
Chapter 11
Science
11.1 Scientific Method
The description of uncertainty, in the numerical form of probability, has an important role to play in science, so it is to this usage that we now turn. Before doing so, a few words must be said about the nature of science, because until these are understood, the role of uncertainty in science may not be properly appreciated.
The central idea in our understanding of science, and one that affects our whole attitude to the subject, is that
The unity of all science consists alone in its method, not in its material.
Science is a way of observing, thinking about, and acting in the world you live in. It is a tool for you to use in order that you may enjoy a better life. It is a way of systematizing your knowledge. Most people, including some scientists, think that science is a subject that embraces topics like chemistry, physics, biology but perhaps not sociology or education; some would have doubts concerning fringe sciences like psychology, and all would exclude what is ordinarily subsumed under the term “arts”. This view is wrong, for science is a method, admittedly a method that has been most successful in those fields that we normally think of as scientific and less so in the arts, but it has the potentiality to be employed everywhere. Like any tool, it varies in its usefulness, just as a spade is good in the garden but less effective in replacing a light bulb. The topic of this chapter is properly called the scientific method, rather than science, but the proper term is cumbersome and the shorter one so commonly used that we shall frequently speak of “science” when precision would really require “scientific method”.
In the inanimate world of physics and chemistry, the scientific method has been enormously successful. In the structure of animate matter, it has been of great importance, producing results in biology and allied subjects. Scientific method has had less impact in fields where human beings play an important role, such as sociology and psychology, yet even there it has produced results of value. Until recently it has had little effect on management, but the emergence of the topic of management science testifies to the role it is beginning to play there, a role that may be hampered by the inadequate education some managers have in mathematical concepts. We have already noted in §6.5 how probability, which as we shall see below is an essential ingredient in scientific method, could be used in legal questions where its development is influenced by the conservatism of the legal profession. Politics and warfare have made limited use of the method. The method has made little contribution to the humanities, though indirectly, through the introduction of new materials developed by science, it has had an impact on them. For example, the media would be quite different without the use of the technological by-products of science, like television and printing. Even the novel may have changed through being produced on a word processor rather than with a pen.
11.2 Science and Education
The recognition that science is a method, rather than a topic, has important consequences, not least in our view of what constitutes a reasonable education. It is not considered a serious defect if a chemist knows nothing about management, or a manager is ignorant of chemistry, for some specialization is necessary in our complicated world. But for anyone, chemist or manager, to know nothing of the scientific method is to deprive them of a tool that could prove of value in their work. It used to be said that education consisted of the three R's, reading, writing, and arithmetic, but the time may have come to change this, and yet preserve the near-alliteration, to reading, writing, and randomness, where randomness is a substitute for probability and scientific method; for, as will be seen, uncertainty, and therefore probability, is central to the scientific approach. To lack a knowledge of scientific method is comparable in seriousness to a lack of an ability to read, or to write. Just as the ability to write does not make you a writer, neither does the understanding of scientific method make you a scientist; what it does is enable you to understand scientific arguments when presented to you, just as you can understand writing. All of us need to understand the tool, many of us need to use it.
It is not only the ability to use the scientific method that is lacking but also the simpler ability to understand it when it is used. It is easy to appreciate and sympathize with a mother whose young child is given a vaccine and then, a few months later, develops a serious illness, attributing the former as the cause of the latter. Yet if that mother has a sound grasp of the scientific method (not of the science of vaccination) she would be able to understand that the evidence for causation is fragile, and she would see the social implications of not giving infants the vaccine. We must at least understand the tool, even if we never use it. Here is a tool that has been of enormous benefit to all of us, has improved the standard of living for most of us, and has the potentiality to enhance it for all, yet many people do not have an inkling of what it is about. We do not need to replace our leaders by scientists, that might be even worse than the lot we do have, but we do require leaders who can at least appreciate, but better still use, the methodology of science.
In this connection it is worth noting that many scientists do not understand scientific method. This curious state of affairs comes about because of the technological sophistication of some branches of science, so that some scientists are essentially highly skilled technicians who understandably do not deal with the broad aspect of their field but rather, are extremely adept at producing data that, as we shall see, play a central role in science. There is a wider aspect to this. Some philosophers of science see the method as a collection of paradigms; when a paradigm exhibits defects, it is replaced by another. Scientific method is seen at its height during a paradigm shift but many scientists spend all their lives working within a paradigm and make little use of the method. My own field of statistics is currently undergoing a paradigm shift that is proving difficult to make. An eminent scientist once said that it is impossible to complete the introduction of a new paradigm until the practitioners of the old one have died. Another, when asked advice about introducing new ideas, said succinctly “Attend funerals”. But this is descriptive; we shall see later that change is integral to normative science.
The appreciation that science is a tool can help to lessen the conflict that often exists between science and other attempts to understand and manage the world, such as religion. There is no conflict between a saw and an axe in dealing with a tree; they are merely different tools for the same task. Similarly there is no conflict at a basic level between a scientist and a poet. Conflict can arise when the two tools produce different answers, as when the Catholic religion gave way and admitted, on the basis of scientific evidence, that the sun, and not the earth, was the center of the solar system. Poetry can conflict with science because of its disregard of facts, as when Babbage protested at Tennyson's line “Every moment dies a man, every moment one is born,” arguing that one and one-sixteenth is born; or when a modern poet did not realize there is a material difference between tears of emotion and those caused by peeling onions.
Let us pass from general considerations and ask the question: If science is a method, of what does it consist and, more specifically, what has it to do with uncertainty?
11.3 Data Uncertainty
One view is that scientific pronouncements are true, that they have the authority of science and there is no room for uncertainty. Bodies falling freely in a vacuum do so with constant acceleration irrespective of their mass. The addition of an acid to a base produces salt and water. These are statements that are regarded as true or, expressed differently, have for you probability 1. Many of the conclusions of science are thought by all, except by people we would regard as cranks, to be true, to be certain. Yet we should recall Cromwell's rule (§6.8) and remember that many scientific results, once thought to be true, ultimately turned out to need modification. The classic example is Newton's laws that have been replaced by Einstein's, though the former are adequate for use on our planet. Then there are statements about evolution like “Apes and men are descended from a common ancestor”, which for almost everyone who has contributed to the field are true, but where others have serious doubts, thereby emphasizing that probability is personal. There may be serious differences here between the descriptive and normative views. However, most readers will have probability nearly 1 for many scientific pronouncements. The departure from 1, that you recognize as necessary because of Cromwell, is so slight as to be ignored almost all the time. It is not here that uncertainty enters as an important ingredient of the scientific method but elsewhere.
Anything like a thorough treatment of scientific methodology would take too long and be out of place in a book on uncertainty. Our concern is with the role of uncertainty, and therefore of probability, in science. A simplified version of the scientific method notes three phases. First, the accumulation of data either in the field or in the laboratory; second, the development of theories based on the data; and third, use of the theories to predict and control features of our world. In essence, observe, think, act. None of these phases is productive on its own, their strengths come in combination, in thinking about data and testing the thoughts against reality. The classic example of the triplet is the observation of the motions of the heavenly bodies, the introduction of Newton's laws, and their use to predict the tides. Some aspects of the final phase are often placed in the realm of technology, rather than science, but here we take the view that engineering is part of the scientific method that embraces action as well as contemplation. The production of theories alone has little merit; their value mainly lies in the actions that depend on them.
Immediately the three aspects are recognized, it becomes clear where one source of uncertainty is present—in the data—for we have seen in §9.1 that the variation inherent in nature leads to uncertainty about measurements. Scientists have always understood the variability present in their observations and have taken serious steps to reduce it. Among the tools used to do this are careful control in the laboratory, repetition in similar circumstances, and recording associated values in recognition of Simpson's paradox. The early study of how to handle this basic variation was known as the theory of errors because the discrepancies were wrongly thought of as errors; as mistakes on the scientist's part. This is incorrect and we now appreciate that variation, and hence uncertainty, is inherent in nature. Reference was made above to the mother whose child became seriously ill after vaccination. To attribute cause and effect here may be to ignore unavoidable variability. The scientific method therefore uses data and recognizes and handles the uncertainty present therein.
To a scientist, it is appalling that there are many people who do not like data, who eschew the facts that result from careful observation and experiment. Perhaps I should not use the word “facts” but to me the observation that the temperature difference is 2.34 °C is a fact, despite the next time the observation is 2.71 °C. The measurement is the fact, not the true temperature. We are all familiar with the phrase, “Do not bother me with facts, my mind is made up”. It is a natural temptation to select the “facts” that suit your position and ignore embarrassing evidence that does not. Some scientists can be seen doing this, my position is that this is a description of bad science; normative scientists are scrupulous with regard to facts, as will be demonstrated in §11.6. The best facts are numerical, because this permits easier combination of facts (§3.1), but there are those who argue that some things cannot be measured. Scientific method would dispute this, only admitting that some features of life are hard to measure. Older civilizations would have used terms like “warm”, “cold” to describe the day, whereas nowadays we measure using temperature expressed in degrees, and when this proves inadequate we include wind speed and use wind chill. Yes, some things are hard to measure, and until the difficulty is overcome it may be necessary to use other methodologies besides science. We do not know how to measure the quality of a piece of music, though the amount of money people are prepared to pay to hear Elton John, rather than Verdi (§2.4), tells us something, though surely not all, about their respective merits.
