widely used, but vulnerable to buffer overflows.
C, C-Plus, C++—The C programming language replaced B and was designed by Dennis Ritchie. C was originally designed for UNIX; it is popular and widely used, but vulnerable to buffer overflows.
![]() FORTRAN—This language features an optimized compiler that is widely used by scientists for writing numerically intensive programs.
FORTRAN—This language features an optimized compiler that is widely used by scientists for writing numerically intensive programs.
![]() Java—A relatively new language developed in 1995 by Sun Microsystems, it uses a sandbox scheme for security.
Java—A relatively new language developed in 1995 by Sun Microsystems, it uses a sandbox scheme for security.
Note
Sandbox Scheme A sandbox scheme is a software security mechanism designed to limit the the ability of untrusted code. This allows programs from unknown or untrusted vendors to be executed on a system without the fear that the programs will access privileged commands.
![]() Visual Basic—This programming language was designed for anyone to use and makes it possible to develop practical programs quickly.
Visual Basic—This programming language was designed for anyone to use and makes it possible to develop practical programs quickly.
This list offers details on just some of the available programming languages. Others include .NET, Prolog, Python, Perl, and Ruby. Computer languages can be designed to be like machine language and can be made more natural so that humans can easily understand them. This is why languages are placed into generations. The generation of the programming language defines where it fits into this hierarchy. The five generations of computer languages are as follows:
![]() Generation One—Machine language
Generation One—Machine language
![]() Generation Two—Assembly language
Generation Two—Assembly language
![]() Generation Three—High-level language, such as FORTRAN
Generation Three—High-level language, such as FORTRAN
![]() Generation Four—Very high-level language, such as Structured Query Language (SQL)
Generation Four—Very high-level language, such as Structured Query Language (SQL)
![]() Generation Five—Natural language, such as Prolog or LISP
Generation Five—Natural language, such as Prolog or LISP
Note
Decompilers When a programmer writes programs to be sold to the public, the source code normally is not provided. Decompilers can analyze the compiled code and rebuild the original source code. The software license might prohibit decompiling, but unscrupulous competitors or software hackers might still attempt it.
Operating Systems
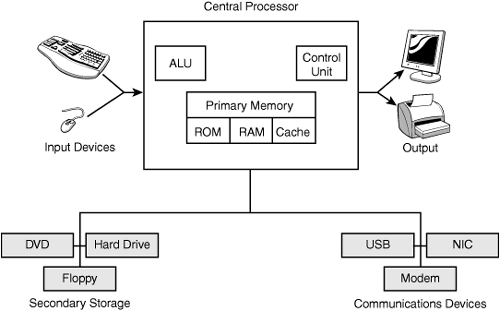
An operating system (OS) is key to computer operation because it is the computer program that controls software resources and interacts with system hardware. The OS performs everything from low-level tasks to higher-level interaction with the user. The OS is responsible for managing resources such as the processor, memory, disk space, RAM, and so on. The OS also provides a stable, defined platform that applications can use. This allows the application to deal with the OS and not have to directly address the hardware. The OS is responsible for managing the following key resources (see Figure 5.8):
![]() Input devices—Keyboard, mouse, microphone, webcam, and so on
Input devices—Keyboard, mouse, microphone, webcam, and so on
![]() Output devices—Monitor, printer, soundcard, and so on
Output devices—Monitor, printer, soundcard, and so on
![]() Memory—RAM, ROM, CMOS, virtual memory, and so on
Memory—RAM, ROM, CMOS, virtual memory, and so on
![]() CPU usage—Available time, processing order
CPU usage—Available time, processing order
![]() Network communication—Modems, network interface card (NIC), Bluetooth, and so on
Network communication—Modems, network interface card (NIC), Bluetooth, and so on
![]() External storage—DVD drive, CD-ROM drive, floppies, hard drive, USB drives, and so on
External storage—DVD drive, CD-ROM drive, floppies, hard drive, USB drives, and so on
Figure 5.8 Operating system management duties.
