
2
The QOS Tools
As with any technology, as QOS matures and evolves, new developments always occur and features are always being added. However, before diving deeply into the specifics and all possible variations and evolutions of each QOS tool, the first step is to understand the basic structure of each tool. This chapter presents a high-level view of the fundamental QOS tools. The complexities and specifics of these tools are explained in Part Two of this book.
In a general sense, a QOS tool is simply a building block. It receives input, processes it, and produces specific output. The relationship between the input and output depends on the internal mechanisms of the QOS tools.
Examining each QOS building block separately, focusing on the results each one delivers, allows us to determine how to combine them to achieve the desired behavior.
To explain the QOS building blocks, this chapter focuses on a single router that is part of a network in which QOS is implemented. The router has an ingress interface on which traffic arrives at the router and an egress interface from which traffic departs the router. It is between these two interfaces that QOS tools are applied to the traffic. We are using a router just as an example; it could have been any other QOS-capable device like a switch or a server.
2.1 Classifiers and Classes of Service
Classifiers perform a task that is somewhat analogous to an “identification” process. They inspect the incoming traffic, identify it, and then decide to which class of service it belongs.
The basis of QOS is traffic differentiation, and the concept of a class of service is fundamental to the operation of QOS. Assigning traffic to different classes of service provides the necessary differentiation. From the point of view of a router, the class of service assigned to a packet defines how the router behaves toward it. The concept of traffic differentiation is present in every QOS tool, and as a result, classes of service are present across the entire QOS design.
A classifier has one input, the incoming packet, and it has N possible outputs, where N is the number of possible classes of service into which the packet can be classified. By definition, a classified packet is a packet assigned to a class of service. The decision made by the classifier regarding which class of service a packet belongs to can be seen as a set of IF/THEN rules, where the IF statement specifies the match conditions and, if those conditions are met, the THEN statement specifies the class of service into which the packet is classified, as illustrated in Figure 2.1.

Figure 2.1 The classifier operation
Several possibilities exist for what can be used in the match conditions of the IF statements. The classifier can simply look at the ingress interface on which the packet has arrived and assign all traffic received on that interface to a certain class of service, based on a specific rule. Or, as another example, the classifier can use information that was placed in the packet headers by previous routers specifically for the purpose of telling downstream neighbors about a previous classification decision. More details about the range of possibilities regarding what can be used in the match conditions of the IF statement are given in Chapter 5.
Coming back to the analogy of the routing and forwarding world, when an IP packet arrives at a router, a route lookup is performed to decide where the packet is destined. The classifier concept is similar: the classifier inspects the packet and makes a decision regarding the class of service to which it belongs.
The classifier tool can also be used in a chain fashion. In a scenario of N chain classifiers, the next-in-chain classifier receives packets that have already been classified, meaning that a class of service has already been assigned. This previous classification provides one extra input to be used in the match conditions of the IF/THEN set of rules.
Assuming for ease of understanding a scenario in which N = 2, a packet crosses the first classifier and exits with a class of service assigned to it. Then it reaches the second classifier, which has three possible choices regarding the previously assigned class of service: (i) to accept it as is, (ii) to increase the granularity (e.g., by splitting “business” into “business in contract” and “business out of contract”), or (iii) to change it completely. (A complete change is a somewhat awkward decision and is usually reserved only when correcting a previous classification error.)
2.2 Metering and Coloring—CIR/PIR Model
In Chapter 1, we discussed parameters such as delay and jitter that allow differentiation between different traffic types. However, one further step can be taken in terms of granularity, which is to differentiate first between traffic types and then, within a traffic type, to differentiate even further. Returning to the road metaphor, this is akin to differentiating first between trucks and ambulances and then, for only ambulances, differentiating between whether the siren is on or off.
The metering tool provides this second level of granularity. It measures the traffic arrival rate and assigns colors to traffic according to that rate.
So looking at the classifier and metering tools together, the classifier assigns traffic to classes of service, which each have assigned resources, and the metering tool allows traffic inside a single class of service to be differentiated according to its arrival rate.
To achieve proper metering, we first present here a well-established model in the industry, the committed information rate (CIR)/peak information rate (PIR) model, which is inherited from the Frame Relay realm. However, it is first worth pointing out that this model is not part of any mandatory standard whose use is enforced. CIR/PIR is just a well-known model used in the networking world. One of the many references that can be found for it is RFC 2698 [1].
The foundations of this model are the definition of two traffic rates, CIR and PIR. CIR can be defined as the guaranteed rate, and PIR is the peak rate in terms of the maximum admissible traffic rate.
The CIR/PIR model has three traffic input rate intervals, where each has an associated color, as illustrated in Figure 2.2.

