
CHAPTER 11
DATABASE CONTROI ISSUES: SECURITY, BACKUP AND RECOVERY, CONCURRENCY
We've said that data is a corporate resource and that corporate resources must be carefully managed. Different corporate resources have different management requirements. Money must be protected from theft. Equipment must be secured against misuse. Buildings may require security guards. Data, too, is a corporate resource and has its own peculiar concerns that we have termed database control issues. We will discuss the three main database control issues in this chapter. The first, data security, involves protecting the data from theft, malicious destruction, unauthorized updating, and more. The second, backup and recovery, refers to having procedures in place to recreate data that has been lost for any reason. The third, concurrency control, refers to problems that can occur when two or more transactions or users attempt to update a piece of data simultaneously. Certainly, these very important issues require well thought out and standardized solutions. Indeed, entire books have been written about each one! Our goal in this chapter is to introduce each of these topics, discuss why they are important, explain what can go wrong, and highlight several of the main solutions for each.
OBJECTIVES
- List the major data control issues handled by database management systems.
- List and describe the types of data security breaches.
- List and describe the types of data security measures.
- Describe the concept of backup and recovery.
- Describe the major backup and recovery techniques.
- Explain the problem of disaster recovery.
- Describe the concept of concurrency control.
- Describe such concurrency control issues and measures as the lost update problem, locks and deadlock, and versioning.
CHAPTER OUTLINE
Introduction
Data Security
- The Importance of Data Security
- Types of Data Security Breaches
- Methods of Breaching Data Security
- Types of Data Security Measures
Backup and Recovery
- The Importance of Backup and Recovery
- Backup Copies and Journals
- Forward Recovery
- Backward Recovery
- Duplicate or “Mirrored” Databases
- Disaster Recovery
Concurrency Control
- The Importance of Concurrency Control
- The Lost Update Problem
- Locks and Deadlock
- Versioning
Summary
INTRODUCTION
In today's world, not a week goes by without a news story involving data being compromised in some way. One week a hacker breaks into a company's computer and steals credit-card numbers. The next week someone breaks into the trunk of a parked car and steals a laptop computer that turns out to have confidential data on its hard drive. The week after that a hurricane or earthquake causes major damage to some company's computer center and a great deal of data is lost. And so on.
With industries of every kind as dependent on their data as they are today, it is critical that they protect their information systems and the data they contain as carefully as they can. This involves a wide range of technologies and actions ranging from anti-virus software to firewalls to employee training to sophisticated backup and recovery arrangements, and beyond (all of which we will delve into in this chapter). Companies invest a great deal of money in these because breaches in computer and data security can lead to loss of profits, loss of the public's trust, and lawsuits. All of this has really become a major issue in information systems today.
CONCEPTS IN ACTION
11-A HILTON HOTELS
Hilton Hotels is one of the world's premiere lodging companies. Since opening its first hotel in 1919, Hilton has grown to a worldwide presence of over 2000 hotel properties today. Headquartered in Beverly Hills, CA, the company operates hotels under the names Hilton, Conrad, Doubletree, Embassy Suites, Hampton Inn, Hampton Inns and Suites, Hilton Garden Inn, and Homewood Suites by Hilton. Among the most famous Hilton Hotels are the Beverly Hilton in Beverly Hills, CA, the Waldorf Astoria in New York City, and the Hilton Hawaiian Village.
Hilton is a leader in information technology in its industry, and one of its leading-edge database applications is its Guest Profile Manager (GPM.) This is a customer relationship management (CRM) system that strives to achieve guest recognition and guest acknowledgement at all customer “touch points.” These include email, contact at the hotel front desk, special channels on the in-room television, the Audix voice mail system, and post-stay surveys. For example, in the CRM spirit of developing a personalized relationship with the customer, when a guest checks in at any Hilton property, the front desk clerk receives information on their terminal that allows them to say, “Welcome back to Hilton, Mr. Smith,” or “Welcome, Ms. Jones. I understand this is your first visit to this hotel (or to Hilton Hotels).” Both the front desk clerk and the housekeeping staff also get information on customer preferences and past complaints, such as wanting a room with good water pressure and not wanting a noisy room. Targeted customers such as frequent guests might find fruit baskets, bottled water, or bathrobes in their rooms. The system even prepares personalized voice-mail greetings on the guest's in-room telephone.

“Photo Courtesy of Hilton Hotels”
The system, uses an Informix DBMS on a Sun Microsystems platform. The database contains both current reservations information and guest history, making it an interesting hybrid of a transaction processing system and a data warehouse. The pending reservations relation contains about two million records, while the one-year “stay summary” contains 60 million records. The database is shared for reservations, CRM, and other purposes. In addition, some of the data is copied into an offline data mart for marketing query purposes, using SQL Server as the DBMS and SAS software. Some of the data is organized in a classic data mart “star schema” arrangement using Epiphany software. In addition to Hilton's access by its hotels and marketing staff, Hilton provides its guests with access to their own records, including their history data, through the Hilton web site.
DATA SECURITY
The Importance of Data Security
With data taking its place as a corporate resource and so much of today's business dependent on data and the information systems that process it, good data security is absolutely critical to every company and organization. A data security breach can dramatically affect a company's ability to continue normal functioning. But even beyond that, companies have a responsibility to protect data that often affects others beyond the company itself. Customer data, which for example can be financial, medical, or legal in nature, must be carefully guarded. When customers give a company personal data they expect the company to be very careful to keep it confidential. Banks must be sure that the money they hold, now in the form of data, cannot be tampered with or leaked outside of the bank. Individuals want personal information that insurance companies keep about them to remain confidential. Also, when a company has access to a trading partner's data in a supply chain arrangement, the partner company expects its data to remain secure. Governments, charged with protecting their citizens, must protect sensitive defense data from unauthorized intrusion. And the list goes on and on.
Types of Data Security Breaches
There are several different ways that data and the information systems that store and process it can be compromised.
Unauthorized Data Access Perhaps the most basic kind of data security breach is unauthorized data access. That is, someone obtains data that they are not authorized to see. This can range from seeing, say, a single record of a database table to obtaining a copy of an entire table or even an entire database. You can imagine an evil company wanting to steal a competitor's customer list or new product plans, the government of one country wanting to get hold of another country's defense plans, or even one person simply wanting to snoop on his neighbor's bank account. Sometimes the stolen data consists of computer passwords or security codes so that data or property can be stolen at a later time. And a variety of different people can be involved in the data theft, including a company's own employees, a trading partner's employees, or complete outsiders. In the case of a company's own employees, the situation can be considerably more complicated than that of an outsider breaking in and stealing data. An employee might have legitimate access to some company data but might take advantage of his access to the company's information systems to steal data he is not authorized to see. Or he might remove data from the company that he is authorized to see (but not to remove).