An OS has the capability to interact with the CPU in different ways so that there are different levels of control. In user mode, the operator has limited ability to perform privileged functions. In supervisory mode, the user has total access to the security kernel and has complete access to all memory, devices, and instructions. Some system utilities and other processes run in supervisory mode and, therefore, must be closely controlled because they could be used to bypass normal security mechanisms. Some types of malware, such as rootkits, have the capability to run in supervisory mode. This means that they can corrupt the kernel and do basically anything they want, including lie to the user about their presence, thereby avoiding detection.
Exam Alert
Supervisory Mode CISA candidates should know that any user allowed to run programs in kernel mode can bypass any type of security mechanism and gain complete control of the system. Many system utilities run in supervisory mode and should be under strict control.
Secondary Storage
Other than using long-term storage of information and programs, the OS can use secondary storage. A modern OS can also use secondary storage for virtual memory, the combination of the computer’s primary memory, RAM, and secondary storage, the hard drive. By combining these two technologies, the OS can make the CPU believe that it has much more memory than it actually does. If the OS is running short on RAM, it can instruct the CPU to use the hard drive as storage. Virtual memory uses the hard drive to save data in pages that can be swapped back and forth between the hard drive and RAM, as needed.
Caution
Information Leakage Security issues are possible with sensitive data written to swap that becomes accessible to non-supervisor users.
Although memory plays an important part in the world of storage, other long-term types of storage are also needed. One of these is sequential storage. Anyone who is old enough to remember the Commodore 64 knows about sequential storage: These earlier computers used a cassette tape recorder to store programs. Tape drives are a type of sequential storage that must be read sequentially from beginning to end. Indexed sequential storage is similar to sequential storage, except that it logically orders data according to a key and then accesses the data based on the key. Finally, the direct access method does not require a sequential read; the system can identify the location of the information and go directly to that location to read the data.
Data Communication Software
At a miminum level, data communications requires the following:
![]() A source (transmitter)
A source (transmitter)
![]() A communication channel (voice, line, and so on)
A communication channel (voice, line, and so on)
![]() A receiver
A receiver
In the world of electronic communications, the receiver is known as a data sink. The data sink is any electronic device that is capable of receiving a data signal. One-way communication is referred to as simplex. Two-way communication is known as duplex. Duplex communication systems allow both parties to send and receive date simultaneously. Data communication systems are designed to accurately transmit communication between two points. Without data communications, computer operations wouldn’t be possible. One person who helped make that a reality was Bob Beaman. Bob helped lead the team that developed the American Standard Code for Information Interchange (ASCII) standard. ASCII was of great importance at the time it was developed in 1967 because it defined a 128-character set. This standard was used for years to come for computer communications. ASCII was not the first communication standard to be developed, however. The Extended Binary Coded Decimal Interchange Code (EBCDIC) was developed in early 1960 by IBM and designed for use with mainframe systems. It debuted alongside the IBM 360. EBCDIC uses 8 bits and has a 256-character set. Unicode is an industry standard designed to replace previous standards. Unicode uses 16 bits, so it can support more than 65,000 unique characters. This makes it useful for languages other than English, including Chinese and Japanese characters.
Database-Management Systems
Databases provide a convenient method by which to catalog, index, and retrieve information. Databases consist of collections of related records, such as name, address, phone number, and date of birth. The structured description of the objects of these databases and their relationship is known as the schema. Databases are widely used. As an example, if you go online to search for flight times from Houston to Las Vegas, the information most likely is pulled from a database as well as the stored user’s credit card number that was previously provided to the airline. If you are not familiar with databases, you need to know these terms:
![]() Aggregation—The process of combining several low-sensitivity items to produce a high-sensitivity data item.
Aggregation—The process of combining several low-sensitivity items to produce a high-sensitivity data item.
![]() Attribute—An attribute of a component of a database, such as a table, field, or column.
Attribute—An attribute of a component of a database, such as a table, field, or column.
