
CHAPTER 12
CLIENT/SERVER DATABASE AND DISTRIBUTED DATABASIE
Simply put, the question in this chapter is, “Where is the database located?” I Often, the obvious answer is, “It's in the computer itself!” That is, it is located on one of the computer's disk drives. If the computer in question is a stand-alone personal computer, of course the database is stored on the PC's hard drive or perhaps on a flash disk. (Where else could it be?!) The same can be and often is true of much larger computer systems. A company can certainly choose to have its databases stored in its mainframe computer, while providing access to the computer and its databases on a broad, even worldwide scale. This chapter will describe alternative arrangements in which the data is decentralized and not stored in one central location.
OBJECTIVES
- Describe the concepts and advantages of the client/server database approach.
- Describe the concepts and advantages of the distributed database approach.
- Explain how data can be distributed and replicated in a distributed database.
- Describe the problem of concurrency control in a distributed database.
- Describe the distributed join process.
- Describe data partitioning in a distributed database.
- Describe distributed directory management.
CHAPTER OUTLINE
Introduction
Client/Server Databases
Distributed Database
- The Distributed Database Concept
- Concurrency Control in Distributed Databases
- Distributed Joins
- Partitioning or Fragmentation
- Distributed Directory Management
- Distributed DBMSs: Advantages and Disadvantages
Summary
INTRODUCTION
Over the years, two arrangements for locating data other than “in the computer itself” have been developed. Both arrangements involve computers connected to one another on networks. One, known as “client/server database,” is for personal computers connected together on a local area network. The other, known as “distributed database,” is for larger, geographically dispersed computers located on a wide-area network. The development of these networked data schemes has been driven by a variety of technical and managerial advantages, although, as is so often the case, there are some disadvantages to be considered as well.
CLIENT/SERVER DATABASES
A local-area network (LAN) is an arrangement of personal computers connected together by communications lines, Figure 12.1. It is “local” in the sense that the PCs must be located fairly close to each other, say within a building or within several nearby buildings. Additional components of the LAN that can be utilized or shared by the PCs can be other, often more powerful “server” computers and peripheral devices such as printers. The PCs on a LAN can certainly operate independently but they can also communicate with one another. If, as is often the case, a LAN is set up to support a department in a company, the members of the department can communicate with each other, send data to each other, and share such devices as high-speed printers. Finally, a gateway computer on the LAN can link the LAN and its PCs to other LANs, to one or more mainframe computers, or to the Internet.
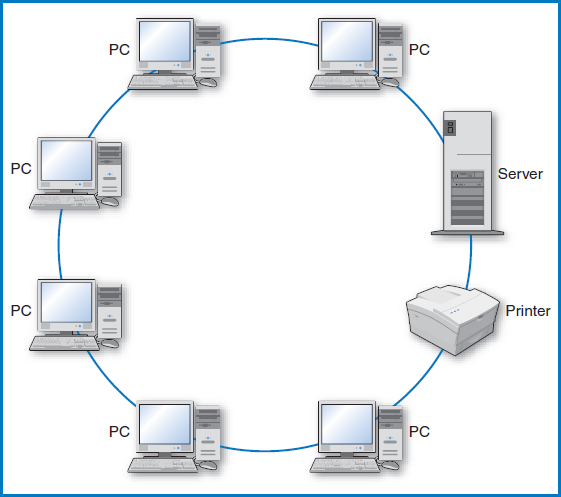
FIGURE 12.1 Local area network (LAN)
CONCEPTS IN ACTION
12-A HASBRO
Hasbro is a world leader in children's and family leisure time entertainment products and services, including the design, manufacture, and marketing of games and toys ranging from traditional to high-tech. Headquartered in Pawtucket, RI, Hasbro was founded in 1923 by the Hassenfeld brothers (hence the company name). Over the years, the Hasbro family has expanded through internal growth plus acquisitions that include Milton Bradley (founded in 1860), Parker Brothers (founded in 1883), Tonka, Kenner, and Playskool. Included among its famous toys are MR. POTATO HEAD®, G.I. Joe®, Tonka Trucks®, Play Doh®, Easy Bake Oven®, Transformers®, Furby®, Tinkertoy®, and the games Monopoly® (the world's all-time best-selling game), Scrabble®, Chutes and Ladders®, Candy Land®, The Game of Life®, Risk®, Clue®, Sorry®, and Yahtzee®.
Hasbro keeps track of this wide variety of toys and games with a database application called PRIDE (Product Rights Information Database), which was implemented in 2001. PRIDE's function is to track the complete life cycle of Hasbro's contract to produce or market each of its products. This includes the payment of royalties to the product's inventor or owner, Hasbro's territorial rights to sell the product by country or area of the world, distribution rights by marketing channel, various payment guarantees and advances, and contract expiration and renewal criteria. A variety of Hasbro departments use PRIDE, including accounting for royalty payments, marketing for worldwide marketing plans, merchandising, product development, and legal departments throughout the world.
PRIDE utilizes the Sybase DBMS and runs on an IBM RS-6000 Unix platform. Actual scanned images of the contracts are stored in the database. The system is designed to store amendments to the contracts, including tracking which amendments are in effect at any point in time. It is also designed to incorporate data corrections and to search the scanned contracts for particular text. The main database table is the Contract Master table, which has 7,000 records and a variety of subtables containing detailed data about royalties, territories, marketing channels, agents, and licensors. These tables produce a variety of customizable reports and queries. The data can also be exported to MS Excel for further processing in spreadsheets.