Unauthorized Data or Program Modification Another exposure is unauthorized data modification. In this situation, someone changes the value of stored data that they are not entitled to change. Imagine a bank employee increasing her own bank account balance or that of a friend or relative. Or consider an administrative employee in a university changing a student's grade (or, for that matter, the student breaking into the university computer to change his own grade!). In more sophisticated cases a person might manage to change one of a company's programs to modify data now or at a later time.
Malicious Mischief The field of reference has to be expanded when discussing malicious mischief as a data security issue. To begin with, someone can corrupt or even erase some of a company's data. As with data theft, this can range from a single record in a table to an entire table or database. But there is even more to malicious mischief. Data can also be made unusable or unavailable by damaging the hardware on which it is stored or processed! Thus, in terms of malicious mischief, the hardware as well as the data has to be protected and this is something that we will address.
Methods of Breaching Data Security
Methods of breaching data security fall into several broad categories, Figure 11.1. Some of these require being on a company's premises while others don't.
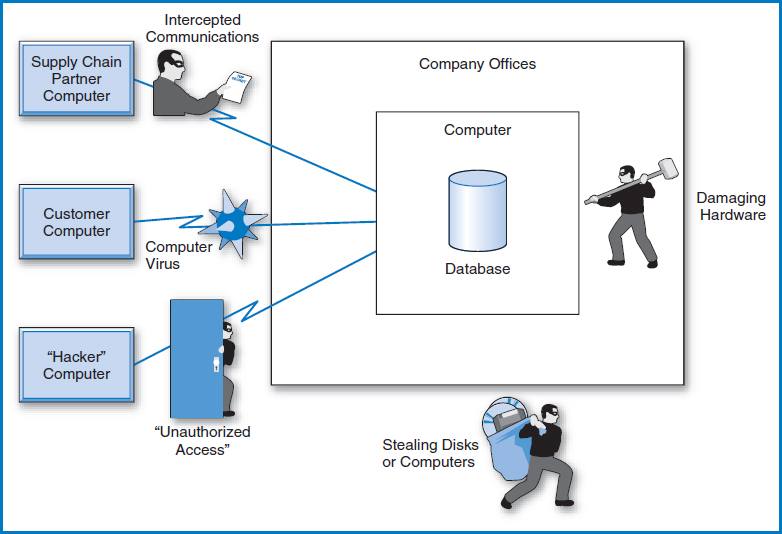
FIGURE 11.1 Data security breaches
Unauthorized Computer Access One method of stealing data is gaining unauthorized access to a company's computer and its data. This can be accomplished in a variety of ways. One is by “hacking” or gaining access from outside the company. Some hackers are software experts who can exploit faults in a company's software. Others use stolen identification names and passwords to enter a computer looking like legitimate users. Indeed, as we suggested earlier, some data thieves actually are legitimate users: company employees who have authorized access to the company's computer system but are intent on stealing data they are authorized to see or breaking into databases for which they do not have access. In all these cases, data is “downloaded” or copied and used illicitly from then on.
Intercepting Data Communications Intercepting data communications is the computer version of the old concept of “wiretapping.” While data may be well protected in a company's computers, once it is transmitted outside the company it becomes subject to being stolen during transmission. Some data transmission media are more subject to interception than others. Tapping a simple “twisted-pair” telephone line or a coaxial cable takes skill but is feasible. When data is bounced off satellites it is also subject to interception. On the other hand, the light pulses going fiber-optic transmission lines cannot be tapped.
Stealing Disks or Computers Can disks or even computers (with data on their hard drives) be stolen? That would have been difficult years ago when all computers were mainframes and all disks were very large. But today, it is very possible. Flash disks and CDs have the potential to be stolen from company offices or, for example, from hotel rooms in which company employees on travel are staying. Laptop computers can be stolen, too, and many have been taken by organized teams of thieves as the laptops go through airport security stations. Even desktop computers have been stolen from company offices.
Computer Viruses A computer virus is a malicious piece of software that is capable of copying itself and “spreading” from computer to computer on diskettes and through telecommunications lines. Strictly speaking, a computer virus doesn't have to cause harm, but most are designed to do just that. Computer viruses have been designed to corrupt data, to scramble system and disk directories that locate files and database tables, and to wipe out entire disks. Some are designed to copy themselves so many times that the sheer number of copies clogs computers and data communications lines. Computer viruses that travel along data communications lines are also called, “worms.”
Damaging Computer Hardware All of the previous methods of breaching data security have something in common: they're deliberate. However, this last category, damaging computer hardware, can be deliberate or accidental. Even when accidental, the issue of damaging hardware has always been considered to fall into the computer security realm. Computers and disks can and have been damaged in many ways and it's not been a matter of anything “high-tech,” either. They have been damaged or ruined by fires, coffee spills, hurricanes, and disgruntled or newly fired employees with hammers or any other hard objects handy. We will discuss security measures for these problems but, in truth, no security measures for them are foolproof. That's one of the reasons that backup and recovery procedures, as discussed later in this chapter, are so very important.
Types of Data Security Measures
With the critical importance of data and all of the possible threats to data security, it is not surprising that the information systems industry has responded with an array of data security measures to protect the data and the hardware on which it is stored and processed, Figure 11.2.
Physical Security of Company Premises In the 1950s, some progressive companies in New York and other large cities put their mainframe computers on the ground floor behind big picture windows so that everyone could see how, well, progressive they were. Those days are long gone. Today, suppose your company is located in a skyscraper it shares with other companies. Where do you put your mainframe computer (or your several LAN servers, which are often placed in the same room for precisely the security reasons we're talking about?) Here are some rules of thumb, often learned from hard experience.
- Don't put the computer in the basement because of the possibility of floods.
- Don't put the computer on the ground floor because of the possibility of a truck driving into the building, accidentally or on purpose. (I know of a company that had its computer center in a low-rise building adjoining an interstate highway. They eventually put up concrete barriers outside of the building because they were concerned about just this possibility.)
FIGURE 11.2 Data security measures
- Don't put the computer above the eighth floor because that's as high as firetruck ladders can reach.
- Don't put the computer on the top floor of the building because it is subject to helicopter landing and attack.
- If you occupy at least three floors of the building, don't put the computer on your topmost floor because its ceiling is another company's floor, and don't put the computer on your bottommost floor because its floor is another company's ceiling.
- Whatever floor you put the computer on, keep it in an interior space away from the windows.