![]() Field—The smallest unit of data within a database.
Field—The smallest unit of data within a database.
![]() Foreign key—An attribute in one table whose value matches the primary key in another table.
Foreign key—An attribute in one table whose value matches the primary key in another table.
![]() Granularity—The control one has over someone’s view of a database. Highly granular databases have the capability to restrict certain fields or rows from unauthorized individuals.
Granularity—The control one has over someone’s view of a database. Highly granular databases have the capability to restrict certain fields or rows from unauthorized individuals.
![]() Relation—Data that is represented by a collection of tables.
Relation—Data that is represented by a collection of tables.
The data elements required to define a database are known as metadata. Metadata is best described as being data about data. As an example, the number 310 has no meaning, but when described with other data, it is understood as the information that represents the area code used for Beverly Hills and Malibu residents. Organizations treasure data and the relationships that can be deduced between the individual elements. That’s data mining, the process of analyzing data to find and understand patterns and relationships between the data. The patterns discovered in this data can help companies understand their competitors and understand usage patterns of their customers to carry out targeted marketing. As an example, you might never have noticed that in most convenience stores the diapers are located near the refrigerated section of the store, where beer and sodas are kept. The store owners have placed these items close to each other as data mining has revealed that men are usually the ones that buy diapers in convenience stores, and they are also the primary demographic to purchase beer. By placing the diapers close by, both items increase in total sales. Although many of us might not naturally think of these types of relationships, data mining can uncover how seemingly unrelated items might actually be connected. Data mining operations require the collection of large amounts of data. All of this data can be stored in a data warehouse, a database that contains data from many different databases. These warehouses have been combined, integrated, and structured so that they can provide trend analysis and be used to make business decisions.
Many companies use knowledge-management systems to tie together all of an organization’s information—databases, document management, business processes, and information systems—into one knowledge repository. This is referred to as customer relationship management (CRM). It’s how businesses determine how to interact with their customers. Businesses use knowledge-management systems to further these goals. The knowledge-management system can interpret the data derived from these systems and automate the knowledge extraction. This knowledge-discovery process takes the form of data mining, in which patterns are discovered through artificial intelligence techniques.
Database Structure
Databases can be centralized or distributed depending on the database-management system (DBMS) that is implemented. The DBMS enables the database administrator to control all aspects of the database, including design, functionality, and security. Per ISACA, three primary types of database structures exist:
![]() Hierarchical database-management systems (HDMS)
Hierarchical database-management systems (HDMS)
![]() Network database-management systems (NDMS)
Network database-management systems (NDMS)
![]() Relational database-management systems (RDMS)
Relational database-management systems (RDMS)
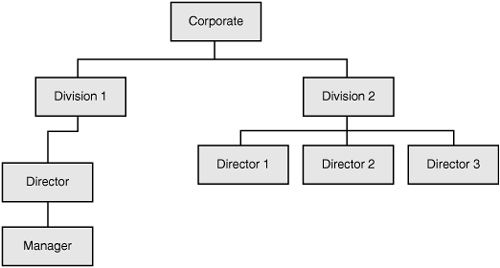
With the HDMS, the database takes the form of a parent-child structure. These are considered 1:N (one-to-many) mappings. Each record can have only one owner; because of this restriction, a hierarchical database often cannot be used to relate to structures in the real world. However, it is easy to implement, modify, and search. Figure 5.9 shows an example of an HDMS.
The NDMS was created in 1971 and is based on mathematical set theory. This type of database was developed to be more flexible than a hierarchical database. The network database model is considered a lattice structure because each record can have multiple parent and child records. Although this design can work well in stable environments, it can be extremely complex. Figure 5.10 shows an example of an NDMS.
Figure 5.9 Hierarchical database.