From a scientific viewpoint, the best facts, the best data, are often obtained under carefully controlled conditions such as those that are encountered in a laboratory. This is perhaps why laypersons often associate science with white-coated men and women surrounded by apparatus. There are many disciplines where laboratory conditions would not tell all the story and work in the field is essential; then, as we have seen in §8.2, other factors enter. Herein lies an explanation of why physics and chemistry have proceeded faster in scientific development than botany or zoology, which have themselves made more progress than psychology or sociology, and why the scientific method finds little application in the humanities. Recall that science is a method and does not have a monopoly on tools of discovery, so its disappointing performance in the humanities is no reflection on its merit elsewhere, anymore than a spade is unsound because it is of little use in replacing a light bulb.
11.4 Theories
When scientists have obtained data, what do they do with them? They formulate theories. This is the second stage in the method, where the hard evidence of the senses is combined with thought; where data and reason come together to produce results. To appreciate this combination it is necessary to understand the meaning of a theory and the role it plays in the analysis. One way to gain this appreciation is to look at earlier work before the advent of modern science.
Early man, the hunter, must have been assiduous in the gathering of data to help him in the hunt and in his survival. He will have noted the behavior of the animals, of how they responded to the weather and the seasons, of how they could be approached more effectively to be killed. All these data will have been subject to variation, for an animal does not always respond in the same way, so that the hunter will have had to develop general rules from the variety of observations in the field. From this synthesis, he must have predicted what animals were likely to do when engaged in the future. Indeed, we can say that one of the central tasks of man must always have been to predict the future from observations on the past. Let us put this remark into the modern context of the language and mode of thinking that has been developed in this book. Thinking of future data, F say, which is surely uncertain now, and therefore described by probability, is dependent on past data, D, in the form ![]() , your probability of the future, given your experience of the past. Expressed in modern terms, a key feature of man's endeavor must always have been, and remains so today, to assess
, your probability of the future, given your experience of the past. Expressed in modern terms, a key feature of man's endeavor must always have been, and remains so today, to assess ![]() .
.
The same procedure can be seen later in the apprenticeship system where a beginner would sit at the foot of the master for a number of years and steadily acquire the specific knowledge that the latter had. In the wheelwright's shop, he would have understood what woods to use for the spokes, that different woods were necessary for the rim and how they could be bent to the required shape, so that eventually he could build as good a wheel as his mentor. Again we have ![]() where F is the apprentice's wheel and D those of the master that he has watched being built, using past data on the behavior of the woods to predict future performance of the new wheel.
where F is the apprentice's wheel and D those of the master that he has watched being built, using past data on the behavior of the woods to predict future performance of the new wheel.
The situation is no different today when a financial advisor tries to predict the future behavior of the stock market on the basis of its past performance; or when you go to catch the train, using your experience of how late it has been in the past; or when a farmer plants his seed using his experience of past seasons. Prediction on the basis of experience is encapsulated in a probability, though it is not a probability you can easily assess or calculate with. Conceptually it is an expression of your opinion of the future based on the past. How does this differ from science? As a start in answering this question, let us take a simple example that has been used before but we look at it somewhat differently. The example, as a piece of science, is ridiculously simple, yet it does contain the basic essentials upon which real science, with its complexity, can be built. Remember that simplicity can be a virtue, as will later be seen when we consider real theories, rather than the toy one of our example.
We return to the urn of §6.9, containing a large number of balls, all indistinguishable except that some are colored red, some white, and from which you are to withdraw balls in a way that you think is random. This forms part of your knowledge base and remains fixed throughout what follows. Suppose you have two rival theories, R that the urn contains two red balls for every white one, and W that the proportions are reversed with two white to every red (§6.9), conveniently calling the first the red urn, the second the white one. Suppose that you do not know whether the urn before you is the red or the white one. It will further be supposed that your uncertainty about which urn it is, is captured by your thinking that they are equally probable, though this is not important for what follows. In other words, for you p (R) = p (W) = ½. Now suppose that you have taken a ball from the urn and found it to be white, this being the past data D in the exposition above, and enquire about the event that the next ball will be red, future data F. Recall that earlier we used lowercase letters for experiences with the balls, reserving capital letters for the constitutions of the urns, so that past data here is w and you are interested in the future data being r. In probability terms, you need ![]() . In §7.6 we saw how to calculate this by extending the conversation to include R and W, the rival possibilities, so that
. In §7.6 we saw how to calculate this by extending the conversation to include R and W, the rival possibilities, so that
When this situation was considered in §6.9, our interest lay in ![]() , your probability, after a white ball had been withdrawn, that the urn was red, and its value was found, by Bayes rule, to be
, your probability, after a white ball had been withdrawn, that the urn was red, and its value was found, by Bayes rule, to be ![]() , down from its original value of ½. Similarly
, down from its original value of ½. Similarly ![]() , is up from ½. These deal with two of the probabilities on the right-hand side of (11.1) but here our concern is primarily with the other two. Let us begin with
, is up from ½. These deal with two of the probabilities on the right-hand side of (11.1) but here our concern is primarily with the other two. Let us begin with ![]() ; in words, the probability that the future drawing will yield a red ball, given that the urn is the red one from which a white ball has been drawn. Now it was supposed that the urn contains a large number of balls, so that the withdrawal of one ball, of whatever color, has no significant effect on the withdrawal of another ball and the probability of getting a future red ball remains the same as before, depending only on whether it was the red R or the white W urn. In our notation,
; in words, the probability that the future drawing will yield a red ball, given that the urn is the red one from which a white ball has been drawn. Now it was supposed that the urn contains a large number of balls, so that the withdrawal of one ball, of whatever color, has no significant effect on the withdrawal of another ball and the probability of getting a future red ball remains the same as before, depending only on whether it was the red R or the white W urn. In our notation, ![]() or, better still, using the language of §4.3, r and w are independent, given R. Once you know the constitution of the urn, successive withdrawals are independent, a result which follows from your belief in the randomness of the selection of the balls. The same phenomenon occurs with the white urn and the remaining probability on the right,
or, better still, using the language of §4.3, r and w are independent, given R. Once you know the constitution of the urn, successive withdrawals are independent, a result which follows from your belief in the randomness of the selection of the balls. The same phenomenon occurs with the white urn and the remaining probability on the right, ![]() will simplify to
will simplify to ![]() . It is this conditional independence that we wish to emphasize, so let us display the result:
. It is this conditional independence that we wish to emphasize, so let us display the result:
Now translate this result back into the language of the scientific method, where we have already met past data D, which in the urn example is w, and the future data F, here r, so that all that is lacking is the new idea of a theory. It does not stretch the English language too far to say that you are entertaining the theory that the urn is red, and comparing it with an alternative theory that it is white. If we denote a theory by the Greek letter theta, ![]() , we may equate R with
, we may equate R with ![]() and W with
and W with ![]() . Here
. Here ![]() is the complement of
is the complement of ![]() , meaning
, meaning ![]() is false, or
is false, or ![]() is true. Accepting this translation, (11.2) says
is true. Accepting this translation, (11.2) says
![]()
or that past and future data are independent, given ![]() . The same result obtains with
. The same result obtains with ![]() in place of
in place of ![]() .
.
This is the important role that a theory plays in the manipulation of uncertainty within the scientific method, in that it enables the mass of past data D to be forgotten, in the evaluation of future uncertainty, and replaced by the theory. Instead of ![]() all you need is
all you need is ![]() . This is usually an enormous simplification, as in the classic example mentioned above where past data are the vast number of observations on the heavenly bodies, the theory is that of Newton, and parts of the future data concern prediction of the tides. We have emphasized in §2.6 the great virtue of simplicity. Here is exposed a brilliant example where all the observations on the planets and stars over millennia can be forgotten and replaced by a few simple laws that, with the aid of mathematics and computing, can evaluate the tides.
. This is usually an enormous simplification, as in the classic example mentioned above where past data are the vast number of observations on the heavenly bodies, the theory is that of Newton, and parts of the future data concern prediction of the tides. We have emphasized in §2.6 the great virtue of simplicity. Here is exposed a brilliant example where all the observations on the planets and stars over millennia can be forgotten and replaced by a few simple laws that, with the aid of mathematics and computing, can evaluate the tides.
There is a point about the urn discussion that was omitted in order not to interrupt the flow but is now explored. Although r and w are independent, given R, according to (11.2), they are not independent, given just ![]() . The reader who cares to do the calculations in (11.1) will find that
. The reader who cares to do the calculations in (11.1) will find that ![]() , down from the original value of p (r) = ½, the withdrawal of a white ball making the occurrence of a red one slightly less probable. This provides a simple, yet vivid, example of how independence is always conditional on other information. Here r and w are dependent given only the general knowledge base, which is here that the urns are either 2/3 red or 2/3 white and that the withdrawals are, for you, random. Yet when, to that knowledge base, is added the theory, that R obtains, they become independent. Much writing about probability fails to mention this dependence and talks glibly about independence without reference to the conditions, so failing to describe an essential ingredient of the scientific method. The urn phenomenon extends generally when F and D are dependent on the apprentice's knowledge base, but are independent for the scientist in possession of the theory.