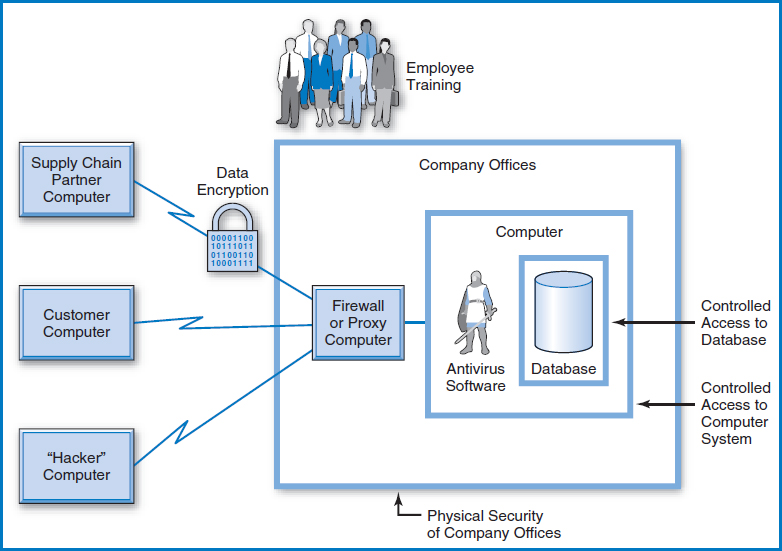
Another issue is personnel access to the computer room. Obviously, such access should be limited to people with a legitimate need to be in the room. Access to the room is controlled by one or a combination of:
- Something they know, such as a secret code to be punched in.
- Something they have, such as a magnetic stripe card, possibly combined with a secret code.
- Some part of them that can be measured or scanned. These “biometric” systems can be based on fingerprints, the dimensions and positions of facial features, retinal blood vessel patterns, or voice patterns.
There are also “electric-eye” devices that protect against a second person following right behind an authorized person into the secure room.
Believe it or not, a critical physical security issue involves the company's offices and cubicles. These contain PCs and possibly even LAN servers that contain their own data and provide access to the company's larger computers and to other PCs and servers. Such a simple procedure as locking your office door when you leave it, even for a short period of time, can be critical to data security. Logging off or going into a password-protected mode, especially when doorless cubicles are involved, is an alternative.
Controlled Access to the Computer System What if someone has gained access to a company's offices and tries to access the computer system and its database from a PC or terminal from within? For that matter, what if someone tries to access a company's computer by dialing into it or otherwise accessing it through telecommunications lines from the outside? The first line of defense to prevent unauthorized entry to a computer system is to set up a combined ID tag/password necessary to get into the system. ID tags are often publicly known (at least within the company), but passwords must be kept secret, should be changed periodically, and should not be written down, to reduce the risk of someone else learning them. Passwords should not appear on the terminal screen when they are typed in, and the user should create them himself to reduce the chance of his forgetting them. There are a variety of rules of thumb for creating passwords. They should not be too long or too short, say 6–12 characters. They should not be obvious, like a person's own name. They should not be so difficult to remember that the person herself has to write them down, since this is a security exposure in itself because someone else could see it.
Controlled Access to the Database An additional layer of data security controls access to the data itself, once a legitimate user or an outsider has successfully gained entry to the computer system. This layer involves restricting access to specific data so that only specific people can retrieve or modify it. Some systems have such controls in the operating system or in other utility software. Basically, these controls involve a grid that lists users on one axis and data resources, such as databases or tables, on another axis, to indicate which users are authorized to retrieve or modify which data resources. Also, an additional layer of passwords associated with the various data resources can be introduced Even after a legitimate user has given his system password to gain entry to the computer system, these additional passwords would be needed to gain access to specific data resources.
At the DBMS level, a user should not be able simply to access any data he wants to Users have to be given explicit authorization to access data. Relational DBMSs have a very flexible and effective way of authorizing users to access data that at the same time serves as an excellent data security feature. We are referring to the combination of the logical view, or simply the “view” concept, and the SQL GRANT command. With this combination, users, either individually or in groups (for example everyone in the Accounting Department), can be restricted to accessing only certain database tables or only certain data within a database table. Furthermore, their access to this data can be restricted to read-only access or can include the ability to update data or even to insert new or delete existing rows in the table. The GRANT command is supported by several tables in the relational catalog.
How do these two features work in combination? First, using the CREATE VIEW statement, a view of a database table, consisting of a subset of the rows and/or columns, is created and named. This is done with an embedded SELECT statement! (Isn't that clever?) The desired rows and/or columns are identified just as if they were being retrieved, but instead of being retrieved they are given a view name. Then, through the GRANT command, a user or a group of users is given access to the view, not to the entire table. In fact, they may not even be aware that there is more to the table than their subset. They simply use the view name in a SELECT statement for data retrieval as if it were a table name.
But how is a user given the authority to access data through the use of a view (or directly using a table name?) That's where the GRANT command comes in. The general form of the GRANT command is:
GRANT privileges ON (view or table) TO users [WITH GRANT OPTION].
Thus, the database administrator grants the ability to read, update, insert, or delete (the “privileges”) on a view or a table to a person or group of people (the “users”). If the WITH GRANT OPTION is included, this person or group can in turn grant other people access to the same data.
So, to allow a person named Glenn to query the SALESPERSON table by executing SELECT commands on it, you would issue the command:
GRANT SELECT ON SALESPERSON TO GLENN;
Data Encryption So far, all of the data security techniques we've covered assume that someone is trying to “break into” the company's offices, its computer, or its DBMS. But data can be stolen in other ways, too. One is through wiretapping or otherwise intercepting some of the huge amounts of data that is transmitted today through telecommunications between a company and its trading partners or customers. Another is by stealing a disk or a laptop computer outside a company's offices, for example in an airport. A solution to this problem is data encryption. When data is encrypted, it is changed, bit by bit or character by character, into a form that looks totally garbled. It can and must be reconverted, or decrypted, back to its original form to be of use. Data may be encrypted as it is sent from the company's computer out onto telecommunications lines to protect against its being stolen while in transit. Or the data may actually be stored in an encrypted form on a disk, say on a diskette or on a laptop's hard drive, to protect against data theft if the diskette or laptop is stolen while an employee is traveling. Of course, highly sensitive data can also be encrypted on a company's disks within its mainframe computer systems or servers. This adds a further level of security if someone breaks into the computer system. Why not then simply encrypt all data wherever it may be? The downside to encryption is that it takes time to decrypt the data when you want to use it and to encrypt it when you want to store it, which can become a performance issue.