Figure 2.2 The CIR/PIR model
Traffic below the CIR is colored green (also commonly called in-contract traffic), traffic that falls in the interval between the CIR and PIR is colored yellow (also commonly called out-of-contract traffic), and traffic above the PIR is colored red.
So following the CIR/PIR model, the metering tool has one input, the traffic arrival rate, and three possible outputs, green, yellow, or red, as illustrated in Figure 2.3.

Figure 2.3 The metering tool
Generally speaking, green traffic should have assured bandwidth across the network while yellow traffic should not, because it can be admitted into the network but it has no strict guarantee or assurance. Red traffic should, in principle, be discarded because it is above the peak rate.
Services that allow yellow traffic are popular and commonly deployed, following the logic that if bandwidth is available, it can be used under the assumption that this bandwidth usage does not impact other traffic types.
Commonly, metering is not a standalone tool. Rather, it is usually the subblock of the policing tool that is responsible for measuring the traffic input rate. The policing building block as a whole applies predefined actions to each different color.
2.3 The Policer Tool
The policer tool is responsible for ensuring that traffic conforms to a defined rate called the bandwidth limit. The output of the policer tool is the traffic that was present at input but that has been limited based on the bandwidth limit parameter, with excess traffic being discarded, as illustrated in Figure 2.4.

Figure 2.4 The policer tool
The behavior of discarding excess traffic is also called hard policing. However, several other actions are possible. For example, the excess traffic can be accepted but marked differently so it can be differentiated inside the router, a behavior commonly called soft policing.
The metering tool is commonly coupled with the policer as a way to increase the policer’s granularity. In this scenario, the metering tool measures the traffic arrival rate and splits the traffic into the three-color scheme previously presented. The policer is responsible for applying actions to the traffic according to its color, as illustrated in Figure 2.5.

Figure 2.5 Combining the policer and the metering tools
The policer can take one of several decisions regarding the traffic: (i) to transmit the traffic, (ii) to discard it, or (iii) to mark it differently and then transmit it.
Another capability associated with the policer tool is burst absorption. However, we leave this topic for Chapter 6, in which we introduce the use of the token bucket concept to implement the policer function.
In a scenario of linked meter and policer tools, the only difference is that the next step in the chain of meter and policer tool receives a packet that is already colored. This color provides an extra input parameter. The color previously assigned can be maintained, raised (e.g., from green to yellow), or lowered.
2.4 The Shaper Function
The shaper function causes a traffic flow to conform to a bandwidth value referred to as the shaping rate. Excess traffic beyond the shaping rate is stored inside the shaper and transmitted only when doing so does not violate the defined shaping rate. When traffic is graphed, you see that the format of the input traffic flow is shaped to conform to the defined shaping rate.
Let us illustrate this behavior using the example shown in Figure 2.6. Here, an input traffic flow exceeds the defined shaping rate (represented as a dotted line) in the time interval between t0 and t1, and packet X (represented as a gray ball) is the last packet in the input traffic flow between t0 and t1.