Photo Courtesy of Hasbro
If one of the main advantages of a LAN is the ability to share resources, then certainly one type of resource to share is data contained in databases. For example, the personnel specialists in a company's personnel department might all need access to the company's personnel database. But then, what are the options for locating and processing shared databases on a LAN? In terms of location, the basic concept is to store a shared database on a LAN server so that all of the PCs (also known as “clients”) on the LAN can access it. In terms of processing, there are a few possibilities in this “two-tiered” client/server arrangement.
The simplest tactic is known as the “file server” approach. When a client computer on the LAN needs to query, update, or otherwise use a file on the server, the entire file (yes, that's right, the entire file) is sent from the server to that client. All of the querying, updating, and other processing is then performed in the client computer. If changes are made to the file, the entire file is then shipped back to the server. Clearly, for files of even moderate size, shipping entire files back and forth across the LAN with any frequency will be very costly. In addition, in terms of concurrency control, obviously the entire file must be locked while one of the clients is updating even one record in it. Other than providing a rudimentary file-sharing capability, this arrangement's drawbacks clearly render it not very practical or useful.
A much better arrangement is variously known as the “database server” or “DBMS server” approach. Again, the database is located at the server. But this time, the processing is split between the client and the server and there is much less network data traffic. Say that someone at a client computer wants to query the database at the server. The query is entered at the client and the client computer performs the initial keyboard and screen interaction processing, as well as initial syntax checking of the query. The system then ships the query over the LAN to the server where the query is actually run against the database. Only the results are shipped back to the client. Certainly, this is a much better arrangement than the file server approach! The network data traffic is reduced to a tolerable level, even for frequently queried databases. Also, security and concurrency control can be handled at the server in a much more contained way. The only real drawback to this approach is that the company must invest in a sufficiently powerful server to keep up with all the activity concentrated there.
Another issue involving the data on a LAN is the fact some databases can be stored on a client PC's own hard drive while other databases that the client might access are stored on the LAN's server. This is known as a “two-tier approach,” Figure 12.2. Software has been developed that makes the location of the data transparent to the user at the client. In this mode of operation, the user issues a query at the client and the software first checks to see if the required data is on the PC's own hard drive. If it is, the data is retrieved from it and that is the end of the story. If it is not there, then the software automatically looks for it on the server. In an even more sophisticated three-tier approach, Figure 12.3, if the software doesn't find the data on the client PC's hard drive or on the LAN server, it can leave the LAN through a “gateway” computer and look for the data on, for example, a large mainframe computer that may be reachable from many LANs.
In another use of the term “three-tier approach,” the three tiers are the client PCs, servers known as “application servers,” and other servers known as “database servers,” Figure 12.4. In this arrangement, local screen and keyboard interaction is still handled by the clients but they can now request a variety of applications to be performed at and by the application servers. The application servers, in turn, rely on the database servers and their databases to supply the data needed by the applications. Although certainly well beyond the scope of LANs, an example of this kind of arrangement is the World Wide Web on the Internet. The local processing on the clients is limited to the data input and data display capabilities of browsers such as Netscape's Communicator and Microsoft's Internet Explorer. The application servers are the computers at company Web sites that conduct the companies' business with the “visitors” working through their browsers. The company application servers in turn rely on the companies' database servers for the necessary data to complete the transactions. For example, when a bank's customer visits his bank's Web site, he can initiate lots of different transactions, ranging from checking his account balances to transferring money between accounts to paying his credit-card bills. The bank's Web application server handles all of these transactions. It in turn sends requests to the bank's database server and databases to retrieve the current account balances, add money to one account and deduct money from another in a funds transfer, and so forth.
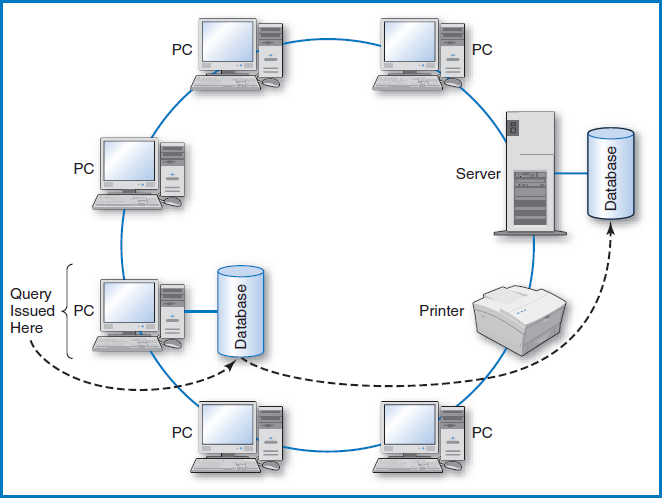
FIGURE 12.2 Two-tier client/server database
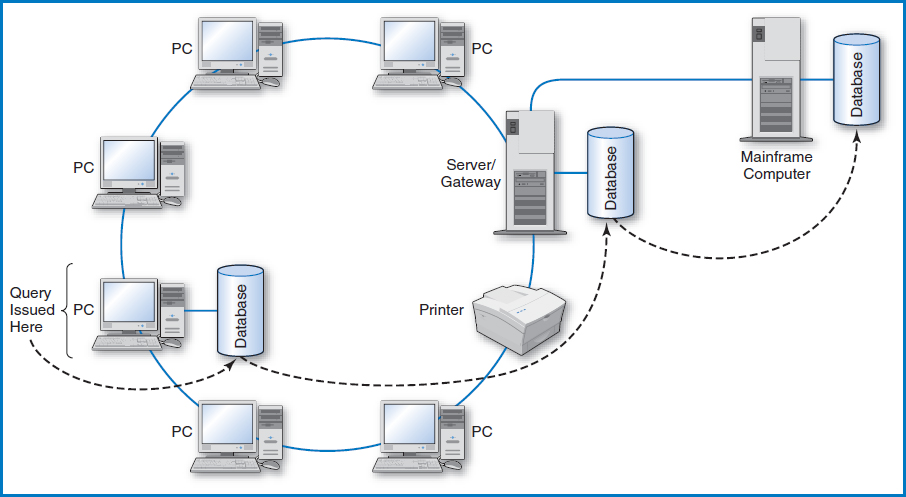
FIGURE 12.3 Three-tier client/server database
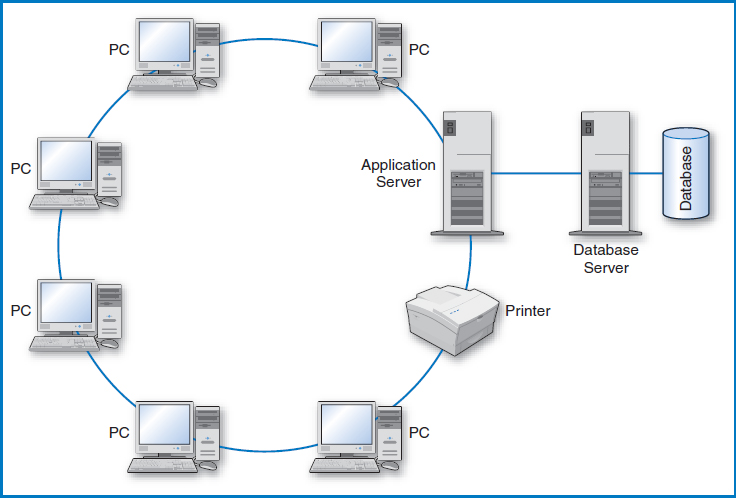