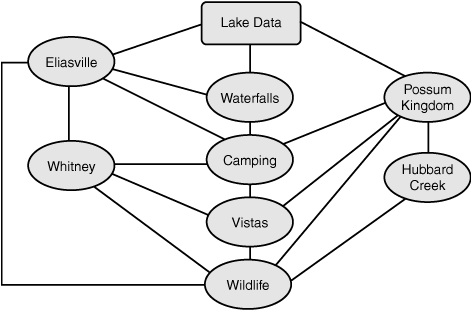
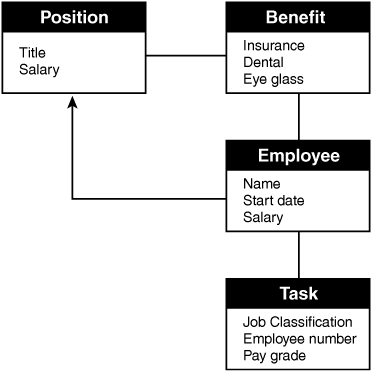
An RDMS database is considered a collection of tables that are linked by their primary keys. This type of database is based on set theory and relational calculations. Many organizations use software based on the relational database design, which uses a structure in which the data and the relationship between the data are organized in tables known as tuples. Most relational databases use SQL as their query language. Figure 5.11 shows an example of an RDMS.
Figure 5.11 Relational database.
All databases need controls that protect the integrity of the data. Database transactions are protected through the use of controls. Integrity must be protected during storage and transactions. Controls to protect the integrity of the data during storage include the following:
![]() Enforcing security so that access to the database is restricted
Enforcing security so that access to the database is restricted
![]() Defining levels of access for those who must have access to the database
Defining levels of access for those who must have access to the database
![]() Establishing controls to verify the accuracy, completeness, and consistency of the data
Establishing controls to verify the accuracy, completeness, and consistency of the data
Controls can be put into place during transactions. These are sometimes referred to as the ACID test, which is defined as follows:
![]() Atomicity—The results of a transaction are either all or nothing.
Atomicity—The results of a transaction are either all or nothing.
![]() Consistency—Transactions are processed only if they meet system-defined integrity constraints.
Consistency—Transactions are processed only if they meet system-defined integrity constraints.
![]() Isolation—The results of a transaction are invisible to all other transactions until the original transaction is complete.
Isolation—The results of a transaction are invisible to all other transactions until the original transaction is complete.
![]() Durability—After completion, the results of the transaction are permanent.
Durability—After completion, the results of the transaction are permanent.
Exam Alert
ACID Test You might be asked in the CISA exam about database management and how to tell if it is adequate for handling transactions. Adequate systems have atomicity, consistency, isolation, and durability.
Software Licensing Issues
Have you ever stopped to read an End-User License Agreement (EULA)? If you haven’t, don’t feel bad—many other users never have. The EULA is a type of contract between the software manufacturer and the end user. EULAs specify the terms of the conditions under which the end user can use the computer program or software. EULAs and software licensing are issues of concern for a CISA because companies have a legal and moral obligation to use software only in an approved manner. Companies caught using illegal software can be subjected to fines, legal fees, and bad press, being identified as a company that uses illegal software. The Business Software Alliance (http://www.bsa.org) pursues companies for illegal software. According to its website, in one case, the defendant received a jail term of more than seven years. IS auditors should review policies and procedures to verify that the company has rules in place that prohibit the use of illegal software. Some companies have employees sign an agreement stating that they will not install or copy software illegally. An IS should also perform random samples of users’ computers to verify that they are loaded only with authorized, approved programs. The users’ applications should be checked against a list of approved programs. Other controls include these:
![]() Disabling the local installation of software
Disabling the local installation of software
![]() Installing application metering
Installing application metering
![]() Using thin clients
Using thin clients
![]() Performing regular compliance scans from the network
Performing regular compliance scans from the network
Exam Alert
Site Licensing The CISA exam might ask you about ways to reduce illegal usage of software. One useful control to prevent unlawful duplication of software on multiple computers at a company’s site is to purchase site licensing. This allows the software to be loaded on as many computers as needed at the organization.