Figure 2.6 The shaper tool
Comparing the input and output traffic flow graphs, the most striking difference is the height of each. The height of the output traffic flow is lower, which is a consequence of complying with the shaping rate. The other difference between the two is the width. The output traffic flow is wider, because the traffic flows for a longer time, as a consequence of how the shaper deals with excess traffic.
Let us now focus on packet X, represented by the gray ball. At input, packet X is present at t1. However, it is also part of excess traffic, so transmitting it at t1 violates the shaping rate. Here, the shaper retains the excess traffic by storing it and transmits packet X only when doing so does not violate the shaping rate. The result is that packet X is transmitted at time t2.
Effectively, the information present at the input and output is the same. The difference is its format, because the input traffic flow format was shaped to conform to the shaping rate parameter.
As Figure 2.6 also shows, the storage of excess traffic introduces delay into its transmission. For packet X, the delay introduced is the difference between t2 and t1.
As highlighted in Chapter 1, some traffic types are more sensitive to the delay parameter, so the fact that the shaping tool inherently introduces delay to sustain excess traffic can make it inappropriate for these traffic types.
Also, the shaper’s ability to store excess traffic is not infinite. There is a maximum amount of excess traffic that can be retained inside the shaper before running out of resources. Once this point is reached, excess traffic is discarded, with the result that the amount of information present at the output is less than that present at input. We revisit this topic in Chapter 6 when discussing how to use the leaky bucket concept to implement the shaper tool.
As with many other QOS tools, the shaper can also be applied in a hierarchical fashion, something we explore in the VPLS case study in this book.
2.5 Comparing Policing and Shaping
A common point of confusion is the difference between policing and shaping. This confusion is usually increased by the fact that traffic leaving the policer conforms to the bandwidth limit value and traffic leaving the shaper conforms to the shaping rate, so at a first glance the two may seem similar. However, they are quite different.
Consider Figure 2.7, in which the policer bandwidth limit and the shaping rate of the shaper are set to the same value, X, represented as a dotted line. The input traffic flow that crosses both tools is also equal, and between times t0 and t1 it goes above the dotted line.

Figure 2.7 Comparing the policer and the shaper tools
The difference between the policed and the shaped flows is visible by comparing the two graphs. The main difference is how each tool deals with excess traffic. The policer discards it, while the shaper stores it, to be transmitted later, whenever doing so does not violate the defined shaping rate.
The result of these two different behaviors is that the policed flow contains less information than the input flow graph because excess traffic is discarded, whereas the shaped output flow contains the same information as the input traffic flow but in a different format, because excess traffic was delayed inside the shaper.
Another point of confusion is that the command-line interface (CLI) on most routers allows you to configure a burst size limit parameter inside the policer definition. However, doing this is not the same as being able to store excess traffic. All these differences are explained in Chapter 6 when we detail the token and leaky bucket concepts used to implement the policer and shaper tools, respectively.
The use of shaping to store excess traffic instead of dropping it has earned it the nickname of “TCP friendly,” because for connection-oriented protocols such as TCP, it is usually better to delay than to drop packets, a concept that is detailed in Chapter 4 of this book.
2.6 Queue
A queue contains two subblocks: a buffer and a dropper. The buffer is where packets are stored while awaiting transmission. It works in a first in, first out (FIFO) fashion, which means that the order in which packets enter the buffer is the same in which they leave. No overtaking occurs inside the buffer. The main parameter that defines the buffer is its length, which is how many packets it is able to store. If the buffer is full, all newly arrived packets are discarded.
For ease of understanding throughout this book, we always consider the situation where packets are placed in queues. However, this is not always the case. In certain queuing schemes, what is placed in the queue is in fact a notification cell, which represents the packet contents inside the router. We discuss this topic in detail in Chapter 7.
The decision whether a packet should be placed in the queue buffer or dropped is taken by the other queue block, the dropper. The dropper has one input, which is the queue fill level. Its output is a decision either to place the packet in the queue or to drop it. The dropper works in an adaptive control fashion, in which the decision to either place the packet in the queue or drop it is taken according to the queue fill level. So as the queue fills up or empties, the dropper behaves differently.
As a QOS tool, the queue has one input, which is the packets entering the queue, and one output, which is the packets leaving the queue, as illustrated in Figure 2.8.