FIGURE 12.4 Another type of three-tier client/server approach
YOUR TURN
12.1 CLIENT/SERVER DATABASE
Universities have many computers on their campuses and many of these are organized into local-area networks. LANs may be found in academic departments or colleges, in administrative units such as the admissions department, in research centers, and so forth. The people utilizing the computers on these LANs probably have data that is unique to their work, and also have a need for data that goes beyond their specific area of work.
QUESTION:
Choose several academic, administrative, and/or research units at your university and think about their data needs. Develop a scheme for organizing the data in the type of three-tier arrangement described in Figure 12.3.
DISTRIBUTED DATABASE
The Distributed Database Concept
In today's world of universal dependence on information systems, all sorts of people need access to companies' databases. In addition to a company's own employees, these include the company's customers, potential customers, suppliers, and vendors of all types. It is certainly possible for a company to concentrate all of its databases at one mainframe computer site with worldwide access to this site provided by telecommunications networks, including the Internet. While the management of such a centralized system and its databases can be controlled in a well contained manner and this can be advantageous, it has potential drawbacks as well. For example, if the single site goes down, then everyone is blocked from accessing the databases until the site comes back up again. Also, the communications costs from the many far-flung PCs and terminals to the central site can be high. One solution to such problems, and an alternative design to the centralized database concept, is known as distributed database.
The idea is that instead of having one centralized database, we are going to spread the data out among the cities on the distributed network, each of which has its own computer and data storage facilities. All this distributed data is still considered to be a single logical database. When a person or process anywhere on the distributed network queries the database, they do not have to know where on the network the data that they are seeking is located. They just issue the query and the result is returned to them. This feature is known as “location transparency.” This arrangement can quickly become rather complex and must be managed by sophisticated software known as a distributed database management system or distributed DBMS.
Distributing the Data Consider a large multinational company with major sites in Los Angeles, Memphis, New York (which is corporate headquarters), Paris, and Tokyo. Let's say that the company has a very important transactional relational database that is used actively at all five sites. The database consists of six large tables, A, B, C, D, E, and F, and response time to queries made to the database is an important factor. If the database was centralized, the arrangement would look like Figure 12.5, with all six tables located in New York.
The first and simplest idea for distributing the data would be to disperse the six tables among all five sites. If particular tables are used at some sites more frequently than at others, it would make sense to locate the tables at the sites at which they are most frequently used. Figure 12.6 shows that we have kept Tables A and B in New York, while moving Table C to Memphis, Tables D and E to Tokyo, and Table to Paris. Say that the reason we moved Table F to Paris is because it is used most frequently there. With Table F in Paris, the people there can use it as much as they want to without running up any telecommunications costs. Furthermore, the Paris employees can exercise “local autonomy” over the data, taking responsibility for its security, backup and recovery, and concurrency control.
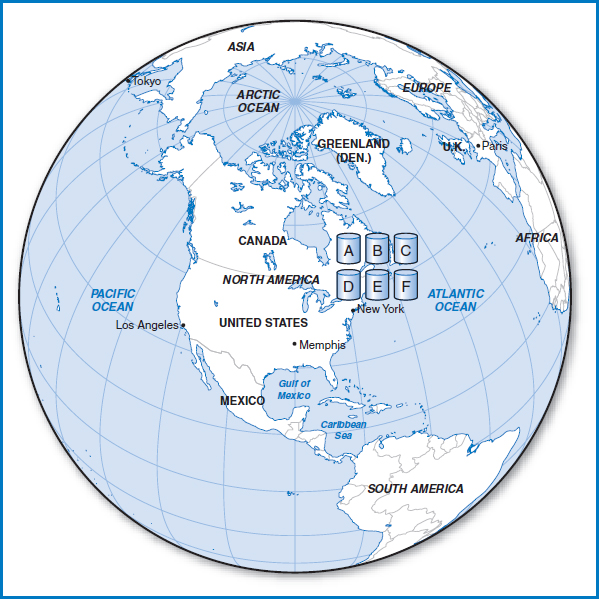
FIGURE 12.5 Centralized database
Unfortunately, distributing the database in this way has not relieved some of the problems with the centralized database and it has introduced a couple of new ones. The main problem that is carried over from the centralized approach is “availability.” In the centralized approach of Figure 12.5, if the New York site went down, no other site on the network could access Table F (or any of the other tables). In the dispersed approach of Figure 12.6, if the Paris site goes down, Table F is equally unavailable to the other sites. A new problem that crops up in Figure 12.6 has to do with joins. When the database was centralized at New York, a query issued at any of the sites that required a join of two or more of the tables could be handled in the standard way by the computer at New York. The result would then be sent to the site that issued the query. In the dispersed approach, a join might require tables located at different sites! While this is not an insurmountable problem, it would obviously add some major complexity (we will discuss this further later in this chapter). Furthermore, while we could (and did) make the argument that local autonomy is good for issues like security control, an argument can also be made that security for the overall database can better be handled at a single central location. Clearly, the simple dispersal of database tables as shown in Figure 12.6 is of limited benefit.