Data encryption techniques can range from simple to highly complex. The simpler the scheme, the easier it is for a determined person to figure it out and “break the code.” The more complex it is, the longer it takes to encrypt and decrypt the data, although this potential performance problem has been at least partially neutralized by the introduction of high-performance hardware encryption chips. Encryption generally involves a data conversion algorithm and a secret key. A very simple alphabetic encryption scheme is as follows. Number the letters of the alphabet from A to Z as 1 to 26. For each letter in the data to be encrypted, add the secret key (some number in this case) to the letter's numeric value and change the letter to the letter represented by the new number. For example, if the key is 4, an A (value 1) becomes an E (since 1+4 = 5 and E is the fifth letter of the alphabet), a B becomes an F, and so on through the alphabet. W wraps around back to the beginning of the alphabet and becomes an A, X becomes a B, and so forth. The recipients must know both the algorithm and the secret key so that they can work the algorithm in reverse and decrypt the data.
Modern encryption techniques typically encrypt data on a bit-by-bit basis using increasingly long keys and very complex algorithms. Consider the data communications case. The two major types of data encryption techniques are symmetric or “private key” and asymmetric or “public key” encryption. Private key techniques require the same long bit-by-bit key for encrypting and decrypting the data (hence the term “symmetric”). But this has an inherent problem. How do you inform the receiver of the data of the private key without the key itself being compromised en route? If the key itself is stolen, the intercepted data can be converted once the conversion algorithm is identified. There are only a few major conversion algorithms; the security is in the key, not in having a great many different conversion algorithms.
The key transmission problem is avoided using algorithms that employ the very clever public-key technique. Here there are two different keys: the public key, which is used for encrypting the data, and the private key, which is used for decrypting it (hence the term “asymmetric”). The public key is not capable of decrypting the data. Thus, the public key can be published for all the world to see. Anyone wanting to send data does so in complete safety by encrypting the data using the algorithm and the openly published public key. Only the legitimate receiver can decrypt the data because only the legitimate receiver has the private key that can decrypt the data with the published public key. The downside of the public-key technique is that encrypting and decrypting tend to be slower than with the private-key technique, resulting in slower application transactions when the public-key technique is used.
A particularly interesting combination of private-key and public-key encryption is used in Secure Socket Layer (SSL) technology on the World Wide Web. Consider a person at home who wants to buy something from an online store on the Web. Her PC and its WWW browser are the “client” and the online store's computer is the “server.” Both sides want to conduct the secure transaction using private-key technology because it's faster, but they have the problem that one side must pick a private key and get it to the other side securely. Here are the basic steps in SSL:
- The client contacts the server.
- The server sends the client its public key for its public-key algorithm (you'll see why in a moment). No one cares if this public key is stolen since it's, well, public!
- The client, using a random number generator, creates a “session key,” the key for the private key algorithm with which the secure transaction (the actual online shopping) will be conducted once everything is set up. But, as we've described, the problem now is how the client can securely transmit the session key it generated to the server, since both must have it to use the faster private-key algorithm for the actual shopping.
- Now, here is the really clever part of the SSL concept. The client is going to send the session key to the server, securely, using a public-key algorithm and the server's public key. The client encrypts the session key using the server's public key and transmits the encrypted session key to the server with the public key algorithm. It doesn't matter if someone intercepts this transmission, because the server is the only entity that has the decrypting private key that goes with its public key!
- Once the session key has been securely transmitted to the server, both the client and the server have it and the secure transaction can proceed using the faster private-key algorithm.
Anti-virus Software Companies (and individuals!) employ anti-virus software to combat computer viruses. There are two basic methods used by anti-virus software. One is based on virus “signatures,” portions of the virus code that are considered to be unique to it. Vendors of anti-virus software have identified and continue to identify known computer viruses and maintain an ever-growing, comprehensive list of their signatures. The anti-virus software contains those signatures and on a real-time basis can check all messages and other traffic coming into the computer to see if any known viruses are trying to enter. The software can also, on request, scan disks of all types to check them for viruses. The other anti-virus method is that the software constantly monitors the computer environment to watch for requests or commands for any unusual activity, such as, for example, a command to format a disk, therefore wiping out all the data on it. The software will typically prevent the command from executing and will ask the person operating the computer whether she really wants this command to take place. Only if the operator confirms the request will it take place.
Firewalls In today's business world, where supply chain partners communicate via computers over networks and customers communicate with companies' Web sites over the Internet, a tremendous amount of data enters and leaves a company's computers every day over data communications lines. This, unfortunately, opens the possibility of a malicious person trying to break into a company's computers through these legitimate channels. Whether they are trying to steal, destroy, or otherwise harm the company's data, they must be stopped. Yet, these data communications channels must be kept open for legitimate business with the company's supply chain partners and customers.
One type of protection that companies use to protect against this problem is the “firewall.” A firewall is software or a combination of hardware and software that protects a company's computer and its data against external attack via data communications lines. There are several types of firewalls. Some that are purely software-based involve checking the network address of the incoming message or components of the content of the message. An interesting firewall that is a combination of hardware and software is the “proxy server,” shown in Figure 11.3. The idea of the proxy server is that the message coming from an outside computer does not go directly to the company's main computer, say a mainframe computer for the sake of argument. Instead, it goes to a separate computer, the proxy server or firewall computer. The proxy server has software that takes apart the incoming message, extracts only those legitimate pieces of data that are supposed to go to the company's mainframe, reformats the data in a form the company's mainframe is expecting, and finally passes on the reformatted data to the company's main computer. In this way, any extraneous parts of the incoming message, including any malicious code, never reaches the company's main computer.
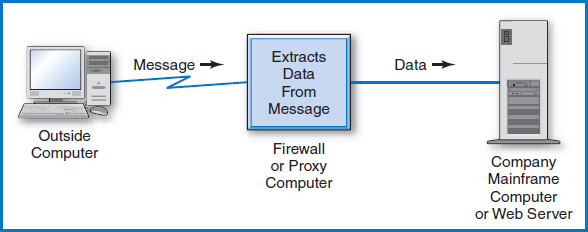
FIGURE 11.3 A firewall protecting a company's computer
Training Employees A surprisingly important data security measure is training a company's employees in good security practices, many of which are very simple and yet very important. What should the company tell its employees in terms of good data security practices? Here are a few samples:
- Log off your computer, or at least lock your office door, when you leave your office, even for just a few minutes.
- Don't write your computer password down anywhere.
- Don't respond to any unusual requests for information about the computer system (or anything else!) from anyone over the telephone. (People posing as employees of the company have phoned company personnel and said that they need their password to check out a problem in the computer system. And this trick has worked!)
- Don't leave flash disks or other storage media lying around your office.