Figure 2.8 The queue operation
When a packet enters a queue, it first crosses the dropper block, which, based on the queue fill level, makes a decision regarding whether the packet should be placed in the FIFO buffer or discarded. If the packet is placed in the buffer, it stays there until it is transmitted. The action of moving a packet out of the queue is the responsibility of the next QOS tool we discuss, the scheduler.
If the queue is full, the decision made by the dropper block is always to drop the packet. The most basic dropper is called the tail drop. Its basic behavior is that, when the queue fill level is less than 100%, all packets are accepted, and once the fill level reaches 100%, all packets are dropped. However, more complex dropper behaviors can be implemented that allow the dropping of packets before the queue buffer fill level reaches 100%. These behaviors are introduced in Chapter 3 and detailed in Chapter 8.
2.7 The Scheduler
The scheduler implements a multiplexing operation, placing N inputs into a single output. The inputs are the queues containing packets to be serviced, and the output is a single packet at a time leaving the scheduler. The scheduler services a queue by removing packets from it.
The decision regarding the order in which the multiple queues are serviced is the responsibility of the scheduler. Servicing possibilities range from fair and even treatment to treating some queues as being privileged in terms of having packets be processed at a faster rate or before other queues.
The scheduler operation is illustrated in Figure 2.9, which shows three queues, each containing a packet waiting for transmission. The scheduler’s task is to decide the order in which queues are serviced. In Figure 2.9, queue 3 (Q3) is serviced first, then Q1, and finally Q2. This servicing order implies that the egress order of the packets is the gray packet first, then the black packet, and finally the white packet. Figure 2.9 provides just a simple scheduler example. In reality, there are multiple possible schemes regarding how the scheduler decides how to service the queues. These are discussed in Chapter 7.

Figure 2.9 The scheduler operation
In some ways, the scheduler operation is the star of the QOS realm. It is the tool by which the QOS principle of favoring some by penalizing others becomes crystal clear. We shall see in detail that if traffic is split into classes of service and each class is mapped into a specific queue, the scheduler provides a very clear and precise method to decide which traffic is favored by being effectively prioritized and transmitted more often.
2.8 The Rewrite Tool
The rewrite tool allows a packet’s internal QOS marking (simply called its marking) to be changed. The exact location of the marking depends on the packet type, for example, whether it is an IP or MPLS packet, but for now simply assume that there is a marking inside the packet. We analyze the different packet types in Chapter 5.
The rewrite tool has one input and one output. The input is a packet that arrives with a certain marking, and the output is the packet with the “new” marking, as illustrated in Figure 2.10.

Figure 2.10 The rewrite operation
Two major scenarios require application of the rewrite tool. In the first scenario, this tool is used to signal information to the next downstream router. The second scenario is when the packet marking is considered untrustworthy. In this case, the router at the edge of the network can rewrite the marking to ensure that the other network routers are not fooled by any untrustworthy marking in the packet. We now focus on the first scenario and leave the second one for Chapter 3, in which we discuss trust boundaries across a QOS network.
When we introduced the PHB concept in Chapter 1, we mentioned the lack of signaling between neighbors or end to end and raised the question of how to signal information between routers. Figure 2.11 illustrates this challenge with a practical example in which two packets, numbered 1 and 2, both with a marking of X, cross router A and are both classified into the class of service COS1. However, packet 1 is colored green and packet 2 yellow. At the other end, router B has a classifier that inspects the packets’ QOS markings to decide to which class of service they belong.

Figure 2.11 Information propagation
If router A wants to signal to router B that the packets belong to the same class of service but they are colored differently, it has only one option because of the lack of signaling, which is to play with the packet-marking parameters used by router B’s classification process. For example, if router A applies the rewrite tool to the second packet and changes its marking from X to Y, router B’s classifier can differentiate between the two packets, as illustrated in Figure 2.12.

Figure 2.12 Rewrite tool applicability
However, router A cannot control the classification rules that router B uses because of the lack of signaling. So the success of the rewriting scheme always depends on the router B classifier configuration being coherent so that the marking of X is translated into COS1 and color green and the marking of Y is also translated into COS1 but retains the color yellow. Consistency is crucial.
2.9 Example of Combining Tools
Now that we have presented each tool separately, we combine them all in this section in a simple walkthrough example to illustrate how they can be used together on a router. However, this should be seen as just an example that glues all the tools together. It is not a recommendation for how to combine QOS tools nor of the order in which to combine them.
In fact, the sole input to the decision regarding which tools to use and the order in which to use them is the behavior that is required to be implemented. To this end, our example starts by presenting the network topology and defining the desired behavior. Then we discuss how to combine the tools to match the defined requirements.
The example topology is the simple scenario illustrated in Figure 2.13. A router with one ingress and one egress interface is receiving black and white traffic. The differentiating factor between the two types of packets is the markings they carry. Hence, the markings are the parameter used by the classifier. The PHB requirements to be implemented are summarized in Table 2.1.