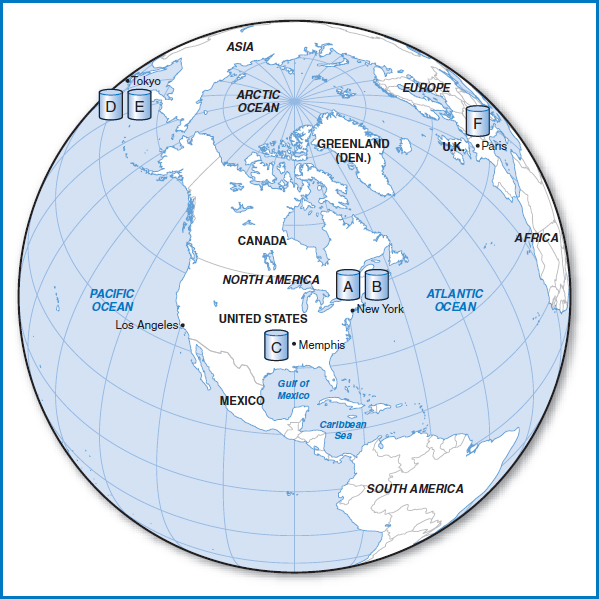
FIGURE 12.6 Distributed database with no data replication
Let's introduce a new option into the mix. Suppose that we allow database tables to be duplicated—the term used with distributed database is “replicated”—at two or more sites on the network. There are several clear advantages to this idea, as well as, unfortunately, a couple of disadvantages. On the plus side, the first advantage is availability. If a table is replicated at two or more sites and one of those sites goes down, everyone everywhere else on the network can still access the table at the other site(s). Also, if more than one site requires frequent access to a particular table, the table can be replicated at each of those sites, again minimizing telecommunications costs during data access. And copies of a table can be located at sites having tables with which it may have to be joined, allowing the joins to take place at those sites without the complexity of having to join tables across multiple sites. On the down side, if a table is replicated at several sites, it becomes more of a security risk. But the biggest problem that data replication introduces is that of concurrency control. As we have already seen, concurrency control is an issue even without replicated tables. With replicated tables, it becomes even more complex. How do you keep data consistent when it is replicated in tables on three continents? More about this issue later.
Assuming, then, that data replication has some advantages and that we are willing to deal with the disadvantages, what are the options for where to place the replicated tables? Figure 12.7 shows the maximum approach of replicating every table at every site. It's great for availability and for joins, but it's the absolute worst arrangement for concurrency control. Every change to every table has to be reflected at every site. It's also a security nightmare and, by the way, it takes up a lot of disk space.
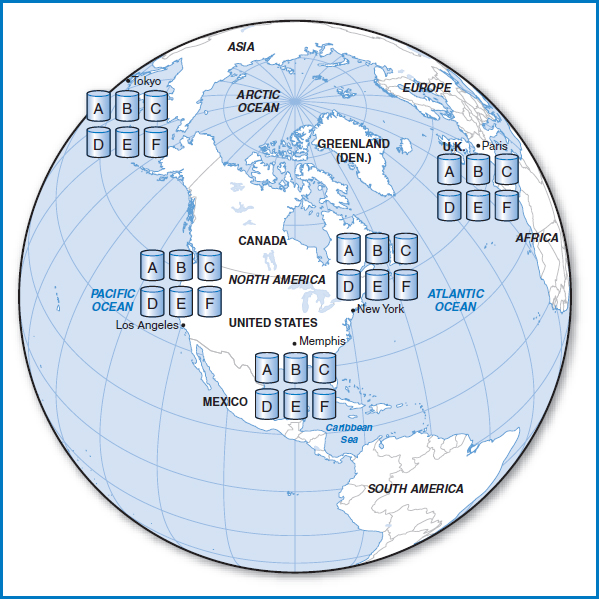
FIGURE 12.7 Distributed database with maximum data replication
The concept in Figure 12.8 is to have a copy of the entire database at headquarters in New York and to replicate each table exactly once at one of the other sites. Again, this improves availability, at least to the extent that each table is now at two sites. Because each table is at only two sites, the security and concurrency exposures are limited. Any join that has to be executed can be handled at New York. So, this arrangement sounds pretty good, but it is limiting. What if a particular table is used heavily at both Tokyo and Los Angeles? We would like to place copies of it at both of those sites, but we can't because the premise is to have one copy in New York and only one other copy elsewhere. Also, New York would tend to become a bottleneck, with all of the joins and many of the other accesses being sent there. Still, the design of Figure 12.8 appears to be an improvement over the design of Figure 12.7. Can we do better still?