Chapter Summary
This chapter examined information systems operations and discussed how controlling and monitoring are two big concerns. You can’t roll out a new system overnight; this must be planned and budgeted for over time. Monitoring is so important because it enables the company to discover needs early on and gives the company more time to plan for change. Monitoring is also important because it enables the company to track response. If someone calls the help desk, does he get help in an hour, or must he wait two weeks? Monitoring also allows for the discovery of repetitive problems and catches errors early on before they become major problems.
This chapter also reviewed computer hardware, offering an in-depth look at hardware items such as the CPU, RAM, and ROM. It introduced the concept of integrity as it applies to the CPU and OS. Specifically, systems can run in different states. In the general user state, users are limited in their ability to access privileged functions. In the supervisor state, users can access the most privileged areas of the system. Supervisor state provides unrestricted access to all areas of the system.
Finally, this chapter discussed databases. As an auditor, your primary concerns are with database design, access, administration, interfaces, and portability. Databases can take on different designs, such as hierarchical, network, or relational. Access deals with the various ways in which a database can be accessed and what controls, such as indexes, are in place to minimize access time.
Key Terms
![]() Audit reduction tools
Audit reduction tools
![]() Delay window
Delay window
![]() Digital video disc (DVD)
Digital video disc (DVD)
![]() Emergency fix
Emergency fix
![]() Hierarchical database-management systems (HDMS)
Hierarchical database-management systems (HDMS)
![]() Interpreter
Interpreter
![]() Major release
Major release
![]() Minor release
Minor release
![]() Network database-management system (NDMS)
Network database-management system (NDMS)
![]() Radio frequency identification (RFID)
Radio frequency identification (RFID)
![]() Random access memory (RAM)
Random access memory (RAM)
![]() Read-only memory (ROM)
Read-only memory (ROM)
![]() Relational database-management system (RDMS)
Relational database-management system (RDMS)
![]() Variance-detection tools
Variance-detection tools
![]() Virtual memory
Virtual memory
Apply Your Knowledge
This chapter covered IT delivery and support. The two exercises presented here show you how to check a computer to verify that it is running legal software and show you how to measure latency or delay.
Exercises
5.1 Product Validation
In this exercise, you learn how to verify that you are not running a counterfeit copy of the Windows operating system.
Estimated Time: 10 minutes
1. Go to http://www.microsoft.com/resources/howtotell/en/default.mspx. This site provides information on how to tell if the Microsoft operating system software you are running is a valid copy.
2. Click on the counterfeit link, http://www.microsoft.com/resources/howtotell/en/counterfeit.mspx. This page gives you information on how you can detect pirated software and illegal copies.
3. Launch the counterfeit gallery to see examples of what counterfeit software looks like.
4. Now return to the previous page, http://www.microsoft.com/resources/howtotell/en/default.mspx, and click on the Windows validation assistant.
5. Click on the Run Windows Validate Now button and follow the onscreen instructions.
6. You have now validated the copy of Windows you are running on your computer.
5.2 Measuring Latency
In this exercise, you learn how to use the ping command to measure latency.
Estimated Time: 10 minutes
1. Go to Start, Run and enter cmd to open a command prompt.
2. At the command prompt, enter ping 127.0.0.1. This is the local loopback address. You should see a time of less than 10ms.
3. Now ping your local gateway. If you do not know the address, you can discover it by typing ipconfig/all at the command line. After pinging your default gateway, you should still see a time of less than 10ms.
4. Now ping an Internet address, such as 64.233.161.99. In the following example, the time increases to 40ms:
C:>ping 64.233.161.99
Reply from 64.233.161.99: bytes=32 time=40ms TTL=245
Reply from 64.233.161.99: bytes=32 time=40ms TTL=245
Reply from 64.233.161.99: bytes=32 time=40ms TTL=245
Reply from 64.233.161.99: bytes=32 time=30ms TTL=245
5. Now ping an even more distant site. I am in the United States, so I chose http://www.google.cn. My pings took even longer—about 51ms in this example:
C:>ping www.google.cn
Reply from 72.14.203.161: bytes=32 time=50ms TTL=242
Reply from 72.14.203.161: bytes=32 time=51ms TTL=242
Reply from 72.14.203.161: bytes=32 time=51ms TTL=242
Reply from 72.14.203.161: bytes=32 time=52ms TTL=242
These results prove that ping can be used to measure latency and that generally the delay increases with congestion or as distance to the target increases.