Figure 2.13 Traffic flow across the router
Table 2.1 PHB requirements
| Traffic | Class of service | Metering and policing | Queue | Scheduler | Egress rate | Rewrite | ||
| Rate | Color | Action | ||||||
| <1 M | Green | Accept | ||||||
| Black | COS1 | >5 M < 7 M | Yellow | Accept | Use Q1 | Limit | None | |
| >7 M | Red | Drop | Prioritize Q1 | Mbps | ||||
| <1 M | Green | Accept | store excess |
|||||
| White | COS2 | >1 M < 2 M | Yellow | Accept | Use Q2 | Marking = X | ||
| >2 M | Red | Drop | None | |||||
Starting with the classification requirements, black packets should be placed in the class of service COS1 and white packets in COS2. Both types of traffic are metered and policed to implement the coloring requirements listed in Table 2.1. In terms of the queuing and scheduling requirements, black packets should be placed in Q1, which has a higher priority on egress, and white packets are placed in Q2. The rate of traffic leaving the router should not exceed 8 megabits per second (Mbps), but the rate control should also ensure that excess traffic is stored whenever possible rather than being discarded.
The final requirement regards the rewrite rules. White packets colored yellow should have their marking set to the value X before leaving the router, to signal this coloring scheme to the next downstream router.
These requirements are all the necessary details regarding the PHB. Let us now combine the QOS tools previously presented to achieve this PHB, as illustrated in Figure 2.14. In Figure 2.14, only three white and three black packets are considered for ease of understanding.

Figure 2.14 Tools combination scenario
The first step is classification, to inspect the packets’ markings and identify the traffic. Black traffic is mapped to the class of service COS1 and white traffic to the class of service COS2. From this point onward the traffic is identified, meaning that the behavior of all the remaining tools toward a specific packet is a function of the class of service assigned by the classifier.
The metering and policing tools are the next to be applied. The metering tool colors each packet according to the input arrival rate. The result is that for both the white and black traffic types, one packet is marked green, one marked yellow, and the third marked red. As per the defined requirements, the policer drops the red packet and transmits all the others. The result is that black packet 3 and white packet 3 are discarded.
Now moving to the egress interface, packets are placed into the egress queues, with black packets going to Q1 and white packets to Q2. We assume that because of the current queue fill levels, the dropper associated with each queue allows the packets to be put into the queues. The requirements state that the scheduler should prioritize Q1. As such, the scheduler first transmits packets in Q1 (these are black packets 1 and 2), and only after Q1 is empty does it transmit the packets present in Q2 (white packets 1 and 2). This transmission scheme clearly represents an uneven division of resources applied by the QOS tool to comply with the requirement of prioritizing black traffic.
The shaper block then imposes the desired outbound transmission rate, and when possible, excess traffic is stored inside the shaper.
The last block applied is the rewrite tool, which implements the last remaining requirement that white packets colored yellow should have their marking rewritten to the value X. The rewrite block is usually applied last (but this is not mandatory), following the logic that spending cycles to rewrite the packets markings should occur only once they have passed through other QOS tools that can drop them, such as the policer.
The behavior described previously takes place inside one router. Let us make the example more interesting by adding a downstream neighbor (called router N) that maintains the same set of requirements listed in Table 2.1. For ease of understanding, we again assume that only white and black traffic is present, as illustrated in Figure 2.15.