The principle behind making this concept work is flexibility in placing replicated tables where they will do the most good. We want to:
- Place copies of tables at the sites that use them most heavily in order to minimize telecommunications costs.
FIGURE 12.8 Distributed database with one complete copy in one city
- Ensure that there are at least two copies of important or frequently used tables to realize the gains in availability.
- Limit the number of copies of any one table to control the security and concurrency issues.
- Avoid any one site becoming a bottleneck.
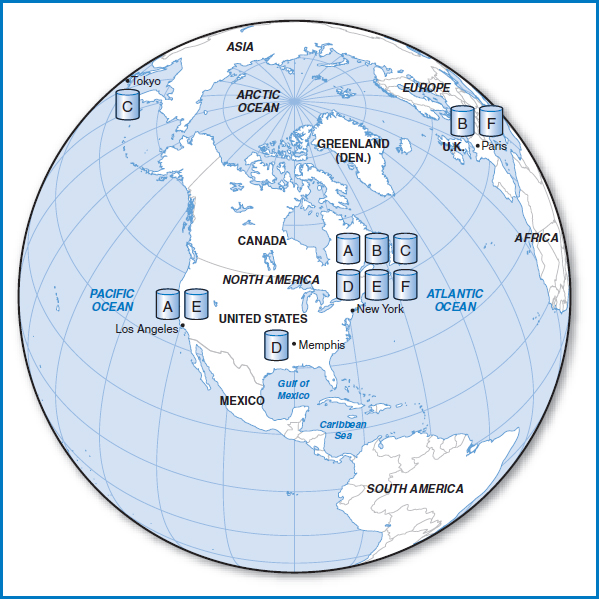
Figure 12.9 shows an arrangement of replicated tables based on these principles. There are two copies of each of Tables A, B, E, and F, and three copies of Table D. Apparently, Table C is relatively unimportant or infrequently used, and it is located solely at Los Angeles.
Concurrency Control in Distributed Databases
In Chapter 11, we discussed concurrency control in terms of the problems involved in multiple people or processes trying to update a record at the same time. When we allow replicated tables to be dispersed all over the country or the world in a distributed database, the problems of concurrent update expand, too. The original possibility of the “lost update” is still there. If two people attempt to update a particular record of Table B in New York at the same time, everything we said about the problem of concurrent update earlier remains true. But now, in addition, look at what happens when geographically dispersed, replicated files are involved. In Figure 12.9, if one person updates a particular value in a record of Table B in New York at the same time that someone else updates the very same value in the very same record of Table B in Paris, clearly the results are going to be wrong. Or if one person updates a particular record of Table B in New York and then right after that a second person reads the same record of Table B in Paris, that second person is not going to get the latest, most up-to-date data. The protections discussed earlier that can be set up to handle the problem of concurrent update in a single table are not adequate to handle the new, expanded problem.
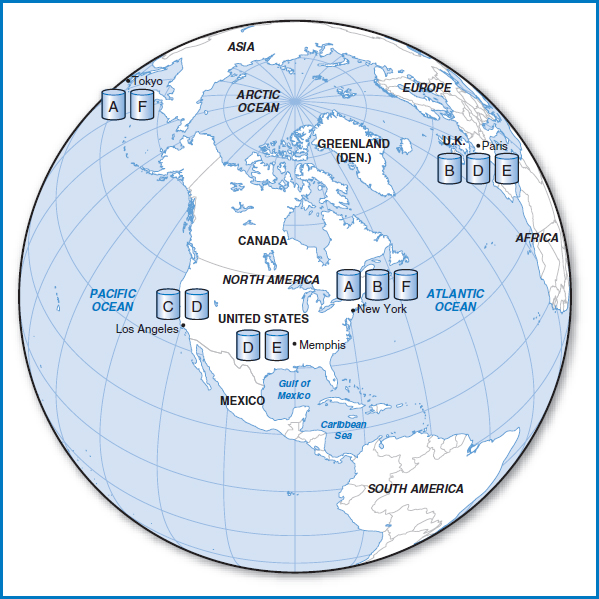
FIGURE 12.9 Distributed database with targeted data replication
If the nature of the data and of the applications that use it can tolerate retrieved data not necessarily being up-to-the-minute accurate, then several “asynchronous” approaches to updating replicated data can be used. For example, the site at which the data was updated, New York in the above example involving Table B, can simply send a message to the other sites that contain a copy of the same table (in this case Paris) in the hope that the update will reach Paris reasonably quickly and that the computer in Paris will update that record in Table B right away. In another asynchronous scheme, one of the sites can be chosen to accumulate all of the updates to all of the tables. That site can then regularly transmit the changes to all of the other sites. Or each table can have one of the sites be declared the “dominant” site for that table. All of the updates for a particular table can be sent to the copy of the table at its dominant site, which can then transmit the updates to the other copies of the table on some timed or other basis.
But if the nature of the data and of the applications that use it require all of the data in the replicated tables worldwide always to be consistent, accurate, and up-to-date, then a more complex “synchronous” procedure must be put in place. While there are variations on this theme, the basic process for accomplishing this is known as the “two-phase commit.” The two-phase commit works like this. Each computer on the network has a special log file in addition to its database tables. So, in Figure 12.9, each of the five cities has one of these special log files. Now, when an update is to be made at one site, the distributed DBMS has to do several things. It has to freeze all the replicated copies of the table involved, send the update out to all the sites with the table copies, and then be sure that all the copies were updated. After all of that happens, all of the replicated copies of the table will have been updated and processing can resume. Remember that, for this to work properly, either all of the replicated files must be updated or none of them must be updated. What we don't want is for the update to take place at some of the sites and not at the others, since this would obviously leave inconsistent results.