- Don't take flash disks or other storage media out of the building.
- Don't assume that a stranger in the building is there legitimately: always check. (People have posed as telephone repairpersons to tap a company's data communications lines.)
YOUR TURN
11.1 PROTECTING YOUR DATA
What about protecting your own data on your own PC? (If you don't have one, think about someone you know who does.) Think about the data you have stored on your PC's hard drive. Have you stored personal data such as your Social Security Number or your birth date? Have you written personal letters to people and stored them on your hard drive before sending them? How about your bank records? Tax records? Personal medical information?
QUESTION:
What kinds of personal data do you have on your PC? Describe the methods you currently use to protect your PC and its data. If it's a laptop, what precautions do you take when carrying it with you outside your home or dorm? Do you think you should increase the security in and for your PC? If so, how would you go about doing it?
BACKUP AND RECOVERY
The Importance of Backup and Recovery
Regardless of how sophisticated information systems have become, we have to be prepared to handle a variety of events that can affect or even destroy data in a database. Trouble can come from something as simple as a legitimate user entering an incorrect data value or from something as overwhelming as a fire or some other disaster destroying an entire computer center and everything in it. Thus the results can range in consequence from a single inaccurate data value to the destruction of all the installation's databases, with many other possibilities in between. In the information systems business we have to assume that from time to time something will go wrong with our data and we have to have the tools available to correct or reconstruct it. These operations come under the heading of backup and recovery. In this section we will take a look at some of the basic backup and recovery techniques.
Backup Copies and Journals
The fundamental ideas in backup and recovery are fairly straightforward in concept and some have been around for a long time. They begin with two basic but very important tasks: backing up the database and maintaining a journal. First, there is backup. On a regularly scheduled basis, say once per week, a company's databases must be “backed up” or copied. The backup copy must be put in a safe place, away from the original in the computer system. (There have been cases of the copy being kept in the computer room only to have a fire destroy both the original and the copy.) There are several possibilities for storing the backup copy. For example, it may be kept in a fire-proof safe in a nearby company building. Or it may be kept in a bank vault. Often, during the next back-up cycle, the previous backup copy becomes the “grandfather copy” and is sent even farther away to a distant state or city for additional security.
The other basic backup and recovery task is maintaining a disk log or journal of all changes that take place in the data. This includes updates to existing records, insertion of new records, and deletion of existing records. Notice that it does not include the recording of simple read operations that do not change the stored data in any way. There are two types of database logs. One, which is variously called a “change log” or a “before and after image log,” literally records the value of a piece of data just before it is changed and the value just after it is changed. So, if an employee gets a raise in salary and the salary attribute value of his personnel record is to be changed from 15.00 (dollars per hour) to 17.50, the change log identifies the record by its unique identifier (e.g. its employee number) within its table name, the original salary attribute value of 15.00, and the new salary attribute value of 17.50. The other type of log, generally called a “transaction log,” keeps a record of the program that changed the data and all of the inputs that the program used. A very important point about both kinds of logs is that a new log is started immediately after the data is backed up (i.e., a backup copy of the data is made). You'll see why in a moment.
Now, how are backups and logs used in backup and recovery operations? Actually, it depends on the reason for the backup and recovery operation and, yes, there is more than one reason or set of circumstances that require some kind of backup and recovery.
Forward Recovery
First let's consider a calamity that destroys a disk, or an only slightly lesser calamity that destroys a database or a particular database table. The disk or the database or the table has to be recreated and the recovery procedure in this case is called “forward recovery” or “roll-forward recovery” (the word “roll” in “roll forward” comes from the earlier use of tapes to record the logs). Let's look at this by considering a lost table. To recreate the lost table, you begin by readying the last backup copy of the table that was made and readying the log with all of the changes made to the table since the last backup copy was made. The point is that the last backup copy is, well, a copy of the table that was lost, which is what you want, except that it doesn't include the changes to the data that were made since the backup copy was made. To fix this, a “recovery program” begins by reading the first log entry that was recorded after the last backup copy was made. In other words, it looks at the first change that was made to the table right after the backup copy was made. The recovery program updates the backup copy of the table with this log entry. Then, having gone back to the beginning of the log, it continues rolling forward, making every update to the backup copy of the table in the same order in which they were originally made to the database table itself. When this process is completed, the lost table has been rebuilt or recovered, Figure 11.4! This process can be performed with either a change log or a transaction log. Using the change log, the “after images” are applied to the backup copy of the database. Using the transaction log, the actual programs that updated the database are rerun. This tends to be a simpler but slower process.
One variation of the forward recovery process when a change log is used is based on the recognition that several changes may have been made to the same piece of data since the last backup copy of the table was made. If that's the case, then only the last of the changes to the particular piece of data, which after all shows the value of this piece of data at the time the table was destroyed, needs to be used in updating the database copy in the roll-forward operation.
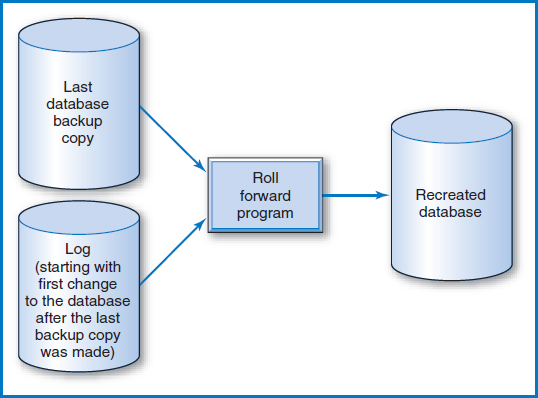
FIGURE 11.4 Forward recovery
If the database environment is a volatile one in which changes are made frequently and it is common for the same piece of data to be updated several times between backup operations, then the roll-forward operation as we have described it may be needlessly inefficient. Instead, it may be worthwhile to sort through the log prior to the roll-forward operation to find the last change made to each piece of data that was updated since the last backup copy was made. Then only those final changes need be applied to the backup copy in the roll-forward operation.
Backward Recovery
Now let's consider a different situation. Suppose that in the midst of normal operation an error is discovered that involves a piece of recently updated data. The cause might be as simple as human error in keying in a value, or as complicated as a program ending abnormally and leaving in the database some, but not all, changes to the database that it was supposed to make. Why not just correct the incorrect data and not make a big deal out of it? Because in the interim, other programs may have read the incorrect data and made use of it, thus compounding the error in other places in the database.