, down from the original value of p (r) = ½, the withdrawal of a white ball making the occurrence of a red one slightly less probable. This provides a simple, yet vivid, example of how independence is always conditional on other information. Here r and w are dependent given only the general knowledge base, which is here that the urns are either 2/3 red or 2/3 white and that the withdrawals are, for you, random. Yet when, to that knowledge base, is added the theory, that R obtains, they become independent. Much writing about probability fails to mention this dependence and talks glibly about independence without reference to the conditions, so failing to describe an essential ingredient of the scientific method. The urn phenomenon extends generally when F and D are dependent on the apprentice's knowledge base, but are independent for the scientist in possession of the theory.
Returning to the scientific method, it proceeds by collecting data in the form of experimental results in the laboratory, as in physics or chemistry, or in the field, as in biology, or by observation in nature, as in sociology or archaeology. It then studies what is ordinarily a vast collection of information. Next, by a process that need not concern us here because it hardly has anything to do with uncertainty, a theory is developed, not by experimentation or observation, but by thought. In this process, the scientist considers the data, tries to find patterns in it, sorts it into groups, discarding some, accepting others; generally manipulating data so that some order becomes apparent from the chaos. This is the “Eureka!” phase where bright ideas are born out of a flash of inspiration, Most flashes turn out, next day, to be wrong and the idea has to be abandoned but a few persist, often undergoing substantial modification and ultimately emerge as a theory that works for the original set of data. This theory goes out into the world and is tested against further data. Neither observation nor theory on their own are of tremendous value. The great scientific gain comes in their combination; in the alliance between contact with reality and reasoning about concepts that relate to that reality. The brilliance of science comes about through this passage from data to theory and then, back to more data and, more fruitfully, action in the face of uncertainty. Let us now look at the role of uncertainty not only in the data, where its presence has been noted, but in the theory.
11.5 Uncertainty of a Theory
As mentioned in the first paragraph of §11.3, many people think that a scientific theory is something that is true, or even worse, think that any scientific statement has behind it the authority of science and is therefore correct. Thus when a scientist recently said that a disease, usually known by its initials as BSE, does not cross species from cattle to humans, this was taken as fact. What the scientist should have said was “my probability that it does not cross is …”, quoting a figure that was near one, like 0.95. There is a variety of reasons why this was not done. That most sympathetic to the scientist, is that we live in a society that, outside gambling, abhors uncertainty and prefers an appearance of truth, as when the forecaster says it will rain tomorrow when he really means there is a high probability of rain. A second reason why the statement about BSE was so firm is that scientists, at the time, had differing views about the transfer across species, so that one might have said 0.95, another 0.20. We should not be surprised at this because, from the beginning, it has been argued that uncertainty, and therefore probability, is personal. The reason for the possible difference is that the data on BSE were not extensive and, to some extent, contradictory and, as we will see below, it is only on the basis of substantial evidence that scientists reach agreement. Scientists do not like to be seen disagreeing in public, for much of what respect they have derives from an apparent ability to make authoritative statements, which might be lost if they were to adopt an attitude less assertive. A third, related reason for scientists often making a firm statement, when they should incorporate uncertainty, is that they need coherently to change their views yet they like to appear authoritative, or feel the public wants them to be. This change comes about with the acquisition of new data and the consequent updating by Bayes rule. If the original statement was well supported, then the change will usually be small, but if, as with BSE, the data are slight, then a substantial shift in scientific opinion is reasonable. It is people with rigid views who are dangerous, not those who can change coherently with extra data. I was once at a small dinner party when a senior academic made a statement, only to have a young lady respectfully point out that was not what he had said a decade ago. He asked what he had said, she told him, he thought for a while and then said “Good, that shows I have learnt something in the last ten years”. Scientists, and indeed all of us, do not react to new information as much as we ought, instead adhering to outmoded paradigms. A fourth, and less important, reason for making firm statements is that scientists commonly adopt the frequency view of probability (§7.7), which does not apply to a specific statement about a disease because there is no obvious series in which to embed it. This reason will be discussed further when significance tests are considered in §§11.9 and 14.4.
The truth of the matter is that when it is first formulated, and in the early stages of its investigation, any theory is uncertain with the originator of the theory having high probability that it is true, whereas colleagues, even setting aside personal animosities, are naturally sceptical. It is only with the accumulation of more data that agreement between investigators can be attained and the theory given a probability near to 0 or 1, so that, in the latter case, it can be reasonably asserted to be true, whereas in the former, it can be dismissed. To see how this works let us return to the urns with two “theories”, R and W. In §6.8 we saw that in repeated drawings of balls from the urn, every red ball doubled the odds in favor of it being the red urn and every white ball halved the odds. If it really was the red urn, R, with twice as many red as white balls, in the long run there would be twice as many doublings as halvings and the odds on R would increase without limit. Equivalently, your probability of R would tend to 1. Similarly were it the white urn W, its probability would tend to 1. In other words, the accumulation of data, in this case repeated withdrawals of balls from the urn, results in the true theory, R or W, being established beyond reasonable doubt, to use the imprecise, legal terminology, or with probability almost 1.
Another illustration of how agreement is reached by the accumulation of data, even though there was dispute at the start, is provided by the evaluation of a chance in §7.7. Recall that, in an exchangeable series of length n, an event had occurred r times and it was argued that ![]() might be your probability that it would occur next time; here m and g referring to your original view and
might be your probability that it would occur next time; here m and g referring to your original view and ![]() . As the length n of the series increases, nf and n become large in comparison with mg and m so that the expression reduces almost to
. As the length n of the series increases, nf and n become large in comparison with mg and m so that the expression reduces almost to ![]() , irrespective of your original views.
, irrespective of your original views.
11.6 The Bayesian Development
To see how this works in general, take the probability of future data, given the theory and past experience, ![]() , which, as was seen in § 11.4, does not depend on the past data, so may be written
, which, as was seen in § 11.4, does not depend on the past data, so may be written ![]() . We now examine how this coheres with your uncertainty about the theory,
. We now examine how this coheres with your uncertainty about the theory, ![]() . Since D, explicitly or implicitly, occurs everywhere as a conditional, becoming part of your knowledge base, it can be omitted from the notation and can (nearly) be forgotten, so that you are left with
. Since D, explicitly or implicitly, occurs everywhere as a conditional, becoming part of your knowledge base, it can be omitted from the notation and can (nearly) be forgotten, so that you are left with ![]() and
and ![]() . Applying Bayes rule in its odds form (§6.5, with a change of notation)
. Applying Bayes rule in its odds form (§6.5, with a change of notation)
![]()
Here your initial odds ![]() —which depends on past data omitted from the notation—is updated by future, further data F, to revise your odds to
—which depends on past data omitted from the notation—is updated by future, further data F, to revise your odds to ![]() . “Future” here means after the theory
. “Future” here means after the theory ![]() has been formulated on the basis of past data. Suppose now that F is highly probable on
has been formulated on the basis of past data. Suppose now that F is highly probable on ![]() , but not on
, but not on ![]() ; then Bayes rule shows that
; then Bayes rule shows that ![]() will be larger than
will be larger than ![]() , because the likelihood ratio will exceed one, so that the theory will be more strongly supported. (Recall, again from §6.5, that the rule can be written in terms of likelihoods.) The result in the last sentence may alternatively be expressed by saying that if
, because the likelihood ratio will exceed one, so that the theory will be more strongly supported. (Recall, again from §6.5, that the rule can be written in terms of likelihoods.) The result in the last sentence may alternatively be expressed by saying that if ![]() is more likely than
is more likely than ![]() on the basis of F, its odds, and therefore its probability, will increase. This is how science proceeds; as data supporting a theory grows, so your probability of it grows. If the data do not support the theory, your probability decreases. In this way Bayes and data test a theory. Science proceeds by checking the theory against increasing amounts of data until it can be accepted and BSE asserted to cross species, or rejected, showing that it cannot. It is not until this stage that scientific authority is really authoritative. Before then, the statements are uncertain.
on the basis of F, its odds, and therefore its probability, will increase. This is how science proceeds; as data supporting a theory grows, so your probability of it grows. If the data do not support the theory, your probability decreases. In this way Bayes and data test a theory. Science proceeds by checking the theory against increasing amounts of data until it can be accepted and BSE asserted to cross species, or rejected, showing that it cannot. It is not until this stage that scientific authority is really authoritative. Before then, the statements are uncertain.
There are some details to be added to the general exposition just given about the establishment of a theory. Notice that a theory never attains a probability of 1. Your probability can only get very close to 1, as a consequence of which scientific theories do not have the force of logic. It is true that ![]() but it is only highly probable, on the evidence we have, that Einstein's analysis is correct. This is in accordance with Cromwell's rule and scientists should always remember they might be mistaken as they were with Newton's laws. These worked splendidly and with enormous success until some behavior of the planet Mercury did not agree with Newtonian predictions, leading ultimately to Einstein replacing Newton. In practice, the distinction between logical truth and scientific truth does not matter, only occasionally, as with Mercury, does it become significant.
but it is only highly probable, on the evidence we have, that Einstein's analysis is correct. This is in accordance with Cromwell's rule and scientists should always remember they might be mistaken as they were with Newton's laws. These worked splendidly and with enormous success until some behavior of the planet Mercury did not agree with Newtonian predictions, leading ultimately to Einstein replacing Newton. In practice, the distinction between logical truth and scientific truth does not matter, only occasionally, as with Mercury, does it become significant.