Exam Questions
1. Which of the following is the most important concern for an auditor reviewing the contracts for delivery of IT services?
![]() A. Service-level agreements
A. Service-level agreements
![]() B. Help desk
B. Help desk
![]() C. Problem management
C. Problem management
![]() D. Nonessential backup
D. Nonessential backup
2. In web services, a proxy server is most often used for which of the following:
![]() A. Reduce the load of the client system
A. Reduce the load of the client system
![]() B. Improve direct access
B. Improve direct access
![]() C. Interface to access the private domain
C. Interface to access the private domain
![]() D. Provide high-level security services
D. Provide high-level security services
3. You have been asked to audit a database to evaluate the referential integrity. Which of the following should you review?
![]() A. Field
A. Field
![]() B. Aggregation
B. Aggregation
![]() C. Composite key
C. Composite key
![]() D. Foreign key
D. Foreign key
4. Which of the following is the most important security concern when reviewing the use of USB memory sticks?
![]() A. The memory sticks might not be compatible with all systems.
A. The memory sticks might not be compatible with all systems.
![]() B. The memory sticks might lose information or become corrupted.
B. The memory sticks might lose information or become corrupted.
![]() C. Memory sticks can copy a large amount of data.
C. Memory sticks can copy a large amount of data.
![]() D. Memory sticks’ contents cannot be backed up.
D. Memory sticks’ contents cannot be backed up.
5. You are an auditor for a financial organization and have been asked which of the following would be the best tool to detect abnormal spending patterns and flag them:
![]() A. Relational database
A. Relational database
![]() B. Manual audit techniques
B. Manual audit techniques
![]() C. Neural network
C. Neural network
![]() D. Intrusion-prevention system
D. Intrusion-prevention system
6. Which of the following is the most common failure with audit logs?
![]() A. Audit logs can be examined only by auditors.
A. Audit logs can be examined only by auditors.
![]() B. Audit logs use parsing tools that distort the true record of events.
B. Audit logs use parsing tools that distort the true record of events.
![]() C. Audit logs are not backed up.
C. Audit logs are not backed up.
![]() D. Audit logs are collected but not analyzed.
D. Audit logs are collected but not analyzed.
7. The ping command can be used to measure which of the following?
![]() A. Latency
A. Latency
![]() B. Best path
B. Best path
![]() C. Computer configuration
C. Computer configuration
![]() D. Firewall settings
D. Firewall settings
8. Which of the following is the greatest concern with the use of utility software?
![]() A. It can be used to scan or defrag a hard drive.
A. It can be used to scan or defrag a hard drive.
![]() B. It runs with privileged access.
B. It runs with privileged access.
![]() C. It might not have controls that log who used it or when.
C. It might not have controls that log who used it or when.
![]() D. It can be used to improve operational efficiency.
D. It can be used to improve operational efficiency.
9. Which of the following are two primary components of the CPU?
![]() A. RAM, cache, and the logic processing unit
A. RAM, cache, and the logic processing unit
![]() B. The control unit and the scalar processor
B. The control unit and the scalar processor
![]() C. The control unit and the arithmetic logic unit
C. The control unit and the arithmetic logic unit
![]() D. The primary address unit and the arithmetic logic unit
D. The primary address unit and the arithmetic logic unit
10. Which of the following is the primary bus standard today?
![]() A. PCI
A. PCI
![]() B. ISA
B. ISA
![]() C. MCA
C. MCA
![]() D. VESA
D. VESA
Answers to Exam Questions
1. A. Service-level agreements are the most important concern for the auditor because they specify the agreed-upon level of service. Answer B is incorrect because although the help desk is important, it is not used to measure delivery of service; the same is true for answer C, problem management. Answer D is also incorrect because a nonessential backup would not be important here.