So the discovered error, and in fact all other changes that were made to the database since the error was discovered, must be “backed out.” The process is called “backward recovery” or “rollback.” Essentially, the idea is to start with the database in its current state (note: backup copies of the database have nothing to do with this procedure) and with the log positioned at its last entry. Then a recovery program proceeds backwards through the log, resetting each updated data value in the database to its “before” image, until it reaches the point where the error was made. Thus the program “undoes” each transaction in the reverse order (last-in, first-out) from which it was made, Figure 11.5. Once all the data values in the tainted updates are restored to what they were before the data error occurred, the transactions that updated them must be rerun. This can be a manual process or, if a transaction log was maintained as well as a change log, a program can roll forward through the transaction log, automatically rerunning all of the transactions from the point at which the data error occurred.
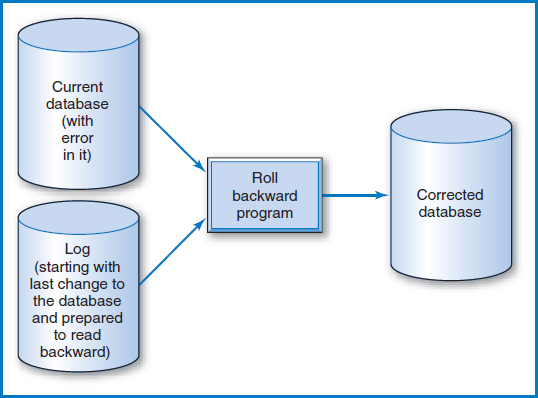
FIGURE 11.5 Backward recovery
Another note about backward recovery: some systems are capable of automatically initiating a roll-backward operation to undo the changes made to the database by a partially completed and then halted or failed transaction. This is called “dynamic backout.” There are situations in which it is helpful to restore the database to the point at which there is confidence that all changes to the database up to that point are accurate. Some systems are capable of writing a special record to the log, known as a “checkpoint,” that specifies this kind of stable state.
Duplicate or “Mirrored” Databases
A backup and recovery technique of a very different nature is known as duplicate or “mirrored” databases. Two copies of the entire database are maintained and both are updated simultaneously, Figure 11.6. If one is destroyed, the applications that use the database can just keep on running with the duplicate database. This is a relatively expensive proposition, but allows continuous operation in the event of a disk failure, which may justify the cost for some applications. By the way, this arrangement is of no help in the case of erroneous data entry (see backward recovery above) because the erroneous data will be entered in both copies of the database!
The greater the “distance” between the two mirrored copies of the database, the greater the security. If both are on the same disk (not a good idea!) and the disk fails or is destroyed, both copies of the database are lost. If the two copies are on different disks but are in the same room and a fire hits the room, both might be destroyed. If they are on disks in two different buildings in the same city, that's much better, but a natural disaster such as a hurricane could affect both. Thus, some companies have kept duplicate databases hundreds of miles apart to avoid such natural disasters.
Disaster Recovery
Speaking of natural disasters, the author lived through Hurricane Andrew in Miami, FL, in August, 1992 and learned about disaster recovery first-hand! The information systems of two major companies and a host of smaller ones were knocked out of service by this hurricane. Miami companies in buildings with major roof and window damage actually found fish that the hurricane had lifted out of the ocean and deposited in their computers (I'm not kidding!). They also discovered that when the salt water from the ocean saturated the ceiling tiles in their offices, wet flakes from the tiles fell down onto their computer equipment, ruining some of it. A company that thought that it was keeping its database backup copies in a safe place in another part of the city didn't take into account that the roof of the backup site would not stand up to a major hurricane and lost its backup copies.
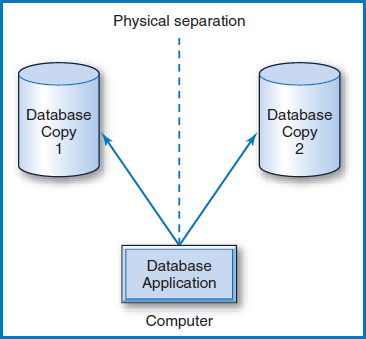
FIGURE 11.6 Mirrored databases
As its name implies, disaster recovery involves rebuilding an entire information system or significant parts of one after a catastrophic natural disaster such as a hurricane, tornado, earthquake, building collapse, or even a major fire. There are several approaches to preparing for such disasters. They tend to be expensive or complex or both, but with today's critical dependence on information systems, companies that want to be careful and prepared have little choice. The possibilities include:
- Maintain totally mirrored systems (not just databases) in different cities.
- Contract with a company that maintains hardware similar to yours so that yours can be up and running again quickly after a disaster. The companies providing these so-called “hot sites” make money by contracting their services with many companies, assuming that they will not all suffer a disaster and need the hot site at the same time.
- Maintain space with electrical connections, air conditioning, etc., into which new hardware can be moved if need be. These so-called “cold sites” are not nearly as practical as they once were because of the online nature and mission-critical character of today's information systems. They simply take too long to get up and running.
- Make a reciprocal arrangement with another company with hardware similar to yours to aid each other in case one suffers a disaster. Obviously, the two companies should be in different industries and must not be competitors!
- Build a computer center that is relatively disaster proof. After Hurricane Andrew, one of the large affected companies in Miami rebuilt their computer center in a building they started referring to as “the bunker.”
YOUR TURN
11.2 WHEN DISASTER STRIKES
Disasters can take many forms and can affect individuals as well as businesses. A disaster can take the form of a natural disaster such as a hurricane, earthquake, or tornado, but it can also take the form of fire, theft of your PC or laptop, or even a very damaging computer virus.
QUESTION:
What would be the consequences to you if a disaster struck and you lost all your personal data? What precautions have you taken to back up your important personal data? Do you think you should take further precautions? If so, what might they be?
CONCURRENCY CONTROL
The Importance of Concurrency Control
Generally speaking, today's application systems, and especially those running within the database environment, assume that many people using these systems will require access to the same data at the same time. Modern hardware and systems software are certainly capable of supporting such shared data access. One very common example of this capability is in airline reservations, where several different reservations clerks, as well as customers on the Web, may have simultaneous requests for seats on the same flight. Another example is an industrial or retail inventory application in which several employees on an assembly line or in an order fulfillment role simultaneously seek to update the same inventory item.
When concurrent access involves only simple retrieval of data, there is no problem. But when concurrent access requires data modification, the two or more users attempting to update the data simultaneously have a rather nasty way of interfering with each other that doesn't happen if they are merely performing data retrievals. This is certainly the case in the airline reservations and inventory examples, since selling seats on flights and using items in inventory require that the number of seats or inventory items left be revised downwards; i.e., many of the database accesses involve updates. The result can be inaccurate data stored in the database!