To appreciate a second feature of the acquisition of knowledge through Bayes, return to the urns and suppose the red theory, R, is correct so that more red balls are withdrawn than white, with every red ball doubling the odds, every white ball halving it. In the numerical work it was supposed that you initially thought the two theories were equally probable, p (R) = p (W) = ½. Consider what would happen had you thought the red theory highly improbable, say p (R) = .01, odds of about 1 in 100; then the doubling would still occur twice as often as the halving and the odds would grow just the same and truth attained. The only distinction would be that with p (R) = 0.01 rather than 0.50, you would take longer to get there. Suppose the scientist whose initial opinion had been equally divided between the two possibilities had reached odds of 10,000 to 1, then his sceptical colleague would be at 100 to 1 since the former has the odds of 1 to 1 multiplied by 10,000, whereas the latter with only one hundredth but the same multiplication will be at 100 to 1. The two odds may seem very different, but the probabilities 0.9999 and 0.9900 are not so very different on a scale from 0 to 1. The same happens with a general theory ![]() , where people vary in their initial assessments
, where people vary in their initial assessments ![]() , and it takes more evidence to convince some people than others, but all get there eventually, except for the opinionated one with
, and it takes more evidence to convince some people than others, but all get there eventually, except for the opinionated one with ![]() who never learns since all multiplications of zero, remain zero.
who never learns since all multiplications of zero, remain zero.
An important question to ask is what constitutes a good theory? We have seen that it is necessary for you to assess ![]() in order to use Bayes rule and update your opinion about the theory in a coherent manner, so you would prefer a theory in which this can easily be done. In other words, you want a theory that enables you to easily predict future outcomes. One that fails to do so, or makes prediction very difficult, is useless. This is another reason for preferring simple theories. But there is more to it than that for you need the likelihood ratio to update your odds. Recall, from Bayes rule as displayed above, that this ratio is
in order to use Bayes rule and update your opinion about the theory in a coherent manner, so you would prefer a theory in which this can easily be done. In other words, you want a theory that enables you to easily predict future outcomes. One that fails to do so, or makes prediction very difficult, is useless. This is another reason for preferring simple theories. But there is more to it than that for you need the likelihood ratio to update your odds. Recall, from Bayes rule as displayed above, that this ratio is
![]()
where ![]() is the complement of
is the complement of ![]() . (There are some tricky concepts involved with
. (There are some tricky concepts involved with ![]() but these are postponed until §11.8.) What happens is that as each data set F is investigated, your odds are multiplied by the ratio, so what you would like would be ratios that are very large or very small, for these will substantially alter your odds, whereas a ratio around 1 will scarcely affect it. Concentrating on very large values of the ratio, what you would like would be a theory
but these are postponed until §11.8.) What happens is that as each data set F is investigated, your odds are multiplied by the ratio, so what you would like would be ratios that are very large or very small, for these will substantially alter your odds, whereas a ratio around 1 will scarcely affect it. Concentrating on very large values of the ratio, what you would like would be a theory ![]() that predicts data F of high probability, but with smaller probability were the theory false,
that predicts data F of high probability, but with smaller probability were the theory false, ![]() . A famous example is provided by the general theory of relativity, which predicted that the trajectory of a beam of light would be perturbed by a gravitational field as it passed by a massive object. Indeed, it predicted the actual extent of the bending in an eclipse, so that when an expedition was sent to observe the eclipse and found the bending to be what had been predicted,
. A famous example is provided by the general theory of relativity, which predicted that the trajectory of a beam of light would be perturbed by a gravitational field as it passed by a massive object. Indeed, it predicted the actual extent of the bending in an eclipse, so that when an expedition was sent to observe the eclipse and found the bending to be what had been predicted, ![]() was near 1, whereas other theories predicted no bending,
was near 1, whereas other theories predicted no bending, ![]() near 0. The likelihood ratio was enormous and relativity became not proved, but most seriously considered. A good theory is one that makes lots of predictions that can be tested, preferably predictions that are less probable were the theory not true. Bearing in mind the distinction between probability and likelihood, what is wanted are data that are highly likely when the theory is true, and unlikely when false. A good theory cries out with good testing possibilities.
near 0. The likelihood ratio was enormous and relativity became not proved, but most seriously considered. A good theory is one that makes lots of predictions that can be tested, preferably predictions that are less probable were the theory not true. Bearing in mind the distinction between probability and likelihood, what is wanted are data that are highly likely when the theory is true, and unlikely when false. A good theory cries out with good testing possibilities.
There are theories that lack possible tests. For example, reincarnation, which asserts that the soul, on the death of one animal, passes into the birth of another. I cannot think of any way of testing this, even if we remove the notion of soul and think of one animal becoming another. The question that we have met before, “How do you know that?”, becomes relevant again. There are other theories that are destructible and therefore of little interest, such as “there are fairies at the bottom of my garden”. This is eminently testable using apparatus sensitive to different wavelengths, to sound, to smell, to any phenomenon we are familiar with. The result is always negative. The only possibility left is that fairies do not exhibit movement, emit light or sound, do not do anything that is in our ken. If so, the fairy theory is untestable and is as unsatisfactory as reincarnation. Of course, one day we may discover a new sense and then fairies may become of interest because they can be tested using the new sense but not for the moment.
11.7 Modification of Theories
The above development of scientific method is too simple to cover every case but our contention is that the principle, demonstrated with the urn of two possible constitutions, underlies every scientific procedure. There are many technical difficulties to be surmounted, which are unsuitable for a book at this level, but uncertainty is ever present in the early stages of the development of any theory. Uncertainty must be described by probability if the scientist is to be coherent. Probability updates by Bayes, so the ideas already expounded are central to any investigation bearing the name of science. Here we discuss two extensions of the Bayesian logic.
It often happens that, in testing a theory against future data, one realizes that the theory as stated is false but that a modification might be acceptable, so that the old theory is replaced by a new one. For example, suppose that when taking the balls from the urn that might be red R or white W, we find a blue ball. One immediate possibility is that the blue has slipped into the urn by accident, so that this piece of data can be ignored. Scientists, often with good reason, reject outliers, the name given to values that lie outside what the theory predicts. Here the blue ball might be regarded as an outlier. But if further blue balls appear then both theories seem doubtful and it would be better to have theories that admit at least three colors, or even four. There is a fascinating problem that concerns how many different colors of balls there are in the urns. This is a simplified version of how many species are there, not in the urn, but on our planet.
Let us pursue another variant of the urn scenario in which 100, say, balls have been taken, of which 50 are found to be red, and 50 white. This is most improbable on both theories but immediately suggests the possibility that the numbers of red and white balls in the urn are equal, a “theory” that will be referred to as the intermediate possibility I. There are now three theories, R, W, and I, and it is necessary to revise your probabilities. There are no difficulties with the data uncertainties, thus ![]() and
and ![]() , as before, and the new one,
, as before, and the new one, ![]() , but the uncertainties for the three theories need care. You need to assess your probabilities for them and, in doing so, to ensure that they cohere with your original assessments for R and for W before I was introduced. As an aid in reducing confusion, let your new values be written with asterisks,
, but the uncertainties for the three theories need care. You need to assess your probabilities for them and, in doing so, to ensure that they cohere with your original assessments for R and for W before I was introduced. As an aid in reducing confusion, let your new values be written with asterisks, ![]() , and
, and ![]() , necessarily adding to 1, and consider how these must cohere with the values p (R) and p (W), also adding to 1, before the desirability of including I arose. In the former scenario, you were supposing that the event, R or W, was true, probability 1, so if, in the extended case you were to condition on this event, the new values should be the same as the old. That is, in the new setup with I included, the probability of it being the red urn, conditional on it being either the red or white urn—not the intermediate—must equal your original probability of it being red. In symbols
, necessarily adding to 1, and consider how these must cohere with the values p (R) and p (W), also adding to 1, before the desirability of including I arose. In the former scenario, you were supposing that the event, R or W, was true, probability 1, so if, in the extended case you were to condition on this event, the new values should be the same as the old. That is, in the new setup with I included, the probability of it being the red urn, conditional on it being either the red or white urn—not the intermediate—must equal your original probability of it being red. In symbols
![]()
Similarly ![]() , though the first equality will automatically make the second hold. These are the only coherence conditions that must obtain when the scenario is extended to include I. The condition may more simply be expressed by saying that p * (R) and p * (W) must be in the same ratio as the original p (R) and p (W). (A proof of this result is provided at the end of this section.) Here is a numerical example. Suppose you originally thought p (R) = 1/3. p (W) = 2/3, the white urn being twice as probable as the red. Suppose the introduction of the intermediate urn suggests
, though the first equality will automatically make the second hold. These are the only coherence conditions that must obtain when the scenario is extended to include I. The condition may more simply be expressed by saying that p * (R) and p * (W) must be in the same ratio as the original p (R) and p (W). (A proof of this result is provided at the end of this section.) Here is a numerical example. Suppose you originally thought p (R) = 1/3. p (W) = 2/3, the white urn being twice as probable as the red. Suppose the introduction of the intermediate urn suggests ![]() . Then
. Then ![]() must still be twice
must still be twice ![]() as originally. This is achieved with
as originally. This is achieved with ![]() and the three new probabilities add to one.
and the three new probabilities add to one.