2. C. Proxies provide several services, including load balancing and caching. Most importantly, the proxy stands in place of the real client and acts as an interface to the private domain, thereby preventing direct access. Answer A is incorrect because the proxy is not used to reduce the load of a client. Answer B is incorrect because a proxy prevents direct access. Answer D is incorrect because although proxy servers provide some level of security, they do not allow high-level security such as an application or kernel firewall.
3. D. The foreign key refers to an attribute in one table whose value matches the primary key in another table. Answer A is incorrect because the field refers to the smallest unit of data within a database. Answer B is incorrect because aggregation refers to the process of combining several low-sensitivity items to produce a higher-sensitivity data item. Answer C is incorrect because the composite key refers to two or more columns that together are designated as the computer’s primary key.
4. C. Memory sticks can copy and hold large amounts of information. This presents a security risk because someone can easily place one of these devices in his pocket and carry the information out of the company. Although answers A, B, and D are important, they are not the most important security concern.
5. C. Neural networks use predictive logic and can analyze data and learn patterns. Answer A is incorrect because a relational database would not be useful in detecting fraud or abnormal spending. Answer B is incorrect because manual audit techniques could be used but would not be the most efficient or cost-effective. Answer D is incorrect because intrusion-prevention systems typically examine traffic entering the organization from the Internet and attempt to alert and prevent malicious activity.
6. D. One of the most common problems with audit logs is that they are collected but not analyzed. Many times no one is interested in the audit logs until someone reports a problem. Answers A, B, and C are all important concerns but are not the most common failure.
7. A. The ping command can be used to measure latency. Answer B is incorrect because ping does not specify best path. Answer C is incorrect because ping is not used to verify the computer configuration; that is the IP config command. Answer D is incorrect because ping is not used to verify firewall settings.
8. B. Utility programs can operate outside the bounds of normal security controls and function in a supervisor state. Thus, these utilities must be controlled and restricted. Answer A is incorrect because it is not a concern, but an advantage. Answer C is incorrect because although not having an audit trail is a concern, of most concern is the fact that utility programs can be very powerful. Answer D is incorrect because, again, it is an advantage, not a disadvantage.
9. C. Two primary components of the CPU include the control unit and the arithmetic logic unit. Therefore, answers A, B, and D are incorrect.
10. A. The PCI, or Peripheral Component Interface, bus was developed by Intel and served as a replacement for the ISA, MCA, and VESA bus standards. Therefore, answers B, C, and D are incorrect.
Need to Know More?
![]() How CPUs Work: http://computer.howstuffworks.com/microprocessor.htm
How CPUs Work: http://computer.howstuffworks.com/microprocessor.htm
![]() Problem Management Techniques: http://www.daveeaton.com/scm/PMTools.html
Problem Management Techniques: http://www.daveeaton.com/scm/PMTools.html
![]() USB Description: http://www.interfacebus.com/Design_Connector_USB.html
USB Description: http://www.interfacebus.com/Design_Connector_USB.html
![]() Understanding Databases: http://msdn2.microsoft.com/en-us/library/ms189638.aspx
Understanding Databases: http://msdn2.microsoft.com/en-us/library/ms189638.aspx
![]() Auditing Databases: http://en.wikipedia.org/wiki/Database_audit
Auditing Databases: http://en.wikipedia.org/wiki/Database_audit
![]() Database Security: http://www.governmentsecurity.org/articles/DatabaseSecurityCommon-sensePrinciples.php
Database Security: http://www.governmentsecurity.org/articles/DatabaseSecurityCommon-sensePrinciples.php
![]() Capacity Management: http://www.smthacker.co.uk/capacity_management.htm
Capacity Management: http://www.smthacker.co.uk/capacity_management.htm