Let's look at an example using Table D in Figure 12.9. Copies of Table D are located in Los Angeles, Memphis, and Paris. Say that someone issues an update request to a record in Table D in Memphis. In the first or “prepare” phase of the two-phase commit, the computer in Memphis sends the updated data to Los Angeles and Paris. The computers in all three cities write the update to their logs (but not to their actual copies of Table D at this point). The computers in Los Angeles and Paris attempt to lock their copies of Table D to get ready for the update. If another process is using their copy of Table D then they will not be able to do this. Los Angeles and Paris then report back to Memphis whether or not they are in good operating shape and whether or not they were able to lock Table D. The computer in Memphis takes in all of this information and then decides whether to continue with the update or to abort it. If Los Angeles and Paris report back that they are up and running and were able to lock Table D, then the computer in Memphis will decide to go ahead with the update. If the news from Los Angeles and Paris was bad, Memphis will decide not to go ahead with the update. So, in the second or “commit” phase of the two-phase commit, Memphis sends its decision to Los Angeles and Paris. If it decides to complete the update, then all three cities transfer the updated data from their logs to their copy of Table D. If it decides to abort the update, then none of the sites transfer the updated data from their logs to their copy of Table D. All three copies of Table D remain as they were and Memphis can start the process all over again.
The two-phase commit is certainly a complex, costly, and time-consuming process. It should be clear that the more volatile the data in the database is, the less attractive is this type of synchronous procedure for updating replicated tables in the distributed database.
Distributed Joins
Let's take a look at the issue of distributed joins, which came up earlier. In a distributed database in which no single computer (no single city) in the network contains the entire database, there is the possibility that a query will be run from one computer requiring a join of two or more tables that are not all at the same computer. Consider the distributed database design in Figure 12.9. Let's say that a query is issued at Los Angeles that requires the join of Tables E and F. First of all, neither of the two tables is located at Los Angeles, the site that issued the query. Then, notice that none of the other four cities has a copy of both Tables E and F. That means that there is no one city to which the query can be sent for complete processing, including the join.
In order to handle this type of distributed join situation, the distributed DBMS must have a sophisticated ability to move data from one city to another to accomplish the join. In Chapter 4, we described the relational DBMS's relational query optimizer as an expert system that figures out an efficient way to respond to and satisfy a relational query. Similarly, the distributed DBMS must have its own built-in expert system that is capable of figuring out an efficient way to handle a request for a distributed join. This distributed DBMS expert system will work hand in hand with the relational query optimizer, which will still be needed to determine which records of a particular table are needed to satisfy the join, among other things. For the query issued from Los Angeles that requires a join of Tables E and F, there are several options:
- Figure out which records of Table E are involved in the join and send copies of them from either Memphis or Paris (each of which has a copy of Table E) to either New York or Tokyo (each of which has a copy of the other table involved in the join, Table F). Then, execute the join in whichever of New York or Tokyo was chosen to receive the records from Table E and send the result back to Los Angeles.
- Figure out which records of Table F are involved in the join and send copies of them from either New York or Tokyo (each of which has a copy of Table F) to either Memphis or Paris (each of which has a copy of the other table involved in the join, Table E). Then, execute the join in whichever of Memphis or Paris was chosen to receive the records from Table F and send the result back to Los Angeles.
- Figure out which records of Table E are involved in the join and send copies of them from either Memphis or Paris (each of which has a copy of Table E) to Los Angeles, the city that initiated the join request. Figure out which records of Table F are involved in the join and send copies of them from either New York or Tokyo (each of which has a copy of Table F) to Los Angeles. Then, execute the join in Los Angeles, the site that issued the query.
How does the distributed DBMS decide among these options? It must consider:
- The number and size of the records from each table involved in the join.
- The distances and costs of transmitting the records from one city to another to execute the join.
- The distance and cost of shipping the result of the join back to the city that issued the query in the first place.
For example, if only 20 records of Table E are involved in the join while all of Table F is needed, then it would make sense to send copies of the 20 Table E records to a city that has a copy of Table F. The join can then be executed at the Table F city and the result sent back to Los Angeles. Looking at the arrangement of tables in Figure 12.9, one solution would be to send the 20 records from Table E in Memphis to New York, one of the cities with Table F. The query could then be executed in New York and the result sent to Los Angeles, which issued the query. Why Memphis and New York rather than Paris and Tokyo, the other cities that have copies of Tables E and F, respectively? Because the distance (and probably the cost) between Memphis and New York is much less than the distances involving Paris and Tokyo. Finally, what about the option of shipping the data needed from both tables to Los Angeles, the city that issued the query, for execution? Remember, the entirety of Table F is needed for the join in this example. Shipping all of Table F to Los Angeles to execute the join there would probably be much more expensive than the New York option.
Partitioning or Fragmentation
Another option in the distributed database bag-of-tricks is known as “partitioning” or “fragmentation.” This is actually a variation on the theme of file partitioning that we discussed in the context of physical database design.
In horizontal partitioning, a relational table can be split up so that some records are located at one site, other records are located at another site, and so on. Figure 12.10 shows the same five-city network we have been using as an example, with another table, Table G, added. The figure shows that subset G1 of the records of Table G is located in Memphis, subset G2 is located in Los Angeles, and so on. A simple example of this would be the company's employee table: the records of the employees who work in a given city are stored in that city's computer. Thus, G1 is the subset of records of Table G consisting of the records of the employees who work in Memphis, G2 is the subset consisting of the employees who work in Los Angeles, and so forth. This certainly makes sense when one considers that most of the query and access activity on a particular employee's record will take place at his work location. The drawback is that when one of the sites, say the New York headquarters location, occasionally needs to run an application that requires accessing the employee records of everyone in the company, it must collect them from every one of the five sites.