The need to include additional elements in a discussion often arises, and the technique applied to the simple, urn example is frequently used to ensure coherence. The original situation is described as a small world. In the example it includes R, W, and the results, like r, of withdrawing balls. The inclusion of additional elements, here just I, gives a large world of which the smaller is a part. Coherence is then reached by making probabilities in the large world, which are conditional on the small world, agree with the original values in the small world, as expressed in the displayed equation above.
Even the most enthusiastic supporter of the thesis of this book cannot simultaneously contemplate every feature of the universe. A user of the scientific method cannot consider the butterfly flapping its wings in the Amazon rain forest when studying human DNA in the laboratory. It is necessary to embrace a small world that is adequate for the purpose. We have seen from Simpson in §8.2, the dangers of making the world too small. If it is made too big then it may become so complex that the scientist has real difficulty in making sense of it. Somewhere there is a happy, medium-sized world that includes only the essentials and excludes the redundant. Here our normative approach has little to say. There is art in finding an appropriate world. Probability, utility, and MEU are powerful tools that need to be used with discretion. Even a practitioner of the scientific method needs art. There is further reference to this matter at the end of §13.3.
Here is a proof of the result stated above. The multiplication rule (§5.3), says that, for any two events E and F, ![]() provided p (E) is not zero. If F implies E, in the sense that F being true necessarily means E is also true, then the event EF is the same as F and the equation becomes
provided p (E) is not zero. If F implies E, in the sense that F being true necessarily means E is also true, then the event EF is the same as F and the equation becomes ![]() . Now R implies the event “R or W ”, so the displayed equation above can be written
. Now R implies the event “R or W ”, so the displayed equation above can be written
![]()
Interchanging the roles of R and W, we similarly have
![]()
Dividing the term on the left-hand side of the first equation by the similar term in the second equation, the probability p *(R or W) cancels, and the result may be equated to the result of a similar operation on the right-hand sides, with the result
![]()
as was asserted above.
11.8 Models
One difficulty that often arises in applying the methods just expounded is that, although a theory ![]() may be precise and well defined, its complement
may be precise and well defined, its complement ![]() may not be. More correctly, although the theory predicts future data in the form
may not be. More correctly, although the theory predicts future data in the form ![]() , it is not always clear what data to anticipate if the theory is false and
, it is not always clear what data to anticipate if the theory is false and ![]() , needed to form the likelihood ratio, may be elusive. An example is provided by the theory of relativity—what does it mean for future data at the eclipse if it is false? One possibility is to see the eclipse experiment of §11.6 as a contest between Einstein and Newton so that the two predictions are compared, just as the red and white urns were, and Newton is thought of as the complement of Einstein. This is hardly satisfactory because it was already realized at the time of the experiment that something could be wrong with Newton as a result of observations on the movement of Mercury. A better procedure, and the one that is commonly adopted, goes like this. In the eclipse experiment, relativity predicted the amount of the bending of light to be 6 degrees, so that other possibilities are that the bending is any value other than 6; 5 or 7, or even 0 that was Newton's value. Consequently it is possible to think of the theory saying the bending is 6, and the theory being false meaning the bending is not 6. This means that the value 6 is to be compared, not with just one value, but with several. We saw in §7.5 how this could be done with a few alternatives and technical sophistications make it possible to handle all values besides 6. Generally it happens in the context of a particular experiment that the theory
, needed to form the likelihood ratio, may be elusive. An example is provided by the theory of relativity—what does it mean for future data at the eclipse if it is false? One possibility is to see the eclipse experiment of §11.6 as a contest between Einstein and Newton so that the two predictions are compared, just as the red and white urns were, and Newton is thought of as the complement of Einstein. This is hardly satisfactory because it was already realized at the time of the experiment that something could be wrong with Newton as a result of observations on the movement of Mercury. A better procedure, and the one that is commonly adopted, goes like this. In the eclipse experiment, relativity predicted the amount of the bending of light to be 6 degrees, so that other possibilities are that the bending is any value other than 6; 5 or 7, or even 0 that was Newton's value. Consequently it is possible to think of the theory saying the bending is 6, and the theory being false meaning the bending is not 6. This means that the value 6 is to be compared, not with just one value, but with several. We saw in §7.5 how this could be done with a few alternatives and technical sophistications make it possible to handle all values besides 6. Generally it happens in the context of a particular experiment that the theory ![]() implies a quantity, let us denote it by another Greek letter
implies a quantity, let us denote it by another Greek letter ![]() (phi), which has a definite value. You can take all values of
(phi), which has a definite value. You can take all values of ![]() other than this to constitute
other than this to constitute ![]() . In most experiments, the data will contain an element of uncertainty so that you will need to think about
. In most experiments, the data will contain an element of uncertainty so that you will need to think about ![]() , rather than
, rather than ![]() , and recognize that
, and recognize that ![]() implies a special value for
implies a special value for ![]() . It is usual to denote this special value by
. It is usual to denote this special value by ![]() . The theory says
. The theory says ![]() , the complement, or alternative, to the theory says
, the complement, or alternative, to the theory says ![]() . We refer to the use of
. We refer to the use of ![]() as a model and
as a model and ![]() is called the parameter of the model. In general, for an experiment the theory suggests a model and your uncertainty is expressed in terms of the parameter, rather than the theory. It will be seen how this is done in the next section, but for the moment let us look at the concept of a model.
is called the parameter of the model. In general, for an experiment the theory suggests a model and your uncertainty is expressed in terms of the parameter, rather than the theory. It will be seen how this is done in the next section, but for the moment let us look at the concept of a model.
The relationship between a theory and its models is akin to that between strategy and tactics: strategy describing the overall method or theory, tactics dealing with particular situations or models. In our example, relativity is supposed to apply everywhere, producing models for individual scenarios. One way of appreciating the distinction between a theory and a model is to recognize that a theory incorporates an explanation for many phenomena, whereas a model does not and is specific. The theory of general relativity applied to the whole universe and, when applied to the eclipse, predicted a bending of 6 degrees. There was no theory that predicted 3 degrees, for example. The model, by contrast, only applies to the eclipse and, in that specific context, embraced both 6 degrees and 3 degrees. Scientists have found models so useful as a way of thinking about data that they have been extensively used even without a theory, just as a military battle can use tactics without an overall strategy. Here is an example. Consider a scientist who is interested in the dependence of one quantity on several others, as when a manufacturer, using the scientific method, enquires how the quality of the product depends on temperature, quality of the raw material, and the operator of the manufacturing process (§4.7). We refer to the dependent quantity, and the explanatory quantities and seek to determine how the latter influences the former, or equivalently, how the former depends on the latter. The dependent quantity will be denoted by y and we will, for ease of exposition, deal with two explanatory quantities, w and x. Many writers use the term variable where we have used quantity.
Within the framework developed in this book, the dependence of y on w and x is expressed through your probability of y, conditional on w and x (and your knowledge base), ![]() and it is usual to refer to this probability structure as the model. Notice that there are a lot of distributions here, one for each value of w and x, so that the model is quite complicated and some simplification is desirable. It was seen in §9.3, and again in §10.4, that an important feature of a quantity is its expectation, which is a number, rather than a possibly large collection of numbers that is a distribution, so interest has centered on
and it is usual to refer to this probability structure as the model. Notice that there are a lot of distributions here, one for each value of w and x, so that the model is quite complicated and some simplification is desirable. It was seen in §9.3, and again in §10.4, that an important feature of a quantity is its expectation, which is a number, rather than a possibly large collection of numbers that is a distribution, so interest has centered on ![]() , what you expect the quantity to be for given values of the explanatory quantities. Even the expectation is hard to handle in general and a simplification that is often employed is to suppose the expectation of the dependent quantity is linear in the explanatory quantities; that is
, what you expect the quantity to be for given values of the explanatory quantities. Even the expectation is hard to handle in general and a simplification that is often employed is to suppose the expectation of the dependent quantity is linear in the explanatory quantities; that is
![]()
where ![]() (alpha) and
(alpha) and ![]() (beta), the first two letters of the Greek alphabet, are parameters, like
(beta), the first two letters of the Greek alphabet, are parameters, like ![]() above. A useful convention has arisen that the Roman alphabet is used for quantities that can be observed and the Greek for quantities that are not directly observable but are integral to the model, like the parameters. What the displayed equation says is that if w is changed by a unit amount, and x remains constant, then you expect y to change by an amount
above. A useful convention has arisen that the Roman alphabet is used for quantities that can be observed and the Greek for quantities that are not directly observable but are integral to the model, like the parameters. What the displayed equation says is that if w is changed by a unit amount, and x remains constant, then you expect y to change by an amount ![]() , whatever value x takes or whatever value w had before the change. A similar conclusion holds with the roles of x and w reversed, but here the change in y is
, whatever value x takes or whatever value w had before the change. A similar conclusion holds with the roles of x and w reversed, but here the change in y is ![]() .
.