The Lost Update Problem
Using the airline reservations application as an example, here is what can happen with simultaneous updates, Figure 11.7. And before we begin the example, bear in mind that we are not talking about simultaneous updates only at the “microsecond” level. As you are about to see, the problem can occur when the time spans involved are in seconds or minutes. Suppose that there are 25 seats left on Acme Airlines flight #345 on March 12. One day, at 1:45 PM, a reservations clerk, Ms. Brown, is phoned by a customer who is considering booking four seats on that particular flight. Brown retrieves the record for the flight from the database, notes that there are 25 seats available, and begins to discuss the price and other details with her customer. At 1:48 PM, another reservations clerk, Mr. Green receives a call from another customer with a larger family who is considering booking six seats on the very same flight. Green retrieves the record for the flight from the database and notes that there are 25 seats available. At 1:52 PM, Brown's customer decides to go ahead and book four seats on the flight. Brown completes the transaction and four seats are deducted from the number of seats available on the flight, updating the database record to show that there are now 21 seats available. Then, at 1:56 PM, Green's customer decides to book six seats on the flight. Green completes this transaction and six seats are deducted from the number of seats (25) that Green thought were available on the flight, leaving the database showing that 19 seats are now available.
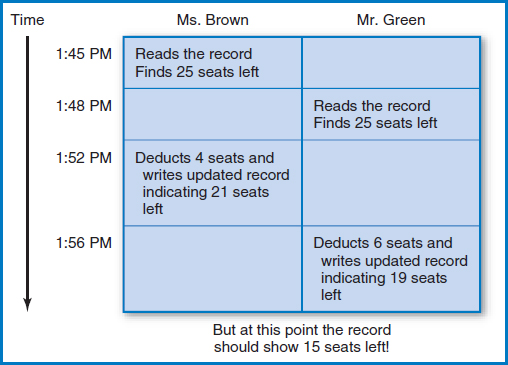
FIGURE 11.7 The lost update problem
So, the record for flight #345 on March 12 now shows that there are 19 seats available. But shouldn't it show only 15, since a total of 10 seats were sold? Yes, but the point is that neither of the clerks knew that the other was in the process of selling seats on the flight at the same time that the other was. Both Brown and Green started off knowing that there were 25 seats left. When Brown deducted four seats, for a couple of minutes the record showed that there were 21 seats left. But then when Green deducted his six, he was deducting them from the original 25 seats that he saw when he originally retrieved the record from the database, not from the 21 seats that were left after Brown's sale.
By the way, you might question the likelihood of two clerks going after the same record simultaneously in a large airline reservations system. Have you ever tried to book a reservation on a flight from New York to Miami for Christmas week in the week before Christmas week? The likelihood of this kind of conflict is very real in the airline reservations application and in countless other applications of every type imaginable.
Locks and Deadlock
The usual solution to this problem is to introduce what are known as software “locks.” When a user begins an update operation on a piece of data, the DBMS locks that data. Any attempt to begin another update operation on that same piece of data will be blocked or “locked out” until the first update operation is completed and its lock on the data is released. This effectively prevents the lost-update problem. The level or “granularity” of lockout can vary. Lockout at a high level, for instance at the level of an entire table, unfortunately prevents much more than that one particular piece of data from being modified while the update operation is going on, but is a low-overhead solution since only one lock is needed for the entire table. Lockout at a lower level, the record level for instance, doesn't prevent access or updates to the rest of the table, but is a comparatively high-overhead solution because every record must have a lock that can be set.
Unfortunately, as so often happens, the introduction of this beneficial device itself causes other problems that did not previously exist. Follow the next scenario, Figure 11.8: consider an inventory situation in which clerks must find out if sufficient quantities of each of two parts, say nuts and bolts, are available to satisfy an order. If there are enough parts, then the clerks want to take the parts from inventory and update the quantity remaining values in the database. Each clerk can fill the order only if enough of both parts are available. Each clerk must access and lock the record for one of the two parts while accessing the record for the other part. Proceeding with this scenario, suppose two clerks, Mr. White and Ms. Black, each request a quantity of nuts and bolts. White happens to list the nuts before the bolts in his query. At 10:15 AM, he accesses and locks the record for nuts. Ms. Black happens to list the bolts before the nuts in her query. At 10:16 AM, she accesses and locks the record for bolts. Then, at 10:17 AM, White tries to access the record for bolts but finds it locked by Black. And 10:18 AM, Black tries to access the record for nuts but finds it locked by White. Both queries then wait endlessly for each other to release what they each need to proceed. This is called “deadlock” or “the deadly embrace.” It actually bears a close relationship to the “gridlock” traffic problem that major cities worry about during rush hour.
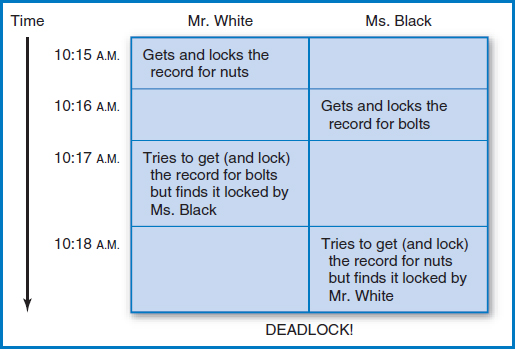
FIGURE 11.8 Deadlock
Does the prospect of deadlock mean that locks should not be used? No, because there are two sorts of techniques for handling deadlock: deadlock prevention and deadlock detection. Outright deadlock prevention sounds desirable but turns out to be difficult. Basically, a transaction would have to lock all the data it will need, assuming it can even figure this out at the beginning of the transaction (often the value of one piece of data that a program retrieves determines what other data it needs). If the transaction finds that some of the data it will need is unavailable because another transaction has it locked, all it can do is release whatever data it has already locked and start all over again.
So the usual way to handle deadlock is to let it occur, detect it when it does, and then abort one of the deadlocked transactions, allowing the other to finish. The one that was backed out can then be run again. One way to detect deadlock is through a timeout, meaning that a query has been waiting for so long that the assumption is it must be deadlocked. Another way to detect deadlock is by maintaining a resource usage matrix that dynamically keeps track of which transactions or users are waiting for which pieces of data. Software can continuously monitor this matrix and determine when deadlock has occurred.
Versioning
There is another way to deal with concurrent updates, known as “versioning,” that does not involve locks at all. Basically, each transaction is given a copy or “version” of the data it needs for an update operation, regardless of whether any other transaction is using the same data for an update operation at the same time. Each transaction records its result in its own copy of the data. Then each transaction tries to update the actual database with its result. At that point, monitoring software checks for conflicts between two or more transactions that are trying to update the same data at the same time. If it finds a conflict, it allows one of the transactions to update the database and makes the other(s) start over again. The hope is that conflicts will not occur often, allowing the applications to proceed along more efficiently without the need for locks.