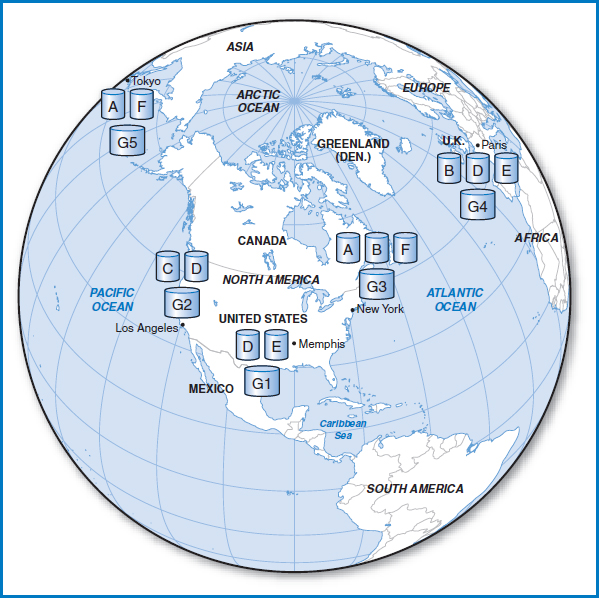
FIGURE 12.10 Distributed database with data partitioning/fragmentation
YOUR TURN
12.2 DISTRIBUTED DATABASES
Now think about a consortium of universities around the world that are engaged in common research projects. Some data is needed only by one or a subset of the universities, while other data is needed by most or all of them. We know that the universities can communicate with one another via the Internet.
QUESTION:
Think about a research project, perhaps in the medical field, that would involve a widely dispersed consortium of universities. Plot the universities on a world map. Devise a plan for locating and perhaps replicating database tables at the university locations. Justify your placement and replication.
In vertical partitioning, the columns of a table are divided up among several cities on the network. Each such partition must include the primary key attribute(s) of the table. This arrangement can make sense when different sites are responsible for processing different functions involving an entity. For example, the salary attributes of a personnel table might be stored in one city while the skills attributes of the table might be stored in another city. Both partitions would include the employee number, the primary key of the full table. Note that bringing the different pieces of data about a particular employee back together again in a query would require a multi-site join of the two fragments of that employee's record.
Can a table be partitioned both horizontally and vertically? Yes, in principle! Can horizontal and vertical partitions be replicated? Yes again, in principle! But bear in mind that the more exotic such arrangements become, the more complexity there is for the software and the IT personnel to deal with.
Distributed Directory Management
In discussing distributed databases up to this point, we've been taking the notion of location transparency for granted. That is, we've been assuming that when a query is issued at any city on the network, the system simply “knows” where to find the data it needs to satisfy that query. But that knowledge has to come from somewhere and that place is in the form of a directory. A distributed DBMS must include a directory that keeps track of where the database tables, the replicated copies of database tables (if any), and the table partitions (if any) are located. Then, when a query is presented at any city on the network, the distributed DBMS can automatically use the directory to find out where the required data is located and maintain location transparency. That is, the person or process that initiated the query does not have to know where the data is, whether or not it is replicated, or whether or not it is partitioned.
Which brings up an interesting question: where should the directory itself be stored? As with distributing the database tables themselves, there are a number of possibilities, some relatively simple and others more complex, with many of the same kinds of advantages and disadvantages that we've already discussed. The entire directory could be stored at only one site, copies of the directory could be stored at several of the sites, or a copy of the directory could be stored at every site. Actually, since the directory must be referenced for every query issued at every site and since the directory data will change only when new database tables are added to the database, database tables are moved, or new replicated copies or partitions are set up (all of which are fairly rare occurrences), the best solution generally is to have a copy of the directory at every site.
Distributed DBMSs: Advantages and Disadvantages
At this point it will be helpful to pause, review, and summarize the advantages and disadvantages of the distributed database concept and its various options. Figure 12.11 provides this summary, which includes the advantages and disadvantages of a centralized database for comparison.

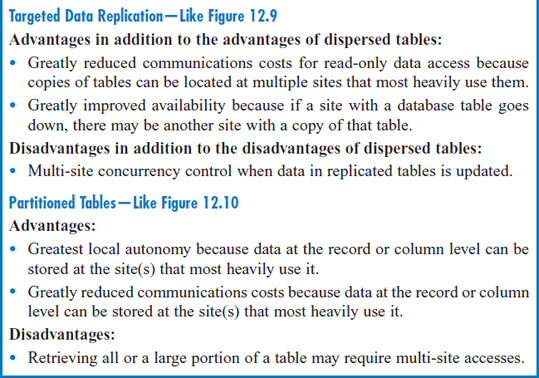
FIGURE 12.11 Advantages and disadvantages of centralized and distributed database approaches
SUMMARY
Local area networks are designed to share data. In a two-tier approach, data is stored on a server on the LAN. The data can be accessed by a client PC on the LAN using either the file server approach or the database server approach. In the file server approach, entire files are shipped from the server to the client PC for processing. In the database server approach, the processing is split between the client PC and the server, with the query ultimately being processed at the server. There are two uses of the term ‘three-tier approach.’ In one, the three tiers are the client PC's hard drive, the server, and computers beyond the LAN. In the other, the three tiers are the client PC, the LAN's application server, and the LAN's database server.