We have continually emphasized the merits of simplicity, provided it is not carried to excess, and here we have an instance of possible excess, because the effect on y of a change in x may well depend on the value of w at the time of the change, a possibility denied by the above model. For example, suppose you are interested in the dependence of the amount, y, the product of a chemical process, on two explanatory quantities, w the temperature of the reaction and x the amount of catalyst used. It could happen that the efficacy of the catalyst might depend on the temperature, a feature not present in the above model, so that the simplicity of the model would then be an inadequate description of the true state of affairs. A valuable recipe is to keep things simple, but not too simple. Another feature of the above model that requires watching relates to the distinction made in §4.7 between “do x ” and “see x ”. Does the model reflect what you expect to happen to y when you see x change, or your expectation were you to make the change, and instead “do x ”?
When discussing Simpson's paradox in §8.2, it was seen how the relationship between two quantities could change when a third quantity is introduced. A similar phenomenon can arise here, where the relationship between y and w can alter when x is included. It does not follow that even if
![]()
and therefore, if ![]()
![]()
that, when x is unstated,
![]()
Even if ![]() is linear, as in the original model with w and y, so that
is linear, as in the original model with w and y, so that
![]()
it does not follow that ![]() . Recall that
. Recall that ![]() is the change you expect in y were w to change by a unit amount to
is the change you expect in y were w to change by a unit amount to ![]() , when x is held fixed. In contrast,
, when x is held fixed. In contrast, ![]() is the change you expect in y were w to change by a unit amount, when nothing is said about x. It is easy to construct examples in which the quantities,
is the change you expect in y were w to change by a unit amount, when nothing is said about x. It is easy to construct examples in which the quantities, ![]() and
and ![]() , are different, but it suffices to remark that our original example with Simpson's paradox will do, for the change in recovery (y) went one way when only treatment (w) was considered, but the opposite way when sex (x) was included as well. Thus in that case
, are different, but it suffices to remark that our original example with Simpson's paradox will do, for the change in recovery (y) went one way when only treatment (w) was considered, but the opposite way when sex (x) was included as well. Thus in that case ![]() and
and ![]() had opposite signs, an apparently effective treatment becoming harmful.
had opposite signs, an apparently effective treatment becoming harmful.
Models have been used with great success in many applications of the scientific method and I have no desire to denigrate them, only to issue a word of caution that they need careful thought and can carry the virtue of simplicity too far. Models are no substitute for a theory, any more than tactics are for a strategy; it is best to have an overall strategy or theory that, in particular cases, provides tactics or model. This is why a scientist, properly “a user of the scientific method”, likes to have a general explanation of a class of phenomena, of how things work, rather than just an observation of it working. The model may show y increases with w, but it is preferable to understand why this happens.
11.9 Hypothesis Testing
It was mentioned in the last section that a theory ![]() often leads, in a particular experiment, to a model incorporating a parameter
often leads, in a particular experiment, to a model incorporating a parameter ![]() , the truth of the theory implying that the parameter has a particular value,
, the truth of the theory implying that the parameter has a particular value, ![]() , so that investigating the theory becomes a question of seeing whether
, so that investigating the theory becomes a question of seeing whether ![]() is a reasonable value for
is a reasonable value for ![]() . The same situation arises with models that are not supported by theory, when a particular parametric value assumes especial importance. For example, in the linear model
. The same situation arises with models that are not supported by theory, when a particular parametric value assumes especial importance. For example, in the linear model
![]()
![]() might be such a special value, saying that w has no effect on your expectation of y, assuming x held fixed. Such situations have assumed considerable importance in some branches of science, so much so that some people have seen in them the central core of the scientific method. From the viewpoint developed here, this centrality is wrong. Nevertheless the topic is of considerable importance and therefore merits serious attention. We begin with an example.
might be such a special value, saying that w has no effect on your expectation of y, assuming x held fixed. Such situations have assumed considerable importance in some branches of science, so much so that some people have seen in them the central core of the scientific method. From the viewpoint developed here, this centrality is wrong. Nevertheless the topic is of considerable importance and therefore merits serious attention. We begin with an example.
In Example 4 of Chapter 1, the effect of selenium on cancer was discussed. In order to investigate this a clinical trial is set up with some patients being given selenium and others a placebo. It is not an easy matter to set up a trial in which one can be reasonably certain that any effects observed are truly due to selenium and not due to other spurious causes. A considerable literature has grown up on the design of such trials, and it can be taken that a modern clinical trial takes account of this work and is capable of proper interpretation. The design need not concern us here; all we need is confidence that any observed difference between the two sets of patients is due to the selenium and not due to anything else. This difference is reflected in the parameter, referred to previously as ![]() , of interest. In this formulation the value
, of interest. In this formulation the value ![]() is of special interest because, if correct, it would mean that selenium had no effect on cancer, whereas a positive value would indicate a beneficial effect and a negative one a harmful effect. Incidentally, the trial would hardly have been set up if the negative value was thought reasonably probable. In our notation
is of special interest because, if correct, it would mean that selenium had no effect on cancer, whereas a positive value would indicate a beneficial effect and a negative one a harmful effect. Incidentally, the trial would hardly have been set up if the negative value was thought reasonably probable. In our notation ![]() is small. All procedures that are widely used develop their own necessary nomenclature, which is now introduced.
is small. All procedures that are widely used develop their own necessary nomenclature, which is now introduced.
The value of special interest ![]() is called the null value and the assertion that
is called the null value and the assertion that ![]() , the null hypothesis. In what follows it will be supposed that
, the null hypothesis. In what follows it will be supposed that ![]() , as in the selenium example. The nonnull values of the parameter are called the alternatives, or alternative hypotheses, and the procedure to be developed is termed a test of the null hypothesis. A convenient way of thinking about the whole business is to regard the null hypothesis as an Aunt Sally, or straw man, that the trial attempts to knock down. In the selenium trial, the hope is that the straw man will be overthrown and the metal shown to be of value. If a theory has provided the null value, then every attempt at an overthrow that fails, thereby enhances the theory, and some philosophers have considered this the main feature of the scientific method. Notice that the use of the straw man does not make explicit mention of other men, of alternative hypotheses. With these preliminaries, we are ready to test the null, that the null hypothesis is true, the parameter assumes the null value,
, as in the selenium example. The nonnull values of the parameter are called the alternatives, or alternative hypotheses, and the procedure to be developed is termed a test of the null hypothesis. A convenient way of thinking about the whole business is to regard the null hypothesis as an Aunt Sally, or straw man, that the trial attempts to knock down. In the selenium trial, the hope is that the straw man will be overthrown and the metal shown to be of value. If a theory has provided the null value, then every attempt at an overthrow that fails, thereby enhances the theory, and some philosophers have considered this the main feature of the scientific method. Notice that the use of the straw man does not make explicit mention of other men, of alternative hypotheses. With these preliminaries, we are ready to test the null, that the null hypothesis is true, the parameter assumes the null value, ![]() ; against the alternative that it is false, the parameter is not zero, written
; against the alternative that it is false, the parameter is not zero, written ![]() .
.
We know how to do this, for if we think of ![]() as corresponding to the red urn, R, and
as corresponding to the red urn, R, and ![]() to the alternative possibility of a white urn, W, then
to the alternative possibility of a white urn, W, then
![]()
where o denotes the odds. The ratio of probabilities is the likelihood ratio and D denotes the data from the trial. In words, the equation expresses your opinion, in the form of odds of the null hypothesis on the basis of the results of the trial, appearing on the left, in terms of the same odds before the trial, on the right. The latter, multiplied by the likelihood ratio, expresses how the probability of the data on the null hypothesis differs from that on the alternative. In other words, the analysis for the two possible urns is analogous to null against alternative, showing how your opinion is altered by the withdrawal of balls, here replaced by looking at the patients in the trial. Remember that all odds and probabilities are also conditional on an unstated knowledge base, here dependent on the careful design of the clinical trial.
It was seen in the case with the urns in §11.4 that every withdrawal of a red ball, more probable on R than on W, enhanced your probability that it was the red urn; while every white ball reduced that probability. Similarly here, data more likely on the null than on the alternative give a likelihood ratio in excess of one and the odds, or equally, the probability, of the null is increased; whereas if the alternative is more likely, the probability is decreased. (Notice the distinction between likely and probable.) And just as you eventually reach assurance about which urn it is by taking out a lot of balls, you eventually learn whether the null is reasonably true by performing a large trial. You eventually learn if the selenium is useless, or effective; being either beneficial ![]() , or harmful
, or harmful ![]() . Many clinical trials do not reach such assurance and many tests of a theory are not conclusive. However repeated trials and tests, like repeated experiences with balls, can settle the issue. It is important to bear in mind, as was seen in §11.4, that some people will be more easily convinced than others. Bayes's result displayed above describes the manner in which a null value, or a theory, can be tested. Before the subject is left, three matters deserve attention.
. Many clinical trials do not reach such assurance and many tests of a theory are not conclusive. However repeated trials and tests, like repeated experiences with balls, can settle the issue. It is important to bear in mind, as was seen in §11.4, that some people will be more easily convinced than others. Bayes's result displayed above describes the manner in which a null value, or a theory, can be tested. Before the subject is left, three matters deserve attention.
The first has already been touched upon, in that people will start from differing views about the null, some thinking it highly probable, others having severe doubts, yet others being intermediate. This reflects reality but their differences will, as we have seen, be ironed out by the accumulation of data and the multiplying effect of the likelihood ratio.