Figure 2.15 Adding a downstream neighbor
What set of tools should router N implement to achieve consistency? The same?
The PHB concept implies that once packets leave a router, all the previous classification is effectively lost, so the first mandatory step for router N to take is to classify traffic. It should not only differentiate between white and black packets but should also take into account that packets with a marking of X represent white packets that were colored yellow by its neighbor. Otherwise, having the upstream router use the rewrite tool becomes pointless.
Regarding metering and policing, if the rates defined in Table 2.1 have been imposed by the upstream router, router N does not need to apply such tools. However, this decision touches the topic of trust relationships. If router N cannot trust its neighbor to impose the desired rates, it must apply tools to enforce them itself. Trust relationships are covered in Chapter 3.
Regarding queuing and scheduling, it is mandatory for router N to implement the scheme described previously, because this is the only possible way to ensure that the requirement of prioritizing black traffic is applied consistently across all the routers that the traffic crosses.
Let us now remove router N from the equation and replace it by adding bidirectional traffic, as illustrated in Figure 2.16. Achieving the set of requirements shown in Table 2.1 for the bidirectional traffic in Figure 2.16 is just a question of replicating tools. For example, all the tools we presented previously are applied to interface A, but some, such as metering and policing, are applied only to traffic entering the interface (ingress from the router’s perspective), and others, such as shaping, queuing, and scheduling, are applied only to traffic leaving the interface (egress from the router’s perspective).

Figure 2.16 Bidirectional traffic
This is a key point to remember; QOS tools are always applied with a sense of directionality, so if, for example, it is required to police both the traffic that enters and leaves an interface, effectively what is applied is one policer in the ingress direction and another policer in the egress direction.
Any QOS tool can be applied at the ingress or egress; the impetus for such decisions is always the desired behavior. This example uses policing as an ingress tool and shaping as an egress tool. However, this design should never be seen as mandatory, and as we will see in Chapter 6, there are scenarios in which these two tools should be applied in the opposite order. The only exception is the classifier tool. Because the PHB concept implies that any classification done by a router is effectively lost once traffic leaves the router toward its next downstream neighbor, applying it on egress is pointless.
This simple example is drawn from a basic set of requirements. Parts Two and Three of this book show examples of using these tools to achieve greater levels of complexity and granularity.
2.10 Delay and Jitter Insertion
Two QOS tools can insert delay, the shaper and a combination of queuing and scheduling. Because the value of inserted delay is not constant, both tools can also introduce jitter.
The shaper can sustain excess traffic at the expense of delaying it. This means that there is a trade-off between how much excess traffic can be stored and the maximum delay that can possibly be inserted. We explore this topic further in Chapter 6, in which we present the leaky bucket concept used to implement shaping.
Let us now focus on the queuing and scheduling tool. The delay inserted results from a multiplexing operation applied by this QOS tool, as follows. When multiple queues containing packets arrive in parallel at the scheduler, the scheduler selects one queue at a time and removes one or more packets from that queue. While the scheduler is removing packets from the selected queue, all the other packets in this particular queue, as well as all packets in other queues, must wait until it is their turn to be removed from the queue.
Let us illustrate this behavior with the example in Figure 2.17, which shows two queues named A and B and a scheduler that services them in a round-robin fashion, starting by servicing queue A.

Figure 2.17 Two queues and a round-robin scheduler
Packet X is the last packet inside queue B, and we are interested in calculating the delay introduced into its transmission. The clock starts ticking.
The first action taken by the scheduler is to remove black packet 1 from queue A. Then, because the scheduler is working in a round-robin fashion, it next turns to queue B and removes white packet 3 from the queue. This leads to the scenario illustrated in Figure 2.18, in which packet X is sitting at the head of queue B.