SUMMARY
There are three major technological and methodological subfields of database management that involve the protection of data: data security, backup and recovery, and concurrency control. Data security issues include types of data security breaches, methods of breaching data security, and types of data security measures, such as anti-virus software, firewalls, data encryption, and employee training, among others.
Backup and recovery includes creating backup copies of data and maintaining journals, procedures such as forward recovery, backward recovery, arrangements such as duplicate or “mirrored” databases, and the separate but related subfield of disaster recovery. Concurrency control includes issues such as the lost-update problem and deadlock and fixes that include locks and versioning.
KEY TERMS
Anti-virus software
Backup and recovery
Backward recovery
Before and after image log
Biometric systems
Change log
Checkpoint
Cold site
Computer virus
Concurrency control
Data encryption
Data security
Database control issues
Deadlock
Disaster recovery
Duplicate database
Dynamic backout
Firewall
Forward recovery
GRANT
Hot site
Locks
Lost update problem
Mirrored database
Password
Physical security
Private key encryption
Proxy server
Public key encryption
Reciprocal agreement
Resource usage matrix
Rollback
Roll forward
Secure Socket Layer (SSL) technology
Signature
Transaction log
Versioning
Wiretapping
QUESTIONS
- Explain why data security is important.
- Compare unauthorized data access with unauthorized data modification. Which do you think is the more serious issue? Explain.
- Name and briefly describe three methods of breaching data security. Which do you think is potentially the most serious? Explain.
- How does the physical security of company premises affect data security?
- How do magnetic stripe cards and fingerprints compare in terms of physical security protection?
- Describe the rules for creating a good password.
- Explain how the combination of views and the SQL GRANT command limits access to a relational database.
- What is data encryption and why is it important to data security?
- In your own words, describe how Secure Socket Layer (SSL) technology works.
- In your own words, describe how a proxy server firewall works.
- Explain why backup and recovery is important.
- What is a journal or log? How is one created?
- Describe the two different problems that forward recovery and backward recovery are designed to handle. Do mirrored databases address one of these two problems or yet a third one? Explain.
- In your own words, describe how forward recovery works.
- In your own words, describe how backward recovery works.
- What is disaster recovery? Can the techniques for backup and recovery be used for disaster recovery?
- Explain why concurrency control is important.
- What is the lost-update problem?
- What are locks and how are they used to prevent the lost-update problem?
- What is deadlock and how can it occur?
EXERCISES
- A large bank has a headquarters location plus several branches in each city in a particular region of the country. As transactions are conducted at each branch, they are processed online against a relational database at headquarters. You have been hired as the bank's Director of Data Security. Design a comprehensive set of data security measures to protect the bank's data.
- The bank in Exercise 1, which it totally dependent on its relational database, must be able to keep running in the event of the failure of any one table on one disk drive, in the event of a major disaster to its headquarters computer, or in the event of any catastrophe between these two extremes. Describe the range of techniques and technologies that you would implement to enable the bank to recover from this wide range of failures.
The Tasty Seafood Restaurant is a large restaurant that specializes in fresh fish and seafood. Because its reputation for freshness is important to Tasty, it brings in a certain amount of each type of fish daily and, while trying to satisfy all of its customers, would rather run out of a type of fish than carry it over to the next day. After taking a table's order, a waiter enters the order into a touch-screen terminal that is connected to a computer in the kitchen. The order is sent from the touch-screen terminal to the computer only after all of it has been entered.
At 8:00 PM there are 10 servings of salmon, 15 servings of flounder, and eight orders of trout left in the kitchen. At 8:03 PM, waiter Frank starts entering an order that includes five servings of salmon, six of flounder, and four of trout. At the same time, on another touch-screen terminal, waitress Mary starts entering an order that includes one serving of salmon, three of flounder, and two of trout. At 8:05 PM, before the other two have finished entering their orders, waitress Tina starts entering an order that includes six servings of salmon, one of flounder, and five of trout. Frank finishes entering his order at 8:06 PM, Mary finishes at 8:07 PM, and Tina finishes at 8:09 PM.
- What would the result of all of this be in the absence of locks?
- What would the result be with a locking mechanism in place?
- What would happen if versioning was in use?
- Construct examples of the lost update problem, the use of locks, deadlock, and versioning for the case of a joint bank account (i.e. two people with access to the same bank account).
MINICASES
- Happy Cruise Lines is headquartered in New York and in addition has regional offices in the cruise port cities of Miami, Houston, and Los Angeles. New York has a large server and several LANs. The other three sites each have a single LAN with a smaller server. The company's four offices communicate with each other via land-based telecommunications lines. The company's ships, each of which has a server on board, communicate with the New York headquarters via satellite. Also located in New York is the company's Web site, through which passengers and travel agents can book cruises.
- Devise a data security strategy for Happy Cruise Lines that incorporates appropriate data security measures.
- Happy Cruise Line's main relational database (see Minicase 5.1), located in New York, is considered critical to the company's functioning. It must be kept up and running as consistently as possible and it must be quickly recoverable if something goes wrong. Devise backup and recovery and disaster recovery strategies for the company.
- A particularly popular Christmas-week cruise is booking up fast. There are only a few cabins left and the company wants to be careful to not “overbook” the cruise. With customers, travel agents, and the company's own reservations agents all accessing the database at the same time, devise a strategy that will avoid overbooking.
- The Super Baseball League maintains a substantially decentralized IS organization with the focus on the individual teams. Each team has a server with a LAN at its stadium or offices near the stadium. The League has a server with a LAN at its Chicago headquarters. The league and each of the teams maintain a Web site at their locations. People can get general information about the league at the league's Web site; they can get information about the individual teams as well as buy game tickets through each team's Web site. Data collected at the team locations, such as player statistics updates and game attendance figures, is uploaded nightly to the server at league headquarters via telephone lines.
- Devise a data security strategy for the Super Baseball League, incorporating appropriate data security measures.
- The Super Baseball League's main relational database (see Minicase 5.2), located at its headquarters in Chicago, is for the most part a repository of data collected from the teams. The league wants to keep the headquarters database up and running, but it is more important to keep the individual team databases in their stadiums or offices up and running with as little downtime as possible. Devise backup and recovery and disaster recovery strategies for the Super Baseball League.
- Fans can order or buy tickets from the individual teams over the telephone, through the teams' Web sites, or in person at the teams' box offices. All of this activity takes place simultaneously. Devise a strategy that will avoid selling a particular seat for a particular game more than once.