The second matter is a variant of the first in that people will differ in their initial probabilities for the data when the alternative is true, the denominator in Bayes rule, ![]() , and may also have trouble thinking about it. To see how this may be handled, consider the selenium trial where there are two possibilities, that the selenium is beneficial,
, and may also have trouble thinking about it. To see how this may be handled, consider the selenium trial where there are two possibilities, that the selenium is beneficial, ![]() , or harmful,
, or harmful, ![]() . Replace these by
. Replace these by ![]() and
and ![]() , respectively, a simplification that in practice is silly and is introduced here only for ease of exposition, the realistic case involving mathematical technicalities. The procedure in the silly case carries over to realism. Now extend the conversation to include the possible alternative values of
, respectively, a simplification that in practice is silly and is introduced here only for ease of exposition, the realistic case involving mathematical technicalities. The procedure in the silly case carries over to realism. Now extend the conversation to include the possible alternative values of ![]() ,
,
![]()
It ordinarily happens that the two probabilities of the data on the right are easily obtained for they are, in spirit, similar to the numerator of the likelihood ratio ![]() . It is the other two probabilities on the right that can cause trouble. In the selenium case,
. It is the other two probabilities on the right that can cause trouble. In the selenium case, ![]() is presumably large because the trial was set up in the expectation that selenium is beneficial. Necessarily
is presumably large because the trial was set up in the expectation that selenium is beneficial. Necessarily ![]() is small, the two adding to one. With them in place, the calculation can proceed. People may disagree, but again Bayes rule can eventually lead to reasonably firm conclusions.
is small, the two adding to one. With them in place, the calculation can proceed. People may disagree, but again Bayes rule can eventually lead to reasonably firm conclusions.
11.10 Significance Tests
The third matter is quite different in character, for although the setting up of a null hypothesis and its attempted destruction, occupies a central role in handling uncertainty, most writers on the topic do not use the methods based on Bayes rule just described, instead preferring a technique that commits a variant of the prosecutor's fallacy (§6.6), terming it not just a test (of the null hypothesis) but a significance test. (Recall that mathematicians often use a common word in a special setting, so it is with “significance” here, so do not attach much of its popular interpretation to this technical usage.) To see how a significance test works, stay with the selenium trial but suppose that the relevant data, that were written D, consist of a single number, written d. For example, d might be the difference in recovery rates between patients receiving selenium and those on the placebo. The discussion of sufficiency in §6.9 is relevant. There it was seen that not all the data from the urns were needed for coherent inference, rather a single number sufficed. Again the argument to be presented extends to cases where restriction to a single number is unrealistic. If the null hypothesis, ![]() , is true, then your probability distribution for d is
, is true, then your probability distribution for d is ![]() and is usually available. Indeed it is the numerator of the likelihood ratio just used. This distribution expresses your opinion that some values of d have high probability, whereas others are improbable. For example, it will usually happen, bearing in mind you are supposing
and is usually available. Indeed it is the numerator of the likelihood ratio just used. This distribution expresses your opinion that some values of d have high probability, whereas others are improbable. For example, it will usually happen, bearing in mind you are supposing ![]() and the selenium is ineffectual, that you think values of the difference d near zero will be the most probable, while large values of d of either sign will be improbable. The procedure used in a significance test is to select, before seeing the data, values of d that, in total, you think have small probability and to declare the result “significant” if the actual value of d obtained in the trial is one of them. Figure 11.1 shows a possible distribution for you, centered around d = 0, with a set of values in the tails that you deem improbable (see also Fig. 9.6). The actual probability you assign to this set is called the significance level and the result of the trial is said to be significant if the difference d actually observed falls in this set. For historical reasons, the significance level is denoted by the Greek letter alpha,
and the selenium is ineffectual, that you think values of the difference d near zero will be the most probable, while large values of d of either sign will be improbable. The procedure used in a significance test is to select, before seeing the data, values of d that, in total, you think have small probability and to declare the result “significant” if the actual value of d obtained in the trial is one of them. Figure 11.1 shows a possible distribution for you, centered around d = 0, with a set of values in the tails that you deem improbable (see also Fig. 9.6). The actual probability you assign to this set is called the significance level and the result of the trial is said to be significant if the difference d actually observed falls in this set. For historical reasons, the significance level is denoted by the Greek letter alpha, ![]() . To recapitulate, if the trial result is one of these improbable values then, on the idea that improbable events don't happen, or at least happen rarely, doubt is cast on the assumption that
. To recapitulate, if the trial result is one of these improbable values then, on the idea that improbable events don't happen, or at least happen rarely, doubt is cast on the assumption that ![]() or that the null hypothesis is true. Referring to the figure, if d lies in the tails by exceeding +c, or being less than − c, an improbable event for you has happened and doubt may be cast on the null hypothesis or, as is often said, either an improbable event has occurred or the null hypothesis is false.
or that the null hypothesis is true. Referring to the figure, if d lies in the tails by exceeding +c, or being less than − c, an improbable event for you has happened and doubt may be cast on the null hypothesis or, as is often said, either an improbable event has occurred or the null hypothesis is false.
Figure 11.1 Probability distribution of d on the null hypothesis, with the tails for a significance test shaded.
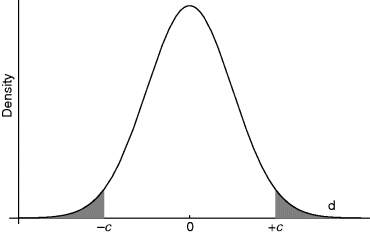
Let us look at some features of this popular method. The most attractive is that the approach uses your probabilities for d only when ![]() , the alternatives
, the alternatives ![]() never occur and the difficulties mentioned above of assessing probabilities for nonzero values do not arise. This makes the significance test rather simple to use. A second feature is that the only probability used is
never occur and the difficulties mentioned above of assessing probabilities for nonzero values do not arise. This makes the significance test rather simple to use. A second feature is that the only probability used is ![]() , the level. Some users fix this before the trial results and, for historical reasons again, use three values 0.05, 0.01, and 0.001. Others let
, the level. Some users fix this before the trial results and, for historical reasons again, use three values 0.05, 0.01, and 0.001. Others let ![]() be the least value that produces significance for the observed value of d, corresponding in the example to c being selected to be +d or − d. Evidence against the null is held to be strong only if the value of
be the least value that produces significance for the observed value of d, corresponding in the example to c being selected to be +d or − d. Evidence against the null is held to be strong only if the value of ![]() produced this way is 0.05 or less. A third feature is that the test does not only use your probability of the difference observed in the trial, as does Bayes, but instead your probability of the set of improbable values, in the example those exceeding c without regard to sign. This has been elegantly expressed by saying that a significance test does not use only the value of d observed, but also those values that might have occurred but did not.
produced this way is 0.05 or less. A third feature is that the test does not only use your probability of the difference observed in the trial, as does Bayes, but instead your probability of the set of improbable values, in the example those exceeding c without regard to sign. This has been elegantly expressed by saying that a significance test does not use only the value of d observed, but also those values that might have occurred but did not.
The first two features make a significance test simple to use and perhaps account for its popularity. It is this popularity that has virtually forced me to include the test in a book about uncertainty. Yet, from our perspective, the third feature exposes its folly because it uses the probability of an aspect of the data, lying in the tails of your distribution, when the null hypothesis is true, rather than what our development demands, your probability that ![]() given the data. This is almost the prosecutor's fallacy, confusing
given the data. This is almost the prosecutor's fallacy, confusing ![]() with
with ![]() , replacing d in the first probability with values of d in the set. The contradiction goes even deeper than this because the significance test tries to make an absolute statement about
, replacing d in the first probability with values of d in the set. The contradiction goes even deeper than this because the significance test tries to make an absolute statement about ![]() , whereas Bayes makes statements comparing
, whereas Bayes makes statements comparing ![]() with alternatives
with alternatives ![]() . There are no absolutes in this world, everything is comparative; a property that a significance test fails adequately to recognize. This section has dealt only with one type of significance test. There are other significance tests, that also employ the probability distribution of the data on the null hypothesis, where the null hypothesis has a more complicated structure than that treated here. Their advantages and disadvantages are similar to those expounded here. There is more on significance tests in §14.4.
. There are no absolutes in this world, everything is comparative; a property that a significance test fails adequately to recognize. This section has dealt only with one type of significance test. There are other significance tests, that also employ the probability distribution of the data on the null hypothesis, where the null hypothesis has a more complicated structure than that treated here. Their advantages and disadvantages are similar to those expounded here. There is more on significance tests in §14.4.
11.11 Repetition
An essential ingredient of the scientific method is the interaction between observation and reason. The process begins with the collection of data, for example, in the form of experiments performed in a laboratory, which are thought about, resulting in the production of a theory, which is then tested by further experimentation. The strength of science lies in this seesaw between outward contact with reality and inward thought. It is not practical experience on its own, or deep contemplation in the silence of one's room, that produces results, but rather the combination of the two, where the practitioner and the theorist meet. A typical scenario is one in which a scientist performs an experiment and develops a theory, which is then investigated by other scientists who attempt to reproduce the original results in the laboratory. It is this ability to repeat, to verify for yourself, that lies at the heart of the scientific method. The original experiments may have been done in Europe, but the repetitions can be performed in America, India, China, or Africa, or anywhere else, for science is international in methodology and ultimately everywhere the same after sufficient experimentation. Of course, since the results are developed by human beings, there will be differences in character between the sciences of Pakistan and Brazil, but Newton's laws are the same in the dry deserts of Asia as in the humidity of the Amazon.