Figure 2.18 Packet X standing at the queue B head
Continuing its round-robin operation, the scheduler now services queue A by removing black packet 2. It again services queue B, which finally results in the removal of packet X. The clock stops ticking.
In this example, the delay introduced into the transmission of packet X is the time that elapses while the scheduler removes black packet 1 from queue A, white packet 3 from queue B, and black packet 2 from queue A.
Considering a generic queuing and scheduling scenario, when a packet enters a queue, the time it takes until the packet reaches the head of the queue depends on two factors, the queue fill level, that is, how many packets are in front of the packet, and how long it takes for the packet to move forward to the head of the queue. For a packet to move forward to the queue head, all the other packets queued in front of it need to be removed first.
As a side note, a packet does not wait indefinitely at the queue head to be removed by the scheduler. Most queuing algorithms apply the concept of packet aging. If the packet is at the queue head for too long, it is dropped. This topic is discussed in Chapter 7.
The speed at which packets are removed from the queue is determined by the scheduler’s properties regarding how fast and how often it services the queue, as shown with the example in Figures 2.17 and 2.18. But for now, let us concentrate only on the queue fill level, and we will return to the scheduler’s removal speed shortly.
It is not possible to predict the queue fill level, so we have to focus on the worst-case scenario of a full queue, which allows us to calculate the maximum delay value that can be inserted into the packet’s transmission. When a packet enters a queue and when this results in the queue becoming full, this particular packet becomes the last one inside a full queue. So in this case, the delay inserted in that packet’s transmission is the total queue length, as illustrated in Figure 2.19.
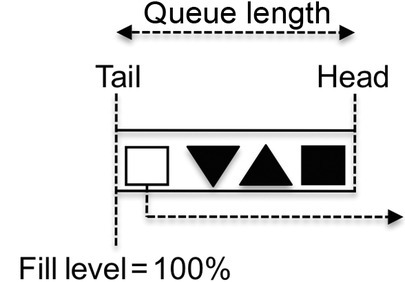
Figure 2.19 Worst-case delay scenario with a full queue
To summarize our conclusions so far, the maximum delay that can be inserted in a packet’s transmission by the queuing and scheduling tools is the length of the queue into which the packet is placed.
Now if we take into account the role played by the scheduler in determining the speed at which packets are removed, the conclusion drawn in the previous paragraph becomes a reasonable approximation of the delay.
Let us demonstrate how the accuracy of this conclusion varies according to the scheduler’s properties. The example in Figure 2.20 shows two queues that are equal in the sense that both have a length of 10 ms, each contain two packets, and both are full.

Figure 2.20 Two equal queues
Packets X and Y are the last packets in the full queues A and B, respectively. In this case, the scheduler property that is implemented is that as long as packets are present in queue A, this queue is always serviced first. The result of this behavior leads the scheduler to first remove black packets 1 and X. Only then does it turn to queue B, leading to the scenario illustrated in Figure 2.21.

Figure 2.21 Uneven scheduler operation
This example shows that the previous conclusion drawn—that the maximum delay that can be inserted by the queuing and scheduling tools is the length of the queue on which the packet is placed—is much more accurate for packet X than for packet Y, because the scheduler favors the queue A at the expense of penalizing queue B.
So, for packets using queue A, to state that the maximum possible delay that can be inserted is 10 ms (the queue length) is a good approximation in terms of accuracy. However, this same statement is less accurate for queue B.
In a nutshell, the queue size can be seen as the maximum amount of delay inserted, and this approximation becomes more accurate when the scheduling scheme favors one particular queue and becomes less accurate for other queues.
Regarding jitter, the main factors that affect it are also the queue length and the queue fill level, along with a third phenomenon called the scheduler jumps that we discuss later in this section. As the gap between introducing no delay and the maximum possible value of delay widens, the possible value of jitter inserted also increases.
As illustrated in Figure 2.22, the best-case scenario for the delay parameter is for the packet to be mapped into an empty queue. In this case, the packet is automatically placed at the queue head, and it has to wait only for the scheduler to service this queue. The worst-case scenario has already been discussed, one in which the packet entering a queue is the last packet that the queue can accommodate. The result is that as the queue length increases, the maximum possible variation of delay (jitter) increases as well.

Figure 2.22 Best-case and worst-case scenarios in terms of jitter insertion
Scheduler jumps are a consequence of having multiple queues, so the scheduler services one queue and then needs to jump to service other queues. Let us illustrate the effect such a phenomenon has in terms of jitter by considering the example in Figure 2.23, in which a scheduler services three queues.