In a distributed database, different parts of a single logical database are stored in different geographic locations. There are a variety of approaches to locating the different parts of the database, all with different associated advantages and disadvantages, but in all cases the distribution should be transparent to the user. One option, replicating data at different sites, requires sophisticated concurrency control, including the two-phase commit protocol. Distributed joins may have to be accomplished if the tables needed in a query are not co-located at a single site. Distributed database can include partitioning tables with different partitions of a particular table stored at different sites.
KEY TERMS
Application server
Client
Client/server database
Database server
Database server approach
Distributed data
Distributed database
Distributed database management
Distributed join
Distributed directory management
File server approach
Fragmentation
Gateway computer
Local area network (LAN)
Local autonomy
Location transparency
Partitioning
Replicated data
Server
Three-tiered client/server approach
Two-phase commit
Two-tiered client/server approach
QUESTIONS
- What is a client/server database system?
- Explain the database server approach to client/server database.
- What are the advantages of the database server approach to client/server database compared to the file server approach?
- What is data transparency in client/server database? Why is it important?
- Compare the two-tier arrangement of client/server database to the three-tier arrangement.
- What is a distributed database? What is a distributed database management system?
- Why would a company be interested in moving from the centralized to the distributed database approach?
- What are the advantages of locating a portion of a database in the city in which it is most frequently used?
- What are the advantages and disadvantages of data replication in a distributed database?
- Describe the concept of asynchronous updating of replicated data. For what kinds of applications would it work or not work?
- Describe the two-phase commit approach to updating replicated data.
- Describe the factors used in deciding how to accomplish a particular distributed join.
- Describe horizontal and vertical partitioning in a distributed database.
- What are the advantages and disadvantages of horizontal partitioning in a distributed database?
- What are the advantages and disadvantages of vertical partitioning in a distributed database?
- What is the purpose of a directory in a distributed database? Where should the directory be located?
- Discuss the problem of directory management for distributed database. Do you think that, as an issue, it is more critical, less critical, or about the same as the distribution of the data itself? Explain.
EXERCISES
- Australian Boomerang, Ltd. wants to design a distributed relational database. The company is headquartered in Perth and has major operations in Sydney, Melbourne, and Darwin. The database involved consists of five tables, labeled A, B, C, D, and E, with the following characteristics:
Table A consists of 500,000 records and is heavily used in Perth and Sydney.
Table B consists of 100,000 records and is frequently required in all four cities.
Table C consists of 800 records and is frequently required in all four cities.
Table D consists of 75,000 records. Records 1-30,000 are most frequently used in Sydney. Records 30,001–75,000 are most frequently used in Melbourne.
Table E consists of 20,000 records and is almost exclusively in Perth.
Design a distributed relational database for Australian Boomerang. Justify your placement, replication, and partitioning of the tables.
- Canadian Maple Trees, Inc. has a distributed relational database with tables in computers in Halifax, Montreal, Ottawa, Toronto, and Vancouver. The database consists of twelve tables, some of which are replicated in multiple cities. Among them are tables A, B, and C, with the following characteristics.
Table A consists of 800,000 records and is located in Halifax, Montreal, and Vancouver.
Table B consists of 100,000 records and is located in Halifax and Toronto.
Table C consists of 20,000 records and is located in Ottawa and Vancouver.
Telecommunications costs among Montreal, Ottawa, and Toronto are relatively low, while telecommunications costs between those three cities and Halifax and Vancouver are relatively high.
A query is issued from Montreal that requires a join of tables A, B, and C. The query involves a single record from table A, 20 records from table B, and an undetermined number of records from table C. Develop and justify a plan for solving this query.
MINICASES
- Consider the Happy Cruise Lines relational database in Minicase 5.1.The company has decided to reconfigure this database as a distributed database among its major locations: New York, which is its headquarters, and its other major U.S. ports, Miami, Los Angeles, and Houston. Distributed and replicated among these four locations, the tables have the following characteristics:
SHIP consists of 20 records and is used in all four cities.
CRUISE consists of 4,000 records. CRUISE records are used most heavily in the cities from which the cruise described in the record began.
PORT consists of 42 records. The records that describe Atlantic Ocean ports are used most heavily in New York and Miami. The records that describe Caribbean Sea ports are used most heavily in Houston and Miami. The records that describe Pacific Ocean ports are used most heavily in Los Angeles.
VISIT consists of 15,000 records and is primarily used in New York and Los Angeles.
PASSENGER consists of 230,000 records and is primarily used in New York and Los Angeles.
VOYAGE consists of 720,000 records and is used in all four cities.
Design a distributed relational database for Happy Cruise Lines. Justify your placement, replication, and partitioning of the tables.
- Consider the Super Baseball League relational database in Minicase 5.2. The league has decided to organize its database as a distributed database with replicated tables. The nodes on the distributed database will be Chicago (the league's headquarters), Atlanta, San Francisco (where the league personnel office is located), and Dallas. The tables have the following characteristics:
TEAM consists of 20 records and is located in Chicago and Atlanta.
COACH consists of 85 records and is located in San Francisco and Dallas.
WORKEXP consists of20,000 records and is located in San Francisco and Dallas.
BATS consists of 800,000 records and is located in Chicago and Atlanta.
PLAYER consists of 100,000 records and is located in San Francisco and Atlanta.
AFFILIATION consists of 20,000 records and is located in Chicago and San Francisco.
STADIUM consists of 20 records and is located only in Chicago.
Assume that telecommunications costs among the cities are all about the same.
Develop and justify a plan for solving the following queries:
- A query is issued from Chicago to get a list of all the work experience of all the coaches on the Dodgers.
- A query is issued from Atlanta to get a list of the names of the coaches who work for the team based at Smith Memorial Stadium.
- A query is issued from Dallas to find the names of all the players who have compiled a batting average of at least. 300 while playing on the Dodgers.