The simplest form of repetition, exemplified by the tossing of a coin, is captured by the concept of exchangeability (§7.3), where one scientist repeats the work of another, tossing the coin a further time. It has been shown in §11.5 how each successful repetition enhances the theory by increasing its probability, or odds, by the use of Bayes rule. Pure repetition, pure exchangeability, rarely happens and more commonly the second scientist modifies the experiment, testing the theory, trying in a friendly way to destroy it and being delighted when there is a failure to do so. Experience shows that exchangeability continues to be basic, only being modified in ways that need not concern us here, to produce concepts like partial exchangeability. Often the repetition will not go as expected, and in extreme cases the theory will be abandoned. More often the theory will be modified to account for the observations and this new theory itself tested by further experimentation. It has been seen how this happens in the example of §11.7. Repeatability is a cornerstone of the scientific method and the ability of one scientist to reproduce the results of another is essential to the procedure.
It is this ability to repeat earlier work, often in a modified form, that distinguishes beliefs based on science from those that do not use the rigor of the scientific method. An illustration of these ideas is provided by the differences between Chinese and Western medicines, with acupuncture, for example, being accepted in the former but regarded with suspicion in the latter. If A is the theory of acupuncture, then roughly p (A) is near 1 in China and small in the West, though the actual values will depend on who “you” are that is doing the assessing. The scientific procedure is clear; experiences with the procedure can be examined and trials with acupuncture carried out. The results of some trials have recently been reported and suggest little curative effects save in relief from dental pain and in the alleviation of unpleasant experiences resulting from intrusive cancer therapies. These have the effect of lowering p (A) by Bayes, or modifying the theory, limiting its effect to pain relief. The jury is still out on acupuncture, but there is no need for China and the West to be hostile. The tools are there for their reconciliation. Incidentally, this discussion brings out a difference between a theory and a model. The evidence about the benefits to dental health of acupuncture is described by a model saying how a change in one quantity, the insertion of a needle, produces a change in another, pain; but there is only the vaguest theory to explain how the pain relief happens or how acupuncture works.
The preceding argument works well where laboratory or field experiments are possible but there are cases where these are nonexistent or of limited value. Let us take an example that is currently giving rise to much debate, the theory of evolution of life on this planet, mainly developed by Darwin. The first point to notice is that Darwin followed the procedure already described in that he studied some data, part of which was that from the journey on the “Beagle”, developed his theory, and then spent several years testing it, for example, by using data on pigeons, before putting it all together in his great book, “The Origin of Species”; a book which is both magnificent science and great literature. The greater part of the book is taken up with the testing, the theory occupying only a small portion of the text. This commonly happens because a good theory is simple, as when three rules describe uncertainty or E = mc 2 encapsulates relativity. However, Darwin's examples were mostly on domestic species. More complete testing involved extensive investigations of fossils that cannot be produced on demand, as can results in a laboratory. One would have liked to have a complete sequence from ape to man, whereas one was dependent on what chance would yield from digs based on limited knowledge. The result is that although it was known what data would best test the theory of evolution, in the sense of giving a dramatic likelihood ratio, these data were not available. Nevertheless data have been accumulating since the theory become public, likelihood ratios evaluated, and probabilities updated. The result is the general acceptance of the theory, at least in modified forms which are still the subjects of debate. Incidentally, support for evolution was provided by ideas of Mendelian genetics that supplied a mechanism to explain how the modification of species could happen.
Creationists, and others opposed to Darwin, often say that evolution is only a theory. In this they are correct but then so is relativity or any of the other ideas that make science so successful, producing results that the creationists enjoy. A distinction between many theories and that of evolution is that the data available for testing the latter cannot be completely planned. Evolution is not a faith because it can be, and has been, tested, whereas faith is largely immune to testing. It is public exposure to trial, this attempted destruction of hypotheses, that helps make science the great method that it is.
11.12 Summary
This chapter is concluded by a recapitulation of the role of uncertainty in scientific method, followed by a few miscellaneous comments. The methodology begins with data D, followed by the development using reason of a theory ![]() , or at least a model, and the testing of theory or model on further data F. There is then an extra stage, discussed in Chapter 10, of action based on the theory or model. The initial uncertainty about
, or at least a model, and the testing of theory or model on further data F. There is then an extra stage, discussed in Chapter 10, of action based on the theory or model. The initial uncertainty about ![]() is described by
is described by ![]() , your probability of the theory based on the original data. Ordinarily this probability will vary substantially from scientist to scientist but will be updated by further data F using Bayes rule
, your probability of the theory based on the original data. Ordinarily this probability will vary substantially from scientist to scientist but will be updated by further data F using Bayes rule
![]()
(Recall that typically F and D will be independent given ![]() .) As data F accumulate with successive updatings, either
.) As data F accumulate with successive updatings, either ![]() comes to be accepted, or is modified, or is destroyed. In this way general agreement among scientists is reached. At bottom, the sequence is as follows: Experience of the real world, thought, further experience, followed by action. The strength of the method lies in its combination of all four stages and does not reside solely in any subset of them.
comes to be accepted, or is modified, or is destroyed. In this way general agreement among scientists is reached. At bottom, the sequence is as follows: Experience of the real world, thought, further experience, followed by action. The strength of the method lies in its combination of all four stages and does not reside solely in any subset of them.
The simple form of Bayes rule just given hides the fact that, in addition to ![]() , you also need
, you also need ![]() , your probability of the data assuming the theory is false. The odds form shows this more clearly:
, your probability of the data assuming the theory is false. The odds form shows this more clearly:
![]()
absorbing D into the knowledge base. The scientific method is always comparative and there are no absolutes in the world of science. It follows from this comparative attitude that a good theory is one that enables you to think of an experiment that will lead to data that are highly probable on ![]() , highly improbable on
, highly improbable on ![]() , or vice versa, so that the likelihood ratio is extreme and your odds substantially changed. One way to get a large likelihood ratio is to have
, or vice versa, so that the likelihood ratio is extreme and your odds substantially changed. One way to get a large likelihood ratio is to have ![]() , because since
, because since ![]() is less than 1, and often substantially less, the ratio must then exceed 1. To get
is less than 1, and often substantially less, the ratio must then exceed 1. To get ![]() requires logic. The simplest way to handle logic is by mathematics. This explains why mathematics is the language of science. It is why we have felt it necessary to include a modicum of mathematics in developing the theory that probability is the appropriate mechanism for the study of uncertainty. It helps to explain why physics has advanced more rapidly than biology. Physical theories are mathematical and traditional, biological ones less so, although modern work on Mendelian genetics and the structure of DNA use more mathematics, often of a different character from that used in the applications to physics. The scientific method has, by contrast, made less progress in economics because the intrusion of erratic human behavior into economic systems has previously prevented the use of mathematics. Economic theories tend to be normative, based on rational expectation, or MEU; whereas they could try to be descriptive, to reflect the activities of people who are incoherent and have not been trained in maximizing expected utility.
requires logic. The simplest way to handle logic is by mathematics. This explains why mathematics is the language of science. It is why we have felt it necessary to include a modicum of mathematics in developing the theory that probability is the appropriate mechanism for the study of uncertainty. It helps to explain why physics has advanced more rapidly than biology. Physical theories are mathematical and traditional, biological ones less so, although modern work on Mendelian genetics and the structure of DNA use more mathematics, often of a different character from that used in the applications to physics. The scientific method has, by contrast, made less progress in economics because the intrusion of erratic human behavior into economic systems has previously prevented the use of mathematics. Economic theories tend to be normative, based on rational expectation, or MEU; whereas they could try to be descriptive, to reflect the activities of people who are incoherent and have not been trained in maximizing expected utility.
There are some areas of enquiry that seem ripe for study by the scientific method, yet it is rarely used. Britons are, because of suitable soils and moderate climate, keen gardeners; yet the bulk of gardening literature has little scientific content. An article will extol the beauty of some variety of tree and make modest reference to suitable soils and climate but the issue of how the topmost leaves get nutrition from the roots many feet below receives no mention. The suggestion here is not that the many handsome articles in newspapers abandon their artistic attitude and discuss osmosis but rather that the balance between science and the arts needs some correction. Another topic that needs even more corrective balance is cookery. There are many books and television programs with numerous recipes, yet when a lady recently discussed how to boil an egg, taking into account the chemistry of albumen and yolk, several chefs howled in anger. To hear about the science of cookery go to the food chemists, who mostly work for the food industry, and they will explain the science of boiling, frying, and braising. Recently one chef has entered the scene using scientific ideas and, as a result, received great praise from Michelin and others, so all is not despair. We have seen in §10.14 how the scientific method is connecting with legal affairs. This is happening in two ways. First by the increasing use of science-based evidence like DNA. Second by examining the very structure of the legal argument, using Bayes rule to incorporate evidence, and MEU to reach a decision.
Scientific method is one, successful way of understanding and controlling the world about us. It is not the only method but it deserves more attention and understanding than it has hitherto received. One reason for its success is that it can handle uncertainty through a proper use of probability.