Figure 2.23 Jitter insertion due to scheduler jumps
In its operation, the scheduler removes three packets from Q1 and then two packets from Q2 and other two packets from Q3. Only then does it jump again to Q1 to remove packets from this queue. As illustrated in Figure 2.23, the implications in terms of jitter is that the time elapsed between the transmission of black packets 2 and 3 is smaller than the time elapsed between the transmission of black packets 3 and 4. This is jitter. Scheduler jumps are inevitable, and the only way to minimize them is to use the minimum number of queues, but doing so without compromising the traffic differentiation that is achieved by splitting traffic into different queues.
As discussed in Chapter 8, a queue that carries real-time traffic typically has a short length, and the scheduler prioritizes it with regards to the other queues, meaning it removes more packets from this queue compared with the others to minimize the possible introduction of delay and jitter. However, this scheme should be achieved in a way that assures that the other queues do not suffer from complete resource starvation.
2.11 Packet Loss
At a first glance, packet loss seems like something to be avoided, but as we will see, this is not always the case because in certain scenarios, it is preferable to drop packets rather than transmit them.
Three QOS tools can cause packet loss: the policer, the shaper, and the queuing. From a practical perspective, QOS packet loss tools can be divided into two groups depending on whether traffic is dropped because of an explicitly defined action or is dropped implicitly because not enough resources are available to cope with it.
The policer belongs to the first group. When traffic exceeds a certain rate and if the action defined is to drop it, traffic is effectively dropped and packet loss occurs. Usually, this dropping of packets by the policer happens for one of two reasons: either the allowed rate has been inaccurately dimensioned or the amount of traffic is indeed above the agreed or expected rate and, as such, it should be dropped.
The shaper and queuing tools belong to the second group. They drop traffic only when they run out of resources, where the term resources refers to the maximum amount of excess traffic that can be sustained for the shaper and the queue length for the queuing tool (assuming that the dropper drops traffic only when the fill level is 100%).
As previously discussed, there is a direct relationship between the amount of resources assigned to the shaper and queuing tools (effectively, the queue length) and the maximum amount of delay and jitter that can be inserted. Thus, limiting the amount of resources implies lowering the maximum values of delay and jitter that can be inserted, which is crucial for real-time traffic because of its sensitivity to these parameters. However, limiting the resources has the side effect of increasing the probability of dropping traffic.
Suppose a real-time traffic stream crossing a router has the requirement that a delay greater than 10 ms is not acceptable. Also suppose that inside the router, the real-time traffic is placed in a specific egress queue whose length is set to less than 10 ms to comply with the desired requirements. Let us further suppose that in a certain period of time, the amount of traffic that arrives at the router has an abrupt variation in volume, thus requiring 30 ms worth of buffering, as illustrated in Figure 2.24.

Figure 2.24 Traffic dropped due to the lack of queuing resources
The result is that some traffic is dropped. However, the packet loss introduced can be seen as a positive situation, because we are not transmitting packets that violate the established service agreement. Also, as previously discussed, for a real-time stream, a packet that arrives outside the time window in which it is considered relevant not only adds no value but also causes more harm than good because the receiver must still spend cycles processing an already useless packet.
This perspective can be expanded to consider whether it makes sense to even allow this burst of 30 ms worth of traffic to enter the router on an ingress interface if, on egress, the traffic is mapped to a queue whose length is only 10 ms. This is a topic that we revisit in Chapter 6, in which we discuss using the token bucket concept to implement policing and to deal with traffic bursts.
2.12 Conclusion
The focus of this chapter has been to present the QOS tools as building blocks, where each one plays a specific role in achieving various goals. As the demand for QOS increases, the tools become more refined and granular. As an example, queuing and scheduling can be applied in a multiple level hierarchical manner. However, the key starting point is understanding what queuing and scheduling can achieve as building blocks in the QOS design.
Some tools are more complex than others. Thus, in Part Two of this book we dive more deeply into the internal mechanics of classifiers, policers, and shapers and the queuing and scheduling schemes.
We have also presented an example of how all these tools can be combined. However, the reader should always keep in mind that the required tools are a function of the desired end goal.
In the next chapter, we focus on some of the challenges and particulars involved in a QOS deployment.
Reference
- [1] Heinanen, J., Finland, T. and Guerin, R. (1999) RFC 2698, A Two-Rate Three-Color Marker, September 1999. https://tools.ietf.org/html/rfc2698 (accessed August 19, 2015).